Forecasting China’s Natural Gas Consumption Based on AdaBoost-Particle Swarm Optimization-Extreme Learning Machine Integrated Learning Method

Abstract
:1. Introduction
- When analyzing the factors affecting China’s natural gas, this paper considers the factors of previous research and combines the current development status of China’s natural gas consumption, focusing on the unique influencing factors of natural gas consumption, namely import dependence. At the same time, in order to avoid problems such as multi-collinearity and over-fitting, the random forest algorithm is used to calculate the Gini Importance of each factor, and the core factors of China’s natural gas are extracted as the independent variables of the established prediction model.
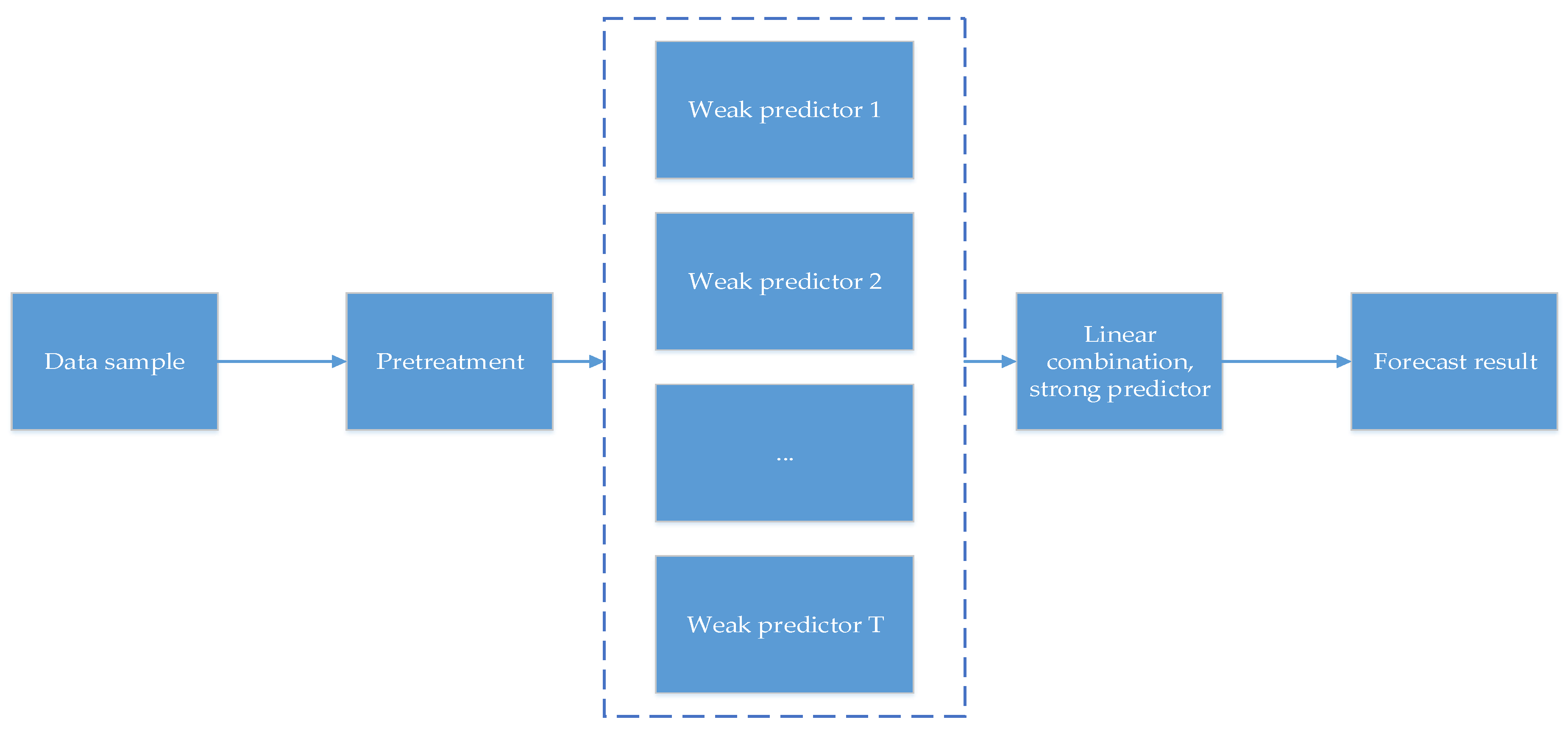
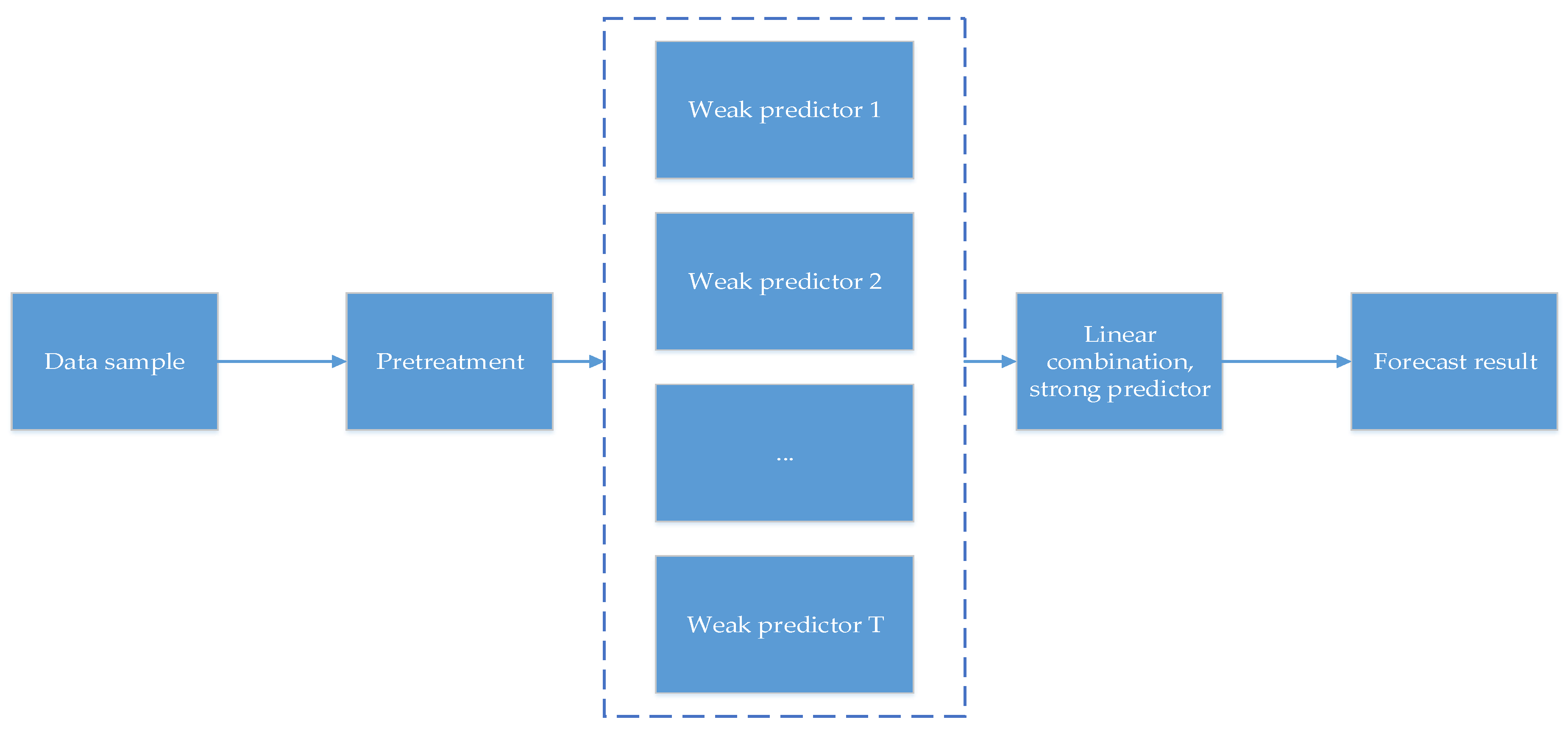
- Based on the advantages of the combined prediction method, this paper uses the PSO algorithm to optimize the input weight matrix and hidden layer deviation of the ELM method, which leads to improvement of the generalization ability of the ELM algorithm. At the same time, the AdaBoost algorithm is used to integrate several weak predictors into a high-precision strong predictor, and the Chinese natural gas consumption prediction model is constructed to further improve the prediction accuracy.
- This paper verifies the superiority of the AdaBoost-PSO-ELM method by comparing the relative error and prediction accuracy of PSO-ELM, AdaBoost-ELM and ELM. Then combined with the prediction model training parameters and the time series prediction results of each core influencing factors, the trend of natural gas consumption in 2018–2030 is predicted, which provides a reference for future policy formulation.
2. Methodology
2.1. Random Forest Algorithm
- Using the bootstrap sample to form each decision tree, and predicting or classifying the corresponding OOB, then obtaining the voting score of each sample in the OOB in the samples, recorded as ;
- Randomly change the value of the variable in the OOB sample to form a new OOB test sample, and then use the established random forest to predict or classify the new OOB. According to the number of correct samples, the voting score of each sample is obtained, namely:
- Subtracting the -th row vector corresponding to the matrix (1) by , summing the average and then dividing by the standard error to obtain the importance score of the variable , namely:
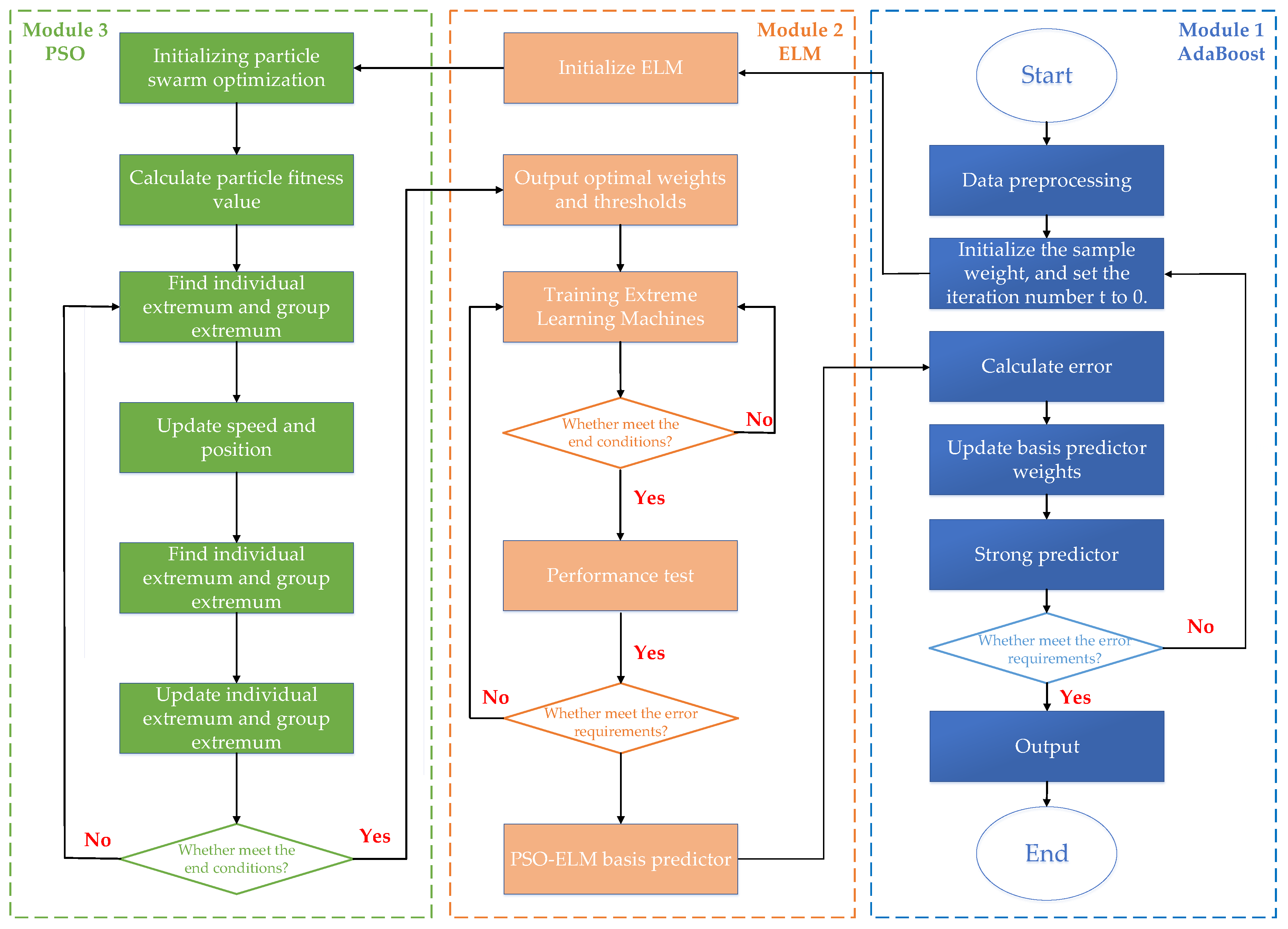
2.2. AdaBoost Algorithm
2.3. Improved ELM Theory Based on PSO Algorithm
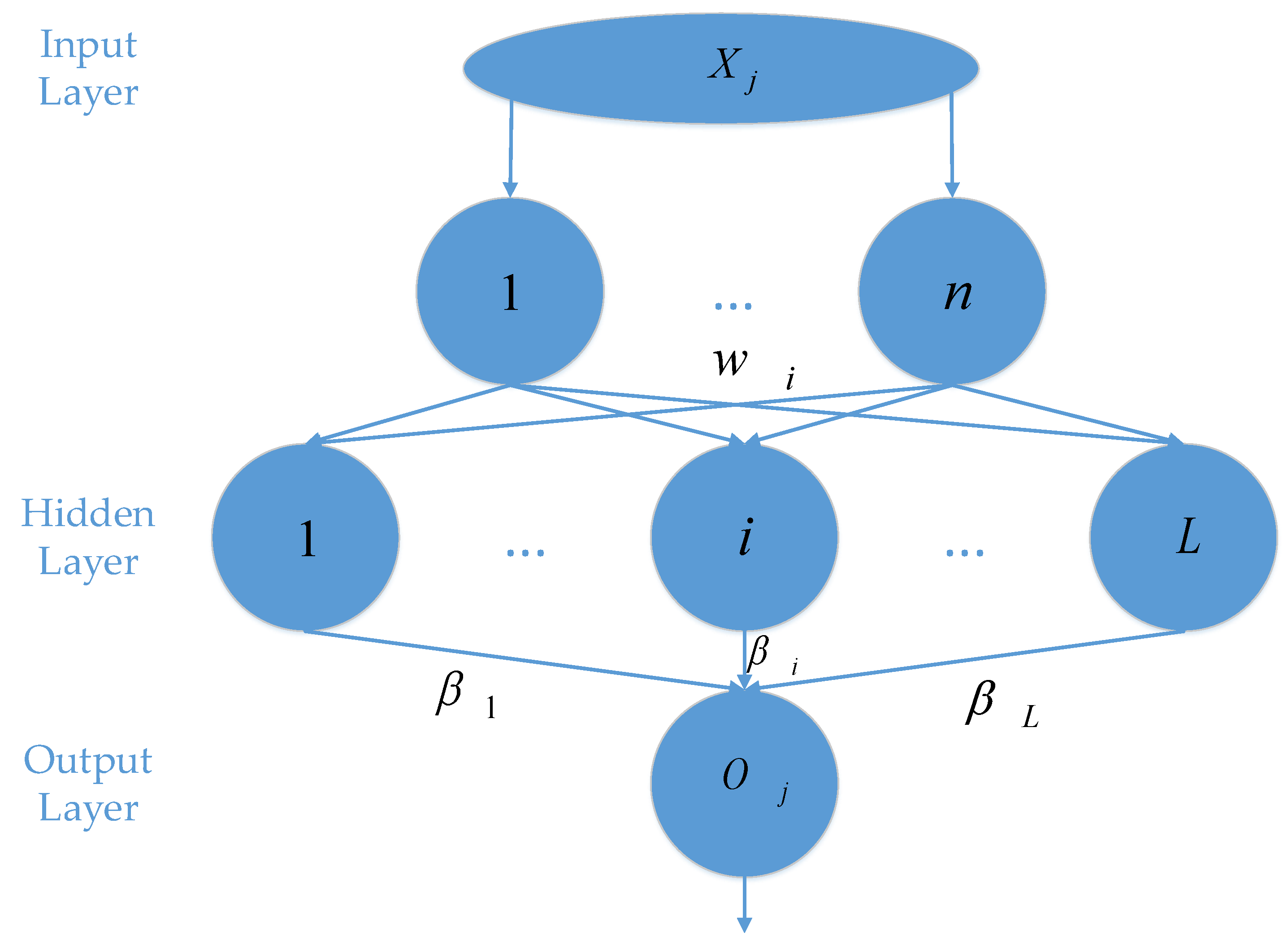
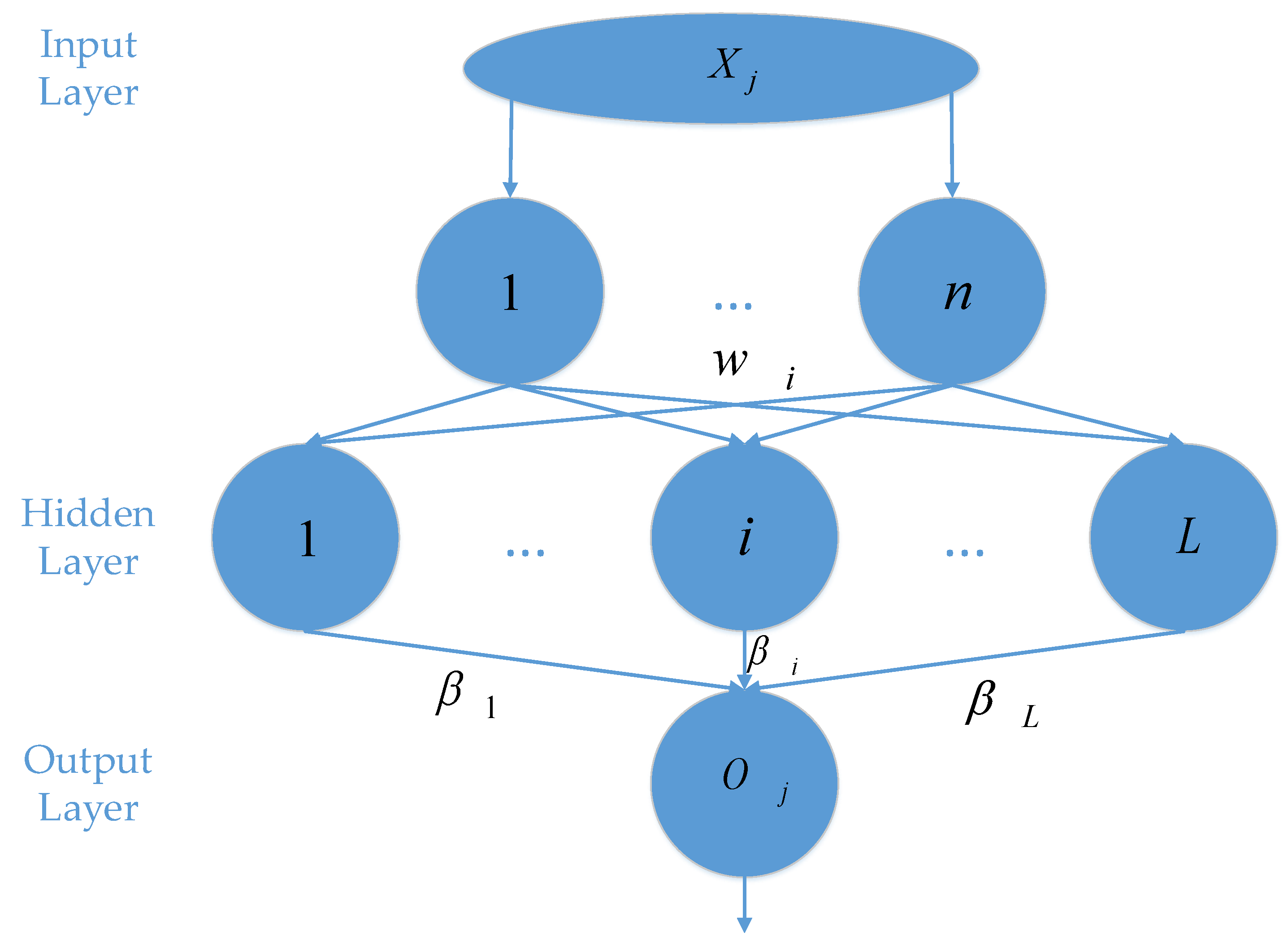
2.3.1. Extreme Learning Machine
2.3.2. Particle Swarm Optimization
2.3.3. Calculation Steps of PSO Optimizing ELM Algorithm
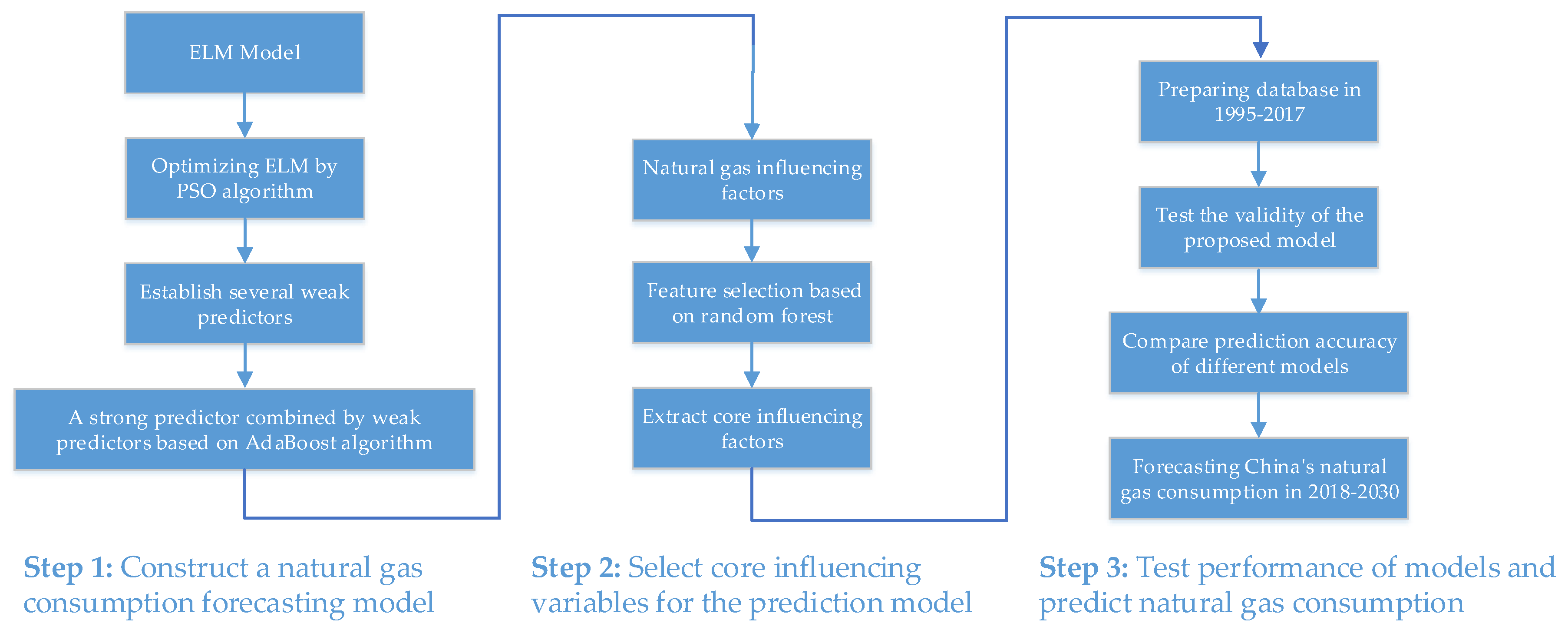
2.4. Establishing Natural Gas Consumption Forecasting Model based on AdaBoost-PSO-ELM Integrated Learning
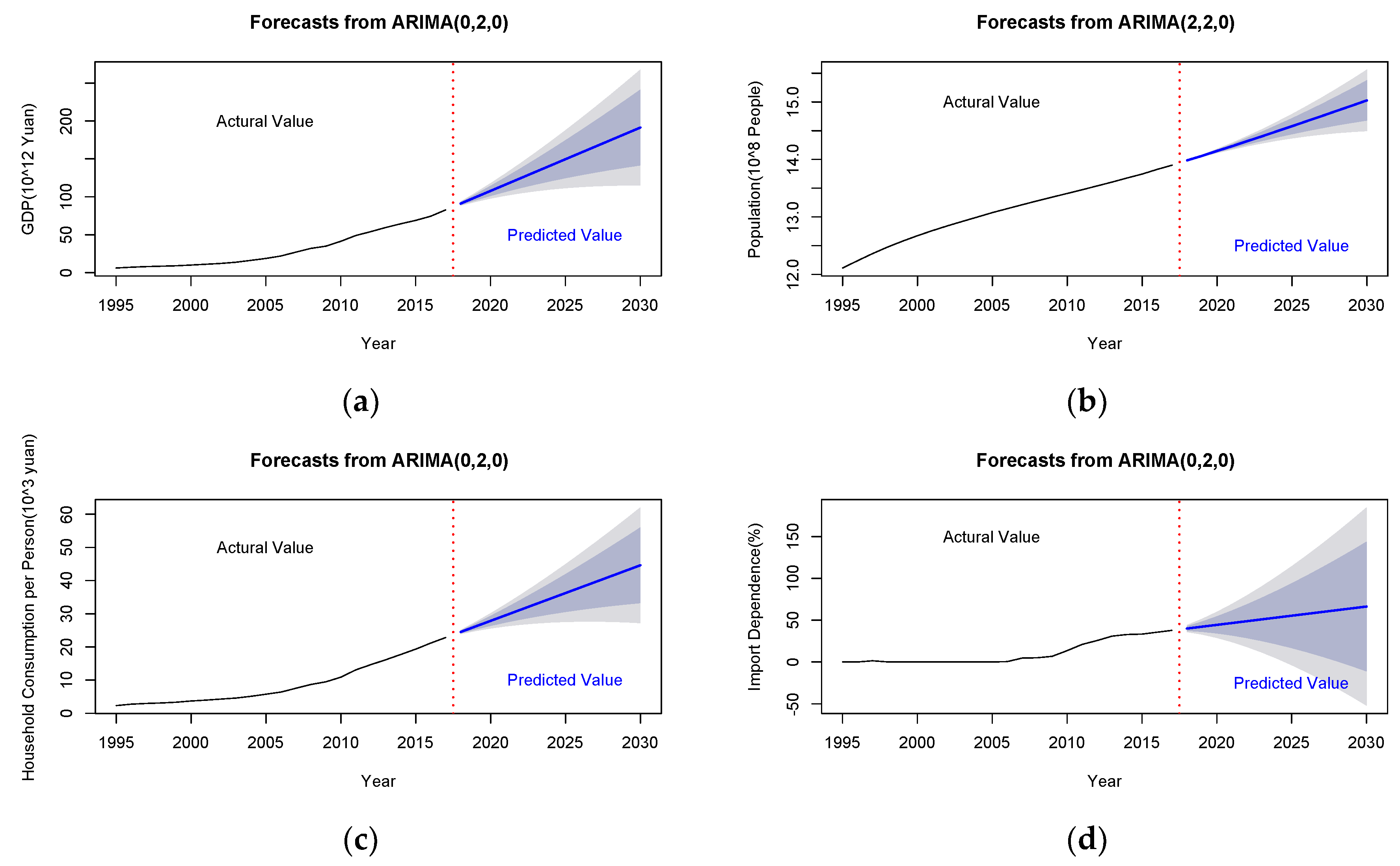
3. Extraction of Core Factors Affecting Natural Gas Consumption
3.1. Analysis of Current Natural Gas Consumption
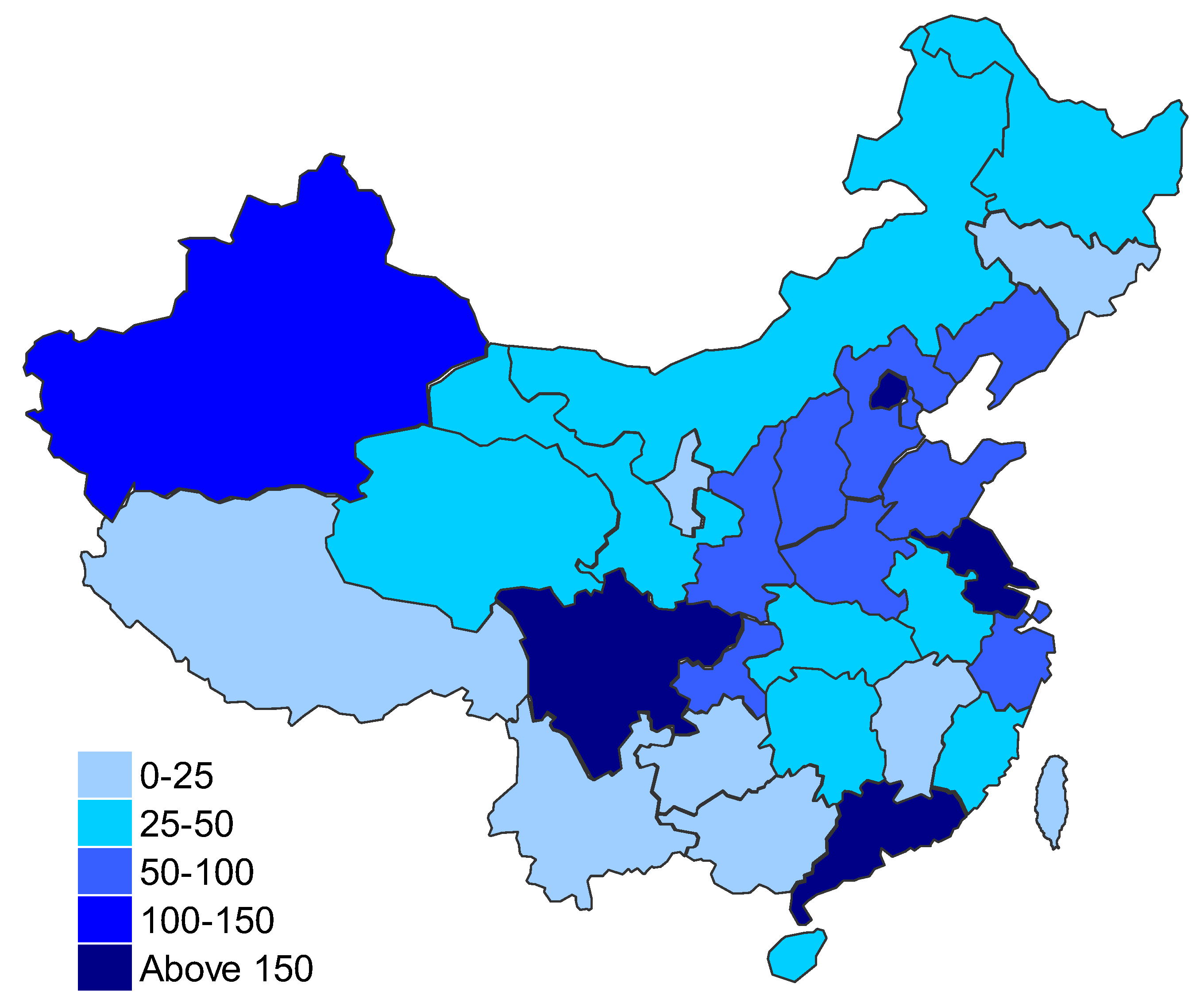
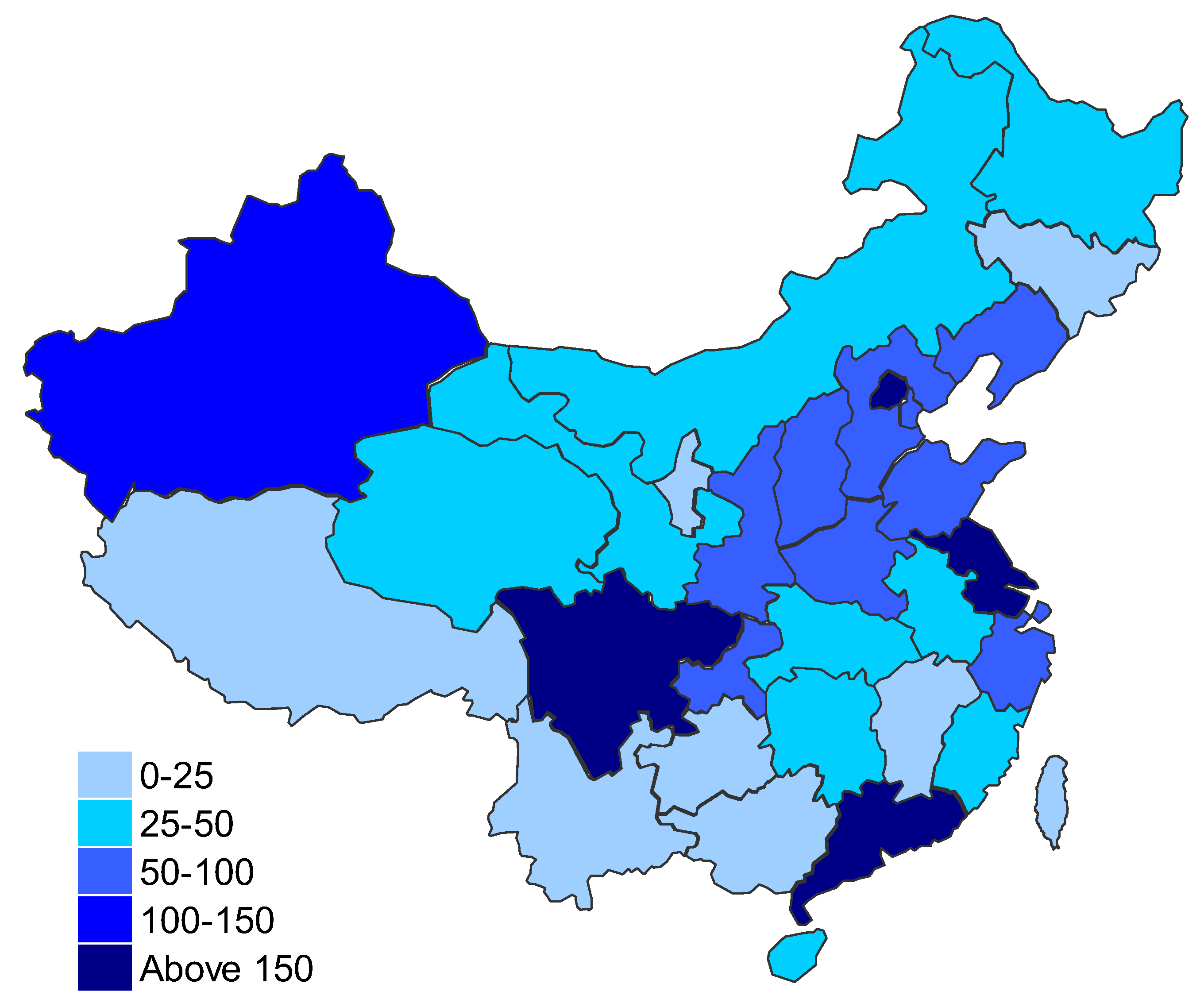
- From the perspective of different provinces, natural gas consumption is mainly in North China, Yangtze River Delta and Pearl River Delta; while Sichuan Province has become the largest consumer of natural gas, as shown in Figure 5.
- From the perspective of different industries, the proportion of industrial consumption in total is stable at around 60%, the proportion of residential consumption is stable at around 20%, and the consumption of transportation, storage and post accounts for about 15%; in addition, 5% is used in other industries, as shown in Figure 6.
3.2. Extraction of Core Factors Affecting Natural Gas Consumption
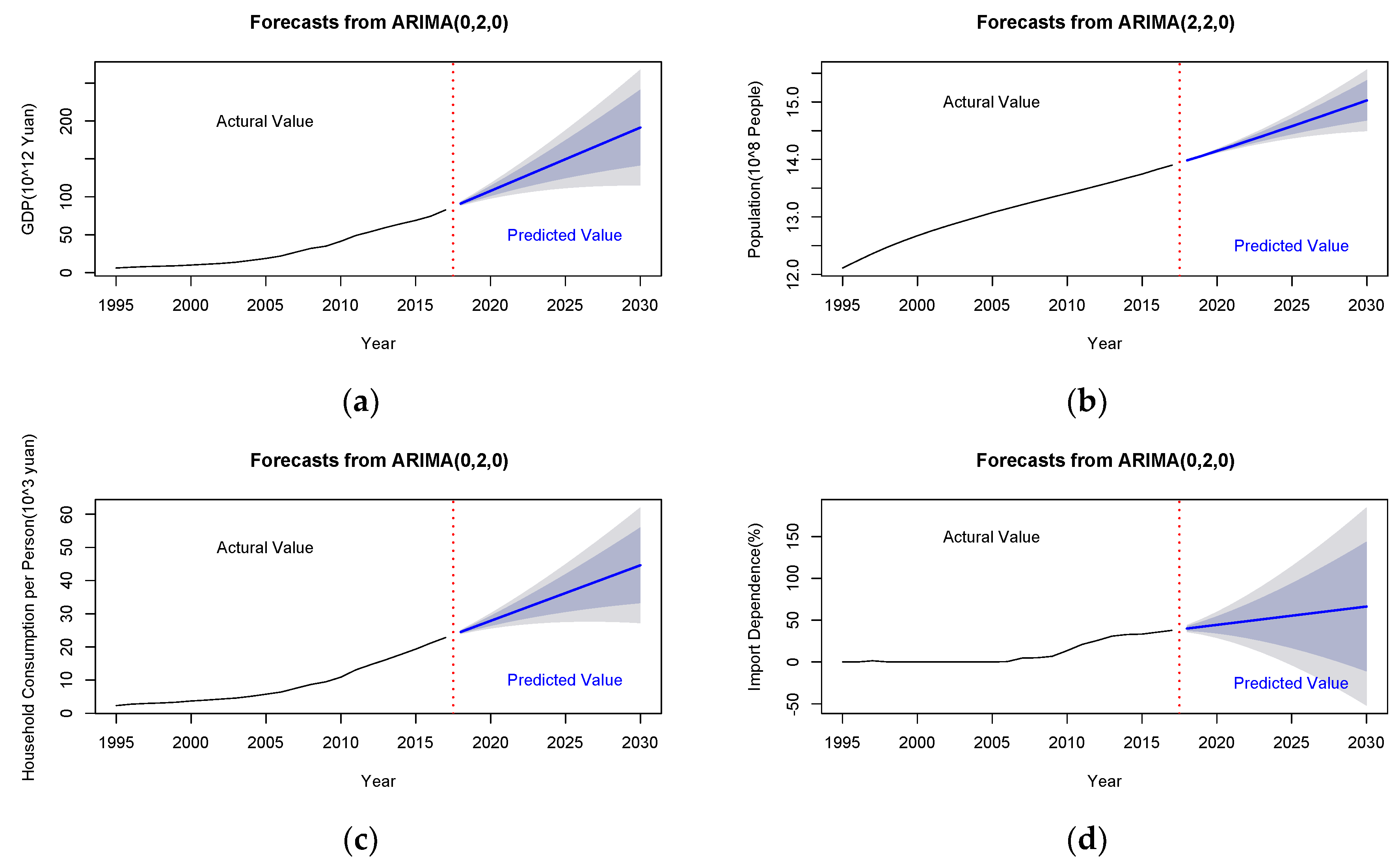
- Economic growth (): Since mankind entered the industrial era, energy has become an important factor in a country’s economic development and social progress, and it provides the necessary impetus for economic growth. Economic development is inseparable from energy, so economic growth will promote the consumption of natural gas.
- Population (): Population is the most fundamental component of the social system, and the consumption of natural gas is generated by people. In the absence of changes in other conditions, the population has a positive relationship with the total demand for natural gas, that is, the larger the population, the greater the demand for natural gas consumption.
- Household consumption (): With the continuous improvement of people’s living and consumption levels, the demand for clean energy continues to increase, directly driving the growth of natural gas consumption. At the same time, the negative impact of traditional energy on the ecological environment has prompted changes in the existing energy consumption structure. Therefore, the level of household consumption is a core factor in the consumption of natural gas.
- Import dependence (): Import dependence = import quantity/(yield quantity + import quantity − export quantity), the import dependence of natural gas reflects the contradiction between supply and demand of natural gas. Since 2017, due to the tightening of China’s environmental protection policies and the “coal to gas” program, China’s natural gas consumption has been growing rapidly. In the future, China’s natural gas supply gap will still be large, and imported pipeline gas and Liquefied Natural Gas (LNG) will still be important ways to make up for the tightness of the gas source. Therefore, the index of import dependence can be used as a core factor affecting natural gas consumption.
4. Empirical Research
4.1. Database
4.2. Natural Gas Consumption Forecasting Based on AdaBoost-PSO-ELM model
4.2.1. Parameter Setting
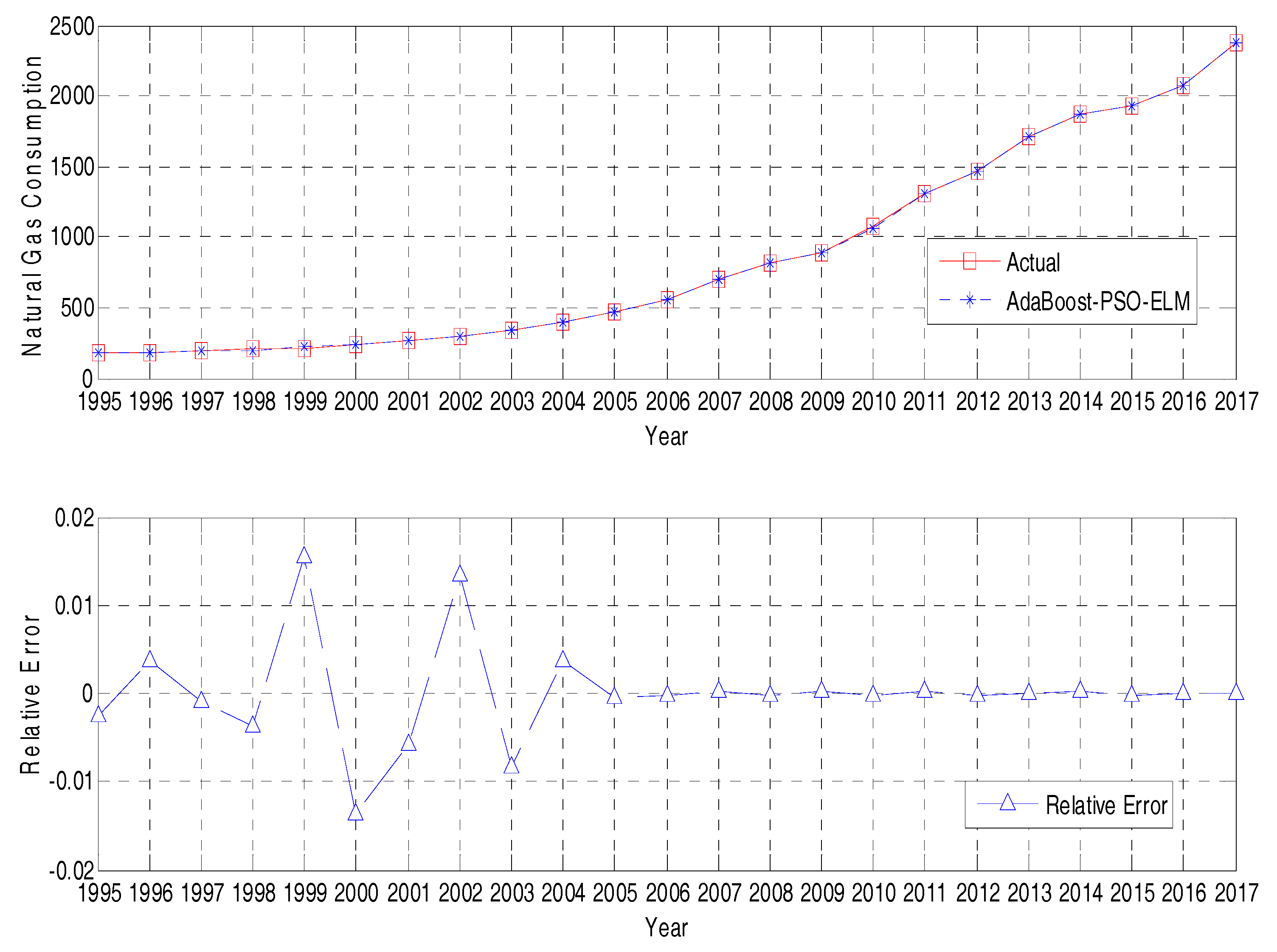
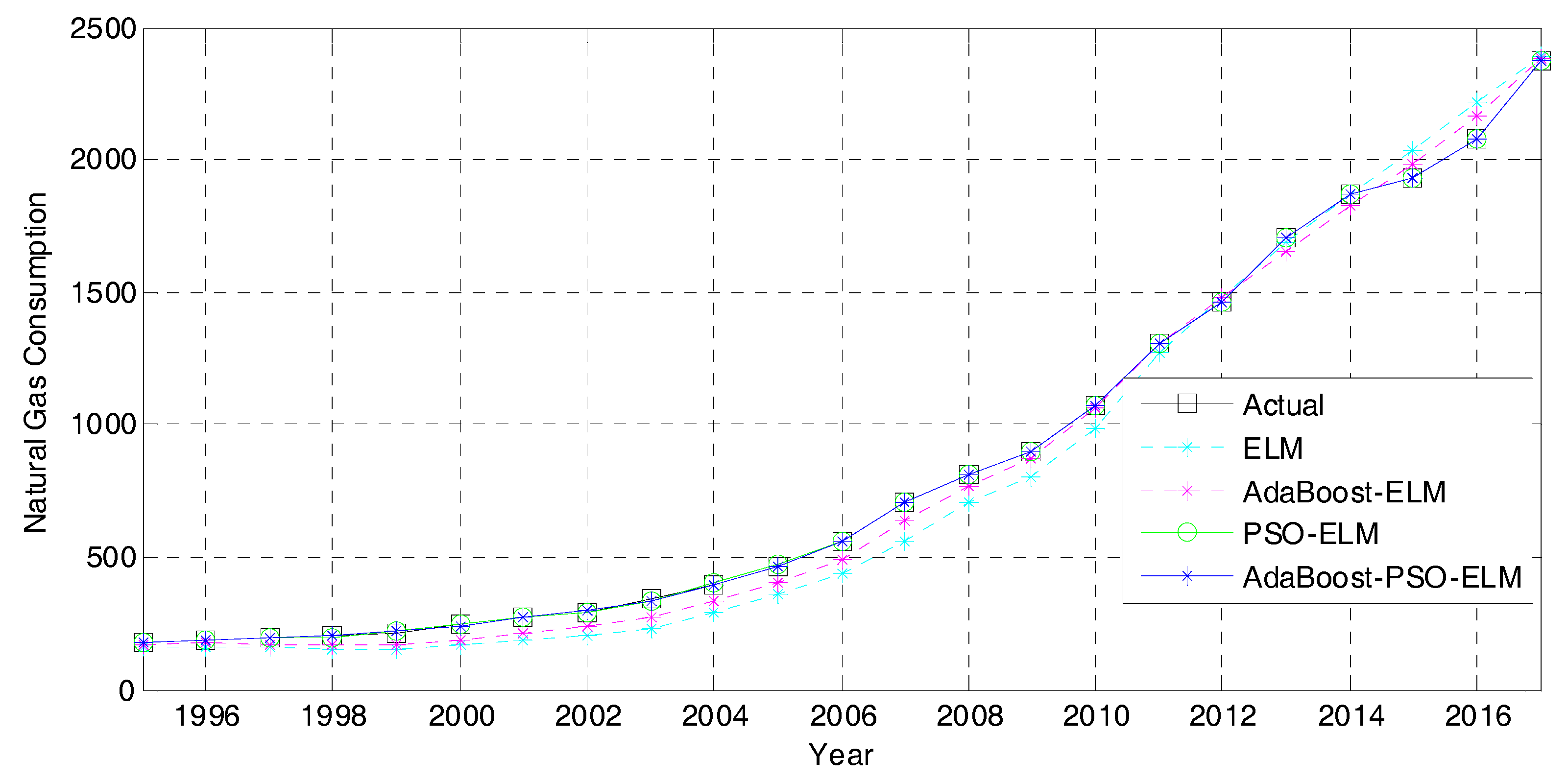
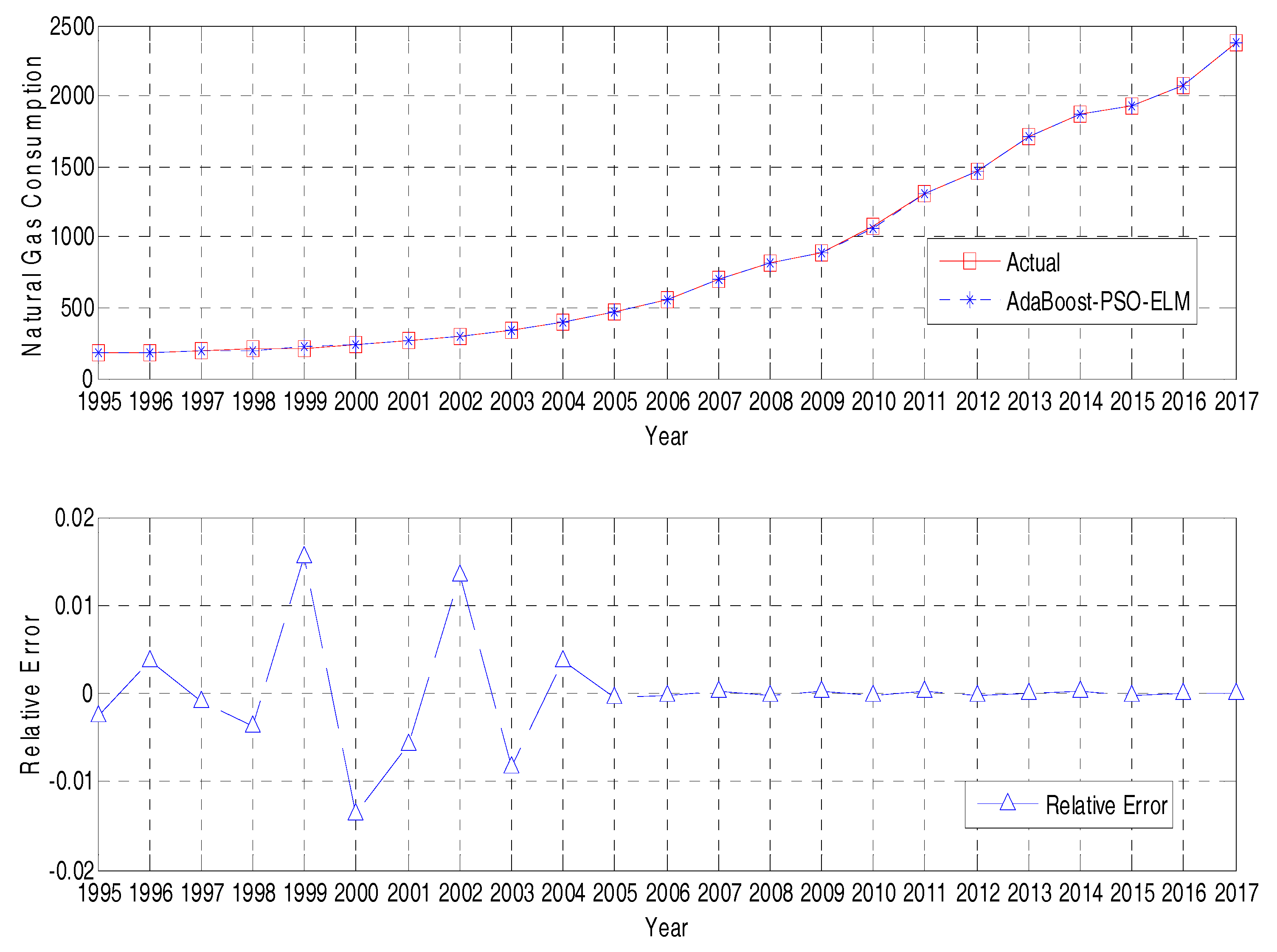
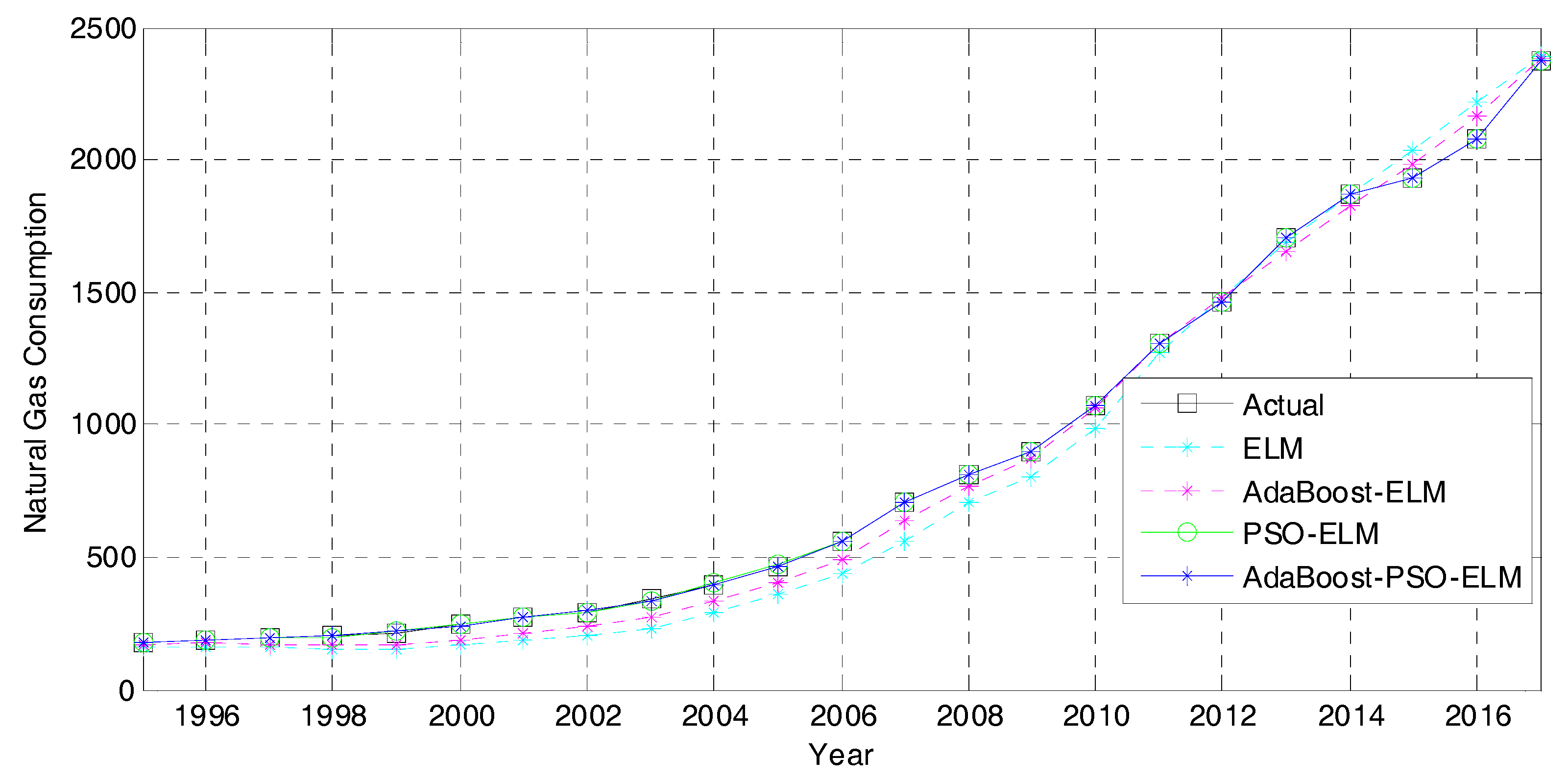
4.2.2. Forecasting Result
4.3. Discussion
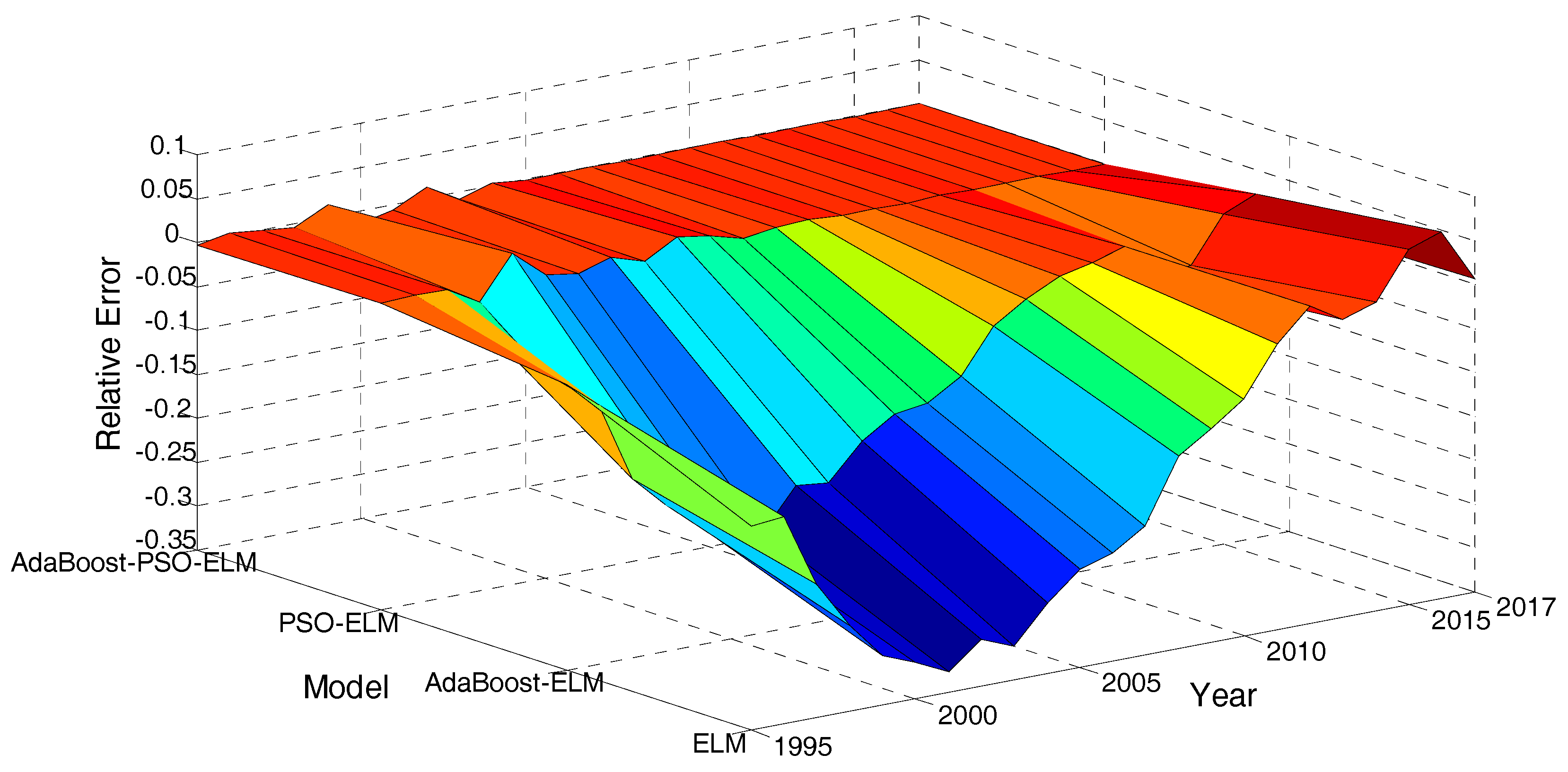
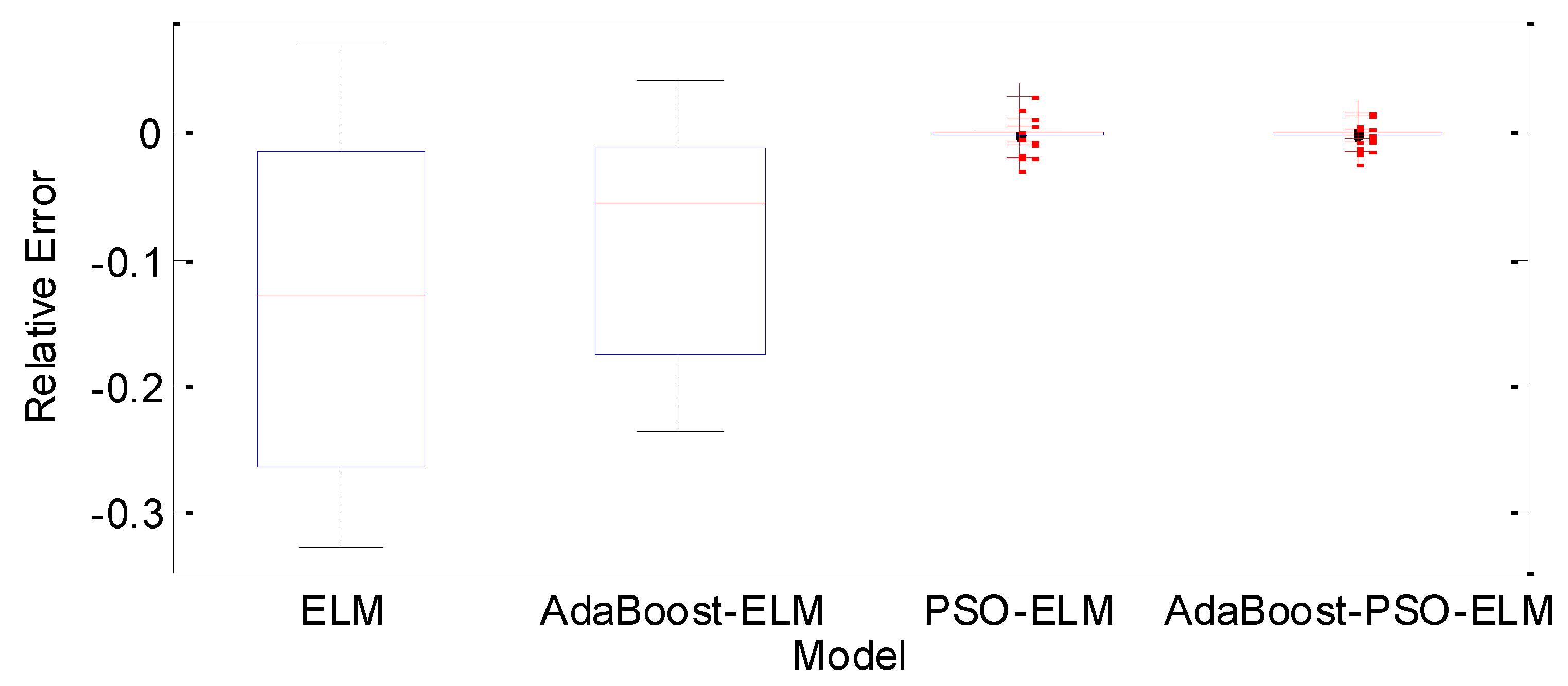
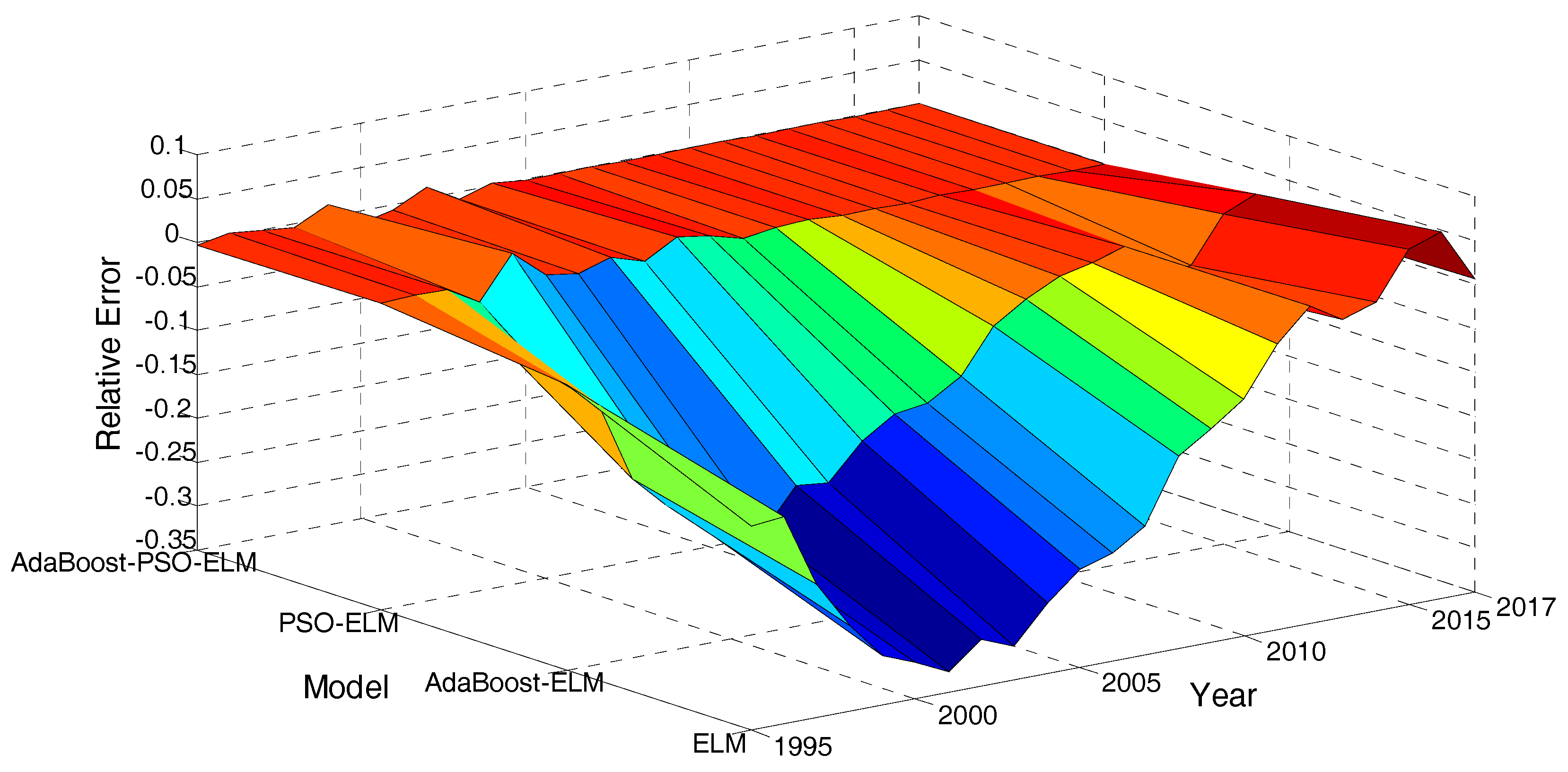
4.3.1. Relative Error Analysis
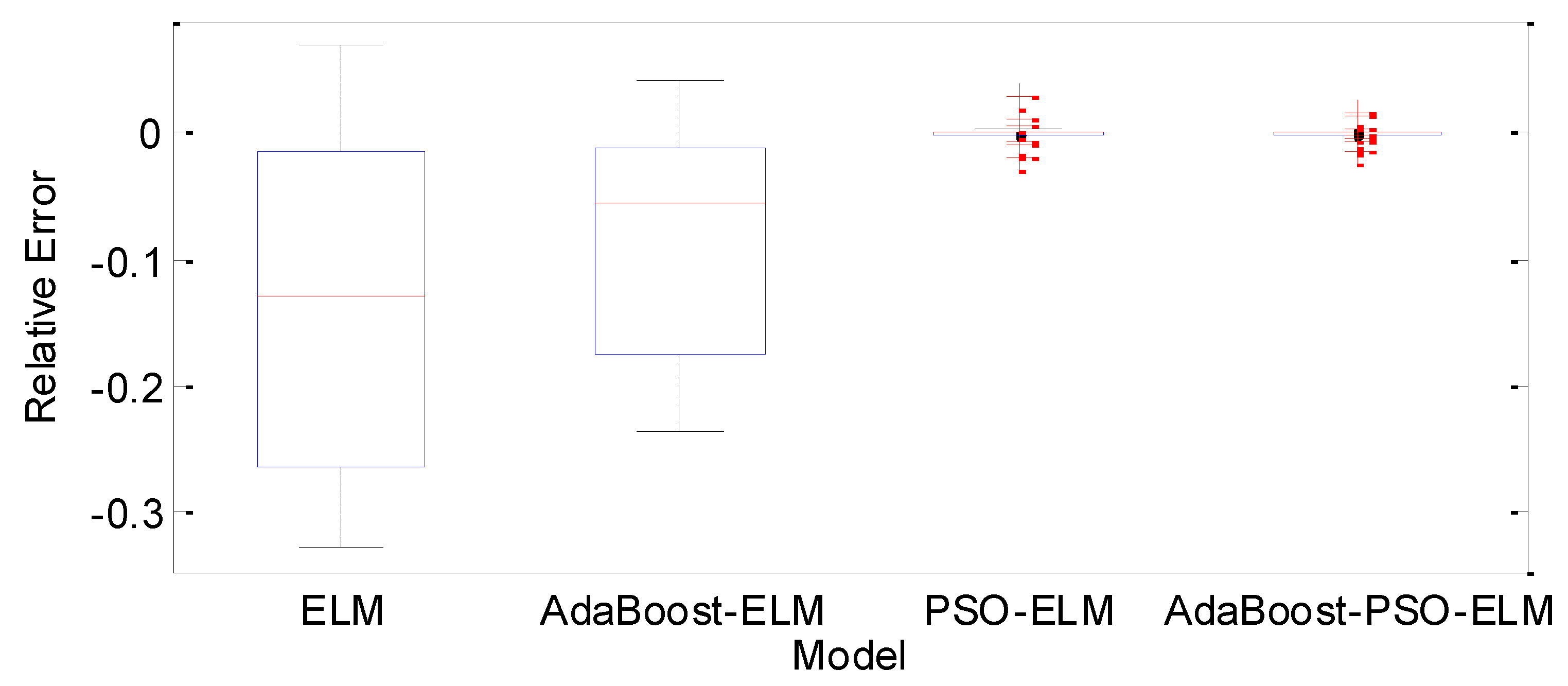
4.3.2. Prediction Accuracy Analysis
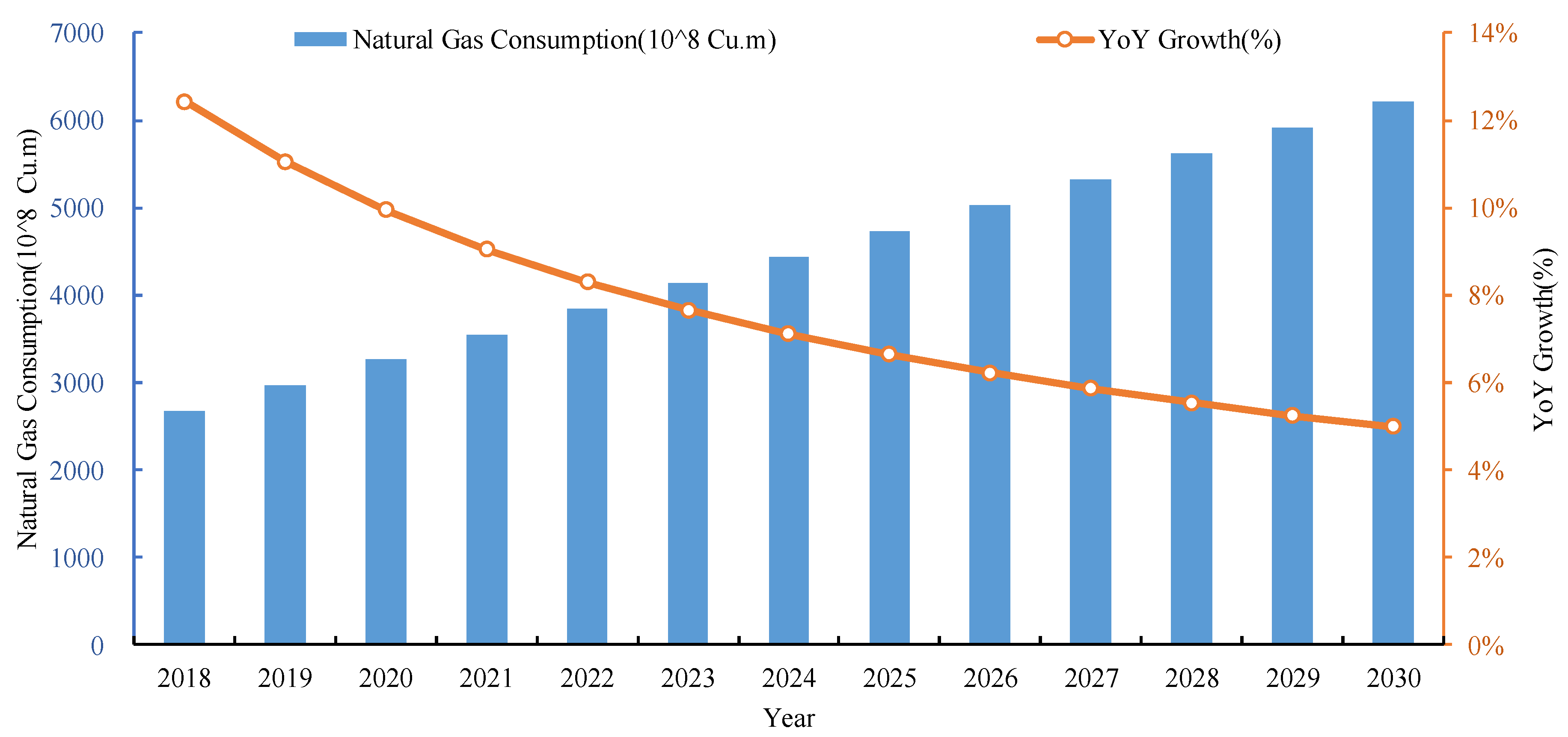
4.4. Prediction of Future Trends
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dong, X.C.; Pi, G.L.; Ma, Z.W.; Dong, C. The Reform of the Natural Gas Industry in the PR of China. Renew. Sustain. Energy Rev. 2017, 73, 582–593. [Google Scholar] [CrossRef]
- Zeng, B. Forecasting the Relation of Supply and Demand of Natural Gas in China During 2015–2020 Using a Novel Grey Model. J. Intell. Fuzzy Syst. 2017, 32, 141–155. [Google Scholar] [CrossRef]
- Zhang, Y.; Ji, Q.; Fan, Y. The Price and Income Elasticity of China’s Natural Gas Demand: A Multi-Sectoral Perspective. Energy Policy 2018, 113, 332–341. [Google Scholar] [CrossRef]
- BP Statistical Review of World Energy. Available online: https://www.bp.com/zh_cn/china/reports-and-publications.html (accessed on 20 October 2018).
- National Development and Reform Commission, National Energy Administration. China’s Energy Development “13th Five-Year Plan”. Available online: http://www.ndrc.gov.cn/zcfb/zcfbtz/201701/t20170117_835278.html (accessed on 20 October 2018).
- National Development and Reform Commission. China’s Natural Gas Development “13th Five-Year Plan”. Available online: http://www.ndrc.gov.cn/fzgggz/fzgh/ghwb/gjjgh/201706/t20170607_850207.html (accessed on 20 October 2018).
- Das, A.; McFarlane, A.A.; Chowdhury, M. The Dynamics of Natural Gas Consumption and GDP in Bangladesh. Renew. Sustain. Energy Rev. 2013, 22, 269–274. [Google Scholar] [CrossRef]
- Li, J.C.; Dong, X.C.; Shangguan, J.X.; Li, J.; Hook, M. Forecasting the Growth of China’s Natural Gas Consumption. Energy 2011, 36, 1380–1385. [Google Scholar] [CrossRef]
- Xu, G.Z. Analysis of factors affecting China’s natural gas consumption based on LMDI. China Coal 2016, 42, 32–37. [Google Scholar]
- Luo, D.K.; Xu, P. Natural gas demand forecasting based on improved BP. Oil-Gasfield Surf. Eng. 2008, 27, 20–21. [Google Scholar]
- Wang, D.Y.; Liu, Y.L.; Wu, Z.; Fu, H.X.; Shi, Y.; Guo, H.X. Scenario Analysis of Natural Gas Consumption in China Based on Wavelet Neural Network Optimized by Particle Swarm Optimization Algorithm. Energies 2018, 11, 825. [Google Scholar] [CrossRef]
- Zhen, Q.; Guo, X.Q.; Yan, Q. Decomposition of natural gas consumption in China based on industry perpective. China Min. Mag. 2018, 2, 50–57. [Google Scholar]
- Apergis, N.; Payne, J.F. Natural Gas Consumption and Economic Growth: A Panel Investigation of 67 Countries. Appl. Energy 2010, 87, 2759–2763. [Google Scholar] [CrossRef]
- Gao, J.; Dong, X.C. Stimulating factors of urban gas consumption in China. Nat. Gas Ind. 2018, 3, 130–137. [Google Scholar]
- Wang, T.; Lin, B.Q. China’s Natural Gas Consumption and Subsidies—From a Sector Perspective. Energy Policy 2014, 65, 541–551. [Google Scholar] [CrossRef]
- Aguilera, R.F. The role of natural gas in a low carbon Asia Pacific. Appl. Energy 2014, 113, 1195–1800. [Google Scholar] [CrossRef]
- Fan, G.F.; Wang, A.; Hong, W.C. Combining Grey Model and Self-Adapting Intelligent Grey Model with Genetic Algorithm and Annual Share Changes in Natural Gas Demand Forecasting. Energies 2018, 11, 1625. [Google Scholar] [CrossRef]
- Wu, L.F.; Liu, S.F.; Chen, H.J.; Zhang, N. Using a Novel Grey System Model to Forecast Natural Gas Consumption in China. Math. Probl. Eng. 2015, 2015, 686501. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, J. Forecasting Natural Gas Consumption in China by Bayesian Model Averaging. Energy Rep. 2015, 1, 216–220. [Google Scholar] [CrossRef]
- Shaikh, F.; Ji, Q. Forecasting Natural Gas Demand in China: Logistic Modelling Analysis. Electr. Power Energy Syst. 2016, 77, 25–32. [Google Scholar] [CrossRef]
- Karade, Y.; Ozdemir, G.; Aydemira, E. Breeder hybrid algorithm approach for natural gas demand forecasting model. Energy 2017, 12, 1269–1284. [Google Scholar] [CrossRef]
- Szoplik, J. Forecasting of Natural Has Consumption with Artifical Neural Networks. Energy 2015, 85, 208–220. [Google Scholar] [CrossRef]
- Iranmanesh, H.; Abdollahzade, M.; Miranian, A. Mid-Term Energy Demand Forecasting by Hybrid Neuro-Fuzzy Models. Energies 2012, 5, 1–21. [Google Scholar] [CrossRef]
- Bai, Y.; Li, C. Daily Natural Gas Consumption Forecasting based on a Structure-Calibrated Support Vector Regression Approach. Energy Build. 2016, 127, 571–579. [Google Scholar] [CrossRef]
- Kaytez, F.; Taplamacioglu, M.C.; Cam, E.; Hardalac, F. Forecasting Electricity Consumption: A Comparison of Regression Analysis, Neural Networks and Least Squares Support Vector Machines. Electr. Power Energy Syst. 2015, 67, 431–438. [Google Scholar] [CrossRef]
- Nieto, P.J.G.; Fernández, J.R.A.; Suárez, V.M.G.; Muñiz, C.D.; García-Gonzalo, E.; Bayón, R.M. A hybrid PSO Optimized SVM-based Method for Predicting of the Cyanotoxin Content from Experimental Cyanobacteria Concentrations in the Trasona Reservoir: A Case Study in Northern Spain. Appl. Math. Comput. 2015, 260, 170–187. [Google Scholar] [CrossRef]
- Barman, M.; Choudhury, N.B.D.; Sutradhar, S. A Regional Hybrid GOA-SVM Model based on Similar Day Approach for Short-Term Load Forecasting in Assam, India. Energy 2018, 145, 710–720. [Google Scholar] [CrossRef]
- Wei, N.; Li, C.J.; Li, C.; Xie, H.Y.; Du, Z.W.; Zhang, Q.S.; Zeng, F.H. Short-Term Forecasting of Natural Gas Consumption Using Factor Selection Algorithm and Optimized Support Vector Regression. J. Energy Resour. Technol. 2018, 141, 032701. [Google Scholar] [CrossRef]
- Zeng, Y.R.; Zeng, Y.; Choi, B.; Wang, L. Multifactor-Influenced Energy Consumption Forecasting Using Enhanced Back-Propagation Neural Network. Energy 2017, 127, 381–396. [Google Scholar] [CrossRef]
- National Development and Reform Commission. Available online: http://www.ndrc.gov.cn/jjxsfx/201809/t20180930_900073.html (accessed on 24 October 2018).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Jiao, R.H.; Su, C.J.; Lin, B.Y.; Mo, R.F. Short-Term Forecasting by Grey Model with Weather Factor based Correction. Power Syst. Technol. 2013, 3, 720–725. [Google Scholar]
- Schapire, R.E. The Boosting Approach to Machine Learning: An Overview; Springer: New York, NY, USA, 2003; pp. 149–171. [Google Scholar]
- Cao, Y.; Miao, Q.G.; Liu, J.C.; Gao, L. Advance and Prospects of AdaBoost Algorithm. Acta Autom. Sin. 2013, 39, 745–758. [Google Scholar] [CrossRef]
- Li, M.B.; Huang, G.B.; Saratchandran, P.; Sundararajan, N. Fully Complex Extreme Learning Machine. Neurocomputing 2005, 10, 306–314. [Google Scholar] [CrossRef]
- Couceiro, M.; Ghamisi, P. Particle Swarm Optimization; Springer: New York, NY, USA, 2015; pp. 1–10. [Google Scholar]



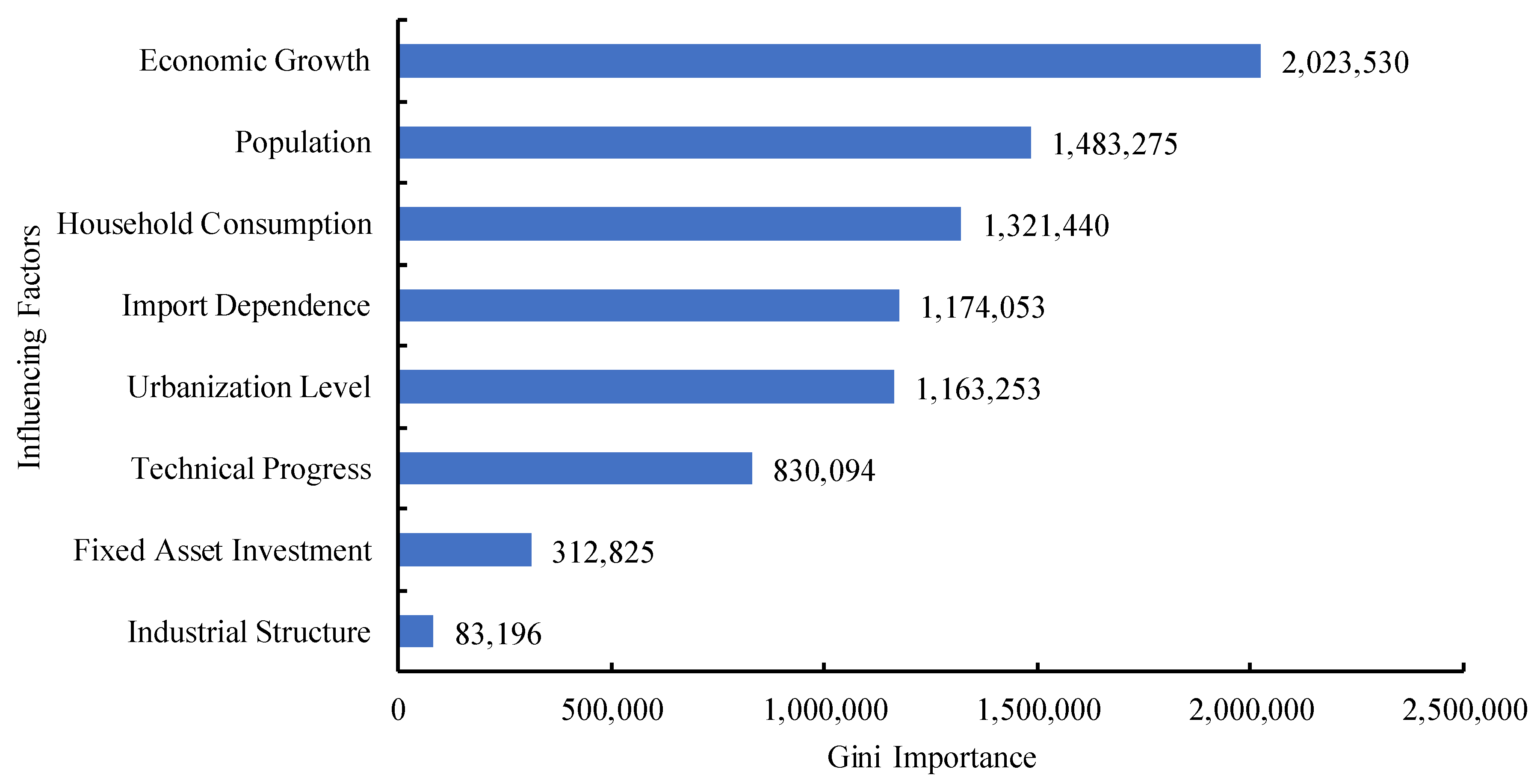


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
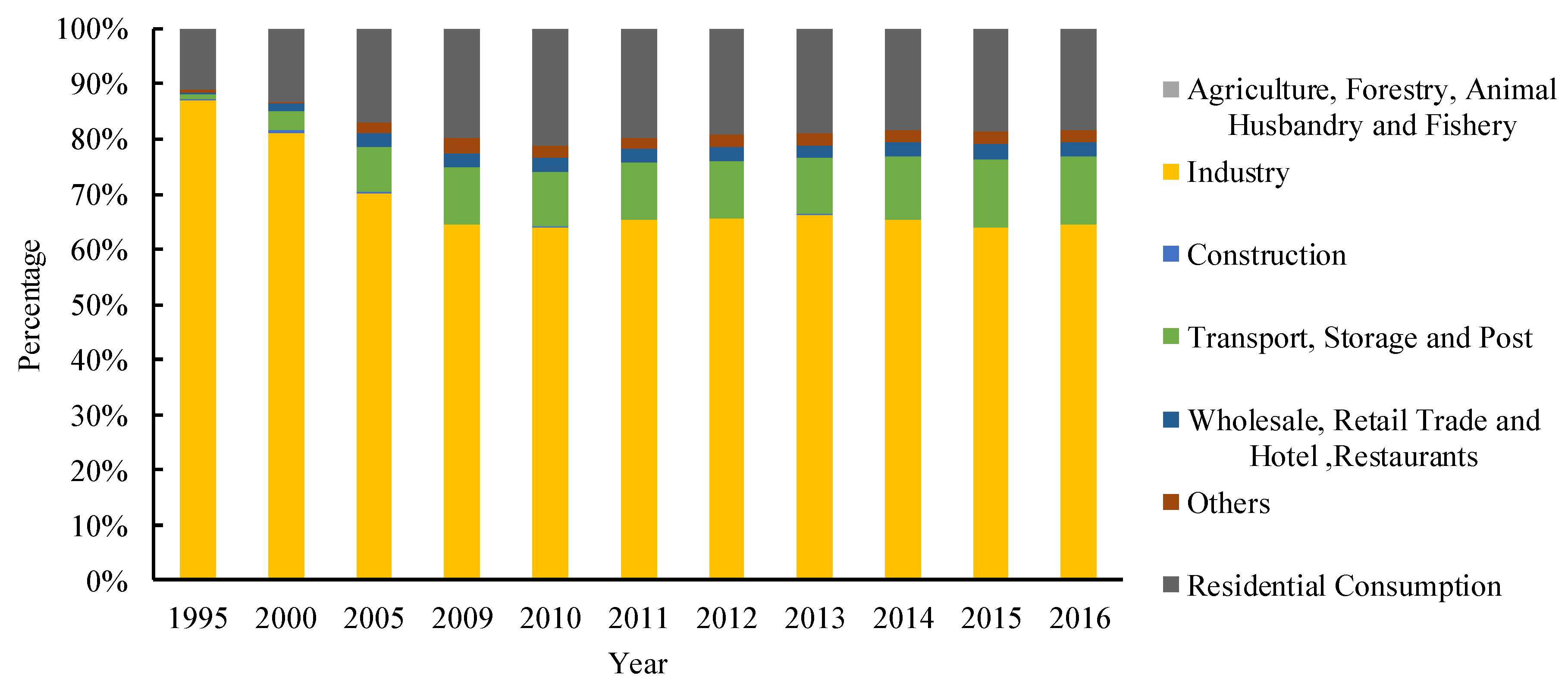{kind=link}
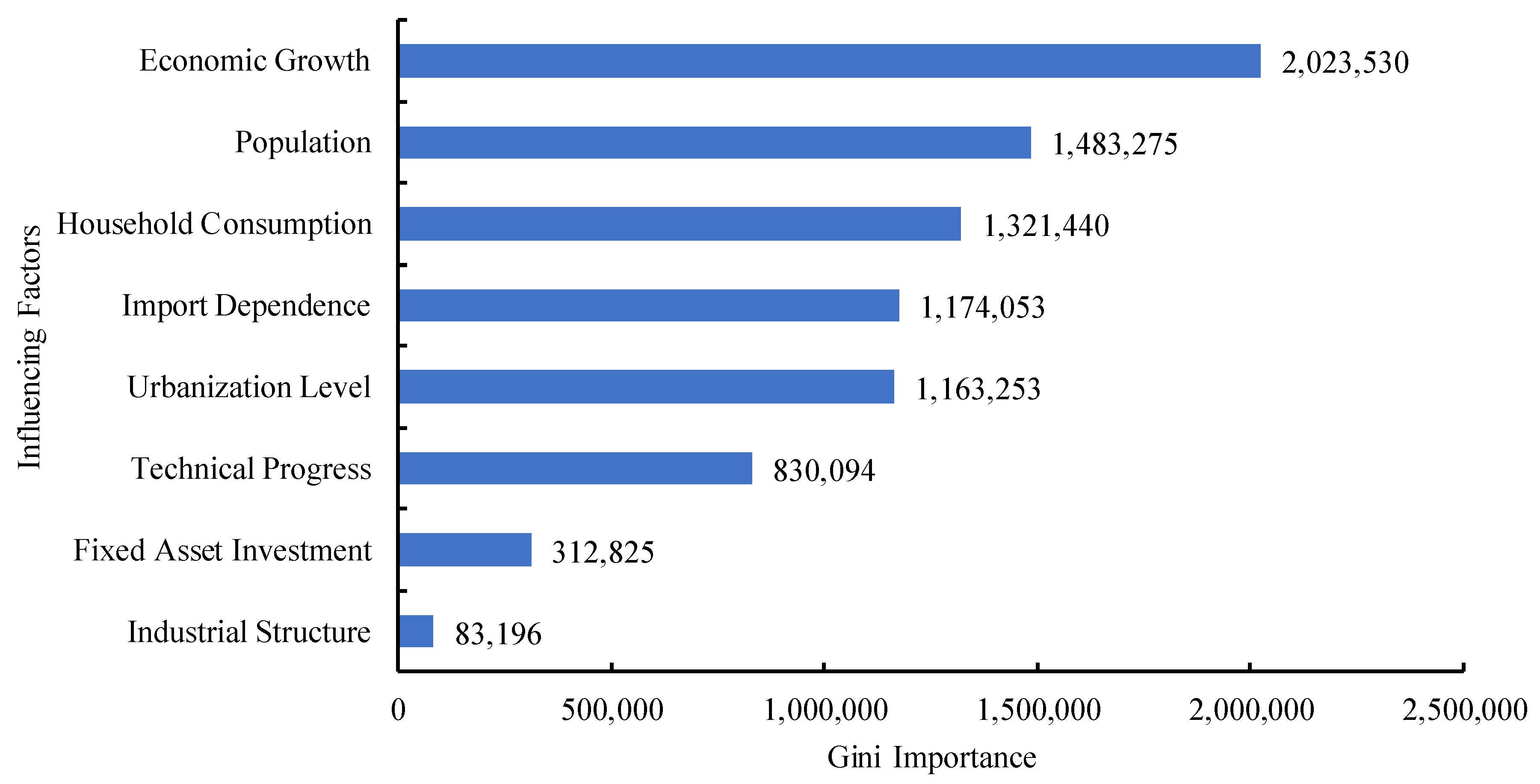{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Natural Gas Consumption (108 Cu.m) | GDP (108 Yuan) | Population (104 People) | Household Consumption per Person (Yuan) | Import Dependence (%) |
|---|---|---|---|---|---|
| 1995 | 177.41 | 61,340 | 121,121 | 2318 | 0.13 |
| 1996 | 184.88 | 71,814 | 122,389 | 2750 | 0.00 |
| 1997 | 195.44 | 79,715 | 123,626 | 2963 | 1.43 |
| 1998 | 202.57 | 85,196 | 124,761 | 3112 | 0.13 |
| 1999 | 214.94 | 90,564 | 125,786 | 3332 | 0.12 |
| 2000 | 245.03 | 100,280 | 126,743 | 3707 | 0.01 |
| 2001 | 274.30 | 110,863 | 127,627 | 3973 | 0.00 |
| 2002 | 291.84 | 121,717 | 128,453 | 4288 | 0.00 |
| 2003 | 339.08 | 137,422 | 129,227 | 4592 | 0.00 |
| 2004 | 396.72 | 161,840 | 129,988 | 5123 | 0.00 |
| 2005 | 467.63 | 187,319 | 130,756 | 5754 | 0.00 |
| 2006 | 561.41 | 219,439 | 131,448 | 6399 | 0.47 |
| 2007 | 705.23 | 270,232 | 132,129 | 7553 | 4.68 |
| 2008 | 812.94 | 319,516 | 132,802 | 8685 | 5.03 |
| 2009 | 895.20 | 349,081 | 133,450 | 9491 | 6.75 |
| 2010 | 1069.41 | 413,030 | 134,091 | 10,892 | 13.56 |
| 2011 | 1305.30 | 489,301 | 134,735 | 13,102 | 21.01 |
| 2012 | 1463.00 | 540,367 | 135,404 | 14,663 | 25.64 |
| 2013 | 1705.37 | 595,244 | 136,072 | 16,150 | 30.91 |
| 2014 | 1868.94 | 643,974 | 136,782 | 17,732 | 32.86 |
| 2015 | 1931.75 | 689,052 | 137,462 | 19,349 | 33.35 |
| 2016 | 2078.06 | 743,586 | 138,271 | 21,166 | 35.60 |
| 2017 | 2373.00 | 827,122 | 139,008 | 22,841 | 37.80 |
| Model | R2 | MSE | MAE | MAPE |
|---|---|---|---|---|
| ELM | 0.9637 | 41.8220 | 17.4555 | 0.0467 |
| AdaBoost-ELM | 0.9969 | 29.3581 | 12.0851 | 0.0292 |
| PSO-ELM | 0.9999 | 0.8624 | 0.2470 | 0.0008 |
| AdaBoost-PSO-ELM | 0.9999 | 0.8435 | 0.2379 | 0.0008 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
De, G.; Gao, W. Forecasting China’s Natural Gas Consumption Based on AdaBoost-Particle Swarm Optimization-Extreme Learning Machine Integrated Learning Method. Energies 2018, 11, 2938. https://doi.org/10.3390/en11112938
De G, Gao W. Forecasting China’s Natural Gas Consumption Based on AdaBoost-Particle Swarm Optimization-Extreme Learning Machine Integrated Learning Method. Energies. 2018; 11(11):2938. https://doi.org/10.3390/en11112938
Chicago/Turabian StyleDe, Gejirifu, and Wangfeng Gao. 2018. "Forecasting China’s Natural Gas Consumption Based on AdaBoost-Particle Swarm Optimization-Extreme Learning Machine Integrated Learning Method" Energies 11, no. 11: 2938. https://doi.org/10.3390/en11112938
APA StyleDe, G., & Gao, W. (2018). Forecasting China’s Natural Gas Consumption Based on AdaBoost-Particle Swarm Optimization-Extreme Learning Machine Integrated Learning Method. Energies, 11(11), 2938. https://doi.org/10.3390/en11112938