1. Introduction
Electric load forecasting (ELF) is essential for the effective and stable planning and operation of power systems [
1]. Forecasting models are constructed based on historical load series and exogenous variables (e.g., weather, economic, and social factors), and the models are used to predict future loads for a specified period of time ahead. Various decisions related to power systems depend on the future behavior of loads, such as unit commitment, spinning reserve reduction, economic dispatch, automatic generation control, reliability analysis, maintenance scheduling, and energy commercialization [
2,
3]. ELF, especially, has major effects on deregulated electricity markets (e.g., demand response management [
4,
5,
6]) and their participants because the prices on the markets are determined by the predicted future loads. Therefore, accurate and robust ELF can contribute greatly to decision making related to power systems. However, it is difficult to precisely forecast time-series loads because they exhibit a high degree of seasonality and nonlinear characteristics.
In recent decades, a wide range of methods has been proposed for ELF. In particular, artificial intelligence-based methods such as artificial neural networks (ANNs) [
7,
8,
9,
10] and support vector regression (SVR) [
11,
12,
13,
14,
15] have been applied successfully to ELF due to their excellent learning capacity and nonlinear mapping ability without requiring any prior domain knowledge. However, ANNs based on the empirical risk minimization principle often suffer from over-fitting problems. Furthermore, when derivative-based optimization techniques are used for training ANNs, they are likely to be trapped in a local minimum. Compared to ANNs, over-fitting problems can be overcome in SVR because it is based on the structural risk minimization principle [
16,
17], i.e., the learning error and generalization capability are considered simultaneously.
The importance of ELF and its difficulty have motivated extensive studies, but the problem of input selection for ELF models remains an open question. In ELF, a major issue is selecting significant inputs (SIs) from many initial input candidates (IICs). Three main reasons necessitate input selection procedures [
18,
19]. First, properly selected inputs decrease the complexity of the model, and thus facilitate more efficient learning. Second, the forecasting performance can be improved by removing redundant inputs that are irrelevant to the outputs and dependent on other inputs. Finally, we can gain valuable insights into the fundamental features of loads and their prediction mechanism. In the following, we summarize several previous studies on input selection methods for load forecasting.
Ghofrani et al. [
20] proposed a new input selection framework by combining correlation analysis and the
l2-norm for short-term load forecasting (STLF). Koprinska et al. [
21] used mutual information (MI), RReliefF, and a correlation-based method for feature selection of the load forecasting model. Sheikhan and Mohammadi [
22] developed a feature selection method by combining a genetic algorithm with ant colony optimization for STLF. Tikka and Hollmén [
23] proposed sequential backward input selection for ELF, which is based on a linear model and a cross-validation resampling procedure. Sorjamaa et al. [
24] combined a direct prediction strategy with three input selection criteria, i.e.,
k-nearest neighbors approximation method, MI, and nonparametric noise estimation, for ELF. Da Silva et al. [
25] used filter methods based on phase-space embedding and MI and Bayesian wrapper methods for ANN-based ELF. Hu et al. [
19] proposed a hybrid filter-wrapper approach with a partial MI and firefly algorithm for STLF feature selection.
In general, the methods mentioned above can be categorized as filter (model-free) or wrapper (model-based) methods [
26,
27,
28,
29]. In filter methods, after statistical analyses between the potential inputs and output, the inputs with strong relationships to the output are selected as SIs. In wrapper methods, the accuracy of learning machines is used as a selection criterion and the best input combinations are explored by sequential search procedures, such as backward elimination, forward selection, stepwise selection, and metaheuristics. Filter methods can select SIs without learning machines, but these methods do not consider the prediction accuracy, and thus they often perform worse than wrapper methods. Linear correlation (LC) analysis, frequently used in filter methods, with nonlinear predictors can degrade the forecasting performance because they cannot identify nonlinear relationships between inputs and output. In wrapper approaches, the best input combinations are determined by the sequential search procedures, so the computational complexity grows exponentially with the number of IICs. Furthermore, depending on the structure and parameter identification methods used for wrappers, biased input selection results may be obtained.
In summary, instead of only considering the one-to-one statistical correlations, input selection methods for data-driven load forecasting should be able to tackle both the many-to-one nonlinear relationships between dependent and independent variables and the accuracy of the forecasting machines.
In this paper, we propose a new input selection procedure based on the group method of data handling (GMDH) and the bootstrap method for ELF. Although there are several previous studies where GMDH is employed for ELF [
30,
31], this paper is the first attempt to use GMDH only for input selection. Generally, GMDH networks have been widely used for modeling the nonlinear relationships between variables. Compared with the previous approaches, this paper focuses on the fact that, based only on a given dataset, the GMDH algorithm can not only determine the network structures but also select the inputs with significant explanatory powers for predicting the outputs. In the GMDH algorithm, the GMDH networks where polynomial neurons are hierarchically connected with each other are automatically constructed using learning datasets collected from target systems. Among a number of IICs, the remaining elements in the input layer of the finally constructed GMDH network are considered as relevant inputs. The learning dataset should be divided into training and test datasets to construct the GMDH network. In this study, bootstrap method is applied for the data division. The learning dataset is divided randomly by bootstrap sampling, so the relevant inputs are different each time. Therefore, in the proposed method, after constructing GMDH networks several times using bootstrapping, the inputs that appear frequently in the input layers of the completed networks are finally selected as the SIs.
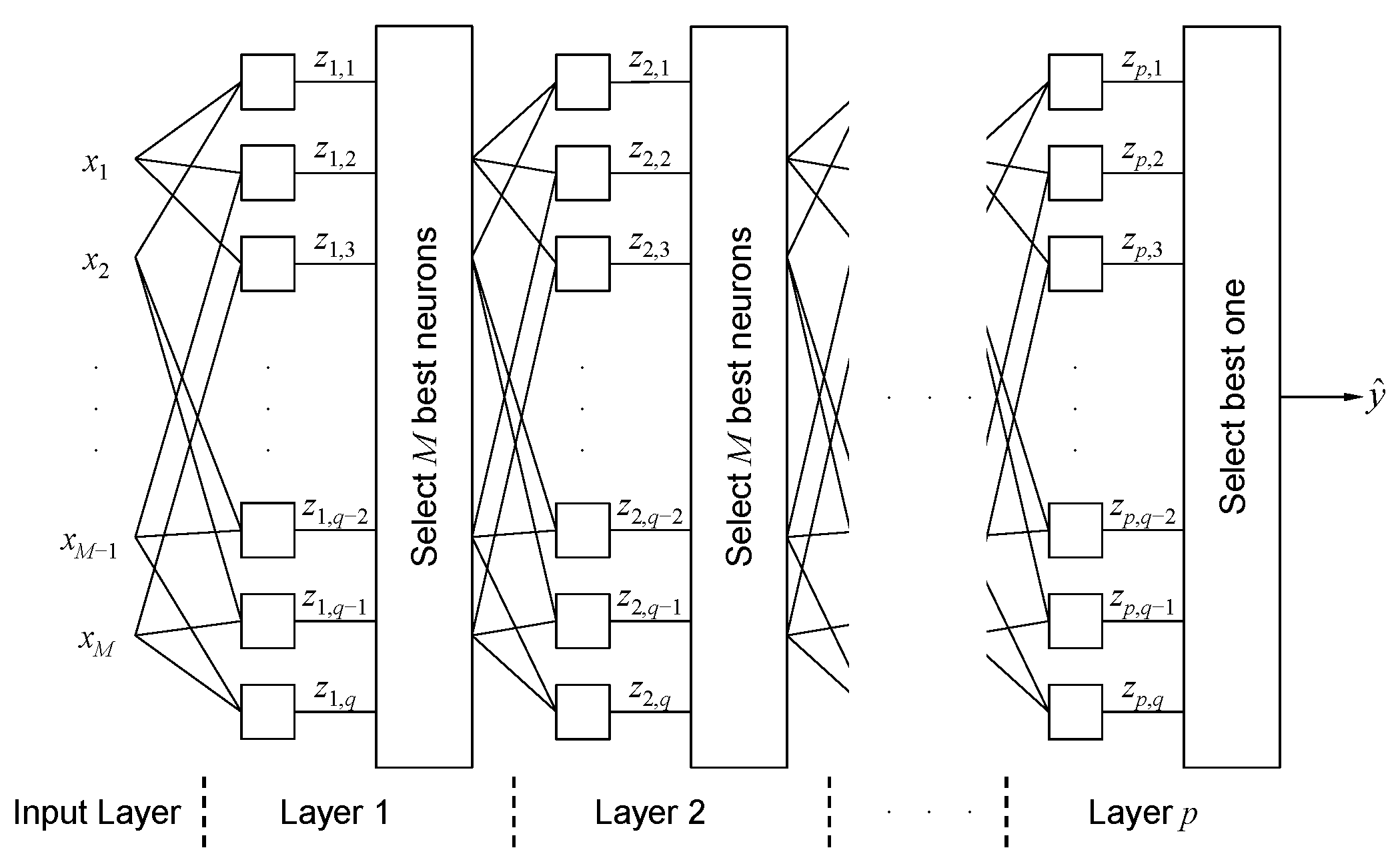
The main advantages of the proposed input selection method combining the GMDH and bootstrap method can be briefly summarized as follows. First, based on the GMDH network structures in which the polynomial neurons are hierarchically connected with each other (see
Figure 1), the method can select significant inputs by taking many-to-one nonlinear relationships between explanatory and target variables into consideration. Second, since prediction accuracy is used as the input selection criterion (see
Section 2.2), it is expected that the method achieves improved forecasting performance compared to filter methods based only on the statistical analyses.
To verify the performance of the proposed method, we use hourly load data from South Korea with seasonality, weekly and daily periodicity. LC- and MI-based filter methods are employed as comparison methods. In addition, hybrid approaches that combine the filter methods with the proposed method are also examined. In total, five input selection methods are investigated. Prediction models are constructed via ν-SVR, and we compare the one-hour, one-day, and one-week-ahead forecasting performance of the five input selection methods.
The remainder of this paper is organized as follows.
Section 2 explains the procedure for GMDH network building. In
Section 3, the new input selection method based on GMDH and bootstrap sampling, LC- and MI-based filter methods, and hybrid approaches are described.
Section 4 briefly summarizes
ν-SVR. In
Section 5, we present the experimental results, and discuss the results in detail in
Section 6. Finally, we give our conclusions in
Section 7.
2. Group Method of Data Handling
Ivakhnenko first proposed the GMDH algorithm in 1968, which is a self-organizing modeling technique [
32,
33,
34]. In the GMDH method, as shown in
Figure 1, complex and nonlinear modeling is performed by the GMDH network where polynomial neurons are hierarchically connected in a forward direction.
A quadratic two-variable polynomial is commonly used as a transfer function for each neuron and their coefficients can be estimated by the least-squares method. When the number of entering inputs and/or the order of the polynomials become larger, the number of parameters to be estimated rapidly increases. To build a GMDH network, only the learning dataset collected from target systems is needed, and relevant inputs as well as the network structure can be determined automatically.
Let be a learning dataset for GMDH network building, where x = [x1, x2, …, xM]T is an input vector composed of IICs and M is the number of the IICs. In layer 1, (q = M(M − 1)/2) neurons that consider all combinations of the initial inputs are generated and only the outputs of M neurons that satisfy a selection criterion are used as inputs for the next layer. In the same manner, q neurons are generated from layer 2 based on the M neurons selected in the previous layer. This layer extension process continues in a forward direction until a stopping criterion is satisfied. After stopping the extension process, the output layer and neuron are fixed and all of the elements connected with the output neuron are found sequentially by backward search.
2.1. Parameter Estimation for Polynomial Neurons
In the GMDH network, the output,
z, of an arbitrary neuron is calculated as
where
xu and
xl are two inputs of the neuron and
θ = [
θ0, …,
θ5]
T is composed of its polynomial coefficients. The same learning dataset
D is employed repeatedly to estimate parameters for each neuron. After substituting
D into (1), the
n linear equations are formulated in concise matrix form, i.e.,
Xθ =
z. Using the least-squares method, the parameter vector
θ can be optimized as
In (2), if the determinant of
XTX is close to zero, then the estimator
is rather susceptible to round off errors and its performance deteriorates. In this study, the polynomial coefficients are estimated using singular value decomposition, as follows [
35,
36]:
where
X+ is the pseudo-inverse of
X, the columns of matrices
V and
U correspond to the eigenvectors of
XTX and
XXT, respectively, and the main diagonal components of
S+ are composed of the reciprocals of
r singular values.
2.2. Construction of the GMDH Network
To build the GMDH network, layer extension is performed in the forward direction until the stopping criterion is satisfied. Next, the output layer and neuron are fixed and a search for all of the elements connected to the output neuron is conducted by backward tracing, i.e., from the output to input layer. After finishing the search in the backward direction, we can obtain not only the GMDH network structure, but also relevant inputs in the input layer.
In the proposed method, checking error criterion (
CEC) [
37] is employed: (1) to select the neurons whose outputs will be used as inputs for the next layer; and (2) to determine whether the layer extension process should be stopped. The number of layers in the GMDH networks is closely related to the model’s complexity. The deeper the networks, the more complex their structures; in this case, many unnecessary inputs can be selected together with significant inputs. On the other hand, if the networks are too shallow, input variables with great explanatory powers can be missed. To calculate the
CEC, the learning dataset
D is separated into dataset A,
, and dataset B,
, using the bootstrap method [
38]. In the bootstrap method, after applying
n sampling with replacement to
D, we obtain
n data pairs. Each data pair in
D has the same probability of being selected during the sampling process. Among the
n sampled data pairs, only unique pairs comprise
DA for training and
DB consists of the remaining data pairs, i.e.,
DB =
D\
DA for testing. The ratio of
DA relative to
DB is approximately 6:4.
Using
DA, the parameter vector of a neuron is estimated by (3) and the outputs are calculated based on
DB,
,
k = 1, …,
nB. The
CEC of the neuron is computed by
After calculating the
CEC for
q neurons in the
ith layer, i.e.,
CEC(
i,
j),
j = 1, …,
q, they are arranged in ascending order and only the
M neurons with the smallest
CEC values are selected. If an early stopping condition,
CEC(
i − 1) ≤
CEC(
i),
i ≥ 2, (where
CEC(
i) = min
j{
CEC(
i,
j)},
j = 1, …,
q), is satisfied or the current layer is equal to the predefined maximum layer, then the layer extension is halted. Then, the output layer
p* and output neuron
q* are selected as follows:
After selecting the output neuron, all of the elements connected with the neuron are found by a sequential search in the backward direction. In each layer, neurons without any connections to the output neuron are removed and the remaining neurons and their connections are preserved. The GMDH network is finally constructed after finishing the backward search from the output to input layer. Algorithm 1 describes the procedure for constructing the GMDH network.
| Algorithm 1. Constructing the GMDH network. |
Input: learning dataset D
Divide D into DA and DB using bootstrap method
Imax ← maximum layer
BN ← {x1, …, xM} //where BN denotes the set of ‘best neurons’.
for i from 1 to Imax
Create (q = M(M − 1)/2) neurons in ith layer based on BN
for j from 1 to q
Estimate of jth neuron using DA
Calculate CEC(i, j) for jth neuron using DB
end
CEC(i) = minj{CEC(i, j)}, j = 1, …, q
if i ≥ 2 then
if CEC(i − 1) ≤ CEC(i) then
break this loop
end
end
BN ← M neurons in ith layers with smallest CEC(i, j), j = 1, …, q
end
p* ← argmini{CEC(i)}
q* ← argminj{CEC(p*, j)}
Remove all neurons in p*th layer except for q*th neuron
p ← p*
repeat
p ← p − 1
Find the neurons in pth layer connected with neurons in (p + 1)th layer
Remove all neurons and their connections in pth layer except for the founded neurons
until p == 0
return GMDH network structure and a set of relevant inputs, |
From the final constructed GMDH network, we can confirm the inputs in the input layer connected with the output neuron and they are regarded as relevant inputs.
4. ν-Support Vector Regression
In this section, we briefly summarize
ν-SVR [
41] as proposed by Schölkopf et al. Let
denote a collected learning dataset, where
is an
n-dimensional input vector and
is the target output. The basic idea of SVR is to find a linear regression function after transforming the original space into a high-dimensional feature space, which is defined as
where
ϕ(∙) is a nonlinear mapping function from the input to feature space, and
w and
b are parameters of
f that should be estimated from the learning dataset. The constrained optimization problem of
ν-SVR is defined by introducing two positive slack variables
and
, as follows [
42]:
where
is a regularization term, the parameter
controls the number of support vectors and training errors, and
C is a regularization constant that determines the tradeoff between the model’s complexity and its accuracy. The training errors of regression function
f are penalized by
ξi and
ξi*, if they are larger than
ε. The size of
ε is traded off against the model’s complexity and slack variables via a constant
ν [
41]. As described in (9), SVR avoids under-fitting and over-fitting by minimizing both the regularization term and training errors.
By introducing Lagrange multipliers
αi and
αi*, and applying Karush-Kuhn-Tucker conditions [
43], the constrained optimization problem given by (9) is reformulated as follows:
where
Q is a kernel matrix and its entry in the
ith row and
jth column is
Qi,j =
K(
xi,
xj) ≡
ϕ(
xi)
Tϕ(
xj). The kernel function
K(
xi,
xj) defined in the input space is the same as the inner product of
xi and
xj in the feature space. The nonlinear mapping and inner products can be calculated in the original input space using the kernel function. In this paper, among the widely used kernel functions, such as polynomial, radial basis function (RBF), and sigmoidal kernels, we employed the RBF kernel function defined as
where
γ controls the width of the RBF function. By solving (10), we can obtain the approximated regression function as follows:
The prediction accuracy of
ν-SVR depends on the selection of appropriate design parameters, i.e.,
ν,
C, and
γ. Trial and error, cross-validation, grid search, and global optimization have been applied widely for determining the parameter values [
2]. The aim of this paper is to examine the performance of the proposed input selection methods, so the procedures for selecting the design parameters will not be described in detail. In this study, the method presented in [
3] is used to determine the design parameters.
5. Experimental Results
To verify the performance of the proposed method, hourly load data from South Korea between 1 January 2012 and 31 December 2014 was used.
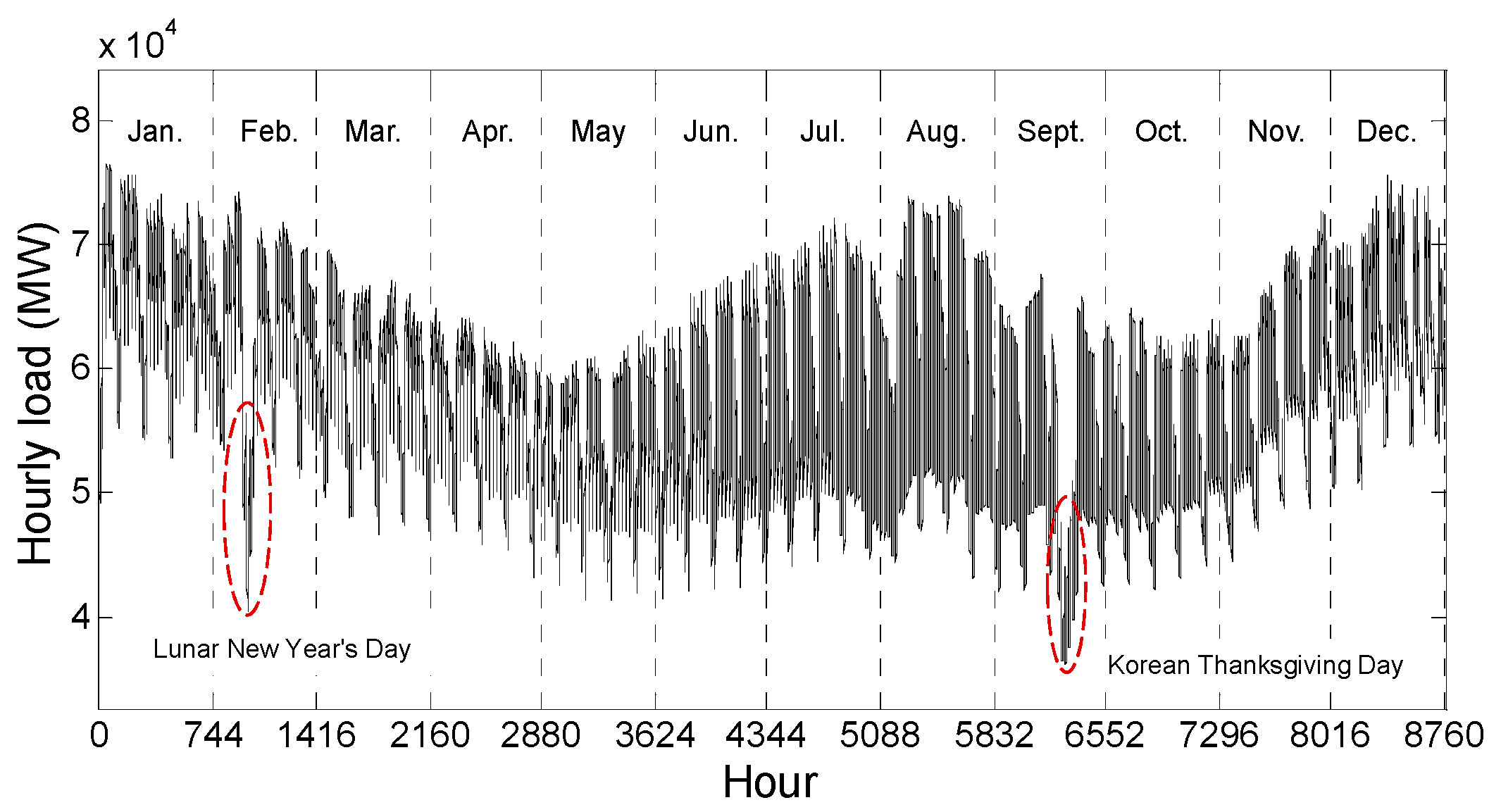
Figure 2 shows the hourly load curves for South Korea during one year (i.e., 2013) and
Figure 3 shows an example of the weekly profile for the curves during three weeks from 7 January 2013 until 27 January 2013.
As shown in
Figure 2 and
Figure 3, the target loads exhibit clear seasonality with weekly and daily periodicities. The load demand is usually higher in the summer and winter seasons compared with the spring and autumn seasons. The demand for electricity is higher on weekdays (from Monday to Friday) compared with weekends and the load demand is slightly higher on Saturday than Sunday. The minimum load on Monday is lower than that on other working days. In addition, the load demand on special days (e.g., national holidays and election days) exhibit remarkably unusual behavior. In this paper, we are not concerned with hourly load forecasting on special days, i.e., we focus only on hourly load forecasting for ordinary days.
To validate the seasonal forecasting performance, we select three months as validation months, i.e., April, July and November in 2014, where the objective is to predict their hourly load demands one hour, one day, and one week ahead. For the one-day and one-week-ahead forecasts that correspond to multi-step-ahead predictions, we employed the recursive strategy [
44] explained in
Appendix A.
5.1. Data Preparation
To prepare the learning dataset, we considered historical time-series load data {
φt,
t = 1, …,
N}. For example, to predict the hourly load demand from 1 to 30 April in 2014, the load data from 1 January 2012 to 31 March 2014 is employed to prepare the learning data. After organizing the learning data matrix described in (13) using
N historical data, the max-min normalization process is applied to each column as presented in (14).
where Φ
i,j is the original component in the
ith row and
jth column of
Φ and Φ′
i,j is its normalized value. The learning data matrix is an (
N −
d) × (
d + 1) matrix, where
d is the window size, i.e., the number of IICs. In this paper, to capture the daily and weekly periodicities of the target load, we chose a one-week window size, i.e.,
d = 168. The last column in
Φ is composed of the desired outputs and the remaining columns consist of 168 IICs. Each row vector in
Φ corresponds to an input-output learning data pair.
To take account of the seasonality, we reformulated a new matrix Φnew composed of the row vectors of Φ, where the last column’s components (i.e., desired outputs) only correspond to the load values of a validation month and the previous month. For example, to forecast the hourly load during April in 2014, Φnew is made up of row vectors where the desired outputs correspond to the hourly load during March and April in 2012 and 2013 and March in 2014.
Finally, the row vectors that contain hourly load values on special days are removed from Φnew. In other words, if only one component of the row vectors corresponds to the hourly load for special days, the row vectors are discarded. This is necessary because the hourly load curves for special days have different shapes from those for normal days. If the prediction models for normal days are trained by learning data with load values on special days, biased forecasting results could be obtained.
The input selection methods explained in
Section 3 were applied to the learning dataset prepared according to the procedures described above.
5.2. Input Selection Results
In this subsection, we present the results of applying the input selection methods to the prepared learning dataset. As explained in
Section 3, we employed five input selection methods, which are abbreviated as follows.
- (1)
‘LC’: LC-based filter method.
- (2)
‘MI’: MI-based filter method.
- (3)
‘GMDH’: the proposed method described in Algorithm 2.
- (4)
‘LC + GMDH’: hybrid input selection method combining ‘LC’ and ‘GMDH’.
- (5)
‘MI + GMDH’: hybrid input selection method combining ‘MI’ and ‘GMDH’.
(Note: The acronyms, LC and MI, denote the RFs, but the abbreviations, ‘LC’ and ‘MI’, refer to the LC- and MI-based filter methods.)
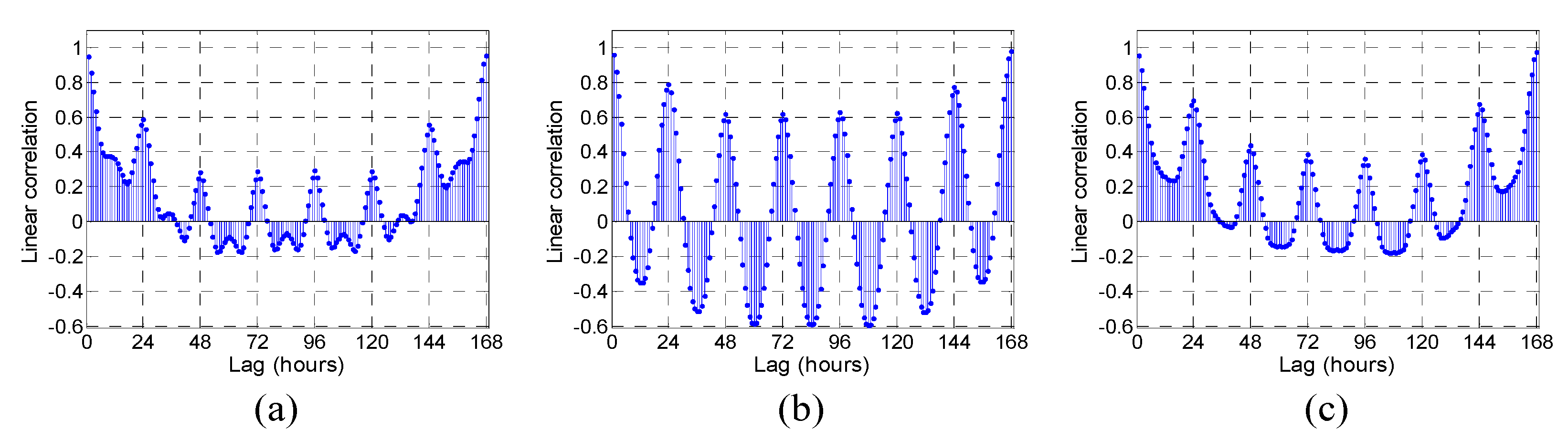
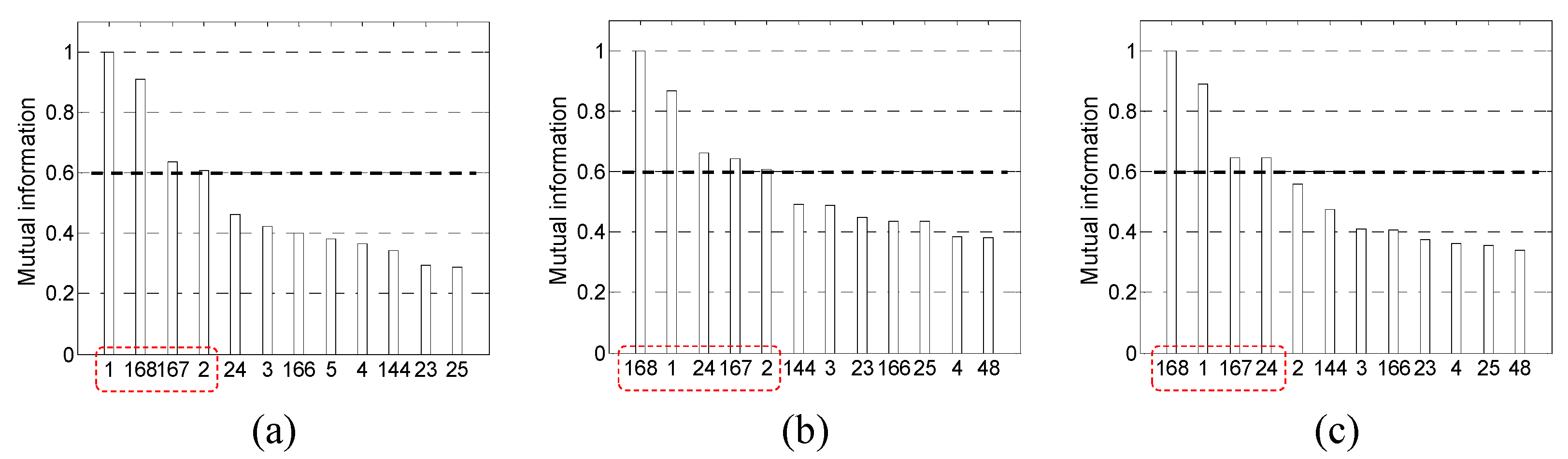
Figure 4 and
Figure 5 show the LC and MI values calculated using the prepared learning dataset for predicting the loads in April, July and November in 2014.
In
Figure 5, the MI values are normalized in a range of [0, 1].
Figure 4 and
Figure 5 demonstrate that the shapes of LC and MI differ from the validation months because the target loads exhibit distinct seasonal behaviors. Daily and weekly periodicities can also be observed in these figures. In the filter methods based on LC and MI, after rearranging the calculated
RF values in descending order,
m inputs with
RF values greater than or equal to the predefined
RFth are finally selected as SIs.
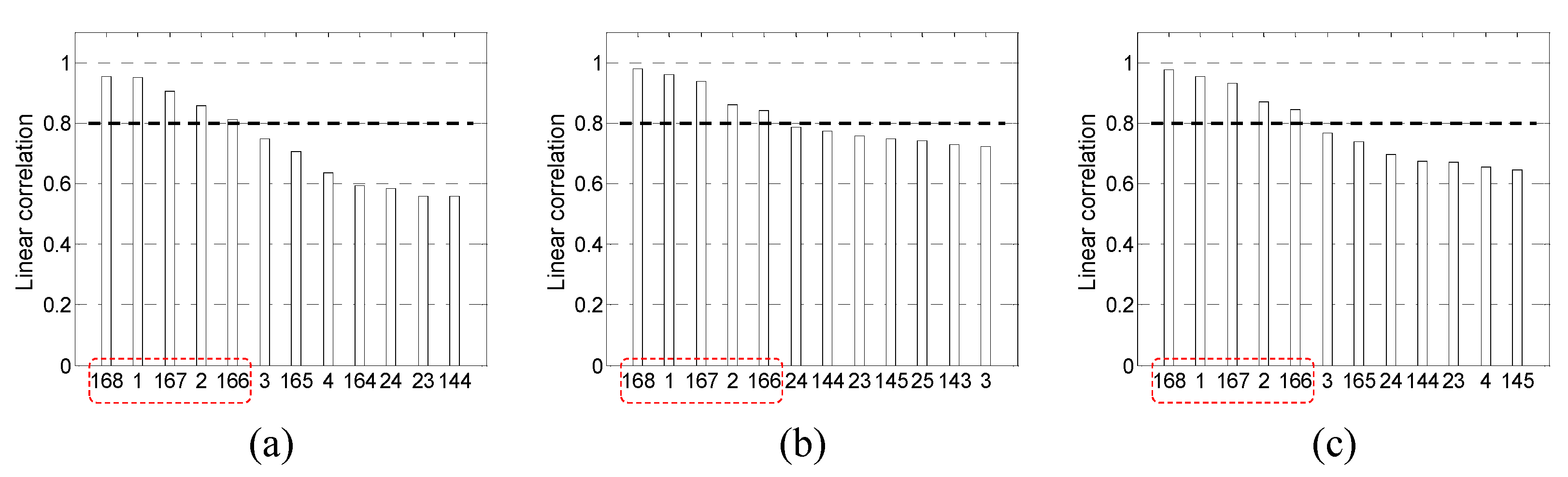
Figure 6 and
Figure 7 show the input selection results using ‘LC’ and ‘MI’.
As shown in
Figure 6 and
Figure 7, the threshold values for LC and MI are set as 0.8 and 0.6, respectively, and they are indicated by dashed thick solid black lines. The selected inputs are indicated by dashed red lines in the figures.
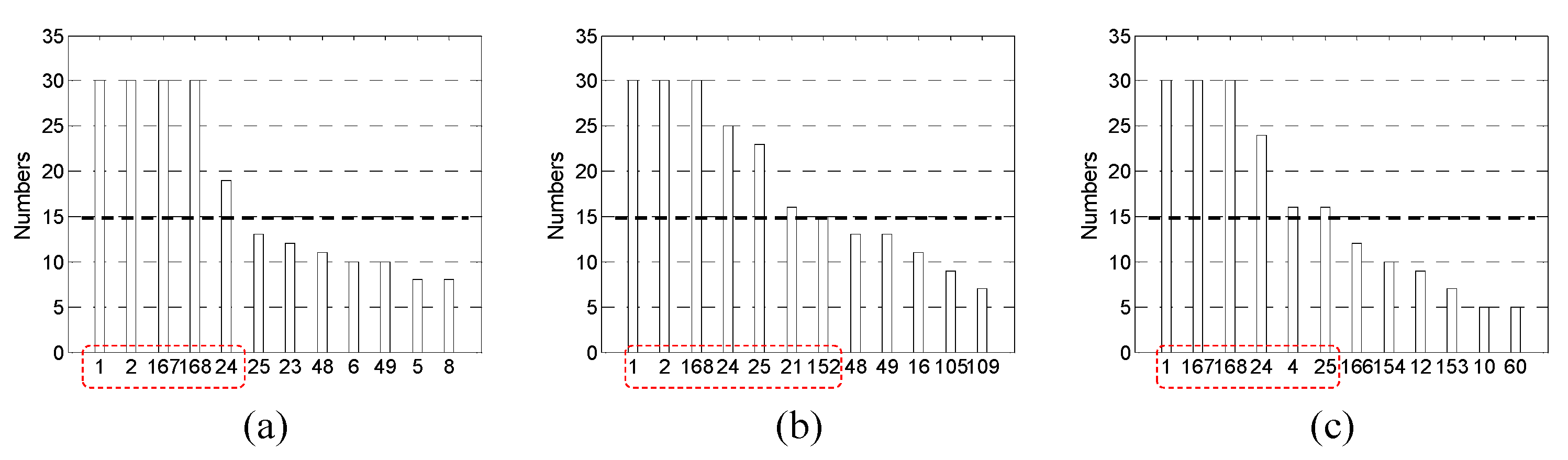
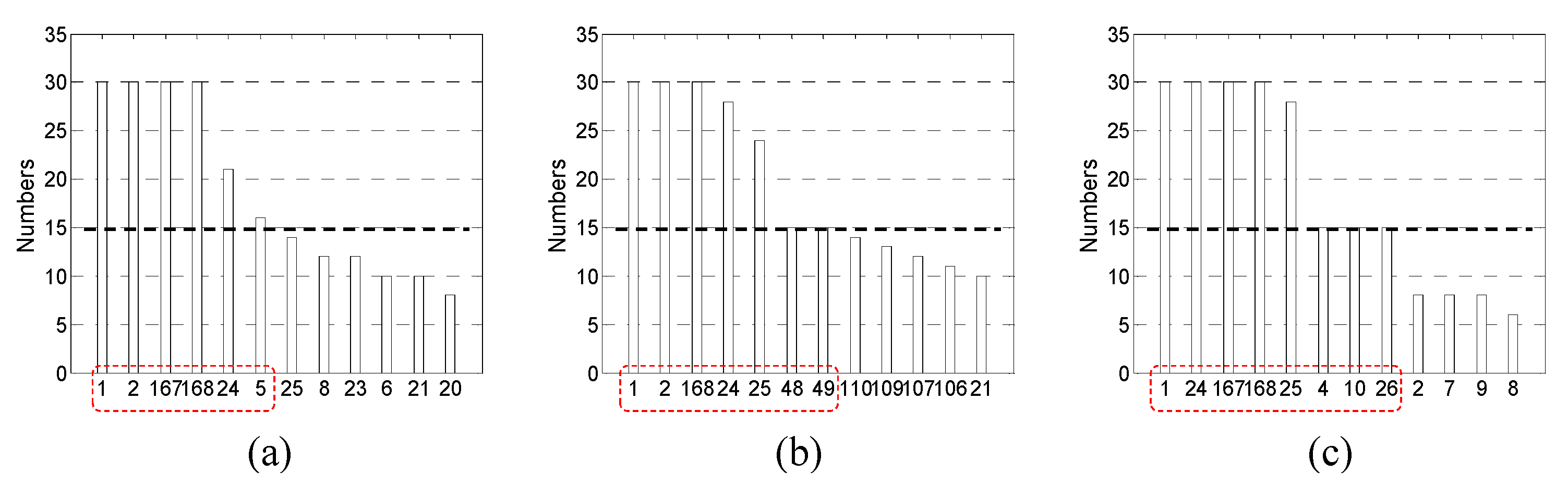
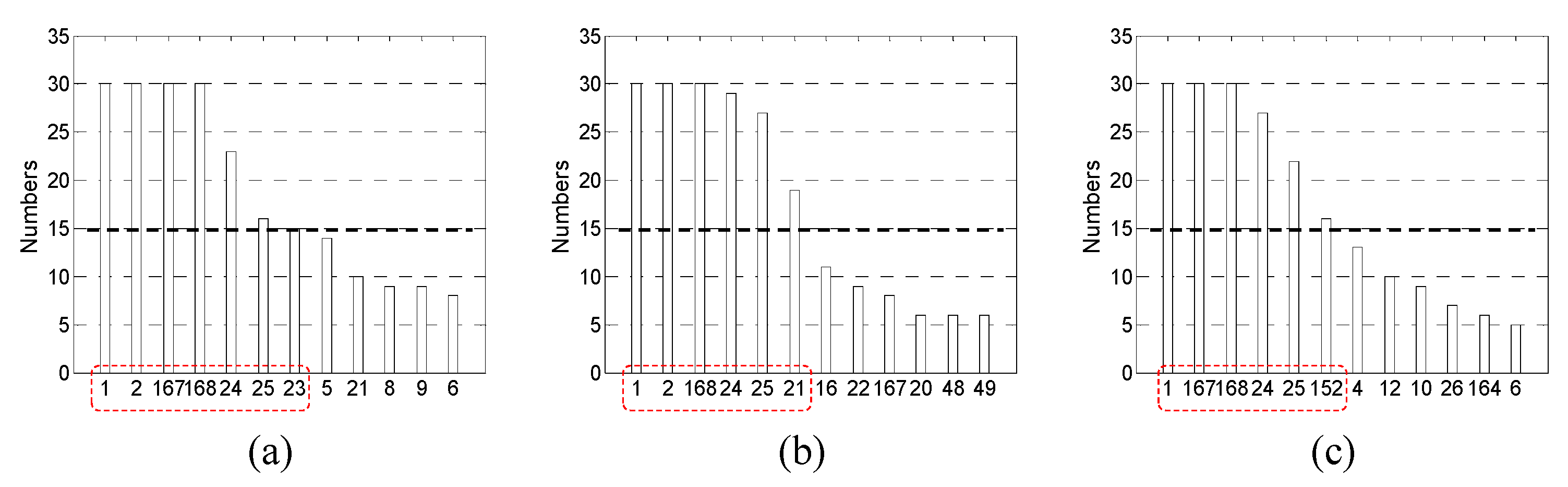
As explained in
Section 3.2, in the ‘GMDH’, GMDH networks were constructed independently
r times on the same conditions. In this paper,
r is set to 30. In
Table 1, and the maximum layer,
Imax, is set to 5 based on several trial-and-errors. Note that
Imax corresponds to the maximum acceptable depth of the GMDH networks. Through several prior experiments, we confirmed that the forecasting performance may be degraded when
Imax is too large (e.g.,
Imax ≥ 7) or too small (e.g.,
Imax ≤ 3). If
Imax is set to be excessively large values, and consequently, too many inputs are selected, then it is difficult to intuitively understand the predictive principles of target data.
Table 1 lists the results of applying Algorithm 1 for 30 times to the prepared learning dataset for predicting the loads in April 2014.
After the relevant input set
Xi is joined into the union
, the frequency of each element in
X,
Nj (
j = 1, …, 168), is counted. Next,
Nj are arranged in descending order and the
m inputs that satisfy a condition, i.e.,
Nj ≥
Nth, are finally selected, where
Nth is the threshold value of
Nj. In the hybrid methods, after removing many redundant inputs using ‘LC’ or ‘MI’, ‘GMDH’ is applied to the remaining inputs. In this study, two-thirds of the IICs were filtered by ‘LC’ or ‘MI’.
Figure 8,
Figure 9 and
Figure 10 show the input selection results using ‘GMDH’, ‘LC + GMDH’ and ‘MI + GMDH’, respectively.
As shown in
Figure 8,
Figure 9 and
Figure 10, the threshold value,
Nth, is set as 15 and the values are marked by dashed thick solid black lines in the figures. The inputs for which
Nj is greater than or equal to
Nth, i.e.,
Nj ≥
Nth, are enclosed within dashed red lines.
Table 2 summarizes the SIs selected by the five methods for each validation month (i.e., April, July, and November in 2014). As listed in
Table 2, the loads in the same hour during the past several days (i.e.,
φt−23 and
φt−167) as well as several recent loads (i.e.,
φt and
φt−1) are useful for predicting future loads.
In addition to the selected SIs listed in
Table 2, we also employed binary-valued vectors used in [
45], i.e.,
and
, for ELF models to keep track of the daily and weekly periodicities, where
w and
h are vectors of zero with a 1 in the position of the day of the week and the hour of the day for the load under consideration, respectively.
5.3. Forecasting Results
After conducting the input selection procedures,
ν-SVR learning was carried out with the SIs and binary-valued vectors,
w and
h. For example, when the load demand during April 2014 was predicted with ‘LC’, the input vector for
ν-SVR corresponds to
x = [
φt,
φt−1,
φt−165,
φt−166,
φt−167,
wt+1,
ht+1]
T. In this paper, we used LIBSVM [
46] to implement
ν-SVR. The accuracy of the ELF was measured using six performance indices, which were also employed in [
2,
3], i.e., mean absolute percentage error (MAPE), symmetric mean absolute percentage error (SMAPE), mean absolute error (MAE), normalized mean squared error (NMSE), relative error percentage (REP) and magnitude of maximum error (MME). In the following, we only present the results of the performance comparisons using MAPE, which is defined as
where
Ai and
Fi are the actual and predicted values for the
ith validation dataset, respectively, and
N is the number of validation dataset. The performance comparisons using the other indices are presented in
Appendix B.
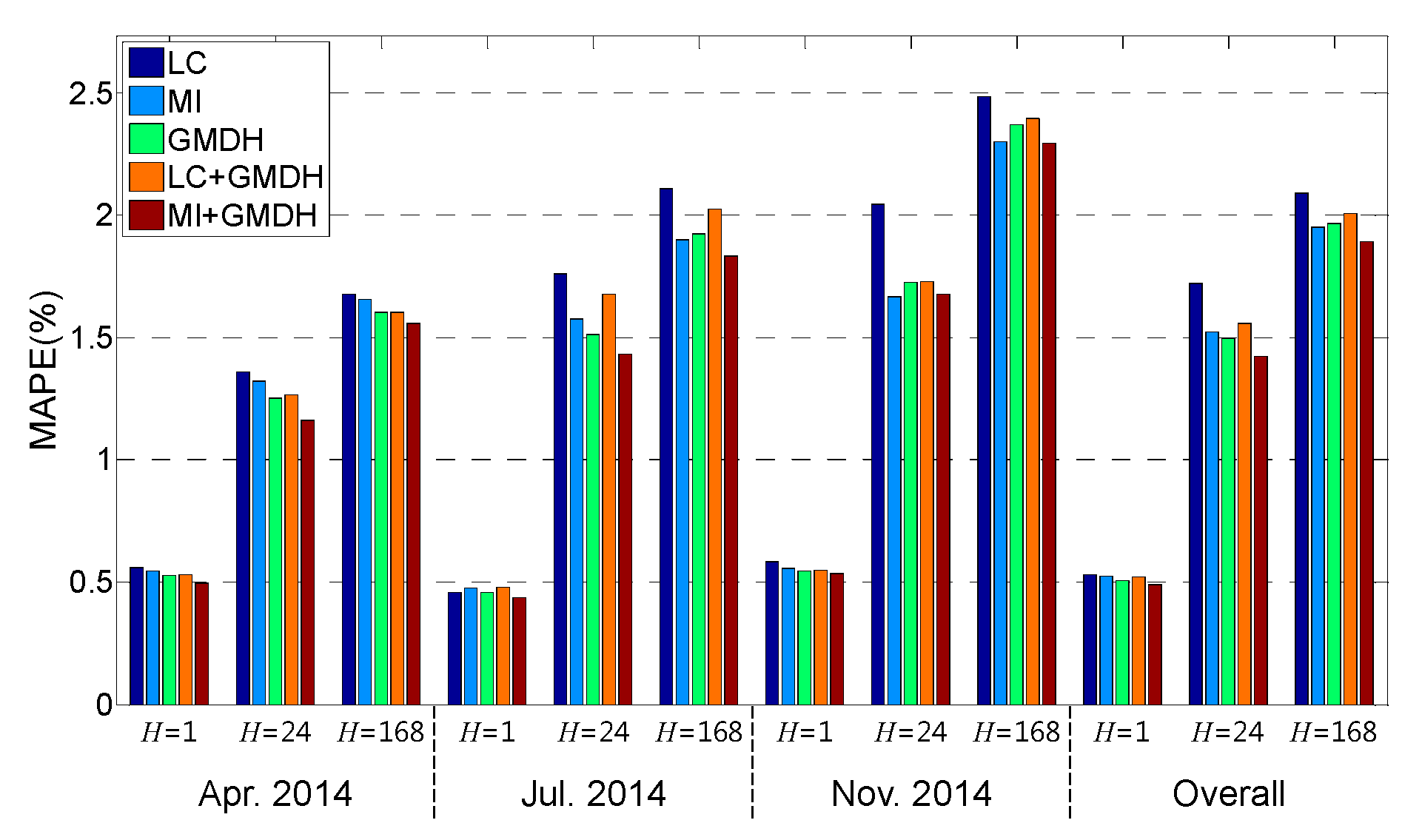
Table 3 and
Figure 11 illustrate the MAPE values of each validation month and the overall values for five input selection methods.
In
Table 3, the best entries among ‘LC’, ‘MI’ and ‘GMDH’ are indicated by the superscript plus sign and the best entries among the five input selection methods are highlighted by the superscript asterisk. When
H = 1, i.e., in the case of one-hour ahead forecasting, MAPE values of every validation month are similar to each other; but when
H = 24 and 168, they are quite different. This can be attributed to the fact that load variations in July and November are higher than those in April because of seasonal effects; it can be observed that MAPE values for multi-step ahead forecasting in July and November are larger than those in April.
As illustrated in
Table 3 and
Figure 11, ‘GMDH’ shows the best prediction performance among ‘LC’, ‘MI’, and ‘GMDH’ in terms of the overall MAPE, except for one-week-ahead forecasting. Among the five methods, ‘MI + GMDH’ shows the best forecasting performance, except for the one-day-ahead forecast for November 2014. Let us look at how much ‘MI + GMDH’ improves the overall MAPE compared with the other methods. For one-hour-ahead forecasting, the percentage improvements with ‘MI + GMDH’ are 8.19%, 6.79%, 3.80%, and 5.72% compared with the four methods, respectively. For one-day and one-week-ahead forecasting, ‘MI + GMDH’ improves the overall MAPE compared with the other methods by 17.35%, 6.45%, 4.91%, and 8.64%, and by 9.34%, 2.93%, 3.64%, and 5.65%, respectively.
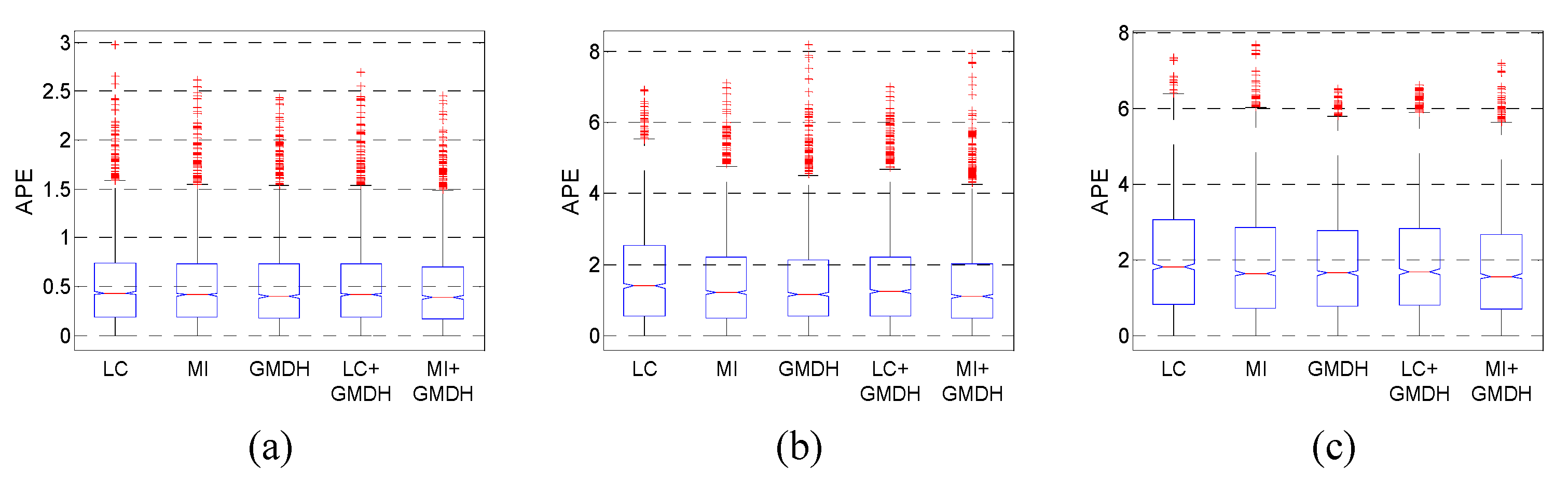
Figure 12 shows box plots of the overall absolute percentage errors. As shown in
Figure 12, ‘MI + GMDH’ exhibits superior performance compared with the other methods.
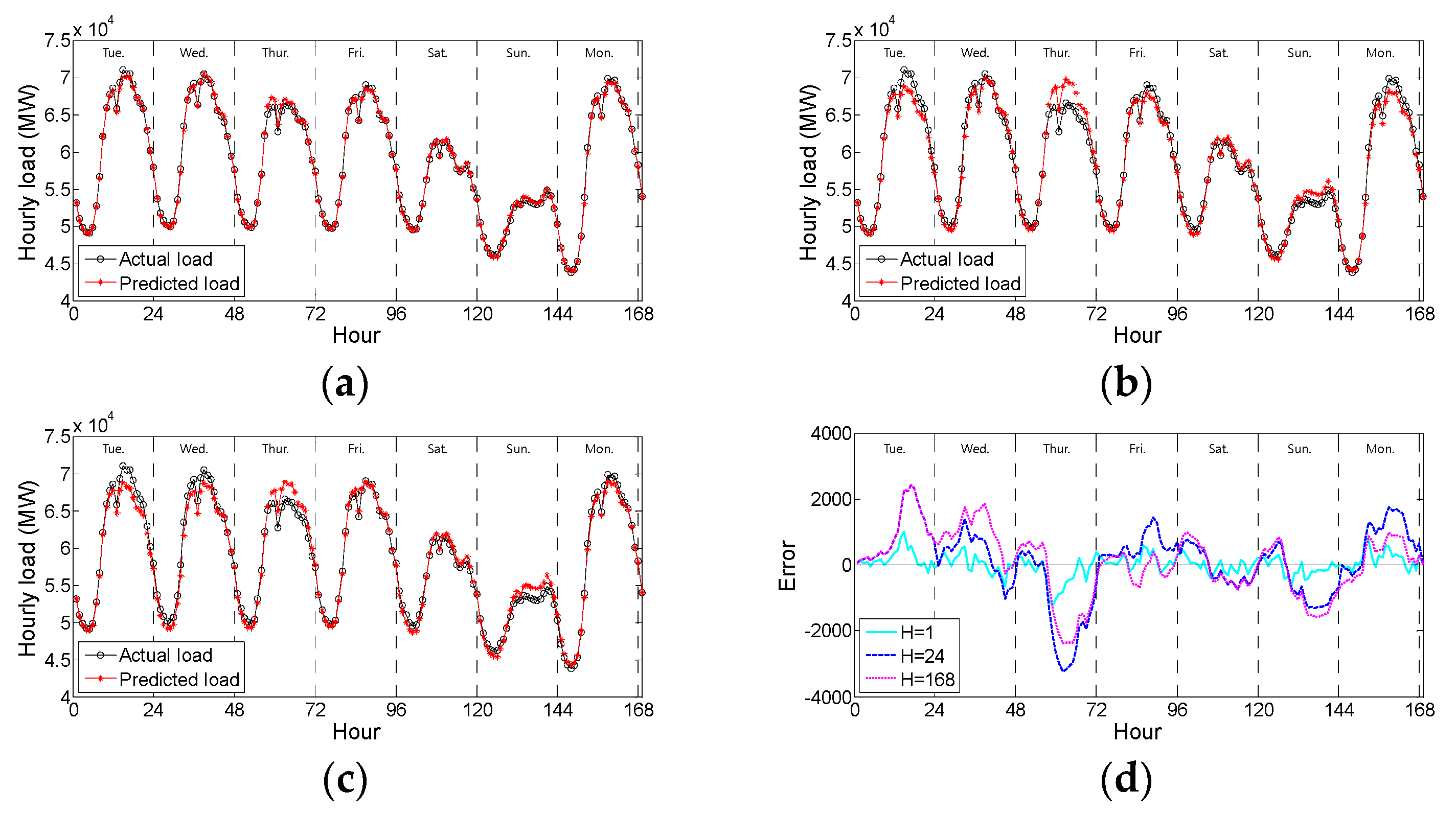
Figure 13 shows examples of the actual and predicted load curves obtained using ‘MI + GMDH’ and
ν-SVR. Due to space constraints, the load curves for the other validation months and periods are not presented. In
Figure 13, the load values predicted by ‘MI + GMDH’ and
ν-SVR are very similar to the actual values.
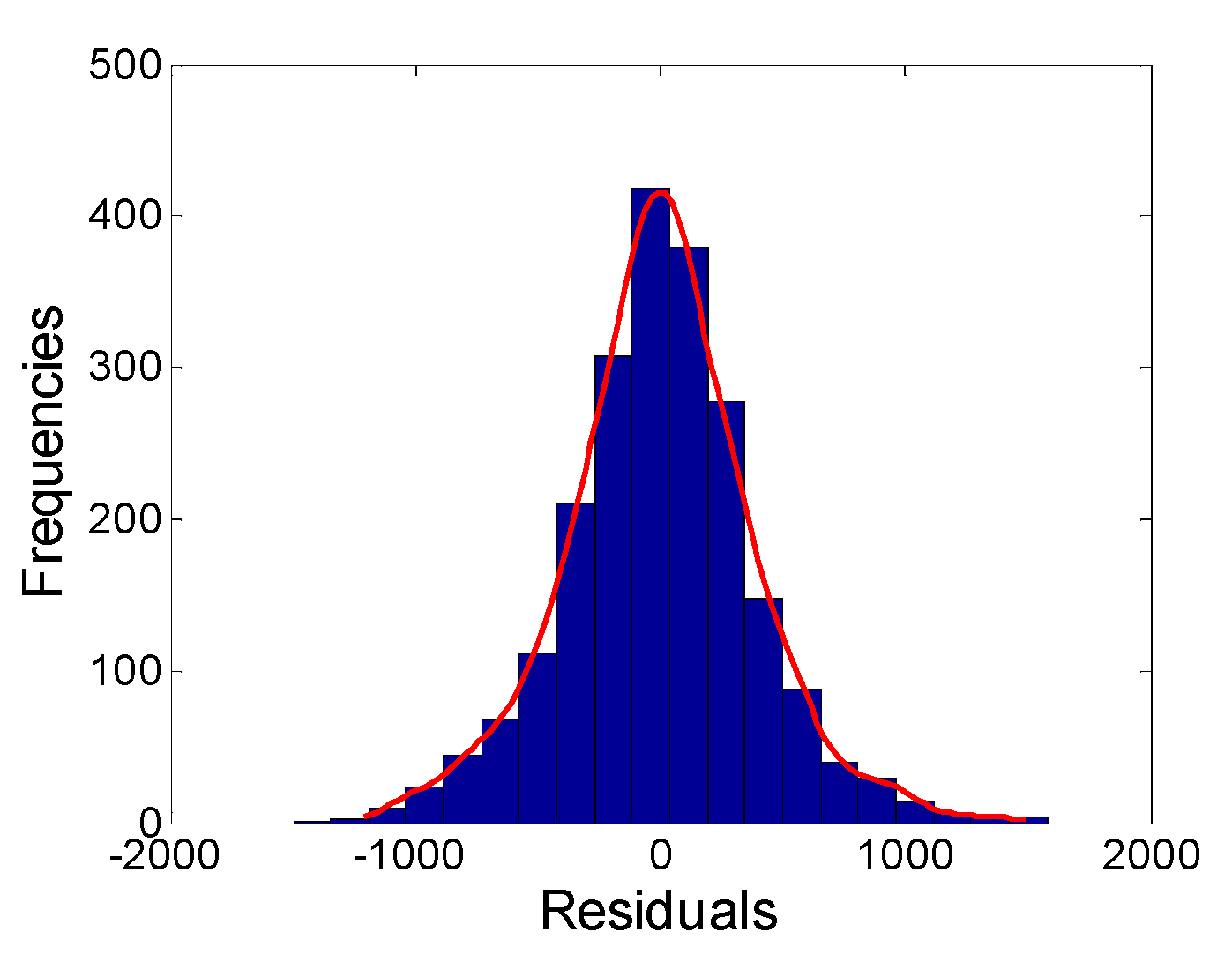
Figure 14 shows a histogram of illustrating the one-hour-ahead prediction errors by ‘MI + GMDH’ and
ν-SVR for July 2014.
As shown in
Figure 14, the errors are centered symmetrically on zero and there are no severe outliers.
Figure 15 illustrates the results of linear regression analysis between the actual and predicted load values by ‘MI + GMDH’ and
ν-SVR for July 2014.
The results for the other validation months are not presented due to space limitations. In
Figure 15, the
X and
Y axes correspond to the actual and predicted load values, respectively, the black circles are scatter plots of the data points, i.e., (
X,
Y), and the dashed black lines and thick solid blue lines indicate the straight lines,
Y =
X, and the best linear regression lines, respectively. The
r2 values presented above the figures represent the relationships between
X and
Y. A value close to 1 indicates that
X and
Y have a strong linear relationship. As illustrated in
Figure 15, we can confirm that there are strong linear relationships between the actual and predicted load values.
6. Discussion
Based on the experimental results presented in
Section 5, we can highlight several key findings. Let us begin with the comparisons between the filter methods (i.e., ‘LC’ and ‘MI’) and ‘GMDH’. At one-hour and one-day ahead forecasting, ‘GMDH’ performed better than the filter methods in terms of the overall MAPE. There are two main reasons for the improved performance of ‘GMDH’: (1) ‘GMDH’ can capture many-to-one nonlinear relationships between inputs and output via hierarchical network structure, whereas ‘LC’ or ‘MI’ can only capture one-to-one linear or nonlinear relationships; and (2) unlike filter methods that select SIs based on statistical
RF, the prediction accuracy (i.e.,
CEC) is employed as an input selection criterion in ‘GMDH’.
Second, we consider the performance comparisons between ‘GMDH’ and the hybrid methods. In all cases, ‘MI + GMDH’ obtained the best forecasts in terms of the overall MAPE. The load series has nonlinear characteristics and ν-SVR with a nonlinear kernel (i.e., RBF kernel) was used for the prediction models, so the hybrid method that combines ‘MI’ with ‘GMDH’ performed better. The prediction results of ‘LC + GMDH’ were poor compared with ‘GMDH’ alone because LC-based filtering procedure may remove the inputs with weak linear but strong nonlinear relationships with the output.
Finally, let us discuss the performance of the five methods in terms of their computational time requirements.
Table 4 lists the computational time required by each input selection method for April 2014.
The learning dataset is composed of 2904 input-output pairs and 168 IICs comprise the input part for each pair. The computer used to measure the computational time had 8 GB of RAM and a 2.8 GHz quad-core CPU. The result shows clearly that the computational efficiency of ‘GMDH’ is higher than that of ‘MI’. The computational time required by ‘LC + GMDH’ is much less than that of ‘GMDH’ alone because the number of inputs handled by ‘GMDH’ is reduced to one-third of the IICs by the LC-based filtering procedure.
7. Conclusions
In this study, we proposed a new input selection procedure, which combines GMDH with a bootstrap method for SVR-based short-term hourly load forecasting. After constructing GMDH networks many times under the same experimental conditions, the inputs that remain frequently in the input layers were finally selected as SIs. The networks were constructed several times because each relevant input is different due to the random division of the learning dataset. Indeed, only constructing a single network could yield biased input selection results. In experimental assessments, we employed LC- and MI-based filter methods for comparison, and also verified the performance of two hybrid methods. In total, five input selection methods were examined in this study. To illustrate the performance of the proposed method, an hourly load dataset from South Korea was used and the one-hour, one-day and one-week-ahead forecasting performances were compared.
The experimental results showed that the proposed method can select SIs in an effective manner. The forecasting performance of the proposed method (i.e., ‘GMDH’) was better than that of the LC- and MI-based filter methods. To be specific, in one-hour, one-day, and one-week ahead forecasts, ‘GMDH’ improves the overall MAPE values by 0.024, 0.226, and 0.124, respectively, over ‘LC’. Although the overall MAPE with H = 168 worsens by 0.014, when H = 1 and 24, ‘GMDH’ improves the overall MAPE values by 0.016 and 0.025, respectively, compared with ‘MI’. In addition, the computational efficiency of the proposed method was higher than that of the MI-based filter method. Among the five methods, ‘MI + GMDH’ achieved the best prediction accuracy. When H = 1, 24, and 168, ‘MI + GMDH’ outperforms ‘GMDH’, with 0.019, 0.073, and 0.072, respectively, improvements in overall MAPE values.
Let us summarize the main reasons for the improved performance of the proposed method. First, the proposed method can perform input selection by capturing many-to-one nonlinear relationships between potential inputs and output via the hierarchical structure of the GMDH network. Second, compared with the filter methods, the prediction accuracy (i.e., CEC) is employed as a selection criterion, which improves the prediction performance. Finally, SIs are selected by constructing GMDH networks many times, thereby facilitating more robust input selections.
In future research, the proposed method will be applied to hourly load forecasting on special days and daily peak load forecasting. Moreover, the proposed method can be used in various real-world applications such as financial time-series analysis, process monitoring, and nonlinear function approximations.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














