A Novel Locality Algorithm and Peer-to-Peer Communication Infrastructure for Optimizing Network Performance in Smart Microgrids


Abstract
1. Introduction
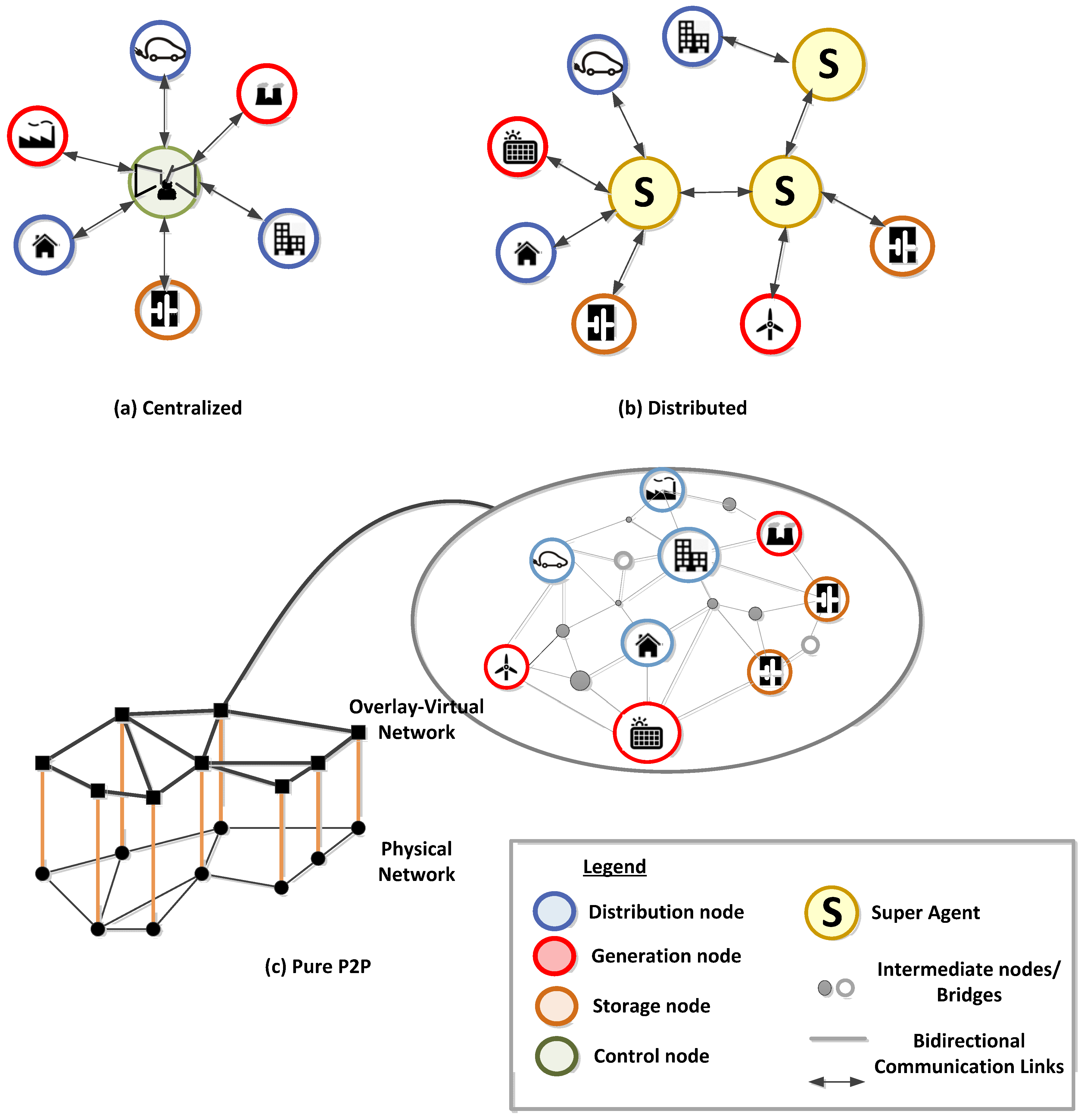
2. Peer-to-Peer Approach for Decentralized MG’s Control
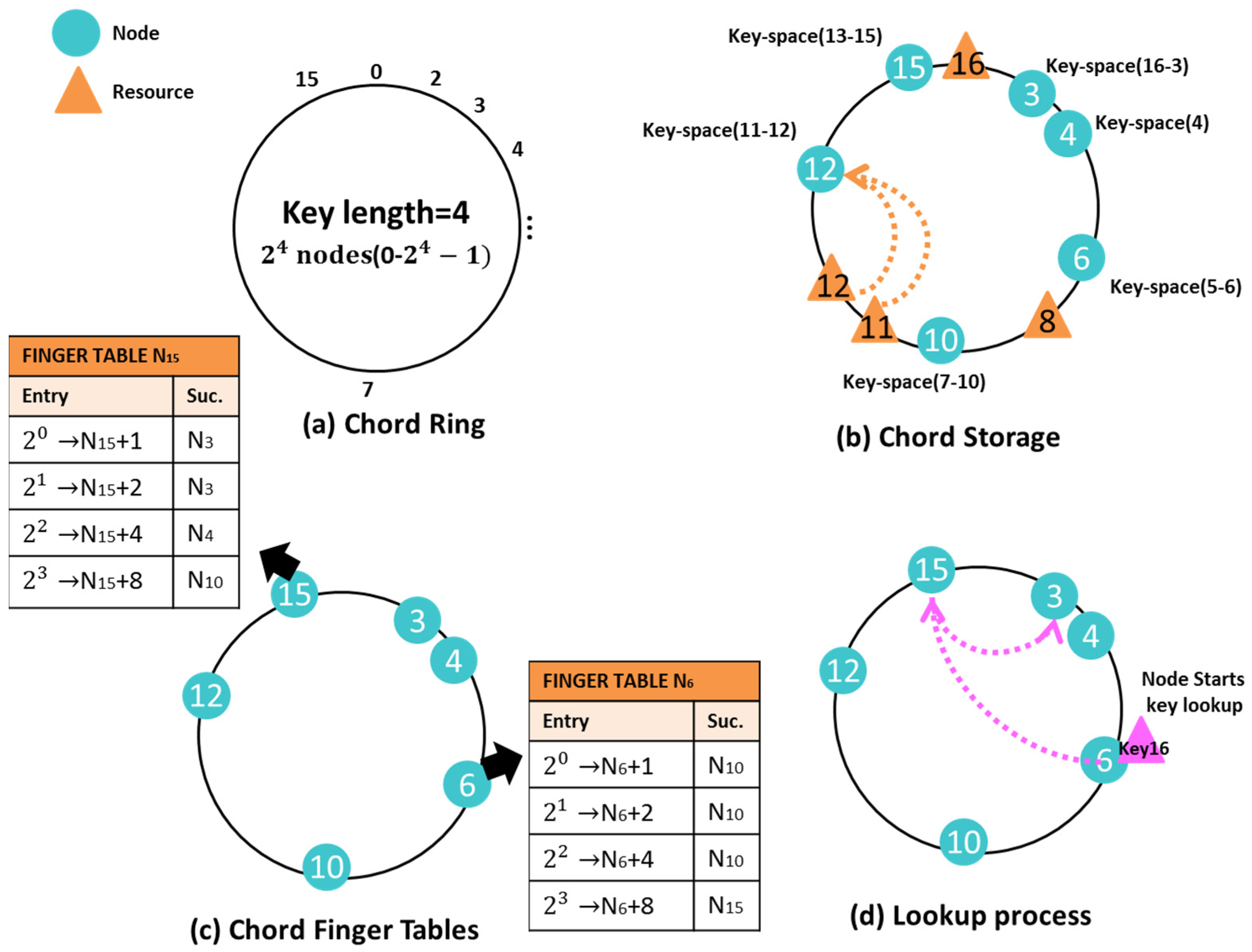
3. Description of the Chosen DHT Algorithm
- (1)
- Firstly it checks if the node that started the search is in charge of that key. If this is true the search is over and the algorithm ends.
- (2)
- Otherwise the node will employ its finger table to localize the closest successor of the target node’s key and request the search of the key to the target node.
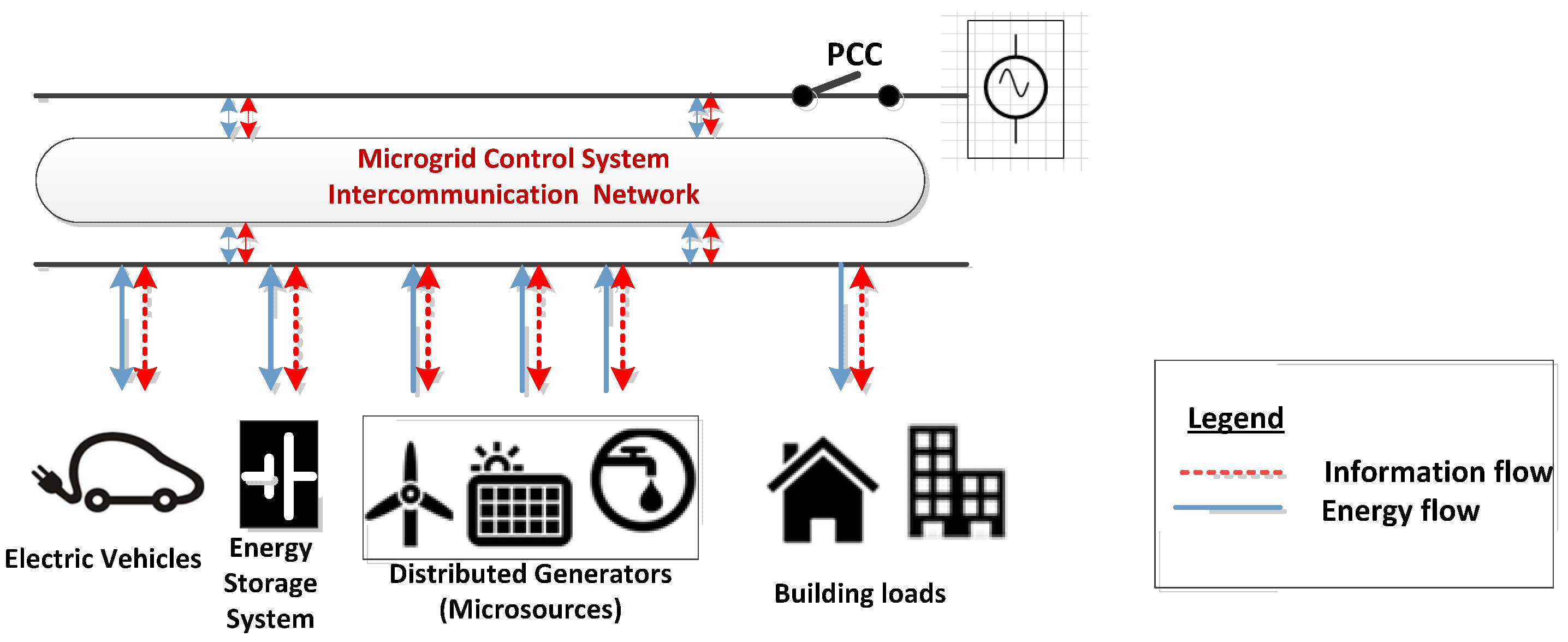
4. Network Requirements for Smart Microgrids
- (1)
- An application layer to retrieve data from the system. In conventional DHTs, the nodes store the keys to locate information of the key it is responsible for. Thus, each node should establish its own methods to retrieve this information. To achieve this objective a communication infrastructure based on a stack protocol with an application layer has to be developed according to the goals of the microgrid.
- (2)
- A communication system able to achieve efficient and scalable routing for enhancing network performance, resulting in a highly distributed communication system, with low network traffic and latencies. Conventional DHTs do not consider locality issues. However, locality lets one create clusters with similar interests, reducing the network overhead and latencies.
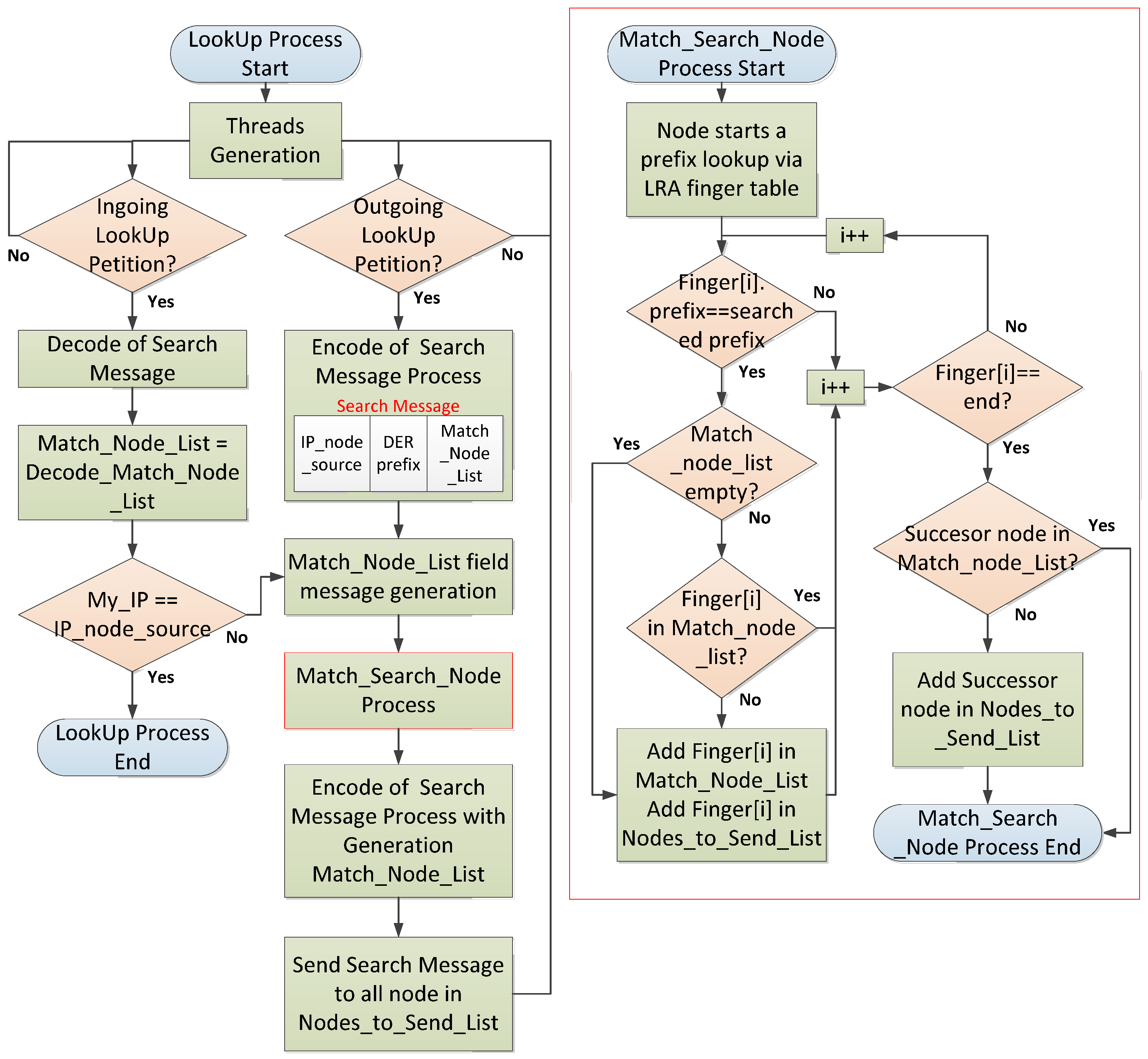
5. Proposed Locality-Routing Algorithm
6. Proposal of a Layered Communication Architecture and an Application Protocol for MG’s
6.1. Network Layer
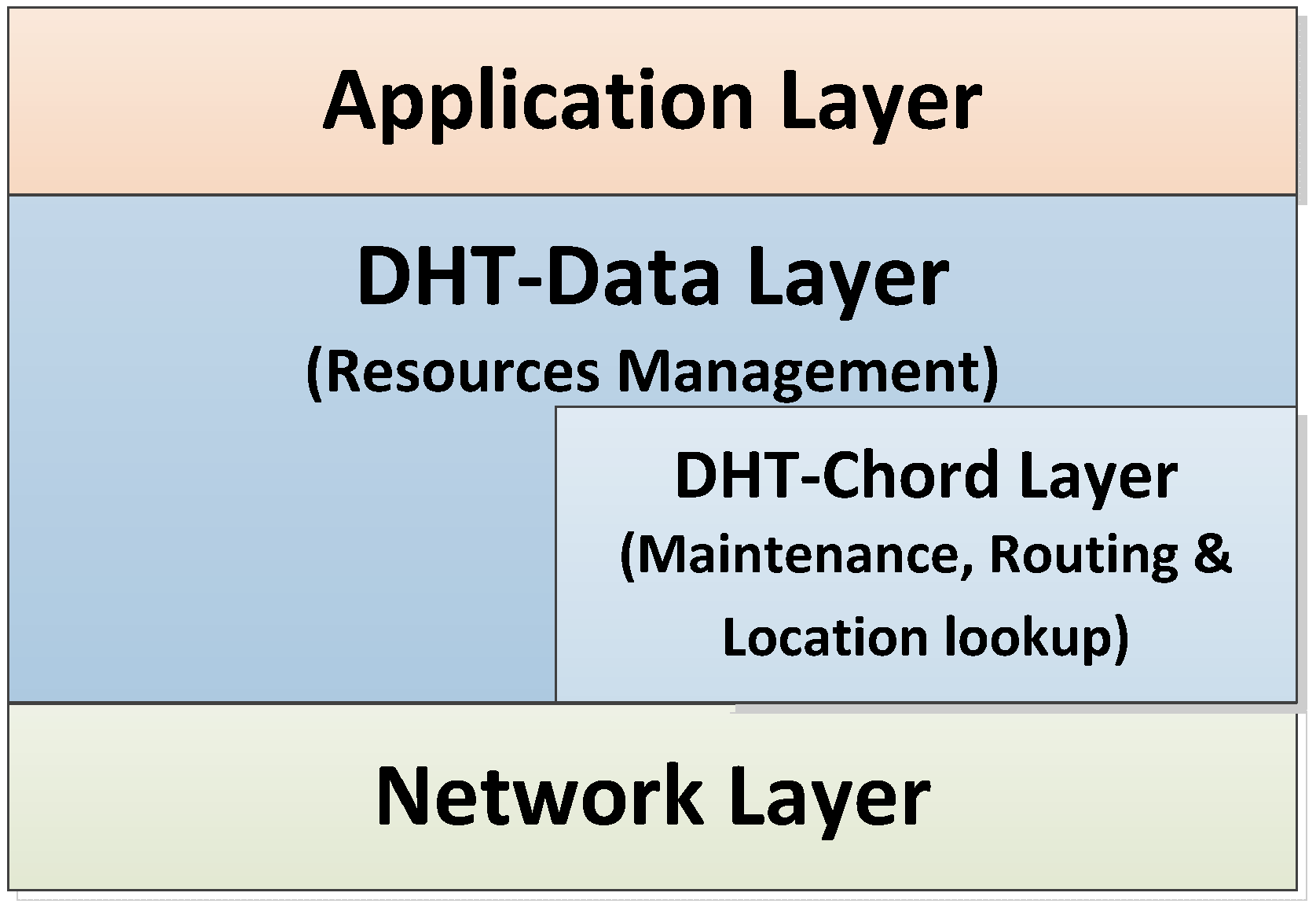
6.2. P2P Layer
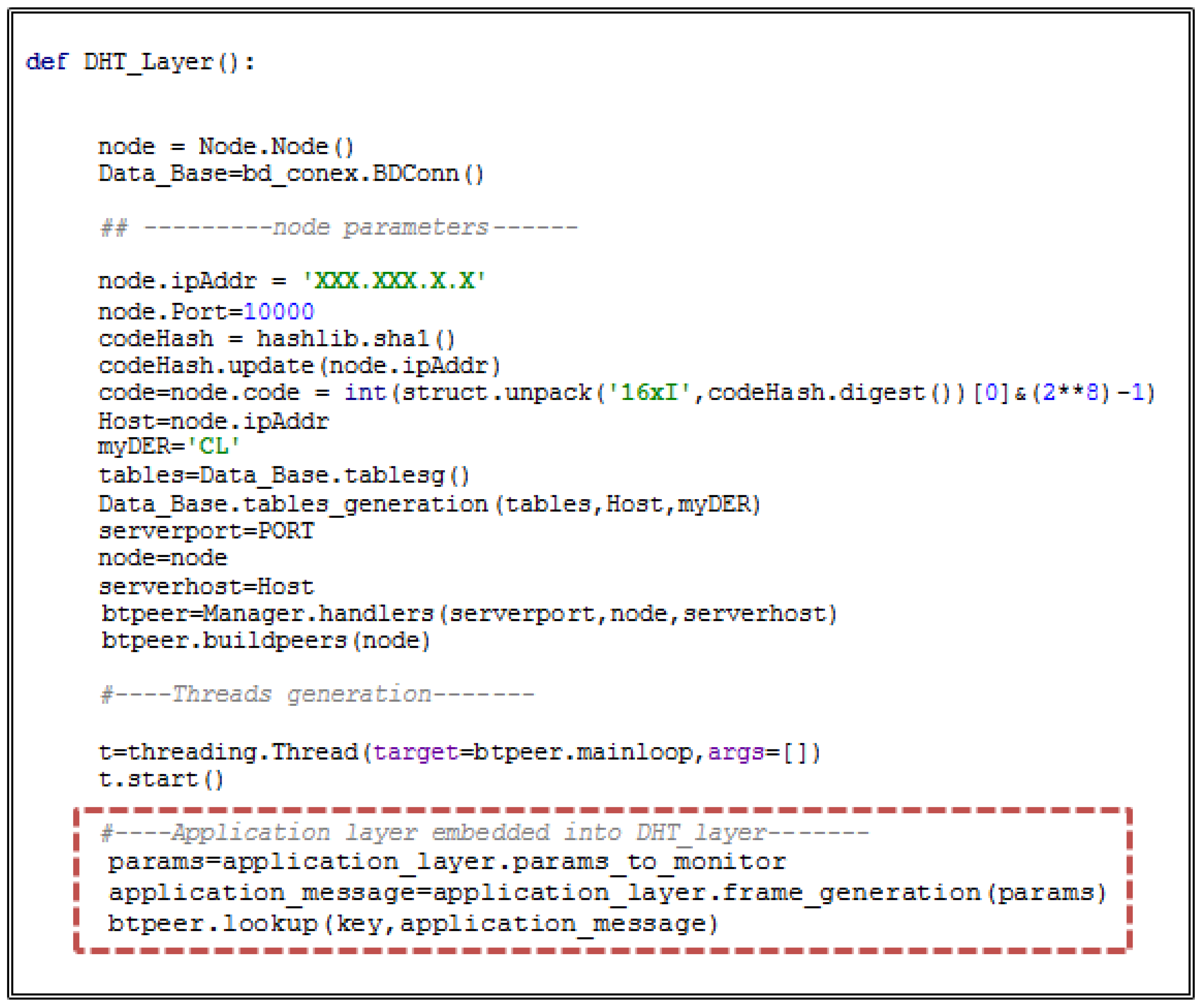
6.3. Application Layer
7. Experimental Results
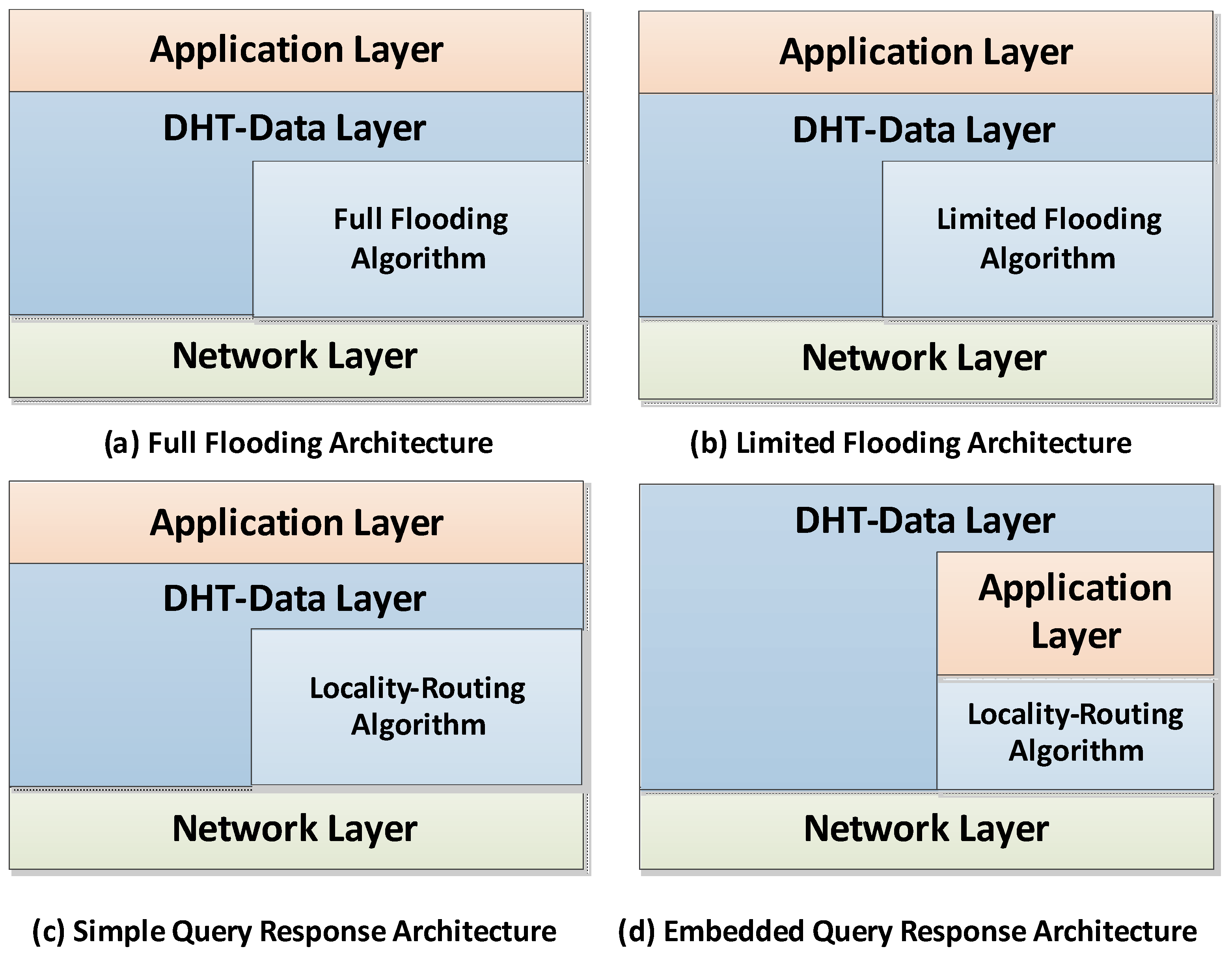
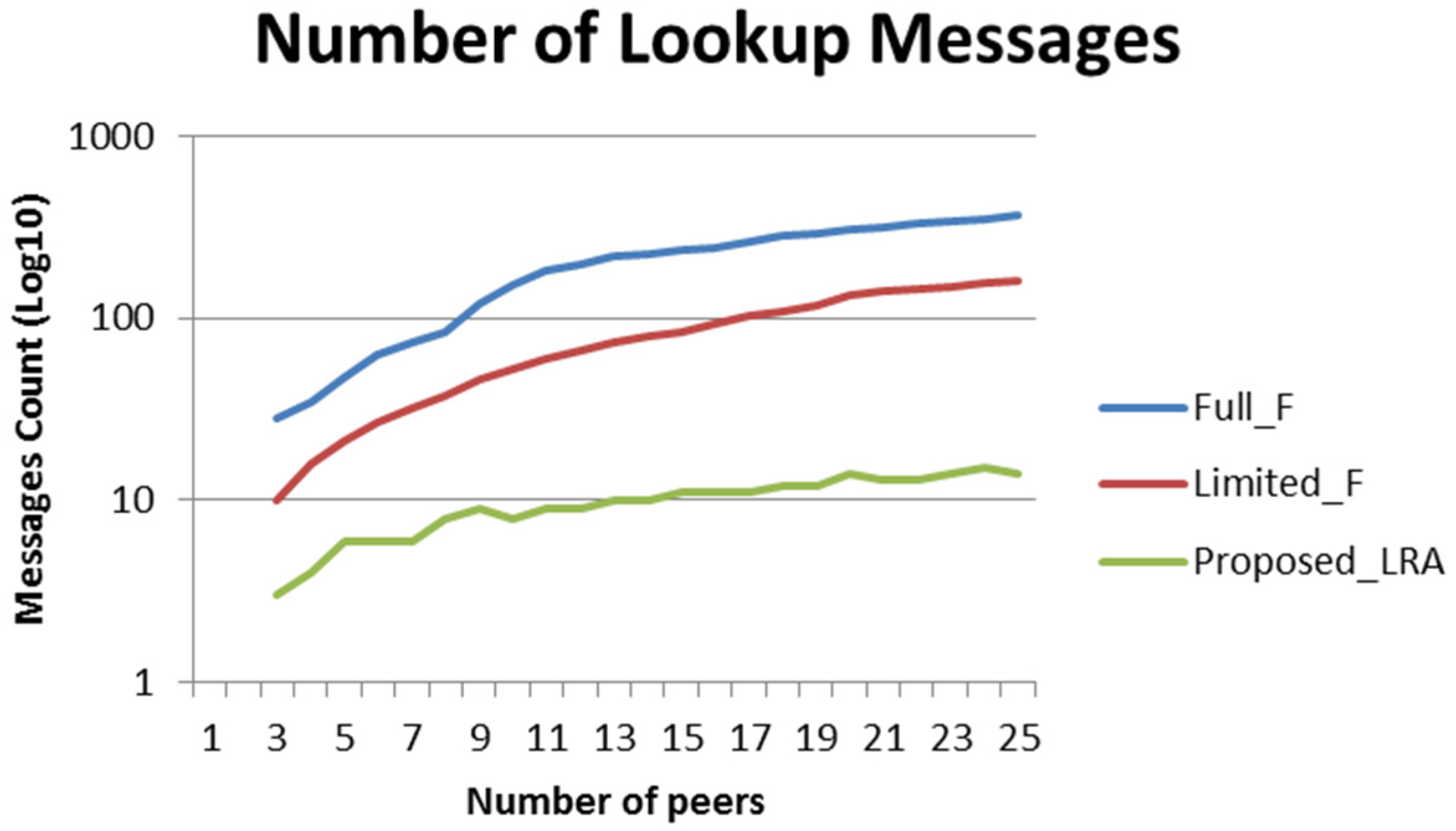
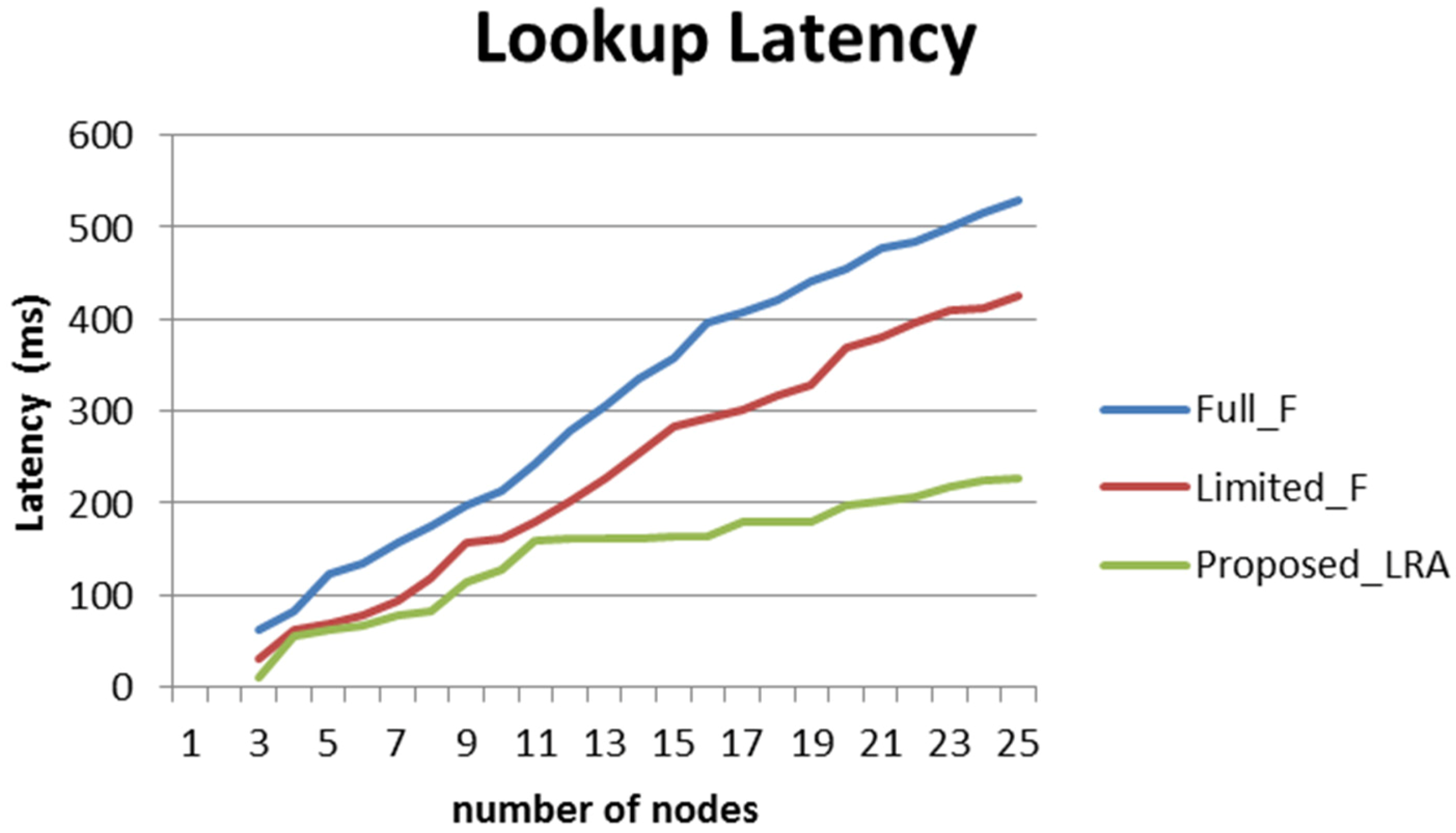
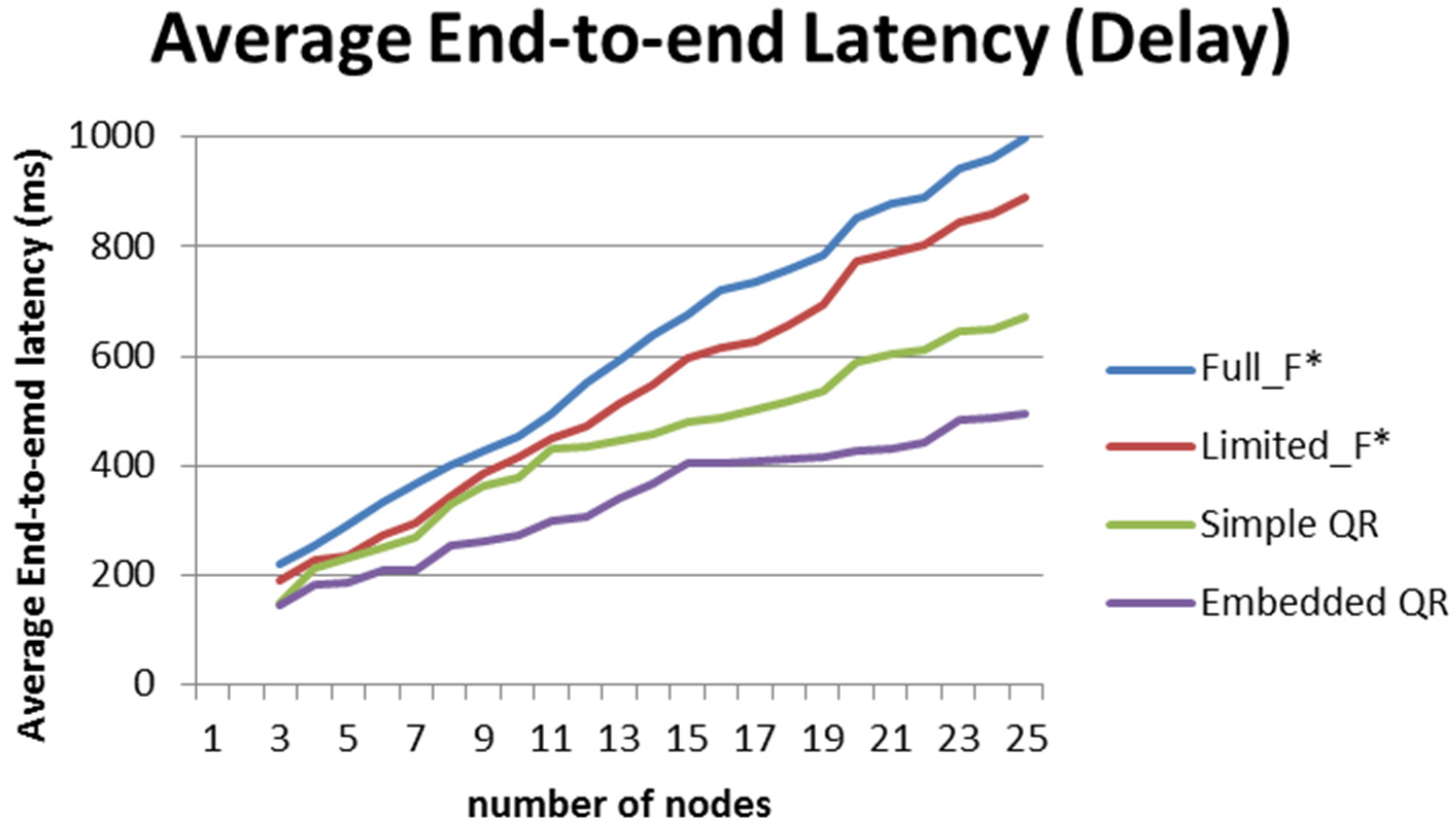
7.1. Algorithms Comparison
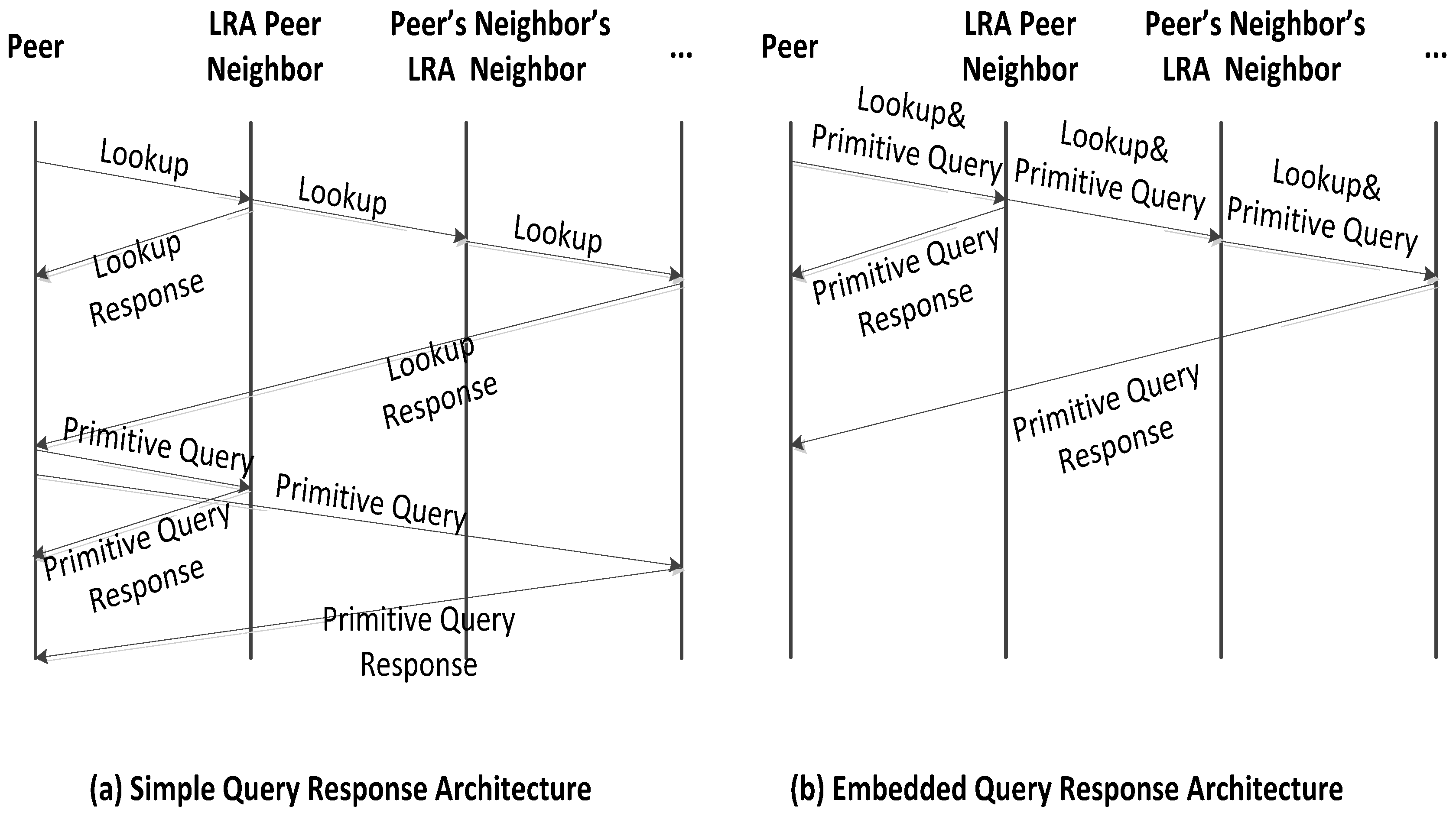
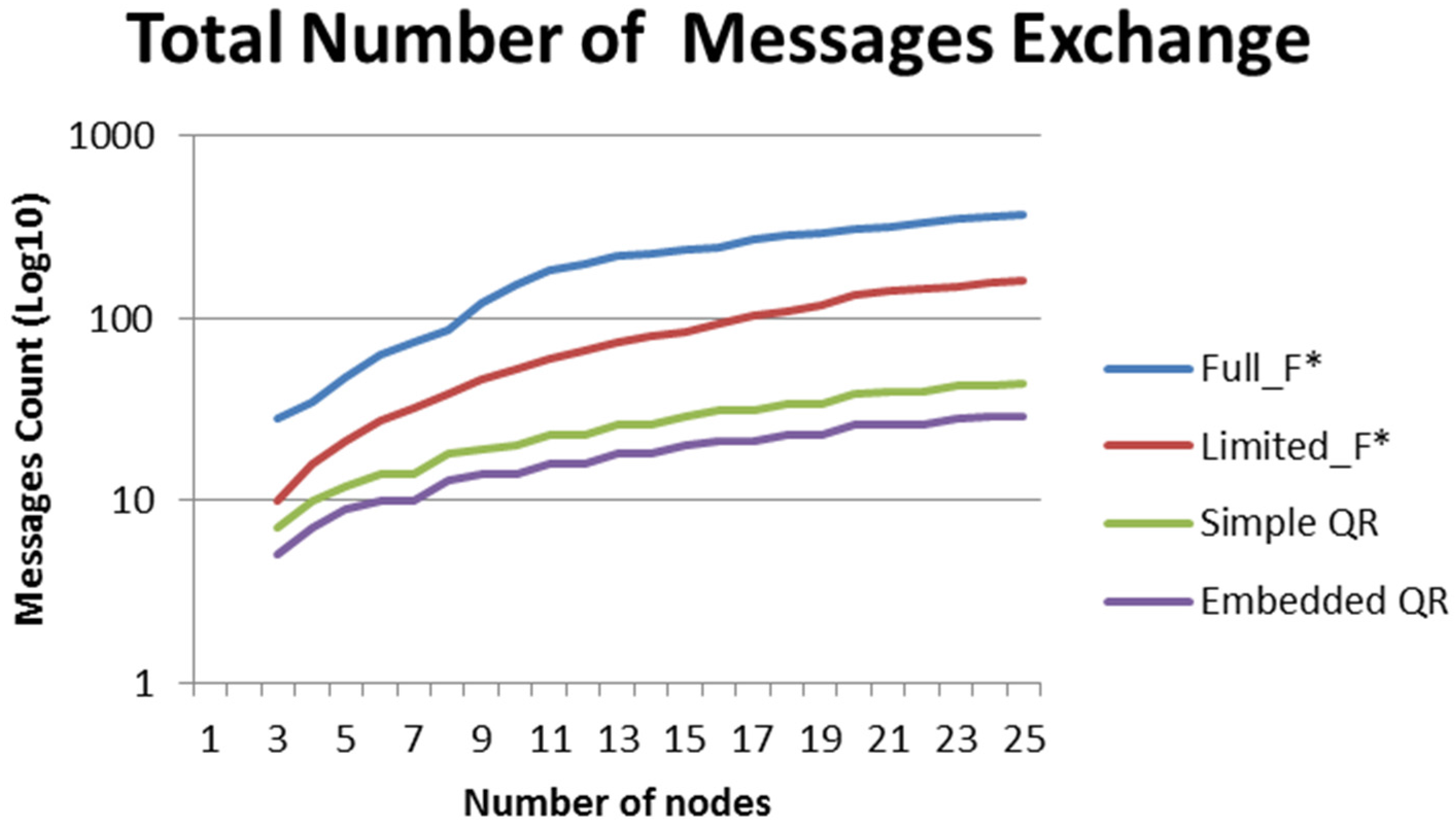
7.2. Communication Architectures Comparison
- Total number of messages exchange: this refers to the total number of messages that have to be exchanged among all peers both for lookup of the match peers and for sharing information among them.
- End-to-end Latency: it contains the information obtained from the total nodes in the network regarding the lookup latency and the processing latency.
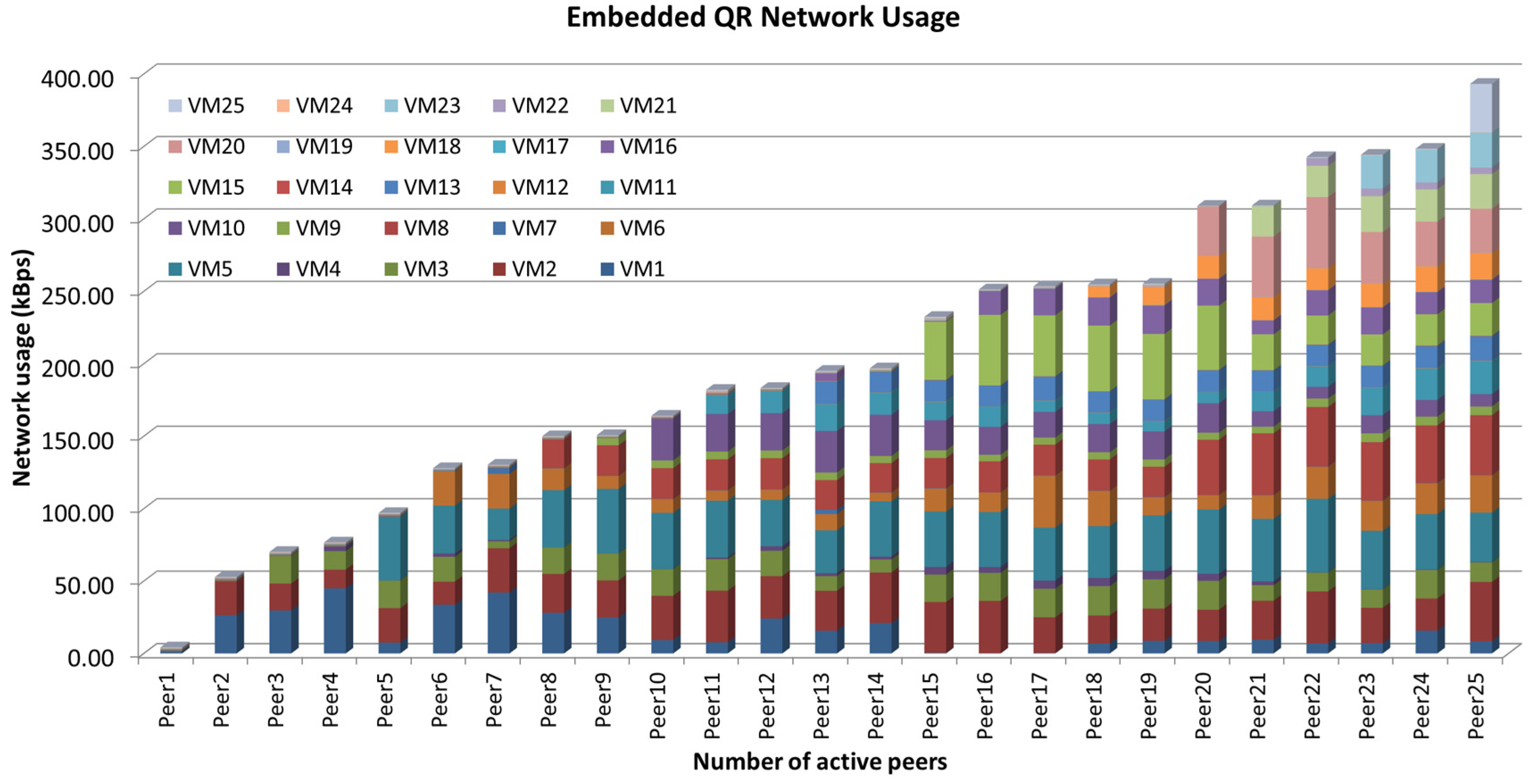
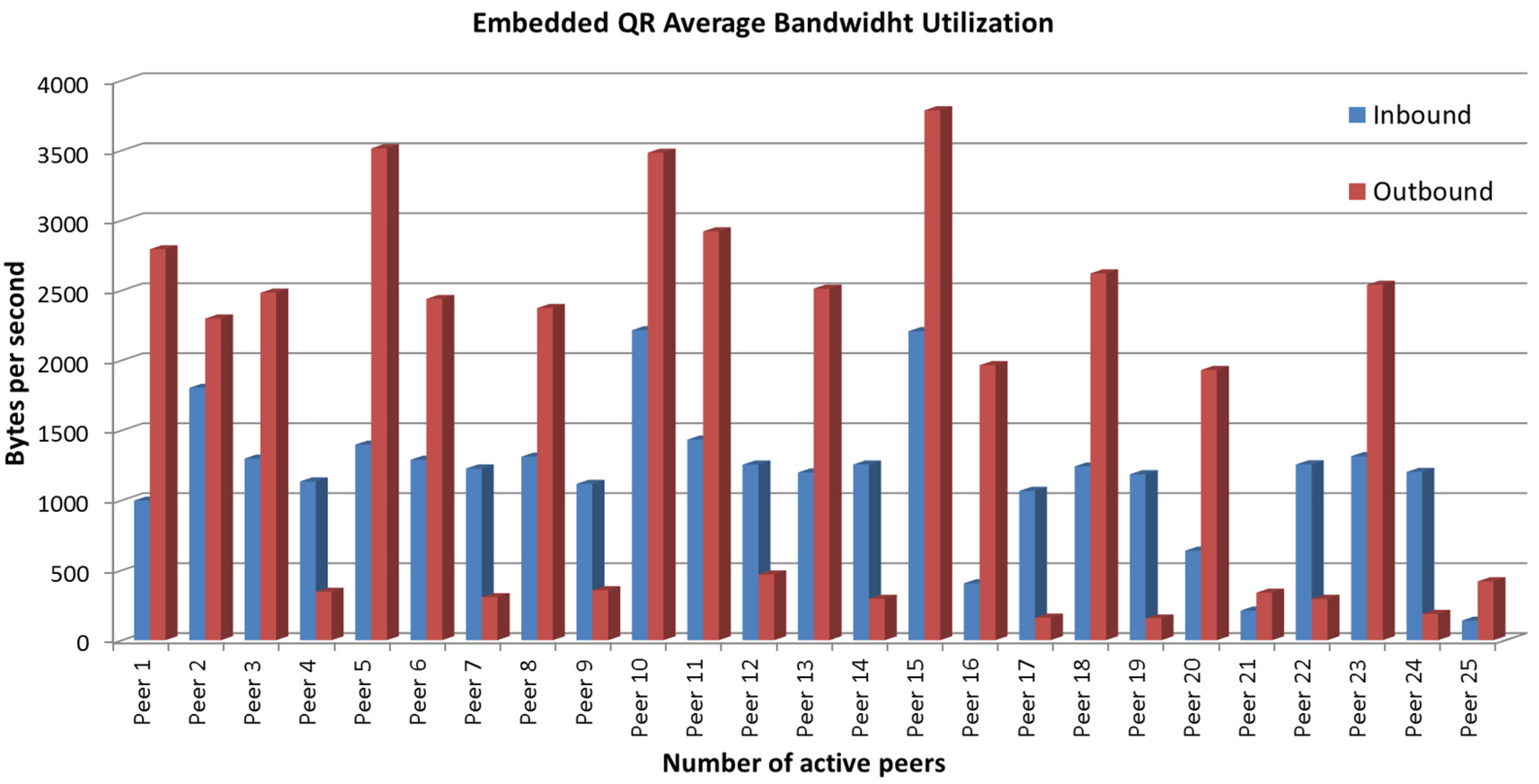
7.3. Network Performance Analysis
8. Discussion of Results, Conclusions and Future Work
- -
- The clusters in the proposed algorithm have been organized around a specific type of DER, such as critical loads, distributed generators, etc. In order to add flexibility to the algorithm, it would be interesting to study the clusters’ classification from other features different that the nature of the DER.
- -
- The proposed algorithm creates one overlay layer on top of the physical network. However multiple overlays layers could be created to provide other microgrid services. For example, in a second layer, multicast services could be provided. These services could very useful in the microgrid context. For example, when a set of real-time control signal needs to be distributed to a large set of participants. This issue could be carried out by means of tunnels [91] which can give multicast services access to the end peers. Overlay multicast can also be perceived as topic-based publish/subscribe [92].
- -
- The proposed solutions have a certain security degree due to redundant link and self-reconfiguration [19] have been implemented. However, the system is sensitive to malicious attacks such as Sybil or Eclipse [93,94]. Thus additional security procedures should be studied and implemented to reduce the sensitivity to malicious attacks.
- -
- The IEC 61850 standard has been widely used in smart substations and it has been also proposed to smart microgrids. It defines priority Generic Object Oriented Substation Events (GOOSE) messages and switching Ethernet for fast and reliable transmissions among DERs. The objective is to improve the transmission efficiency and guarantee that the transmission time of each message is lower than 4 ms [95,96,97]. The protocol stack should implement this communication mechanism.
- -
- The proposed solutions have been validated by means of experimental results that have been carried out by means of virtual machines. The achieved results take into account most of the system physical limitations. Therefore, it can be concluded that the proposed solutions are an interesting approach to the problem of communications in smart microgrids. However, additional experiments should be carried out by means of a real microgrid to completely validate the concept. For instance, the proposed network architecture has been dedicated to the P2P protocol. Nevertheless, other network traffic could be also generated in order to evaluate the performance of the proposed techniques in other traffic scenarios. This is one of the future works that should be performed.
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Reduan, H.; Khyan, J. A comprehensive review of the application characteristics and traffic requirements of a smart grid communications network. Comput. Netw. 2013, 57, 825–845. [Google Scholar]
- Dada, J.O. Towards understanding the benefits and challenges of Smart/Micro-Grid for electricity supply system in Nigeria. Renew. Sustain. Energy Rev. 2014, 38, 1003–1014. [Google Scholar] [CrossRef]
- Lidula, N.; Rajapakse, A. Microgrids research: A review of experimental microgrids and test system. Renew. Sustain. Energy Rev. 2011, 15, 186–202. [Google Scholar] [CrossRef]
- Hussain, A.; Arif, S.M.; Aslam, M.; Shah, S.D.A. Optimal siting and sizing of tri-generation equipment for developing an autonomous community microgrid considering uncertainties. Sustain. Cities Soc. 2017, 32, 318–330. [Google Scholar] [CrossRef]
- Dehghanpour, K.; Colson, C.; Nehrir, H. A survey on smart agent-based microgrids for resilient/self-healing grids. Energies 2017, 10, 620. [Google Scholar] [CrossRef]
- Palizban, O.; Kauhaniemi, K.; Guerrero, J.M. Microgrids in active network management—Part II: System operation, power quality and protection. Renew. Sustain. Energy Rev. 2014, 36, 440–441. [Google Scholar] [CrossRef]
- Shi, W.; Li, N.; Chu, C.C.; Gadh, R. Real-time energy management in microgrids. IEEE Trans. Smart Grid 2017, 8, 228–238. [Google Scholar] [CrossRef]
- Deng, R.; Yang, Z.; Chow, M.Y.; Chen, J. A survey on demand response in smart grids: Mathematical models and approaches. IEEE Trans. Ind. Inform. 2015, 11, 570–582. [Google Scholar] [CrossRef]
- Kroposki, B.; Basso, T.; DeBlasio, R. Microgrid standards and technologies. In Proceedings of the IEEE Power and Energy Society General Meeting—Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008. [Google Scholar]
- Goodarzi, H.M.; Kazemi, M.H. A novel optimal control method for islanded microgrids based on droop control using the ICA-GA algorithm. Energies 2017, 10, 485. [Google Scholar] [CrossRef]
- Erol-Kantarci, M.; Kantarci, B.; Mouftah, H.T. Reliable overlay topology design for the smart microgrid network. IEEE Netw. 2011, 25, 38–43. [Google Scholar] [CrossRef]
- Youssef, K.H. Optimal management of unbalanced smart microgrids for scheduled and unscheduled multiple transitions between grid-connected and islanded modes. Electr. Power Syst. Res. 2016, 141, 104–113. [Google Scholar] [CrossRef]
- Giotitsas, C.; Pazaitis, A.; Kostakis, V. A peer-to-peer approach to energy production. Technol. Soc. 2015, 42, 28–38. [Google Scholar] [CrossRef]
- Kazmi, S.A.; Shahzad, M.K.; Khan, A.Z.; Shin, D.R. Smart distribution networks: A review of modern distribution concepts from a planning perspective. Energies 2017, 10, 501. [Google Scholar] [CrossRef]
- Amoretti, M. The peer-to-peer paradigm applied to hydrogen energy distribution. In Proceedings of the IEEE Region 8, EUROCON 2009, International Conference (IEEE EUROCON’09), St. Petersburg, Russia, 18–23 May 2009. [Google Scholar]
- Almasalma, H.; Engels, J.; Deconinck, G. Peer-to-peer control of microgrids. In Proceedings of the 8th IEEE Benelux IAS/PELS/PES/ Young Researchers Symposium in Electrical Power Engineering, Eindhoven, The Netherlands, 12–13 May 2016. [Google Scholar]
- Werth, A.; Andre, A.; Kawamoto, D.; Morita, T.; Tajima, S.; Yanagidaira, D.; Tanaka, K. Peer-to-peer control system for DC microgrids. IEEE Trans. Smart Grid 2016. [Google Scholar] [CrossRef]
- Deconinck, G.; Labeeuw, W.; Vandael, S.; Beitollahi, H.; de Craemer, K.; Duan, R.; Belmans, R. Communication overlays and agents for dependable smart power grids. In Proceedings of the 2010 5th International Conference on Critical Infrastructure (CRIS), Beijing, China, 20–22 September 2010. [Google Scholar]
- Deconinck, G.; Vanthournout, K.; Beitollahi, H.; Qui, Z.; Duan, R.; Nauwelaers, B.; van Lil, E.; Driesen, J.; Belmans, R. A robust semantic overlay network for microgrid control applications. Archit. Dependable Syst. 2008, 5135, 101–123. [Google Scholar]
- Li, D.; Lu, X.; Wang, B.; Su, J.; Cao, J.; Chan, K.C.; Leong, H.V. Delay-bounded range queries in DHT-based peer-to-peer systems. In Proceedings of the 26th IEEE International Conference on Distributed Computing Systems (ICDCS 2006), Lisbon, Portugal, 4–7 July 2006. [Google Scholar]
- Wu, W.; Chen, Y.; Zhang, X.; Shi, X.; Cong, L.; Deng, B.; Li, X. LDHT: Locality-aware distributed hash tables. In Proceedings of the 2008 International Conference on IEEE in Information Networking (ICOIN), Busan, Korea, 23–25 January 2008. [Google Scholar]
- Sit, E. Storing and Managing Data in a Distributed Hash Table. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2008. [Google Scholar]
- Cheema, A.S.; Muhammad, M.; Gupta, I. Peer-to-peer discovery of computational resources for grid applications. In Proceedings of the 6th IEEE/ACM International Workshop on Grid Computing, Washington, DC, USA, 13–14 November 2005. [Google Scholar]
- Fantar, S.G.; Youssef, H. Exploiting locality using geographic coordinates and semantic proximity in Chord. In Proceedings of the 15th IEEE Symposium on Computers and Communications (ISCC), Riccione, Italy, 22–25 June 2010. [Google Scholar]
- Sripanidkulchai, K.; Maggs, B.; Zhang, H. Efficient content location using interest-based locality in peer-to-peer systems. In Proceedings of the Twenty-Second Annual Joint Conference of the IEEE Computer and Communications (INFOCOM), San Francisco, CA, USA, 30 March–3 April 2003. [Google Scholar]
- Bandara, H.D.; Jayasumana, A.P. Collaborative applications over peer-to-peer systems—Challenges and solutions. P2P Netw. Appl. 2013, 6, 257–276. [Google Scholar] [CrossRef]
- Palizban, O.; Kauhaniemi, K. Hierarchical control structure in microgrids with distributed generation: Island and grid-connected mode. Renew. Sustain. Energy Rev. 2015, 44, 797–813. [Google Scholar] [CrossRef]
- Khatibzadeh, A.; Besmi, M.; Mahabadi, A.; Haghifam, M.R. Multi-agent-based controller for voltage enhancement in AC/DC hybrid microgrid using energy storages. Energies 2017, 10, 169. [Google Scholar] [CrossRef]
- Planasa, E.; Gil-de-Murob, A.; Andreua, J.; Kortabarriaa, I.; de Alegríaa, I.M. General aspects, hierarchical controls and droop methods in microgrids: A review. Renew. Sustain. Energy Rev. 2013, 17, 147–159. [Google Scholar] [CrossRef]
- Olivares, D.; Mehrizi-Sani, A.; Etemadi, A.; Canizares, C.; Iravani, R.; Kazerani, M.; Hajimiragha, A.; Gomis-Bellmunt, O.; Saeedifard, M.; Palma-Behnke, R.; et al. Trends in microgrid control. IEEE Trans. Smart Grid 2014, 5, 1905–1919. [Google Scholar] [CrossRef]
- Vandoorn, T.L.; Vasquez, J.C.; de Kooning, D.M.; Guerrero, J.M.; Vandevelde, L. Microgrids: Hierarchical control and an overview of the control and reserve management strategies. IEEE Ind. Electron. Mag. 2013, 7, 42–55. [Google Scholar] [CrossRef]
- Zhou, B.; Li, W.; Chan, K.W.; Cao, Y.; Kuang, Y.; Liu, X.; Wang, X. Smart home energy management systems: Concept, configurations, and scheduling strategies. Renew. Sustain. Energy Rev. 2016, 61, 30–40. [Google Scholar] [CrossRef]
- Nampuraja, E. Smart grid management system. Infosys Labs Brief. 2011, 9, 31–38. [Google Scholar]
- Ancillotti, E.; Bruno, R.; Conti, M. The role of communication systems in smart grids: Architectures, technical solutions and research challenges. Comput. Commun. 2013, 36, 1665–1697. [Google Scholar] [CrossRef]
- Llaria, A.; Terrasson, G.; Curea, O.; Jiménez, J. Application of wireless sensor and actuator networks to achieve intelligent microgrids: A promising approach towards a global smart grid deployment. Appl. Sci. 2016, 6, 61. [Google Scholar] [CrossRef]
- Siow, L.K.; So, P.L.; Gooi, H.B.; Luo, F.L.; Gajanayake, C.J.; Vo, Q.N. Wi-fi based server in microgrid energy management system. In Proceedings of the TENCON 2009—2009 IEEE Region 10 Conference, Singapore, 23–26 November 2009. [Google Scholar]
- Mao, R.; Li, H.; Xu, Y.; Li, H. Wireless communication for controlling microgrids: Co-simulation and performance evaluation. In Proceedings of the 2013 IEEE Power and Energy Society General Meeting (PES), Vancouver, BC, Canada, 21–25 July 2013. [Google Scholar]
- Elkhorchani, H.; Grayaa, K. Smart micro grid power with wireless communication architecture. In Proceedings of the 2014 International Conference on Electrical Sciences and Technologies in Maghreb (CISTEM), Tunis, Tunisia, 3–6 November 2014. [Google Scholar]
- Luna, A.C.; Diaz, N.L.; Graells, M.; Vasquez, J.C.; Guerrero, J.M. Cooperative energy management for a cluster of households prosumers. IEEE Trans. Consum. Electron. 2016, 62, 235–242. [Google Scholar] [CrossRef]
- Gungor, V.C.; Lu, B.; Hancke, G.P. Opportunities and challenges of wireless sensor networks in smart grid. IEEE Trans. Ind. Electron. 2010, 57, 3557–3564. [Google Scholar] [CrossRef]
- Yang, Y.; Lambert, F.; Divan, D. A survey on technologies for implementing sensor networks for power delivery systems. In Proceedings of the 2007 IEEE Power Engineering Society General Meeting, Tampa, FL, USA, 24–28 June 2007. [Google Scholar]
- Bayindir, R.; Hossain, E.; Kabalci, E.; Perez, R. A comprehensive study on microgrid technology. Int. J. Renew. Energy Res. 2014, 4, 1094–1107. [Google Scholar]
- Colson, C.M.; Nehir, M.H. A review of challenges to real-time power management of microgrids. In Proceedings of the 2009 IEEE Power & Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009. [Google Scholar]
- Zhao, C.; He, J.; Cheng, P.; Chen, J. Consensus-based energy management in smart grid with transmission losses and directed communication. IEEE Trans. Smart Grid 2016, 8. [Google Scholar] [CrossRef]
- Lo, C.H.; Ansaria, N. Decentralized controls and communications for autonomous distribution networks in smart grid. IEEE Trans. Smart Grid 2013, 4, 66–77. [Google Scholar] [CrossRef]
- Li, C.; Savaghebi, M.; Guerrero, J.; Coelho, E.A.; Vasquez, J.C. Operation cost minimization of droop-controlled AC microgrids using multiagent-based distributed control. Energies 2016, 9, 717. [Google Scholar] [CrossRef]
- Wu, X.; Jiang, P.; Lu, J. Multiagent-based distributed load shedding for islanded microgrids. Energies 2014, 7, 6050–6062. [Google Scholar] [CrossRef]
- Kantamneni, A.; Brown, L.; Parker, G.; Wayne, W. Survey of multi-agent systems for microgrid control. Eng. Appl. Artif. Intell. 2015, 45, 192–203. [Google Scholar] [CrossRef]
- Lopes, A.L.; Botelho, L. Improving multi-agent based resource coordination in peer-to-peer networks. J. Netw. 2008, 3, 38–47. [Google Scholar] [CrossRef]
- Babaoglu, O.; Meling, H.; Montresor, A. Anthill: A framework for the development of agent-based peer-to-peer systems. In Proceedings of the IEEE 22nd International Conference on Distributed Computing Systems, Vienna, Austria, 2–5 July 2002. [Google Scholar]
- Cameron, A.; Stumptner, M.; Nandagopal, N.; Mayer, W.; Mansell, T. Rule-based peer-to-peer framework for decentralized real-time service oriented architectures. Sci. Comput. Progr. 2015, 97, 202–234. [Google Scholar] [CrossRef]
- Beitollahi, H.; Deconinck, G. Peer-to-peer networks applied to power grid. In Proceedings of the 2nd International Conference on Risks and Security of Internet and Systems (CRISIS), Marrakech, Morocco, 2–5 July 2007. [Google Scholar]
- Zhang, C.; Wu, J.; Cheng, M.; Zhou, Y.; Long, C. A bidding system for peer-to-peer energy trading in a grid-connected microgrid. Energy Procedia 2016, 103, 147–152. [Google Scholar] [CrossRef]
- Malatras, A. State-of-the-art survey on P2P overlay networks in pervasive computing environments. J. Netw. Comput. Appl. 2015, 55, 1–23. [Google Scholar] [CrossRef]
- De Mello, E.R.; van Moorsel, A.; da Silva Fraga, J. Evaluation of P2P search algorithms for discovering trust paths. In Proceedings of the Fourth European Performance Engineering Workshop (EPEW 2007), Berlin, Germany, 27–28 September 2007. [Google Scholar]
- Wehrle, K.; Steinmetz, R. Peer-to-peer systems and applications. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Lua, E.K.; Crowcroft, J.; Pias, M.; Sharma, R.; Lim, S. A survey and comparison of peer-to-peer overlay network schemes. IEEE Commun. Surv. Tutor. 2005, 7, 72–93. [Google Scholar]
- Buford, J.; Yu, H.; Lua, E.K. P2P Networking and Applications; Morgan Kaufmann: Burlington, MA, USA, 2009. [Google Scholar]
- Xu, J.; Kumar, A.; Yu, A.X. On the fundamental tradeoffs between routing table size and network diameter in peer-to-peer networks. IEEE J. Sel. Areas Commun. 2004, 22, 151–163. [Google Scholar] [CrossRef]
- Nasri, M.; Ginn, H.L.; Moallem, M. Application of intelligent agent systems for real-time coordination of power converters (RCPC) in microgrids. In Proceedings of the 2014 IEEE Energy Conversion Congress and Exposition (ECCE), Pittsburgh, PA, USA, 14–18 September 2014. [Google Scholar]
- Stoica, I.; Morris, R.; Karger, D.; Kaashoek, M.F.; Balakrishnan, H. Chord: A scalable peer-to-peer lookup service for internet applications. Comput. Commun. Rev. 2001, 31, 149–160. [Google Scholar] [CrossRef]
- Ratnasamy, S.; Francis, P.; Handley, M.; Karp, R.; Shenker, S. A scalable content-addressable network. In Proceedings of the 2001 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, San Diego, CA, USA, 27–31 August 2001. [Google Scholar]
- Rowstron, A.; Druschel, P. Pastry: Scalable, decentralized object location, and routing for large-scale peer-to-peer systems. In Lecture Notes in Computer Science; Guerraoui, R., Ed.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 329–350. [Google Scholar]
- Zhao, B.Y.; Kubiatowicz, J.; Joseph, A.D. Tapestry: An Infrastructure for Fault-Tolerant Wide-Area Location and Routing; Technical Report UCB-CSB-01–1141; University of California: Oakland, CA, USA, 2001. [Google Scholar]
- Joung, Y.J.; Yang, L.W.; Fang, C.T. Keyword search in DHT-based peer-to-peer networks. IEEE J. Sel. Areas Commun. 2007, 25. [Google Scholar] [CrossRef]
- Jafari, N.; Sharifi, F. A comprehensive study of the resource discovery techniques in peer-to-peer networks. P2P Netw. Appl. 2015, 8, 474–492. [Google Scholar]
- Stoica, I.; Morris, R.; Liben-Nowell, D.; Karger, D.R.; Kaashoek, M.F.; Dabek, F.; Balakrishnan, H. Chord: A scalable peer-to-peer lookup protocol for internet applications. IEEE/ACM Trans. Netw. 2003, 11, 17–32. [Google Scholar] [CrossRef]
- Gottron, C.; König, A.; Steinmetz, R. A survey on security in mobile peer-to-peer architectures—Overlay-based vs. underlay-based approaches. Future Internet 2010, 2, 505–532. [Google Scholar] [CrossRef]
- Seyedi, Y.; Karimi, H.; Guerrero, J.M. Centralized disturbance detection in smart microgrids with noisy and intermittent synchrophasor data. IEEE Trans. Smart Grid 2016. [Google Scholar] [CrossRef]
- Youssef, T.A.; Elsayed, A.T.; Mohammed, O.A. Data distribution service-based interoperability framework for smart grid testbed infrastructure. Energies 2016, 9, 150. [Google Scholar] [CrossRef]
- Safdar, S.; Hamdaoui, B.; Cotilla-Sanchez, E.; Guizani, M. A survey on communication infrastructure for micro-grids. In Proceedings of the 9th International Wireless Communications and Mobile Computing Conference (IWCMC 2013), Sardinia, Italy, 1–5 July 2013. [Google Scholar]
- Xin, L.; Xia, H.; Chien, A. Validating and scaling the microgrid: A scientific instrument for grid dynamics. J. Grid Comput. 2004, 2, 141–161. [Google Scholar]
- Kansal, P.; Bose, A. Bandwidth and latency requirements for smart transmission grid applications. IEEE Trans. Smart Grid 2012, 3, 1344–1352. [Google Scholar] [CrossRef]
- International Electrotechnical Commission (IEC). IEC 61850–7-420 Communication Networks and System in Power Utility Automation—Part 7-420: Basic Communication Structure—Distributed Energy Resources Logical Nodes; IEEE: Piscataway, NJ, USA, 2009. [Google Scholar]
- International Electrotechnical Commission (IEC). IEC 61850–5 Communication Networks and Systems in Substations—Part 5: Communication Requirements for Functions and Device Models; IEEE: Piscataway, NJ, USA, 2004. [Google Scholar]
- Institute of Electrical and Electronics Engineers (IEEE). IEEE Standard Communication Delivery Time Performance Requirements for Electric Power Substation Automation; IEEE Standards Association: Piscataway, NJ, USA, 2005; pp. 1–24. [Google Scholar]
- Kuo, M.T.; Lu, S.D. Design and implementation of real-time intelligent control and structure based on multi-agent systems in microgrids. Energies 2013, 6, 6045–6059. [Google Scholar] [CrossRef]
- Ktari, S.; Hecker, A.; Labiod, H. Structured flooding search in Chord overlays. In Proceedings of the GIIS’09 Second International Conference on Global Information Infrastructure Symposium, Hammemet, Tunisia, 23–26 June 2009. [Google Scholar]
- Del Val, E.; Rebollo, M.; Botti, V. Enhancing decentralized service discovery in open service-oriented multi-agent systems. Auton. Agents Multi-agent Syst. 2014, 28, 1–30. [Google Scholar] [CrossRef]
- Di Mauro, D.; Augusto, J.C.; Origlia, A.; Cutugno, F. A framework for distributed interaction in intelligent environments. In Proceedings of the 2017 European Conference on Ambient Intelligence, Málaga, Spain, 26–28 April 2017. [Google Scholar]
- Howell, S.; Rezgui, Y.; Hippolyte, J.L.; Jayan, B.; Li, H. Towards the next generation of smart grids: Semantic and holonic multi-agent management of distributed energy resources. Renew. Sustain. Energy Rev. 2017, 77, 193–214. [Google Scholar] [CrossRef]
- Frey, S.; Diaconescu, A.; Menga, D.; Demeure, I. A generic holonic control architecture for heterogeneous multiscale and multiobjective smart microgrids. ACM Trans. Auton. Adapt. Syst. 2015, 2, 9. [Google Scholar] [CrossRef]
- Miers, C.C.; Simplicio, M.A.; Gallo, D.S.; Carvalho, T.C. A taxonomy for locality algorithms on peer-to-peer networks. IEEE Lat. Am. Trans. 2010, 8, 323–331. [Google Scholar] [CrossRef]
- Porsinger, T.; Janik, P.; Leonowicz, Z.; Gono, R. Modelling and optimization in microgrids. Energies 2017, 10, 523. [Google Scholar] [CrossRef]
- Holzapfel, S.; Wacker, A.; Weis, T.; Wander, M. An architecture for complex P2P systems. In Proceedings of the 2012 IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 14–17 January 2012. [Google Scholar]
- Muhammad, A.; Muhammad, Z.; Muhammad, A.; Amjad, U. TCP/IP based intelligent load management system in micro-grids network using MATLAB/Simulink. Energy Power Eng. 2012, 4, 283–289. [Google Scholar]
- Bani-Ahmed, A.; Weber, L. Microgrid communication: State of the art and future trends. In Proceedings of the 3rd International Conference on Renewable Energy Research and Applications, Milwaukee, WI, USA, 19–22 October 2014. [Google Scholar]
- Shin, I.J.; Song, B.K.; Eom, D.S. International Electronical Committee (IEC) 61850 mapping with constrained application protocol (CoAP) in smart grids based European telecommunications standard institute Machine-to-Machine (M2M) environment. Energies 2017, 10, 393. [Google Scholar] [CrossRef]
- Piagi, P.; Lasseter, R.-H. Autonomous control of microgrids. In Proceedings of the 2006 IEEE Power Engineering Society General Meeting, Montreal, QC, USA, 18–22 June 2006. [Google Scholar]
- Loh, P.C.; Li, D.; Chai, Y.K.; Blaabjerg, F. Autonomous operation of hybrid microgrid with AC and DC subgrids. IEEE Trans. Power Electron. 2013, 28, 2214–2223. [Google Scholar] [CrossRef]
- Wauters, T.; de Turck, F.; Develder, C. Overlay networks for smart grids. Available online: http://users.atlantis.ugent.be/cdvelder/papers/2013/wauters2013sgv.pdf (accessed on 24 August 2017).
- Eugster, P.T.; Felber, P.A.; Guerraoui, R.; Kermarrec, A.M. The many faces of publish/subscribe. ACM Comput. Surv. 2003, 35, 114–131. [Google Scholar] [CrossRef]
- Wang, L. Attacks against peer-to-peer networks and countermeasures. In Proceedings of the T-110.5290 Seminar on Network Security, Helsinki, Finland, 11–12 Desember 2006. [Google Scholar]
- Jaideep, G.; Battula, B.P. Survey on the present state-of-the-art of P2P networks, their security issues and counter measures. Int. J. Appl. Eng. Res. 2016, 11, 616–620. [Google Scholar]
- Ali, I. High-speed peer-to-peer communication based protection scheme implementation and testing in laboratory. Int. J. Comput. Appl. 2012, 38, 16–24. [Google Scholar] [CrossRef]
- Yoo, B.; Yang, S.; Yang, H.; Kim, W.; Jeong, Y.; Han, B.; Jang, K. Communication architecture of the IEC 61850-based micro grid system. J. Electr. Eng. Technol. 2011, 6, 605–612. [Google Scholar] [CrossRef]
- Dou, X.; Quan, X.; Wu, Z.; Hu, M.; Yang, K.; Yuan, J.; Wang, M. Hybrid multi-agent control in microgrids: Framework, models and implementations based on IEC 61850. Energies 2015, 8, 31–58. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
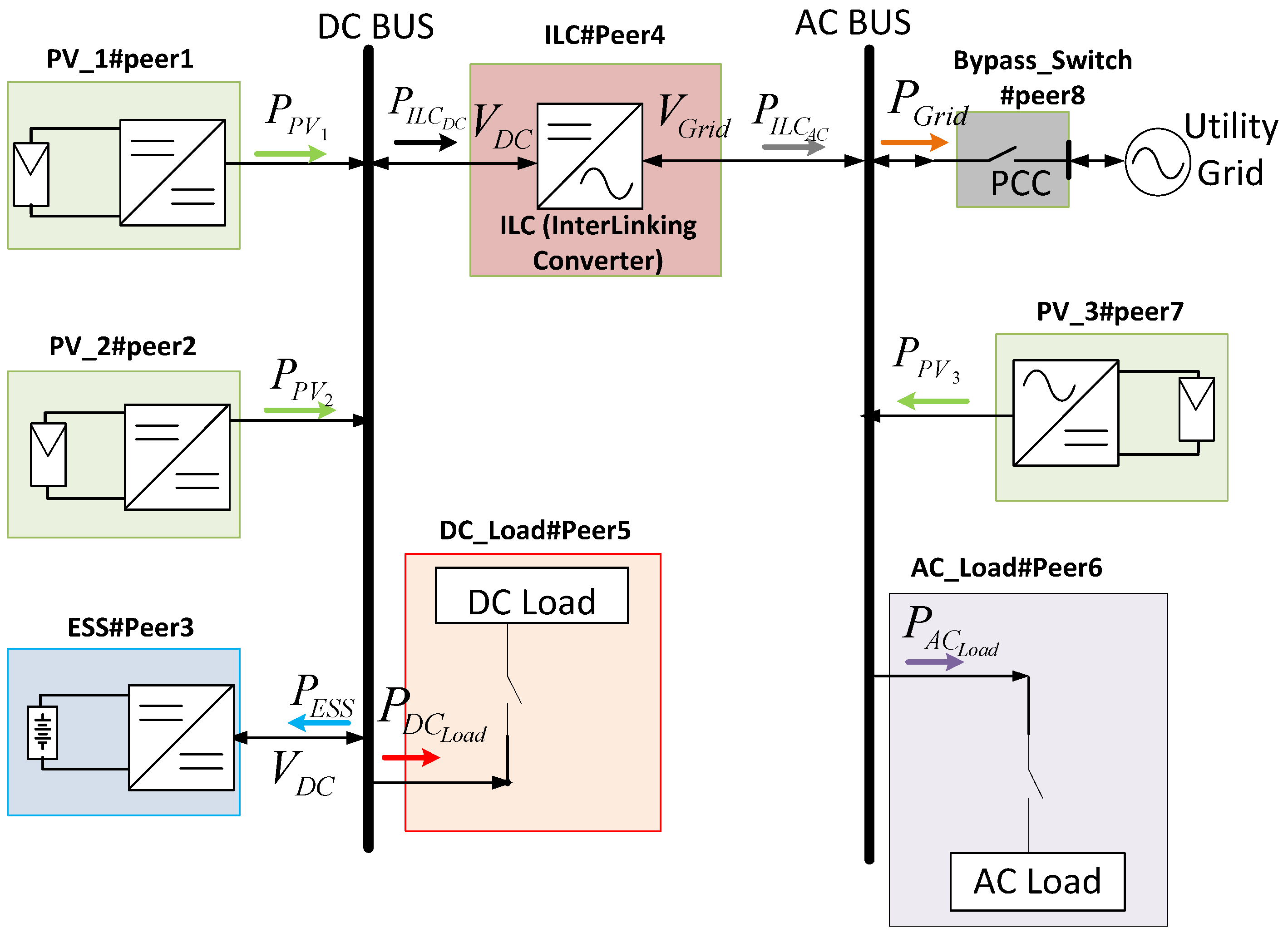
| Application | Network Requirements | |
|---|---|---|
| Bandwidth | Latency | |
| Demand response | 14–100 Kbps | 500 ms–several minutes |
| Distributed energy resources and storage | 9.6–56 Kbps | 20 ms–15 s |
| Distributed management | 9.6–100 Kbps | 100 ms–2 s |
| Abbreviation | Definition |
|---|---|
| PPVn | Power supplied by the photovoltaics (PV) arrays |
| PPV | PV power generated by the DC MG |
| PDCLoad | Overall power consumed by the DC loads |
| PGrid | Power injected from the HY MG to the grid |
| PILC_AC | Power injected from the DC bus to the AC bus by the InterLinked Converter (ILC), measured at the AC side of the ILC |
| PILC_DC | Power injected from the DC bus to the AC bus by the ILC, measured at the DC side of the ILC |
| PESS | Battery bank charge power seen from the DC bus |
| PACLoad | Overall power consumed by the AC loads |
| PAC_DGs | Power supplied by the AC DGs |
| VGrid | RMS value of the grid voltage |
| VDC | DC bus voltage |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marzal, S.; González-Medina, R.; Salas-Puente, R.; Figueres, E.; Garcerá, G. A Novel Locality Algorithm and Peer-to-Peer Communication Infrastructure for Optimizing Network Performance in Smart Microgrids. Energies 2017, 10, 1275. https://doi.org/10.3390/en10091275
Marzal S, González-Medina R, Salas-Puente R, Figueres E, Garcerá G. A Novel Locality Algorithm and Peer-to-Peer Communication Infrastructure for Optimizing Network Performance in Smart Microgrids. Energies. 2017; 10(9):1275. https://doi.org/10.3390/en10091275
Chicago/Turabian StyleMarzal, Silvia, Raul González-Medina, Robert Salas-Puente, Emilio Figueres, and Gabriel Garcerá. 2017. "A Novel Locality Algorithm and Peer-to-Peer Communication Infrastructure for Optimizing Network Performance in Smart Microgrids" Energies 10, no. 9: 1275. https://doi.org/10.3390/en10091275
APA StyleMarzal, S., González-Medina, R., Salas-Puente, R., Figueres, E., & Garcerá, G. (2017). A Novel Locality Algorithm and Peer-to-Peer Communication Infrastructure for Optimizing Network Performance in Smart Microgrids. Energies, 10(9), 1275. https://doi.org/10.3390/en10091275