
An Optimized Prediction Intervals Approach for Short Term PV Power Forecasting

Abstract
1. Introduction
2. Methodology
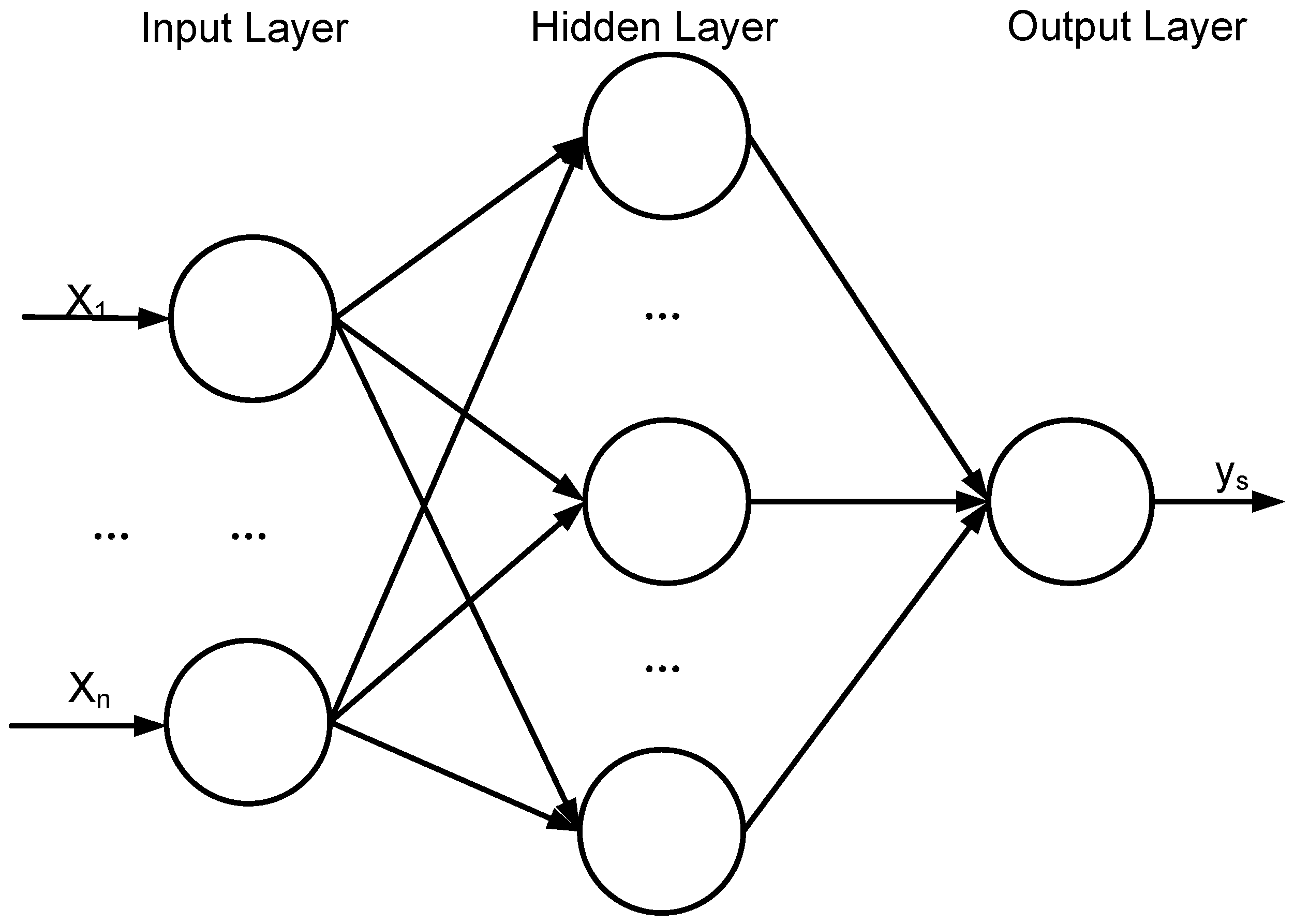
2.1. ELM
2.2. Improved DE
2.3. PIs Construction and Assessment
2.3.1. PI Formulation
2.3.2. Metrics for PIs Quality
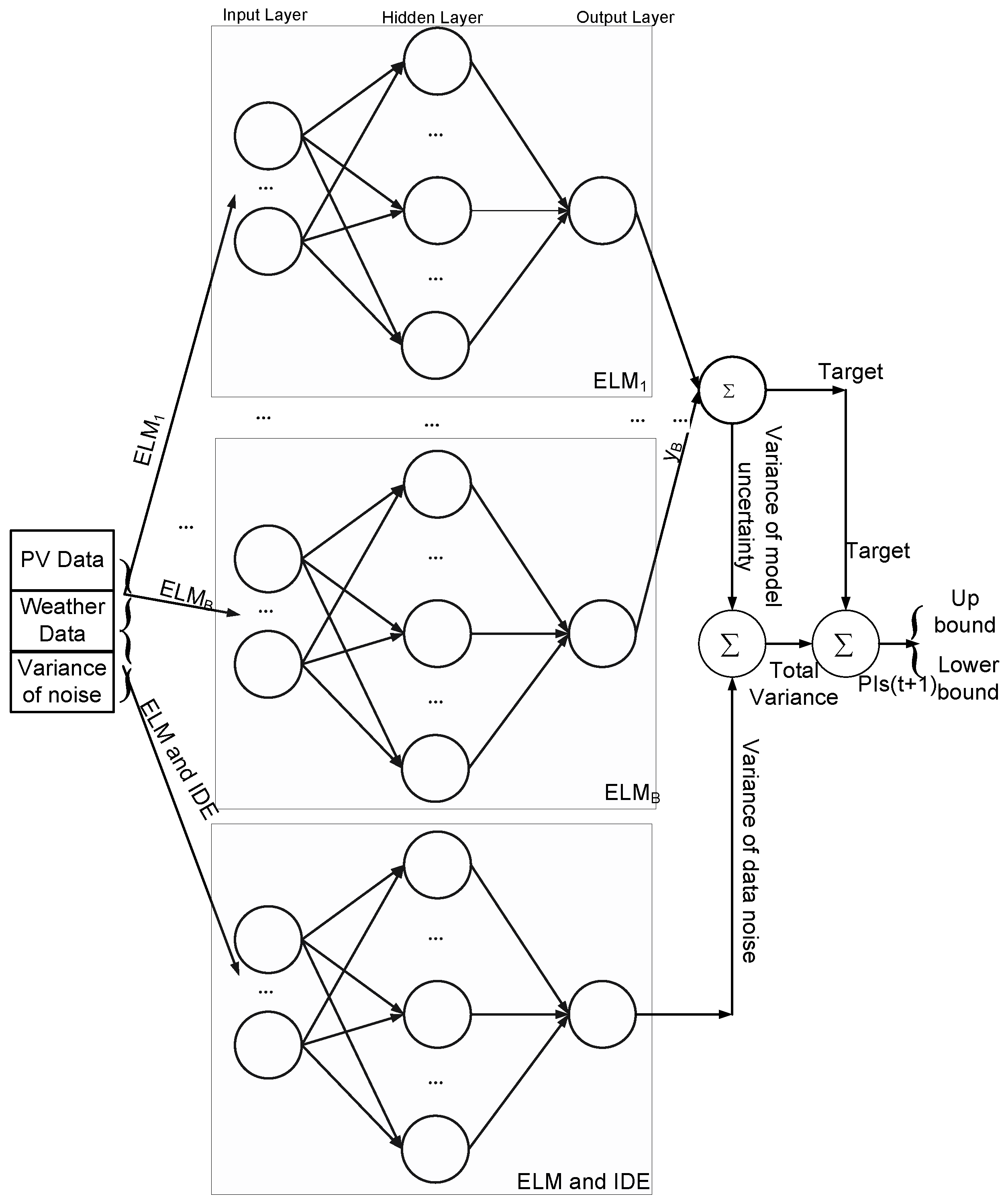
2.4. Traditional Bootstrap Method for PIs Construction
2.4.1. Variance of Model Uncertainty
2.4.2. Variance of Data Noise
3. Proposed Method
3.1. PIs Based Cost Function
3.2. Overall Procedures
4. Experimental Analysis
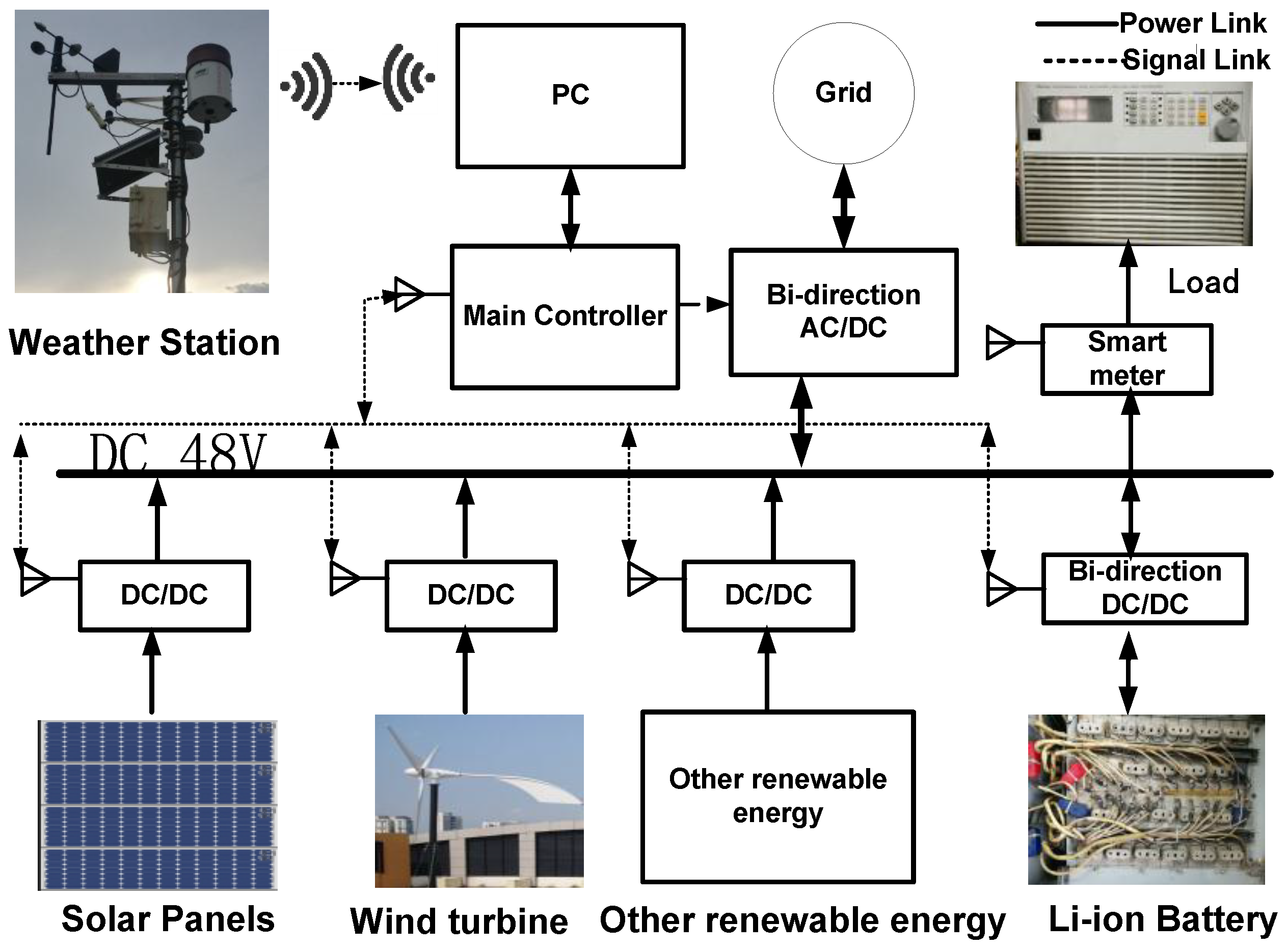
4.1. Experimental Data Description
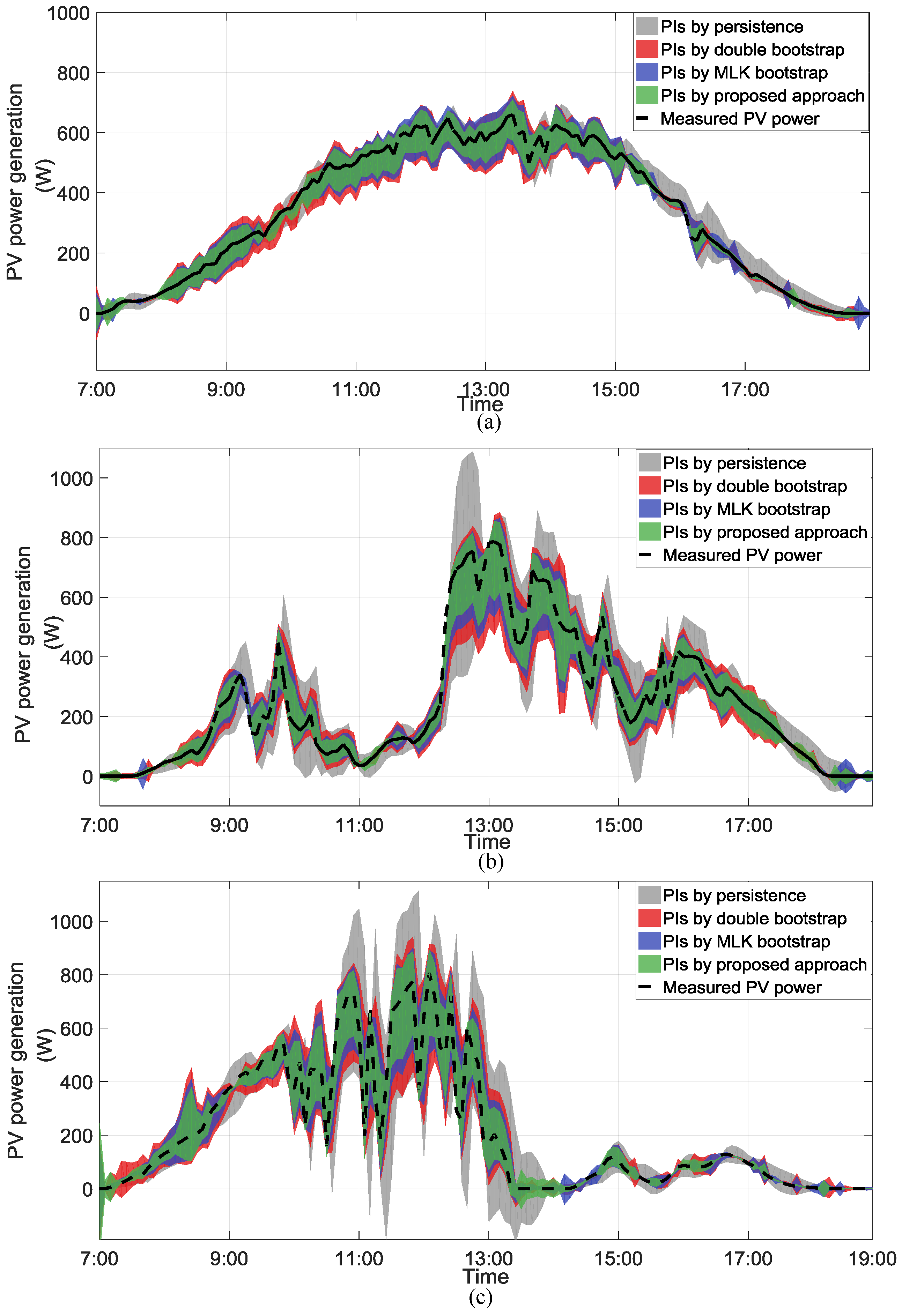
4.2. Experimental Results and Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Simoes, S.; Zeyringer, M.; Mayr, D.; Huld, T.; Nijs, W.; Schmidt, J. Impact of different levels of geographical disaggregation of wind and PV electricity generation in large energy system models: A case study for Austria. Renew. Energy 2017, 105, 183–198. [Google Scholar] [CrossRef]
- Bracale, A.; Caramia, P.; Carpinelli, G.; Fazio, A.R.D.; Ferruzzi, G. A bayesian method for short-term probabilistic forecasting of photovoltaic generation in smart grid operation and control. Energies 2013, 6, 733–747. [Google Scholar] [CrossRef]
- Zhang, J.; Florita, A.; Hodge, B.M.; Lu, S.; Hamann, H.F.; Banunarayanan, V.; Brockway, A.M. A suite of metrics for assessing the performance of solar power forecasting. Sol. Energy 2015, 111, 157–175. [Google Scholar] [CrossRef]
- Yao, E.; Samadi, P.; Wong, V.W.S.; Schober, R. Residential demand side management under high penetration of rooftop photovoltaic units. IEEE Trans. Smart Grid 2016, 7, 1597–1608. [Google Scholar] [CrossRef]
- Wan, C.; Zhao, J.; Song, Y.; Xu, Z.; Lin, J.; Hu, Z. Photovoltaic and solar power forecasting for smart grid energy management. CSEE J. Power Energy Syst. 2015, 1, 38–46. [Google Scholar] [CrossRef]
- Bae, K.Y.; Han, S.J.; Dan, K.S. Hourly solar irradiance prediction based on support vector machine and its error analysis. IEEE Trans. Power Syst. 2017, 32, 935–945. [Google Scholar] [CrossRef]
- Bracale, A.; Carpinelli, G.; Falco, P.D. A probabilistic competitive ensemble method for short-term photovoltaic power forecasting. IEEE Trans. Sustain. Energy 2016, 8, 551–560. [Google Scholar] [CrossRef]
- Han, S.J.; Bae, K.Y.; Park, H.S.; Dan, K.S. Solar power prediction based on satellite images and support vector machine. IEEE Trans. Sustain. Energy 2016, 7, 1255–1263. [Google Scholar]
- Bacher, P.; Madsen, H.; Nielsen, H.A. Online short-term solar power forecasting. Sol. Energy 2009, 83, 1772–1783. [Google Scholar] [CrossRef]
- Huang, C.M.; Chen, S.J.; Yang, S.P.; Kuo, C.J. One-day-ahead hourly forecasting for photovoltaic power generation using an intelligent method with weather-based forecasting models. IET Gener. Transm. Distrib. 2015, 9, 1874–1882. [Google Scholar] [CrossRef]
- Asrari, A.; Wu, T.X.; Ramos, B. A hybrid algorithm for short-term solar power prediction—Sunshine state case study. IEEE Trans. Sustain. Energy 2017, 8, 582–591. [Google Scholar] [CrossRef]
- Golestaneh, F.; Pinson, P.; Gooi, H.B. Very short-term nonparametric probabilistic forecasting of renewable energy generation—With application to solar energy. IEEE Trans. Power Syst. 2016, 31, 3850–3863. [Google Scholar] [CrossRef]
- Bludszuweit, H.; Dominguez-Navarro, J.A.; Llombart, A. Statistical analysis of wind power forecast error. IEEE Trans. Power Syst. 2008, 23, 983–991. [Google Scholar] [CrossRef]
- Wan, C.; Lin, J.; Song, Y.; Xu, Z.; Yang, G. Probabilistic forecasting of photovoltaic generation: An efficient statistical approach. IEEE Trans. Power Syst. 2016, 32, 2471–2472. [Google Scholar] [CrossRef]
- Sperati, S.; Alessandrini, S.; Monache, L.D. An application of the ECMWF ensemble prediction system for short-term solar power forecasting. Sol. Energy 2016, 133, 437–450. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Lower upper bound estimation method for construction of neural network-based prediction intervals. IEEE Trans. Neural Netw. 2011, 22, 337–346. [Google Scholar] [CrossRef] [PubMed]
- Wan, C.; Lin, J.; Wang, J.; Song, Y.; Dong, Z.Y. Direct quantile regression for nonparametric probabilistic forecasting of wind power generation. IEEE Trans. Power Syst. 2016, 32, 2767–2778. [Google Scholar] [CrossRef]
- Shrivastava, N.A.; Khosravi, A.; Panigrahi, B.K. Prediction interval estimation of electricity prices using pso-tuned support vector machines. IEEE Trans. Ind. Inform. 2015, 11, 322–331. [Google Scholar] [CrossRef]
- Wan, C.; Xu, Z.; Wang, Y.; Dong, Z.Y.; Wong, K.P. A hybrid approach for probabilistic forecasting of electricity price. IEEE Trans. Smart Grid 2014, 5, 463–470. [Google Scholar] [CrossRef]
- Zhang, G.; Wu, Y.; Wong, K.P.; Xu, Z.; Dong, Z.Y.; Iu, H.C. An advanced approach for construction of optimal wind power prediction intervals. IEEE Trans. Power Syst. 2015, 30, 2706–2715. [Google Scholar] [CrossRef]
- Li, S.; Goel, L.; Wang, P. An ensemble approach for short-term load forecasting by extreme learning machine. Appl. Energy 2016, 170, 22–29. [Google Scholar] [CrossRef]
- Lorenz, E.; Hurka, J.; Heinemann, D.; Beyer, H.G. Irradiance forecasting for the power prediction of grid-connected photovoltaic systems. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2009, 2, 2–10. [Google Scholar] [CrossRef]
- David, M.; Ramahatana, F.; Trombe, P.J.; Lauret, P. Probabilistic forecasting of the solar irradiance with recursive arma and garch models. Sol. Energy 2016, 133, 55–72. [Google Scholar] [CrossRef]
- Dong, Z.; Yang, D.; Reindl, T.; Walsh, W.M. Short-term solar irradiance forecasting using exponential smoothing state space model. Energy 2013, 55, 1104–1113. [Google Scholar] [CrossRef]
- Rana, M.; Koprinska, I.; Agelidis, V.G. 2d-interval forecasts for solar power production. Sol. Energy 2015, 122, 191–203. [Google Scholar] [CrossRef]
- Kavousi-Fard, A.; Khosravi, A.; Nahavandi, S. A new fuzzy-based combined prediction interval for wind power forecasting. IEEE Trans. Power Syst. 2016, 31, 18–26. [Google Scholar] [CrossRef]
- Ding, A.A. Prediction intervals for artificial neural networks. J. Am. Stat. Assoc. 1997, 92, 748–757. [Google Scholar]
- Ak, R.; Fink, O.; Zio, E. Two machine learning approaches for short-term wind speed time-series prediction. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 1734–1747. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, A.; Nahavandi, S.; Srinivasan, D.; Khosravi, R. Constructing optimal prediction intervals by using neural networks and bootstrap method. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1810–1815. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Wang, P.; Goel, L. Short-term load forecasting by wavelet transform and evolutionary extreme learning machine. Electr. Power Syst. Res. 2015, 122, 96–103. [Google Scholar] [CrossRef]
- Chen, X.; Dong, Z.Y.; Meng, K.; Xu, Y.; Wong, K.P.; Ngan, H.W. Electricity price forecasting with extreme learning machine and bootstrapping. IEEE Trans. Power Syst. 2012, 27, 2055–2062. [Google Scholar] [CrossRef]
- Wan, C.; Xu, Z.; Pinson, P.; Dong, Z.Y.; Wong, K.P. Probabilistic forecasting of wind power generation using extreme learning machine. IEEE Trans. Power Syst. 2014, 29, 1033–1044. [Google Scholar] [CrossRef]
- Qin, A.K.; Huang, V.L.; Suganthan, P.N. Differential evolution algorithm with strategy adaptation for global numerical optimization. IEEE Trans. Evol. Comput. 2009, 13, 398–417. [Google Scholar] [CrossRef]
- Davison, A.C.; Hinkley, D.V. Bootstrap methods and their application. Technometrics 1997, 94, 216–217. [Google Scholar]
- Alessandrini, S.; Monache, L.D.; Sperati, S.; Cervone, G. An analog ensemble for short-term probabilistic solar power forecast. Appl. Energy 2015, 157, 95–110. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seasons | PINC | Value | Persistence | BNN | Double Bootstrap | MLE Bootstrap | Proposed Bootstrap |
|---|---|---|---|---|---|---|---|
| Northeast monsoon | 90% | PICP | 76.74 | 94.65 | 93.75 | 94.10 | 94.79 |
| MPIW | 19.01 | 13.19 | 17.83 | 16.90 | 12.53 | ||
| 95% | PICP | 79.86 | 96.21 | 95.28 | 95.93 | 96.38 | |
| MPIW | 26.83 | 17.21 | 20.57 | 20.32 | 15.26 | ||
| 99% | PICP | 83.98 | 98.35 | 96.75 | 98.32 | 98.79 | |
| MPIW | 37.12 | 18.92 | 20.82 | 22.90 | 18.53 | ||
| Inter monsoon (NS) | 90% | PICP | 75.35 | 93.13 | 91.35 | 92.71 | 93.06 |
| MPIW | 14.88 | 12.57 | 15.70 | 13.88 | 12.38 | ||
| 95% | PICP | 77.39 | 96.23 | 94.35 | 95.65 | 96.12 | |
| MPIW | 24.71 | 14.92 | 18.12 | 16.15 | 14.84 | ||
| 99% | PICP | 78.81 | 98.50 | 96.78 | 97.69 | 98.52 | |
| MPIW | 35.36 | 17.67 | 21.26 | 19.73 | 17.32 | ||
| Southwest monsoon | 90% | PICP | 78.82 | 92.95 | 90.63 | 91.67 | 93.06 |
| MPIW | 20.06 | 13.64 | 17.62 | 15.77 | 13.35 | ||
| 95% | PICP | 78.82 | 95.72 | 94.63 | 95.21 | 95.98 | |
| MPIW | 26.06 | 16.59 | 20.15 | 18.59 | 16.23 | ||
| 99% | PICP | 78.82 | 97.36 | 90.63 | 91.67 | 97.25 | |
| MPIW | 34.06 | 20.12 | 23.27 | 21.14 | 19.80 | ||
| Inter monsoon (SN) | 90% | PICP | 75.27 | 92.68 | 89.93 | 90.28 | 92.71 |
| MPIW | 26.54 | 13.25 | 17.66 | 14.09 | 12.57 | ||
| 95% | PICP | 76.93 | 95.57 | 94.93 | 95.28 | 95.62 | |
| MPIW | 36.57 | 15.89 | 20.95 | 17.38 | 15.83 | ||
| 99% | PICP | 78.56 | 98.65 | 97.93 | 97.28 | 98.71 | |
| MPIW | 46.51 | 19.53 | 22.16 | 20.17 | 19.13 |
| Weather conditions | PINC | Value | Persistence | BNN | Double Bootstrap | MLE Bootstrap | Proposed Bootstrap |
|---|---|---|---|---|---|---|---|
| Sunny | 90% | PICP | 88.89 | 95.03 | 94.44 | 93.75 | 95.14 |
| MPIW | 8.00 | 6.96 | 9.72 | 8.53 | 6.81 | ||
| 95% | PICP | 89.83 | 97.10 | 96.15 | 96.58 | 97.14 | |
| MPIW | 16.12 | 12.15 | 15.81 | 13.87 | 11.76 | ||
| 99% | PICP | 91.65 | 98.93 | 97.64 | 98.15 | 98.87 | |
| MPIW | 23.25 | 15.96 | 19.63 | 18.52 | 15.95 | ||
| Cloudy | 90% | PICP | 81.94 | 93.15 | 92.36 | 93.06 | 93.18 |
| MPIW | 17.55 | 9.79 | 14.94 | 11.76 | 9.83 | ||
| 95% | PICP | 83.94 | 96.68 | 95.03 | 95.37 | 96.79 | |
| MPIW | 31.55 | 15.89 | 19.12 | 16.19 | 15.83 | ||
| 99% | PICP | 84.94 | 98.35 | 96.36 | 97.01 | 98.25 | |
| MPIW | 39.65 | 16.57 | 23.06 | 19.76 | 16.23 | ||
| Thunderstorm | 90% | PICP | 78.47 | 90.87 | 90.07 | 90.28 | 90.97 |
| MPIW | 19.74 | 10.96 | 15.90 | 13.17 | 10.88 | ||
| 95% | PICP | 81.63 | 95.50 | 94.86 | 95.28 | 95.96 | |
| MPIW | 39.74 | 16.70 | 20.14 | 18.20 | 16.65 | ||
| 99% | PICP | 84.57 | 98.15 | 96.39 | 96.28 | 98.03 | |
| MPIW | 48.74 | 21.94 | 25.51 | 23.17 | 21.72 |
| Method | Training Time (s) | Test Time (s) |
|---|---|---|
| BNN Bootstrap | 8579.32 | 5.730 |
| MLE Bootstrap | 138.67 | 0.425 |
| Double Bootstrap | 147.19 | 0.836 |
| Proposed Bootstrap | 135.53 | 0.421 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, Q.; Zhuang, S.; Sheng, H.; Wang, S.; Xiao, J. An Optimized Prediction Intervals Approach for Short Term PV Power Forecasting. Energies 2017, 10, 1669. https://doi.org/10.3390/en10101669
Ni Q, Zhuang S, Sheng H, Wang S, Xiao J. An Optimized Prediction Intervals Approach for Short Term PV Power Forecasting. Energies. 2017; 10(10):1669. https://doi.org/10.3390/en10101669
Chicago/Turabian StyleNi, Qiang, Shengxian Zhuang, Hanmin Sheng, Song Wang, and Jian Xiao. 2017. "An Optimized Prediction Intervals Approach for Short Term PV Power Forecasting" Energies 10, no. 10: 1669. https://doi.org/10.3390/en10101669
APA StyleNi, Q., Zhuang, S., Sheng, H., Wang, S., & Xiao, J. (2017). An Optimized Prediction Intervals Approach for Short Term PV Power Forecasting. Energies, 10(10), 1669. https://doi.org/10.3390/en10101669