1. Introduction
In 2014, the IPCC’s Fifth Assessment Report (AR5) showed that the cumulative CO
2 emissions largely determined the global mean surface warming in the late 21st century and later, and even if carbon dioxide emissions were stopped, many aspects of climate change would continue for centuries. The report also pointed out that human activity was the main reason for climate change since the 1950s and unless the greenhouse gas emissions were controlled, global warming would reach a dangerous level in the future [
1,
2]. Global carbon project website statistics show that in 2015 the global total CO
2 emissions reached 36.2 billion tons, of which China accounted for 28.77%, more than the sum of the United States and the European Union [
3]. In recent years, China has taken active measures to combat climate change and China pledged that the CO
2 emissions per unit of GDP would decrease by 60–65% in 2030 compared with 2005 at the Paris International Climate Conference in 2015 [
4]. Furthermore, China’s government issued the “13th Five-Year Plan for the Control of Greenhouse Gas Emissions”, of which the main objective was to reduce CO
2 emissions per unit of GDP by 18% in 2020 based on 2015 and the total amount of CO
2 emissions had been effectively controlled [
5]. Beijing, as one of the most developed cities in China and a core city in global competition, can further improve its comprehensive strength by reducing its CO
2 emissions and carbon intensity and developing a low-carbon economy. Thus, there is a great need to introduce a scientific forecast model based on profound analysis of the influencing factors to predict CO
2 emissions and then take practical and effective actions to achieve the goal of transforming Beijing into a low-carbon city.
Various approaches have been used to forecast CO
2 emissions in recent years. Ahmed [
6] introduced cointegration incorporated with an Auto Regressive Distributed Lag bounds testing approach to investigate the relationship between CO
2 emissions and the main influencing factors in Pakistan with time series data from 1971 to 2008 based on the assumption of an environmental Kuznets curve. Similarly, Chinese scholars (e.g., Shao [
7], Tong [
8], Yin et al. [
9] and Lin et al. [
10]) also carried out research on the environmental Kuznets curve for China’s carbon emissions and analyzed the main factors that affected carbon emissions based on data from certain provinces or cities. Holden [
11] constructed a benchmarking methodology for UK greenhouse gas emissions estimation in road freight transport, integrating weight utilization, capacity utilization, driving distance and associated greenhouse gas emissions with a data envelopment analysis (DEA) method and then tested it in a group of simulated fleets. Sheinbaum et al. [
12] studied the energy and CO
2 emissions trends of Mexico’s iron and steel industry from 1970–2006 using international comparisons and log mean divisia index. This paper held the opinion that energy efficiency improvement and share compression of fuel had a significant influence on CO
2 emissions reduction. Based on a least squares support vector machine, Sun et al. [
13] analyzed CO
2 emission change trends of residential consumption and three major industries as well as proposed cointegration and Granger causality test to select influence factors of three major industries and residential consumption CO
2 emissions. Through the above studies, the main factors that influence carbon emissions include economic progress, population indices, energy intensity, industrial structure and technical level, etc.
Because of the objective and quantifiable advantages of qualitative analysis, the studies of carbon emissions are always based on models with mathematical functions. However, the situation in the real world is complicated and a single model cannot cover all possibilities. Therefore, combined with scenario analysis, a model can predict CO
2 emissions in different scenarios effectively and provide better assistance for energy forecasting, optimizing and planning [
14]. Azam et al. [
15] adopted a long-range energy alternatives planning (LEAP) model to estimate the energy consumption and CO
2 emissions of road transportation in Malaysia from 2012 to 2040 under a business-as-usual scenario and three other alternative fuel policy scenarios: biodiesel vehicles (BIO), natural gas vehicles (NGV) and hybrid electric vehicles (HEV). The finding implied that the road transportation energy consumption and carbon emissions reduction of Malaysia were most effective under a natural gas vehicle (NGV) scenario. Kumar [
16] employed a LEAP model to construct different energy scenarios and estimated CO
2 emissions with the least cost method and then discussed the application of renewable energy in India’s future power supply system. The finding showed that under the Accelerated Renewable Energy Technology (ARET) scenario, renewable energy could probably account for 23% of the electricity generation and the carbon emissions could decrease 74% by 2050. Combined with scenario analysis, Liu [
17] set three scenarios in the different applications of economic development mode and different traffic development mode using the LEAP model to forecast the main carbon emissions of the Jiangxi transportation industry in 2010–2030. The results showed that increasing the scope of using the new energy and renewable energy would help achieve the sustainable development of energy and the environment.
The abovementioned studies mostly selected a country, province or industry as the research object, which could effectively reflect the general characteristics of CO
2 emissions in the macro field. However, the specific carbon emissions characteristics of a city could not be reflected. Feng et al. [
18] analyzed the development trend of energy demand, energy structure and CO
2 emissions of Beijing under three different scenarios of business-as-usual, basic-policy and low-carbon from 2007–2030. Their findings showed that the building and transport sectors were identified as promising fields for achieving low-carbon growth in Beijing over the next decades. By constructing a LEAP-Shanghai model, Chang [
19] designed three comprehensive scenarios, i.e., the baseline scenario, the emissions reduction scenario and the enhanced emissions reduction scenario. This study proved that the key to long-term energy-savings and carbon emissions reduction was to exercise a reasonable control over the growth rate of economic development. In order to find suitable scenarios for the Beijing-Tianjin-Hebei rejoin, Wen [
20] chose some potential driving factors of carbon emissions to build extended stochastic impacts by regression on stochastic impacts by regression on a population, affluence and technology (STIRPAT) model. The results showed that improvement of technological level, adjustment of industry and energy consumption structures were critical factors for the control of carbon emissions. Li [
21] introduced the back propagation (BP) neural network optimized by improved particle swarm optimization algorithm (IPSO) to calculate the carbon emissions and carbon intensity reduction potential under various scenarios for 2016 and 2020 in Beijing. The results indicated that energy structure adjustment, industrial structure adjustment and technical progress could drive the decline in carbon intensity. However, the LEAP model relies mainly on the judgment of experts, which has strong subjectivity. Multiple collinearity problems can easily arise between different influencing factors in the STIRPAT model and the BP neural network algorithm is likely to lead to low model accuracy, premature or overfitting problems [
22]. Therefore, looking for a more appropriate method in forecasting of carbon emissions is imperative.
Support vector machine (SVM) shows excellent performance in solving small samples, nonlinear and high dimensional estimation problems [
23], suggesting it has a great potential in forecasting carbon emissions. However, the standard SVM approach also has some limitations, and the parameter setting of the SVM is crucial to improve its performance. In this paper, we introduce a novel carbon emissions prediction approach combining a genetic algorithm and support vector machine (GA-SVM) to enhance the prediction precision, in which GA is employed to optimize the parameters of SVM. Meanwhile, in order to solve the overfitting problem caused by outliers in the data, slack variable
is introduced to support vector machine (SVM) and in this way the outliers can exist as a common point, so that neither the support vector machine nor hyperplane can be affected by it. In particular, cointegration and Granger causality test are proposed to select the influencing factors of CO
2 emissions prediction in Beijing as well as check the influence factors with different leading lengths [
13]. Then, the CO
2 emissions prediction can be obtained under different scenarios using the selected factors, and we can find the major influencing factors of CO
2 emissions among the comparisons of 36 kinds of scenarios.
The rest of this paper is organized as follows: in
Section 2, a genetic algorithm (GA) is used to optimize the initial weight and threshold values of a support vector machine (SVM) and the new SVM optimized by GA (GA-SVM) is proposed, then we use cointegration and Granger causality test to select the influencing factors of CO
2 emissions prediction and present the analysis of the data.
Section 3 sets the scenario parameters and presents a brief description of different scenarios;
Section 4 forecasts the CO
2 emissions in Beijing from 2016–2020 and compares the prediction results under different scenarios; According to the comparison results, some recommendations for improvement are put forward in
Section 5.
2. Method and Data
In this work, a GA-SVM model has been employed to forecast carbon emissions, because SVM has a superior forecasting performance and GA can be used to select suitable parameters for SVM. In accordance with the purpose of this paper, the following procedures were formulated: optimizing the parameters of SVM model with GA and then training GA-SVM model; calculating the CO2 emissions with the conversion formula in Beijing from 1990 to 2015; selecting the factors influencing CO2 emissions with cointegration and Granger causality test. Before these procedures were carried out, we briefly introduce the genetic algorithm and support vector machine and described how the genetic algorithm optimized support vector machine in detail. In addition, the raw data of CO2 emissions in Beijing from 1990 to 2015 is obtained through the conversion of fossil fuel combustion depending on the China Energy Statistical Yearbook and Beijing Statistical Yearbook.
2.1. Genetic Algorithms
Genetic algorithm (GA) is a global optimization search algorithm, proposed by the University of Michigan’s John Holland [
24]. It is based on natural selection and genetic theory to simulate biological selection, crossover and mutation and finally get the optimal solution. Because genetic algorithms are robust, random, global, and suitable for parallel processing, they are always used to solve various complex optimization problems. In the optimization process, GA generates multiple starting points randomly in the solution space and starts the search at the same time. The fitness function is used to guide the search direction. Therefore, group search strategy and genetic operators are two main characteristics of genetic algorithm. Genetic algorithms belong to category of evolutionary algorithms, which use techniques inspired by natural evolution, such as inheritance, mutation, selection and crossover, to solve optimization problems. However, the performance of GA will be greatly affected by the determinations of genetic operators so that the selection of parameters needs further study to overcome this weakness. The basic steps of the genetic algorithm are as follows:
- (1)
Encoding the parameters and obtaining the population chromosomes;
- (2)
Calculating the fitness value of each individual in the population based on the fitness function;
- (3)
Obtaining the new population after selection, crossover, and mutation operations;
- (4)
Repeating step 2 and step 3 until the default conditions are met.
2.2. Support Vector Machine
Support Vector Machine (SVM) originated from the Statistical Learning Theory proposed by Vapnik [
25] in 1995. It constructs the optimal separating hyperplane on the principle of structural risk minimization seeking to minimize the classification error of unknown samples, which makes it have a good generalization performance in the case of small sample. The basic concept of SVM is to map nonlinearly original data into a higher dimensional feature space to solve the linear problem. Thus, considering the set of data
, where
is the input vector,
is the corresponding output value, i = 1, 2,…, n. the SVM regression function takes the form:
where
is the non-linear mapping function from the input space x, which denotes the high dimensional feature space. w is the weight vector and b is the bias term. w and b are estimated by minimizing the regularized risk function:
where 1/2
is the regularization term, C is the punishment parameter, which represents the ability of prediction for regression and is considered to specify the trade-off between the empirical risk and the model flatness.
is the
-insensitive loss function, which is defined as the following form:
In Equation (3), if the error of forecasting vale is equal or greater than , the loss equals , otherwise the loss equals zero.
To estimate w and b, Equation (2) is transformed into Equation (4) by introducing two positive slack variables and :
Minimize:
subject to:
where two slack variables
and
measure the error of the up and down sides, respectively.
The above formulation leads to maximization optimization problem [
26], which is solved employing the following Lagrangian form:
Maximize:
subject to:
where
,
is Lagrangian multipliers,
−
corresponding data points are support vector.
An optimal weight vector of the regression hyperplane is obtained by calculating
and
:
Hence, the regression function is:
in Equation (7), known as the kernel function, where the value of kernel function equals the inner product of two vector and in the feature space and , that is K( = , where i, j = 1, 2,, m.
In SVM, the popular kernel functions are:
Sigmoid function: =.
Polynomial basis function: =.
Radial basis function (RBF): = exp ().
Compared with two other kernel functions, fewer free parameters need to be determined using the radial basis function, thus, optimizing parameters will become easy. Moreover, SVMs constructed by radial basis function perform much better than polynomial basis function and sigmoid function ones. Thus, RBF is employed in SVM in this paper and the selection of C,
and
plays an important role in the forecasting performance of the SVM [
27].
2.3. GA-SVM Model
As described previously, the forecasting performance of SVM is highly dependent on its parameters. In the proposed work, genetic algorithm (GA) is used to optimize the initial weight and threshold values of SVM and the new SVM optimized by GA can get a better training effect and improve the prediction accuracy.
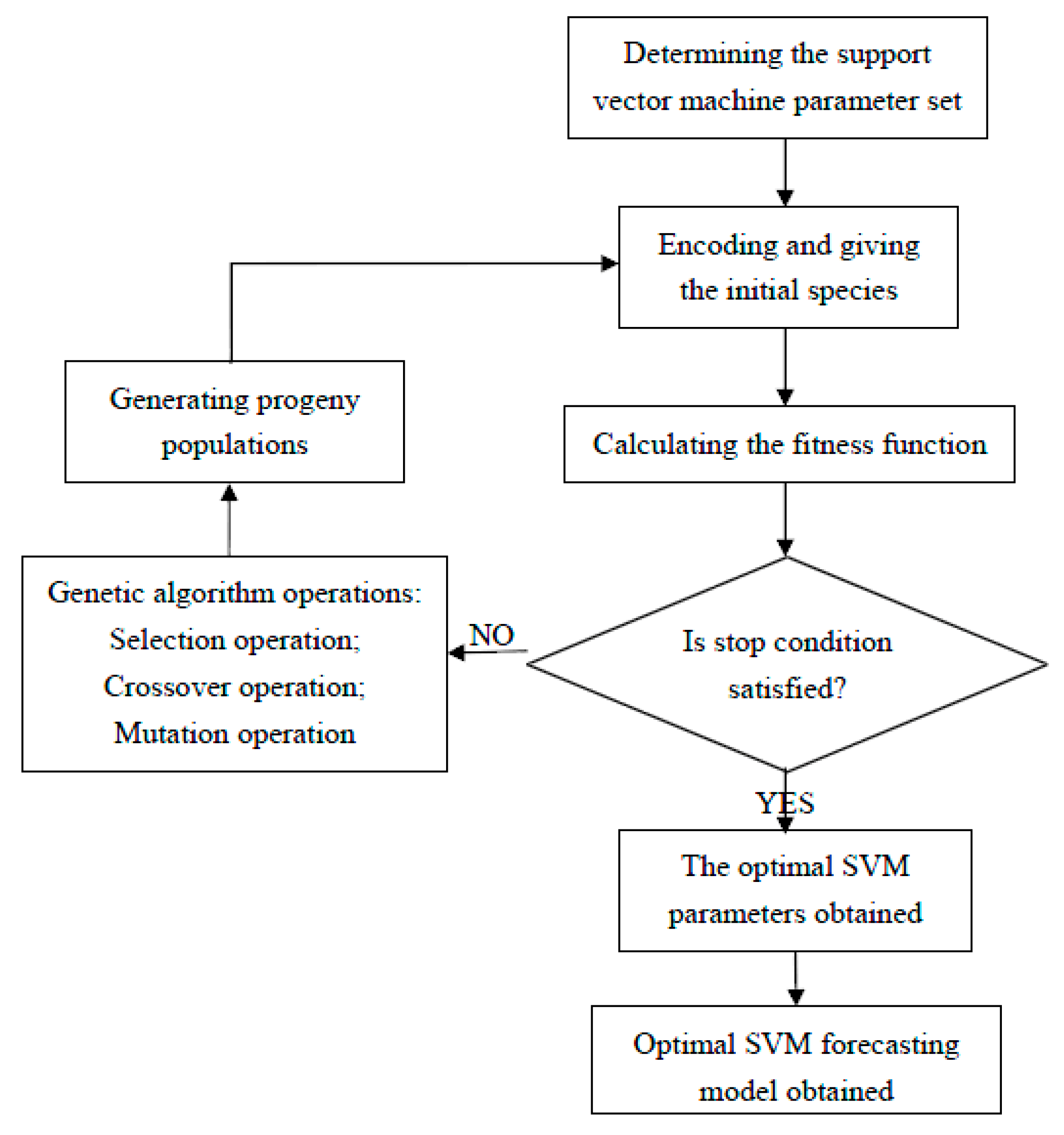
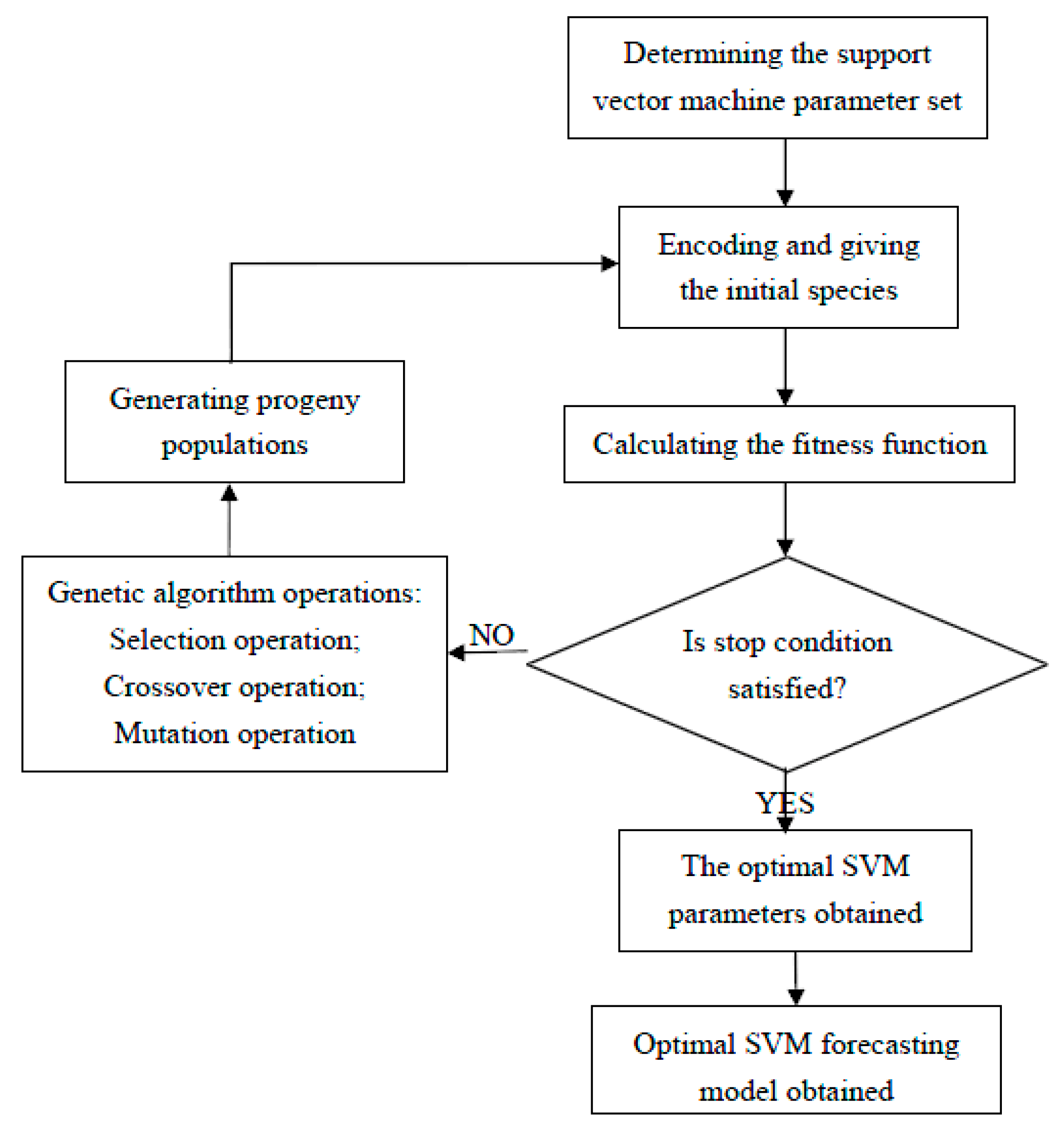
Figure 1 illustrates the proposed GA-SVM approach.
The detailed description is as follows:
- (1)
Encoding and giving the initial species: in this study, the three parameters, C, and are encoded to generate chromosomes in a binary format. Thus, according to the calculation precision required, an initial population of chromosomes which represent the values of three parameters can be generated randomly.
- (2)
Calculating the fitness function: a cross validation method is used in calculating the fitness function to prevent over-fitting or under-fitting phenomenon in GA-SVM model [
28]. In M-fold cross validation, the training set is divided into M equal subsets. One of the subsets is taken as testing set in turn and (M-1) subsets are taken as training set in the SVM regression model, then the above procedure is repeated so that each subset is validated once [
29]. We used five-fold cross validation in this paper. In addition, mean absolute percentage error (MAPE) is selected as the fitness function, which is as follows:
where m represents the number of training samples;
and
are the actual and predicted values respectively. The chromosome with a smaller value of MAPE has a better chance of surviving in the next generation.
- (3)
Genetic algorithm operators—selection, crossover and mutation operations—are carried out to generate the progeny. The chromosomes with better fitness values are more likely to be selected into the next generation using means of the roulette wheel. Genes between two chromosomes are exchanged randomly to find better solutions with a crossover probability of 0.7. Mutation is performed to alter binary code form 0 to 1 with a probability of 0.7. The evolutionary process is repeated from step 2 to step 3 until stop conditions are satisfied.
This paper introduces the Libsvm3.22 toolboxes in Matlab R2013b and trains the SVM with radial basis function kernel. According to the setting of parameters in the training function in the Libsvm3.22 toolboxes, the three parameters to be optimized in SVM can be obtained i.e., “−c” represents C, “−g” represents , “−p” represents . Since this paper trains SVM with the radial basis function kernel in the Libsvm3.22 toolboxes which has only one parameter . Therefore, the parameter “-g” can be used to set its value.
To enhance the reliability of the training results, 22 samples are picked as training samples at random, which are selected from data during 1990–2015 and the remaining four samples are used as the test group. The running result shows that the average test error of our GA-SVM model is 1.62%, which demonstrates conformance to the requirements to forecast the future carbon emissions in Beijing. In this paper, we use s cross validation approach in the GA-SVM model and the cross validation results are further optimized by the GA algorithm so that the uncertainty is reduced [
30]. In this way, the presence of uncertainty will not have much impact on the prediction accuracy of the GA-SVM model and the fitting result and prediction precision are satisfactory. In summary, the forecasting accuracy of GA-SVM model maintains a level around 98%, indicating that the uncertainty does not reduce predicative capability for the model.
Table 1 gives the initial parameters of genetic algorithms used in the proposed GA-SVM model. The values of these parameters based on numerous experiments can provide the smallest MAPE on the training set.
2.4. Data Source and Conversion
This paper chooses the energy consumption and other relevant data of Beijing from 1990 to 2015 and the CO
2 emissions are calculated by the conversion formula. First of all, the annual energy consumption of different kinds of energy, including coal, coke, crude oil, gasoline, kerosene, diesel oil, fuel, natural gas and power are obtained from China Energy Statistical Yearbook and Beijing Statistical Yearbook. Secondly, the annual consumption data of the relevant fossil fuels are converted into standard coal according to the general calculation principle of comprehensive energy consumption.
Table S1 shows the relevant conversion coefficients. Finally, according to the 2006 IPCC Guidelines for National Greenhouse Gas Inventories [
31], the standard coal data can be converted into CO
2 emissions by the conversion coefficients of different fossil fuels, which are shown in
Table S2. In order to eliminate the impact of price factor, we calculate the value of per capita GDP and energy intensity based on the constant price of 1978, which is the base year. Thus, CO
2 emissions from 1990–2015 in Beijing can be calculated as follows:
where C represents the total CO
2 emissions, i is energy types,
refers to CO
2 emissions of energy i.
represents the consumption of energy i,
is the standard coal conversion coefficients of energy i, and
refers to the CO
2 emissions coefficients of energy i. The amount of CO
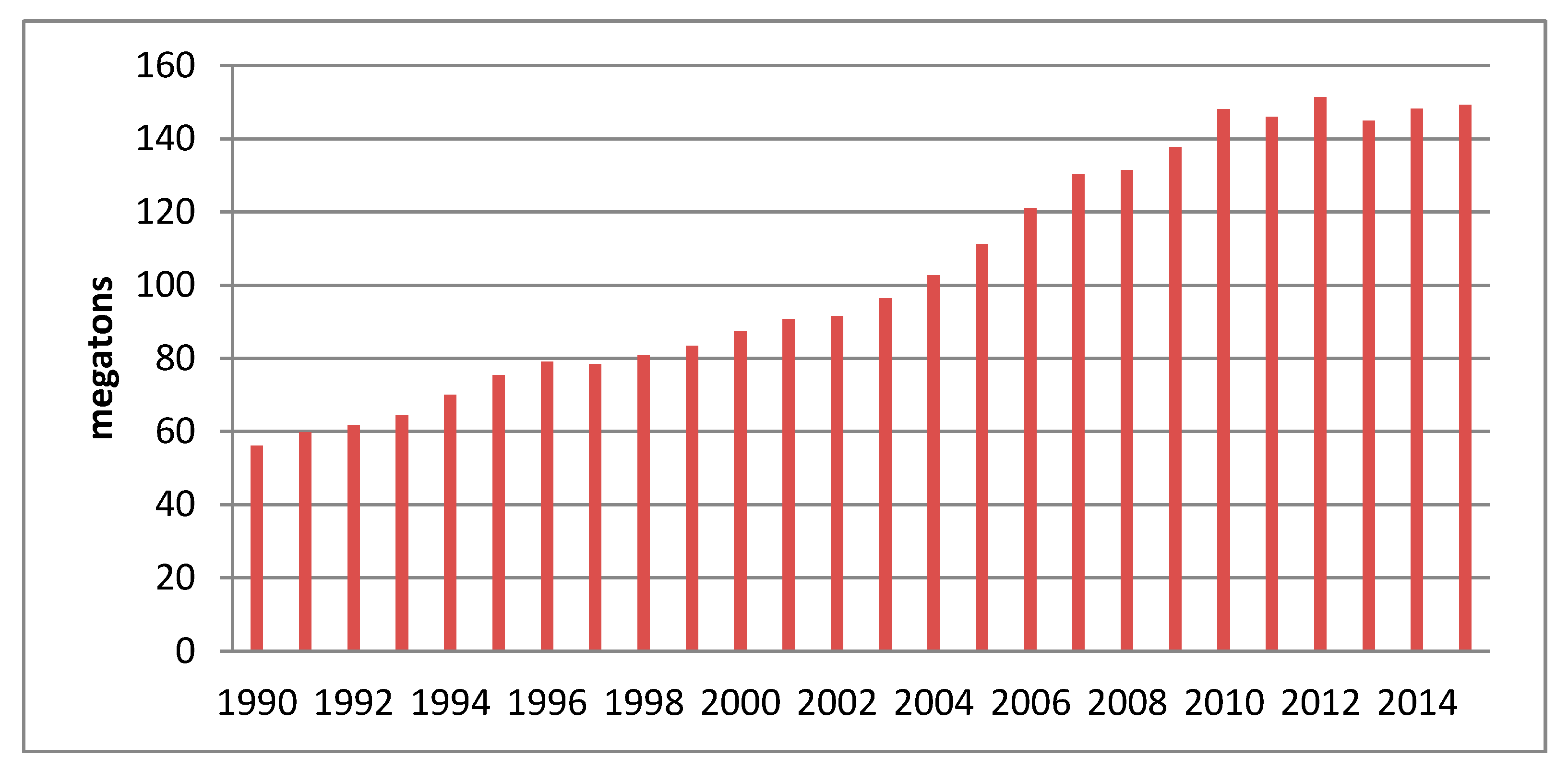
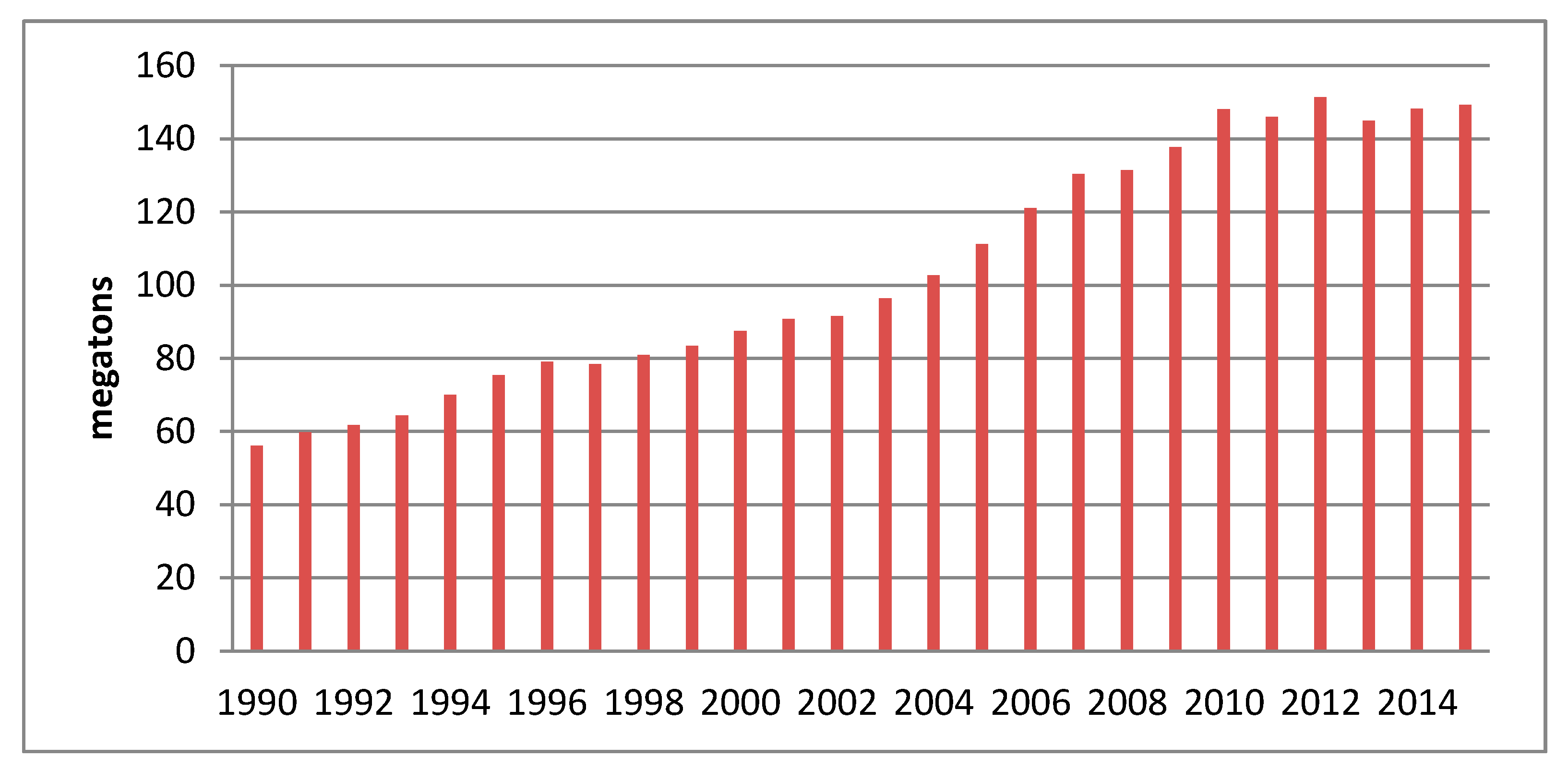
2 emissions in Beijing from 1990 to 2015 according to Equation (9), is shown in
Figure 2.
2.5. Cointegration and Granger Causality Test
In the macroeconomic econometric analysis, Engle and Granger [
32] proposed the cointegration method that has become one of the most important tools to analyze the long-term equilibrium relationship between non-stationary economic variables. This paper employs Johansen test [
33] for cointegratioin analysis between variables under the environment of EViews (Econometrics Views) 7.0.
Table 2 shows that there do exist cointegration relationships between CO
2 emissions and per capita GDP, resident population, transportation possession quantity, technological level as well as energy intensity, whereas for economic structure and urbanization level, the Granger causality test may result in spurious regression for the variables have no cointegration relationship with CO
2 emissions.
The cointegration test results show the existence of long-term stable correlation between CO
2 emissions and the pre-selection factors but do not indicate the causality of them. Thus, the Granger causality test between these variables is required. Meanwhile, the Akaike information criterion (AIC) is used to select lags and the results are shown in
Table 3.
As shown in
Table 3, the suppositions that “Per capita GDP does not cause CO
2 emissions”, “Resident population does not cause CO
2 emissions”, “Transportation possession quantity does not cause CO
2 emissions”, “Technological level does not cause CO
2 emissions”, “Energy intensity does not cause CO
2 emissions” are rejected on the significance level of 0.1, indicating that per capita GDP, resident population, transportation possession quantity, technological level and energy intensity will affect CO
2 emissions under certain lag phases. Therefore, this paper chooses per capita GDP 2 years ahead (Lag2), resident population 3 years ahead (Lag3), transportation possession quantity 3 years ahead (Lag3), technological level 2 years ahead (Lag2) and energy intensity 2 years ahead (Lag2) as variables for SVM input when forecasting CO
2 emissions.
4. Results and Discussion
The parameters of different development scenarios were used as predictive inputs of the GA-SVM model to predict carbon emissions in Beijing from 2016 to 2020, and then the growth rates of carbon emissions in 2020 based on 2016 in 32 kinds of scenarios were calculated. The prediction results in different scenarios were as follows.
4.1. Prediction Results of Carbon Emissions in the Base Development Scenario
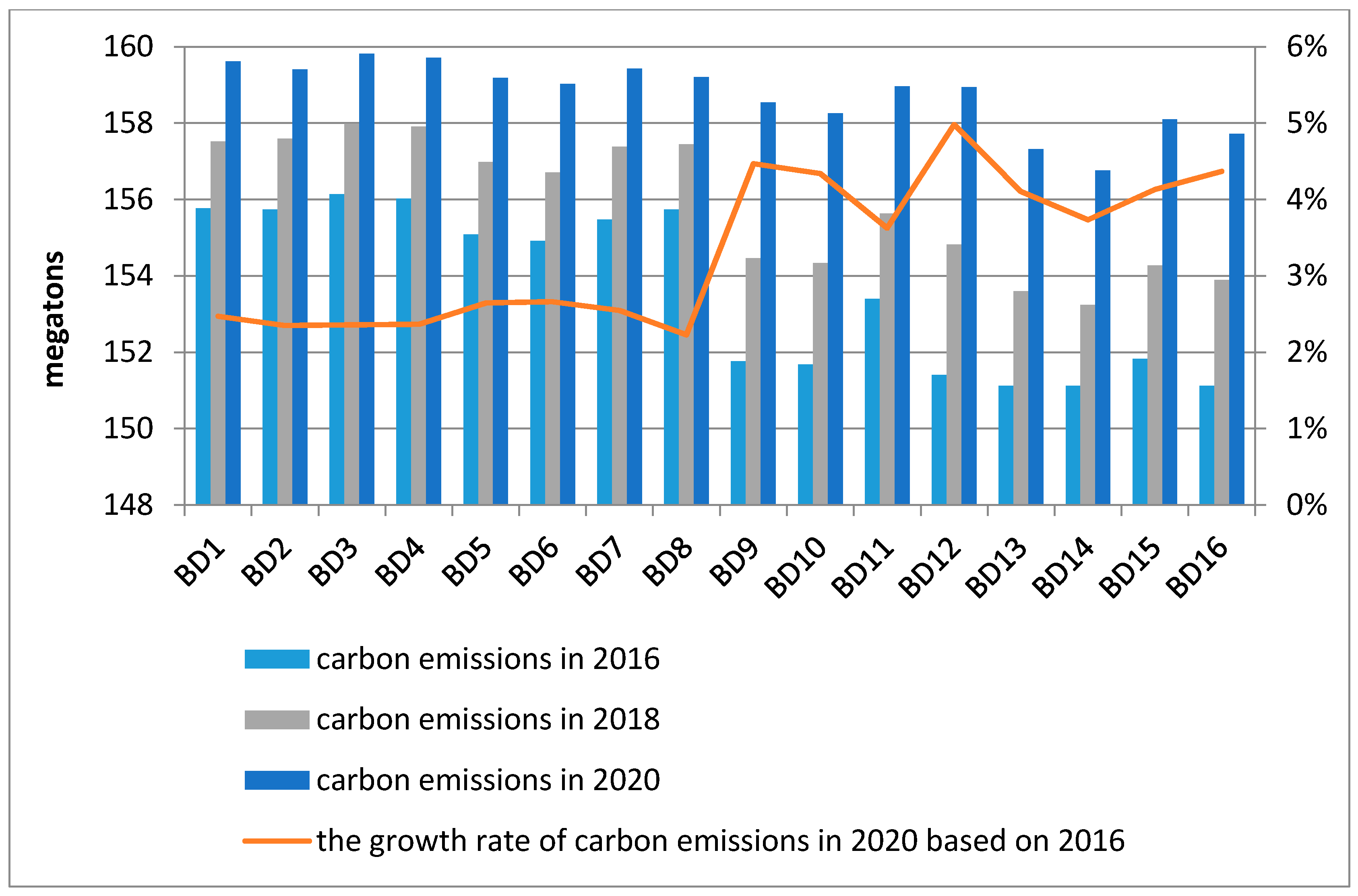
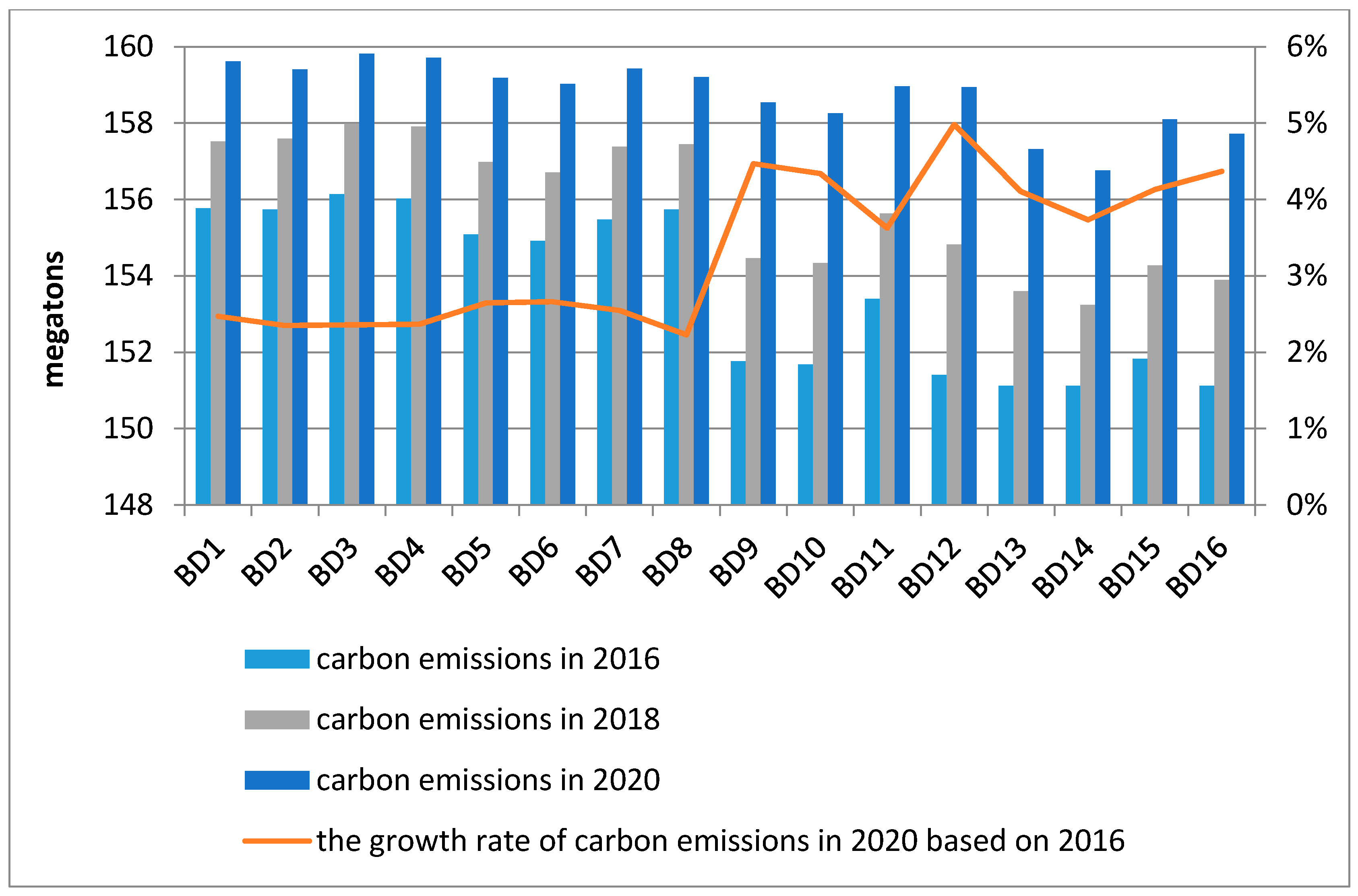
The base development scenarios conclude 16 kinds of series, of which the energy intensity is set at low rate. The prediction values of carbon emissions of Beijing in 2016, 2018 and 2020 are shown in
Figure 3.
Figure 3 shows the prediction results of carbon emissions of Beijing for the base development scenarios from 2016 to 2020, wherein carbon emissions in 2020 show an increase of about 2% to 5% compared with 2016 in all series. Through the comparison of the growth rate of carbon emissions in 2020 based on 2016, 16 kinds of scenarios can be divided into two categories: low growth rate (2−3%) of carbon emissions from scenario BD1 to BD8; high growth rate (3−5%) of carbon emissions from scenario BD9 to BD16, while carbon emissions in the former are higher than that in the latter. As we can know from
Figure 3, carbon emissions will reach a peak in scenario BD3, in which the economic growth rate, resident population growth rate and transportation possession quantity growth rate are set at the medium level, and the energy intensity enhancement rate and technical progress rate are at the low level. In addition, carbon emissions will reach minimum in BD14, in which the economic growth rate, resident population growth rate, transportation possession quantity growth rate and energy intensity enhancement rate are at the low level, the technical progress rate is at the medium level.
It is obvious that the lower economic growth rate and transportation possession quantity growth rate are conducive to a decrease of CO2 emissions. In contrast, the higher technical progress rate contributes to reduce CO2 emissions. Through the comparison of BD1 and BD9 (BD2 and BD10, BD3 and BD11, BD4 and BD12, BD5 and BD13, BD6 and BD14, BD7 and BD15, BD8 and BD16), the contribution of economic growth rate on carbon emissions is 1.88%. Similarly, the contribution of resident population growth rate, transportation possession quantity growth rate and technical progress rate on carbon emissions are obtained, which are 0.57%, 0.28% and 0.18%. It means that if the economic growth rate increases by 1%, the carbon emissions will correspondingly increase by 1.88% in 2020 and if the resident population growth rate, transportation possession quantity growth rate and technical progress rate increase by 1%, the carbon emissions will increase by 0.57%, 0.28% and 0.18%, respectively, in 2020.
4.2. Prediction Results of Carbon Emissions in the Low Carbon Development Scenario
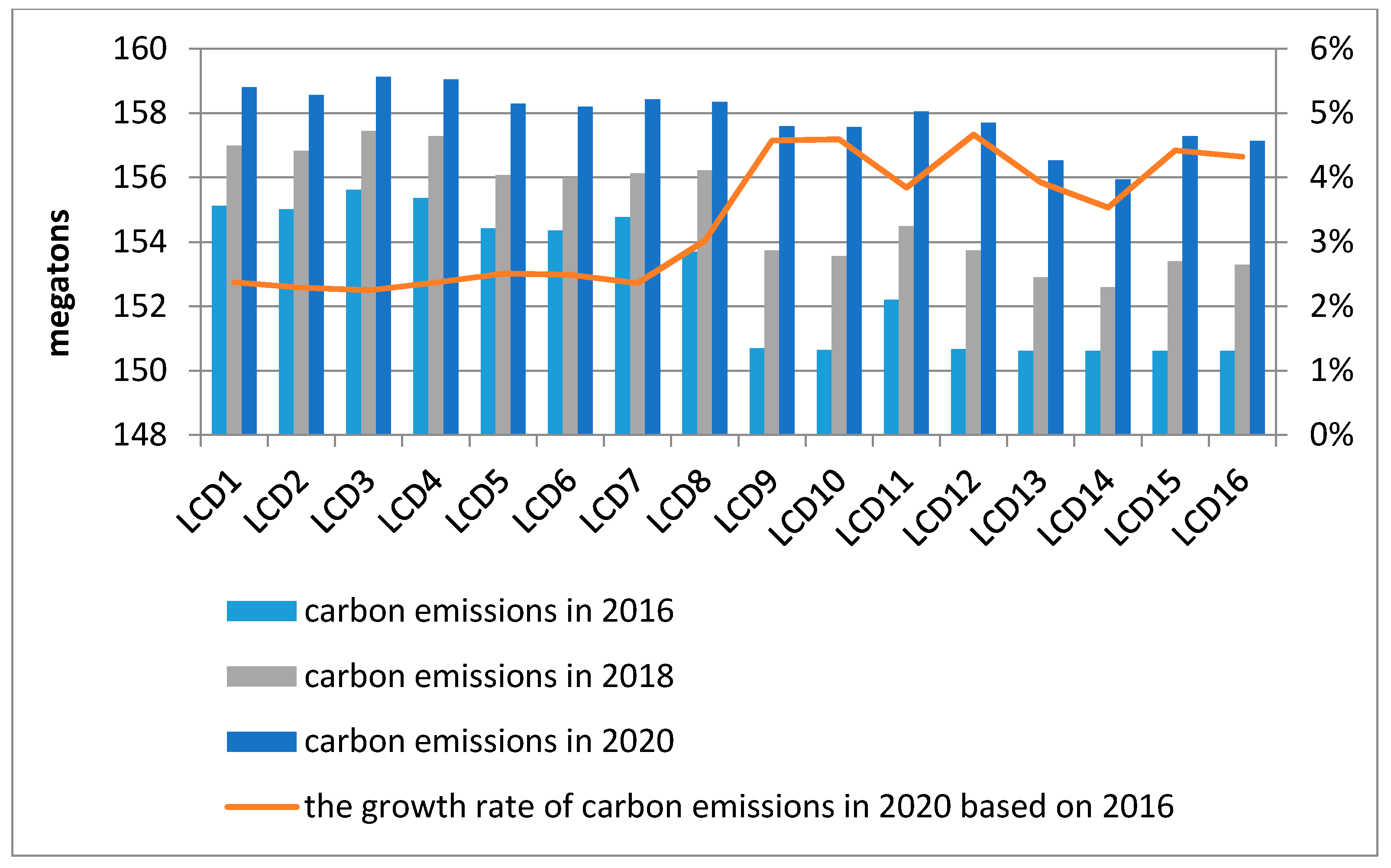
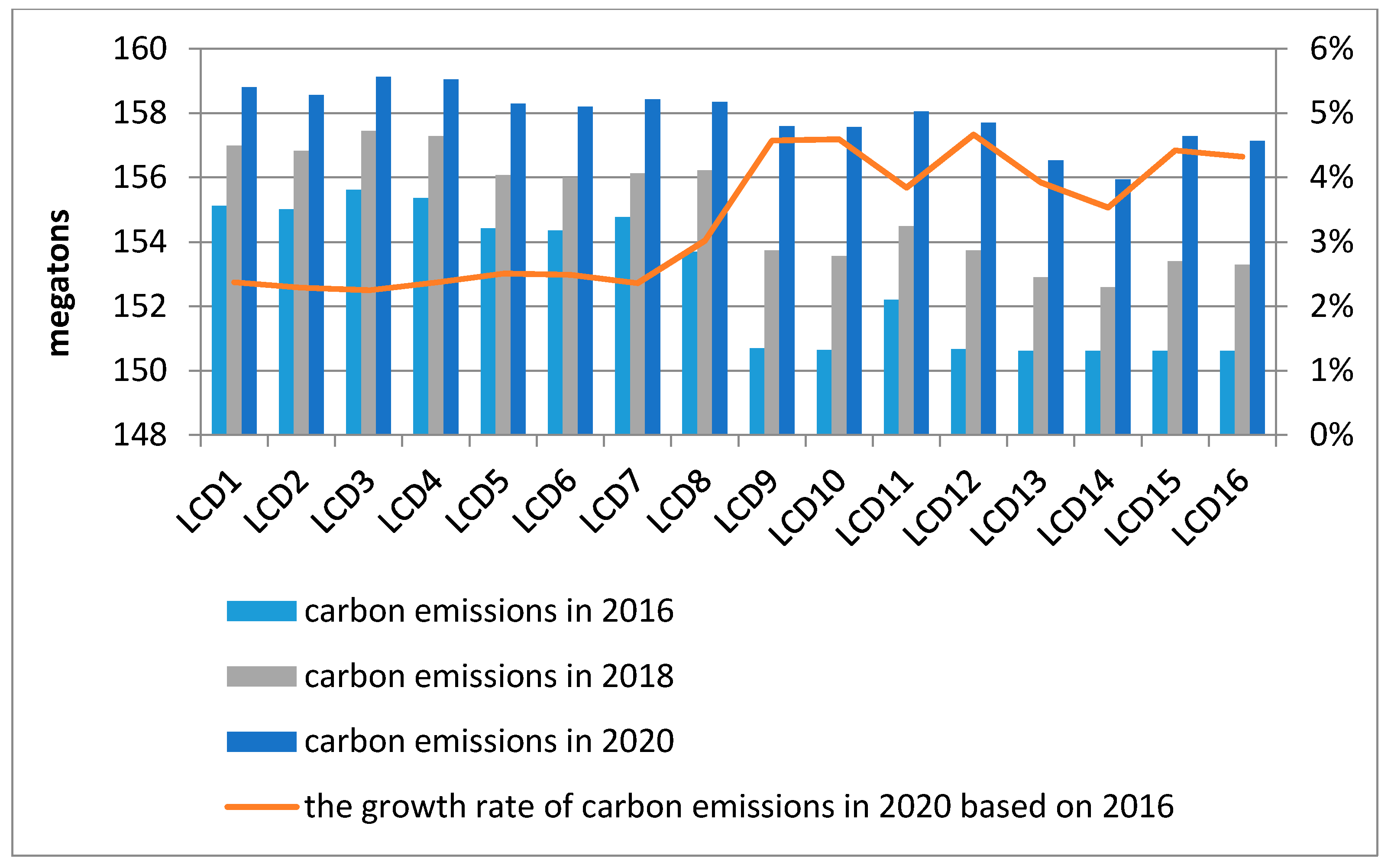
The low carbon development scenarios comprise 16 kinds of series, of which the energy intensity is set at medium rate. The prediction values of carbon emissions of Beijing in 2016, 2018 and 2020 are shown in
Figure 4.
As shown in
Figure 4, the prediction results for low carbon development scenarios indicate that carbon emissions from scenario LCD1 to LCD8 in 2020 are higher than ones from scenario LCD9 to LCD16, while the growth rate of carbon emissions in 2020 compared with 2016 in the former are higher than that in the latter, which within the range of 2−5%.In light of
Figure 4 , carbon emissions will peak in scenario LCD3, in which the economic growth rate, resident population growth rate , transportation possession quantity growth rate and energy intensity enhancement rate are at the medium level, the technical progress rate is at the low level. Besides, carbon emissions will reach the lowest value in scenario14, in which the energy intensity enhancement rate and technical progress rate are at the medium level, the economic growth rate, resident population growth rate and transportation possession quantity growth rate are at the low level.
Through the comparison of LCD1 and LCD9 (LCD2 and LCD10, LCD3 and LCD11, LCD4 and LCD12, LCD5 and LCD13, LCD6 and LCD14, LCD7 and LCD15, LCD8 and LCD16), the contribution of economic growth rate on carbon emissions is 1.85%. Similarly, the contributions of resident population growth rate, transportation possession quantity growth rate and technical progress rate on carbon emissions are obtained, which are 0.54%, 0.36% and 0.21%. It means that if the economic growth rate increases by 1%, the carbon emissions will increase by 1.85% in 2020 correspondingly and if the resident population growth rate, transportation possession quantity growth rate and technical progress rate increase by 1%, the carbon emissions will increase by 0.54%, 0.36% and 0.21% respectively in 2020. Additionally, the contribution of energy intensity enhancement rate is 0.54% through the comparison of BD1 and LCD1 (BD2 and LCD2, BD3 and LCD3,…, BD15 and LCD15, BD16 and LCD16), which mean that if the energy intensity enhancement rate increases by 1%, the carbon emissions will increase by 0.54% in 2020.
4.3. Comparison between the Base Development Scenario and Low Carbon Development Scenario
Compared with the base development scenario, the prediction values of carbon emissions of Beijing for a low carbon development scenario in 2020 are lower under each corresponding scenario, such as BD1 and LCD1. The growth rates of carbon emissions in 2020 based on 2016 in the two main scenarios are similar, which start low and then ascend and fluctuate around 4% in the sequence of scenarios. The comparison of two main scenarios demonstrates that economic growth, resident population growth and energy intensity enhancement are the major growth factors of carbon emissions for Beijing during 2016 to 2020, of which the contributions exceed 0.5% in two main scenarios. However, transportation possession quantity growth and technical progress have no significant influence on the growth of carbon emissions, of which the contributions are less than 0.4% in two main scenarios. In conclusion, the comparison results prove that economic growth, resident population growth and energy intensity enhancement are the leading contributors to carbon emissions growth for Beijing. The comparison results for two main development scenarios are shown in
Table 10.


{kind=link}
{kind=link}
{kind=link}
{kind=link}