
Measuring Comprehensive, General Health Literacy in the General Adult Population: The Development and Validation of the HLS19-Q12 Instrument in Seventeen Countries


 , , , , and
on behalf of the HLS19 Consortium of the WHO Action Network M-POHL
, , , , and
on behalf of the HLS19 Consortium of the WHO Action Network M-POHL
Abstract
:1. Introduction
- What is the impact of using dichotomous versus polytomous scoring of HLS19-Q12 on its psychometric properties?
- What are the factorial validity and dimensionality of the two scoring versions of HLS19-Q12?
- How well does HLS19-Q12 fulfil aspects, respectively, of content and face validity and of construct validity measured as discriminant validity and concurrent predictive validity?
- Since HLS19-Q12 is offered as a short form of HLS19-Q47, how well do the two scoring versions of the short form represent the long form?
- These research questions will be answered partly by using analyses of dichotomous scored data of different chapters of the HLS19 International Report [12] and by new additional analyses using polytomous scored data.
2. Materials and Methods
2.1. Development of the Instrument for Measuring Comprehensive, General HL in HLS19
2.1.1. Development of Its Predecessor, the HLS-EU-Q12
2.1.2. Adaptation of the HLS-EU-Q12 to the HLS19-Q12
2.1.3. Translation Process and Field Testing
2.2. Data Collection
- 6.
- … to find out where to get professional help when you are ill? (Instructions: such as doctor, nurse, pharmacist, psychologist)
- 7.
- … to understand information about what to do in a medical emergency?
- 8.
- … to judge the advantages and disadvantages of different treatment options?
- 9.
- … to act on advice from your doctor or pharmacist?
- 10.
- … to find information on how to handle mental health problems? (Instruction: stress, depression or anxiety)
- 11.
- … to understand information about recommended health screenings or examinations?
- 12.
- … to judge if information on unhealthy habits, such as smoking, low physical activity or drinking too much alcohol, are reliable?
- 13.
- … to decide how you can protect yourself from illness using information from the mass media? (Instructions: e.g., Newspapers, TV or Internet)
- 14.
- … to find information on healthy lifestyles such as physical exercise, healthy food or nutrition?
- 15.
- … to understand advice concerning your health from family or friends?
- 16.
- … to judge how your housing conditions may affect your health and well-being?
- 17.
- … to make decisions to improve your health and well-being?”
2.3. Analyses concerning Dimensionality of the Score
2.3.1. Items, Score, and CFA
- Standardized Root Mean Square Residual (SRMSR) ≤ 0.08
- Root Mean Square Error of Approximation (RMSEA) ≤ 0.06
- Tucker-Lewis Index (TLI) ≥ 0.95
- Comparative Fit Index (CFI) ≥ 0.95
2.3.2. IRT Analyses
2.4. Calculation of Aggregate Measures
2.4.1. Calculation of an Overall Score
- Type D. The score is calculated as the percentage (ranging from 0 to 100) of items with valid responses that were answered with “very easy” or “easy” (i.e., the items were implicitly dichotomized).
- Type P. The score is calculated as the sum of the item’s numeric values (1 = “very difficult”, 2 = “difficult”, 3 = “easy”, 4 = “very easy”) scaled to a range from 0 to 100.
2.4.2. Calculation of Levels
- Excellent: “very easy” ≥ 50 AND “very difficult” + “difficult” < 8.334For “excellent”, the number of answers with “very easy” should be above 1/2 and the answers for “very difficult” + “difficult” should be no more than 1/12.
- Sufficient: “very easy” + “easy” > 83.33For a level of “sufficient” HL, at least 10 out of the 12 items should be answered with “very easy” or “easy” and not more than 2 out of 12 with “very difficult” or “difficult”.
- Problematic: all respondents who are not in the groups “excellent”, “sufficient”, or “inadequate” (i.e., once the three other categories have been calculated)The level of “problematic” is the intersecting set of not “excellent”, not “sufficient” and not “inadequate”.
- Inadequate: “very easy” < 8.334, “very difficult” AND “difficult” ≥ 50For “inadequate”, the number of answers with “very difficult” + “difficult” should be above 1/2 and for “very easy” should be no more than 1/12.
- Excellent: > 83.33 (i.e., 10/12 to (incl.) 12/12)
- Sufficient: > 66.67 and ≤ 83.33 (i.e., 8/12 to (incl.) 10/12)
- Problematic: > 50 and ≤ 66.67 (i.e., 6/12 to (incl.) 8/12)
- Inadequate: ≤ 50 (i.e., 0 to (incl.) 6/12)
2.5. Validity
2.6. Extent of Representation of Long form HLS19-Q47
3. Results
3.1. Psychometric Properties
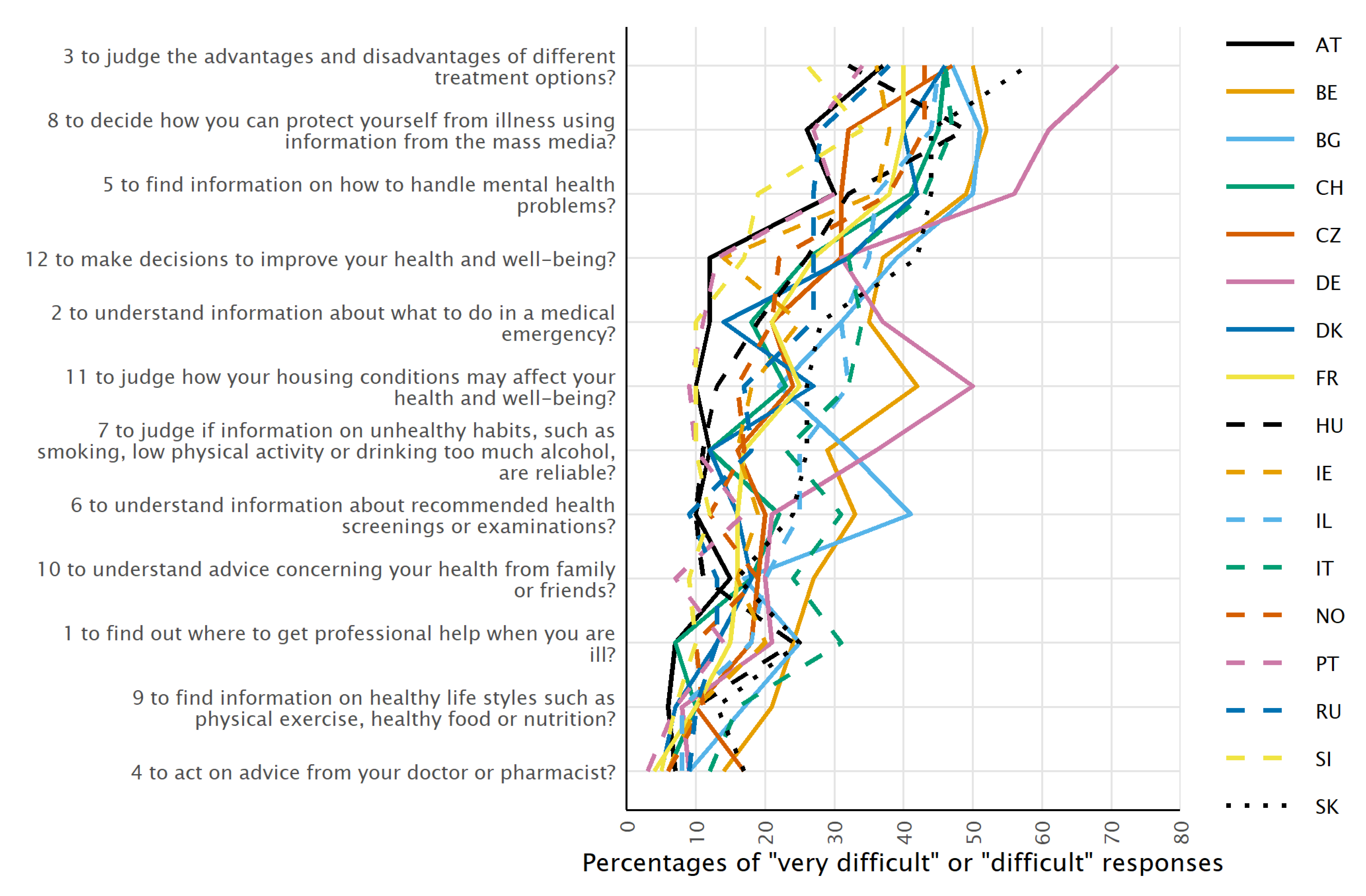
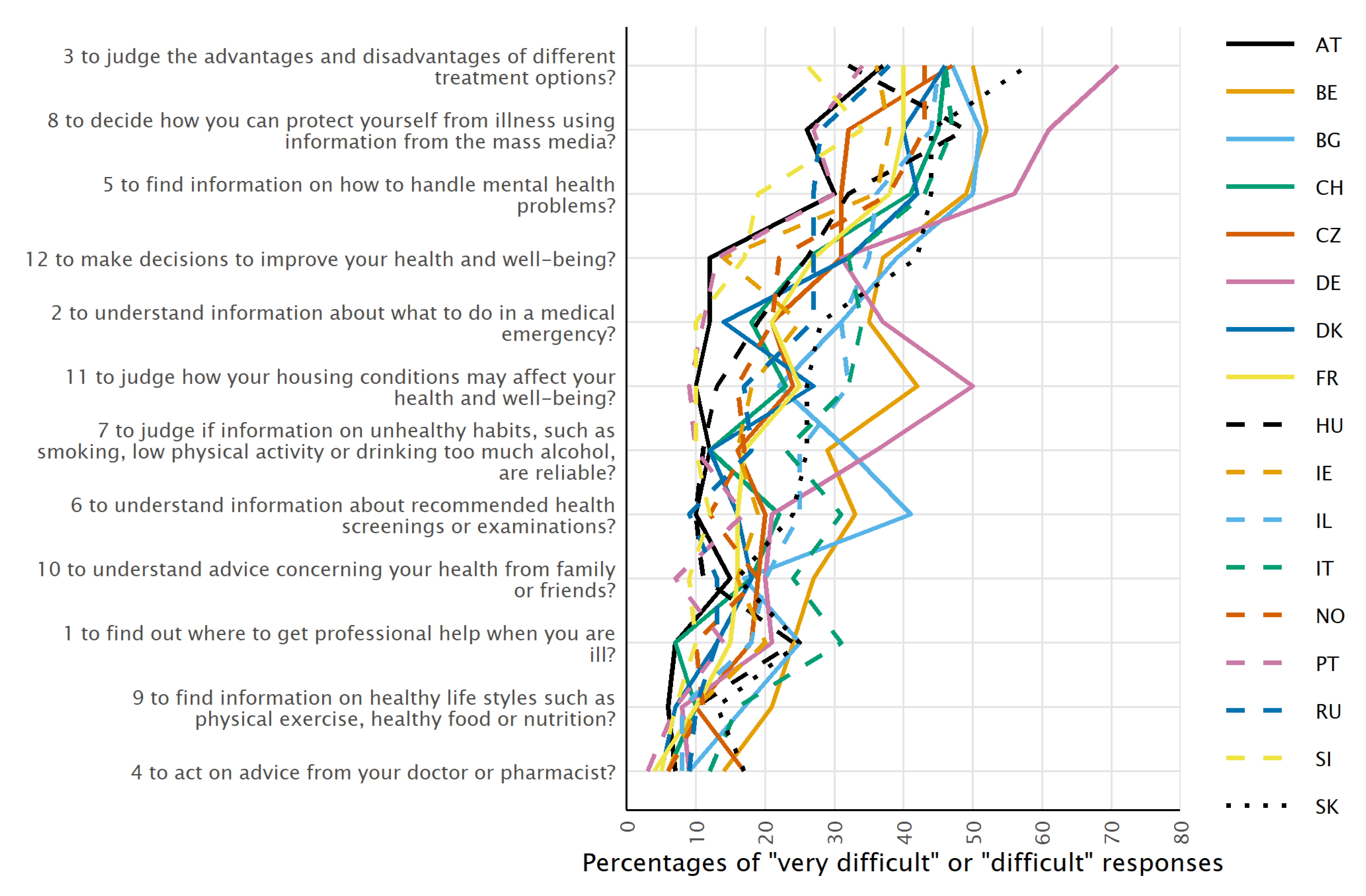
3.1.1. Average Difficulty of the Items
3.1.2. Non-IRT Analyses
Internal Consistency
Single Factor Confirmatory Factor Analyses
- item 4, “to act on advice from your doctor or pharmacist”,
- item 6, “to understand information about recommended health screenings or examinations”,
- item 9, “to find information on healthy lifestyles such as physical exercise, healthy food, or nutrition”,
- item 10, “to understand advice concerning your health from family or friends”.
- item 6, “to understand information about recommended health screenings or examinations”,
- item 10, “to understand advice concerning your health from family or friends”.
3.1.3. IRT Analyses
Partial Credit Model (PCM) for Polytomous Items
Rasch Model
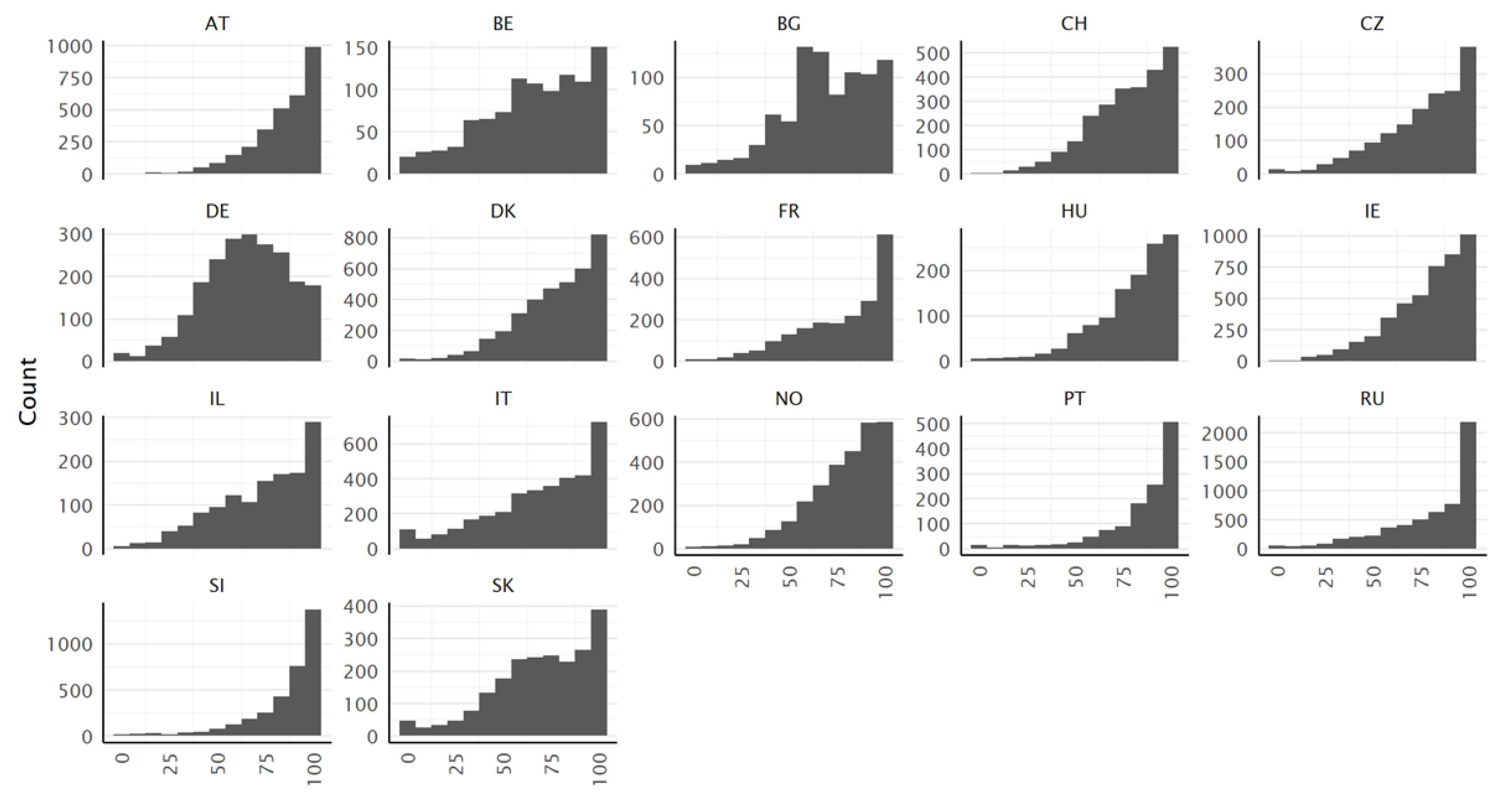
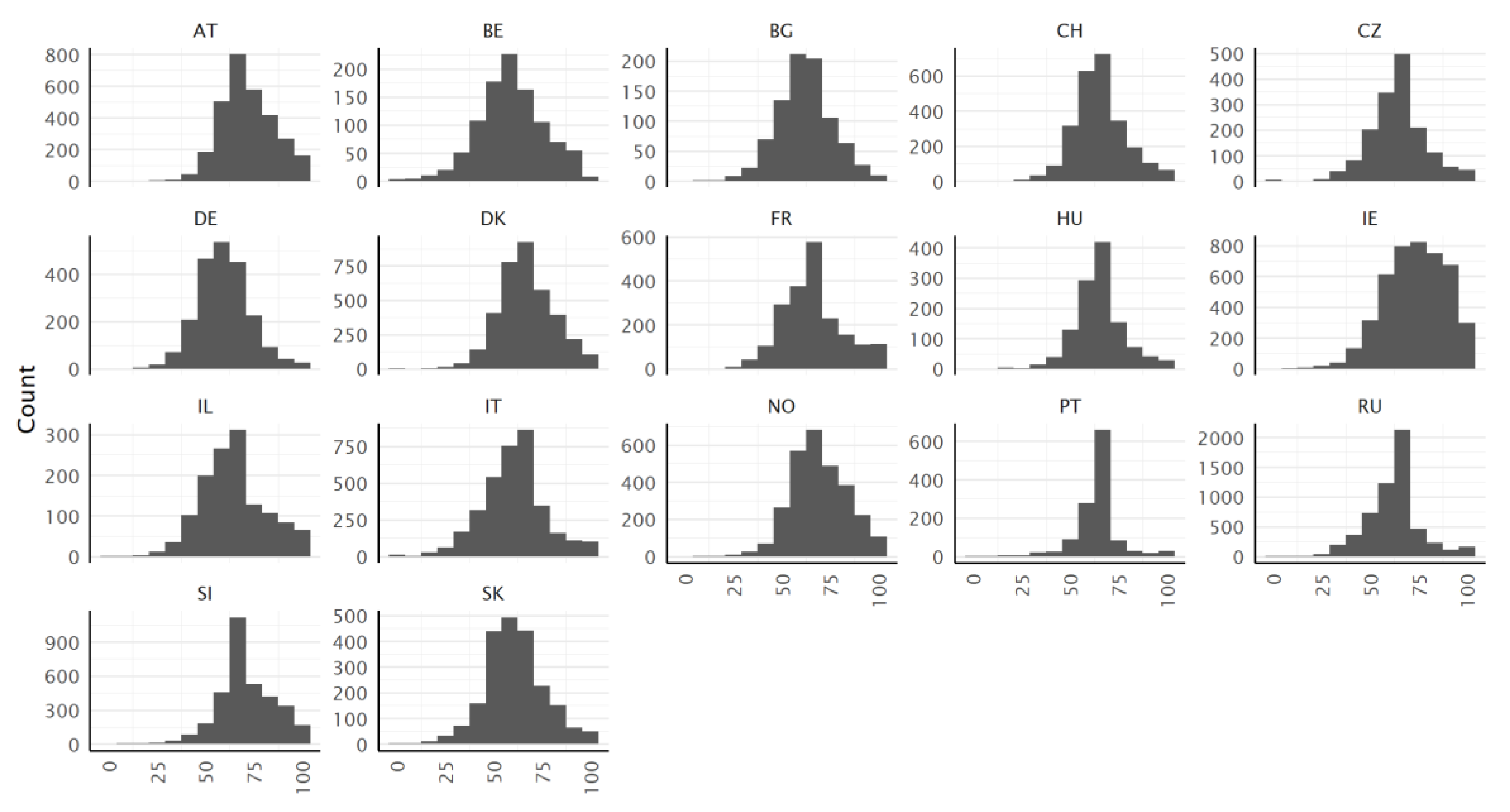
3.2. Distribution of the Score Values
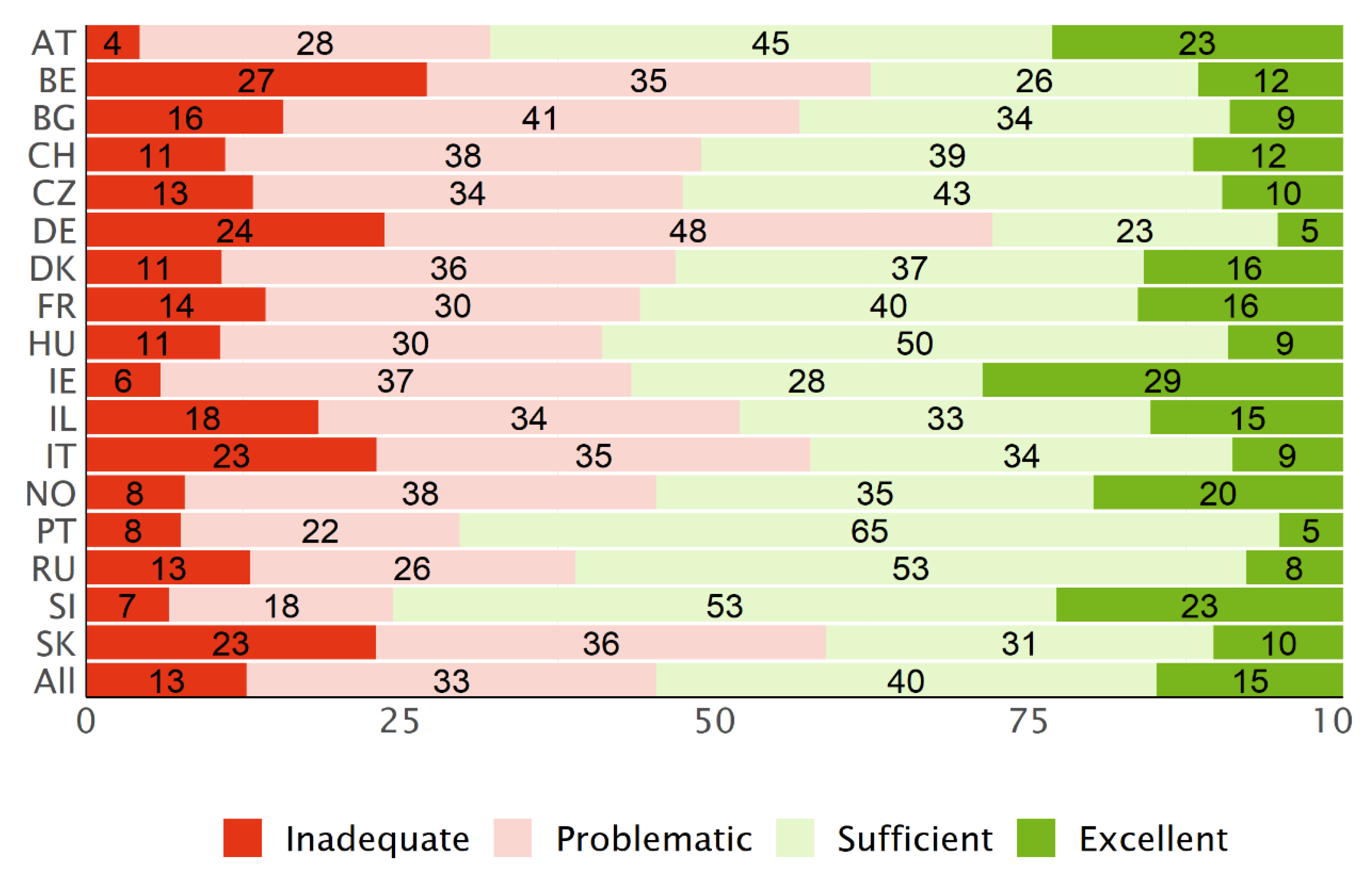
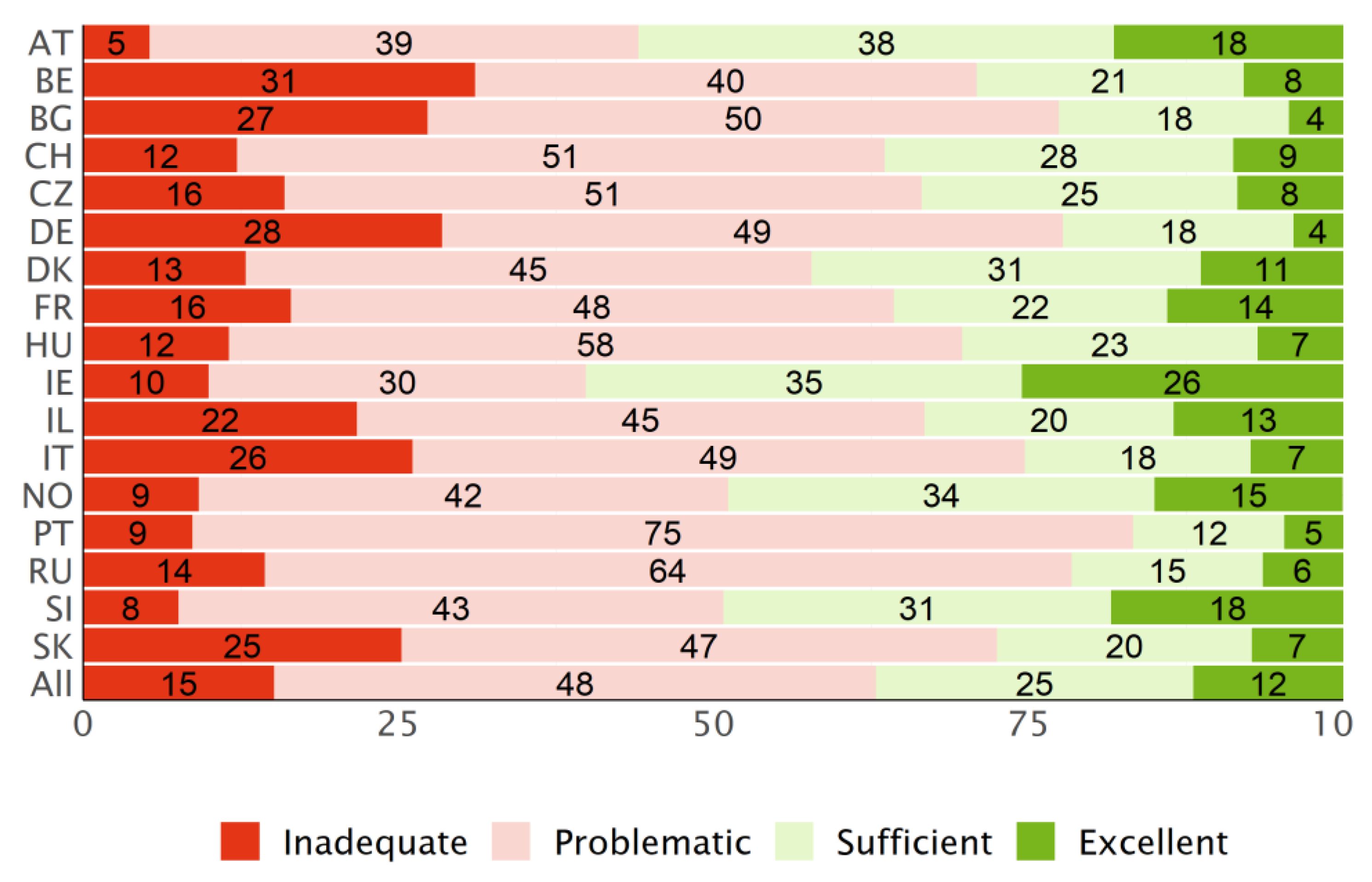
3.3. Distribution of the Levels
3.4. Validity Characteristics
3.4.1. Content and Face Validity
3.4.2. Discriminant Validity
3.4.3. Concurrent Predictive Validity—Associations with Determinants (Social Gradient)
3.4.4. Concurrent Predictive Validity—Associations with Consequences
3.5. Representation of the Long Form (HLS19-Q47)
4. Discussion
4.1. Using Dichotomous or Polytomous Scores (Research Question 1)
4.2. Psychometric Properties (Factorial Validity/Dimensionality) (Research Question 2)
4.3. Validity (Research Question 3)
4.3.1. Content and Face Validity
4.3.2. Discriminant Validity
4.3.3. Concurrent Predictive Validity
4.4. Representation of Long Form HLS19-Q47 (Research Question 4)
4.5. Strengths and Limitations
5. Conclusions
6. Use the Instrument
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kickbusch, I.; Pelikan, J.M.; Apfel, F.; Tsouros, A.D. Health Literacy: The Solid Facts; World Health Organization (WHO) Regional Office for Europe: Copenhagen, Denmark, 2013. [Google Scholar]
- Quaglio, G.; Sørensen, K.; Rübig, P.; Bertinato, L.; Brand, H.; Karapiperis, T.; Dinca, I.; Peetso, T.; Kadenbach, K.; Dario, C. Accelerating the health literacy agenda in Europe. Health Promot. Int. 2016, 32, 1074–1080. [Google Scholar] [CrossRef] [PubMed]
- HLS-EU Consortium. Comparative Report on Health Literacy in Eight EU Member States; Second Extended and Revised Version, Date 22 July 2014; The European Health Literacy Survey HLS-EU: Wien, Austria, 2012. [Google Scholar]
- Sørensen, K.; Pelikan, J.M.; Röthlin, F.; Ganahl, K.; Slonska, Z.; Doyle, G.; Fullam, J.; Kondilis, B.; Agrafiotis, D.; Uiters, E.; et al. Health literacy in Europe: Comparative results of the European health literacy survey (HLS-EU). Eur. J. Public Health 2015, 25, 1053–1058. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- M-POHL. Concept Note. For a WHO Action Network on Measuring Population and Organizational Health Literacy (M-POHL Network) within the European Health Information Initiative (EHII); M-POHL: Vienna, Austria, 2018. [Google Scholar]
- Dietscher, C.; Pelikan, J.; Bobek, J.; Nowak, P. The action network on measuring population and organizational health literacy (M-POHL) a network under the umbrella of the WHO European health information initiative (EHII). Public Health Panor. 2019, 5, 71. [Google Scholar]
- M-POHL. The Vienna Statement on the Measurement of Population and Organizational Health Literacy in Europe; M-POHL: Vienna, Austria, 2018. [Google Scholar]
- Sørensen, K.; Van den Broucke, S.; Fullam, J.; Doyle, G.; Pelikan, J.; Slonska, Z.; Brand, H.; (HLS-EU) Consortium Health Literacy Project European. Health literacy and public health: A systematic review and integration of definitions and models. BMC Public Health 2012, 12, 80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sørensen, K.; van den Broucke, S.; Pelikan, J.M.; Fullam, J.; Doyle, G.; Slonska, Z.; Kondilis, B.; Stoffels, V.; Osborne, R.H.; Brand, H. Measuring health literacy in populations: Illuminating the design and development process of the European Health Literacy Survey Questionnaire (HLS-EU-Q). BMC Public Health 2013, 13, 948. [Google Scholar] [CrossRef] [Green Version]
- Pelikan, J.M.; Ganahl, K. Measuring Health Literacy in General Populations: Primary Findings from the HLS-EU Consortium’s Health Literacy Assessment Effort. Stud. Health Technol. Inf. 2017, 240, 34–59. [Google Scholar] [CrossRef]
- Pelikan, J.M.; Straßmayr, C.; Ganahl, K. Health Literacy Measurement in General and Other Populations: Further Initiatives and Lessons Learned in Europe (and Beyond). In Health Literacy in Clinical Practice and Public Health; New Initiatives and Lessons Learned at the Intersection with other Disciplines; Logan, G.D., Siegel, E.R., Eds.; IOS Press: Amsterdam, The Netherlands, 2020; pp. 170–191. [Google Scholar] [CrossRef]
- The HLS19 Consortium of the WHO Action Network M-POHL. International Report on the Methodology, Results, and Recommendations of the European Health Literacy Population Survey 2019-2021 (HLS19) of M-POHL; Austrian National Public Health Institute: Vienna, Austria, 2021. [Google Scholar]
- Schaeffer, D.; Vogt, D.o.; Berens, E.-M.; Messer, M.; Quenzel, G.; Hurrelmann, K. Health literacy in Deutschland. In Health Literacy. Forschungsstand und Perspektiven; Schaeffer, D., Pelikan, J.M., Eds.; Hogrefe: Bern, Switzerland, 2017; p. 144. [Google Scholar]
- Schaeffer, D.; Vogt, D.; Berens, E.-M.; Hurrelmann, K. Gesundheitskompetenz der Bevölkerung in Deutschland: Ergebnisbericht; Universität Bielefeld, Fakultät für Gesundheitswissenschaften: Bielefeld, Germany, 2016. [Google Scholar]
- Pelikan, J.M.; Ganahl, K. Die europäische gesundheitskompetenz-studie: Konzept, instrument und ausgewählte Ergebnisse. In Health Literacy. Forschungsstand und Perspektiven; Schaeffer, D., Pelikan, J.M., Eds.; Hogrefe: Bern, Switzerland, 2017; p. 125. [Google Scholar]
- Pelikan, J.M.; Ganahl, K.; van den Broucke, S.; Sørensen, K. Measuring health literacy in Europe: Introducing the European Health Literacy Survey Questionnaire (HLS-EU-Q) In International Handbook of Health Literacy. Research, Practice and Policy across the Life-Span; Okan, O., Bauer, U., Pinheiro, P., Levin-Zamir, D., Sorensen, K., Eds.; Policy Press: Bristol, UK, 2019; p. 138. [Google Scholar]
- Pelikan, J.M.; Röthlin, F.; Ganahl, K.; Peer, S. Measuring comprehensive health literacy in general populations–the HLS-EU instruments. In Proceedings of the International Conference of Health Literacy and Health Promotion, Taipei, Taiwan, 6 October 2014; p. 57. [Google Scholar]
- Röthlin, F.; Pelikan, J.M.; Ganahl, K. Die Gesundheitskompetenz der 15-jährigen Jugendlichen in Österreich. Abschlussbericht der österreichischen Gesundheitskompetenz Jugendstudie im Auftrag des Hauptverbands der Österreichischen Sozialversicherungsträger; Ludwig Boltzmann Institut für Health Promotion Research: Wien, Austria, 2013. [Google Scholar]
- Ganahl, K.; Dahlvik, J.; Pelikan, J.M. Health literacy and experienced communication in health care among immigrants in Austria. Findings from the Austrian health literacy immigrant study. In Proceedings of the 25th International Conference on Health Promoting Hospitals and Health Services, Vienna, Austria, 12–14 April 2017. [Google Scholar]
- Ganahl, K.; Dahlvik, J.; Röthlin, F.; Alpagu, F.; Sikic-Fleischhacker, A.; Peer, S.; Pelikan, J.M. Gesundheitskompetenz bei personen mit migrationshintergrund aus der türkei und ex-jugoslawien in Österreich. In Ergebnisse Einer Quantitativen und Qualitativen Studie; Ludwig Boltzmann Institut Forschungsbericht: Wien, Austria, 2016. [Google Scholar]
- Wangdahl, J.M.; Dahlberg, K.; Jaensson, M.; Nilsson, U. Psychometric validation of Swedish and Arabic versions of two health literacy questionnaires, eHEALS and HLS-EU-Q16, for use in a Swedish context: A study protocol. BMJ Open 2019, 9, e029668. [Google Scholar] [CrossRef]
- Gele, A.A.; Pettersen, K.S.; Torheim, L.E.; Kumar, B. Health literacy: The missing link in improving the health of Somali immigrant women in Oslo. BMC Public Health 2016, 16, 1134. [Google Scholar] [CrossRef] [Green Version]
- Wangdahl, J.M.; Lytsy, P.; Mårtensson, L.; Westerling, R. Health literacy and refugees’ experiences of the health examination for asylum seekers–a Swedish cross-sectional study. BMC Public Health 2015, 15, 1162. [Google Scholar] [CrossRef]
- Lorini, C.; Santomauro, F.; Grazzini, M.; Mantwill, S.; Vettori, V.; Lastrucci, V.; Bechini, A.; Boccalini, S.; Bussotti, A.; Bonaccorsi, G. Health literacy in Italy: A cross-sectional study protocol to assess the health literacy level in a population-based sample, and to validate health literacy measures in the Italian language. BMJ Open 2017, 7, e017812. [Google Scholar] [CrossRef]
- Lorini, C.; Lastrucci, V.; Mantwill, S.; Vettori, V.; Bonaccorsi, G. Measuring health literacy in Italy: A validation study of the HLS-EU-Q16 and of the HLS-EU-Q6 in Italian language, conducted in Florence and its surroundings. Ann. dell’Ist. Super. Sanità 2019, 55, 10–18. [Google Scholar] [CrossRef]
- Soenaryati, S.; Rachmani, E. Media use behavior and health literacy on high school students in Semarang. Adv. Sci. Lett. 2017, 23, 3493–3496. [Google Scholar] [CrossRef]
- Gerich, J.; Moosbrugger, R. Subjective estimation of health literacy—What is measured by the HLS-EU scale and how is it linked to empowerment? Health Commun. 2016, 33, 254–263. [Google Scholar] [CrossRef] [PubMed]
- Rouquette, A.; Nadot, T.; Labitrie, P.; Broucke, S.V.D.; Mancini, J.; Rigal, L.; Ringa, V. Validity and measurement invariance across sex, age, and education level of the French short versions of the European Health Literacy Survey Questionnaire. PLoS ONE 2018, 13, e0208091. [Google Scholar] [CrossRef] [PubMed]
- Rouquette, A.; Rigal, L.; Mancini, J.; Guillemin, F.; Broucke, S.V.D.; Allaire, C.; Azogui-Levy, S.; Ringa, V.; Hassler, C. Health Literacy throughout adolescence: Invariance and validity study of three measurement scales in the general population. Patient Educ. Couns. 2021, 105, 996–1003. [Google Scholar] [CrossRef] [PubMed]
- Emiral, G.Ö.; Atalay, B.; Aygar, H.; Göktas, S. Health literacy scale-European union-Q16: A validity and reliability study in Turkey. Int. Res. J. Med. Sci. 2018, 6, 1–7. [Google Scholar]
- Uemura, K.; Yamada, M.; Okamoto, H. Effects of active learning on health literacy and behavior in older adults: A randomized controlled trial. J. Am. Geriatr. Soc. 2018, 66, 1721–1729. [Google Scholar] [CrossRef] [PubMed]
- Gustafsdottir, S.S.; Sigurdardottir, A.K.; Arnadottir, S.A.; Heimisson, G.T.; Mårtensson, L. Translation and cross-cultural adaptation of the European Health Literacy Survey Questionnaire, HLS-EU-Q16: The Icelandic version. BMC Public Health 2020, 20, 61. [Google Scholar] [CrossRef]
- Coman, M.A.; Forray, A.I.; Broucke, S.V.D.; Chereches, R.M. Measuring health literacy in Romania: Validation of the HLS-EU-Q16 survey questionnaire. Int. J. Public Health 2022, 67, 1604272. [Google Scholar] [CrossRef]
- Mohamad, E.M.W.; Kaundan, M.K.; Hamzah, M.R.; Azlan, A.A.; Ayub, S.H.; Tham, J.S.; Ahmad, A.L. Establishing the HLS-M-Q18 short version of the European health literacy survey questionnaire for the Malaysian context. BMC Public Health 2020, 20, 580. [Google Scholar] [CrossRef]
- Rasch, G. Studies in mathematical psychology: I. In Probabilistic Models for Some Intelligence and Attainment Tests; Danmarks Pædagogiske Institut: Copenhagen, Denmark, 1960; p. 80. [Google Scholar]
- Van Duong, T.; Chang, P.W.; Yang, S.-H.; Chen, M.-C.; Chao, W.-T.; Chen, T.; Chiao, P.; Huang, H.-L. A new comprehensive short-form health literacy survey tool for patients in general. Asian Nurs. Res. 2017, 11, 30–35. [Google Scholar] [CrossRef] [PubMed]
- Duong, T.V.; Aringazina, A.; Kayupova, G.; Nurjanah; Pham, T.V.; Pham, K.M.; Truong, T.Q.; Nguyen, K.T.; Oo, W.M.; Su, T.T.; et al. Development and validation of a new short-form health literacy instrument (HLS-SF12) for the general public in six Asian countries. HLRP Health Lit. Res. Pract. 2019, 3, e91–e102. [Google Scholar] [CrossRef] [Green Version]
- Van Duong, T.; Nguyen, T.T.P.; Pham, K.M.; Nguyen, K.T.; Giap, M.H.; Tran, T.D.X.; Nguyen, C.X.; Yang, S.-H.; Su, C.-T. Validation of the short-form health literacy questionnaire (HLS-SF12) and its determinants among people living in rural areas in Vietnam. Int. J. Environ. Res. Public Health 2019, 16, 3346. [Google Scholar] [CrossRef] [Green Version]
- Finbråten, H.S.; Wilde-Larsson, B.; Nordström, G.; Pettersen, K.S.; Trollvik, A. Guttersrud, establishing the HLS-Q12 short version of the European health literacy survey questionnaire: Latent trait analyses applying Rasch modelling and confirmatory factor analysis. BMC Health Serv. Res. 2018, 18, 506. [Google Scholar] [CrossRef] [PubMed]
- Waldherr, K.; Alfers, T.; Peer, S.; Pelikan, J.M. Development and Validation of the HLS-EU-Q12; Vienna, Austria. 2019. Available online: https://m-pohl.net/sites/m-pohl.net/files/inline-files/Waldherr%20et%20al%202019.pdf (accessed on 1 September 2022).
- Masters, G.N. A rasch model for partial credit scoring. Psychometrika 1982, 47, 149–174. [Google Scholar] [CrossRef]
- Storms, H.; Claes, N.; Aertgeerts, B.; Broucke, S.V.D. Measuring health literacy among low literate people: An exploratory feasibility study with the HLS-EU questionnaire. BMC Public Health 2017, 17, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Domanska, O.M.; Firnges, C.; Bollweg, T.M.; Sørensen, K.; Holmberg, C.; Jordan, S. Do adolescents understand the items of the European Health Literacy Survey Questionnaire (HLS-EU-Q47)–German version? Findings from cognitive interviews of the project “Measurement of Health Literacy Among Adolescents” (MOHLAA) in Germany. Arch. Public Health 2018, 76, 46. [Google Scholar] [CrossRef] [Green Version]
- Finbråten, H.S.; Pettersen, K.S.; Wilde-Larsson, B.; Nordström, G.; Trollvik, A.; Guttersrud, Ø. Validating the european health literacy survey questionnaire in people with type 2 diabetes: Latent trait analyses applying multidimensional Rasch modelling and confirmatory factor analysis. J. Adv. Nurs. 2017, 73, 2730–2744. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.-J.; Lin, G.-H.; Lu, W.-S.; Tam, K.-W.; Chen, C.; Hou, W.-H.; Hsieh, C.-L. Validation of the European health literacy survey questionnaire in women with breast cancer. Cancer Nurs. 2018, 41, E40–E48. [Google Scholar] [CrossRef]
- IBM Corp. IBM SPSS Statistics for Windows, Version 27.0.; IBM Corp.: Armonk, NY, USA, 2020. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Eisinga, R.; Grotenhuis, M.t.; Pelzer, B. The reliability of a two-item scale: Pearson, Cronbach, or Spearman-Brown? Int. J. Public Health 2013, 58, 637–642. [Google Scholar] [CrossRef]
- Kline, R.B. Principles and Practice of Structural Equation Modeling; Guilford Publications: New York, NY, USA, 2015. [Google Scholar]
- Zumbo, B.D.; Gadermann, A.M.; Zeisser, C. Ordinal versions of coefficients alpha and theta for Likert rating scales. J. Mod. Appl. Stat. Methods 2007, 6, 29. [Google Scholar] [CrossRef] [Green Version]
- Chalmers, R.P. On misconceptions and the limited usefulness of ordinal alpha. Educ. Psychol. Meas. 2017, 78, 1056–1071. [Google Scholar] [CrossRef] [PubMed]
- Zumbo, B.D.; Kroc, E. A measurement is a choice and stevens’ scales of measurement do not help make it: A response to chalmers. Educ. Psychol. Meas. 2019, 79, 1184–1197. [Google Scholar] [CrossRef] [PubMed]
- Revelle, W. Psych: Procedures for Psychological, Psychometric, and Personality Research, Northwestern University: Evanston, Illinois, United States. 2021. Available online: https://mran.revolutionanalytics.com/snapshot/2021-09-26/web/packages/psych/psych.pdf (accessed on 3 October 2022).
- Prudon, P. Confirmatory factor analysis: A brief introduction and critique. Compr. Psychol. 2015, 4, 18. [Google Scholar] [CrossRef] [Green Version]
- Roussel, Y. lavaan: An R package for structural equation modeling. J. Stat. Softw. 2012, 48, 36. Available online: https://www.jstatsoft.org/v48/i02/ (accessed on 3 October 2022).
- Beaujean, A.A. Latent Variable Modeling Using R: A Step-by-Step Guide; Routledge: London, UK, 2014. [Google Scholar]
- Rosseel, Y. The Lavaan Tutorial; Ghent University: Ghent, Belgium, 2021. [Google Scholar]
- Waldherr, K.; Alfers, T.; Peer, S. Development and Validation of the HLS-EU-Q12; M-POHL: Vienna, Austria, 2021; Available online: https://m-pohl.net/sites/m-pohl.net/files/inline-files/Waldherr%20et%20al_0.pdf (accessed on 1 September 2022).
- Guttersrud, Ø.; Le, C.; Pettersen, K.S.; Finbråten, H.S. Rasch Analyses of Data Collected in 17 Countries. A Technical Report to Support Decision-Making within the M-POHL Consortium. Oslo, Norway. 2021. Available online: https://m-pohl.net/sites/m-pohl.net/files/inlinefiles/Guttersrud%20et%20al_Rasch%20analyses%20of%20data%20colllected%20in%2017%20countries_2021_0.pdf (accessed on 1 September 2022).
- Fischer, G.H. Rasch Models. In Handbook of Statistics, Psychometrics; Rao, C.R., Sinharay, S., Eds.; Elsevier Science Publishers: Amsterdam, The Netherlands, 2006; Volume 26, pp. 515–585. [Google Scholar]
- Mair, P.; Hatzinger, R.; Maier, M.J. eRm: Extended Rasch Modeling. 1.0-1. 2020. Available online: http://cran.r-project.org/package=eRm (accessed on 3 October 2022).
- Sveidqvist, K.; Bostock, M.; Pettitt, C.; Daines, M.; Kashcha, A.; Iannone, R. DiagrammeR: Create Graph Diagrams and Flowcharts Using R. R Package Version 0.9. 0. 2017. Available online: https://CRAN.R-project.org/package=DiagrammeR (accessed on 11 March 2022).
- Chalmers, R.P. mirt: A multidimensional item response theory package for the R environment. J. Stat. Softw. 2012, 48, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Adams, R.J. Reliability as a measurement design effect. Stud. Educ. Evaluation 2005, 31, 162–172. [Google Scholar] [CrossRef]
- Maydeu-Olivares, A. Goodness-of-fit assessment of item response theory models. Meas. Interdiscip. Res. Perspect. 2013, 11, 71–101. [Google Scholar] [CrossRef]
- Hagell, P. Testing rating scale unidimensionality using the principal component analysis (PCA)/t-test protocol with the Rasch model: The primacy of theory over statistics. Open J. Stat. 2014, 4, 456–465. [Google Scholar] [CrossRef] [Green Version]
- Smith, E.V., Jr. Detecting and evaluating the impact of multidimensionality using item fit statistics and principal component analysis of residuals. J. Appl. Meas. 2002, 3, 205–231. [Google Scholar]
- Agresti, A.; Coull, B.A. Approximate is better than “exact” for interval estimation of binomial proportions. Am. Stat. 1998, 52, 119. [Google Scholar] [CrossRef]
- Yen, W.M. Effects of local item dependence on the fit and equating performance of the three-parameter logistic model. Appl. Psychol. Meas. 1984, 8, 125–145. [Google Scholar] [CrossRef]
- Linacre, J.; Wright, B. Rasch Measurement Transactions; MESA Press: Chicago, IL, USA, 1995. [Google Scholar]
- Smith, A.B.; Rush, R.; Fallowfield, L.J.; Velikova, G.; Sharpe, M. Rasch fit statistics and sample size considerations for polytomous data. BMC Med. Res. Methodol. 2008, 8, 33. [Google Scholar] [CrossRef] [PubMed]
- Wright, B.; Linacre, J. Reasonable mean-square fit values. Rasch Meas. Trans. 1994, 8, 371. [Google Scholar]
- Thissen, D.; Cai, L.; Bock, R. The nominal categories model. In Handbook of Polytomous Item Response Theory Models; Nering, M., Ostini, R., Eds.; Routledge: London, UK, 2010; pp. 43–75. [Google Scholar]
- Andersen, E.B. A goodness of fit test for the rasch model. Psychometrika 1973, 38, 123–140. [Google Scholar] [CrossRef]
- Fischer, G.H. On the existence and uniqueness of maximum-likelihood estimates in the Rasch model. Psychometrika 1981, 46, 59–77. [Google Scholar] [CrossRef]
- Fischer, G.H.; Scheiblechner, H. Algorithms and programs for the probabilistic test model of Rasch. Psychol. Beiträge 1970, 12, 23–51. [Google Scholar]
- Rasch, G. Probabilistic Models for Some Intelligence and Attainment Tests, 2nd ed.; University of Chicago Press: Chicago, IL, USA, 1980. [Google Scholar]
- Ponocny, I. Nonparametric goodness-of-fit tests for the rasch model. Psychometrika 2001, 66, 437–459. [Google Scholar] [CrossRef]
- Baccolini, V.; Rosso, A.; Di Paolo, C.; Isonne, C.; Salerno, C.; Migliara, G.; Prencipe, G.P.; Massimi, A.; Marzuillo, C.; De Vito, C.; et al. What is the prevalence of low health literacy in european union member states? A systematic review and meta-analysis. J. Gen. Intern. Med. 2021, 36, 753–761. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.G.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Lumley, T. Complex Surveys: A Guide to Analysis Using R; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 565. [Google Scholar]
- Hu, L.T.; Bentler, P.M. Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Struct. Equ. Model. A Multidiscip. J. 1999, 6, 1–55. [Google Scholar] [CrossRef]
- García-Pérez, M.A. Order-constrained estimation of nominal response model parameters to assess the empirical order of categories. Educ. Psychol. Meas. 2017, 78, 826–856. [Google Scholar] [CrossRef] [PubMed]
- Pelikan, J.M.; Röthlin, F.; Ganahl, K. Measuring health literacy in general populations in Europe. Selected results from the HLS-EU Study. In Proceedings of the 21 IUHPE World Conference on Health Promotion, Pattaya, Thailand, 27 August 2013. [Google Scholar]
- Osborne, R.; Elsworth, G.; Hawkins, M.; Cheng, C.; Elmer, S. Measurement of Health Literacy: Assumptions and Potential Consequences Locally and Globally; Swinburne University of Technology: Melbourne, Australia, 2021. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Health Literacy | Access/Obtain Information Relevant for Health | Understand Information Relevant for Health | Appraise/Judge/Evaluate Information Relevant for Health | Apply/Use Information Relevant for Health |
|---|---|---|---|---|
| Health Care | (1) Ability to access information on medical or clinical issues | (2) Ability to understand medical information and derive meaning | (3) Ability to interpret and evaluate medical information | (4) Ability to make informed decisions on medical issues |
| Disease Prevention | (5) Ability to access information on risk factors | (6) Ability to understand information on risk factors and derive meaning | (7) Ability to interpret and evaluate information on risk factors | (8) Ability to judge the relevance of information on risk factors |
| Health Promotion | (9) Ability to update oneself on health issues | (10) Ability to understand health-related information and derive meaning | (11) Ability to interpret and evaluate information on health-related issues | (12) Ability to form a reflected opinion on health issues |
| Country | Languages | Type of Data Collection | Sampling Procedure | Item Set | n | n for IRT 4 |
|---|---|---|---|---|---|---|
| Austria (AT) | German | CATI | Multi-stage random sampling | Q12 | 2967 | 2471 |
| Belgium (BE) | Dutch, French | CAWI | Quota sampling | Q22 | 1000 | 1000 |
| Bulgaria (BG) | Bulgarian | CAPI, CAWI | Proportional stratified sampling and random quota sampling | Q47 | 865 | - |
| Czech Republic (CZ) | Czech | CATI, CAWI | Random digital procedure and random quota sampling | Q22 | 1599 | 1459 |
| Denmark (DK) | Danish | CAWI | Multi-stage random sampling | Q22 | 3602 | 3506 |
| France (FR) | French | CAWI 3 | Quota sampling | Q22 | 2003 | 2003 |
| Germany (DE) | German | PAPI | Multi-stage random and quota sampling | Q47 | 2143 | 1991 |
| Hungary (HU) | Hungarian | CATI | Multi-stage random sampling | Q22 | 1195 | 1021 |
| Ireland (IE) | English | CATI | Random digit dialing approach | Q47 | 4487 | 4172 |
| Israel (IL) | Hebrew, Arab, Russian | CATI, CAWI | Multi-stage random sampling | Q22 | 1315 | 1294 |
| Italy (IT) | Italian | CATI, CAWI | Proportional stratified sampling | Q47 | 3500 | - |
| Norway (NO) | Norwegian | CATI | Random sampling procedure within each stratum | Q47 | 2855 | 2387 |
| Portugal (PT) | Portuguese | CATI | Random stratified sampling | Q12 | 1247 | 922 |
| Russian Federation 1 (RU) | Russian | PAPI | Multi-stage random sampling | Q22 | 5660 | 4752 |
| Slovakia (SK) | Slovak | CAPI | Multi-stage random sampling | Q22 | 2145 | 2144 |
| Slovenia (SI) | Slovenian | CAPI, SAQ, CAWI | Multi-stage random sampling | Q47 | 3360 | 3178 |
| Switzerland (CH) | French, German, Italian | CAWI 2 | Multi-stage random sampling | Q12 | 2502 | 2370 |
| Dichotomized Items | Polytomous Items | |||
|---|---|---|---|---|
| Cronbach’s Alpha | Ordinal Alpha | Cronbach’s Alpha | Ordinal Alpha | |
| AT | 0.67 | 0.84 | 0.84 | 0.89 |
| BE | 0.82 | 0.91 | 0.88 | 0.91 |
| BG | 0.78 | 0.89 | 0.83 | 0.88 |
| CH | 0.72 | 0.86 | 0.84 | 0.88 |
| CZ | 0.78 | 0.89 | 0.84 | 0.88 |
| DE | 0.73 | 0.86 | 0.8 | 0.84 |
| DK | 0.75 | 0.89 | 0.86 | 0.9 |
| FR | 0.81 | 0.91 | 0.89 | 0.92 |
| HU | 0.76 | 0.89 | 0.84 | 0.89 |
| IE | 0.72 | 0.86 | 0.82 | 0.87 |
| IL | 0.8 | 0.9 | 0.88 | 0.91 |
| IT | 0.85 | 0.93 | 0.89 | 0.92 |
| NO | 0.73 | 0.87 | 0.84 | 0.88 |
| PT | 0.87 | 0.96 | 0.9 | 0.94 |
| RU | 0.86 | 0.94 | 0.9 | 0.93 |
| SI | 0.82 | 0.93 | 0.89 | 0.93 |
| SK | 0.81 | 0.91 | 0.88 | 0.91 |
| Mean | 0.78 | 0.9 | 0.86 | 0.9 |
| Dichotomized Items | Polytomous Items | |||||||
|---|---|---|---|---|---|---|---|---|
| SRMSR | RMSEA | CTI | TLI | SRMSR | RMSEA | CTI | TLI | |
| AT | 0.07 | 0.03 | 0.97 | 0.96 | 0.05 | 0.07 | 0.98 | 0.98 |
| BE | 0.08 | 0.05 | 0.98 | 0.97 | 0.05 | 0.06 | 0.99 | 0.99 |
| BG | 0.07 | 0.04 | 0.99 | 0.98 | 0.06 | 0.06 | 0.98 | 0.98 |
| CH | 0.07 | 0.03 | 0.98 | 0.97 | 0.05 | 0.07 | 0.98 | 0.97 |
| CZ | 0.05 | 0.03 | 0.99 | 0.99 | 0.04 | 0.05 | 0.99 | 0.99 |
| DE | 0.07 | 0.04 | 0.97 | 0.96 | 0.06 | 0.07 | 0.97 | 0.96 |
| DK | 0.06 | 0.03 | 0.98 | 0.98 | 0.05 | 0.06 | 0.99 | 0.98 |
| FR | 0.05 | 0.02 | 1.00 | 0.99 | 0.04 | 0.07 | 0.99 | 0.99 |
| HU | 0.07 | 0.03 | 0.98 | 0.98 | 0.05 | 0.06 | 0.99 | 0.98 |
| IE | 0.06 | 0.03 | 0.97 | 0.96 | 0.05 | 0.06 | 0.98 | 0.97 |
| IL | 0.06 | 0.03 | 0.99 | 0.99 | 0.05 | 0.06 | 0.99 | 0.99 |
| IT | 0.05 | 0.04 | 0.99 | 0.99 | 0.04 | 0.07 | 0.99 | 0.99 |
| NO | 0.07 | 0.04 | 0.97 | 0.96 | 0.04 | 0.05 | 0.99 | 0.98 |
| PT | 0.05 | 0.02 | 1.00 | 1.00 | 0.06 | 0.10 | 0.99 | 0.99 |
| RU | 0.05 | 0.04 | 0.99 | 0.99 | 0.05 | 0.07 | 0.99 | 0.99 |
| SI | 0.04 | 0.02 | 1.00 | 1.00 | 0.04 | 0.06 | 0.99 | 0.99 |
| SK | 0.06 | 0.04 | 0.99 | 0.98 | 0.05 | 0.07 | 0.99 | 0.99 |
| Mean | 0.06 | 0.03 | 0.98 | 0.98 | 0.05 | 0.07 | 0.99 | 0.98 |
| Total Samples | AT | BE | CH | CZ | DE | DK | FR | HU | IE | IL | NO | PT | RU | SI | SK |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WLE | 0.83 | 0.88 | 0.84 | 0.85 | 0.81 | 0.85 | 0.88 | 0.84 | 0.79 | 0.87 | 0.83 | 0.84 | 0.88 | 0.87 | 0.88 |
| EAP | 0.85 | 0.88 | 0.84 | 0.85 | 0.80 | 0.86 | 0.89 | 0.85 | 0.82 | 0.89 | 0.84 | 0.85 | 0.89 | 0.89 | 0.89 |
| By Data Collection Method | CHCAWI | CHCATI | CZCAWI | CZCATI | ILCAWI | ILCATI | SICAWI | SICAPI |
|---|---|---|---|---|---|---|---|---|
| WLE | 0.84 | 0.81 | 0.85 | 0.85 | 0.87 | 0.84 | 0.87 | 0.88 |
| EAP | 0.85 | 0.81 | 0.85 | 0.86 | 0.89 | 0.85 | 0.89 | 0.89 |
| PCA/t-Test | AT | BE | CH | CZ | DE | DK | FR | HU | IE | IL | NO | PT | RU | SI | SK |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Total sample | 9.3 (8.2) | 8.8 (7.2) | 8.9 (7.8) | 8.0 (6.7) | 9.1 (8.0) | 11.2 (10.2) | 7.4 (6.3) | 14.6 (12.6) | 6.1 (5.4) | 7.0 (5.7) | 5.7 (4.9) | 14.0 (11.9) | 9.0 (8.2) | 8.5 (7.5) | 11.6 (10.3) |
| Random sample | 7.7 (6.1) | 9.3 (7.6) | 11.1 (9.2) | 10.4 (8.6) | 11.0 (9.1) | 10.8 (8.9) | 8.6 (6.9) | 14.0 (12.0) | 6.9 (5.4) | 8.3 (7.0) | 2.1 (1.3) | 12.4 (10.4) | 6.8 (5.3) | 11.3 (9.4) | 12.8 (10.7) |
| SRMSR | 0.060 | 0.066 | 0.064 | 0.054 | 0.065 | 0.057 | 0.059 | 0.078 | 0.070 | 0.049 | 0.063 | 0.075 | 0.050 | 0.078 | 0.056 |
| By Data Collection Method | CHCAWI | CHCATI | CZCAWI | CZCATI | ILCAWI | ILCATI | SICAWI | SICAPI |
|---|---|---|---|---|---|---|---|---|
| PCA/t-test | 9.6 (8.4) | 16.5 (11.2) | 9.2 (7.6) | 11.7 (8.9) | 8.8 (7.2) | 7.2 (4.7) | 9.0 (7.6) | 9.0 (7.8) |
| SRMSR | 0.065 | 0.110 | 0.056 | 0.078 | 0.054 | 0.079 | 0.078 | 0.067 |
| Item Pair | Countries |
|---|---|
| 1 (access, HC)—2 (understand, HC) | PT a,b |
| 6 (understand, DP)—7 (appraise, DP) | FR a,c, HU b, SI a,d |
| 7 (appraise, DP)—9 (access, HP) | PT a,b |
| 9 (access, HP)—10 (understand, HP) | PT a,b |
| CH | CHCAWI | DE | FR | IE | NO | SI | SICAWI | SICAPI | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Item | 8 | 8 | 10 | 1 | 8 | 8 | 8 | 12 | 8 | 8 |
| Infit | 1.15 | 1.15 | 1.15 | 1.17 | 1.21 | 1.16 | 1.35 | 1.13 | 1.33 | 1.28 |
| t | 5.13 | 5.07 | 4.38 | 4.88 | 9.57 * | 5.60 | 12.69 * | 4.88 | 8.34 | 7.14 |
| Type D Score | Type P Score | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | Q25 | Median | Q75 | Mean | SD | Q25 | Median | Q75 | |
| AT | 84.8 | 16.1 | 75.0 | 90.9 | 100.0 | 71.8 | 13.6 | 63.3 | 69.7 | 80.6 |
| BE | 65.7 | 26.7 | 50.0 | 66.7 | 91.7 | 59.4 | 17.0 | 50.0 | 58.3 | 69.4 |
| BG | 68.5 | 23.1 | 54.5 | 66.7 | 90.0 | 59.0 | 13.7 | 50.0 | 58.3 | 66.7 |
| CH | 77.3 | 19.6 | 66.7 | 83.3 | 91.7 | 65.4 | 13.3 | 55.6 | 63.9 | 72.2 |
| CZ | 76.3 | 22.3 | 63.6 | 83.3 | 91.7 | 64.2 | 14.1 | 55.6 | 63.9 | 72.2 |
| DE | 64.9 | 21.9 | 50.0 | 66.7 | 83.3 | 58.9 | 13.6 | 50.0 | 58.3 | 66.7 |
| DK | 77.4 | 20.5 | 66.7 | 83.3 | 91.7 | 66.6 | 14.5 | 58.3 | 66.7 | 77.8 |
| FR | 77.5 | 22.9 | 58.3 | 83.3 | 100.0 | 65.9 | 15.5 | 55.6 | 63.9 | 75.0 |
| HU | 79.8 | 19.8 | 66.7 | 83.3 | 91.7 | 64.6 | 12.5 | 58.3 | 63.9 | 69.4 |
| IE | 78.8 | 19.5 | 66.7 | 83.3 | 91.7 | 72.3 | 16.3 | 61.1 | 72.2 | 86.1 |
| IL | 73.0 | 23.9 | 58.3 | 75.0 | 91.7 | 64.0 | 16.4 | 52.8 | 63.9 | 75.0 |
| IT | 69.1 | 27.4 | 50.0 | 75.0 | 91.7 | 60.1 | 16.4 | 50.0 | 61.1 | 69.4 |
| NO | 78.8 | 19.2 | 66.7 | 83.3 | 91.7 | 68.9 | 14.4 | 58.3 | 66.7 | 80.0 |
| PT | 84.8 | 20.5 | 80.0 | 91.7 | 100.0 | 63.8 | 11.5 | 60.0 | 63.9 | 66.7 |
| RU | 80.3 | 23.3 | 66.7 | 90.9 | 100.0 | 63.5 | 13.2 | 55.6 | 63.9 | 66.7 |
| SI | 86.0 | 19.1 | 83.3 | 91.7 | 100.0 | 70.4 | 14.7 | 63.9 | 66.7 | 80.6 |
| SK | 69.7 | 25.1 | 50.0 | 75.0 | 91.7 | 60.8 | 15.5 | 50.0 | 61.1 | 69.4 |
| All | 76.0 | 22.9 | 58.3 | 83.3 | 91.7 | 64.7 | 15.2 | 55.6 | 63.9 | 72.2 |
| Correlation of HLS19-Q12 (D Type) with | Correlation of HLS19-Q12 (P Type) with | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| HLS19-COM-P- Q11 | HLS19-COM-P- Q6 | HLS19- DIGI | HLS19- NAV | HLS19- VAC | HLS19-COM-P- Q11 | HLS19-COM-P- Q6 | HLS19- DIGI | HLS19- NAV | HLS19- VAC | |
| AT | 0.37 | 0.34 | 0.46 | 0.56 | 0.43 | 0.54 | 0.52 | 0.53 | 0.59 | 0.64 |
| BE | - | 0.27 | 0.44 | 0.41 | 0.43 | - | 0.35 | 0.52 | 0.42 | 0.49 |
| BG | - | 0.49 | - | - | 0.53 | - | 0.61 | - | - | 0.54 |
| CH | - | - | 0.49 | 0.56 | - | - | - | 0.52 | 0.62 | - |
| CZ | - | 0.47 | 0.57 | 0.55 | 0.44 | - | 0.51 | 0.59 | 0.59 | 0.46 |
| DE | 0.54 | 0.50 | 0.59 | 0.60 | 0.54 | 0.59 | 0.56 | 0.56 | 0.64 | 0.61 |
| DK | - | 0.47 | 0.54 | - | - | - | 0.55 | 0.59 | - | - |
| FR | - | 0.52 | 0.59 | 0.63 | - | - | 0.60 | 0.67 | 0.70 | - |
| HU | - | 0.36 | 0.50 | - | 0.43 | - | 0.47 | 0.52 | - | 0.51 |
| IE | - | - | 0.49 | - | 0.55 | - | - | 0.58 | - | 0.64 |
| IL | - | - | 0.67 | - | - | - | - | 0.72 | - | - |
| IT | - | - | - | - | 0.72 | - | - | - | - | 0.79 |
| NO | - | - | 0.48 | - | 0.55 | - | - | 0.59 | - | 0.69 |
| PT | - | - | 0.55 | 0.53 | 0.45 | - | - | 0.61 | 0.58 | 0.49 |
| RU | - | - | - | - | - | - | - | - | - | - |
| SI | 0.48 | 0.45 | - | 0.61 | 0.61 | 0.57 | 0.55 | - | 0.67 | 0.73 |
| SK | - | - | 0.54 | - | - | - | - | 0.58 | - | - |
| Mean | 0.46 | 0.43 | 0.53 | 0.56 | 0.52 | 0.57 | 0.52 | 0.58 | 0.60 | 0.60 |
| Unstandardized | Standardized | R2 | Valid Count | Total Count | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Sex | Age | Edu | Stat | Fin | Sex | Age | Edu | Stat | Fin | ||||
| AT | 91.70 | 2.30 | −0.07 | −0.32 | 0.12 | −4.26 | 0.07 | −0.08 | −0.03 | 0.01 | −0.21 | 0.05 | 2689 | 2967 |
| BE | 42.26 | 1.21 | 0.05 | −0.84 | 3.43 | 1.14 | 0.02 | 0.03 | −0.06 | 0.20 | 0.05 | 0.04 | 985 | 1000 |
| BG | 52.40 | 1.55 | −0.13 | 1.24 | 3.44 | −4.32 | 0.03 | −0.08 | 0.11 | 0.26 | −0.18 | 0.25 | 724 | 865 |
| CH | 77.13 | 0.31 | 0.00 | −0.27 | 0.99 | −2.52 | 0.01 | 0.00 | −0.03 | 0.08 | −0.15 | 0.04 | 2009 | 2502 |
| CZ | 68.90 | 4.05 | 0.14 | −1.66 | 1.73 | −4.44 | 0.09 | 0.11 | −0.14 | 0.13 | −0.21 | 0.10 | 1563 | 1599 |
| DE | 56.91 | 3.10 | −0.12 | 1.55 | 1.25 | −3.24 | 0.07 | −0.10 | 0.13 | 0.09 | −0.15 | 0.09 | 1822 | 2143 |
| DK | 65.83 | 2.43 | 0.10 | 0.39 | 1.20 | −5.14 | 0.06 | 0.07 | 0.03 | 0.10 | −0.19 | 0.08 | 3563 | 3602 |
| FR | 72.55 | 1.85 | 0.00 | −0.66 | 2.04 | −3.37 | 0.04 | 0.00 | −0.04 | 0.14 | −0.15 | 0.06 | 1969 | 2003 |
| HU | 83.79 | −1.10 | 0.13 | 0.28 | 0.07 | −4.56 | −0.03 | 0.11 | 0.03 | 0.01 | −0.28 | 0.09 | 1122 | 1195 |
| IE | 70.19 | 2.06 | 0.07 | 0.50 | 1.35 | −4.59 | 0.06 | 0.05 | 0.05 | 0.11 | −0.24 | 0.10 | 4277 | 4487 |
| IL | 66.42 | 3.47 | 0.14 | −1.28 | 1.78 | −4.62 | 0.07 | 0.09 | −0.09 | 0.14 | −0.21 | 0.10 | 1154 | 1315 |
| IT | 81.40 | 2.51 | −0.07 | 0.20 | 0.09 | −6.47 | 0.05 | −0.05 | 0.01 | 0.01 | −0.27 | 0.08 | 3248 | 3500 |
| NO | 72.38 | 2.63 | 0.00 | 0.42 | 1.02 | −5.33 | 0.07 | 0.00 | 0.04 | 0.08 | −0.15 | 0.04 | 2675 | 2855 |
| PT | 91.24 | −2.85 | −0.19 | 0.82 | 1.70 | −3.11 | −0.07 | −0.15 | 0.08 | 0.11 | −0.18 | 0.15 | 1168 | 1247 |
| RU | 83.94 | 2.22 | −0.21 | 0.56 | 2.20 | −5.44 | 0.04 | −0.15 | 0.03 | 0.16 | −0.27 | 0.22 | 5012 | 5660 |
| SI | 91.55 | 1.19 | −0.14 | 0.19 | 1.07 | −3.07 | 0.03 | −0.13 | 0.02 | 0.09 | −0.20 | 0.10 | 3164 | 3360 |
| SK | 69.35 | 3.54 | −0.16 | 0.45 | 2.50 | −6.79 | 0.07 | −0.11 | 0.04 | 0.16 | −0.32 | 0.21 | 1794 | 2145 |
| All | 78.05 | 1.69 | −0.05 | −0.47 | 1.42 | −4.17 | 0.04 | −0.04 | −0.04 | 0.10 | −0.21 | 0.07 | ||
| Unstandardized | Standardized | R2 | Valid Count | Total Count | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Sex | Age | Edu | Stat | Fin | Sex | Age | Edu | Stat | Fin | ||||
| AT | 78.82 | 1.87 | −0.13 | −0.04 | 0.31 | −3.70 | 0.07 | −0.16 | −0.00 | 0.03 | −0.21 | 0.08 | 2689 | 2967 |
| BE | 42.66 | 1.10 | 0.04 | −0.40 | 2.22 | 0.55 | 0.03 | 0.04 | −0.04 | 0.20 | 0.04 | 0.04 | 985 | 1000 |
| BG | 54.11 | 2.20 | −0.13 | 0.40 | 1.87 | −2.82 | 0.07 | −0.14 | 0.06 | 0.22 | −0.19 | 0.26 | 724 | 865 |
| CH | 65.38 | 0.70 | −0.03 | 0.15 | 0.59 | −1.94 | 0.03 | −0.04 | 0.02 | 0.07 | −0.17 | 0.05 | 2009 | 2502 |
| CZ | 56.54 | 2.94 | 0.07 | −0.69 | 1.34 | −2.56 | 0.10 | 0.08 | −0.09 | 0.16 | −0.20 | 0.09 | 1563 | 1599 |
| DE | 53.80 | 1.67 | −0.09 | 1.05 | 0.80 | −1.72 | 0.06 | −0.11 | 0.14 | 0.09 | −0.13 | 0.09 | 1822 | 2143 |
| DK | 56.63 | 2.36 | 0.03 | 0.39 | 1.04 | −2.83 | 0.08 | 0.03 | 0.04 | 0.13 | −0.15 | 0.07 | 3563 | 3602 |
| FR | 59.31 | 1.18 | −0.01 | −0.09 | 1.54 | −1.74 | 0.04 | −0.01 | −0.01 | 0.15 | −0.11 | 0.05 | 1969 | 2003 |
| HU | 64.57 | −0.26 | 0.07 | 0.53 | 0.09 | −2.58 | −0.01 | 0.10 | 0.08 | 0.01 | −0.24 | 0.08 | 1122 | 1195 |
| IE | 64.28 | 2.28 | 0.07 | 0.21 | 1.10 | −3.63 | 0.07 | 0.07 | 0.03 | 0.11 | −0.22 | 0.10 | 4277 | 4487 |
| IL | 58.31 | 3.12 | 0.06 | −0.64 | 1.13 | −2.66 | 0.09 | 0.06 | −0.07 | 0.13 | −0.17 | 0.07 | 1154 | 1315 |
| IT | 69.21 | 1.16 | −0.10 | 0.49 | 0.03 | −3.75 | 0.04 | −0.11 | 0.06 | 0.00 | −0.27 | 0.09 | 3248 | 3500 |
| NO | 63.00 | 2.58 | −0.02 | 0.57 | 0.59 | −3.25 | 0.09 | −0.03 | 0.07 | 0.06 | −0.12 | 0.04 | 2675 | 2855 |
| PT | 63.35 | −1.60 | −0.09 | 0.82 | 1.21 | −1.45 | −0.07 | −0.14 | 0.15 | 0.15 | −0.16 | 0.19 | 1168 | 1247 |
| RU | 62.12 | 1.65 | −0.14 | 0.93 | 1.04 | −2.41 | 0.06 | −0.18 | 0.09 | 0.14 | −0.22 | 0.18 | 5012 | 5660 |
| SI | 70.30 | 2.21 | −0.14 | 0.77 | 0.92 | −1.97 | 0.08 | −0.17 | 0.11 | 0.10 | −0.17 | 0.14 | 3164 | 3360 |
| SK | 57.77 | 2.25 | −0.09 | 0.41 | 1.77 | −4.07 | 0.07 | −0.10 | 0.06 | 0.19 | −0.31 | 0.22 | 1794 | 2145 |
| All | 63.77 | 1.52 | −0.05 | −0.01 | 1.07 | −2.70 | 0.05 | −0.06 | −0.00 | 0.12 | −0.20 | 0.08 | ||
| Unstandardized | Standardized | R2 | Valid Count | Total Count | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | HL | Sex | Age | Edu | Stat | Fin | HL | Sex | Age | Edu | Stat | Fin | ||||
| AT | 2.38 | −0.01 | −0.02 | 0.01 | −0.03 | −0.06 | 0.14 | −0.18 | −0.01 | 0.23 | −0.06 | −0.11 | 0.14 | 0.16 | 2691 | 2967 |
| BE | 3.56 | 0.00 | 0.07 | 0.00 | −0.04 | −0.14 | −0.02 | −0.14 | 0.05 | 0.08 | −0.08 | −0.27 | −0.03 | 0.13 | 988 | 1000 |
| BG | 2.63 | −0.01 | 0.02 | 0.01 | −0.07 | −0.05 | 0.11 | −0.20 | 0.01 | 0.26 | −0.19 | −0.11 | 0.13 | 0.38 | 721 | 865 |
| CH | 2.41 | −0.01 | −0.07 | 0.01 | −0.01 | −0.08 | 0.10 | −0.15 | −0.04 | 0.22 | −0.03 | −0.18 | 0.15 | 0.16 | 2019 | 2502 |
| CZ | 2.16 | 0.00 | −0.05 | 0.02 | −0.06 | −0.07 | 0.13 | −0.08 | −0.03 | 0.35 | −0.11 | −0.13 | 0.16 | 0.24 | 1567 | 1599 |
| DE | 1.98 | −0.01 | −0.03 | 0.02 | −0.01 | −0.05 | 0.10 | −0.14 | −0.02 | 0.41 | −0.03 | −0.09 | 0.13 | 0.26 | 1845 | 2143 |
| DK | 3.08 | −0.01 | −0.08 | 0.01 | −0.02 | −0.07 | 0.18 | −0.22 | −0.05 | 0.11 | −0.03 | −0.14 | 0.17 | 0.16 | 3561 | 3602 |
| FR | 2.60 | −0.01 | −0.01 | 0.01 | 0.01 | −0.12 | 0.08 | −0.16 | −0.01 | 0.24 | 0.02 | −0.22 | 0.10 | 0.17 | 2003 | 2003 |
| HU | 2.06 | −0.01 | 0.08 | 0.02 | −0.02 | −0.07 | 0.16 | −0.12 | 0.04 | 0.31 | −0.05 | −0.12 | 0.22 | 0.27 | 1124 | 1195 |
| IE | 2.37 | 0.00 | −0.02 | 0.01 | −0.04 | −0.06 | 0.13 | −0.11 | −0.02 | 0.11 | −0.10 | −0.11 | 0.16 | 0.11 | 4301 | 4487 |
| IL | 1.98 | 0.00 | −0.02 | 0.02 | 0.00 | −0.08 | 0.10 | −0.13 | −0.01 | 0.31 | −0.01 | −0.16 | 0.12 | 0.17 | 1154 | 1315 |
| IT | 2.37 | 0.00 | 0.00 | 0.01 | 0.01 | −0.07 | 0.10 | −0.12 | 0.00 | 0.24 | 0.02 | −0.14 | 0.16 | 0.14 | 3240 | 3500 |
| NO | 2.54 | −0.01 | 0.04 | 0.01 | −0.04 | −0.09 | 0.25 | −0.14 | 0.02 | 0.18 | −0.09 | −0.17 | 0.15 | 0.13 | 2681 | 2855 |
| PT | 2.00 | 0.00 | 0.13 | 0.02 | −0.04 | −0.05 | 0.10 | −0.12 | 0.09 | 0.35 | −0.11 | −0.09 | 0.16 | 0.35 | 1168 | 1247 |
| RU | 2.32 | 0.00 | 0.02 | 0.01 | −0.03 | −0.02 | 0.10 | −0.14 | 0.02 | 0.36 | −0.05 | −0.06 | 0.17 | 0.29 | 5079 | 5660 |
| SI | 1.90 | −0.01 | 0.04 | 0.02 | −0.03 | −0.04 | 0.13 | −0.15 | 0.02 | 0.37 | −0.07 | −0.08 | 0.18 | 0.31 | 3184 | 3360 |
| SK | 1.71 | 0.00 | 0.03 | 0.02 | −0.02 | −0.06 | 0.11 | −0.07 | 0.01 | 0.42 | −0.05 | −0.11 | 0.16 | 0.33 | 1794 | 2145 |
| All | 2.39 | −0.01 | 0.01 | 0.01 | −0.02 | −0.07 | 0.12 | −0.15 | 0.01 | 0.26 | −0.05 | −0.15 | 0.16 | 0.21 | ||
| Unstandardized | Standardized | R2 | Valid Count | Total Count | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | HL | Sex | Age | Edu | Stat | Fin | HL | Sex | Age | Edu | Stat | Fin | ||||
| AT | 2.33 | −0.01 | −0.02 | 0.01 | −0.02 | −0.06 | 0.15 | −0.17 | −0.01 | 0.22 | −0.05 | −0.11 | 0.14 | 0.16 | 2691 | 2967 |
| BE | 3.66 | −0.01 | 0.08 | 0.00 | −0.03 | −0.14 | −0.02 | −0.14 | 0.05 | 0.08 | −0.08 | −0.27 | −0.03 | 0.13 | 988 | 1000 |
| BG | 2.94 | −0.01 | 0.03 | 0.01 | −0.08 | −0.05 | 0.10 | −0.23 | 0.02 | 0.24 | −0.20 | −0.12 | 0.13 | 0.38 | 721 | 865 |
| CH | 2.60 | −0.01 | −0.06 | 0.01 | −0.01 | −0.08 | 0.10 | −0.17 | −0.04 | 0.21 | −0.03 | −0.18 | 0.15 | 0.16 | 2019 | 2502 |
| CZ | 2.20 | −0.01 | −0.05 | 0.02 | −0.05 | −0.07 | 0.14 | −0.08 | −0.03 | 0.35 | −0.11 | −0.13 | 0.16 | 0.24 | 1567 | 1599 |
| DE | 2.13 | −0.01 | −0.03 | 0.02 | −0.01 | −0.05 | 0.10 | −0.14 | −0.02 | 0.41 | −0.03 | −0.09 | 0.13 | 0.26 | 1845 | 2143 |
| DK | 3.22 | −0.01 | −0.07 | 0.01 | −0.02 | −0.06 | 0.19 | −0.23 | −0.04 | 0.10 | −0.03 | −0.14 | 0.17 | 0.16 | 3561 | 3602 |
| FR | 2.76 | −0.01 | −0.01 | 0.01 | 0.01 | −0.11 | 0.09 | −0.18 | −0.01 | 0.24 | 0.02 | −0.21 | 0.11 | 0.18 | 2003 | 2003 |
| HU | 2.24 | −0.01 | 0.08 | 0.02 | −0.02 | −0.07 | 0.16 | −0.14 | 0.05 | 0.31 | −0.04 | −0.12 | 0.22 | 0.27 | 1124 | 1195 |
| IE | 2.41 | −0.01 | −0.02 | 0.01 | −0.04 | −0.06 | 0.13 | −0.11 | −0.01 | 0.11 | −0.10 | −0.11 | 0.16 | 0.11 | 4301 | 4487 |
| IL | 2.23 | −0.01 | −0.01 | 0.02 | 0.00 | −0.07 | 0.09 | −0.18 | −0.01 | 0.31 | −0.01 | −0.16 | 0.11 | 0.18 | 1154 | 1315 |
| IT | 2.50 | −0.01 | 0.00 | 0.01 | 0.01 | −0.07 | 0.10 | −0.13 | 0.00 | 0.23 | 0.03 | −0.14 | 0.16 | 0.14 | 3240 | 3500 |
| NO | 2.59 | −0.01 | 0.04 | 0.01 | −0.04 | −0.09 | 0.25 | −0.13 | 0.02 | 0.17 | −0.09 | −0.17 | 0.15 | 0.13 | 2681 | 2855 |
| PT | 2.02 | −0.01 | 0.13 | 0.02 | −0.04 | −0.05 | 0.10 | −0.10 | 0.09 | 0.35 | −0.10 | −0.09 | 0.17 | 0.34 | 1168 | 1247 |
| RU | 2.49 | −0.01 | 0.03 | 0.01 | −0.02 | −0.02 | 0.10 | −0.16 | 0.02 | 0.35 | −0.04 | −0.06 | 0.17 | 0.29 | 5079 | 5660 |
| SI | 1.89 | −0.01 | 0.05 | 0.02 | −0.02 | −0.04 | 0.13 | −0.15 | 0.03 | 0.36 | −0.06 | −0.08 | 0.19 | 0.31 | 3184 | 3360 |
| SK | 1.81 | 0.00 | 0.03 | 0.02 | −0.02 | −0.05 | 0.11 | −0.08 | 0.02 | 0.42 | −0.05 | −0.10 | 0.15 | 0.33 | 1794 | 2145 |
| All | 2.59 | −0.01 | 0.02 | 0.01 | −0.02 | −0.07 | 0.12 | −0.19 | 0.01 | 0.26 | −0.04 | −0.14 | 0.16 | 0.21 | ||
| HLS19-Q47 × HLS19-Q12 | Type | BG | DE | IE | IT | NO | SI | All |
|---|---|---|---|---|---|---|---|---|
| General HL | D | 0.928 | 0.920 | 0.903 | 0.951 | 0.897 | 0.928 | 0.931 |
| P | 0.945 | 0.944 | 0.941 | 0.969 | 0.950 | 0.963 | 0.958 | |
| Health Care | D | 0.856 | 0.844 | 0.823 | 0.889 | 0.802 | 0.871 | 0.864 |
| P | 0.898 | 0.886 | 0.882 | 0.928 | 0.885 | 0.930 | 0.911 | |
| Disease Prevention | D | 0.861 | 0.848 | 0.817 | 0.894 | 0.802 | 0.869 | 0.863 |
| P | 0.852 | 0.885 | 0.866 | 0.923 | 0.875 | 0.921 | 0.896 | |
| Health Promotion | D | 0.815 | 0.787 | 0.777 | 0.863 | 0.762 | 0.795 | 0.809 |
| P | 0.858 | 0.830 | 0.871 | 0.904 | 0.864 | 0.885 | 0.876 | |
| Access/obtain information relevant for health | D | 0.809 | 0.786 | 0.775 | 0.843 | 0.741 | 0.837 | 0.812 |
| P | 0.849 | 0.847 | 0.847 | 0.891 | 0.840 | 0.903 | 0.871 | |
| Understand information relevant for health | D | 0.761 | 0.778 | 0.772 | 0.865 | 0.788 | 0.801 | 0.806 |
| P | 0.763 | 0.818 | 0.843 | 0.900 | 0.867 | 0.891 | 0.860 | |
| Appraise/judge/evaluate information relevant for health | D | 0.876 | 0.843 | 0.762 | 0.874 | 0.765 | 0.809 | 0.847 |
| P | 0.904 | 0.873 | 0.822 | 0.908 | 0.844 | 0.885 | 0.886 | |
| Apply/use information relevant for health | D | 0.779 | 0.792 | 0.747 | 0.861 | 0.758 | 0.807 | 0.802 |
| P | 0.826 | 0.830 | 0.830 | 0.898 | 0.849 | 0.877 | 0.864 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pelikan, J.M.; Link, T.; Straßmayr, C.; Waldherr, K.; Alfers, T.; Bøggild, H.; Griebler, R.; Lopatina, M.; Mikšová, D.; Nielsen, M.G.; et al. Measuring Comprehensive, General Health Literacy in the General Adult Population: The Development and Validation of the HLS19-Q12 Instrument in Seventeen Countries. Int. J. Environ. Res. Public Health 2022, 19, 14129. https://doi.org/10.3390/ijerph192114129
Pelikan JM, Link T, Straßmayr C, Waldherr K, Alfers T, Bøggild H, Griebler R, Lopatina M, Mikšová D, Nielsen MG, et al. Measuring Comprehensive, General Health Literacy in the General Adult Population: The Development and Validation of the HLS19-Q12 Instrument in Seventeen Countries. International Journal of Environmental Research and Public Health. 2022; 19(21):14129. https://doi.org/10.3390/ijerph192114129
Chicago/Turabian StylePelikan, Jürgen M., Thomas Link, Christa Straßmayr, Karin Waldherr, Tobias Alfers, Henrik Bøggild, Robert Griebler, Maria Lopatina, Dominika Mikšová, Marie Germund Nielsen, and et al. 2022. "Measuring Comprehensive, General Health Literacy in the General Adult Population: The Development and Validation of the HLS19-Q12 Instrument in Seventeen Countries" International Journal of Environmental Research and Public Health 19, no. 21: 14129. https://doi.org/10.3390/ijerph192114129
APA StylePelikan, J. M., Link, T., Straßmayr, C., Waldherr, K., Alfers, T., Bøggild, H., Griebler, R., Lopatina, M., Mikšová, D., Nielsen, M. G., Peer, S., & Vrdelja, M., on behalf of the HLS19 Consortium of the WHO Action Network M-POHL. (2022). Measuring Comprehensive, General Health Literacy in the General Adult Population: The Development and Validation of the HLS19-Q12 Instrument in Seventeen Countries. International Journal of Environmental Research and Public Health, 19(21), 14129. https://doi.org/10.3390/ijerph192114129