4.1. LASSO
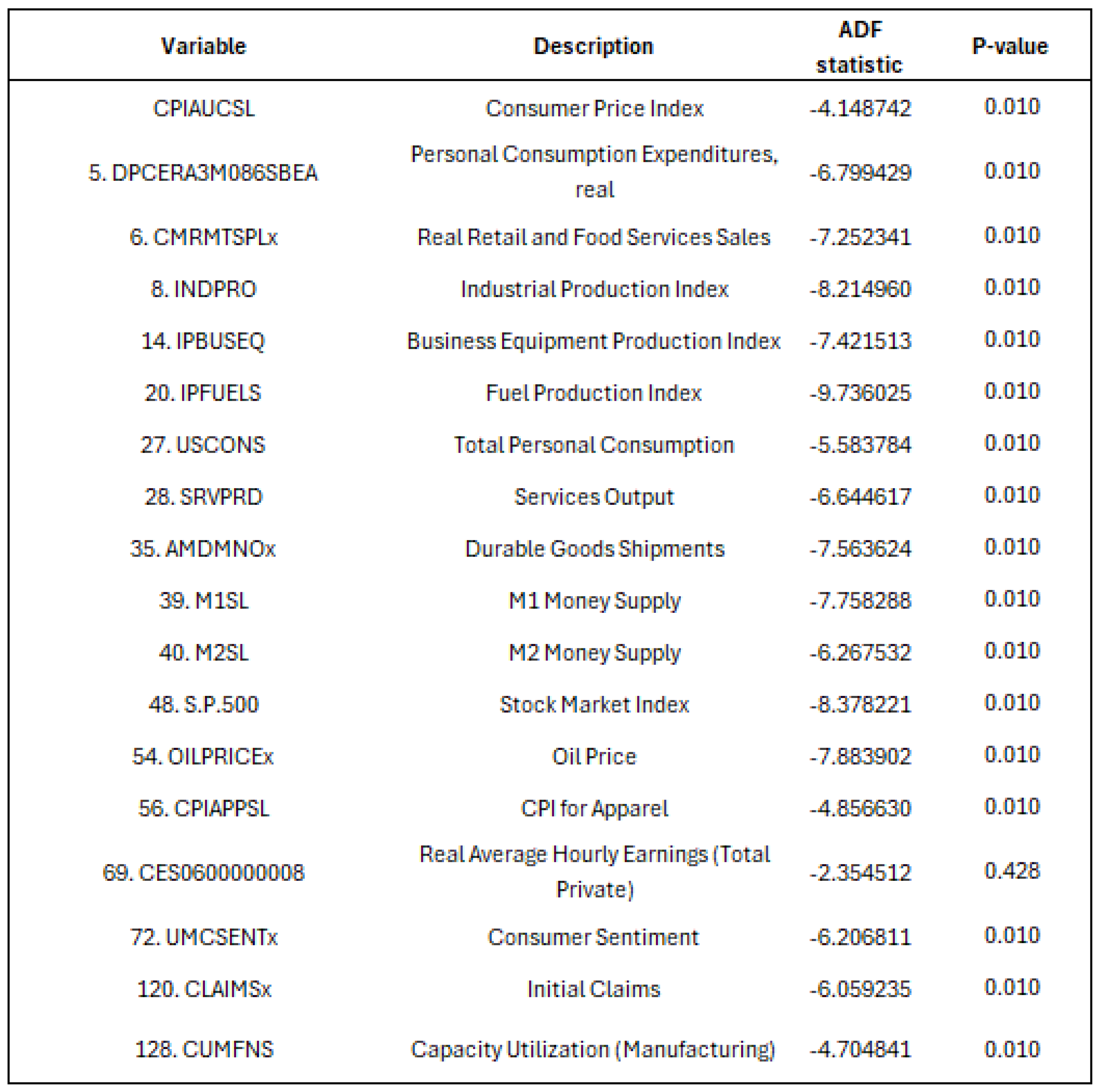
Inflation forecasting typically employs huge datasets containing a lot of variables, some of which may be irrelevant for prediction purposes. The Least Absolute Shrinkage and Selection Operator (LASSO) has the ability to select only the most important covariates, discarding irrelevant information and keeping the error of the prediction as small as possible (
Freijeiro-González et al., 2022).
LASSO combines properties from both subset selection and ridge regression. This makes it able to produce explicable models (like subset selection), and be as stable as a ridge regression. LASSO minimizes the residual sum of squares while constraining the sum of the absolute values of the coefficients to be less than a specified constant. This constraint causes LASSO to shrink some coefficients exactly to zero, effectively performing variable selection and resulting in more interpretable models (
Tibshirani, 1996).
The Lasso model contains:
Data
predictor variables
and responses
We either assume that the observations are independent or that the s are conditionally independent given the s.
We assume that the
s are standardized so that
Letting
the lasso estimate
is obtained by solving the following optimization problem:
subject to
Here, is a tuning parameter. Now, for all t, the solution for is . We can assume without loss of generality that and hence omit .
The parameter
controls the amount of shrinkage that is applied to the estimates. Let
be the full least squares estimates and let
. Values of
will cause shrinkage of the solutions toward 0, and some coefficients may be exactly equal to 0. For example, if
, the effect will be roughly similar to finding the best subset of size
. It is not necessary for the design matrix to be of full rank for the model to be specified (
Tibshirani, 1996).
We include LASSO in our model to address overfitting and optimism bias. LASSO regression aims to identify the subset of variables and their associated coefficients that minimize prediction error by imposing a penalty on the regression coefficients. This penalty shrinks coefficients toward zero by constraining the sum of their absolute values to be less than a fixed threshold, controlled by the regularization parameter (
). As a result, less important variables receive coefficients exactly equal to zero, effectively performing variable selection and enhancing model generalizability.
After the shrinkage, variables with regression coefficients equal to zero are excluded from the model (
Ranstam & Cook, 2018).
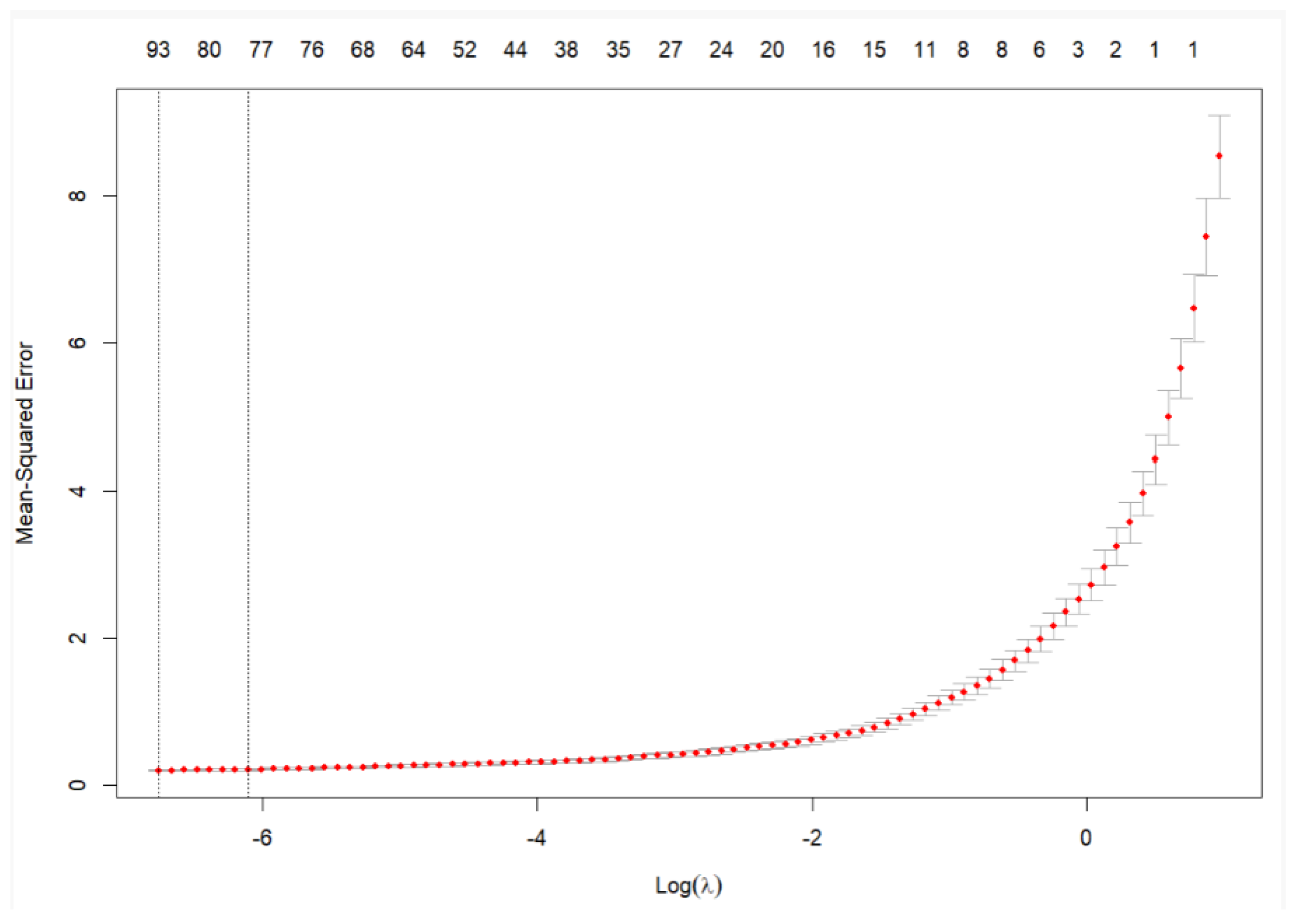
We employ an automated k-fold cross-validation procedure to select the optimal value of . In this approach, the dataset is randomly partitioned into k equally sized subsets. For each iteration, subsets are used to train the model, while the remaining subset is used for validation. This process is repeated k times, with each subset serving once as the validation set. The cross-validation error is computed for a range of values, and the value of that minimizes the average validation error across the k folds is selected. This chosen is then used to estimate the final model.
This technique reduces overfitting without the need to reserve a subset of the dataset exclusively for internal validation. A disadvantage of the LASSO approach is that one may not be able to reliably interpret the regression coefficients in terms of independent risk factors since the focus is on the best combined prediction and not on the accuracy of the estimation (
Ranstam & Cook, 2018).
4.2. LSTM
As depicted in
Figure 3, the LSTM model is a variant of recurrent neural networks (RNNs) (
Almosova & Andresen, 2023). Unlike other neural networks, a recurrent neural network updates by time step. This means that the model will adjust forecasts based on previous time steps. RNN models have proven particularly useful for data-sensitive sequences such as time series analysis, natural language processing, and sound recognition (
Mullainathan & Spiess, 2017). For example, in the context of music recognition, one could observe a pattern in the sound, making it possible to predict what is to come next or which song you are listening to (
Bishop, 2006). For such models it is crucial that there is a pattern in the data, and that the sequence of the data anticipates later values.
The RNN model is able to update its memory based on previous steps and consider long-term trends and patterns in the data (
Tsui et al., 2018). Consider an abnormal drop in inflation for one month, which deviates from previous time steps in the data. The RNN takes into account the underlying pattern in the data based on previous observations, and considers the fall in inflation as an abnormality. What makes inflation behavior abnormal, and which patterns the model detects to label the drop in inflation as abnormal, is inherently difficult to grasp.
LSTM, on the other hand, differs from other RNNs as it possesses an enhanced capability of capturing long-term trends in the data (
Tsui et al., 2018). Consider an inflationary episode from the 1970s that exhibits a similar pattern to a recent event. An LSTM model is capable of recognizing these historical similarities in temporal patterns and incorporating them into its forecasting process. However, it does not assign equal weight to all past events. Instead, the influence of the historical episode is modulated based on its relevance, with more emphasis typically placed on recent observations. This dynamic weighting allows LSTM to integrate both long-term dependencies and short-term fluctuations, enabling it to capture complex temporal relationships and generate more contextually informed predictions (
Lenza et al., 2023).
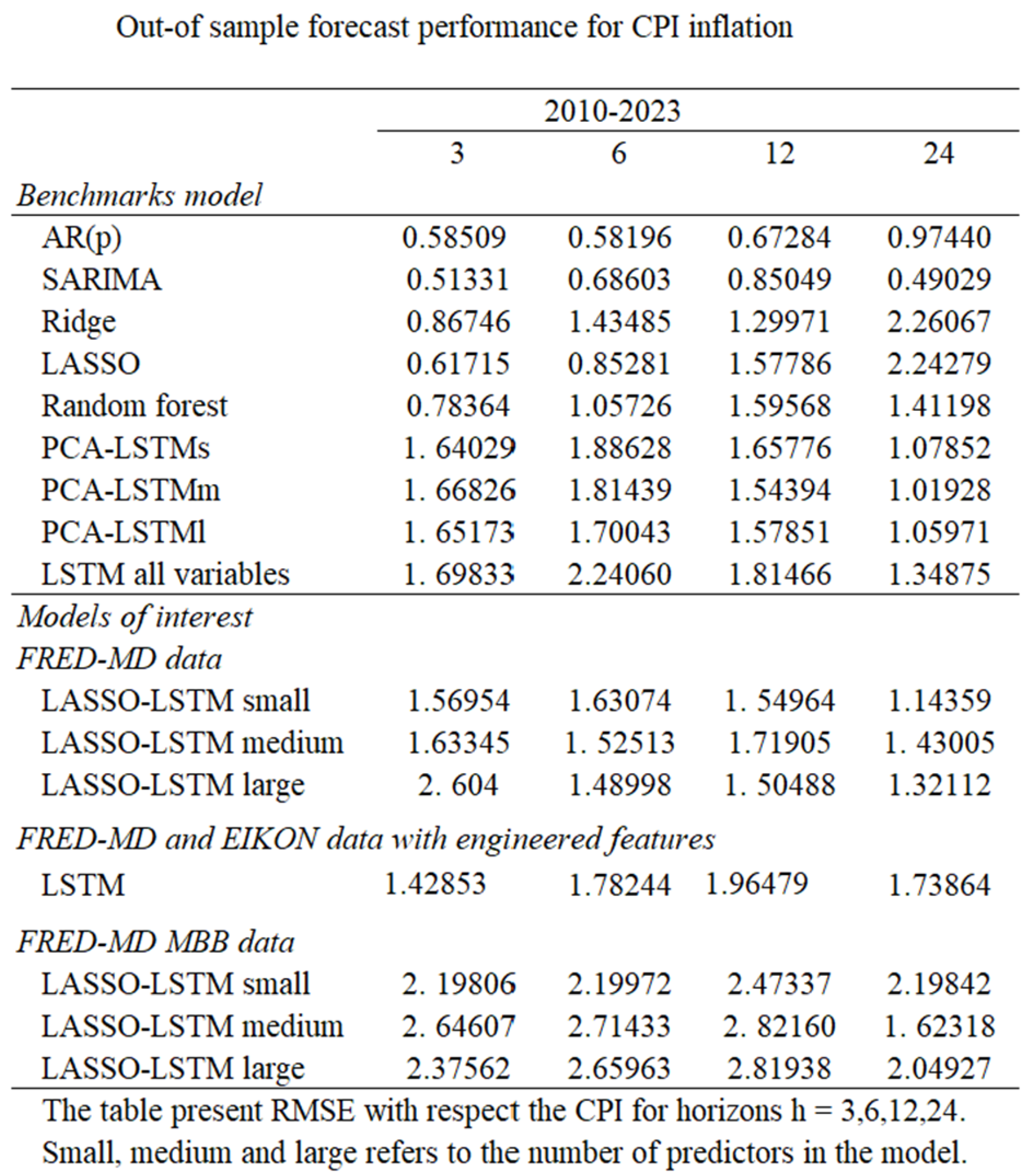
LSTM has proven to be highly efficient for sequential data and has been used to compute univariate forecasts of monthly US CPI inflation. LSTM slightly outperforms autoregressive models (AR), Neural Networks (NN), and Markov-switching models, but its performance is on par with the SARIMA model (
Almosova & Andresen, 2023). Recently, it has become harder to outperform naive univariate random walk-type forecasts of US inflation, but since the mid-80s, inflation has also become less volatile and easier to predict.
Atkeson et al. (
2001) show that averaging over the last 12 months gives a more accurate forecast of the 12-month-ahead inflation than a backward-looking Phillips curve. Macroeconomic literature argues that the inflation process might be changing over time, making a non-linear model more precise in predicting inflation. Basically, there are four main advantages of the LSTM method (
Almosova & Andresen, 2023).
1. LSTMs are flexible and data-driven. It means that researchers do not have to specify the exact form of the non-linearity. Instead, the LSTM will infer this from the data itself.
2. Under some mild regulatory conditions, LSTMs and neural networks of any type, in general, can approximate any continuous function arbitrarily accurately. At the same time, these models are more parsimonious than many other non-linear time series models.
3. LSTMs were developed specifically for sequential data analysis and have proved to be very successful with this task.
4. The recent development of the optimization routines for NNs and the libraries that employ computer GPUs has made the training of NNs and recurrent neural networks significantly more feasible.
In contrast to classical time series models, the LSTM network does not suffer from data instabilities or unit root problems. Nor does it suffer from the vanishing gradient problem of general RNNs, which can destroy the long-term memory of these networks. LSTM may be applied to forecasting any macroeconomic time series, provided that there are enough observations to estimate the model.
LSTMs perform particularly well at long horizons and during periods of high macroeconomic uncertainty. This is due to their lower sensitivity to temporary and sudden price changes compared to traditional models in the literature. One should note that their performance is not outstanding, for instance, compared to the random forest model (
Lenza et al., 2023). A simplified, visual representation of an LSTM recurrent structure is provided in
Figure 4.
A common weakness of machine learning techniques, including neural networks, is the lack of interpretability (
Mullainathan & Spiess, 2017). For inflation in particular this could be a problem, since much of the effort is devoted to understanding the underlying inflation process, sometimes at the expense of marginal increases in forecasting gains. LSTM is, on average, less affected by sudden, short-lived movements in prices compared to other models. Random forest has proved sensitive to the downward pressure on prices caused by the global financial crisis (GFC). Machine learning models are more prone to instabilities in performance due to their sensitivity to model specification (
Almosova & Andresen, 2023). This also applies to the LSTM network. Lastly, LSTM-implied factors display high correlation with business cycle indicators, informing on the usefulness of such signals as inflation predictors.
The LSTM model is characterized by two key components: the cell state, which acts as the long-term memory, and the hidden state, representing the short-term memory. A schematic representation of an LSTM cell is provided in
Figure 5. Initially, both states are assigned default values (often zeros), and they are subsequently updated as new input sequences are processed. The model uses sigmoid and tanh activation functions within its gating mechanisms—namely the input, forget, and output gates—to regulate the flow of information. These functions determine how much of the new input is retained, how much of the previous state is forgotten, and how the internal memory is updated, thereby enabling the LSTM to capture complex temporal dependencies over time.
4.3. LASSO-LSTM
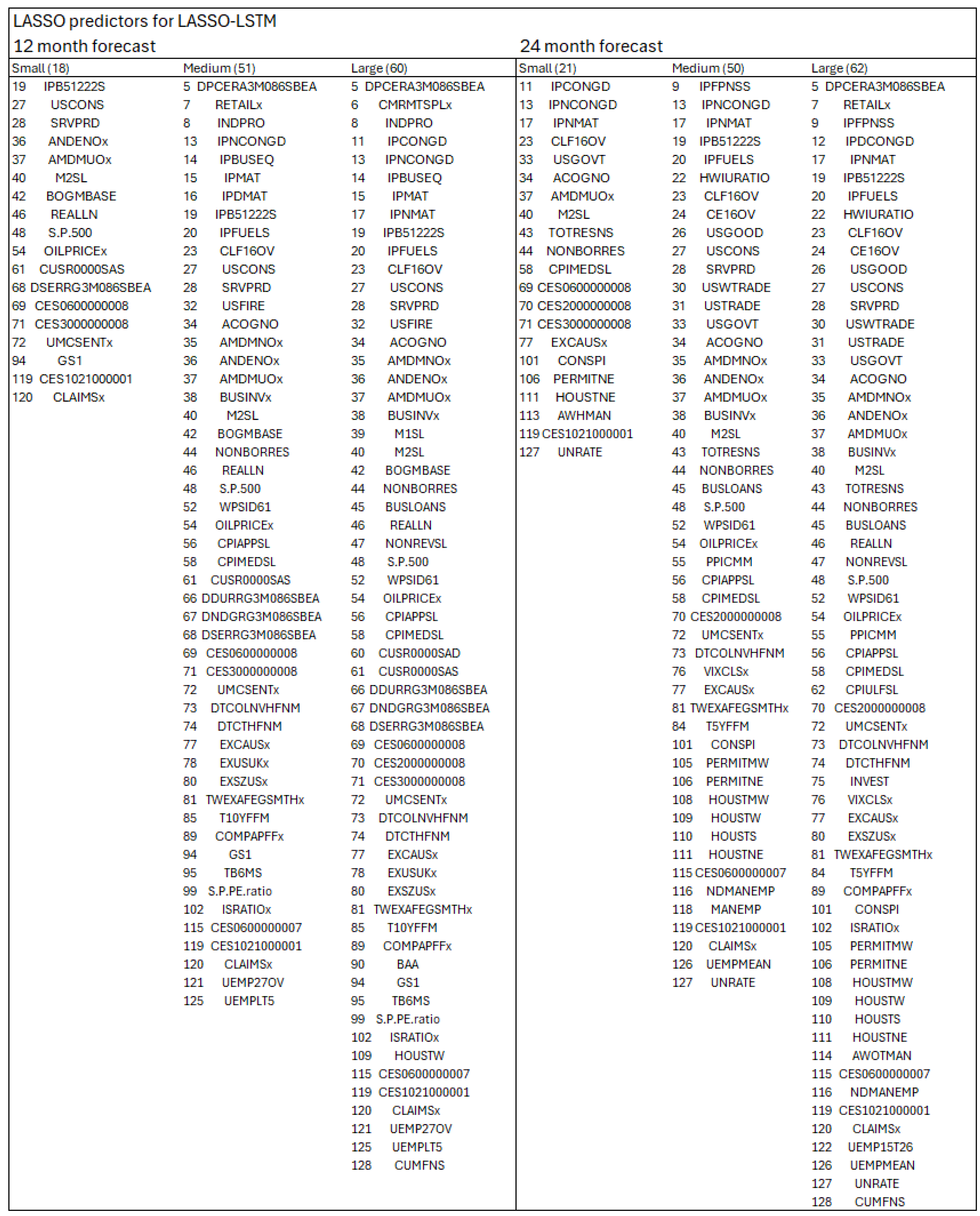
The LASSO-LSTM model is a hybrid machine learning framework that combines the strengths of LASSO regression and Long Short-Term Memory (LSTM) networks. The process begins with LASSO, which serves as a feature selection mechanism. Unlike ordinary least squares (OLS), LASSO introduces a penalty on the regression coefficients, shrinking less informative coefficients toward zero and effectively excluding irrelevant predictors from the model. This dimensionality reduction mitigates overfitting and enhances interpretability. The selected subset of predictors is then used to train the LSTM, which captures temporal dependencies and non-linear patterns in the data. The regularization parameter in LASSO plays a critical role, as it directly influences the number and type of features passed to the LSTM, thereby shaping the final model’s complexity and performance.
In this study, the regularization parameter is calibrated at three distinct levels—small, medium, and large—corresponding to LASSO-LSTM architectures of varying complexity. A larger regularization term leads to greater coefficient shrinkage in the LASSO step, resulting in fewer selected predictors and thus a smaller and more constrained LSTM architecture. This multi-scale approach allows us to systematically evaluate the trade-off between underfitting and overfitting in the context of macroeconomic forecasting. By comparing model performance across architectures, we gain insight into how regularization impacts predictive accuracy and model generalization under different data conditions.
LSTM models, while effective at capturing complex temporal patterns, are prone to overfitting in medium-sized, high-dimensional macroeconomic datasets. As shown by (
Paranhos, 2024), larger LSTM architectures do not always outperform smaller ones. To mitigate this, LASSO is applied for feature selection, retaining only the most relevant predictors and improving model efficiency and generalization.
The selected features feed into the LSTM input layer. Architecture size is adjusted based on regularization strength: larger models, more susceptible to overfitting, are constrained with fewer layers and dropout applied; smaller models, less prone to overfitting, allow for more layers and reduced dropout. The LASSO-LSTM thus combines feature selection and temporal modeling to enhance predictive performance while controlling complexity.
An alternative and widely used method for feature reduction is Principal Component Analysis (PCA) (
Tsui et al., 2018). While both PCA and LASSO aim to manage high-dimensional data, their objectives and implications differ. PCA identifies components that explain the greatest variance in the data, often resulting in linear combinations of variables that lack direct interpretability. In contrast, LASSO performs variable selection by shrinking less relevant coefficients toward zero, retaining only the most influential predictors. This feature selection preserves interpretability, making LASSO-LSTM particularly valuable in policy contexts, where understanding which variables drive the forecast is essential, especially for central banks and decision-makers.
4.4. ARIMA and SARIMA
Seasonal Autoregressive Integrated Moving Average (SARIMA) extends the ARIMA model by explicitly accounting for seasonality in time series data. While ARIMA assumes either non-seasonal data or that seasonal patterns have been removed—typically through seasonal differencing—SARIMA incorporates seasonal terms directly, enabling more accurate modeling of data with recurring cycles (
Dubey et al., 2021).
An ARIMA(p, d, q) model can be represented by Equation (1) below:
Here is a constant, are the coefficients of the autoregressive part with p lags, are the coefficients of the moving average part with q lags, and is the error term at time t. The error terms are typically assumed to be i.i.d. variables drawn from a normal distribution with zero mean.
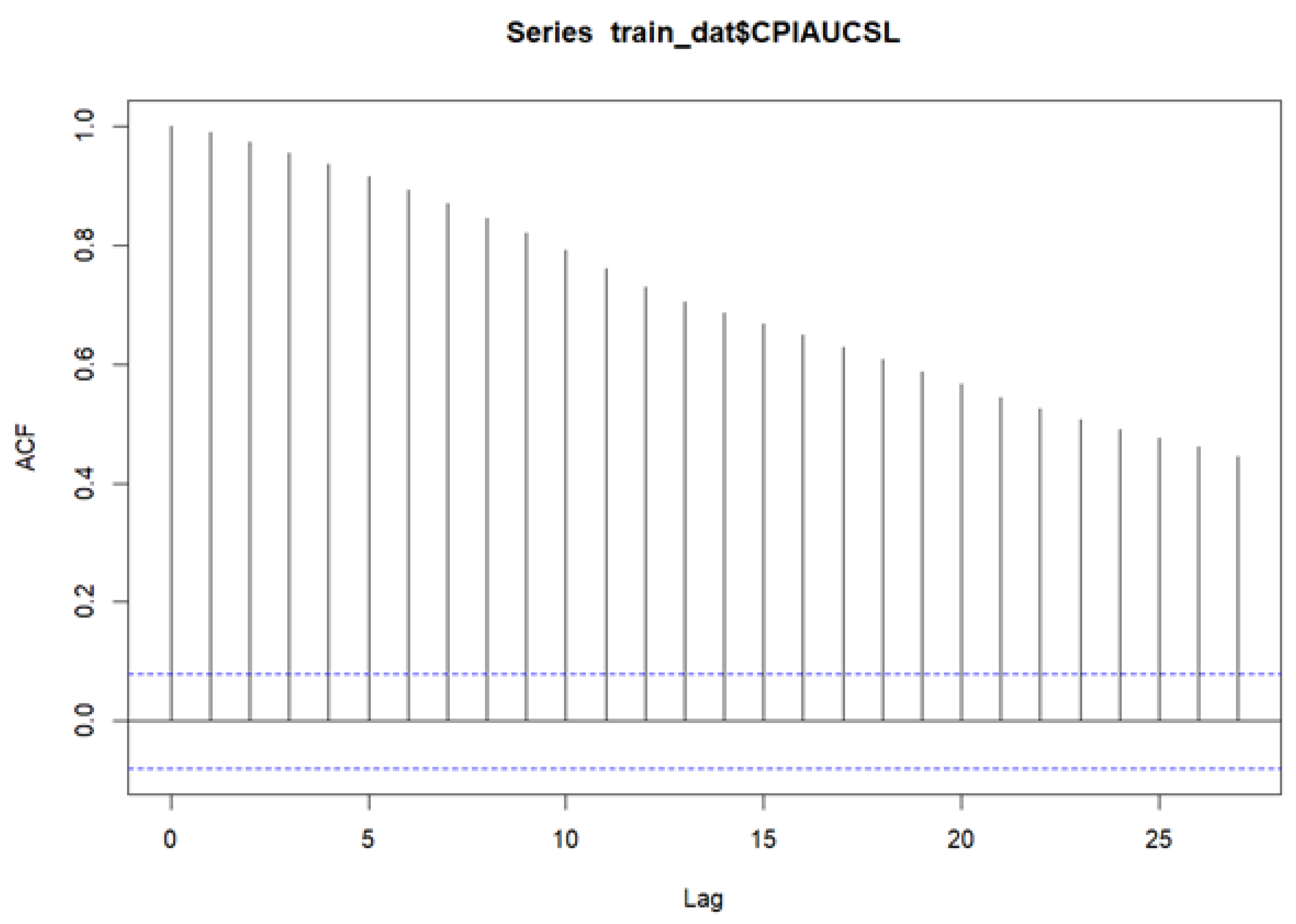
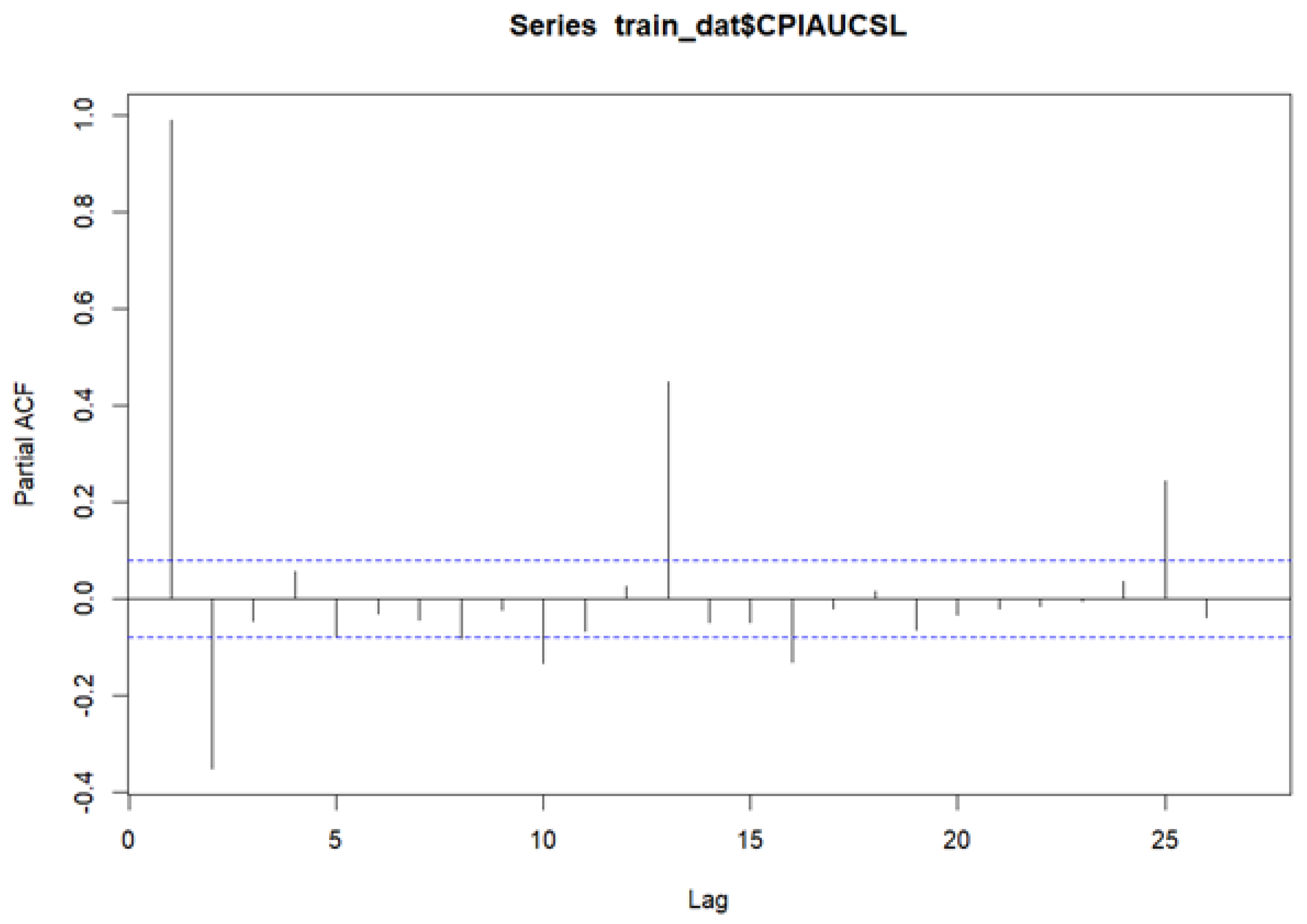
The SARIMA model is built on a linear combination of lagged values and forecast errors. Its effectiveness depends on selecting optimal values for the parameters p, d, and q, which correspond to the autoregressive order, the degree of differencing, and the moving average order, respectively. The differencing order d is chosen to achieve stationarity, typically when the autocorrelation function (ACF) decays to zero. The autoregressive term p is identified by examining the partial autocorrelation function (PACF), where significant spikes beyond the confidence bounds indicate the appropriate lag order.
Equation (2) illustrates the concept of partial autocorrelation, where the response variable y and predictor
are adjusted for the effects of intermediate variables
and
. The PAC between y and
is defined as the correlation between the residuals from regressing y on
and
, and those from regressing
on the same predictors. This isolates the direct linear relationship between y and
, controlling for the influence of the intervening variables.
The
hth order partial autocorrelation can be represented as (3):
The q is calculated based on the Autocorrelation (AC) and denotes the error of the lagged forecast:
Here,
: The mean of the time series;
k: The lag, where ;
N: The complete series value.
If one requires seasonal patterns in the time series, a seasonal term can be added, which produces a SARIMA model. This model can be written as (5):
Here (p, d, q) represent the non-seasonal part, and (P, D, Q) represents the seasonal part of the model. s represents the period number in a season. In this study we employ SARIMA as we assume there exists seasonality in inflation data.
A Seasonal ARIMA (SARIMA) model extends ARIMA by incorporating seasonal differencing at lag s to remove additive seasonal effects, introducing seasonal autoregressive (AR) and moving average (MA) terms. Just as lag-1 differencing removes trends, seasonal differencing addresses cyclical patterns. Seasonal components and lag structures are typically identified through ACF and PACF plots—both at short lags (for non-seasonal terms) and seasonal lags (e.g., 12 months for annual seasonality).
SARIMA is designed for univariate time series with seasonal structure and introduces three additional seasonal parameters (P, D, Q), along with the seasonal period s. It serves as a strong benchmark in inflation forecasting due to its consistent performance. Economic variables like inflation often exhibit seasonality driven by factors such as sales cycles, holidays, or production trends, making SARIMA especially relevant.
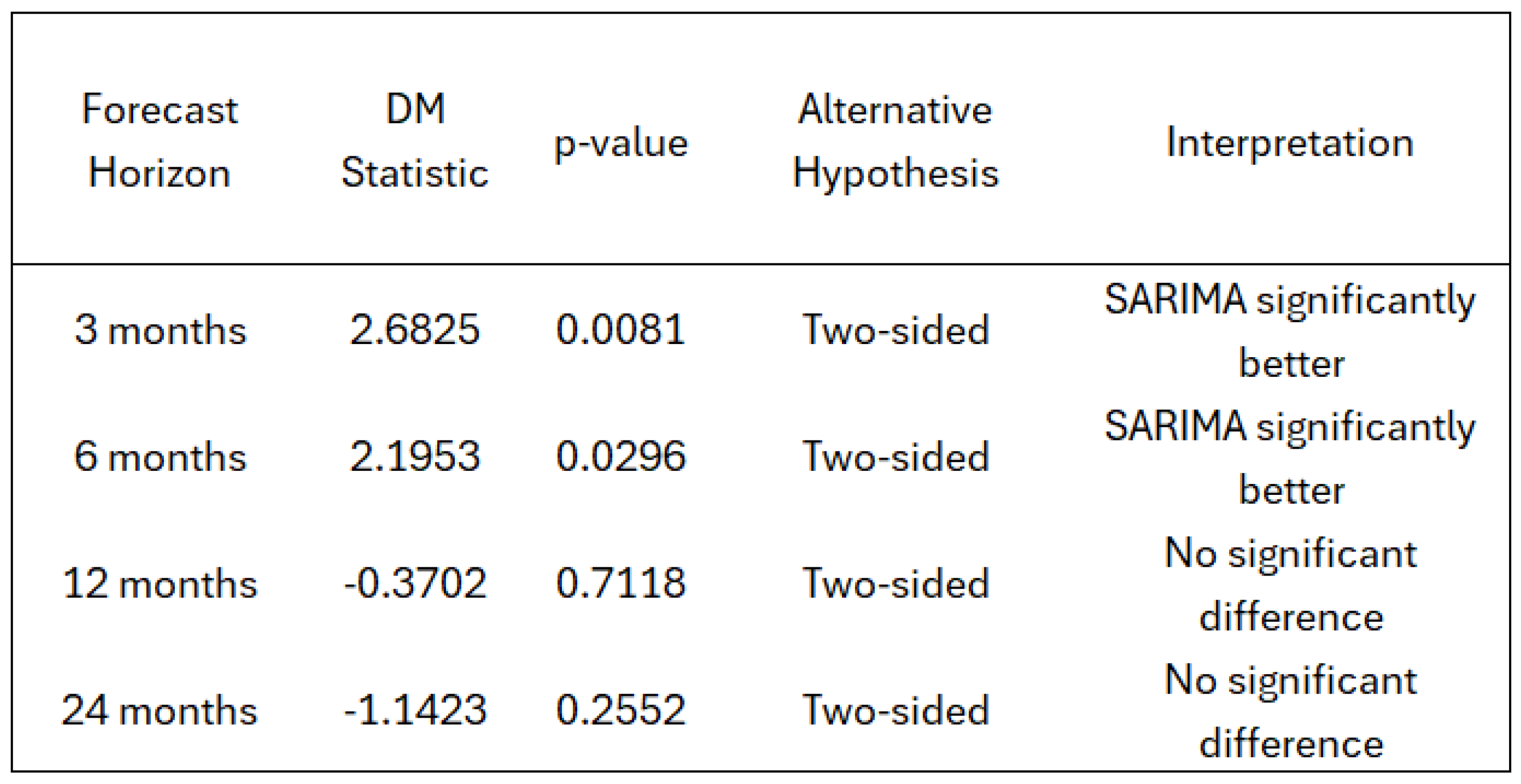
Several studies have found that SARIMA frequently outperforms classical models like VAR, AR, and ARIMA, and performs comparably to, or better than, modern machine learning models such as LSTM and feedforward neural networks (
Paranhos, 2024). Given its proven effectiveness, SARIMA is used in this study as the primary benchmark against which we evaluate neural network models.
4.6. Network Training
4.6.1. LSTM
We begin by dividing the dataset into training data, two validation sets, and an out-of-sample test set. The training and validation data span from 1960 to 1997 and are used for model development, while the out-of-sample period ranges from 2010 to the end of 2023.
Model tuning starts with an initial set of hyperparameters used to train the model across thousands of epochs. Each epoch is first evaluated on the initial validation set, and the best-performing epoch is then tested on the second validation set. This tuning process is repeated across multiple hyperparameter combinations. The top-performing epochs from each round are compared using the second validation set, and the best configuration is selected for final testing on the out-of-sample data.
Feature selection is conducted prior to tuning, using both LASSO and PCA, based on the training data and the first validation set. For LASSO-LSTM and PCA-LSTM models, selected features guide input construction.
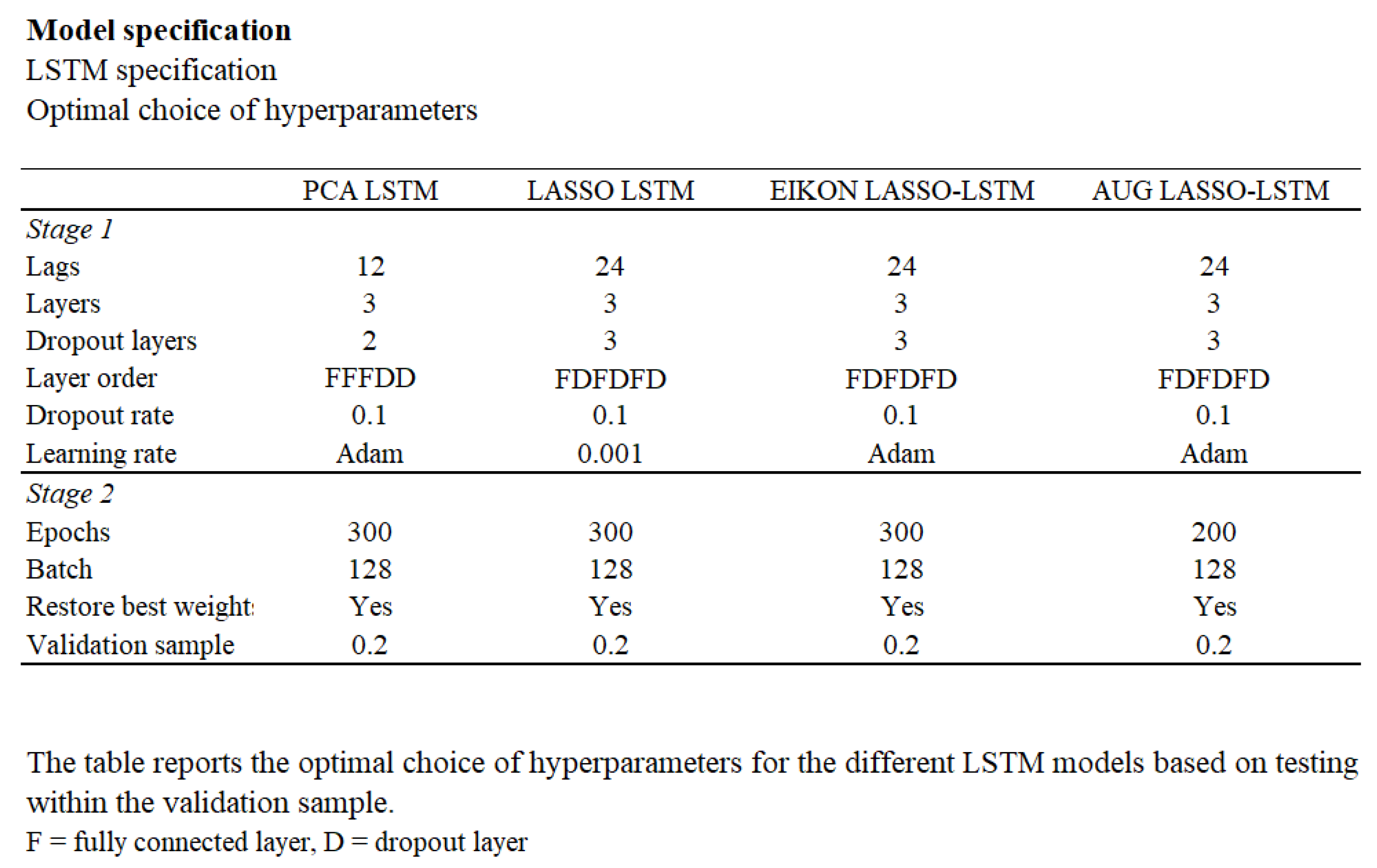
The specification of the LSTM model consists of four main components:
1. Feature Selection—Relevant variables are identified independently using LASSO or PCA, ensuring dimensionality reduction and interpretability before model training.
2. Model Configuration—This involves defining the model architecture, including lag structure, number and type of layers, dropout rates, and learning rate.
3. Training and Optimization—Training parameters such as the number of epochs, batch size, and validation procedures are set and executed.
4. Model Evaluation—Competing models are evaluated using performance metrics to identify the configuration that generalizes best to unseen data.
For a summary of model specifications, refer to
Figure 6.
4.6.2. Other Machine Learning Models
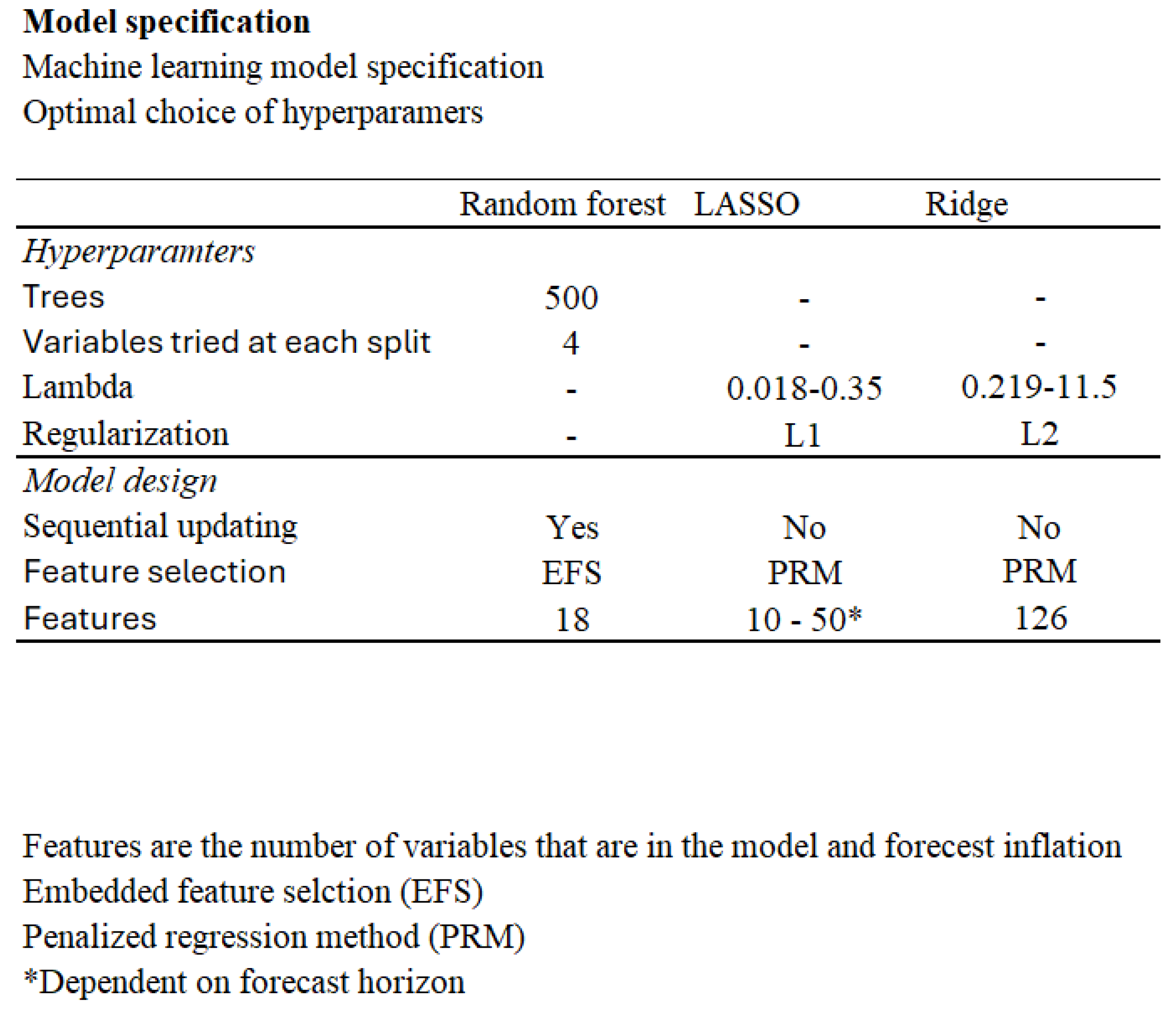
The data used for the remaining machine learning models in this study is divided into three segments: training, validation, and out-of-sample. The period from 1960 to 2010 is reserved for training and validation. An overview of the optimal hyperparameter configurations for each model is provided in
Figure 7.
The modeling process begins with embedded feature selection, where predictors are chosen using the training data and validation set. This step is particularly important for the Random Forest algorithm, as it helps identify the most relevant variables before training.
Unlike the other models, Random Forest is implemented with sequential updating, meaning that each forecast incorporates all available data up to the forecast point. As new data becomes available, it is added to the training set, enabling the model to remain responsive to evolving patterns. However, the original feature set and hyperparameters—selected during initial training—remain fixed throughout the forecasting horizon. This setup balances adaptability with consistency, ensuring that the model adjusts to new information while preserving its foundational structure.
LASSO and Ridge regression models follow a similar structure, trained on the training and validation datasets. Their penalty terms are tuned based on performance on the validation sample.
Once optimal configurations are established, all models are evaluated on a reserved out-of-sample dataset to assess their forecasting performance.
4.6.3. Univariate Time Series Models
The specification of the AR(p) model was guided by analyses of the Autocorrelation Function (ACF), Partial Autocorrelation Function (PACF), and the Bayesian Information Criterion (BIC). The SARIMA model was similarly determined using these diagnostics. Both models rely on maximum likelihood estimation, and alternative estimation techniques were not explored. As forecasts are generated, the models are updated sequentially, re-estimating the coefficients while keeping the selected hyperparameters fixed. The optimal hyperparameter configurations for each model are presented in
Figure 8.
Sequential Updating Procedure.
All models are evaluated in a real-time forecasting framework using a sequential updating approach. At each time point t, models are retrained on all data available up to t, and forecasts are produced for t + h. As new observations become available, the training window expands accordingly. For the AR(p) and SARIMA models, only the coefficients are re-estimated at each step, while the model orders remain fixed. In the case of LASSO, Ridge, and Random Forest, feature selection and hyperparameters are pre-determined and held constant, with models re-fitted sequentially. LSTM models are retrained at each step using a fixed architecture and consistent hyperparameter settings. This procedure ensures a fair and dynamically updated out-of-sample evaluation across all model types.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}