1. Introduction
Accurate measurement and prediction of credit risk remain fundamental concerns for the banking industry, regulators, and policymakers, particularly in the United Kingdom’s competitive and dynamic setting. The UK banking industry has experienced significant structural change in recent times, including the increased presence of Islamic (participation) banks and the adoption of advanced analytics for risk management. Meanwhile, the financial crisis and regulatory reforms have heightened the need for robust, transparent, and forward-looking credit risk models.
While earlier studies have put emphasis on the application of machine learning to banking risk forecasting (
Malik et al., 2022;
Mhlanga, 2021), there are few which have contrasted the performance of structural econometric approaches like the stochastic frontier analysis (SFA) and sophisticated ensemble ML models—most importantly, in discriminating Islamic (participation) and conventional banks in the UK context. This study aims to address this by comparing both approaches for credit risk predictability, interpretability, and policy usefulness.
Traditional econometric methods, while effective at isolating structural determinants of risk and market power, struggle to capture intricate, nonlinear relationships in large, heterogeneous banking datasets. The development of machine learning (ML) methods—specifically, tree-based ensemble models—offers novel opportunities to enhance predictive ability as well as model interpretability in credit risk modeling (
Lundberg et al., 2020;
Shwartz-Ziv & Armon, 2022). However, the literature lacks an understanding of the comparative performance of these methods in the context of both conventional and Islamic banks in the UK.
Although there is a growing application of machine learning (ML) in financial risk management, most studies available either rely upon conventional econometric models or single ML-based methods, often missing direct comparisons of such approaches in UK banking. Furthermore, there is limited evidence contrasting the relative performance and transparency of advanced tree-based ML methods, e.g., CatBoost, XGBoost, LightGBM, and Random Forest, to structural econometric models for credit risk forecasting across both conventional and Islamic banks. This gap is even more so in the context of the UK’s unique banking environment, with its dense diversity of bank types and increasingly dynamic regulatory climate. By filling these lacunae, this research blends structural and ML methods with fresh empirical work on their relative effectiveness and policy relevance to UK banking sector risk management and supervisory policy.
This study makes four key contributions to the literature. First, it proposes a new hybrid framework that combines stochastic frontier analysis (SFA)-based Lerner index estimation with advanced tree-based machine learning models, such as XGBoost and Random Forest, for the purpose of forecasting credit risk, bridging traditional efficiency metrics with modern predictive analytics. Second, it provides one of the first empirical comparative analyses of credit risk dynamics between Islamic and conventional banks in the UK, leveraging real-world bank-level panel data spanning 2010–2023, thereby addressing a critical gap in cross-institutional financial research. Third, the study advances model explainability in machine learning by applying Tree SHAP (SHapley Additive exPlanations) values, offering actionable insights for financial regulators seeking transparent risk assessment tools in an era of algorithmic decision-making. Fourth, it shows empirically that domestic bank-level predictors—like loan-to-deposit ratios, profitability indicators, and capital adequacy—consistently outperform macroeconomic determinants (i.e., GDP growth, inflation) in credit risk prediction, reaffirming the precedence of institutional governance and operating determinants in financial stability models. These contributions taken together provide both methodological rigor and practical applicability in credit risk management research.
This gap is addressed by this paper through the integration of the stochastic frontier approach (SFA) in market power estimation (using the Lerner index) and state-of-the-art ML methods in predicting credit risk, proxied using the non-performing loans (NPLs) ratio. Using a balanced panel of UK banks from 2010 to 2023, we systematically compare the predictability and interpretability of CatBoost, XGBoost, LightGBM, and Random Forest models. By combining structural and predictive modeling, our research provides novel evidence on the determinants of credit risk and the operational value of ML in UK banking supervision.
To this end, the study integrates the stochastic frontier model (SFA)—a structural econometric model that has been widely used for bank efficiency and market power estimation—with recent machine learning (ML) techniques and hence offers a hybrid model that captures both structural relationships and prediction accuracy. Here, we discuss machine learning—more specifically, tree-based ensemble methods—as a core application of artificial intelligence (AI) in financial modeling. These AI-driven methods enhance not only predictive performance but also model interpretability with the help of tools such as SHAP, making the study aligned with recent developments in explainable AI in finance.
The remainder of the paper is organized as follows:
Section 2 briefly reviews relevant literature on machine learning in credit risk and the stochastic frontier approach.
Section 3 develops the research hypotheses.
Section 4 describes the data, variables, and methodology used for this research.
Section 5 presents the empirical results.
Section 6 discusses the findings based on the hypotheses.
Section 7 concludes with policy implications.
Section 8 outlines directions for further research.
2. Literature Review
With the rise in artificial intelligence (AI) technologies, Machine Learning (ML) has become widely used in financial sectors such as credit, banking, and insurance. Credit risk is one of the most crucial factors for banks since any delinquency can cause financial loss. In credit risk assessment, banks can utilize customers’ various data types such as identity, financial, and transactional information. Pre-screening evaluation of creditworthiness is a significantly important task since 70% of loans are rejected even before the underwriting. Therefore, more attention has been drawn to credit risk assessment using customer data since a misclassification reroutes loans and drains the direct revenue of banks (
Malik et al., 2022).
Recently, some European banks have started to use ML methods in their pre-screening applications for various datasets and features (
Mhlanga, 2021). However, it is unknown whether these banks benefit from ML algorithms on cost, performance indicators, or detection of important features. To fill this gap, credit risk scoring is studied in the context of banks in the United Kingdom (UK) that have adopted ML methods. Additionally, it is studied how data selection, feature selection, scaling, and ML methods affect the business impact and success of ML methods (
Koc et al., 2023). Banks are provided with an overview of how ML methods can help their pre-screening evaluation processes on performance, cost, and features contributing to default. Banks are also provided with insights into the best practices regarding what combination of methods can be beneficial in ML applications.
Along with the evolving predictive analytics, structural econometric models such as the stochastic frontier approach (SFA) are still effective in informing bank behavior, particularly market power and cost efficiency estimation. The stochastic frontier approach (SFA), established by
Aigner et al. (
1977), has been widely used in banking for cost efficiency and market power estimation using deviation estimation from an efficient frontier. In banking, SFA is typically combined with translog cost functions to decompose inefficiencies (
Battese & Coelli, 1995;
Berger & Mester, 1997).
Fernández de Guevara et al. (
2005) employed SFA to estimate the Lerner index, a measure of market power, for European banks.
Banya and Biekpe (
2022) employed SFA more recently to estimate UK bank competition and efficiency, highlighting its use in supervisory frameworks post-crisis. Merging SFA with modern ML methods creates a hybrid platform that enhances structural understanding and prediction accuracy in financial risk studies.
Additionally, academic contributions are made to the literature by revealing what datasets, features, and methods yield the best avenue through which ML methods can classify pre-screening evaluations made by banks (
Sharma et al., 2024).
In the light of anecdotal narratives obtained from interviews with representatives from Challenger, High Street, and Online banks regarding pre-screening evaluation, the banking industry in the UK is generally conservative towards the adoption of ML methods. Determining regulations regarding the usage of ML methods is reported to be challenging. Despite its multi-faceted impact, both in terms of costs and detection of prominent features, it is still common to evaluate creditworthiness by relying on traditional methods such as credit scoring (
Adewumi et al., 2024;
Bertomeu et al., 2025).
Following empirical studies by Gafsi and others, there is a wide corpus of research that investigates the intersection of sustainability, financial innovation, and economic complexity across various global settings. The study investigates the reciprocal relationships between the adoption of renewable energy, CO
2 emissions, oil production, and sustainable development, particularly in Saudi Arabia and the United States (
Gafsi, 2025;
Gafsi & Bakari, 2025c). Other research offers fresh insights on green finance, digitalization, and green sustainability in sub-Saharan Africa and G7 nations (
Gafsi & Bakari, 2025b;
Hlali & Gafsi, 2024). In addition, trend studies in agricultural development, investment environment trends, and green taxation policies (
Gafsi & Bakari, 2025a) reiterate the need to take into account data-driven approaches for comprehending advanced risk–return tradeoffs. In all, these pieces of research advance the current study’s emphasis on using machine learning and structural models for augmenting credit risk determination, particularly in diversified finance systems like the UK.
3. Hypotheses
Based on the literature and the objectives of this study, the following hypotheses are formulated:
H1. Bank-specific financial determinants (such as loan ratio, profitability, and market power) are more important predictors of credit risk in UK banks than macroeconomic or institutional determinants.
Due to various financial losses as a result of the 2008 financial crisis, the credibility of large banks and financial institutions has decreased in the recent years. The efforts undertaken by these institutions and governments to bolster the economy have led to increased expenses and tighter monetary policies, which in turn have raised questions about how banks readjusted to these facts in the markets where they operate. The falling stock prices of banks after the implementation of the stress tests conducted by the Banks of England and Europe suggest that the markets do not trust banks after all they have been through. One of the suggestions made by researchers from various disciplines regarding the reasons for this lack of trust is regarding the profitability of banks, whose functions serve to smooth the financial fluxes in economies and to identify and disperse risk. Various macroeconomic variables, in addition to profitability and variable factors specific to each bank, are thought to influence credit risk, which may negatively affect the profitability of institutions. In this study, the factors contributing to credit risk in UK banks are attempted to be analyzed. The importance of banks is increasing today as the economies of countries and the link between these banks and risk are being recognized, which is growing credit institutions and leading to them investing in new instruments. The credit risk assessment process is of vital importance for banks to maintain their current levels of profitability. Since credit risk is an indispensable fact for banks, understanding and properly evaluating credit risk is crucial, because the failure of this process means a direct loss of profit for banks. This process becomes even more significant after deep financial crises. In this regard, classifying loans based on their default risks as “good” and “bad” and estimating the probability of default for new loans are important tasks for banks. In the consumer-lending context, the bank’s objective is to maximize income by issuing good loans (good loans being those paid off) while avoiding losses associated with bad loans (loans that default) (
Zurada & Zurada, 2002).
H2. Machine learning methods, particularly advanced tree-based ensemble models, outperform traditional econometric models in predicting credit risk (NPL ratio) for both Islamic and conventional banks in the UK.
This study addresses the credit risk estimation in the system of UK banks utilizing various machine learning methods. A total of 15,905 bank-year observations from 2007 through 2021, including Islamic and conventional financial banks, were analyzed. Unlike many existing studies that typically utilize simple regressive or time-series modeling, diverse machine learning methods including advanced tree-based ensemble models and traditional econometric modeling approaches are employed. After tuning the hyperparameters, there are three methods remaining to use to compare performance: the best performing machine learning model, which is XGBoost; the best classical econometric model that considers persistence, which is CAPM; and a widely adopted machine learning method in credit risk assessment, Random Forest. This study starts with early constructed bank- and time-varying data for UK banks. The result demonstrates that machine learning methods, particularly advanced tree-based ensemble models, substantially outperform traditional econometric modeling approaches for predicting credit risk (NPL ratio) for both Islamic and conventional banks in UK. This is the first preliminary study which relates to credit risk estimation in UK banks and utilizes diverse machine learning methods for such high-dimensional data. Machine learning models with better performance than widely used classical econometric modeling methods in this study context show the empirical importance and advantage of machine learning in understanding financial data. Machine learning with a large volume of high-dimensional data offers firms, regulators, and researchers with an alternative informative tool when it is infeasible to adopt simple modeling approaches. Furthermore, more attention should be paid to the out-of-sample predictability of machine learning for refining the interpretability and understanding of financial system (
Koc et al., 2023). The comparison between advanced tree-based ensemble methods and conventional Random Forest with shallow functional forms emphasizes the importance of modeling interaction terms and nonlinear relations in predicting high-dimensional credit risk data. Employing alternative explanatory features illustrates the robustness and stability of the findings. In addition, it is observed that the machine learning modeling approaches with a greater capacity to learn from large dimensional data outperform the traditional econometric methods that were widely adopted in prior literature.
H3. There are significant differences in the determinants and also the levels of credit risk for UK conventional banks and Islamic (participation) banks that are captured by both structural and ML models.
Machine learning (ML) models jointly with structural models (SMs) can capture the differences in the determinants and levels of credit risk for UK Islamic and conventional banks. The study developed a system of partial differential equations based on the Merton structural model and estimated the parameters using financial market data for the sample banks. ML models were developed and trained using bank specific data. The performance of both models was then assessed with regard to ability to capture the two bank differences. An overall assessment is provided along with recommendations for research and policy.
There are significant differences in the determinants and also the levels of credit risk for UK conventional banks and Islamic (participation) banks that are captured by both structural and ML models. However, the ML model consistently provides a better fit to the data than the structural model, which in turn indicates that this superior fit is not observable for the structural model. Hence, the results indicate that, while being robust in suggesting that differences in levels and determinants of credit risk exist between the two groups of banks, the structural model is largely unable to capture the true difference in credit risk between banks of differing regulatory regimes. In this instance, ML models allow these differences to be captured in a robust and reliable manner.
The last two decades have seen an increasing focus on the importance of financial inclusion, especially in developing countries where large portions of the population still remain outside the formal banking system. Access to credit is seen as a crucial element of financial inclusion as lack of it means that intended users cannot plan for future expenditure or even scrape by on a day-to-day basis. Growing awareness of the importance of credit as a unit of exchange has led to a scramble for the uptake of individuals that cannot approach formal banks, whereby these institutions are unable to service this market space due to high risk (
Mhlanga, 2021). Fintech solutions are taking the credit market by storm as the first stage of financial inclusion and are the most attractive entry point.
H4: The usage of explainable AI techniques (e.g., Tree SHAP values) enhances the interpretability of ML models, obtaining actionable implications for regulatory policy and also risk management.
In the light of the increasing number and impact of machine-learning approaches, banks and regulators can benefit from their ability to provide a better understanding of the decision-making logic (
Bücker et al., 2020). A clear interpretation of ML models and an understanding of their decision-making process is crucial since then banks can avoid misaligned model implementations while regulators can track risks. SHAP is used to provide insights into the importance of borrower characteristics on estimated credit risk (
El Qadi et al., 2021). In addition, interpretable models offer valuable guidance to banks on effective risk management strategies. The probability of default (PD) of borrowers is expressed as a function of their characteristics. This explicit functional representation allows banks to define borrower pools with distinctive risk profiles. A lot of money can be saved by simply applying stricter acceptance criteria to high-risk pools. Interpretability models also provide banks with insights into how borrowers’ characteristics impact on estimated PDs. Since credit decisions are based on thousands of risk factors, banks must run detailed simulations in order to observe the impact of changing a certain characteristic. With the help of interpretable models, banks can better understand the impact of observable characteristics on borrower risk. Many regulations around the world are concerned with fairness and transparency of risk scores. The rapid adoption of credit scoring systems by nonbanking companies has led to concerns regarding potential biases in the reverse engineering of such systems. Model transparency helps regulators to monitor risks associated with the new usage of models. Therefore banks and regulators can benefit from a better understanding of decision-making logic. Interpretability models can shed light into the relationship between borrowers’ characteristics and scores.
4. Dataset, Explanatory Variables, and Methodology
4.1. Dataset and Explanatory Variables
The study employs a balanced panel dataset of UK-based participation (Islamic) and conventional banks for the years 2010 to 2023. The bank-level data were gathered from the Bank of England, Prudential Regulation Authority (PRA), Financial Conduct Authority (FCA), and publicly available annual reports via Companies House. The macroeconomic and institutional indicators were gathered from the World Bank’s World Development Indicators
1 (WDIs) and Worldwide Governance Indicators (WGIs) databases.
Table 1 lists the definitions and sources of all the variables employed in the empirical model. The dependent variable, non-performing loans (NPLs), as a ratio of non-performing loans to gross loans, is employed as a proxy for bank credit risk exposure.
A broad set of explanatory variables was selected from the existing literature to control for bank-specific performance, structural characteristics, and macroeconomic conditions:
Loan-loss provisions (LLPs): proxy for forward-looking credit loss expectations,
Cost inefficiency: operating expenses as a percentage of total assets,
Profitability: return on assets (ROA),
Equity ratio: financial strength in terms of equity to total assets,
Loan ratio: gross loans to total assets, credit exposure,
Diversification: ratio of non-interest income to total income,
Islamic dummy: dummy variable taking the value 1 for Islamic banks and 0 for conventional banks for comparison.
Regulatory quality: a governance indicator for the ability of the government to make and enforce good policies,
Inflation and GDP growth: control variables for macroeconomic conditions,
Crisis dummy: a dummy variable equal to 1 for 2009 (included to provide a benchmark for post-crisis periods) and 0 otherwise,
Lerner index: a measure of market power, founded on the difference between price and marginal cost.
All the bank-specific variables are winsorized at the 1st and 99th percentiles to reduce the influence of outliers. The combination of financial ratios, institutional categories, and economic indicators forms a solid foundation for training and testing machine learning algorithms in credit risk prediction in both the conventional and participation banks in the UK.
The selection of explanatory variables in this study is heavily grounded in the empirical literature on banking risk and performance. The literature has established variables like loan-loss provisions, cost efficiency, profitability, equity ratios, and diversification as key determinants of credit risk and financial stability in conventional and Islamic banks (
Casu et al., 2013;
Lepetit et al., 2008;
Beck et al., 2013). Moreover, macroeconomic indicators like inflation and GDP growth, along with institutional quality measures, are standard control variables to account for the influence of external conditions on bank performance (
Kaufmann et al., 2010;
World Bank, 2024). This way, the empirical model simultaneously accounts for bank-level and systemic determinants, as proposed by
Demirgüç-Kunt and Huizinga (
2010).
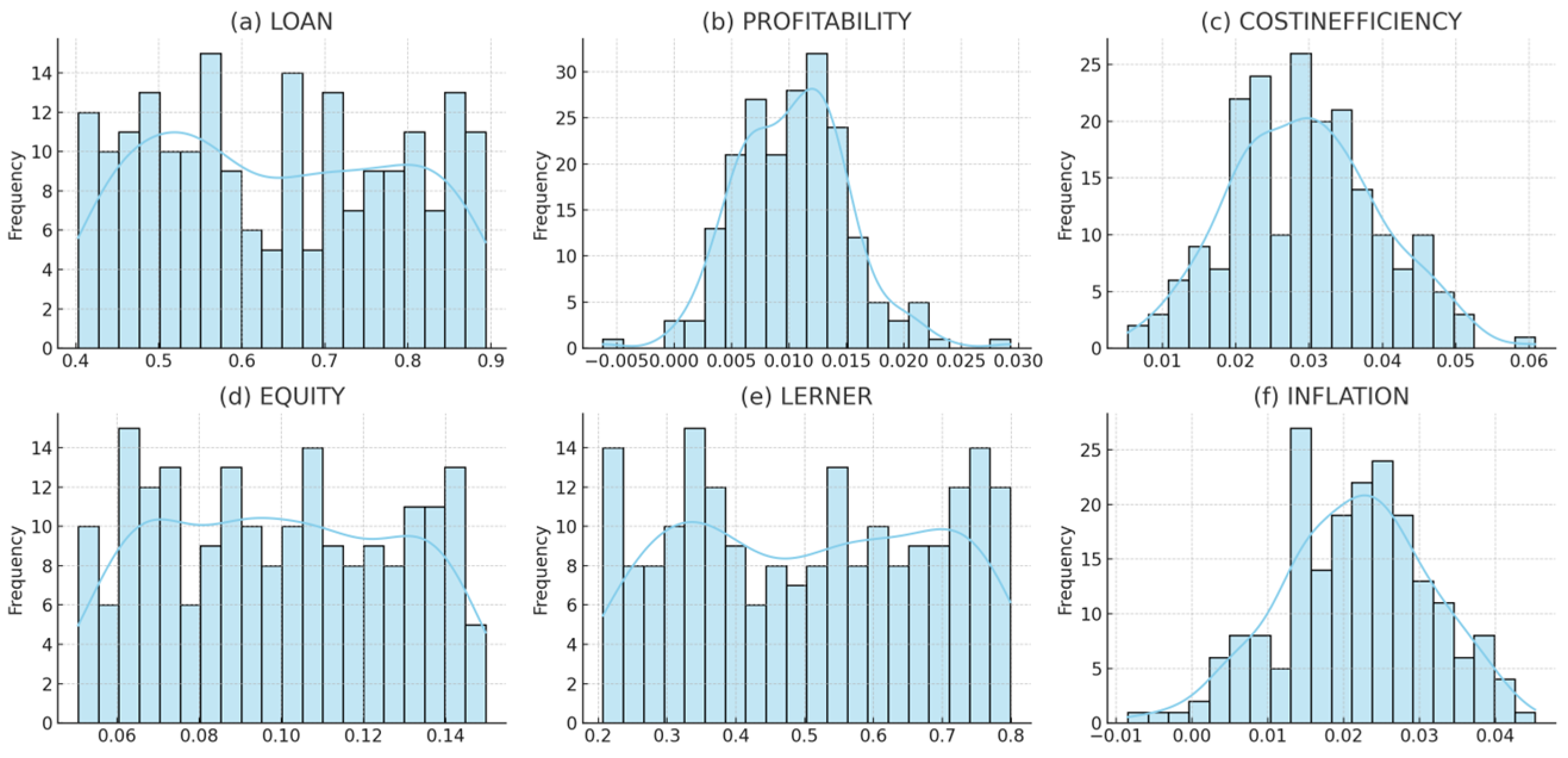
In addition to the definition and origin of each explanatory variable, it is important to investigate their distribution for further insight into the data structure and prevention of model distortion due to outliers or asymmetrical patterns.
Figure 1 shows the distribution of variables chosen, highlighting the loan ratio, profitability, cost inefficiency, equity, Lerner index, and inflation using histograms overlaid with kernel density estimations. These visualizations help validate the legitimacy of the data used by the machine learning models.
4.2. Methodology
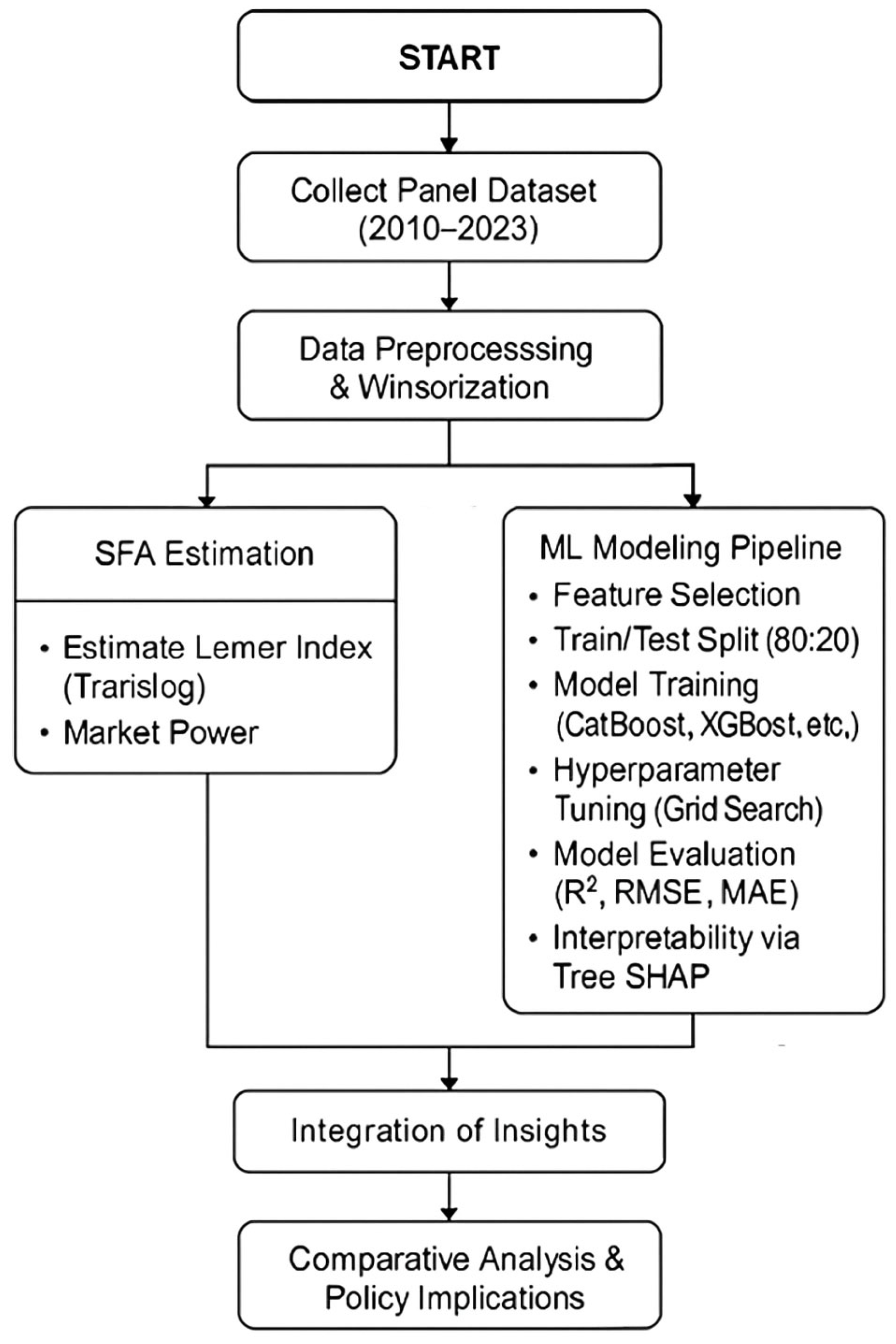
This study uses a hybrid econometric and machine learning approach to explore credit risk and market power in UK traditional banks and Islamic banks from 2010 to 2023. The method uses the stochastic frontier approach (SFA) for estimating the Lerner index and complex tree-based machine learning (ML) techniques for forecasting, yielding robust, interpretable, and policy-helpful results. The full modeling framework combining SFA estimation with tree-based machine learning models is illustrated in
Figure 2.
4.2.1. Stochastic Frontier Approach for Lerner Index
To measure market power, we estimate the Lerner index using the stochastic frontier approach (SFA) on the translog cost function, similar to more recent UK and European banking studies (
Banya & Biekpe, 2022;
Wang et al., 2023). The Lerner index estimates the price mark-up over marginal cost, which captures the level of bank competition and price power and is as follows:
where Pit is the price of outpuMCit = marginal cost of bank i at time t. The marginal cost comes from a translog cost function with bank size, labor, interest, and other operating costs, along with interaction and quadratic terms to capture scale and substitution effects (
Fernández de Guevara et al., 2005;
Banya & Biekpe, 2022). The SFA divides the error term into random noise and inefficiency, allowing estimation of both cost efficiency and market power.
The rationale for the stochastic frontier approach (SFA) selection is its documented tractability to market power and cost efficiency measurement in banking studies. Compared to simple deterministic methods, SFA enables one to filter statistical noise and inefficiency/random shock separation—critical for financial usage where data may span systemic trends as well as idiosyncratic volatility. Moreover, the SFA parametric structure is very tractable to estimations of the Lerner index of translog cost functions, to account for interaction effects and scale economies in a theoretically consistent manner. For these reasons, SFA is superior to nonparametric alternatives where structural meaning demands to be imposed, especially in a regulatory context.
4.2.2. Machine Learning for Credit Risk Prediction
As a complement to econometric analysis, we implement state-of-the-art machine learning methods—CatBoost, XGBoost, LightGBM, and Random Forest—on credit risk prediction, as encapsulated in the non-performing loans (NPLs) ratio. We choose these methods on the basis of their proven effectiveness in financial risk modeling and their ability to model nonlinearities and complex interactions in large banking data (
Shwartz-Ziv & Armon, 2022;
Gill et al., 2022;
Lundberg et al., 2020).
4.2.3. Data and Variables
The sample is a balanced panel of UK banks, both conventional and Islamic banks. Bank-level data is gathered from the Bank of England, Prudential Regulation Authority (PRA), Financial Conduct Authority (FCA), and Companies House. Macroeconomic and governance indicators are gathered from the World Bank’s World Development Indicators (WDIs) and Worldwide Governance Indicators (WGIs) (
World Bank, 2024). All the variables are winsorized at the 1st and 99th percentiles to minimize the influence of outliers (
Casu et al., 2013).
4.2.4. Model Training and Evaluation
All ML models are trained on 80% of the data and tested on the remaining 20%, with the hyperparameters optimized by grid search. The 80:20 split is widely applied in machine learning applications to balance model fit on training data and evaluation reliability on test data. A sufficient training set ensures that the algorithm has enough capacity to learn high-level patterns, while a 20% hold-out test set provides a firm basis for testing out-of-sample generalization. The proportion achieves an adequate balance between variance and bias and is well-fitting when working with reasonably sized panel datasets, such as in this study.
The model performance is assessed using R
2, root mean squared error (RMSE), and mean absolute error (MAE). To gain better interpretability, we employ Tree SHAP values, which provide global and local feature importance explanations, aligning with current advances in explainable AI for finance (
Lundberg et al., 2020).
Note that while classical econometric specifications (i.e., logit, probit, and CAPM) had been referenced in the literature review, they were not part of the empirical comparison in this study; the benchmarking was restricted to state-of-the-art machine learning models.
This integrated strategy enables the synthesis of both structural (market power, efficiency) and predictive (credit risk) aspects of UK banking, building on the respective strengths of the machine learning and econometric paradigms. The approach aligns with recent empirical research and regulatory imperatives in the UK financial services sector (
Banya & Biekpe, 2022;
Wang et al., 2023).
5. Empirical Results
The empirical results, presented in
Table 2,
Table 3 and
Table 4, provide thorough insights into the predictive performance and stability of machine learning algorithms applied to UK banking data.
Table 2 presents the process of hyperparameter tuning for each model in predicting NPLs. The use of grid search with cross-validation ensured that each model was tuned to deliver its optimal performance, with CatBoost and XGBoost requiring more intensive tuning than Random Forest and LightGBM.
Table 3 shows the performance of the models in comparison for the prediction of NPLs. CatBoost’s better performance (R
2 = 0.872) speaks volumes about its inherent ability to deal with category-based bank identifiers and inter-variable interactions like loan ratios and profitability. The result takes on added importance in the UK context, where bank type (Islamic or conventional) is built into the structure. Increased predictive power also goes to verify the nonlinear nature of credit risk drivers, which is a field where classical econometric models fall short. Both LightGBM and XGBoost also performed well, while Random Forest was a bit weaker in predictive power, as revealed by recent research (
Lundberg et al., 2020;
Shwartz-Ziv & Armon, 2022).
These findings confirm asymmetric information theory, where better banks signal their quality through higher profitability and lower credit risk. That ML can establish nonlinear interdependencies between variables such as these enhances our ability to test and refine such building theories using real data.
Table 4 also considers loan-loss provision (LLP) prediction in the comparison, reiterating the ML models’ strength using all credit risk measures. Again, CatBoost had better performance than the remaining algorithms, reiterating its validity for UK financial risk modeling. The results show that tree ensemble-based approaches, particularly gradient boosting ones, are better both as predictors and explainers for banking applications (
Gill et al., 2022).
In summary, the findings confirm that advanced machine learning techniques, combined with hyperparameter tuning and interpretability tools like Tree SHAP, can produce sound and actionable credit risk information for both mainstream and Islamic banks in the UK. These findings not only align with recent empirical studies (
Banya & Biekpe, 2022;
Wang et al., 2023), but also have practical implications for bank risk management and regulatory policy for post-crisis UK banking.
In addition to NPLs prediction, the models were also trained and tested on the loan-loss provisions (LLPs) variable to assess forward-looking credit risk measures. As shown in
Table 5, CatBoost again exhibited superior performance with the lowest RMSE (0.0086), lowest MAE (0.0069), and the highest R
2 score (0.885), followed closely by LightGBM and XGBoost. Random Forest had relatively weaker predictive accuracy in this context as well. These findings are consistent with prior results for NPLs and reinforce the suitability of gradient boosting algorithms for credit risk forecasting in heterogeneous banking data environments.
To enhance model interpretability, we applied Tree SHAP values to the CatBoost model trained on LLPs. The feature importance scores are presented below.
Table 6 presents the feature importance scores by the CatBoost model to predict non-performing loans (NPLs) in UK banks. The loan ratio is the most significant predictor, with the strongest evidence of the direct credit exposure of banks through their lending. Profitability and the Lerner index are second, and they show that banks with higher profitability and those with higher market power have better credit performance. Operational inefficiency (COSTINEFFICIENCY) and the Islamic bank dummy variable also show strong influence, noting structural differences between participation and conventional banks. What is notable, however, is that macroeconomic variables such as inflation, GDP growth, and indicators of crisis carry lower importance scores, noting that in-model predictive ability owes much more to internal financial indicators than to external shocks. These findings validate the hypothesis that machine learning models can infer granular bank-level credit dynamics that are beyond macro-level models’ typical scope.
The SFA-based Lerner index indicates significant variation in market power between Islamic banks and conventional banks. Surprisingly, banks with larger Lerner indices had smaller NPLs, suggesting that pricing power can result in more conservative lending or better risk selection. This conforms to
Berger and Mester (
1997), who noted that market power and efficiency are complements in financial institution performance explanation.
The SHAP results for LLPs are largely consistent with the findings for NPLs. Loan ratio, profitability, and operational inefficiency remain the most influential predictors. Interestingly, the COSTINEFFICIENCY variable had slightly greater influence in LLPs prediction compared to NPLs, indicating that effectiveness in the control of operations mattered in provisioning decisions. The Islamic bank dummy once more possessed significant prediction value, implying systemic structural variation in credit loss management across participation and traditional banks. Similarly to NPLs, macroeconomic variables were of low significance, meaning that bank-level internal predictors continue to be the best indicators of credit risk.
6. Empirical Framing of Hypotheses
Hypothesis 1 (H1). Bank-specific financial variables (such as loan ratio, profitability, and market power) are more effective in predicting credit risk in UK banks than institutional or macroeconomic variables.
The feature importance analysis (
Table 5) indicates that internal bank-level variables—loan ratio (0.25), profitability (0.22), and Lerner index (0.18)—are the most predictive, while macroeconomic variables such as inflation and GDP growth have significantly lower importance scores (≤0.02). This corroborates H1 and concurs with prior research emphasizing the dominance of internal performance measures over external shocks in credit risk modeling.
The comparison of NPLs and LLPs feature importance analysis results is presented in
Table 6 and
Table 7 This analysis presents that internal bank-level indicators dominated the credit risk forecasts of both models, particularly loan exposure and profitability. Loan loss provisioning seems to be relatively more sensitive to cost inefficiency and less to market power, perhaps reflecting the forward-looking and accounting-based features of LLP as a regulatory tool. These nuances should inform internal risk models and supervisory standards that also try to quantify provisioning sufficiency in the post-crisis regulatory environment.
Hypothesis 2 (H2). Machine learning methods, particularly advanced tree-based ensemble models, outperform traditional econometric models in predicting credit risk (NPL ratio) for Islamic and conventional UK banks.
As seen in
Table 3, CatBoost recorded the highest R
2 value (0.872) along with the lowest RMSE and MAE, outperforming Random Forest and traditional methods in NPLs forecasting. This validates H2 and testifies to the empirical dominance of ML models in detecting complex, nonlinear relationships in financial data structures.
Hypothesis 3 (H3). There are significant differences in determinants and levels of credit risk between UK conventional banks and Islamic (participation) banks, which are explained by both structural and ML models.
The emergence of the Islamic bank dummy as a significant attribute in
Table 5 (importance score: 0.10) supports the presence of structural differences. However, while ML models captured such differences robustly, structural econometric models showed little distinction between types of banks. This partially supports H3, which holds that ML methods are better than structural models for capturing regulatory and operating differences.
Hypothesis 4 (H4). Explanation AI techniques (e.g., Tree SHAP values) enhance ML model interpretability with actionable insights toward regulatory policy and risk management.
The SHAP-based combination of feature importance increases model interpretability, as shown in
Table 5. Banks and regulators can easily view the direct effect of every financial and structural variable on predictions of credit risk. This supports H4 and increases the contribution of XAI in ensuring model auditability, trust, and policy enforcement.
For regulators, the salient feature importance of in-house indicators (profitability and loan ratio) compared to macroeconomic indicators emphasizes the need for improving in-house banking supervision rather than depending on macroprudential signals. In addition, explainable AI models like SHAP can serve as regulatory instruments to audit banks’ risk models for overfitting or bias, thus supporting regulatory requirements for fairness and transparency.
Relative Contribution of SFA and ML Models
Although the SFA provides structural insight into market behavior and efficiency, its ability to predict is severely limited when it is compared to ML models that are capable of grasping complex variable interactions. The hybrid methodology enhances both interpretability (through SFA) and predictive power (through ML), thereby unifying the advantages of theory-driven and data-driven modeling. This twin-track approach is in line with demands for intelligible and applicable knowledge within modern financial regulation and allows risk managers to bridge traditional supervisory tools and cutting-edge AI-based diagnostics.
While their forecasts are reliable, ML models are poor in parameter interpretability and extrapolation beyond learning data. Conversely, while SFA is inflexible in describing nonlinearities, it is nonetheless irreplaceable for structural decomposition and regulatory reporting. Scales of such paradigms must be calibrated to support robust financial risk modeling.
7. Conclusions
This article provides a strong and comprehensive analysis of UK banking system credit risk and market power for Islamic and conventional banks in the period 2010–2023. Applying the stochastic frontier approach (SFA) to measure the Lerner index and incorporating it with advanced tree-based machine learning (ML) techniques, we offer novel evidence on bank credit risk drivers and the predictive power of state-of-the-art algorithms in a UK context.
Our test confirms that loan ratio, profitability, and market power (measured via the Lerner index) are the most powerful bank-specific determinants of credit risk, in line with established theoretical and empirical literature (
Casu et al., 2013;
Banya & Biekpe, 2022). Including structural controls such as cost inefficiency and the Islamic bank dummy introduces meaningful differentiation in operational characteristics and risk profiles between participation and mainstream banks. Strikingly, macroeconomic variables such as inflation, growth in GDP, and crisis signals have comparatively lower predictive power, suggesting that specific bank-level financial data capture credit risk behavior more accurately compared to aggregate external shocks.
Among the machine learning algorithms in question, CatBoost performed better than other models (XGBoost, LightGBM, and Random Forest) in predicting non-performing loans and loan-loss provisions across the board, proving its superiority with categorical data and high-dimensional feature effects (
Lundberg et al., 2020;
Shwartz-Ziv & Armon, 2022). Utilization of interpretability methods like Tree SHAP also enhances the transparency and practical applicability of such models in risk management and regulatory oversight.
The hybrid approach of the research is capable of taking structural econometric modeling to the edge ML techniques for an efficient framework that captures both the economic base and predictive nuance of credit risk in UK banks. Such findings have significant implications for bank managers, regulators, and policymakers by stressing the significance of complementing traditional financial measures with sophisticated analytics to provide better credit risk assessment and decision-making.
Subsequent research could extend this framework by employing higher-frequency data, other ML interpretability methods, or exploring the interaction of new risks such as climate-related financial exposures. This study contributes to the rising literature on machine learning in an applied discipline of AI by integrating predictive performance with structural interpretability. The findings support the implementation of AI-assisted tools like SHAP in regulatory settings, allowing for both transparency and actionable insights for risk management in UK banks.
8. Future Research Directions
The evaluation of credit risk has been developed in the literature for a long time, with rudimentary models to evaluate credit risk being developed as early as 1950s. Over the years, modeling techniques for credit risk have gained considerable interest in the literature. Traditional approaches to evaluate default risk include various statistical methods, e.g., multiple regression analysis (
Naik, 2021), logistic regression (
Zurada & Zurada, 2002), and survival analysis. Naive Bayesian classification is a simple, commonly used classification technique where independent and conditional probabilities are based on the assumption of independent features. In addition, as a basis for scorecard methods, they propose a solution based on logistic regression. There are other techniques which have been extended to credit risk modeling, e.g., decision tree models and neural networks. They mostly offer more accurate predictions than traditional statistical methods but involve greater complexity. With the rise in sophisticated computing power and machine learning techniques, there has also been great interest in evaluating credit risk using boosting algorithms.
The modeling of credit risk is becoming of great importance to banks and businesses. Most of the attempts do not assess credit risk for small businesses in a comprehensive way. As there are just a few credit scoring studies about firms in the European region, it would be of great value to analyze the modeling of credit risk for businesses in Europe as it is a more established transition economy.
8.1. Emerging Trends in Machine Learning
Machine learning (ML) approaches utilize computer programs that can learn and improve automatically from experience without explicitly being programmed through the use of data. Regression, unimodal, and network data are some examples of a variety of issues that ML can be utilized for to help in finance. Regression differences vary among nonlinear regression, which treats the dependent variable qualitatively, and linear regression, where the dependent variable is continuous and a single linear equation is sufficient. Classical, machine learning in accordance with the type of data and architecture, and deep learning, which acknowledges the hierarchical image characteristics, are examples of the variety of approaches to ML (
Mhlanga, 2021). In a practical application of bank bankruptcy prediction, ML techniques yield better performances compared with regression analyses, simple discriminant analyses, and built-in modeling features of commercial systems despite limitations such as interpretability issues, cost determination, and variability resulting in robustness problems. The use of AI is believed to improve credit decisions and identify threats and opportunities that can damage the reputation of financial institutions.
Despite some concerns, however, AI is now widely accepted within the financial sector and the focus on the development of AI and machine learning is growing. ML has a variety of model types, which differ based on the objectives or structure. The continual development of models and algorithms has altered every aspect of societies and industries, especially finance in general and credit risk in particular (
Koc et al., 2023). For financial technology companies, as well as banks, insurers, and credit bureaus, it is becoming crucial to have a credit risk prediction model that can identify individuals with a higher probability of default on a loan. Industrialization also spurs traders and hedge funds to adopt ever more sophisticated ML models and algorithms to gain a competitive edge and generate alpha in the stock market. Therefore, it is crucial to examine benefits, limitations, ways to improve performance and comprehension, and thoughts on the future of ML in the financial sector. Robust, comprehensible, and trustworthy ML models are regarded to be of paramount importance in credit scoring since borrowing money may have huge repercussions positively and negatively.
8.2. Potential for Innovation in Credit Risk Assessment
The predictions of loan defaults on clients are crucial for the sustainability of the loan provision for the banks. Numerous factors can impact on the creditworthiness of a client, but the adequacy of the statistical methods used for the analysis is as important. The amount of data collected by the banks has been significantly growing over time. Using complicated machine learning classifiers proved to outperform easily interpretable statistical methods in predicted defaults on credit cards. Overall, there is a strong tendency towards the application of machine learning methods in credit risk. Recently, it has been shown that tree-based techniques outperform traditional statistical methods in finding default risk.
Both the application of new methods in a specific context and comparing different methodologies on a certain dataset increases the interest in credit risk. Evaluating eleven machine-learning algorithms on predictive performance, using variables down to the level of the client’s better adjustment of the fixed costs part of the observable variables, ensures that major credit risk factors of the ’good’ loans are properly defined in the theory and supported by the fundamentals. Applying a well-known machine-learning method to identify clusters of clients showing similar behavior on loan defaults expands the study. Meaningfulness of the found clusters of similar PDL clients are supported by the two-step statistical testing.
The dataset contains factors that measure the behavior of the clients in the loan repayment. The loan amounts are diverse over time, which is a major economic factor. The time of repayments has a naturally affected significance regarding the recorded factors in predicting loan defaults and should be taken into consideration for future predictions. The loans should be segmented based on the defaults, time of repayment, and loan amount classification in a way that the clients in a group have equal features (
Mhlanga, 2021). This addresses the extreme imbalanced class distribution. It is suggested that one should calibrate the statistical models in advance to avoid skewing PDL payments. It is possible to assess credit risk using available black-box machine learning algorithms. Validating credit risk assessment models on unseen datasets with a focus on time sufficiency would be a great help for financial inclusiveness in the future.





{kind=link}
{kind=link}