
Triple-Entry Accounting and Other Secure Methods to Preserve User Privacy and Mitigate Financial Risks in AI-Empowered Lifelong Education



Abstract
1. Introduction
2. Materials and Methods
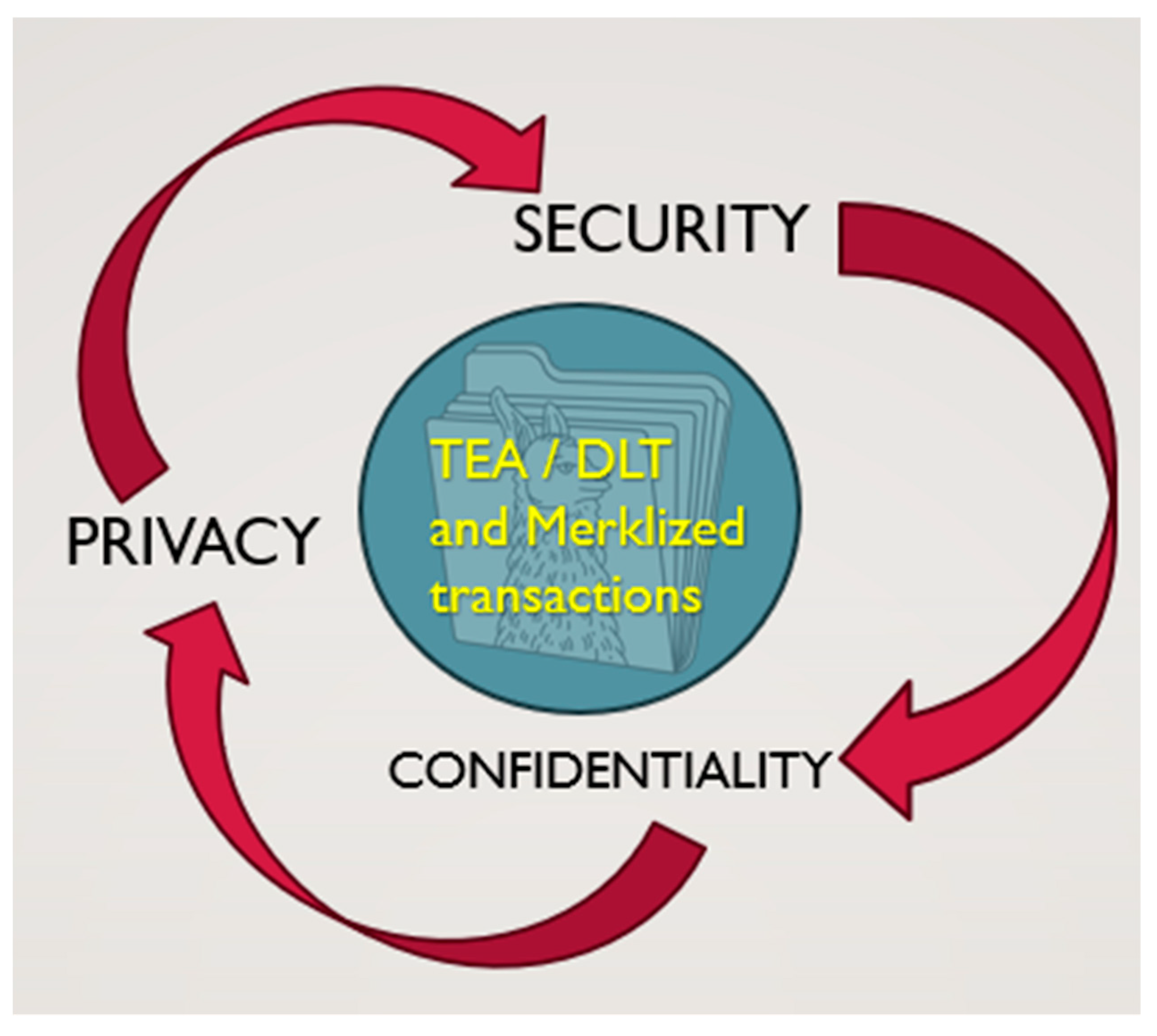
2.1. TEA and DLT Method
- TEA incorporates a third entry, known as the ‘reputation entry’, to provide additional transparency and trust in financial transactions.
- In triple-entry accounting, each transaction is recorded not only in the debit and credit entries but also in a separate entry that captures the ‘reputation’ or ‘proof’ of the transaction (Sunde & Wright, 2023).
- This reputation entry is created using cryptographic techniques and serves as an immutable record that can be verified by all parties involved in the transaction.
- TEA forms the foundation of blockchain technology (Sgantzos et al., 2023; Ibañez et al., 2023; Arunda, 2023).
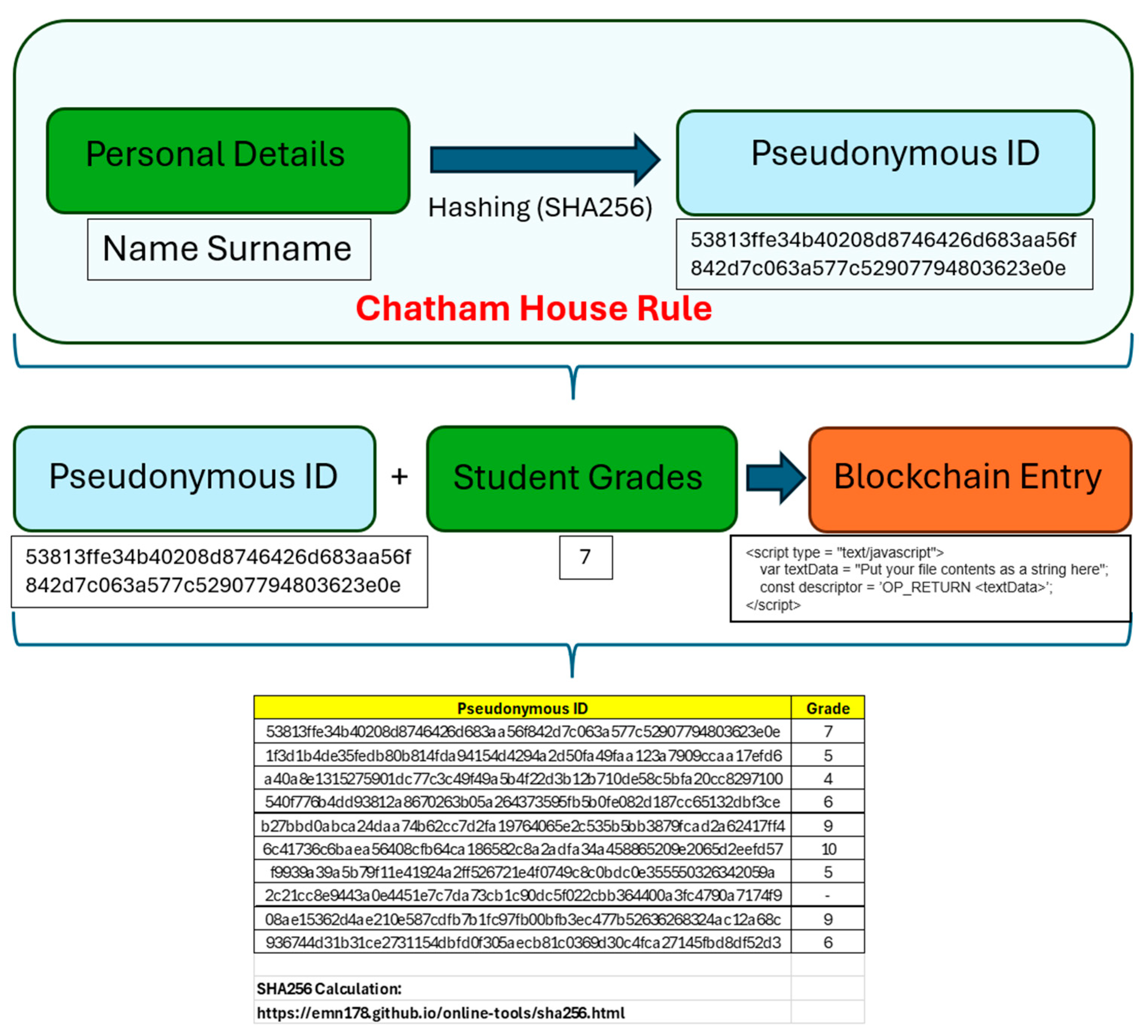
- We begin with Pseudonymization of student’s personal details.
- We make a string containing Pseudonymous ID + Student grades for each student.
- We store the data on the blockchain (either for each student or as a class)
“When a meeting, or part thereof, is held under the Chatham House Rule, participants are free to use the information received, but neither the identity nor the affiliation of the speaker(s), nor that of any other participant, may be revealed”.
- 1st party: Teacher/AI Educator
- 2nd party: Students
- 3rd party: DLT record.
2.2. Enhanced Privacy for DLT Stored Data Using Merklized Transactions
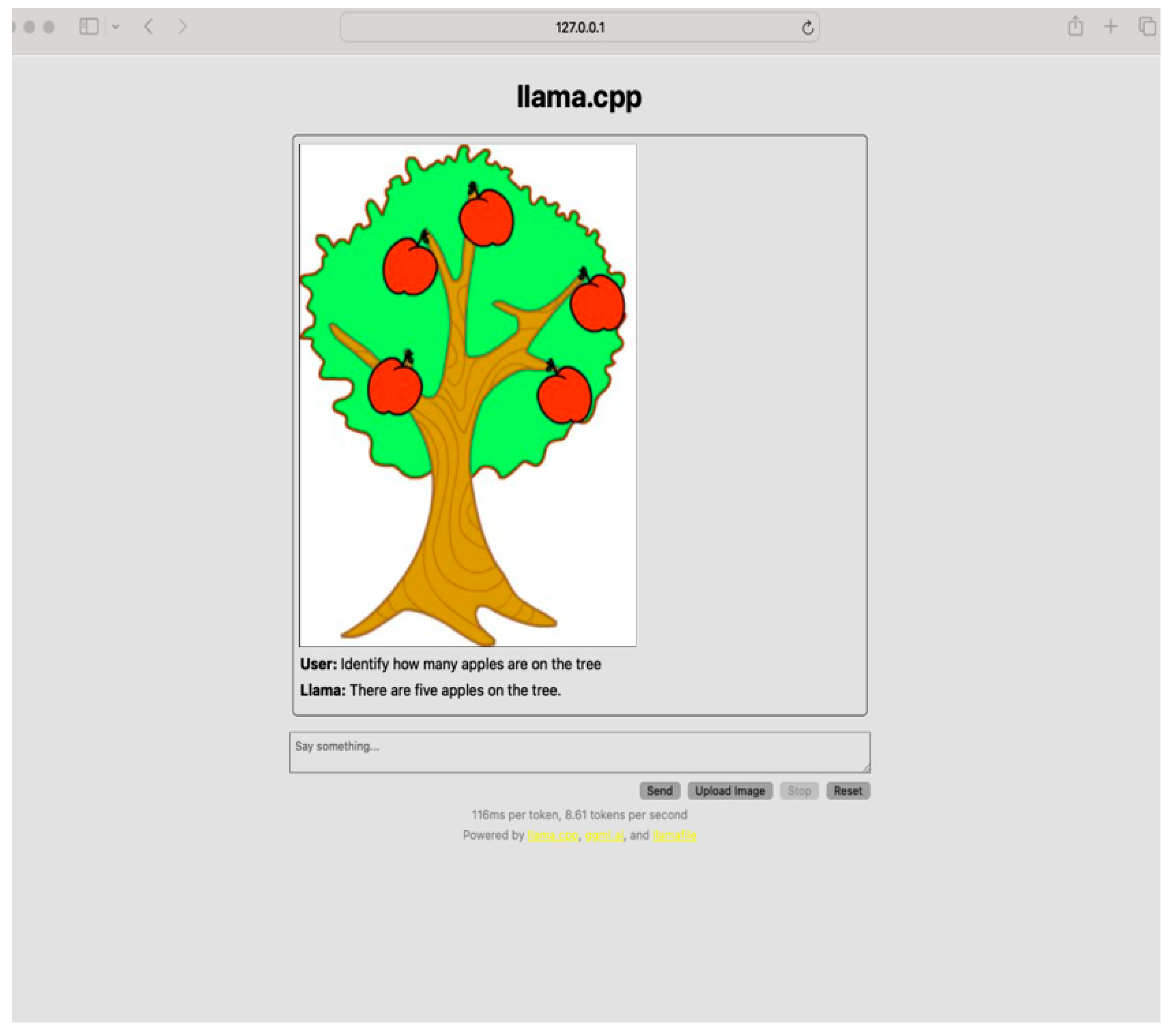
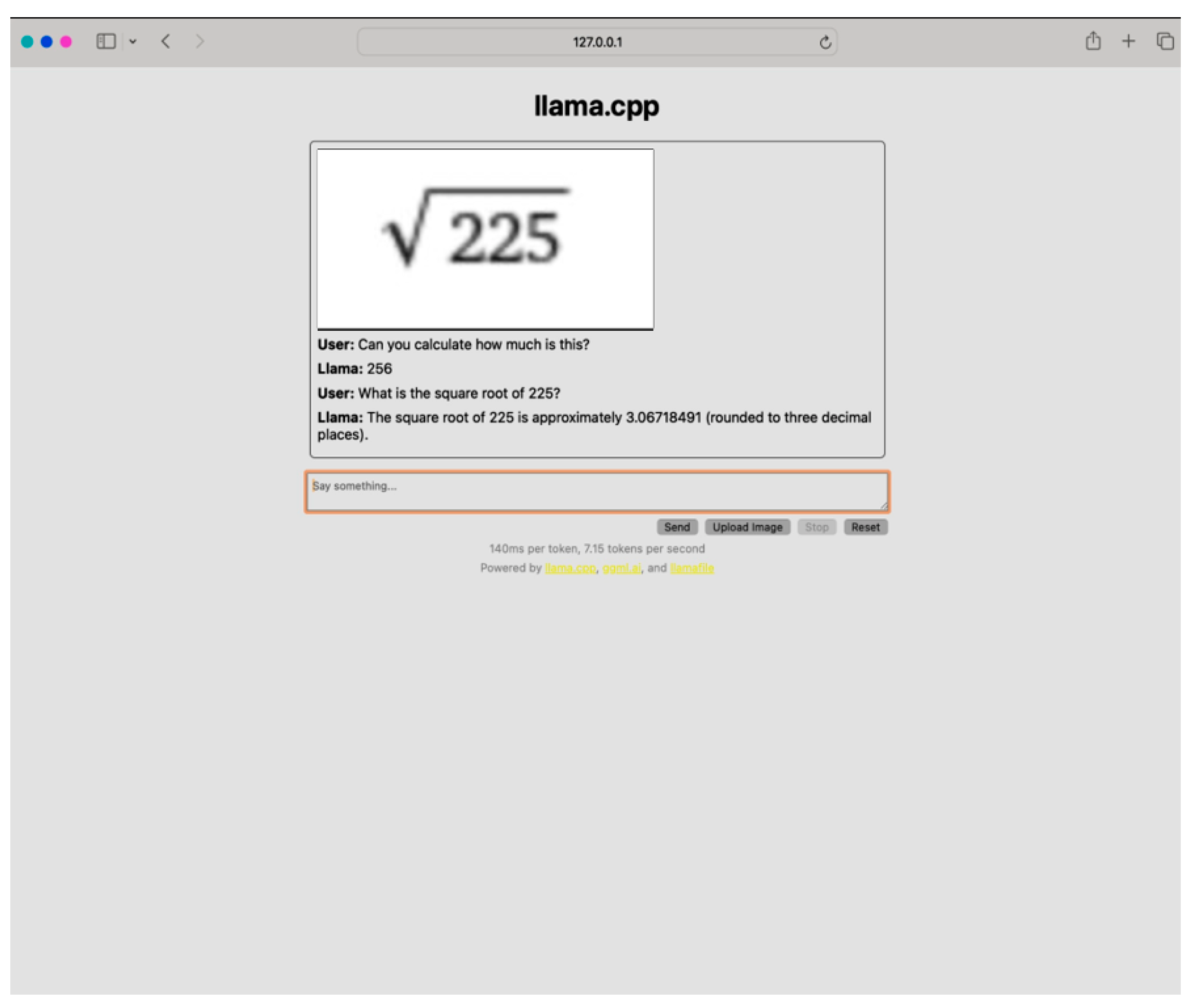
2.3. The Use of an Offline LLM to Ensure Privacy
- Computer Model: Apple, Los Altos, California, USA, MacPro (Late 2013)
- CPU: Intel, Santa Clara, California, USA, Xeon E5 2.7 GHz, 12-Core,
- GPU: AMD, Santa Clara, California, USA, FirePro D300, 2 Gb
- RAM: OWC, Woodstock, Illinois, USA, 64 Gb, 1866 MHz DDR3.
- HDD: Apple, Los Altos, California, USA, 512 Gb NVMe
- Double Entry Bookkeeping compared to TEA-DLT:
- Limitations: Traditional accounting methods such as the double-entry bookkeeping system are basically based on the trust of the parties involved, making those systems susceptible to fraud and errors. They do not provide a standalone verification mechanism, meaning that discrepancies can often go unnoticed.
- Justification for the use of TEA and DLT: TEA introduces a third entry, adding a layer of transparency and traceability that double entry bookkeeping method lacks. DLT records entries on a decentralized ledger, ensuring data integrity and immutability which significantly mitigates the risk of unauthorized alterations.
- User education compared to TEA-DLT/Merklized transactions/Offline LLMs:
- Limitations: There is an inalienable truth in the history of computing: that almost always, with a few exceptions of machine failure, the single point of failure in system security is the user. Therefore, it is impossible for somebody to ensure that the user is fully aware of all vulnerabilities.
- Justification for the use of our proposed methods: TEA introduces a trustless way to mitigate user errors and non-compliance. Using a cryptographic proof for each entry, it isolates the trust from the associated parties and therefore ensures system security. The same stands for the Merklized transactions and offline LLMs.
- Privacy-preserving Techniques (anonymization, pseudonymization):
- Limitations: While classic techniques like anonymization and pseudonymization help reduce identifiable information via obscuring personal details, these techniques remain vulnerable to re-identification through advanced data analysis methods. This creates an ongoing privacy risk.
- Justification for our proposed methods: TEA coupled with DLT offers stronger privacy protection. This combined approach allows transaction verification using cryptographic signatures, for example Secure Hashing Algorithm (SHA-256) (Khovratovich et al., 2011) or Elliptic Curve Digital Signatures Algorithm (ECDSA) (Johnson et al., 2001), while keeping sensitive identifiers secure. By processing data in isolated, encrypted environments and recording transactions on a distributed ledger, the system significantly reduces the risk of data being traced back to individuals. Finally, the offline LLMs provide a priori the isolation of personal data.
- Centralized systems:
- Limitations: Current privacy protection systems often concentrate data storage and management in centralized locations. This centralization creates vulnerable targets for attackers. In case of a compromised system, it can result in massive data breaches and privacy violations, since all protected information is stored in one place. The concentration of sensitive data in a single location essentially creates a “honey pot” that attracts malicious actors and increases the potential impact of any successful breach.
- Justification for our proposed methods: By decentralizing data storage through distributed ledgers, TEA enhances security against potential single-point failures. The strong point of this approach enables multiple parties to validate and audit transactions without relying on a central authority. Merklized transactions also rely on the same TEA principles, while offline LLMs preserve privacy through isolation.
3. Results
- Enhanced efficiency with low latency due to the absence of network delays and communication bottlenecks that can hinder online models’ performance in processing large amounts of data simultaneously.
- Improved privacy, as offline models do not require continuous internet connectivity or access to user-specific information, thus reducing potential security risks associated with online data transmission and storage.
- Increased scalability since offline models can be preprocessed and stored locally, allowing for faster loading times and reduced resource consumption during inference compared to their online counterparts that require continuous updates via the internet.
- No maintenance costs: offline models eliminate the need for cloud infrastructure, data storage, and bandwidth expenses associated with maintaining an online model’s functionality.
- Limited real-time responsiveness and adaptability since offline models do not receive continuous updates or access to new data sources, which can reduce their ability to respond quickly to evolving situations or provide up-to-date information in real-time scenarios.
- Increased storage requirements due to the need for large amounts of memory and processing power to store preprocessed offline models, potentially leading to higher hardware costs and resource constraints during inference.
- Potential wrong or outdated answers if the model is not properly maintained or updated over time, as old information may become inaccurate or irrelevant without continuous refinement through online updates.
- Greater dependency on preprocessing steps, since offline models require extensive preparation before they can be used for inference, which might increase the overall computational complexity and time required to process data compared to their online counterparts which can quickly adapt to new inputs in real time.
4. Discussion
- Practical Considerations for Privacy Implementation
- To successfully integrate privacy-preserving methods in AI-enhanced lifelong education, several key practical factors must be addressed:
- Institutional Factors
- Educational institutions need strong leadership support and mind-changing practices to foster innovation while prioritizing data privacy. They should consider upgrading the technological infrastructure, faculty training needs, and take into account existing legal policies. By making partnerships with industry, they can gain expertise and resources for implementing privacy solutions.
- Regulatory Factors
- Institutions must comply with privacy laws like GDPR. A thorough and detailed compliance strategy should be developed, with legal expertise to navigate regulatory complexities and reduce risks.
- Economic Factors
- Privacy-preserving implementations are expensive and require financial investment, and the cost depends on the method. Institutions should conduct cost-benefit analyses, consider long-term savings from preventing data breaches, explore funding opportunities, and apply changes gradually throughout a multi-year policy to manage budgets.
- Policy Contexts
- The existing educational policies also affect technology implementation. Institutions should review their current policies for compatibility with new methodologies and engage in advocacy for regulations that support innovation while protecting privacy.
- Industry Collaboration
- Partnerships with specialized technology companies provide tools, training, and support for implementing privacy-preserving methods. Such collaborations provide knowledge sharing and development of solutions aligned with educational needs.
- By addressing institutional, regulatory, economic, and policy considerations while fostering industry partnerships, we believe that a much needed framework will be created, for educational institutions to effectively leverage AI while protecting student privacy.
5. Conclusions
- −
- Triple-Entry Accounting with Distributed Ledger Technology
- −
- Merkle trees implementation
- −
- Offline multimodal AI tutor model without internet connectivity
- −
- There are implementation challenges with Triple-Entry Accounting and DLT due to method complexity
- −
- Technical difficulties with Merklized transactions implementation
- −
- Offline LLMs face challenges with periodic updates to maintain current knowledge
- −
- Limited accessibility for remote schools where these models could be most beneficial
- −
- Real-world application testing of each method to empirically evaluate strengths and weaknesses
- −
- Further research into personalized learning as a key factor in privacy-preserving AI education
- −
- Exploration of the humanitarian aspects of education in relation to technological approaches
- −
- A planned forthcoming manuscript addressing personalized learning and the ideal AI-empowered lifelong education system
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| DLT | Distributed Ledger Technology |
| ECDSA | Elliptic Curve Digital Signature Algorithm |
| GDPR | General Data Protection Regulation |
| GPT | Generative Pre-trained Transformers |
| GPT4All | Generative Pre-trained Transformers for All |
| ID(s) | Identification(s) |
| LLaMA | Large Language Model Meta™ AI |
| LLaVA | Large Language and Vision Assistant |
| LLM(s) | Large Language Model(s) |
| RAG | Retrieval Augmented Generation |
| RLHF | Reinforcement Learning from Human Feedback |
| SHA-256 | 256-bit Secure Hashing Algorithm |
| TEA | Triple-Entry Accounting |
References
- Akgun, S., & Greenhow, C. (2021). Artificial intelligence in education: Addressing ethical challenges in K-12 settings. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8455229/ (accessed on 17 January 2024).
- Almpanis, T., & Paul, J.-R. (2022). Lecturing from home: Exploring academics’ experiences of remote teaching during a pandemic. International Journal of Educational Research Open, 3, 100133. [Google Scholar] [CrossRef]
- Archambault, S. (2021). Student privacy in the digital age. BYU Education & Law Journal, 2021(1), 6. Available online: https://scholarsarchive.byu.edu/byu_elj/vol2021/iss1/6/ (accessed on 18 January 2024).
- Arunda, B. (2023). Blockchain in accounting: Triple-entry accounting. Available online: https://www.linkedin.com/pulse/blockchain-accounting-triple-entry-benjamin-arunda/ (accessed on 17 January 2024).
- Billett, S. (2010). The perils of confusing lifelong learning with lifelong education. International Journal of Lifelong Education, 29(4), 401–413. [Google Scholar] [CrossRef]
- Boutin, C. (2022). There’s more to AI bias than biased data. NIST report highlights. Available online: https://www.nist.gov/news-events/news/2022/03/theres-more-ai-bias-biased-data-nist-report-highlights (accessed on 16 January 2023).
- Chan, C. (2023). A comprehensive AI policy education framework for university teaching and learning. International Journal of Educational Technology in Higher Education, 20, 38. [Google Scholar] [CrossRef]
- Chatham House. (2022). The Chatham House rule. Available online: https://www.chathamhouse.org/about-us/chatham-house-rule (accessed on 17 January 2024).
- Children’s Online Privacy Protection Act (COPPA). (2013). Children’s online privacy protection rule: A six-step compliance plan for your business. Federal trade commission. Available online: https://www.ftc.gov/business-guidance/resources/childrens-online-privacy-protection-rule-six-step-compliance-plan-your-business (accessed on 23 January 2024).
- Commoncrawl. (2023). The common crawl corpus. Dataset. Available online: https://commoncrawl.org/get-started (accessed on 20 January 2024).
- Cullican, J. (2023). AI in education: Privacy concerns and data security: Navigating the complex landscape. Available online: https://www.linkedin.com/pulse/ai-education-privacy-concerns-data-security-complex-jamie-culican/ (accessed on 15 January 2024).
- Dave, R. H. (Ed.). (1976). Foundations of lifelong education. UNESCO Institute for Education, and Pergamon Press. [Google Scholar]
- Davis, J. (2024). Enhanced scalability and privacy for blockchain data using Merklized transactions. Frontiers in Blockchain, 6, 2624–7852. [Google Scholar] [CrossRef]
- Davis, W. (2023). Sarah silverman is suing open AI and meta for copyright infringement. Available online: https://www.theverge.com/2023/7/9/23788741/sarah-silverman-openai-meta-chatgpt-llama-copyright-infringement-chatbots-artificial-intelligence-ai (accessed on 20 January 2024).
- De Laat, M., Joksimovic, S., & Ifenthaler, D. (2020). Artificial intelligence, real-time feedback and workplace learning analytics to support in situ complex problem-solving: A commentary. The International Journal of Information and Learning Technology, 37(5), 267–277. [Google Scholar] [CrossRef]
- Ethayarajh, K., Choi, Y., & Swayamdipta, S. (2023). Stanford human preferences dataset. Available online: https://huggingface.co/datasets/stanfordnlp/SHP (accessed on 20 January 2024).
- Gan, W., Qi, Z., Wu, J., & Lin, J. C. (2023). Large language models in education: Vision and opportunities. Available online: https://arxiv.org/pdf/2311.13160.pdf (accessed on 12 January 2024).
- GDPR. (2025). GDPR fines/penalties. European Commission. Available online: https://gdpr-info.eu/issues/fines-penalties (accessed on 7 February 2025).
- Grigg, I. (2005). Triple entry accounting. Systemics Inc. Available online: https://iang.org/papers/triple_entry.html (accessed on 12 January 2024).
- Holmes, W., Persson, J., Chounta, I. A., Wasson, B., & Dimitrova, V. (2022). Artificial intelligence and education: A critical view through the lens of human rights, democracy and the rule of law. Council of Europe. ISBN 978-92-871-9236-3. Available online: https://rm.coe.int/prems-092922-gbr-2517-ai-and-education-txt-16x24-web/1680a956e3 (accessed on 15 January 2024).
- Hood, S. (2023). Introducing llamafile. Available online: https://hacks.mozilla.org/2023/11/introducing-llamafile/ (accessed on 16 January 2024).
- Huggingface. (2023). Byte-pair encoding tokenization. Available online: https://huggingface.co/course/chapter6/5?fw=pt (accessed on 20 January 2024).
- Ibañez, J. I., Bayer, C. N., Tasca, P., & Xu, J. (2023). REA, triple-entry accounting and blockchain: Converging paths to shared ledger systems. Journal of Risk and Financial Management, 16, 382. [Google Scholar] [CrossRef]
- Jennings, J. (2023). AI in education: Privacy and security. Available online: https://www.esparklearning.com/blog/ai-in-education-privacy-and-security/ (accessed on 15 January 2024).
- Johnson, D., Menezes, A., & Vanstone, S. (2001). The Elliptic Curve Digital Signature Algorithm (ECDSA). International Journal of Information Security, 1, 36–63. [Google Scholar] [CrossRef]
- Karpathy, A. (2023). On the hallucination problem. Available online: https://twitter.com/karpathy/status/1733299213503787018 (accessed on 16 January 2024).
- Khan Academy. (2023). Khanmingo AI tutor. Online AI tutor. Available online: https://www.khanacademy.org/khan-labs (accessed on 12 January 2024).
- Khovratovich, D., Rechberger, C., & Savelieva, A. (2011). Bicliques for preimages: Attacks on Skein-512 and the SHA-2 family. Available online: https://eprint.iacr.org/2011/286.pdf (accessed on 27 February 2025).
- LeCun, Y. (2023). How not to be stupid about AI, with Yann LeCun. Available online: https://www.wired.com/story/artificial-intelligence-meta-yann-lecun-interview/ (accessed on 16 January 2024).
- Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., & Lee, Y. J. (2023). LLaVA-NeXT: Improved reasoning, OCR, and world knowledge. Available online: https://llava-vl.github.io/blog/2024-01-30-llava-next/ (accessed on 8 June 2024).
- Manyika, J., & Hsiao, S. (2023). An overview of bard: An early experiment with generative AI. Available online: https://ai.google/static/documents/google-about-bard.pdf (accessed on 16 January 2024).
- Manyika, J., Silberg, J., & Presten, B. (2019). What do we do about the biases in AI? Available online: https://hbr.org/2019/10/what-do-we-do-about-the-biases-in-ai (accessed on 16 January 2023).
- Melendez, S., & Pasternack, A. (2019). Here are the data brokers quietly buying and selling your personal information. Available online: https://www.fastcompany.com/90310803/here-are-the-data-brokers-quietly-buying-and-selling-your-personal-information (accessed on 23 January 2024).
- NomicAI. (2023). GPT4All: An ecosystem of open-source on-edge large language models. Available online: https://github.com/nomic-ai/gpt4all (accessed on 16 January 2024).
- Nowicki, J. M. (2020). Data security: Recent K-12 data breaches show that students are vulnerable to harm. GAO-20-644. Available online: https://www.gao.gov/products/gao-20-644 (accessed on 7 June 2024).
- Oakley, J., & Cocking, D. (2001). Virtue ethics and professional roles. Cambridge University Press. [Google Scholar]
- Poquet, O., & De Laat, M. (2021). Developing capabilities: Lifelong learning in the age of AI. British Journal of Educational Technology, 52(4), 1695–1708. [Google Scholar] [CrossRef]
- Proser, Z. (2023). Retrieval augmented generation (RAG). Available online: https://www.pinecone.io/learn/retrieval-augmented-generation/ (accessed on 16 January 2023).
- Rubenson, K. (2019). Assessing the status of lifelong learning: Issues with composite indexes and surveys on participation. International Review of Education, 65(2), 295–317. [Google Scholar] [CrossRef]
- Scheid, M. (2019). The educator’s role: Privacy, confidentiality, and security in the classroom. Student privacy compass. Available online: https://studentprivacycompass.org/scheid1/ (accessed on 12 January 2024).
- Sen, A. (1985). Commodities and capabilities. North-Holland. [Google Scholar]
- Sgantzos, K., Grigg, I., & Hemairy, M. A. (2022). Multiple neighborhood cellular automata as a mechanism for creating an AGI on a blockchain. Journal of Risk and Financial Management, 15, 360. [Google Scholar] [CrossRef]
- Sgantzos, K., Hemairy, M. A., Tzavaras, P., & Stelios, S. (2023). Triple-entry accounting as a means of auditing large language models. Journal of Risk and Financial Management, 16, 383. [Google Scholar] [CrossRef]
- Stelios, S. (2020). Professional engineers: Interconnecting personal virtues with human good. Business and Professional Ethics Journal, 39(2), 253–267. [Google Scholar] [CrossRef]
- Su, J. (苏嘉红), & Yang, W. (杨伟鹏). (2023). Unlocking the power of ChatGPT: A framework for applying generative AI in education. ECNU Review of Education, 6(3), 355–366. [Google Scholar] [CrossRef]
- Sunde, T. V., & Wright, C. S. (2023). Implementing triple entry accounting as an Audit Tool—An extension to modern accounting systems. Journal of Risk and Financial Management, 16(11), 478. [Google Scholar] [CrossRef]
- Tarquini, L. (2016). Il Falco e il Topo Manualetto di Gestione Aziendale. Lulu.com. ISBN-10: 1326893939, ISBN-13:978-1326893934. [Google Scholar]
- Thompson, A. D. (2023). Microsoft bing chat” (Sydney/GPT-4). Available online: https://lifearchitect.ai/bing-chat/ (accessed on 16 January 2024).
- Tuijnman, A., & Boström, A. K. (2002). Changing notions of lifelong education and lifelong learning. International Review of Education, 48, 93–110. [Google Scholar] [CrossRef]
- Vigliarolo, B. (2024). Adobe users just now getting upset over content scanning allowance in Terms of Use. The Register. Available online: https://www.theregister.com/2024/06/06/adobe_users_upset_over_content/ (accessed on 7 June 2024).
- Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., Wei, C., Yu, B., Yuan, R., Sun, R., Yin, M., Zheng, B., Yang, Z., Liu, Y., Huang, W., … Chen, W. (2023). MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI. arXiv. [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Triple-Entry Accounting (TEA) | Merkle Trees | Offline Models |
|---|---|---|---|
| Data Integrity | Ensures integrity through cryptographic verification and consensus mechanism among parties. | Uses cryptographic hashes to verify individual transaction data integrity through tree structure. | Depends on the integrity of the model’s preloaded data and requires manual updates for changes. |
| User Privacy | Provides privacy through pseudonymization; sensitive data is not stored in plain text. | Offers privacy by allowing verification of data without revealing underlying information due to hash function. | Enhances privacy by storing data locally without network exposure; user data are not transmitted. |
| Scalability | Potentially scalable but could be challenged by increased transaction volumes requiring processing power. | Highly scalable due to efficient storage and verification of large data sets using tree structures. | Scalability may be limited by local hardware capabilities and the need for frequent updates. |
| Real-time Accessibility | Provides real-time access to data and transactions, important for educational settings. | Not inherently designed for real-time usage, verification may cause slight delays. | Limited real-time flexibility; dependent on prior updates and local processing power. |
| Implementation Complexity | Requires more sophisticated infrastructure and expertise for setup and maintenance. | Easier to implement in existing blockchain structures; relatively straightforward in integration. | Implementation complexity varies; requires extensive preprocessing, but can be simpler for isolated environments. |
| Compliance with Regulations | Designed to align with data protection regulations (e.g., GDPR) by explicitly managing consent and access rights. | Generally complies depending on implementation; requires careful management of user data within the blockchain. | Can comply with data regulations by isolating sensitive information and ensuring local storage without transmission. |
| Cost-Effectiveness | May incur higher costs with initial setup and ongoing operational expenses. | Generally more cost-effective for verifying large datasets due to minimal computational overheads. | Potentially cost-effective as it reduces dependence on cloud services and network infrastructure. |
| User Experience | Users may require knowledge of the system; the learning curve can impact usability initially. | Generally offers a seamless experience for users as they benefit from efficient data verification. | Enhanced user satisfaction due to ease of access to resources without potential online restrictions. |
| Criteria | Triple-Entry Accounting (TEA) | Merkle Trees | Offline Models |
|---|---|---|---|
| Data Integrity (Score out of 10) | 9 | 8 | 7 |
| User Privacy (Score out of 10) | 8 | 9 | 9 |
| Scalability (Transactions per second) | Blockchain-dependent | Blockchain-dependent | Token-dependent |
| Implementation Cost (EUR) | Fees-dependent. Can be as low as EUR 0.00001 per record | Fees-dependent. Can be as low as EUR 0.00001 per record | EUR 300–600 for the current setup |
| Implementation Time (Months) | 1 | 1 | 1 |
| User Experience (Satisfaction Score out of 10) | 7 | 8 | 9 |
| Compliance Score (out of 10) | 9 | 9 | 10 |
| Efficiency (Resource Usage %) | Blockchain-dependent: 1–70% | Blockchain-dependent: 1–70% | 40% compared to the online models. |
| Method/Case Study | Privacy Preservation | User Trust | Implementation Challenges | Overall Effectiveness |
|---|---|---|---|---|
| Proposed Method: Triple-Entry Accounting (TEA) | High | Moderate | Complexity in managing and verifying transactions | High |
| Proposed Method: Merkle Trees | High | Moderate | Integration into existing systems may be challenging | High |
| Proposed Method: Offline AI Models | Very High | High | Difficulty in periodic updates and current knowledge | Moderate |
| Akgun and Greenhow (2021) | Moderate | Low | Varies by institution and technology adopted | Moderate |
| Chan (2023) | Moderate to High | Moderate | Differences in application effectiveness across sectors | High |
| Holmes et al. (2022) | Moderate to High | High | Data gathering and longitudinal study complexity | High |
| J. Davis (2024) | High | Moderate | Complexity of blockchain integration | High |
| Boutin (2022) | Moderate | Low | Educational implementation varies; reliance on user commitment | Moderate |
| Archambault (2021) | High | Moderate | Varies significantly by demographic and institutional policy | Moderate to High |
| Method | Security | Privacy | Computational Cost |
|---|---|---|---|
| Triple-Entry Accounting (TEA) and DLT | High; employs cryptographic verification and consensus mechanisms, ensuring data integrity and security among parties. | Provides privacy through pseudonymization; sensitive data are not directly stored. | May incur higher initial setup costs and ongoing operational expenses. |
| Merkle Trees | High; utilizes cryptographic hashes to verify individual transaction data integrity, maintaining security. | Allows verification of data without revealing sensitive information, enhancing user privacy. | Generally more cost-effective for large datasets due to minimal computational overhead. |
| Offline Models | Moderate; relies on the inherent security of the local environment and lack of external threats. | Enhances privacy by storing data locally and not requiring online access. | Potentially cost-effective initially but long-term costs for hardware maintenance and data storage must be considered. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sgantzos, K.; Tzavaras, P.; Al Hemairy, M.; Porras, E.R. Triple-Entry Accounting and Other Secure Methods to Preserve User Privacy and Mitigate Financial Risks in AI-Empowered Lifelong Education. J. Risk Financial Manag. 2025, 18, 176. https://doi.org/10.3390/jrfm18040176
Sgantzos K, Tzavaras P, Al Hemairy M, Porras ER. Triple-Entry Accounting and Other Secure Methods to Preserve User Privacy and Mitigate Financial Risks in AI-Empowered Lifelong Education. Journal of Risk and Financial Management. 2025; 18(4):176. https://doi.org/10.3390/jrfm18040176
Chicago/Turabian StyleSgantzos, Konstantinos, Panagiotis Tzavaras, Mohamed Al Hemairy, and Eva R. Porras. 2025. "Triple-Entry Accounting and Other Secure Methods to Preserve User Privacy and Mitigate Financial Risks in AI-Empowered Lifelong Education" Journal of Risk and Financial Management 18, no. 4: 176. https://doi.org/10.3390/jrfm18040176
APA StyleSgantzos, K., Tzavaras, P., Al Hemairy, M., & Porras, E. R. (2025). Triple-Entry Accounting and Other Secure Methods to Preserve User Privacy and Mitigate Financial Risks in AI-Empowered Lifelong Education. Journal of Risk and Financial Management, 18(4), 176. https://doi.org/10.3390/jrfm18040176