
A Rank Estimator Approach to Modeling Default Frequencies


Abstract
:1. Introduction
2. Rank Estimators for Expected Default Frequencies
- How can one find the rank variable?
- Does the choice of the rank variable depend on the credit rating?
- What is the functional relationship between the rank variable and the EDF?
- Does this relationship depend on the credit rating?
3. A Minimally Data-Intensive Model
3.1. Modeling Strategy
- Hypothesis I: the DD in (4) is the default rank variable for the public corporates.
- Hypothesis II: the mean annual default rates are sufficient statistics for the EDF in each credit rating category.
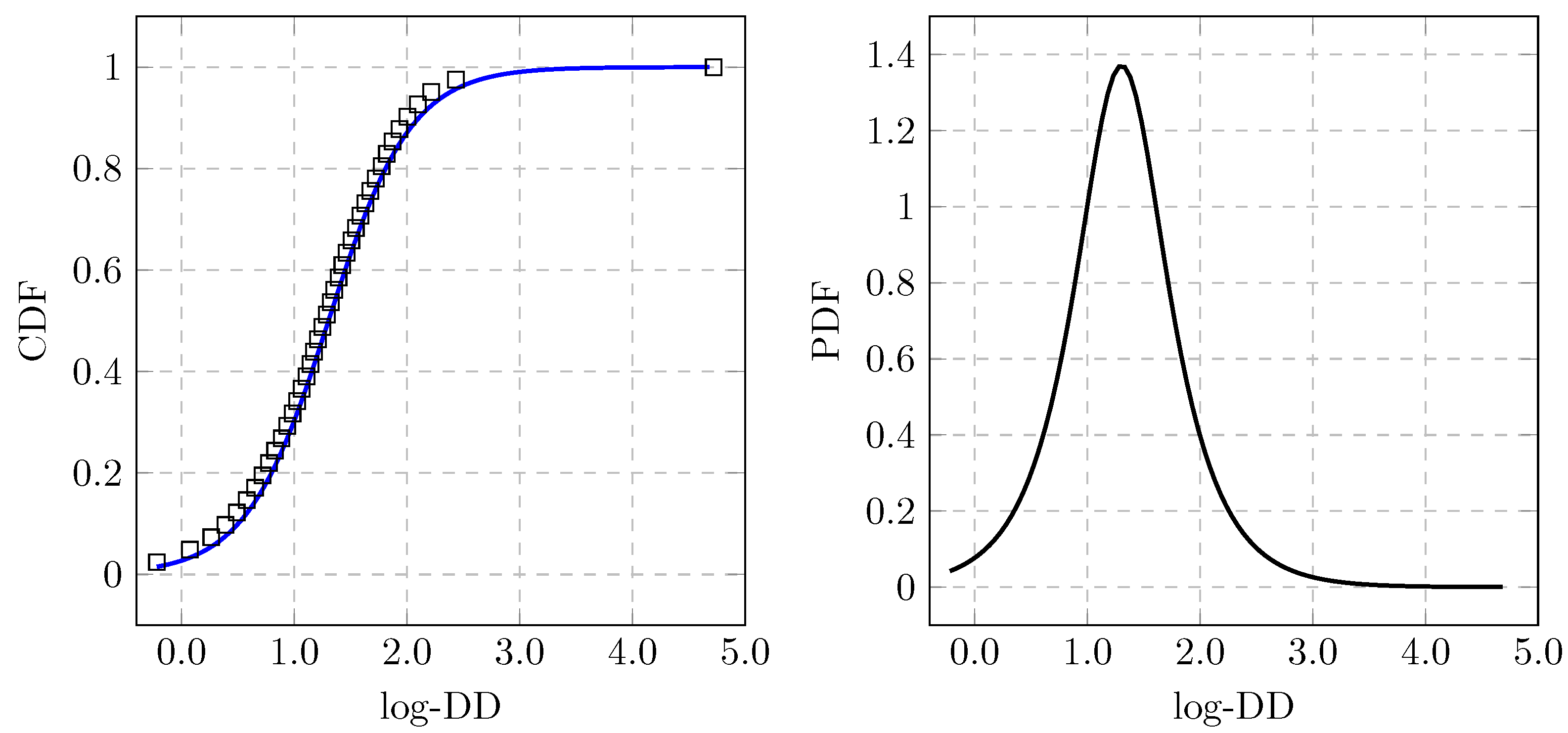
- The empirical distribution of DDs, representing the distribution of the rank variable of the underlying population, is estimated from an empirical sample of DDs.
- The empirical distribution of the EDFs is estimated from the summary statistics of historical annual default rates.
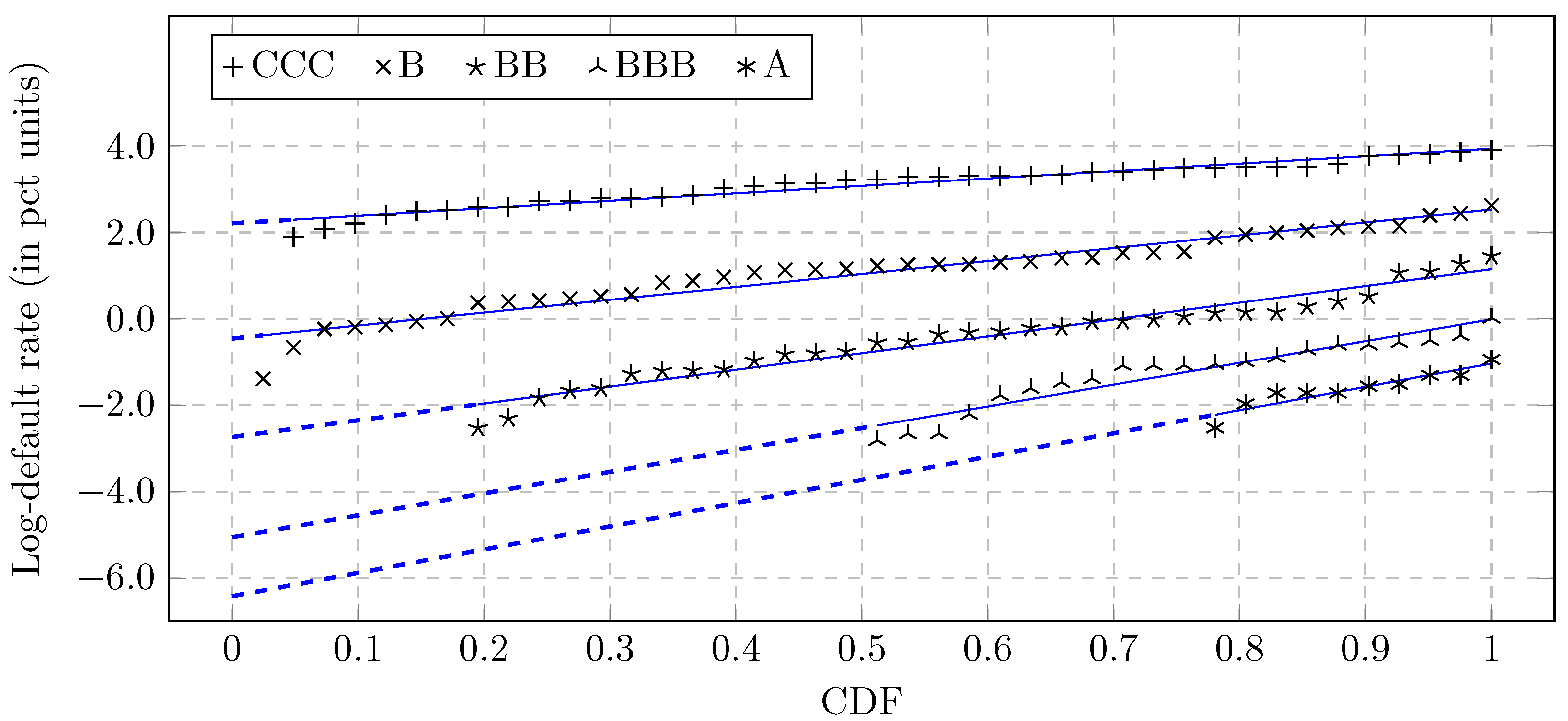
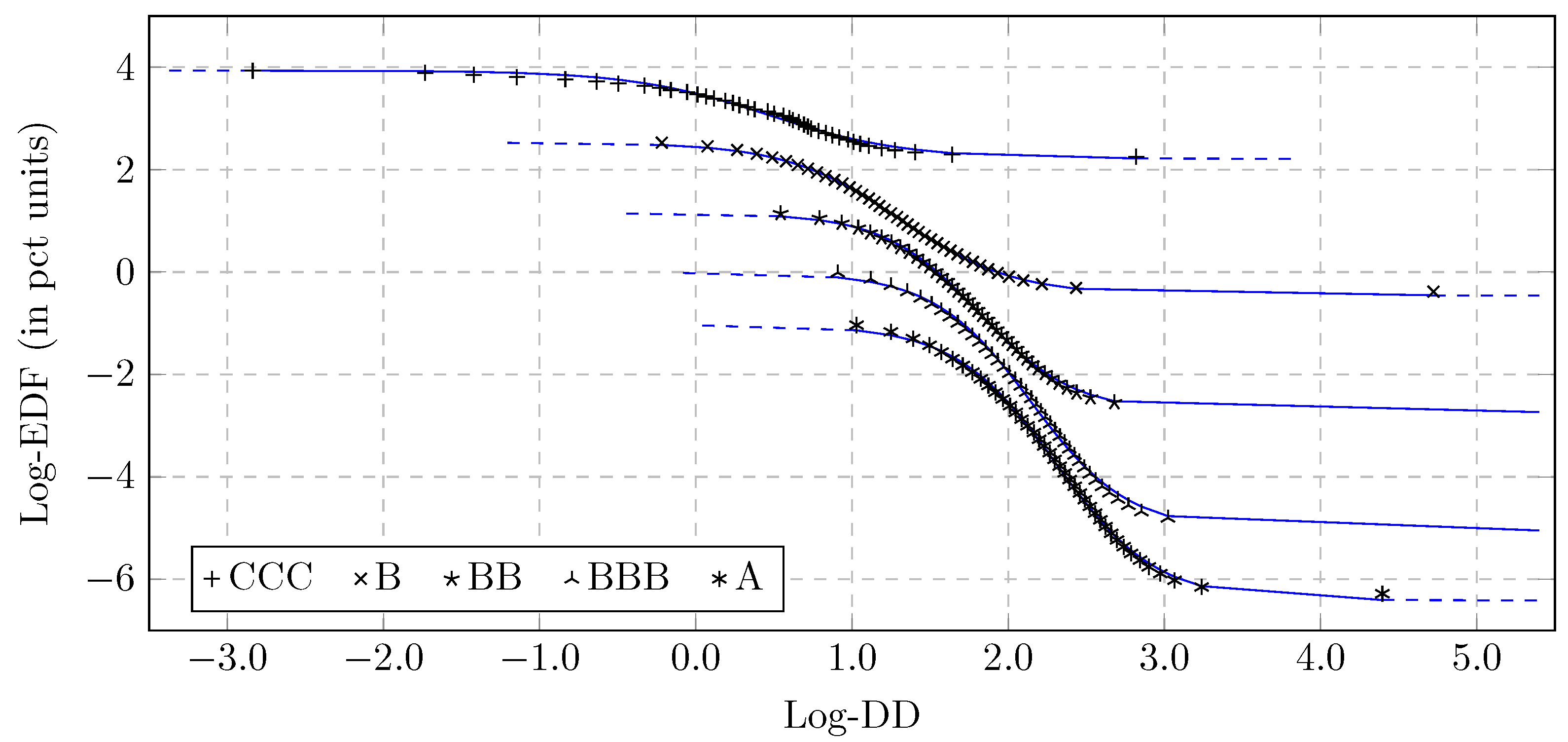
- A quantile matching strategy is applied to establish a relation between DD and EDF. This results in the correspondence as a discrete function with a domain determined by the chosen quantile points in the EDF axis.
- The discrete function from the previous step is approximated using a differentiable function.
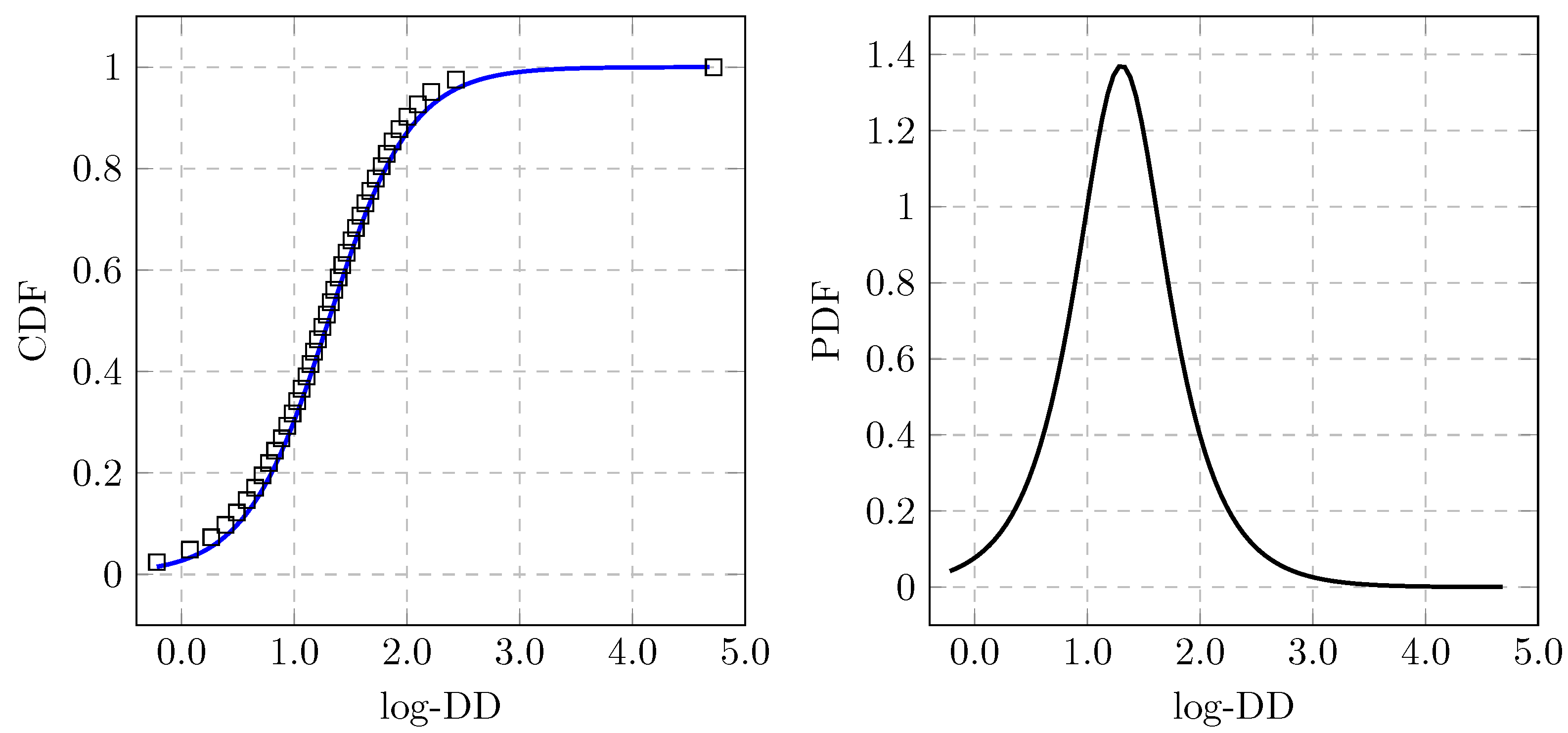
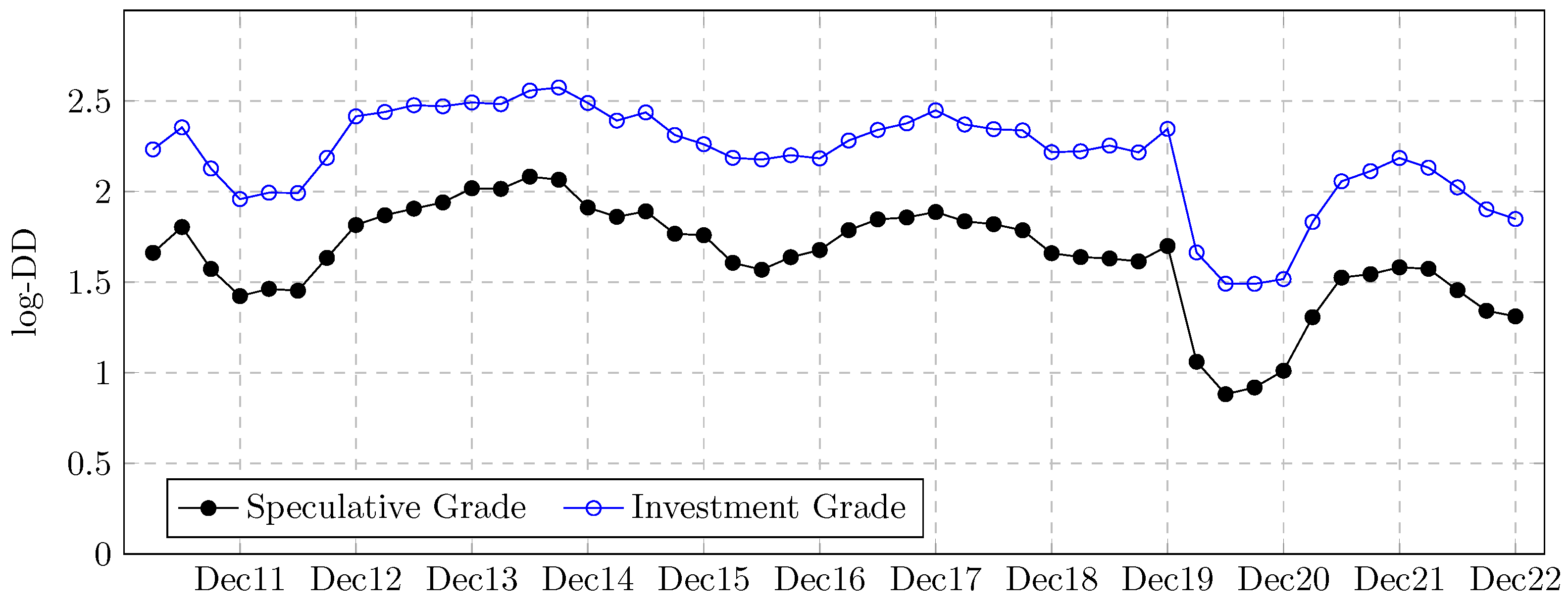
3.2. Distance-to-Default
3.3. Expected Default Frequency
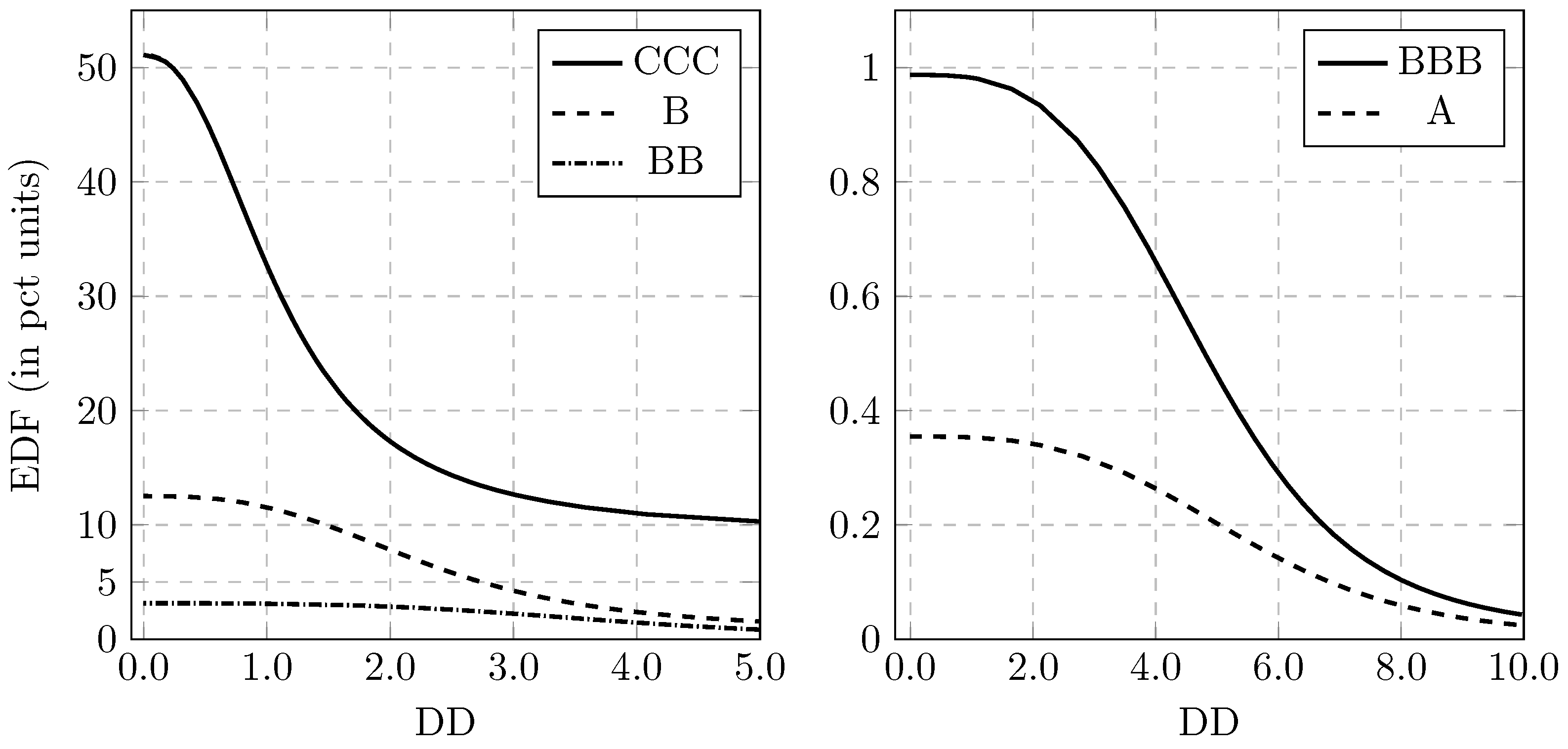
3.4. Model Specification
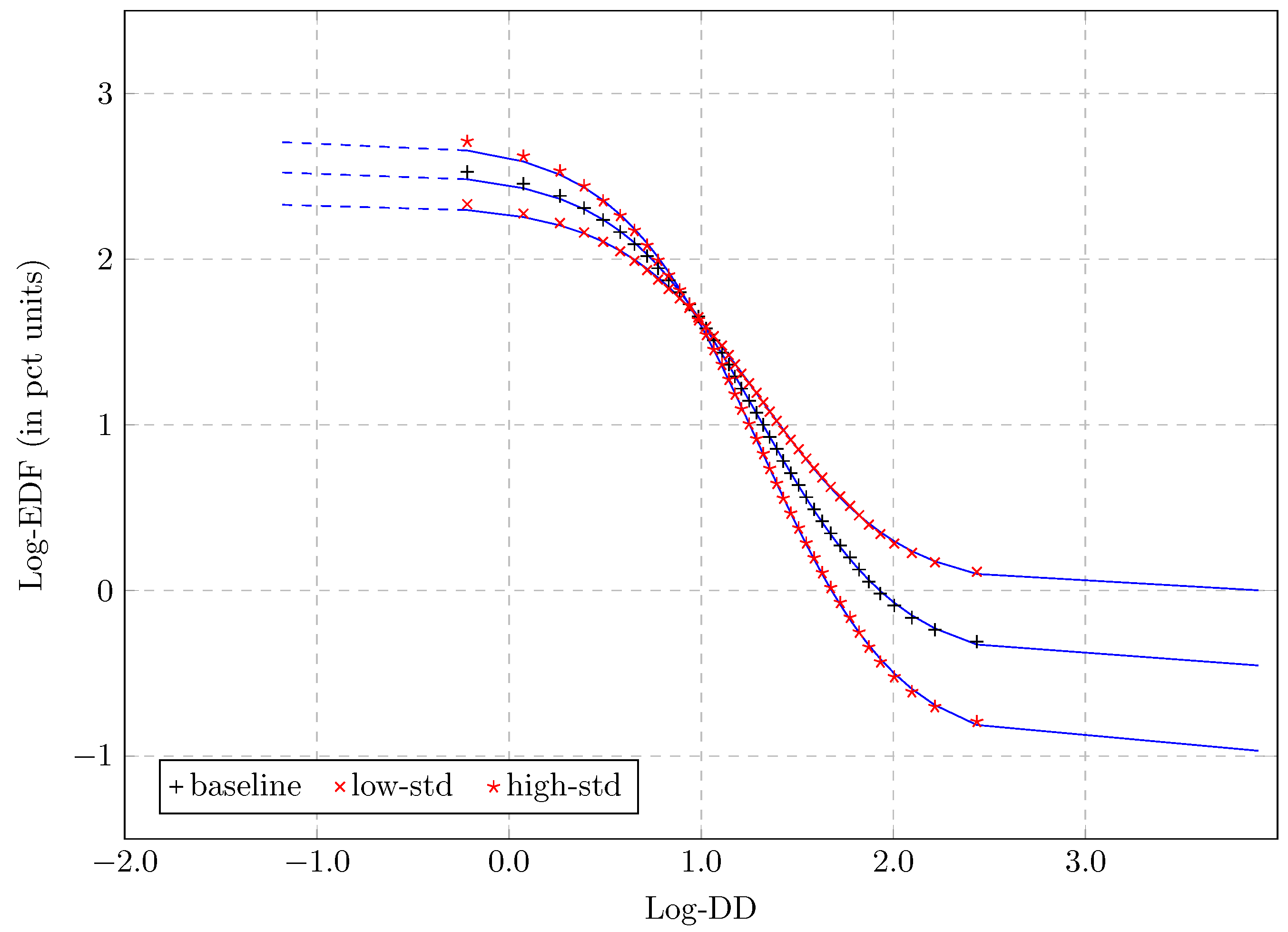
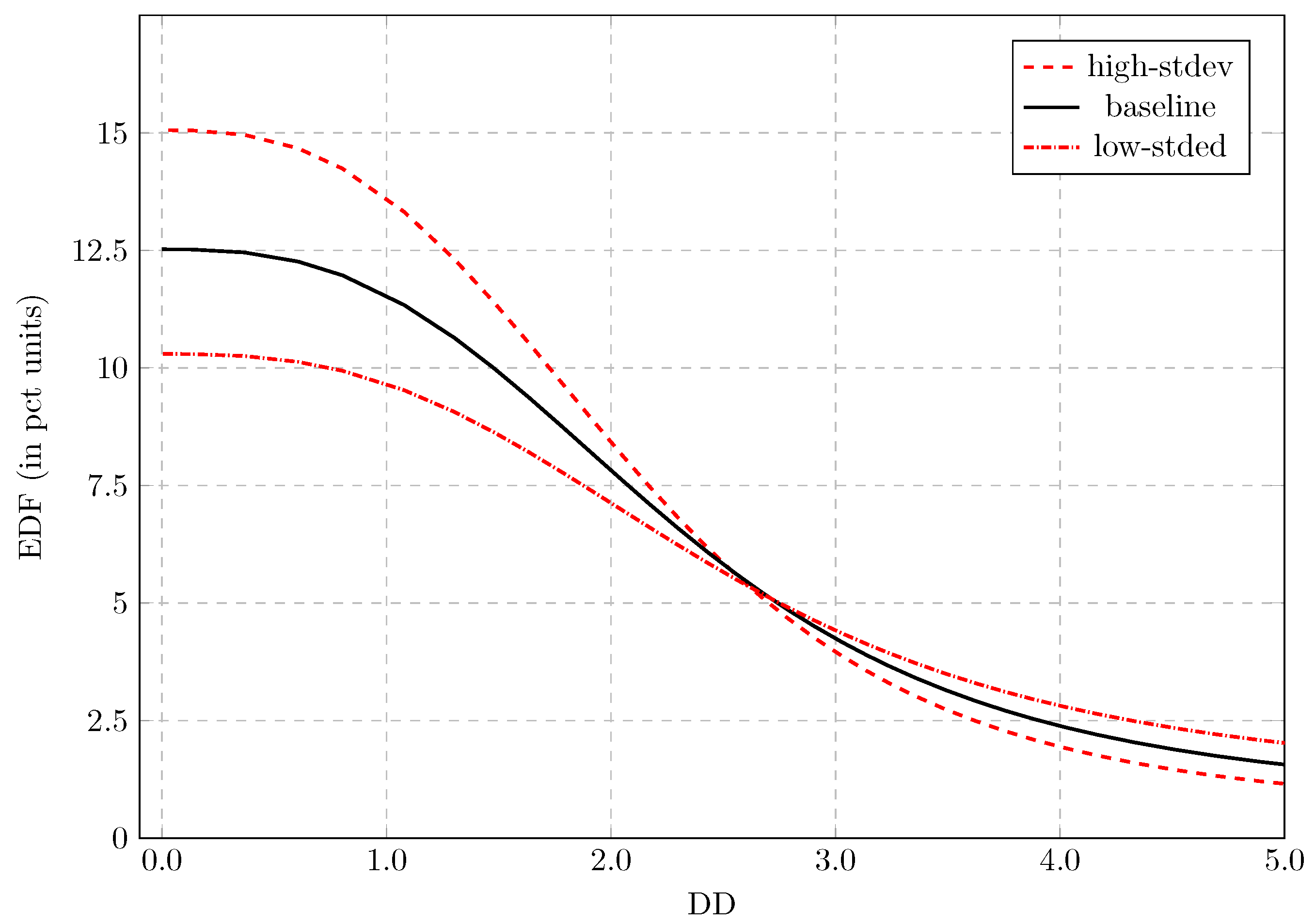
3.5. Sensitivity to the Parameters
- How can the minimum and maximum EDFs in each rating category be determined?
4. Discussion
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- The standard deviation of the daily stock returns over a one-year historical window is used as the initial prior for the asset volatility.
- The time series of the asset values is solved by inverting the Black–Scholes call option pricing formula with the option values equal to the market capitalizations with a strike equal to the debt estimate over the annual window. The debt estimate is kept constant over the window. The asset volatility used in this step is solved in the previous step of the iteration.
- The standard deviation of the asset returns estimated using the asset prices from the previous step is selected as the new asset volatility estimate.
- Steps 2 and 3 are repeated until the asset volatility stabilizes. The criteria for stabilization is that the change from the previous estimate has a magnitude less than .
- The final asset value is solved by inverting the call option pricing formula for the option value equal to the most recent market capitalization and the asset volatility equal to the stabilized volatility. The stabilized volatility is then used as the final asset volatility.
| 1 | For the ranking variable, being an observable is not the crucial point. For instance, the rank could depend on implied volatilities. However, unlike the default experience D, the ranking variable can only use the information available at the time associated with it. |
| 2 | How to justify this definition of EDF? From the definitions of ETDF and conditional expectation, it follows that
|
References
- Albrecher, Hansjörg, Jan Beirlant, and Jozef L. Teugels. 2017. Reinsurance: Actuarial and Statistical Aspects. Statistics in Practice. Hoboken: John Wiley & Sons. [Google Scholar]
- Berndt, Antje, Rohan Douglas, Darrell Duffie, and Mark Ferguson. 2018. Corporate credit risk premia. Review of Finance 22: 419–54. [Google Scholar] [CrossRef]
- Bharath, Sreedhar T., and Tyler Shumway. 2008. Forecasting default with the Merton distance to default model. Review of Financial Studies 21: 1339–69. [Google Scholar] [CrossRef]
- Bohn, Jeffrey R. 2000. An empirical assessment of a simple contingent-claims model for the valuation of risky debt. The Journal of Risk Finance 1: 55–77. [Google Scholar] [CrossRef]
- Campbell, John Y., Jens Hilscher, and Jan Szilagyi. 2008. In search of distress risk. The Journal of Finance 63: 2899–939. [Google Scholar] [CrossRef]
- Cappon, Andre, Alexander Gorenstein, Stephan Mignot, and Guy Manuel. 2018. Credit ratings, default probabilities, and logarithms. The Journal of Structure Finance 24: 39–49. [Google Scholar] [CrossRef]
- Chava, Sudheer, and Robert A. Jarrow. 2004. Bankruptcy prediction with industry effects. Review of Finance 8: 537–69. [Google Scholar] [CrossRef]
- Crouhy, Michel, Dan Galai, and Robert Mark. 2000. A comparative analysis of current credit risk models. Journal of Banking & Finance 24: 59–117. [Google Scholar] [CrossRef]
- Denzler, Stefan M., Michel M. Dacorogna, Ulrich A. Müller, and Alexander J. McNeil. 2006. From default probabilities to credit spreads: Credit risk models do explain market prices. Finance Research Letters 3: 79–95. [Google Scholar] [CrossRef]
- Duffie, Darrell, and Kenneth J. Singleton. 2003. Credit Risk. Princeton: Princeton University Press. [Google Scholar]
- Frey, Rüdiger, and Alexander J. McNeil. 2003. Dependent defaults in models of portfolio credit risk. Journal of Risk 6: 59–92. [Google Scholar] [CrossRef]
- Gapen, Michael, Dale Gray, Cheng Hoon Lim, and Yingbin Xiao. 2008. Measuring and analyzing sovereign risk with contingent claims. IMF Staff Papers 55: 109–48. [Google Scholar] [CrossRef]
- Gordy, Michael, and Erik Heitfield. 2001. Of Moody’s and Merton: A Structural Model of Bond Rating Transitions, Technical Report; Federal Reserve.
- Gray, Dale F., Robert C. Merton, and Zvi Bodie. 2007. Contingent claims approach to measuring and managing sovereign credit risk. Journal of Investment Management 5: 5–28. [Google Scholar] [CrossRef]
- Gupton, Greg M., Christopther C. Finger, and Mickey Bhatia. 1997. Creditmetrics. Technical Report. New York: J. P. Morgan. [Google Scholar]
- Harju, Antti J. 2013. Edf-Rank-Estimator. Available online: https://github.com/harju-aj/edf-rank-estimator (accessed on 1 October 2023).
- Hull, John C., and Alan White. 2000. Valuing credit default swaps I: No counterparty default risk. Journal of Derivatives 8: 29–40. [Google Scholar] [CrossRef]
- Jessen, Cathrine, and David Lando. 2015. Robustness of distance-to-default. Journal of Banking & Finance 50: 493–505. [Google Scholar] [CrossRef]
- Kealhofer, Stephen. 2003a. Quantifying credit risk I: Default prediction. Financial Analyst Journal 59: 30–44. [Google Scholar] [CrossRef]
- Kealhofer, Stephen. 2003b. Quantifying credit risk II: Debt valuation. Financial Analysts Journal 59: 78–92. [Google Scholar] [CrossRef]
- Kraemer, N. W., J. Palmer, M. R. Nivritti, I. Sundaram, F. Lyndon, and M. Abinash. 2022. Default, Transition, and Recovery: 2021 Annual Global Corporate Default and Rating Transition Study, Technical Report. S&P Global.
- McNeil, Alexander J., Rüdiger Frey, and Paul Embrechts. 2005. Quantitative Risk Management—Concepts, Techniques and Tools. Princeton: Princeton University Press. [Google Scholar]
- Merton, Robert C. 1974. On the pricing of corporate debt: The risk structure of interest rates. Journal of Finance 29: 449–70. [Google Scholar] [CrossRef]
- Stephanou, Constantinos, and Juan Carlos Mendoza. 2005. Credit Risk Measurement under Basel II: An Overview and Implementation Issues for Developing Countries. World Bank Policy Research Working Paper 3556. Washington, DC: World Bank. [Google Scholar]
- Vassalou, Maria, and Yuhang Xing. 2004. Default risk in equity returns. Journal of Finance 59: 831–68. [Google Scholar] [CrossRef]
- Zhang, Benjamin Yibin, Hao Zhou, and Haibin Zhu. 2009. Explaining credit default swap spreads with the equity volatility and jump risks of individual firms. Review of Financial Studies 22: 5099–131. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Percentile | CCC | B | BB | BBB | A |
|---|---|---|---|---|---|
| 5th percentile | 0.18 | 1.10 | 2.23 | 3.08 | 3.52 |
| 25th percentile | 0.88 | 2.33 | 4.15 | 5.68 | 6.58 |
| 50th percentile | 1.62 | 3.55 | 5.98 | 8.44 | 9.79 |
| 75th percentile | 2.35 | 5.28 | 8.25 | 11.55 | 13.68 |
| 95th percentile | 4.07 | 9.11 | 12.45 | 17.25 | 21.35 |
| Variable | CCC | B | BB | BBB | A |
|---|---|---|---|---|---|
| Sample mean | 24.6 | 4.09 | 0.84 | 0.19 | 0.05 |
| Fitted mean | 24.4 | 3.99 | 0.79 | 0.19 | 0.07 |
| Sample stdev | 11.9 | 3.25 | 0.99 | 0.25 | 0.10 |
| Fitted stdev | 11.8 | 3.21 | 0.80 | 0.24 | 0.09 |
| 9.12 | 0.63 | 0.065 | 0.006 | 0.002 | |
| 51.1 | 12.5 | 3.15 | 0.99 | 0.35 | |
| 2.21 | −0.45 | −2.74 | −5.05 | −6.41 | |
| 3.93 | 2.52 | 1.15 | −0.013 | −1.04 | |
| R-squared | 0.95 | 0.94 | 0.95 | 0.92 | 0.87 |
| Parameter | CCC | B | BB | BBB | A |
|---|---|---|---|---|---|
| Q | 1.05 | 3.58 | 5.94 | 6.91 | 7.15 |
| B | 2.27 | 2.74 | 3.28 | 3.22 | 3.10 |
| Rating | High-Limit | DD 1 | DD 2 | DD 4 | DD 6 | DD 8 | DD 10 | Low-Limit | Mean | Stdev |
|---|---|---|---|---|---|---|---|---|---|---|
| CCC | 51.1 | 33.2 | 17.4 | 11.0 | 9.86 | 9.50 | 9.35 | 9.12 | 24.4 | 11.8 |
| B | 12.5 | 11.5 | 7.82 | 2.38 | 1.18 | 0.87 | 0.76 | 0.63 | 3.99 | 3.21 |
| BB | 3.15 | 3.12 | 2.86 | 1.46 | 0.48 | 0.20 | 0.12 | 0.06 | 0.79 | 0.80 |
| BBB | 0.99 | 0.98 | 0.94 | 0.66 | 0.29 | 0.10 | 0.04 | 0.006 | 0.19 | 0.24 |
| A | 0.35 | 0.35 | 0.34 | 0.26 | 0.14 | 0.06 | 0.02 | 0.002 | 0.07 | 0.09 |
| Hypothesis | Mean | Stdev | Rel-Stdev | Q | B | ||
|---|---|---|---|---|---|---|---|
| Low-stdev | 3.99 | 2.57 | 3.58 | 2.74 | 1.00 | 10.3 | |
| Baseline | 3.99 | 3.21 | 3.58 | 2.74 | 0.63 | 12.5 | |
| High-stdev | 3.99 | 3.86 | 3.58 | 2.74 | 0.38 | 15.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Harju, A.J. A Rank Estimator Approach to Modeling Default Frequencies. J. Risk Financial Manag. 2023, 16, 444. https://doi.org/10.3390/jrfm16100444
Harju AJ. A Rank Estimator Approach to Modeling Default Frequencies. Journal of Risk and Financial Management. 2023; 16(10):444. https://doi.org/10.3390/jrfm16100444
Chicago/Turabian StyleHarju, Antti J. 2023. "A Rank Estimator Approach to Modeling Default Frequencies" Journal of Risk and Financial Management 16, no. 10: 444. https://doi.org/10.3390/jrfm16100444
APA StyleHarju, A. J. (2023). A Rank Estimator Approach to Modeling Default Frequencies. Journal of Risk and Financial Management, 16(10), 444. https://doi.org/10.3390/jrfm16100444