1. Introduction
Modeling and forecasting financial markets are a challenging activities for both investors and researchers equally. Generally, financial markets are extremely manipulated by a number of factors such as interest rates, political issues, inflation rates and foreign exchange rates. More precisely, the uncertainty of stock markets produces high volatility that makes the forecasting stage very complex. Volatility forecasting is an important financial matter, and a precise and accurate volatility forecast is important to traders, investors and financial analysts. Before the 1980s, researchers were relying on ARIMA models, however, many financial time series violate the assumptions of the ARIMA model (cf.
Brockwell and Davis 2016;
Teräsvirta 2009).
Fortunately,
Engle (
1982) suggested a stationary non-linear model for economical time series and introduced the Autoregressive Conditionally Heteroscedastic (ARCH) model, wherein the conditional variance of a series
changes according to an autoregressive-type process. Subsequently,
Francq and Zakoïan (
2012);
Grublytė et al. (
2017) discussed the properties of maximum likelihood (MLE) and ordinary least squares (OLS) estimates of ARCH model parameters. They also investigated the consistency and the asymptotic normality of the OLS estimator for the ARCH model.
In this article, we are interested in estimating the parameter vector of the ARCH model when some prior information is available in the form of potential linear restrictions on the parameters in the parameter space. Practically, an ample number of variables may be collected and included in the model in an initial stage. However, due to model complexity (in terms of both interpretation and variation), estimation when a subset of parameters are under linear restrictions is an important problem in such scenarios. In order to form such constraints, one requires some prior information about the parameter space under consideration. One possible source of prior information may be distinguishing which predictors are of most interest and which are not. An alternative source of prior information, specifically uncertain prior information (UPI), might be obtained from previous studies or expert knowledge that search for some specified patterns.
This paper is organized as follows:
Section 2 discuss the recent findings of modeling time series data using ARCH family models.
Section 3 discusses the parameters’ estimation of the ARCH model.
Section 4 is dedicated to introducing the concept of restricted, pretest and shrinkage estimations of the ARCH model. We derive the asymptotic properties of the estimators and compare their performances using risk analysis and the mean squared error in
Section 5. We conduct an extensive simulation study for our selected model and demonstrate the application of the proposed estimators in real-life problems in
Section 6. In
Section 7 we give some conclusions.,
2. Literature Review
Various studies have investigated the dilemma of having a financial time series with high volatility. For instance,
Peiris and Peiris (
2011) examined the volatility of different sectors in the Colombo Stock Exchange (CSE) and they applied ARCH/GARCH models on the monthly time series data of 20 sectors in CSE from 2005 to 2010. They investigated the impact of macroeconomic factors on volatility. As a result, they found that sixteen out of twenty sectors in CSE had significant volatility and both ARCH and GARCH terms on the fitted models for individual sectors were significant. Subsequently,
Rathnayaka et al. (
2013) carried out a study to understand the trends and cyclic patterns in CSE in order to predict future behaviors during seven years since January 2007. They investigated the causal relationships between market performances and economic growth conditions related to Sri Lanka. Their results revealed that both microeconomic and macroeconomic conditions had a direct impact on stock market volatility.
Recently,
Wang (
2021) utilized GARCH models to analyze Bitcoin’s returns and volatility. As the GARCH (1,1) model was adopted, the outcome found that the returns and volatility of Bitcoin have clustering characteristics and returns and the volatility of Bitcoin is a persistent process; however, its effect gradually reduces with time. To overcome the limitations of the GARCH (1,1) model, researchers had used TARCH and EGARCH models to overcome the
Leverage Effect of the returns and volatility of Bitcoin.
In practice, regression models usually do not possess a pre-defined UPI; thus, model selection criterion such as
Akaike’s Information Criterion (AIC)
Akaike (
1974),
Bayesian Information Criterion (BIC)
Schwarz (
1978) or any other technique can be used to construct a sub-model. Now, it is up to the practitioner to use a sub-model based on fewer predictors (under-fitted model) or to lean towards a so-called full or over-fitted model. Alternatively, one may utilize the prior information to test whether some parameters are indeed zero, or more generally, whether the full vector of parameters are under linear restrictions. To do this, we will explore the pretesting strategy to improve the post-estimation inference of the ARCH model. Furthermore, we will implement the use of the Stein-type shrinkage estimator as an alternative to pretesting which shrinks the full model estimator in the direction of the restrictions. This leads to more efficient estimators when the shrinkage is adaptive. In the first stage, we select a sub-model by variable selection method or impose a linear restriction on the parameter space to obtain a submodel. In the second stage, we combine the sub-model with the full model via a test statistic to improve the estimation efficiency.
Many studies have considered incorporating the UPI in the estimation process to obtain efficient estimators for many statistical models. Recently,
Ahmed et al. (
2015) proposed efficient estimators for the regression coefficients of the spatial conditional autoregressive model under the availability of uncertain auxiliary information about these coefficients.
Al-Momani et al. (
2016) proposed shrinkage and penalty estimators for the spatial error model.
Thomson et al. (
2016) investigated the relative performances of pretest and shrinkage estimators for time series following generalized linear models. In all these cases, shrinkage estimators outperformed classical estimators.
Dawod et al. (
2018) introduced Bayesian estimation strategies for jointly monitoring the linear profile.
Al-Momani et al. (
2019) proposed the use of the pretest, shrinkage and positive shrinkage in estimating the large-scale regression parameter vector in the spatial moving average and showed that the positive shrinkage dominated all other estimators in terms of the relative efficiency of the mean squared error with respect to the classical maximum likelihood estimator. For more details, the reader is referred to (
Ahmed and Raheem 2012;
Emmert-Streib and Dehmer 2019;
Yüzbaşı and Ahmed 2020;
Ejaz Ahmed and Yüzbaşı 2016,
2017;
Ahmed 2014) for detailed information on the subject.
3. Estimating ARCH(q) Parameters
Following
Francq and Zikoïan (
2010), we introduce the ARCH model and consider the existence of a strictly stationary solution to this model.
where
is the error term, independently and identically distributed with a mean 0 and variance 1,
,
,
are unknown constants, ∀
i = 1, …,
q and
j = 1, …,
p, and
.
If the ARCH(q) model holds the conditions and , then the uniquely strictly stationary solution of the model is a weak white noise.
The Ordinary Least Squares (OLS) method will be used to estimate the parameters of ARCH(q). The OLS method uses the autoregressive representation on the squares of the observed process and no distributional assumptions are needed for the error term ().
The autoregressive AR(q) representation can be obtained by applying some mathematical transformations as follows
where
is the sequence containing a martingale difference when
, denoting by
the
-field generated by {
}.
By substituting
from Equation (
3) in Equation (2), we obtain
The true parameter will be denoted by , where .
Assuming that we observe
, observations of length
n from a process
and considering
as initial values of the process, these initial values can be chosen to be zeros. By introducing the vector
, we can rewrite Equation (
4) as a linear system as follows
and in a matrix format as
where
.
3.1. Estimation of the Parameter
Assuming
X is of full rank,
is invertible, and the OLS estimator is given by
In the forthcoming sections, we will refer to this estimator as unrestricted estimator (UE) or simply by .
3.2. Estimation of
Assuming that follows normal distribution with mean 0 and variance and with the following conditions:
is non-anticipative strictly stationary solution of the model in Equation (
1).
.
P.
.
Then,
is estimated by
, where
where
are estimated by Equation (
7).
3.3. Estimation of the Information Matrices
Accordingly,
Francq and Zikoïan (
2010) define
A and
B as
,
respectively, where
Then, the estimates of
A and
B are respectively, given by
where
. The fourth-order moment of the process
is
; that is also consistently estimated by
.
3.4. Asymptotic Distribution of OLS Estimator
Weiss (
1986) was the pioneer who discussed the properties of maximum likelihood and the least squares estimates of the parameters of both the regression and ARCH models in parallel with the properties of various tests of the model that are available. He did not assume that the errors are normally distributed.
Rich et al. (
1991) introduced another attractive way to estimate the parameters of the ARCH model without assuming normality condition. They used the generalized method of moments of
Hansen (
1982) and showed that, under fairly weak conditions, the estimator is consistent and asymptotically normally distributed.
Francq and Zikoïan (
2004,
2012) proved the consistency and asymptotic normality of OLS. In this subsection, we list two theorems by
Francq and Zikoïan (
2010) about the consistency and asymptotic normality of the OLS estimator for
.
Theorem 1 (
Francq and Zikoïan 2010).
Consistency of OLS estimates: If is a sequence of estimators satisfying the OLS solution for ARCH under the assumptions (1)–(4) in Section 3.2, thenas is a consistent estimator for θ and where p denotes convergence in probability. Theorem 2 (
Francq and Zikoïan 2010).
Referring to A and B given in Equations (9) and (10), we havewhere , has asymptotic multivariate normal distribution and L denotes convergence in distribution. 4. Efficient Estimation Strategies
Usually in the case of the corresponding model is recognized as a full model because all parameters are included even though some of them may not have a significant effect. In this section, we will consider different estimation methods of when some UPIs are available.
4.1. Restricted Estimator
UPI(s) can be formulated as a linear hypothesis in which some of the given parameters are zeros or there is a restriction on some parameters. Then, the estimated parameters under such UPI is known as the restricted estimator (RE) and is simply denoted by . The derivation idea of this estimator is given below:
Suppose that the UPI is formulated in the form of the null hypothesis:
where
R is
known matrix of rank(m) (
) (cf.
Neter et al. 1996) and
r is an
vector of known constants.
Under the restrictions given in Equation (
13), the method uses the Lagrange Multiplier for each restriction. The method minimizes the following function,
with respect to
and
to obtain the restricted estimator. This estimator is denoted by
and defined by
given by Equation (
15) is a biased estimator for
unless the restriction given in Equation (
13) is true.
Theorem 3. The Wald test statistic for testing the hypothesis in Equation (13) is given bywhere is estimated in Equation (8) and it can be shown that . We will use as a level of significance for testing purposes.
4.2. Pretest Estimator
The pretest estimate of
denoted by
is defined by:
where
is given in Equation (
16) and
is the
-critical value from the distribution. For more details, the reader can refer to
Bancroft (
1944);
Saleh (
2006);
Stein (
1956).
The pretest estimator is a binary choice function which chooses if the null hypothesis is rejected and if the test fails to reject the null hypothesis.
can be rewritten in a more attractive way as follows:
where
I(
A) is the indicator function of the set
A.
4.3. Shrinkage Estimator
The shrinkage estimator of
Stein (
1956) denoted by
is defined by:
It is clear that is no longer a binary choice regardless of whether is rejected. The shrinkage estimator is a smoothed function of the two choices. does not represent a convex combination of and and suffers from a phenomenon known as over-shrinkage which occurs when is smaller than () and hence, an unexpected sign for some of the estimated parameters may be obtained.
4.4. Positive Shrinkage Estimator
A modified version of James–Stein estimator was proposed by
Stein (
1966) to overcome the phenomenon of the over-shrinkage estimator known as the positive part shrinkage estimator. This estimator is denoted by
and defined as:
where
.
5. Asymptotic Results
In this section, we will study the asymptotic behavior of the proposed estimators . We will show that the restricted and unrestricted estimators are jointly asymptotically normal. In addition, we will define and extract expressions for the asymptotic distributional quadratic bias and the asymptotic quadratic risk of the estimators relying on the joint normality of and .
5.1. Joint Normality of the Unrestricted and Restricted Estimators
The asymptotic distribution of all the estimators under hypothesis (
13) are the same. Hence, we will study the asymptotic properties under a class of local alternatives that is given by
where
is a
fixed vector in
. If we set
, the local alternative becomes as in (
13) which is a linear hypothesis representing the candidate null subspace.
Some distributional results involving the estimators and are given in the following theorem.
Theorem 4. Under the local alternatives in (21) and the regularity conditions (1)–(4) appearing in Section 3.2 and assuming thatas and C is a positive definite matrix (p.d.m), then we havewhere Proof. The proof of the theorem is located in the
Appendix A. □
5.2. Asymptotic Bias and Quadratic Bias
Assuming local alternatives in (
21), and under the assumptions of Theorem (4), the asymptotic distributional bias
and the quadratic bias
where
are given in the following theorem.
Theorem 5. Under the assumptions of Theorem (4) and the local alternatives in (21), we havewhere is the non-centrality parameter and is the non-central chi-square distribution function with q-degrees of freedom and non-centrality parameter . 5.3. Quadratic Weighted Risks
For any estimator
of
, define the quadratic loss as
where
W is a positive semidefinite matrix of order
, and
is the trace of the matrix
A.
The asymptotic mean squared error matrix
is given by
and the asymptotic quadratic risk (AQR) is defined as
The asymptotic weighted quadratic risk expressions are given in the following Theorem.
Theorem 6. Under the assumptions of Theorem 4, we haveThe proof can be found in Appendix C. 5.4. Risk Analysis of the Estimators
In this section, all estimators will be compared based on their asymptotic quadratic risk. We will not carry out all derivations; instead, we will give a summary of our results as follows:
- i.
Comparison of
and
: The risk of
is constant, whereas the risk of
depends on
; hence, the difference in their risks is
where
is a symmetric idempotent matrix with rank
(≤
q). Therefore, by Courant’s theorem—see
Saleh (
2006)—there exists an orthogonal matrix
such that
and
Then
where
By Courant’s theorem, see
Saleh (
2006), we have
where
are, respectively, the minimum and the maximum characteristic roots of
, and
, so,
performs better than
when
whereas
performs better than
whenever
- ii.
Comparison of
and
:
performs better than
when
where the opposite holds whenever
- iii.
Comparison of
and
:
performs better than
whenever
Note that involves the matrix W, hence, dominates . As , the risk difference approaches 0 from below.
- iv.
Comparison of and : The risk difference is non-negative for all so we have As a result, we can conclude that which means that uniformly dominates the unrestricted estimator.
6. Numerical Studies
In this section, we will carry out a numerical study to investigate the performance of the proposed estimators. In the first subsection, we aim to examine the relative performance of the restricted, pretest and shrinkage estimators while appointing the unrestricted estimator as a benchmark for comparison. A real dataset from the S&P500 stock market will be used to compare the performance of the estimators to confirm the analytical results obtained in the previous section.
6.1. Monte Carlo Simulation Experiments
The Monte Carlo simulation experiments will be conducted to compare the restricted, pretest and shrinkage estimators with respect to the unrestricted estimator. The following algorithm is used for the Monte Carlo simulation
We consider the model in Equation (
5), we partition
as
, where
is a
of non-zeros and
is
vector of zeros. We define the parameter
where
,
and
denotes the Euclidean norm.
values were chosen to vary from 0 to
and
and 15.
Generate an error term () from standard normal distribution.
Generate the matrix of size with initial values estimated from standard normal distribution with and 150.
Estimate a matrix .
Estimate the vector
Estimate the unrestricted, restricted, pretest, shrinkage and positive shrinkage estimators.
Compute the simulated mean squared errors (SMSE) for each estimator using the following formula
where
denotes any one of {
}.
Repeat steps (2)–(7) K times. We found that is a suitable choice to obtain stable results.
Compute the simulated relative efficiency (SRE) as follows
where
is appointed as benchmark. A value greater than one of the
indicates that
performs better than
and vice versa.
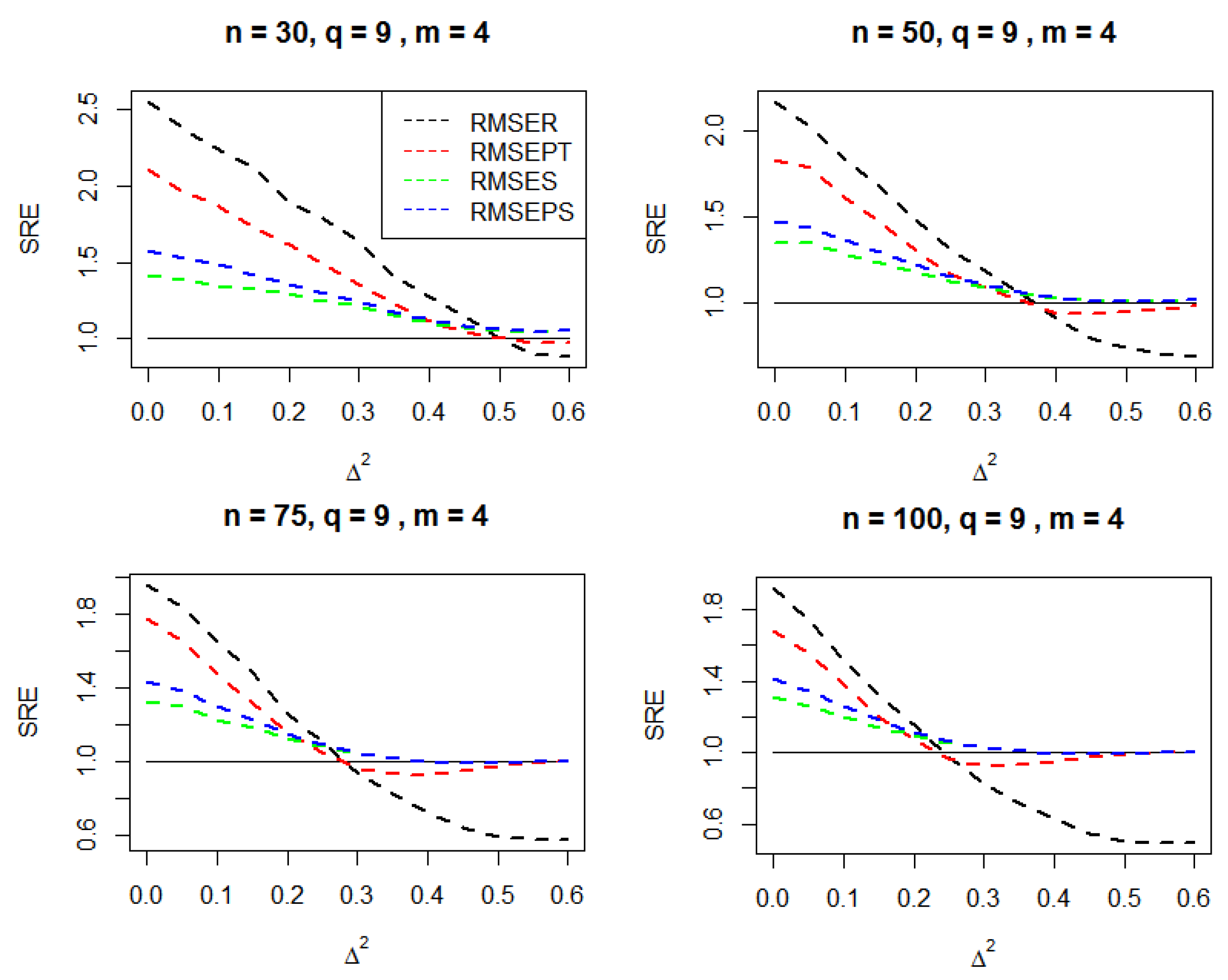
Results of these simulations are reported in
Figure 1,
Figure 2,
Figure 3 and
Figure 4. The numerical results effectively assure our analytical results that the positive shrinkage estimator plays the role of a safeguard against the high risks associated with the reduced model that we obtained under the set of local alternatives.
shows the best performance under the null space and it degrades towards zero as the value of
goes way from the null space.
As the value of increases, the superiority changes from to and , respectively, and dominates other estimators, because it acts as a safeguard against the high risks associated with the reduced model.
6.2. Application on Standard & Poor 500 (SP500) Stock Market
The “sp500dge” dataset contains daily closing prices of the Standard & Poor 500 (SP500) stock market that has been used by
Ding et al. (
1993). The dataset is also available in
fGarch/R-package produced by
Wuertz and Chalabi (
2008). Following the illustrative example of
Ding et al. (
1993), we considered the most recent returns as our targeted subset from 3 December 1988 to 30 August 1991. This contains 1000 daily returns (i.e., the official working days in the financial market is 252).
To fit the ARCH model, we first conducted a Lagrange–Multiplier (LM) test to check the effect of ARCH; more details about this test can be found in
Tsay (
2005). Then, we fit an ARCH model with an adequate order. The order
is an adequate selection for our data which represents the full model that given by Formula (
30).
is then obtained by fitting the full model.
In order to obtain the UPI from the data, we used AIC and BIC selection criteria to pick the significant order under the forward selection strategy the selected order under the auxiliary information of AIC and BIC represents the reduced model given by Formula (
31). Consequently, from the reduced model, we compute
, the restricted estimator.
To assess the performance of the estimators, we use the relative efficiency of the mean squared error (RMSE) with respect to the true parameters
which will be estimated by
, where
can be any of the estimators. The approach is based on the bootstrapping method which is similar to that introduced by
Freedman (
1981).
After fitting the full model on the original data, the procedure is conducted in two steps. The first step is as follows:
Select a sample of size n from the residuals of the full model, say with replacement.
Compute the observations
as follows
where
is the
ith fitted observation from the full model applied on the original data, and
is the
ith residual in (1).
Fit the ARCH model on to obtain .
Repeat steps (1)–(3) a number of times K until stable results are obtained—we found that worked well.
Compute the average of K iterations which will represent the true parameter .
After the true parameters’ vector has been estimated in the previous step, the second step is conducted as follows:
Select a sample of size n from the residuals of the full model, say with replacement.
Compute
as follows
where
is the
ith fitted observation from the full model applied on the original data and
is the
ith residual in (1).
Fit both the full and reduced models and compute and , then obtain , and .
Compute the predicted values
using the estimated parameters of all estimators
where
Compute the Bootstrapping Mean Squared Error (MSEB) of
the estimator
as follows:
Repeat steps (1)–(5) a number of times K until stable results are obtained. We found that is an adequate number of iterations.
Compute the relative efficiency of the mean squared error (RMSE) as follows,
Results of the RMSEs for our data are reported in
Table 1.
It is clear that outperforms all other estimators which indicates that the restriction given by the null hypothesis is correct. comes the second and then it is . performs better than even though it was the worst among other estimators. This may be an indication that the AIC/BIC selection criteria worked quite well on this dataset.
7. Conclusions
In this article, we investigated the performance of the pretest and James–Stein (shrinkage) estimators to estimate the parameter’s vector of the ARCH model. These estimators were first analytically compared via their asymptotic quadratic risk and asymptotic mean square error matrices and then numerically compared using simulated and real datasets to confirm our analytical results. However, the reduced model in some cases might not be the right choice: analytical and numerical results showed that the pretest and James–Stein estimators represent a safeguard against the high risks associated with the reduced model that we obtain under the set of local alternatives.
Historically, the ARCH model is the simplest version of ARCH family models; however, its drawback is that it requires many parameters to adequately describes the volatility of such phenomena, and the positive James–Stein estimator should successfully overcome this dilemma by providing a parsimonious submodel (reduced model). To obtain a UPI, we used AIC and BIC selection criteria to select the reduced model.
According to our research findings, it is recommended that the positive James–Stein estimator is used as it outperforms all other estimators regardless of whether the restriction given by the null hypothesis is true. In addition, the proposed estimation strategy can be applied to different ARCH family models.
Author Contributions
Conceptualization, A.B.A.D. and M.A.-M.; methodology, A.B.A.D. and M.A.-M.; software, A.B.A.D.; formal analysis, A.B.A.D.; investigation, M.A.-M.; writing—original draft, A.B.A.D.; writing—review and editing, A.B.A.D. and M.A.-M.; supervision, M.A.-M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used in the real example part can be found in fGarch/R-package, as produced by
Wuertz and Chalabi (
2008).
Acknowledgments
The authors thank the Academic Editor and and the three reviewers for their valuable comments and suggestions which significantly improved the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 4
- (1)
- (2)
where
I is the identity matrix.
is a linear combination in
that can be represented in a matrix format as
where
and
are given as follows
From Theorem 4 part (1), as
and by Slutsky’s Theorem,
with
and
which are given by
and
Similarly, we can prove Formulas (1)–(6).
Appendix B. Proof of Theorem 5
The proof of Formulas (1) and (2) are straightforward.
- (3)
As
, with Slutsky’s theorem, we have
and
, then,
Similarly, we can prove Formulas (4) and (5).
Appendix C. Proof of Theorem 6
- (1)
Part (1) is straightforward.
- (2)
Note that
Then, by Theorem 4 part (2), we have
Similarly, Formulas (3)–(5) can be proven.
References
- Ahmed, S. Ejaz, Abdulkadir Hussein, and Marwan Al-Momani. 2015. Efficient estimation for the conditional autoregressive model. Journal of Statistical Computation and Simulation 85: 2569–81. [Google Scholar] [CrossRef]
- Ahmed, S. Ejaz, and Bahadır Yüzbaşı. 2016. Big data analytics: Integrating penalty strategies. International Journal of Management Science and Engineering Management 11: 105–15. [Google Scholar] [CrossRef]
- Ahmed, S. Ejaz, and Bahadır Yüzbaşı. 2017. High dimensional data analysis: Integrating submodels. In Big and Complex Data Analysis. Cham: Springer, pp. 285–304. [Google Scholar]
- Ahmed, S. Ejaz, and Enayetur Raheem. 2012. Shrinkage and absolute penalty estimation in linear regression models. Wiley Interdisciplinary Reviews: Computational Statistics 4: 541–53. [Google Scholar] [CrossRef]
- Ahmed, S. Ejaz. 2014. Penalty, Shrinkage and Pretest Strategies: Variable Selection and Estimation. Berlin and Heidelberg: Springer. [Google Scholar]
- Akaike, Hirotugu. 1974. A new look at the statistical model identification. IEEE Transactions on Automatic Control 19: 716–23. [Google Scholar] [CrossRef]
- Al-Momani, Marwan, Abdulkadir Hussein, and S. Ejaz. Ahmed. 2016. Penalty and related estimation strategies in the spatial error model. Statistica Neerlandica 71: 4–30. [Google Scholar] [CrossRef] [Green Version]
- Al-Momani, Marwan, Syed Ejaz Ahmed, and Abdul A. Hussein. 2019. Efficient Estimation Strategies for Spatial Moving Average Model. In BiometricsProceedings of the Thirteenth International Conference on Management Science and Engineering Management. Cham: Springer, pp. 520–43. [Google Scholar]
- Bancroft, Theodore Alfonso. 1944. On biases in estimation due to the use of preliminary tests of significance. The Annals of Mathematical Statistics 15: 190–204. [Google Scholar] [CrossRef]
- Brockwell, Peter J., and Richard A. Davis. 2016. Introduction to Time Series and Forecasting. New York: Springer. [Google Scholar]
- Dawod, Abdaljbbar, Marwan Al-Momani, and Saddam Akber Abbasi. 2018. On efficient estimation strategies in monitoring of linear profiles. The International Journal of Advanced Manufacturing Technology 96: 3977–91. [Google Scholar] [CrossRef]
- Ding, Zhuanxin, Clive W. J. Granger, and Robert F. Engle. 1993. A long memory property of stock market returns and a new model. Journal of Empirical Finance 1: 83–106. [Google Scholar] [CrossRef]
- Emmert-Streib, Frank, and Matthias Dehmer. 2019. High-Dimensional LASSO-Based Computational Regression Models: Regularization, Shrinkage, and Selection. Machine Learning and Knowledge Extraction 1: 359–83. [Google Scholar] [CrossRef] [Green Version]
- Engle, Robert F. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica: Journal of the Econometric Society 50: 987–1007. [Google Scholar] [CrossRef]
- Francq, Christian, and Jean-Michel Zikoïan. 2004. Maximum likelihood estimation of pure garch and arma-garch processes. Bernoulli 10: 605–37. [Google Scholar] [CrossRef]
- Francq, Christian, and Jean-Michel Zikoïan. 2010. Garch Models: Structure, Statistical Inference and Financial Applications. Hoboken: John Wiley & Sons. [Google Scholar]
- Francq, Christian, and Jean-Michel Zakoïan. 2012. Strict stationarity testing and estimation of explosive and stationary generalized autoregressive conditional heteroscedasticity models. Econometrica 80: 821–61. [Google Scholar]
- Freedman, David A. 1981. Bootstrapping regression models. The Annals of Statistics 9: 1218–28. [Google Scholar] [CrossRef]
- Grublytė, Ieva, Donatas Surgailis, and Andrius Škarnulis. 2017. Qmle for quadratic arch model with long memory. Journal of Time Series Analysis 38: 535–51. [Google Scholar] [CrossRef]
- Hansen, Lars Peter. 1982. Large sample properties of generalized method of moments estimators. Econometrica: Journal of the Econometric Society 50: 1029–54. [Google Scholar] [CrossRef]
- Neter, John, Michael H. Kutner, Christopher J. Nachtsheim, and William Wasserman. 1996. Applied Linear Statistical Models. Chicago: Irwin Chicago, vol. 4. [Google Scholar]
- Peiris, Ushan, and T. S. G. Peiris. 2011. Measuring stock market volatility in an emerging economy: Empirical evidence from the colombo stock exchange (CSE). In International Research Conference. Durgapur: University of Kelaniya-Sri Lanka. [Google Scholar]
- Rathnayaka, R. M., D. M. Seneviratne, and S. C. Nagahawatta. 2013. Statistical techniques approach for evaluating the market fluctuations; the case study in colombo stock exchange. In International Conference on Business & Information. Durgapur: University of Kelaniya-Sri Lanka. [Google Scholar]
- Rich, Robert W., Jennie Raymond, and John Scott Butler. 1991. Generalized instrumental variables estimation of autoregressive conditional heteroskedastic models. Economics Letters 35: 179–85. [Google Scholar] [CrossRef]
- Saleh, A. K. Md Ehsanes. 2006. Theory of Preliminary Test and Stein-Type Estimation with Applications. Hoboken: John Wiley & Sons, vol. 517. [Google Scholar]
- Schwarz, Gideon. 1978. Estimating the dimension of a model. The Annals of Statistics 6: 461–64. [Google Scholar] [CrossRef]
- Stein, Charles. 1966. An approach to the recovery of interblock information in balanced incomplete block designs. In Research Paper in statistics: Festschrift for J. Neyman. London: Wiley, pp. 351–66. [Google Scholar]
- Stein, Charles. 1956. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In Volume 1 Contribution to the Theory of Statistics, Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability. Berkeley: University of California Press, vol. 1, pp. 197–206. [Google Scholar]
- Teräsvirta, Timo. 2009. An introduction to univariate garch models. In Handbook of Financial Time Series. Berlin and Heidelberg: Springer, pp. 17–42. [Google Scholar]
- Thomson, T., S. Hossain, and M. Ghahramani. 2016. Efficient estimation for time series following generalized linear models. Australian & New Zealand Journal of Statistics 58: 493–513. [Google Scholar]
- Tsay, Ruey S. 2005. Analysis of Financial Time Series. Hoboken: John Wiley & Sons, vol. 48. [Google Scholar] [CrossRef]
- Wang, Changlin. 2021. Different garch models analysis of returns and volatility in bitcoin. Data Science in Finance and Economics 1: 37–59. [Google Scholar] [CrossRef]
- Weiss, Andrew A. 1986. Asymptotic theory for arch models: Estimation and testing. Econometric Theory 2: 107–31. [Google Scholar] [CrossRef] [Green Version]
- Wuertz, Diethelm, and Yohan Chalabi. 2008. fgarch: Rmetrics-Autoregressive Conditional Heteroskedastic Modelling, r Package Version 290.76. Available online: https://www.rmetrics.org (accessed on 3 April 2022).
- Yüzbaşı, Bahadır, and S. Ejaz Ahmed. 2020. Ridge Type Shrinkage Estimation of Seemingly Unrelated Regressions Furthermore, Analytics of Economic and Financial Data from “Fragile Five” Countries. Journal of Risk and Financial Management 13: 131. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}