Trend Prediction Classification for High Frequency Bitcoin Time Series with Deep Learning

Abstract
1. Introduction
2. Task Settings
2.1. Classification Problem
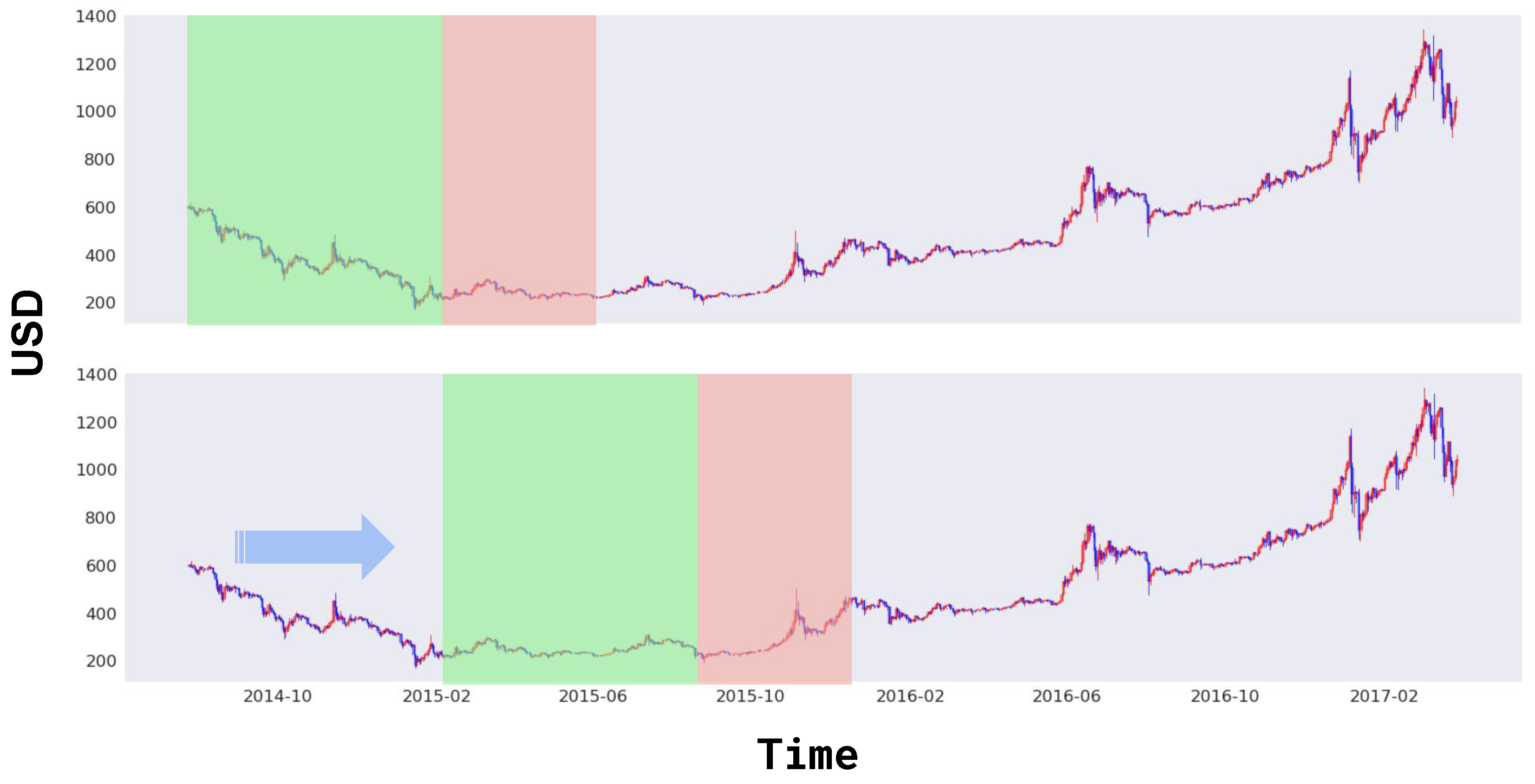
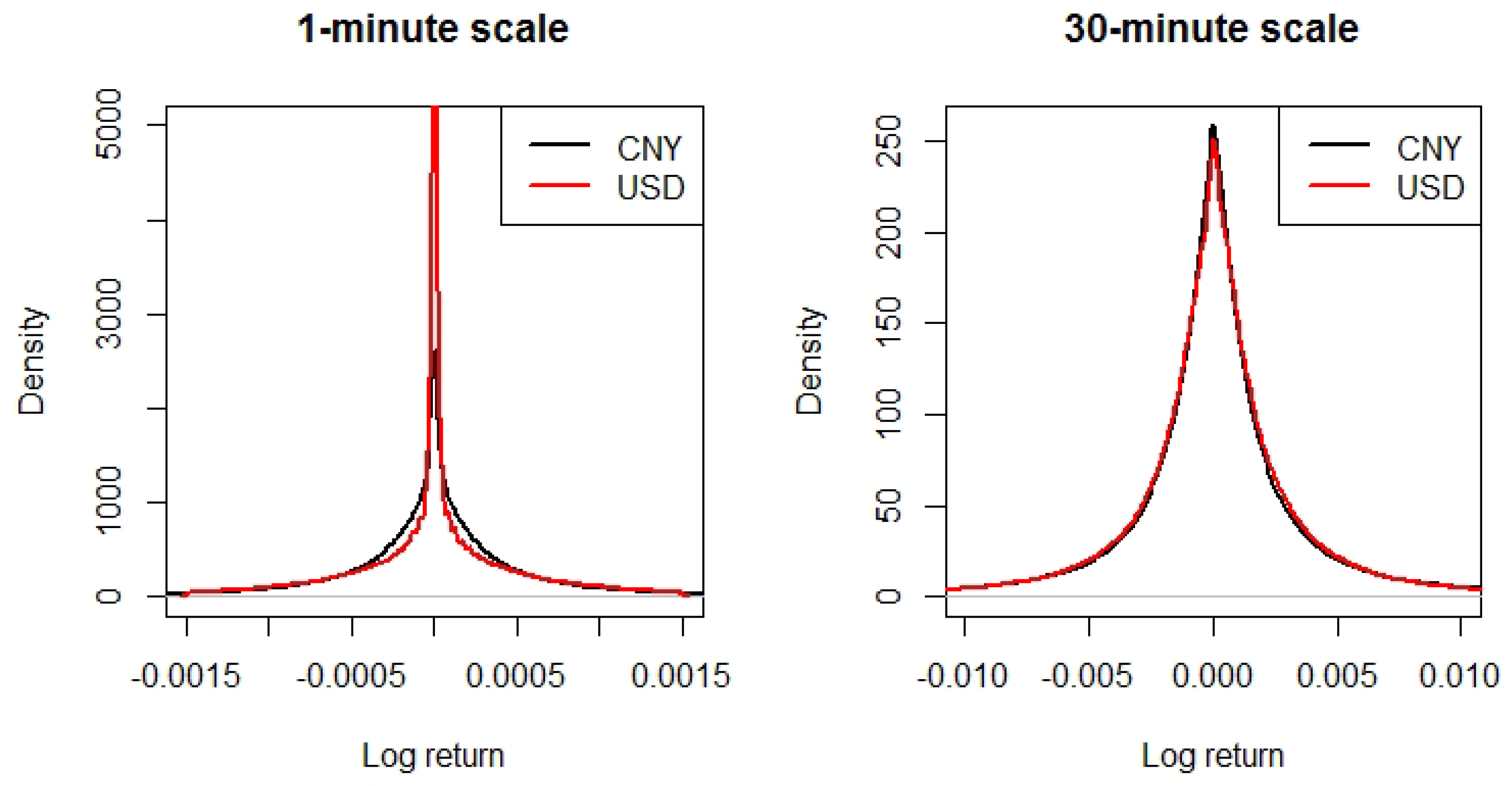
2.2. Non-Stationarity
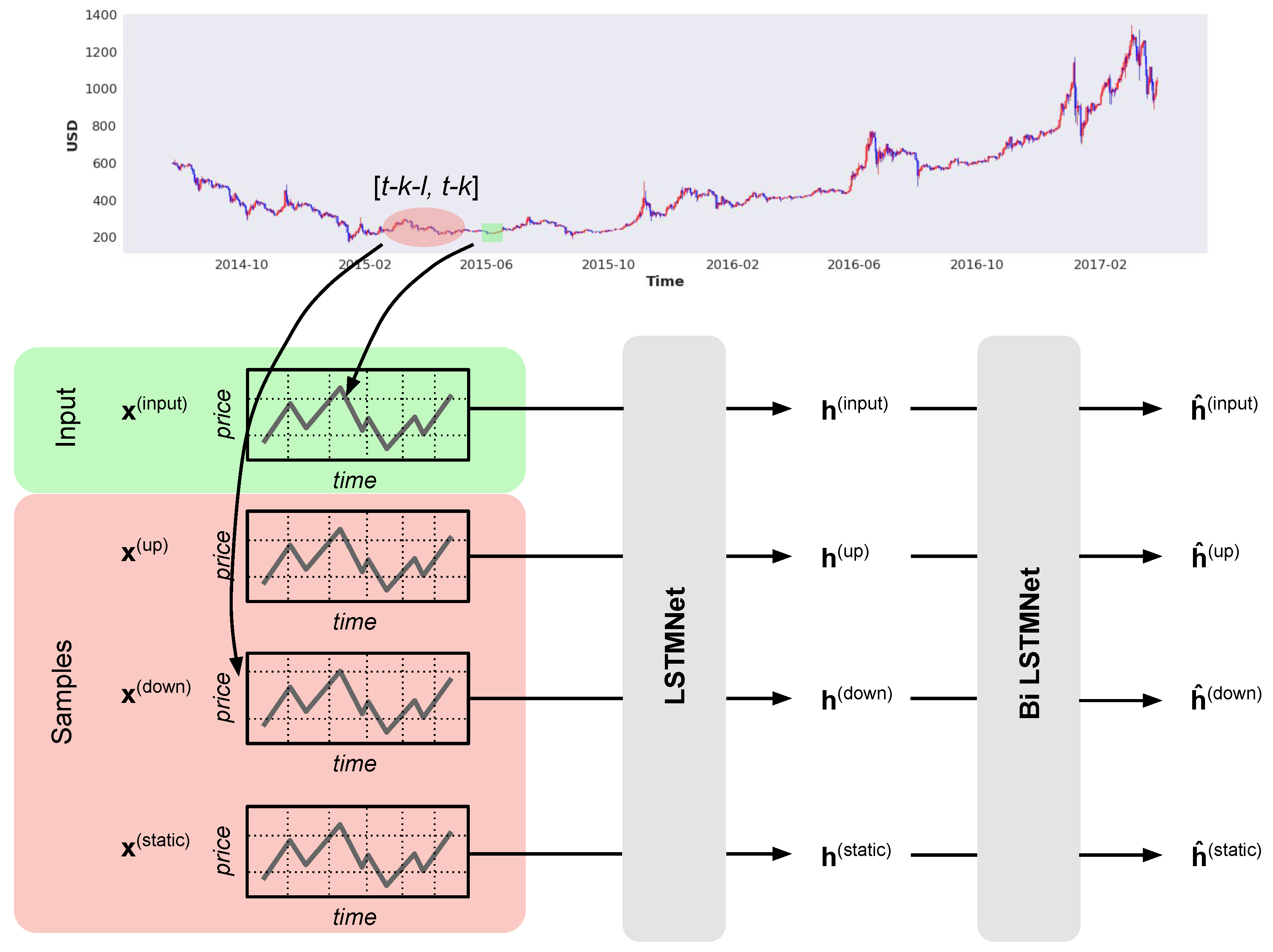
3. Random Sampling Method
3.1. Concept
3.2. Sampling Scheme
3.3. Encoder
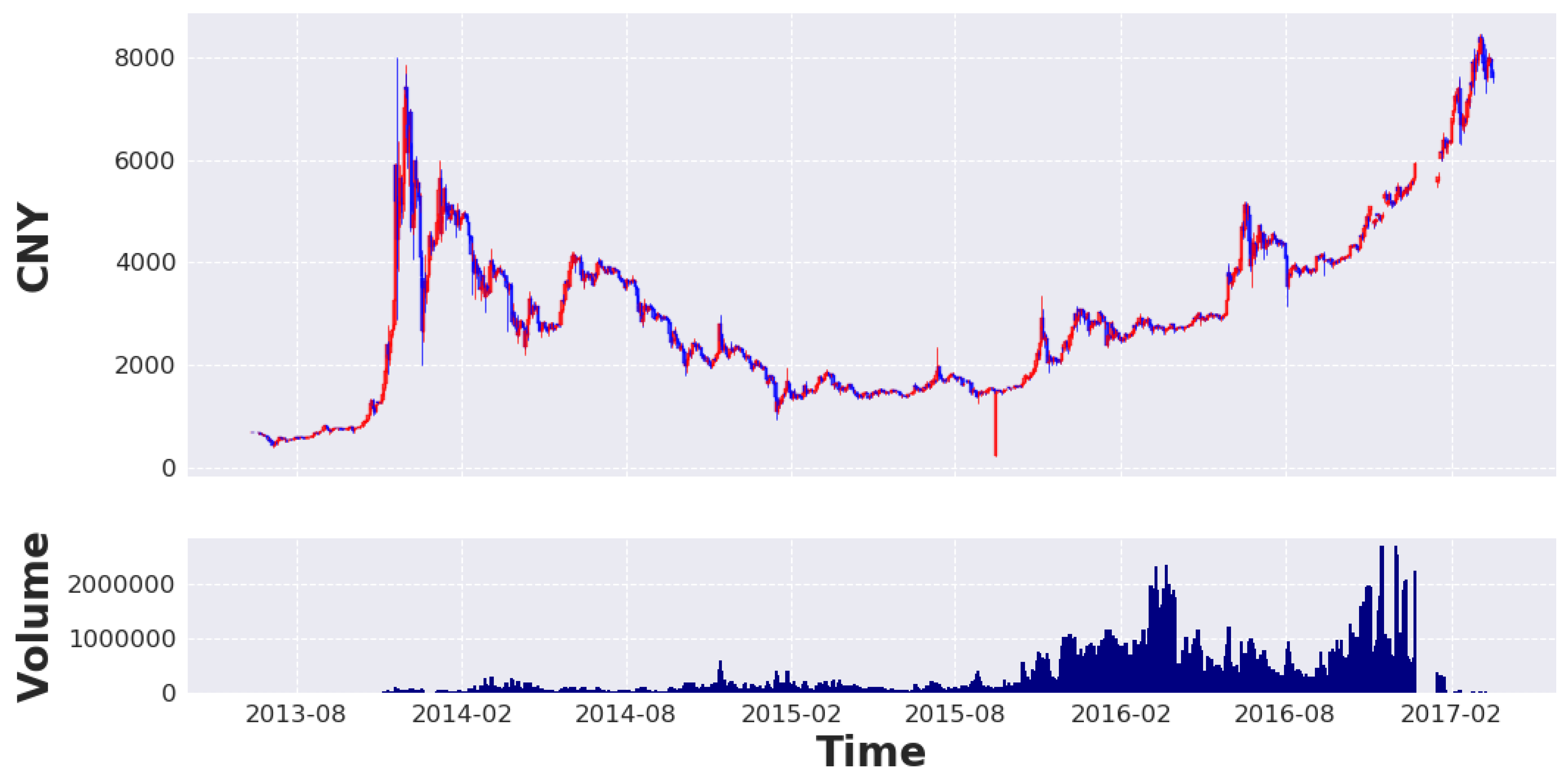
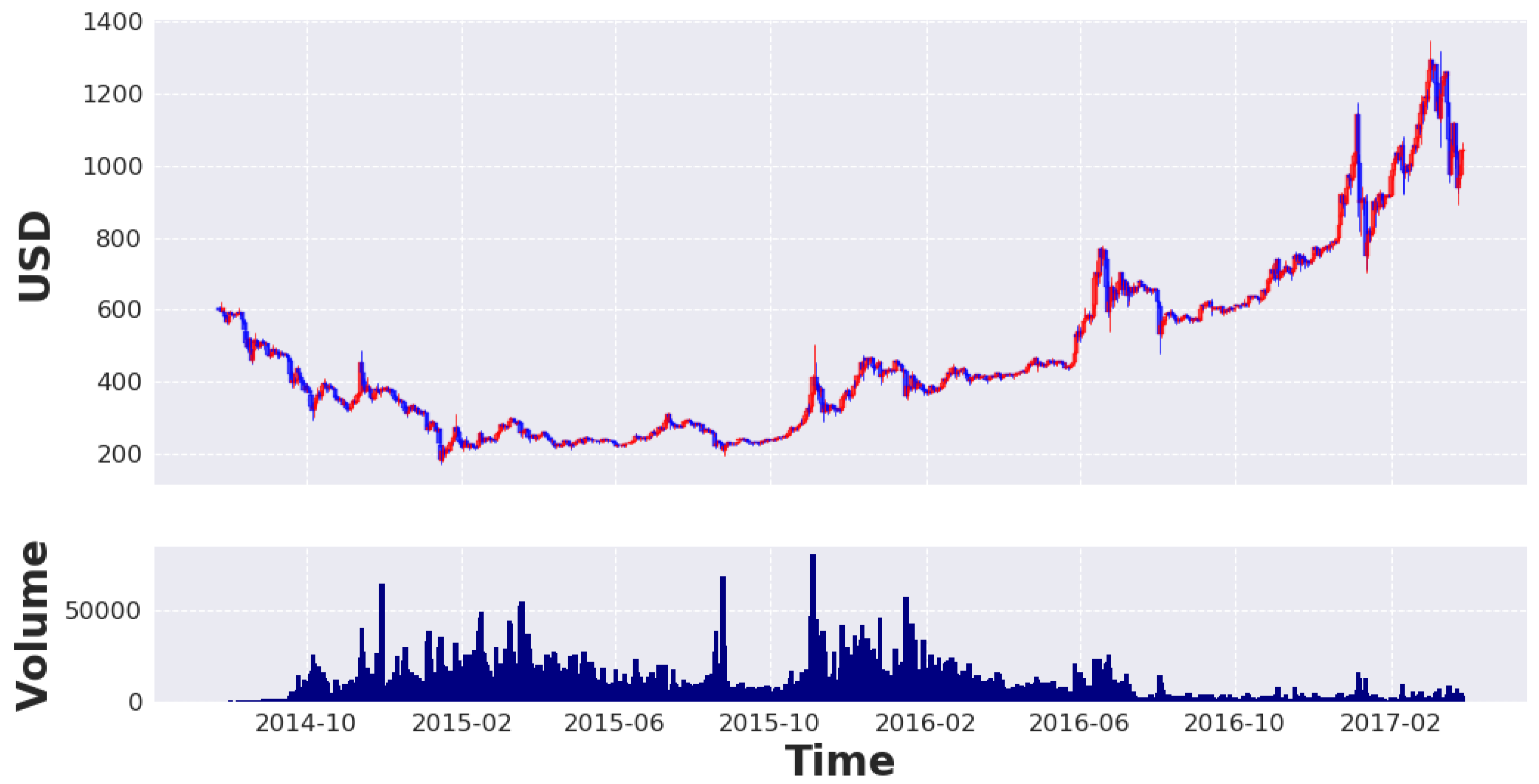
4. Dataset
5. Preprocessing of Data
5.1. Input
5.2. Target
6. Experiment
6.1. Settings
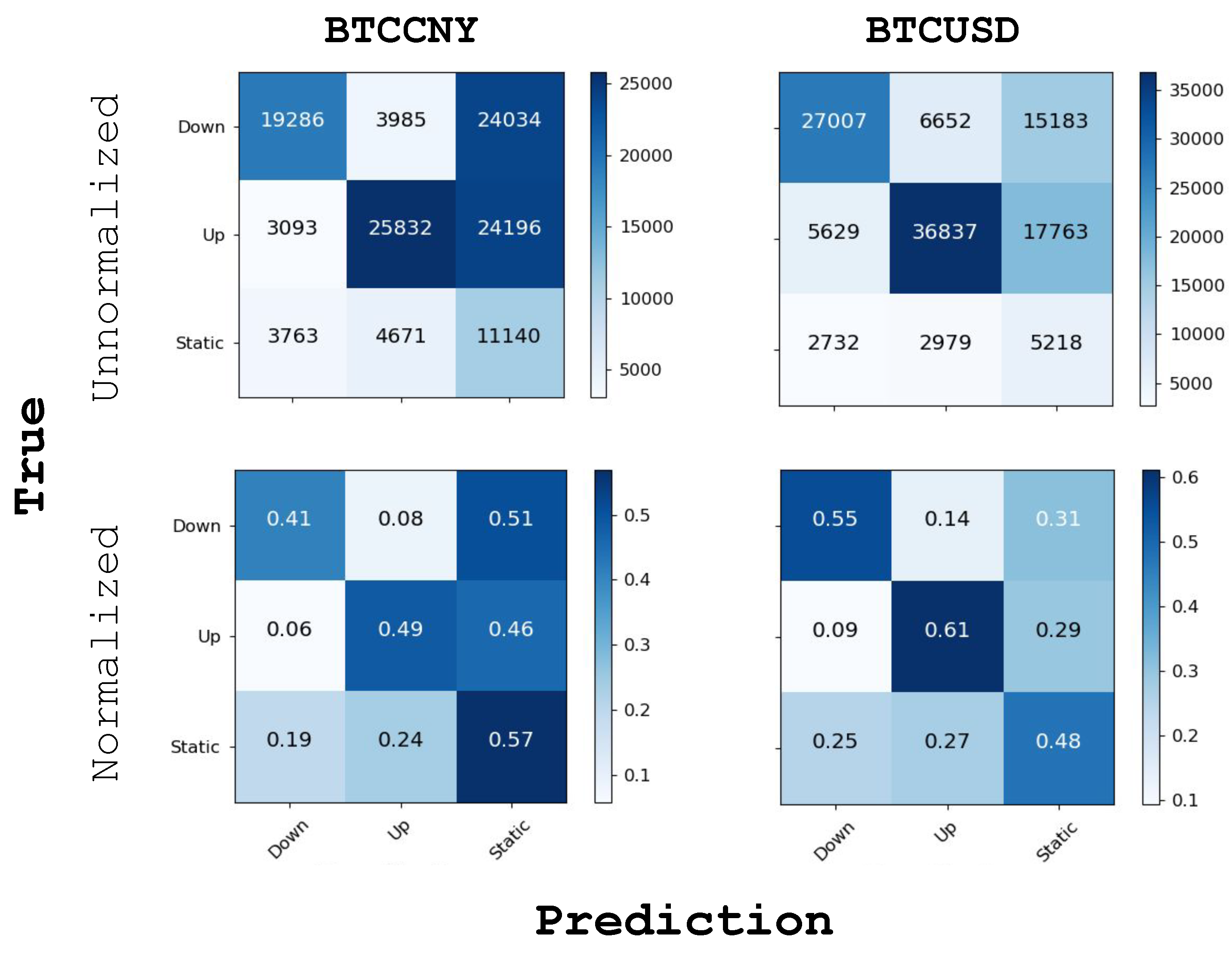
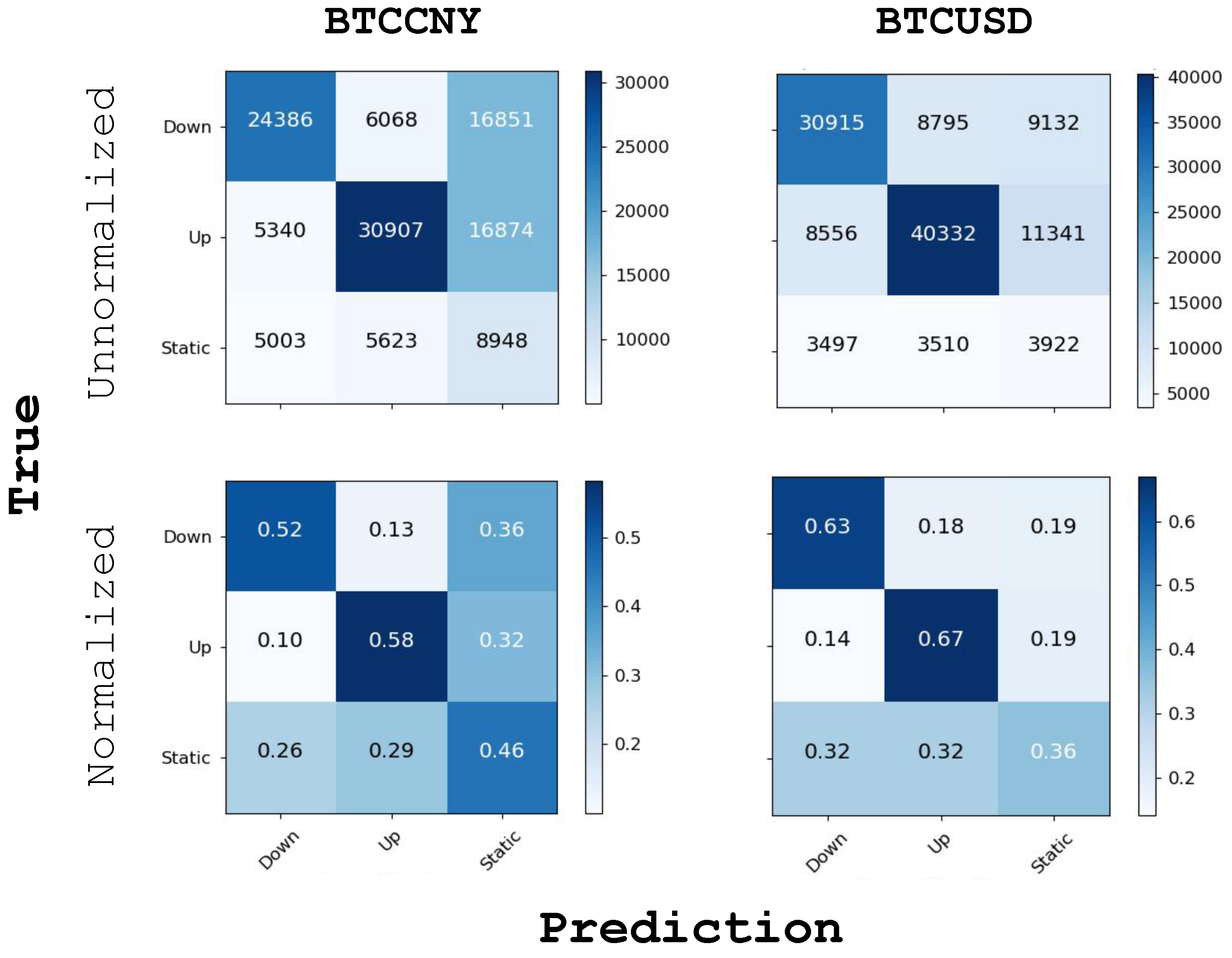
6.2. Trend Prediction
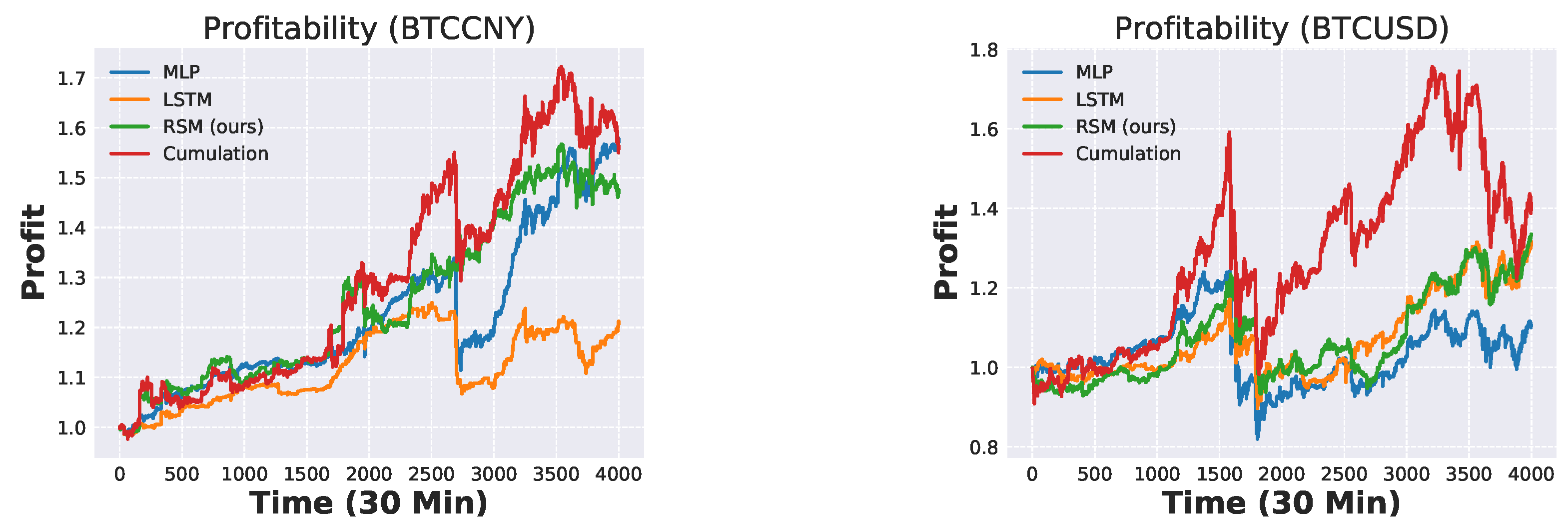
6.3. Profitability
6.4. Alternative Sampling Schemes
6.5. Universal Patterns
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
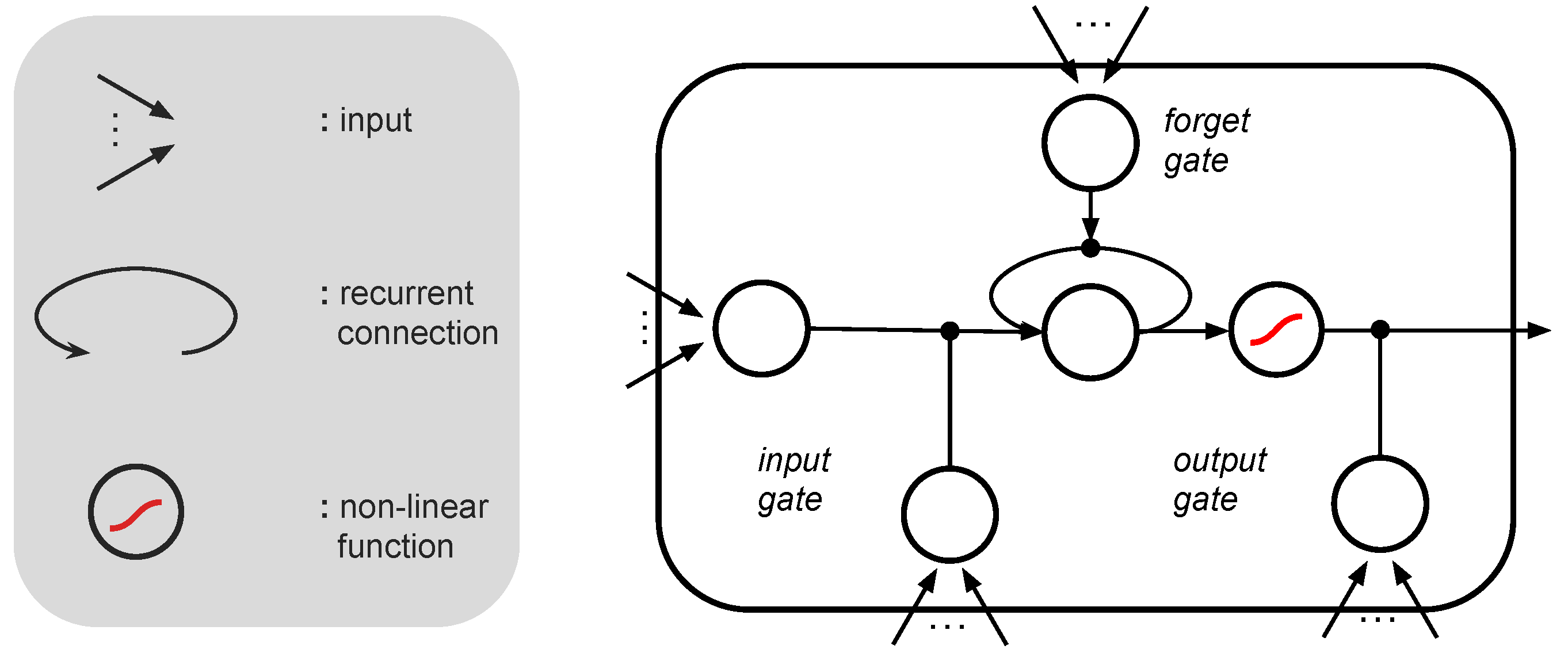
Appendix A. Long Short-Term Memory

References
- Andrychowicz, Marcin, Misha Denil, Sergio Gomez, Matthew W. Hoffman, David Pfau, Tom Schaul, Brendan Shillingford, and Nando De Freitas. 2016. Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Processing Systems. Cambridge: The MIT Press, pp. 3981–89. [Google Scholar]
- Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate. arXiv, arXiv:1409.0473. [Google Scholar]
- Bariviera, Aurelio F., Maria Jose Basgall, Waldo Hasperue, and Marcelo Naiouf. 2017. Some stylized facts of the bitcoin market. Physica A: Statistical Mechanics and its Applications 484: 82–90. [Google Scholar] [CrossRef]
- Cinbis, Ramazan Gokberk, Jakob Verbeek, and Cordelia Schmid. 2011. Unsupervised metric learning for face identification in tv video. Paper presented at the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, November 6–13; pp. 1559–66. [Google Scholar]
- Dixon, Matthew, Diego Klabjan, and Jin Hoon Bang. 2017. Classification-based financial markets prediction using deep neural networks. Algorithmic Finance 6: 67–77. [Google Scholar] [CrossRef]
- Gers, Felix A., Jürgen Schmidhuber, and Fred A. Cummins. 2000. Learning to forget: Continual prediction with lstm. Neural Computation 12: 2451–71. [Google Scholar] [CrossRef] [PubMed]
- Gkillas, Konstantinos, and Paraskevi Katsiampa. 2018. An application of extreme value theory to cryptocurrencies. Economics Letters 164: 109–11. [Google Scholar] [CrossRef]
- Gkillas, Konstantinos, Stelios Bekiros, and Costas Siriopoulos. 2018. Extreme Correlation in Cryptocurrency Markets. Available online: https://ssrn.com/abstract=3180934 (accessed on 14 January 2019).
- Glorot, Xavier, Antoine Bordes, and Yoshua Bengio. 2011. Deep sparse rectifier neural networks. Paper presented at the Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, April 11–13; pp. 315–23. [Google Scholar]
- Graves, Alex, Greg Wayne, and Ivo Danihelka. 2014. Neural turing machines. arXiv, arXiv:1410.5401. [Google Scholar]
- Greff, Klaus, Rupesh K. Srivastava, Jan Koutník, Bas R. Steunebrink, and Jürgen Schmidhuber. 2017. Lstm: A search space odyssey. IEEE Transactions on Neural Networks and Learning Systems 28: 2222–32. [Google Scholar] [CrossRef] [PubMed]
- Hilliard, Nathan, Lawrence Phillips, Scott Howland, Artem Yankov, Courtney D. Corley, and Nathan O. Hodas. 2018. Few-shot learning with metric-agnostic conditional embeddings. arXiv, arXiv:1802.04376. [Google Scholar]
- Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. Long short-term memory. Neural Computation 9: 1735–80. [Google Scholar] [CrossRef] [PubMed]
- Kingma, Diederik P., and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv, arXiv:1412.6980. [Google Scholar]
- Koch, Gregory. 2015. Siamese neural networks for one-shot image recognition. Paper presented at the 32 nd International Conference on Machine Learning, Lille, France, July 6–11. [Google Scholar]
- Koutmos, Dimitrios. 2018. Bitcoin returns and transaction activity. Economics Letters 167: 81–85. [Google Scholar] [CrossRef]
- Kristoufek, Ladislav. 2018. On bitcoin markets (in)efficiency and its evolution. Physica A: Statistical Mechanics and its Applications 503: 257–62. [Google Scholar] [CrossRef]
- Lake, Brenden, Chia-ying Lee, James Glass, and Josh Tenenbaum. 2014. One-shot learning of generative speech concepts. Paper presented at Annual Meeting of the Cognitive Science Society, Quebec City, QC, Canada, July 23–26, vol. 36. [Google Scholar]
- Lake, Brenden, Ruslan Salakhutdinov, Jason Gross, and Joshua Tenenbaum. 2011. One shot learning of simple visual concepts. Paper presented at Annual Meeting of the Cognitive Science Society, Boston, MA, USA, July 20–23, vol. 33. [Google Scholar]
- Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum. 2015. Human-level concept learning through probabilistic program induction. Science 350: 1332–38. [Google Scholar] [CrossRef] [PubMed]
- Li, Fe-Fei, Rob Fergus, and Pietro Perona. 2003. A bayesian approach to unsupervised one-shot learning of object categories. Paper presented at the 2003 Ninth IEEE International Conference on Computer Vision, Nice, France, October 13–16; pp. 1134–41. [Google Scholar]
- Li, Fei-Fei, Rob Fergus, and Pietro Perona. 2006. One-shot learning of object categories. IEEE Transactions on Pattern Analysis and Machine Intelligence 28: 594–611. [Google Scholar]
- Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. 2015. Effective approaches to attention-based neural machine translation. arXiv, arXiv:1508.04025. [Google Scholar]
- Mäkinen, Milla, Juho Kanniainen, Moncef Gabbouj, and Alexandros Iosifidis. 2018. Forecasting of jump arrivals in stock prices: New attention-based network architecture using limit order book data. arXiv, arXiv:1810.10845. [Google Scholar]
- Ravi, Sachin, and Hugo Larochelle. 2017. Optimization as a model for few-shot learning. Paper presented at International Conference on Learning Representations (ICLR), Toulon, France, April 24–26. [Google Scholar]
- Santoro, Adam, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. 2016. One-shot learning with memory-augmented neural networks. arXiv, arXiv:1605.06065. [Google Scholar]
- Schuster, Mike, and Kuldip K Paliwal. 1997. Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing 45: 2673–81. [Google Scholar] [CrossRef]
- Sirignano, Justin, and Rama Cont. 2018. Universal Features of Price Formation in Financial Markets: Perspectives From Deep Learning. Available online: https://ssrn.com/abstract=3141294 (accessed on 1 December 2018).
- Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems. Cambridge: The MIT Press, pp. 3104–12. [Google Scholar]
- Vinyals, Oriol, Charles Blundell, Timothy Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. 2016. Matching networks for one shot learning. In Advances in Neural Information Processing Systems. Cambridge: The MIT Press, pp. 3630–38. [Google Scholar]
- Wu, Yonghui, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, and et al. 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv, arXiv:1609.08144. [Google Scholar]
- Xing, Eric P., Michael I. Jordan, Stuart J. Russell, and Andrew Y. Ng. 2003. Distance metric learning with application to clustering with side-information. In Advances in Neural Information Processing Systems. Cambridge: The MIT Press, pp. 521–28. [Google Scholar]
- Yao, Yushi, and Zheng Huang. 2016. Bi-directional LSTM recurrent neural network for chinese word segmentation. arXiv, arXiv:1602.04874. [Google Scholar]
- Zhang, Zihao, Stefan Zohren, and Stephen Roberts. 2018. Deeplob: Deep convolutional neural networks for limit order books. arXiv, arXiv:1808.03668. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Recall | Precision | F1 Score | |
|---|---|---|---|---|
| MLP | 0.4766 | 0.4570 | 0.4822 | 0.4511 |
| LSTM | 0.4688 | 0.4877 | 0.5581 | 0.4657 |
| RSM (ours) | 0.5353 | 0.5182 | 0.5458 | 0.5092 |
| Accuracy | Recall | Precision | F1 Score | |
|---|---|---|---|---|
| MLP | 0.5559 | 0.4945 | 0.4978 | 0.4786 |
| LSTM | 0.5759 | 0.5464 | 0.5717 | 0.5034 |
| RSM (ours) | 0.6264 | 0.5538 | 0.5488 | 0.5367 |
| CNY | USD | |
|---|---|---|
| MLP | 1.5787 | 1.1055 |
| LSTM | 1.2124 | 1.3157 |
| RSM (ours) | 1.4761 | 1.3346 |
| Accuracy | Recall | Precision | F1 Score | |
|---|---|---|---|---|
| first week | 0.4031 | 0.4860 | 0.6076 | 0.4152 |
| global | 0.5364 | 0.5238 | 0.5503 | 0.5124 |
| Accuracy | Recall | Precision | F1 Score | |
|---|---|---|---|---|
| MLP | 0.4992 | 0.5004 | 0.5176 | 0.5005 |
| LSTM | 0.5475 | 0.5452 | 0.5668 | 0.5492 |
| RSM (ours) | 0.5746 | 0.5695 | 0.5762 | 0.5713 |
| Accuracy | Recall | Precision | F1 Score | |
|---|---|---|---|---|
| MLP | 0.4917 | 0.4927 | 0.5052 | 0.4905 |
| LSTM | 0.5242 | 0.5332 | 0.5752 | 0.5291 |
| RSM (ours) | 0.5526 | 0.5504 | 0.5637 | 0.5499 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shintate, T.; Pichl, L. Trend Prediction Classification for High Frequency Bitcoin Time Series with Deep Learning. J. Risk Financial Manag. 2019, 12, 17. https://doi.org/10.3390/jrfm12010017
Shintate T, Pichl L. Trend Prediction Classification for High Frequency Bitcoin Time Series with Deep Learning. Journal of Risk and Financial Management. 2019; 12(1):17. https://doi.org/10.3390/jrfm12010017
Chicago/Turabian StyleShintate, Takuya, and Lukáš Pichl. 2019. "Trend Prediction Classification for High Frequency Bitcoin Time Series with Deep Learning" Journal of Risk and Financial Management 12, no. 1: 17. https://doi.org/10.3390/jrfm12010017
APA StyleShintate, T., & Pichl, L. (2019). Trend Prediction Classification for High Frequency Bitcoin Time Series with Deep Learning. Journal of Risk and Financial Management, 12(1), 17. https://doi.org/10.3390/jrfm12010017