
StEduCov: An Explored and Benchmarked Dataset on Stance Detection in Tweets towards Online Education during COVID-19 Pandemic



Abstract
:1. Introduction
- A new dataset for stance detection. The dataset consists of 16,572 tweets containing user stances toward distance education during the COVID-19 pandemic.
- A thorough text analysis of the collected dataset. We implemented a set of text mining tasks, such as topic modelling, tweet classification and sentiment analysis.
- A comprehensive benchmarking using traditional machine learning and recent deep learning models for stance detection.
2. Related Work
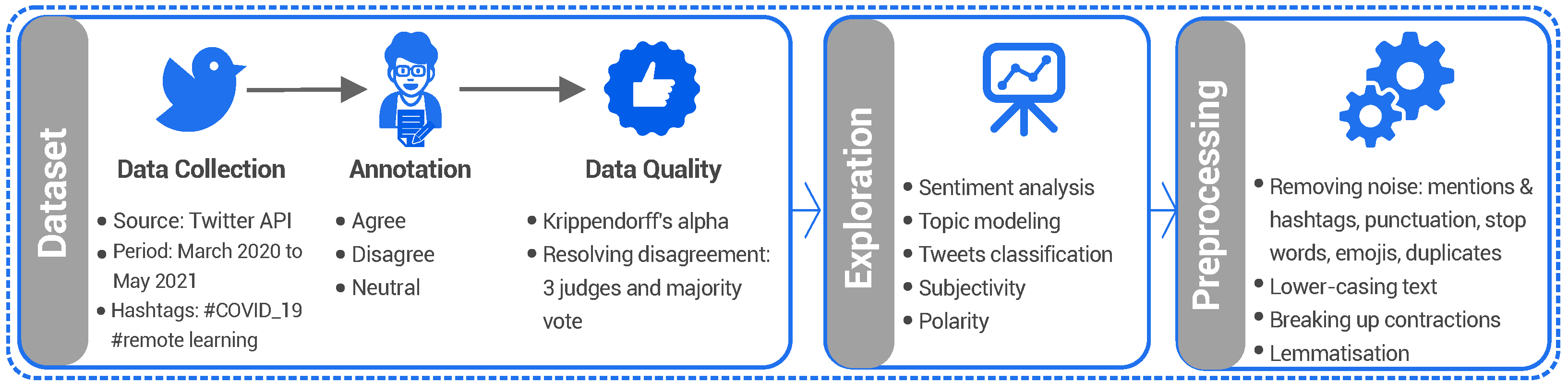
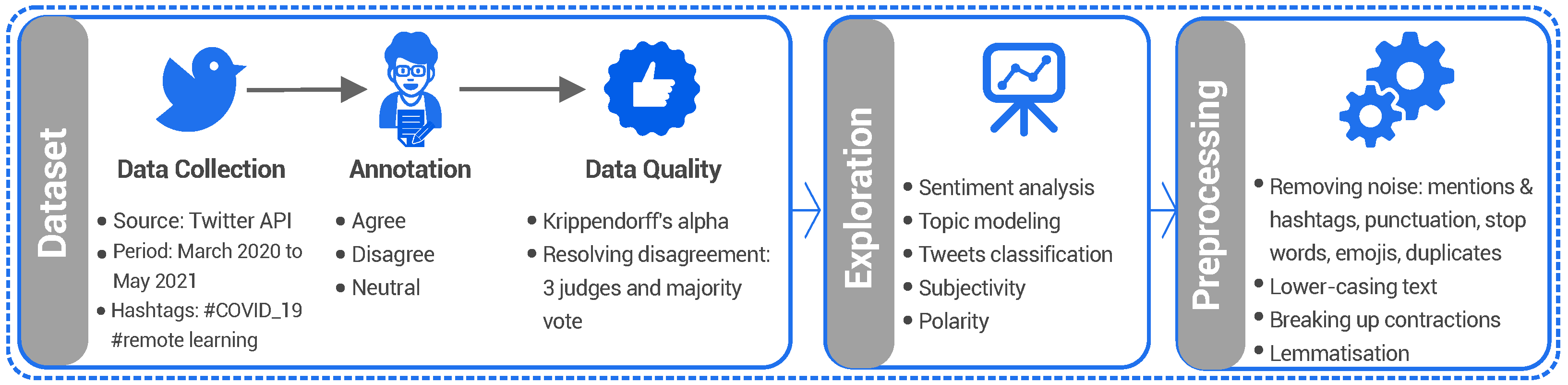
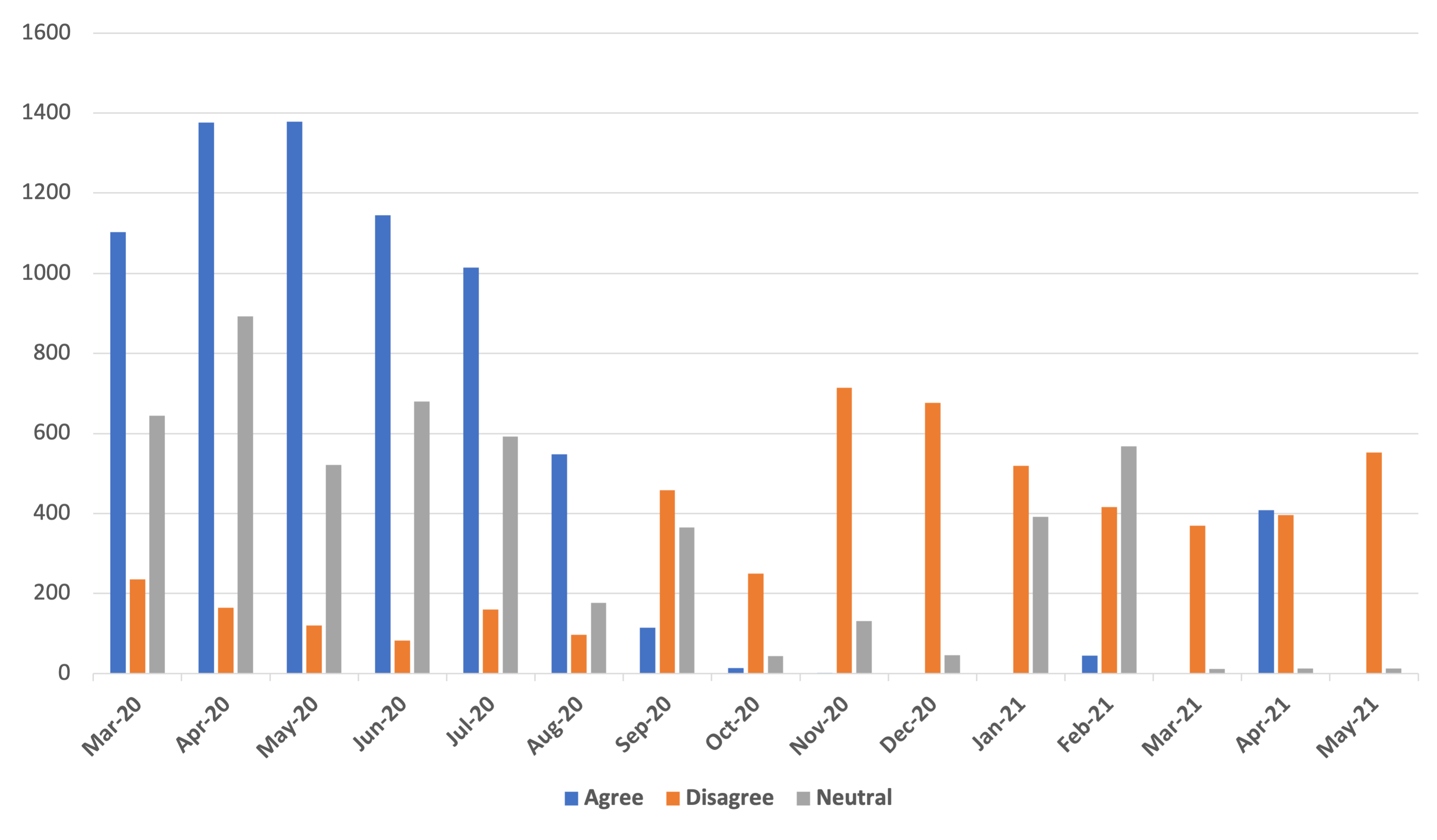
3. StEduCov Dataset
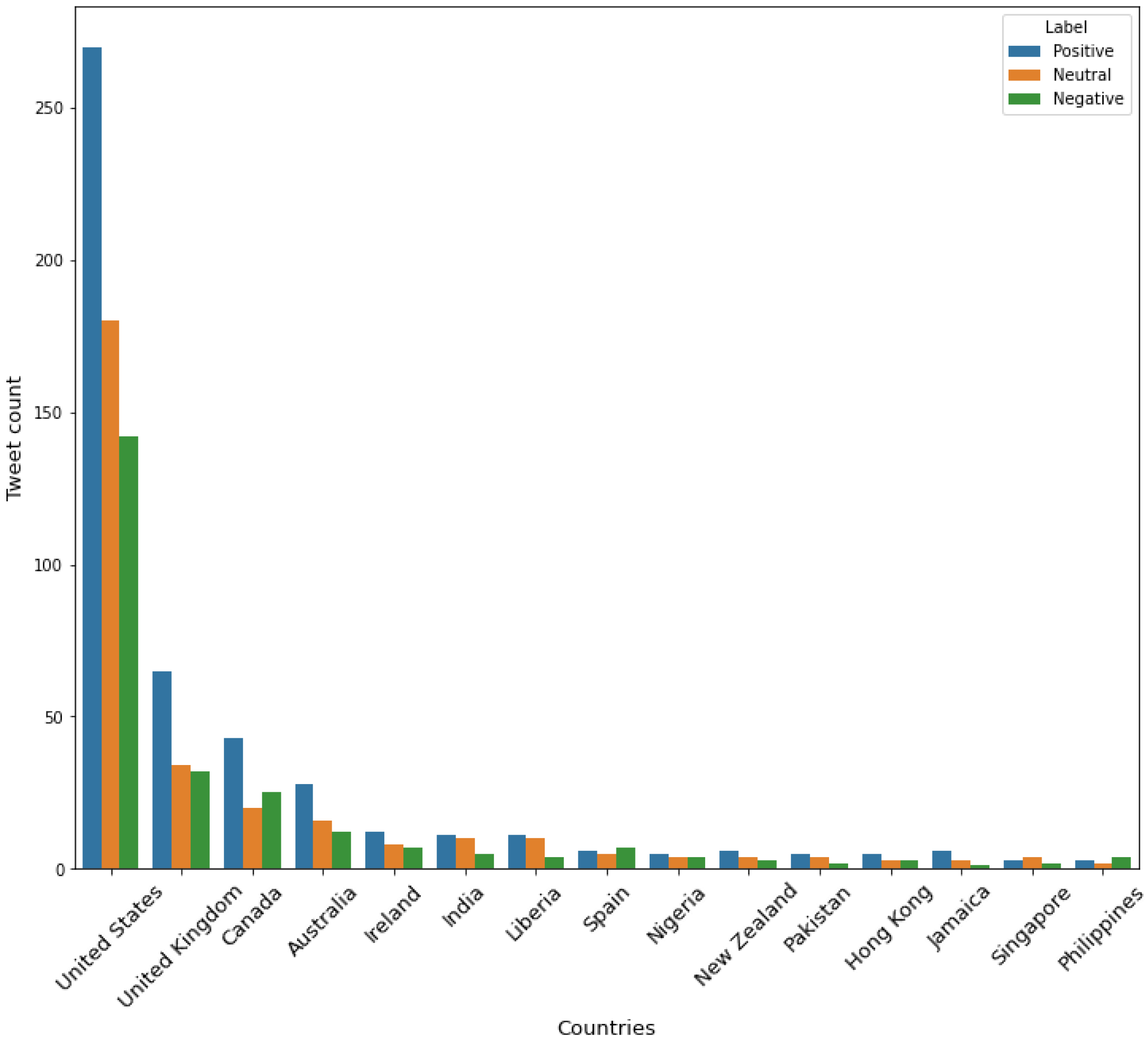
3.1. Data Collection
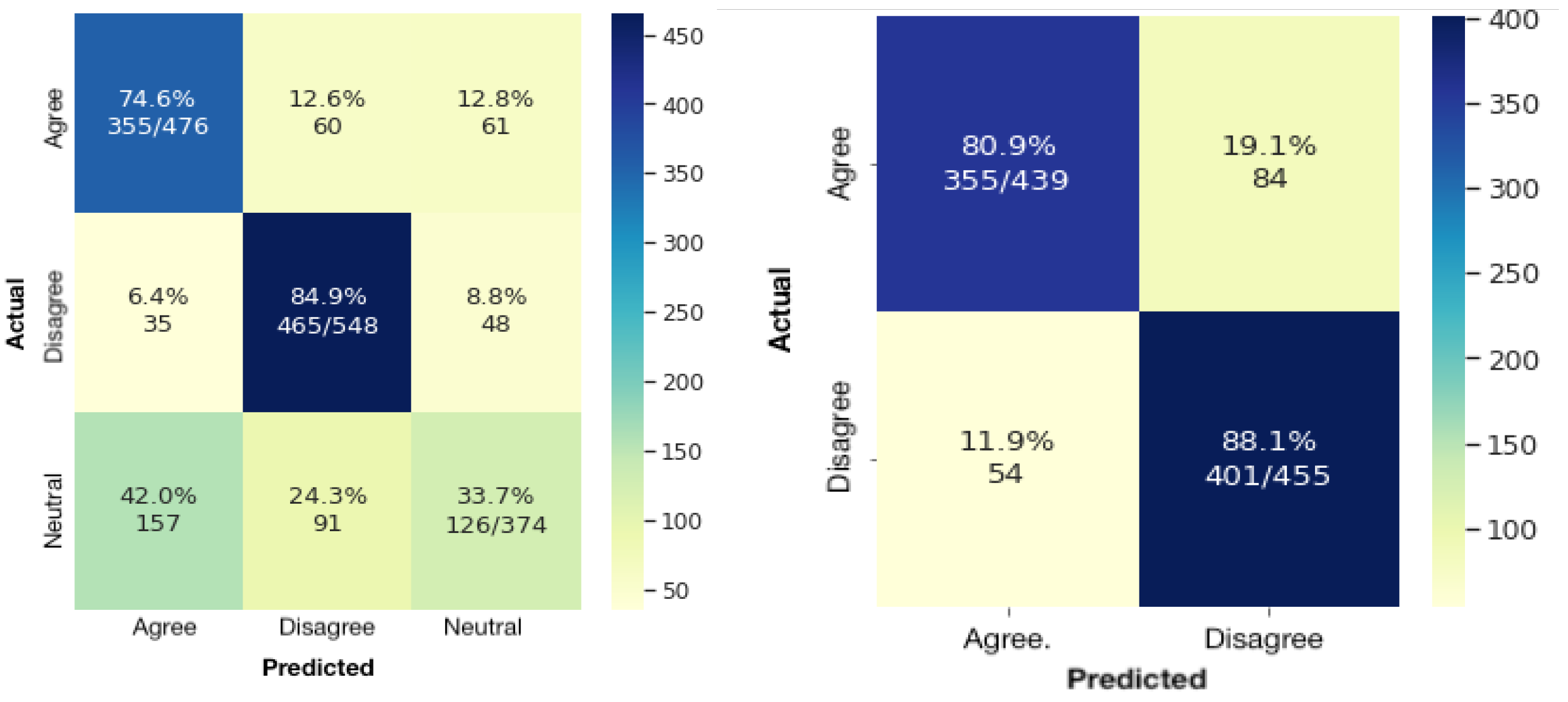
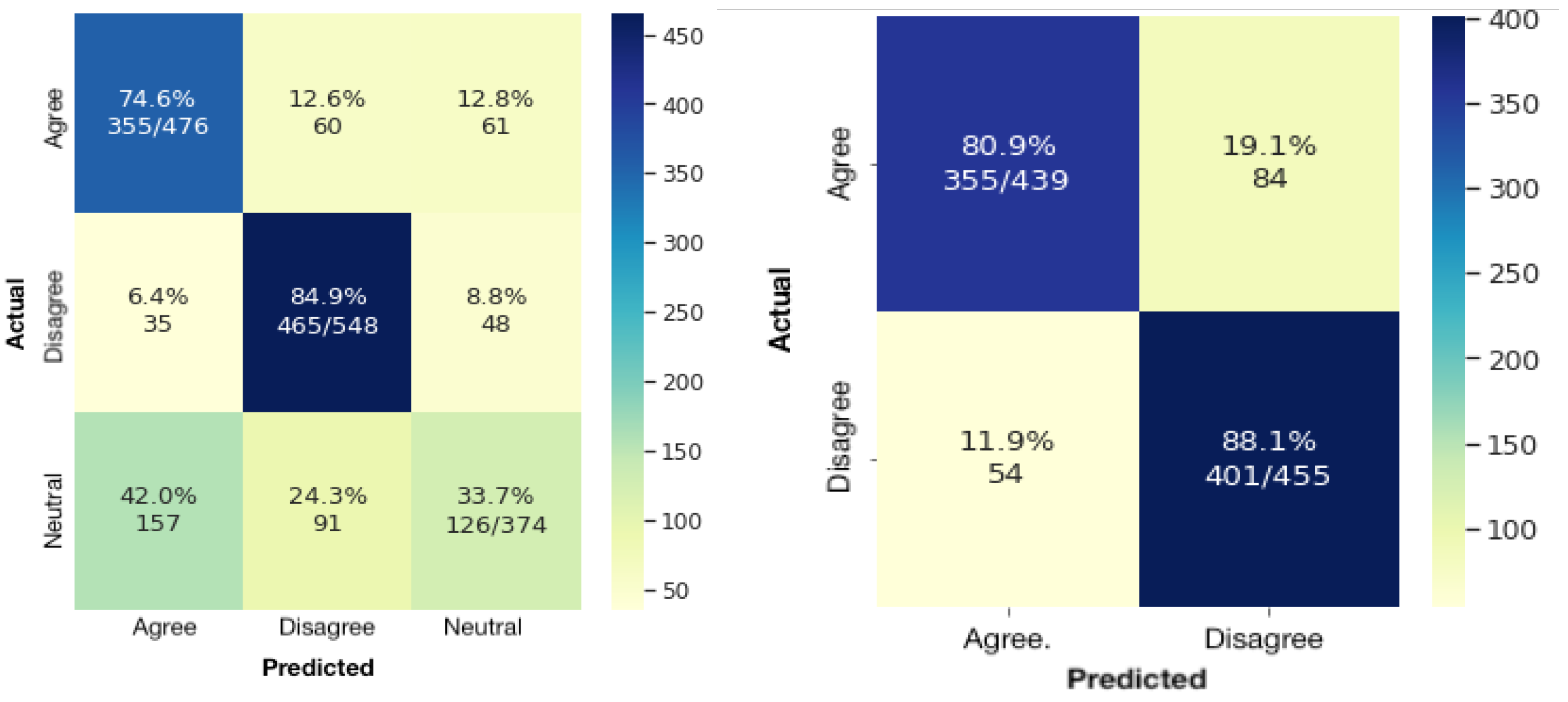
3.2. Annotation and Inter-Annotator Agreement
- Neutral: If the tweet is neither against nor in favour of online education. For example, “there’s no improvement nor plan”. Furthermore, announcements and tweets offering online courses were considered neutral.
- Disagree: there should be a clear negative statement about online education or its impact. Furthermore, if the tweet is negative but refers to other people, e.g., ‘my children hate online learning’, it should be annotated as disagree.
- Agree: highlighting the benefits of online education or expressing a desire or intention to continue with remote learning.
- If two annotators agree on one stance but a third annotator labels it differently, the majority vote is taken to determine the label of the tweet.
- If three annotators classified the tweet into three stances, the reviewer decided on one of them.
4. Data Exploration
- Topic modelling: Classifying the collected tweets into several distinct topics.
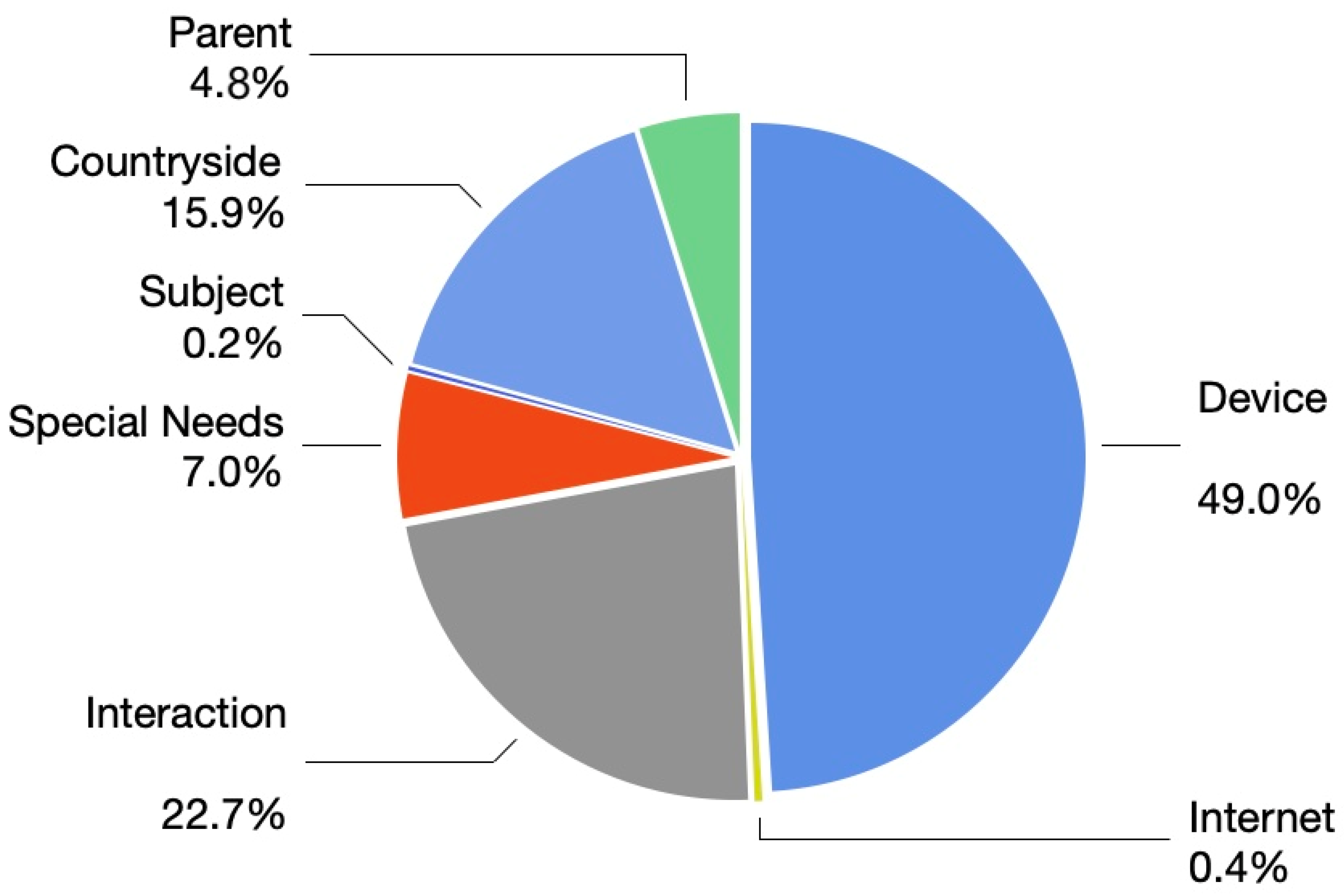
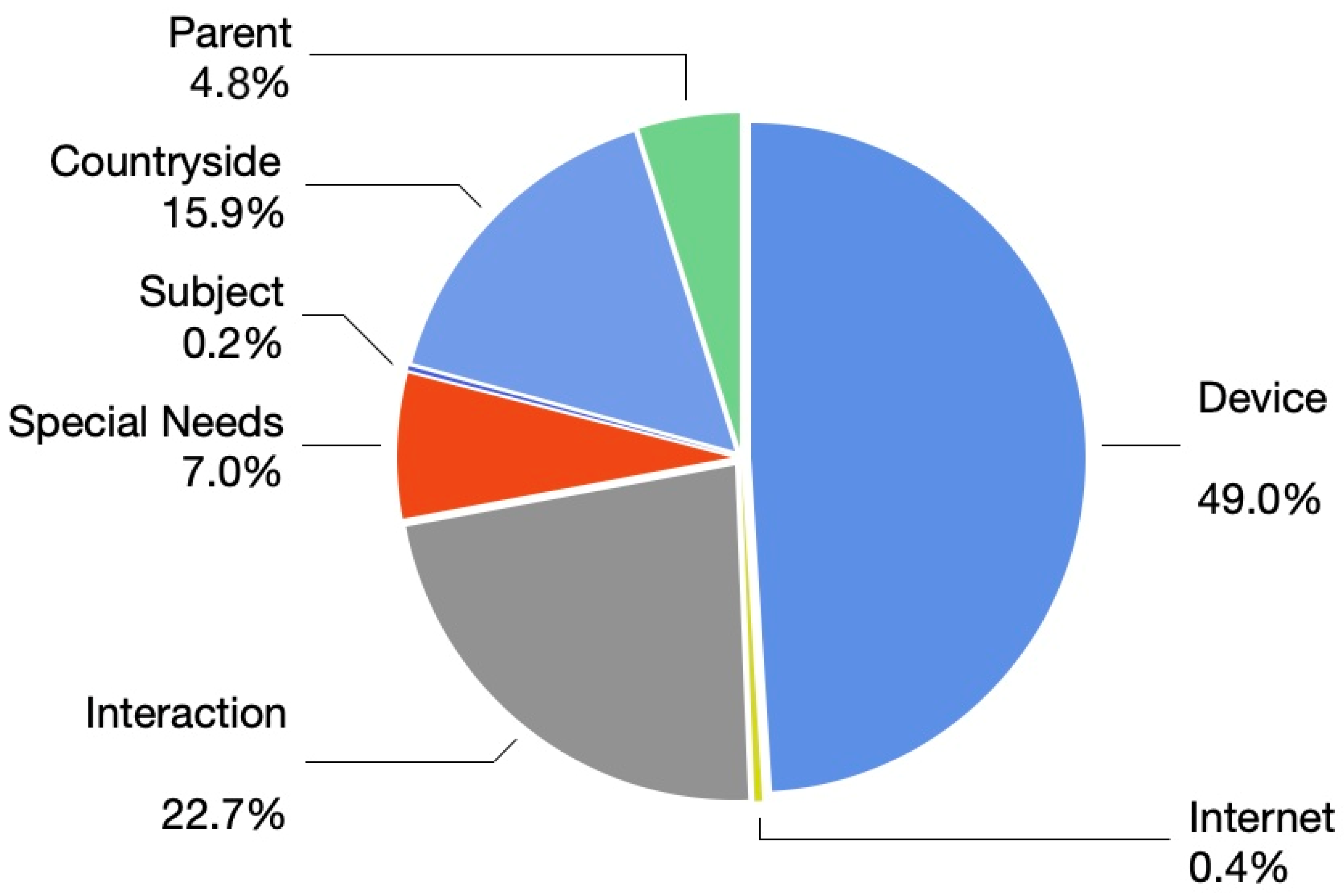
- Tweet classification: Relating the tweets to one of several categories, namely: device, parent, subject, countryside, interaction, special needs, and internet.
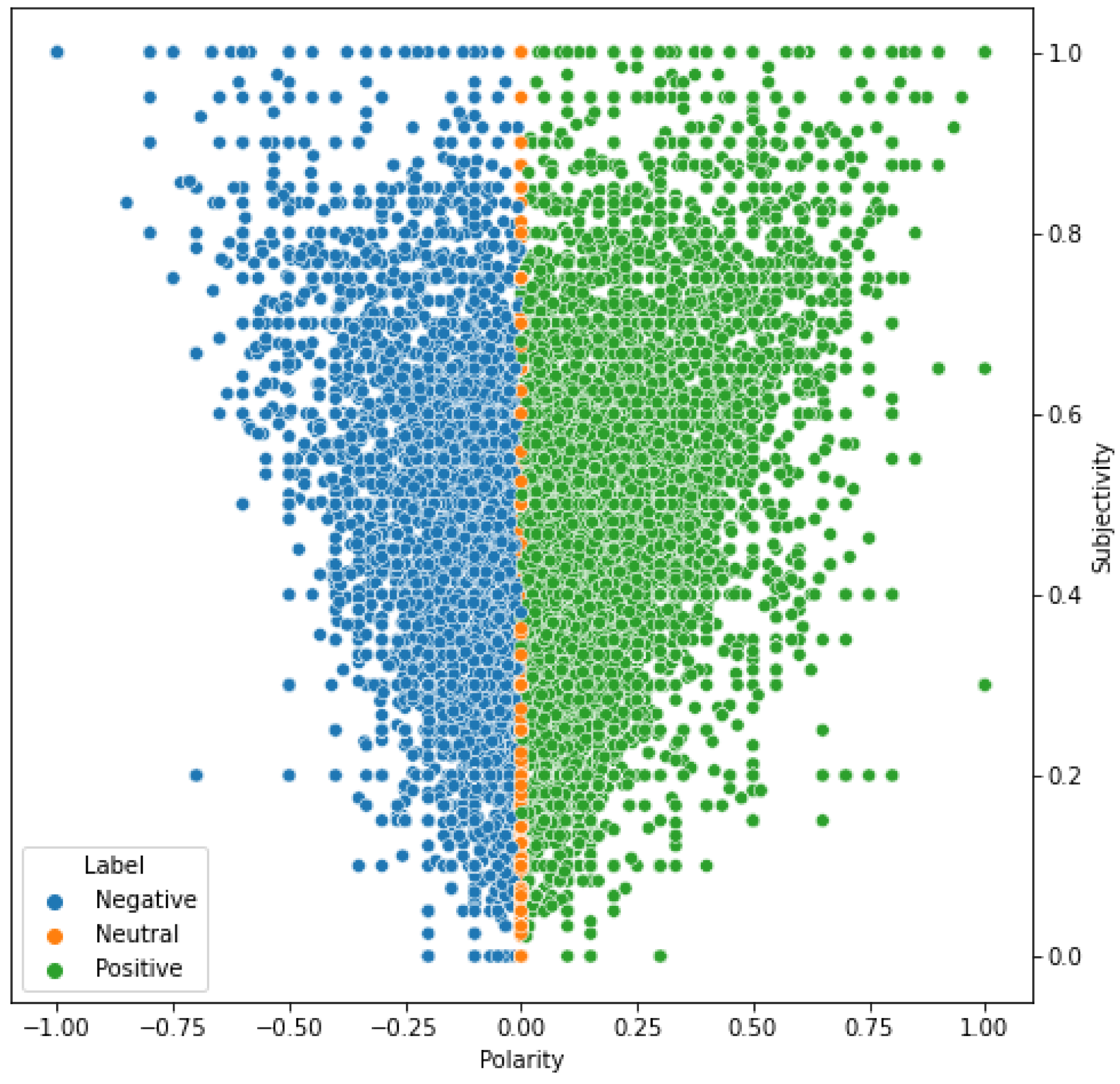
- Sentiment Analysis: Revealing correlations of the distribution of sentiments over stances.
4.1. Topic Modelling
4.2. Tweet Classification
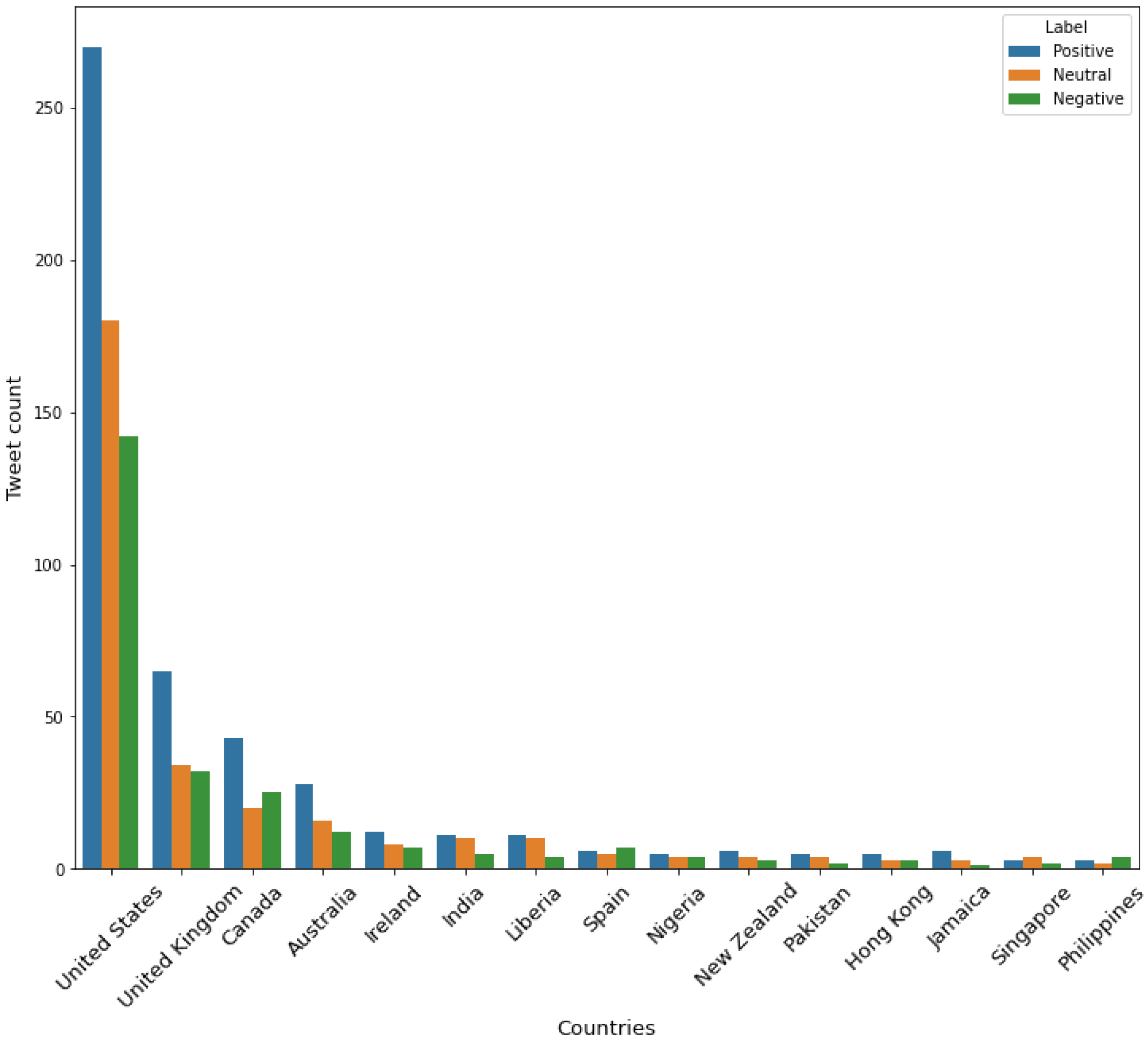
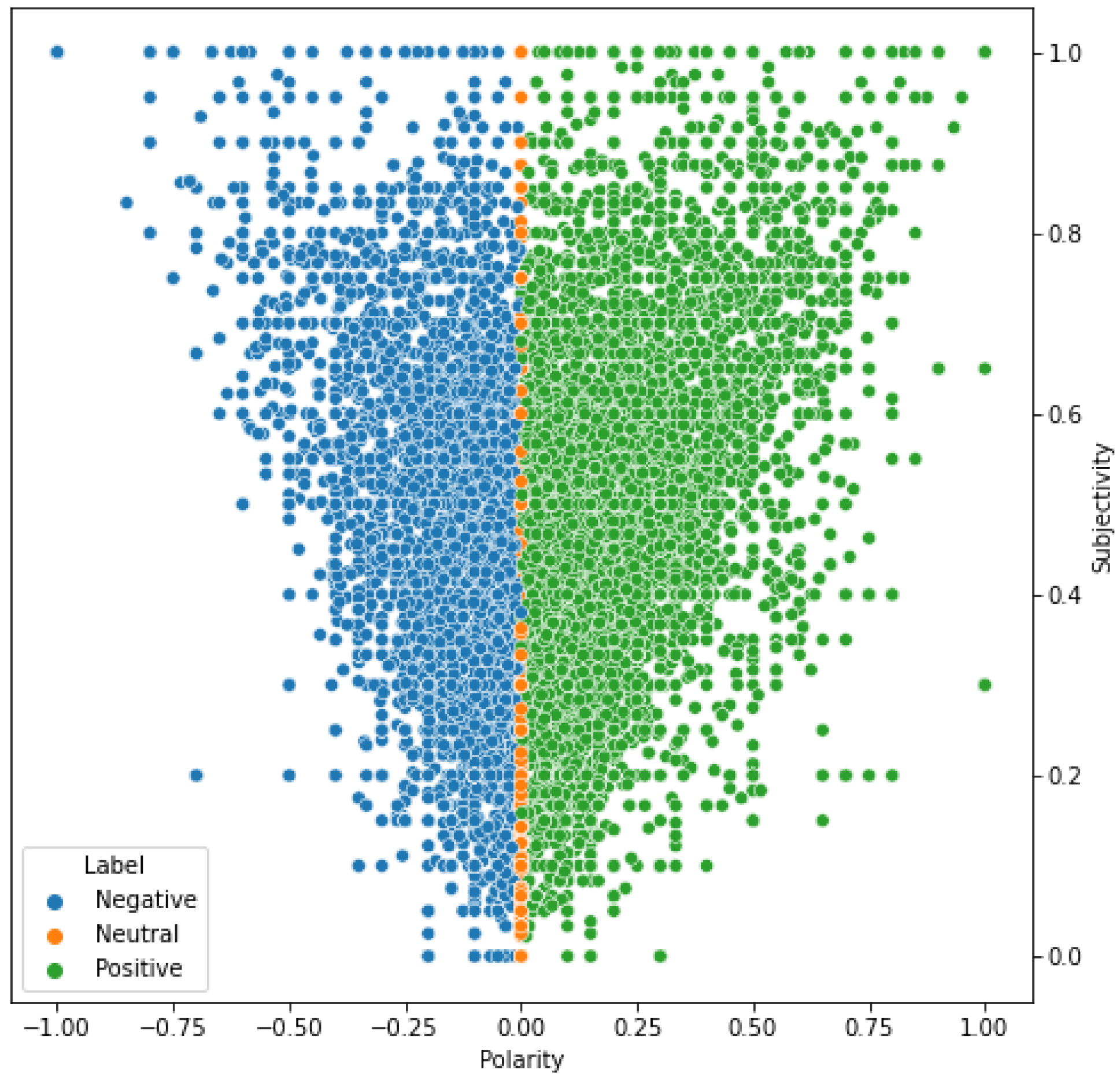
4.3. Sentiment Analysis
5. Benchmarking
5.1. Preprocessing
5.2. Benchmarked Models
5.2.1. Traditional Machine Learning Models
- Logistic Regression (LR) [27]: Using a logistic function, logistic regression can be used to estimate discrete values from independent features. Because logistic regression produces a probability (0 ≤ x ≤ 1), the output values will be between 0 and 1.
- Random Forest (RF) [28]: A random forest is composed of individual decision trees that form an ensemble. Each individual tree in the random forest generates a class prediction, and the class with the highest votes becomes the model’s prediction. This technique eliminates overfitting issues due to the random selection of input samples and features.
- K-Nearest Neighbour (KNN) [29]: KNN may be used for both classification and regression, but it is more typically used for classification. Because KNN is a non-parametric classification method, no data distribution assumption is applied. To classify a data point, its k closest neighbours are determined. A data point’s class is often chosen through a majority vote among neighbouring data points.
- Support Vector Machines (SVM) [30]: This method considers a hyper-plane in an N-dimensional space. Hyperplanes are decision boundaries used to categorise data points. SVM works better with longer texts.
- Naive Bayes (NB) [31]: NB is a probabilistic model that allows one to catch model uncertainty in a principled way by calculating probabilities. NB yields a better results with short texts.
- Decision Trees (DT) [32]: The decision tree approach involves the construction of classification models in a tree-like structure. Iteratively, the dataset is segmented and the decision tree is created. This method generates a tree with decision nodes. If certain events occur, the decision node determines the class of the ext. The ID3 algorithm is used to construct decision trees, in which it utilizes entropy and information gain to construct a DT.
5.2.2. Deep Learning Models
- Long Short-Term Memory (Bi-LSTM): Bi-directional long-short-term memory networks are based on LSTM and are initialised with Glove embeddings, which can capture contextual information and long-term dependencies [33].
- Attention-based biLSTM (Att biLSTM): In the multi-head attention based biLSTM model, by using multiple heads of attention, the model may simultaneously pay attention to data coming from several representation subspaces located at various points in space [34].
- Bidirectional Encoder Representations from Transformers (BERT): This is a transformer-based architecture and a bidirectional model. As opposed to static embeddings produced by fastText and word2vec, BERT produces contextualised word embeddings where the vector for the word is computed based on the context in which it appears [35].
- Convolutional Neural Network (CNN): A neural network is made up of three types of layers: convolutional, pooling, and fully connected layers. The first two layers, convolution and pooling, extract features, and the third, a completely connected layer, maps the extracted features into the final classification [36].
- Naive Bayes SVM (NBSVM): This model was proposed by [37] and was implemented as a neural network, which demonstrated that it could compete with more advanced neural network architectures. The implementation of this model employs two embedding layers for storing naive Bayes log-count ratios and the set of weights that have been learnt. The dot product of these two vectors is then computed, which becomes the prediction.
5.3. Experimental Setup
- Hardware: Two PCs were utilised to train the classification algorithms simultaneously, as deep learning models take days to train: (a) an AsusTek PC computer with 125 GiB of RAM and four Quadro RTX 6000 GPUs; (b) a Google Cloud Platform virtual instance with 8 vCPUs, 52 GB of RAM and one Nvidia Tesla K80.
- Training: HuggingFace transformers were used to fine-tune the BERT models utilising the Pytorch framework, which supports GPU processing. Furthermore, the Keras framework is used to implement and customise the LSTM, CNN and NBSVM models. The Ktrain library was used to train the NBSVM model and it was implemented as a neural network. All hyper-parameters are listed in Table 4 for each model.
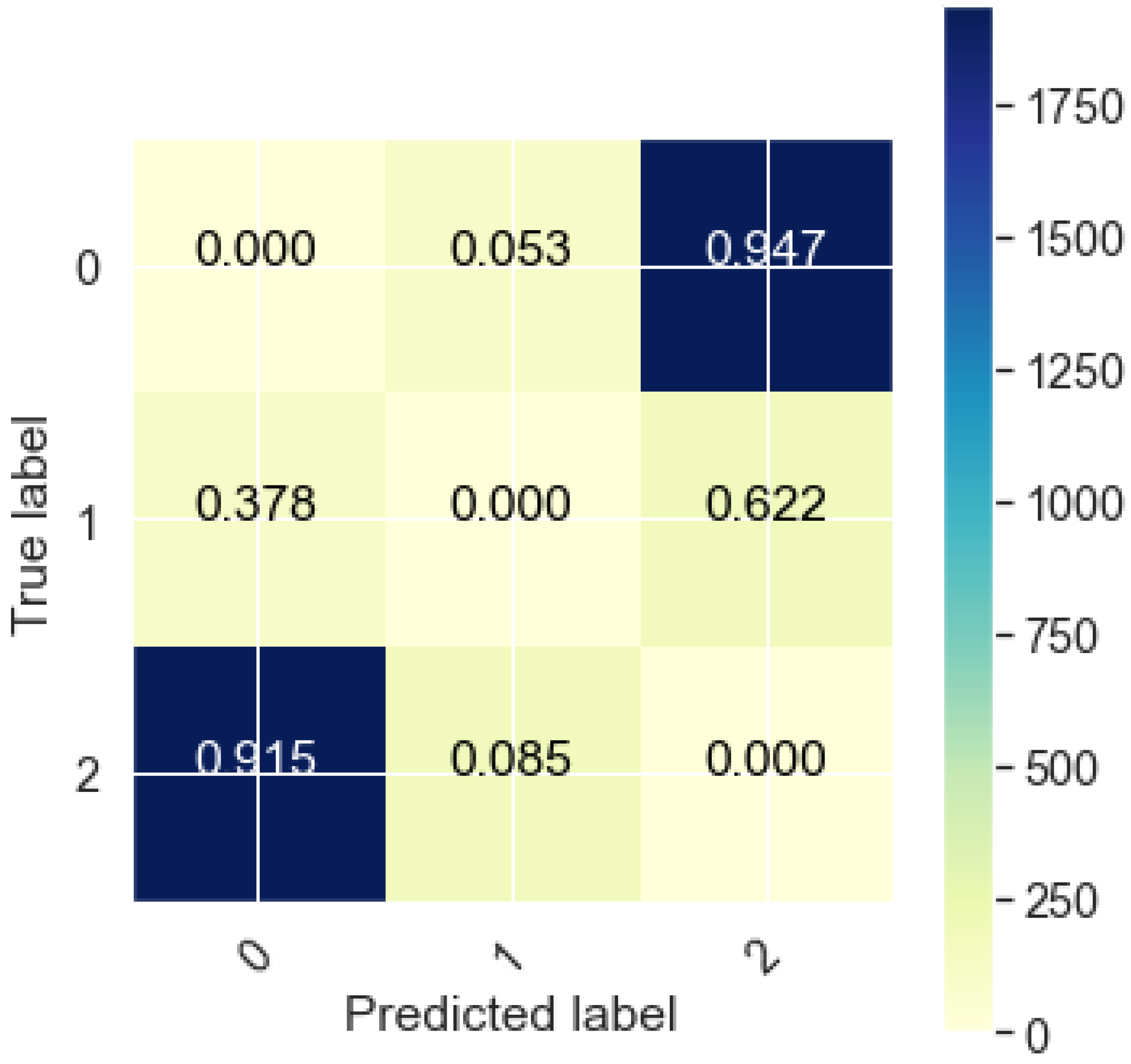
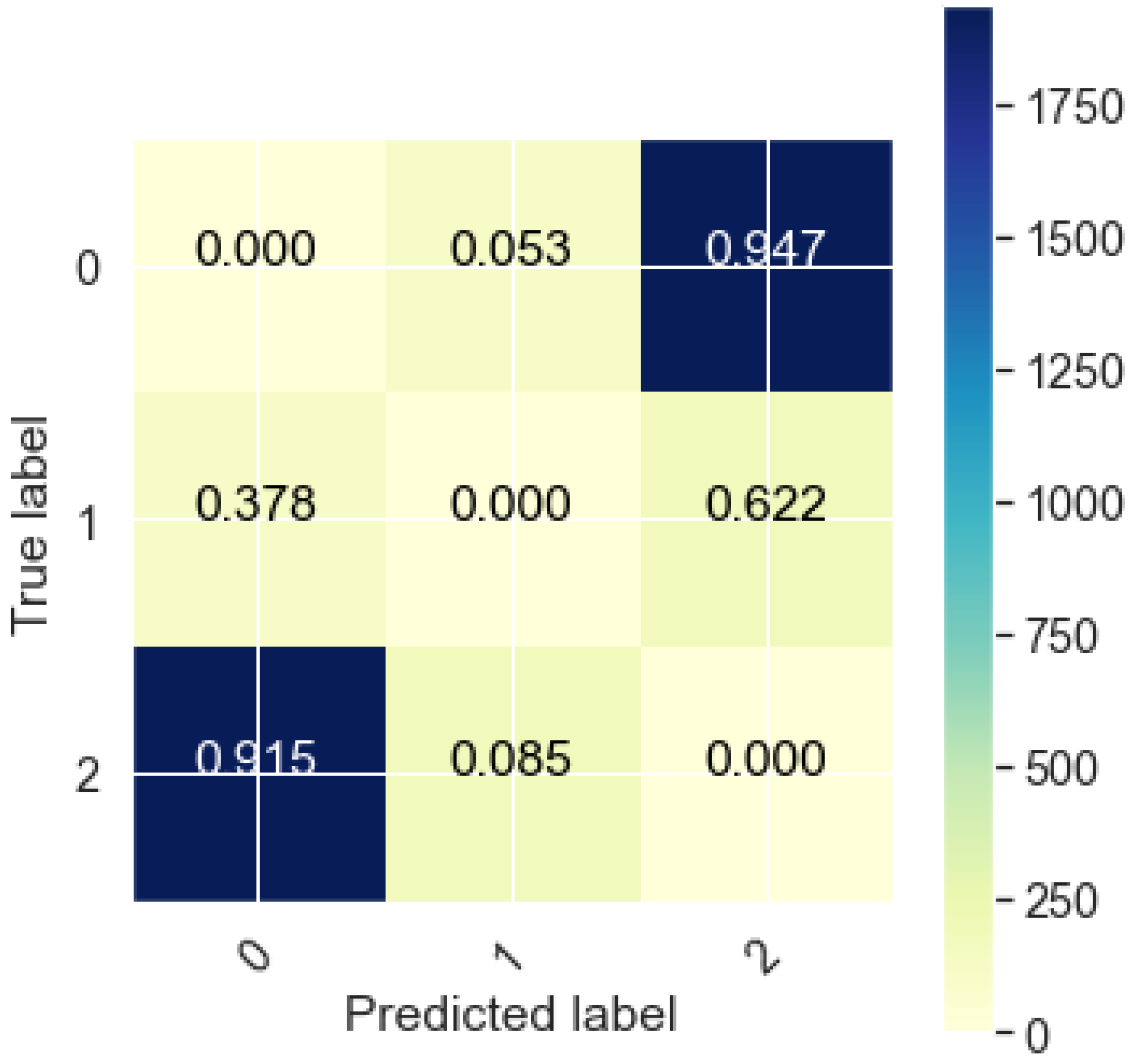
6. Results and Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Glandt, K.; Khanal, S.; Li, Y.; Caragea, D.; Caragea, C. Stance Detection in COVID-19 Tweets. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; Volume 1, pp. 1596–1611. [Google Scholar] [CrossRef]
- Mutlu, E.C.; Oghaz, T.; Jasser, J.; Tutunculer, E.; Rajabi, A.; Tayebi, A.; Ozmen, O.; Garibay, I. A stance data set on polarized conversations on Twitter about the efficacy of hydroxychloroquine as a treatment for COVID-19. Data Brief 2020, 33, 106401. [Google Scholar] [CrossRef] [PubMed]
- Miao, L.; Last, M.; Litvak, M. Tracking social media during the COVID-19 pandemic: The case study of lockdown in New York State. Expert Syst. Appl. 2022, 187, 115797. [Google Scholar] [CrossRef] [PubMed]
- Alqurashi, T. Stance Analysis of Distance Education in the Kingdom of Saudi Arabia during the COVID-19 Pandemic Using Arabic Twitter Data. Sensors 2022, 22, 1006. [Google Scholar] [CrossRef] [PubMed]
- Murakami, A.; Raymond, R. Support or oppose? Classifying positions in online debates from reply activities and opinion expressions. In Proceedings of the Coling 2010: Posters, Beijing, China, 23–27 August 2010; pp. 869–875. [Google Scholar]
- Thomas, M.; Pang, B.; Lee, L. Get out the vote: Determining support or opposition from Congressional floor-debate transcripts. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006; pp. 327–335. [Google Scholar]
- Somasundaran, S.; Wiebe, J. Recognizing Stances in Ideological On-Line Debates. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, USA, 5 June 2010; pp. 116–124. [Google Scholar]
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. SemEval-2016 Task 6: Detecting Stance in Tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 31–41. [Google Scholar] [CrossRef]
- Walker, M.; Anand, P.; Abbott, R.; Grant, R. Stance Classification using Dialogic Properties of Persuasion. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Montreal, QC, Canada, 3–8 June 2012; pp. 592–596. [Google Scholar]
- Walker, M.A.; Anand, P.; Abbott, R.; Tree, J.E.F.; Martell, C.; King, J. That is your evidence?: Classifying stance in online political debate. Decis. Support Syst. 2012, 53, 719–729. [Google Scholar] [CrossRef]
- Hasan, K.S.; Ng, V. Stance classification of ideological debates: Data, models, features, and constraints. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–18 October 2013; pp. 1348–1356. [Google Scholar]
- Qiu, M.; Sim, Y.; Smith, N.A.; Jiang, J. Modeling user arguments, interactions, and attributes for stance prediction in online debate forums. In Proceedings of the 2015 SIAM International Conference on Data Mining, Vancouver, BC, Canada, 30 April–2 May 2015; pp. 855–863. [Google Scholar]
- Zhang, S.; Qiu, L.; Chen, F.; Zhang, W.; Yu, Y.; Elhadad, N. We make choices we think are going to save us: Debate and stance identification for online breast cancer CAM discussions. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 1073–1081. [Google Scholar]
- Barbieri, F.; Camacho-Collados, J.; Neves, L.; Espinosa-Anke, L. Tweeteval: Unified benchmark and comparative evaluation for tweet classification. arXiv 2020, arXiv:2010.12421. [Google Scholar]
- Song, Y.; Wang, J.; Jiang, T.; Liu, Z.; Rao, Y. Targeted Sentiment Classification with Attentional Encoder Network. In Proceedings of the 28th International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; pp. 93–103. [Google Scholar]
- Allaway, E.; McKeown, K. Zero-Shot Stance Detection: A Dataset and Model using Generalized Topic Representations. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 8913–8931. [Google Scholar]
- Conforti, C.; Berndt, J.; Pilehvar, M.T.; Giannitsarou, C.; Toxvaerd, F.; Collier, N. Will-They-Won’t-They: A Very Large Dataset for Stance Detection on Twitter. arXiv 2020, arXiv:2005.00388. [Google Scholar]
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. A dataset for detecting stance in tweets. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 3945–3952. [Google Scholar]
- Hou, Y.; van der Putten, P.; Verberne, S. The COVMis-Stance dataset: Stance Detection on Twitter for COVID-19 Misinformation. arXiv 2022, arXiv:2204.02000. [Google Scholar]
- Roy, A.; Fafalios, P.; Ekbal, A.; Zhu, X.; Dietze, S. Exploiting stance hierarchies for cost-sensitive stance detection of Web documents. J. Intell. Inf. Syst. 2022, 58, 1–19. [Google Scholar] [CrossRef]
- Pougué-Biyong, J.; Semenova, V.; Matton, A.; Han, R.; Kim, A.; Lambiotte, R.; Farmer, D. DEBAGREEMENT: A comment-reply dataset for (dis) agreement detection in online debates. In Proceedings of the Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), Online, 20 August 2021. [Google Scholar]
- Alhindi, T.; Alabdulkarim, A.; Alshehri, A.; Abdul-Mageed, M.; Nakov, P. AraStance: A Multi-Country and Multi-Domain Dataset of Arabic Stance Detection for Fact Checking. In Proceedings of the Fourth Workshop on NLP for Internet Freedom: Censorship, Disinformation, and Propaganda, Online, 6 June 2021; pp. 57–65. [Google Scholar] [CrossRef]
- Baheti, A.; Sap, M.; Ritter, A.; Riedl, M. Just Say No: Analyzing the Stance of Neural Dialogue Generation in Offensive Contexts. arXiv 2021, arXiv:2108.11830. [Google Scholar]
- Hamad, O.; Shaban, K.; Hamdi, A. StEduCov: A Dataset on Stance Detection in Tweets Towards Online Education During COVID-19 Pandemic. Available online: http://ieee-dataport.org/9221 (accessed on 15 April 2022).
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Spina, D.; Gonzalo, J.; Amigó, E. Learning Similarity Functions for Topic Detection in Online Reputation Monitoring. In Proceedings of the 37th International ACM SIGIR Conference on Research and Development in Information Retrieval, Gold Coast, Australia, 6–11 July 2014; pp. 527–536. [Google Scholar]
- Ramadhan, W.; Novianty, S.A.; Setianingsih, S.C. Sentiment analysis using multinomial logistic regression. In Proceedings of the 2017 International Conference on Control, Electronics, Renewable Energy and Communications (ICCREC), Yogyakarta, Indonesia, 26–28 September 2017; pp. 46–49. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Lanjewar, R.; Mathurkar, S.; Patel, N. Implementation and comparison of speech emotion recognition system using Gaussian Mixture Model (GMM) and K-Nearest Neighbor (K-NN) techniques. Procedia Comput. Sci. 2015, 49, 50–57. [Google Scholar] [CrossRef] [Green Version]
- Crammer, K.; Singer, Y. On the algorithmic implementation of multiclass kernel-based vector machines. J. Mach. Learn. Res. 2001, 2, 265–292. [Google Scholar]
- Ren, J.; Lee, S.D.; Chen, X.; Kao, B.; Cheng, R.; Cheung, D. Naive bayes classification of uncertain data. In Proceedings of the 2009 Ninth IEEE International Conference on Data Mining, Miami Beach, FL, USA, 6–9 December 2009; pp. 944–949. [Google Scholar]
- Mingers, J. An empirical comparison of pruning methods for decision tree induction. Mach. Learn. 1989, 4, 227–243. [Google Scholar] [CrossRef] [Green Version]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Wei, J.; Liao, J.; Yang, Z.; Wang, S.; Zhao, Q. BiLSTM with multi-polarity orthogonal attention for implicit sentiment analysis. Neurocomputing 2020, 383, 165–173. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 4 June 2019; pp. 4171–4186. [Google Scholar]
- Wei, W.; Zhang, X.; Liu, X.; Chen, W.; Wang, T. Pkudblab at semeval-2016 task 6: A specific convolutional neural network system for effective stance detection. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 384–388. [Google Scholar]
- Wang, S.; Manning, C. Baselines and Bigrams: Simple, Good Sentiment and Topic Classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Jeju Island, Korea, 8–14 July 2012; pp. 90–94. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Tweet |
|---|---|
| Agree | So this mean ALL students are required to return back to in-person school? What if we choose online learning due to level of risk? I will no expose my children or elders in our home! |
| Disagree | #onlinelearning Put kids at risk for suicide & depression. Punishment & lack of concern is not the solution & mental illness is not the goal. Intervene or they’ll shut down. |
| Neutral | Remote learning has never been and will never be a 100% effective replacement for anything, but it’s complimentary and can be effective when it is designed to be effective, which is very much not what we’re doing here. |
| Words | Retw. | Fav. | Reply | Friends | Follow. | |
|---|---|---|---|---|---|---|
| Total | 205 K | 25 K | 274 M | 13 K | 31 M | 369 M |
| Min | 3 | 0 | 0 | 0 | 0 | 0 |
| Max | 76 | 3 K | 1 M | 1 K | 274 K | 50 M |
| Avg | 18.2 | 1.5 | 15 K | 0.8 | 2 K | 21 K |
| Stdv | 6.4 | 29.1 | 40 K | 13 | 6 K | 536 K |
| Rank | Topic |
|---|---|
| 0 | mental health, children pandemic |
| 1 | screen time, social distancing |
| 2 | face face, kids back |
| 3 | guidance easiest, easiest memorising |
| 4 | local districts kids |
| BERT | NBSVM | biLSTM | CNN | |
|---|---|---|---|---|
| Hidden dimension | 960 | 2 | 300 | 300 |
| Dropout ratio | 0.3 | 0.3 | 0.25 | 0.3 |
| Learning rate | - | |||
| Optimizer | AdamW | Adam | Adam | Adam |
| Batch size | 8 | 64 | 64 | 16 |
| Epochs | 7 | 7 | 40 | 8 |
| Target: Agree with Online Education (Agree) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| LR | RF | KNN | SVM | NB | DT | NBSVM | biLSTM | CNN | BERT | Att biLSTM | |
| Acc | 70.90% | 73.60% | 80.00% | 67.00% | 70.70% | 56.70% | 59.10% | 59.30% | 73.80% | 74.60% | 79.90% |
| Pr | 67.00% | 58.00% | 45.00% | 60.00% | 63.00% | 52.00% | 67.00% | 63.00% | 60.00% | 65.00% | 60.00% |
| Re | 71.00% | 74.00% | 80.00% | 67.00% | 71.00% | 57.00% | 59.00% | 59.00% | 74.00% | 75.00% | 80.00% |
| F1 | 69.00% | 65.00% | 57.00% | 63.00% | 66.00% | 54.00% | 63.00% | 61.00% | 66.00% | 69.00% | 69.00% |
| Target: Disagree with online education (Disagree) | |||||||||||
| LR | RF | KNN | SVM | NB | DT | NBSVM | biLSTM | CNN | BERT | Att biLSTM | |
| Acc | 83.40% | 80.20% | 59.30% | 76.90% | 91.10% | 65.10% | 91.80% | 72.50% | 75.60% | 84.90% | 69.20% |
| Pr | 68.00% | 63.00% | 66.00% | 68.00% | 64.00% | 64.00% | 63.00% | 70.00% | 73.00% | 75.00% | 74.00% |
| Re | 84.00% | 80.00% | 59.00% | 77.00% | 91.00% | 65.00% | 92.00% | 72.00% | 76.00% | 85.00% | 69.00% |
| F1 | 75.00% | 71.00% | 62.00% | 72.00% | 75.00% | 64.00% | 75.00% | 71.00% | 74.00% | 80.00% | 72.00% |
| Target: Neutral | |||||||||||
| LR | RF | KNN | SVM | NB | DT | NBSVM | biLSTM | CNN | BERT | Att biLSTM | |
| Acc | 33.00% | 26.00% | 14.60% | 40.30% | 18.20% | 32.00% | 32.40% | 44.90% | 34.60% | 33.70% | 31.80% |
| Pr | 50.00% | 63.00% | 52.00% | 55.00% | 62.00% | 37.00% | 60.00% | 44.00% | 50.00% | 54.00% | 64.00% |
| Re | 33.00% | 26.00% | 15.00% | 40.00% | 18.00% | 32.00% | 32.00% | 45.00% | 35.00% | 34.00% | 32.00% |
| F1 | 40.00% | 37.00% | 23.00% | 47.00% | 28.00% | 34.00% | 42.00% | 45.00% | 41.00% | 41.00% | 39.00% |
| Traditional Models | Deep Learning Models | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| LR | RF | KNN | SVM | NB | DT | NBSVM | biLSTM | CNN | BERT | Att biLSTM | |
| Acc | 63.10% | 62.80% | 52.60% | 62.00% | 62.70% | 52.90% | 63.10% | 60.20% | 63.00% | 68.00% | 62.70% |
| Pr | 63.20% | 62.30% | 54.40% | 61.10% | 62.80% | 52.50% | 63.00% | 60.20% | 62.00% | 66.00% | 62.00% |
| F1 | 62.80% | 59.90% | 49.80% | 61.30% | 58.50% | 52.60% | 60.60% | 60.20% | 62.00% | 66.00% | 61.10% |
| Traditional Models | Deep Learning Models | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| LR | RF | KNN | SVM | NB | DT | NBSVM | biLSTM | CNN | BERT | Att-biLSTM | |
| Acc | 84.8% | 83.6% | 76.0% | 84.0% | 83.8% | 75.0% | 83.1% | 83.0% | 84.6% | 84.3% | 81.7% |
| Pr | 84.8% | 83.7% | 76.7% | 84.0% | 84.8% | 75.0% | 84.7% | 83.0% | 85.0% | 83.6% | 81.8% |
| F1 | 84.8% | 83.6% | 76.0% | 83.9% | 83.7% | 75.0% | 82.8% | 83.0% | 85.3% | 84.9% | 81.6% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hamad, O.; Hamdi, A.; Hamdi, S.; Shaban, K. StEduCov: An Explored and Benchmarked Dataset on Stance Detection in Tweets towards Online Education during COVID-19 Pandemic. Big Data Cogn. Comput. 2022, 6, 88. https://doi.org/10.3390/bdcc6030088
Hamad O, Hamdi A, Hamdi S, Shaban K. StEduCov: An Explored and Benchmarked Dataset on Stance Detection in Tweets towards Online Education during COVID-19 Pandemic. Big Data and Cognitive Computing. 2022; 6(3):88. https://doi.org/10.3390/bdcc6030088
Chicago/Turabian StyleHamad, Omama, Ali Hamdi, Sayed Hamdi, and Khaled Shaban. 2022. "StEduCov: An Explored and Benchmarked Dataset on Stance Detection in Tweets towards Online Education during COVID-19 Pandemic" Big Data and Cognitive Computing 6, no. 3: 88. https://doi.org/10.3390/bdcc6030088
APA StyleHamad, O., Hamdi, A., Hamdi, S., & Shaban, K. (2022). StEduCov: An Explored and Benchmarked Dataset on Stance Detection in Tweets towards Online Education during COVID-19 Pandemic. Big Data and Cognitive Computing, 6(3), 88. https://doi.org/10.3390/bdcc6030088