
Sample-Efficient Deep Learning Techniques for Burn Severity Assessment with Limited Data Conditions

 , and
, and
Abstract
:1. Introduction
- We present sample-efficient deep learning models for burn severity assessment using various techniques. Through extensive experiments, we demonstrate the feasibility of these sample-efficient models with limited training data.
- We build a large dataset containing 13,715 burn images with professionally annotated information, on which not only the high-accuracy burn severity assessment model is trained but also various limited data conditions can be emulated to evaluate the sample-efficient models.
- We discuss the dataset conditions under which sample-efficient deep learning techniques can be productively applied.
2. Burn Severity Assessment
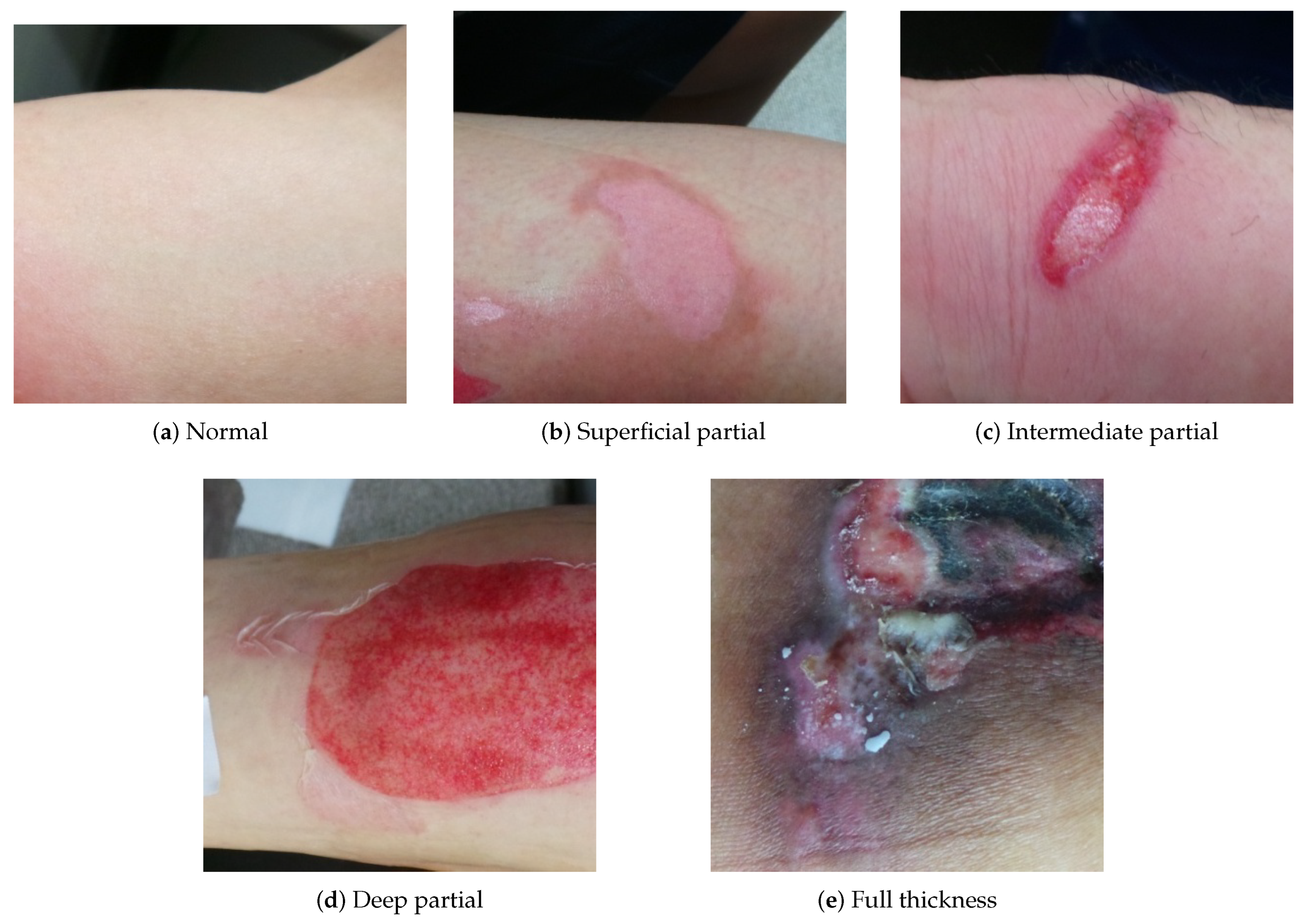
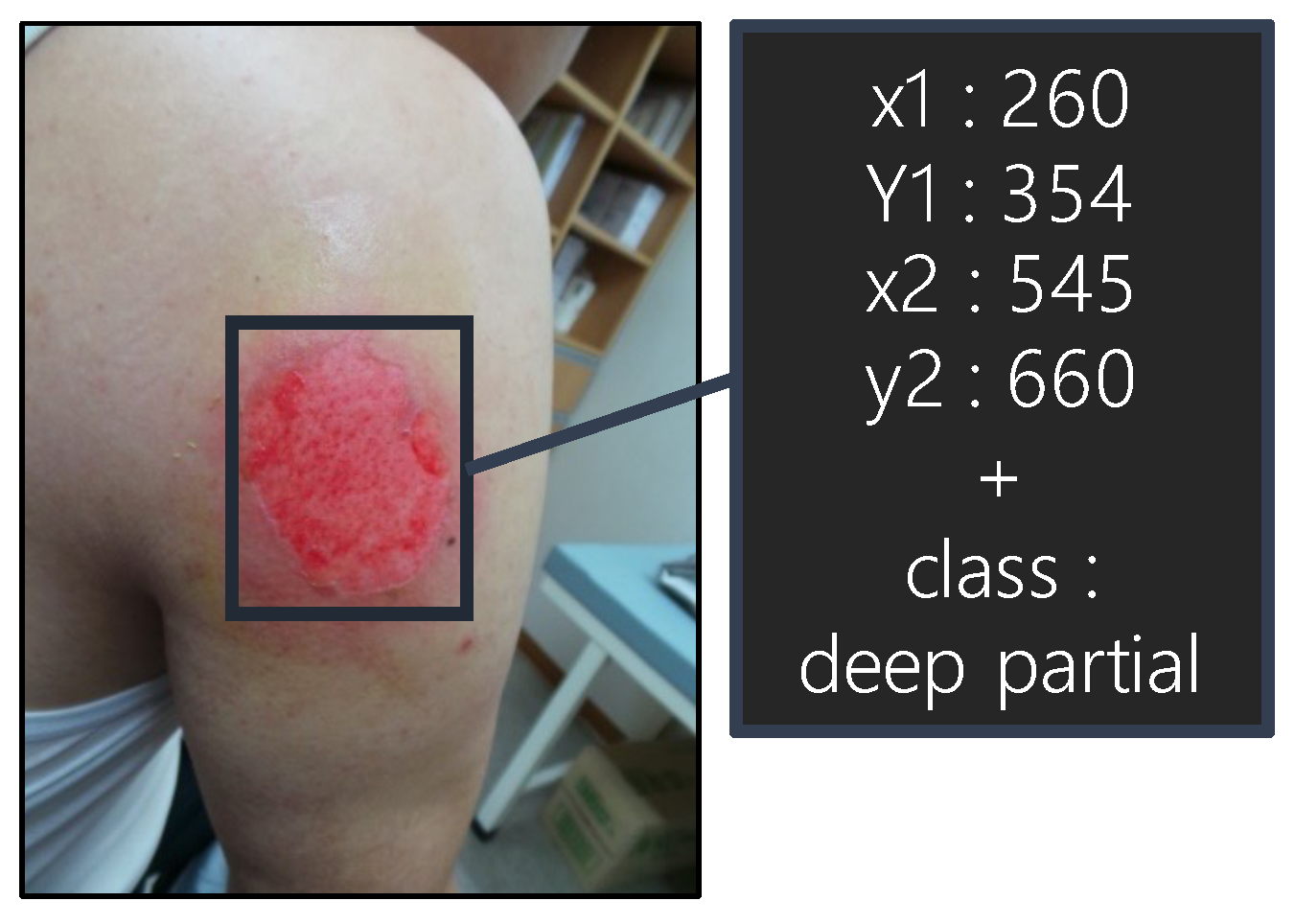
2.1. Burn Image Dataset
2.2. CNN Models
3. Methods
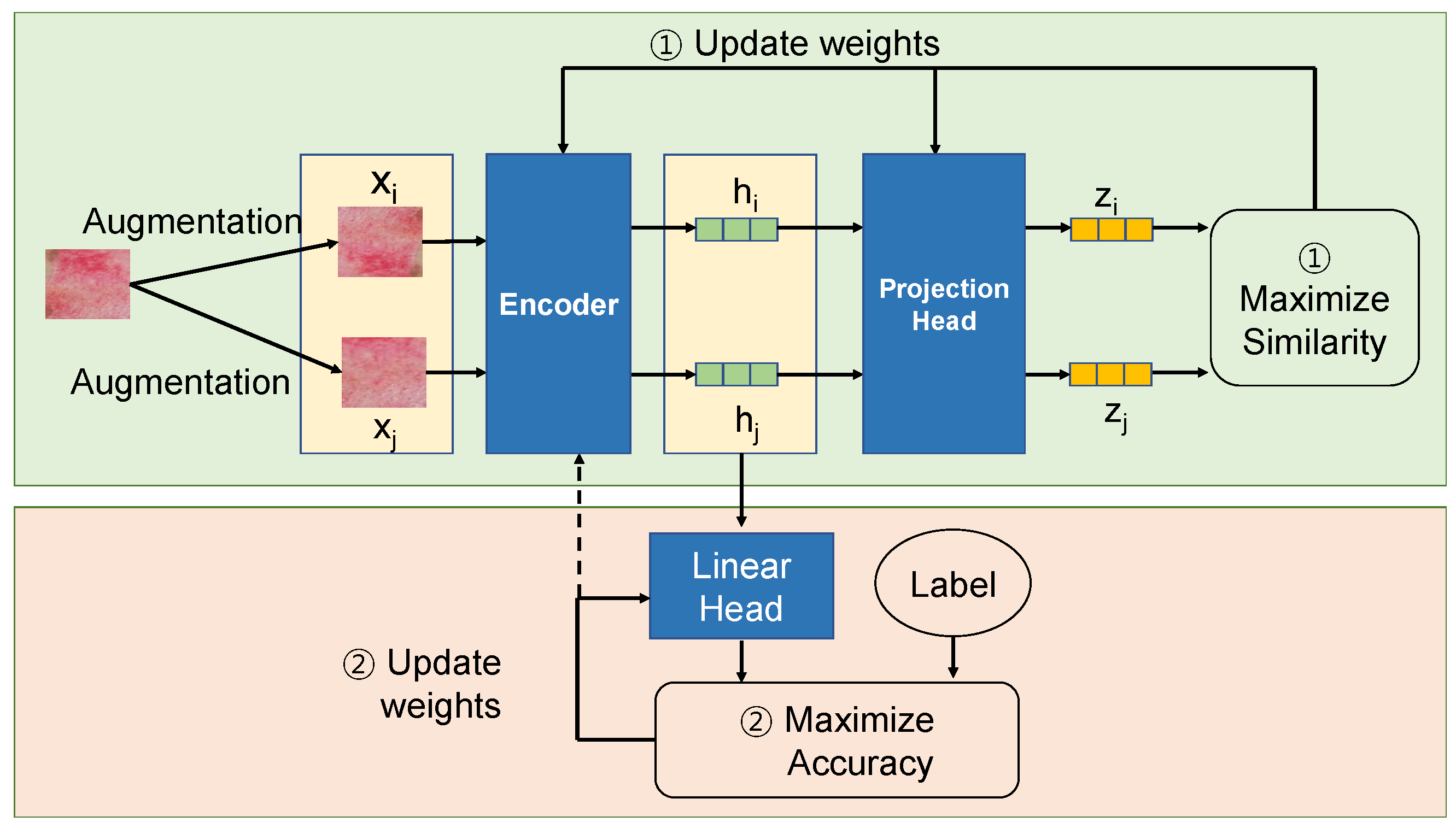
3.1. Self-Supervised Learning
3.2. Federated Learning
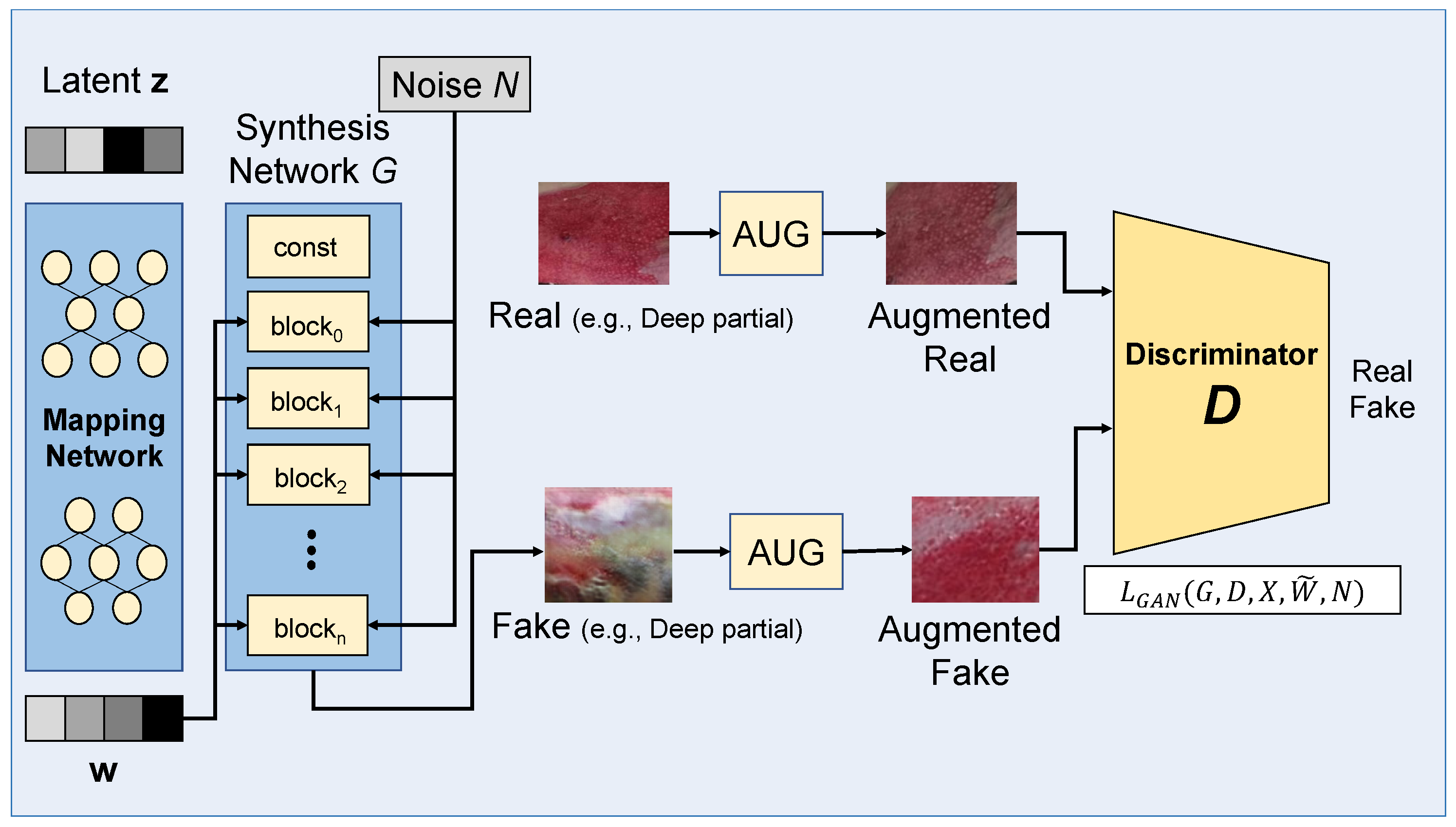
3.3. Learning with Data Augmentation
4. Results
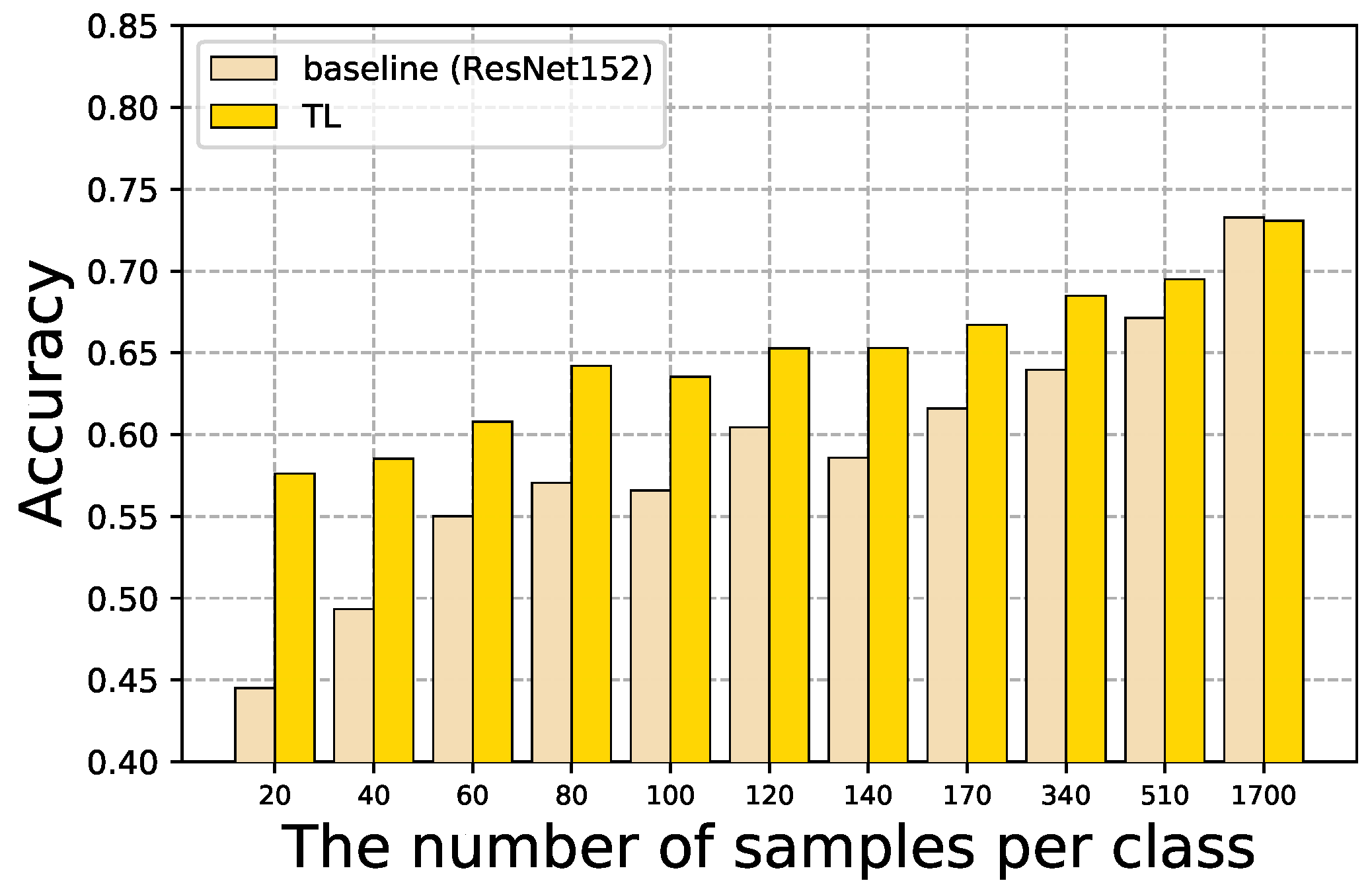
4.1. Baseline and TL
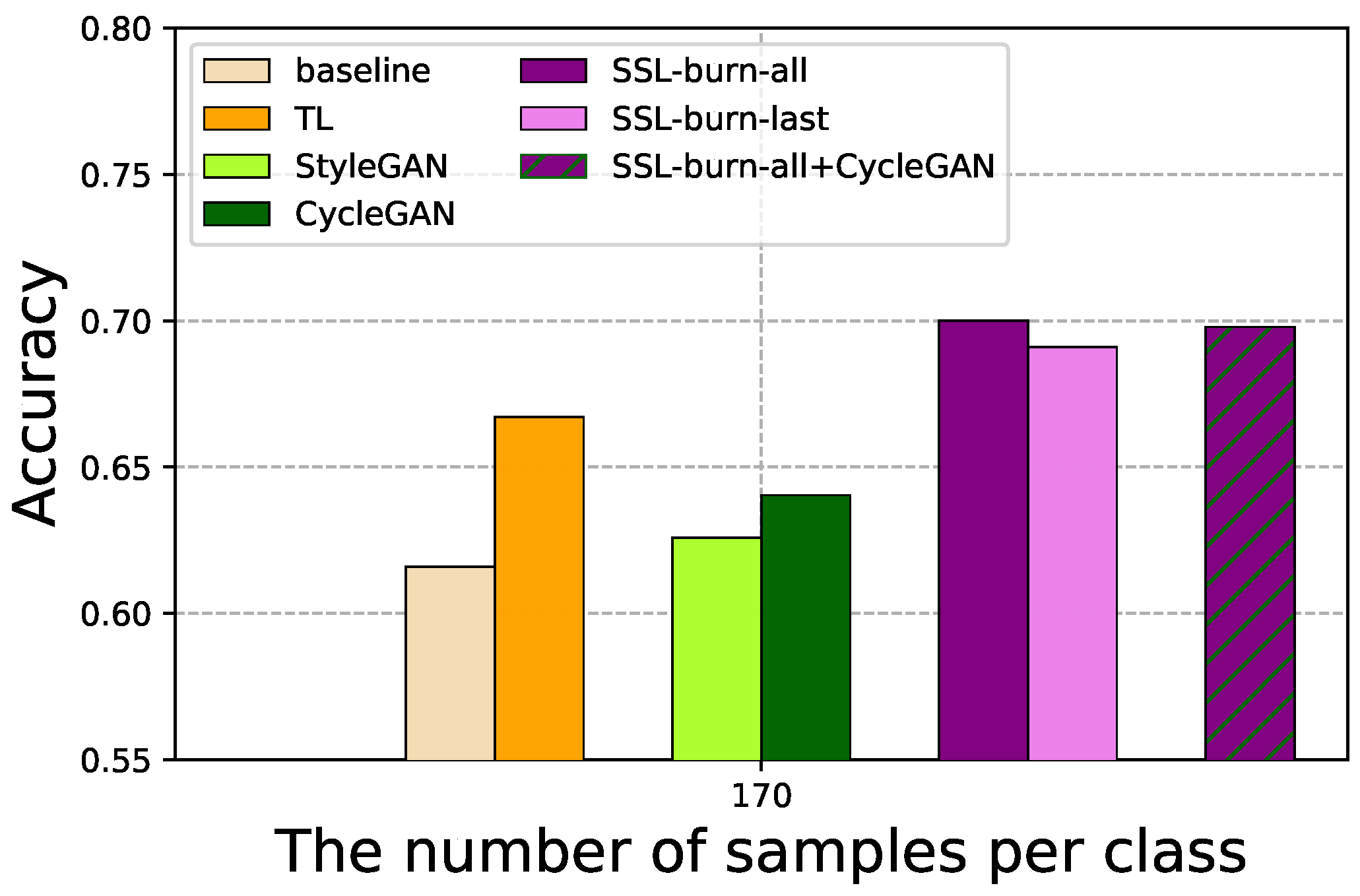
4.2. SSL for Limited Labeled Data
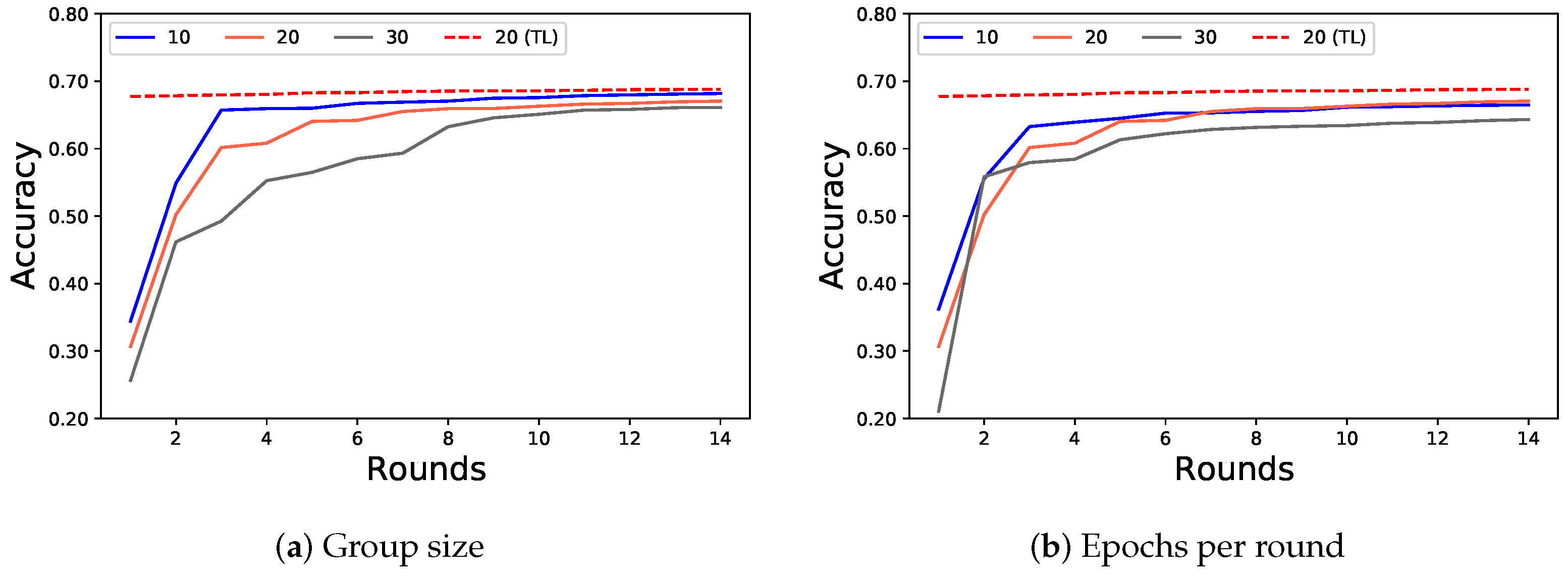
4.3. FL for Multiple Institutions
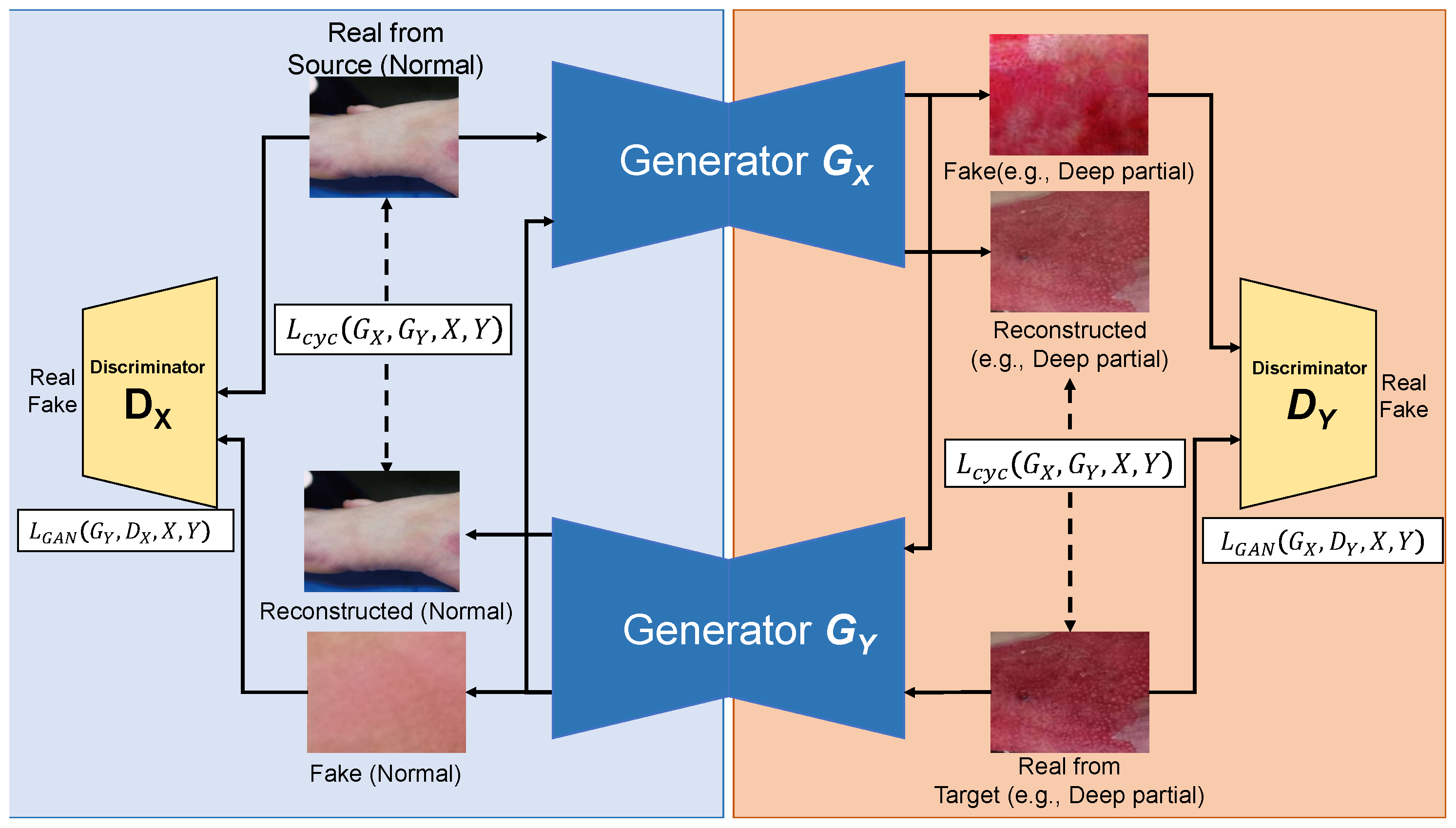
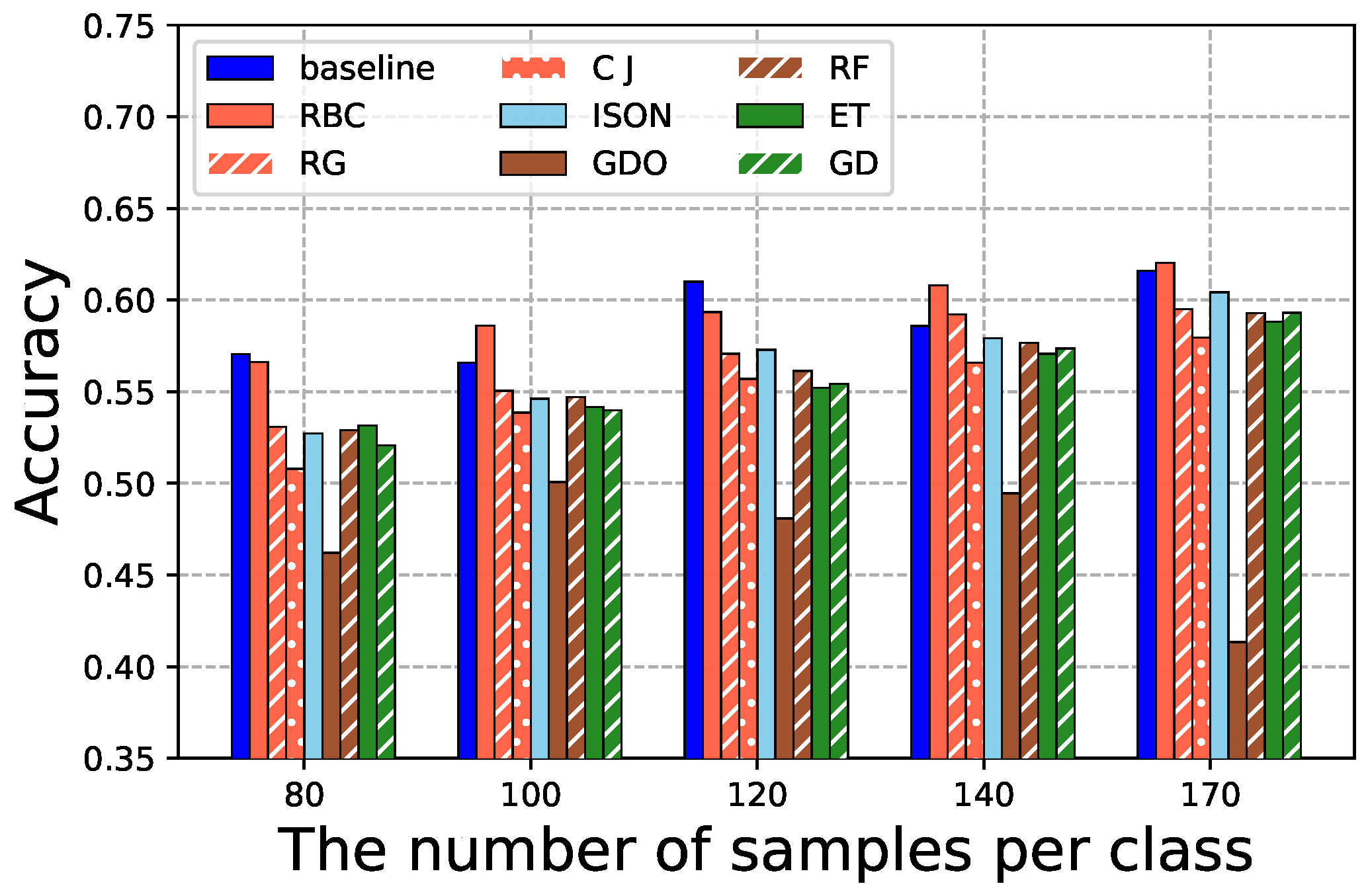
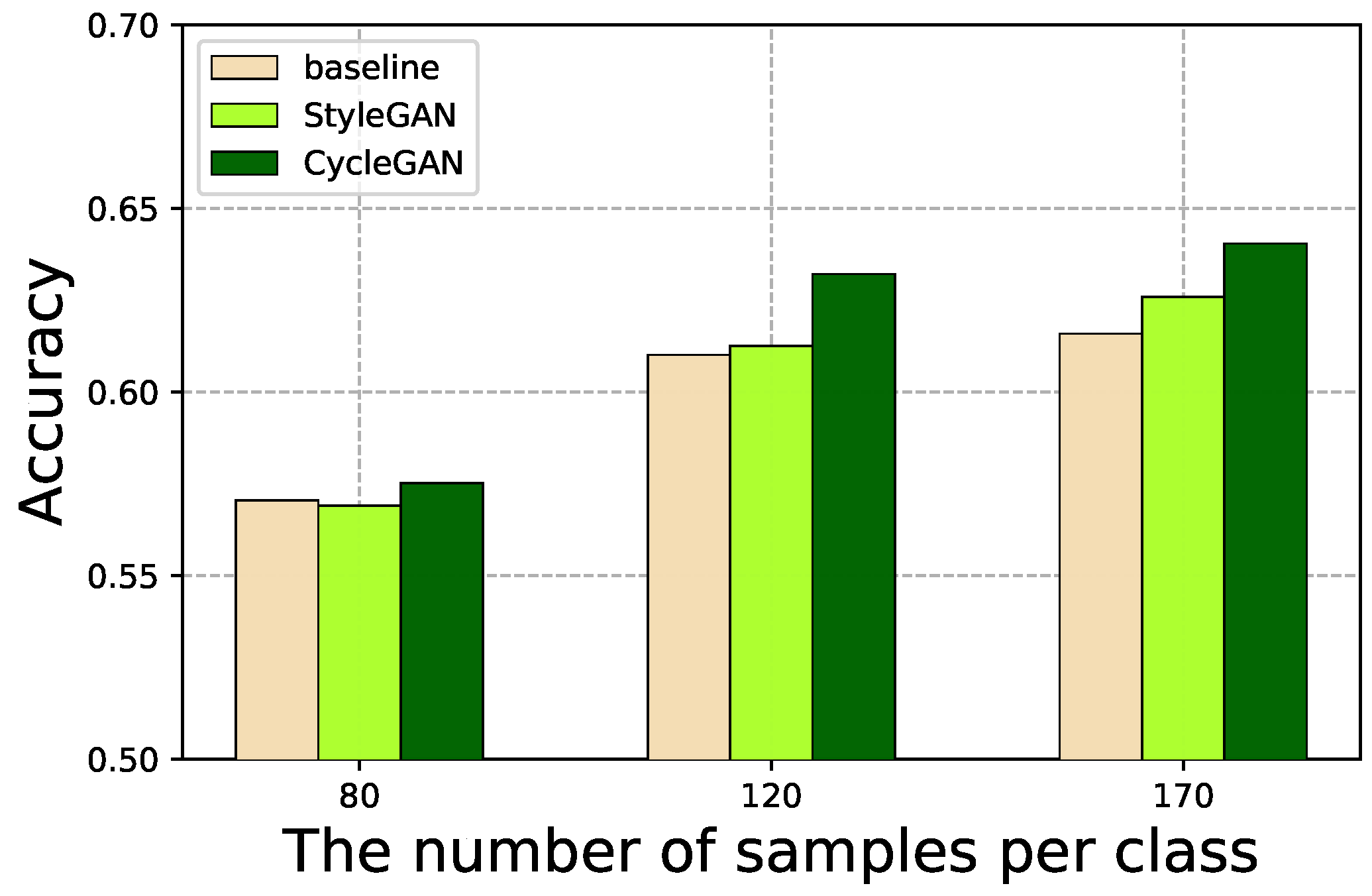
4.4. GAN-Based Data Augmentation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kwasigroch, A.; Grochowski, M.; Mikołajczyk, A. Self-Supervised Learning to Increase the Performance of Skin Lesion Classification. Electronics 2020, 9, 1930. [Google Scholar] [CrossRef]
- Xia, Y.; Yang, D.; Li, W.; Myronenko, A.; Xu, D.; Obinata, H.; Mori, H.; An, P.; Harmon, S.A.; Turkbey, E.B.; et al. Auto-FedAvg: Learnable Federated Averaging for Multi-Institutional Medical Image Segmentation. arXiv 2021, arXiv:2104.10195. [Google Scholar]
- Skandarani, Y.; Jodoin, P.M.; Lalande, A. GANs for Medical Image Synthesis: An Empirical Study. arXiv 2021, arXiv:2105.05318. [Google Scholar]
- Armanious, K.; Jiang, C.; Fischer, M.; Küstner, T.; Hepp, T.; Nikolaou, K.; Gatidis, S.; Yang, B. MedGAN: Medical image translation using GANs. Comput. Med. Imaging Graph. 2020, 79, 101684. [Google Scholar] [CrossRef]
- Emami, H.; Dong, M.; Nejad-Davarani, S.; Glide-Hurst, C. Generating Synthetic CTs from Magnetic Resonance Images using Generative Adversarial Networks. Med. Phys. 2018, 45, 3627–3636. [Google Scholar] [CrossRef]
- Qin, Z.; Liu, Z.; Zhu, P.; Xue, Y. A GAN-based Image Synthesis Method for Skin Lesion Classification. Comput. Methods Programs Biomed. 2020, 195, 105568. [Google Scholar] [CrossRef] [PubMed]
- Barile, B.; Marzullo, A.; Stamile, C.; Durand-Dubief, F.; Sappey-Marinier, D. Data Augmentation using Generative Adversarial Neural Networks on Brain Structural Connectivity in Multiple Sclerosis. Comput. Methods Programs Biomed. 2021, 206, 106113. [Google Scholar] [CrossRef]
- Abazari, M.; Ghaffari, A.; Rashidzadeh, H.; Badeleh, S.M.; Maleki, Y. A Systematic Review on Classification, Identification, and Healing Process of Burn Wound Healing. Int. J. Low. Extrem. Wounds 2022, 21, 18–30. [Google Scholar] [CrossRef]
- Chauhan, J.; Goyal, P. Deep Learning based Fully Automatic Efficient Burn Severity Estimators for Better Burn Diagnosis. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Shanthi, T.; Sabeenian, R.; Anand, R. Automatic Diagnosis of Skin Diseases using Convolution Neural Network. Microprocess. Microsyst. 2020, 76, 103074. [Google Scholar] [CrossRef]
- Rashid, J.; Ishfaq, M.; Ali, G.; Saeed, M.R.; Hussain, M.; Alkhalifah, T.; Alturise, F.; Samand, N. Skin Cancer Disease Detection Using Transfer Learning Technique. Appl. Sci. 2022, 12, 5714. [Google Scholar] [CrossRef]
- Kassem, M.A.; Hosny, K.M.; Damasevicius, R.; Eltoukhy, M.M. Machine Learning and Deep Learning Methods for Skin Lesion Classification and Diagnosis: A Systematic Review. Diagnostics 2021, 11, 1390. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.I.; Shah, J.L.; Bhat, M.M. CoroNet: A Deep Neural Network for Detection and Diagnosis of COVID-19 from Chest X-ray Images. Comput. Methods Programs Biomed. 2020, 196, 105581. [Google Scholar] [CrossRef] [PubMed]
- Xie, F.; Yang, J.; Liu, J.; Jiang, Z.; Zheng, Y.; Wang, Y. Skin Lesion Segmentation using High-resolution Convolutional Neural Network. Comput. Methods Programs Biomed. 2020, 186, 105241. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Cirillo, M.D.; Mirdell, R.; Sjöberg, F.; Pham, T. Time-Independent Prediction of Burn Depth using Deep Convolutional Neural Networks. J. Burn. Care Res. Off. Publ. Am. Burn. Assoc. 2019, 40, 857–863. [Google Scholar] [CrossRef] [PubMed]
- Abubakar, A.; Ugail, H.; Bukar, A. Assessment of Human Skin Burns: A Deep Transfer Learning Approach. J. Med. Biol. Eng. 2020, 40, 321–333. [Google Scholar] [CrossRef]
- Chauhan, J.; Goyal, P. Convolution Neural Network for Effective Burn Region Segmentation of Color Images. Burns 2021, 47, 854–862. [Google Scholar] [CrossRef]
- Gouda, N.; Amudha, J. Skin Cancer Classification using ResNet. In Proceedings of the IEEE International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 30–31 October 2020; pp. 536–541. [Google Scholar]
- Yang, W.; Zhang, H.; Yang, J.; Wu, J.; Yin, X.; Chen, Y.; Shu, H.; Luo, L.; Coatrieux, G.; Gui, Z.; et al. Improving Low-Dose CT Image Using Residual Convolutional Network. IEEE Access 2017, 5, 24698–24705. [Google Scholar] [CrossRef]
- Wang, H.; Xia, Y. ChestNet: A Deep Neural Network for Classification of Thoracic Diseases on Chest Radiography. arXiv 2018, arXiv:1807.03058. [Google Scholar]
- Cheplygina, V. Cats or CAT scans: Transfer learning from natural or medical image source data sets? Curr. Opin. Biomed. Eng. 2019, 9, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Reddy, A.S.B.; Juliet, D.S. Transfer Learning with ResNet-50 for Malaria Cell-Image Classification. In Proceedings of the International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; pp. 945–949. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- van Engelen, J.E.; Hoos, H. A Survey on Semi-supervised Learning. Mach. Learn. 2019, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Wang, F. Federated Learning for Healthcare Informatics. J. Healthc. Inform. Res. 2021, 5, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Kaissis, G.; Makowski, M.R.; Rückert, D.; Braren, R.F. Secure, Privacy-preserving and Federated Machine Learning in Medical Imaging. Nat. Mach. Intell. 2020, 2, 305–311. [Google Scholar] [CrossRef]
- Konecný, J.; McMahan, H.B.; Yu, F.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated Learning: Strategies for Improving Communication Efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Feki, I.; Ammar, S.; Kessentini, Y.; Muhammad, K. Federated learning for COVID-19 screening from Chest X-ray images. Appl. Soft Comput. 2021, 106, 107330. [Google Scholar] [CrossRef]
- Bdair, T.; Navab, N.; Albarqouni, S. FedPerl: Semi-supervised Peer Learning for Skin Lesion Classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI); de Bruijne, M., Cattin, P.C., Cotin, S., Padoy, N., Speidel, S., Zheng, Y., Essert, C., Eds.; Springer: Cham, Switzerland, 2021; pp. 336–346. [Google Scholar]
- Kaissis, G.; Ziller, A.; Passerat-Palmbach, J.; Ryffel, T.; Usynin, D.; Trask, A.; Lima, I.; Mancuso, J.; Jungmann, F.; Steinborn, M.M.; et al. End-to-end Privacy Preserving Deep Learning on Multi-institutional Medical Imaging. Nat. Mach. Intell. 2021, 3, 1–12. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Sandfort, V.; Yan, K.; Pickhardt, P.; Summers, R. Data Augmentation using Generative Adversarial Networks (CycleGAN) to Improve Generalizability in CT Segmentation Tasks. Sci. Rep. 2019, 9, 1–9. [Google Scholar] [CrossRef]
- Loey, M.; Smarandache, F.; Khalifa, N.E.M. Within the Lack of Chest COVID-1 X-ray Dataset: A Novel Detection Model Based on GAN and Deep Transfer Learning. Symmetry 2020, 12, 651. [Google Scholar] [CrossRef] [Green Version]
- Kazeminia, S.; Baur, C.; Kuijper, A.; Ginneken, B.V.; Navab, N.; Albarqouni, S.; Mukhopadhyay, A. GANs for Medical Image Analysis. Artif. Intell. Med. 2020, 109, 101938. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4396–4405. [Google Scholar]
- Chartsias, A.; Joyce, T.; Dharmakumar, R.; Tsaftaris, S.A. Adversarial Image Synthesis for Unpaired Multi-modal Cardiac Data. In Proceedings of the Simulation and Synthesis in Medical Imaging, Québec City, QC, Canada, 10 September 2017; pp. 3–13. [Google Scholar]
- Hamghalam, M.; Wang, T.; Lei, B. High Tissue Contrast Image Synthesis via Multistage Attention-GAN: Application to Segmenting Brain MR Scans. Neural Netw. 2020, 132, 43–52. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Shuai, R.; Ma, L.; Liu, W.; Hu, D.; Wu, M. Dermoscopy Image Classification Based on StyleGAN and DenseNet201. IEEE Access 2021, 9, 8659–8679. [Google Scholar] [CrossRef]
- Yang, H.; Sun, J.; Carass, A.; Zhao, C.; Lee, J.; Xu, Z.; Prince, J. Unpaired Brain MR-to-CT Synthesis Using a Structure-Constrained CycleGAN. In Proceedings of the DLMIA/ML-CDS@MICCAI, Granada, Spain, 20 September 2018; pp. 174–182. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Fey, M.; Lenssen, J.E. Fast Graph Representation Learning with PyTorch Geometric. arXiv 2019, arXiv:1903.02428. [Google Scholar]
- Johnson, R.M.; Richard, R. Partial-thickness Burns: Identification and Management. Adv. Ski. Wound Care 2003, 16, 178–189. [Google Scholar] [CrossRef]
- Karthik, J.; Nath, G.S.; Veena, A. Deep Learning-Based Approach for Skin Burn Detection with Multi-level Classification. In Advances in Computing and Network Communications; Springer: Singapore, 2021; pp. 31–40. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Normal | Super. | Inter. | Deep | Full |
|---|---|---|---|---|---|
| Training dataset | 1700 | 1700 | 1700 | 1700 | 1700 |
| Test dataset | 2779 | 2033 | 1770 | 2386 | 726 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, H.; Shin, H.; Choi, W.; Park, J.; Park, M.; Koh, E.; Woo, H. Sample-Efficient Deep Learning Techniques for Burn Severity Assessment with Limited Data Conditions. Appl. Sci. 2022, 12, 7317. https://doi.org/10.3390/app12147317
Shin H, Shin H, Choi W, Park J, Park M, Koh E, Woo H. Sample-Efficient Deep Learning Techniques for Burn Severity Assessment with Limited Data Conditions. Applied Sciences. 2022; 12(14):7317. https://doi.org/10.3390/app12147317
Chicago/Turabian StyleShin, Hyunkyung, Hyeonung Shin, Wonje Choi, Jaesung Park, Minjae Park, Euiyul Koh, and Honguk Woo. 2022. "Sample-Efficient Deep Learning Techniques for Burn Severity Assessment with Limited Data Conditions" Applied Sciences 12, no. 14: 7317. https://doi.org/10.3390/app12147317
APA StyleShin, H., Shin, H., Choi, W., Park, J., Park, M., Koh, E., & Woo, H. (2022). Sample-Efficient Deep Learning Techniques for Burn Severity Assessment with Limited Data Conditions. Applied Sciences, 12(14), 7317. https://doi.org/10.3390/app12147317