The Consistency and Quality of ChatGPT Responses Compared to Clinical Guidelines for Ovarian Cancer: A Delphi Approach

 , , , ,
, , , , 
Abstract
1. Introduction
2. Materials and Methods
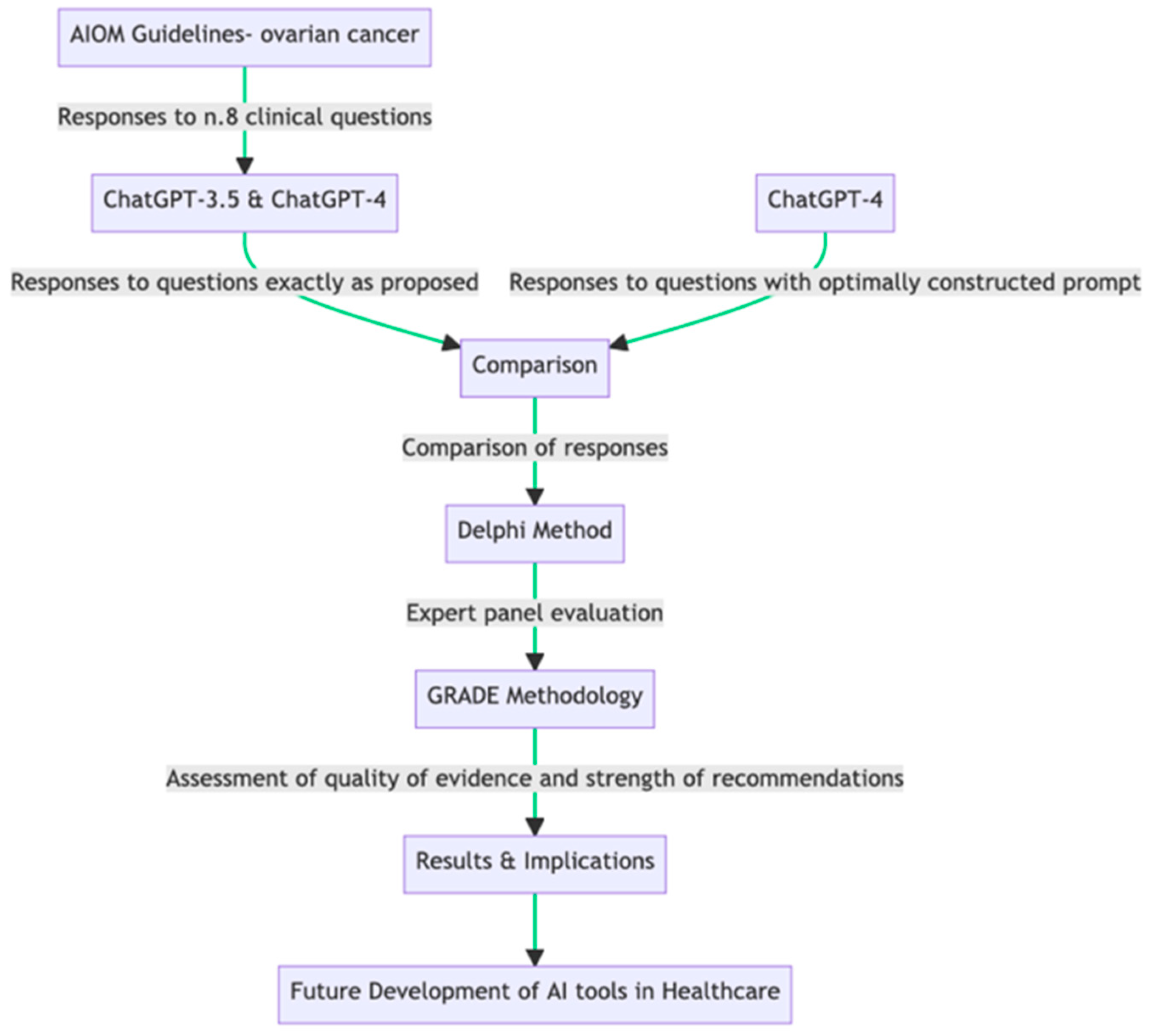
2.1. Study Design

{kind=link}
| (a) | |
|---|---|
| n.# | Clinical Question |
| 1 | In patients with advanced epithelial carcinoma of the ovary undergoing complete macroscopic resection and with negative lymph nodes on imaging and intraoperative evaluation (P), is systematic lymphadenectomy (I) recommended over non lymphadenectomy (C) in terms of overall survival, PFS, quality of life, and complications (O)? |
| 2 | In patients with advanced epithelial carcinoma of the ovary, stage IIIC-IV (P) is primary surgery (I) recommended over neoadjuvant chemotherapy followed by interval surgery (C) in terms of overall survival, PFS, quality of life, and complications (O)? |
| 3 | In patients with platinum-sensitive recurrence of epithelial carcinoma of the ovary (P), is cytoreductive surgery followed by chemotherapy (I) recommended over chemotherapy alone (C) in terms of overall survival, PFS, and complications (O)? |
| 4 | In patients with FIGO stage IIIB-IV ovarian cancer (P), is bevacizumab administration in combination and maintenance at the end of first-line chemotherapy (I) recommended compared with chemotherapy alone (C) in terms of overall survival (OS), progression-free survival (PFS), and complications (O)? |
| 5 | In patients with low-grade FIGO stage II-IV serous ovarian cancer (P), is maintenance hormone therapy recommended at the end of first-line platinum-based chemotherapy (I) compared with no maintenance (C) in terms of overall survival (OS), progression-free survival (PFS), and complications (O)? |
| 6 | In BRCA-mutated patients with high-grade FIGO stage III-IV serous ovarian and endometrioid cancer (P), is maintenance therapy with Olaparib at the end of first-line platinum-based chemotherapy (I) recommendable compared with non maintenance (C) in terms of PFS, time to next chemotherapy, time to second subsequent progression (PFS2), quality of life, overall survival, and tolerability (O)? |
| 7 | In patients with high-risk FIGO stage III-IV (P) serous and endometrioid ovarian cancer, is maintenance therapy with Niraparib at the end of first-line platinum-based chemotherapy (I) recommendable compared with non maintenance (C) in terms of PFS, time to next chemotherapy, time to second subsequent progression (PFS2), quality of life, overall survival, and tolerability? |
| 8 | In patients with stage I (P) immature teratoma, is adjuvant treatment (I) recommended over no treatment (C) in terms of overall survival (OS), disease-free survival (DFS), and tolerability (O)? |
| (b) | |
| Model | Prompt |
| ChatGPT-3.5 | [Clinical Question #] * (as proposed from source document) |
| ChatGPT-4 | [Clinical Question #] * (as proposed from source document) |
| ChatGPT-4 | Act as an Italian multidisciplinary oncology group. We ask a question using the PICO method. Reply extensively based on national and international guidelines and current evidence, indicate the limitations of the evidence, and indicate the ratio of benefits to harms. Also, provide answers with a formal GRADE approach indicating the overall quality of evidence and strength of recommendation. § [Clinical Question #] * |
2.2. Statistics
3. Results
| Domains | Questions | Mean | CI (±95%) |
|---|---|---|---|
| clarity | How do you think the guideline expresses its recommendations? | 4.28 | 0.14 |
| How does the ChatGPT-3.5 model’s response to the clinical question express its recommendations? | 1.23 | 0.12 | |
| How does the ChatGPT-4 model’s response to the clinical question express its recommendations? | 2.23 | 0.21 | |
| How does the prompted ChatGPT-4 model’s response to the clinical question express its recommendations? | 3.31 | 0.21 | |
| relevance | How relevant is the evidence in the guideline for the recommendations? | 4.35 | 0.15 |
| How relevant is the evidence presented in the ChatGPT-3.5 model’s response to the clinical question for the recommendations made? | 1.36 | 0.09 | |
| How relevant is the evidence presented in the ChatGPT-4 model’s response to the clinical question for the recommendations made? | 2.25 | 0.24 | |
| How relevant is the evidence presented in the prompted ChatGPT-4 model’s response to the clinical question for the recommendations made? | 3.15 | 0.24 | |
| comprehensiveness | How comprehensive are the guidelines in addressing the topic? | 4.53 | 0.13 |
| How comprehensive is the ChatGPT-3.5 model’s response to the clinical question in addressing the topic? | 1.11 | 0.06 | |
| How comprehensively does the ChatGPT-4 model’s response to the clinical question is in addressing the topic? | 2.13 | 0.22 | |
| How comprehensive is the prompted ChatGPT-4 model’s response to the clinical question in addressing the topic? | 2.95 | 0.23 | |
| applicability | How applicable is the guide to clinical practice? | 4.28 | 0.14 |
| How applicable is the ChatGPT-3.5 model’s response to the clinical question to clinical practice? | 1.23 | 0.12 | |
| How applicable is the ChatGPT-4 model’s response to the clinical question to clinical practice? | 2.26 | 0.23 | |
| How applicable is the prompted ChatGPT-4 model’s response to the clinical question to clinical practice? | 2.82 | 0.27 | |
| quality | According to the GRADE approach, how would you rate the strength of the recommendations and the quality of the evidence presented in the guideline?According to the GRADE approach | 2.3 | 0.16 |
| How would you rate the recommendations’ strength and the evidence’s quality presented in the ChatGPT-3.5 model’s response?According to the GRADE approach | 1.88 | 0.12 | |
| How would you rate the recommendations’ strength and the evidence’s quality presented in the ChatGPT-4 model’s response?According to the GRADE approach | 2.49 | 0.26 | |
| How would you rate the recommendations’ strength and the evidence’s quality presented in the prompted ChatGPT-4 model’s response? | 2.38 | 0.26 |
| Domain 1 | Domain 2 | Mean Difference | Adjusted p-Value | Lower Bound | Upper Bound | Reject Null Hypothesis |
|---|---|---|---|---|---|---|
| ChatGPT-3.5 | ChatGPT-4 | 0.91 | 0.0618 | −0.037 | 1.857 | False |
| ChatGPT-3.5 | Guidelines | 2.586 | 0.001 | 1.639 | 3.533 | True |
| ChatGPT-3.5 | Prompted ChatGPT-4 | 1.56 | 0.0012 | 0.613 | 2.507 | True |
| ChatGPT-4 | Guidelines | 1.676 | 0.001 | 0.729 | 2.623 | True |
| ChatGPT-4 | Prompted ChatGPT-4 | 0.65 | 0.242 | −0.297 | 1.597 | False |
| Guidelines | Prompted ChatGPT-4 | −1.026 | 0.0314 | −1.973 | −0.079 | True |
4. Discussion
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Armstrong, D.K.; Alvarez, R.D.; Bakkum-Gamez, J.N.; Barroilhet, L.; Behbakht, K.; Berchuck, A.; Chen, L.; Cristea, M.; DeRosa, M.; Eisenhauer, E.L.; et al. Ovarian Cancer, Version 2.2020, NCCN Clinical Practice Guidelines in Oncology. J. Natl. Compr. Cancer Netw. 2021, 19, 191–226. [Google Scholar] [CrossRef] [PubMed]
- I Numeri Del Cancro 2023. Associazione Italiana Registri Tumori. Available online: https://www.registri-tumori.it/cms/notizie/i-numeri-del-cancro-2023 (accessed on 26 February 2024).
- National Comprehensive Cancer Network—Home. Available online: https://www.nccn.org (accessed on 7 February 2024).
- Colombo, N.; Sessa, C.; Du Bois, A.; Ledermann, J.; McCluggage, W.G.; McNeish, I.; Morice, P.; Pignata, S.; Ray-Coquard, I.; Vergote, I.; et al. ESMO–ESGO Consensus Conference Recommendations on Ovarian Cancer: Pathology and Molecular Biology, Early and Advanced Stages, Borderline Tumours and Recurrent Disease. Ann. Oncol. 2019, 30, 672–705. [Google Scholar] [CrossRef] [PubMed]
- Linee Guida Carcinoma Dell’ovaio. Available online: https://www.aiom.it/linee-guida-aiom-2021-carcinoma-dellovaio/ (accessed on 7 February 2024).
- OpenAI. Available online: https://openai.com/ (accessed on 7 February 2024).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Xu, L.; Sanders, L.; Li, K.; Chow, J.C.L. Chatbot for Health Care and Oncology Applications Using Artificial Intelligence and Machine Learning: Systematic Review. JMIR Cancer 2021, 7, e27850. [Google Scholar] [CrossRef] [PubMed]
- Papachristou, N.; Kotronoulas, G.; Dikaios, N.; Allison, S.J.; Eleftherochorinou, H.; Rai, T.; Kunz, H.; Barnaghi, P.; Miaskowski, C.; Bamidis, P.D. Digital Transformation of Cancer Care in the Era of Big Data, Artificial Intelligence and Data-Driven Interventions: Navigating the Field. Semin. Oncol. Nurs. 2023, 39, 151433. [Google Scholar] [CrossRef] [PubMed]
- Taber, P.; Armin, J.S.; Orozco, G.; Del Fiol, G.; Erdrich, J.; Kawamoto, K.; Israni, S.T. Artificial Intelligence and Cancer Control: Toward Prioritizing Justice, Equity, Diversity, and Inclusion (JEDI) in Emerging Decision Support Technologies. Curr. Oncol. Rep. 2023, 25, 387–424. [Google Scholar] [CrossRef] [PubMed]
- Tawfik, E.; Ghallab, E.; Moustafa, A. A Nurse versus a Chatbot—The Effect of an Empowerment Program on Chemotherapy-Related Side Effects and the Self-Care Behaviors of Women Living with Breast Cancer: A Randomized Controlled Trial. BMC Nurs. 2023, 22, 102. [Google Scholar] [CrossRef] [PubMed]
- Xue, V.W.; Lei, P.; Cho, W.C. The Potential Impact of ChatGPT in Clinical and Translational Medicine. Clin. Transl. Med. 2023, 13, e1216. [Google Scholar] [CrossRef]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in Medicine: An Overview of Its Applications, Advantages, Limitations, Future Prospects, and Ethical Considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef] [PubMed]
- Taylor, E. We Agree, Don’t We? The Delphi Method for Health Environments Research. HERD 2020, 13, 11–23. [Google Scholar] [CrossRef]
- Guyatt, G.H.; Oxman, A.D.; Vist, G.E.; Kunz, R.; Falck-Ytter, Y.; Alonso-Coello, P.; Schünemann, H.J. GRADE: An Emerging Consensus on Rating Quality of Evidence and Strength of Recommendations. BMJ 2008, 336, 924–926. [Google Scholar] [CrossRef]
- Yeo, Y.H.; Samaan, J.S.; Ng, W.H.; Ting, P.-S.; Trivedi, H.; Vipani, A.; Ayoub, W.; Yang, J.D.; Liran, O.; Spiegel, B.; et al. Assessing the Performance of ChatGPT in Answering Questions Regarding Cirrhosis and Hepatocellular Carcinoma. Clin. Mol. Hepatol. 2023, 29, 721. [Google Scholar] [CrossRef] [PubMed]
- Cascella, M.; Montomoli, J.; Bellini, V.; Bignami, E. Evaluating the Feasibility of ChatGPT in Healthcare: An Analysis of Multiple Clinical and Research Scenarios. J. Med. Syst. 2023, 47, 33. [Google Scholar] [CrossRef] [PubMed]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.K.; Chua, M.; Rickard, M.; Lorenzo, A. ChatGPT and Large Language Model (LLM) Chatbots: The Current State of Acceptability and a Proposal for Guidelines on Utilization in Academic Medicine. J. Pediatr. Urol. 2023, 19, 598–604. [Google Scholar] [CrossRef] [PubMed]
- Schulte, B. Capacity of ChatGPT to Identify Guideline-Based Treatments for Advanced Solid Tumors. Cureus 2023, 15, e37938. [Google Scholar] [CrossRef]
- Kothari, A.N. ChatGPT, Large Language Models, and Generative AI as Future Augments of Surgical Cancer Care. Ann. Surg. Oncol. 2023, 30, 3174–3176. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, Z.; Naffakh, N.; Reizine, N.M.; Weinberg, F.; Jain, S.; Gadi, V.K.; Bun, C.; Nguyen, R.H.-T. Relevance and Accuracy of ChatGPT-Generated NGS Reports with Treatment Recommendations for Oncogene-Driven NSCLC. JCO 2023, 41, 1555. [Google Scholar] [CrossRef]
- Cheng, K.; Wu, H.; Li, C. ChatGPT/GPT-4: Enabling a New Era of Surgical Oncology. Int. J. Surg. 2023. ahead of print. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimi, B.; Howard, A.; Carlson, D.J.; Al-Hallaq, H. ChatGPT: Can a Natural Language Processing Tool Be Trusted for Radiation Oncology Use? Int. J. Radiat. Oncol. Biol. Phys. 2023, 116, 977–983. [Google Scholar] [CrossRef] [PubMed]
- Haemmerli, J.; Sveikata, L.; Nouri, A.; May, A.; Egervari, K.; Freyschlag, C.; Lobrinus, J.A.; Migliorini, D.; Momjian, S.; Sanda, N.; et al. ChatGPT in Glioma Patient Adjuvant Therapy Decision Making: Ready to Assume the Role of a Doctor in the Tumour Board? BMJ Health Care Inform. 2023, 30, e100775. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Gomaa, A.; Semrau, S.; Haderlein, M.; Lettmaier, S.; Weissmann, T.; Grigo, J.; Tkhayat, H.B.; Frey, B.; Gaipl, U.; et al. Benchmarking ChatGPT-4 on a Radiation Oncology in-Training Exam and Red Journal Gray Zone Cases: Potentials and Challenges for Ai-Assisted Medical Education and Decision Making in Radiation Oncology. Front. Oncol. 2023, 13, 1265024. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piazza, D.; Martorana, F.; Curaba, A.; Sambataro, D.; Valerio, M.R.; Firenze, A.; Pecorino, B.; Scollo, P.; Chiantera, V.; Scibilia, G.; et al. The Consistency and Quality of ChatGPT Responses Compared to Clinical Guidelines for Ovarian Cancer: A Delphi Approach. Curr. Oncol. 2024, 31, 2796-2804. https://doi.org/10.3390/curroncol31050212
Piazza D, Martorana F, Curaba A, Sambataro D, Valerio MR, Firenze A, Pecorino B, Scollo P, Chiantera V, Scibilia G, et al. The Consistency and Quality of ChatGPT Responses Compared to Clinical Guidelines for Ovarian Cancer: A Delphi Approach. Current Oncology. 2024; 31(5):2796-2804. https://doi.org/10.3390/curroncol31050212
Chicago/Turabian StylePiazza, Dario, Federica Martorana, Annabella Curaba, Daniela Sambataro, Maria Rosaria Valerio, Alberto Firenze, Basilio Pecorino, Paolo Scollo, Vito Chiantera, Giuseppe Scibilia, and et al. 2024. "The Consistency and Quality of ChatGPT Responses Compared to Clinical Guidelines for Ovarian Cancer: A Delphi Approach" Current Oncology 31, no. 5: 2796-2804. https://doi.org/10.3390/curroncol31050212
APA StylePiazza, D., Martorana, F., Curaba, A., Sambataro, D., Valerio, M. R., Firenze, A., Pecorino, B., Scollo, P., Chiantera, V., Scibilia, G., Vigneri, P., Gebbia, V., & Scandurra, G. (2024). The Consistency and Quality of ChatGPT Responses Compared to Clinical Guidelines for Ovarian Cancer: A Delphi Approach. Current Oncology, 31(5), 2796-2804. https://doi.org/10.3390/curroncol31050212