Large Language Models in Oncology: Revolution or Cause for Concern?

 , ,
, ,  ,
, 
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Methods
- ✓
- Neoplasms OR cancer OR Tumours/Tumors OR Oncology OR malignancies;
- ✓
- Large language model OR LLM;
- ✓
- GoogleBard OR ChatGPT OR Claude OR Perplexity.
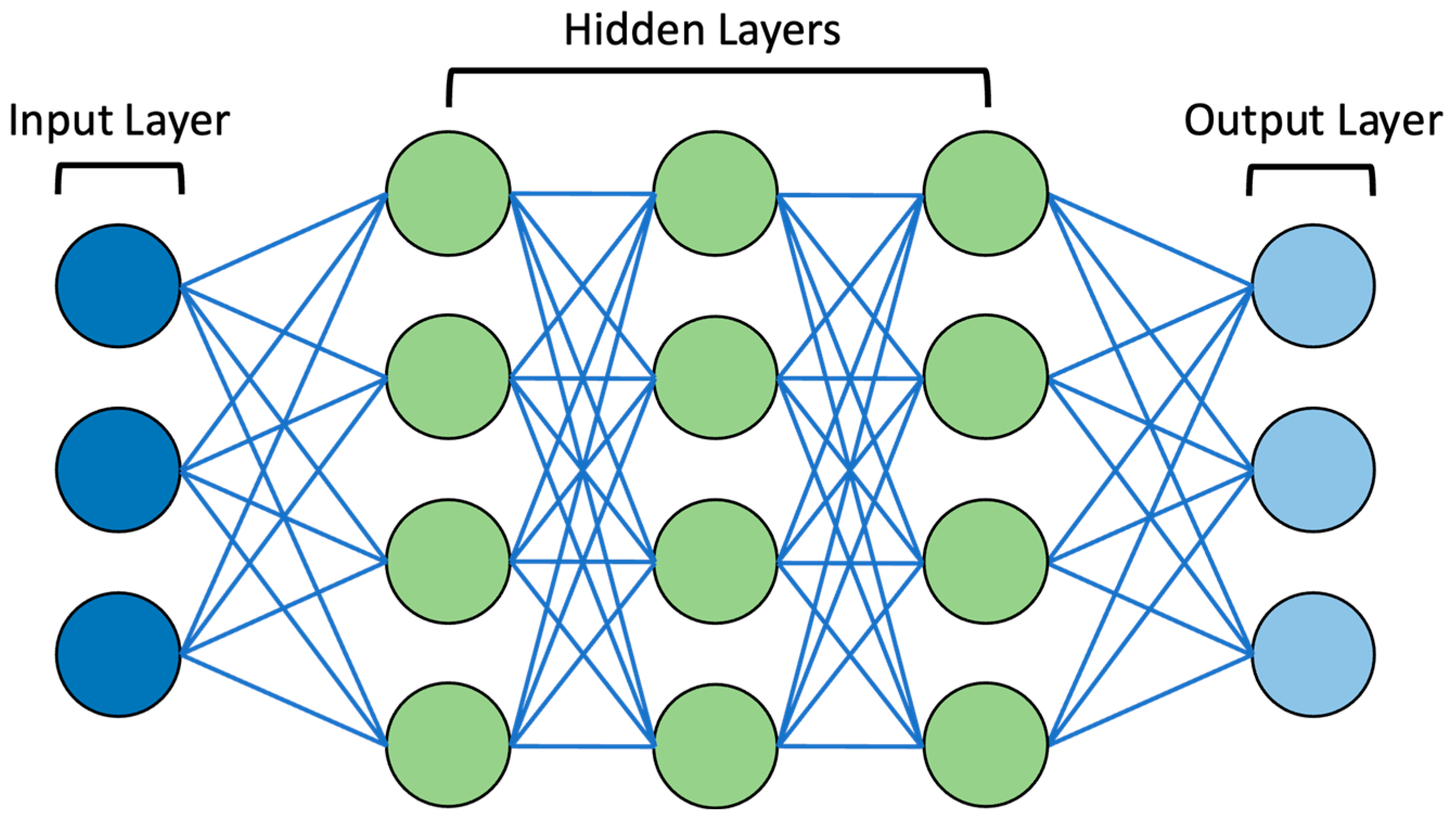
3. Large Language Model Function
4. A Cause for Revolution
4.1. Oncological Clinical Practice
4.2. Cancer Patient Support and Education
4.3. Educating Students and Healthcare Professionals in Oncology
4.4. Oncology Research
5. A Cause for Concern
5.1. Data Accuracy
5.2. Accountability
5.3. Data Security
5.4. Research Integrity
6. Strengths and Limitations
7. Conclusions and Future Directions
Author Contributions
Funding
Conflicts of Interest
References
- Turing, A.M. Computing Machinery and Intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- Haug, C.J.; Drazen, J.M. Artificial Intelligence and Machine Learning in Clinical Medicine, 2023. N. Engl. J. Med. 2023, 388, 1201–1208. [Google Scholar] [CrossRef]
- Kaul, V.; Enslin, S.; Gross, S.A. History of Artificial Intelligence in Medicine. Gastrointest. Endosc. 2020, 92, 807–812. [Google Scholar] [CrossRef]
- Schwartz, W.B.; Patil, R.S.; Szolovits, P. Artificial Intelligence in Medicine. Where Do We Stand? N. Engl. J. Med. 1987, 316, 685–688. [Google Scholar] [CrossRef]
- Floridi, L. AI and Its New Winter: From Myths to Realities. Philos. Technol. 2020, 33, 1–3. [Google Scholar] [CrossRef]
- Topol, E.J. High-Performance Medicine: The Convergence of Human and Artificial Intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Lungren, M.P. The Current and Future State of AI Interpretation of Medical Images. N. Engl. J. Med. 2023, 388, 1981–1990. [Google Scholar] [CrossRef]
- Mithany, R.H.; Aslam, S.; Abdallah, S.; Abdelmaseeh, M.; Gerges, F.; Mohamed, M.S.; Manasseh, M.; Wanees, A.; Shahid, M.H.; Khalil, M.S.; et al. Advancements and Challenges in the Application of Artificial Intelligence in Surgical Arena: A Literature Review. Cureus 2023, 15, e47924. [Google Scholar] [CrossRef]
- Lee, P.; Bubeck, S.; Petro, J. Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. N. Engl. J. Med. 2023, 388, 1233–1239. [Google Scholar] [CrossRef]
- OpenAI. ChatGPT. Available online: https://chat.openai.com (accessed on 3 January 2024).
- Google. Bard. Available online: https://bard.google.com/chat (accessed on 3 January 2024).
- Anthropic-Claude. Meet Claude. Available online: https://www.anthropic.com/product (accessed on 3 January 2024).
- Perplexity. Perplexity AI. Available online: https://www.perplexity.ai (accessed on 3 January 2024).
- Shreve, J.T.; Khanani, S.A.; Haddad, T.C. Artificial Intelligence in Oncology: Current Capabilities, Future Opportunities, and Ethical Considerations. Am. Soc. Clin. Oncol. Educ. Book 2022, 42, 1–10. [Google Scholar] [CrossRef]
- Kanan, C.; Sue, J.; Grady, L.; Fuchs, T.J.; Chandarlapaty, S.; Reis-Filho, J.S.; Salles, P.G.O.; da Silva, L.M.; Ferreira, C.G.; Pereira, E.M. Independent Validation of Paige Prostate: Assessing Clinical Benefit of an Artificial Intelligence Tool within a Digital Diagnostic Pathology Laboratory Workflow. J. Clin. Oncol. 2020, 38, e14076. [Google Scholar] [CrossRef]
- Pun, F.W.; Ozerov, I.V.; Zhavoronkov, A. AI-Powered Therapeutic Target Discovery. Trends. Pharmacol. Sci. 2023, 44, 561–572. [Google Scholar] [CrossRef]
- Uprety, D.; Zhu, D.; West, H.J. ChatGPT—A Promising Generative AI Tool and Its Implications for Cancer Care. Cancer 2023, 129, 2284–2289. [Google Scholar] [CrossRef]
- Rassy, E.; Parent, P.; Lefort, F.; Boussios, S.; Baciarello, G.; Pavlidis, N. New Rising Entities in Cancer of Unknown Primary: Is There a Real Therapeutic Benefit? Crit. Rev. Oncol. Hematol. 2020, 147, 102882. [Google Scholar] [CrossRef]
- IBM. AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What’s the Difference? Available online: https://www.ibm.com/blog/ai-vs-machine-learning-vs-deep-learning-vs-neural-networks/ (accessed on 13 January 2024).
- Fine, T.L. Feedforward Neural Network Methodology, 3rd ed.; Springer: New York, NY, USA, 1999. [Google Scholar]
- Oustimov, A.; Vu, V. Artificial Neural Networks in the Cancer Genomics Frontier. Transl. Cancer. Res. 2014, 3, 191–201. [Google Scholar]
- Cowan, J.D. Advances in Neural Information Processing Systems 2. Neural Networks: The Early Days; Touretzky, D., Ed.; Morgan Kaufmann: San Mateo, CA, USA, 1990. [Google Scholar]
- Tran, K.A.; Kondrashova, O.; Bradley, A.; Williams, E.D.; Pearson, J.V.; Waddell, N. Deep Learning in Cancer Diagnosis, Prognosis and Treatment Selection. Genome. Med. 2021, 13, 152. [Google Scholar] [CrossRef]
- Massion, P.P.; Antic, S.; Ather, S.; Arteta, C.; Brabec, J.; Chen, H.; Declerck, J.; Dufek, D.; Hickes, W.; Kadir, T.; et al. Assessing the Accuracy of a Deep Learning Method to Risk Stratify Indeterminate Pulmonary Nodules. Am. J. Respir. Crit. Care. Med. 2020, 202, 241–249. [Google Scholar] [CrossRef]
- da Silva, L.M.; Pereira, E.M.; Salles, P.G.; Godrich, R.; Ceballos, R.; Kunz, J.D.; Casson, A.; Viret, J.; Chandarlapaty, S.; Ferreira, C.G.; et al. Independent Real-world Application of a Clinical-grade Automated Prostate Cancer Detection System. J. Pathol. 2021, 254, 147–158. [Google Scholar] [CrossRef]
- IBM. What Is Natural Language Processing? Available online: https://www.ibm.com/topics/natural-language-processing (accessed on 13 January 2024).
- Iannantuono, G.M.; Bracken-Clarke, D.; Floudas, C.S.; Roselli, M.; Gulley, J.L.; Karzai, F. Applications of Large Language Models in Cancer Care: Current Evidence and Future Perspectives. Front. Oncol. 2023, 13, 1268915. [Google Scholar] [CrossRef]
- IBM. What Is Generative AI? Available online: https://research.ibm.com/blog/what-is-generative-AI (accessed on 13 January 2024).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Birhane, A.; Kasirzadeh, A.; Leslie, D.; Wachter, S. Science in the Age of Large Language Models. Nat. Rev. Phys. 2023, 5, 277–280. [Google Scholar] [CrossRef]
- IBM. What Are Large Language Models? Available online: https://www.ibm.com/topics/large-language-models (accessed on 8 March 2024).
- Mitchell, M.; Krakauer, D.C. The Debate over Understanding in AI’s Large Language Models. Proc. Natl. Acad. Sci. USA 2023, 120, e2215907120. [Google Scholar] [CrossRef]
- Bender, E.M.; Koller, A. Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 5185–5198. [Google Scholar]
- Cadamuro, J.; Cabitza, F.; Debeljak, Z.; De Bruyne, S.; Frans, G.; Perez, S.M.; Ozdemir, H.; Tolios, A.; Carobene, A.; Padoan, A. Potentials and Pitfalls of ChatGPT and Natural-Language Artificial Intelligence Models for the Understanding of Laboratory Medicine Test Results. An Assessment by the European Federation of Clinical Chemistry and Laboratory Medicine (EFLM) Working Group on Artificial Intelligence (WG-AI). Clin. Chem. Lab. Med. 2023, 61, 1158–1166. [Google Scholar]
- Srivastav, S.; Chandrakar, R.; Gupta, S.; Babhulkar, V.; Agrawal, S.; Jaiswal, A.; Prasad, R.; Wanjari, M.B. ChatGPT in Radiology: The Advantages and Limitations of Artificial Intelligence for Medical Imaging Diagnosis. Cureus 2023, 15, e41435. [Google Scholar] [CrossRef]
- Rao, A.; Kim, J.; Kamineni, M.; Pang, M.; Lie, W.; Dreyer, K.J.; Succi, M.D. Evaluating GPT as an Adjunct for Radiologic Decision Making: GPT-4 Versus GPT-3.5 in a Breast Imaging Pilot. J. Am. Coll. Radiol. 2023, 20, 990–997. [Google Scholar] [CrossRef]
- Becker, G.; Kempf, D.E.; Xander, C.J.; Momm, F.; Olschewski, M.; Blum, H.E. Four Minutes for a Patient, Twenty Seconds for a Relative—An Observational Study at a University Hospital. BMC. Health Serv. Res. 2010, 10, 94. [Google Scholar] [CrossRef]
- Clusmann, J.; Kolbinger, F.R.; Muti, H.S.; Carrero, Z.I.; Eckardt, J.-N.; Laleh, N.G.; Löffler, C.M.L.; Schwarzkopf, S.-C.; Unger, M.; Veldhuizen, G.P.; et al. The Future Landscape of Large Language Models in Medicine. Commun. Med. 2023, 3, 141. [Google Scholar] [CrossRef]
- Liu, J.; Wang, C.; Liu, S. Utility of ChatGPT in Clinical Practice. J. Med. Internet Res. 2023, 25, e48568. [Google Scholar] [CrossRef]
- Schukow, C.; Smith, S.C.; Landgrebe, E.; Parasuraman, S.; Folaranmi, O.O.; Paner, G.P.; Amin, M.B. Application of ChatGPT in Routine Diagnostic Pathology: Promises, Pitfalls, and Potential Future Directions. Adv. Anat. Pathol. 2024, 31, 15–21. [Google Scholar] [CrossRef]
- Sorin, V.; Klang, E.; Sklair-Levy, M.; Cohen, I.; Zippel, D.B.; Balint Lahat, N.; Konen, E.; Barash, Y. Large Language Model (ChatGPT) as a Support Tool for Breast Tumor Board. NPJ. Breast Cancer 2023, 9, 44. [Google Scholar] [CrossRef]
- Haemmerli, J.; Sveikata, L.; Nouri, A.; May, A.; Egervari, K.; Freyschlag, C.; Lobrinus, J.A.; Migliorini, D.; Momjian, S.; Sanda, N.; et al. ChatGPT in Glioma Adjuvant Therapy Decision Making: Ready to Assume the Role of a Doctor in the Tumour Board? BMJ Health. Care Inform. 2023, 30, e100775. [Google Scholar] [CrossRef]
- Schulte, B. Capacity of ChatGPT to Identify Guideline-Based Treatments for Advanced Solid Tumors. Cureus 2023, 15, e37938. [Google Scholar] [CrossRef]
- ClinicalTrials.gov. Treatment Recommendations for Gastrointestinal Cancers via Large Language Models. Available online: https://clinicaltrials.gov/study/NCT06002425 (accessed on 15 January 2024).
- Gierman, H.J.; Goldfarb, S.; Labrador, M.; Weipert, C.M.; Getty, B.; Skrzypczak, S.M.; Catasus, C.; Carbral, S.; Singaraju, M.; Singleton, N.; et al. Genomic Testing and Treatment Landscape in Patients with Advanced Non-Small Cell Lung Cancer (ANSCLC) Using Real-World Data from Community Oncology Practices. J. Clin. Oncol. 2019, 37, 1585. [Google Scholar] [CrossRef]
- Waterhouse, D.M.; Tseng, W.-Y.; Espirito, J.L.; Robert, N.J. Understanding Contemporary Molecular Biomarker Testing Rates and Trends for Metastatic NSCLC Among Community Oncologists. Clin. Lung Cancer 2021, 22, e901–e910. [Google Scholar] [CrossRef]
- West, H.J.; Lovly, C.M. Ferrying Oncologists Across the Chasm of Interpreting Biomarker Testing Reports: Systematic Support Needed to Improve Care and Decrease Disparities. JCO Oncol. Pract. 2023, 19, 530–532. [Google Scholar] [CrossRef]
- Blum, J.; Menta, A.K.; Zhao, X.; Yang, V.B.; Gouda, M.A.; Subbiah, V. Pearls and Pitfalls of ChatGPT in Medical Oncology. Trends. Cancer 2023, 9, 788–790. [Google Scholar] [CrossRef]
- Calixte, R.; Rivera, A.; Oridota, O.; Beauchamp, W.; Camacho-Rivera, M. Social and Demographic Patterns of Health-Related Internet Use Among Adults in the United States: A Secondary Data Analysis of the Health Information National Trends Survey. Int. J. Environ. Res. Public Health 2020, 17, 6856. [Google Scholar] [CrossRef]
- Johnson, S.B.; King, A.J.; Warner, E.L.; Aneja, S.; Kann, B.H.; Bylund, C.L. Using ChatGPT to Evaluate Cancer Myths and Misconceptions: Artificial Intelligence and Cancer Information. JNCI Cancer Spectr. 2023, 7, pkad015. [Google Scholar] [CrossRef]
- Haver, H.L.; Ambinder, E.B.; Bahl, M.; Oluyemi, E.T.; Jeudy, J.; Yi, P.H. Appropriateness of Breast Cancer Prevention and Screening Recommendations Provided by ChatGPT. Radiology 2023, 307, e230424. [Google Scholar] [CrossRef]
- Yeo, Y.H.; Samaan, J.S.; Ng, W.H.; Ting, P.-S.; Trivedi, H.; Vipani, A.; Ayoub, W.; Yang, J.D.; Liran, O.; Spiegel, B.; et al. Assessing the Performance of ChatGPT in Answering Questions Regarding Cirrhosis and Hepatocellular Carcinoma. Clin. Mol. Hepatol. 2023, 29, 721–732. [Google Scholar] [CrossRef]
- Pan, A.; Musheyev, D.; Bockelman, D.; Loeb, S.; Kabarriti, A.E. Assessment of Artificial Intelligence Chatbot Responses to Top Searched Queries About Cancer. JAMA Oncol. 2023, 9, 1437–1440. [Google Scholar] [CrossRef]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef]
- Varma, J.R.; Fernando, S.; Ting, B.Y.; Aamir, S.; Sivaprakasam, R. The Global Use of Artificial Intelligence in the Undergraduate Medical Curriculum: A Systematic Review. Cureus 2023, 15, e39701. [Google Scholar] [CrossRef]
- Cascella, M.; Cascella, A.; Monaco, F.; Shariff, M.N. Envisioning Gamification in Anesthesia, Pain Management, and Critical Care: Basic Principles, Integration of Artificial Intelligence, and Simulation Strategies. J. Anesth. Analg. Crit. Care 2023, 3, 33. [Google Scholar] [CrossRef]
- Almarie, B.; Teixeira, P.E.P.; Pacheco-Barrios, K.; Rossetti, C.A.; Fregni, F. Editorial—The Use of Large Language Models in Science: Opportunities and Challenges. Princ. Pract. Clin. Res. 2023, 9, 1–4. [Google Scholar] [CrossRef]
- Wang, S.; Scells, H.; Koopman, B.; Zuccon, G. Can ChatGPT Write a Good Boolean Query for Systematic Review Literature Search? arXiv 2023, arXiv:2302.03495. [Google Scholar]
- Karkera, N.; Acharya, S.; Palaniappan, S.K. Leveraging Pre-Trained Language Models for Mining Microbiome-Disease Relationships. BMC Bioinform. 2023, 24, 290. [Google Scholar] [CrossRef]
- MosaicML. BioMedLM: A Domain-Specific Large Language Model for Biomedical Text. Available online: https://www.mosaicml.com/blog/introducing-pubmed-gpt (accessed on 9 March 2024).
- Luo, R.; Sun, L.; Xia, Y.; Qin, T.; Zhang, S.; Poon, H.; Liu, T.-Y. BioGPT: Generative Pre-Trained Transformer for Biomedical Text Generation and Mining. Brief. Bioinform. 2022, 23, bbac409. [Google Scholar] [CrossRef]
- OpenAI. Introducing GPTs. Available online: https://openai.com/blog/introducing-gpts (accessed on 9 March 2024).
- van Dis, E.A.M.; Bollen, J.; Zuidema, W.; van Rooij, R.; Bockting, C.L. ChatGPT: Five Priorities for Research. Nature 2023, 614, 224–226. [Google Scholar] [CrossRef]
- IBM. What Are AI Hallucinations? Available online: https://www.ibm.com/topics/ai-hallucinations (accessed on 13 January 2024).
- Cao, J.J.; Kwon, D.H.; Ghaziani, T.T.; Kwo, P.; Tse, G.; Kesselman, A.; Kamaya, A.; Tse, J.R. Accuracy of Information Provided by ChatGPT Regarding Liver Cancer Surveillance and Diagnosis. AJR Am. J. Roentgenol. 2023, 221, 556–559. [Google Scholar] [CrossRef]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of Hallucination in Natural Language Generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Ahmad, M.A.; Yaramis, I.; Roy, T.D. Creating Trustworthy LLMs: Dealing with Hallucinations in Healthcare AI. arXiv 2023, arXiv:2311.01463. [Google Scholar]
- Es, S.; James, J.; Espinosa-Anke, L.; Schockaert, S. RAGAS: Automated Evaluation of Retrieval Augmented Generation. arXiv 2023, arXiv:2309.15217. [Google Scholar]
- Cao, Z.; Wong, K.; Lin, C.-T. Weak Human Preference Supervision for Deep Reinforcement Learning. IEEE. Trans. Neural. Netw. Learn. Syst. 2021, 32, 5369–5378. [Google Scholar] [CrossRef] [PubMed]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models Are Zero-Shot Reasoners. arXiv 2022, arXiv:2205.11916. [Google Scholar]
- Renze, M.; Guven, E. The Effect of Sampling Temperature on Problem Solving in Large Language Models. arXiv 2024, arXiv:2402.05201. [Google Scholar]
- Nyariro, M.; Emami, E.; Caidor, P.; Abbasgholizadeh Rahimi, S. Integrating Equity, Diversity and Inclusion throughout the Lifecycle of AI within Healthcare: A Scoping Review Protocol. BMJ Open 2023, 13, e072069. [Google Scholar] [CrossRef] [PubMed]
- Parikh, R.B.; Teeple, S.; Navathe, A.S. Addressing Bias in Artificial Intelligence in Health Care. JAMA 2019, 322, 2377–2378. [Google Scholar] [CrossRef] [PubMed]
- Hamel, L.M.; Penner, L.A.; Albrecht, T.L.; Heath, E.; Gwede, C.K.; Eggly, S. Barriers to Clinical Trial Enrollment in Racial and Ethnic Minority Patients with Cancer. Cancer Control 2016, 23, 327–337. [Google Scholar] [CrossRef] [PubMed]
- Meskó, B. Prompt Engineering as an Important Emerging Skill for Medical Professionals: Tutorial. J. Med. Internet Res. 2023, 25, e50638. [Google Scholar] [CrossRef]
- Heston, T.; Khun, C. Prompt Engineering in Medical Education. Int. Med. Educ. 2023, 2, 198–205. [Google Scholar] [CrossRef]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large Language Models in Medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef] [PubMed]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large Language Models Encode Clinical Knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Zhu, K.; Wang, J.; Zhou, J.; Wang, Z.; Chen, H.; Wang, Y.; Yang, L.; Ye, W.; Zhang, Y.; Gong, N.Z.; et al. PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts. arXiv 2023, arXiv:2306.04528. [Google Scholar]
- Wang, L.; Chen, X.; Deng, X.; Wen, H.; You, M.; Liu, W.; Li, Q.; Li, J. Prompt Engineering in Consistency and Reliability with the Evidence-Based Guideline for LLMs. npj Digit. Med. 2024, 7, 41. [Google Scholar] [CrossRef] [PubMed]
- Khan, B.; Fatima, H.; Qureshi, A.; Kumar, S.; Hanan, A.; Hussain, J.; Abdullah, S. Drawbacks of Artificial Intelligence and Their Potential Solutions in the Healthcare Sector. Biomed. Mater. Devices 2023, 1, 731–738. [Google Scholar] [CrossRef] [PubMed]
- EIT Digital. A European Approach to Artificial Intelligence a Policy Perspective. Available online: https://futurium.ec.europa.eu/system/files/2022-03/EIT-Digital-Artificial-Intelligence-Report.pdf (accessed on 3 January 2024).
- U.S. Food and Drug Administration. Clinical Decision Support Software Guidance for Industry and Food and Drug Administration Staff. Available online: https://www.fda.gov/media/109618/download (accessed on 3 January 2024).
- Santoni de Sio, F.; van den Hoven, J. Meaningful Human Control over Autonomous Systems: A Philosophical Account. Front. Robot. AI 2018, 5, 15. [Google Scholar] [CrossRef] [PubMed]
- Hille, E.M.; Hummel, P.; Braun, M. Meaningful Human Control over AI for Health? A Review. J. Med. Ethics 2023, jme-2023-109095. [Google Scholar] [CrossRef] [PubMed]
- U.S. Department of Health and Human Service. HIPAA for Professionals. Available online: https://www.hhs.gov/hipaa/for-professionals/index.html (accessed on 3 January 2024).
- National Cyber Security Centre. ChatGPT and Large Language Models: What’s the Risk? Available online: https://www.ncsc.gov.uk/blog-post/chatgpt-and-large-language-models-whats-the-risk (accessed on 3 January 2024).
- European Data Protection Board. EDPB Resolves Dispute on Transfers by Meta and Creates Task Force on Chat GPT. Available online: https://edpb.europa.eu/news/news/2023/edpb-resolves-dispute-transfers-meta-and-creates-task-force-chat-gpt_en (accessed on 3 January 2024).
- Sadasivan, V.S.; Kumar, A.; Balasubramanian, S.; Wang, W.; Feizi, S. Can AI-Generated Text Be Reliably Detected? arXiv 2023, arXiv:2303.11156. [Google Scholar]
- Saadé, R.G.; Morin, D.; Thomas, J.D.E. Critical Thinking in E-Learning Environments. Comput. Hum. Behav. 2012, 28, 1608–1617. [Google Scholar] [CrossRef]
- Tools Such as ChatGPT Threaten Transparent Science. Here Are Our Ground Rules for Their Use. Nature 2023, 613, 612. [Google Scholar] [CrossRef] [PubMed]
- Thorp, H.H. ChatGPT Is Fun, but Not an Author. Science 2023, 379, 313. [Google Scholar] [CrossRef] [PubMed]
- Flanagin, A.; Bibbins-Domingo, K.; Berkwits, M.; Christiansen, S.L. Nonhuman “Authors” and Implications for the Integrity of Scientific Publication and Medical Knowledge. JAMA 2023, 329, 637. [Google Scholar] [CrossRef] [PubMed]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caglayan, A.; Slusarczyk, W.; Rabbani, R.D.; Ghose, A.; Papadopoulos, V.; Boussios, S. Large Language Models in Oncology: Revolution or Cause for Concern? Curr. Oncol. 2024, 31, 1817-1830. https://doi.org/10.3390/curroncol31040137
Caglayan A, Slusarczyk W, Rabbani RD, Ghose A, Papadopoulos V, Boussios S. Large Language Models in Oncology: Revolution or Cause for Concern? Current Oncology. 2024; 31(4):1817-1830. https://doi.org/10.3390/curroncol31040137
Chicago/Turabian StyleCaglayan, Aydin, Wojciech Slusarczyk, Rukhshana Dina Rabbani, Aruni Ghose, Vasileios Papadopoulos, and Stergios Boussios. 2024. "Large Language Models in Oncology: Revolution or Cause for Concern?" Current Oncology 31, no. 4: 1817-1830. https://doi.org/10.3390/curroncol31040137
APA StyleCaglayan, A., Slusarczyk, W., Rabbani, R. D., Ghose, A., Papadopoulos, V., & Boussios, S. (2024). Large Language Models in Oncology: Revolution or Cause for Concern? Current Oncology, 31(4), 1817-1830. https://doi.org/10.3390/curroncol31040137