A Machine Learning Approach to Predict Stress Hormones and Inflammatory Markers Using Illness Perception and Quality of Life in Breast Cancer Patients

Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Measures
2.3. Procedure
2.4. Data Analysis
3. Results
3.1. Data Analysis Using SPSS
3.1.1. Characteristics of Breast Cancer Patients
3.1.2. Quality of Life and Illness Perception
3.1.3. Stress Hormones and Psychosocial Factors
3.1.4. Inflammatory Markers and Psychosocial Factors
3.2. Data Analysis with Artificial Intelligence (AI) Methods
3.2.1. Comparing Consistently the Machine Learning Algorithms
3.2.2. Gradient Boosting for Classification
Grid Search for Hyperparameters
3.2.3. Feature Selection for Machine Learning in Python
Feature Selection
Feature Selection for Machine Learning
Univariate Selection
Recursive Feature Elimination
Principal Component Analysis
Feature Importance
3.2.4. Machine Learning Results
4. Discussion
4.1. Illness Perception and Quality of Life
4.2. Ilness Perception, Quality of Life and Stress Hormones
4.3. Quality of Life, Illness Perception and Inflammatory Markers
5. Limitations and Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Comparing the Machine Learning Algorithms in Python with Scikit-Learn
Appendix A.2. Choosing the Best Machine Learning Model
Appendix A.3. Careful Comparison of Machine Learning Models
Appendix B
| # compare algorithms |
| import pandas |
| import matplotlib.pyplot as plt |
| from sklearn import model_selection |
| from sklearn.linear_model import LogisticRegression |
| from sklearn.tree import DecisionTreeClassifier |
| from sklearn.neighbors import KNeighborsClassifier |
| from sklearn.discriminant_analysis import LinearDiscriminantAnalysis |
| from sklearn.naive_bayes import GaussianNB |
| from sklearn.svm import SVC |
| # load dataset |
| dataframe = pandas.read_csv(‘ACTH.csv’) |
| array = dataframe.values |
| X = array[:,0:12] |
| Y = array[:,12] |
| # prepare models |
| models = [] |
| models.append((‘LR’, LogisticRegression())) |
| models.append((‘LDA’, LinearDiscriminantAnalysis())) |
| models.append((‘KNN’, KNeighborsClassifier())) |
| models.append((‘CART’, DecisionTreeClassifier())) |
| models.append((‘NB’, GaussianNB())) |
| models.append((‘SVM’, SVC())) |
| # evaluate each model in turn |
| results = [] |
| names = [] |
| scoring = ‘accuracy’ |
| for name, model in models: |
| kfold = model_selection.KFold(n_splits = 10, shuffle = True) |
| cv_results = model_selection.cross_val_score(model, X, Y, cv = kfold, scoring = scoring) |
| results.append(cv_results) |
| names.append(name) |
| msg = “%s: %f (%f)” % (name, cv_results.mean(), cv_results.std()) |
| print(msg) |
| # boxplot algorithm comparison |
| fig = plt.figure() |
| fig.suptitle(‘Algorithm Comparison’) |
| ax = fig.add_subplot(111) |
| plt.boxplot(results) |
| ax.set_xticklabels(names) |
| plt.show() |
Appendix C
Appendix C.1. Developing a Gradient Boosting Machine Ensemble in Python
Appendix C.2. Gradient Boosting Machines Algorithm
- Tree constraints: such as the depth of the trees and the number of trees used in the ensemble.
- Weighted updates: such as a learning rate used to limit how much each tree contributes to the ensemble.
- Random sampling: such as fitting trees to random subsets of features and samples. The use of random sampling often leads to a change in the name of the algorithm in “stochastic gradient boosting”.
Appendix C.3. Interface (API) Scikit-Learn Gradient Boosting (API)
| # check scikit-learn version |
| import sklearn |
| print(sklearn.__version__) |
| OUT |
| 0.22.2.post1 |
Appendix D
| # evaluate gradient boosting algorithm for classification |
| from numpy import mean |
| from numpy import std |
| from sklearn.datasets import make_classification |
| from sklearn.model_selection import cross_val_score |
| from sklearn.model_selection import RepeatedStratifiedKFold |
| from sklearn.ensemble import GradientBoostingClassifier |
| # define the model |
| model = GradientBoostingClassifier() |
| # define the evaluation method |
| cv = RepeaedStratifiedKFold(n_splits = 10, n_repeats = 3, random_state = 1) |
| # evaluate the model on the dataset |
| n_scores = cross_val_score(model, X, y, scoring = ‘accuracy’, cv = cv, n_jobs = −1) |
| # report performance |
| print(‘Mean Accuracy: %.3f (%.3f)’ % (mean(n_scores), std(n_scores))) |
Appendix E
| # example of grid searching key hyperparameters for gradient boosting on a classification dataset |
| from sklearn.datasets import make_classification |
| from sklearn.model_selection import RepeatedStratifiedKFold |
| from sklearn.model_selection import GridSearchCV |
| from sklearn.ensemble import GradientBoostingClassifier |
| # define the model with default hyperparameters |
| model = GradientBoostingClassifier() |
| # define the grid of values to search |
| grid = dict() |
| grid[‘n_estimators’] = [10, 50, 100, 500] |
| grid[‘learning_rate’] = [0.0001, 0.001, 0.01, 0.1, 1.0] |
| grid[‘subsample’] = [0.5, 0.7, 1.0] |
| grid[‘max_depth’] = [3, 7, 9] |
| # define the evaluation procedure |
| cv = RepeatedStratifiedKFold(n_splits = 10, n_repeats = 3, random_state = 1) |
| # define the grid search procedure |
| grid_search = GridSearchCV(estimator = model, param_grid = grid, n_jobs = −1, cv = cv, scoring = ‘accuracy’) |
| # execute the grid search |
| grid_result = grid_search.fit(X, Y) |
| # summarize the best score and configuration |
| print(“Best: %f using %s” % (grid_result.best_score_, grid_result.best_params_)) |
| # summarize all scores that were evaluated |
| means = grid_result.cv_results_[‘mean_test_score’] |
| stds = grid_result.cv_results_[‘std_test_score’] |
| params = grid_result.cv_results_[‘params’] |
| for mean, stdev, param in zip(means, stds, params): |
| print(“%f (%f) with: %r” % (mean, stdev, param)) |
Appendix F
| # make predictions using gradient boosting for classification |
| from sklearn.datasets import make_classification |
| from sklearn.ensemble import GradientBoostingClassifier |
| # define the model |
| model = GradientBoostingClassifier() |
| # fit the model on the whole dataset |
| model.fit(X, y) |
| # make a single prediction |
| row = [13, 15, 23, 24, 21, 14, 20, 156, 11.62, 23.79, 24, 25.2] |
| yhat = model.predict([row]) |
| # summarize prediction |
| print(‘Predicted Class: %d’ % yhat[0]) |
Appendix G
| # feature selection with univariate statistical tests |
| from pandas import read_csv |
| from numpy import set_printoptions |
| from sklearn.feature_selection import SelectKBest |
| from sklearn.feature_selection import f_classif |
| # feature extraction |
| test = SelectKBest(score_func = f_classif, k = 4) |
| fit = test.fit(X, Y) |
| # summarize scores |
| set_printoptions(precision = 3) |
| print(fit.scores_) |
| features = fit.transform(X) |
| # summarize selected features |
| print(features[0:5,:]) |
Appendix H
| # feature extraction with RFE |
| from pandas import read_csv |
| from sklearn.feature_selection import RFE |
| from sklearn.linear_model import LogisticRegression |
| # feature extraction |
| model = LogisticRegression(solver = ‘lbfgs’) |
| rfe = RFE(model, 3) |
| fit = rfe.fit(X, Y) |
| print(“Num Features: %d” % fit.n_features_) |
| print(“Selected Features: %s” % fit.support_) |
| print(“Feature Ranking: %s” % fit.ranking_) |
Appendix I
| # feature extraction with PCA |
| import numpy |
| from pandas import read_csv |
| from sklearn.decomposition import PCA |
| # feature extraction |
| pca = PCA(n_components = 3) |
| fit = pca.fit(X) |
| # summarize components |
| print(“Explained Variance: %s” % fit.explained_variance_ratio_) |
| print(fit.components_) |
Appendix J
| # feature importance with extra trees classifier |
| from pandas import read_csv |
| from sklearn.ensemble import ExtraTreesClassifier |
| # feature extraction |
| model = ExtraTreesClassifier(n_estimators = 10) |
| model.fit(X, Y) |
| print(model.feature_importances_) |
References
- WHO. Breast Cancer: Prevention and Control. Available online: http://www.who.int/cancer/detection/breastcancer/en/ (accessed on 30 May 2021).
- Anghel, R.A. Ghid de Management al Cancerului la San; Ministry of Health: Bucharest, Romania, 2009.
- Furtunescu, F.; Bohiltea, R.; Voinea, S.; Georgescu, T.; Munteanu, O.; Neacsu, A.; Pop, C. Breast Cancer Mortality Gaps in Romanian Women Compared to the EU after 10 Years of Accession: Is Breast Cancer Screening a Priority for Action in Romania? Review of the Statistics. Exp. Ther. Med. 2021, 21, 268. [Google Scholar] [CrossRef]
- Mancini, A.D.; Bonanno, G.A. Predictors and Parameters of Resilience to Loss: Toward an Individual Differences Model. J. Pers. 2009, 77, 1805–1832. [Google Scholar] [CrossRef]
- Bultz, B.D.; Carlson, L.E. Emotional Distress: The Sixth Vital Sign—Future Directions in Cancer Care. Psychooncology 2006, 15, 93–95. [Google Scholar] [CrossRef]
- Holland, J.C.; Bultz, B.D. The NCCN Guideline for Distress Management: A Case for Making Distress the Sixth Vital Sign. J. Natl. Compr. Canc. Netw. 2007, 5, 3–7. [Google Scholar] [CrossRef] [PubMed]
- Fradgley, E.A.; Bultz, B.D.; Kelly, B.J.; Loscalzo, M.J.; Grassi, L.; Sitaram, B. Progress toward Integrating Distress as the Sixth Vital Sign: A Global Snapshot of Triumphs and Tribulations in Precision Supportive Care. J. Psychosoc. Oncol. Res. Pract. 2019, 1, e2. [Google Scholar] [CrossRef]
- Forner, D.; Murnaghan, S.; Porter, G.; Mason, R.J.; Hong, P.; Taylor, S.M.; Bentley, J.; Hirsch, G.; Noel, C.W.; Rigby, M.H.; et al. Psychosocial Distress in Adult Patients Awaiting Cancer Surgery during the COVID-19 Pandemic. Curr. Oncol. 2021, 28, 173. [Google Scholar] [CrossRef]
- Hoffman, M.A.; Lent, R.W.; Raque-Bogdan, T.L. A Social Cognitive Perspective on Coping with Cancer: Theory, Research, and Intervention. Couns. Psychol. 2013, 41, 240–267. [Google Scholar] [CrossRef]
- Brandberg, Y.; Johansson, H.; Hellström, M.; Gnant, M.; Möbus, V.; Greil, R.; Foukakis, T.; Bergh, J. Long-Term (up to 16 Months) Health-Related Quality of Life after Adjuvant Tailored Dose-Dense Chemotherapy vs. Standard Three-Weekly Chemotherapy in Women with High-Risk Early Breast Cancer. Breast Cancer Res. Treat. 2020, 181, 87–96. [Google Scholar] [CrossRef] [PubMed]
- Smyth, E.N.; Shen, W.; Bowman, L.; Peterson, P.; John, W.; Melemed, A.; Liepa, A.M. Patient-Reported Pain and Other Quality of Life Domains as Prognostic Factors for Survival in a Phase III Clinical Trial of Patients with Advanced Breast Cancer. Health Qual. Life Outcomes 2016, 14, 52. [Google Scholar] [CrossRef]
- Quinten, C.; Martinelli, F.; Coens, C.; Sprangers, M.A.G.; Ringash, J.; Gotay, C.; Bjordal, K.; Greimel, E.; Reeve, B.B.; Maringwa, J.; et al. A Global Analysis of Multitrial Data Investigating Quality of Life and Symptoms as Prognostic Factors for Survival in Different Tumor Sites: Quality of Life Prognostic for Survival. Cancer 2014, 120, 302–311. [Google Scholar] [CrossRef]
- Goodwin, P.J.; Ennis, M.; Bordeleau, L.J.; Pritchard, K.I.; Trudeau, M.E.; Koo, J.; Hood, N. Health-Related Quality of Life and Psychosocial Status in Breast Cancer Prognosis: Analysis of Multiple Variables. J. Clin. Oncol. 2004, 22, 4184–4192. [Google Scholar] [CrossRef]
- Lee, C.K.; Hudson, M.; Simes, J.; Ribi, K.; Bernhard, J.; Coates, A.S. When Do Patient Reported Quality of Life Indicators Become Prognostic in Breast Cancer? Health Qual. Life Outcomes 2018, 16, 13. [Google Scholar] [CrossRef]
- Thong, M.S.Y.; Kaptein, A.A.; Vissers, P.A.J.; Vreugdenhil, G.; van de Poll-Franse, L.V. Illness Perceptions Are Associated with Mortality among 1552 Colorectal Cancer Survivors: A Study from the Population-Based PROFILES Registry. J. Cancer Surviv. 2016, 10, 898–905. [Google Scholar] [CrossRef]
- Thong, M.S.Y.; Mols, F.; Kaptein, A.A.; Boll, D.; Vos, C.; Pijnenborg, J.M.A.; van de Poll-Franse, L.V.; Ezendam, N.P.M. Illness Perceptions Are Associated with Higher Health Care Use in Survivors of Endometrial Cancer—A Study from the Population-Based PROFILES Registry. Support. Care Cancer 2019, 27, 1935–1944. [Google Scholar] [CrossRef] [PubMed]
- Iskandarsyah, A.; de Klerk, C.; Suardi, D.R.; Sadarjoen, S.S.; Passchier, J. Consulting a Traditional Healer and Negative Illness Perceptions Are Associated with Non-Adherence to Treatment in Indonesian Women with Breast Cancer: Non-Adherence to Treatment in Indonesian Women with Breast Cancer. Psychooncology 2014, 23, 1118–1124. [Google Scholar] [CrossRef]
- Kaptein, A.A.; Yamaoka, K.; Snoei, L.; van der Kloot, W.A.; Inoue, K.; Tabei, T.; Kroep, J.R.; Krol-Warmerdam, E.; Ranke, G.; Meirink, C.; et al. Illness Perceptions and Quality of Life in Japanese and Dutch Women with Breast Cancer. J. Psychosoc. Oncol. 2013, 31, 83–102. [Google Scholar] [CrossRef] [PubMed]
- Ashley, L.; Marti, J.; Jones, H.; Velikova, G.; Wright, P. Illness Perceptions within 6 Months of Cancer Diagnosis Are an Independent Prospective Predictor of Health-Related Quality of Life 15 Months Post-Diagnosis: Illness Perceptions Predict Future HRQoL. Psychooncology 2015, 24, 1463–1470. [Google Scholar] [CrossRef]
- Carlson, L.E.; Campbell, T.S.; Garland, S.N.; Grossman, P. Associations among Salivary Cortisol, Melatonin, Catecholamines, Sleep Quality and Stress in Women with Breast Cancer and Healthy Controls. J. Behav. Med. 2007, 30, 45–58. [Google Scholar] [CrossRef] [PubMed]
- Koeppen, B.; Stanton, B. Berne & Levy Physiology, 7th ed.; Elsevier: Amsterdam, The Netherlands, 2009; ISBN 978-0-323-39394-2. [Google Scholar]
- Miller, G.E.; Chen, E.; Zhou, E.S. If It Goes up, Must It Come down? Chronic Stress and the Hypothalamic-Pituitary-Adrenocortical Axis in Humans. Psychol. Bull. 2007, 133, 25–45. [Google Scholar] [CrossRef]
- Herriot, H.; Wrosch, C.; Hamm, J.M.; Pruessner, J.C. Stress-Related Trajectories of Diurnal Cortisol in Older Adulthood Over 12 Years. Psychoneuroendocrinology 2020, 121, 104826. [Google Scholar] [CrossRef]
- Heim, C.; Ehlert, U.; Hellhammer, D.H. The Potential Role of Hypocortisolism in the Pathophysiology of Stress-Related Bodily Disorders. Psychoneuroendocrinology 2000, 25, 1–35. [Google Scholar] [CrossRef]
- Tsigos, C.; Chrousos, G.P. Hypothalamic–Pituitary–Adrenal Axis, Neuroendocrine Factors and Stress. J. Psychosom. Res. 2002, 53, 865–871. [Google Scholar] [CrossRef]
- Reiche, E.M.V.; Morimoto, H.K.; Nunes, S.M.V. Stress and Depression-Induced Immune Dysfunction: Implications for the Development and Progression of Cancer. Int. Rev. Psychiatry 2005, 17, 515–527. [Google Scholar] [CrossRef]
- Falagas, M.E.; Zarkadoulia, E.A.; Ioannidou, E.N.; Peppas, G.; Christodoulou, C.; Rafailidis, P.I. The Effect of Psychosocial Factors on Breast Cancer Outcome: A Systematic Review. Breast Cancer Res. 2007, 9, R44. [Google Scholar] [CrossRef] [PubMed]
- Seok, J.-H.; Kim, L.S.; Hong, N.; Hong, H.J.; Kim, S.-J.; Kang, H.J.; Jon, D.-I. Psychological and Neuroendocrinological Characteristics Associated with Depressive Symptoms in Breast Cancer Patients at the Initial Cancer Diagnosis. Gen. Hosp. Psychiatry 2010, 32, 503–508. [Google Scholar] [CrossRef]
- Saxton, J.M.; Scott, E.J.; Daley, A.J.; Woodroofe, M.N.; Mutrie, N.; Crank, H.; Powers, H.J.; Coleman, R.E. Effects of an Exercise and Hypocaloric Healthy Eating Intervention on Indices of Psychological Health Status, Hypothalamic-Pituitary-Adrenal Axis Regulation and Immune Function after Early-Stage Breast Cancer: A Randomised Controlled Trial. Breast Cancer Res. 2014, 16, 3393. [Google Scholar] [CrossRef]
- Edwards, S.; Hucklebridge, F.; Clow, A.; Evans, P. Components of the Diurnal Cortisol Cycle in Relation to Upper Respiratory Symptoms and Perceived Stress. Psychosom. Med. 2003, 65, 320–327. [Google Scholar] [CrossRef]
- Ju, H.-B.; Kang, E.-C.; Jeon, D.-W.; Kim, T.-H.; Moon, J.-J.; Kim, S.-J.; Choi, J.-M.; Jung, D.-U. Associations Among Plasma Stress Markers and Symptoms of Anxiety and Depression in Patients with Breast Cancer Following Surgery. Psychiatry Investig. 2018, 15, 133–140. [Google Scholar] [CrossRef]
- Ferrans, C.E.; Powers, M.J. Quality of Life Index: Development and Psychometric Propreties. Adv. Nurs. Sci. 1985, 8, 15–24. [Google Scholar] [CrossRef]
- Moss-Morris, R.; Weinman, J.; Petrie, K.; Horne, R.; Cameron, L.; Buick, D. The Revised Illness Perception Questionnaire (IPQ-R). Psychol. Health 2002, 17, 1–16. [Google Scholar] [CrossRef]
- Lee, Y.; Baek, J.-M.; Jeon, Y.-W.; Im, E.-O. Illness Perception and Sense of Well-Being in Breast Cancer Patients. Patient Prefer. Adherence 2019, 13, 1557–1567. [Google Scholar] [CrossRef]
- Dempster, M.; McCorry, N.K. The Factor Structure of the Revised Illness Perception Questionnaire in a Population of Oesophageal Cancer Survivors: Factor Structure of the IPQ-R. Psychooncology 2012, 21, 524–530. [Google Scholar] [CrossRef]
- Zhang, N.; Fielding, R.; Soong, I.; Chan, K.K.K.; Lee, C.; Ng, A.; Sze, W.K.; Tsang, J.; Lee, V.; Lam, W.W.T. Psychometric Assessment of the Chinese Version of the Brief Illness Perception Questionnaire in Breast Cancer Survivors. PLoS ONE 2017, 12, e0174093. [Google Scholar] [CrossRef]
- Remillard, A.J.; O’Reilly, R.; Gorecki, D.K.; Blackshaw, S.L.; Quinn, D.; Keegan, D.L. The Noncompliance Factor in the Dexamethasone Suppression Test. Biol. Psychiatry 1993, 33, 755–756. [Google Scholar] [CrossRef]
- Raschka, S.; Mirjalili, V. Python Machine Learning: Machine Learning and Deep Learning with Python, Scikit-Learn, and TensorFlow 2; Packt Publishing: Birmingham, UK, 2019; ISBN 1-78995-575-0. [Google Scholar]
- Brownlee, J. A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning. Machine Learning Mastery. 2016. Available online: https://machinelearningmastery.com/gentle-introduction-gradient-boosting-algorithm-machine-learning/ (accessed on 31 May 2021).
- Piryonesi, S.M.; El-Diraby, T.E. Data Analytics in Asset Management: Cost-Effective Prediction of the Pavement Condition Index. J. Infrastruct. Syst. 2020, 26, 04019036. [Google Scholar] [CrossRef]
- Kaggle. Your Machine Learning and Data Science Community. Available online: https://www.kaggle.com/ (accessed on 31 May 2021).
- Google Colaboratory. Available online: https://colab.research.google.com/notebooks/intro.ipynb#recent=true (accessed on 31 May 2021).
- Brownlee, J. An Introduction to Feature Selection. Machine Learning Mastery. 2014. Available online: machinelearningmastery.com/an-introduction-to-feature-selection/ (accessed on 31 May 2021).
- Brownlee, J. Feature Selection in Python with Scikit-Learn. Machine Learning Mastery. 2014. Available online: https://machinelearningmastery.com/feature-selection-machine-learning-python/ (accessed on 31 May 2021).
- Rozema, H.; Völlink, T.; Lechner, L. The Role of Illness Representations in Coping and Health of Patients Treated for Breast Cancer. Psychooncology 2009, 18, 849–857. [Google Scholar] [CrossRef] [PubMed]
- Crumpei, I. Factors Involved in Breast Cancer Treatment Choice and Their Impact on Patients’ Resilience. Arch. Clin. Cases 2015, 2, 95–102. [Google Scholar] [CrossRef]
- Bombard, Y.; Rozmovits, L.; Trudeau, M.E.; Leighl, N.B.; Deal, K.; Marshall, D.A. Patients’ Perceptions of Gene Expression Profiling in Breast Cancer Treatment Decisions. Curr. Oncol. 2014, 21, e203–e211. [Google Scholar] [CrossRef] [PubMed]
- Carlson, L.E.; Speca, M.; Patel, K.D.; Goodey, E. Mindfulness-Based Stress Reduction in Relation to Quality of Life, Mood, Symptoms of Stress and Levels of Cortisol, Dehydroepiandrosterone Sulfate (DHEAS) and Melatonin in Breast and Prostate Cancer Outpatients. Psychoneuroendocrinology 2004, 29, 448–474. [Google Scholar] [CrossRef]
- Lutgendorf, S.K.; Weinrib, A.Z.; Penedo, F.; Russell, D.; DeGeest, K.; Costanzo, E.S.; Henderson, P.J.; Sephton, S.E.; Rohleder, N.; Lucci, J.A.; et al. Interleukin-6, Cortisol, and Depressive Symptoms in Ovarian Cancer Patients. J. Clin. Oncol. 2008, 26, 4820–4827. [Google Scholar] [CrossRef] [PubMed]
- Hsiao, F.-H.; Chang, K.-J.; Kuo, W.-H.; Huang, C.-S.; Liu, Y.-F.; Lai, Y.-M.; Jow, G.-M.; Ho, R.T.H.; Ng, S.-M.; Chan, C.L.W. A Longitudinal Study of Cortisol Responses, Sleep Problems, and Psychological Well-Being as the Predictors of Changes in Depressive Symptoms among Breast Cancer Survivors. Psychoneuroendocrinology 2013, 38, 356–366. [Google Scholar] [CrossRef] [PubMed]
- Schulte, F. Biologic, Psychological, and Social Health Needs in Cancer Care: How Far Have We Come? Curr. Oncol. 2014, 21, 161–162. [Google Scholar] [CrossRef][Green Version]



{kind=link}
{kind=link}
| Mean (SD) | N | % | |
|---|---|---|---|
| Age (mean) | 53(11.6) | ||
| Years since treatment | 4.7(5.01) | ||
| 6 months–1 year | 23 | 32.8 | |
| 1–5 years | 22 | 31.4 | |
| 5–10 years | 13 | 18.5 | |
| 10–20 years | 12 | 17.1 | |
| Type of intervention | |||
| Conservative intervention | 22 | 31 | |
| Mastectomy | 48 | 69 | |
| Type of treatment | |||
| Radiotherapy | 11 | 15.7 | |
| Chemotherapy | 16 | 22.8 | |
| Radio + Chemotherapy | 38 | 54.2 | |
| Other treatments | 5 | 7.14 | |
| Relationship status | |||
| Married/in a relationship | 50 | 71.4 | |
| Single/divorced | 20 | 28.5 | |
| Education level | |||
| At least high school | 63 | 90 | |
| Cancer stage | |||
| Stage I | 27 | 38.5 | |
| Stage II | 30 | 42.8 | |
| Stage III | 13 | 18.5 |
| Health | Social | Psychological | Family | |
|---|---|---|---|---|
| Timeline | −0.17 | −0.21 | −0.30 * | −0.14 |
| Time cyclical | −0.25 * | 0.22 | −0.15 | −0.17 |
| Consequences | −0.44 ** | −0.36 ** | −0.38 ** | −0.20 |
| Personal control | −0.01 | 0.08 | 0.006 | −0.02 |
| Treatment control | 0.16 | 0.15 | 0.26 * | 0.16 |
| Coherence | 0.40 ** | 0.33 ** | 0.36 ** | 0.27 * |
| Emotions | −0.51 ** | −0.54 ** | −58 ** | −0.35 ** |
| Identity | 0.08 | 0.04 | 0.05 | −0.09 |
| Variables | Quality of Life | ||
|---|---|---|---|
| ΔR2 | ΔF | Β | |
| Time cyclical | 0.06 | 4.11 * | −0.02 |
| Consequences | 0.14 | 11.57 *** | −0.19 |
| Coherence | 0.11 | 9.93 ** | 0.22* |
| Emotions | 0.10 | 11.36 *** | −0.40 *** |
| First Assessment | Second Assessment | t-Test | |||
|---|---|---|---|---|---|
| M | SD | M | SD | ||
| ESR (mm/1 h) | 6.63 | 5.208 | 5.04 | 2.87 | 1.45 |
| Fibrinogen (mg/dL) | 385.53 | 62.81 | 360.38 | 61.200 | 3.24 ** |
| CRP (mg/dL) | 0.67 | 2.26 | 0.17 | 1.37 | 0.81 |
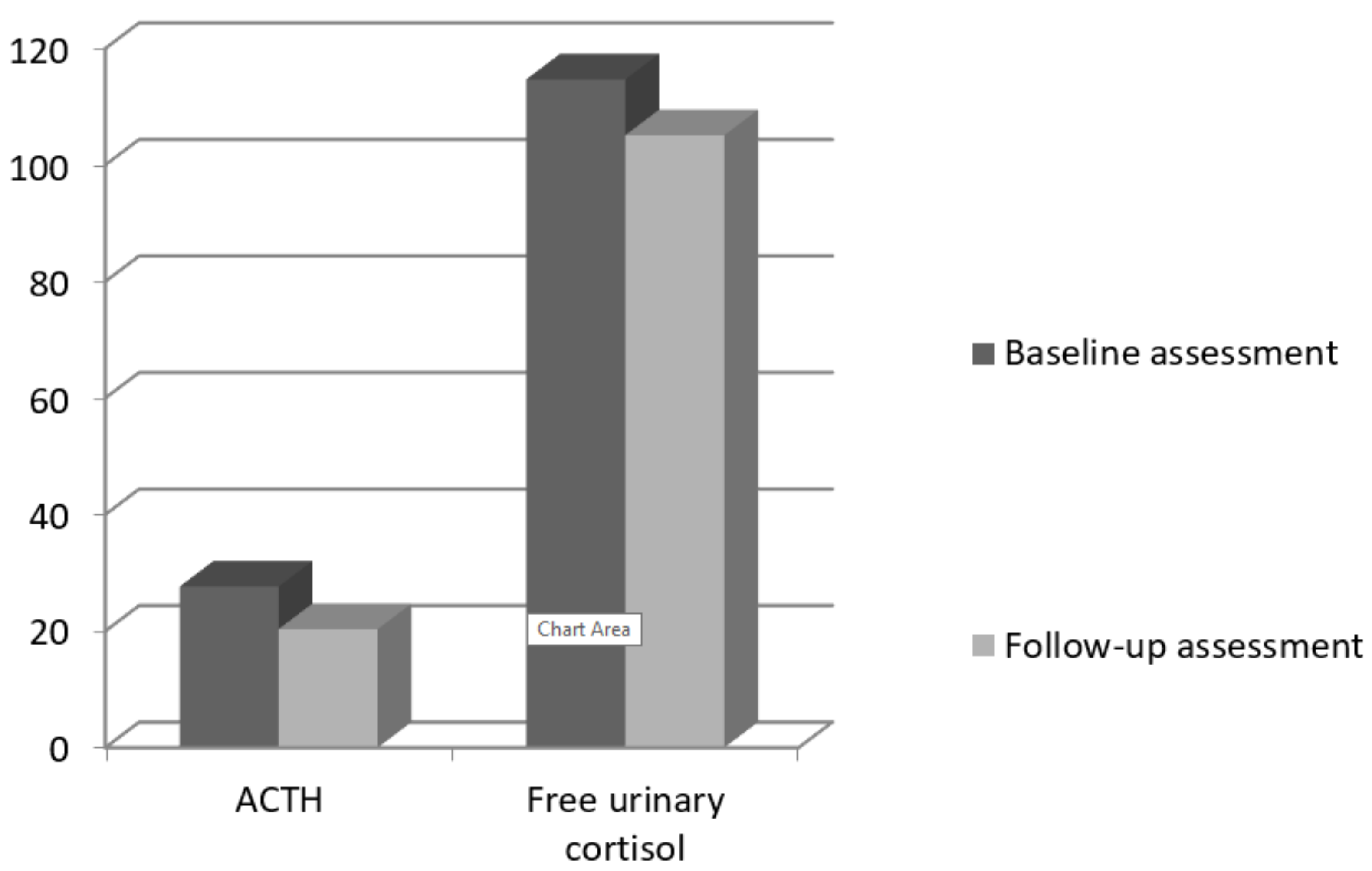
| ACTH (pg/mL) | 26.76 | 26.01 | 20.34 | 32.29 | 1.45 |
| Cortisol | 121 | 56.83 | 105.09 | 57.26 | 0.99 |
| qolH | qolS | qolP | qolF | ipT | ipCy | ipCo | ipP | ipT | Ipcoh | ipE | ipI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cortisol | 0.09 | −0.04 | −0.06 | 0.007 | 0.09 | −0.12 | −0.22 | 0.06 | −0.08 | 0.06 | 0.01 | −0.21 |
| ACTH | −0.13 | −0.12 | −0.06 | −0.57 ** | 0.08 | −0.01 | −0.04 | −0.11 | −0.24 ^ | −0.06 | 0.05 | 0.06 |
| Variables | ACTH | |||
|---|---|---|---|---|
| ΔR2 | ΔF | Β | Β | |
| Step 1 | Step 2 | |||
| Step 1 | 0.02 | 0.16 | ||
| Age | 0.07 | 0.09 | ||
| Years since diagnosis | −0.12 | −0.09 | ||
| Cancer stage | −0.02 | −0.04 | ||
| Step 2 | 0.48 | 10.13 *** | ||
| Family quality of life | −0.66 *** | |||
| Treatment control | −0.07 | |||
| qolH | qolS | qolP | qolF | ipT | ipCy | ipCo | ipP | ipT | ipcoh | ipE | ipI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ESR | −0.18 | −0.10 | −0.13 | −0.08 | 0.34 * | 0.07 | 0.08 | −0.06 | 0.06 | 0.01 | 0.23 | −0.06 |
| CRP | −0.21 | −0.02 | 0.07 | −0.04 | −0.08 | 0.12 | −0.07 | 0.04 | 0.13 | −0.03 | −0.01 | −0.25 |
| FBG | 0.09 | 0.03 | 0.10 | −0.05 | 0.26 ^ | −0.02 | −0.06 | 0.09 | 0.09 | 0.03 | 0.02 | −0.01 |
| Data Bases | Targets = 0 (Decrease or Stagnation) = 1 (growth) | Features | ||
|---|---|---|---|---|
| Stress Hormones | Inflammatory markers | Illness perception | Quality of life | |
| ACTH.csv | ACTH | CRP | 0 IPQtimeline (−) | 8 hfsub (health QL) |
| CLU.csv | CLU | ESR | 1 IPQticyclical (−) | 9 socsub (social QL) |
| CRP.csv | FBG | 2 IPQconsequences (−) | 10 pspsub (psychological QL) | |
| ESR.csv | 3 IPQpersonal control (+) | 11 famsub (family QL) | ||
| FBG.csv | 4 IPQtreatment control (+) | |||
| 5 IPQillness coherence (+) | ||||
| 6 IPQemotional (−) | ||||
| 7 IPQidentity (−) | ||||
| LR | LDA | KNN | CART | NB | SVM | |
|---|---|---|---|---|---|---|
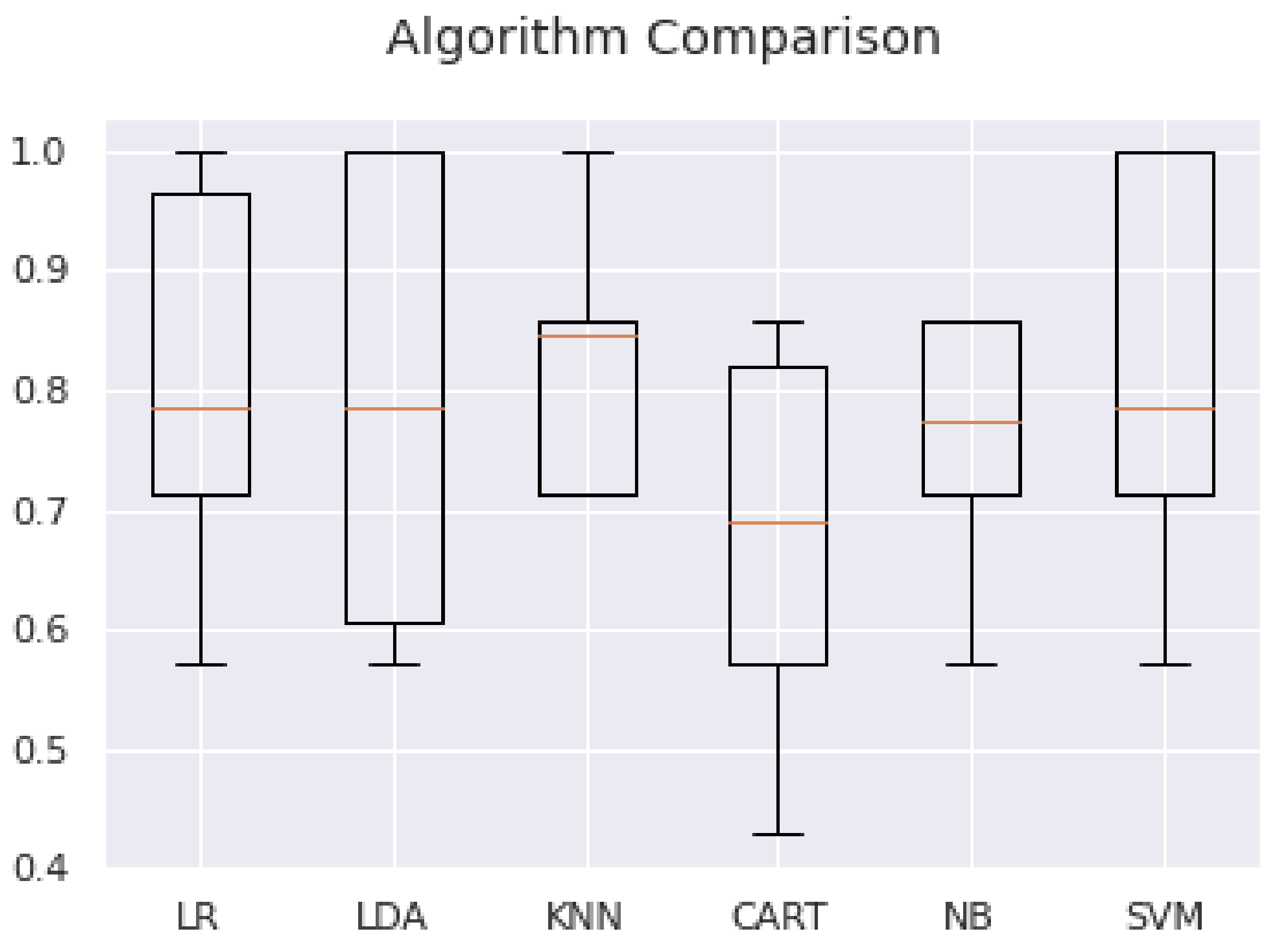
| M (SD) | 0.738 (0.109) | 0.771 (0.171) | 0.778 (0.157) | 0.623 (0.128) | 0.740 (0.188) | 0.809 (0.132) |
| Selected Features | All Features |
|---|---|
| LR: 0.800000 (0.159079) | LR: 0.754762 (0.180089) |
| LDA: 0.800000 (0.182946) | LDA: 0.752381 (0.213809) |
| KNN: 0.811905 (0.090633) | KNN: 0.795238 (0.100000) |
| CART: 0.680952 (0.139728) | CART: 0.638095 (0.203373) |
| NB: 0.769048 (0.092857) | NB: 0.695238 (0.118952) |
| SVM: 0.814286 (0.169633) | SVM: 0.811905 (0.127975) |
| LR | LDA | KNN | CART | NB | SVM | GBM | |
|---|---|---|---|---|---|---|---|
| ACTH | 0.738095 | 0.771429 | 0.778571 | 0.623810 | 0.740476 | 0.809524 | 0.811905 |
| CLU | 0.385714 | 0.304762 | 0.390476 | 0.523810 | 0.461905 | 0.376190 | 0.521429 |
| CRP | 0.626190 | 0.590476 | 0.404762 | 0.452381 | 0.550000 | 0.364286 | 0.616667 |
| ESR | 0.578571 | 0.535714 | 0.466667 | 0.566667 | 0.664286 | 0.664286 | 0.700000 |
| FBG | 0.552381 | 0.609524 | 0.595238 | 0.464286 | 0.628571 | 0.680952 | 0.680952 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Crumpei-Tanasă, I.; Crumpei, I. A Machine Learning Approach to Predict Stress Hormones and Inflammatory Markers Using Illness Perception and Quality of Life in Breast Cancer Patients. Curr. Oncol. 2021, 28, 3150-3171. https://doi.org/10.3390/curroncol28040275
Crumpei-Tanasă I, Crumpei I. A Machine Learning Approach to Predict Stress Hormones and Inflammatory Markers Using Illness Perception and Quality of Life in Breast Cancer Patients. Current Oncology. 2021; 28(4):3150-3171. https://doi.org/10.3390/curroncol28040275
Chicago/Turabian StyleCrumpei-Tanasă, Irina, and Iulia Crumpei. 2021. "A Machine Learning Approach to Predict Stress Hormones and Inflammatory Markers Using Illness Perception and Quality of Life in Breast Cancer Patients" Current Oncology 28, no. 4: 3150-3171. https://doi.org/10.3390/curroncol28040275
APA StyleCrumpei-Tanasă, I., & Crumpei, I. (2021). A Machine Learning Approach to Predict Stress Hormones and Inflammatory Markers Using Illness Perception and Quality of Life in Breast Cancer Patients. Current Oncology, 28(4), 3150-3171. https://doi.org/10.3390/curroncol28040275