1. Introduction
There is clear empirical evidence that links short-term exposure to ambient air pollution with a wide range of societal and economic impacts, including on health (e.g., [
1,
2,
3]), productivity (e.g., [
4,
5,
6]), and learning (e.g., [
7,
8]). However, as pollutants tend to vary spatially and temporally, studies are often challenged by imprecise air pollution estimates to establish such impacts. Air pollutants, such as nitrogen dioxide (
), ozone (
), and particulate matter (PM), originate from different sources, disperse differentially, and can uniquely interact with other environmental factors, such as temperature and humidity, over time. These complexities are further compounded by the computational demands required to model air pollution concentrations at high spatial and temporal resolutions, which makes precise or accurate exposure assessment challenging. Instead, studies often rely on sparse air pollution measurements from monitoring stations and simple assumptions when assigning air pollution exposure to individuals or geographical locations (e.g., schools, factories, hospitals, etc.). As a result, studies may be biased due to measurement error as robust, local, and frequent air pollution levels continue to be difficult to estimate. Thus, the use of air pollution exposures estimated with biases hinders the identification of the air pollution impact on individual outcomes.
In an ideal research setting, individuals would be equipped with personal portable monitors to collect precise and accurate estimates of their exposure as they move across space and time. While this is the most-accurate way of tracking personal exposure, it is extremely costly, cumbersome, mainly available for small samples over a limited amount of time, and not necessarily informative for policy design. In a similar vain, low-cost sensors are suggested as an alternative; but their reliability, availability, and precision are still an issue, and they currently do not support the development of national models. To circumvent these limitations, various exposure assessment methods have been developed to assign air pollution concentrations to a given location (e.g., residential address or hospital). The most-simplistic approach is proximity-based assessments, which are based on the proximity of a location to an emission source or monitoring station to assess changes in ambient air quality [
9]. Another approach is spatial interpolation, which generates estimates for unsampled locations using the covariance and distance between the unsampled location and sampled location (e.g., from air monitoring stations). This rests on the principle that near things are more related than distant things [
10]. The most-commonly used spatial interpolation techniques is inverse distance weighting (IDW). Although IDW may seem to be an acceptable approach that produces high-frequency time series datasets, it lacks sensitivity to topological variation and atmospheric conditions that may influence some air pollutants. These methods heavily rely on the availability of monitoring data and may produce overly smoothed concentration surfaces, in cases of a limited number of monitoring stations [
11]. IDW also has the potential to lead to systematic estimation bias, especially with sparse monitoring networks and topological complexity. On the other hand, dispersion models are mathematical simulations of how air pollutants disperse in the atmosphere. Dispersion models estimate the concentration of pollutants as they travel away from an emission source, how they interact with other pollutants in the atmosphere, and how they are dispersed due to meteorological conditions [
12]. Dispersion models are capable of modelling concentrations for short-term (e.g., hourly) and long-term (e.g., annually) averaging periods. The drawback is that dispersion models are demanding both in terms of input data and computational power. In places with no, or limited, air pollution monitoring stations, economists have also explored the use of satellite data (e.g., [
13,
14]). Satellite information on air pollution can occasionally be obtained at high temporal frequency; however, its use requires expensive pre-processing, and data are not often available at the required spatial resolution [
15]. Its accuracy is dependent on the spatiotemporal characteristics of the air pollutant considered. The availability of satellite sensors is disproportionately spread globally, increasing the difficulty in studying low- and middle-income settings. Therefore, such estimates are often not readily available nor easily accessible to social science researchers.
Economists interested in the impact of air quality on societal outcomes often develop economic models using natural experiments or simple exposure assessment methods. Natural experiments rely on an exogenous change in emission sources (e.g., the closure of factories or a change in government policies) to overcome measurement challenges and avoid the need to accurately quantify changes in air pollution concentrations. While this method might be able to uncover causal relationships, it is not suitable to establish concentration–response relationships. Therefore, to assess concentration–response relationships, economists tend to employ simple exposure assessment methods (e.g., nearest-neighbour matching or IDW). These methods sacrifice either the temporal frequency by relying on annual averages or the geographical precision by assigning the same air pollution level to a large number of locations.
In this paper, we propose a simplified exposure assessment approach to produce temporally and spatially highly resolved estimates for the main regulated air pollutants: nitrogen dioxide (), ozone (), and particulate matter with a diameter smaller than 10 µm () and smaller than 2.5 µm (). Our method relies on land use regression (LUR) models to derive robust estimates of local air pollution levels. Compared to dispersion models, LUR models are less challenging in terms of input data and computational processing and can account for high spatial variability. With their relatively low demand on the input data, LUR models have the potential to provide an improved, yet accessible, robust alternative to weighted averages whilst capturing the spatial heterogeneity of air pollution. Traditional LUR models are widely used in predicting long-term (e.g., annual) air pollution estimates. However, since typical land use input variables (e.g., road distribution, population density, etc.) are fairly constant over time, their application to estimate short-term (e.g., daily) exposures is limited. (Therefore, they are commonly used to develop annual models as the variables (e.g., land use, road length) are time-invariant. It is, in principle, possible to develop daily LUR models, but the lack of daily data required to build the model is generally a restriction. Over the last decade, there has been increasing interest in combining different modelling techniques to overcome their respective limitations, so-called “hybrid models”. Our methodology accounts for both environmental characteristics that may influence emission and dispersion patterns and daily variability. This approach relies on LUR and allows for the derivation of estimates at a fine geographical scale, as well as at a high time frequency, which increases the accuracy compared to the standard IDW.
To illustrate the effectiveness of this approach, we developed daily air pollution estimates (
daily LUR) across England. We validated the models in space and time using an independent subset of data from the monitoring stations. Similarly, we estimated the weighted averages of pollution measurements using IDW. We assigned both our daily LUR and IDW estimates to hospitals in the National Health Service (NHS) in England and assessed the impact of the daily variation of air pollution on accident and emergency (A&E) visits between 2010 and 2011 using a flexible multiple fixed effects distributed lag model [
6,
16]. This allowed us to quantify the impact of different air pollution exposure assessment models on health outcomes. The differences incurred by exposure assessments may subsequently influence policy perspectives.
Our results varied by pollutant. , , and demonstrated notable discrepancies between the two exposure assessment approaches—with daily LUR estimates resulting in statistically significant effects, while IDW estimates suggesting no impact of air pollution on A&E visits. The effect sizes using IDW were half those estimated by daily LUR. Conversely, health estimates from were similar when using IDW measurements and daily LUR estimates.
Our findings suggest that the use of IDW risks the introduction of a substantial downward bias, which has the potential to limit the ability of uncovering potential economic estimates and underestimate the potential effects of air pollution. This paper proposes a simpler methodology to improve the accuracy of assigning air pollution exposure across space for studies that require temporally high-resolution information (e.g., daily or weekly). It should be clear that the daily LUR is not the panacea to pollution exposure and that there are more complex methods to assign pollution exposure, for example using machine learning (e.g., random forest, XGBoost, neural networks). However, they require more data and are computationally intensive. Therefore, the daily LUR represents a user-friendly improvement over the IDW method.
The remainder of the paper is structured as follows: The next section presents a brief background of air pollution assessment techniques (
Section 2).
Section 3 presents our proposed exposure assessment technique.
Section 4 applies this technique to a case study, outlining our health setting and empirical approach. Findings from this case study are reported in
Section 5 and compare estimates between the techniques. Finally,
Section 6 discusses the implications of our findings and concludes.
2. Background on Air Pollution Exposure Assignment
Air pollution is one of the most-serious environmental concerns of our generation: not only is it closely linked with anthropogenic activities related to climate change, it also directly affects individuals’ health and well-being. Air pollution has given rise to extensive research documenting increased mortality (e.g., [
1,
2,
3]) and morbidity (e.g., [
17,
18]) and decreased productivity and human capital (e.g., [
4,
5,
6]) and school performance (e.g., [
7,
8]). Given the complexity in accurately estimating air pollution levels, economic studies often have to make trade-offs between temporal and spatial precision in estimating air pollution or circumvent estimating air quality altogether. Approaches can be broadly categorised into four types of air pollution studies on economic outcomes: studies using (i) specific sources of air pollution (e.g., emissions from a factory), (ii) natural experiments that provide a rapid exogenous change in the ambient air quality (e.g., policy changes), (iii) air pollution modelling (e.g., modelling air quality with satellite-based products in [
19]), and (iv) monitoring stations capturing specific pollutants at a specific location.
The first approach utilises variation in specific sources of air pollution, such as emissions from traffic (e.g., [
20,
21,
22]) or manufacturing sites (e.g., [
23]). In these studies, the impact of ambient air quality is only indirectly captured by a relative change of activity at the source. The main issues with this approach are that it only captures the effect of a unique variation in a local source, often without knowledge of its impact on the overall air quality, and it assumes that the emissions from other sources (e.g., manufacturing sector) remain constant over the period of the evaluation. Additional assumptions on the spatial extent of impacts are also required. While it may serve to demonstrate that a change in air pollution is beneficial or detrimental to the outcome of interest, this approach cannot inform dose–response relationships and peaks of air pollution (e.g., [
21,
24,
25]).
Secondly, natural experiments or quasi-experimental approaches (e.g., [
3,
24,
26]) are commonly adopted and focus on abrupt, and often unanticipated, changes in ambient air pollution levels. These research designs typically come from changes in environmental policy, such as the introduction of the 1970 Clean Air Act (e.g., [
3,
24,
27]) or the closure of power plants (e.g., [
28]). The advantage of this approach is that it controls for the issues of residential sorting, as well as acclimatisation. The former refers to the possible bias from individuals choosing their residential location as a function of ambient air quality and their individual susceptibility to, or preference for, air quality. A natural experiment typically offers an abrupt change in air quality, and the observed effect is more likely to be a result that can be attributed to the change in air quality as opposed to behavioural changes, such as avoidance behaviour (see [
17,
29,
30] for a discussion on
avoidance behaviour). Due to this, it could be argued any detected effects are close to causal. However, it only relies on a single and local variation in average air quality across a specific population and often does not capture daily changes in air pollution concentrations.
The third approach, using annual air pollution models, predicts spatially granular estimates, via data-intensive and complex models, but is only feasible for annual estimates due to the complexity of the models [
31]. This presents an attractive option to researchers due to its ability to provide air pollution at a fine granular scale that captures the heterogeneity of a pollutant’s geographical distribution (e.g., [
32]). However, as estimates are often limited to long-term annual averages, they fail to account for the burdens imposed by short-lived pollutants (e.g., ozone) and prevent one from obtaining short-term variations that may have separate effects on the outcomes of interest (e.g., health and academic performance [
33]).
Finally, economists also use direct measurements from ground monitoring stations (e.g., [
6,
16,
34]) or satellites (e.g., [
35,
36]). Monitoring stations are becoming increasingly prevalent, particularly in urban locations. They represent a valuable source of information, often on an hourly basis, that captures temporal changes at their location (e.g., [
37] with
and black smoke, [
1,
38,
39,
40] with CO,
, and
,
1] with
and
, and [
2] with
and
). Such time series data are easy to obtain and straightforward to analyse; however, air pollution monitoring networks often remain sparse, and assumptions are required to obtain proxies of local air pollution concentrations in areas without monitoring stations. A common approach has been to assign a point of interest, an area, or an individual to their nearest monitoring station (nearest neighbour matching). However, this has been shown to be a poor marker in spatial assessments of air pollution exposures [
41] as it disregards the various essential dispersion characteristics of each pollutant. Another naive practice has been to average the stations’ values across the neighbourhood of the points of interest [
42,
43,
44]. While this offers frequent estimates, its geographical aggregation, similar to nearest neighbour matching, is likely to introduce a large bias as it does not account for the regional characteristics that affect air pollution sources and dispersion.
There is growing interest in exploring the effects of, and accounting for, short- and long-term variation in air pollution without sacrificing spatial granularity. On the one hand, advanced modelling, in principle, could achieve higher temporal frequency, but requires high computational power and more input data than are often available. These models are often challenging to implement across a large geographical area (e.g., across a country) or over a long time period. On the other hand, daily or hourly air pollution measurements are easily accessible given the wide availability of monitoring stations, but suffer from systematic biases when the pollutant’s dispersion characteristics and local topography are not accounted for. Therefore, these limitations present a need for an approach in air pollution exposure assignment that is both (1) accessible to social scientists, amongst other disciplines, and (2) considerate to the range of influencing factors of each pollutant, which enables a more accurate air pollution assignment to provide robust evidence of the impacts of air pollution concentrations on a wide range of outcomes.
3. Methodology
Our modelling approach was based on an LUR model, which is a widely used air pollution exposure assessment method to estimate annual average air pollution concentrations for environmental epidemiology [
45,
46,
47]. LUR models have been developed for cities in North America [
48], Europe [
49], Asia [
50], Australia [
51], South Africa [
52], and larger geographic areas including North America [
53,
54], Europe [
55,
56], Australia [
57], and Asia [
58]. The spatial resolution of LUR models provides the opportunity for estimates on a fine geographical scale, depending on their land use variables—typically ranging from 100 m by 100 m to 1 km by 1 km. In order to obtain air pollution estimates of more frequent temporal variation (i.e., daily), we propose temporal scaling of the traditional LUR (
daily LUR). This approach offers a more accessible and reliable way of estimating daily ambient air pollution in various geographical settings as opposed to predictions derived purely from empirical relationships.
We modelled the annual LUR model using a standard methodology and detail its steps in
Appendix A. This begins by gathering air pollution measurements at monitoring stations, then identifying variables that can (a) predict the measured air pollution concentrations from various sources (e.g., road traffic and industrial plants) and sinks (e.g., forests) and (b) estimate the direction of their effects using a regression model. We combined the traditional land use input variables with a chemical transport model (CTM). The CTM estimates simulate the physical and chemical processes of pollutant transport based on emission inventories (location, strength, size) and meteorological inputs (e.g., temperature, relative humidity, wind speed, and wind direction). The model was then calibrated and validated against data from monitoring stations, before the production of concentration surfaces.
The daily LUR estimates proposed in this paper were derived as follows: once validated annual surfaces were obtained, the annual estimates were scaled to obtain temporal variation using measurements from air pollution monitoring stations. The granularity depends on the requirements of the study. For example, one may have individual health data geocoded at the level of a geographic unit
p. Supposing we have LUR estimates for
N geographic units,
p, we take the centroid of each unit and assume the centroid
to be representative of the entire unit. Modelled annual air pollution concentrations
are extracted from the LUR surface at all geographic unit centroids. Daily exposure for each
p,
, is calculated by scaling monitored daily concentrations to annual concentrations such as
where
and
are the measured daily and annual concentration from the nearest background monitoring station of the geographic unit centroid
, respectively;
is the estimated annual concentration of each geographic unit extracted from the LUR surface.
In practice, it is unlikely that the outcome data and LUR estimates are at the same geographical scale. If outcome data are geocoded for an aggregated area,
q, which is larger than
p, the annual concentration for each
q,
, is calculated by averaging all modelled annual air pollution concentrations
for each
p within each
q (Equation (
2)), again assuming the centroid
to be representative of the entire area
q. Daily exposure for each
,
, is then calculated using the aggregated annual exposure (Equation (
3)).
where
q is the geographic area,
is the estimated annual concentration of each geographic unit extracted from the LUR surface,
N is the number of geographic units,
p, within each aggregated area
q, and
and
are the measured daily and annual concentration from the nearest background monitoring station of geographic unit centroid
, respectively.
4. Case Study: A&E Visits to the English National Health Service
To assess the performance of the daily LUR model, compared to IDW, we applied the air pollution exposure assignment approach described in
Section 3 and IDW to a healthcare setting in England. We modelled A&E visits to hospitals in the NHS across England from 1 April 2010 to 31 March 2011 as a function of air pollution assigned to the neighbourhood of the hospital, controlling for various confounders. A&E visits do not require a diagnosis, and therefore, the majority of the visits are unclassified in terms of disease or visit purpose. We began by quantifying the differences between air pollution concentrations from different exposure assignment techniques. We subsequently quantified the differences in the estimated air-pollution-associated A&E visits using the two different exposure assignment techniques. This allowed us to illustrate how the use of daily LUR estimates performs against IDW estimates when identifying its impact on social outcomes.
4.1. Study Population and Data Sources
All observations were unique at the day and hospital level with the sum of A&E visits to the hospital on that day. All observations were then assigned an air pollution concentration using daily LUR and IDW to the centroid of the hospital postcode district (PCD) level. Further, they were also assigned meteorological characteristics measured from the nearest monitoring station, including important confounders, temperature, and relative humidity. We matched all data at the hospital visit date level between 1 April and 31 March 2011. Summary statistics describing our air pollution data can be found in
Appendix B. Below, the emphasis is on further detailing each dataset implored in our empirical illustration.
The Automatic Urban and Rural Monitoring Network (AURN) [
59] provides ratified daily mean measured concentrations of four major health-relevant pollutants:
,
,
, and
. The AURN classifies monitoring stations as background urban, background suburban, background rural, traffic urban, industrial urban, and industrial suburban. We only included background sites to avoid the influence of road traffic and industrial emissions, which can result in biased exposure assignment (i.e., overprediction). The completeness of the data was checked for each pollutant and each monitoring station based on a 75% completeness site selection rule. A monitoring station was included if it had more than 75% daily mean measurements over (a) an entire year and (b) within each month. This site selection rule ensures that the available daily data of each site have a good representativeness of a year when they are averaged for the annual mean. For
and
, this selection rule resulted in too few sites; therefore, a less-stringent criterion of 50% data completeness applied for these two pollutants. After applying the above criterion, the number of selected monitoring stations used in Equation (
A1) (
Appendix A) over this study year was 59 for
, 63 for
, 38 for
, and 25 for
.
The meteorological data, which are used as confounders in
Section 4.5, came from the Met Office Integrated Data Archive System (MIDAS) database. It provides meteorological characteristics collected by the Met Office. The meteorological conditions aspects are captured by irregularly spaced stations across England. The dataset contains daily and hourly meteorological measurements, such as daily air temperature and relative humidity, provided by 106 stations.
A&E visits came from the Hospital Episode Statistics (HES) database from NHS Digital across 220 hospitals in England. These are the universe of visits over that period. The mean number of daily A&E visits was 200 (SD 124) per hospital. The mean age of all visits was 37.9 (SD 6.6) years old, with 48.8% of patients being female. The data provide information on hospital utilisation. Each observation includes details on visit type (e.g., treatment, diagnosis type), socioeconomic status (Index of Multiple Deprivation), patient characteristics (e.g., age group and gender), and hospital specifics (e.g., postcode). Data are collected during a patient’s visit to the provider for multiple administrative and financial purposes. Due to a high rate of missing values in the classification of diagnoses or treatments, we used all-cause A&E visits.
4.2. Pollution Assignment Methods
We began by estimating an LUR model for England and then applying the methodology outlined in
Section 3. For our LUR model, we obtained six types of Geographic Information System (GIS)-derived land use data including: land cover, population/household, road network, traffic, topography, and building. The predictors were chosen mostly based on the ones used in the European Study of Cohorts for Air Pollution Effects (ESCAPE) study [
60], with one predictor on building volume as a proxy for street ventilation [
61]. When estimating our annual air pollution surface (Stage 3 in
Appendix A) to derive daily LUR estimates, we used a resolution of 25 m by 25 m because it is the smallest resolution of the datasets (i.e., land cover). At this resolution, the spatial variation of the variables is not aggregated. However, as previously mentioned, the resolution can be adjusted according to the study needs. Given the size of the selected monitoring stations, we used a 5-fold cross-validation. This allowed an adequate amount of sample data to be included in each fold and used in the validation. Models are summarised by several measurements including the adjusted
, root-mean-squared error (RMSE), and coefficient (
) in
Appendix B Table A1.
We then implemented the strategy outlined in
Section 3 to obtain air pollution estimates by daily LUR. We applied the scaling in Equation (
3) to an LUR model (described in
Appendix A) for 2778 PCDs across England over the same period. For our application, we used the centroid of each PCD. Air pollution estimates were assigned to each NHS hospital using their PCD. Air pollution was assigned at the hospital level as this analysis looked at the contemporaneous impact on A&E visits. A&E visits capture the immediate effects of deviations in air pollution levels. As the average distance of a patient’s residential postcode district to his/her A&E hospital is 13.3 km (SD 10.9), with a maximum distance of 223 km, the assignment of air pollution at the hospital level reduces the risk of inaccurately assigning location exposure.
As a comparison, a spatial interpolation of monitoring data using IDW is included. IDW does not involve statistical modelling: it is based on the distance weighting of nearest monitoring stations to a location. Air pollution exposure at each PCD
j on day
t,
, equals the average values of daily measurements from
k monitoring stations within a 50 km radius, with weights proportional to the inverse of the square of the distance between their residence and the monitoring station (Equation (
4)).
where
is the measured daily concentration at each monitoring station
k on day
t;
d is the distance between postcode centroid
j and monitoring station
k. We used a maximum radius of 50 km to include a moderate number (
n) of monitoring stations. For instances where a PCD has no monitoring stations within 50 km, we used the nearest monitoring station (
).
4.3. Defining Air Pollution Bins
The primary exposure variables of interest in this analysis were seven 5 daily air pollution bins, constructed for and , ranging from values under 5 to over 30 . For , six 10 daily air pollution bins were constructed ranging from values under 10 to over 50 . Finally, seven 10 daily air pollution bins were constructed for ranging from values under 10 to over 60 . These thresholds were used to ease the comparison of the air pollution assessment methods. These variables indicate whether air pollution measured at a given NHS hospital falls in the specified air pollution range. As daily air pollution is defined at the NHS hospital level (hospital-day), we preserved the spatial variation in air pollution to allow for the identification of its effects. The 0–10 bin ( and ) and 0–5 bin ( and ) were the reference categories and omitted in all regressions; consequently, all estimates were interpreted as the impact of a day in the given air pollution range relative to a day in either the 0–5 or 0–10 range.
4.4. Quantifying the Differences in Exposure Assessment Approaches
In this section, we compare air pollution estimates derived from different air pollution exposure assignment methods (daily LUR and IDW) and any differences that may be subsequently introduced in air pollution–health impact analysis. We first compared annual air pollution concentrations spatially through maps to illustrate the geographical variation in air pollution concentrations. Second, we compared the correlations of daily estimated air pollution concentrations with observed values (i.e., air pollution measurements) at monitoring stations that we used as a benchmark to quantify the potential bias introduced by daily LUR and IDW. Our third comparison was similar to the second, but using annual levels, we randomly omitted some air pollution monitoring stations to derive the air pollution estimates at the monitoring station and compared the derived estimates to actual measurements taken at these locations. Finally, we describe how air pollution exposure assigned to hospitals was classified into different treatment bins—potentially creating different treatment intensities and, thus, impacting the overall conclusion.
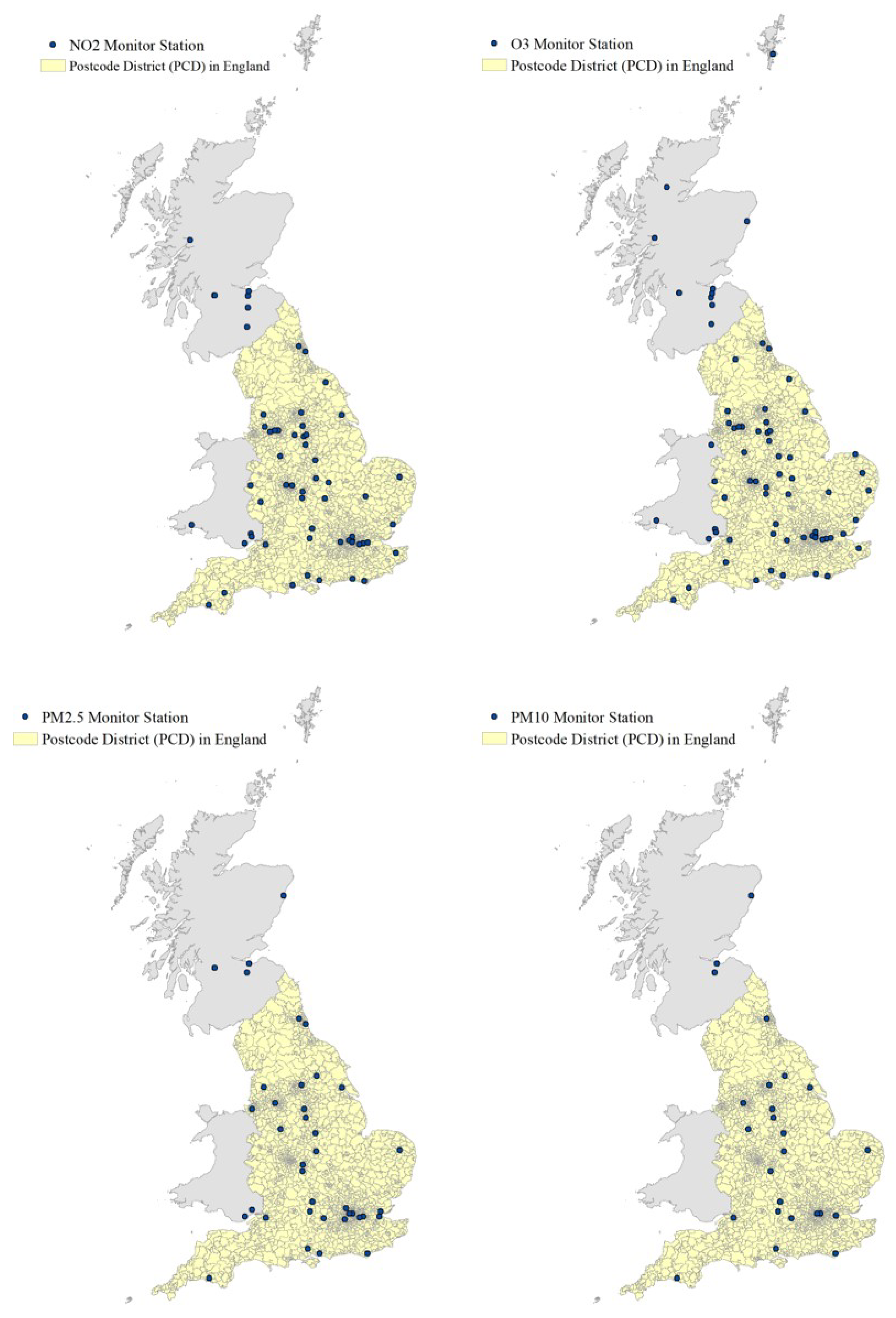
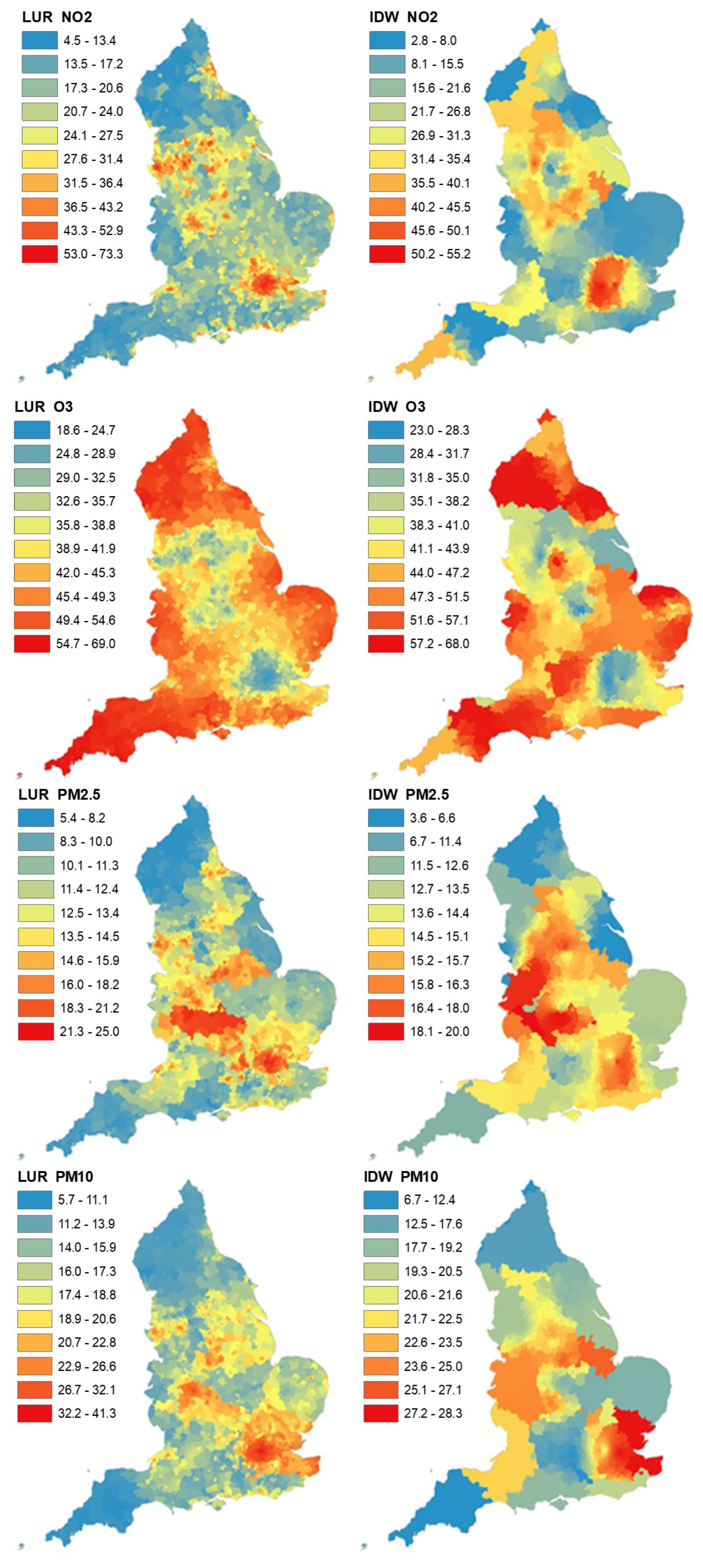
The spatial distribution of the monitoring stations for
,
,
, and
is shown in
Figure 1. We included stations from Wales and Scotland to “borrow” measurements from monitoring stations, within 50 km of England. We produced air pollution surfaces at the PCD level to visually compare the spatial pattern generated from the two approaches (daily LUR and IDW). The comparison of the maps provides an insight into the spatial heterogeneity of the different methods. Greater spatial granularity enables the identification of hot spots of air pollution, which are often in densely populated areas (e.g., London, Birmingham) and, therefore, essential to assess the impact of air pollution on individuals.
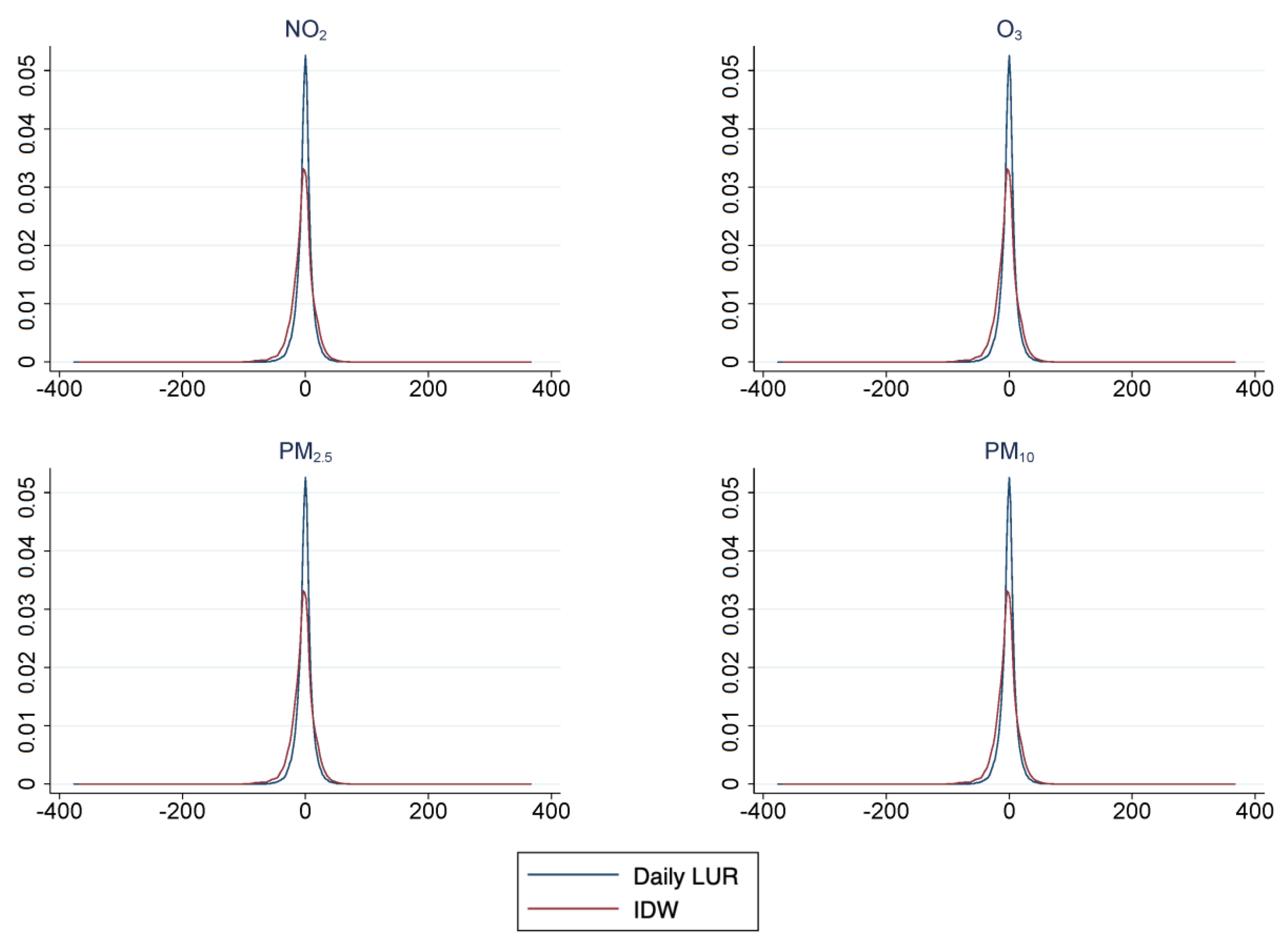
Whilst the comparisons of daily air pollution estimates are insightful, they are not representative of the precision of IDW in other locations, as the comparisons occurred at monitoring stations where the IDW estimates were calculated from. In order to assess the precision of IDW, we further explored the magnitude of any discrepancies through a “bench-marking” approach. The measurements at monitoring stations (
MONs) were considered
true observations of air pollution exposure that we can use to compare against air pollution estimates derived from the other exposure assignment methods. Specifically, we were interested in the difference between these true observations and the concentrations derived using assignment methods. We applied the daily LUR model and IDW to obtain daily air pollution estimates, for all four pollutants, at each monitoring station, while excluding the station in question from its own measurement/estimation. For example, for IDW estimate at monitoring station
A, we deliberately excluded measurements from
A and used measurements from the second-nearest station,
B. This was to mimic situations where a location for estimation is not near a monitoring station. We then calculated the absolute difference (
) at the monitoring station,
m, following
where
is the air pollution concentration at the monitoring station,
m, on day
d, estimated through air pollution technique
i.
i can be from: IDW or daily LUR.
is the average daily air pollution concentration reported at monitoring station
m on day
d. The same bench-marking calculations were conducted using IDW, daily LUR, and satellite monitors (SAT) at an annual level for
and
. Annual calculations were estimated as this was the most granular temporal scale available using satellite monitors. These results mirror the results that are presented in the paper with a larger deviation observed for SAT for
.
To compare daily estimates from the daily LUR and IDW, as described in
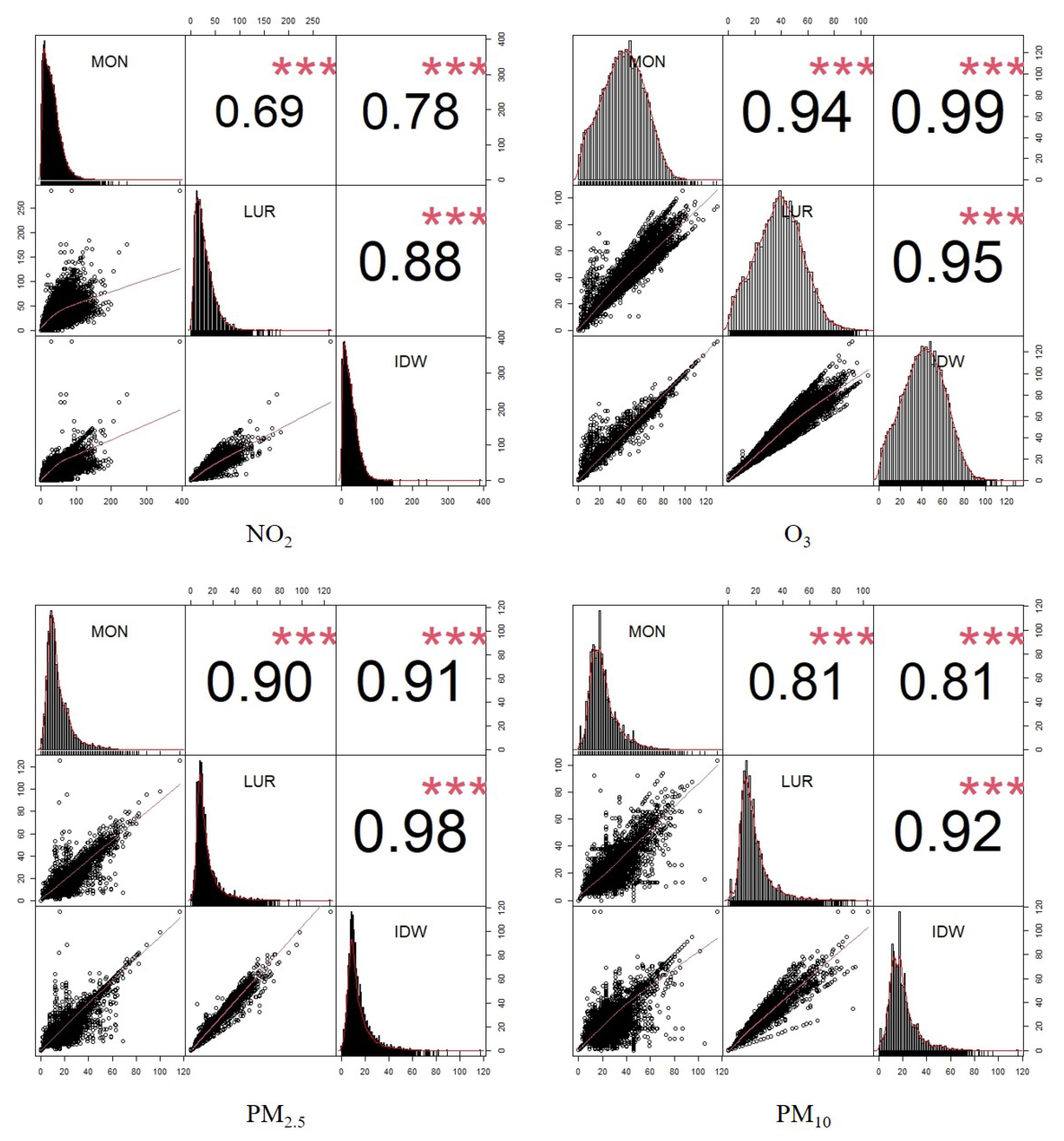
Section 4.2, we produced pairwise scatter plots that compare daily estimates against measurements recorded from monitoring stations. We used the Pearson correlation coefficient (Pearson’ r) to indicate the strength of the linear relationship between the two sets of data.
In addition, the accuracy and precision of the models were quantified by regressing daily predictions (from the “bench-marking” approach, where values from the station in question were excluded) against daily measurements and summarised in terms of the coefficient of determination (R), root-mean-squared error (RMSE), beta, and intercept.
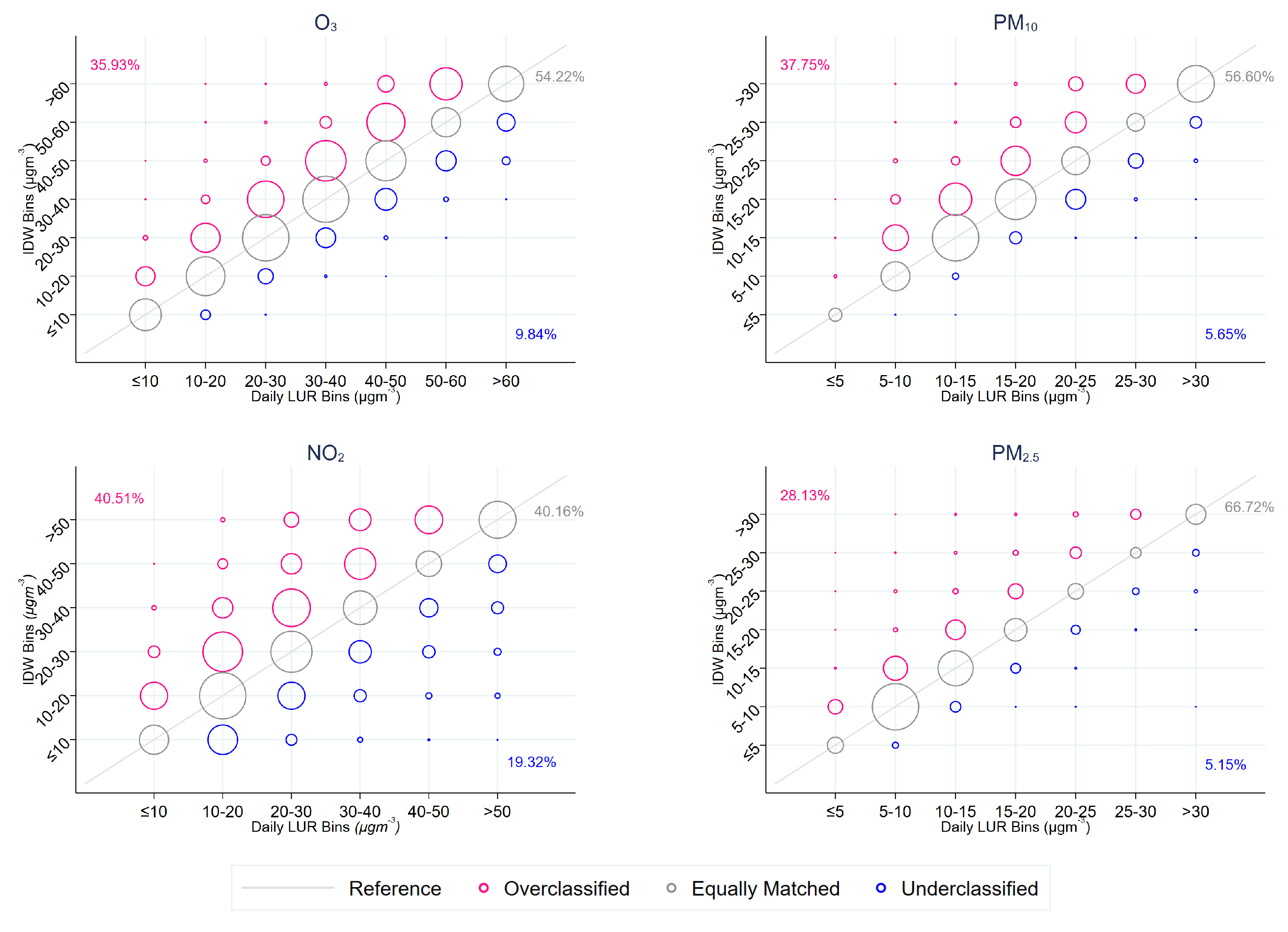
It could be argued that the conventional modelling approach in social sciences, by flexibly modelling air pollution impacts through the use of indicator bins, small deviations in concentrations from different air pollution exposure methods are unimportant should observations be properly classified into correct indicator bins. However, mismeasurement of an individual’s or unit’s air pollution exposure risks misclassification of individuals to indicator bins. To assess how the classification varies across the different methods, we compared any deviations between the assigned bins from daily LUR and the IDW for each observation by calculating the percentage of observations that did not fall into the same indicator bin category.
4.5. Identification Strategy
To identify the effects of each pollutant, we exploited the panel structure of our data and built on the panel approach used in [
6,
16,
62]. We introduced NHS hospital fixed effects (FE), which account for local air quality baselines and allowed us to identify the impact of short-term air pollution variation around the local average air quality. Implicitly, NHS hospitals without high peaks of air pollution throughout the year form a counterfactual for NHS hospitals that do have peaks in that same year, after accounting for fixed differences between the NHS hospitals and for common time effects. Naturally, many hospitals had multiple events over the period of the analyses. An attractive feature of this approach is that it builds in placebo tests that should identify likely violations of this assumption. Furthermore, this identification strategy relies on the unpredictable and presumably random daily local variation in air pollution.
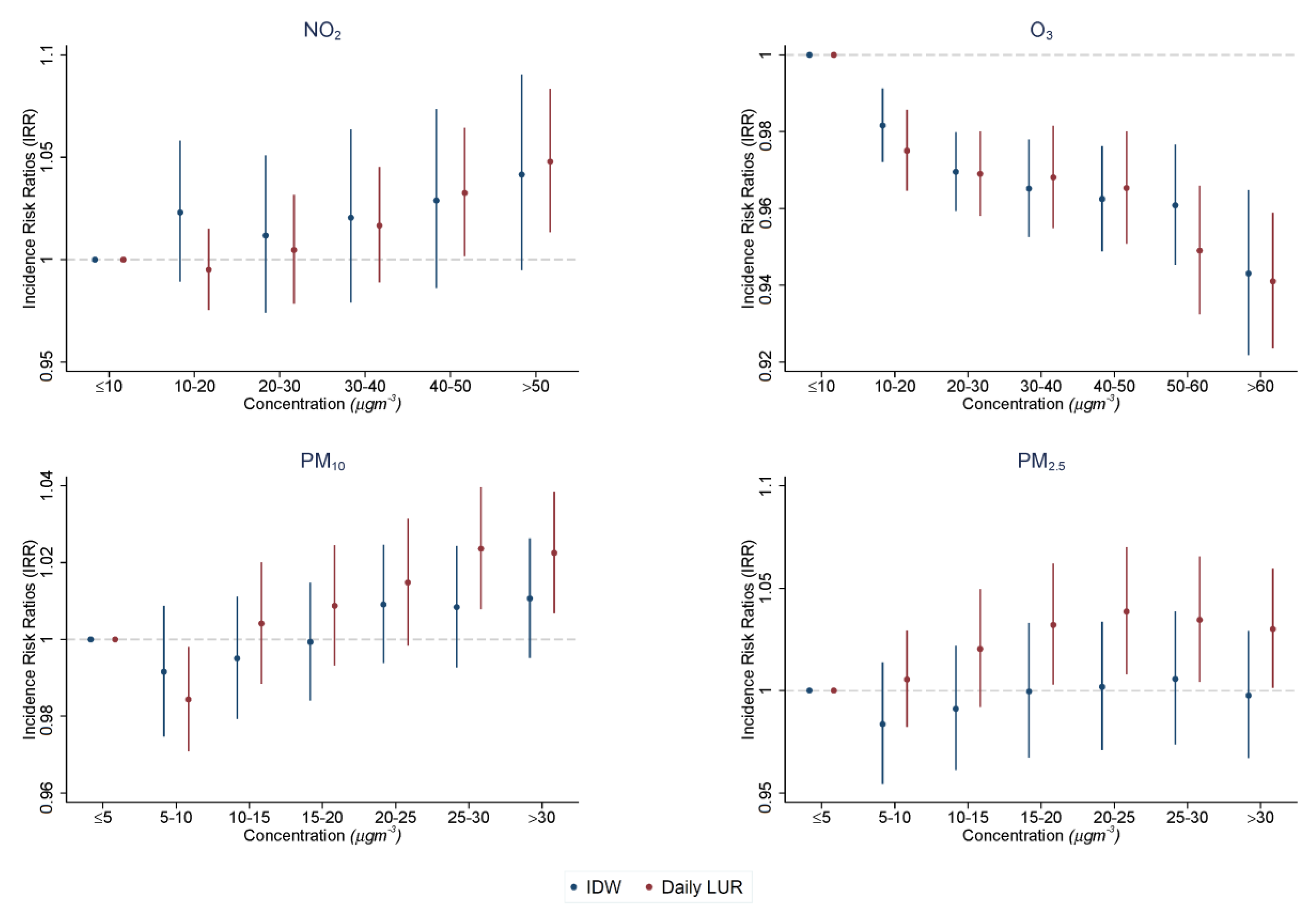
Using a panel dataset, we employed a distributed lag Poisson regression model with multiple fixed effects to estimate the effect of air pollution on daily A&E visits and for the three days following a day in which air pollution falls into an extreme air pollution bin. Equation (
6) denotes the reduced form relationship between air pollution and A&E visits. The total net effect of air pollution on A&E visits was flexibly modelled by including a series of indicator variables for air pollution.
The goal was to estimate the net effect of air pollution on day
d on the number of A&E visits (
) per NHS hospital,
j, per day,
d, and for three days following day
d:
are a series of regressors that equal 1 if the daily air pollution at NHS hospital j falls into a predefined air pollution bin and zero otherwise. For each pollutant, regressions were run separately using the air pollution bins described above. Consequently, these coefficients semi-parametrically describe the pollution–visits relationship, the net of seasonal influences and relative to the lowest air pollution bin (i.e., 0 to 5 or 0 to 10 ) that is omitted in all regressions.
, , and are indicator variables for up to 3 days following a day in a predefined air pollution bin of extreme air pollution exposure and zero otherwise. Therefore, the extreme air pollution lag effect was estimated for 30 days following a day of extreme air pollution.
A&E visits, health, and air pollution vary seasonally. A series of time-fixed effects for day of the week (), school and bank holidays (), and month () intended to control for the seasonal effects of cyclical variation. The use of time-fixed effects makes no assumptions on seasonal form, does not constrain the model, and avoids specification errors. Additionally, as seasonality is measured at a relatively fine scale, the flexibility inherited from such granular fixed effects also accounts for health changes that are driven by long-term behavioural changes. In addition, fixed effects for NHS hospitals were also included for 220 NHS hospitals over our study period (). As our observed geographical unit was the NHS hospital, the inclusion of these fixed effects also captures population grouping effects, such as residential sorting. Overall, these variables account for the influence of unobserved confounding factors.
and represent the daily mean temperature (in Celsius) and daily relative humidity on day d at NHS hospital j and were included as potential confounders of the effect of air pollution on A&E visits. Finally, represents the standard idiosyncratic disturbance term.
We used clustered and robust standard errors to allow for arbitrary within-group correlations at the hospital level. All analyses were conducted with Stata MP v15 [
63].
6. Conclusions
Ambient air pollution is an environmental factor with wide-ranging effects on human health and well-being. The assessment of air pollution exposure on social outcomes requires the estimation of air pollution, which has been performed in the economic literature in several ways. We illustrated how a widely used method in the social sciences, IDW, misclassifies air pollution concentrations, particularly in areas with sparse monitoring networks. We proposed a simpler computational approach, based on land use regression (LUR), that increases the geographical precision and accuracy compared to IDW, while still offering estimates of high temporal frequency. Our LUR outperformed IDW in our cross-validation study using various indicators of performance.
The difference in parameter estimates for the IDW approach and the daily LUR model was likely due to the inability of the IDW approach to account for different emission sources (such as road traffic, industrial activities) and topographies. We observed that, on average, air pollution concentrations derived from daily LUR showed smaller prediction errors than IDW and, thus, a higher accuracy. The instability of the IDW approach was also documented by [
32], who compared this with a dispersion model to find the latter outperforming the inverse distance approach, when using annual air pollution concentrations. Whilst the use of dispersion models provides reliable air pollution estimates, their use is computationally demanding and generally inaccessible for wider contexts.
Our findings showed that the IDW approach, which has been the convention to measure air pollution in previous economic studies, is likely to exacerbate measurement error in exposure assignment due to its lower accuracy and precision. The level of these varies by pollutant. For PM, which comprises atmospheric aerosol particles that fluctuate less geographically compared to and travel long distances, both and displayed small discrepancies in their assigned air pollution exposure and, therefore, negligible differences in the estimated health impacts. For both pollutants, we failed to identify health impacts using IDW, otherwise observed with daily LUR. Contrastingly, is a pollutant that diffuses rapidly and, therefore, exhibits a higher degree of spatial variation. In this case, the two concentrations assigned using the two different methods were largely different, being in agreement for less than half of our observations. Although this resulted in similar point estimates of the impact of air pollution concentrations on the health outcome, the variability observed was much smaller under the daily LUR approach, which resulted in statistically significant health impacts. Finally, health estimates associated with were relatively unresponsive to exposure assessment approaches. Overall, the daily LUR model approach was able to account for some of the spatio-temporal variation associated with each pollutant, resulting in (i) the assignment of a more accurate and precise air pollution concentration and (ii) a more precise estimate of associated health impacts.
It is important to acknowledge that the economic significance of any variation created by the choice of pollution exposure method will vary with the pollution–outcome dose–response function related to the outcome of interest. In our illustration, the use of IDW resulted in an overestimation of air pollution effects on hospital utilisation, compared to the daily LUR. However, as other outcomes (e.g., mortality, obesity, productivity, etc.) carry their own unique relationship with air pollution, the associated sensitivity to exposure assignment may be of different magnitudes. In instances where large changes in air pollution are required to identify an impact on the outcome (e.g., obesity), the consequence of this difference in pollution exposure assignment may be smaller than in studies where small changes in air pollution are meaningful (e.g., mortality).
This paper illustrated how LUR models can be adapted to construct a reliable and frequent measure of local air pollution exposure. The daily LUR has several important advantages over other exposure assignment techniques, including less stringent data requirements, low computational costs, and the consideration of environmental characteristics, topological variation, and atmospheric conditions. Still, some of the emission sources and process characteristics used in the daily LUR model could be subject to imprecise measurement. While this approach is not devoid of measurement error, we have begun to bridge the gaps in accurate air pollution modelling for economic assessment. Most importantly, the availability of accessible LUR models for various cities and countries allows for this technique to be used in less-studied contexts (e.g., low- and middle-income countries with poorer and sparse monitoring networks).
These findings emphasise the need to be mindful of the exposure assessment technique utilised in economic studies as, depending on the pollutant, conventional approaches may introduce degrees of measurement error and variability that have the potential to bias the analysis and underestimate the impacts of air pollution. Our results may contribute to a more accurate evaluation of air pollution impacts and, subsequently, inform future environmental policies.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






