
Disease- and Drug-Related Knowledge Extraction for Health Management from Online Health Communities Based on BERT-BiGRU-ATT


Abstract
1. Introduction
2. Related Works
2.1. Research on Knowledge Extraction from OHCs
2.2. Research on Medical Text Knowledge Extraction
2.3. Research on Medical Knowledge Extraction Based on Deep Learning
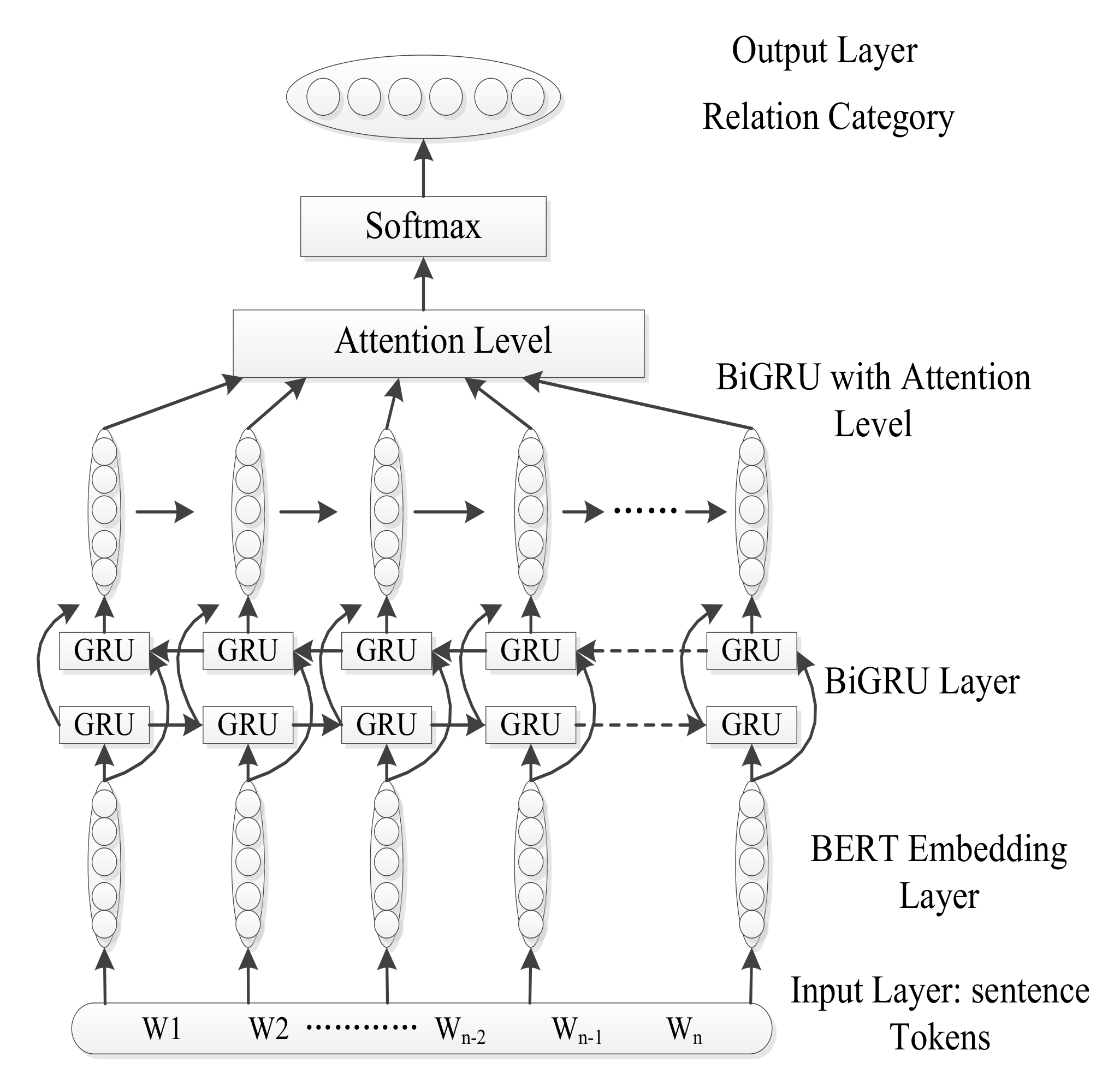
3. Methodology
3.1. Bert Word Embeddings
3.2. BIGRU
3.3. Attention Mechanism
3.4. Softmax Output Layer
4. Experimental Setup
4.1. Data Description
4.2. Parameters Setup
5. Experimental Results
5.1. Main Results
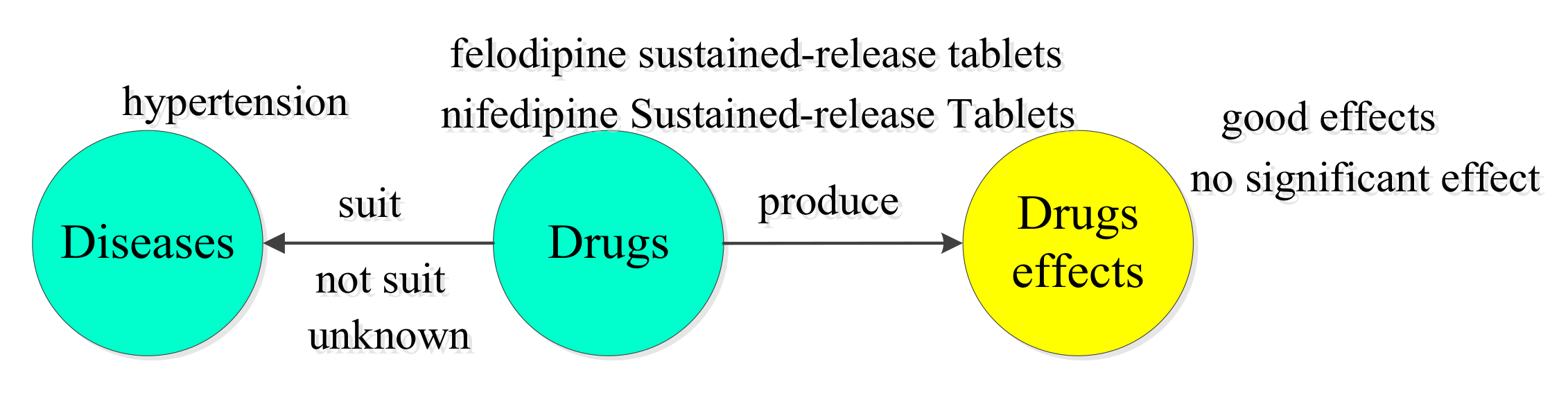
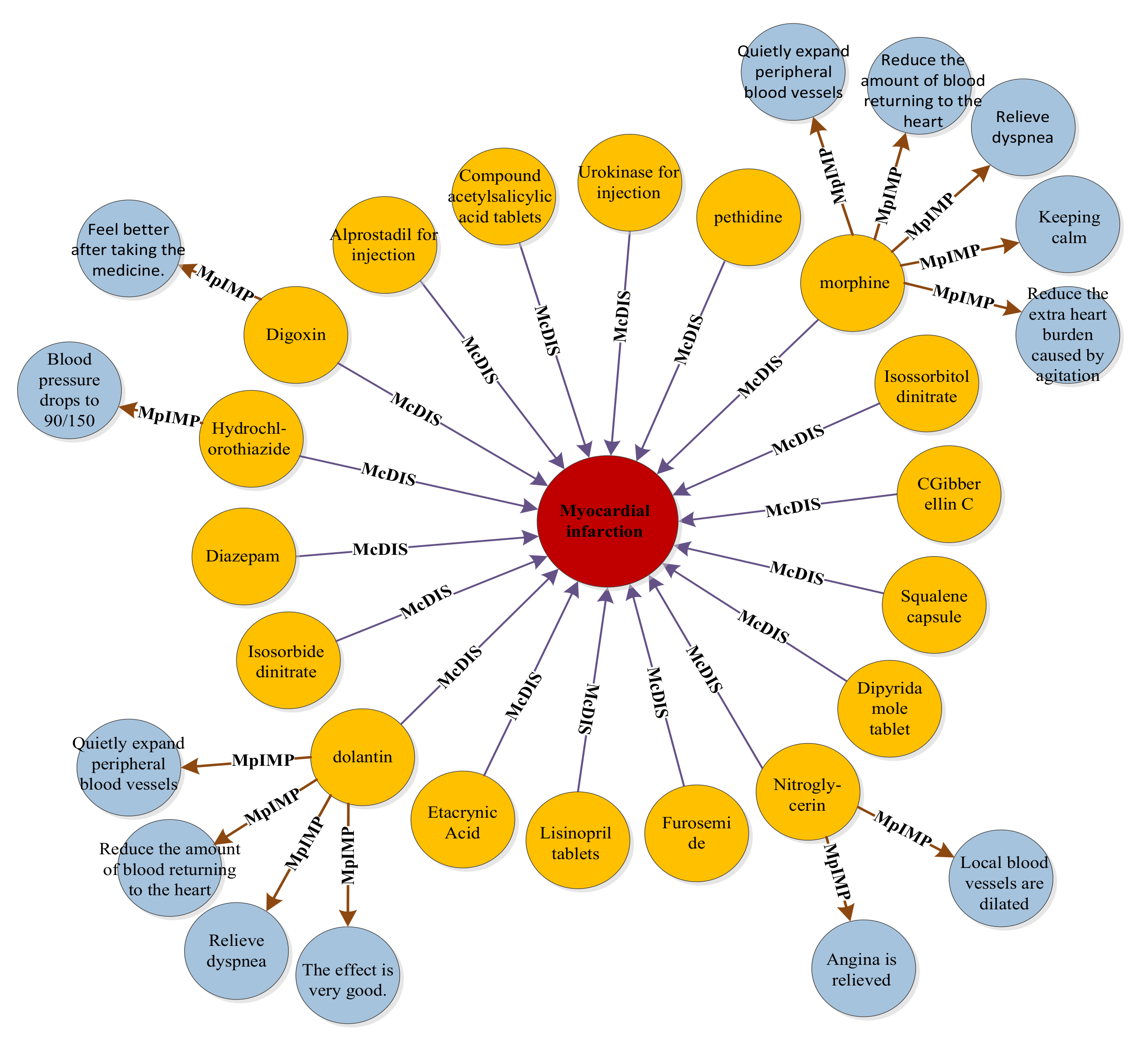
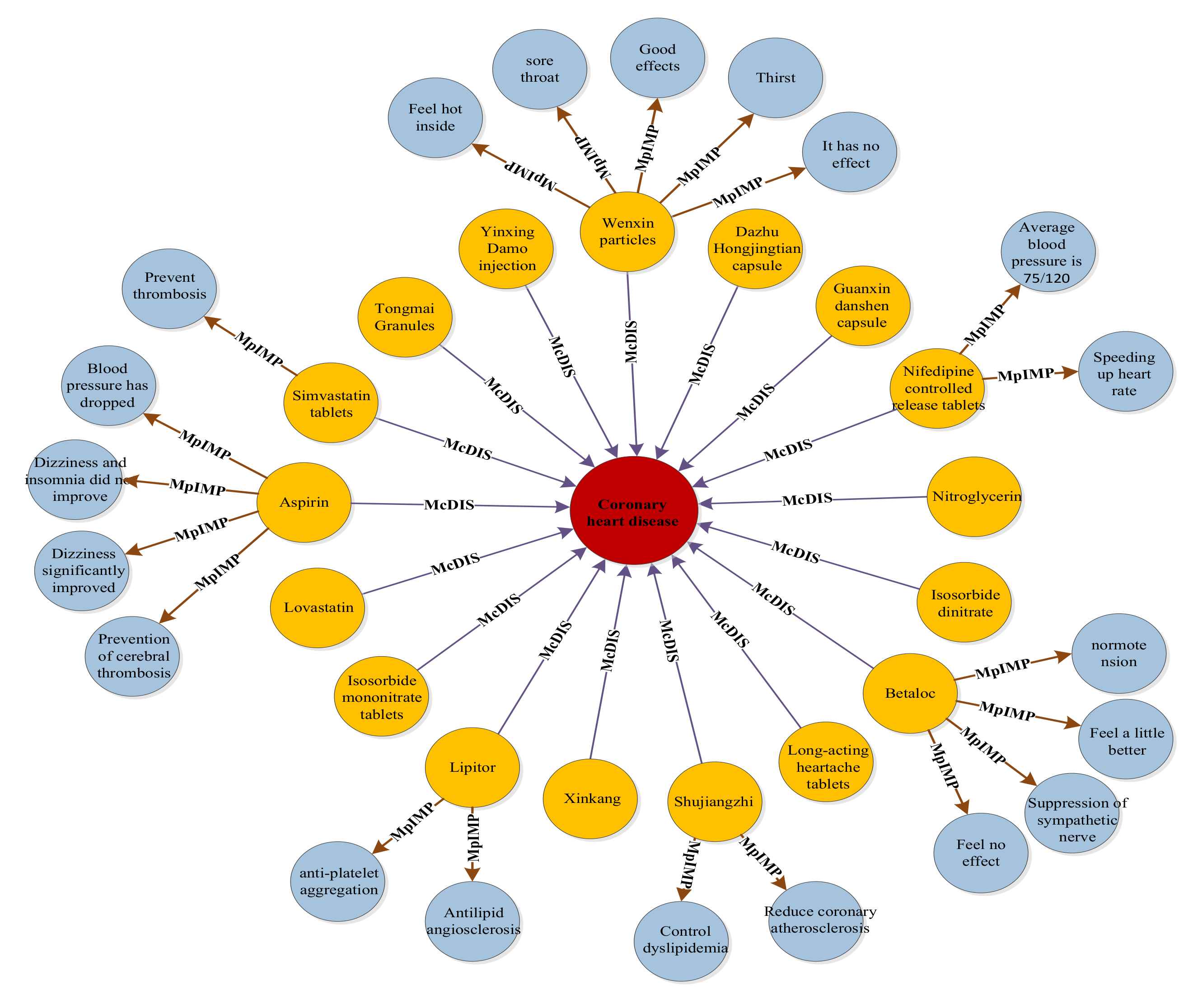
5.2. BERT-BiGRU-ATT Model Application
6. Discussion and Conclusions
6.1. Theoretical Contributions
6.2. Practical Implications
6.3. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bardhan, I.; Chen, H.; Karahanna, E. Connecting systems, data, and people: A multidisciplinary research roadmap for chronic disease management. MIS Q. 2020, 44, 185–200. [Google Scholar]
- Rastegar-Mojarad, M.; Liu, H.; Nambisan, P. Using social media data to identify potential candidates for drug repurposing: A feasibility study. JMIR Res. Protoc. 2016, 5, e5621. [Google Scholar]
- Zhang, T.; Wang, K.; Li, N.; Hurr, C.; Luo, J. The Relationship between Different Amounts of Physical Exercise, Internal Inhibition, and Drug Craving in Individuals with Substance-Use Disorders. Int. J. Environ. Res. Public Health 2021, 18, 12436. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.C.; Hwang, S.J. Patient-centered self-management in patients with chronic kidney disease: Challenges and implications. Int. J. Environ. Res. Public Health 2020, 17, 9443. [Google Scholar]
- Mehta, D.; Jackson, R.; Paul, G.; Shi, J.; Sabbagh, M. Why do trials for Alzheimer’s disease drugs keep failing? A discontinued drug perspective for 2010–2015. Expert Opin. Investig. Drugs 2017, 26, 735–739. [Google Scholar] [CrossRef]
- Wang, L.; Alexander, C.A. Big data analytics in medical engineering and healthcare: Methods, advances and challenges. J. Med. Eng. Technol. 2020, 44, 267–283. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.N. Off-Label Drug Use Detection Based on Heterogeneous Network Mining. In Proceedings of the IEEE International Conference on Healthcare Informatics (ICHI), Park City, UT, USA, 23–26 August 2017; p. 331. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Mimouni, Y.; Jaberi, E.; Paret, N.; Boussaha, I.; Vial, T.; Jacqz-Aigrain, E.; Alberti, C.; Guittard, L.; Remontet, L.; et al. Relationship between adverse drug reactions and unlicensed/off-label drug use in hospitalized children (EREMI): A study protocol. Therapies 2021, 76, 675–685. [Google Scholar]
- Antipov, E.A.; Pokryshevskaya, E.B. The Effects of Adverse Drug Reactions on Patients’ Satisfaction: Evidence From Publicly Available Data on Tamiflu (Oseltamivir). Int. J. Med. Inf. 2019, 125, 30–36. [Google Scholar] [CrossRef]
- Swathi, D.N. Predicting Drug Side-Effects From Open Source Health Forums Using Supervised Classifier Approach. In Proceedings of the 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 796–800. [Google Scholar] [CrossRef]
- Kang, K.; Tian, S.; Yu, L. Drug Adverse Reaction Discovery Based on Attention Mechanism and Fusion of Emotional Information. Autom. Control. Comput. Sci. 2020, 54, 391–402. [Google Scholar] [CrossRef]
- Zhang, Y.L.; Li, X.M.; Zhang, Z. Disease-Pertinent Knowledge Extraction in Online Health Communities Using GRU Based on a Double Attention Mechanism. IEEE Access 2020, 8, 95947–95955. [Google Scholar] [CrossRef]
- Fan, B.; Fan, W.; Smith, C.; Garner, H. Adverse Drug Event Detection and Extraction from Open Data: A Deep Learning Approach. Inf. Process. Manag. 2020, 57, 102131. [Google Scholar] [CrossRef]
- Zheng, W.; Lin, H.F.; Zhao, Z.H.; Xu, B.; Zhang, Y.; Yang, Z.; Wang, J. A Graph Kernel Based on Context Vectors for Extracting Drug–Drug Interactions. J. Biomed. Inf. 2016, 61, 34–43. [Google Scholar] [CrossRef] [PubMed]
- Martínez, P.; Martínez, J.L.; Segura-Bedmar, I.; Moreno-Schneider, J.; Luna, A.; Revert, R. Turning User Generated Health-Related Content Into Actionable Knowledge Through Text Analytics Services. Comput. Ind. 2016, 78, 43–56. [Google Scholar] [CrossRef]
- Yu, T.; Li, J.H.; Yu, Q.; Tian, Y.; Shun, X.; Xu, L.; Zhu, L.; Gao, H. Knowledge Graph for TCM Health Preservation: Design, Construction, and Applications. Artif. Intell. Med. 2017, 77, 48–52. [Google Scholar] [CrossRef] [PubMed]
- Anastopoulos, I.N.; Herczeg, C.K.; Davis, K.N.; Dixit, A.C. Multi-drug Featurization and Deep Learning Improve Patient-Specific Predictions of Adverse Events. Int. J. Environ. Res. Public Health 2021, 18, 2600. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, L.; Rastegar-Mojarad, M.; Moon, S.; Shen, F.; Afzal, N.; Liu, S.; Zeng, Y.; Mehrabi, S.; Sohn, S.; et al. Clinical information extraction applications: A literature review. J. Biomed. Inform. 2018, 77, 34–49. [Google Scholar]
- Lv, X.; Guan, Y.; Yang, J.; Wu, J. Clinical relation extraction with deep learning. Int. J. Hybrid Inf. Technol. 2016, 9, 237–248. [Google Scholar] [CrossRef]
- Iqbal, E.; Mallah, R.; Rhodes, D.; Wu, H.; Romero, A.; Chang, N.; Dzahini, O.; Pandey, C.; Broadbent, M.; Stewart, R.; et al. ADEPt, a Semantically Enriched Pipeline for Extracting Adverse Drug Events From Free-Text Electronic Health Records. PLoS ONE 2017, 12, e0187121. [Google Scholar] [CrossRef]
- Eftimov, T.; Koroušić Seljak, B.; Korošec, P. A Rule-Based Named-Entity Recognition Method for Knowledge Extraction of Evidence-Based Dietary Recommendations. PLoS ONE 2017, 12, e0179488. [Google Scholar] [CrossRef] [PubMed]
- Kholghi, M.; Sitbon, L.; Zuccon, G.; Nguyen, A. Active learning: A step towards automating medical concept extraction. J. Am. Med. Inform. Assoc. 2016, 23, 289–296. [Google Scholar] [CrossRef]
- Peng, Y.F.; Wei, C.H.; Lu, Z.Y. Improving Chemical Disease Relation Extraction With Rich Features and Weakly Labeled Data. J. Cheminform 2016, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Mahendran, D.; McInnes, B.T. Extracting adverse drug events from clinical notes. AMIA Summits Transl. Sci. Proc. 2021, 2021, 420–429. [Google Scholar] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Li, L.S.; Wan, J.; Zheng, J.Q.; Wang, J. Biomedical Event Extraction Based on GRU Integrating Attention Mechanism. BMC Bioinform. 2018, 19, 285. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Cheng, Y.; Uzuner, Ö.; Szolovits, P.; Starren, J. Segment convolutional neural networks (Seg-CNNs) for classifying relations in clinical notes. J. Am. Med. Inform. Assoc. 2018, 25, 93–98. [Google Scholar]
- Yadav, S.; Ramesh, S.; Saha, S.; Ekbal, A. Relation extraction from biomedical and clinical text: Unified multitask learning framework. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 19, 1105–1116. [Google Scholar]
- Gruetzemacher, R.; Gupta, A.; Paradice, D. 3D Deep Learning for Detecting Pulmonary Nodules in CT Scans. J. Am. Med. Inform. Assoc. 2018, 25, 1301–1310. [Google Scholar] [CrossRef]
- Xiao, C.; Choi, E.; Sun, J. Opportunities and Challenges in Developing Deep Learning Models Using Electronic Health Records Data: A Systematic Review. J. Am. Med. Inform. Assoc. 2018, 25, 1419–1428. [Google Scholar] [CrossRef]
- Jimenez, C.; Molina, M.; Montenegro, C. Deep Learning—Based Models for Drug-Drug Interactions Extraction in the Current Biomedical Literature. In Proceedings of the International Conference on Information Systems and Software Technologies (ICI2ST), Quito, Ecuador, 13–15 November 2019; pp. 174–181. [Google Scholar] [CrossRef]
- Dua, M.; Makhija, D.; Manasa, P.Y.L.; Mishra, P. A CNN–RNN–LSTM Based Amalgamation for Alzheimer’s Disease Detection. J. Med. Biol. Eng. 2020, 40, 688–706. [Google Scholar] [CrossRef]
- Zeng, X.; Song, X.; Ma, T.; Pan, X.; Zhou, Y.; Hou, Y.; Zhang, Z.; Li, K.; Karypis, G.; Cheng, F. Repurpose Open Data to Discover Therapeutics for COVID-19 Using Deep Learning. J. Proteome Res. 2020, 19, 4624–4636. [Google Scholar] [CrossRef]
- Watts, J.; Khojandi, A.; Vasudevan, R.; Ramdhani, R. Optimizing Individualized Treatment Planning for Parkinson’s Disease Using Deep Reinforcement Learning. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 5406–5409. [Google Scholar] [CrossRef]
- Yuan, S.; Yu, B. HClaimE: A Tool for Identifying Health Claims in Health News Headlines. Inform. Process. Manag. 2019, 56, 1220–1233. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, N.; Pun, S.H.; Vai, M.I.; Yang, Y.; Miao, Q. A Unified Knowledge Extraction Method Based on BERT and Handshaking Tagging Scheme. Appl. Sci. 2022, 12, 6543. [Google Scholar]
- Arnaud, É.; Elbattah, M.; Gignon, M.; Dequen, G. Learning Embeddings from Free-text Triage Notes using Pretrained Transformer Models. In Proceedings of the 15th International Joint Conference on Biomedical Engineering Systems and Technologies; SCITEPRESS: Setúbal, Portugal, 2022; Volume 5, pp. 835–841. [Google Scholar]
- Liu, Y.; Song, Z.; Xu, X.; Rafique, W.; Zhang, X.; Shen, J.; Khosravi, M.R.; Qi, L. Bidirectional GRU networks-based next POI category prediction for healthcare. Int. J. Intell. Syst. 2022, 37, 4020–4040. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Cauteruccio, F.; Corradini, E.; Terracina, G.; Ursino, D.; Virgili, L. Extraction and analysis of text patterns from NSFW adult content in Reddit. Data Knowl. Eng. 2022, 138, 101979. [Google Scholar] [CrossRef]
- Chollet, F. Keras: The Python Deep Learning Library. Astrophysics Source Code Library ascl-1806. 2018. Available online: https://ui.adsabs.harvard.edu/abs/2018ascl.soft06022C (accessed on 5 December 2021).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://s3-us-west-2.amazonaws.com/openaiassets/researchcovers/languageunsupervised/languageunderstandingpaper.pdf (accessed on 5 December 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | DsDIS | DnsDIS | DpEFF | Others | Total |
|---|---|---|---|---|---|
| 120ask | 4246 | 1532 | 2461 | 1493 | 9732 |
| Category | Precision | Recall | F-Score |
|---|---|---|---|
| DsDIS | 89.04% | 87.76% | 88.40% |
| DnsDIS | 86.85% | 84.51% | 85.67% |
| DpEFF | 84.64% | 85.67% | 85.15% |
| Others | 80.30% | 78.37% | 79.32% |
| Total | 88.46% | 86.09% | 87.26% |
| Category | Precision | Recall | F-Score |
|---|---|---|---|
| Word2Vec-BiGRU-ATT (Baseline) | 77.95% | 78.53% | 78.24% |
| fastText-BiGRU-ATT | 79.45% | 77.63% | 78.53% |
| GPT-BiGRU-ATT | 82.27% | 80.76% | 81.51% |
| BERT-BiGRU-ATT | 88.46% | 86.09% | 87.26% |
| Category | Precision | Recall | F-Score |
|---|---|---|---|
| LSTM (Baseline) | 72.15% | 70.59% | 71.36% |
| GRU | 82.42% | 81.06% | 81.73% |
| BERT-BiGRU | 84.95% | 82.32% | 83.61% |
| BERT-BiGRU-ATT | 88.46% | 86.09% | 87.26% |
| Head Entity | Tail Entity | Q&A Sentences | True Relation | The Top Three Predication Relation (Probability) |
|---|---|---|---|---|
| arteriosclerosis | nifedipine sustained-release tablets | Hello, arteriosclerosis refers to many factors. Usually, you should pay attention to not smoking and not drinking alcohol, consuming nonhigh-fat, nonhigh-sugar, and nonhigh-salt foods, drinking plenty of water, and exercising properly. Suggestions: You can take some captopril, nifedipine sustained-release tablets or other drugs as appropriate and check your blood pressure regularly. | DsDIS | 1. DsDIS (0.924124) 2. DpEFF (0.473218) 3. DnsDIS (0.145164) |
| antimalarials | favism | Favism is caused by mutations that affect the regulation of erythrocyte glucose-6-phosphate dehydrogenase; it is a hereditary hemolytic disease and is more common in men. Suggestions: It is necessary to pay attention to whether there is hemolysis; if there is, you need active treatment to prevent anemia and acute renal failure. Usually, you should avoid eating broad beans and their products, avoid taking drugs of oxidative properties (including antimalarials, sulfonamides, etc.), and actively prevent and treat it. The disease can still be controlled. | DnsDIS | 1. DnsDIS (0.913346) 2. Others (0.336215) 3. DpEFF (0.074103) |
| captopril | blood pressure was still 100,160 | It became apparent that I have had hypertension for more than two months, and my blood pressure was still 100,160 after taking captopril for one month. After that, I had taken hyzaar for a month, and my blood pressure dropped to 90,133. However, hyzaar is too expensive. Can I change to other less expensive drugs? | DpEFF | 1. DpEFF (0.903671) 2. Others (0.384623) 3. DsDIS (0.104216) |
| Shensong Yangxin Capsule | myocardial ischemia | Can a 62-year-old man take a type of Shensong Yangxin Capsule for treating myocardial ischemia? | Others | 1. Others (0.854143) 2. DsDIS (0.568127) 3. DnsDIS (0.134755) |
| Time | Patient’s Question (Female, 27 Years Old, Hypertension) | Physician’s Reply |
|---|---|---|
| 25 January 2018 | “Nifedipine sustained-release tablets” have the effect of “accelerating heart rhythm.” | “Nifedipine sustained-release tablets” have the effect of “accelerating heart rhythm.” |
| 25 January 2018 | How should I take enalapril maleate tablet? | “Hypertension” applies to “enalapril maleate tablet,” and the specific dosage needs to be determined according to the individual’s constitution and condition. |
| 26 January 2018 | Drug effects of hypertension: higher low pressure, normal pressure high pressure. | “Hypertension” applies to “calcium antagonists” and “nifedipine sustained-release tablets.” |
| 2 February 2018 | Hypertensive drug effect: stable blood pressure. | Hypertension” applies to “amlodipine,” “irbesartan,” and “betaloc.” |
| 8 February 2018 | The effect of antihypertensive drugs: the amount of menstruation is light. | I suggest you evaluate further. |
| 8 February 2018 | “Nifedipine sustained-release tablets” has the drug effect of “increasing heart rate and uncomfortable heart;” “enalapril maleate tablet” has the effect of “not effective.” | “Hypertension” suits “nifedipine sustained-release tablets,” “benazepril tablets” and “betaloc” have the effect of “slow heart rate” |
| 9 February 2018 | “Enalapril maleate tablet” has the effect of being “not very effective.” Can I use hydrochlorothiazide tablets? | “Hypertension” can be treated with “enalapril maleate tablets” and “hydrochlorothiazide tablets;” “hydrochlorothiazide tablets” have a “hypokalemia” drug effect. |
| 13 February 2018 | I have hypertension, can I take enalapril maleate tablets, felodipine sustained-release tablets and betaloc simultaneously? | “Hypertension” can be treated with “enalapril maleate tablets,” “felodipine sustained-release tablets,” and “betaloc.” |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Li, X.; Yang, Y.; Wang, T. Disease- and Drug-Related Knowledge Extraction for Health Management from Online Health Communities Based on BERT-BiGRU-ATT. Int. J. Environ. Res. Public Health 2022, 19, 16590. https://doi.org/10.3390/ijerph192416590
Zhang Y, Li X, Yang Y, Wang T. Disease- and Drug-Related Knowledge Extraction for Health Management from Online Health Communities Based on BERT-BiGRU-ATT. International Journal of Environmental Research and Public Health. 2022; 19(24):16590. https://doi.org/10.3390/ijerph192416590
Chicago/Turabian StyleZhang, Yanli, Xinmiao Li, Yu Yang, and Tao Wang. 2022. "Disease- and Drug-Related Knowledge Extraction for Health Management from Online Health Communities Based on BERT-BiGRU-ATT" International Journal of Environmental Research and Public Health 19, no. 24: 16590. https://doi.org/10.3390/ijerph192416590
APA StyleZhang, Y., Li, X., Yang, Y., & Wang, T. (2022). Disease- and Drug-Related Knowledge Extraction for Health Management from Online Health Communities Based on BERT-BiGRU-ATT. International Journal of Environmental Research and Public Health, 19(24), 16590. https://doi.org/10.3390/ijerph192416590