
A Scoping Review of Approaches to Improving Quality of Data Relating to Health Inequalities
 , ,
, ,
Abstract
1. Introduction
2. Methods
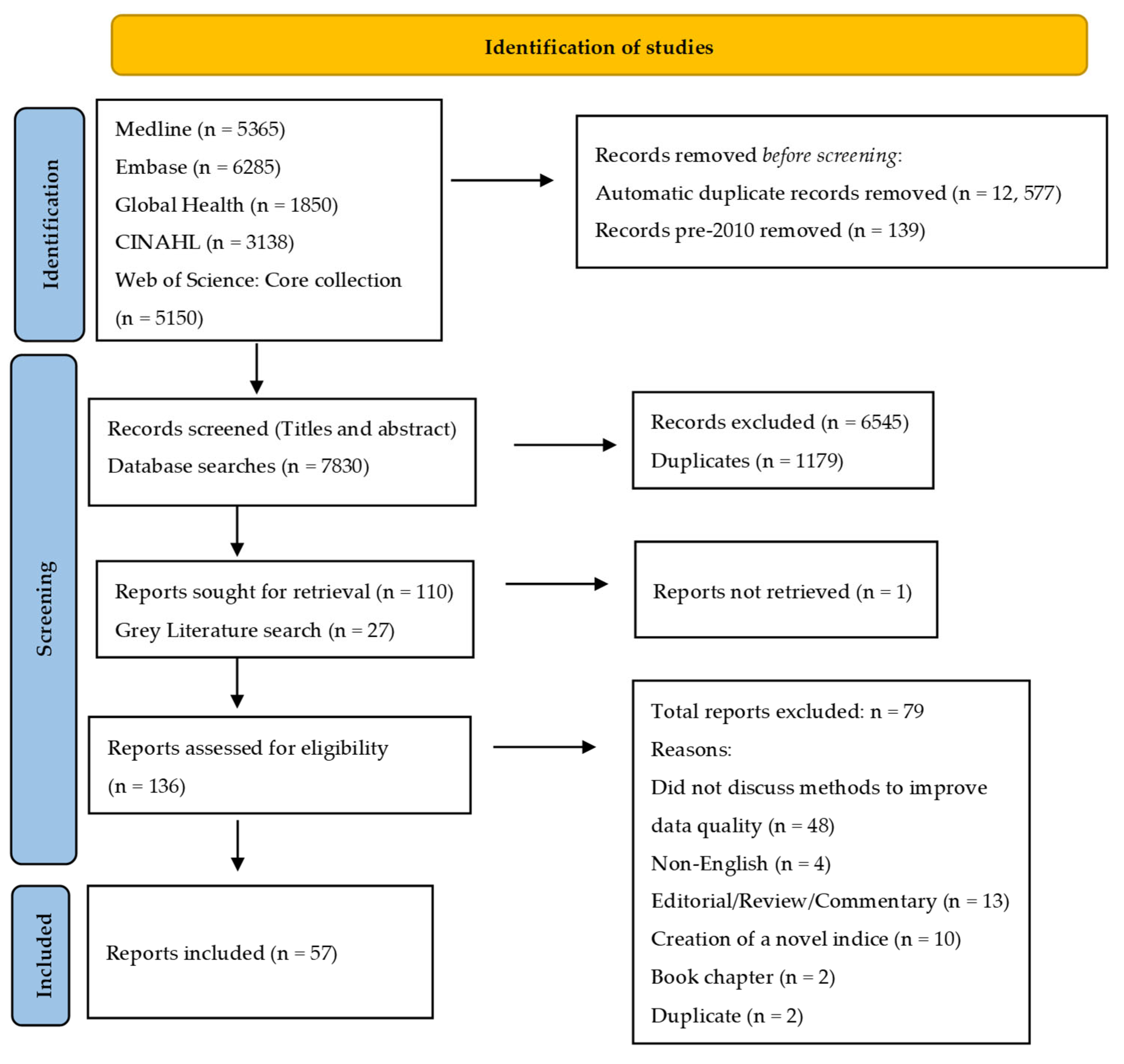
2.1. Article Identification and Selection
2.2. Inclusion and Exclusion Criteria
2.3. Data Extraction and Synthesis
3. Results
3.1. Distal Initiatives
3.2. Wider Actions to Enable Improvements in Data Quality
3.3. Data Collection Instruments, Systems and Standardisation
3.4. Methodological Approaches to Improve Data Completeness and Accuracy
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Public Health England. COVID-19 Place-Based Approach to Reducing Health Inequalities. PHE Publications Gateway Number: GOV-8343. 2020. Available online: https://www.gov.uk/government/publications/health-inequalities-place-based-approaches-to-reduce-inequalities (accessed on 20 January 2022).
- NHS England. NHS Operational Planning and Contracting Guidance 2021/22. 2021. Available online: https://www.england.nhs.uk/operational-planning-and-contracting/ (accessed on 20 January 2022).
- NHS England/ Equality and Health Inequalities Team. Monitoring Equality and Health Inequalities: A position Paper. 2015. Available online: https://www.england.nhs.uk/wp-content/uploads/2015/03/monitrg-ehi-pos-paper.pdf (accessed on 20 January 2022).
- Scobie, S.; Spencer, J.; Raleigh, V. Ethnicity Coding in English Health Service Datasets. 2021. Available online: https://www.nhsrho.org/news/ethnicity-coding-in-english-health-service-datasets/ (accessed on 20 January 2022).
- The Government Data Quality Hub. The Government Data Quality Framework. 2020. Available online: https://www.gov.uk/government/publications/the-government-data-quality-framework/the-government-data-quality-framework (accessed on 19 November 2022).
- Public Health England. Local Action on Health Inequalities Understanding and Reducing Ethnic Inequalities in Health. 2018. Available online: publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/730917/local_action_on_health_inequalities.pdf (accessed on 20 January 2022).
- Public Health England. COVID-19: Review of Disparities in Risks and Outcomes; PHE Publications Gateway Number: GW-1447; Public Health England: London, UK, 2020. [Google Scholar]
- NHS England. Third Phase of NHS Response to COVID-19. NHS. 2020. Available online: https://www.england.nhs.uk/coronavirus/publication/third-phase-response/ (accessed on 20 January 2022).
- Office for National Statistics. Equalities Data Audit, Final Report. 2018. Available online: https://www.ons.gov.uk/methodology/methodologicalpublications/generalmethodology/onsworkingpaperseries/equalitiesdataauditfinalreport (accessed on 20 January 2022).
- Marmot, M. Fair Society, Healthy Lives: The Marmot Review; Marmot Review: London, UK, 2010. [Google Scholar]
- Marmot, M.; Allen, J.; Boyce, T.; Goldbatt, P.; Morrison, J. Health Equity in England: The Marmot Review 10 Years On; Institute of Health Equity: London, UK, 2020. [Google Scholar]
- Office for Health Improvement and Disparities. Beyond the Data one Year on—Companion Narrative Data and Literature. 2021. Available online: https://www.london.gov.uk/what-we-do/health/health-inequalities/london-health-inequalities-strategy (accessed on 20 January 2022).
- Centre for Equalities and Inclusion. Available online: https://www.ons.gov.uk/aboutus/whatwedo/programmesandprojects/onscentres/centreforequalitiesandinclusion (accessed on 24 January 2022).
- NHS Race and Health Observatory. Available online: https://www.nhsconfed.org/networks-countries/nhs-race-and-health-observatory (accessed on 24 January 2022).
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.J.; Horsley, T.; Weeks, L.; et al. PRISMA Extension for Scoping Reviews (PRISMA-ScR): Checklist and Explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef] [PubMed]
- Bozorgmehr, K.; Goosen, S.; Mohsenpour, A.; Kuehne, A.; Razum, O.; Kunst, A.E. How Do Countries’ Health Information Systems Perform in Assessing Asylum Seekers’ Health Situation? Developing a Health Information Assessment Tool on Asylum Seekers (HIATUS) and Piloting It in Two European Countries. Int. J. Environ. Res. Public Health 2017, 14, 894. [Google Scholar] [CrossRef] [PubMed]
- Allen, V.C.; Lachance, C.; Rios-Ellis, B.; Kaphingst, K.A. Issues in the Assessment of “Race” Among Latinos: Implications for Research and Policy. Hisp. J. Behav. Sci. 2011, 33, 411–424. [Google Scholar] [CrossRef] [PubMed]
- Anderson, M.L.; Riker, T.; Gagne, K.; Hakulin, S.; Higgins, T.; Meehan, J.; Stout, E.; Pici-D’Ottavio, E.; Cappetta, K.; Craig, K.S.W. Deaf Qualitative Health Research: Leveraging Technology to Conduct Linguistically and Sociopolitically Appropriate Methods of Inquiry. Qual. Health Res. 2018, 28, 1813–1824. [Google Scholar] [CrossRef]
- Andrews, R.M. Race and Ethnicity Reporting in Statewide Hospital Data: Progress and Future Challenges in a Key Resource for Local and State Monitoring of Health Disparities. J. Public Health Manag. Pract. 2011, 17, 167–173. [Google Scholar] [CrossRef]
- Azar, K.M.J.; Moreno, M.R.; Wong, E.C.; Shin, J.J.; Soto, C.; Palaniappan, L.P. Accuracy of Data Entry of Patient Race/Ethnicity/Ancestry and Preferred Spoken Language in an Ambulatory Care Setting. Health Serv. Res. 2012, 47, 228–240. [Google Scholar] [CrossRef]
- Becker, T.; Babey, S.H.; Dorsey, R.; Ponce, N.A. Data Disaggregation with American Indian/Alaska Native Population Data. Popul. Res. Policy Rev. 2021, 40, 103–125. [Google Scholar] [CrossRef]
- Berry, C.; Kaplan, S.A.; Mijanovich, T.; Mayer, A. Moving to patient reported collection of race and ethnicity data: Implementation and impact in ten hospitals. Int. J. Health Care Qual. Assur. 2014, 27, 271–283. [Google Scholar] [CrossRef]
- Beltran, V.M.; Harrison, K.M.; Hall, H.I.; Dean, H.D. Collection of social determinant of health measures in U.S. national surveillance systems for HIV, viral hepatitis, STDs, and TB. Public Health Rep. 2011, 126 (Suppl. S3), 41–53. [Google Scholar] [CrossRef]
- Bilheimer, L.T.; Klein, R.J. Data and Measurement Issues in the Analysis of Health Disparities. Health Serv. Res. 2010, 45, 1489–1507. [Google Scholar] [CrossRef]
- Block, R.G.; Puro, J.; Cottrell, E.; Lunn, M.R.; Dunne, M.J.; Quinones, A.R.; Chung, B.W.; Pinnock, W.; Reid, G.M.; Heintzman, J. Recommendations for improving national clinical datasets for health equity research. J. Am. Med. Inform. Assoc. 2020, 27, 1802–1807. [Google Scholar] [CrossRef]
- Blosnich, J.R.; Cashy, J.; Gordon, A.J.; Shipherd, J.C.; Kauth, M.R.; Brown, G.R.; Fine, M.J. Using clinician text notes in electronic medical record data to validate transgender-related diagnosis codes. J. Am. Med. Inform. Assoc. 2018, 25, 905–908. [Google Scholar] [CrossRef]
- Cahill, S.R.; Baker, K.; Deutsch, M.B.; Keatley, J.; Makadon, H.J. Inclusion of Sexual Orientation and Gender Identity in Stage 3 Meaningful Use Guidelines: A Huge Step Forward for LGBT Health. LGBT Health 2016, 3, 100–102. [Google Scholar] [CrossRef]
- Chakkalakal, R.J.; Green, J.C.; Krumholz, H.M.; Nallamothu, B.K. Standardized data collection practices and the racial/ethnic distribution of hospitalized patients. Med. Care 2015, 53, 666–672. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, H.Y.; Tseng, T.S.; Wen, H.; DeVivo, M.J. Racial Differences in Data Quality and Completeness: Spinal Cord Injury Model Systems’ Experiences. Top. Spinal Cord Inj. Rehabil. 2018, 24, 110–120. [Google Scholar] [CrossRef]
- Clarke, L.C.; Rull, R.P.; Ayanian, J.Z.; Boer, R.; Deapen, D.; West, D.W.; Kahn, K.L. Validity of Race, Ethnicity, and National Origin in Population-based Cancer Registries and Rapid Case Ascertainment Enhanced with a Spanish Surname List. Med. Care 2016, 54, e1–e8. [Google Scholar] [CrossRef]
- Craddock Lee, S.J.; Grobe, J.E.; Tiro, J.A.; Lee, S.J.C. Assessing race and ethnicity data quality across cancer registries and EMRs in two hospitals. J. Am. Med. Inform. Assoc. 2016, 23, 627–634. [Google Scholar] [CrossRef]
- Cruz, T.M. Perils of data-driven equity: Safety-net care and big data’s elusive grasp on health inequality. Big Data Soc. 2020, 7. [Google Scholar] [CrossRef]
- Cruz, T.M. Shifting Analytics within US Biomedicine: From Patient Data to the Institutional Conditions of Health Care Inequalities. Sex. Res. Soc. Policy 2022, 19, 287–293. [Google Scholar] [CrossRef]
- Davidson, E.M.; Douglas, A.; Villarroel, N.; Dimmock, K.; Gorman, D.; Bhopal, R.S. Raising ethnicity recording in NHS Lothian from 3% to 90% in 3 years: Processes and analysis of data from Accidents and Emergencies. J. Public Health 2021, 43, e728–e738. [Google Scholar] [CrossRef]
- Derose, S.F.; Contreras, R.; Coleman, K.J.; Koebnick, C.; Jacobsen, S.J. Race and Ethnicity Data Quality and Imputation Using US Census Data in an Integrated Health System: The Kaiser Permanente Southern California Experience. Med. Care Res. Rev. 2013, 70, 330–345. [Google Scholar] [CrossRef] [PubMed]
- Donald, C.; Ehrenfeld, J.M. The Opportunity for Medical Systems to Reduce Health Disparities Among Lesbian, Gay, Bisexual, Transgender and Intersex Patients. J. Med. Syst. 2015, 39, 178. [Google Scholar] [CrossRef]
- Escarce, J.J.; Carreón, R.; Veselovskiy, G.; Lawson, E.H. Collection of Race and Ethnicity Data by Health Plans Has Grown Substantially, But Opportunities Remain to Expand Efforts. Health Aff. 2011, 30, 1984–1991. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Fortune, N.; Badland, H.; Clifton, S.; Emerson, E.; Rachele, J.; Stancliffe, R.J.; Zhou, Q.S.; Llewellyn, G. The Disability and Wellbeing Monitoring Framework: Data, data gaps, and policy implications. Aust. N. Z. J. Public Health 2020, 44, 227–232. [Google Scholar] [CrossRef] [PubMed]
- Frank, J.; Haw, S. Best Practice Guidelines for Monitoring Socioeconomic Inequalities in Health Status: Lessons from Scotland. Milbank Q. 2011, 89, 658–693. [Google Scholar] [CrossRef]
- Fremont, A.; Weissman, J.S.; Hoch, E.; Elliott, M.N. When Race/Ethnicity Data Are Lacking: Using Advanced Indirect Estimation Methods to Measure Disparities. Rand Health Q. 2016, 6, 16. [Google Scholar]
- Haas, A.P.; Lane, A.; Working Grp, P. Collecting Sexual Orientation and Gender Identity Data in Suicide and Other Violent Deaths: A Step Towards Identifying and Addressing LGBT Mortality Disparities. LGBT Health 2015, 2, 84–87. [Google Scholar] [CrossRef]
- Hannigan, A.; Villarroel, N.; Roura, M.; LeMaster, J.; Basogomba, A.; Bradley, C.; MacFarlane, A. Ethnicity recording in health and social care data collections in Ireland: Where and how is it measured and what is it used for? Int. J. Equity Health 2019, 19, 2. [Google Scholar] [CrossRef]
- Jorgensen, S.; Thorlby, R.; Weinick, R.M.; Ayanian, J.Z. Responses of Massachusetts hospitals to a state mandate to collect race, ethnicity and language data from patients: A qualitative study. BMC Health Serv. Res. 2010, 10, 352. [Google Scholar] [CrossRef]
- Khunti, K.; Routen, A.; Banerjee, A.; Pareek, M. The need for improved collection and coding of ethnicity in health research. J. Public Health 2021, 43, e270–e272. [Google Scholar] [CrossRef]
- Knox, S.; Bhopal, R.S.; Thomson, C.S.; Millard, A.; Fraser, A.; Gruer, L.; Buchanan, D. The challenge of using routinely collected data to compare hospital admission rates by ethnic group: A demonstration project in Scotland. J. Public Health 2020, 42, 748–755. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Tanjasiri, S.; Cockburn, M. Challenges in Identifying Native Hawaiians and Pacific Islanders in Population-Based Cancer Registries in the U.S. J. Immigr. Minor. Health 2011, 13, 860–866. [Google Scholar] [CrossRef] [PubMed]
- Mathur, R.; Bhaskaran, K.; Chaturvedi, N.; Leon, D.A.; vanStaa, T.; Grundy, E.; Smeeth, L. Completeness and usability of ethnicity data in UK-based primary care and hospital databases. J. Public Health 2014, 36, 684–692. [Google Scholar] [CrossRef]
- Pinto, A.D.; Glattstein-Young, G.; Mohamed, A.; Bloch, G.; Leung, F.H.; Glazier, R.H. Building a Foundation to Reduce Health Inequities: Routine Collection of Sociodemographic Data in Primary Care. J. Am. Board Fam. Med. 2016, 29, 348–355. [Google Scholar] [CrossRef] [PubMed]
- Polubriaginof, F.C.G.; Ryan, P.; Salmasian, H.; Shapiro, A.W.; Perotte, A.; Safford, M.M.; Hripcsak, G.; Smith, S.; Tatonetti, N.R.; Vawdrey, D.K. Challenges with quality of race and ethnicity data in observational databases. J. Am. Med. Inform. Assoc. 2019, 26, 730–736. [Google Scholar] [CrossRef]
- Ryan, R.; Vernon, S.; Lawrence, G.; Wilson, S. Use of name recognition software, census data and multiple imputation to predict missing data on ethnicity: Application to cancer registry records. BMC Med. Inf. Decis. Mak. 2012, 12, 3. [Google Scholar] [CrossRef]
- Russell, A.M.; Bryant, L.; House, A. Identifying people with a learning disability: An advanced search for general practice. Br. J. Gen. Pr. 2017, 67, e842–e850. [Google Scholar] [CrossRef]
- Saperstein, A. Capturing complexity in the United States: Which aspects of race matter and when? Ethn. Racial Stud. 2012, 35, 1484–1502. [Google Scholar] [CrossRef]
- Shah, S.N.; Russo, E.T.; Earl, T.R.; Kuo, T. Measuring and Monitoring Progress Toward Health Equity: Local Challenges for Public Health. Prev. Chronic Dis. 2014, 11, E159. [Google Scholar] [CrossRef]
- Siegel, B.; Sears, V.; Bretsch, J.K.; Wilson, M.; Jones, K.C.; Mead, H.; Hasnain-Wynia, R.; Ayala, R.K.; Bhalla, R.; Cornue, C.M.; et al. A Quality Improvement Framework for Equity in Cardiovascular Care: Results of a National Collaborative. J. Healthc. Qual. 2012, 34, 32–43. [Google Scholar] [CrossRef]
- Smith, L.; Norman, P.; Kapetanstrataki, M.; Fleming, S.; Fraser, L.K.; Parslow, R.C.; Feltbower, R.G. Comparison of ethnic group classification using naming analysis and routinely collected data: Application to cancer incidence trends in children and young people. BMJ Open 2017, 7, e016332. [Google Scholar] [CrossRef]
- Smylie, J.; Firestone, M. Back to the basics: Identifying and addressing underlying challenges in achieving high quality and relevant health statistics for indigenous populations in Canada. Stat. J. IAOS 2015, 31, 67–87. [Google Scholar] [CrossRef]
- Tan-McGrory, A.; Bennett-AbuAyyash, C.; Gee, S.; Dabney, K.; Cowden, J.D.; Williams, L.; Rafton, S.; Nettles, A.; Pagura, S.; Holmes, L.; et al. A patient and family data domain collection framework for identifying disparities in pediatrics: Results from the pediatric health equity collaborative. BMC Pediatr. 2018, 18, 18. [Google Scholar] [CrossRef]
- Thorlby, R.; Jorgensen, S.; Siegel, B.; Ayanian, J.Z. How Health Care Organizations Are Using Data on Patients’ Race and Ethnicity to Improve Quality of Care. Milbank Q. 2011, 89, 226–255. [Google Scholar] [CrossRef]
- Wang, K.R.; Nardini, H.G.; Post, L.; Edwards, T.; Nunez-Smith, M.; Brandt, C. Information Loss in Harmonizing Granular Race and Ethnicity Data: Descriptive Study of Standards. J. Med. Internet Res. 2020, 22, e14591. [Google Scholar] [CrossRef]
- Webster, P.S.; Sampangi, S. Did We Have an Impact? Changes in Racial and Ethnic Composition of Patient Populations Following Implementation of a Pilot Program. J. Healthc. Qual. 2017, 39, e22–e32. [Google Scholar] [CrossRef]
- Wei-Chen, L.; Veeranki, S.P.; Serag, H.; Eschbach, K.; Smith, K.D. Improving the Collection of Race, Ethnicity, and Language Data to Reduce Healthcare Disparities: A Case Study from an Academic Medical Center. Perspect. Health Inf. Manag. 2016, 13. [Google Scholar]
- Wolff, M.; Wells, B.; Ventura-DiPersia, C.; Renson, A.; Grov, C. Measuring Sexual Orientation: A Review and Critique of US Data Collection Efforts and Implications for Health Policy. J. Sex Res. 2017, 54, 507–531. [Google Scholar] [CrossRef]
- Zhang, X.Z.; Hailu, B.; Tabor, D.C.; Gold, R.; Sayre, M.H.; Sim, I.; Jean-Francoi, B.; Casnoff, C.A.; Cullen, T.; Thomas, V.A.; et al. Role of Health Information Technology in Addressing Health Disparities Patient, Clinician, and System Perspectives. Med. Care 2019, 57, S115–S120. [Google Scholar] [CrossRef]
- Hutt, P.; Gilmour, S. Tackling Inequalities in General Practice: An Enquiry into the Qualtiy of General Practice in England. 2010. Available online: https://www.kingsfund.org.uk/sites/default/files/field/field_document/health-inequalities-general-practice-gp-inquiry-research-paper-mar11.pdf (accessed on 24 January 2022).
- Scottish Government. Improving Data and Evidence on Ethnic Inequalities in Health: Initial Advice and Recommendations from the Expert Reference Group on Ethnicity and COVID-19. 2020. Available online: https://www.gov.scot/publications/expert-reference-group-on-covid-19-and-ethnicity-recommendations-to-scottish-government/ (accessed on 24 January 2022).
- NHS England. Advancing Mental Health Equalities Strategy. 2020. Available online: https://www.england.nhs.uk/publication/advancing-mental-health-equalities-strategy/ (accessed on 24 January 2022).
- NHS. NHS Mental Health Implementation Plan 2019/20–2023/24. 2019. Available online: https://www.longtermplan.nhs.uk/publication/nhs-mental-health-implementation-plan-2019-20-2023-24/ (accessed on 24 January 2022).
- NHS Race and Health Observatory. Ethnic Health Inequalities and the NHS: Driving Progress in a Changing System. 2021. Available online: https://www.nhsrho.org/publications/ethnic-health-inequalities-and-the-nhs/ (accessed on 24 January 2022).
- NHS England. Improving Identification of People with a Learning Disability: Guidance for General Practice. 2019. Available online: https://www.england.nhs.uk/publication/improving-identification-of-people-with-a-learning-disability-guidance-for-general-practice/ (accessed on 24 January 2022).
- National Services Scotland. Measuring Use of Health Services by Equality Group. 2017. Available online: https://www.isdscotland.org/Health-Topics/Equality-and-Diversity/Publications/2017-06-27/2017-06-27-Measuring-Use-of-Health-Services-by-Equality-Group-Report.pdf (accessed on 24 January 2022).
- Abouzeid, M.; Bhopal, R.S.; Dunbar, J.A.; Janus, E.D. The potential for measuring ethnicity and health in a multicultural milieu – the case of type 2 diabetes in Australia. Ethn. Health 2014, 19, 424–439. [Google Scholar] [CrossRef][Green Version]
- Cummins, C.; Winter, H.; Cheng, K.K.; Maric, R.; Silcocks, P.; Varghese, C. An assessment of the Nam Pehchan computer program for the identification of names of south Asian ethnic origin. J. Public Health Med. 1999, 21, 401–406. [Google Scholar] [CrossRef] [PubMed]
- National Services Scotland. Improving Data Collection for Equality and Diversity Monitoring: All Scotland Ethnicity Completeness in SMR01 and SMR00; National Services Scotland: Glasgow, Scotland, 2011. [Google Scholar]
- Iqbal, G.; Gumber, A.; Johnson, M.; Szczepura, A.; Wilson, S.; Dunn, J. Improving ethnicity data collection for health statistics in the UK. Divers. Health Care 2009, 6, 267–285. [Google Scholar]
- NHS Digital. [MI] Ethnic Category Coverage. 2022. Available online: https://digital.nhs.uk/data-and-information/publications/statistical/mi-ethnic-category-coverage/current (accessed on 24 January 2022).
- Hogberg, P.; Henriksson, G.; Borrell, C.; Ciutan, M.; Costa, G.; Georgiou, I.; Halik, R.; Hoebel, J.; Kilpelainen, K.; Kyprianou, T.; et al. Monitoring Health Inequalities in 12 European Countries: Lessons Learned from the Joint Action Health Equity Europe. Int. J. Env. Res. Public Health 2022, 19, 7663. [Google Scholar] [CrossRef] [PubMed]
- Hosseinpoor, A.R.; Bergen, N.; Schlotheuber, A.; Boerma, T. National health inequality monitoring: Current challenges and opportunities. Glob. Health Action 2018, 11, 1392216. [Google Scholar] [CrossRef]


{kind=link}
| Author, Year | Title | Type of Data Discussed | Distal Factors | Wider Actions to Enable Improvements in Data Collection | Data Collection Instruments, Systems, and Standardisation | Methodological Approaches to Improve Data Quality and Accuracy |
|---|---|---|---|---|---|---|
| Abouzeid, M et al. 2014 [16] | The potential for measuring ethnicity and health in a multicultural milieu—the case of type 2 diabetes in Australia | Ethnicity | ✓ | ✓ | ✓ | ✓ |
| Allen, VC et al. 2011 [17] | Issues in the Assessment of “Race” Among Latinos: Implications for Research and Policy | Ethnicity | ✓ | ✓ | ✓ | |
| Anderson, ML et al. 2018 [18] | Deaf Qualitative Health Research: Leveraging Technology to Conduct Linguistically and Sociopolitically Appropriate Methods of Inquiry | Disability | ✓ | ✓ | ||
| Andrews, RM 2011 [19] | Race and Ethnicity Reporting in Statewide Hospital Data: Progress and Future Challenges in a Key Resource for Local and State Monitoring of Health Disparities | Ethnicity | ✓ | ✓ | ✓ | |
| Azar, KMJ et al. 2012 [20] | Accuracy of Data Entry of Patient Race/Ethnicity/Ancestry and Preferred Spoken Language in an Ambulatory Care Setting | Ethnicity | ✓ | ✓ | ||
| Becker, T et al. 2021 [21] | Data Disaggregation with American Indian/Alaska Native Population Data | Ethnicity | ✓ | ✓ | ✓ | ✓ |
| Berry C et al. 2013 [22] | Moving to patient reported collection of race and ethnicity data Implementation and impact in ten hospitals | Ethnicity | ✓ | |||
| Beltran VM et al. 2011 [23] | Collection of social determinants of health measures in U.S. national surveillance systems for HIV, viral hepatitis, STDs, and TB | Infectious disease | ✓ | ✓ | ✓ | ✓ |
| Bilheimer LT et al. 2010 [24] | Data and Measurement Issues in the Analysis of Health Disparities | General | ✓ | ✓ | ✓ | ✓ |
| Block RG et al. 2020 [25] | Recommendations for improving national clinical datasets for health equity research | General | ✓ | ✓ | ✓ | |
| Blosnich JR et al. 2018 [26] | Using clinician text notes in electronic medical record data to validate transgender-related diagnosis codes | Gender | ✓ | |||
| Bozorgmehr, K et al. 2017 [16] | How Do Countries’ Health Information Systems Perform in Assessing Asylum Seekers’ Health Situation? Developing a Health Information Assessment Tool on Asylum Seekers (HIATUS) and Piloting It in Two European Countries | General | ✓ | |||
| Cahill SR et al. 2016 [27] | Inclusion of Sexual Orientation and Gender Identity in Stage 3 Meaningful Use Guidelines: A Huge Step Forward for LGBT Health | Gender | ✓ | |||
| Chakkalakal RJ et al. 2015 [28] | Standardized Data Collection Practices and the Racial/Ethnic Distribution of Hospitalized Patients | Ethnicity | ✓ | ✓ | ||
| Chen Y et al. 2018 [29] | Racial Differences in Data Quality and Completeness: Spinal Cord Injury Model Systems’ Experiences | Ethnicity | ✓ | ✓ | ||
| Clarke LC et al. 2016 [30] | Validity of Race, Ethnicity, and National Origin in Population-based Cancer Registries and Rapid Case Ascertainment Enhanced with a Spanish Surname List | Ethnicity | ✓ | |||
| Craddock L et al., 2016 [31] | Assessing race and ethnicity data quality across cancer registries and EMRs in two hospitals | Ethnicity | ✓ | ✓ | ||
| Cruz, TM 2020 [32] | Perils of data-driven equity: Safety-net care and big data’s elusive grasp on health inequality | General | ✓ | |||
| Cruz, TM 2021 [33] | Shifting Analytics within US Biomedicine: From Patient Data to the Institutional Conditions of Health Care Inequalities | General | ✓ | ✓ | ✓ | |
| Davidson E et al., 2021 [34] | Raising ethnicity recording in NHS Lothian from 3% to 90% in 3 years: processes and analysis of data from Accidents and Emergencies | Ethnicity | ✓ | ✓ | ✓ | |
| Derose, SF et al. 2013 [35] | Race and Ethnicity Data Quality and Imputation Using US Census Data in an Integrated Health System: The Kaiser Permanente Southern California Experience | Ethnicity | ✓ | ✓ | ||
| Donald C and Ehrenfeld JM 2015 [36] | The Opportunity for Medical Systems to Reduce Health Disparities Among Lesbian, Gay, Bisexual, Transgender and Intersex Patients | Gender | ✓ | ✓ | ✓ | |
| Escarce, J et al. 2011 [37] | Collection Of Race and Ethnicity Data By Health Plans Has Grown Substantially, But Opportunities Remain To Expand Efforts | Ethnicity | ✓ | ✓ | ✓ | |
| Fortune, N et al. 2020 [38] | The Disability and Wellbeing Monitoring Framework: data, data gaps, and policy implications | Disability | ✓ | ✓ | ✓ | ✓ |
| Frank, J and Haw S 2011 [39] | Best Practice Guidelines for Monitoring Socioeconomic Inequalities in Health Status: Lessons from Scotland | Gender | ✓ | ✓ | ✓ | |
| Fremont, A et al. 2016 [40] | When Race/Ethnicity Data Are Lacking: Using Advanced Indirect Estimation Methods to Measure Disparities | Ethnicity | ✓ | |||
| Haas, AP et al. 2015 [41] | Collecting Sexual Orientation and Gender Identity Data in Suicide and Other Violent Deaths: A Step Towards Identifying and Addressing LGBT Mortality Disparities | Gender | ✓ | |||
| Hannigan, A et al. 2019 [42] | Ethnicity recording in health and social care data collections in Ireland: where and how is it measured and what is it used for? | Ethnicity | ✓ | ✓ | ✓ | |
| Jorgensen S et al., 2010 [43] | Responses of Massachusetts hospitals to a state mandate to collect race, ethnicity and language data from patients: a qualitative study | Ethnicity | ✓ | ✓ | ✓ | |
| Khunti, K et al. 2021 [44] | The need for improved collection and coding of ethnicity in health research | Ethnicity | ✓ | |||
| Knox et al. 2019 [45] | The challenge of using routinely collected data to compare hospital admission rates by ethnic group: a demonstration project in Scotland | Ethnicity | ✓ | ✓ | ||
| Liu, L et al. 2011 [46] | Challenges in Identifying Native Hawaiians and Pacific Islanders in Population-Based Cancer Registries in the U.S. | Ethnicity | ✓ | |||
| Mathur et al., 2013 [47] | Completeness and usability of ethnicity data in UK-based primary care and hospital databases | Ethnicity | ✓ | ✓ | ||
| Pinto, AD et al. 2016 [48] | Building a Foundation to Reduce Health Inequities: Routine Collection of Sociodemographic Data in Primary Care | General | ✓ | ✓ | ||
| Polubriaginof, FCG et al. 2019 [49] | Challenges with quality of race and ethnicity data in observational databases | Ethnicity | ✓ | ✓ | ||
| Ryan et al. 2012 [50] | Use of name recognition software, census data and multiple imputation to predict missing data on ethnicity: application to cancer registry records | Ethnicity | ✓ | |||
| Russell AM et al. 2017 [51] | Identifying people with a learning disability: an advanced search for general practice | Learning disability | ✓ | |||
| Saperstein, A. 2012 [52] | Capturing complexity in the United States: which aspects of race matter and when? | Ethnicity | ✓ | |||
| Shah, SN et al. 2014 [53] | Measuring and Monitoring Progress Toward Health Equity: Local Challenges for Public Health | General | ✓ | ✓ | ✓ | ✓ |
| Siegel, B et al. 2012 [54] | A Quality Improvement Framework for Equity in Cardiovascular Care: Results of a National Collaborative | General | ✓ | ✓ | ||
| Smith L et al., 2017 [55] | Comparison of ethnic group classification using naming analysis and routinely collected data: application to cancer incidence trends in children and young people | Ethnicity | ✓ | |||
| Smylie, J and Firestone M 2015 [56] | Back to the basics: Identifying and addressing underlying challenges in achieving high quality and relevant health statistics for indigenous populations in Canada | Ethnicity | ✓ | |||
| Tan-McGrory, A et al. 2018 [57] | A patient and family data domain collection framework for identifying disparities in pediatrics: Results from the pediatric health equity collaborative | General | ✓ | ✓ | ||
| Thorlby R et al. 2011 [58] | How Health Care Organizations Are Using Data on Patients’ Race and Ethnicity to Improve Quality of Care | Ethnicity | ✓ | ✓ | ✓ | ✓ |
| Wang KR et al. 2020 [59] | Information Loss in Harmonizing Granular Race and Ethnicity Data: Descriptive Study of Standards | Ethnicity | ✓ | ✓ | ||
| Webster P and Sampangi S, 2014 [60] | Did We Have an Impact? Changes in Racial and Ethnic Composition of Patient Populations Following Implementation of a Pilot Program | Ethnicity | ✓ | ✓ | ✓ | |
| Wei-Chen, L et al. 2016 [61] | Improving the Collection of Race, Ethnicity, and Language Data to Reduce Healthcare Disparities: A Case Study from an Academic Medical Center | General | ✓ | ✓ | ||
| Wolff, M et al. 2017 [62] | Measuring Sexual Orientation: A Review and Critique of US Data Collection Efforts and Implications for Health Policy | Gender | ✓ | ✓ | ✓ | ✓ |
| Zhang XZ et al. 2019 [63] | Role of Health Information Technology in Addressing Health Disparities Patient, Clinician, and System Perspectives | General | ✓ | ✓ | ✓ | |
| Hutt P and Gilmour S 2010 [64] | Tackling inequalities in general practice | General | ✓ | ✓ | ||
| Scottish Government 2020 [65] | Improving data and evidence on ethnic inequalities in health: Initial advice and recommendations from the expert reference group on ethnicity and COVID-19 | Ethnicity | ✓ | ✓ | ✓ | ✓ |
| NHS England, 2020 [66] | Advancing mental health equalities strategy | General | ✓ | ✓ | ||
| NHS, 2019 [67] | NHS Mental Health Implementation Plan 2019/20–2023/24 | General | ✓ | ✓ | ||
| NHS Race and Health Observatory, 2021 [68] | Ethnic health inequalities and the NHS: Driving progress in a changing system | Ethnicity | ✓ | ✓ | ✓ | |
| Scobie S, Spencer J and Raleigh V, 2021 [4] | Ethnicity coding in English health service datasets | Ethnicity | ✓ | ✓ | ✓ | ✓ |
| NHS England, 2019 [69] | Improving identification of people with a learning disability: guidance for general practice | Learning disability | ✓ | ✓ | ||
| National Services Scotland, 2017 [70] | Measuring use of health services by equality group | General | ✓ | ✓ | ✓ | |
| Total citations | 57 | 26 | 28 | 43 | 27 |
| Theme | Point in the Data Pathway | Actions |
|---|---|---|
| Distal factors | Upstream of data collection and analysis | Mandating data collection |
| Legal safeguards to ensure nondiscrimination | ||
| Legislation incentivising data collection | ||
| Prioritisation in policy | ||
| Wider actions to enable improvements in data collection | Preparing for data collection | Achieving senior-level buy-in in organisations involved in data collection |
| Engagement activities with citizens, patients, and communities | ||
| Staff training programmes on purpose and mechanisms for data collection | ||
| Developing guidance on how data can be used | ||
| Demonstration of the value of data collection and analysis for organisations | ||
| Data collection instruments, systems, and standardisation | Data collection | Using multidisciplinary groups to inform data collection instruments, systems, and standardisation |
| Creating standardised definitions and coding practices across organisations | ||
| Improving granularity of data fields | ||
| Developing standardised processes for collecting and recording data | ||
| Developing audit processes to monitor data quality aspects | ||
| Creating IT systems to facilitate data collection | ||
| Periodic revision of definitions and categories | ||
| Methodological approaches to improve data quality and accuracy | Data analysis | Linking with other data sources |
| Use of proxy variables | ||
| Imputation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moorthie, S.; Peacey, V.; Evans, S.; Phillips, V.; Roman-Urrestarazu, A.; Brayne, C.; Lafortune, L. A Scoping Review of Approaches to Improving Quality of Data Relating to Health Inequalities. Int. J. Environ. Res. Public Health 2022, 19, 15874. https://doi.org/10.3390/ijerph192315874
Moorthie S, Peacey V, Evans S, Phillips V, Roman-Urrestarazu A, Brayne C, Lafortune L. A Scoping Review of Approaches to Improving Quality of Data Relating to Health Inequalities. International Journal of Environmental Research and Public Health. 2022; 19(23):15874. https://doi.org/10.3390/ijerph192315874
Chicago/Turabian StyleMoorthie, Sowmiya, Vicki Peacey, Sian Evans, Veronica Phillips, Andres Roman-Urrestarazu, Carol Brayne, and Louise Lafortune. 2022. "A Scoping Review of Approaches to Improving Quality of Data Relating to Health Inequalities" International Journal of Environmental Research and Public Health 19, no. 23: 15874. https://doi.org/10.3390/ijerph192315874
APA StyleMoorthie, S., Peacey, V., Evans, S., Phillips, V., Roman-Urrestarazu, A., Brayne, C., & Lafortune, L. (2022). A Scoping Review of Approaches to Improving Quality of Data Relating to Health Inequalities. International Journal of Environmental Research and Public Health, 19(23), 15874. https://doi.org/10.3390/ijerph192315874