Abstract
Background: For improving health literacy (HL) by national and international public health policy, measuring population HL by a comprehensive instrument is needed. A short instrument, the HLS19-Q12 based on the HLS-EU-Q47, was developed, translated, applied, and validated in 17 countries in the WHO European Region. Methods: For factorial validity/dimensionality, Cronbach alphas, confirmatory factor analysis (CFA), Rasch model (RM), and Partial Credit Model (PCM) were used. For discriminant validity, correlation analysis, and for concurrent predictive validity, linear regression analysis were carried out. Results: The Cronbach alpha coefficients are above 0.7. The fit indices for the single-factor CFAs indicate a good model fit. Some items show differential item functioning in certain country data sets. The regression analyses demonstrate an association of the HLS19-Q12 score with social determinants and selected consequences of HL. The HLS19-Q12 score correlates sufficiently highly (r ≥ 0.897) with the equivalent score for the HLS19-Q47 long form. Conclusions: The HLS19-Q12, based on a comprehensive understanding of HL, shows acceptable psychometric and validity characteristics for different languages, country contexts, and methods of data collection, and is suitable for measuring HL in general, national, adult populations. There are also indications for further improvement of the instrument.
1. Introduction
International and national policy documents and studies have highlighted the relevance of comprehensive, general health literacy (HL) in general adult populations and recommended measuring and improving it, both by investing in research and by implementing HL policies based on the study results [1,2]. In Europe, the results of the HLS-EU study [3,4] were a driving force for HL agenda setting. The HLS-EU study was conducted from 2009 to 2012 in eight European countries supported by the European Commission. The results demonstrated the relevance of comprehensive, general HL for adult populations concerning public health and health policy. Therefore, the WHO’s report “Health Literacy: The solid facts” [1], which used the theory-based HLS-EU definition of HL and the results of the study, recommend regular, standardized measurement of HL in the general population. Following up on this recommendation, the WHO founded the Action Network on Measuring Population and Organizational Health Literacy (M-POHL) [5,6,7] in 2018, to support the availability of high-quality internationally comparative data on population and organizational HL.
After first publications of the HLS-EU study [3,4,8,9], many countries in Europe and Asia conducted surveys on national population HL, using the HLS-EU study design, partly extending its methodology by including additional instruments and variables as well as more complex analyses of data [10,11]. Since there was little coordination between these studies and their findings were published in individual reports or articles, it was difficult to compare results across countries and the HLS-EU methodology was not developed further in a consensual manner. Therefore, M-POHL considered it important to conduct a multinational standardized study, the Health Literacy Population Survey 2019–2021 (HLS19) [12], and by that, to establish a network for regular follow-up surveys. An International Coordination Center was established to provide a study protocol and enable international coordination. In each of the 17 participating countries in the WHO European Region, a National Study Center (NSC) was contracted to conduct the HLS19 project: Austria (AT), Belgium (BE), Bulgaria (BG), Czech Republic (CZ), Denmark (DK), France (FR), Germany (DE), Hungary (HU), Ireland (IE), Israel (IL), Italy (IT), Norway (NO), Portugal (PT), Russian Federation (RU), Slovakia (SK), Slovenia (SI), and Switzerland (CH) [12].
The HLS19 built on the conceptual framework and definition of comprehensive, general HL developed in the HLS-EU study and its theory-based measurement instruments, the HLS-EU-Q47, the HLS-EU-Q16, the HLS-EU-Q12 and HLS-EU-Q6. HL was defined as “…people’s knowledge, motivation, and competencies to access, understand, appraise and apply information to form judgments and take decisions in terms of healthcare, disease prevention and health promotion to improve quality of life during the life course” [8]. With its definition and concept, the HLS-EU study acknowledged a public health perspective of HL by focusing not only on the patient’s participation in health care but also on people’s prevention and health promotion activities. HL was considered a multidimensional/multifaceted concept [8], which can be illustrated by a 12-cell matrix with four aspects of dealing with health-related information in three domains of health-related tasks (Table 1). The HLS-EU measurement instrument HLS-EU-Q12 operationalized this concept by selecting or creating items for each cell of this 12-cell matrix. By using the self-reported, experienced difficulty of each task as the measurement dimension, the items of the HLS-EU instrument reflect the relational interpretation of HL [3], since the experienced difficulty of a task depends on personal competency as well as on situational demands and resources of the context in which the task is performed.

Table 1.
Matrix of subdimensions of HL based on the HLS-EU Conceptual Model [8] used for developing the HLS19 instruments.
In the years following HLS-EU, work on the internal differentiation of the comprehensive, general concept and definition of HL and corresponding measurement instruments was continued. It was considered important to follow this trend of differentiation in the HLS19 study and to develop and use additional, specific concepts and instruments to measure selected relevant aspects of the comprehensive concept of HL in general adult populations with similar operationalization of their items. Thus, in HLS19, the intention was once again to measure general, comprehensive population HL in all participating countries at least by the short form HLS19-Q12 but also four specific HL areas as optional packages: (1) digital HL (8 items), (2) communicative HL (with physicians in health care services; long form with 11 items, short form with 6 items), (3) navigational HL (12 items), and (4) vaccination HL (4 items), which are used for validating discriminant validity of HLS19-Q12 in this article and are presented in detail in respective chapters of the International Report [12]. The HLS19-Q12 builds on the HLS-EU-Q12 but follows the adaptions in wording of response categories and of selected items of measuring comprehensive, general HL in HLS19.
The aim of this paper is to examine four research questions concerning HLS19-Q12 by using survey data from 17 participating countries of HLS19:
- What is the impact of using dichotomous versus polytomous scoring of HLS19-Q12 on its psychometric properties?
- What are the factorial validity and dimensionality of the two scoring versions of HLS19-Q12?
- How well does HLS19-Q12 fulfil aspects, respectively, of content and face validity and of construct validity measured as discriminant validity and concurrent predictive validity?
- Since HLS19-Q12 is offered as a short form of HLS19-Q47, how well do the two scoring versions of the short form represent the long form?
- These research questions will be answered partly by using analyses of dichotomous scored data of different chapters of the HLS19 International Report [12] and by new additional analyses using polytomous scored data.
2. Materials and Methods
2.1. Development of the Instrument for Measuring Comprehensive, General HL in HLS19
2.1.1. Development of Its Predecessor, the HLS-EU-Q12
The HLS-EU-Q12 is the short form of the HLS-EU-Q47. Following the original HLS-EU study, HLS-EU-Q47 was used in many follow-up studies for the general population (including all provinces in DE [13,14]), but also for patients, adolescents and students, elderly migrants and asylum seekers, and some other specific subpopulations. Due to the length of HLS-EU-Q47, with 47 items, taking about ten minutes to apply in a personal interview, a demand for shorter forms of the instrument arose. Therefore, the HLS-EU-Q16 was developed based on the data of the 8 original HLS-EU countries [10,11,15,16,17] and further validated for two additional studies in CZ and HU [10], an Austrian study of adolescents [10,18] and an Austrian study on two groups of migrants [10,19,20]. Later studies validating or applying the instruments in further languages were published: in Swedish and Arabic [21], in Somali [22], in Arabi, Dari, and Somali [23], in Italian [24,25], in Indonesian [26], in Austrian German [27], in French [28,29], in Turkish [30], in Japanese [31], in Islandic [32], in Romanian [33], and in an adapted Q18 version in Malaysian [34].
Besides the advantage of being short, though, there are also certain disadvantages of HLS-EU-Q16 (and the HLS-EU-Q6), especially not fulfilling the 12 elements of the underlying theoretical matrix properly. The aim was to develop a shorter version as a subset of the Q47, including as many items of the Q47 as possible, to fulfil the HLS-EU matrix using dichotomous Rasch analyses [35]. That succeeded for 16 items, with the problem of overrepresenting certain cells of the matrix and finding no fitting item for one cell. Furthermore, there was a loss of information by dichotomization of categories and therefore just three instead of four HL levels could be constructed for the scale. Since 16 items were still considered too long for certain research purposes, also a shorter scale, the HLS-EU-Q6, was developed using confirmatory factor analysis (CFA) and was later also validated in the French language [28]. This version represents the matrix of comprehensive, general HL even less well.
Later, independently of the HLS-EU consortium, but using their translated instruments an Asian short form, a 12-item instrument was developed using Taiwanese data [36] and validated for more Asian countries as the HL-SF12 [37] and for people living in rural areas in Vietnam [38]. In addition, a Norwegian HLS-Q12 version was developed and validated [39].
These Q12 short forms differ concerning the methodology used (CFA or Item Response Theory (IRT) modelling), based on data from one country or more countries of different quality and sample size, and the degree of fulfilment of the underlying theoretical model and matrix of comprehensive, general HL.
Therefore, it was decided for HLS19 to develop a new short form based on the HLS-EU-Q12 using the original HLS-EU data, with just one indicator in each cell using IRT (Hambleton & Swaminathan, 1985) analyses [40]. Learning from the HLS-EU-Q16 instrument and the later developed short forms (the Norwegian HLS-Q12 and the Taiwanese HL-SF12), a 12-item instrument was developed. On the basis of data from the eight HLS-EU countries, IRT analyses were conducted to achieve maximum overlap with the HLS-EU-Q16 and to identify a 12-item set with the lowest deviance from the assumptions of the Partial Credit Model (PCM; [41]) when analyzed separately for each of the original HLS-EU-countries and two further countries [40]: AT, BG, DE (North Rhine-Westphalia), Greece (GR), IE, Netherlands (NL), Poland (PL), and Spain (ES) (from the HLS-EU study) as well as data from HU and the CZ. It was considered important that just one item represents each cell of the HLS-EU matrix and that items form a locally independent scale (unidimensional and having no response dependency) with an acceptable data-model fit when using the PCM [40]. As such, the 12-item set is not only slightly shorter than the HLS-EU-Q16 but also better represents the underlying model and definition of the HLS-EU instruments.
2.1.2. Adaptation of the HLS-EU-Q12 to the HLS19-Q12
Changes in the wording of response categories and selected items were performed for the total HLS19-Q47, and by that, also for its related short forms. The original qualifier “fairly” from the 4-point rating scale was removed from the response categories, as it was considered prone to creating differences in translations and interpretations across languages and countries. Item revisions involved both rewording as well as adding or removing examples from individual items. Out of the 12 items of the HLS19-Q12, 11 were modified. Criteria for revising the wording of items included: wording which was too complex or difficult to understand (based on expert views and qualitative studies) [39,42,43], the harmonization of similar terms across items (e.g., health and well-being, examples of types of media), indications of difficulties based on quantitative aspects such as high non-response proportions in the HLS-EU, response dependency, item fit (under-discriminating items, differential item functioning (DIF)) of certain items used in other short forms of the HLS-EU-Q47 [39,44,45], and items that do not clearly relate to the use of health-related information. Criteria for removing or adding examples were the use of gender-neutral examples (e.g., removing breast exam), adaptation to societal changes in lifestyle and health-related or medical practices.
The modified instrument was first tested in a focus group study in RU in August 2019 and then field-tested in DE in November 2019. The results of the German field-test were considered for the final English version of the HLS19-Q47 and thereby its short form, the HLS19-Q12.
2.1.3. Translation Process and Field Testing
The HLS19-Q12 instrument was translated by 16 out of the 17 countries (IE used the original English version) into their national language(s). Each NSC organized the translation process. This was mostly done by the data collection agencies and/or other professional translation services. Two forward translations were implemented by ten countries (AT, BE (Dutch translation), CH (German translation), DE, DK, HU, IT, NO, SI, and SK). One forward translation was chosen by countries that cooperated with other countries using the same language (BE for the French translation, CH for the French and Italian translations). Back translation was performed by four countries (IL, NO, RU, and SI). The different translations and, if applicable, additional quality assurance methods for the translated instruments were agreed upon by the HLS19 NSCs in the participating countries. All countries, except BG, performed a field test.
2.2. Data Collection
From November 2019 until June 2021, the instrument was tested as part of population-based surveys in 17 countries participating in HLS19 (Table 2). Countries could choose between collecting data on just the 12 items of the HLS19-Q12 or a set of 22 items, which also allows one to calculate the HLS19-Q16 short version or the full batterie of the HLS19-Q47. Data collection was carried out guided by the HLS19 study protocol in the participating countries by national data collection agencies with three exceptions (BG, DK, and SK), where data collection was carried out by the HLS19 NSCs. Due to the SARS-CoV-2 pandemic, the surveys vary with respect to data collection method. Telephone-based (CATI), web-based (CAWI), self-administered (SAQ), or face-to-face interviews (PAPI/CAPI) were used. Some countries that had originally planned to use face-to-face interviews switched to CATI or CAWI interviews for pragmatic reasons. Few countries used different survey methods for different sub-populations depending on their accessibility by different data collection methods. Data were collected based on multi-stage random sampling or quota sampling procedures in most countries (Table 2). The data sets were submitted to the HLS19 International Coordination Center for data control and creating an English language international data template file for further analysis. Post-stratification weights were applied to improve the estimation of population parameters. For most data sets, the weights were calculated by the HLS19 NSCs to best fit the sampling procedure [12].
Table 2.
Main characteristics of the national HLS19 surveys.
Since the surveys differed regarding sampling, data collection, language, length of interview, and location of the HL item set in the questionnaire, most analyses were done by the International Coordination Center by country. In some analyses, a reference value (e.g., a mean across all countries weighted equally) is given to facilitate interpretation.
In the HLS19 questionnaires, HLS19-Q12 was introduced with the following statement: “It is not always easy to get understandable, reliable, and useful information on health-related topics. With the following questions we would like to find out which tasks related to handling health information are more or less easy or difficult. On a scale from very easy to very difficult, how easy would you say it is …” This statement was followed by a set of 12 items:
- 6.
- … to find out where to get professional help when you are ill? (Instructions: such as doctor, nurse, pharmacist, psychologist)
- 7.
- … to understand information about what to do in a medical emergency?
- 8.
- … to judge the advantages and disadvantages of different treatment options?
- 9.
- … to act on advice from your doctor or pharmacist?
- 10.
- … to find information on how to handle mental health problems? (Instruction: stress, depression or anxiety)
- 11.
- … to understand information about recommended health screenings or examinations?
- 12.
- … to judge if information on unhealthy habits, such as smoking, low physical activity or drinking too much alcohol, are reliable?
- 13.
- … to decide how you can protect yourself from illness using information from the mass media? (Instructions: e.g., Newspapers, TV or Internet)
- 14.
- … to find information on healthy lifestyles such as physical exercise, healthy food or nutrition?
- 15.
- … to understand advice concerning your health from family or friends?
- 16.
- … to judge how your housing conditions may affect your health and well-being?
- 17.
- … to make decisions to improve your health and well-being?”
Respondents were asked to choose from one of four response categories: 4 “Very easy”, 3 “Easy”, 2 “Difficult”, 1 “Very difficult”.
2.3. Analyses concerning Dimensionality of the Score
2.3.1. Items, Score, and CFA
General data management and the calculation of the score was done in SPSS 27 [46]. Statistical analyses, were conducted using R [47].
The average difficulty (categories “difficult” + “very difficult” combined) for each item by country was visualized as a line chart.
The internal consistency of the scale was measured by the Cronbach’s alpha and the ordinal alpha coefficient. Cronbach’s alpha can be interpreted as lower bound of the true internal consistency [48]. In the literature, a minimum value of 0.7 is recommended [49]. The ordinal alpha based on tetrachoric (for dichotomized items) or polychoric correlation coefficients (for polytomous items can be interpreted as measures for the internal consistence of an item set if they were measured as continuous variables [50,51,52]. The Cronbach’s alpha and the ordinal alpha coefficients were calculated using the psych package in R [53].
Single-factor CFA were conducted as a first check whether the data fits the assumption of a unidimensional one-factor model so that a single score as a measure of general HL can be calculated. This is relevant because of the multifaceted conceptualization of the original HLS19-Q47 long form. In addition, the CFAs are expected to test if similar results for the dichotomized and polytomous item sets can be shown. For each country, the following fit indices are given: Standardized Root Mean Square Residual (SRMSR), Root Mean Square Error of Approximation (RMSEA), Comparative Fit Index (CTI), and Tucker–Lewis Index (TLI). The following target values are assumed as indications of a good data model fit [54]:
- Standardized Root Mean Square Residual (SRMSR) ≤ 0.08
- Root Mean Square Error of Approximation (RMSEA) ≤ 0.06
- Tucker-Lewis Index (TLI) ≥ 0.95
- Comparative Fit Index (CFI) ≥ 0.95
The CFA was conducted using the lavaan package [55] for R [47]. A weighted least square mean and variance adjusted (WLSMV) estimator with diagonally weighted least squares (DWLS) for model parameters is used [49,56,57].
2.3.2. IRT Analyses
For developing the HLS-EU-Q12, as a short form of the HLS-EU-Q47, the Rasch Model (RM) and PCM were used to select the items to be included into the short form (see above). The HLS-EU-Q12 showed fulfilment of Rasch criteria to a certain degree [58]. Therefore, it is of interest to test if the somewhat adapted HLS19-Q12, when used in 17 languages and 17 countries, also fulfils Rasch criteria. Knowing this also helps in interpreting the differences found in benchmarking between selected countries. Furthermore, results of RM will identify potentials for further improvement of the instrument in a next round of measuring HL by M-POHL. For these reasons, RM and PCM of HLS19-Q12 [58,59] were included in the International Report of HLS19 and this article.
The dichotomous RM [35] and its generalization to polytomous items, the PCM [41], possess some favorable properties, namely, sufficiency of raw scores and item marginals as well as specific objectivity (independence of comparisons of persons from the set of items used and vice versa). These properties are not shared by IRT models that do not belong to the family of RMs [60]. Therefore, the data model fit was tested both against the PCM and the RM. For the latter analyses, the answer categories “very easy” and “easy” as well as “very difficult” and “difficult” were merged.
IRT analyses are based on data collected between November 2019 and February 2021 in 15 HLS19 participating countries (Table 2). Due to very large sample sizes in some countries (e.g., RU and IE), all analyses were conducted also in a random sample of n = 900 for each of the countries, and PCM analyses on item level were additionally also conducted in four randomly chosen independent subsamples in each of the countries (therefore, the sample sizes in the four subsamples varied according to the total sample sizes in the individual countries between n = 230 and n = 1188). Due to the huge number of significance tests, α = 0.001 was chosen for the individual tests. Analyses were conducted in R using the packages eRm 1.0–1 [61], TAM 3.5–19 [62] and mirt 1.33.2 [63]. For those countries, in which different data collection methods were applied (see Table 2), analyses were conducted on the country level and per data-collection method. This is done only for the IRT analyses to check whether items work slightly differently according to the data-collection method.
Analyses of the overall data-model fit for the PCM included calculation of WLE reliability (Warm’s weighted likelihood estimate) and EAP (expected a posteriori) reliability coefficients [62,64] and calculation of the SRMSR, [65], a global fit statistic based on the comparison of residual correlations of item pairs. Under the assumption of unidimensionality, person parameter estimates from a priori defined subsets of items should not differ significantly [60]. Thus, we applied a procedure of combined principal component analysis (PCA) of residuals and paired t-tests [66,67]. Based on PCA of standardized item residuals, we formed two item subsets according to the loadings of the item residuals on the first principal component [66]. Person parameters were estimated in each of the two item subsets and the resulting parameter estimates from the two subsets were compared using paired t-tests [66]. Under the assumption of unidimensionality, the proportion of individuals with significantly different person parameters in the two item subsets is small, i.e., ≤5% of the t-tests are significant, or the lower bound of a 95% confidence interval (CI) of the observed proportion overlaps 5% [66]. In our analysis, the Agresti–Coull CI was used [68]. We assessed local stochastic independence by means of an adjusted variant of Yen’s Q3 statistic [69] for all item pairs, aQ3, and an effect size of model fit (MADaQ3), which is the average of the absolute values of aQ3 statistics, and p-values adjusted according to the Holm procedure [62]. Analyses at item level furthermore included assessing item fit, ordering of response categories and DIF. Item infit statistics and corresponding t-statistics were calculated for the individual items. The expected value of the infit statistic is 1; values > 1 indicate that the item is less predictable than what would be expected according to the IRT model (underfit), values < 1 mean that the item is more predictable than what would be expected according to the expectations of the IRT model (=overfit; [70]). Underfitting items may severely degrade the measurement, whereas overfitting items may overestimate raw score differences [71]. Wright and Linacre [72] suggest that items with infit statistics <0.8 and >1.2 should be eliminated in the construction of a new questionnaire. Smith, Rush, Fallowfield, Velikova, and Sharpe [71] showed that the infit statistic is relatively independent of sample size and there are neglectable differences in the identification of misfit between the cut-off values of 1.2 and 1.3. A central requirement of IRT models is that the item should work invariantly across levels of different person factors, such as gender, education, and health status. We conducted DIF analyses using gender and the dichotomized criteria age (median split) and education (< higher education entrance qualification vs. at least higher education entrance qualification). We conducted a facets analysis in which we set up the criteria as facets (e.g., for gender, item + gender + item × gender) and reran the IRT analysis [62]. The interaction term item*gender yields the DIF magnitude. Furthermore, we applied the Nominal Categories Model to check whether the expected ordering of response categories were supported by the data [73].
For the dichotomous scoring, we conducted Conditional Likelihood-Ratio-Tests (LR-tests; [74]) as global model tests (which simultaneously assess all items regarding DIF) using median test score, education (<higher education entrance qualification vs. at least higher education entrance qualification), median age, and gender as split criteria. A necessary and sufficient condition for a unique solution of the conditional maximum likelihood estimates of the item parameters is well-conditioned data [75]. This means that in every possible partition of the items into two non-empty item subsets at least one person has chosen the answer category 1 on one item in the first subset and answer category 0 on one item in the other subset. Additionally, we calculated individual item-fit statistics (z-statistics [76]), and applied graphical model tests according to Rasch [35], Rasch [77], to examine which items are the source for possible misfit. Furthermore, a global test for local independence, which calculates the sum of absolute deviations between the observed inter-item correlations and the expected correlations [78], was conducted. At the item level, increased correlations between inter-item residuals were checked by means of the Q3-statistic [61]. Additionally, item characteristic curve (ICC) plots were used to graphically inspect model fit of the individual items. The ICC plots show how the probability for response category 1 expected by the RM changes with the values of the latent variable. If the deviations of the observed values from the expected values are small, there is close conformity of the data with the model.
2.4. Calculation of Aggregate Measures
2.4.1. Calculation of an Overall Score
The raw score can be calculated as a summary measure of the 12 items in two ways, referred to as type D and type P scores:
- Type D. The score is calculated as the percentage (ranging from 0 to 100) of items with valid responses that were answered with “very easy” or “easy” (i.e., the items were implicitly dichotomized).
- Type P. The score is calculated as the sum of the item’s numeric values (1 = “very difficult”, 2 = “difficult”, 3 = “easy”, 4 = “very easy”) scaled to a range from 0 to 100.
In either case, the score is calculated only if at least 80% of the items contain valid responses. Otherwise, the score is set to missing.
A score similar to the type D score was already used for the original HLS-EU-Q16 score [18]. The implicit dichotomization has the advantage that it attenuates inequalities due to different extreme response preferences in various subpopulations, which could be beneficial, e.g., for inner national and international comparisons. Under certain conditions, it could also be easier to communicate the meaning of such a score, as it is the mean percentage of items which respondents assessed as “easy” or “very easy”. The disadvantage of the type D score is information loss due to the implicit dichotomization.
A type P score (a sum score scaled to the range of 0 to 50) was already used for the HLS-EU-Q47 score [3].
Higher score values signify a higher level of general HL. A value of 0 denotes the lowest possible and a value of 100 the highest possible level of general HL.
We describe the distributions of these two types of scores by mean, standard deviation, and its quartiles. In addition, density plots by countries are displayed.
2.4.2. Calculation of Levels
Discrete levels of HL that identify respondents with “limited” HL are important in the communication of the results of HL surveys, e.g., Baccolini et al. [79]. We use the following procedures to distinguish between “excellent”, “sufficient”, “problematic”, and “inadequate” levels of general HL. These names for the categorial levels were already used for HLS-EU-Q47.
For the type D score, that is based on the dichotomized items, we propose a procedure that closely reproduces the distribution of the levels based on the type P score but is not derived solely from the score value but also from the percentages of how often certain response categories were selected. For this reason, it is theoretically possible that two respondents with the same type D score value are assigned to different levels of HL. For reasons of comparability and easier comprehensibility, the category labels of the HLS-EU study were retained. These normative labels are defined in a transparent way following a simple ruleset, namely, that these labels should be easy to understand and suggest an intuitive ranking of lower or higher levels of HL. The level of “inadequate”, for example, should be used to describe people for whom most of the tasks included in the HLS19-Q12 were “difficult” or “very difficult”, with one task at the most being “very easy”.
The following definitions of cut-off points (as percentages) for the categorial levels of the HLS19-Q12 were used (as far as possible based on the HLS-EU study):
- Excellent: “very easy” ≥ 50 AND “very difficult” + “difficult” < 8.334For “excellent”, the number of answers with “very easy” should be above 1/2 and the answers for “very difficult” + “difficult” should be no more than 1/12.
- Sufficient: “very easy” + “easy” > 83.33For a level of “sufficient” HL, at least 10 out of the 12 items should be answered with “very easy” or “easy” and not more than 2 out of 12 with “very difficult” or “difficult”.
- Problematic: all respondents who are not in the groups “excellent”, “sufficient”, or “inadequate” (i.e., once the three other categories have been calculated)The level of “problematic” is the intersecting set of not “excellent”, not “sufficient” and not “inadequate”.
- Inadequate: “very easy” < 8.334, “very difficult” AND “difficult” ≥ 50For “inadequate”, the number of answers with “very difficult” + “difficult” should be above 1/2 and for “very easy” should be no more than 1/12.
For the type P score, we follow the procedure established in the HLS-EU study [3], but adapt it to the range of the score from 0 to 100:
- Excellent: > 83.33 (i.e., 10/12 to (incl.) 12/12)
- Sufficient: > 66.67 and ≤ 83.33 (i.e., 8/12 to (incl.) 10/12)
- Problematic: > 50 and ≤ 66.67 (i.e., 6/12 to (incl.) 8/12)
- Inadequate: ≤ 50 (i.e., 0 to (incl.) 6/12)
As in the HLS-EU study, the union of problematic and inadequate levels of general HL is defined as “limited” HL.
2.5. Validity
Content, respectively, face validity is judged by evaluating the procedure of selecting indicators for the measurement instrument.
For measuring discriminant validity, we calculate the weighted Pearson correlation coefficients between the HLS19-Q12 score and the scores of special health literacies also being developed and applied in the HLS19 study: digital HL, communicative HL (with physicians in health care services), navigational HL, and vaccination HL. The correlation coefficients of the scores for special health literacies and the HLS19-Q12 score should be high enough (e.g., r > 0.4) to assume they all measure aspects of HL. Yet, since scores for special health literacies are supposed to measure different constructs, they should not be too high to measure somewhat different constructs. One application of using multiple scores for different aspects of HL, is their use within regression models. In regression analysis, a pairwise correlation coefficient of |r| > 0.7 is often suggested as a rule-of-thumb threshold for collinearity [80]. To use the various scores in regression models, the pairwise Pearson correlation is thus aimed to be in the range of 0.4 to 0.7.
To test concurrent predictive validity of the score, we follow the HLS-EU study [3] concerning determinants of HL that there should be a social gradient of HL in computing simple linear regression models with the general HL score as the outcome variable and gender, age, education, self-perceived social status in society, and financial deprivation as predictor variables. As far as consequences of HL are concerned, there are analyses in the HLS19 International Report [12] on health behavior, health status, and health care utilization with respect to the dichotomous score. Regarding the polytomous score, we just present in this article the example of simple linear regression models with self-perceived health as the outcome variable and general HL, gender, age, education, self-perceived social status in society, and financial deprivation as predictor variables.
Following the approach of the HLS-EU study [3], the predictors were entered as numeric variables into the regression model. We show the unstandardized b coefficients and the standardized β coefficients as a proxy for relative importance. R2, as proportion of the variance in the outcome variable being explained by the predictor variables, is used as a measure for goodness of fit. Following the analyses in the HLS-EU report [3], we focus on the β coefficients. The regression models serve two purposes: (1) Does the general HL score vary with socio-demographic variables, respectively, with self-perceived health in a way comparable to previous studies like HLS-EU? For this reason, we follow the statistical approaches adopted in the HLS-EU study. It should be noted that it is not the goal of this paper to find the best model with HLS19-Q12 as outcome variable or as predictor of other outcome variables, but to compare behavior of the variables in comparison with previous research. (2) Do type D and type P scores yield comparable results? The linear models were computed using the R survey package [81].
2.6. Extent of Representation of Long form HLS19-Q47
Six countries (BG, DE, IE, IT, NO, and SI) participating in HLS19 used the HLS19-Q47 long-form that contains the items of the HLS19-Q12 short form. In order to examine whether the HLS19-Q12 is a useable approximation of the HLS19-Q47 long form and its subdimensions, we show the weighted Pearson correlation coefficients for the score values for general HL and its conceptual subdimensions [3,8]: (1) Health Care, (2) Disease Prevention, (3) Health Promotion, (4) Access/obtain information relevant for health, (5) Understand information relevant for health, (6) Appraise/judge/evaluate information relevant for health, (7) Apply/use information relevant for health.
3. Results
3.1. Psychometric Properties
3.1.1. Average Difficulty of the Items
The overall percentage of participants responding “very difficult” or “difficult” varies between 8.1% and 43.0% for the HLS19-Q12 items with item 4 (“to act on advice from your doctor or pharmacist”) being the easiest item and item 3 (“to judge the advantages and disadvantages of different treatment options”) being the most difficult. In general, the items in the HLS19-Q12 were not rated as predominantly “very difficult” or “difficult”, with the sole exception of DE, where the items 3, 8, and 5 were reported as “very difficult” or “difficult” by 56.1% to 71.2% of the respondents, probably due to somewhat different modes of data collection.
The item difficulties vary by country. The combined percentage of “very difficult” and “difficult” responses ranges from 25.6% (SI) to 71.2% (DE) for the most challenging item 3 (“to judge the advantages and disadvantages of different treatment options”), and from 3.4% (PT) to 17.2% (CZ and SK) for the least difficult item 4 (“to act on advice from your doctor or pharmacist”). Nevertheless, there is a more or less common ranking by difficulty of the tasks across countries (Figure 1).
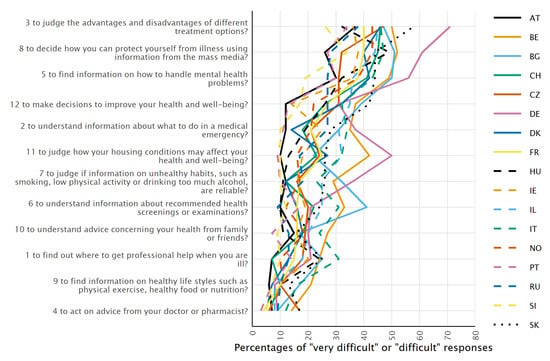
Figure 1.
Percentages of respondents who responded with “very difficult” or “difficult” to the HLS19-Q12 items (ordered by the overall mean), for each country.
3.1.2. Non-IRT Analyses
Internal Consistency
For the dichotomized items, the values of the Cronbach’s alpha coefficients range from 0.67 (AT) to 0.87 (PT). Except for AT, the values are above the recommended target value of 0.7 (Table 3) [49]. The internal consistency, thus, is acceptable for most countries.
Table 3.
Cronbach’s alpha and ordinal alpha for the HLS19-Q12 (polytomous and dichotomized items) for each country, and the mean for all countries (equally weighted).
The Cronbach’s alpha coefficient is expected to be lower for dichotomized items than for the original polytomous items. For the polytomous items (4-point rating scale), the values range from 0.8 (DE) to 0.9 (PT, RU).
The values of the ordinal alpha vary by country from 0.84 to 0.94 for both the dichotomized and the polytomous items.
Single Factor Confirmatory Factor Analyses
For the dichotomized items, all fit indices (Table 3) indicate a good data model fit. It can thus be concluded that the single factor confirmatory model accounts sufficiently well for the correlation patterns among the HLS19-Q12 items.
The items for which the standardized parameter estimates (Supplementary Materials: Table S1) differ the most across countries are (range ≥ 0.4):
- item 4, “to act on advice from your doctor or pharmacist”,
- item 6, “to understand information about recommended health screenings or examinations”,
- item 9, “to find information on healthy lifestyles such as physical exercise, healthy food, or nutrition”,
- item 10, “to understand advice concerning your health from family or friends”.
As these are also among the easiest items (Figure 1), this could cause these discrepancies in the loadings since even small deviances may cause a relatively greater shift.
For the polytomous items (4-point rating scale), the fit indices give a largely similar picture (Supplementary Materials: Table S2), though for some country data, the RMSEA is above the recommended threshold value of 0.06 [54]. All other fit indices are still within the target range. The range of the standardized parameter estimates (Table 4) is greater than or equal to 0.4, meaning these items contribute differently to the score in different countries, for the following two items:
Table 4.
Table model fit of the single-factor confirmatory factor analysis for dichotomized and the polytomous items.
- item 6, “to understand information about recommended health screenings or examinations”,
- item 10, “to understand advice concerning your health from family or friends”.
3.1.3. IRT Analyses
Partial Credit Model (PCM) for Polytomous Items
The WLE and EAP reliability coefficients showed acceptable values ≥ 0.79 in all countries (Table 5) and for all data collection methods (Table 6).
Table 5.
WLE and EAP reliability coefficients for the individual countries independent of data collection method.
Table 6.
WLE and EAP reliability coefficients separately for data collection method for respective countries.
According to the PCA/t-test procedure, in all countries except NO, the proportion of individuals with significant different person parameters in two item subsets identified by means of PCA exceeds 5% in the random sample of n = 900, and only for NO, the lower bound of the CI overlaps 5% also in the total sample. For AT, BE, CHCAWI, CZ, DK, DE, FR, IE, IL, RU, and SI, the lower bound of the CI overlaps 10%. For HU, PT, and SK, the lower bound is > 10% both in the total and the random sample (Table 7). The SRMSR statistics are below the cut-off value of 0.08 for good model fit according to [82] in all countries (see Table 8) except for the CATI mode in CH, and for IL also below the more conservative cut-off value of 0.05 [65].
Table 7.
Results of PCA/t-test procedure (proportion of significant t-tests and lower bound of CI) and the SRMSR statistics for the individual countries.
Table 8.
Results of PCA/t-test procedure (proportion of significant t-tests and lower bound of CI) and the SRMSR statistics separately for data collection method for respective countries.
The global test for local independence yielded significant results in all countries both in the total and the random samples. Analyses for the individual item pairs showed that the residuals of four item pairs are significantly correlated in several countries with a residual correlation of r > 0.30 in at least one of the countries (Table 9). One dependent item pair each was observed in the domains healthcare (HC), disease prevention (DP), and health promotion (HP). One dependent item pair was across DP and HP. Nine other item pairs had significant residual correlations r > 0.20 in several countries and further four dependent item pairs were found only for PT.
Table 9.
Dependent item pairs.
Table 10 shows the significant results for the item infit statistics in the total samples. Item 8 (“to decide how you can protect yourself from illness using information from the mass media”) had significant infit statistics (p < 0.001) in several countries with values of the statistic between 1.15 and 1.35. For IE and SI, the value of the infit statistic is above the cut-off of 1.2, which was suggested by Wright and Linacre [72] for item selection in the development of new questionnaires. All other significant infit statistics indicate overfit of the respective items; however, all infit statistics were > 0.8 (for the infit statistics of all items in the total samples of the different countries see Waldherr, Alfers, and Peer [58]).
Table 10.
Significantly underfitting items.
Several items are affected by DIF in more than one country both in the total and the random sample of n = 900 and/or at least one of the four independent subsamples. Item 6 (“to understand information about recommended health screenings or examinations”) displayed DIF for age in BE, DK, FR, SI, and CH. For participants older than the median age, in the respective countries, it is relatively easier to understand information about recommended health screenings. In DK and SI, item 6 additionally showed DIF with respect to educational background. Item 9 (“to find information on healthy lifestyles such as physical exercise, healthy food or nutrition”) displayed DIF regarding educational background in AT, CZ, FR, SI, and SK and for age in CZ and SI. Furthermore, we observed DIF for item 1 (“to find out where to get professional help when you are ill”) for gender in AT, for item 3 (“to judge the advantages and disadvantages of different treatment options”) for education in AT and CHCATI, for item 5 (“to find information on how to handle mental health problems”) for age in IE, for item 8 (“to decide how you can protect yourself from illness using information from the mass media”) for education in AT and SI, for item 10 (“to understand advice concerning your health from family or friends”) for education in DK, and for item 11 (“to judge how your housing conditions may affect your health and well-being”) for age in DK, IE and NO. In DE, HU, IL, PT, and RU, none of the items had a significant z-statistic for the split criteria used [58].
Applying the Nominal Categories Model to check the empirical ordering of the response categories revealed unordered response categories both in the total and the random samples for item 1 (“to find out where to get professional help when you are ill”) in DE, FR, HU, and IE, item 2 (“to understand information about what to do in a medical emergency”) in FR and IE, item 3 (“to judge the advantages and disadvantages of different treatment options”) in IE and NO, item 4 (“to act on advice from your doctor or pharmacist”) in FR and HU, item 5 (“to find information on how to handle mental health problems”) in HU, item 6 in DE, FR, and IE, item 8 (“to decide how you can protect yourself from illness using information from the mass media”) in IE, item 9 (“to find information on healthy lifestyles such as physical exercise, healthy food or nutrition”) in IE, item 10 (“to understand advice concerning your health from family or friends”) in DE, FR, and IE, and item 11 (“to judge how your housing conditions may affect your health and well-being”) in AT and IE. In the Portuguese data, all items had unordered response categories, and in the Irish data, 11 items had unordered response categories. Closer inspection showed that in PT, at least two third of the persons have chosen the answer category “easy” in all items (e.g., for item 10, approximately 84%). On the contrary, the response category “very difficult” was very rarely chosen (by < 1% of persons) in some items in several countries. The frequency distribution for answer category “very difficult“ varies in PT from 0.30% (item 4) to 13.80% (item 2), for “difficult“ from 3.15% (item 4) to 57.31% (item 3), for “easy“ from 25.06% (item 3) to 83.95% (item 10), and for “very easy“ from 3.82% (item 3) to 67.89% (item 4). This could be the reason for the large number of items with unordered response categories, since in the case of low endorsement rates, in some of the categories, the estimation of the parameters of the Nominal Categories Model may be affected such that response categories are tagged as unordered [83]. In IL, RU, SI, and SK, no unordered response categories were observed in the random samples.
Rasch Model
The likelihood ratio (LR)-test with median score as split criterium yielded significant results (p < 0.001) in the random samples of n = 900 in DE and IE. In AT, PT, RU, and SI, this test could not be conducted due to ill-conditioned data. The LR-tests with split criterium median age were significant in BE, CH, DK, FR, NO, PT, and RU. For gender and educational background, no significant LR-tests were observed. The global model tests for local stochastic independence were significant in the random samples of all countries except for AT and CZ [58].
In the random samples of n = 900, item 1 (“to find out where to get professional help when you are ill”) displayed DIF for median score in FR, item 2 (“to understand information about what to do in a medical emergency”) with respect to age in PT, item 3 (“to judge the advantages and disadvantages of different treatment options”) regarding education in AT, item 6 (“to understand information about recommended health screenings or examinations”) for age in BE and CH, item 8 (“to decide how you can protect yourself from illness using information from the mass media”) for age in BE and for median score in IE, item 9 (“to find information on healthy lifestyles such as physical exercise, healthy food or nutrition”) for education in IL and for age in PT, item 10 (“to understand advice concerning your health from family or friends”) for age in CH and for median score in DE, and item 11 for age in IE [58].
Again, item 8 (“to decide how you can protect yourself from illness using information from the mass media”) has significant infit statistics in IE and SI both in the total and the random samples with values between 1.14 and 1.16, respectively. The ICC plot for SI reveals clear deviations of the observed scores from those expected by the model.
3.2. Distribution of the Score Values
The distributions of the type D scores are negatively (left) skewed for all countries, with a considerable ceiling effect (Figure 2), indicating that the selected HL tasks asked are manageable by many respondents. In most countries, the 75% quantile is close or equal to the maximum value of 100 (Table 11). This ceiling effect does not affect the identification of respondents with low levels of HL. Thus, the score is still sensitive for respondents with lower HL. This skewness could pose problems for some statistical analyses. The distribution of the type D score is approximately symmetric only for the German data.
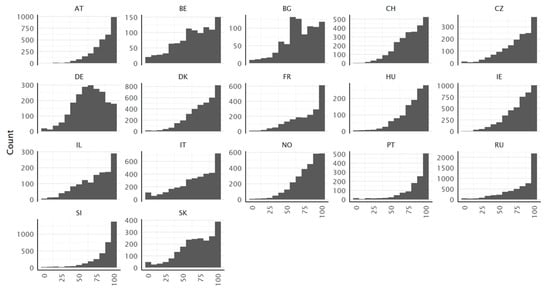
Figure 2.
Histograms of the HLS19-Q12 scores (type D), for all countries.
Table 11.
Descriptive statistics of type D and type P score, for each country and for all countries (equally weighted).
The distributions of the type P scores are approximately symmetrical and almost bell-shaped in most countries (Figure 3). In some countries, the peak of the rather leptokurtic distribution shape is spiky with great excess kurtosis (e.g., PT, RU). In other countries (e.g., AT, FR, IE, IL, NO, or SI), the distribution of the type P score has an unsymmetrical shape.
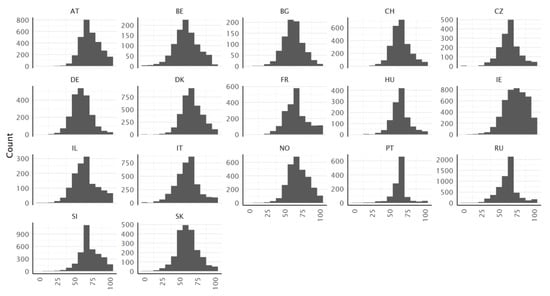
Figure 3.
Histograms of the HLS19-Q12 scores (type P), for all countries.
3.3. Distribution of the Levels
Across all participating countries, about 40% of the respondents have a “sufficient” level of HL and about 15% an “excellent” level (type D, Figure 4). On the other hand, about 33% have a “problematic” level of HL and 13% an “inadequate” level.
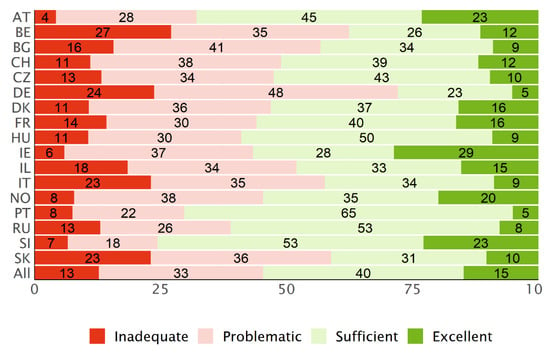
Figure 4.
Distribution of the HLS19-Q12 levels for general HL, based on type D scores, for each country and the mean for all countries.
The type P levels (Figure 5) give a less optimistic view on the general HL among the respondents of the HLS19 surveys. While the pattern of the extreme categories resembles the type D levels (Figure 4), the relation of problematic to sufficient levels of HL differs considerably. In general, the distribution of the four categories is less well balanced than for the type D levels with a dominance of “problematic” HL in most countries. For the PT data, this effect is amplified by the fact that respondents answered “easy“ to an above-average number of questions.
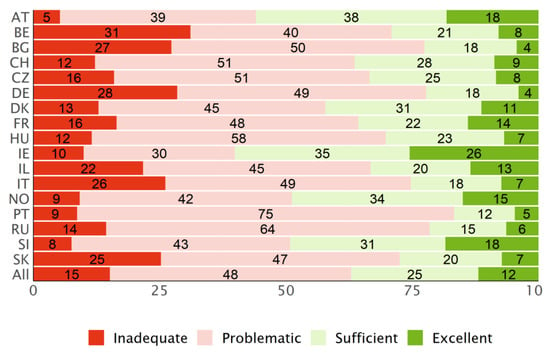
Figure 5.
Distribution of the HLS19-Q12 levels for general HL, based on type P scores, for each country and the mean for all countries.
3.4. Validity Characteristics
3.4.1. Content and Face Validity
By using the theory-based matrix of the comprehensive multifaceted model of general HL for operationalization of HLS19-Q12, i.e., for selection of items for the respective cells of the defining matrix, the content and face validity of the HLS19-Q12 is ensured.
3.4.2. Discriminant Validity
Data for certain specific HL-instruments were collected only in a subset of the participating countries. With a few exceptions, most weighted Pearson correlation coefficients between the HLS19-Q12 score and the scores for special HL are within the target range of 0.4 to 0.7 (Table 12).
Table 12.
Weighted Pearson correlation of HLS19-Q12_score with HLS19 scores for special health literacies.
For the type D score, the value of the correlation coefficients with communicative HL is below 0.4 for AT and BE data. The correlation coefficient with vaccination HL is above 0.7 for the IT data.
For the type P score, the value of the correlation coefficient with digital HL is larger than 0.7 for the IL data, and for vaccination HL for the IT and SI data.
3.4.3. Concurrent Predictive Validity—Associations with Determinants (Social Gradient)
The distribution of the selected socio-demographic and socio-economic predictor variables as examples for associations of general HL with social determinants discussed in the respective literature is described in the Supplementary Materials Table S3.
For the model for the type D score as an outcome variable (Table 13), financial deprivation is a statistically significant predictor (p ≤ 0.01) in every country data but BE. Self-perceived social status in society is the second important predictor variable in most countries. All other variables (sex, age, education) are associated with significant coefficients for some of the country data, but the size of the coefficients is remarkably smaller (e.g., gender) or there is no consistent pattern across all countries: e.g., for age or education, even the sign of the regression coefficient varies. R2 ranges from 0.04 to 0.25 with a median value of 0.09. The residuals show some disadvantageous patterns (what is to be expected given the skewness of the distribution of the type D score values) that question the compliance with some formal assumptions of simple linear models like linearity, normality, or homoscedasticity. This hints at simple linear models not being the optimal choice for modelling type D scores for the given data of the HLS19 surveys.
Table 13.
Multivariable linear regression models of the type D score by five core social determinants (standardized coefficients (β) and R2), for each country and for all countries (equally weighted).
The model for the type P score as outcome variable (Table 14) gives a very similar picture. The standardized coefficients are close to the values in Table 13 with the greatest deviation of coefficients for education for the Slovenian (βD = 0.02 vs. βP = 0.11) and Portuguese (βD = 0.08 vs. βP = 0.15) data, as well as age for the Austrian data (βD = 0.08 vs. βP = 0.16). In general, there is no clear trend, though the coefficients for the type P model are generally higher than those for the type D model. The R2 values deviate at most by 0.04 from the respective values for the type D model. Again, there is no general trend that the R2 for one type of model would be higher or lower than for the other model.
Table 14.
Multivariable linear regression models of the type P score by five core social determinants (standardized coefficients (β) and R2), for each country and for all countries (equally weighted).
Despite the different distributions of the type D and P scores, the two types of models produce largely similar results.
3.4.4. Concurrent Predictive Validity—Associations with Consequences
On average, this multivariable linear regression model for self-perceived health (ranging from 1 = very good to 5 = very bad) with the type D score as predictor variable (Table 15) explains 21% of the variance (varying from 11% in IE to 38% in BG). On average, the predictor with the highest absolute β value is age (varying from β = 0.08 in BE to β = 0.42 in SK) and the predictor with the second highest ß is financial deprivation (varying from −0.03 in BE to 0.22 HU). General HL (varying from β = −0.07 in SK to β = −0.22 in DK) and level in society (varying from −0.06 in RU to −0.27 in BE) are the predictors with the, on average, third highest absolute value for the β coefficient.
Table 15.
Multivariable linear regression models of self-perceived health by general HL (D type) and five core social determinants (standardized coefficients (β) and R2), for each country and for all countries (equally weighted).
The model with the type P score gives comparable results (Table 16). While the values for the β coefficient of general HL are slightly higher in the majority of countries, the difference is very small in most countries and the sign of the differences is generally inconsistent.
Table 16.
Multivariable linear regression models of self-perceived health by general HL (P type) and five core social determinants (standardized coefficients (β) and R2), for each country and for all countries (equally weighted).
3.5. Representation of the Long Form (HLS19-Q47)
The values of the weighted Pearson correlation coefficients are generally slightly lower for the type D scores than for the type P scores. For general HL, the correlation coefficients range from 0.897 to 0.951 for the type D scores and from 0.941 to 0.969 for the type P scores. The correlation coefficients are generally lower for the subdimensions that build on considerably fewer items (Table 17).
Table 17.
Weighted Pearson Correlation of the HLS19-Q12 score (D type and P type) and its subdimensions with their respective long form based on the HLS19-Q47.
4. Discussion
4.1. Using Dichotomous or Polytomous Scores (Research Question 1)
In the International Report of the HLS19 study, the more cautious interpretation of the Likert response format in terms of type D scores was considered to avoid treating ordinal variables as interval scaled. As analyses in this article show, type D and type P scores yield comparable results for most analyses. The type D scores show unwanted patterns of the residuals, which could be interpreted as a sign that other types of models (e.g., a binomial GLM of the difficulty) could be a preferable choice. While the residuals violate the formal assumptions of simple linear models, this does not invalidate the results of such analyses, although the goodness-of-fit is sub-optimal, and the coefficient values could be higher with the choice of a more appropriate model. In general, we suggest using the type P score which also is more compatible with the procedures used in HLS-EU and which show more normally distributed scores. When the focus lies on comparing heterogenous populations or when there is a suspicion that certain subpopulations prefer different extreme response styles, the use of the type D score should be considered.
4.2. Psychometric Properties (Factorial Validity/Dimensionality) (Research Question 2)
With respect to the distributions of scores, the observed ceiling effect, and the relative ease of the suggested tasks of the HLS19-Q12 was unexpected because in the HLS-EU study, some of these tasks were deemed to be rather difficult. Future research should clarify the extent to which this is due to changes in the response categories, changes in the wording of the items, changes in the survey modalities, or actual changes in the average level of HL and the health care systems.
The proportion of a subpopulation with inadequate or limited HL levels is an important measure in the communication of survey results on HL and was also offered for HLS-EU data. The exact definition of cut-off values is to a certain extent arbitrary but was described transparently and justified. Arbitrariness is reflected in the differences between the two ways of calculating discrete levels of HL, but it is plausible that using the original polytomous response categories for difficulty leads to a heightened proportion of the difficult levels. Nevertheless, we recommend using this measure only with caution, along with an explanation of the limitations of such a categorization.
The HLS-EU study published Cronbach’s alpha coefficients only for the HLS-EU-Q47, not for the later developed HLS-EU-Q12 (i.e., the HLS-EU’s predecessor items of the HLS19-Q12). We calculated these values, and they range from 0.64 to 0.86 for the dichotomized items and from 0.81 to 0.92 for the polytomous items. This corresponds to the Cronbach’s alpha coefficients for the HLS19-Q12. The Cronbach’s alpha values and the single-factor analyses support the hypothesis that the HLS19-Q12 is a sufficiently unidimensional scale that is fit to measure general HL on the population level.
The Cronbach’s alpha value is below the recommended threshold of 0.7 only for the Austrian data for the dichotomized items. We still assume a sufficient degree of internal consistency for the Austrian survey for the following reasons: (1) the Cronbach’s alpha should be interpreted as a lower bound, (2) the recommended threshold should not be understood as a hard cut-off value, and (3) the Austrian survey was based on the same German version of the instrument that was also used in DE and CH.
For developing and validating the HLS-EU-Q12, PCM analyses but not CFA models were used [40]. For HLS19-Q12, single-factor CFA models were analyzed in addition to PCM analyses. These CFA models fit the data well, which supports modelling the items of the HLS19-Q12 as manifest variables of a single latent variable, which on grounds of the items’ contents, can be referred to as general HL. The variation of the standardized parameters estimates is slightly lower for the polytomous items.
The psychometric analyses, especially the PCM analyses, suggest opportunities for improvement by modifying items in a future development of the HLS19 questionnaire. Some items display DIF for different person factors, such as age, gender, and educational background.
With regard to IRT analyses, Fischer [60] pointed out that the family of Rasch Models “… should be viewed as a guideline for the construction or improvement of tests, as an ideal to which a test should be gradually approximated, so that measurement can profit from the unique properties of the RM.” [60] Since the HLS19-Q12 is a self-reported, experience-based instrument for measuring and analyzing the HL of populations and not a performance-based test for HL of single individuals, fulfilling Rasch criteria is not considered a necessity for HLS19-Q12, although it is highly desirable to have questionnaires available that fit to an IRT model from the family of RMs. After applying a large number of powerful model tests and strict fitting rules, in line with the nature of a validation study, the null hypothesis of model fit for the HLS19-Q12 cannot be sustained in the 15 countries, for which data were available at the time of the IRT analyses, for both the PCM and the RM. The degree of model violations varies between the countries; for some countries, the deviations seem to be more pronounced with respect to the PCM and for others, with respect to the RM. Whereas some items display misfit and/or DIF in several countries and for more than one split criteria, some other items showed misfit or DIF only in one country and for one split criterium only. The possible reasons are manifold and include, for instance, somewhat different meanings of the items due to translation, social and cultural context, and differences in the health systems. To improve the HLS19-Q12 for all countries, the reasons for model violations have to be examined in more detail for each individual country based on the current results. Nevertheless, some similarities were found across countries which need to be addressed.
Item 6 (“to understand information about recommended health screenings or examinations”) displays DIF for age in 5 of the 15 countries when using the polytomous scoring and in two of the 15 countries for the dichotomous scoring. Item 9 (“to find information on healthy lifestyles such as physical exercise, healthy food or nutrition”) shows DIF with respect to educational background in 5 of the 15 countries for the polytomous scoring and in one country for the dichotomous scoring. The results for item 6 in terms of the polytomous scoring are consistent with those obtained by an independent Norwegian working group of the M-POHL consortium using somewhat different random subsamples in the individual countries and other software [59]. The item is relatively easier for the older age group in the respective countries. A possible reason could be the examples of health screenings provided in the item which could be less familiar to younger persons. Furthermore, most health screening programs (e.g., breast cancer, prostate cancer, colon cancer) are recommended from the age of 40 or 50. They are therefore generally perceived as less relevant by young people. For the other items which displayed DIF in the current validation study, the results are partly consistent with those obtained by the Norwegian working group [59].
Item 8 (“to decide how you can protect yourself from illness using information from the mass media”) shows a significant underfit in several countries both regarding the PCM and the RM, whereby in IE and SI, the infit statistic is > 1.3 for the polytomous scoring and the ICC plot for the RM for SI shows clear model deviations. The results regarding item 8 are also consistent with those obtained by the Norwegian working group [59].
In HLS19-data, unordered response categories were observed for two items in Austria, three items in Germany, eleven items in IE, and for all items in PT. The low endorsement rates in some of the categories could be the reason for the high number of items which were tagged as unordered in some countries [83]. No unordered response categories were observed for the HLS19-Q12 items in HLS-EU data from AT, BG, GR, ES, IR, NL, PL, and DE [58]. The wording of some items and the response categories (“easy” instead of “fairly easy” and “difficult” instead of “fairly difficult”) have been changed between HLS-EU and HLS19, which could be a possible explanation. In some languages (e.g., German), it could be more difficult to discriminate between “very difficult” and “difficult” than between “very difficult” and “fairly difficult”. For those countries with several items with unordered response categories, it is suggested to use the dichotomous scoring; since some of the answer categories are chosen very seldom, there is not much information loss and in many countries the deviation from the RM is less pronounced than from the PCM.
Survey-mode-specific analyses suggest that CAWI worked better than CATI; however, sample sizes for CATI are (too) small, especially in CH (n = 139) and IL (n = 290). However, the Norwegian working group also found some evidence that the different modes have an influence [59].
Although several deviations from the assumptions of the PCM and the RM were observed, which suggests a certain degree of multidimensionality, and some items showed poor measurement properties, from a more practice-oriented point of view, the HLS19-Q12 is a suitable short instrument to measure general HL on a population level to inform health policy. However, from a psychometric point of view, it should currently not be used for decisions on individual person level (e.g., to identify persons with low HL). DIF of some items furthermore poses problems for fair comparisons between subpopulation groups within a country and for comparisons between countries. Absence of DIF, however, is harder to achieve for questionnaires with verbal items compared to, e.g., tests with computational tasks [60].
These IRT analyses offer useful additional information on differences of psychometric properties of the different language and country forms of HLS19-Q12 and should be considered when benchmarking between selected countries. Furthermore, they offer information on potentials for improving the instrument in further rounds of M-POHL population surveys, but they do not question the appropriateness and usefulness of HLS19-Q12 as a self-reported HL population measure for adult national populations.
4.3. Validity (Research Question 3)
4.3.1. Content and Face Validity
As for HLS-EU-Q12, by using the multifaceted theory-based matrix of the general HL for operationalization of HLS19-Q12, i.e., for selection of items for the respective cells of the defining matrix, the content and face validity of the HLS19-Q12 was ensured.
4.3.2. Discriminant Validity
The weighted Pearson correlation coefficients between the HLS19-Q12 score and the scores for special health literacies are within the expected range of 0.4 to 0.7 with only few exceptions. This supports the thesis that the score for general HL measures something different than the other scores so that the scores can most likely be used independently, e.g., in regression analyses, though the scores are closely related.
4.3.3. Concurrent Predictive Validity
For the regression models with general HL as outcome variable, the R2 values were slightly higher on average for the data of the HLS-EU study [3], where the values ranged from 0.08 to 0.29. One could question whether this could also be a consequence of the HLS-EU study relying on standardized sampling procedures across the participating countries and high-quality face-to-face interviews, while in the context of the HLS19 study, mostly CATI and CAWI interviews were used due to pragmatic reasons in the light of the SARS-CoV-2 pandemic. It should be noted that the models in the HLS-EU study used the HLS-EU-Q47 score, which could be another source for deviances. In general, the size of the beta coefficients, which were reported in the HLS-EU study, was smaller for the HLS19 data, but these are sensitive to the variance of the involved variables. At least the signs of the coefficients are comparable for important predictor variables.
For the regression model with general HL as predictor variable and self-perceived health as outcome variable, the possibility of a comparison with HLS-EU data is limited because only models that also include the Newest Vital Sign (NVS) score as predictor variable were published [10,84]. Another deviation is that in the HLS-EU models, the HLS-EU-Q47 score was used that built on the 47-items long form. Since the NVS score is of lesser importance in these published models, they are suitable references, nevertheless. The order of the β coefficients is comparable with the sole exception of financial deprivation that is slightly more prominent in the HLS19 data. The R2 coefficients were slightly higher for the published HLS-EU models.
For type D scores, there are regression analyses for further indicators of hypothesized consequences available in the International Report [12], which strengthen the concurrent predictive validity of the HLS19-Q12 measure.
4.4. Representation of Long Form HLS19-Q47 (Research Question 4)
The correlation of the HLS-EU-Q12 and the HLS-EU-Q47 indices was high in the original total sample of all eight countries (r = 0.955). In the individual countries, the correlations varied between 0.935 and 0.966 [16]. For the general HL score, the correlation of the HLS19-Q12 and the HLS19-Q47, that contains about four times the number of items, is strong enough (for D type 0.931, varying between 0.897 and 0.951; and for P type 0.958, varying between 0.941 and 0.969) to justify the use of the short form as a substitute for the long form.
For the subdimensions, the correlation coefficients are generally above 0.8 for the type P scores and above 0.75 in most countries for the type D scores, while the Cronbach’s alpha coefficients often are below 0.6 for the type D scores of the subdimensions consisting of three or four items. For the type P scores, the Cronbach’s alpha coefficients could be expected to be above 0.7. The use of the sub-scores derived from the HLS19-Q12 short form thus seems questionable for type D scores. If users of this instrument consider this as a necessary requirement, we suggest using the type P scores for the sub-dimensions.
4.5. Strengths and Limitations
With respect to the HLS-EU study and the respective instrument, the HLS19-Q12 instrument has the following advantages: it is available in more languages, it was tested in more countries, with a variety of data collection methods, and there was a more rigorous testing of its dimensionality. In addition, indicators for testing discriminant and concurrent predictive validity of the score showed expected results. In every HLS19 survey, the instrument was proven to work sufficiently well to measure the HL of general adult populations.
From a statistical perspective, the main limitation of the country data collected for the HLS19 study is that some items were estimated as being too easy by a majority of the respondents. The response category “very difficult” was rarely used for some items. It is unclear whether this is a problem with the items, the response categories, or the data collection method (CAWI and especially, CATI). The dichotomization of the items could be one way to avoid statistical problems arising from one extreme response category being rarely selected. It could also be a means to attenuate problems from differing extreme response preferences. It should be noted, though, that the resulting ceiling effect for the D type version could make it more difficult to measure improvements in the average level of HL following an intervention or a change of policies.
Due to difficulties in getting funding and finding suitable agencies for data collection in some countries, data were collected over an extended period of time and in different stages and contexts of the SARS-CoV-19 pandemic, which, besides other differences, affects the comparability of results. That is also true of countries using different kinds of data collection but has the advantage that the instrument is now already validated for various data collection modes.
5. Conclusions
For monitoring and benchmarking comprehensive, general HL in general adult populations on a national and international level, a validated internationally accepted compact measure is needed. The HLS19-Q12 (12 items), based on the HLS-EU-Q47, fulfils this requirement and has been validated in 17 countries and for 17 languages using different types of data collection with acceptable psychometric and validity properties. There are also indications for potential improvements of the instrument. Following the shift in measurement theory and practice [85], the HLS19-Q12 instrument must be validated again, when used in further studies and samples.
6. Use the Instrument
The ownership of the HLS19-Q12 rests with the HLS19 Consortium, which developed the instrument. The HLS19-Q12 can be used by third parties for research purposes free of charge but requires a contractual agreement between the user and the International Coordination Centre of the HLS19 Consortium. An application form with details on the conditions for getting permission to use the instrument can be found at https://m-pohl.net/tools (accessed on 1 October 2022).
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/ijerph192114129/s1, Table S1. Standardized Coefficients Single-Factor CFA of the dichotomized items, Table S2. Standardized Coefficients Single-Factor CFA of the polytomous items, Table S3. Socio-demographic variables included in the regression models.
Author Contributions
Conceptualization, J.M.P., T.L. and C.S.; methodology, J.M.P., T.L., T.A., S.P. and K.W.; software, T.L., D.M., T.A., S.P. and K.W.; formal analysis, T.L., D.M., T.A., S.P. and K.W.; data curation, T.L.; writing—original draft preparation, J.M.P., T.L., C.S. and K.W.; writing—review and editing, R.G., D.M., T.A., S.P., H.B., M.L., M.G.N. and M.V.; visualization, T.L.; supervision, J.M.P. and C.S.; project administration, C.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding, but the data collection was supported either by ministries of health, university, public health institutes, or insurance funds in the different countries. AT: The Austrian Health Literacy Survey was commissioned and financed by the Austrian Federal Health Agency and the Federation of Austrian Social Insurance Institutions. BE: There were no support for data collection in Belgium from any organization. BG: Medical University—Sofia, Faculty of Public Health and AGREEMENT No. D-125/24.06.2020, PROJECT No. 8418/21.11.2019, “GRANT-2020”, MU-Sofia. CH The Swiss Federal Office of Public Health FOPH with a financial contribution from the foundation Health Promotion Switzerland. CZ: Data collection was funded by (all seven) Czech health insurance funds. DE: The German study was funded by the German Federal Ministry of Health, grant number: Kapitel 1504 Titel 54401, ZMV I 1-2518 004 (HLS-GER 2). DK: The distribution of the questionnaire was funded by Aalborg University. FR: The research was supported by the National Public Health agency (Santé Publique France, 21DPPA040-0) and by Ligue contre le cancer (LIGUE2019). HU: The research was supported by the Ministry of Human Capacities, Hungary (IV/956-740 4/2020/EKF). IE: Department of Health, Dublin. IL: The Israel study was funded by the Israel Ministry of Health and Clalit Health Services, Israel. IT: The Italian participation to the Action Network on Measuring Population and Organizational Health Literacy (M-POHL Network) was funded by the Istituto Superiore di Sanità, Rome, Italy; the implementation of the Health Literacy Survey-HLS19 in Italy was funded by the National Centre for Disease Prevention and Control (CCM) of the Italian Ministry of Health and coordinated by the Department of cardiovascular, endocrine–metabolic diseases and aging of the Istituto Superiore di Sanità, Rome, Italy. NO: The Norwegian HLS19 was commissioned and financed by the Norwegian Ministry of Health and Care Services. The Norwegian Directorate of Health funded the data collection and the administrative costs for the whole project, while Oslo Metropolitan University and Inland Norway University of Applied Sciences contributed with the scientific workforce. PT: Direção-Geral da Saúde, Lisbon. RU: The Russian study was supported by the Ministry of Health of the Russian Federation and WHO Europe. SI: The national survey of Health literacy in Slovenia took place within the framework of the project Increasing health literacy in Slovenia-ZaPiS, which is co-financed by the Republic of Slovenia to the amount of 20% of the value and the European Union from the European Social Fund to the amount of 80% of the value. SK: Public Health Authority of the Slovak Republic, Bratislava.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki. In each country, it has been ensured that ethical requirements have been met. For more information about ethical considerations, data protection, and informed consent by country, please see the International Report on the methodology, results, and recommendations of the European Health Literacy Population Survey 2019–2021 (HLS19) of M-POHL [12].
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The dataset is currently available only to members of the M-POHL consortium. From December 2024, it will be made available to external researchers under a set of conditions.
Acknowledgments
The authors would like to thank the HLS19 National Study Centers and their teams for translating the questionnaire, and the collection and provision of data. We especially thank Christopher Le, Hanne Søberg Finbråten, Øystein Guttersrud, and Kjell Sverre Pettersen (Norwegian HLS19 study team) for contributing by performing Rasch modelling of data. We acknowledge Eva-Maria Berens, Nejc Berzelak, Oxana Drapkina, Paulo Jorge Nogueira, Jorge Oliveira, Doris Schaeffer, and Sanja Vrbovšek, who all contributed to the underlying chapters 4 and 5 in the International Report on the methodology, results, and recommendations of the European Health Literacy Population Survey 2019–2021 (HLS19) of M-POHL [12].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kickbusch, I.; Pelikan, J.M.; Apfel, F.; Tsouros, A.D. Health Literacy: The Solid Facts; World Health Organization (WHO) Regional Office for Europe: Copenhagen, Denmark, 2013. [Google Scholar]
- Quaglio, G.; Sørensen, K.; Rübig, P.; Bertinato, L.; Brand, H.; Karapiperis, T.; Dinca, I.; Peetso, T.; Kadenbach, K.; Dario, C. Accelerating the health literacy agenda in Europe. Health Promot. Int. 2016, 32, 1074–1080. [Google Scholar] [CrossRef] [PubMed]
- HLS-EU Consortium. Comparative Report on Health Literacy in Eight EU Member States; Second Extended and Revised Version, Date 22 July 2014; The European Health Literacy Survey HLS-EU: Wien, Austria, 2012. [Google Scholar]
- Sørensen, K.; Pelikan, J.M.; Röthlin, F.; Ganahl, K.; Slonska, Z.; Doyle, G.; Fullam, J.; Kondilis, B.; Agrafiotis, D.; Uiters, E.; et al. Health literacy in Europe: Comparative results of the European health literacy survey (HLS-EU). Eur. J. Public Health 2015, 25, 1053–1058. [Google Scholar] [CrossRef] [PubMed]
- M-POHL. Concept Note. For a WHO Action Network on Measuring Population and Organizational Health Literacy (M-POHL Network) within the European Health Information Initiative (EHII); M-POHL: Vienna, Austria, 2018. [Google Scholar]
- Dietscher, C.; Pelikan, J.; Bobek, J.; Nowak, P. The action network on measuring population and organizational health literacy (M-POHL) a network under the umbrella of the WHO European health information initiative (EHII). Public Health Panor. 2019, 5, 71. [Google Scholar]
- M-POHL. The Vienna Statement on the Measurement of Population and Organizational Health Literacy in Europe; M-POHL: Vienna, Austria, 2018. [Google Scholar]
- Sørensen, K.; Van den Broucke, S.; Fullam, J.; Doyle, G.; Pelikan, J.; Slonska, Z.; Brand, H.; (HLS-EU) Consortium Health Literacy Project European. Health literacy and public health: A systematic review and integration of definitions and models. BMC Public Health 2012, 12, 80. [Google Scholar] [CrossRef] [PubMed]
- Sørensen, K.; van den Broucke, S.; Pelikan, J.M.; Fullam, J.; Doyle, G.; Slonska, Z.; Kondilis, B.; Stoffels, V.; Osborne, R.H.; Brand, H. Measuring health literacy in populations: Illuminating the design and development process of the European Health Literacy Survey Questionnaire (HLS-EU-Q). BMC Public Health 2013, 13, 948. [Google Scholar] [CrossRef]
- Pelikan, J.M.; Ganahl, K. Measuring Health Literacy in General Populations: Primary Findings from the HLS-EU Consortium’s Health Literacy Assessment Effort. Stud. Health Technol. Inf. 2017, 240, 34–59. [Google Scholar] [CrossRef]
- Pelikan, J.M.; Straßmayr, C.; Ganahl, K. Health Literacy Measurement in General and Other Populations: Further Initiatives and Lessons Learned in Europe (and Beyond). In Health Literacy in Clinical Practice and Public Health; New Initiatives and Lessons Learned at the Intersection with other Disciplines; Logan, G.D., Siegel, E.R., Eds.; IOS Press: Amsterdam, The Netherlands, 2020; pp. 170–191. [Google Scholar] [CrossRef]
- The HLS19 Consortium of the WHO Action Network M-POHL. International Report on the Methodology, Results, and Recommendations of the European Health Literacy Population Survey 2019-2021 (HLS19) of M-POHL; Austrian National Public Health Institute: Vienna, Austria, 2021. [Google Scholar]
- Schaeffer, D.; Vogt, D.o.; Berens, E.-M.; Messer, M.; Quenzel, G.; Hurrelmann, K. Health literacy in Deutschland. In Health Literacy. Forschungsstand und Perspektiven; Schaeffer, D., Pelikan, J.M., Eds.; Hogrefe: Bern, Switzerland, 2017; p. 144. [Google Scholar]
- Schaeffer, D.; Vogt, D.; Berens, E.-M.; Hurrelmann, K. Gesundheitskompetenz der Bevölkerung in Deutschland: Ergebnisbericht; Universität Bielefeld, Fakultät für Gesundheitswissenschaften: Bielefeld, Germany, 2016. [Google Scholar]
- Pelikan, J.M.; Ganahl, K. Die europäische gesundheitskompetenz-studie: Konzept, instrument und ausgewählte Ergebnisse. In Health Literacy. Forschungsstand und Perspektiven; Schaeffer, D., Pelikan, J.M., Eds.; Hogrefe: Bern, Switzerland, 2017; p. 125. [Google Scholar]
- Pelikan, J.M.; Ganahl, K.; van den Broucke, S.; Sørensen, K. Measuring health literacy in Europe: Introducing the European Health Literacy Survey Questionnaire (HLS-EU-Q) In International Handbook of Health Literacy. Research, Practice and Policy across the Life-Span; Okan, O., Bauer, U., Pinheiro, P., Levin-Zamir, D., Sorensen, K., Eds.; Policy Press: Bristol, UK, 2019; p. 138. [Google Scholar]
- Pelikan, J.M.; Röthlin, F.; Ganahl, K.; Peer, S. Measuring comprehensive health literacy in general populations–the HLS-EU instruments. In Proceedings of the International Conference of Health Literacy and Health Promotion, Taipei, Taiwan, 6 October 2014; p. 57. [Google Scholar]
- Röthlin, F.; Pelikan, J.M.; Ganahl, K. Die Gesundheitskompetenz der 15-jährigen Jugendlichen in Österreich. Abschlussbericht der österreichischen Gesundheitskompetenz Jugendstudie im Auftrag des Hauptverbands der Österreichischen Sozialversicherungsträger; Ludwig Boltzmann Institut für Health Promotion Research: Wien, Austria, 2013. [Google Scholar]
- Ganahl, K.; Dahlvik, J.; Pelikan, J.M. Health literacy and experienced communication in health care among immigrants in Austria. Findings from the Austrian health literacy immigrant study. In Proceedings of the 25th International Conference on Health Promoting Hospitals and Health Services, Vienna, Austria, 12–14 April 2017. [Google Scholar]
- Ganahl, K.; Dahlvik, J.; Röthlin, F.; Alpagu, F.; Sikic-Fleischhacker, A.; Peer, S.; Pelikan, J.M. Gesundheitskompetenz bei personen mit migrationshintergrund aus der türkei und ex-jugoslawien in Österreich. In Ergebnisse Einer Quantitativen und Qualitativen Studie; Ludwig Boltzmann Institut Forschungsbericht: Wien, Austria, 2016. [Google Scholar]
- Wangdahl, J.M.; Dahlberg, K.; Jaensson, M.; Nilsson, U. Psychometric validation of Swedish and Arabic versions of two health literacy questionnaires, eHEALS and HLS-EU-Q16, for use in a Swedish context: A study protocol. BMJ Open 2019, 9, e029668. [Google Scholar] [CrossRef]
- Gele, A.A.; Pettersen, K.S.; Torheim, L.E.; Kumar, B. Health literacy: The missing link in improving the health of Somali immigrant women in Oslo. BMC Public Health 2016, 16, 1134. [Google Scholar] [CrossRef]
- Wangdahl, J.M.; Lytsy, P.; Mårtensson, L.; Westerling, R. Health literacy and refugees’ experiences of the health examination for asylum seekers–a Swedish cross-sectional study. BMC Public Health 2015, 15, 1162. [Google Scholar] [CrossRef]
- Lorini, C.; Santomauro, F.; Grazzini, M.; Mantwill, S.; Vettori, V.; Lastrucci, V.; Bechini, A.; Boccalini, S.; Bussotti, A.; Bonaccorsi, G. Health literacy in Italy: A cross-sectional study protocol to assess the health literacy level in a population-based sample, and to validate health literacy measures in the Italian language. BMJ Open 2017, 7, e017812. [Google Scholar] [CrossRef]
- Lorini, C.; Lastrucci, V.; Mantwill, S.; Vettori, V.; Bonaccorsi, G. Measuring health literacy in Italy: A validation study of the HLS-EU-Q16 and of the HLS-EU-Q6 in Italian language, conducted in Florence and its surroundings. Ann. dell’Ist. Super. Sanità 2019, 55, 10–18. [Google Scholar] [CrossRef]
- Soenaryati, S.; Rachmani, E. Media use behavior and health literacy on high school students in Semarang. Adv. Sci. Lett. 2017, 23, 3493–3496. [Google Scholar] [CrossRef]
- Gerich, J.; Moosbrugger, R. Subjective estimation of health literacy—What is measured by the HLS-EU scale and how is it linked to empowerment? Health Commun. 2016, 33, 254–263. [Google Scholar] [CrossRef] [PubMed]
- Rouquette, A.; Nadot, T.; Labitrie, P.; Broucke, S.V.D.; Mancini, J.; Rigal, L.; Ringa, V. Validity and measurement invariance across sex, age, and education level of the French short versions of the European Health Literacy Survey Questionnaire. PLoS ONE 2018, 13, e0208091. [Google Scholar] [CrossRef] [PubMed]
- Rouquette, A.; Rigal, L.; Mancini, J.; Guillemin, F.; Broucke, S.V.D.; Allaire, C.; Azogui-Levy, S.; Ringa, V.; Hassler, C. Health Literacy throughout adolescence: Invariance and validity study of three measurement scales in the general population. Patient Educ. Couns. 2021, 105, 996–1003. [Google Scholar] [CrossRef] [PubMed]
- Emiral, G.Ö.; Atalay, B.; Aygar, H.; Göktas, S. Health literacy scale-European union-Q16: A validity and reliability study in Turkey. Int. Res. J. Med. Sci. 2018, 6, 1–7. [Google Scholar]
- Uemura, K.; Yamada, M.; Okamoto, H. Effects of active learning on health literacy and behavior in older adults: A randomized controlled trial. J. Am. Geriatr. Soc. 2018, 66, 1721–1729. [Google Scholar] [CrossRef] [PubMed]
- Gustafsdottir, S.S.; Sigurdardottir, A.K.; Arnadottir, S.A.; Heimisson, G.T.; Mårtensson, L. Translation and cross-cultural adaptation of the European Health Literacy Survey Questionnaire, HLS-EU-Q16: The Icelandic version. BMC Public Health 2020, 20, 61. [Google Scholar] [CrossRef]
- Coman, M.A.; Forray, A.I.; Broucke, S.V.D.; Chereches, R.M. Measuring health literacy in Romania: Validation of the HLS-EU-Q16 survey questionnaire. Int. J. Public Health 2022, 67, 1604272. [Google Scholar] [CrossRef]
- Mohamad, E.M.W.; Kaundan, M.K.; Hamzah, M.R.; Azlan, A.A.; Ayub, S.H.; Tham, J.S.; Ahmad, A.L. Establishing the HLS-M-Q18 short version of the European health literacy survey questionnaire for the Malaysian context. BMC Public Health 2020, 20, 580. [Google Scholar] [CrossRef]
- Rasch, G. Studies in mathematical psychology: I. In Probabilistic Models for Some Intelligence and Attainment Tests; Danmarks Pædagogiske Institut: Copenhagen, Denmark, 1960; p. 80. [Google Scholar]
- Van Duong, T.; Chang, P.W.; Yang, S.-H.; Chen, M.-C.; Chao, W.-T.; Chen, T.; Chiao, P.; Huang, H.-L. A new comprehensive short-form health literacy survey tool for patients in general. Asian Nurs. Res. 2017, 11, 30–35. [Google Scholar] [CrossRef] [PubMed]
- Duong, T.V.; Aringazina, A.; Kayupova, G.; Nurjanah; Pham, T.V.; Pham, K.M.; Truong, T.Q.; Nguyen, K.T.; Oo, W.M.; Su, T.T.; et al. Development and validation of a new short-form health literacy instrument (HLS-SF12) for the general public in six Asian countries. HLRP Health Lit. Res. Pract. 2019, 3, e91–e102. [Google Scholar] [CrossRef]
- Van Duong, T.; Nguyen, T.T.P.; Pham, K.M.; Nguyen, K.T.; Giap, M.H.; Tran, T.D.X.; Nguyen, C.X.; Yang, S.-H.; Su, C.-T. Validation of the short-form health literacy questionnaire (HLS-SF12) and its determinants among people living in rural areas in Vietnam. Int. J. Environ. Res. Public Health 2019, 16, 3346. [Google Scholar] [CrossRef]
- Finbråten, H.S.; Wilde-Larsson, B.; Nordström, G.; Pettersen, K.S.; Trollvik, A. Guttersrud, establishing the HLS-Q12 short version of the European health literacy survey questionnaire: Latent trait analyses applying Rasch modelling and confirmatory factor analysis. BMC Health Serv. Res. 2018, 18, 506. [Google Scholar] [CrossRef] [PubMed]
- Waldherr, K.; Alfers, T.; Peer, S.; Pelikan, J.M. Development and Validation of the HLS-EU-Q12; Vienna, Austria. 2019. Available online: https://m-pohl.net/sites/m-pohl.net/files/inline-files/Waldherr%20et%20al%202019.pdf (accessed on 1 September 2022).
- Masters, G.N. A rasch model for partial credit scoring. Psychometrika 1982, 47, 149–174. [Google Scholar] [CrossRef]
- Storms, H.; Claes, N.; Aertgeerts, B.; Broucke, S.V.D. Measuring health literacy among low literate people: An exploratory feasibility study with the HLS-EU questionnaire. BMC Public Health 2017, 17, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Domanska, O.M.; Firnges, C.; Bollweg, T.M.; Sørensen, K.; Holmberg, C.; Jordan, S. Do adolescents understand the items of the European Health Literacy Survey Questionnaire (HLS-EU-Q47)–German version? Findings from cognitive interviews of the project “Measurement of Health Literacy Among Adolescents” (MOHLAA) in Germany. Arch. Public Health 2018, 76, 46. [Google Scholar] [CrossRef]
- Finbråten, H.S.; Pettersen, K.S.; Wilde-Larsson, B.; Nordström, G.; Trollvik, A.; Guttersrud, Ø. Validating the european health literacy survey questionnaire in people with type 2 diabetes: Latent trait analyses applying multidimensional Rasch modelling and confirmatory factor analysis. J. Adv. Nurs. 2017, 73, 2730–2744. [Google Scholar] [CrossRef]
- Huang, Y.-J.; Lin, G.-H.; Lu, W.-S.; Tam, K.-W.; Chen, C.; Hou, W.-H.; Hsieh, C.-L. Validation of the European health literacy survey questionnaire in women with breast cancer. Cancer Nurs. 2018, 41, E40–E48. [Google Scholar] [CrossRef]
- IBM Corp. IBM SPSS Statistics for Windows, Version 27.0.; IBM Corp.: Armonk, NY, USA, 2020. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Eisinga, R.; Grotenhuis, M.t.; Pelzer, B. The reliability of a two-item scale: Pearson, Cronbach, or Spearman-Brown? Int. J. Public Health 2013, 58, 637–642. [Google Scholar] [CrossRef]
- Kline, R.B. Principles and Practice of Structural Equation Modeling; Guilford Publications: New York, NY, USA, 2015. [Google Scholar]
- Zumbo, B.D.; Gadermann, A.M.; Zeisser, C. Ordinal versions of coefficients alpha and theta for Likert rating scales. J. Mod. Appl. Stat. Methods 2007, 6, 29. [Google Scholar] [CrossRef]
- Chalmers, R.P. On misconceptions and the limited usefulness of ordinal alpha. Educ. Psychol. Meas. 2017, 78, 1056–1071. [Google Scholar] [CrossRef] [PubMed]
- Zumbo, B.D.; Kroc, E. A measurement is a choice and stevens’ scales of measurement do not help make it: A response to chalmers. Educ. Psychol. Meas. 2019, 79, 1184–1197. [Google Scholar] [CrossRef] [PubMed]
- Revelle, W. Psych: Procedures for Psychological, Psychometric, and Personality Research, Northwestern University: Evanston, Illinois, United States. 2021. Available online: https://mran.revolutionanalytics.com/snapshot/2021-09-26/web/packages/psych/psych.pdf (accessed on 3 October 2022).
- Prudon, P. Confirmatory factor analysis: A brief introduction and critique. Compr. Psychol. 2015, 4, 18. [Google Scholar] [CrossRef]
- Roussel, Y. lavaan: An R package for structural equation modeling. J. Stat. Softw. 2012, 48, 36. Available online: https://www.jstatsoft.org/v48/i02/ (accessed on 3 October 2022).
- Beaujean, A.A. Latent Variable Modeling Using R: A Step-by-Step Guide; Routledge: London, UK, 2014. [Google Scholar]
- Rosseel, Y. The Lavaan Tutorial; Ghent University: Ghent, Belgium, 2021. [Google Scholar]
- Waldherr, K.; Alfers, T.; Peer, S. Development and Validation of the HLS-EU-Q12; M-POHL: Vienna, Austria, 2021; Available online: https://m-pohl.net/sites/m-pohl.net/files/inline-files/Waldherr%20et%20al_0.pdf (accessed on 1 September 2022).
- Guttersrud, Ø.; Le, C.; Pettersen, K.S.; Finbråten, H.S. Rasch Analyses of Data Collected in 17 Countries. A Technical Report to Support Decision-Making within the M-POHL Consortium. Oslo, Norway. 2021. Available online: https://m-pohl.net/sites/m-pohl.net/files/inlinefiles/Guttersrud%20et%20al_Rasch%20analyses%20of%20data%20colllected%20in%2017%20countries_2021_0.pdf (accessed on 1 September 2022).
- Fischer, G.H. Rasch Models. In Handbook of Statistics, Psychometrics; Rao, C.R., Sinharay, S., Eds.; Elsevier Science Publishers: Amsterdam, The Netherlands, 2006; Volume 26, pp. 515–585. [Google Scholar]
- Mair, P.; Hatzinger, R.; Maier, M.J. eRm: Extended Rasch Modeling. 1.0-1. 2020. Available online: http://cran.r-project.org/package=eRm (accessed on 3 October 2022).
- Sveidqvist, K.; Bostock, M.; Pettitt, C.; Daines, M.; Kashcha, A.; Iannone, R. DiagrammeR: Create Graph Diagrams and Flowcharts Using R. R Package Version 0.9. 0. 2017. Available online: https://CRAN.R-project.org/package=DiagrammeR (accessed on 11 March 2022).
- Chalmers, R.P. mirt: A multidimensional item response theory package for the R environment. J. Stat. Softw. 2012, 48, 1–29. [Google Scholar] [CrossRef]
- Adams, R.J. Reliability as a measurement design effect. Stud. Educ. Evaluation 2005, 31, 162–172. [Google Scholar] [CrossRef]
- Maydeu-Olivares, A. Goodness-of-fit assessment of item response theory models. Meas. Interdiscip. Res. Perspect. 2013, 11, 71–101. [Google Scholar] [CrossRef]
- Hagell, P. Testing rating scale unidimensionality using the principal component analysis (PCA)/t-test protocol with the Rasch model: The primacy of theory over statistics. Open J. Stat. 2014, 4, 456–465. [Google Scholar] [CrossRef]
- Smith, E.V., Jr. Detecting and evaluating the impact of multidimensionality using item fit statistics and principal component analysis of residuals. J. Appl. Meas. 2002, 3, 205–231. [Google Scholar]
- Agresti, A.; Coull, B.A. Approximate is better than “exact” for interval estimation of binomial proportions. Am. Stat. 1998, 52, 119. [Google Scholar] [CrossRef]
- Yen, W.M. Effects of local item dependence on the fit and equating performance of the three-parameter logistic model. Appl. Psychol. Meas. 1984, 8, 125–145. [Google Scholar] [CrossRef]
- Linacre, J.; Wright, B. Rasch Measurement Transactions; MESA Press: Chicago, IL, USA, 1995. [Google Scholar]
- Smith, A.B.; Rush, R.; Fallowfield, L.J.; Velikova, G.; Sharpe, M. Rasch fit statistics and sample size considerations for polytomous data. BMC Med. Res. Methodol. 2008, 8, 33. [Google Scholar] [CrossRef] [PubMed]
- Wright, B.; Linacre, J. Reasonable mean-square fit values. Rasch Meas. Trans. 1994, 8, 371. [Google Scholar]
- Thissen, D.; Cai, L.; Bock, R. The nominal categories model. In Handbook of Polytomous Item Response Theory Models; Nering, M., Ostini, R., Eds.; Routledge: London, UK, 2010; pp. 43–75. [Google Scholar]
- Andersen, E.B. A goodness of fit test for the rasch model. Psychometrika 1973, 38, 123–140. [Google Scholar] [CrossRef]
- Fischer, G.H. On the existence and uniqueness of maximum-likelihood estimates in the Rasch model. Psychometrika 1981, 46, 59–77. [Google Scholar] [CrossRef]
- Fischer, G.H.; Scheiblechner, H. Algorithms and programs for the probabilistic test model of Rasch. Psychol. Beiträge 1970, 12, 23–51. [Google Scholar]
- Rasch, G. Probabilistic Models for Some Intelligence and Attainment Tests, 2nd ed.; University of Chicago Press: Chicago, IL, USA, 1980. [Google Scholar]
- Ponocny, I. Nonparametric goodness-of-fit tests for the rasch model. Psychometrika 2001, 66, 437–459. [Google Scholar] [CrossRef]
- Baccolini, V.; Rosso, A.; Di Paolo, C.; Isonne, C.; Salerno, C.; Migliara, G.; Prencipe, G.P.; Massimi, A.; Marzuillo, C.; De Vito, C.; et al. What is the prevalence of low health literacy in european union member states? A systematic review and meta-analysis. J. Gen. Intern. Med. 2021, 36, 753–761. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.G.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Lumley, T. Complex Surveys: A Guide to Analysis Using R; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 565. [Google Scholar]
- Hu, L.T.; Bentler, P.M. Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Struct. Equ. Model. A Multidiscip. J. 1999, 6, 1–55. [Google Scholar] [CrossRef]
- García-Pérez, M.A. Order-constrained estimation of nominal response model parameters to assess the empirical order of categories. Educ. Psychol. Meas. 2017, 78, 826–856. [Google Scholar] [CrossRef] [PubMed]
- Pelikan, J.M.; Röthlin, F.; Ganahl, K. Measuring health literacy in general populations in Europe. Selected results from the HLS-EU Study. In Proceedings of the 21 IUHPE World Conference on Health Promotion, Pattaya, Thailand, 27 August 2013. [Google Scholar]
- Osborne, R.; Elsworth, G.; Hawkins, M.; Cheng, C.; Elmer, S. Measurement of Health Literacy: Assumptions and Potential Consequences Locally and Globally; Swinburne University of Technology: Melbourne, Australia, 2021. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).