
Organizing and Analyzing Data from the SHARE Study with an Application to Age and Sex Differences in Depressive Symptoms



Abstract
:1. Introduction
2. Materials and Methods
2.1. SHARE Data
2.2. SHARE Data Management
- data filtering of participants or interviews based on inclusion/exclusion criteria specified in the statistical analysis plan
- management of missing values including data cleaning tasks, such as elimination of inadmissible values, checking for consistency of values
- variable management, for example renaming, deriving new variables by aggregating levels or values from different variables, or by using definitions that are specific to certain waves or types of interview
- formatting or subsetting datasets for different analyses, such as baseline or first interview data or datasets ordered by wave or measurement occasion for longitudinal projects.
2.3. Data Application: Age-Associated Patterns of Depression and Sex Differences
2.3.1. Study Population
2.3.2. Outcome Variable—Depressive Symptoms
2.3.3. Explanatory Variables
- Demographics. Variables include: age, sex, highest education level, region of residence. Educational level was assessed as self-reported highest educational attainment based on the ISCED 1997 classification and recorded into low (ISCED groups 0–2), medium (ISCED groups 3–4), high (ISCED groups 5–6) or other. Countries of residence were classified into four regions: Northern Europe (Denmark and Sweden), Western Europe (Austria, Germany, France, the Netherlands, Switzerland, Belgium, Ireland and Luxembourg), Southern Europe (Spain, Italy, Greece and Portugal) and Eastern Europe (Czech Republic, Poland, Hungary, Slovenia, Estonia and Croatia).
- Body mass index. Self-reported height and weight were converted into body mass index (BMI).
- Chronic diseases. Information on chronic diseases was gathered as response to the question, ‘Has a doctor ever told you that you had any of the following conditions?’ and included 6 conditions (cancer, chronic obstructive pulmonary disease (COPD), coronary heart disease, diabetes, hypertension and stroke) following a consistent approach to measuring occurrence of chronic conditions [14]. The responses were summarized as having 0, 1, or 2+ conditions.
- Life-style factors and health behaviors. Variables included living arrangements, current smoking, physical activity, and instrumental activities of daily living. Physical activity was analyzed as an ordinal scale with vigorous physical activity more than once a week, or one to three times a month, or once a week, or hardly ever or never. The instrumental activities of everyday life (IADL) index is constructed across individual’s difficulty doing each of the following everyday activities [15]: ‘doing work around the house or garden’, ‘leaving the house independently/accessing transportation’, ‘shopping for groceries’, ‘doing personal laundry’, ‘managing money’, ‘preparing a hot meal’, ‘taking medications’ and ‘making telephone calls’. Individuals were instructed to exclude any difficulties expected to last less than three months. This variable was dichotomized as follows: ‘no IADL limitation’ and ‘one or more IADL limitations’. Current smoking was a binary variable. Living arrangement was dichotomized as follows: or ‘not living alone’.
2.3.4. Statistical Analysis for Modeling Depression
3. Results
3.1. SHARE Data
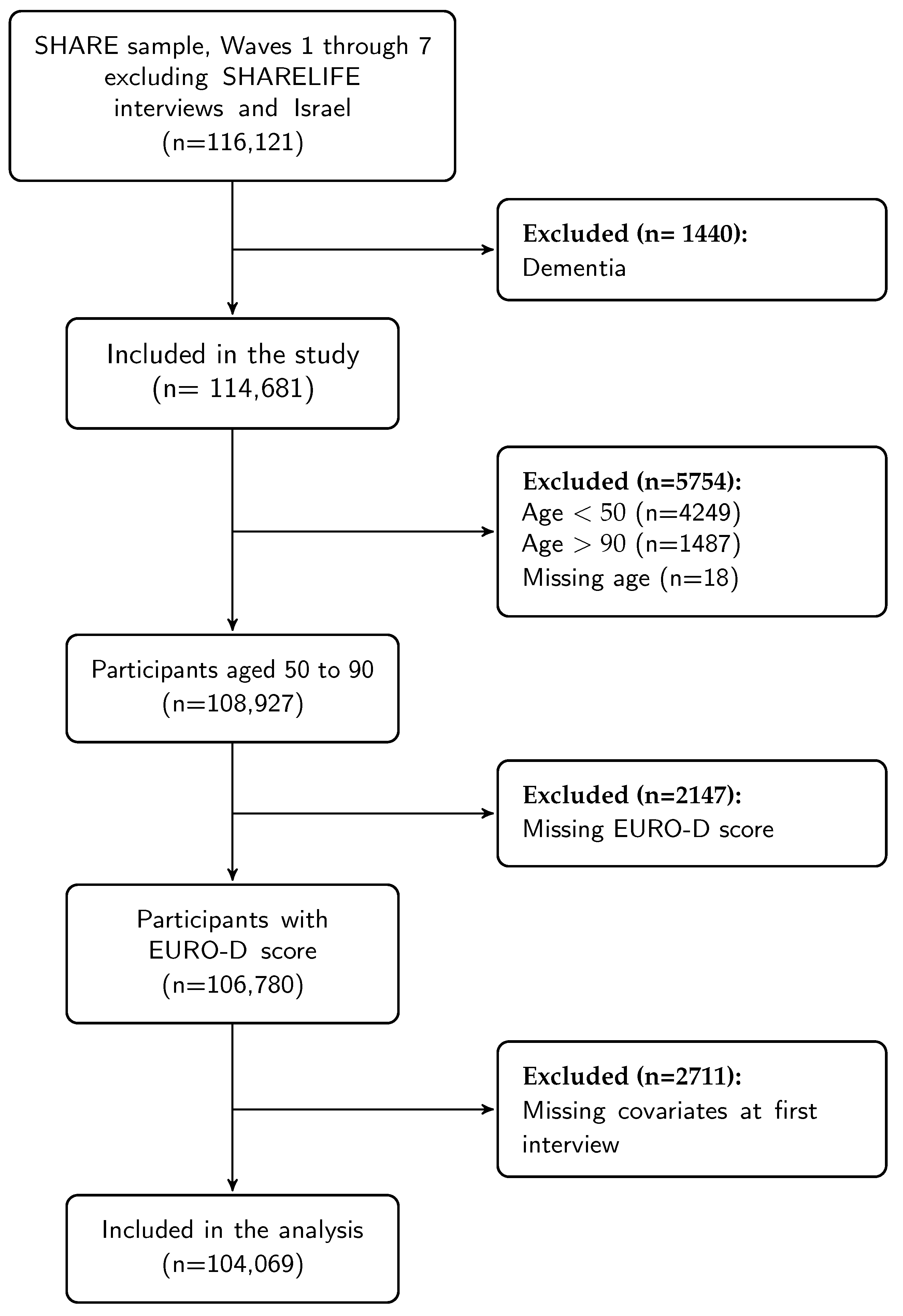
- Number of participants and time metrics. The number of participants can be summarized by wave or first interview (Table 1). The provided R code facilitates the application of exclusion criteria with resulting changes in numbers at each step, e.g., Figure 1. Other time metrics, such as measurement occasion, were defined to facilitate data summaries for number of participants or baseline characteristics. Furthermore, it is also possible to extract information about an individual’s progression throughout the data collection process, for example intermittent participation.
- Missing values. The workflow [13] includes stratifying missing values by wave and questionnaire to identify potential issues for each variable. This made it possible to reduce the number of missing values.
- -
- Marital status had a large proportion of missing data, and the stratification of missing values by type of questionnaire (baseline or longitudinal) showed that this item was missing mostly in longitudinal questionnaires, because the value was recorded only if changes from previous interviews occurred. This information allowed us to define a more complete variable.
- -
- Chronic obstructive pulmonary disease (COPD) was defined as the combination of the answer to two questions in waves 1 and 2 (Selected for questions ph006d6 (Chronic lung disease such as chronic bronchitis or emphysema) or ph006d7 (asthma) from the PH module), while only one question ph006d6 was used from wave 4, which already included asthma.
- -
- The EURO-D score, defined as the sum of selections of 12 symptoms, and the dichotomized version to indicate clinical depression (EURO-D ≥ 4) are available in the gv_health module. These variables were missing if any of the 12 symptoms was missing, thus 7790 interviews had missing EURO-D (out of 258,207). However, 30% of the clinical depression indicator variables could be retrieved based on the available symptoms thus reducing missingness.
- -
- Current smoking in the SHARE module gv_health:cusmoke is missing in all interviews after wave 5. However, smoking status at baseline interviews can be retrieved using responses to questions ‘Have you ever smoked?’ (br:br001_ ) and ‘Are you currently smoking?’ (br:br002_). This removes most of the missing values of the smoking indicator from the baseline interviews and more than 50% of the missing values in the longitudinal interviews.
- -
- Education is recorded only at baseline interviews (ISCED 1997), but its value is reported also in the other waves through the generated variables in the gv_isced module. Replacing missing values based on the first non-missing value reduced missingness by 40% (from 2855 to 1720 interviews).
- -
- Assuming that height does not vary greatly over time we replaced missing values at first interview with the first available measurement. This also reduced the number of missing values of BMI.
3.2. Data Application: Depression in Older Adults
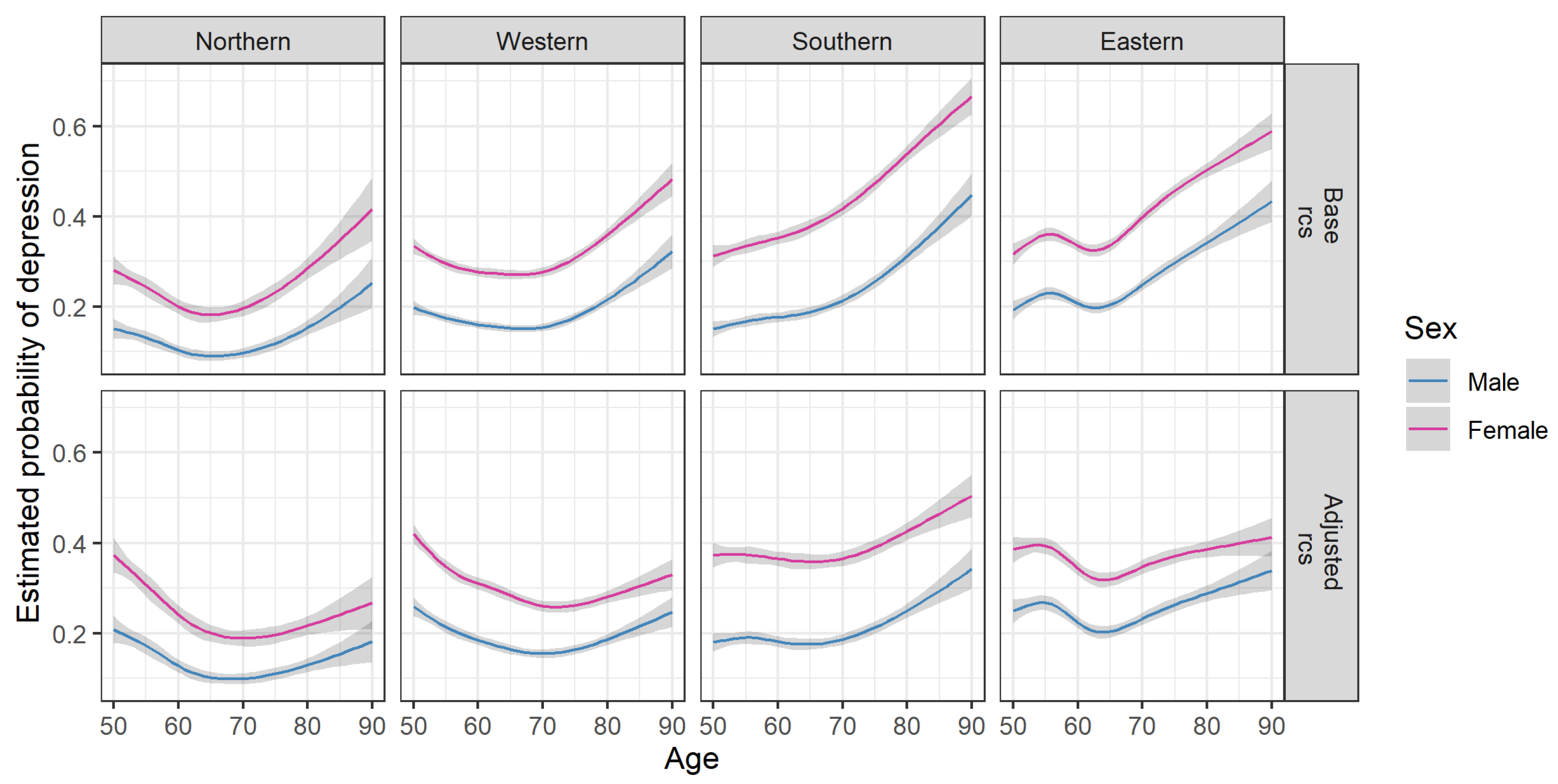
3.3. Analysis of Depressive Symptoms
4. Discussion
4.1. Data Organization
4.2. Data Application: Depression in Older Adults
4.3. Age and Sex Differences in Prevalence of Depression
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SHARE | Survey of Health, Ageing and Retirement in Europe |
| IDA | Initial Data Analysis |
| EURO-D | Europe depression scale |
Appendix A. SHARE Data Organization

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Description | Responder | Waves (1–7) |
|---|---|---|---|
| AC | Activities | all | |
| AS | Assets financial | all | |
| BR | Behavioural risk | all | |
| BS | Blood sample | W6 | |
| CF | Cognitive function | all | |
| CH | Children | family | W2, W5 |
| CM | Household demographics | all | |
| CO | Consumption household | all | |
| CS | Chair stand | all | |
| CV_R | Coverscreen for individuals | all | |
| DN | Demographics and network | all | |
| EP | Employment and pensions | all | |
| EX | Expectations | all | |
| FT | Financial transfers | financial | all |
| GS | Grip strength | all | |
| HC | Health care | all | |
| HH | Household income | household | all |
| HO | Housing household | all | |
| IT | Use of IT technology | W5-7 | |
| IV | Interviewer observations | inteviewer | all |
| LI | Linkage to pension data | all | |
| MC | Mini-childhood | W5 | |
| MH | Mental health | all | |
| PF | Peak flow | W2-3, W6 | |
| PH | Physical health | all | |
| SC | Cover screen | all | |
| SN | Social networks | W4, W6 | |
| SP | Social support | partly family for the couple | all |
| TV | Technical variables | all | |
| WS | Walking speed | W1-2 | |
| XT | End of life | proxy | W2-7 |
| gv_big5 | Big Five personality traits | W7 | |
| gv_children | Combined children information | W6-W7 | |
| gv_dbs | Dried Blood Spots | W6 | |
| gv_deprivation | Indices for material and social deprivation | W5 | |
| gv_grossnet | Net income measures | W1 | |
| gv_health | Physical and mental health | W1-2, W4-7 | |
| gv_housing | Housing and NUTS codes | W1-2, W4-7 | |
| gv_imputations | Imputed values | W1-2, W4-7 | |
| gv_isced | International Standard Classification of Education | W1-2, W4-7 | |
| gv_isco | Classification of occupations | W1 | |
| gv_networks | Information on social networks | W4, W6 | |
| gv_ssw | Social security wealth | W4 | |
| gv_weights | Weights | all |
Appendix B. Data Import with R
Appendix C. Data Application: Depression in Older Adults
Appendix C.1. Analysis of the 12-Item EURO-D Scale
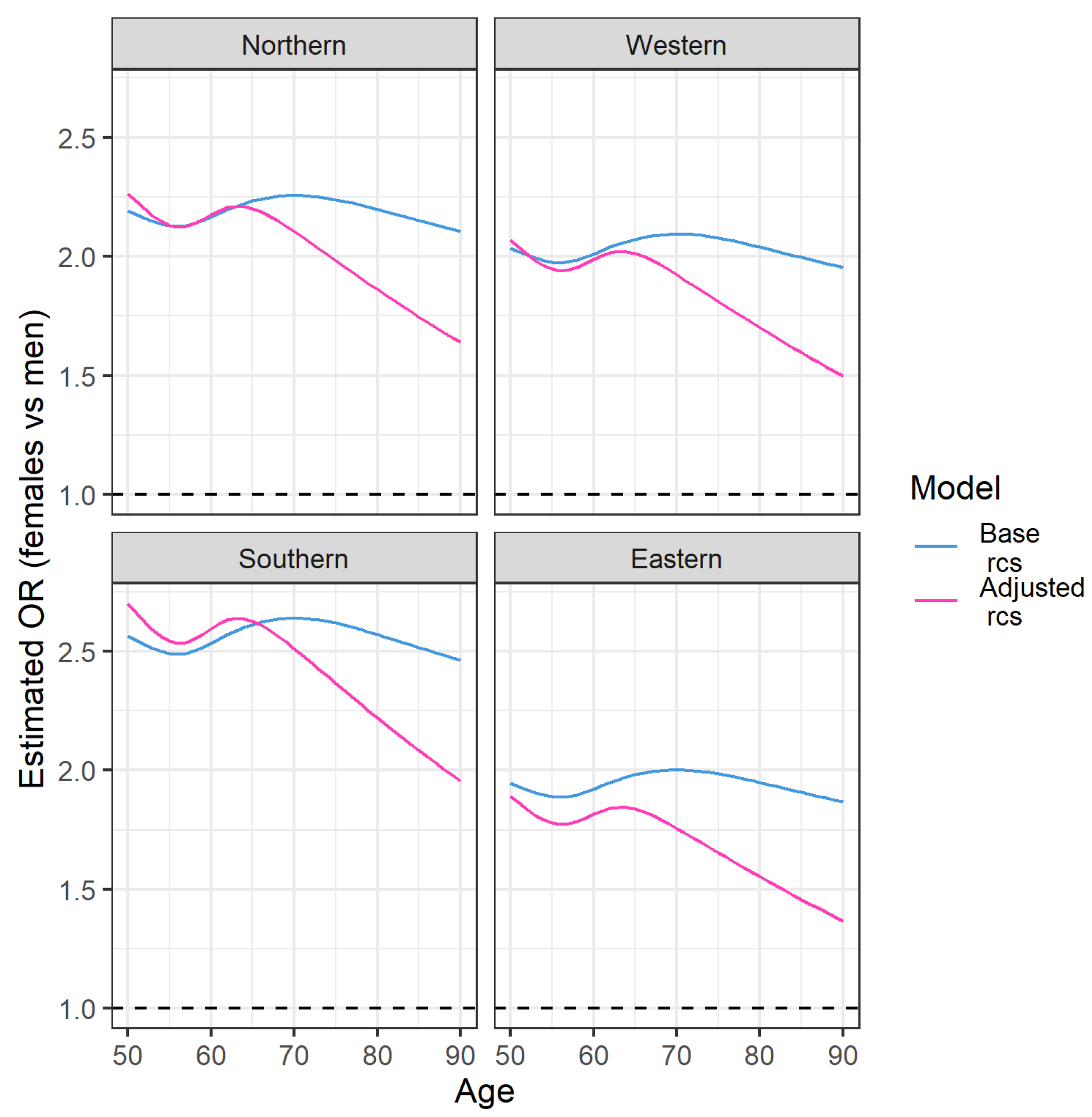
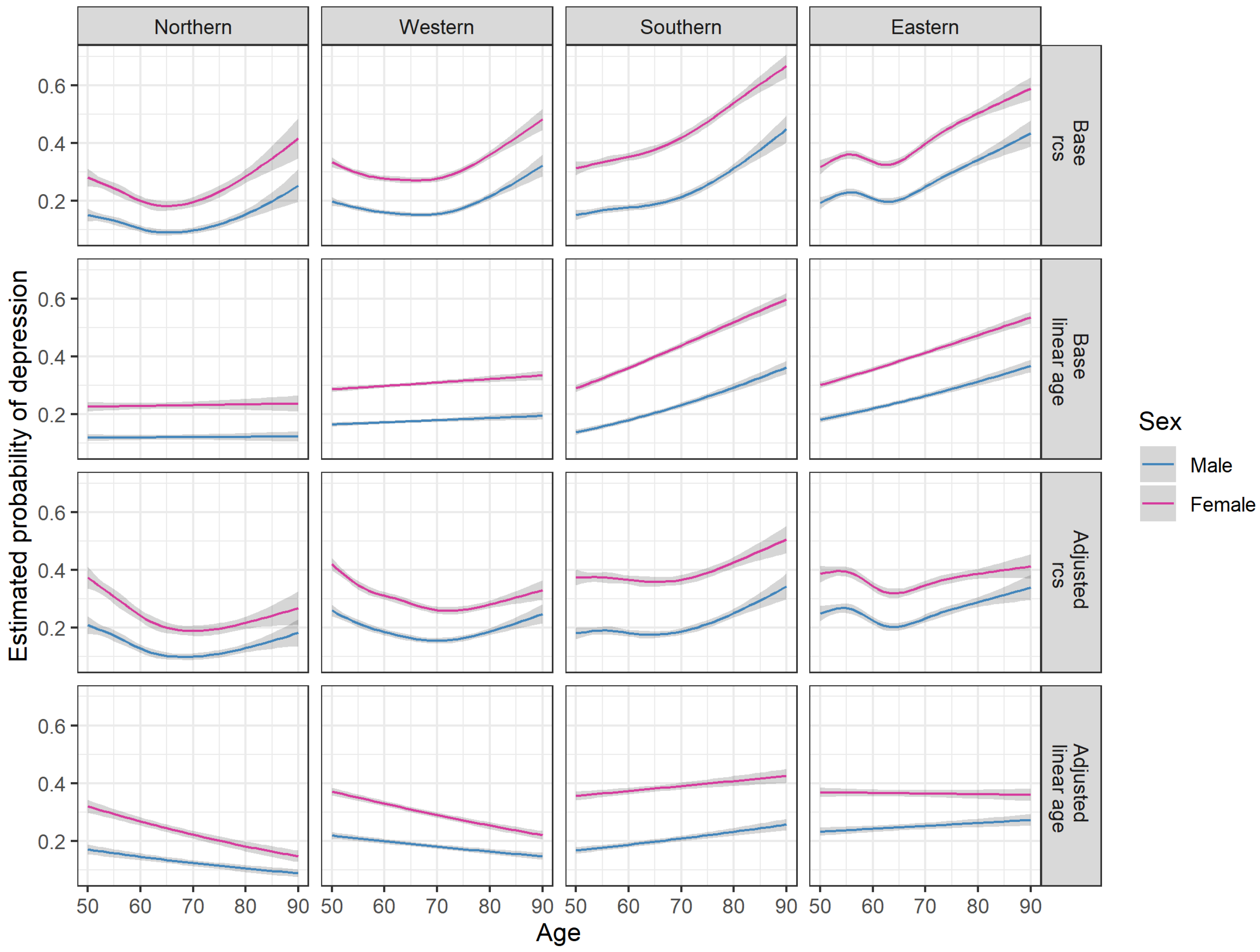
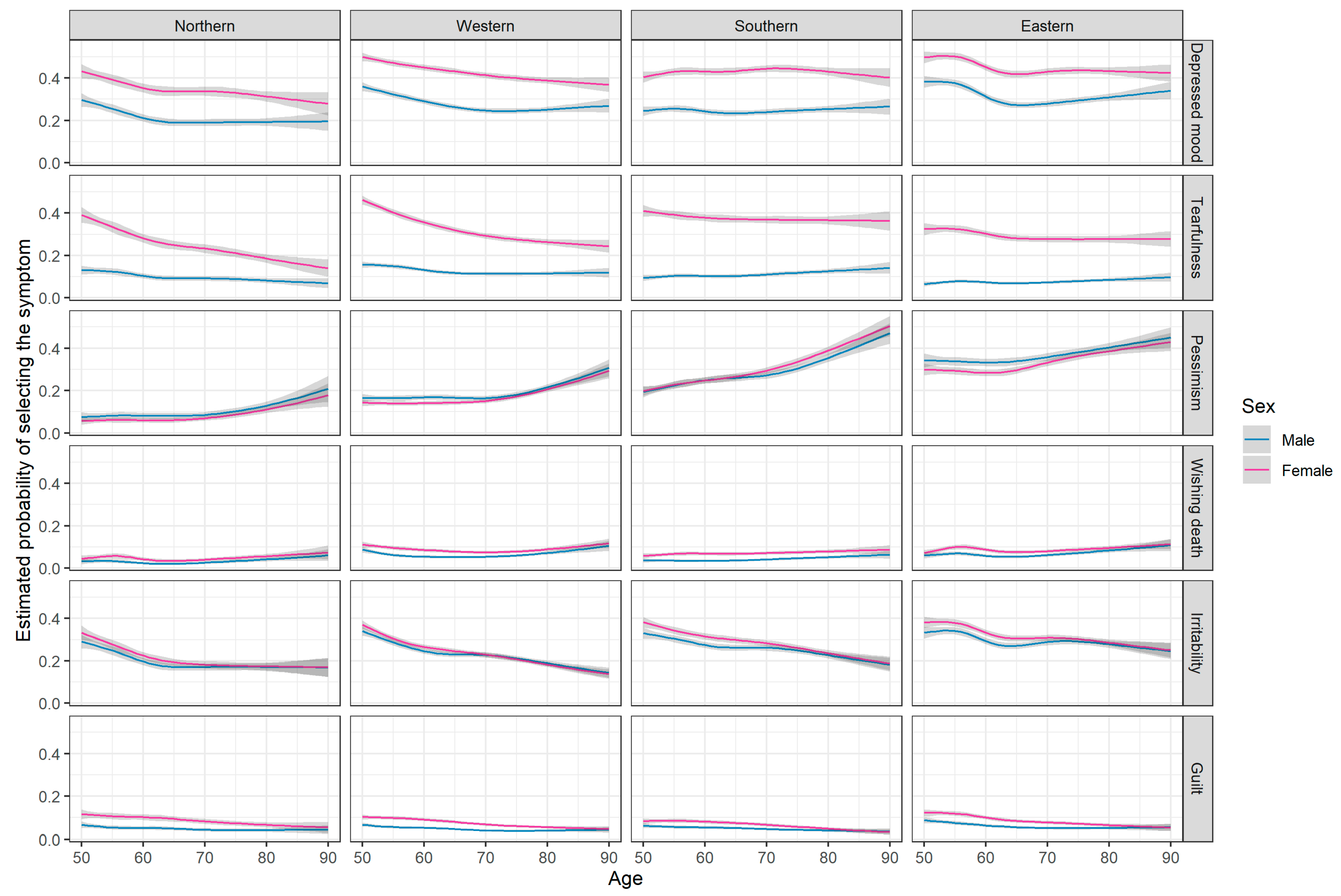
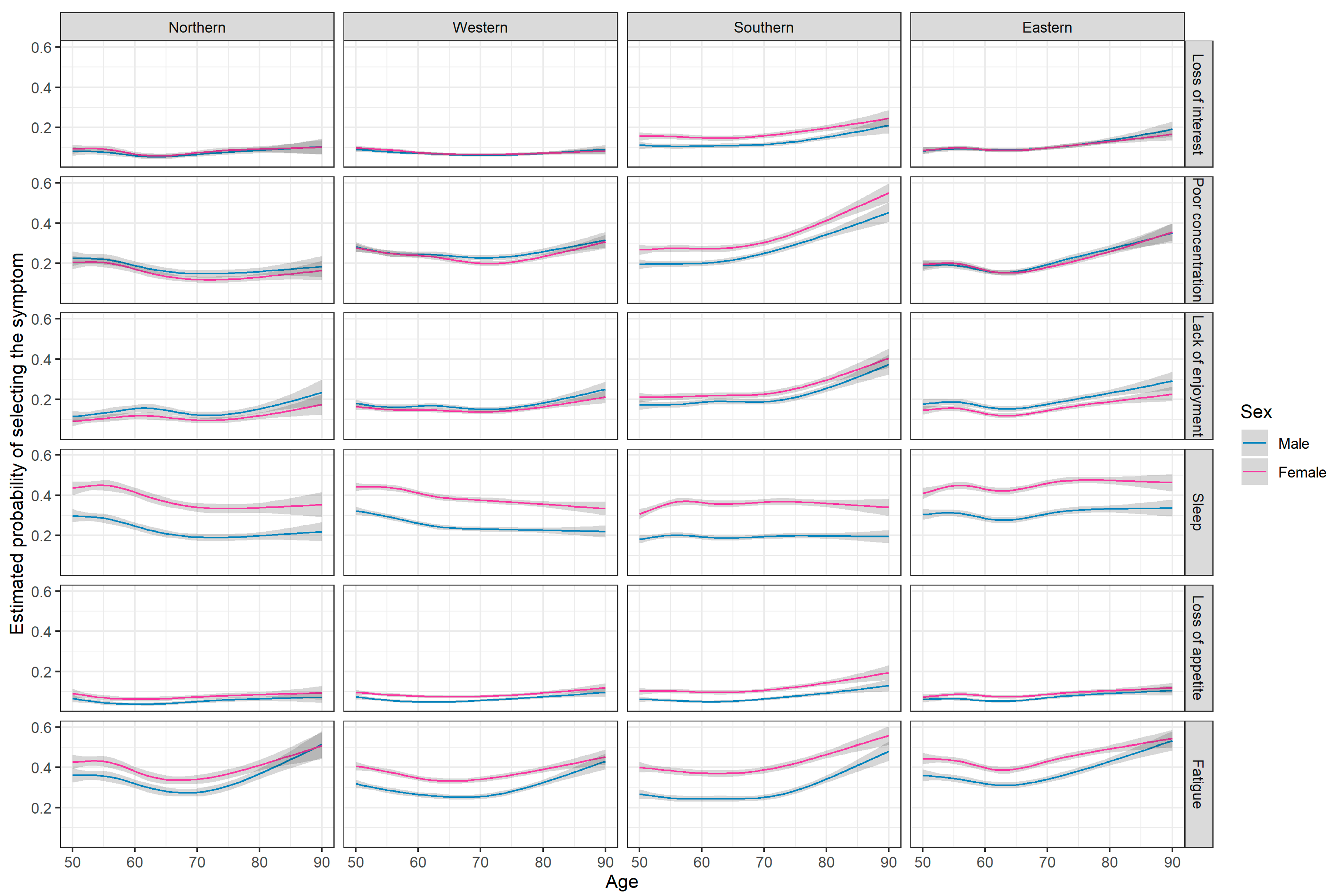
Appendix C.2. Analysis of Single Items of EURO-D
| Overall (n = 104,069) | Northern (n = 11,259) | Western (n = 42,632) | Southern (n = 22,748) | Eastern (n = 27,430) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Male | Female | Male | Female | Male | Female | Male | Female | Male | Female | |
| n = 47,887 | n = 56,182 | n = 5385 | n = 5874 | n = 19,873 | n = 22,759 | n = 10,672 | n = 12,076 | n = 11,957 | n = 15,473 | |
| euro1: Depressed mood | 30% (14,400) | 47% (26,538) | 23% (1255) | 38% (2260) | 31% (6108) | 47% (10,771) | 27% (2873) | 47% (5627) | 35% (4164) | 51% (7880) |
| euro2: Pessimism | 18% (8372) | 18% (10,309) | 6% (326) | 5% (306) | 12% (2429) | 12% (2798) | 22% (2392) | 25% (3008) | 27% (3225) | 27% (4197) |
| euro3: Wishing death | 5% (2499) | 9% (4936) | 3% (143) | 5% (269) | 6% (1119) | 9% (2071) | 4% (463) | 8% (990) | 6% (774) | 10% (1606) |
| euro4: Guilt | 7% (3113) | 10% (5810) | 6% (327) | 12% (680) | 6% (1213) | 10% (2293) | 6% (649) | 9% (1036) | 8% (924) | 12% (1801) |
| euro5: Sleep | 25% (12,198) | 41% (23,138) | 23% (1222) | 38% (2241) | 26% (5073) | 40% (9134) | 20% (2180) | 37% (4508) | 31% (3723) | 47% (7255) |
| euro6: Loss of interest | 8% (3760) | 10% (5587) | 6% (303) | 7% (402) | 6% (1181) | 7% (1602) | 11% (1214) | 16% (1986) | 9% (1062) | 10% (1597) |
| euro7: Irritability | 27% (13,107) | 29% (16,463) | 21% (1111) | 23% (1339) | 26% (5099) | 26% (6012) | 29% (3090) | 31% (3798) | 32% (3807) | 34% (5314) |
| euro8: Loss of appetite | 6% (3044) | 10% (5461) | 5% (262) | 8% (443) | 6% (1158) | 9% (1997) | 7% (773) | 12% (1490) | 7% (851) | 10% (1531) |
| euro9: Fatigue | 29% (13,832) | 39% (21,802) | 29% (1572) | 36% (2094) | 26% (5218) | 35% (7940) | 27% (2903) | 40% (4851) | 35% (4139) | 45% (6917) |
| euro10: Poor concentration | 17% (8021) | 19% (10,721) | 12% (652) | 11% (648) | 17% (3430) | 18% (4148) | 21% (2208) | 28% (3381) | 15% (1731) | 16% (2544) |
| euro11: Lack of enjoyment | 13% (6234) | 13% (7552) | 9% (504) | 8% (452) | 12% (2334) | 12% (2665) | 16% (1756) | 21% (2483) | 14% (1640) | 13% (1952) |
| euro12: Tearfulness | 11% (5440) | 36% (20,045) | 10% (559) | 28% (1646) | 13% (2645) | 36% (8253) | 12% (1259) | 41% (4966) | 8% (977) | 34% (5180) |
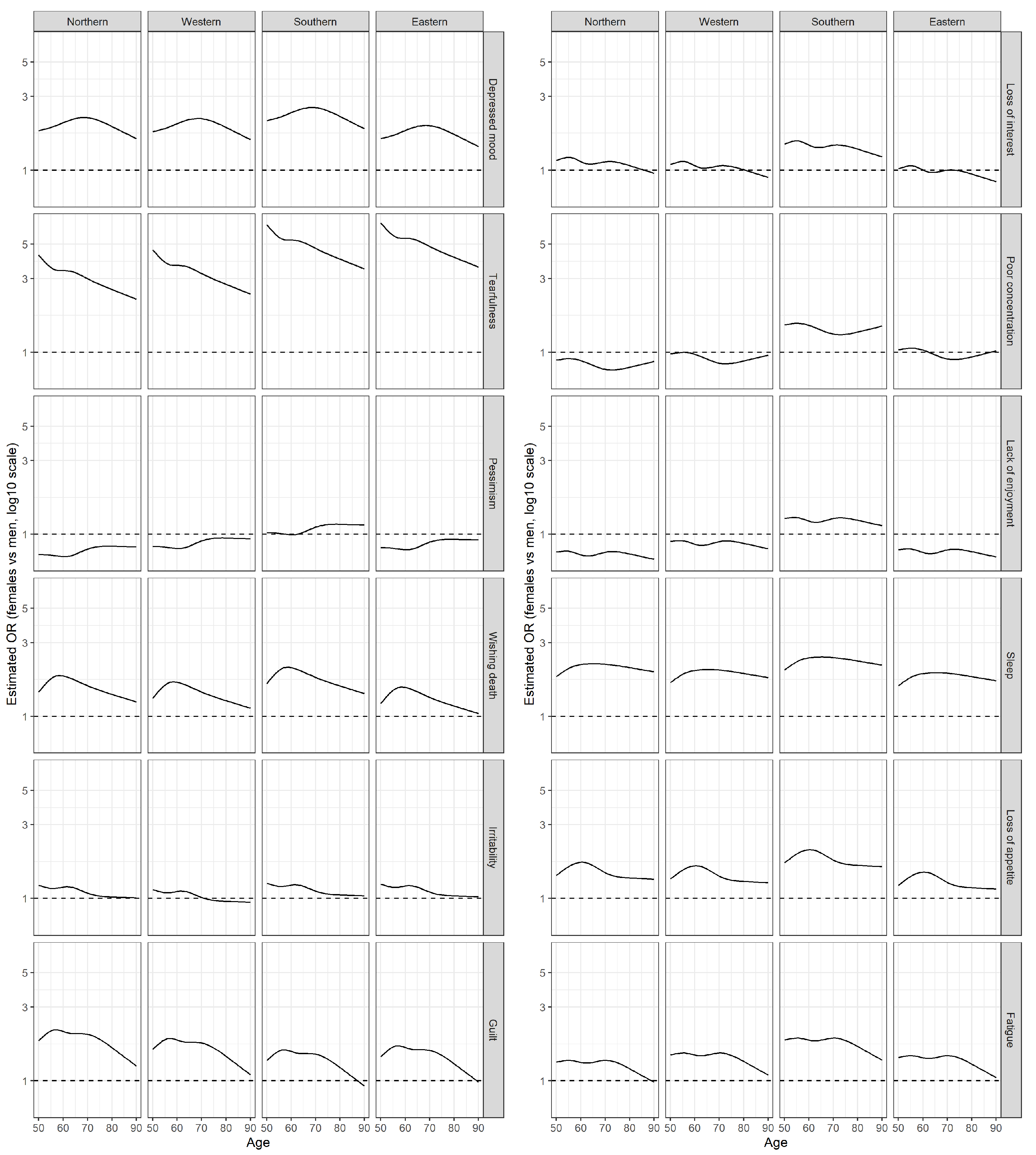
Appendix D. Sampling Design and Weights
References
- Börsch-Supan, A.; Brandt, M.; Hunkler, C.; Kneip, T.; Korbmacher, J.; Malter, F.; Schaan, B.; Stuck, S.; Zuber, S. Data resource profile: The Survey of Health, Ageing and Retirement in Europe (SHARE). Int. J. Epidemiol. 2013, 42, 992–1001. [Google Scholar] [CrossRef] [PubMed]
- Juster, F.; Suzman, R. An overview of the health and retirement study. J. Hum. Resur. 1995, 30, S7–S56. [Google Scholar] [CrossRef]
- Marmot, M.; Banks, J.; Blundell, R.; Lessof, C.; Nazroo, J. Health, Wealth and Lifestyles of the Older Population in England: The 2002 English Longitudinal Study Of Ageing; Institute for Fiscal Studies: London, UK, 2003; ISBN 1903274346. [Google Scholar]
- StataCorp LCC. Stata Statistical Software: Release 17; StataCorp LCC: College Station, TX, USA, 2021. [Google Scholar]
- IBM Corp. IBM SPSS Statistics for Windows, Version 27.0; IBM: Armonk, NY, USA, 2020. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Najsztub, M. READSHARE: Stata Module to Access Survey of Health Ageing and Retirement in Europe (SHARE) Data; Mannheim Research Institute for the Economics of Aging: Mannheim, Germany, 2007. [Google Scholar]
- Albert, P. Why is depression more prevalent in women? J. Psychiatry Neurosci. 2015, 40, 219–221. [Google Scholar] [CrossRef] [PubMed]
- Prince, M.J.; Reischies, F.; Beekman, A.T.; Fuhrer, R.; Jonker, C.; Kivela, S.L.; Lawlor, B.A.; Lobo, A.; Magnusson, H.; Fichter, M.; et al. Development of the EURO–D scale–a European Union initiative to compare symptoms of depression in 14 European centres. Br. J. Psychiatry 1999, 174, 330–338. [Google Scholar] [CrossRef] [PubMed]
- Guerra, M.; Ferri, C.; Llibre, J.; Prina, A.M.; Prince, M. Psychometric properties of EURO-D, a geriatric depression scale: A cross-cultural validation study. BMC Psychiatry 2015, 15, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klevmarken, A.; Hesselius, P.; Swensson, B. The SHARE sampling procedures and calibrated design weights. In The Survey of Health, Ageing, and Retirement in Europe-Methodology; Mannheim Research Institute for the Economics of Aging: Mannheim, Germany, 2005; pp. 28–69. [Google Scholar]
- De Luca, G.; Celidoni, M.; Trevisan, E. Item non response and imputation strategies in SHARE Wave 5. In The Survey of Health, Ageing, and Retirement in Europe-Methodology; Mannheim Research Institute for the Economics of Aging: Mannheim, Germany, 2005; pp. 85–100. [Google Scholar]
- Lusa, L.; Huebner, M. Organizing and Analyzing Data from the SHARE Study; OSF: Charlottesville, VA, USA, 2021. [Google Scholar] [CrossRef]
- Goodman, R.; Posner, S.; Huang, E.; Prekh, A.; Koh, H. Defining and Measuring Chronic Conditions: Imperatives for Research, Policy, Program, and Practice. Prev. Chronic Dis. 2013, 10, E66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Portela, D.; Almada, M.; Midão, L.; Costa, E. Instrumental Activities of Daily Living (iADL) Limitations in Europe: An Assessment of SHARE Data. Int. J. Environ. Res. Public Health 2020, 17, 7387. [Google Scholar] [CrossRef] [PubMed]
- Crimmins, E.M.; Kim, J.K.; Solé-Auró, A. Gender differences in health: Results from SHARE, ELSA and HRS. Eur. J. Public Health 2011, 21, 81–91. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paykel, E.; Brugha, T.; Fryers, T. Size and burden of depressive disorders in Europe. Eur. Neuropsychopharmacol. 2005, 15, 411–423. [Google Scholar] [CrossRef] [PubMed]
- Gallagher, D.; Savva, G.M.; Kenny, R.; Lawlor, B.A. What predicts persistent depression in older adults across Europe? Utility of clinical and neuropsychological predictors from the SHARE study. J. Affect. Disord. 2013, 147, 192–197. [Google Scholar] [CrossRef] [PubMed]
- Harrell, F.J.; Lee, K.; Pollock, B. Regression models in clinical studies: Determining relationships between predictors and response. J. Natl. Cancer Inst. 1988, 80, 1199–1202. [Google Scholar]
- Huebner, M.; le Cessie, S.; Schmidt, C.; Vach, W. A Contemporary Conceptual Framework for Initial Data Analysis. Obs. Stud. 2018, 4, 171–192. [Google Scholar] [CrossRef]
- Schmidt, C.O.; Struckmann, S.; Enzenbach, C.; Reineke, A.; Stausberg, J.; Damerow, S.; Huebner, M.; Schmidt, B.; Sauerbrei, W.; Richter, A. Facilitating harmonized data quality assessments. A data quality framework for observational health research data collections with software implementations in R. BMC Med. Res. Methodol. 2021, 21, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Van den Broeck, J.; Argeseanu Cunningham, S.; Eeckels, R.; Herbst, K. Data Cleaning: Detecting, Diagnosing, and Editing Data Abnormalities. PLoS Med. 2005, 2, e267. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Andreas, S.; Dehoust, M.; Volkert, J.; Schulz, H.; Sehner, S.; Suling, A.; Wegscheider, K.; Ausín, B.; Canuto, A.; Crawford, M.; et al. Affective disorders in the elderly in different European countries: Results from the MentDis_ICF65+ study. PLoS ONE 2019, 14, e0224871. [Google Scholar] [CrossRef] [PubMed]
- Copeland, J.; Beekman, A.; Braam, A.; Dewey, M.; Delespaul, P.; Fuhrer, R.; Hooijer, C.; Lawlor, B.; Kivela, S.; Lobo, A.; et al. Depression among older people in Europe: The EURODEP studies. World Psychiatry 2004, 3, 45–49. [Google Scholar] [PubMed]
- Fiske, A.; Wetherell, J.L.; Gatz, M. Depression in Older Adults. Annu. Rev. Clin. Psychol. 2009, 5, 363–389. [Google Scholar] [CrossRef] [PubMed]
- SHARE. SHARE Release Guide 7.1.1; SHARE Mannheim Research Institute for the Economics of Aging: Mannheim, Germany, 2020. [Google Scholar]
- Lumley, T. Survey: Analysis of Complex Survey Samples; R Package Version 4.0; John Wiley & Sons: Hoboken, NJ, USA, 2020. [Google Scholar]
- Lumley, T. Complex Surveys: A Guide to Analysis Using R; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 565. [Google Scholar]

| First Interview | Northern | Western | Southern | Eastern |
|---|---|---|---|---|
| Wave 1 | 4268 | 13,940 | 6861 | 0 |
| Wave 2 | 1821 | 4489 | 2638 | 4762 |
| Wave 4 | 498 | 13,149 | 4695 | 15,529 |
| Wave 5 | 4320 | 9178 | 4667 | 2439 |
| Wave 6 | 352 | 1875 | 3882 | 4698 |
| Wave 7 | 0 | 1 | 5 | 2 |
| Overall (n = 104,069) | Northern (n = 11,259) | Western (n = 42,632) | Southern (n = 22,748) | Eastern (n = 27,430) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Male | Female | Male | Female | Male | Female | Male | Female | Male | Female | |
| n = 47,887 | n = 56,182 | n = 5385 | n = 5874 | n = 19,873 | n = 22,759 | n = 10,672 | n = 12,076 | n = 11,957 | n = 15,473 | |
| Age Md (Q1, Q3) | 63 (56, 71) | 62 (55, 71) | 63 (56, 71) | 62 (55, 70) | 62 (55, 70) | 62 (55, 70) | 63 (56, 71) | 62 (55, 71) | 63 (57,71) | 63 (56, 72) |
| Age groups: 50–59 | 39% (18,529) | 41% (22,775) | 38% (2056) | 42% (2438) | 41% (8231) | 43% (9782) | 37% (3947) | 40% (4870) | 36% (4295) | 37% (5685) |
| 60–69 | 34% (16,082) | 31% (17,627) | 34% (1825) | 33% (1925) | 33% (6466) | 30% (6866) | 33% (3551) | 31% (3784) | 35% (4240) | 33% (5052) |
| 70–80 | 22% (10,676) | 22% (12,330) | 22% (1187) | 20% (1199) | 21% (4173) | 21% (4712) | 24% (2537) | 22% (2681) | 23% (2779) | 24% (3738) |
| 80+ | 5% (600) | 6% (3450) | 6% (317) | 5% (312) | 6% (637) | 6% (741) | 6% (637) | 6% (741) | 5% (643) | 6% (998) |
| Education: Low | 38% (18,000) | 46% (25,811) | 30% (1641) | 33% (1956) | 28% (5655) | 40% (9082) | 66% (7085) | 73% (8814) | 30% (3619) | 39% (5959) |
| Medium | 39% (18,693) | 35% (19,785) | 38% (2059) | 31% (1836) | 42% (8317) | 38% (8732) | 19% (2072) | 17% (2028) | 52% (6245) | 46% (7189) |
| High | 23% (11,004) | 18% (10,332) | 31% (1651) | 35% (2042) | 29% (5797) | 21% (4822) | 14% (1479) | 10% (1183) | 17% (2077) | 15% (2285) |
| Other | 0% (190) | 0% (254) | 1% (34) | 1% (40) | 1% (104) | 1% (123) | 0% (36) | 0% (51) | 0% (16) | 0% (40) |
| BMI Md (Q1, Q3) | 27 (24, 29) | 26 (23, 29) | 26 (24, 28) | 25 (23, 28) | 26 (24, 29) | 25 (23, 29) | 27 (25, 29) | 26 (23, 29) | 27 (25, 30) | 27 (24, 30) |
| Living alone: Yes | 19% (9253) | 34% (19,189) | 21% (1114) | 30% (1764) | 21% (4269) | 35% (7891) | 14% (1513) | 29% (3505) | 20% (2357) | 39% (6029) |
| Vigorous PA: >1 a week | 41% (19,449) | 32% (17,897) | 50% (2716) | 41% (2432) | 43% (8496) | 35% (8000) | 32% (3461) | 25% (3042) | 40% (4776) | 29% (4423) |
| Once a week | 14% (6519) | 14% (8094) | 14% (732) | 15% (874) | 14% (2856) | 15% (3341) | 12% (1264) | 14% (1681) | 14% (1667) | 14% (2198) |
| 1–3 times a month | 10% (4664) | 10% (5339) | 9% (461) | 8% (448) | 8% (1684) | 7% (1677) | 11% (1144) | 13% (1517) | 11% (1375) | 11% (1697) |
| Hardly ever, or never | 36% (17,255) | 44% (24,852) | 27% (1476) | 36% (2120) | 34% (6837) | 43% (9741) | 45% (4803) | 48% (5836) | 35% (4139) | 46% (7155) |
| Current smoking: Yes | 24% (11,313) | 17% (9311) | 20% (1055) | 21% (1213) | 22% (4399) | 16% (3748) | 25% ( 2656) | 14% (1738) | 27% (3203) | 17% (2612) |
| Chronic diseases: 0 | 47% (22,270) | 49% (27,346) | 49% (2620) | 52% (3071) | 49% (9716) | 53% (12,088) | 49% (5194) | 51% (6132) | 40% (4740) | 39% (6055) |
| 1 | 34% (16,250) | 34% (18,918) | 33% (1758) | 33% (1917) | 33% (6605) | 33% (7398) | 34% (3664) | 34% (4090) | 35% (4223) | 36% (5513) |
| 2+ | 20% (9367) | 18% (9918) | 19% (1007) | 15% (886) | 17% (1814) | 15% (1854) | 17% (1814) | 15% (1854) | 25% (2994) | 25% (3905) |
| IADL: 1+ | 11% (5117) | 18% (10,052) | 8% (446) | 14% (806) | 10% (1953) | 17% (3793) | 10% (1051) | 18% (2226) | 14% (1667) | 21% (3227) |
| EURO-D | 19% (9167) | 34% (18,845) | 12% (646) | 23% (1347) | 17% (3460) | 30% (6864) | 21% (2189) | 39% (4724) | 24% (2872) | 38% (5910) |
| OR | 95% CI LL | 95% CI UL | p-Value | |
|---|---|---|---|---|
| BMI (10 units) | 1.02 | 0.99 | 1.06 | 0.17 |
| Education: Low | 1 | |||
| Medium | 0.75 | 0.72 | 0.77 | <0.01 |
| High | 0.64 | 0.61 | 0.66 | <0.01 |
| Other | 0.98 | 0.79 | 1.22 | 0.87 |
| Current smoking: Yes | 1.24 | 1.20 | 1.29 | <0.01 |
| Chronic diseases: 0 | 1 | |||
| 1 | 1.45 | 1.40 | 1.50 | <0.01 |
| 2+ | 2.52 | 2.41 | 2.62 | <0.01 |
| Vigorous PA : >1 a week | 1 | |||
| Once a week | 1.03 | 0.98 | 1.08 | 0.19 |
| 1–3 times a month | 1.11 | 1.05 | 1.17 | <0.01 |
| Hardly ever, or never | 1.78 | 1.72 | 1.85 | <0.01 |
| Living alone: Yes | 1.41 | 1.37 | 1.46 | <0.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lusa, L.; Huebner, M. Organizing and Analyzing Data from the SHARE Study with an Application to Age and Sex Differences in Depressive Symptoms. Int. J. Environ. Res. Public Health 2021, 18, 9684. https://doi.org/10.3390/ijerph18189684
Lusa L, Huebner M. Organizing and Analyzing Data from the SHARE Study with an Application to Age and Sex Differences in Depressive Symptoms. International Journal of Environmental Research and Public Health. 2021; 18(18):9684. https://doi.org/10.3390/ijerph18189684
Chicago/Turabian StyleLusa, Lara, and Marianne Huebner. 2021. "Organizing and Analyzing Data from the SHARE Study with an Application to Age and Sex Differences in Depressive Symptoms" International Journal of Environmental Research and Public Health 18, no. 18: 9684. https://doi.org/10.3390/ijerph18189684
APA StyleLusa, L., & Huebner, M. (2021). Organizing and Analyzing Data from the SHARE Study with an Application to Age and Sex Differences in Depressive Symptoms. International Journal of Environmental Research and Public Health, 18(18), 9684. https://doi.org/10.3390/ijerph18189684