
One-Year Lesson: Machine Learning Prediction of COVID-19 Positive Cases with Meteorological Data and Mobility Estimate in Japan



Abstract
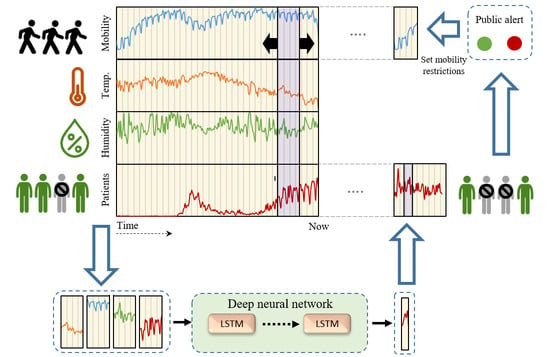
1. Introduction
2. Related Work
3. Materials and Methods
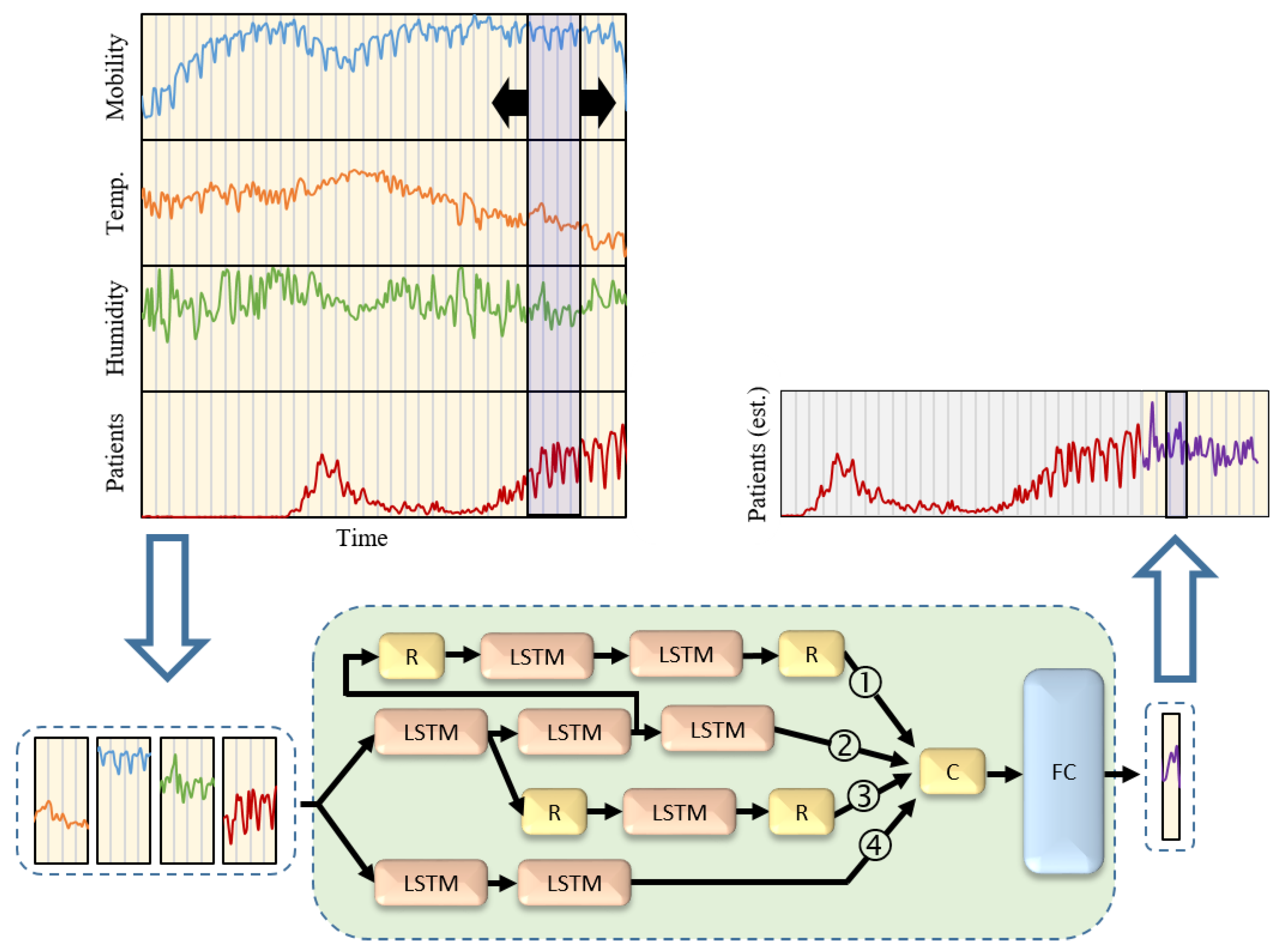
3.1. Daily Positive Cases
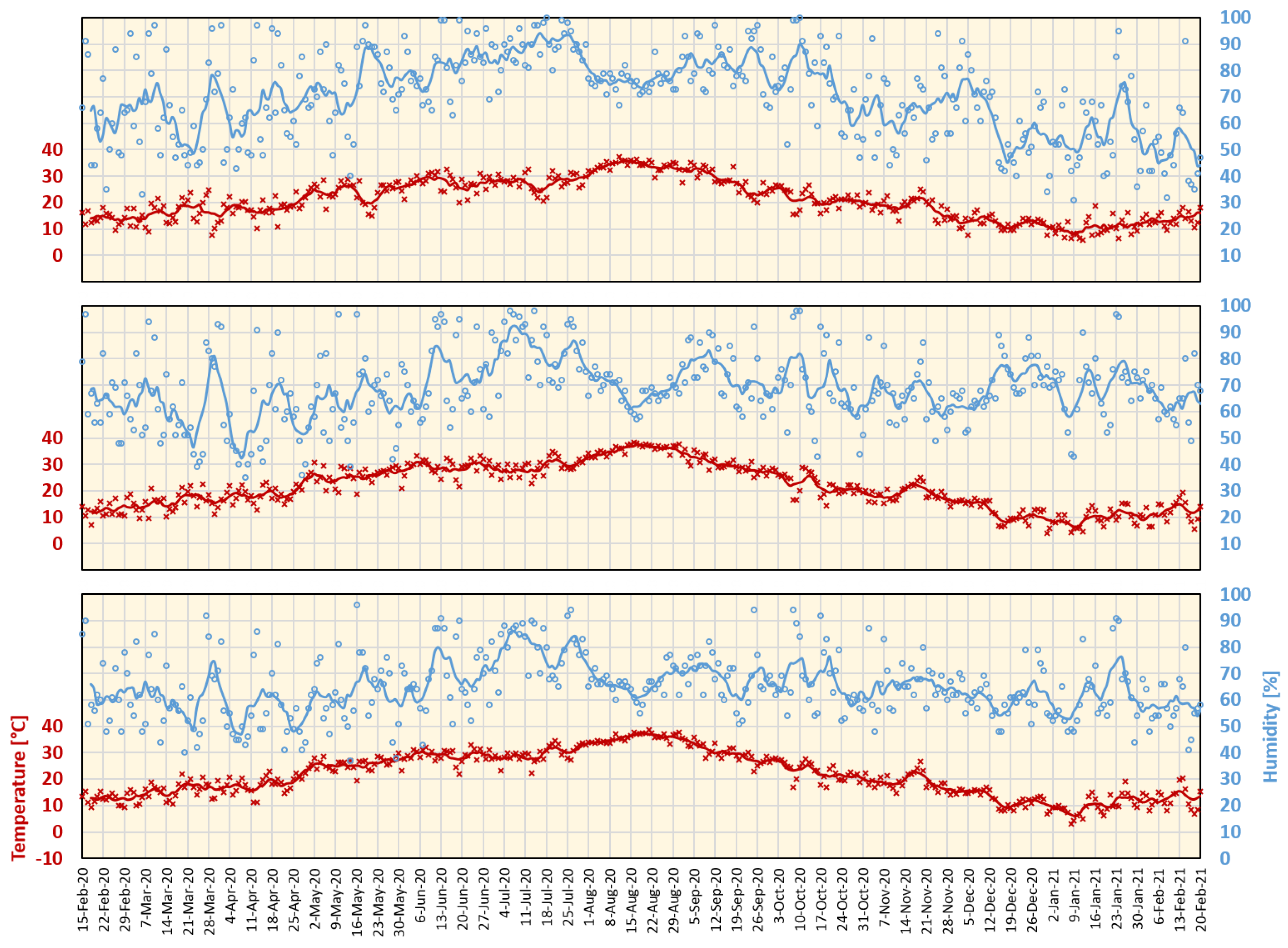
3.2. Meteorological Data
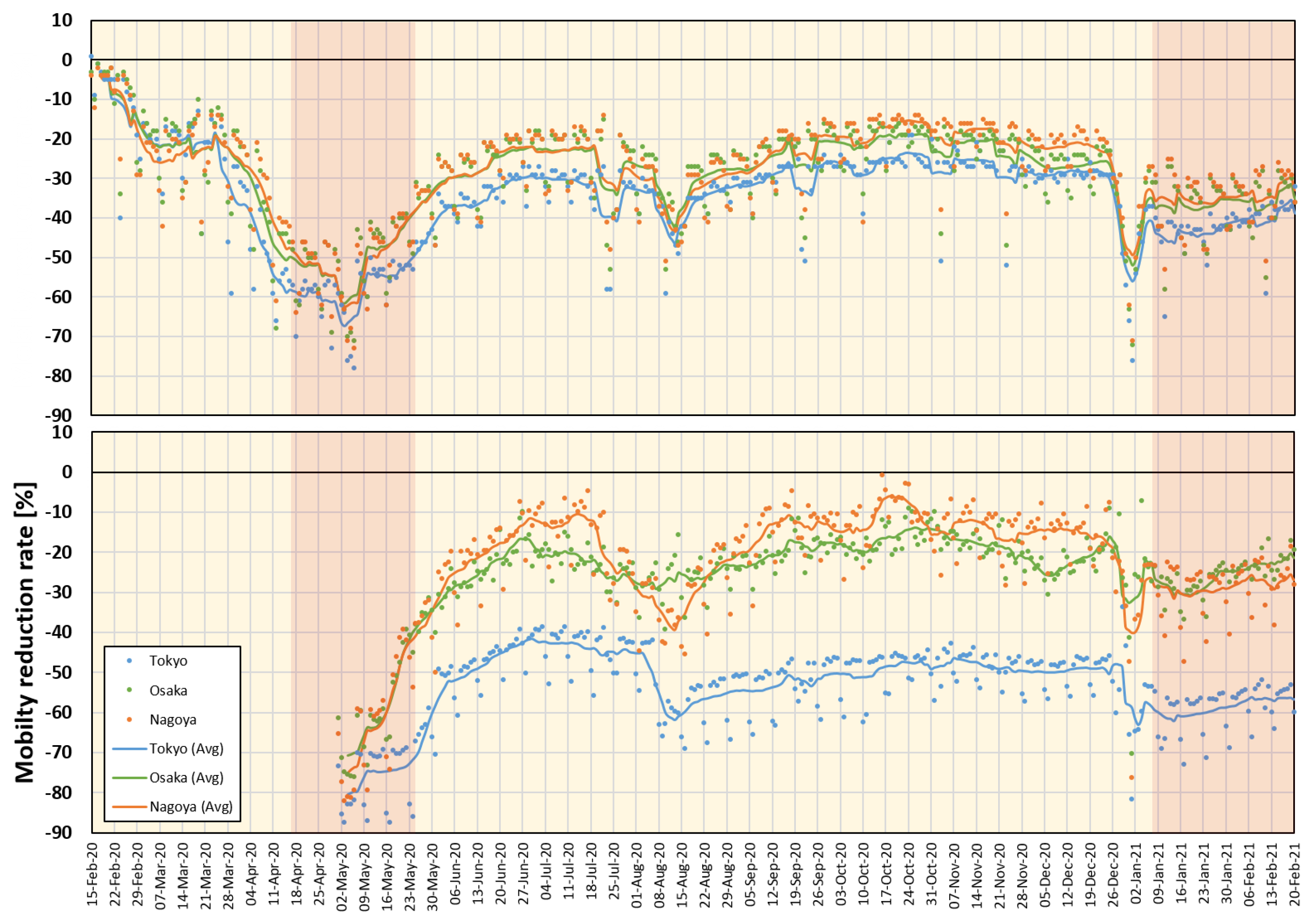
3.3. Mobility Data
3.4. Google Cloud Forecast
3.5. Proposed COVID-19 Prediction Framework
3.6. Evaluation Metrics
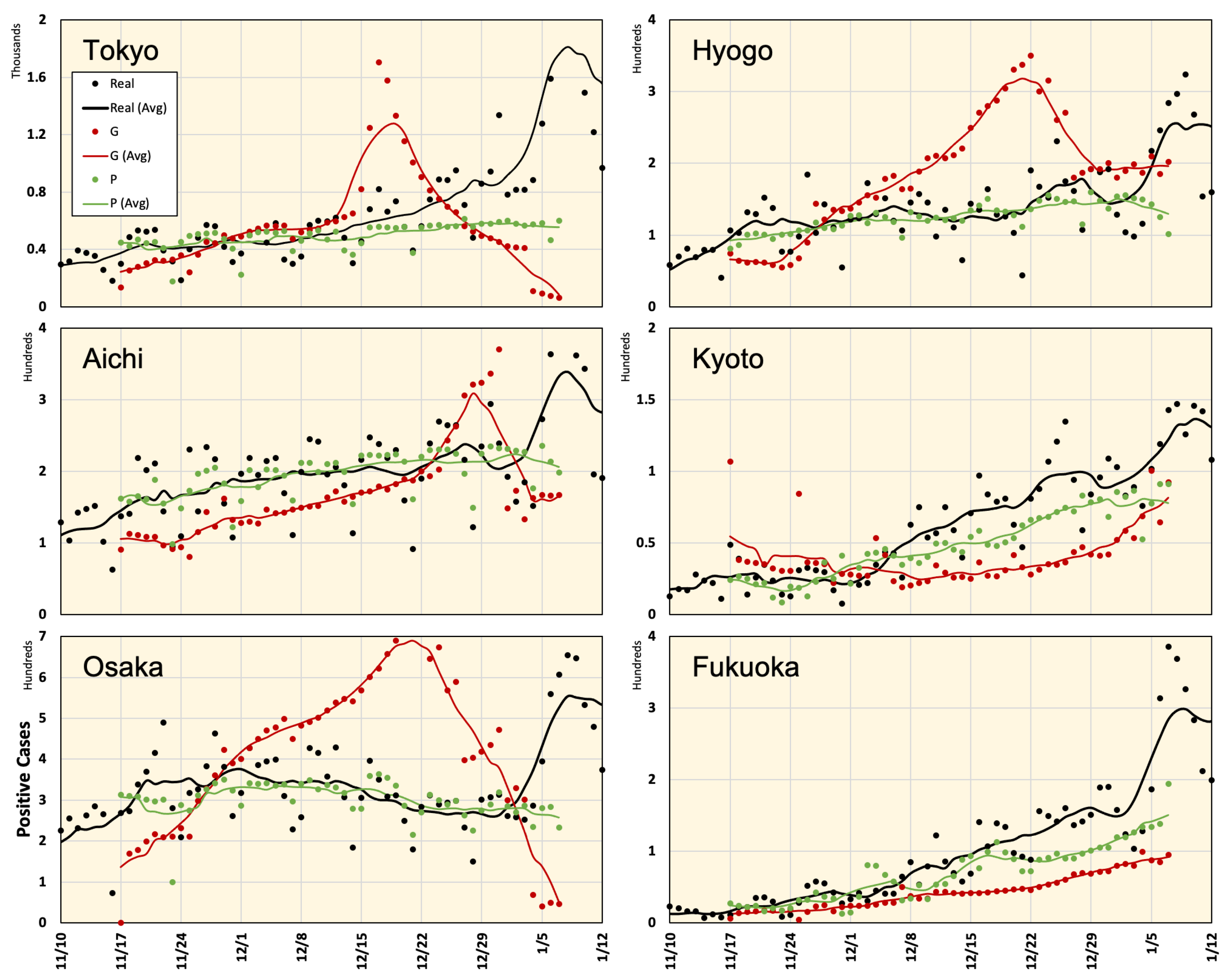
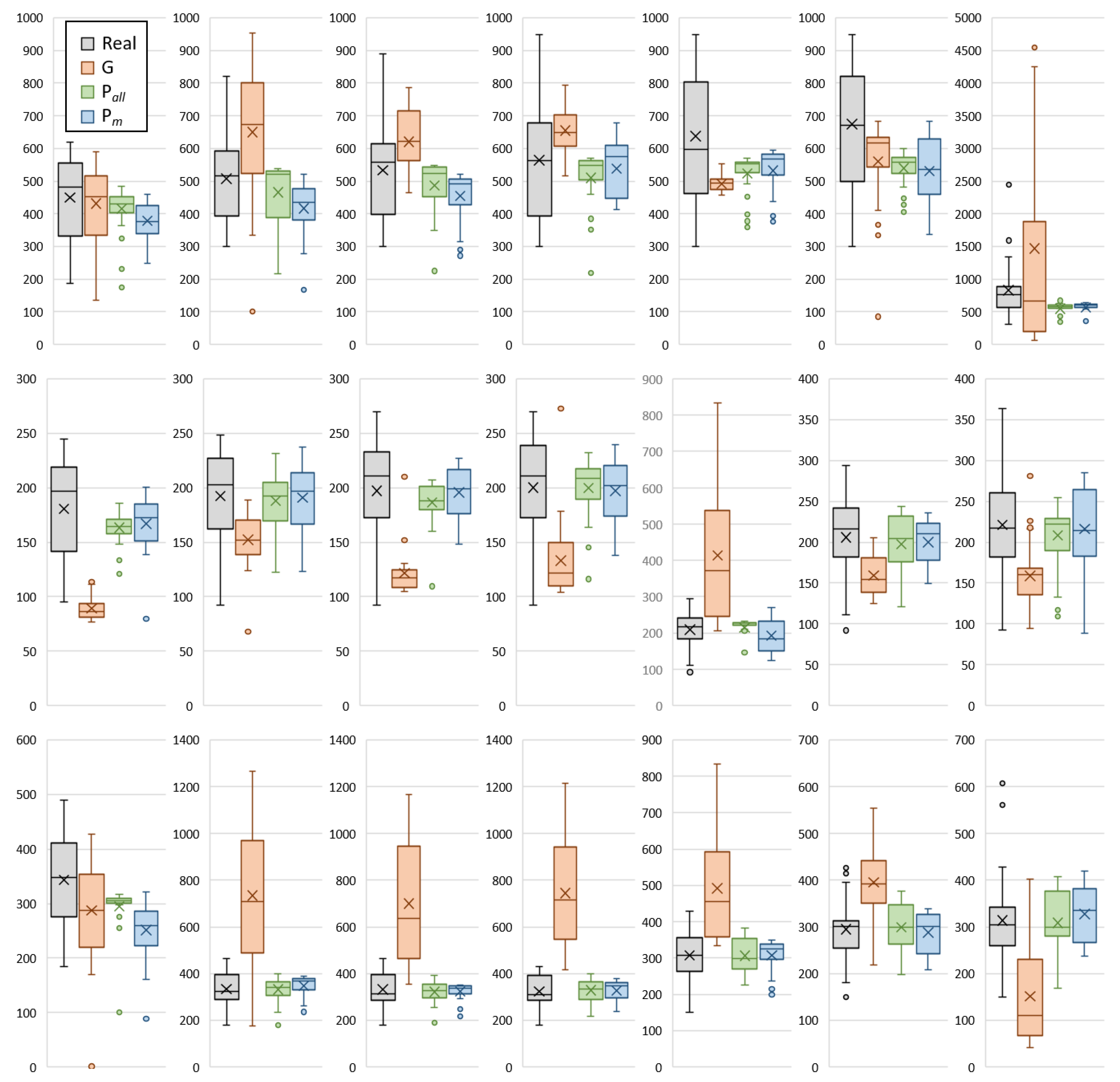
4. Results
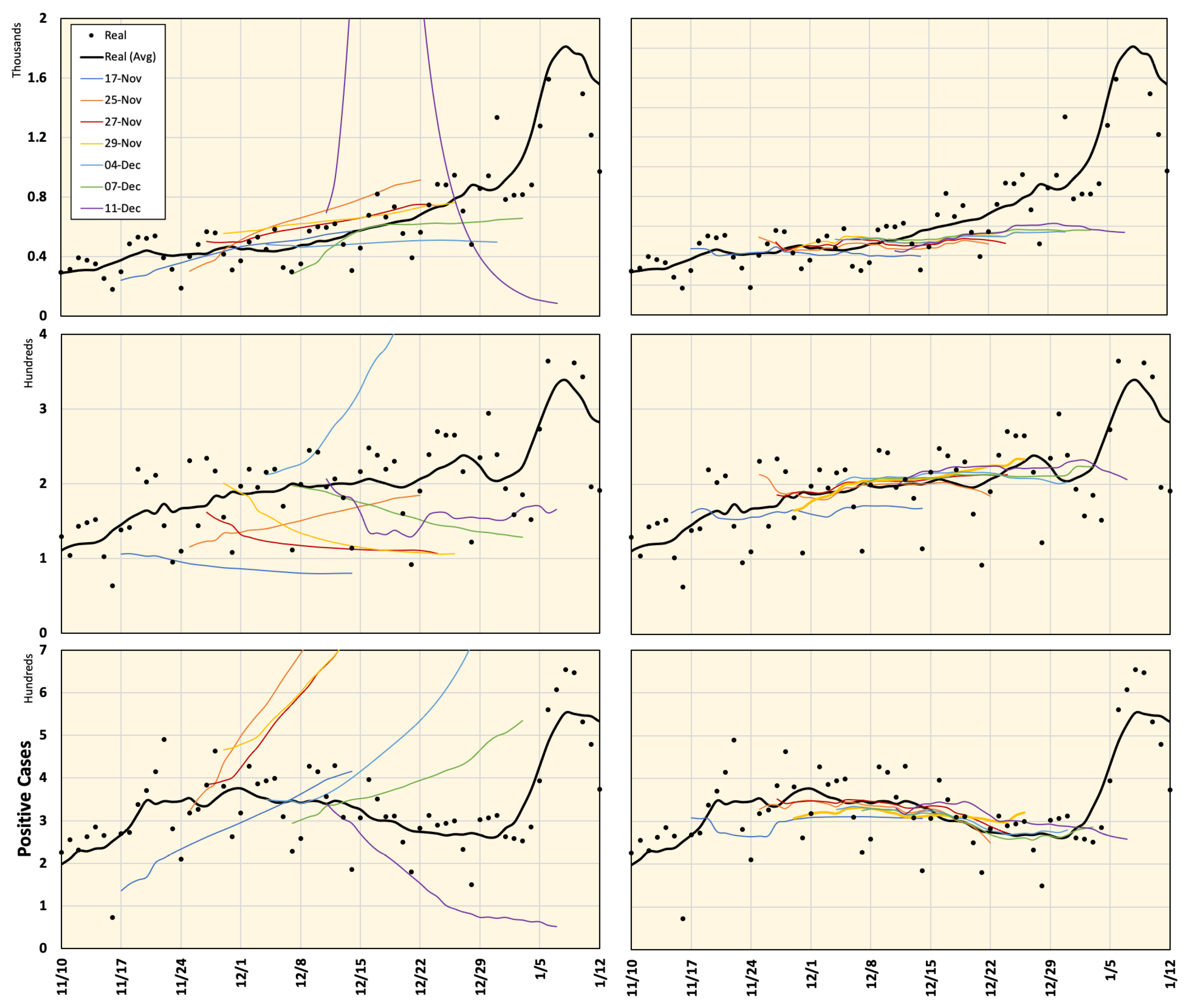
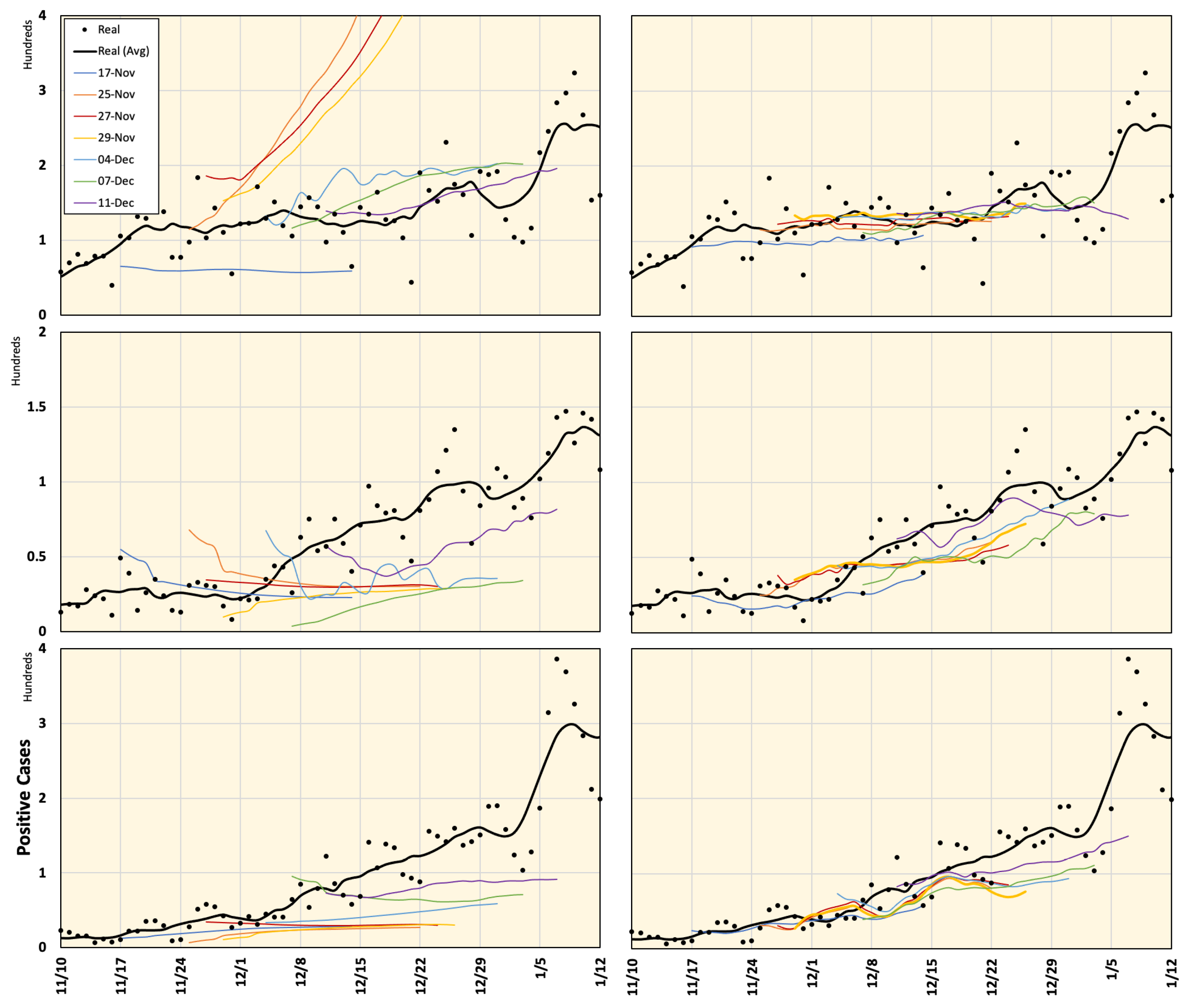
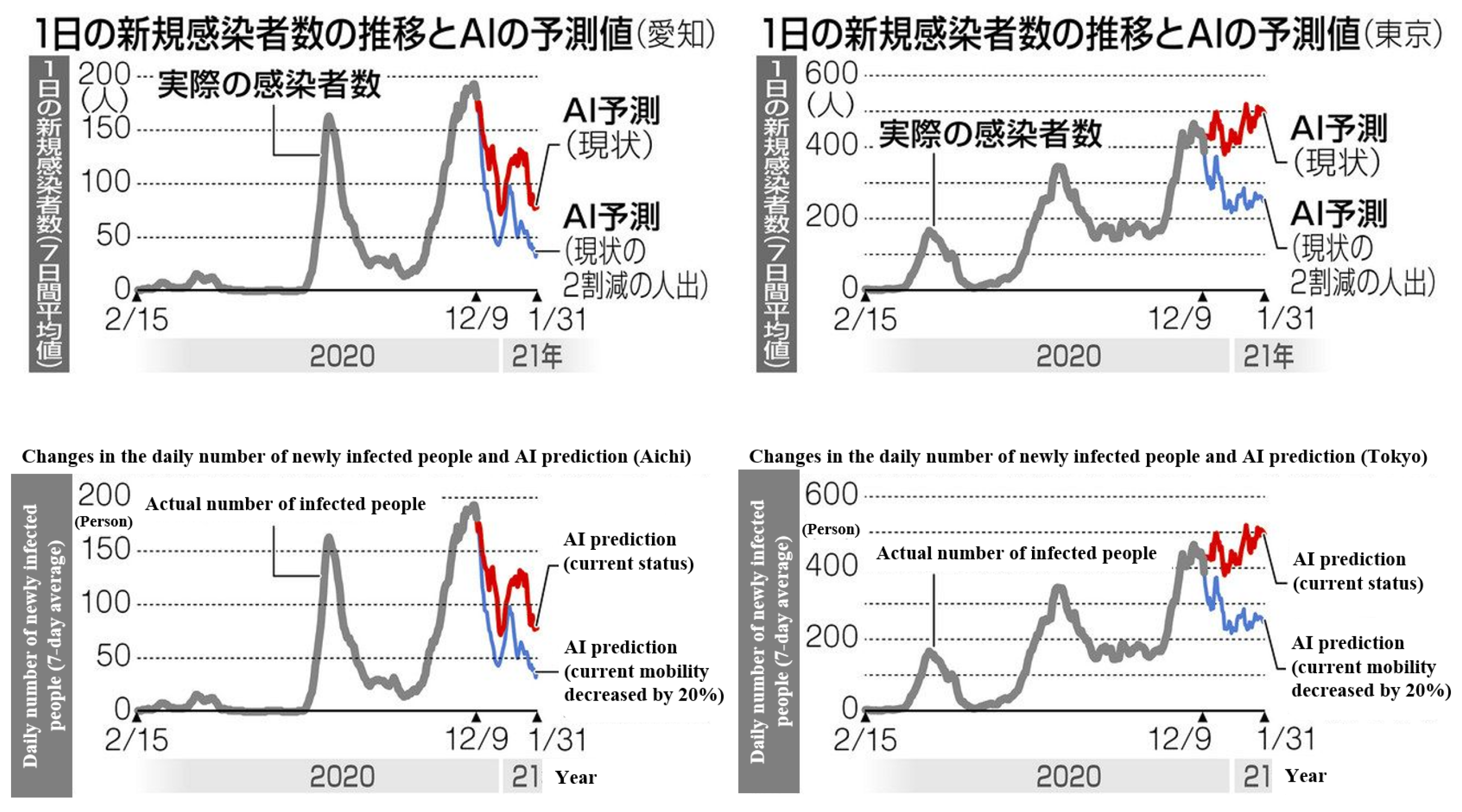
4.1. Prediction of Positive Cases
4.2. Influence of Meteorological Factors
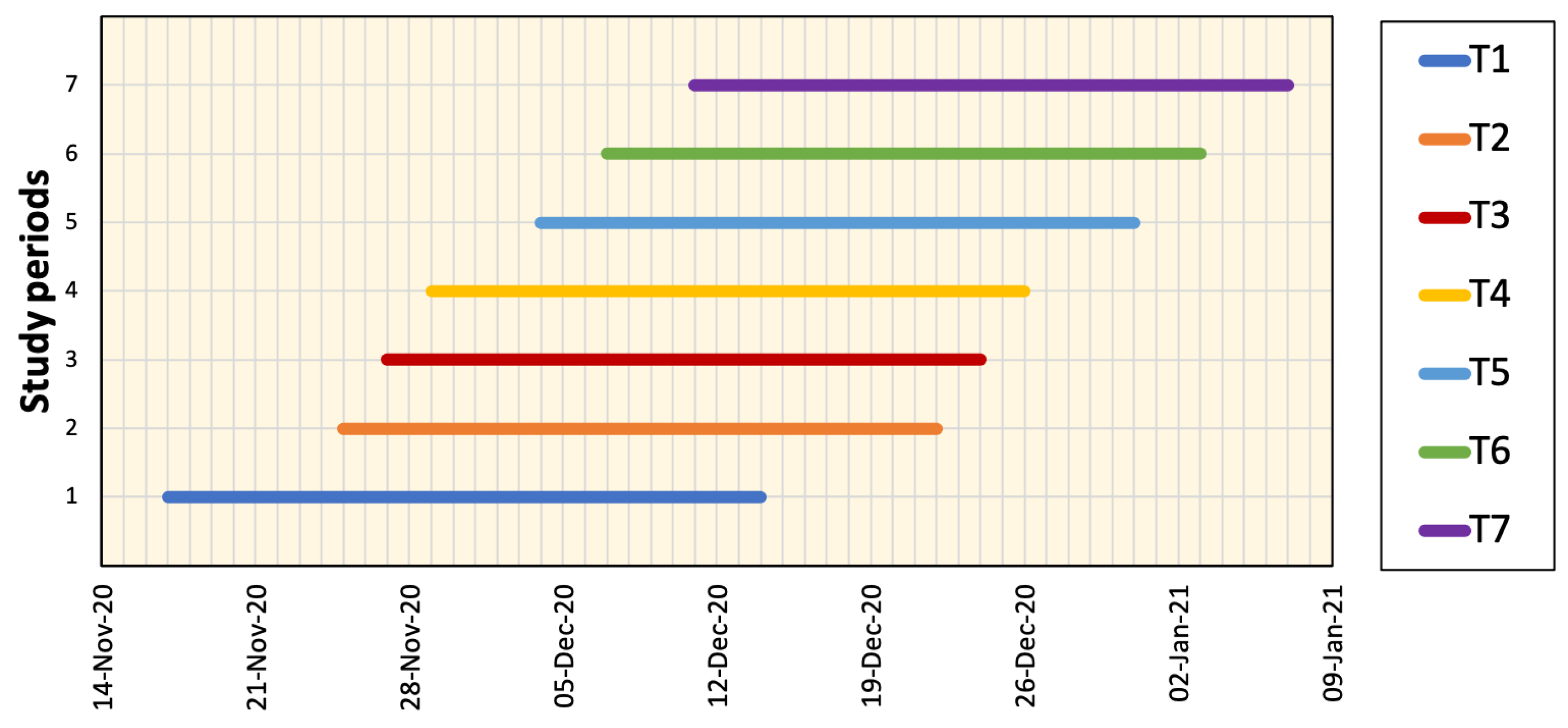
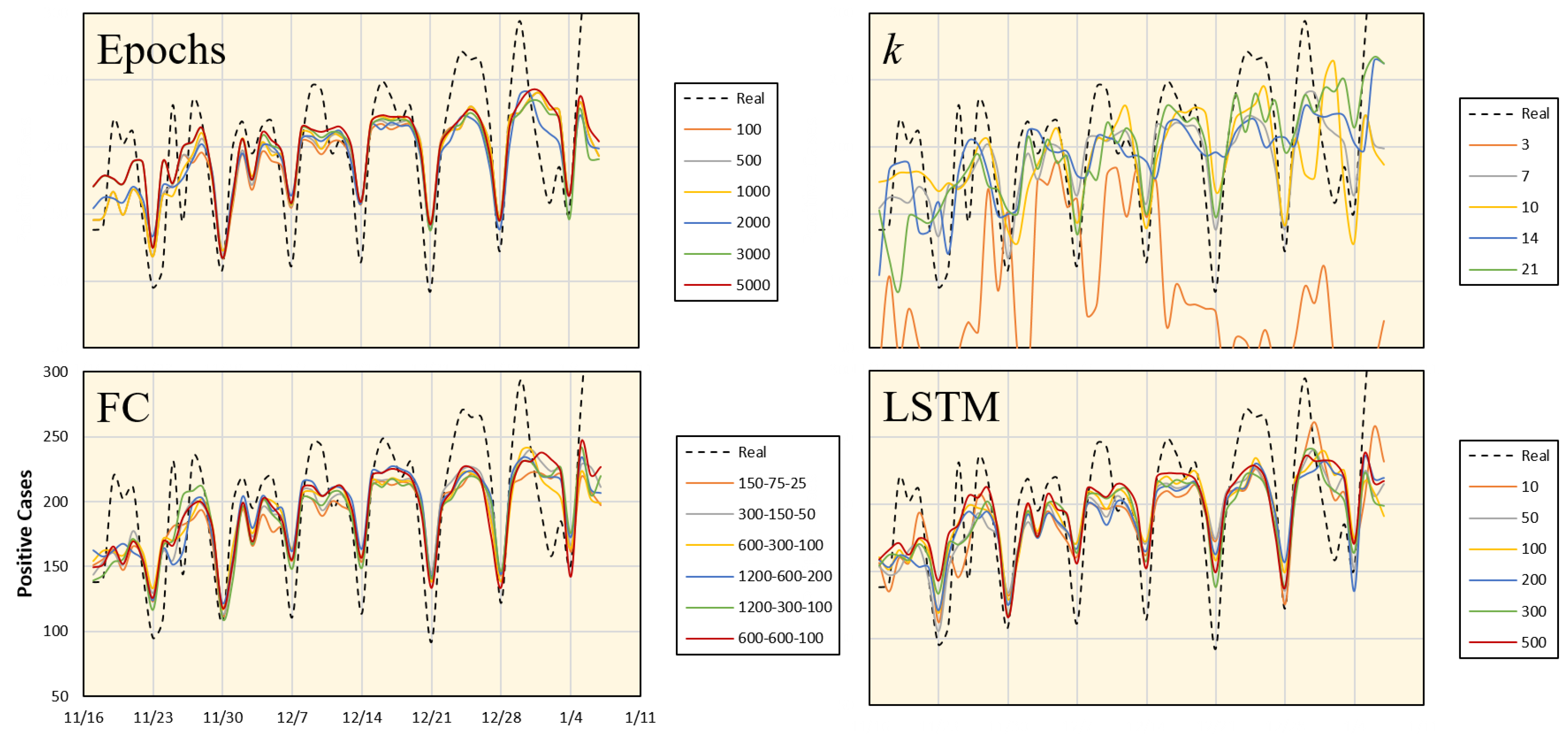
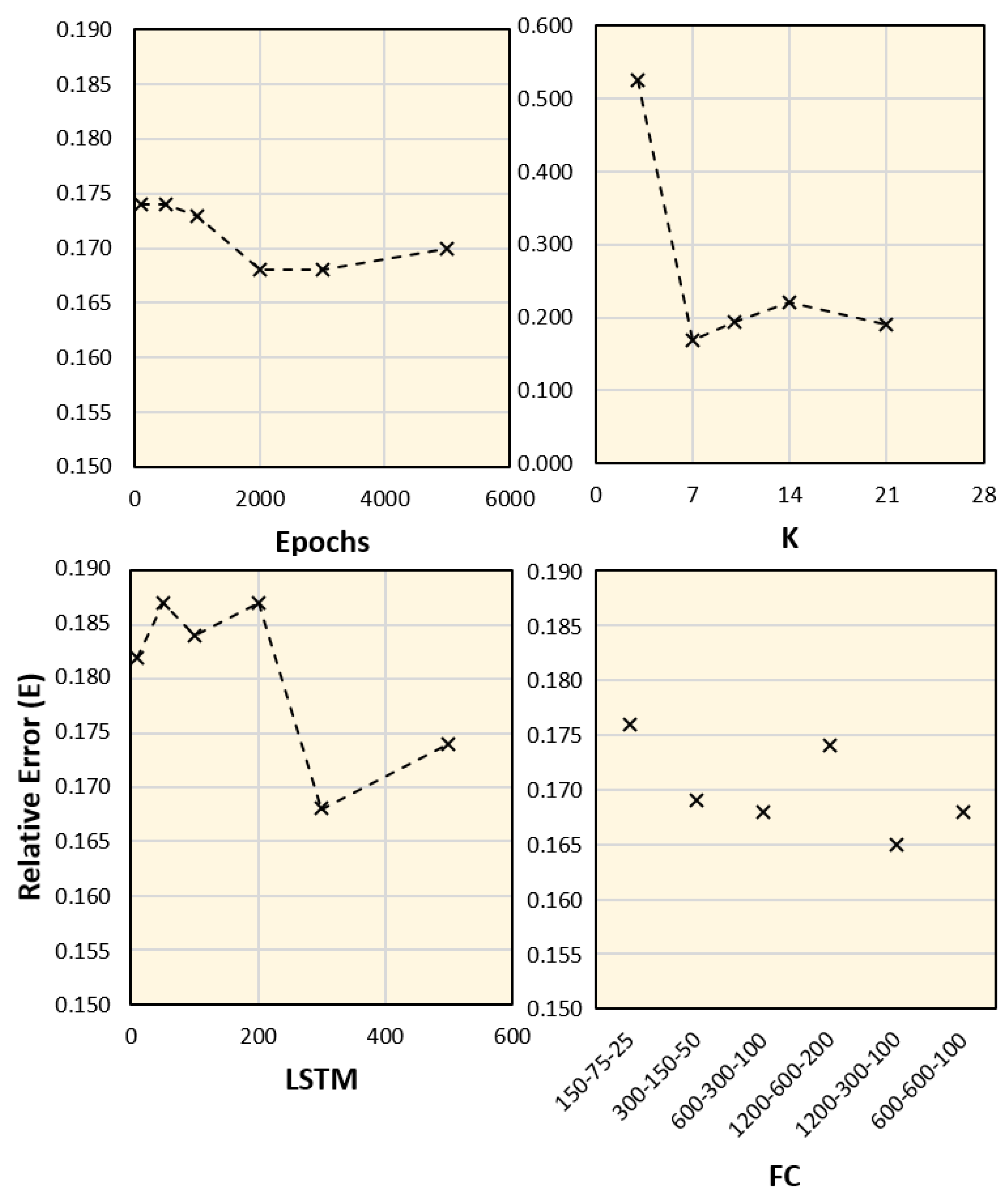
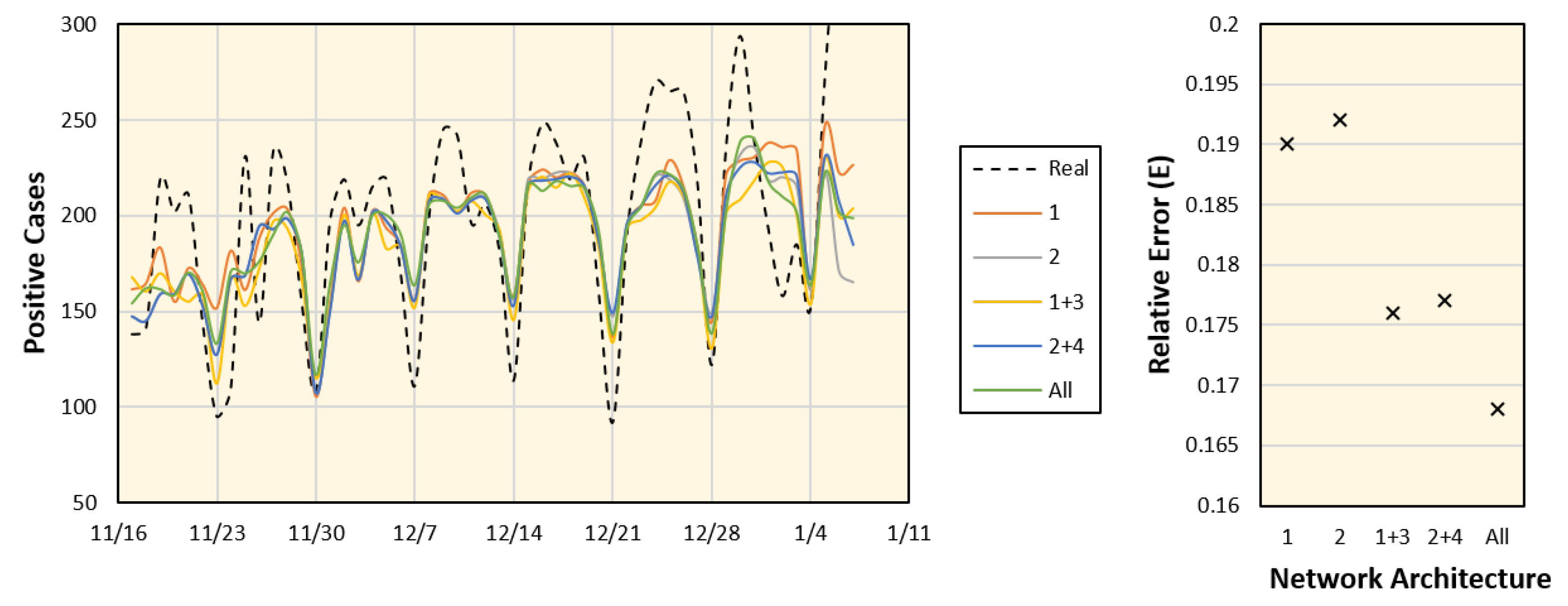
4.3. Parameter Validation and Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Wu, Y.; Jing, W.; Liu, J.; Ma, Q.; Yuan, J.; Wang, Y.; Du, M.; Liu, M. Effects of temperature and humidity on the daily new cases and new deaths of COVID-19 in 166 countries. Sci. Total Environ. 2020, 729, 139051. [Google Scholar] [CrossRef]
- Sarkodie, S.A.; Owusu, P.A. Impact of meteorological factors on COVID-19 pandemic: Evidence from top 20 countries with confirmed cases. Environ. Res. 2020, 191, 110101. [Google Scholar] [CrossRef]
- Salom, I.; Rodic, A.; Milicevic, O.; Zigic, D.; Djordjevic, M.; Djordjevic, M. Effects of Demographic and Weather Parameters on COVID-19 Basic Reproduction Number. Front. Ecolol. Evol. 2021, 8, 524. [Google Scholar] [CrossRef]
- Shaffiee Haghshenas, S.; Pirouz, B.; Shaffiee Haghshenas, S.; Pirouz, B.; Piro, P.; Na, K.S.; Cho, S.E.; Geem, Z.W. Prioritizing and Analyzing the Role of Climate and Urban Parameters in the Confirmed Cases of COVID-19 Based on Artificial Intelligence Applications. Int. J. Environ. Res. Public Health 2020, 17, 3730. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, J.; Yao, J.; Zhang, X.; Li, L.; Xu, X.; He, X.; Wang, B.; Fu, S.; Niu, T.; et al. Impact of meteorological factors on the COVID-19 transmission: A multi-city study in China. Sci. Total Environ. 2020, 726, 138513. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Guo, X.; Pan, H.; Zhong, S. What determines city’s resilience against epidemic outbreak: Evidence from China’s COVID-19 experience. Sustain. Cities Soc. 2021, 70, 102892. [Google Scholar] [CrossRef] [PubMed]
- Verity, R.; Okell, L.C.; Dorigatti, I.; Winskill, P.; Whittaker, C.; Imai, N.; Cuomo-Dannenburg, G.; Thompson, H.; Walker, P.G.; Fu, H.; et al. Estimates of the severity of coronavirus disease 2019: A model-based analysis. Lancet Infect. Dis. 2020, 20, 669–677. [Google Scholar] [CrossRef]
- Flaxman, S.; Mishra, S.; Gandy, A.; Unwin, H.J.T.; Mellan, T.A.; Coupland, H.; Whittaker, C.; Zhu, H.; Berah, T.; Eaton, J.W.; et al. Estimating the effects of non-pharmaceutical interventions on COVID-19 in Europe. Nature 2020, 584, 257–261. [Google Scholar] [CrossRef] [PubMed]
- Ceylan, Z. Estimation of COVID-19 prevalence in Italy, Spain, and France. Sci. Total Environ. 2020, 729, 138817. [Google Scholar] [CrossRef] [PubMed]
- Zhan, C.; Tse, C.K.; Fu, Y.; Lai, Z.; Zhang, H. Modeling and prediction of the 2019 coronavirus disease spreading in China incorporating human migration data. PLoS ONE 2020, 15, e0241171. [Google Scholar] [CrossRef]
- da Silva, R.G.; Ribeiro, M.H.D.M.; Mariani, V.C.; dos Santos Coelho, L. Forecasting Brazilian and American COVID-19 cases based on artificial intelligence coupled with climatic exogenous variables. Chaos Solitons Fractals 2020, 139, 110027. [Google Scholar] [CrossRef]
- Rahimi, I.; Chen, F.; Gandomi, A.H. A Review on COVID-19 Forecasting Models. Neural Comput. Appl. 2021, 20, 1–11. [Google Scholar] [CrossRef]
- Mousavi, M.; Salgotra, R.; Holloway, D.; Gandomi, A.H. COVID-19 Time Series Forecast Using Transmission Rate and Meteorological Parameters as Features. IEEE Comput. Intell. Mag. 2020, 15, 34–50. [Google Scholar] [CrossRef]
- Pinter, G.; Felde, I.; Mosavi, A.; Ghamisi, P.; Gloaguen, R. COVID-19 Pandemic Prediction for Hungary; A Hybrid Machine Learning Approach. Mathematics 2020, 8, 890. [Google Scholar] [CrossRef]
- Wanyan, T.; Vaid, A.; De Freitas, J.K.; Somani, S.; Miotto, R.; Nadkarni, G.N.; Azad, A.; Ding, Y.; Glicksberg, B.S. Relational Learning Improves Prediction of Mortality in COVID-19 in the Intensive Care Unit. IEEE Trans. Big Data 2021, 7, 38–44. [Google Scholar] [CrossRef] [PubMed]
- Devaraj, J.; Madurai Elavarasan, R.; Pugazhendhi, R.; Shafiullah, G.; Ganesan, S.; Jeysree, A.K.; Khan, I.A.; Hossain, E. Forecasting of COVID-19 cases using deep learning models: Is it reliable and practically significant? Results Phys. 2021, 21, 103817. [Google Scholar] [CrossRef] [PubMed]
- Rashed, E.A.; Kodera, S.; Shirakami, H.; Kawaguchi, R.; Watanabe, K.; Hirata, A. Knowledge discovery from emergency ambulance dispatch during COVID-19: A case study of Nagoya City, Japan. J. Biomed. Inform. 2021, 117, 103743. [Google Scholar] [CrossRef] [PubMed]
- Rustam, F.; Reshi, A.A.; Mehmood, A.; Ullah, S.; On, B.; Aslam, W.; Choi, G.S. COVID-19 Future Forecasting Using Supervised Machine Learning Models. IEEE Access 2020, 8, 101489–101499. [Google Scholar] [CrossRef]
- Kumar, P.; Kalita, H.; Patairiya, S.; Sharma, Y.D.; Nanda, C.; Rani, M.; Rahmani, J.; Bhagavathula, A.S. Forecasting the dynamics of COVID-19 pandemic in top 15 countries in April 2020: ARIMA model with machine learning approach. MedRxiv 2020. [Google Scholar] [CrossRef]
- Wang, P.; Zheng, X.; Li, J.; Zhu, B. Prediction of epidemic trends in COVID-19 with logistic model and machine learning technics. Chaos Solitons Fractals 2020, 139, 110058. [Google Scholar] [CrossRef]
- Prem, K.; Liu, Y.; Russell, T.W.; Kucharski, A.J.; Eggo, R.M.; Davies, N.; Flasche, S.; Clifford, S.; Pearson, C.A.; Munday, J.D.; et al. The effect of control strategies to reduce social mixing on outcomes of the COVID-19 epidemic in Wuhan, China: A modelling study. Lancet Public Health 2020, 5, e261–e270. [Google Scholar] [CrossRef]
- Arik, S.O.; Li, C.L.; Yoon, J.; Sinha, R.; Epshteyn, A.; Le, L.T.; Menon, V.; Singh, S.; Zhang, L.; Yoder, N.; et al. Interpretable Sequence Learning for COVID-19 Forecasting. arXiv 2020, arXiv:2008.00646. [Google Scholar]
- Rashed, E.A.; Kodera, S.; Gomez-Tames, J.; Hirata, A. Influence of Absolute Humidity, Temperature and Population Density on COVID-19 Spread and Decay Durations: Multi-Prefecture Study in Japan. Int. J. Environ. Res. Public Health 2020, 17, 5354. [Google Scholar] [CrossRef] [PubMed]
- Kodera, S.; Rashed, E.A.; Hirata, A. Correlation between COVID-19 Morbidity and Mortality Rates in Japan and Local Population Density, Temperature, and Absolute Humidity. Int. J. Environ. Res. Public Health 2020, 17, 5477. [Google Scholar] [CrossRef]
- Diao, Y.; Kodera, S.; Anzai, D.; Gomez-Tames, J.; Rashed, E.A.; Hirata, A. Influence of population density, temperature, and absolute humidity on spread and decay durations of COVID-19: A comparative study of scenarios in China, England, Germany, and Japan. One Health 2021, 12, 100203. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Tomar, A.; Gupta, N. Prediction for the spread of COVID-19 in India and effectiveness of preventive measures. Sci. Total Environ. 2020, 728, 138762. [Google Scholar] [CrossRef]
- Arora, P.; Kumar, H.; Panigrahi, B.K. Prediction and analysis of COVID-19 positive cases using deep learning models: A descriptive case study of India. Chaos Solitons Fractals 2020, 139, 110017. [Google Scholar] [CrossRef]
- Shastri, S.; Singh, K.; Kumar, S.; Kour, P.; Mansotra, V. Time series forecasting of COVID-19 using deep learning models: India-USA comparative case study. Chaos Solitons Fractals 2020, 140, 110227. [Google Scholar] [CrossRef] [PubMed]
- Ayyoubzadeh, S.M.; Ayyoubzadeh, S.M.; Zahedi, H.; Ahmadi, M.; R Niakan Kalhori, S. Predicting COVID-19 Incidence Through Analysis of Google Trends Data in Iran: Data Mining and Deep Learning Pilot Study. JMIR Public Health Surveill 2020, 6, e18828. [Google Scholar] [CrossRef]
- Kafieh, R.; Saeedizadeh, N.; Arian, R.; Amini, Z.; Serej, N.D.; Vaezi, A.; Javanmard, S.H. Isfahan and COVID-19: Deep spatiotemporal representation. Chaos Solitons Fractals 2020, 141, 110339. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Zheng, X.; Ai, G.; Liu, D.; Zhu, B. Time series prediction for the epidemic trends of COVID-19 using the improved LSTM deep learning method: Case studies in Russia, Peru and Iran. Chaos Solitons Fractals 2020, 140, 110214. [Google Scholar] [CrossRef] [PubMed]
- Chimmula, V.K.R.; Zhang, L. Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos Solitons Fractals 2020, 135, 109864. [Google Scholar] [CrossRef] [PubMed]
- Briz-Redón, Á.; Serrano-Aroca, Á. The effect of climate on the spread of the COVID-19 pandemic: A review of findings, and statistical and modelling techniques. Prog. Phys. Geogr. Earth Environ. 2020, 44, 591–604. [Google Scholar] [CrossRef]
- Espejo, W.; Celis, J.E.; Chiang, G.; Bahamonde, P. Environment and COVID-19: Pollutants, impacts, dissemination, management and recommendations for facing future epidemic threats. Sci. Total Environ. 2020, 747, 141314. [Google Scholar] [CrossRef]
- Azuma, K.; Kagi, N.; Kim, H.; Hayashi, M. Impact of climate and ambient air pollution on the epidemic growth during COVID-19 outbreak in Japan. Environ. Res. 2020, 190, 110042. [Google Scholar] [CrossRef]
- He, S.; Peng, Y.; Sun, K. SEIR modeling of the COVID-19 and its dynamics. Nonlinear Dyn. 2020, 101, 1667–1680. [Google Scholar] [CrossRef]
- Rader, B.; Scarpino, S.V.; Nande, A.; Hill, A.L.; Adlam, B.; Reiner, R.C.; Pigott, D.M.; Gutierrez, B.; Zarebski, A.E.; Shrestha, M.; et al. Crowding and the shape of COVID-19 epidemics. Nat. Med. 2020, 26, 1829–1834. [Google Scholar] [CrossRef]
- von Seidlein, L.; Alabaster, G.; Deen, J.; Knudsen, J. Crowding has consequences: Prevention and management of COVID-19 in informal urban settlements. Build. Environ. 2021, 188, 107472. [Google Scholar] [CrossRef]
- Pan, H.; Chen, S.; Gao, Y.; Deal, B.; Liu, J. An urban informatics approach to understanding residential mobility in Metro Chicago. Environ. Plan. Urban Anal. City Sci. 2020, 47, 1456–1473. [Google Scholar] [CrossRef]
- Athey, S. Beyond prediction: Using big data for policy problems. Science 2017, 355, 483–485. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | LSTM Arch. 1 | Data Range 2 | Input Data | Region | |||
|---|---|---|---|---|---|---|---|
| Sk | Bi | Cv | from | to | |||
| [27] | ✓ | 30 January | 4 April | DPC | India | ||
| [28] | ✓ | ✓ | ✓ | 14 March | 14 May | DPC | India |
| [29] | ✓ | ✓ | ✓ | 7 February | 7 July | DPC | India/USA |
| [30] | ✓ | 10 February | 18 March | GT | Iran | ||
| [31] | ✓ | 22 January | 3 May | DPC & SDH | Isfahan (Iran) | ||
| [32] | ✓ | 22 January | 7 July | DPC | Russia, Peru & Iran | ||
| [33] | ✓ | 22 January | 31 March | DPC | Canada | ||
| Region | Population (×1000) | Density (per km2) | Total Cases (till 7 January 2021) | Max. DPC (till 7 January 2021) |
|---|---|---|---|---|
| Tokyo | 13,921 | 6354.8 | 69,140 | 2520 |
| Aichi | 7552 | 1460.0 | 18,332 | 431 |
| Osaka | 8809 | 4631.0 | 32,655 | 607 |
| Hyogo | 5466 | 650.4 | 11,193 | 284 |
| Kyoto | 2583 | 560.1 | 5518 | 143 |
| Fukuoka | 5104 | 1024.8 | 10,364 | 386 |
| Region | Method | T1 | T2 | T3 | T4 | T5 | T6 | T7 | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Tokyo | G | 0.289 | 0.467 | 0.287 | 0.330 | 0.300 | 0.290 | 1.943 | 0.558 |
| P | 0.267 | 0.169 | 0.191 | 0.222 | 0.229 | 0.229 | 0.278 | 0.226 | |
| P | 0.233 | 0.221 | 0.191 | 0.198 | 0.210 | 0.234 | 0.249 | 0.219 | |
| Aichi | G | 0.467 | 0.301 | 0.368 | 0.395 | 1.102 | 0.311 | 0.376 | 0.474 |
| P | 0.201 | 0.148 | 0.189 | 0.162 | 0.150 | 0.157 | 0.187 | 0.171 | |
| P | 0.184 | 0.149 | 0.172 | 0.174 | 0.149 | 0.174 | 0.232 | 0.176 | |
| Osaka | G | 0.318 | 1.464 | 1.334 | 1.477 | 0.802 | 0.505 | 0.533 | 0.919 |
| P | 0.234 | 0.148 | 0.159 | 0.141 | 0.130 | 0.135 | 0.190 | 0.162 | |
| P | 0.283 | 0.171 | 0.166 | 0.151 | 0.132 | 0.141 | 0.214 | 0.180 | |
| Hyogo | G | 0.470 | 1.892 | 1.740 | 1.532 | 0.520 | 0.425 | 0.336 | 0.988 |
| P | 0.282 | 0.286 | 0.244 | 0.229 | 0.248 | 0.216 | 0.336 | 0.263 | |
| P | 0.330 | 0.289 | 0.234 | 0.248 | 0.207 | 0.263 | 0.360 | 0.276 | |
| Kyoto | G | 0.538 | 0.749 | 0.568 | 0.601 | 0.758 | 0.732 | 0.363 | 0.616 |
| P | 0.429 | 0.529 | 0.564 | 0.549 | 0.283 | 0.342 | 0.241 | 0.419 | |
| P | 0.448 | 0.494 | 0.519 | 0.564 | 0.601 | 0.615 | 0.540 | 0.540 | |
| Fukuoka | G | 0.484 | 0.665 | 0.506 | 0.663 | 0.535 | 0.443 | 0.353 | 0.522 |
| P | 0.399 | 0.420 | 0.461 | 0.428 | 0.429 | 0.341 | 0.245 | 0.389 | |
| P | 0.519 | 0.427 | 0.388 | 0.358 | 0.335 | 0.334 | 0.375 | 0.391 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rashed, E.A.; Hirata, A. One-Year Lesson: Machine Learning Prediction of COVID-19 Positive Cases with Meteorological Data and Mobility Estimate in Japan. Int. J. Environ. Res. Public Health 2021, 18, 5736. https://doi.org/10.3390/ijerph18115736
Rashed EA, Hirata A. One-Year Lesson: Machine Learning Prediction of COVID-19 Positive Cases with Meteorological Data and Mobility Estimate in Japan. International Journal of Environmental Research and Public Health. 2021; 18(11):5736. https://doi.org/10.3390/ijerph18115736
Chicago/Turabian StyleRashed, Essam A., and Akimasa Hirata. 2021. "One-Year Lesson: Machine Learning Prediction of COVID-19 Positive Cases with Meteorological Data and Mobility Estimate in Japan" International Journal of Environmental Research and Public Health 18, no. 11: 5736. https://doi.org/10.3390/ijerph18115736
APA StyleRashed, E. A., & Hirata, A. (2021). One-Year Lesson: Machine Learning Prediction of COVID-19 Positive Cases with Meteorological Data and Mobility Estimate in Japan. International Journal of Environmental Research and Public Health, 18(11), 5736. https://doi.org/10.3390/ijerph18115736