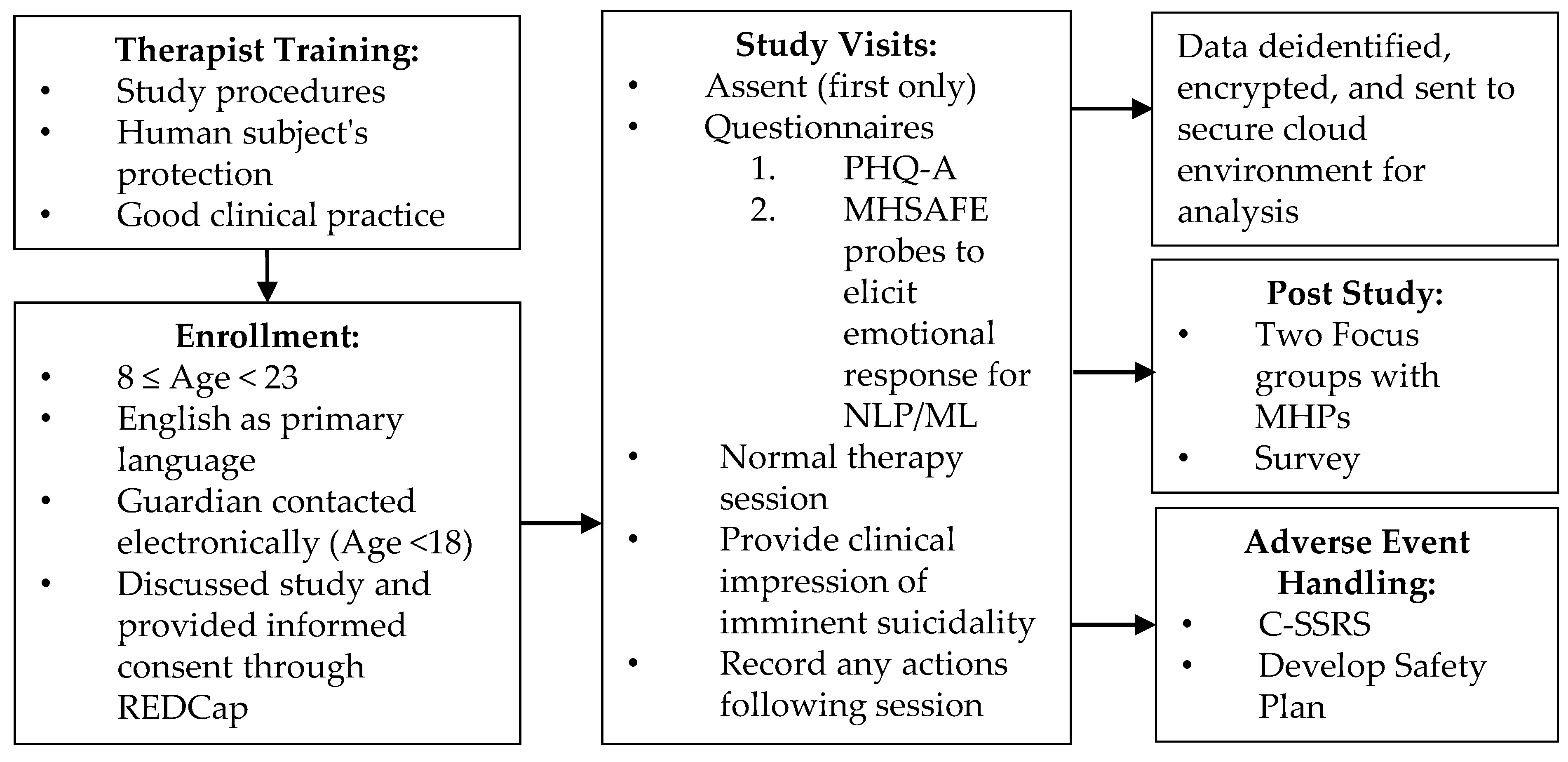
1. Introduction
Suicide rates among adolescents have risen steadily over the last decade, and suicide is now the second leading cause of death among 10–34 year olds [
1]. In settings where suicidal thoughts and behaviors are assessed, such as mental health centers, traditional methods for evaluating risk employ survey screening tools, such as the Patient Health Questionnaire 9 [
2] and the Columbia Suicide Severity Rating Scale [
3]. Although these scales are frequently used and have been widely tested [
2,
3,
4,
5,
6,
7,
8,
9,
10], assessed accuracy of suicide risk is often subject to both the rater’s intuition and the responder’s ability to answer the questions while in distress. Youth in particular may have difficulty responding to such screeners, for reasons such as social desirability [
11], lack of engagement with the rater [
12], and lack of understanding [
13]. Therefore, exploring more objective approaches to identifying youth at risk for suicide is warranted. Additionally, the dynamic and fluid state of suicidality [
14] can be challenging to measure with static screeners. A person’s mental state’s nuances are too idiosyncratic for measurement tools often tested with homogenous populations. Instead, suicide risk data collection should be derived from the content of thoughts of the individual’s experience.
Speech is one of the most complex human activities [
15], coordinating diverse brain regions, and is affected by physical, neurological, and mental health conditions [
16]. Prior research has shown how machine learning models can classify these conditions based on the linguistic and acoustic markers in speech [
16,
17,
18,
19,
20,
21,
22]. Underlying machine learning models’ success is that these conditions cause neurophysiological changes that can be consistently measured with voice data (linguistic and acoustic markers) [
17,
21,
23]. While much of the brain’s structure–function relationship remains unknown [
24], studies on the brains of those with suicide attempts or who died by suicide have found notable differences compared to controls, including a decrease in gray matter and activity changes of specific brain regions [
25,
26].
Machine learning (ML) has emerged as a method by which data from human characteristics, such as speech [
16,
17], physical and social media activity [
27], and electronic medical records [
28,
29], can be analyzed in higher concentration and with better precision. Natural language processing (NLP) has been previously used to identify mental health and suicide-related states using both written and spoken samples, and it has shown that, in addition to content words (what we say), function words (how we say it) are also important to language identification [
18,
19,
30,
31,
32,
33]. Often during these classification tasks, language from controls (those without a condition) and cases (those with a condition) is turned into a vector representing the frequency words—or sequences of words—occurring in each language sample. These vectors are then used to “train” ML models to recognize patterns and create rules that allow for discrimination between cases and controls. The different types of ML models (e.g., support vector machines and extreme gradient boosting) approach the same goal of classifying language as case or control as accurately as possible using different mathematical methods, leading to the emergence of unique rules to accomplish this task.
After an ML model is trained, different evaluation strategies and metrics are used to evaluate performance on data that was not used to train the model [
34,
35]. During validation, new language vectors are shown to the ML model. Given unknown data, the trained ML model returns the probability for a sample belonging to a target class (i.e., case). This result can then be compared to the actual class (i.e., what is known about that language sample) to determine the performance of the ML model. A preferred performance metric for evaluating ML models is the area under the receiver operating characteristic curve (AUC) [
34], which may be interpreted as the probability that a randomly selected case will receive a greater probability for belonging to the case group than a randomly selected control [
36]. An AUC of 0.5 represents a model that predicts as well as random chance, and an AUC of 1.0 is a perfect model. Many mental health diagnostic checklists and inventories perform with AUCs under clinically realistic conditions in the range of 0.7–0.8 [
36,
37].
Previous research explored using NLP to classify suicide risk. In 2016, Pestian et al. performed the Adolescent Controlled Trial (ACT) with 60 adolescents admitted to a large, urban, pediatric emergency department (ED) with suicidal complaints (case) or orthopedic injuries (control) [
18]. They completed the Columbia Suicide Severity Rating Scale (C-SSRS) and a semi-structured interview based on characteristics of suicidality (called the Ubiquitous Questionnaire, UQ). The UQ was designed to elicit language for machine learning model training [
18]. Resulting transcripts were analyzed with a combined NLP/ML approach, which successfully classified 58 of the 60 participants (96.7%) [
18].
Expanding on the ACT, the Suicide Thought Markers (STM) Study recruited 379 adults and children across three sites [
19]. The procedure was similar to the previous study; however, participants with mental illness were also included with the suicidal and control cohorts [
19]. Results from this study suggested that the NLP/ML method identified suicidal people from the interview transcripts with over 90% accuracy [
19]. Specifically, classifiers trained on interview transcripts performed with an AUC of 0.87 ± 0.02 when classifying suicidal thoughts and behaviors versus those with and without mental illness, and an AUC of 0.93 ± 0.02 when classifying suicidal thoughts and behaviors versus controls without mental illness, using a leave-one-interview-out cross-validation technique [
19].
All suicidal participants in the ACT and STM studies demonstrated a risk for suicide that led to their admission to the ED or a psychiatric unit [
18,
19]. Participants’ suicide-related thoughts and behaviors ranged from suicide-related ideations to suicide-related behaviors, including self-harm (type I and II) and suicide attempt (type I and II) [
38], with over 75% of suicidal STM participants scoring ≥ 4 on the C-SSRS’s intensity of suicidal ideation scale [
3,
20]. Therefore, models trained on this language aim to identify those within this range of risk for suicide.
Due to limited innovation and person-centered measurement tools in suicide risk assessment, machine learning, specifically NLP, is timely. This method of both data collection and analysis offers an objective and less biased approach to identifying people with suicidal thoughts and behaviors (STBs). While this study procedure has been successfully implemented to identify these individuals in a variety of settings, such as the ED, in- and outpatient clinics [
18,
19], and in a recent study of individuals with epilepsy and psychiatric comorbidities [
21], it has yet to be implemented as part of outpatient mental health therapy sessions. This feasibility study was conducted in partnership with a child and adolescent mental health agency to understand how this technology integrates into a mental health professional’s (MHP) workflow with adolescents and if the collected language samples can be analyzed with ML methods to predict risk for suicide. Overall, we found MHPs were accepting of the technology and procedures, and ML models trained on language samples from the ACT and STM studies performed well when predicting suicide risk in this new population.
4. Discussion
In this study, we find integrating technology via a smartphone app into mental health therapy sessions and collecting language samples for machine learning models feasible. Models trained on language samples from separate studies that were not collected as part of a mental health therapy session were used to assess how well suicidal risk identified through the PHQ-A could be predicted based on language samples from this pilot. These techniques to capture the language and measure level of suicide risk using NLP and ML methods produced acceptable results, despite being collected in the less controlled environment of adolescent mental health therapy sessions compared to previous trials [
18,
19].
Clinical applications could grant MHPs a different perspective on a client’s level of suicide risk determined by their language, a more dynamic and person-centered characteristic than specific risk factors that do not meaningfully predict outcomes [
59]. It would be reasonable for MHPs to ask the MHSAFE probes as part of regular therapy sessions or at specific intervals to assess congruence of their client’s language, standardized scales, and the MHP’s clinical impression. These data, when combined, may provide a more complete picture of a client’s mental state, and ultimately improve outcomes. In future clinical trials, MHPs will be provided a “dashboard” that displays all collected information entered about a client, with the aim of using the data to inform clinical decision-making. We intend to study how these data may be used clinically to assess and monitor the degree of suicide risk and related mental states over time, and how clinical decision-making is aligned with the dynamic changes of the client’s mental states.
While most of the MHSAFE probe segments were less than 13 minutes, it should be noted that the average interview time in the multi-site STM study was shorter (8.1 ± 4.5 min) [
19]. During training in current trials, we now provide more specific guidelines on asking the probes to make them more concise, although, as noted, some MHPs reported voluntarily using the entire therapy session for the probes if they revealed details that warranted further discussion. We are also investigating model performance on clinical language samples without the MHSAFE probes to determine if the probes are needed for accurate classification; however, previous studies have found the probe responses statistically significant in a hierarchical classifier’s ability to discriminate suicidal and non-suicidal language elicited from the probes versus a combination of 11 other open-ended questions [
43].
Of the ML models tested, the XGB model provided the best discriminative ability when evaluated on the language collected in this study. Interestingly, this model had the poorest discriminative power on all but one site during internal validation of the training data, as seen in
Figure 2. XGB models can create more complex rules for classification than LR and SVM models, which can lead to the model learning from unimportant characteristics (i.e., overfitting). We see in
Table 5 that LR and SVM models had the same top five features for each training group, while the XGB models’ top five features were the most unique. It should be noted the amount of training data varied in the creation of
Figure 2, and it may be that when all of the training data was made available when evaluating model performance on language from this study, the XGB model was better able to identify important features and became more robust.
Figure 3 demonstrates the varying potential for complexity among LR, SVM (radial basis function kernel), and XGB models. Through a singular value decomposition (SVD), large language vectors that represent entire conversations can be reduced into two dimensions [
51,
60]. While some information is lost in this process and model performance is not fully represented in
Figure 3, it may provide insights into model behavior. The red and blue regions of
Figure 3 represent the coordinates learned from the training data (controls without mental illness and suicidal language) for classification as case or control, respectively, and where these regions meet is referred to as the decision boundary. The red and blue points represent language samples collected in this study. In
Figure 3, the decision boundary for the LR (
Figure 3a) and SVM (
Figure 3b) models are smooth, continuous curves, while XGB’s (
Figure 3c) decision boundary has more characteristics, emphasizing its capacity to create more complex, flexible rules for classification. As noted, NLP/ML techniques assume voice data is consistently changed by mental illness in measurable ways [
17,
23]. While in this study we have found a change of setting does not significantly impact model performance, it is likely that as these methods are extended to larger and more diverse groups of individuals, models like XGB that accommodate more complex rules will be required for accurate identification of suicidal risk based on language.
While machine learning models are often referred to as “black boxes” due to their overall technical complexity and lack of transparency into why specific predictions are made, new tools in explainable artificial intelligence (XAI) are being developed to answer this challenge [
61,
62,
63]. Indeed, model interpretability will be essential for therapists and other users to trust and accept this technology, as well as to meet other ethical and regulatory considerations [
61]. Future studies will employ these tools to focus on how specific features and feature interactions influence individual model predictions.
Limitations and Lessons Learned
Some limitations should be noted. First, suicidal risk in this study is determined by the PHQ-A, a less accurate tool than the C-SSRS, and the reason for visit used in previous studies [
18,
19]. The PHQ-A does not discriminate between self-harm and passive thoughts of dying, and each question uses a different time frame reference (two weeks, last month, or whole life). Therefore, the suicidal risk may be overestimated in this sample, although it is also possible that some participants did not disclose suicidal thoughts or behaviors. An overestimation of suicide risk could result in clinical decisions that may not be aligned with the actual present risk. To correct for this, we have now included the C-SSRS short form screener version in each session to provide a more consistent, timely, and accurate standardized risk assessment. This will allow for better data validation during model development.
Second, because the goal of this pilot study was to understand how this tool can work in therapy sessions, some of the procedures were modified from the original ACT and STM studies, and the procedures were carried out at the discretion of the MHP. As noted, the MHSAFE probes are modeled after the UQ, but were altered to support generalizability across multiple settings. MHPs were not always consistent in how they administered the probes. Some began recording at the beginning of the session and stopped after the probes were completed. Some recorded the entire therapy session, and some waited to administer the probes at the end of the session and only began recording when asking the probes. MHPs also reported occasionally asking the probes with slight variations that may have been more age appropriate. For example, instead of asking about emotional pain, one MHP asked if there is “anything that’s really hurting your heart right now?” Going forward, after the pilot, we have revised the training, specifying to record the entire session and to administer the probes preferably at the beginning of therapy. However, we also continue to support flexibility with the therapist and the client’s needs for the session. A final limitation related to procedures was the use of the therapist impression slider rating system. The slider (1–100) was intended for the clinician to provide their impression of the client’s mental state, however, feedback from the clinicians about the slider was that it was not intuitive. The slider was investigator developed and not previously validated, therefore it was not used to assess model performance. We have modified this for future trials to reflect a five-point Likert scale with specific anchor descriptions to better rate the severity of the conditions.
Third, the technology, both with the smartphone app and voice collection, presented some difficulties. Therapists deployed the app on their personal or work phones, and occasionally there were issues with connectivity, app updates, or interruptions from other notifications. Manual transcriptionists reported challenges with a few of the audio files due to poor audio quality that may have been from background noise in the therapist’s office or if the phone was not placed in the optimal position for voice capture. While this likely did not significantly affect the resulting manual transcripts, for this technology to be scalable, this step will need to be automated using automatic speech recognition technology, with a performance that is dependent on audio quality [
64,
65]. We have worked to resolve these issues by improving the app technology, providing a version that can go on a therapist’s computer instead of their smartphone, and is better at instructing the therapists during training where to place the phone or microphone for optimal voice capture.
Lastly, this study was conducted with a single, regional, mental health partner, and the sample recruitment was limited to therapist participation and invitation of clients from their caseloads. A few therapists recorded a majority of the sessions. Although we were able to identify some successes and drawbacks of the process for this pilot, we anticipate that more concerns and barriers might arise when implementing on a broader scale. We are including feedback loops within the larger study design to make continual improvements to assist in maintaining the flow of the session while preserving the integrity of the data/data capture. We are also now recruiting nationally and working to increase diversity and inclusivity in our therapist sample.

 ,
, 



{kind=link}
{kind=link}
{kind=link}