Groundwater Arsenic Distribution in India by Machine Learning Geospatial Modeling



Abstract
1. Introduction
2. Materials and Methods
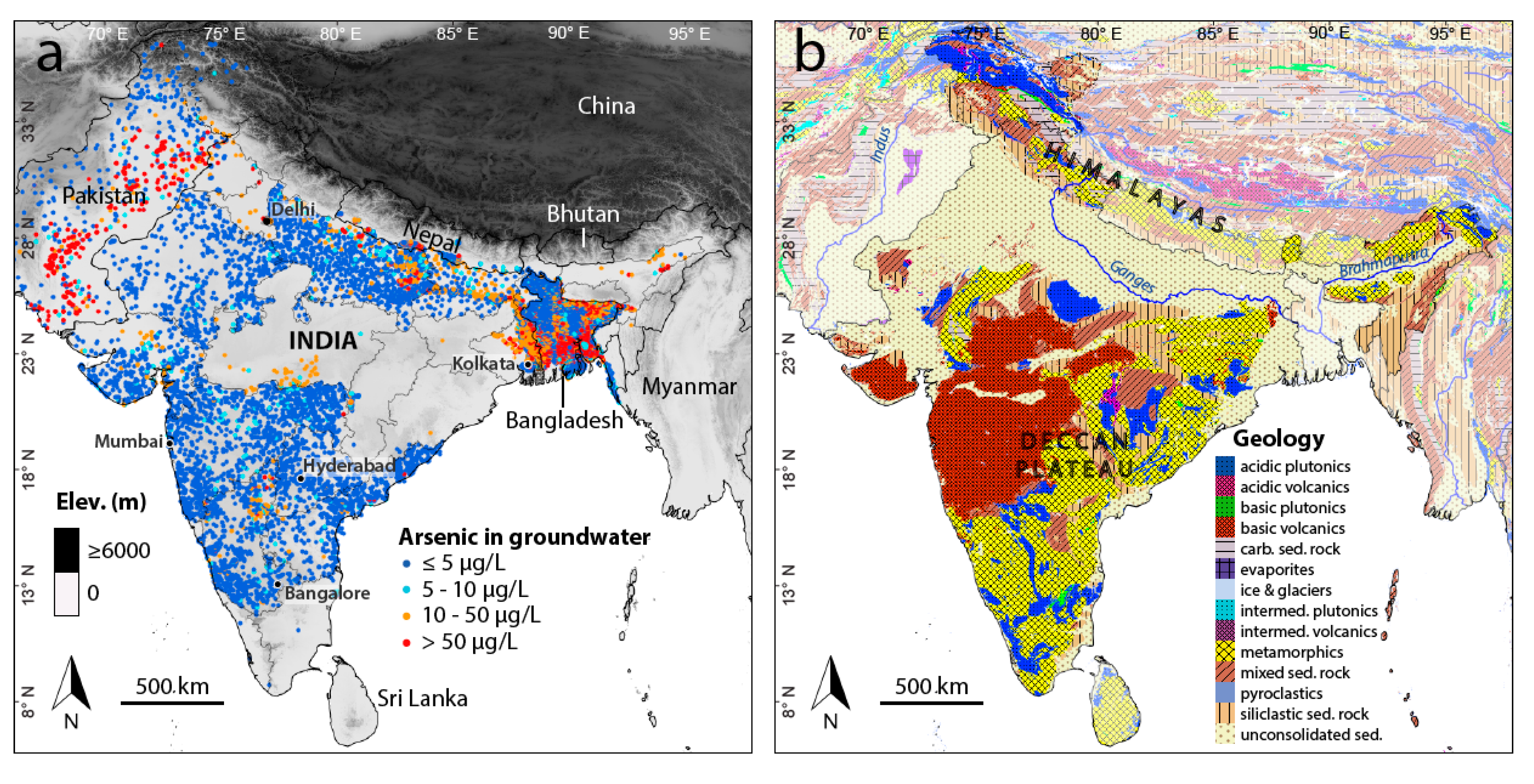
2.1. Arsenic Concentration Measurements
2.2. Predictor Variables
2.3. Prediction Modeling
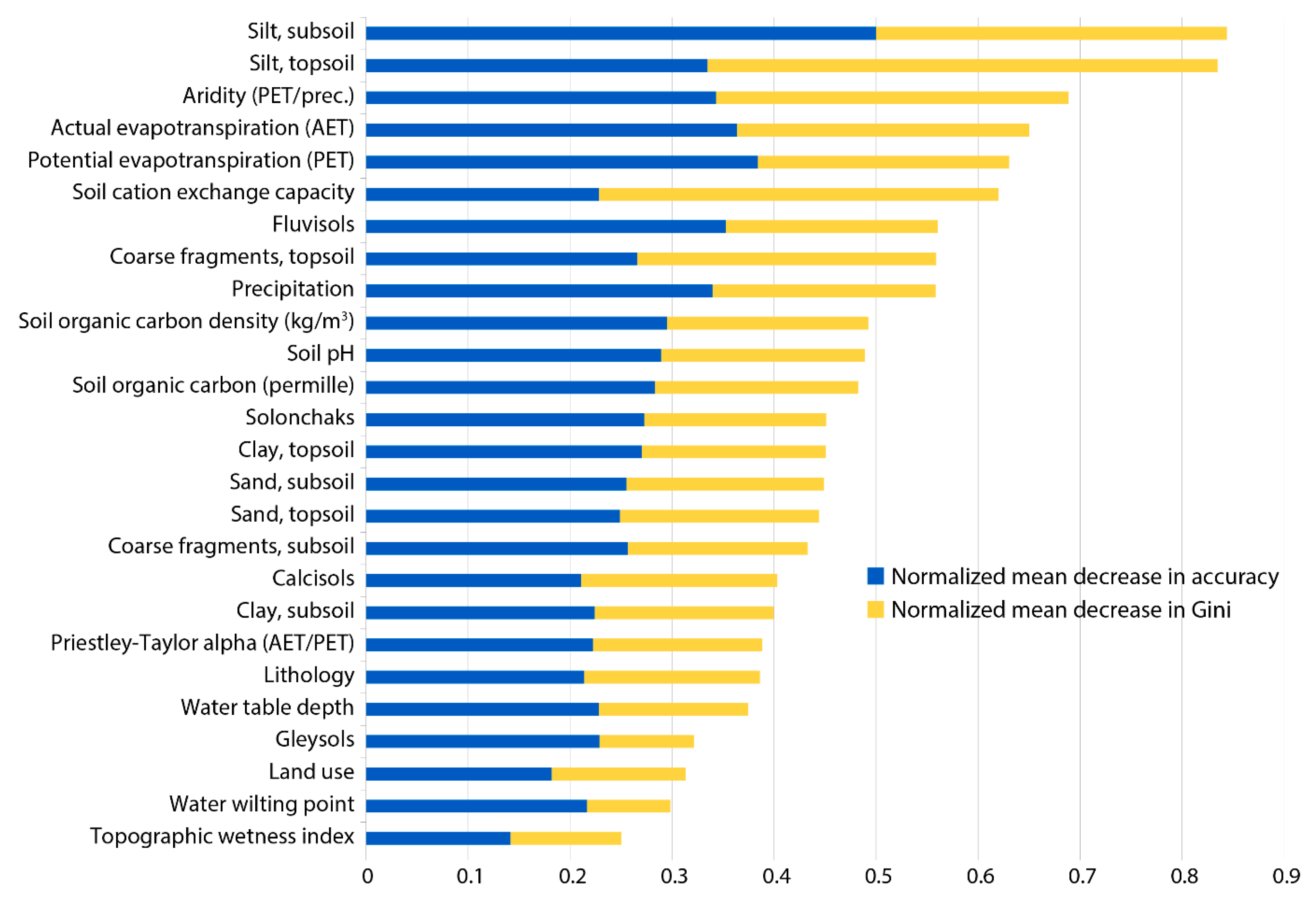
2.4. Importance of Predictor Variables
2.5. Estimating Potentially Affected Population
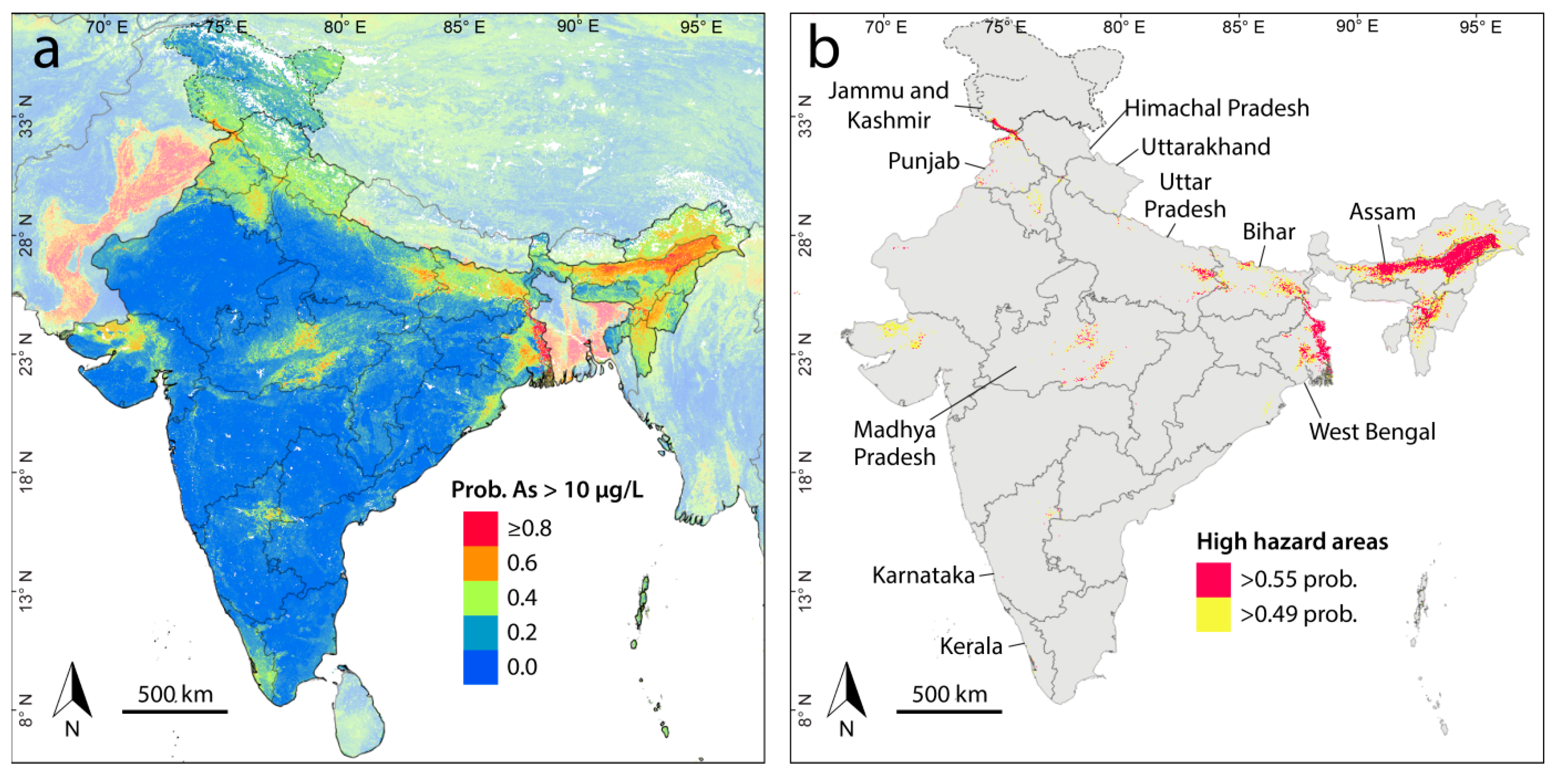
3. Results and Discussion
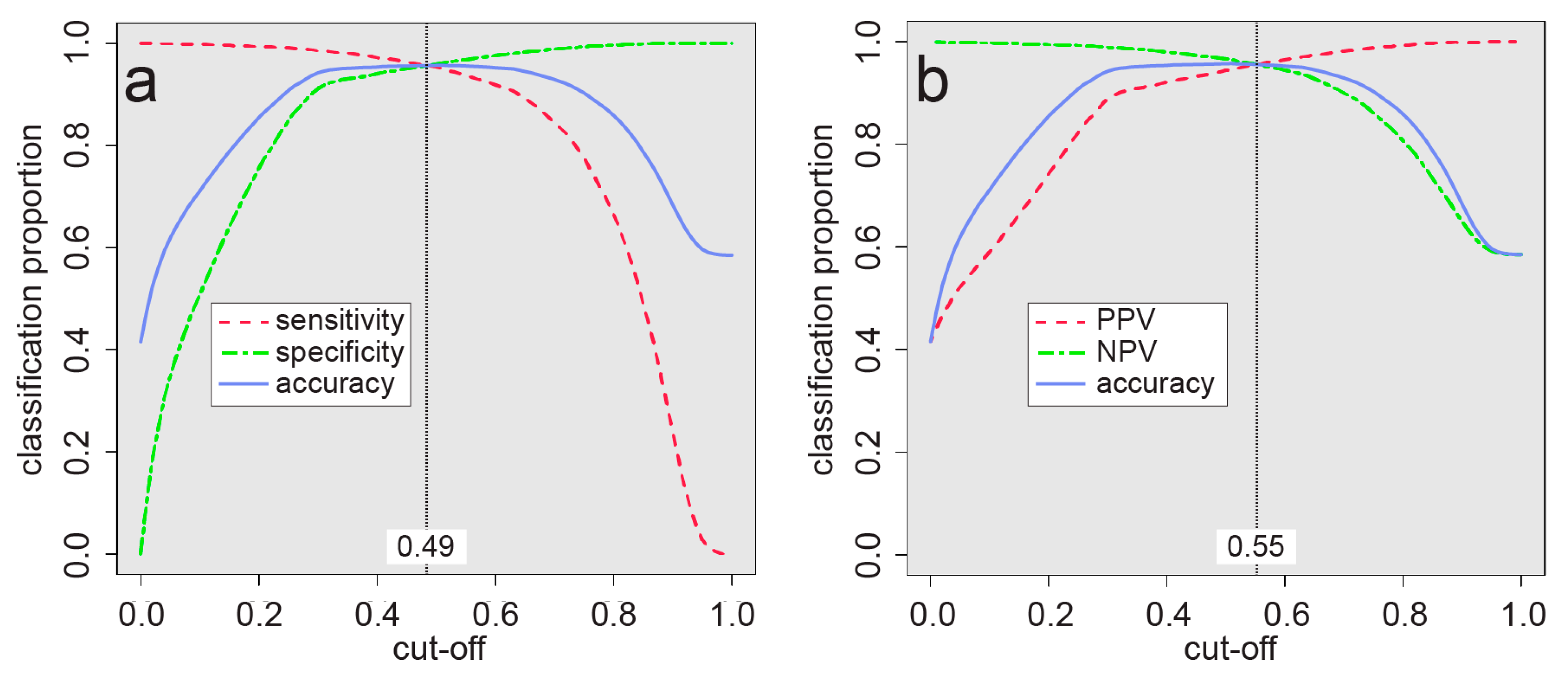
3.1. Arsenic Prediction Model
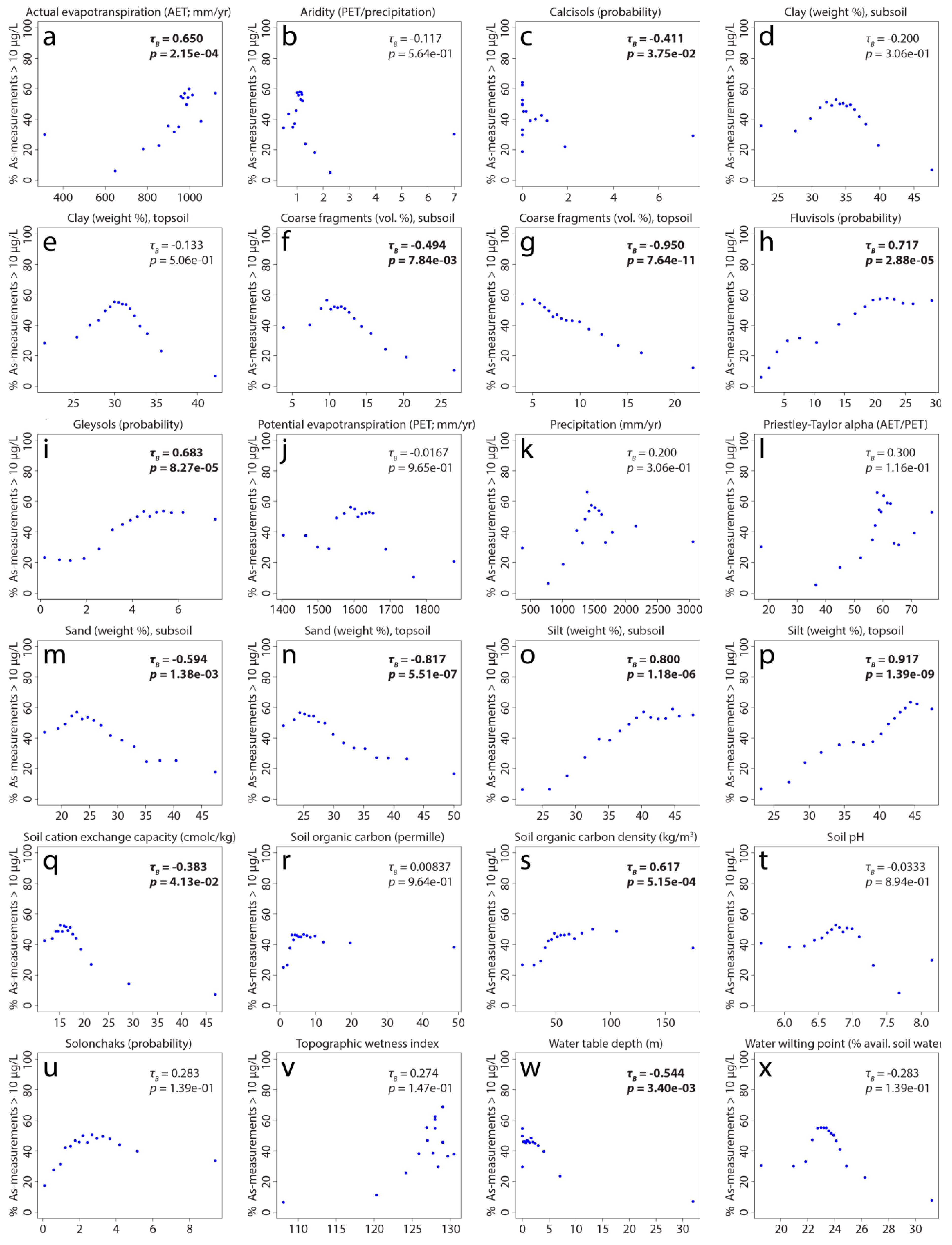
3.2. Influence of Predictor Variables
3.3. Populations at Risk
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rodell, M.; Velicogna, I.; Famiglietti, J.S. Satellite-based estimates of groundwater depletion in India. Nature 2009, 460, 999. [Google Scholar] [CrossRef] [PubMed]
- Famiglietti, J.S. The global groundwater crisis. Nat. Clim. Chang. 2014, 4, 945–948. [Google Scholar] [CrossRef]
- Polya, D.A.; Middleton, D.R. Arsenic in drinking water: Sources & human exposure. In Best Practice Guide on the Control of Arsenic in Drinking Water, 1st ed.; Bhattacharya, P., Polya, D.A., Draganovic, D., Eds.; International Water Association Publishing: London, UK, 2017; Chapter 1; ISBN 9781843393856. [Google Scholar]
- Smedley, P.; Kinniburgh, D. A review of the source, behaviour and distribution of arsenic in natural waters. Appl. Geochem. 2002, 17, 517–568. [Google Scholar] [CrossRef]
- Charlet, L.; Polya, D.A. Arsenic in shallow, reducing groundwaters in southern Asia: An environmental health disaster. Elements 2006, 2, 91–96. [Google Scholar] [CrossRef]
- Podgorski, J.E.; Eqani, S.A.M.A.S.; Khanam, T.; Ullah, R.; Shen, H.; Berg, M. Extensive arsenic contamination in high-pH unconfined aquifers in the Indus Valley. Sci. Adv. 2017, 3. [Google Scholar] [CrossRef] [PubMed]
- Islam, F.S.; Gault, A.G.; Boothman, C.; Polya, D.A.; Charnock, J.M.; Chatterjee, D.; Lloyd, J.R. Role of metal-reducing bacteria in arsenic release from Bengal delta sediments. Nature 2004, 430, 68–71. [Google Scholar] [CrossRef]
- Richards, L.A.; Casanueva-Marenco, M.J.; Magnone, D.; Sovann, C.; Van Dongen, B.E.; Polya, D.A. Contrasting sorption behaviours affecting groundwater arsenic concentration in Kandal Province, Cambodia. Geosci. Front. 2019, 10, 1701–1713. [Google Scholar] [CrossRef]
- Ravenscroft, P.; Brammer, H.; Richards, K. Arsenic Pollution: A GLOBAL Synthesis; Wiley-Blackwell: Chichester, UK, 2009; p. 588. [Google Scholar]
- Polya, D.A.; Lawson, M. Geogenic and anthropogenic arsenic hazard in groundwaters and soils: Distribution, nature, origin, and human exposure routes. In Arsenic—Exposure Sources, Health Risks, and Mechanisms of Toxicity, 1st ed.; States, J.C., Ed.; Wiley: Hoboken, NJ, USA, 2016; Chapter 2; pp. 23–60. ISBN 978-1-118-51114-5. [Google Scholar]
- Dittmar, J.; Voegelin, A.; Roberts, L.C.; Hug, S.J.; Saha, G.C.; Ali, M.A.; Badruzzaman, A.B.M.; Kretzschmar, R. Spatial distribution and temporal variability of arsenic in irrigated rice fields in Bangladesh. 2. Paddy soil. Environ. Sci. Technol. 2007, 41, 5967–5972. [Google Scholar] [CrossRef]
- WHO. Guidelines for drinking-water quality. WHO Chron. 2011, 38, 104–108. [Google Scholar]
- Bureau of Indian Standards (BIS). Indian Standard Drinking Water-Specification (Second Revision) IS: 10500; Bureau of Indian Standards (BIS): New Delhi, India, 2012; p. 16.
- Wu, R.; Podgorski, J.; Berg, M.; Polya, D.A. Geostatistical model of the spatial distribution of arsenic in groundwaters in Gujarat State, India. Environ. Geochem. Health 2020. published online. [Google Scholar] [CrossRef]
- Bindal, S.; Singh, C.K. Predicting groundwater arsenic contamination: Regions at risk in highest populated state of India. Water Res. 2019, 159, 65–76. [Google Scholar] [CrossRef]
- Podgorski, J.; Berg, M. Global threat of arsenic in groundwater. Science 2020, 368, 845–850. [Google Scholar] [CrossRef]
- Kumar, M.; Ramanathan, A.; Rahman, M.M.; Naidu, R. Concentrations of inorganic arsenic in groundwater, agricultural soils and subsurface sediments from the middle Gangetic plain of Bihar, India. Sci. Total Environ. 2016, 573, 1103–1114. [Google Scholar] [CrossRef]
- Shah, B.A. Status of groundwater arsenic pollution of Mirzapur district in Holocene aquifers from parts of the Middle Ganga Plain, India. Environ. Earth Sci. 2015, 73, 1505–1514. [Google Scholar] [CrossRef]
- Ghosh, T.; Kanchan, R. Geoenvironmental appraisal of groundwater quality in Bengal alluvial tract, India: A geochemical and statistical approach. Environ. Earth Sci. 2014, 72, 2475–2488. [Google Scholar] [CrossRef]
- Sailo, L.; Mahanta, C. Arsenic mobilization in the Brahmaputra plains of Assam: Groundwater and sedimentary controls. Environ. Monit. Assess. 2014, 186, 6805–6820. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, S.; Sar, P. Identification and characterization of metabolic properties of bacterial populations recovered from arsenic contaminated ground water of North East India (Assam). Water Res. 2013, 47, 6992–7005. [Google Scholar] [CrossRef]
- Shah, B.A. Role of Quaternary stratigraphy on arsenic-contaminated groundwater from parts of Barak Valley, Assam, North–East India. Environ. Earth Sci. 2012, 66, 2491–2501. [Google Scholar] [CrossRef]
- Chandra, S.; Ahmed, S.; Nagaiah, E.; Singh, S.K.; Chandra, P. Geophysical exploration for lithological control of arsenic contamination in groundwater in Middle Ganga Plains, India. Phys. Chem. Earth Parts A/B/C 2011, 36, 1353–1362. [Google Scholar] [CrossRef]
- Chauhan, V.S.; Nickson, R.; Chauhan, D.; Iyengar, L.; Sankararamakrishnan, N. Ground water geochemistry of Ballia district, Uttar Pradesh, India and mechanism of arsenic release. Chemosphere 2009, 75, 83–91. [Google Scholar] [CrossRef]
- Nath, B.; Stüben, D.; Mallik, S.B.; Chatterjee, D.; Charlet, L. Mobility of arsenic in West Bengal aquifers conducting low and high groundwater arsenic. Part I: Comparative hydrochemical and hydrogeological characteristics. Appl. Geochem. 2008, 23, 977–995. [Google Scholar] [CrossRef]
- Shah, B.A. Role of Quaternary stratigraphy on arsenic-contaminated groundwater from parts of Middle Ganga Plain, UP–Bihar, India. Environ. Geol. 2008, 53, 1553–1561. [Google Scholar] [CrossRef]
- Nickson, R.; Sengupta, C.; Mitra, P.; Dave, S.; Banerjee, A.; Bhattacharya, A.; Basu, S.; Kakoti, N.; Moorthy, N.; Wasuja, M. Current knowledge on the distribution of arsenic in groundwater in five states of India. J. Environ. Sci. Health Part A 2007, 42, 1707–1718. [Google Scholar] [CrossRef]
- McArthur, J.; Ravenscroft, P.; Banerjee, D.; Milsom, J.; Hudson-Edwards, K.A.; Sengupta, S.; Bristow, C.; Sarkar, A.; Tonkin, S.; Purohit, R. How paleosols influence groundwater flow and arsenic pollution: A model from the Bengal Basin and its worldwide implication. Water Resour. Res. 2008, 44, W11411. [Google Scholar] [CrossRef]
- Kar, S.; Maity, J.P.; Jean, J.-S.; Liu, C.-C.; Nath, B.; Yang, H.-J.; Bundschuh, J. Arsenic-enriched aquifers: Occurrences and mobilization of arsenic in groundwater of Ganges Delta Plain, Barasat, West Bengal, India. Appl. Geochem. 2010, 25, 1805–1814. [Google Scholar] [CrossRef]
- Maity, J.P.; Nath, B.; Chen, C.-Y.; Bhattacharya, P.; Sracek, O.; Bundschuh, J.; Kar, S.; Thunvik, R.; Chatterjee, D.; Ahmed, K.M. Arsenic-enriched groundwaters of India, Bangladesh and Taiwan—Comparison of hydrochemical characteristics and mobility constraints. J. Environ. Sci. Health Part A 2011, 46, 1163–1176. [Google Scholar] [CrossRef]
- Paul, D.; Kazy, S.K.; Gupta, A.K.; Pal, T.; Sar, P. Diversity, metabolic properties and arsenic mobilization potential of indigenous bacteria in arsenic contaminated groundwater of West Bengal, India. PLoS ONE 2015, 10, e0118735. [Google Scholar] [CrossRef]
- Saha, D.; Sahu, S. A decade of investigations on groundwater arsenic contamination in Middle Ganga Plain, India. Environ. Geochem. Health 2016, 38, 315–337. [Google Scholar] [CrossRef]
- Sharma, S.; Kaur, J.; Nagpal, A.K.; Kaur, I. Quantitative assessment of possible human health risk associated with consumption of arsenic contaminated groundwater and wheat grains from Ropar Wetand and its environs. Environ. Monit. Assess. 2016, 188, 506. [Google Scholar] [CrossRef]
- Chatterjee, D.; Roy, R.; Basu, B. Riddle of arsenic in groundwater of Bengal Delta Plain—Role of non-inland source and redox traps. Environ. Geol. 2005, 49, 188–206. [Google Scholar] [CrossRef]
- Shukla, D.P.; Dubey, C.; Singh, N.P.; Tajbakhsh, M.; Chaudhry, M. Sources and controls of Arsenic contamination in groundwater of Rajnandgaon and Kanker District, Chattisgarh Central India. J. Hydrol. 2010, 395, 49–66. [Google Scholar] [CrossRef]
- Shah, B.A. Arsenic-contaminated groundwater in Holocene sediments from parts of middle Ganga plain, Uttar Pradesh, India. Curr. Sci. 2010, 98, 1359–1365. [Google Scholar]
- Hazarika, S.; Bhuyan, B. Fluoride, arsenic and iron content of groundwater around six selected tea gardens of Lakhimpur District, Assam, India. Arch. Appl Sci. Res. 2013, 5, 57–61. [Google Scholar]
- Mukherjee, A.; Fryar, A.E.; Rowe, H.D. Regional-scale stable isotopic signatures of recharge and deep groundwater in the arsenic affected areas of West Bengal, India. J. Hydrol. 2007, 334, 151–161. [Google Scholar] [CrossRef]
- Mukherjee, A.; Fryar, A.E.; Eastridge, E.M.; Nally, R.S.; Chakraborty, M.; Scanlon, B.R. Controls on high and low groundwater arsenic on the opposite banks of the lower reaches of River Ganges, Bengal basin, India. Sci. Total Environ. 2018, 645, 1371–1387. [Google Scholar] [CrossRef]
- Olea, R.A.; Raju, N.J.; Egozcue, J.J.; Pawlowsky-Glahn, V.; Singh, S. Advancements in hydrochemistry mapping: Methods and application to groundwater arsenic and iron concentrations in Varanasi, Uttar Pradesh, India. Stoch. Environ. Res. Risk Assess. 2018, 32, 241–259. [Google Scholar] [CrossRef]
- Chidambaram, S.; Thilagavathi, R.; Thivya, C.; Karmegam, U.; Prasanna, M.V.; Ramanathan, A.; Tirumalesh, K.; Sasidhar, P. A study on the arsenic concentration in groundwater of a coastal aquifer in south-east India: An integrated approach. Environ. Dev. Sustain. 2017, 19, 1015–1040. [Google Scholar] [CrossRef]
- UNEP. Water Quality. In 2005 State of the UNEP GEMS/Water Global Network and Annual Report; UNEP: Nairobi, Kenya, 2005. [Google Scholar]
- Kumar, A.; Singh, C.K.; Bostick, B.; Nghiem, A.; Mailloux, B.; van Geen, A. Regulation of groundwater arsenic concentrations in the Ravi, Beas, and Sutlej floodplains of Punjab, India. Geochim. et Cosmochim. Acta 2020, 276, 384–403. [Google Scholar] [CrossRef]
- Ambühl, B. (Department Sanitation, Water and Solid Waste for Development, Eawag, Swiss Federal Institute of Aquatic Science and Technology, 8600 Dübendorf, Switzerland). Unpublished Data Shared by Personal Communication, 2019.
- Richards, L.A.; Kumar, A.; Shankar, P.; Gaurav, A.; Ghosh, A.; Polya, D.A. Distribution and Geochemical Controls of Arsenic and Uranium in Groundwater-Derived Drinking Water in Bihar, India. Int. J. Environ. Res. Public Health 2020, 17, 2500. [Google Scholar] [CrossRef]
- Central Ground Water Board. Groundwater Year Book—2015–2016 Gujarat state and UT of Daman & Diu. Available online: http://cgwb.gov.in/Regions/GW-year-Books/GWYB-2015-16/GWYB%20WCR%202015-16.pdf (accessed on 2 May 2019).
- Central Ground Water Board. Ground Water Quality in Shallow Aquifers in India; Supplemented by further location-specific data for Andhra Pradesh, Rajasthan, Telengana, Uttar Pradesh directly from provided by CGWB, 2019–2020; CGWB: Faridabad, India, 2018. Available online: http://cgwb.gov.in/documents/Waterquality/GW_Quality_in_shallow_aquifers.pdf (accessed on 2 May 2019).
- Kinniburgh, D.; Smedley, P. Arsenic Contamination of Groundwater in Bangladesh; British Geological Survey: Nottingham, UK, 2001. [Google Scholar]
- Shrestha, B.R.; Whitney, J.W.; Shrestha, K.B. The State of Arsenic in Nepal-2003; National Arsenic Steering Committee (Nepal) & Environmental and Public Health Organization (Nepal): Kathmandu, Nepal, 2004; p. 126. ISBN 99933-895-4-4. [Google Scholar]
- Nickson, R.; McArthur, J.; Shrestha, B.; Kyaw-Myint, T.; Lowry, D. Arsenic and other drinking water quality issues, Muzaffargarh District, Pakistan. Appl. Geochem. 2005, 20, 55–68. [Google Scholar] [CrossRef]
- Trabucco, A.; Zomer, R. Global Soil Water Balance Geospatial Database. CGIAR Consortium for Spatial Information. 2010. Published online CGIAR-CSI GeoPortal. Available online: http://www.cgiar-csi.org (accessed on 15 April 2016).
- Trabucco, A.; Zomer, R.J. Global Aridity Index (Global-Aridity) and Global Potential Evapo-Transpiration (Global-PET) Geospatial Database; CGIAR Consortium for Spatial Information. 2009. CGIAR-CSI GeoPortal. Available online: http://www.cgiar-csi.org (accessed on 11 February 2015).
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1-km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Hengl, T.; De Jesus, J.M.; Heuvelink, G.B.; Gonzalez, M.R.; Kilibarda, M.; Blagotić, A.; Shangguan, W.; Wright, M.N.; Geng, X.; Bauer-Marschallinger, B. SoilGrids250m: Global gridded soil information based on machine learning. PLoS ONE 2017, 12, e0169748. [Google Scholar] [CrossRef]
- Friedl, M.A.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X. MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Hengl, T. Global landform and lithology class at 250 m based on the USGS global ecosystem map (Version 1.0). Lithology, Zenodo, 5 October 2018. [Google Scholar] [CrossRef]
- Hengl, T. Global DEM derivatives at 250 m, 1 km and 2 km based on the MERIT DEM (Version 1.0). Topographic Wetness Index, Zenodo, 5 October 2018. [Google Scholar] [CrossRef]
- Fan, Y.; Li, H.; Miguez-Macho, G. Global patterns of groundwater table depth. Science 2013, 339, 940–943. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2014. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1. pp. 278–282. [Google Scholar] [CrossRef]
- Sturges, H.A. The choice of a class interval. J. Am. Stat. Assoc. 1926, 21, 65–66. [Google Scholar] [CrossRef]
- Gao, J. Global Population Projection Grids Based on Shared Socioeconomic Pathways (SSPs), Downscaled 1-km Grids, 2010–2100; NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA, 2019. [Google Scholar]
- JMP Global Data on Water Supply, Sanitation and Hygiene (WASH). Available online: https://washdata.org/data/household#!/ (accessed on 29 August 2019).
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Podgorski, J.E.; Labhasetwar, P.; Saha, D.; Berg, M. Prediction modeling and mapping of groundwater fluoride contamination throughout India. Environ. Sci. Technol. 2018, 52, 9889–9898. [Google Scholar] [CrossRef]
- Ayotte, J.D.; Medalie, L.; Qi, S.L.; Backer, L.C.; Nolan, B.T. Estimating the high-arsenic domestic-well population in the conterminous United States. Environ. Sci. Technol. 2017, 51, 12443–12454. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Sovann, C.; Polya, D. Improved groundwater geogenic arsenic hazard map for Cambodia. Environ. Chem. 2014, 11, 595–607. [Google Scholar] [CrossRef]
- Fendorf, S.; Michael, H.A.; Van Geen, A. Spatial and temporal variations of groundwater arsenic in South and Southeast Asia. Science 2010, 328, 1123–1127. [Google Scholar] [CrossRef] [PubMed]
- Postma, D.; Larsen, F.; Hue, N.T.M.; Duc, M.T.; Viet, P.H.; Nhan, P.Q.; Jessen, S. Arsenic in groundwater of the Red River floodplain, Vietnam: Controlling geochemical processes and reactive transport modeling. Geochim. et Cosmochim. Acta 2007, 71, 5054–5071. [Google Scholar] [CrossRef]
- Rowland, H.; Boothman, C.; Pancost, R.; Gault, A.; Polya, D.; Lloyd, J. The role of indigenous microorganisms in the biodegradation of naturally occurring petroleum, the reduction of iron, and the mobilization of arsenite from West Bengal aquifer sediments. J. Environ. Qual. 2009, 38, 1598–1607. [Google Scholar] [CrossRef]
- Magnone, D.; Richards, L.A.; Polya, D.A.; Bryant, C.; Jones, M.; Van Dongen, B.E. Biomarker-indicated extent of oxidation of plant-derived organic carbon (OC) in relation to geomorphology in an arsenic contaminated Holocene aquifer, Cambodia. Sci. Rep. 2017, 7, 1–12. [Google Scholar] [CrossRef]
- Chakraborti, D.; Rahman, M.M.; Murrill, M.; Das, R.; Patil, S.; Sarkar, A.; Dadapeer, H.; Yendigeri, S.; Ahmed, R.; Das, K.K. Environmental arsenic contamination and its health effects in a historic gold mining area of the Mangalur greenstone belt of Northeastern Karnataka, India. J. Hazard. Mater. 2013, 262, 1048–1055. [Google Scholar] [CrossRef]
- Chakraborti, D.; Rahman, M.M.; Das, B.; Chatterjee, A.; Das, D.; Nayak, B.; Pal, A.; Chowdhury, U.K.; Ahmed, S.; Biswas, B.K. Groundwater arsenic contamination and its health effects in India. Hydrogeol. J. 2017, 25, 1165–1181. [Google Scholar] [CrossRef]
- Sahu, S.; Saha, D. Role of shallow alluvial stratigraphy and Holocene geomorphology on groundwater arsenic contamination in the Middle Ganga Plain, India. Environ. Earth Sci. 2015, 73, 3523–3536. [Google Scholar] [CrossRef]
- Harvey, C.F.; Swartz, C.H.; Badruzzaman, A.B.M.; Keon-Blute, N.; Yu, W.; Ashraf Ali, M.; Jay, J.; Beckie, R.; Niedan, V.; Brabander, D.; et al. Arsenic mobility and groundwater extraction in Bangladesh. Science 2002, 298, 1602–1606. [Google Scholar] [CrossRef]
- Polya, D.A.; Charlet, L. Rising arsenic risk? Nat. Geosci. 2009, 2, 383–384. [Google Scholar] [CrossRef]
- Neumann, R.B.; Ashfaque, K.N.; Badruzzaman, A.B.M.; Ali, M.A.; Shoemaker, J.K.; Harvey, C.F. Anthropogenic influences on groundwater arsenic concentrations in Bangladesh. Nat. Geosci. 2010, 3, 46–52. [Google Scholar] [CrossRef]
- Lawson, M.; Polya, D.A.; Boyce, A.J.; Bryant, C.; Mondal, D.; Shantz, A.; Ballentine, C.J. Pond-derivedorganic carbon driving changes in arsenic hazard found in Asian groundwaters. Environ. Sci. Technol. 2013, 47, 7085–7094. [Google Scholar] [CrossRef] [PubMed]
- Public Health England. Environmental Public Health Tracking in England. Report on Recent Activities December 2018; Public Health England Report GW-352; Public Health England: London, UK, 2019.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country [Data Sources] | Number of Data Points, before Spatial Averaging (% of Total) | Mean (±Standard Deviation) As Concentration, before Spatial Averaging | Number of Data Points, after Spatial Averaging (% of Total) | Mean (±Standard Deviation) As Concentration, after Spatial Averaging |
|---|---|---|---|---|
| India [17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47] | 132,028 (91%) | 53 ± 451 µg/L | 17,528 (74%) | 33 ± 162 µg/L |
| Bangladesh [42,48] | 4215 (3%) | 62 ± 139 µg/L | 3674 (15%) | 56 ± 120 µg/L |
| Nepal [49] | 7575 (5%) | 15 ± 62 µg/L | 1846 (8%) | 16 ± 66 µg/L |
| Pakistan [6,50] | 1279 (1%) | 103 ± 123 µg/L | 760 (3%) | 71 ± 98 µg/L |
| Total | 145,097 | 52 ± 438 µg/L | 23,808 | 37 ± 150 µg/L |
| Variable | Description |
|---|---|
| Climate | |
| Actual evapotranspiration (AET) [51] | Average rate of actual evapotranspiration (mm/yr) |
| Aridity | PET/Precipitation |
| Potential evapotranspiration (PET) [52] | Average rate of potential evapotranspiration (mm/yr) |
| Precipitation [53] | Average rate of precipitation (mm/yr) |
| Priestley-Taylor alpha coefficient [51] | AET/PET |
| Soil | |
| Calcisols [54] | Probability of the occurrence of calcisols |
| Clay, subsoil [54] | Weight % of clay particles (<0.0002 mm) at 2 m depth |
| Clay, topsoil [54] | Weight % of clay particles (<0.0002 mm) at 0 m depth |
| Coarse fragments, subsoil [54] | Volumetric % of coarse fragments (>2 mm) at 2 m depth |
| Coarse fragments, topsoil [54] | Volumetric % of coarse fragments (>2 mm) at 0 m depth |
| Fluvisols [54] | Probability of the occurrence of fluvisols |
| Gleysols [54] | Probability of the occurrence of gleysols |
| Sand, subsoil [54] | Weight % of sand particles (0.05–2 mm) at 2 m depth |
| Sand, topsoil [54] | Weight % of sand particles (0.05–2 mm) at 0 m depth |
| Silt, subsoil [54] | Weight % of silt particles (0.0002–0.05 mm) at 2 m depth |
| Silt, topsoil [54] | Weight % of silt particles (0.0002–0.05 mm) at 0 m depth |
| Soil cation exchange capacity [54] | Cation exchange capacity (cmolc/kg) at 2 m depth |
| Soil organic carbon [54] | Soil organic carbon (permille) at 2 m depth |
| Soil organic carbon density [54] | Soil organic carbon density (kg/m3) at 2 m depth |
| Soil pH [54] | Soil pH measured in water at 2 m depth |
| Solonchaks [54] | Probability of the occurrence of solonchaks |
| Water wilting point [54] | Vol. % of available soil water until wilting point at 2 m depth |
| Other | |
| Land cover [55] | 17 different land cover categories according to the International Geosphere-Biosphere Programme (IGBP) |
| Lithology [56] | 15 different categories of lithology |
| Topographic wetness index [57] | Combination of upslope contributing area and slope |
| Water table depth [58] | Mean water table depth (m) |
| Reference | ||
| Prediction | 0 | 1 |
| 0 | 2223 | 462 |
| 1 | 561 | 1514 |
| Statistic | Value | |
| Accuracy (Acc) | 0.7851 | |
| No information rate (NIR) | 0.5849 | |
| p value (Acc > NIR) | <2.2 × 10−16 | |
| Cohen’s kappa | 0.5606 | |
| Sensitivity | 0.7662 | |
| Specificity | 0.7985 | |
| Positive predictive value | 0.7296 | |
| Negative predictive value | 0.8279 | |
| Prevalence | 0.4151 | |
| Balanced accuracy | 0.7823 | |
| State/Territory | Percentage of Land Area Exposed | Population Exposed |
|---|---|---|
| Andaman and Nicobar | 0.4–2.9% | 300–2700 |
| Andhra Pradesh | <0.1% | 2700–6600 |
| Arunachal Pradesh | 4.3–21.6% | 69,800–157,700 |
| Assam | 42.3–59.7% | 6,536,000–8,771,100 |
| Bihar | 3.0–12.0% | 1,226,800–4,636,500 |
| Chandigarh | n/a | n/a |
| Chhattisgarh | <0.1% | 700–1100 |
| Dadra and Nagar Haveli and Daman and Diu | n/a | n/a |
| Delhi | n/a | n/a |
| Goa | n/a | n/a |
| Gujarat | 0.3–4.0% | 19,300–97,300 |
| Haryana | 0.4–5.0% | 39,200–447,200 |
| Himachal Pradesh | 0.4–0.9% | 36,800–76,900 |
| Jammu and Kashmir | 0.7–1.1% | 337,800–470,800 |
| Jharkhand | 0.2–0.6% | 103,600–231,400 |
| Karnataka | 0.1–0.5% | 29,400–93,900 |
| Kerala | <0.4% | 10,400–77,300 |
| Madhya Pradesh | 0.7–2.1% | 201,200–552,100 |
| Maharashtra | <0.1% | 300–1700 |
| Manipur | 8.6–22.7% | 46,500–121,900 |
| Meghalaya | 0.2–1.5% | 3300–13,800 |
| Mizoram | 4.5–18.0% | 23,500–82,400 |
| Nagaland | 5.9–21.5% | 54,300–188,600 |
| Odisha | <0.4% | 1300–194,600 |
| Puducherry | n/a | n/a |
| Punjab | 2.3–6.8% | 299,100–788,500 |
| Rajasthan | <0.1% | 2300–10,800 |
| Sikkim | n/a | n/a |
| Tamil Nadu | <0.1% | 200–200 |
| Telangana | <0.2% | 4100–12,900 |
| Tripura | 0.1–1.4% | 800–10,000 |
| Uttar Pradesh | 1.0–2.4% | 1,222,800–2,458,500 |
| Uttarakhand | <0.7% | 900–42,300 |
| West Bengal | 12.9–20.5% | 7,432,200–10,144,700 |
| Total | 2.0–4.2% | 17,710,000–29,690,000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Podgorski, J.; Wu, R.; Chakravorty, B.; Polya, D.A. Groundwater Arsenic Distribution in India by Machine Learning Geospatial Modeling. Int. J. Environ. Res. Public Health 2020, 17, 7119. https://doi.org/10.3390/ijerph17197119
Podgorski J, Wu R, Chakravorty B, Polya DA. Groundwater Arsenic Distribution in India by Machine Learning Geospatial Modeling. International Journal of Environmental Research and Public Health. 2020; 17(19):7119. https://doi.org/10.3390/ijerph17197119
Chicago/Turabian StylePodgorski, Joel, Ruohan Wu, Biswajit Chakravorty, and David A. Polya. 2020. "Groundwater Arsenic Distribution in India by Machine Learning Geospatial Modeling" International Journal of Environmental Research and Public Health 17, no. 19: 7119. https://doi.org/10.3390/ijerph17197119
APA StylePodgorski, J., Wu, R., Chakravorty, B., & Polya, D. A. (2020). Groundwater Arsenic Distribution in India by Machine Learning Geospatial Modeling. International Journal of Environmental Research and Public Health, 17(19), 7119. https://doi.org/10.3390/ijerph17197119