1. Introduction
With accelerated urban development and modernization, air pollution is worsening and its impact on human health has been the main research topic in developing countries [
1]. Air pollutants include gaseous pollutants and particulate matter (PM). Studies have shown that PMs with an aerodynamic diameter of 2.5 µm or less (referred to as PM
2.5 or fine particles) have a greater impact on human health [
2,
3]. The impact of both long term (chronic) and short term (acute) exposure to PMs has been widely studied, with the former being most often estimated from cohort studies [
4] and the latter from ecological time-series studies [
5]. However, cohort studies are expensive and time-consuming to implement due to the long follow-up period required for collecting individual-level pollution and disease data [
6]. This has led to the use of spatiotemporal ecological study design in this field [
7,
8], which takes advantage of routinely collected data [
5] such as data from the air quality monitoring (AQM) stations in Beijing and the Causes of Death Registry (CDR) of the Chinese Centers for Disease Control and Prevention [
9]. Although causal inference is an important problem in time-series studies due to the difficulty of selecting an appropriate regression model that can be well fitted to the data, they contribute to and independently corroborate the body of evidence provided by cohort studies [
10].
The semiparametric Poisson regression has been widely used for time-series analyses of air pollution and health, which uses daily mortality or morbidity counts as the outcome, linear terms to measure the percentage of increase in the outcome associated with elevations in air pollution levels, and smooth functions of time and weather variables to adjust for time-varying confounders [
11]. Generalized linear models (GLMs) with parametric splines (e.g., natural cubic splines) [
12] or generalized additive models (GAMs) with nonparametric splines (e.g., smoothing splines or locally weighted smoothers or (LOESS) [
13] are used to estimate effects associated with exposure to air pollution while accounting for smooth fluctuations in outcome that confound the estimated effects of pollution. GAM and GLM can be applied in similar situations, but they serve different analytic purposes. GLM emphasizes estimation and inference for the parameters of the model, while GAM focuses on exploring data non-parametrically. GAM is more suitable for exploring the data and visualizing the relationship between the dependent variable and the independent variables [
14].
The basic form of GAM applied in air pollution and health studies may be expressed using Equation (1) [
11]:
where
Yt is count of daily mortality or morbidity,
β0 denotes the intercept,
t indicates calendar day,
Xt are daily concentrations of the studied air pollutant, i.e., PM
2.5 in our study,
l is the lag time of the pollution exposure (which is generally restricted to one to seven days for acute effects),
S(
t) denotes a smooth function of a covariate (calendar day or meteorological variables such as temperature and humidity). The smooth functions are usually constructed using LOESS, smoothing splines or natural cubic splines.
ϕ is the vector of the regression coefficients associated with vector
DOWt (indicating the 7 days of a week) for the
tth day.
βl is the parameter of interest describing the change in the logarithm of the average mortality count over population per unit of change in
Xt−l, which is generally interpreted as the percentage of increase in mortality for every 10 units or a standard deviation (SD) or interquartile range (IQR) of increase in ambient concentrations of the studied air pollutant at lag
l. The reason that the model is called semiparametric is that it assumes a linear relation with
Xt−l and unknown functional relations with time and weather variables.
The conventional algorithm for fitting GAM (hereinafter called frequentist GAM) is the backfitting algorithm [
15] and the corresponding robust estimation method has also been developed [
16]. A disadvantage of backfitting is that it is difficult to integrate with the estimation of the degree of smoothness of the model terms, so that in practice the user must set these, or select between a modest set of pre-defined smoothing levels. Although the degree of smoothness can be estimated as part of model fitting using generalized cross-validation or by restricted maximum likelihood when the smooth components are represented using smoothing spline, it carries a computational cost [
17]. The computationally efficient approaches such as fully Bayesian method have thus been developed in recent years [
18].
Although there are some applications [
19,
20,
21,
22,
23] of Bayesian GAM analyses in recent years, few of them compared the performance of frequentist and Bayesian GAMs in terms of accuracy and precision. In our study, we examined the estimates from a fully Bayesian GAM using simulated data based on underlying ‘true’ parameters from a genuine time-series study on PM
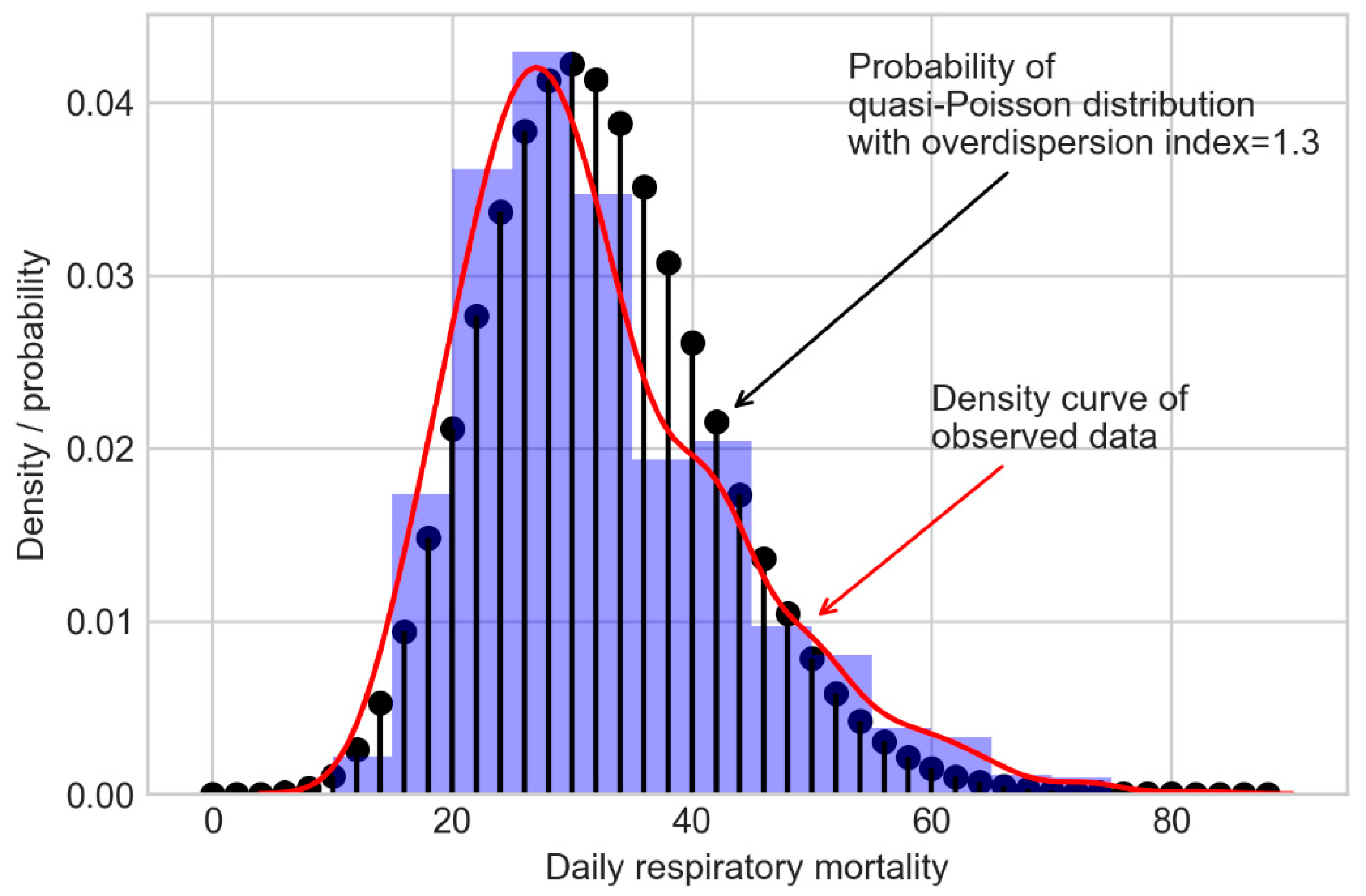
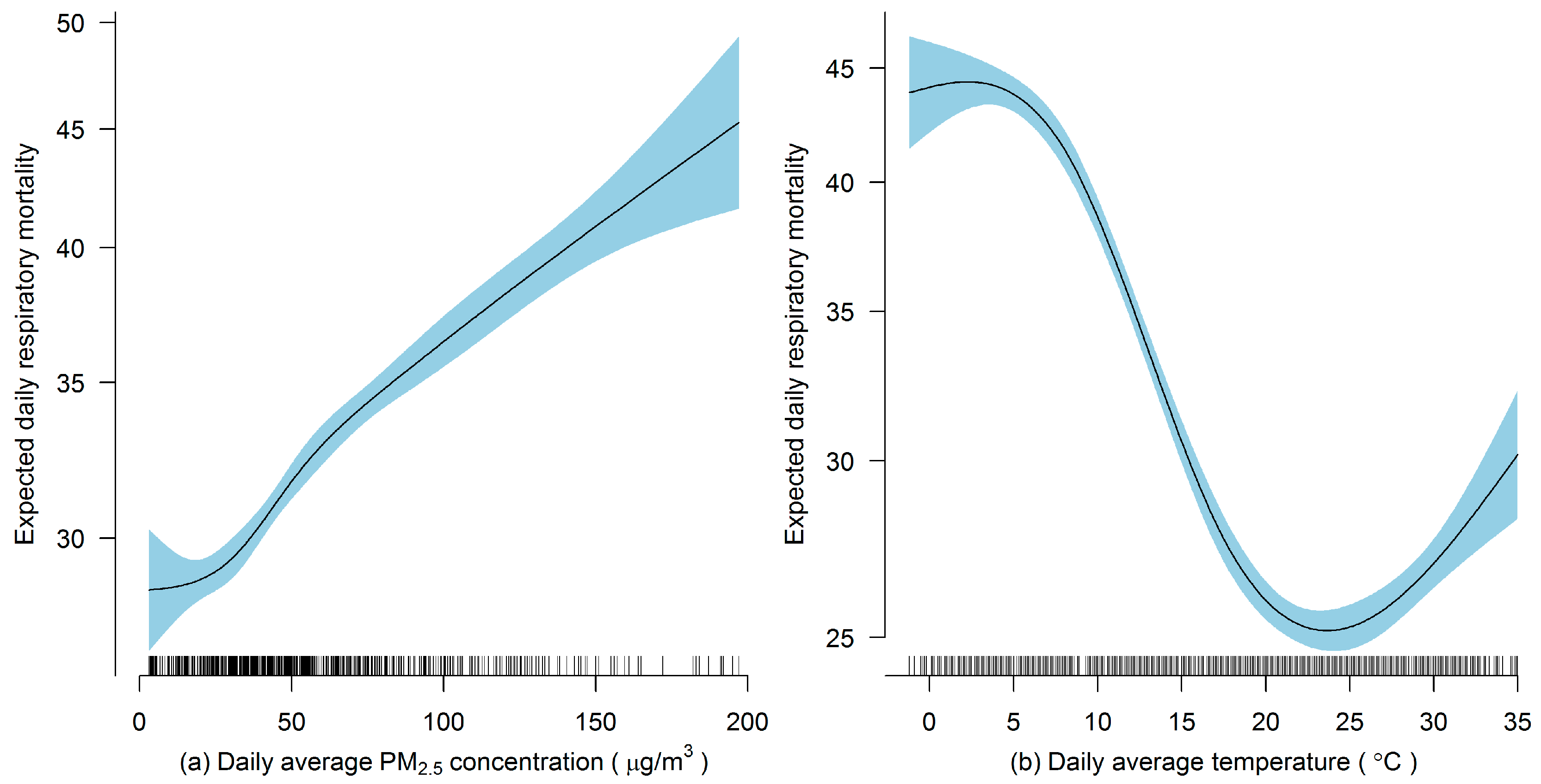
2.5 and respiratory deaths conducted in Shanghai, China.
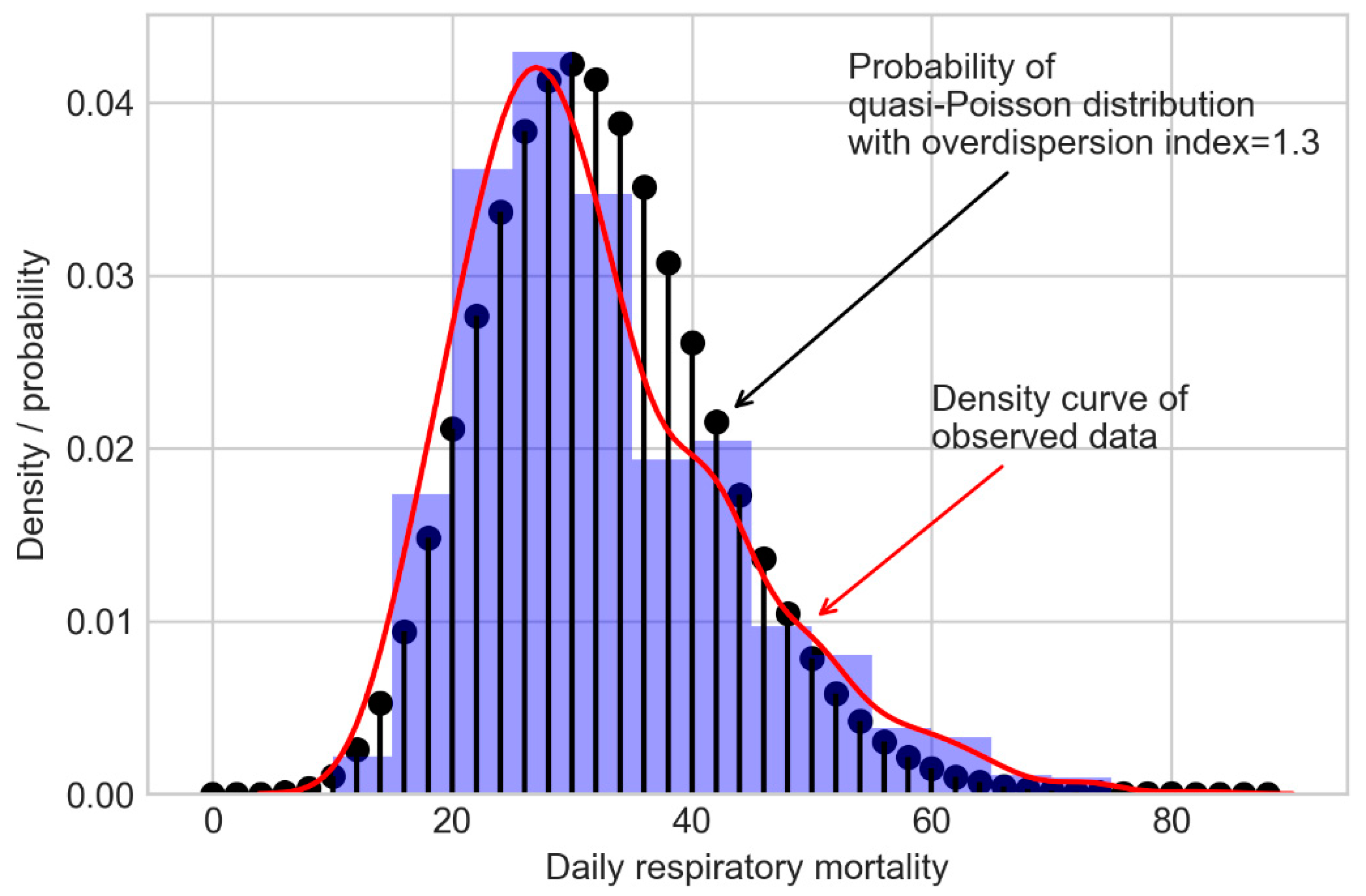
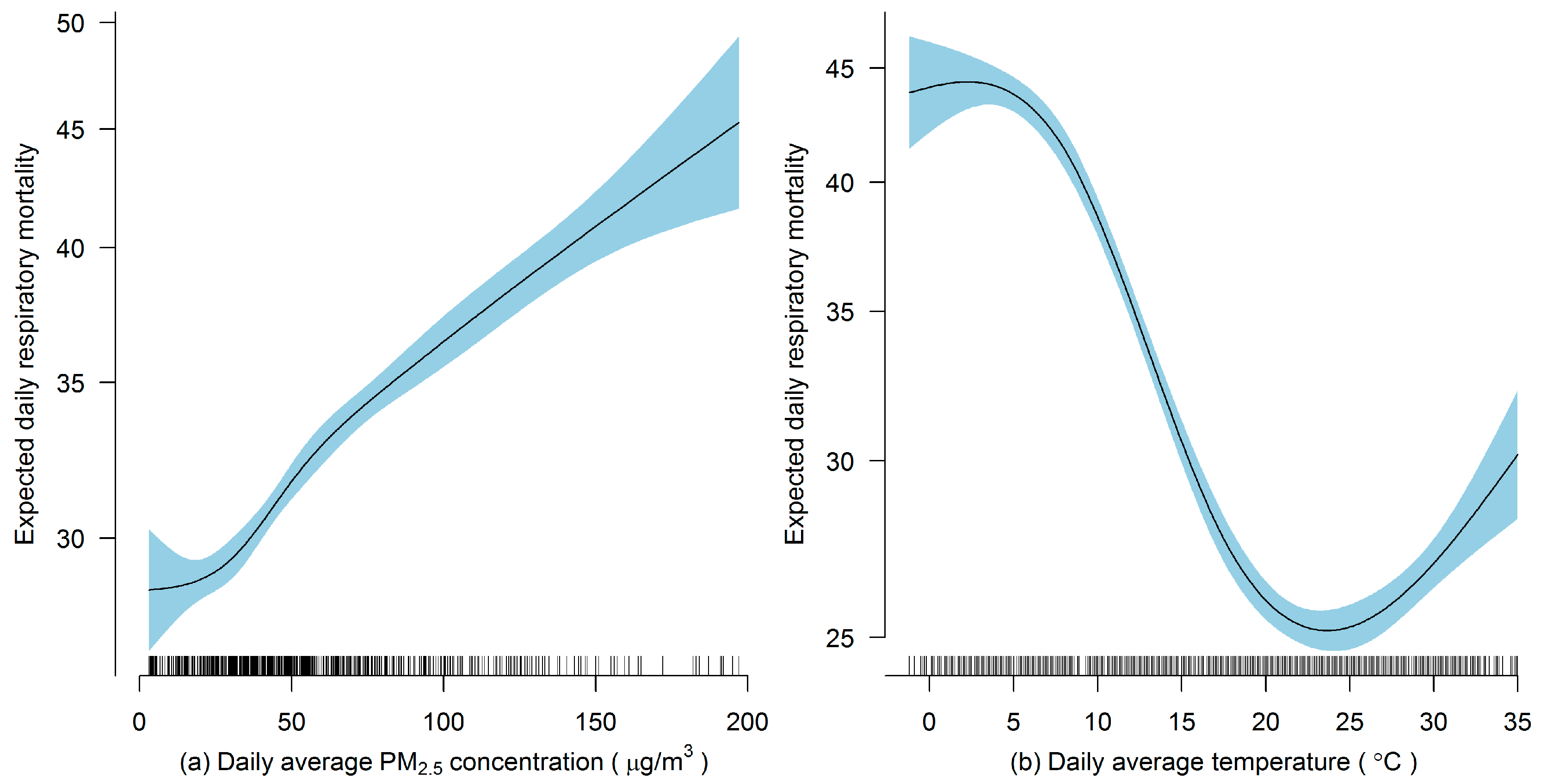
4. Discussion
In the presented study, we evaluated the performance of frequentist and fully Bayesian GAM approaches in a time-series study on the relationship between daily exposure to PM
2.5 and respiratory mortality. According to our estimates, per 10 μg/m
3 increase in PM
2.5 concentration of lag 1 day is associated with an approximately 0.49% increase in daily respiratory deaths in Shanghai between 2012 and 2014, which is consistent with the results from other studies conducted in China [
9,
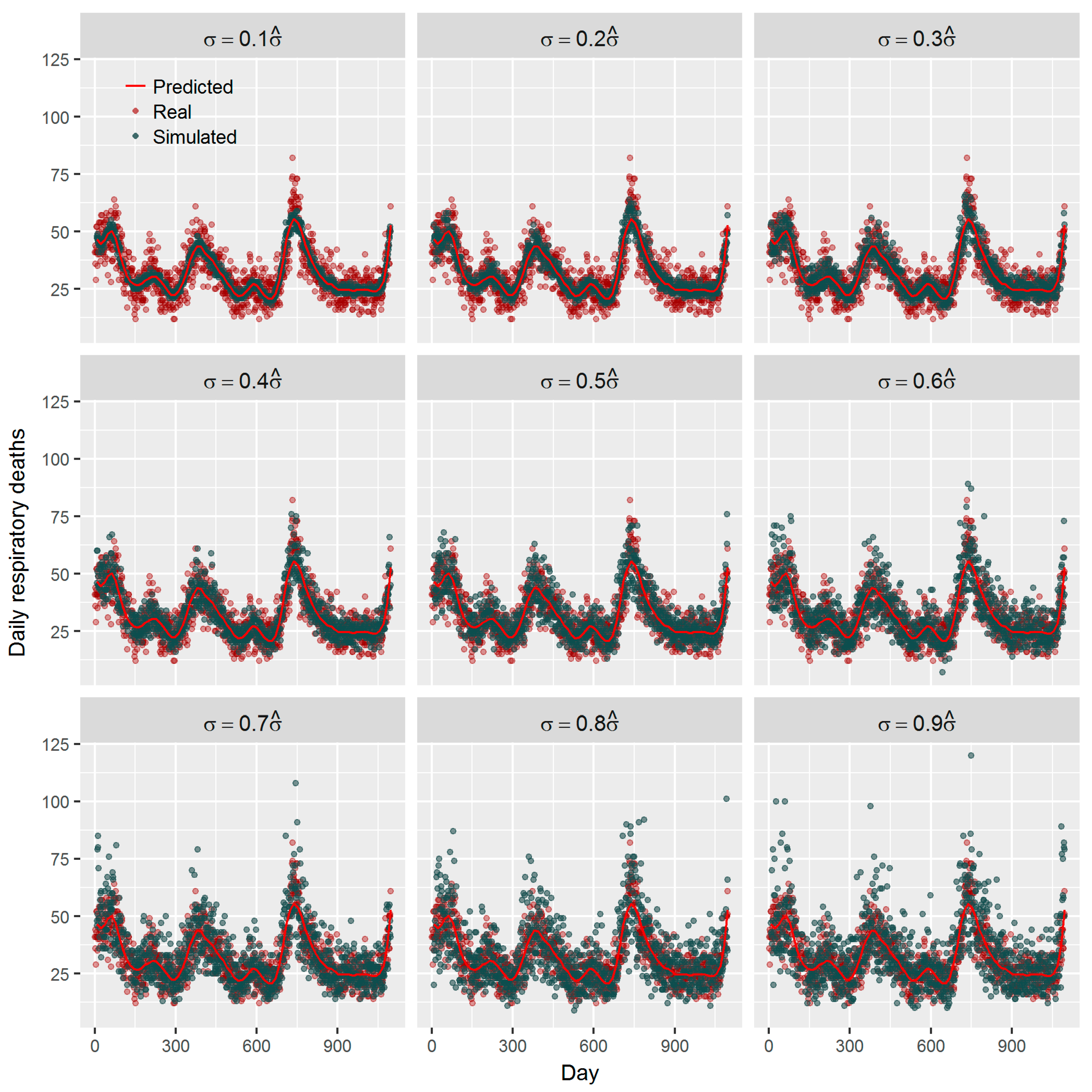
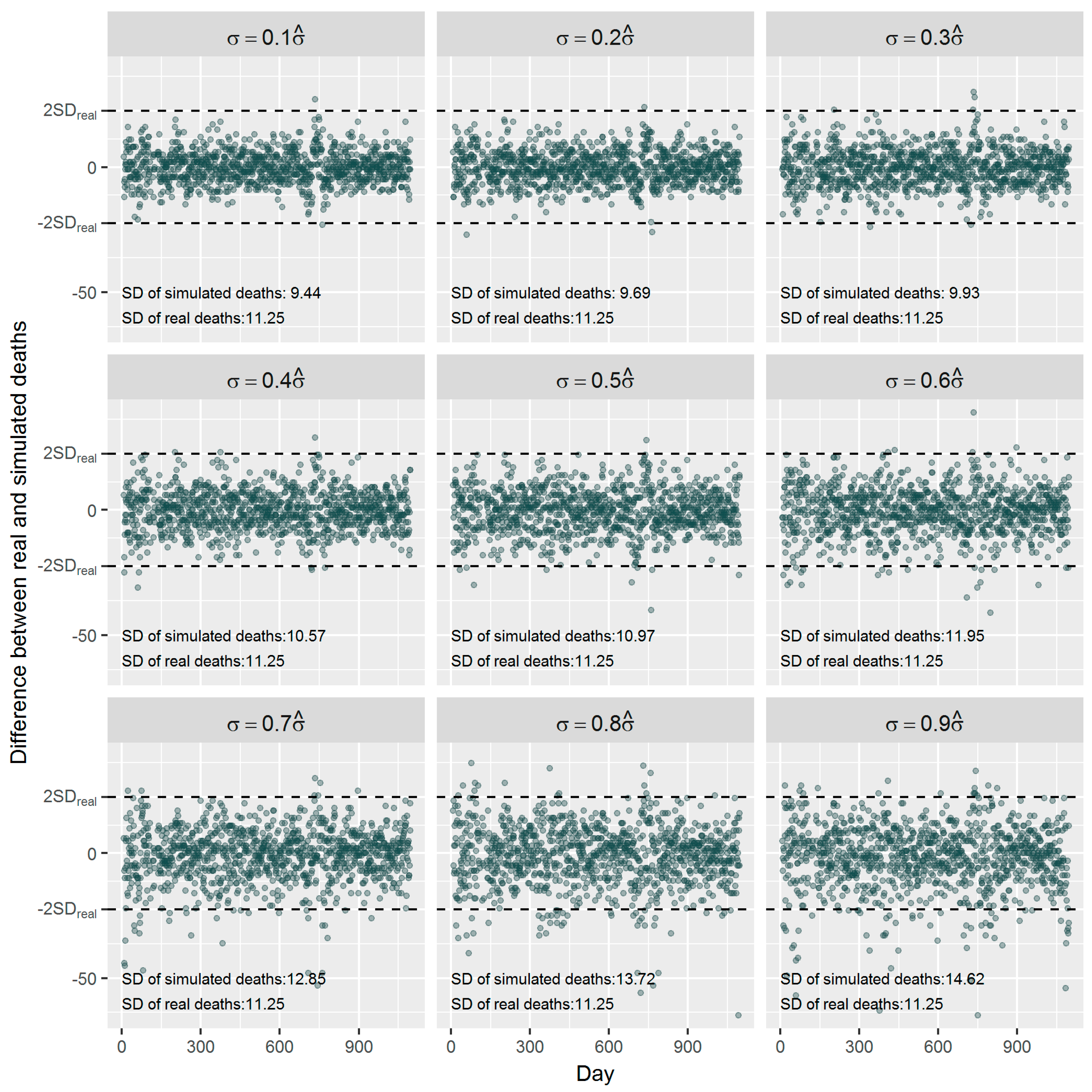
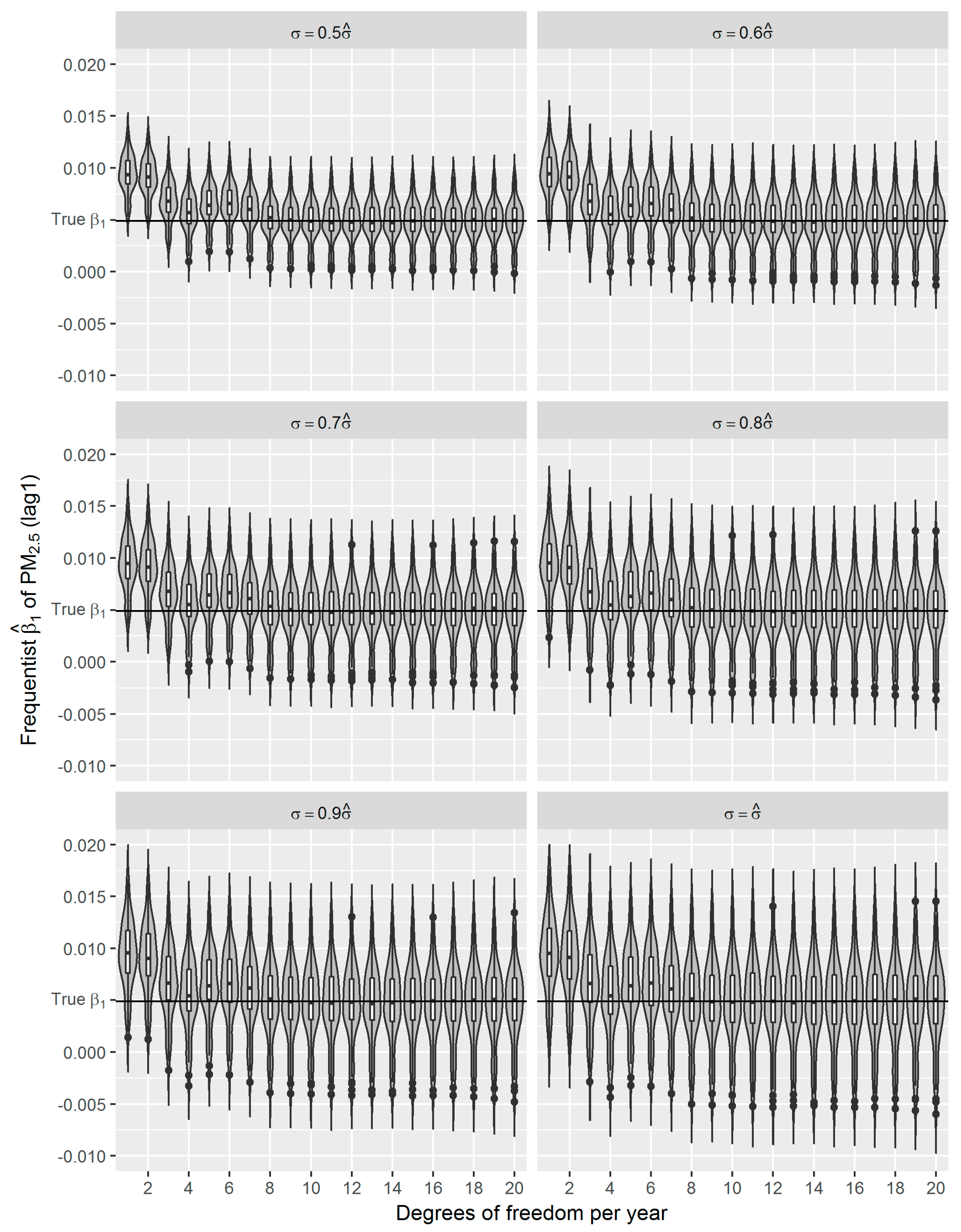
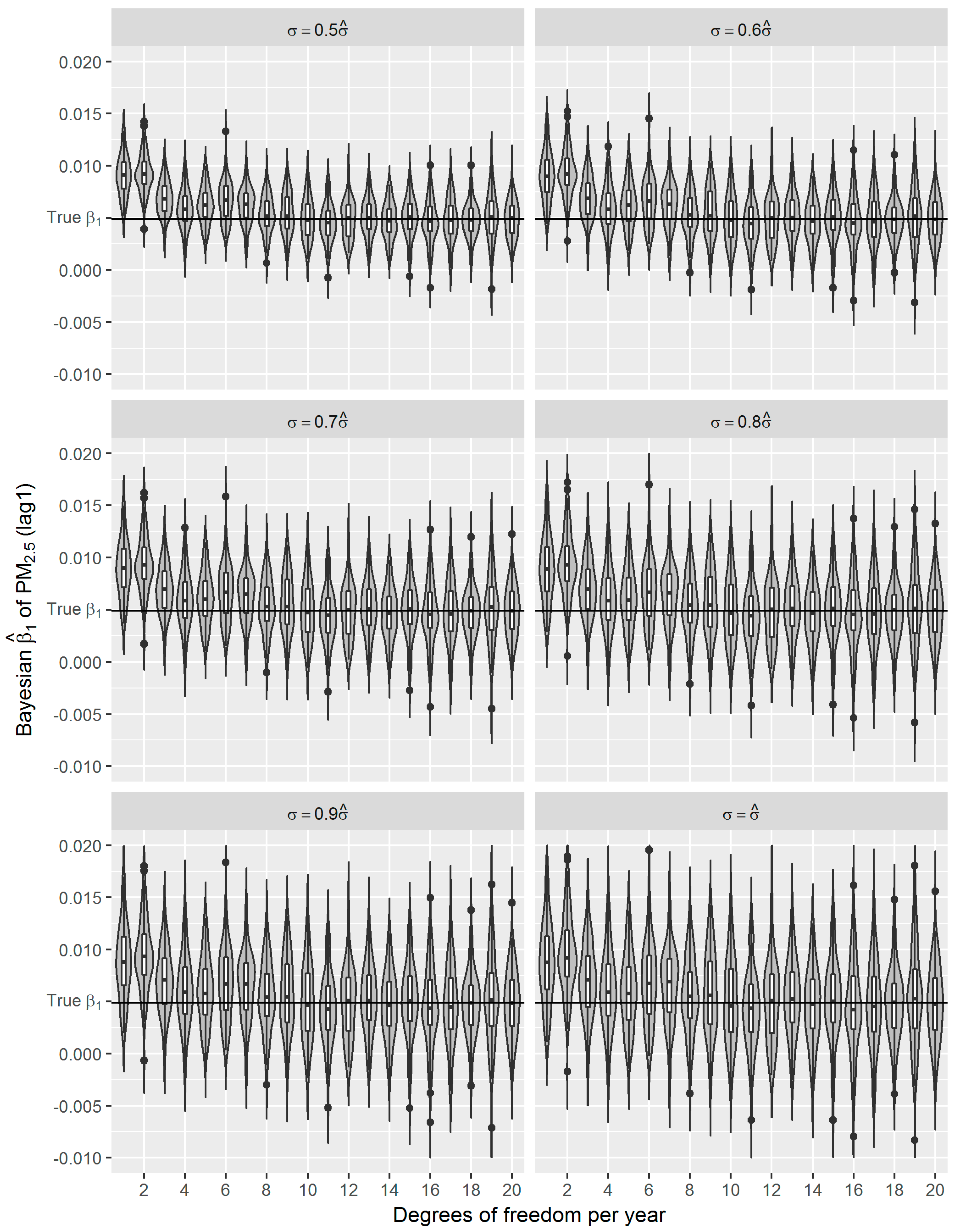
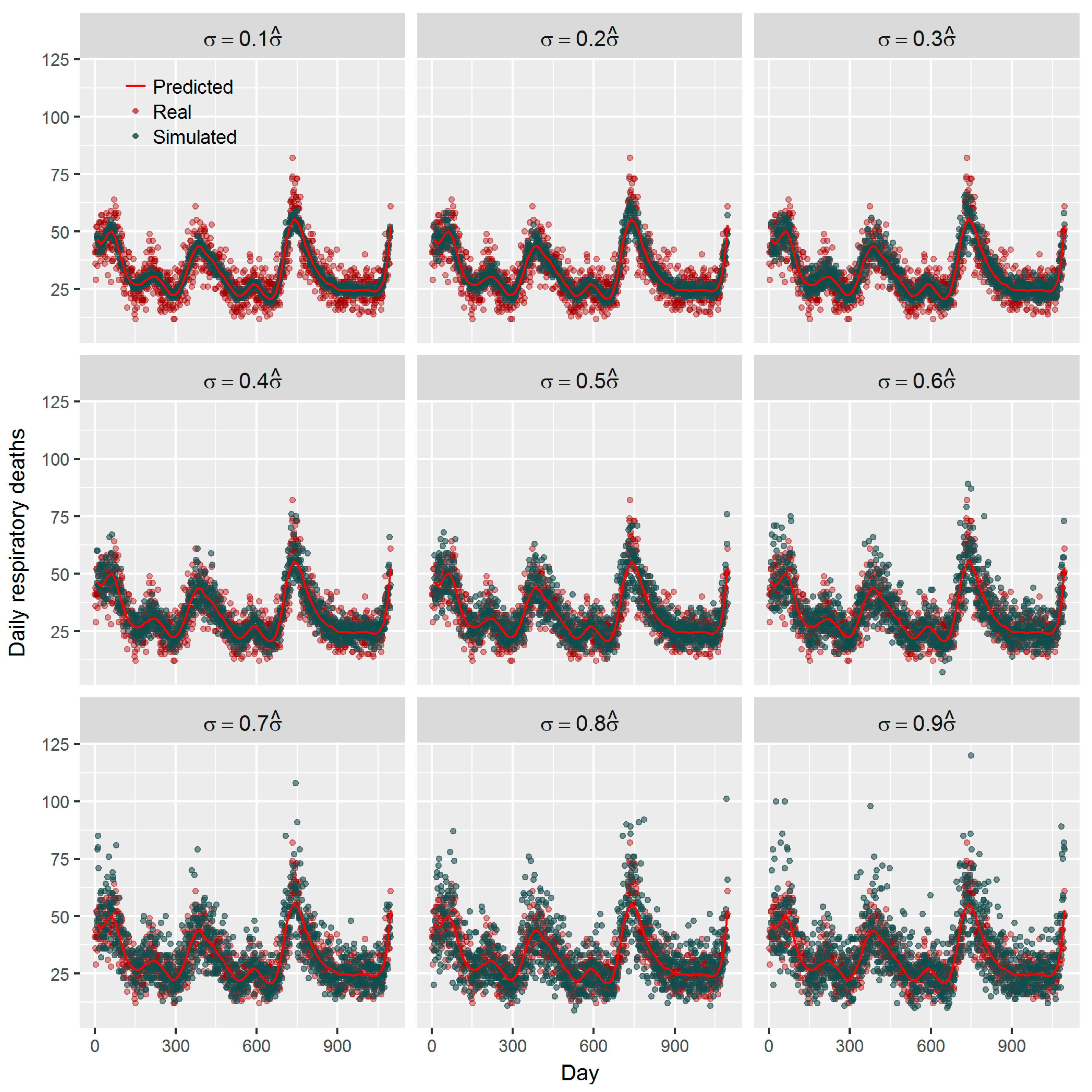
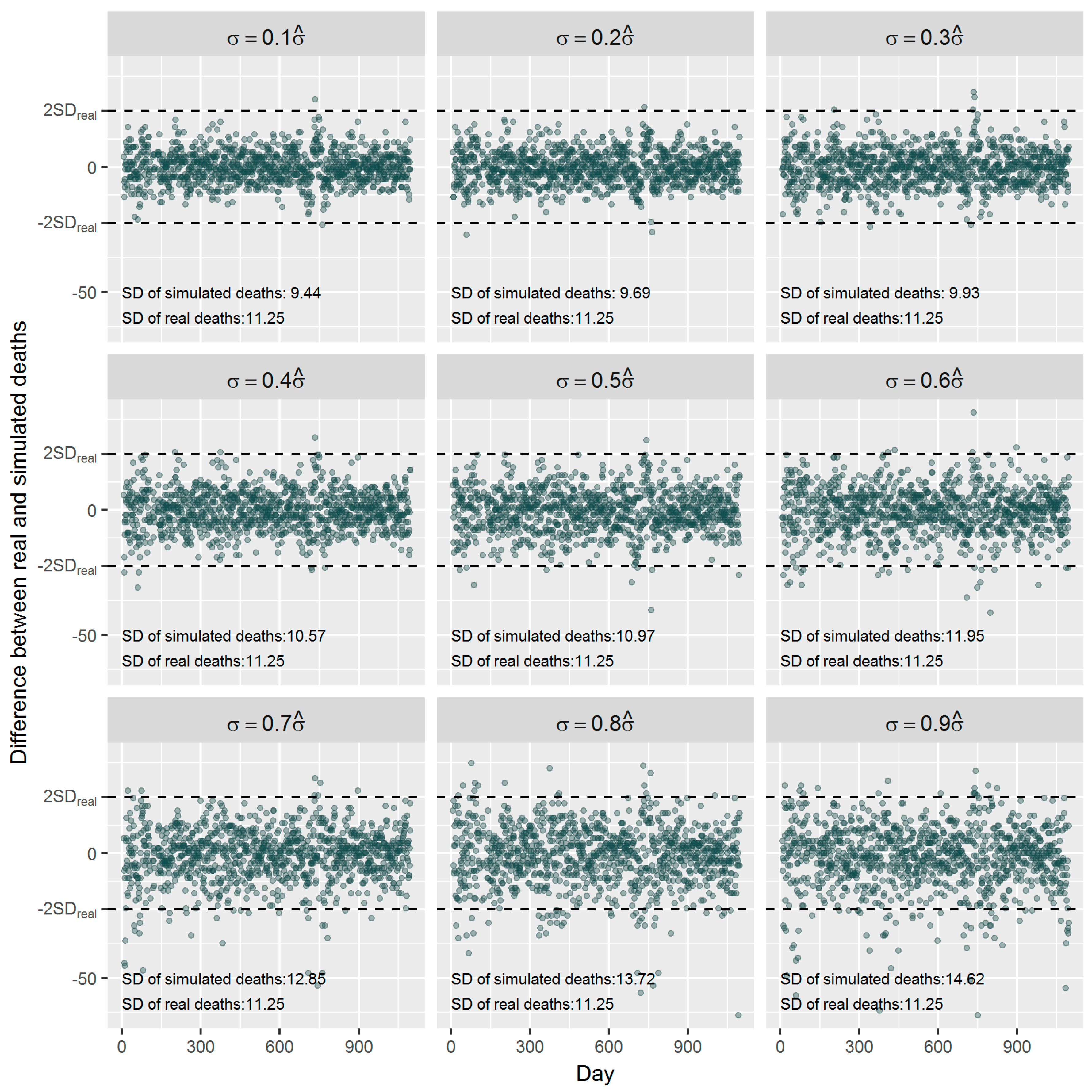
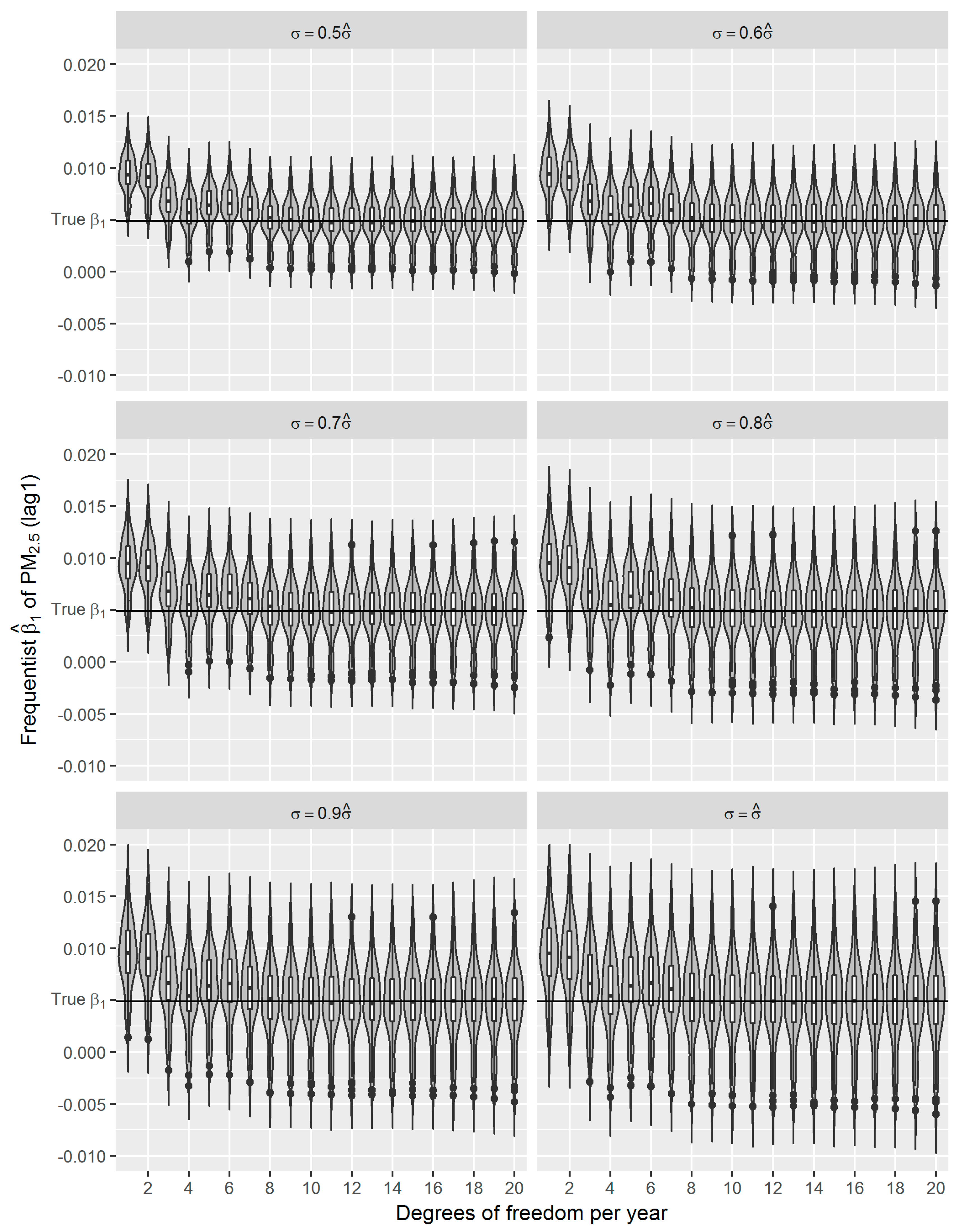
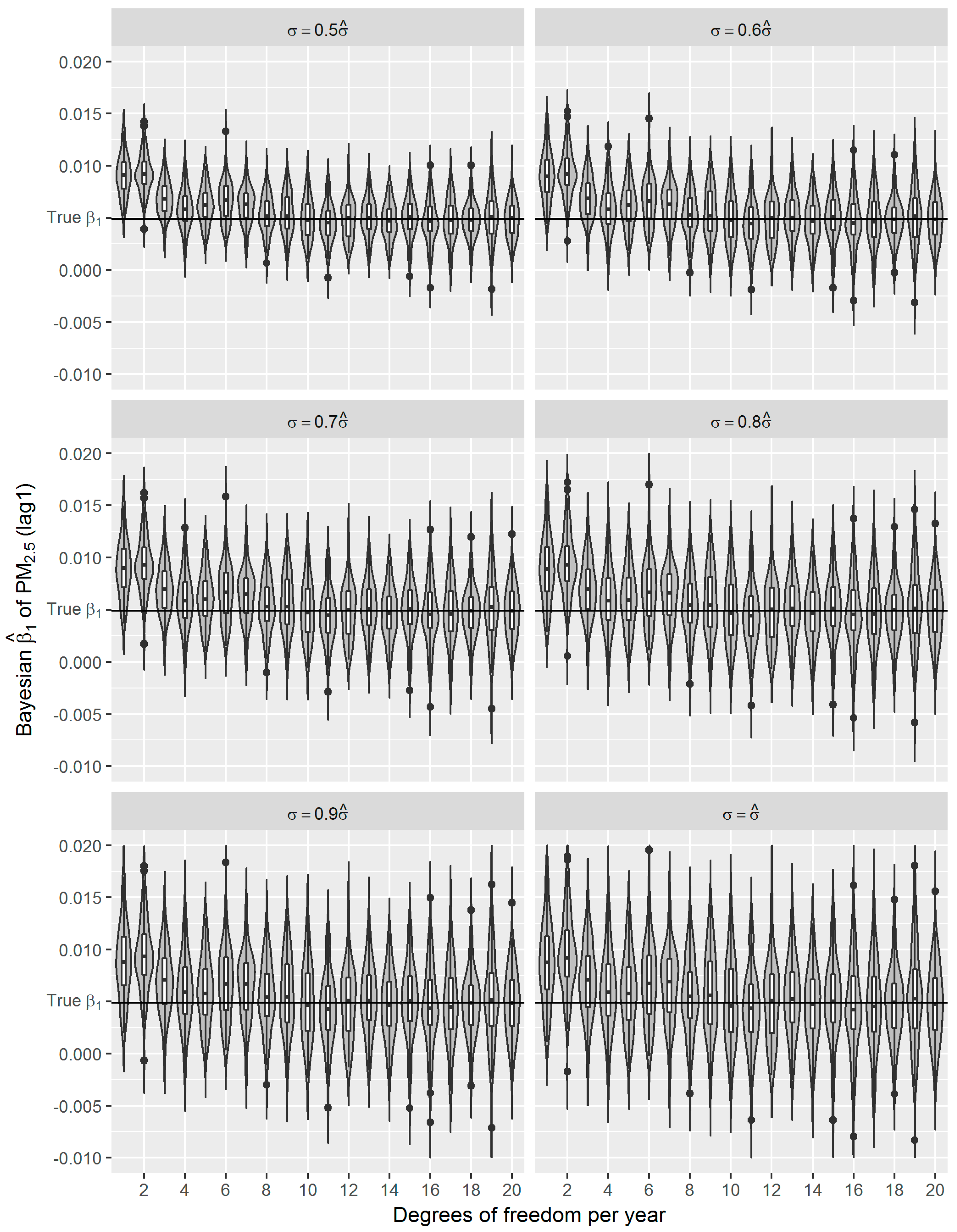
36]. Using the estimated effect as true parameter, we compared the frequentist GAM and Bayesian GAM based on simulation. Both frequentist GAM and Bayesian GAM show the similar mean estimates of the interested parameters. However, the estimates from frequentist GAM showed relatively less fluctuation (
Figure 5 and
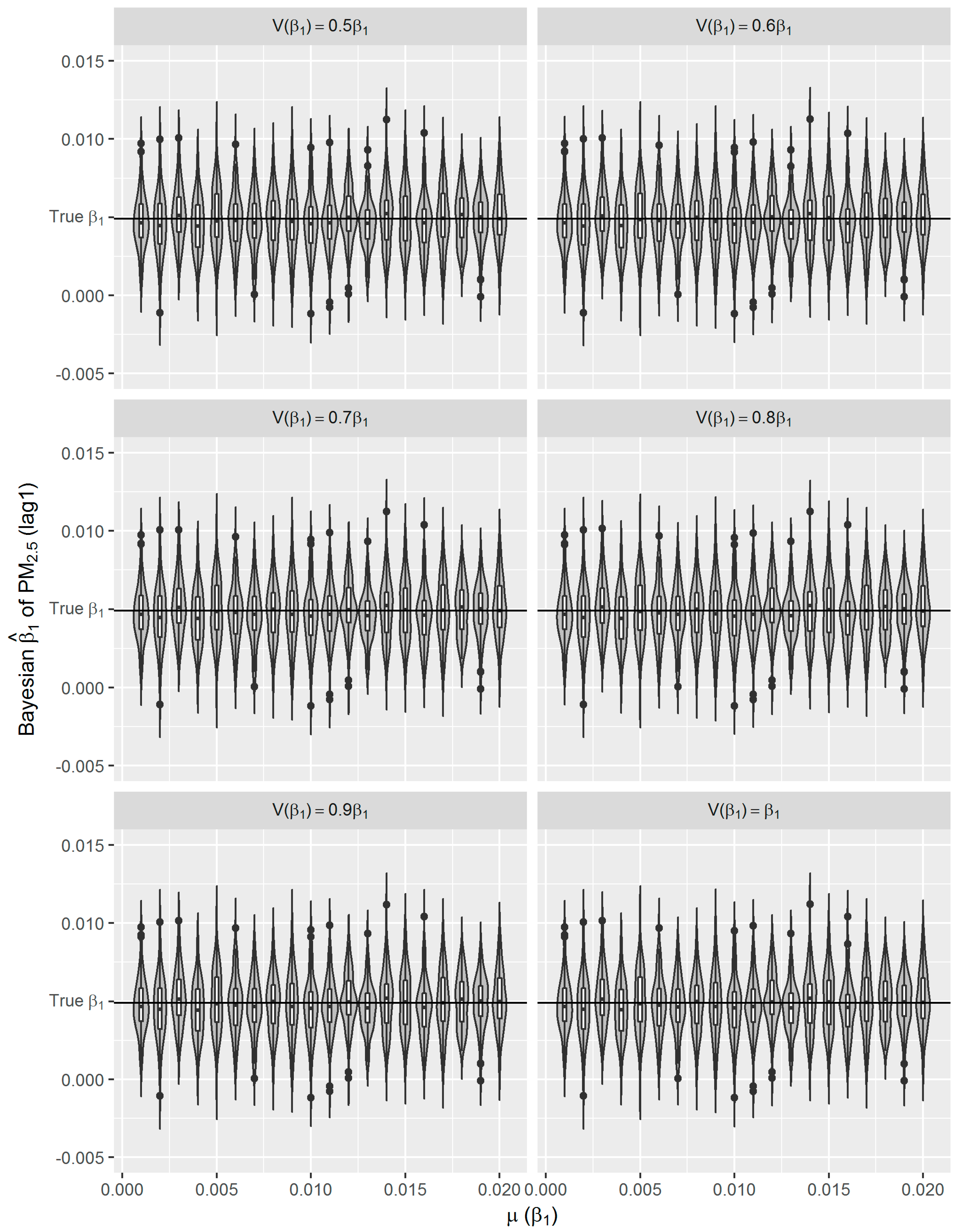
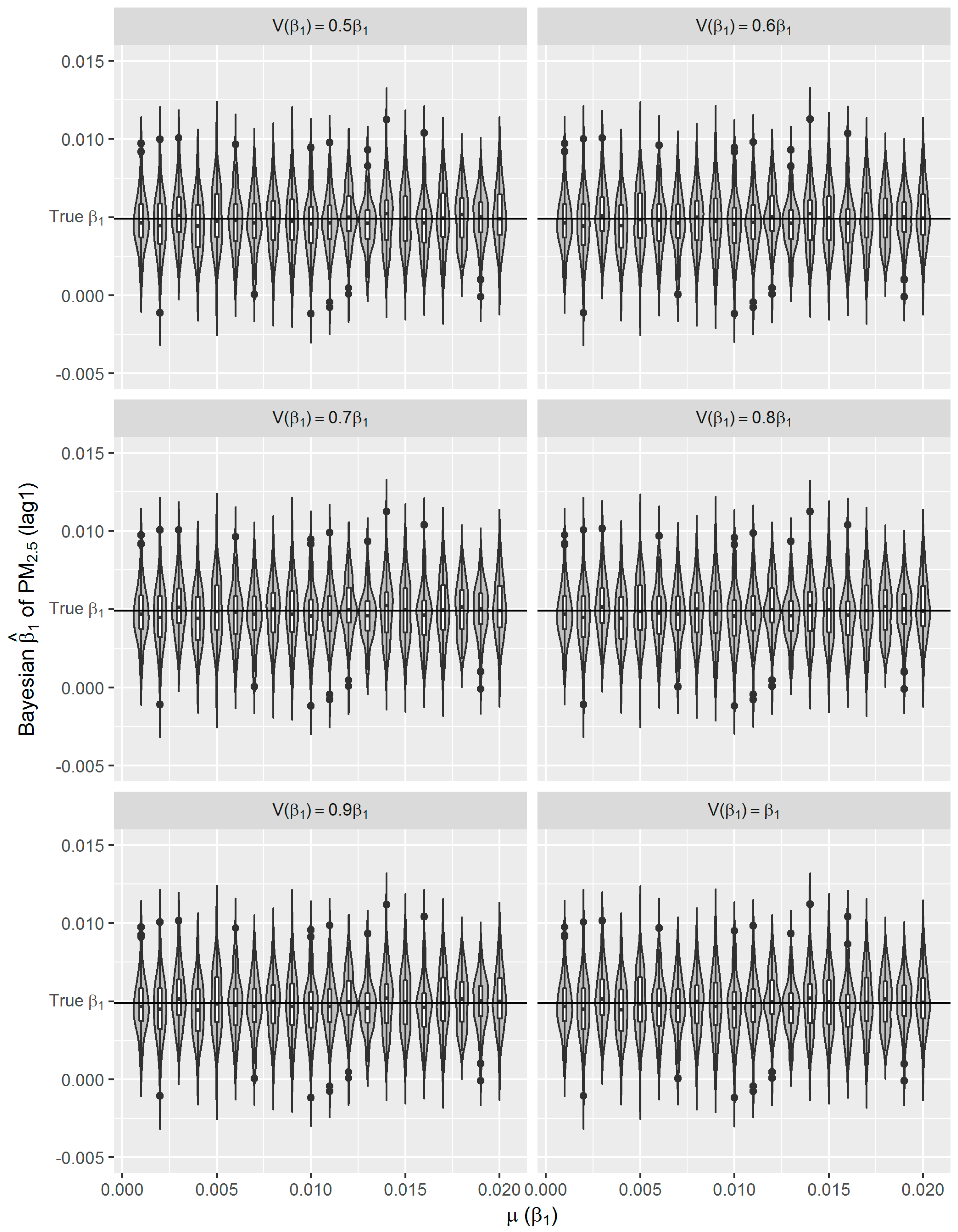
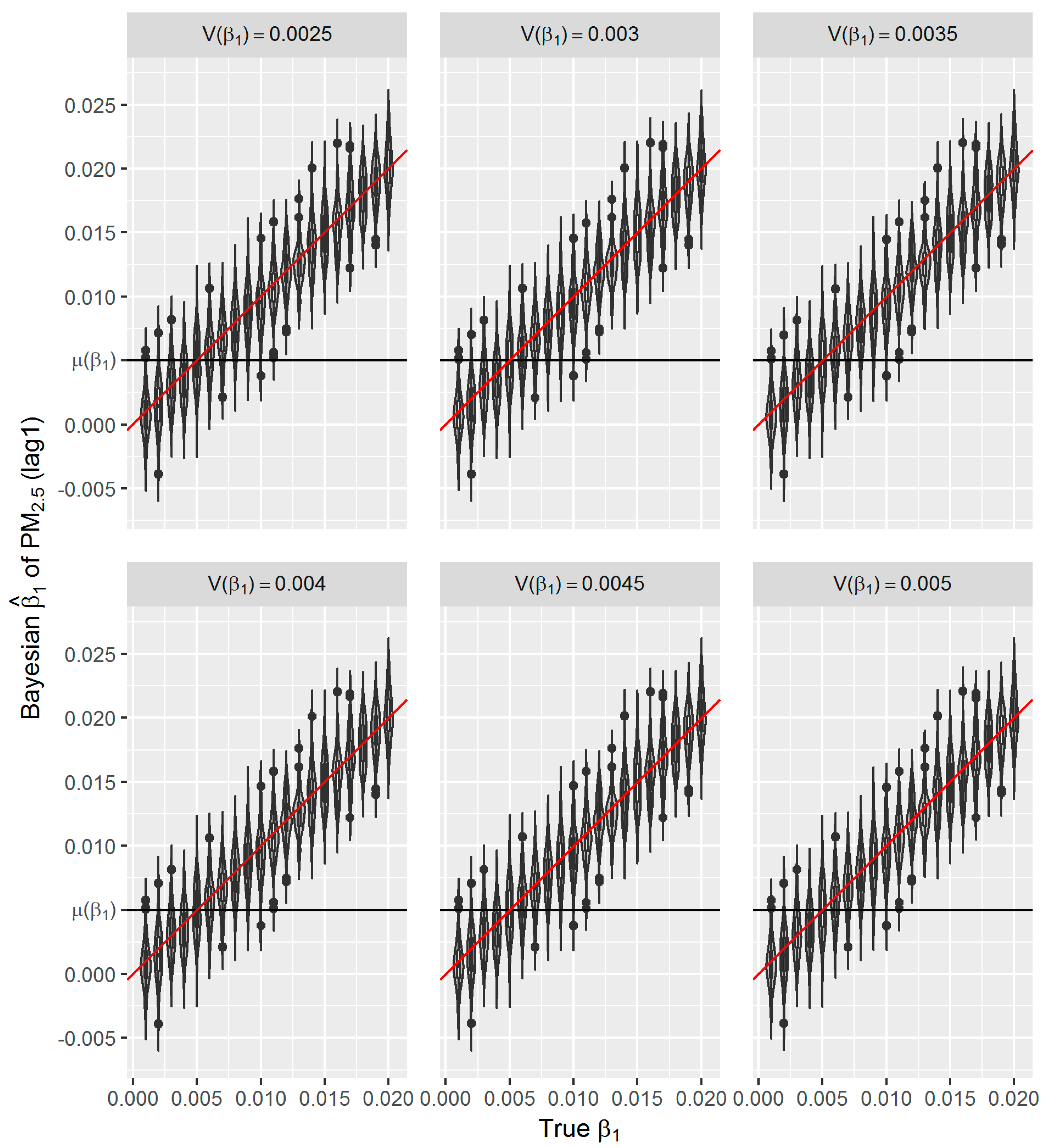
Figure 6), which to some extent reflects the over-confident inferences embedded in this method. Regarding the accuracy and precision of the estimates, both methods gave mean estimates close to the true parameter with comparable confidence intervals. It means that Bayesian GAM might be an ideal alternative to the conventional frequentist GAM. Our simulation study also indicated that when the underlying parameter was true, the informative normal priors had no noticeable influence on the Bayesian estimate (
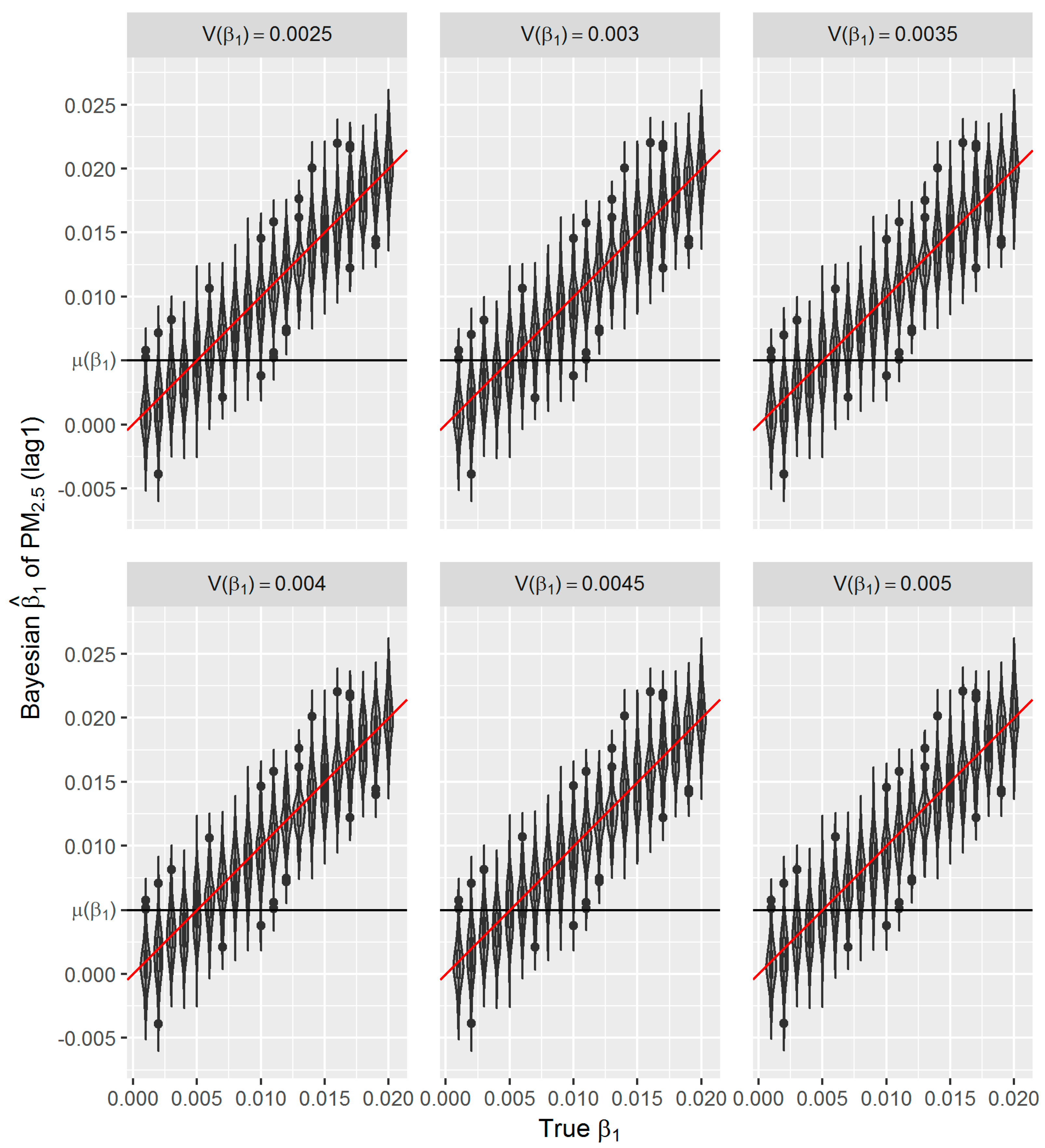
Figure 7), which was only sensitive to the underlying true parameter (
Figure 8). The reason might be the large number of data that we have and the posterior is dominated by the data rather than the prior.
As a flexible extension of GLM introduced by Hastie and Tibshirani [
42], GAM can estimate both linear trends from parametric components and nonlinear trend from any general nonparametric components during the fitting. It has been widely used in time-series studies on air pollution and health effects, controlling for daily variations in meteorological conditions and seasonal trends. The original GAM fitting method estimated the smooth components of the model using non-parametric smoothers, such as smoothing splines or LOESS, via the backfitting algorithm [
42]. By iteratively smoothing partial residuals, backfitting provides a general module to estimate the
Sj terms that are capable of using a wide variety of smoothing methods. The computational cost issue of full spline method has been addressed recently by using Markov random fields to find sparse representations of the smooths, which can be viewed as an empirical Bayesian method [
43]. An alternative approach with particular advantages in high dimensional settings is to use boosting, which typically requires bootstrapping for uncertainty quantification [
44,
45].
Although frequentist GAM gives a rich family of models that have been widely applied, a crucial problem with GAM is the choice of the number and the position of the knots, in terms of analytical tractability. A small number of knots may result in insufficient flexibility to capture the variability of the data while a large one may lead to overfitting. P-splines approach makes a more parsimonious parameterization possible, which is of particular advantage in a Bayesian framework where inference is based on MCMC techniques [
25]. By taking into account the complete likelihood surface rather than plugging in the maximum likelihood estimate of the covariance structure, the approach provides the posterior distributions of the quantities of interest, such as ‘the true parameter has a probability of 0.95 of falling in a 95% credible interval (CI)’, which is more interpretable. Unlike frequentist methods, which provided one estimate for each model parameter, Bayesian methods may provide, for each parameter, a sample of thousands of MCMC estimates from the simulated posterior distribution of the parameter. The reported posterior mean and posterior distribution are the corresponding summaries of the marginal posterior distribution of the parameter.
Due to recent developments in MCMC algorithms, software, and hardware, we can now use MCMC methods to analyze complex models that would have been impossible only a few decades ago [
46]. However, the Bayesian GAM is only available in a few R packages such as gammSlice [
47], R2BayesX [
48], and spikeSlabGAM [
49], which limits its application in a variety of scientific fields. In gammSlice Pham et al. used the slicing sampling method [
50] for GAM fitting and inference within a Bayesian framework [
47]. R2BayesX supports similar models to those in gammSlice. Scheipl used spike-and-slab type prior distributions on the spline coefficients [
49]. Especially, Klein et al. proposed a general class of Bayesian GAM for count data within the GAM framework for location, scale, and shape where semiparametric predictors can be specified for several parameters of a count data distribution [
21].
There are some limitations to our study. First, we did not impose any structure on the relationship of the coefficients of the lagged PM
2.5 concentrations with each other. However, multicollinearity among the lagged independent variables often arises, leading to high variance of the coefficient estimates. We plan to address this problem by constraining the
βl to be a simple function of the lag number using a structured finite distributed lag model in the future [
51]. This problem can also be addressed by a time-scale model which estimates the association between daily smooth variations of pollution and health outcomes by replacing
βlXt−l in Equation (1) with:
where
W1t, …,
Wkt, …,
WKt is a set of predictors obtained by applying a wavelet analysis or Fourier analysis to
Xt to satisfy orthogonality, such that
[
52,
53,
54]. The parameter
βk measures the logarithmic relative rate of the health outcome for increasing air pollution at time scale
k. Time scales of interest include short-term variations within several days and long-term variations within one to two months because it is believed that any effects are dominated by seasonal confounding beyond two months [
54]. Other tools such as auto-regressive moving average model or vector auto-regressive model could be also appropriate [
55]. Second, our simulation framework did not address the issue of measurement error in the covariates. Because such error can in some situations attenuate the estimated effects, it may be useful in the future to employ a more elaborate simulation framework to incorporate the measurement error. Third, our model did not model interaction between PM
2.5 and other covariates yet. The concentration-response relationship between PM
2.5 and respiratory deaths was assumed to be approximately linear, but this might not be true in very low or very high PM
2.5 concentrations. The two limitations can be addressed using varying coefficient model (VCM), where linear
is replaced by
S(
Xt−l)
zl. Estimation of VCM poses no further difficulties since only the
βl in Equation (7) has to be redefined by
S(
Xt−l) multiplying with
Zl. Furthermore, we acknowledge that our study is based on simulated data, and the difference in the results between the frequentist and Bayesian methods is small and might be biased towards a Bayesian approach because of the predefined parameters. Therefore, the evidence to advocate the Bayesian approach over the frequentist one has yet been strong, and a confirmation study using real-world data is needed to address these issues in the future.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}