1. Introduction
People can be exposed to high levels of toxic metals from numerous sources, including contaminated air, water, soil, and food [
1]. Among toxic metals, lead (Pb), mercury (Hg), and cadmium (Cd) are widely dispersed throughout the environment and can be detected in the blood, serum, and urine of people living in polluted areas [
2]. Although the general population is often exposed to these metals simultaneously, most studies concerning the health effects of these metals have been carried out on animals, or on human populations with relatively high levels of exposure to individual metals [
3,
4,
5]. Besides, recent studies show that toxic metals interact with other metals in various tissues [
6,
7]. However, few epidemiological studies have addressed the biological effects of low levels of exposure to mixtures of these metals, particularly with regard to possible interactions between metals.
Exposure to lead, mercury, or cadmium is known to cause various toxic effects and diseases, including disturbance of lipid metabolism or dyslipidemia [
8]. There are many experimental and epidemiological studies showing that exposure to lead alters the concentration of total cholesterol in serum [
9,
10,
11] and a strong positive association between blood concentration of mercury and serum total cholesterol level [
12,
13,
14]. Furthermore, several animal studies have shown that exposure to cadmium significantly increases the serum levels of total cholesterol [
15,
16,
17]. However, we lack information on the effect of combined exposure to these metal mixtures on cholesterol metabolism in the general population.
Recently, machine learning (ML) prediction models, such as logistic regression (LR) models, k-nearest neighbor (KNN), decision trees (DT), random forests (RF), and support vector machines (SVM) have been developed in many areas of health care research [
18,
19,
20]. ML allows intelligent systems to build appropriate prediction models and is increasingly used to develop algorithms that classify individuals with complex interaction factors [
21]. Our hypothesis is that ML analysis of survey data including body burden of metals can be used to identify individuals at high risk of hypercholesterolemia (HC). Therefore, in this study, we aimed to construct several ML models to predict HC in the general population and compare the predictive accuracy of five different ML algorithms based on data from the Korea National Health and Nutrition Examination Survey (KNHANES).
2. Methods
2.1. Study Population
This study was based on data from KNHANES 2008–2013, provided by the Korea Centers for Disease Control and Prevention. Using data from the KNHANES 2008–2013 databases, 10,089 subjects aged 12 years and older who had no missing responses on the questionnaire were included in this study. The KNHANES program was approved by the KNHANES Institutional Review Board (IRB) and was conducted in accordance with the Ethical Principles for Medical Research Involving Human Subjects, as defined by the Helsinki Declaration (IRB approval # 2013-12EXP-03-5C). All study participants provided informed written consent.
2.2. Data Collection
The KNHANES included well-established questions to determine the demographic characteristics and health status of the participants. This included questions on age, sex, income, physical exercise, smoking and drinking habits, and food intake. Daily energy intakes were assessed using 24 h recall and food intake frequency methods. The participants’ heights, weights and waist circumferences were measured. Then, the body mass index (BMI) was calculated as weight (in kilograms) divided by the square of height (in meters). Blood samples were collected by venipuncture after 10–12 h of fasting. Then, the total cholesterol was measured by enzymatic methods using commercially available kits (Sekisui Medical, Tokyo, Japan) within 2 h of blood sampling. The criterion for HC was a total cholesterol level of 240 mg/dL or higher or the use of lipid-lowering medications [
22]. Furthermore, blood lead and cadmium were quantified using Zeeman effect graphite furnace atomic absorption spectrophotometry (Perkin-Elmer AAnalyst 600, Turku, Finland). Blood mercury was measured by cold-vapor atomic absorption spectrometry using a dedicated mercury analyzer (M-6000A; CETAC Technologies, Omaha, NE, USA). Details of the metal analysis have been reported elsewhere [
23]. All blood metal analyses were carried out by a laboratory certified by the Korean Ministry of Health and Welfare.
2.3. Constructing the Data Sets and the Algorithm
All features were extracted from the original dataset and were transformed by scaling each feature to a range between zero and one using the ‘MinMaxScalar’ class from the pre-processing module of the Python scikit-learn library. After data processing, the input features were sex, age, income, BMI, waist circumference, exercise, smoking habits, alcohol drinking, and energy intake, as well as the blood concentrations of lead, mercury, and cadmium. Then, the entire data set was split into training and test sets at a ratio of approximately 7:3. Therefore, 8795 subjects were placed into the training set, while 1294 subjects were placed in the test set. The overall accuracy of each model was evaluated using k-fold cross-validation with k = 10. We used the default hyperparameter configurations unless otherwise specified. The LR model used L2 regularization with a primal formulation. The primal formulation was used because there are more samples than features. The regularization strength was set to 0.1, and the model was trained for 100 iterations before convergence. We used the KNN classifier ‘KNeighborsClassifier’ from sklearn.neighbors and the number of neighbor points was set to 3. In this study, the DT model used Gini impurity to measure the quality of split. The minimum number of samples required to split a node was set to two, and the minimum samples per leaf was set to one. The RF model used ten separate DT estimators and the SVM model used a linear type as its kernel with the shrinking heuristic enabled. The model used a C value of one and probability estimates were enabled to plot a receiving operating characteristic (ROC) curve for the model. All of the models were implemented using the scikit-learn library (version 0.20.1).
2.4. Statistical Analyses
We calculated the frequency and, where appropriate, the percentage or mean and standard deviation of the demographic characteristics to describe the sample population with respect to the HC categories. We compared the values of continuous variables between the HC and control (non-HC) groups using t-tests. The statistical significance of categorical variables between the HC and control groups were determined using the Mantel–Haenszel chi-square test. The prevalence of HC was compared among tertiles of blood metal concentration using multivariate logistic regression after adjusting for the other metals. As a measurement of the performance of the prediction model, the accuracy was calculated for all data, the training set, and the test set. The ROC curve was also used as a metric to measure the prediction model performance. All statistical analyses were carried out using SAS v. 9.4 (SAS Institute Inc., Cary, NC, USA).
3. Results
Table 1 shows the demographic characteristics and metal concentrations of the study population. Of the 10,089 participants included in the study, 46.4% were male and the mean age was 44.9 years. The blood concentrations of lead, mercury, and cadmium were 2.32 μg/dL, 4.55 μg/L, and 1.11 μg/L, respectively. Among the study participants, the prevalence of HC was 12.8%. Compared with the non-HC group, the HC group had significantly higher mean blood concentrations of lead, mercury, and cadmium, as well as mean values of age, BMI, and waist circumference (
p < 0.01). The non-HC group had significantly higher mean monthly incomes, percentage of regular exercise, and mean daily energy intakes than the HC group (
p < 0.01).
Table 2 shows the odds ratios (ORs) for the association of HC with blood metal levels. The trend in adjusted ORs for HC were significantly related to increased blood metal concentration. After adjustment for the other metals, the OR for HC was significantly correlated with blood levels of lead (
p for trend = 0.001), mercury (
p for trend = 0.020), and cadmium (
p for trend < 0.001).
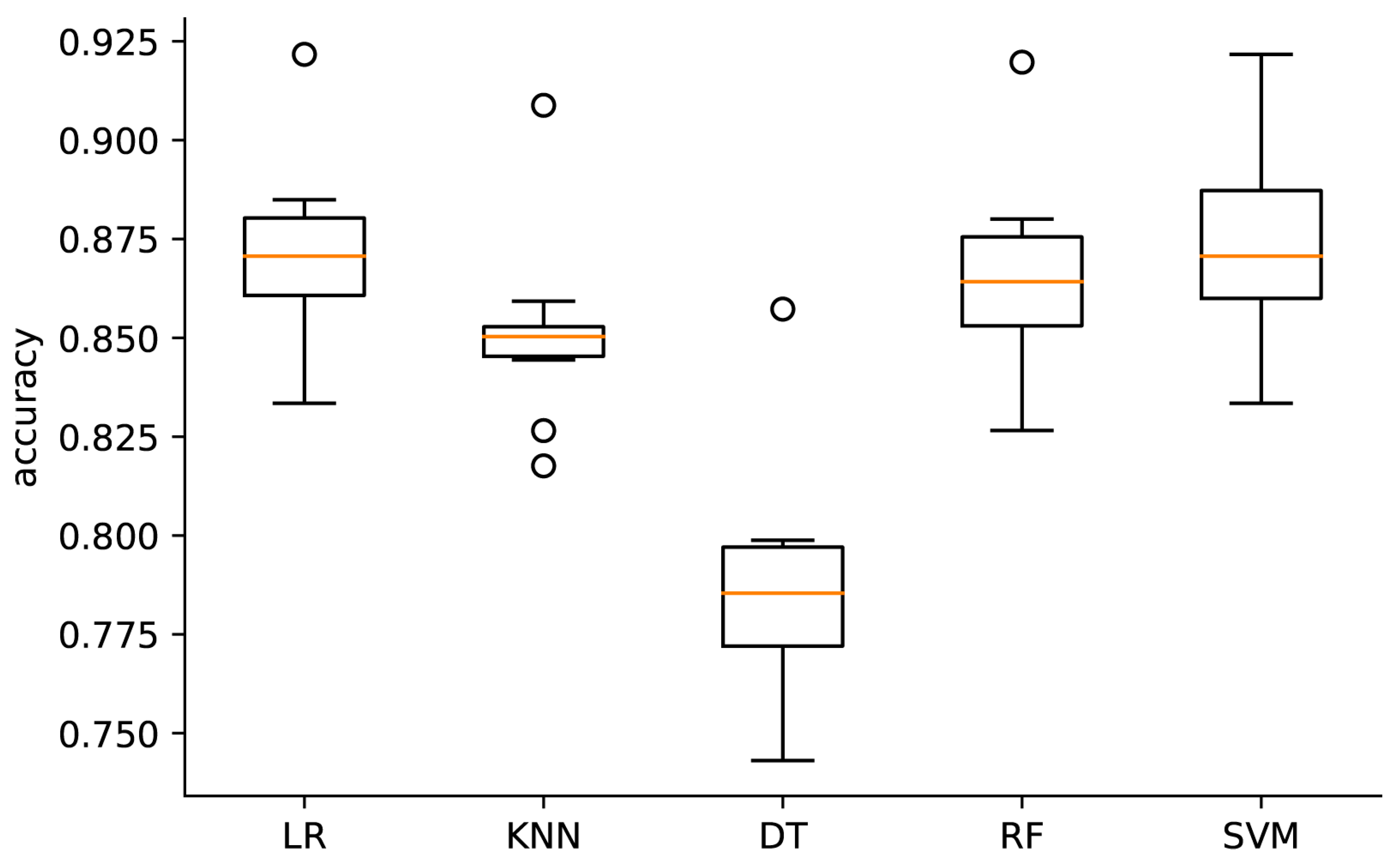
The accuracies of all of the models are shown in
Figure 1. Following the normalization of all features, the SVM model achieved the largest accuracy value (0.872) of all of the models, followed by the LR, RF, KNN, and DT models. There were no significant differences between the SVM model and LR prediction model (
p = 0.174). However, the
p values between the SVM or LR model, and all other models were less than 0.003.
Similarly, following the training of each model with the training dataset, the SVM and LR models had the best accuracy when analyzing the test dataset. On the other hand, the DT model has the lowest accuracy compared to other models (
Table 3).
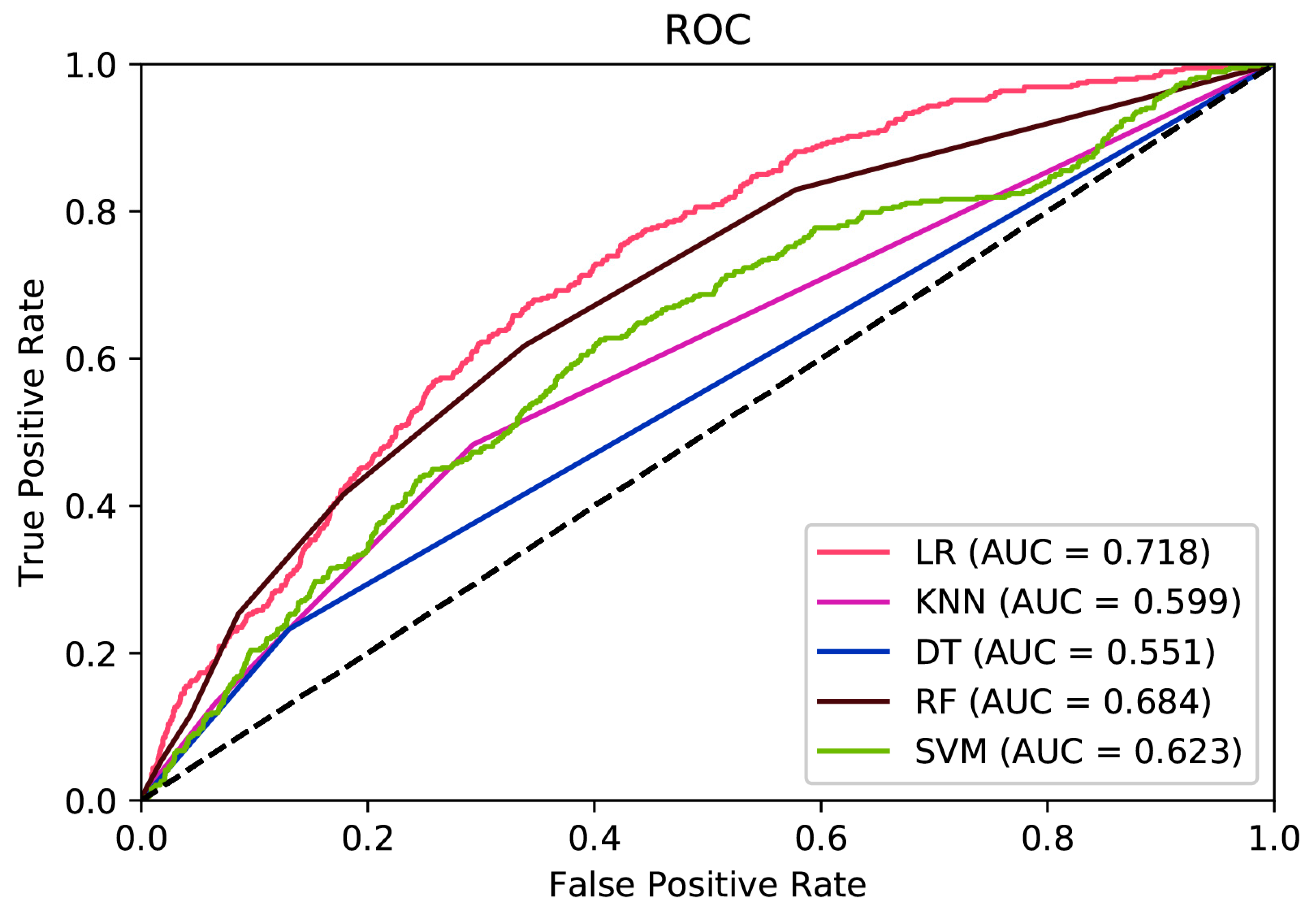
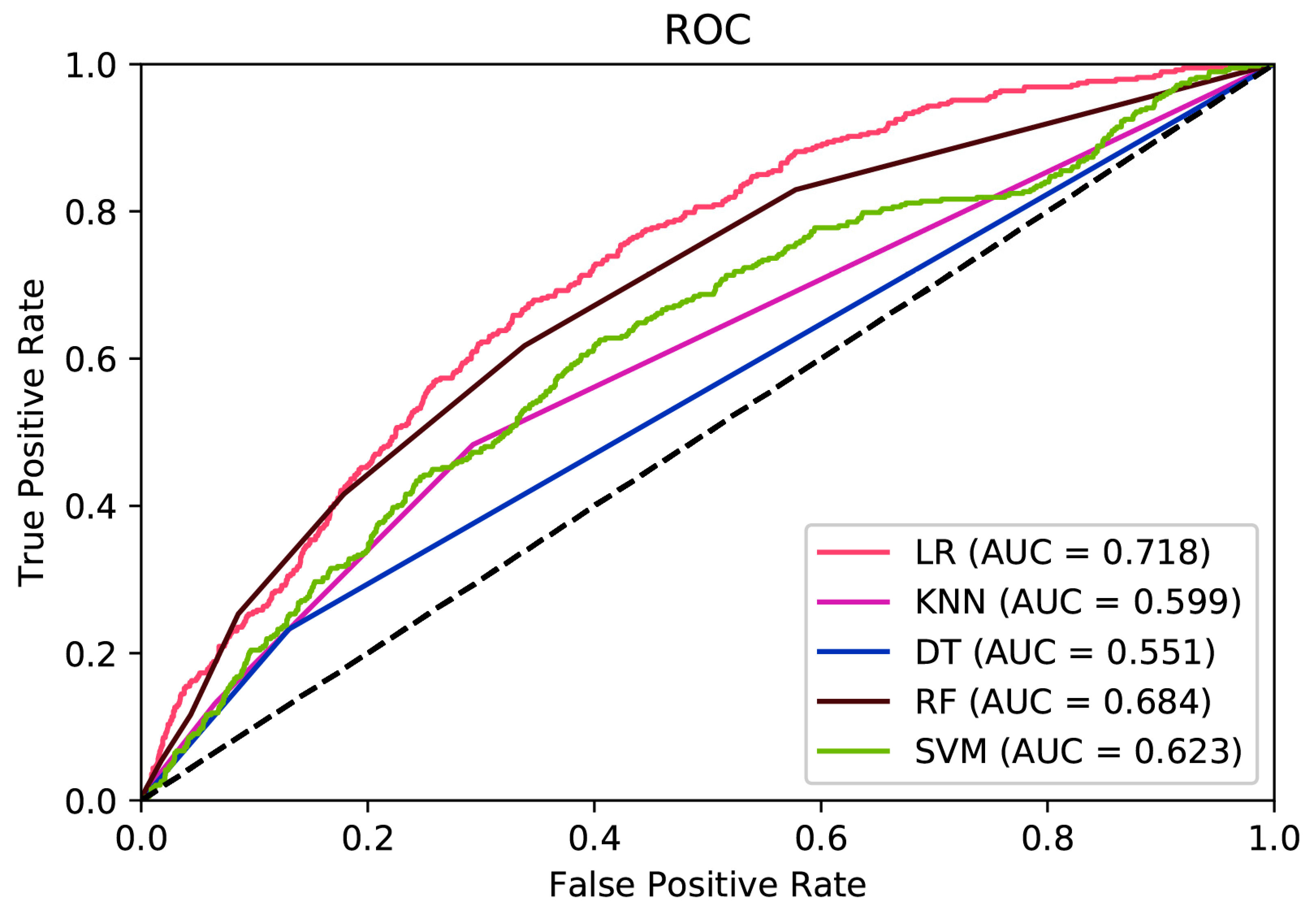
The area under ROC curve (AUC) for all of the prediction models is summarized in
Figure 2. The LR model had the highest area under ROC curve of all of the prediction models. The LR model (AUC = 0.718, 95% CI = 0.688–0.748) was significantly different to all of the other prediction models except the RF model (AUC = 0.684, 95% CI = 0.652–0.714) using the standard 95% confidence interval criteria.
4. Discussion
Accumulating epidemiological and experimental studies have provided strong evidence that lead, mercury, or cadmium exposure can affect lipid metabolism, including the disturbance of total cholesterol levels [
24,
25,
26]. Recently, based on the US National Health and Nutrition Examination Survey (NHANES) 2009–2012, higher levels of lead, mercury, and cadmium detected in the blood were reported to be associated with increased levels of total cholesterol [
27]. This study was carried out to investigate the relative performance of various ML classification methods for predicting HC associated with exposure to metals. To the best of our knowledge, this is the first study to compare the performance of various ML models in terms of predicting HC using data from a nationally representative survey.
In the current study, we presented an empirical comparison of five different techniques for estimating the risk of HC using KNHANES data on 10,089 participants. The LR, RF, and SVM outperformed the DT and KNN techniques, achieving overall accuracies of >0.86 and area under the AUC of >0.60. The results of our study show that complex ML models, such as SVM, tend to outperform simpler models such as DT when predicting HC associated with exposure to heavy metals. As KNN is a non-linear classifier, it tends to perform better with many data points. Therefore, effective feature selection may improve the performance of the KNN classifier [
28].
The strength of this study is that it is based on a large dataset, reflected by the number of participants and the number of important confounding variables, including cigarette smoking, alcohol drinking, physical exercise, and energy intake. Limitations of our study include the lack of more features and lack of further parameter optimization to avoid overfitting. In addition, clinical data, such as history of medication and prevalence of diseases affecting the lipid metabolism, were not included in the models, which may decrease the prediction accuracy of some of the algorithms. Nevertheless, the results of this study suggest that the performance of ML models can be very sensitive to the values of the hyperparameters and selected features. Therefore, the hyperparameters and features used to build ML models should be carefully explored and tuned to achieve the best predictive accuracy.
5. Conclusions
Prediction models using ML algorithms have shown solid prediction capabilities in various application domains including public health and environmental science. In this study, we presented a development and comparison of five popular ML models on predicating HC using a population-based database from the KNHANES. The results of this study showed that prevalence of HC among subjects exposed to lead, mercury, and cadmium could be predicted using different ML approaches with high accuracy. The results also show that various ML techniques can significantly vary in terms of their performance (accuracy and AUC) and that the SVM and LR models were the better models for predicting the risk of HC in the general population following exposure to lead, mercury, and cadmium. These findings suggest that ML approaches could be used as alternative methods in the prediction of the risk of HC due to exposure to metals.
Author Contributions
H.P. contributed to data analysis and interpretation, algorithm analysis, and drafting the manuscript. K.K. contributed to the design of the study, drafting and revision of the manuscript, and supervision of the study. All authors have read and approved the final manuscript.
Funding
This research was supported by the Keimyung University Research Grant of 2017.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhuang, P.; Lu, H.; Li, Z.; Zou, B.; McBride, M.B. Multiple exposure and effects assessment of heavy metals in the population near mining area in South China. PLoS ONE 2014, 9, e94484. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Xie, J.; Zhang, S.; Yin, G.; Gao, Y.; Zhang, Y.; Bo, D.; Li, Z.; Liu, S.; Feng, C.; et al. Lead, cadmium, arsenic, and mercury combined exposure disrupted synaptic homeostasis through activating the Snk-SPAR pathway. Ecotoxicol. Environ. Saf. 2018, 163, 674–684. [Google Scholar] [CrossRef] [PubMed]
- Souza-Talarico, J.N.; Suchecki, D.; Juster, R.P.; Plusquellec, P.; Barbosa Junior, F.; Bunscheit, V.; Marcourakis, T.; de Matos, T.M.; Lupien, S.J. Lead exposure is related to hypercortisolemic profiles and allostatic load in Brazilian older adults. Environ. Res. 2017, 154, 261–268. [Google Scholar] [CrossRef] [PubMed]
- Tsai, T.L.; Kuo, C.C.; Pan, W.H.; Wu, T.N.; Lin, P.; Wang, S.L. Type 2 diabetes occurrence and mercury exposure-From the National Nutrition and Health Survey in Taiwan. Environ. Int. 2019, 126, 260–267. [Google Scholar] [CrossRef] [PubMed]
- Rosales-Cruz, P.; Domínguez-Pérez, M.; Reyes-Zárate, E.; Bello-Monroy, O.; Enríquez-Cortina, C.; Miranda-Labra, R.; Bucio, L.; Gómez-Quiroz, L.E.; Rojas-Del Castillo, E.; Gutiérrez-Ruíz, M.C.; et al. Cadmium exposure exacerbates hyperlipidemia in cholesterol-overloaded hepatocytes via autophagy dysregulation. Toxicology 2018, 398–399, 41–51. [Google Scholar] [CrossRef] [PubMed]
- Pan, S.; Lin, L.; Zeng, F.; Zhang, J.; Dong, G.; Yang, B.; Jing, Y.; Chen, S.; Zhang, G.; Yu, Z.; et al. Effects of lead, cadmium, arsenic, and mercury co-exposure on children’s intelligence quotient in an industrialized area of southern China. Environ. Pollut. 2018, 235, 47–54. [Google Scholar] [CrossRef] [PubMed]
- Diacomanolis, V.; Noller, B.N.; Ng, J.C. Bioavailability and pharmacokinetics of arsenic are influenced by the presence of cadmium. Chemosphere 2014, 112, 203–209. [Google Scholar] [CrossRef] [PubMed]
- Houston, M.C. The role of mercury and cadmium heavy metals in vascular disease, hypertension, coronary heart disease, and myocardial infarction. Altern. Ther. Health Med. 2007, 13, S128–S133. [Google Scholar]
- Abdel-Moneim, A.M.; El-Toweissy, M.Y.; Ali, A.M.; Awad Allah, A.A.; Darwish, H.S.; Sadek, I.A. Curcumin ameliorates lead (Pb (2+))-induced hemato-biochemical alterations and renal oxidative damage in a rat model. Biol. Trace Elem. Res. 2015, 168, 206–220. [Google Scholar] [CrossRef]
- Kim, J.H.; Kang, J.C. The lead accumulation and hematological findings in juvenile rock fish Sebastes schlegelii exposed to the dietary lead (II) concentrations. Ecotoxicol. Environ. Saf. 2015, 115, 33–39. [Google Scholar] [CrossRef]
- Poursafa, P.; Ataee, E.; Motlagh, M.E.; Ardalan, G.; Tajadini, M.H.; Yazdi, M.; Kelishadi, R. Association of serum lead and mercury level with cardiometabolic risk factors and liver enzymes in a nationally representative sample of adolescents: The CASPIAN-III study. Environ. Sci. Pollut. Res. Int. 2014, 21, 13496–13502. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Xu, C.; Fu, Z.; Shu, Y.; Zhang, J.; Lu, C.; Mo, X. Associations between total mercury and methyl mercury exposure and cardiovascular risk factors in US adolescents. Environ. Sci. Pollut. Res. Int. 2018, 25, 6265–6272. [Google Scholar] [CrossRef] [PubMed]
- Al-Zubaidi, E.S.; Rabee, A.M. The risk of occupational exposure to mercury vapor in some public dental clinics of Baghdad city, Iraq. Inhal. Toxicol. 2017, 29, 397–403. [Google Scholar] [CrossRef]
- Cho, Y.M. Fish consumption, mercury exposure, and the risk of cholesterol profiles: Findings from the Korea National Health and Nutrition Examination Survey 2010–2011. Environ. Health Toxicol. 2017, 32, e2017014. [Google Scholar] [CrossRef] [PubMed]
- Treviño, S.; Waalkes, M.P.; Flores Hernández, J.A.; León-Chavez, B.A.; Aguilar-Alonso, P.; Brambila, E. Chronic cadmium exposure in rats produces pancreatic impairment and insulin resistance in multiple peripheral tissues. Arch. Biochem. Biophys. 2015, 583, 27–35. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, T.F.; Batista, P.R.; Leal, M.A.; Campagnaro, B.P.; Nogueira, B.V.; Vassallo, D.V.; Meyrelles, S.S.; Padilha, A.S. Chronic cadmium exposure accelerates the development of atherosclerosis and induces vascular dysfunction in the aorta of ApoE-/- mice. Biol. Trace Elem. Res. 2019, 187, 163–171. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.Y.; Kim, S.J.; Bae, M.A.; Kim, J.R.; Cho, K.H. Cadmium exposure exacerbates severe hyperlipidemia and fatty liver changes in zebrafish via impairment of high-density lipoproteins functionality. Toxicol. In Vitro 2018, 47, 249–258. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; Wang, H.Z.; Mi, H.; Lin, C.D.; Cai, W.W. Using random forest for reliable classification and cost-sensitive learning for medical diagnosis. BMC Bioinform. 2009, 10, S22. [Google Scholar] [CrossRef]
- Furey, T.S.; Cristianini, N.; Duffy, N.; Bednarski, D.W.; Schummer, M.; Haussler, D. Support vector machine classification and validation of cancer tissue samples using microarray expression data. Bioinformatics 2000, 16, 906–914. [Google Scholar] [CrossRef] [PubMed]
- Galatzer-Levy, I.R.; Ma, S.; Statnikov, A.; Yehuda, R.; Shalev, A.Y. Utilization of machine learning for prediction of post-traumatic stress: A re-examination of cortisol in the prediction and pathways to non-remitting PTSD. Transl. Psychiatry 2017, 7, e1070. [Google Scholar] [CrossRef] [PubMed]
- Fujiyoshi, N.; Arima, H.; Satoh, A.; Ojima, T.; Nishi, N.; Okuda, N.; Kadota, A.; Ohkubo, T.; Hozawa, A.; Nakaya, N.; et al. Research Group. Associations between socioeconomic status and the prevalence and treatment of hypercholesterolemia in a general Japanese population: NIPPON DATA2010. J. Atheroscler. Thromb. 2018, 25, 606–620. [Google Scholar] [CrossRef] [PubMed]
- Choi, Y.H.; Park, S.K. Environmental exposures to lead, mercury, and cadmium and hearing loss in adults and adolescents: KNHANES 2010–2012. Environ. Health Perspect. 2017, 125, 067003. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Chen, Z.; Dai, B.; Li, G.; Zhu, G. Low-level lead exposure and cardiovascular disease: The roles of telomere shortening and lipid disturbance. J. Toxicol. Sci. 2018, 43, 623–630. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Lu, Y.H.; Pi, H.F.; Gao, P.; Li, M.; Zhang, L.; Pei, L.P.; Mei, X.; Liu, L.; Zhao, Q.; et al. Cadmium exposure is associated with the prevalence of dyslipidemia. Cell. Physiol. Biochem. 2016, 40, 633–643. [Google Scholar] [CrossRef] [PubMed]
- Hong, D.; Cho, S.H.; Park, S.J.; Kim, S.Y.; Park, S.B. Hair mercury level in smokers and its influence on blood pressure and lipid metabolism. Environ. Toxicol. Pharmacol. 2013, 36, 103–107. [Google Scholar] [CrossRef] [PubMed]
- American Heart Association. Lead, Mercury Exposure Raises Cholesterol Levels. AHA. Available online: http://newsroom.heart.org/news/lead-mercury-exposure-raises-cholesterol-levels (accessed on 11 April 2019).
- Platt, J. Fast Training of Support Vector Machines Using Sequential Minimal Optimization; MIT Press: Cambridge, MA, USA, 1999; Available online: https://dl.acm.org/citation.cfm?id=299094.299105 (accessed on 11 March 2019).
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).


{kind=link}
{kind=link}