Exploring Multidimensional Spatiotemporal Point Patterns Based on an Improved Affinity Propagation Algorithm




Abstract
1. Introduction
2. Basic Concepts
3. Methodology
3.1. Similarity of Multidimensional Attributes
3.2. Distance of the Data Under the Gaussian Kernel
3.3. The P of the Adapted Step Length
3.4. Evaluation Method
3.5. Pseudocode of the MDST-AP Algorithm
| Algorithm 1: MDST-AP algorithm |
| Input: Set of objects (dataset of multidimensional attributes) Gaussian kernel parameter (in Equation (8)) M the number of cluster parameters P (in Equation (14)) Output: C Set of clusters (X is divided into k clusters) |
|
3.6. Reliability and Complexity Analysis
4. Experiments and Analysis
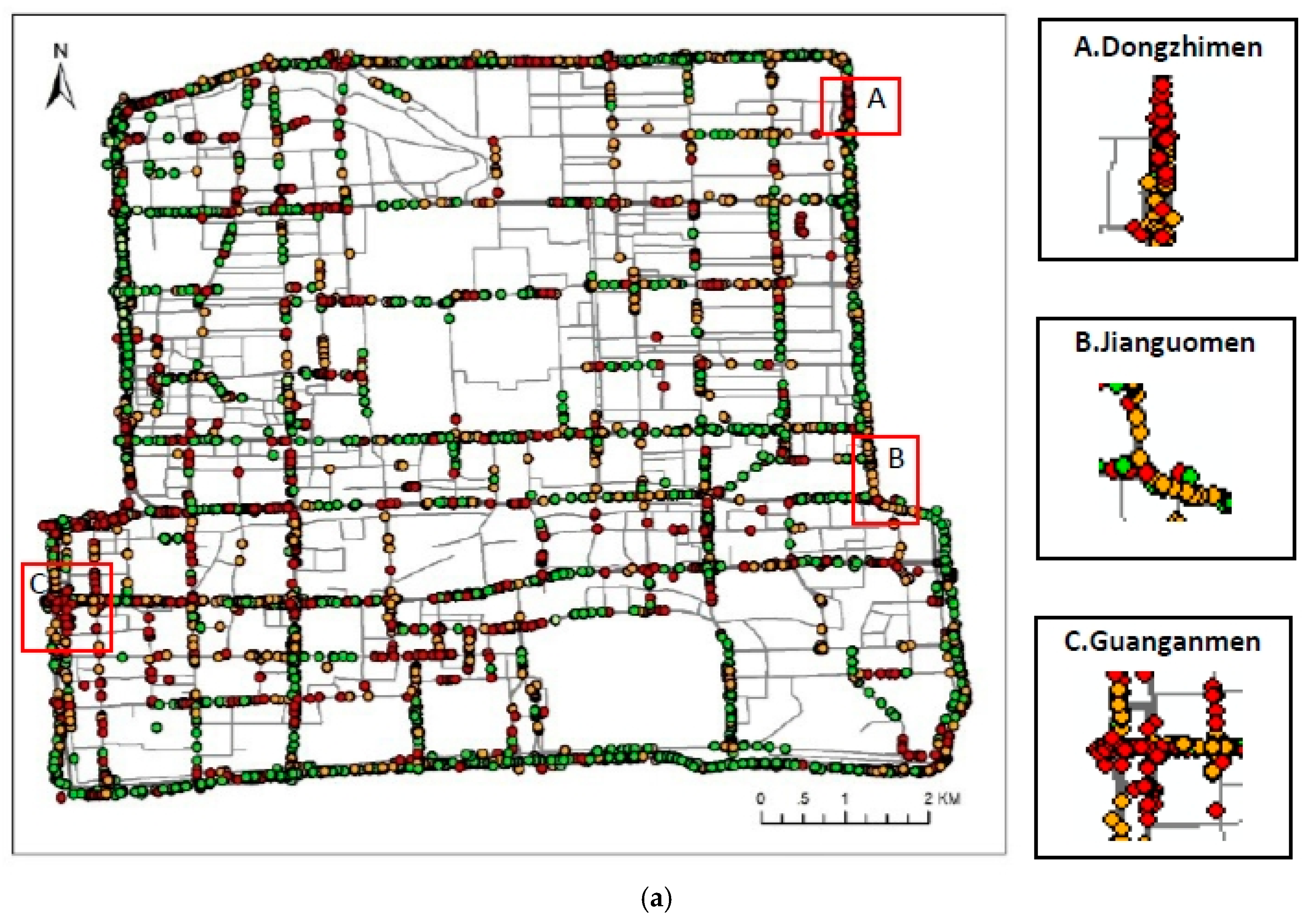
4.1. Study Area and Data Description
- From Monday to Friday, the tendency in the number of GPS records varies over time during the day but is similar at the same time points on different days. The number of GPS records ranges from 9.14 million to 12.48 million per day on weekdays and the average travel volume is approximately 0.45 million per hour. This result indicates that people’s trip times are essentially the same at a given time on weekdays. There are two distinct peaks on weekdays, namely 8:00 and 17:00.
- On Saturday and Sunday, the tendency in the number of GPS records varies over time during the day but is similar at the same time points on different days. The number of GPS records ranges from 8.44 million to 10.87 million per day on weekends and the average travel volume is approximately 0.39 million per hour. This result indicates that people’s trip times are essentially the same at a given time on weekends. Overall, the demand for taxis on weekends is lower than that on weekdays. There are also two distinct peaks on weekends, namely 10:00 and 17:00. Regardless of whether it is a weekday or weekend, the minimum number of taxi records in a day occurs from 3:00 to 4:00.
4.2. Clustering Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sambasivam, S.; Theodosopoulos, N. Advanced data clustering methods of mining web documents. Issues Inf. Sci. Inf. Technol. 2006, 3, 563–579. [Google Scholar] [CrossRef]
- Gelbard, R.; Goldman, O.; Spiegler, I. Investigating diversity of clustering methods: An empirical comparison. Data Knowl. Eng. 2007, 63, 155–166. [Google Scholar] [CrossRef]
- MacQueen, J.B. Some methods for classification and analysis of multivariate observations. In Proceedings of the 5th Symposium on Mathematics Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1967; University of California Press: Oakland, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Ng, R.T.; Han, J.W. Efficient and effective clustering method for spatial data mining. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago, Chile, 12–15 September 1994; Margan Kaufmann Publishers: San Francisco, CA, USA, 1994; pp. 144–155. [Google Scholar]
- Huang, Z.X. Extensions to the k-means algorithm for clustering large data sets with categorical values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. In Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data, Montreal, QC, Canada, 4–6 June 1996; ACM: New York, NY, USA, 1996; pp. 103–114. [Google Scholar]
- Karypis, G.; Han, E.H.; Kumar, V. CHAMELEON: A hierarchical clustering algorithm using dynamic modeling. IEEE Comput. 1999, 32, 68–75. [Google Scholar] [CrossRef]
- Guha, S.; Rastogi, R.; Shim, K. CURE: An efficient clustering algorithm for large databases. Inf. Syst. 2001, 26, 35–58. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; AAAI Press: Menlo Park, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Hinneburg, A.; Keim, D.A. An efficient approach to clustering in large multimedia databases with noise. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 27–31 August 1998; AAAI Press: Menlo Park, CA, USA, 1998; pp. 58–65. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. In Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data, Philadelphia, PA, USA, 1–3 June 1999; ACM: New York, NY, USA, 1999; pp. 49–60. [Google Scholar] [CrossRef]
- Zahn, C.T. Graph-theoretical methods for detecting and describing gestalt clusters. IEEE Trans. Comput. 1971, C20, 68–86. [Google Scholar] [CrossRef]
- Estivill-Castro, V.; Lee, I. AUTOCLUST: Automatic clustering via boundary extraction for mining massive point-data sets. In Proceedings of the 5th International Conference on Geocomputation, University of Greenwich, London, UK, 23–25 August 2002; GeoComputation: Leeds, UK, 2002; pp. 23–25. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. 1977, 39, 1–38. [Google Scholar] [CrossRef]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Fisher, D.H. Knowledge acquisition via incremental conceptual clustering. Mach. Learn. 1987, 2, 139–172. [Google Scholar] [CrossRef]
- Wang, W.; Yang, J.; Muntz, R. STING: A statistical information grid approach to spatial data mining. In Proceedings of the 23rd International Conference on Very Large Databases, Athens, Greece, 26–29 August 1997; Margan Kaufmann Publishers: San Francisco, CA, USA, 1997; pp. 186–195. [Google Scholar]
- Sheikholeslami, G.; Chatterjee, S.; Zhang, A. WaveCluster: A multi-resolution clustering approach for very large spatial database. In Proceedings of the 24th International Conference on Very Large Databases, New York, NY, USA, 24–27 August 1998; Margan Kaufmann Publishers: San Francisco, CA, USA, 1998; pp. 428–439. [Google Scholar]
- Agrawal, R.; Gehrke, J.; Gunopulos, D.; Raghavan, P. Automatic subspace clustering of high dimensional data for data mining applications. In Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data, Seattle, WA, USA, 1–4 June 1998; ACM: New York, NY, USA, 1998; pp. 94–105. [Google Scholar] [CrossRef]
- Tsai, C.F.; Tsai, C.W.; Wu, H.C.; Yang, T. ACODF: A novel data clustering approach for data mining in large databases. J. Syst. Softw. 2004, 73, 133–145. [Google Scholar] [CrossRef]
- Pei, T.; Wang, W.Y.; Zhang, H.C.; Ma, T.; Du, Y.Y.; Zhou, C.H. Density-based clustering for data containing two types of points. Int. J. Geogr. Inf. Sci. 2015, 29, 175–193. [Google Scholar] [CrossRef]
- Nanni, M.; Pedreschi, D. Time-focused clustering of trajectories of moving objects. J. Intell. Inf. Syst. 2006, 27, 267–289. [Google Scholar] [CrossRef]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial-temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Zhao, P.X.; Qin, K.; Ye, X.Y.; Wang, Y.L.; Chen, Y.X. A trajectory clustering approach based on decision graph and data field for detecting hotspots. Int. J. Geogr. Inf. Sci. 2016, 31, 1101–1127. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef]
- Lai, D.R.; Lu, H.T. Identification of community structure in complex networks using affinity propagation clustering method. Mod. Phys. Lett. B 2008, 22, 1547–1566. [Google Scholar] [CrossRef]
- Gan, G.; Ng, M.K.P. Subspace clustering using affinity propagation. Pattern Recognit. 2015, 48, 1455–1464. [Google Scholar] [CrossRef]
- Liu, J.J.; Kan, J.Q. Recognition of genetically modified product based on affinity propagation clustering and terahertz spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2018, 194, 14–20. [Google Scholar] [CrossRef]
- Chen, X.F. The Study of Kernel Methods in Classification, Regression and Clustering with Applications. Ph.D. Thesis, Jiang Nan University, Wuxi, China, 2009. [Google Scholar]
- Wang, C.D.; Lai, J.H.; Suen, C.Y.; Zhu, J.Y. Multi-exemplar affinity propagation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2223–2237. [Google Scholar] [CrossRef]
- Li, Y.J. A clustering algorithm based on maximal θ-distant subtrees. Pattern Recognit. 2007, 40, 1425–1431. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef]
- The UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/index.php (accessed on 8 May 2019).
- Christopher, D.M.; Prabhakar, R.; Hinrich, S. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; ISBN 0521865719. Available online: https://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-clustering-1.html (accessed on 8 May 2019).
- Openshaw, S. The Modifiable Areal Unit Problem; Geo Books: Norwick, UK, 1983; p. 3. ISBN 0860941345. [Google Scholar]
- White, C.E.; Bernstein, D.; Kornhauser, A.L. Some map matching algorithms for personal navigation assistants. Transp. Res. Part C 2000, 8, 91–108. [Google Scholar] [CrossRef]
- Miwa, T.; Kiuchi, D.; Yamamoto, T.; Morikawa, T. Development of map matching algorithm for low frequency probe data. Transp. Res. Part C 2012, 22, 132–145. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Iris | Seeds | Wine Quality, Red | Wine Quality, White |
|---|---|---|---|---|
| Objects | 150 | 150 | 150 | 500 |
| Clusters | 3 | 3 | 6 | 7 |
| Attributes | 4 | 7 | 11 | 11 |
| Algorithms | Measures | Iris | Seeds | Wine Quality, Red | Wine Quality, White |
|---|---|---|---|---|---|
| AP | F-measure | 0.88 | 0.81 | 0.71 | 0.78 |
| Time (s) | 0.38 | 0.44 | 0.54 | 19.29 | |
| MDST-AP | F-measure | 0.93 | 0.89 | 0.76 | 0.82 |
| Time (s) | 0.35 | 0.45 | 0.47 | 15.98 |
| ID | Time | Latitude | Longitude | Speed (km/h) | Direction | Status |
|---|---|---|---|---|---|---|
| 174853 | 20121101001447 | 116.4548645 | 39.9519463 | 51 | 328 | 1 |
| 453468 | 20121102155618 | 116.2787857 | 39.9250107 | 25 | 180 | 0 |
| Day 1 | Day 2 | Day 3 | |||||
|---|---|---|---|---|---|---|---|
| Clusters | DB | Clusters | DB | Clusters | DB | ||
| 8:00 | AP | 82 | 116.18 | 80 | 129.81 | 84 | 128.85 |
| MDST-AP | 18 | 14.51 | 18 | 7.84 | 15 | 13.23 | |
| 17:00 | AP | 82 | 129.23 | 82 | 124.45 | 74 | 190.65 |
| MDST-AP | 18 | 7.51 | 14 | 6.80 | 10 | 9.77 | |
| M | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| λ | ||||||
| 0.5 | Clusters | 13 | 13 | 18 | 18 | 998 |
| DB | 11.46 | 9.57 | 7.51 | 28.03 | 29.84 | |
| 0.8 | Clusters | 16 | 17 | 20 | 24 | 998 |
| DB | 6.89 | 5.47 | 13.44 | 7.23 | 29.84 | |
| 0.9 | Clusters | 21 | 23 | 24 | 28 | 998 |
| DB | 5.73 | 19.62 | 9.78 | 6.37 | 29.84 |
| Cluster | Unimpeded | Mildly Congested | Congested | Very Congested |
|---|---|---|---|---|
| K-means | 87.54 | 28.3 | 83.11 | 91.07 |
| AP | 90.6 | 31.62 | 85.3 | 93.2 |
| MDST-AP | 97.12 | 40.18 | 90.36 | 98.2 |
| Cluster | Unimpeded | Mildly Congested | Congested | Very Congested |
|---|---|---|---|---|
| Weekdays | 25.01 | 1.47 | 37.95 | 35.57 |
| Weekends | 29.31 | 10.89 | 39.15 | 20.65 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, H.; Wu, L.; He, Z.; Hu, S.; Ma, K.; Yin, L.; Tao, L. Exploring Multidimensional Spatiotemporal Point Patterns Based on an Improved Affinity Propagation Algorithm. Int. J. Environ. Res. Public Health 2019, 16, 1988. https://doi.org/10.3390/ijerph16111988
Cui H, Wu L, He Z, Hu S, Ma K, Yin L, Tao L. Exploring Multidimensional Spatiotemporal Point Patterns Based on an Improved Affinity Propagation Algorithm. International Journal of Environmental Research and Public Health. 2019; 16(11):1988. https://doi.org/10.3390/ijerph16111988
Chicago/Turabian StyleCui, Haifu, Liang Wu, Zhanjun He, Sheng Hu, Kai Ma, Li Yin, and Liufeng Tao. 2019. "Exploring Multidimensional Spatiotemporal Point Patterns Based on an Improved Affinity Propagation Algorithm" International Journal of Environmental Research and Public Health 16, no. 11: 1988. https://doi.org/10.3390/ijerph16111988
APA StyleCui, H., Wu, L., He, Z., Hu, S., Ma, K., Yin, L., & Tao, L. (2019). Exploring Multidimensional Spatiotemporal Point Patterns Based on an Improved Affinity Propagation Algorithm. International Journal of Environmental Research and Public Health, 16(11), 1988. https://doi.org/10.3390/ijerph16111988