3.1. Data and Sample
The data analyzed in this study were taken from the 2012 Encuesta de Integración Social y Salud (Social Integration and Health Survey) of the Instituto Nacional de Estadística (INE, Spanish National Institute of Statistics), and specifically from the module conducted on individuals. This survey is the first conducted by the INE fully adapted to the International Classification of Functioning, ICF 2001, of the World Health Organization (WHO). It has been carried out in all EU countries with a common methodology, and this allows obtaining harmonized information at European level on disability and barriers in the social participation of people with disabilities.
The base sample is very broad (n = 16,614), so we divided it into two subsamples, one of which comprised individuals who reported some form of disability (hereafter PWD) (n1 = 2696), and another, which comprised individuals who did not (hereafter Pw/oD) (n2 = 13,918).
The questionnaire of the EISS-2012 includes the officially recognized disability through the possession of a document that certifies a degree equal to or greater than 33% of disability. In our sample the 10.1% possess an official certification of disability (a degree equal to or greater than 33%). This number is slightly higher than the percentage of people with disabilities officially recognized in Spain, 8.5% according to the latest INE data.
In addition, those people who without reporting the degree of disability, have severe difficulties or inability to perform certain daily tasks have been added: Eat alone; getting in or out of bed alone; inability to sit up and get up from a chair; dressing and undressing alone; go to the bathroom alone; take a bath or shower alone. We have registered the impossibility of performing these tasks, mainly due to a chronic or long-term illness, and/or mainly due to a limitation in basic activities (difficulties in seeing, hearing, concentrating, moving). The percentage of people with limitations that are additionally collected in our sample is 6.13%. The average age of people with disabilities is 63.5 years. People with certified disability have an average age of 47.5 years and people with limitations added to our sample have an average age of 70.4 years.
In the people with limitations (6.13% of the sample with disability) are predominant degenerative problems derived from age. In officially recognized persons with disabilities (10.1% of the sample with disabilities) there is a greater variety of congenital and acquired disabilities throughout life (before 65 years of age).
A three-stage sampling approach with stratification of the first-stage units was used. The first stage units were the census sections; the second stage units were the main family dwellings, with all households investigated; and the third stage units were the people. The sampling errors for the total number of people with disabilities was 2.21% (3.77% for men and 2.74 for women) [
28].
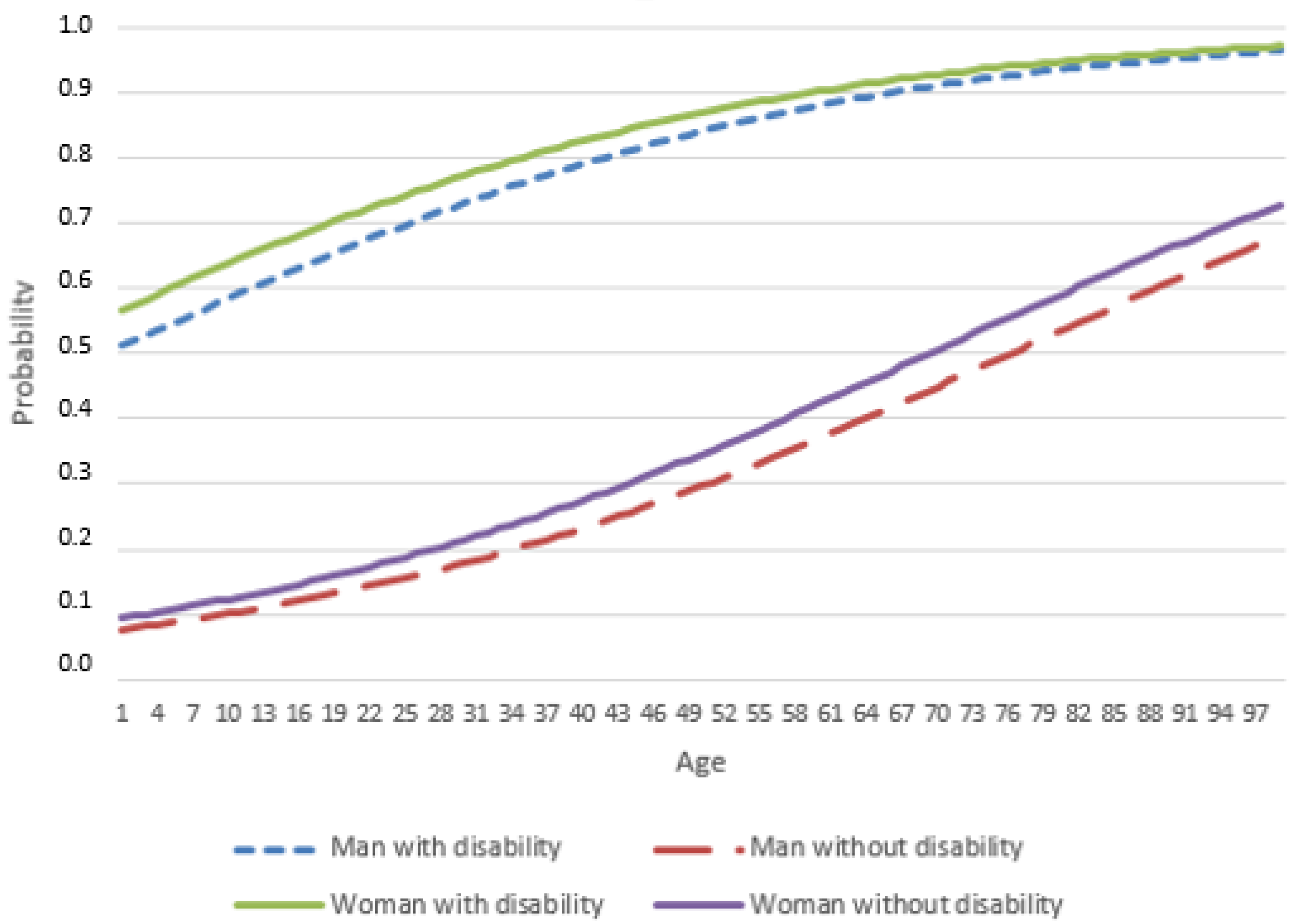
Table 1 shows that the percentages of men and women with disabilities are highest in the over-65 age groups. The average age of people with disability is 63.5 years (the average for men is 61.02 years and the average for women is 64.9 years). The average of people without disability is 47.9 years (the average for men is 47.32 years and the average for women is 48.45 years). Additionally, the average age of people with severe limitation is 65.85 years, while the average age of people without severe limitation is 49.94 years.
3.2. Variables
In its 2008 Disabilities, Independence and Dependency Situations Survey, the Spanish National Institute of Statistics divided the variable age into four categories: (1) Primary productive stage (16 to 30 years); (2) middle productive stage (31 to 47 years); (3) late productive stage (48 to 65 years); and (4) retirement (66 years and above). We used these age group to determine whether significant differences exist in relation to the variables studied.
Most of the variables we used were nominal or ordinal. For some analyses we constructed ad hoc indices from the original variables. These indices were treated as ordinal variables and used to simplify the information via additive processes.
The nature of the initial, nominal and ordinal variables ensured that the problem of collinearity, which is more typical of multiple linear regression analysis with metric variables, did not exist. The indices we included had moderate correlations, which overcomes this problem. For prediction analysis, we opted for logistic regression, which enables individuals to be assigned to groups with a dichotomous dependent variable as the destination. The independent variables can be quantitative, ordinal or nominal. Regression coefficients and their significance were assigned to these variables, making it possible to determine which categories (dummy variables) best predict whether the dependent variable belongs to a specific group.
To determine the size of the population living below the poverty line (for a person living alone in Spain in the reference year (2011), this was 8321 euros per year), we started from the variable income by segment in the household of the person surveyed. We combined this variable with the type of household (calculating the thresholds in accordance with the modified scale of the OECD) and the variable difficulties in meeting certain expenses. We were thus able to assign the poor/not poor dichotomy to the individuals in the sample (though we should point out that this resulting variable is just an approximation). As no quantitative, direct income indicator exists, we had to choose a proxy variable for poverty. The construct for risk of poverty showed that 22.8% of the sample was living below the poverty line (8321 euros per year for a person living alone) in the year studied. This figure is not substantially different from that reported by other statistical sources, such as the 2012 Encuesta de Condiciones de Vida (Living Conditions Survey), which put it at 20.8%. However, as our data slightly overestimates the risk of poverty, this should be taken into account when drawing conclusions. The poor/not poor dichotomous variable was constructed ad hoc from variables of the EISS-2012. As mentioned, it is therefore a proxy variable.
Similarly, we began from a construction of social exclusion (explained more thoroughly in the next section) from various dimensions of the EISS-2012, e.g., social bonds, attendance at cultural shows, Internet use, opportunities for spending time on one’s hobbies, training and employment. The model for constructing a net index of the determinants of social exclusion was an additive one based on the number of determinants of exclusion situations in these dimensions. For comparative purposes, we standardized the net index of social exclusion determinants by creating a Social Exclusion Determinants Index that reflected not so much exclusion itself, but one’s personal situation before the number of determinants that imply that one is excluded from a general set of activities (hobbies, mobility, culture, relationships, employment, training, etc.). We used this index to conduct mean comparison analysis and one-factor ANOVA for those variables that were estimated to potentially be influential factors of social exclusion.
Using the above index, we divided the population into two categories (social exclusion/no social exclusion) based on the average value of the Social Exclusion Determinants Index. The resulting dichotomous variable served as the basis for establishing analyses based on the Odds Ratios (OR).
We should point out that the variable Limitations for conducting certain activities divides people into three categories: (a) Those with severe limitation (6.1% of the sample); (b) those with moderate limitation (11.97%); and (c) those with no limitation (81.4%). This classification results from the direct question on the survey: “In at least the last 6 months, to what extent have you felt limited, due to a health problem in performing activities that people usually perform?”.
To address the complexity of social exclusion, we proposed a synthetic index of determinants based on a range of items divided into the following dimensions: Dimension 1—mobility; Dimension 2—accessibility; Dimension 3—education; Dimension 4—employment; Dimension 5—internet access; Dimension 6—contact and social support; and Dimension 7—leisure. Each dimension comprises a series of dichotomous response items weighted from highest to lowest, as follows: (1) Chronic illness or health problems; (2) long-term limitations in performing basic activities; (3) financial reasons (lack of money, i.e., being unable to afford it); (4) lack of technical support that prevents one from leaving the house at will; and (5) lack of assistance that prevents one from leaving the house at will. After calculating the value in each dimension, we analyzed the main components to determine the contribution of each dimension to the new components. We used the correlations of each dimension with the first component of the analysis as the weighting value for each dimension.
Therefore, not all dimensions have the same importance in the later definition of the Determinants of Social Exclusion index. The importance of each dimension is reflected in
Table 2.
We then prepared a net Determinants of Social Exclusion index, which is the sum of the weighted values of each dimension. The resulting values for each individual indicate their total number of impediments. The scores were then standardized using the following expression so that their values range between 0 and 1:
where SID is the Standardized Index of Determinants,
D1 …
Dn is the sum of the values of each of the indices representing the dimensions considered,
W1 …
Wn are the weights with which each dimension is weighted, and
k is the maximum value of the determinants in a dimension (in our case, this value is 10). The SID ranges from 0, indicating individuals who have no determinant of social exclusion, to 1, indicating the maximum possible accumulation of social exclusion determinants.
In order to consider people as individuals with the greatest number of determinants of exclusion, we adopted the mean of the distribution while bearing in mind that the distribution is strongly asymmetrical to the right. This type of distribution enables us to identify rare and extreme cases. Provided the interquartile range is small, as it is in this case, the mean can be used as a cut-off value to dichotomize the variable. Individuals were thus grouped into those with a number of determinants above the mean and those with a number of determinants below it. This dichotomous variable served as a construct for calculating individual probabilities of risk of exclusion. To simplify the language, we refer to individuals with or without exclusion. In reality, however, we should bear in mind that what we are really discussing is the number of social determinants that people accumulate that bring them closer to or further away from a situation of exclusion. We should also bear in mind that individuals who share the value 1 (exclusion) for the dichotomous variable do not necessarily have no differences between them. The dichotomous variable tells us whether one has more or fewer than the average number of social determinants, while the net index of determinants of exclusion made it possible to establish a scale of exclusion that we later used to identify those most at risk of social exclusion (i.e., those who accumulate the greatest number of social determinants and, therefore, have the highest score in the net index).
This division shows that 71% of the sample (n = 10,343) may be considered not to present social exclusion while 29% (n = 4271) may be considered to present exclusion to varying degrees. Note that this is higher than the percentage of people living in poverty, because more dimensions than finance are measured here. This means that an individual who is not poor may score on certain social exclusion items as being isolated or presenting a highly disabling disease that prevents him/her from conducting relational activities. However, trying to identify this high casuistry would be beyond the scope of this article.








{kind=link}
{kind=link}