
Threat Matrix: A Fast Algorithm for Human–Machine Chinese Ludo Gaming


Abstract
:1. Introduction
- We develop a human–machine gambling Chinese ludo game which is unlike most other chessboard programs; while these involve brute-force algorithms that require high-performance machines, our evaluation function is a simple linear sum of four variables.
- For high-frequency threat computation between any two dice, we innovatively propose the concept of a ‘threat matrix’. Using the threat matrix, our program can instantly acquire the threat value between any two positions, rather than relying on brute-force computing based on the current positions. As a result, our program can reduce the real-time (immediate) computation cost by nearly 88%.
- Threat matrix can run on an 80 × 86 SCM (Single-Chip Microcomputer), and has achieved a 97% winning rate against human players.
2. Chinese Ludo Game
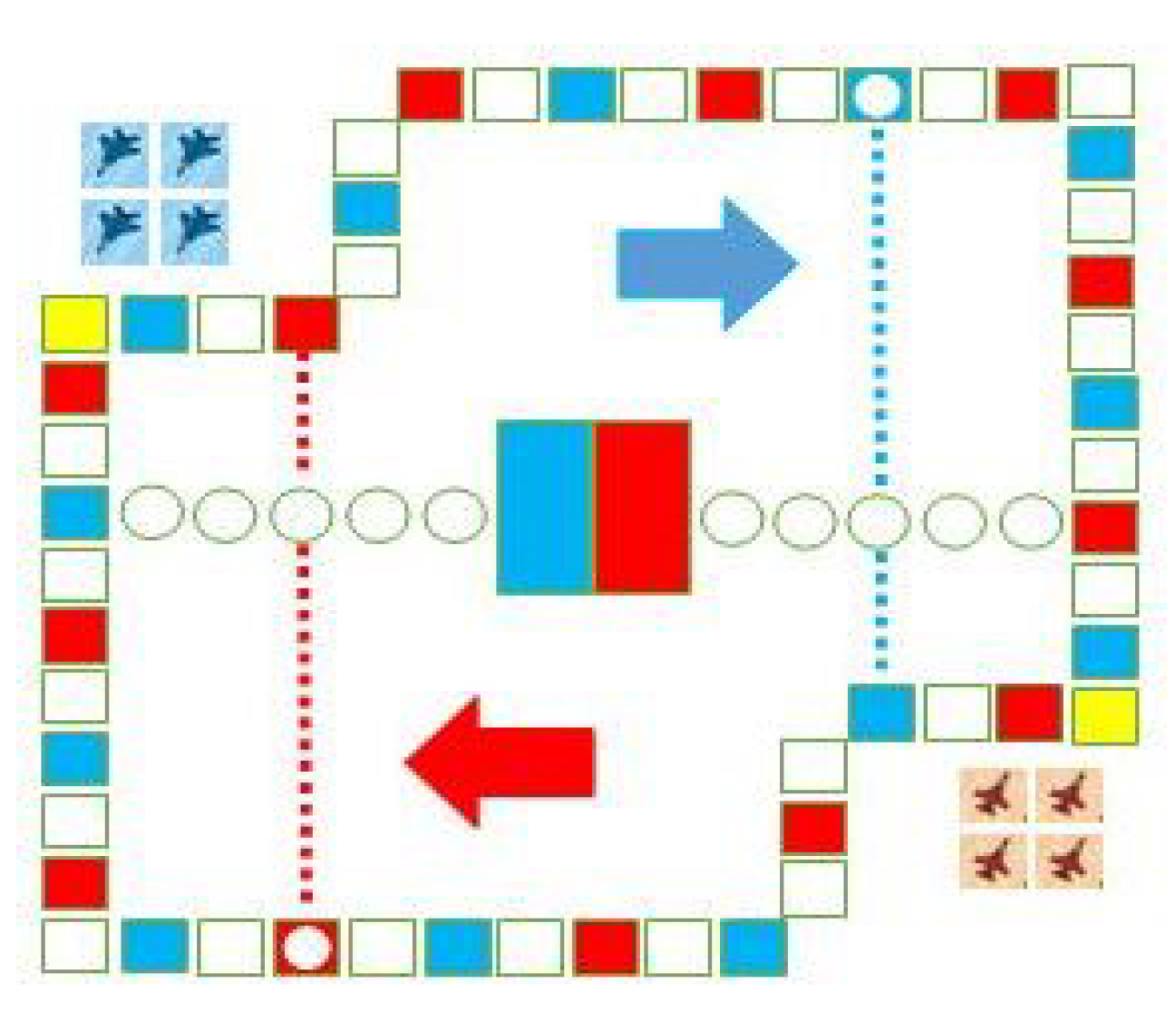
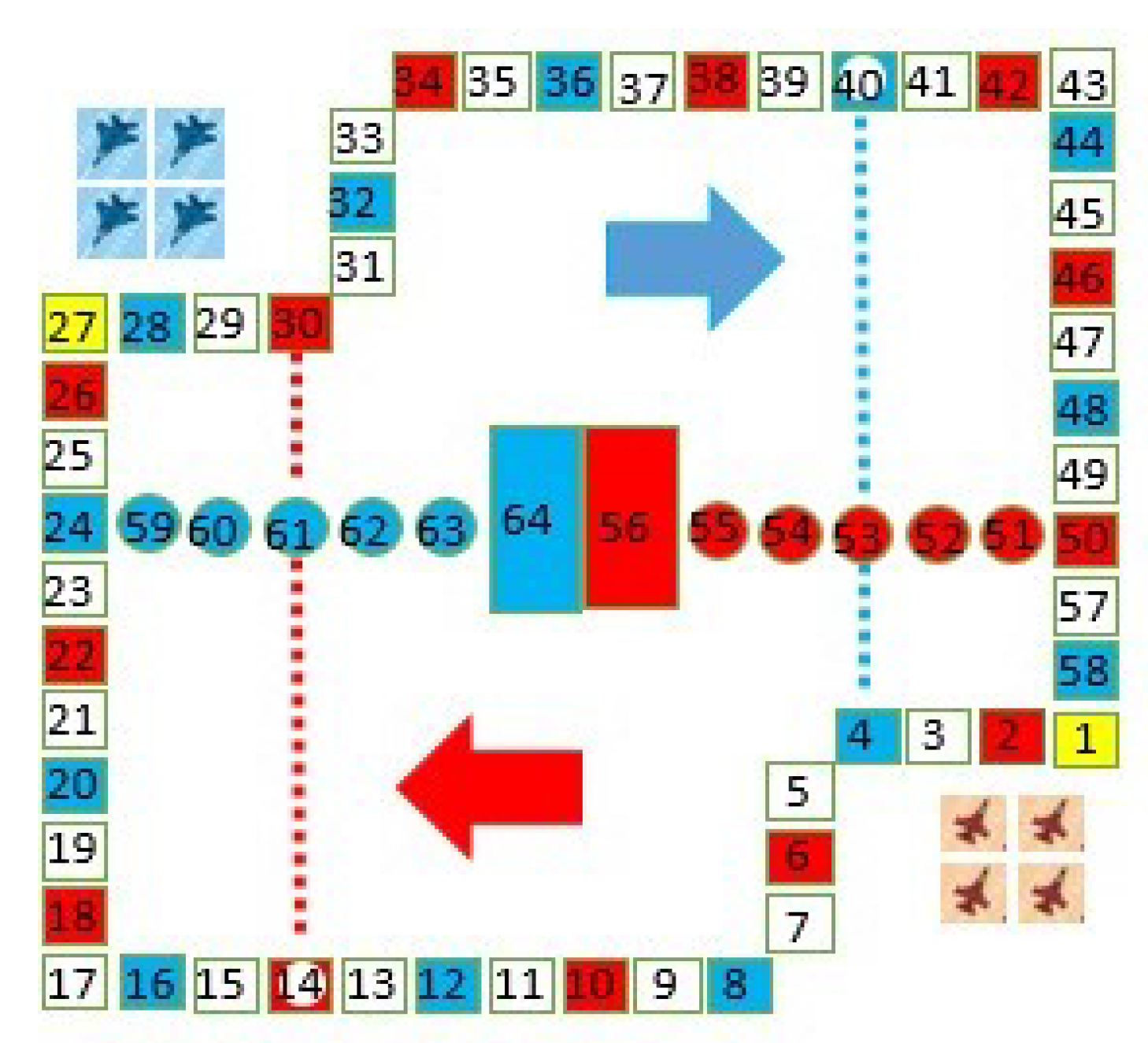
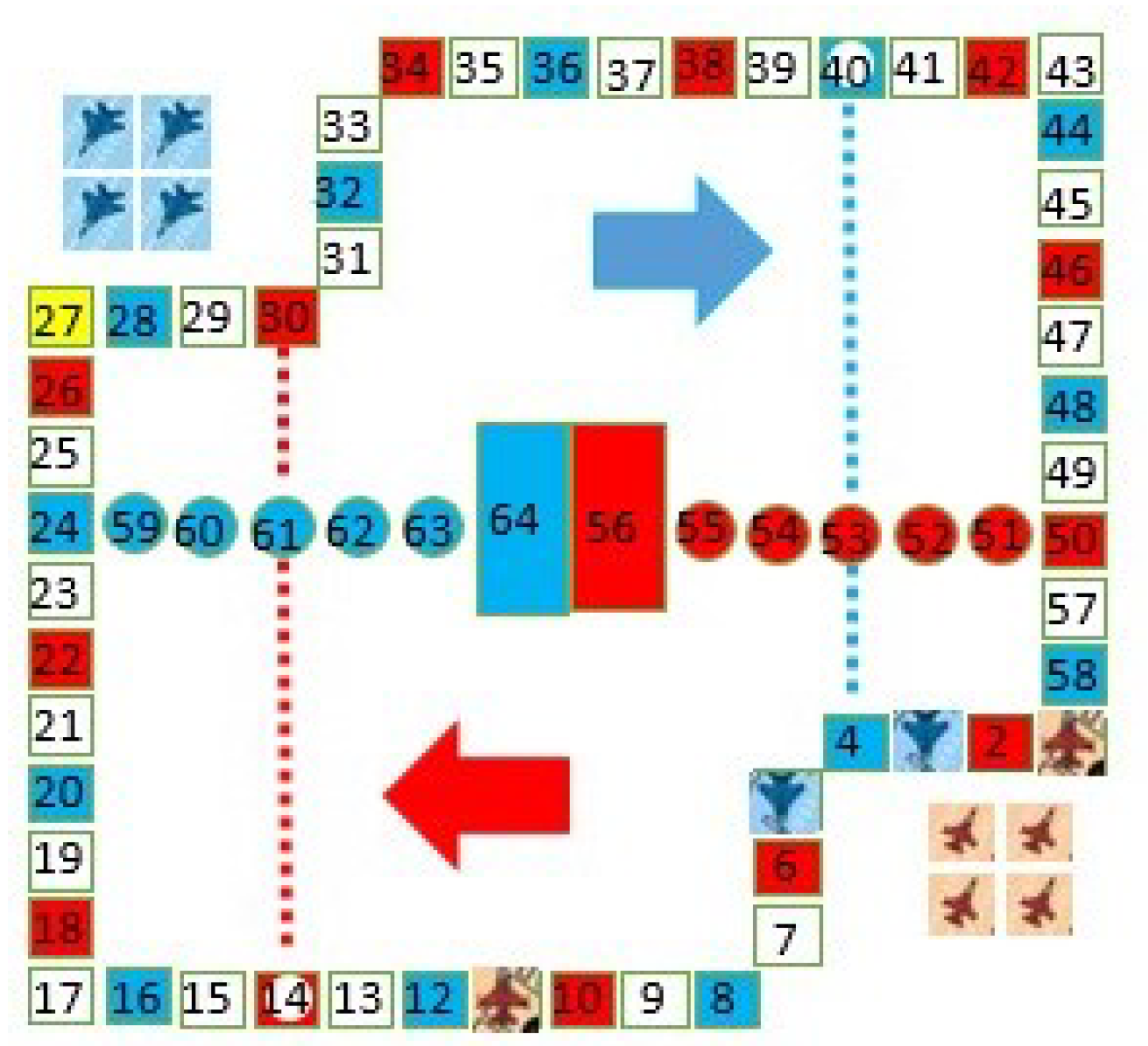
- Composition
- (a)
- Dice: One traditional dice, with each of its six faces showing a different number of dots from 1 to 6.
- (b)
- Board: One board, as shown in Figure 1, with 64 square positions marked with different colors. Each player is assigned a color, either red or blue. The top left corner and the right bottom corner are staging areas (‘hangars’) and the two closed rectangles colored with red and blue in the center are the ending squares corresponding to each game player.
- (c)
- Planes: Each player has four planes, in colors matching those of the board. There are two players, one human and one machine, and eight planes in total.
- 2.
- Game rules
- (a)
- Launch: At the start of the game, all of the planes of the two players are in the staging area. After randomly determine a player to roll the dice first, the players take turns rolling the dice. Only when a player rolls a 6 can s/he select one of her/his planes from its staging area to prepare to fly (in its starting square); the planes fly in the clockwise direction.
- (b)
- Move: When a player has one or more planes in play, s/he selects one to move (fly) over squares of the number shown on the dice. If the landing square is the same color as the plane’s color, the plane can fly directly to the next square in the same color; however, this cannot be done with circles, which is called a ‘jump’. Furthermore, if the landing square has the same color and is connected with a dotted line, the plane can fly along the dotted line, which is called a ‘dotfly’. The rolling of a 6 earns the player an additional roll in that turn, which can repeat until the roll is not 6.
- (c)
- Hit: If the landing square is occupied by the opponent’s plane(s), the opponent’s plane(s), either one or more, is hit and forced to return to the staging area. Planes of the same color are not hit.
- (d)
- Win: The first player who is able to fly all of her/his planes to the ending square wins the game.
3. Evaluation Function
3.1. The Description and Definition of the Chess Position
3.2. Evaluation Function
3.2.1. Incremented Distance after Moving ()
- Regular Move: this is the most common case, where the i-th plane moves forward for R steps; therefore,.
- Jump: if , or 58, that is, squares which have the same color (here, blue), can move four more steps and jump to the next square of the same color, i.e., .
- Dotfly: if = 36 or 40, i.e., two special positions, it can fly along the dotted line, i.e.,thus,where “∥” means the logical operation “OR”.
3.2.2. Opponent’s Hit Value ()
- If , i.e., the current position plus the dice number happens to be the current position of the opponent, the opponent’s plane is hit back to its staging area;
- If , i.e., after the jump the blue plane can hit the opponent’s plane, red loses the position, i.e., .
3.2.3. Increased Threat Value of Blue on Red ()
3.2.4. Increased Threat Value of Red on Blue ()
3.3. Calculating Threat and Threat Matrix
3.3.1. Calculating Threat
- If , the possibility of the opponent’s plane on hitting blue’s plane on by rolling once is
- If , the opponent’s red plane on cannot hit blue’s plane on by rolling once. For it to be possible to hit, the red player must roll 6 the first time, landing on position , then roll again. Thus, the probability is . By analogy to more general cases, if rolling 6 up to seven times continuously the opponent’s red plane on does not threaten the blue plane on according to the board. Thus, if , then
- Calculate the probabilities for special positions. According to the rules, a plane can jump if the landing square is the same color, such as 2, 6, 10, 14, 18, 22, 26, 30, 34, 38, 42, 46, and 50 for red, which can add the extra possibility of the plane on jumping and hitting , in addition to the above two cases.Squares of the same color are separated by three squares. Therefore, after each roll it is possible to land on the same color square. There are thus two cases, as follows.
- (a)
- When and is on the red square (e.g., and ), if the dice roll is 5, the plane on hits the plane on , thus there is no jump; if the dice roll is 2, the plane on first moves onto square 2, then jump onto square 6, then hits the plane on . The probability is
- (b)
- When and is on a red square, then
3.3.2. Threat Matrix
- Real-time computingReal-time computing calculates p for current position using Equations (12)–(15) each time the dice is rolled.However, in order to reduce the manufacturing cost of the game machine, the program runs on an 80 × 86 SCM, which has limited computing and storage power. Although the computing load decreases with respect to certain specific chess positions (such as all eight planes moving into the circle), the computation takes about 3.7 s in extreme cases, which is intolerable to players. We therefore sought faster algorithms to perform the same job.Through our observations, we found that no matter how the game changes, the threat is only ever determined by the positions. This naturally triggers a new idea, i.e., to compute the threat between any two positions and store them in a lookup table that is independent of any single position, herein called the ‘Threat Matrix’.
- Using the Threat Matrix to store pre-calculated threat values
4. Threat Matrix-Based Movement Strategy
| Algorithm 1: Threat matrix-based movement strategy for plane. |
 |
5. Recursion and Complexity Analysis for Multiple Moves
5.1. Recursive for n Plies
5.2. Complexity Analysis
5.2.1. Computation Complexity of One Move
- Complexity of Real-Time ComputingConsidering the most complicated case, where each of Equations (12) and (13) need to be calculated, Equation (12) includes one comparison and Equation (13) includes eight comparisons, while Equations (14) and (15) include two special cases with special positions; thus, there are at most comparisons. The number of all comparisons is at most .There are at most four opposing planes in play, and the number of all comparisons is therefore .The above represents the calculation of one blue plane, and the blue player has four planes; the number of comparisons is therefore
- Computing Complexity Using Threat MatrixAccording to the definition of the threat matrix, there is no need to calculate using Equations (12)–(15) each time, as we can simply look up the pre-calculated matrix. According to Equation (7), we look up the threat matrix twice for each opposing plane. As there are opposing planes, there are at most search instances. Similarly, according to Equation (10), there are at most search instances for . Then, considering the calculation of and , which is , the full computation for one of blue’s planes is .As there are at most four blue planes in play, the maximum computation is
5.2.2. Complexity of More Moves Ahead/per n Plies
6. Experiment Validation
6.1. Contrasting Results for Human versus Machine Play
- Aside from the randomness of dice rolling, the machine is much smarter than humans at this game. Even without the time limit, the winning rate of human players is only 12%. When there is a 10 s time limit, human players win 7% of the time, and when there is a 5 s time limit, human players only win 2% of the time. In addition, from the comparison of reaction times human players takes eight times as long to play as the machine does.
- When reaction time was limited, human players perform much worse and had much less of a chance (less than one quarter) of winning compared with the machine, which indicates that the decision of human players is rushed. Interestingly, through repeated training certain people were able to make more careful judgements within the 5 s time limit.
- Figure 5 shows the comparison of reaction times between a typical human player and the machine. From Figure 5, it can be seen that the threat matrix has a disadvantage compared with human player, namely, that the reaction time of the machine is proportional to the number of planes in play. Thus, the increase in the time spent with the increase in the number of steps is smooth, and there are no fast decisions. However, this is very different for humans. Although it generally takes human players longer, this does not increase in a strictly monotonic fashion, and at times human players make exceptionally fast decisions. Sometimes, the human player spends much less time than her/his average time, or even less than the machine (for example, at 29 steps, 46 steps and 54 steps). The reason for this is there are special positions, such as hit, dotfly, and jump, where human players can make quick decisions without calculation, whereas a machine must evaluate all planes and then make a choice by comparing evaluation functions. In this particular case, the algorithm can be improved. However, the special positions require extra judgments that take up additional memory space and CPU time. After balancing the potential improvements against the resources required, the company abandoned the optional improvements.
6.2. Comparison of One Move Ahead and Two Moves Ahead
6.3. Comparison of Real-Time Computing and the Threat Matrix
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Danilovic, S.; de Voogt, A. Making sense of abstract board games: Toward a cross-ludic theory. Games Cult. 2021, 16, 499–518. [Google Scholar] [CrossRef]
- Abdalzaher, M.S.; Muta, O. A Game-Theoretic Approach for Enhancing Security and Data Trustworthiness in IoT Applications. IEEE Internet Things J. 2020, 7, 11250–11261. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Polese, J.; Sant’Ana, L.; Moulaz, I.R.; Lara, I.C.; Bernardi, J.M.; Lima, M.D.d.; Turini, E.A.S.; Silveira, G.C.; Duarte, S.; Mill, J.G. Pulmonary function evaluation after hospital discharge of patients with severe COVID-19. Clinics 2021, 76. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Ning, H.; Shi, F.; Farha, F.; Xu, Y.; Xu, J.; Zhang, F.; Choo, K.K.R. Artificial intelligence in cyber security: Research advances, challenges, and opportunities. Artif. Intell. Rev. 2021, 55, 1029–1053. [Google Scholar] [CrossRef]
- Fu, Y.; Li, C.; Yu, F.R.; Luan, T.H.; Zhang, Y. A survey of driving safety with sensing, vehicular communications, and artificial intelligence-based collision avoidance. IEEE Trans. Intell. Transp. Syst. 2021, 1–22. [Google Scholar] [CrossRef]
- Morandin, F.; Amato, G.; Gini, R.; Metta, C.; Parton, M.; Pascutto, G.C. SAI a Sensible Artificial Intelligence that plays Go. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A performance evaluation of federated learning algorithms. In Proceedings of the Second Workshop on Distributed Infrastructures for Deep Learning, Rennes, France, 10 December 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–8. [Google Scholar]
- Nkambule, M.S.; Hasan, A.N.; Ali, A.; Hong, J.; Geem, Z.W. Comprehensive evaluation of machine learning MPPT algorithms for a PV system under different weather conditions. J. Electr. Eng. Technol. 2021, 16, 411–427. [Google Scholar] [CrossRef]
- Shayesteh, S.; Nazari, M.; Salahshour, A.; Sandoughdaran, S.; Hajianfar, G.; Khateri, M.; Yaghobi Joybari, A.; Jozian, F.; Fatehi Feyzabad, S.H.; Arabi, H.; et al. Treatment response prediction using MRI-based pre-, post-, and delta-radiomic features and machine learning algorithms in colorectal cancer. Med. Phys. 2021, 48, 3691–3701. [Google Scholar] [CrossRef] [PubMed]
- Paveglio, T.B. From Checkers to Chess: Using Social Science Lessons to Advance Wildfire Adaptation Processes. J. For. 2021, 119, 618–639. [Google Scholar] [CrossRef]
- Torrado, R.R.; Bontrager, P.; Togelius, J.; Liu, J.; Perez-Liebana, D. Deep reinforcement learning for general video game ai. In Proceedings of the 2018 IEEE Conference on Computational Intelligence and Games (CIG), Maastricht, The Netherlands, 14–17 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Zhu, J.; Villareale, J.; Javvaji, N.; Risi, S.; Löwe, M.; Weigelt, R.; Harteveld, C. Player-AI Interaction: What Neural Network Games Reveal About AI as Play. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–17. [Google Scholar]
- Lee, C.S.; Tsai, Y.L.; Wang, M.H.; Kuan, W.K.; Ciou, Z.H.; Kubota, N. AI-FML Agent for Robotic Game of Go and AIoT Real-World Co-Learning Applications. In Proceedings of the 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Lüscher, T.F.; Lyon, A.; Amstein, R.; Maisel, A. Artificial intelligence: The pathway to the future of cardiovascular medicine. Eur. Heart J. 2022, 43, 556–558. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Slumbers, O.; Wan, Z.; Liu, B.; McAleer, S.; Wen, Y.; Wang, J.; Yang, Y. Neural auto-curricula in two-player zero-sum games. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems (NeurIPS 2021), Virtual, 6–14 December 2021. [Google Scholar]
- Bošanskỳ, B.; Lisỳ, V.; Lanctot, M.; Čermák, J.; Winands, M.H. Algorithms for computing strategies in two-player simultaneous move games. Artif. Intell. 2016, 237, 1–40. [Google Scholar] [CrossRef] [Green Version]
- Nangrani, S.; Nangrani, I.S. Artificial Intelligence Based State of Charge Estimation of Electric Vehicle Battery. In Smart Technologies for Energy, Environment and Sustainable Development; Springer: Berlin/Heidelberg, Germany, 2022; Volume 2, pp. 679–686. [Google Scholar]
- Hankey, A. Kasparov versus Deep Blue: An Illustration of the Lucas Gödelian Argument. Cosm. Hist. J. Nat. Soc. Philos. 2021, 17, 60–67. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Bai, W.; Cao, Y.; Dong, J. Research on the application of low-polygon design to Chinese chess: Take the Chinese chess “knight” as an example. In Proceedings of the 2021 the 3rd World Symposium on Software Engineering, Xiamen, China, 24–26 September 2021; pp. 199–204. [Google Scholar]
- Ma, X.; Shang, T. Study on Traditional Ethnic Chess Games in Gansu Province: The Cultural Connotations and Values. Adv. Phys. Educ. 2021, 11, 276–283. [Google Scholar]
- He, H. The Race Card: From Gaming Technologies to Model Minorities by Tara Fickle. J. Asian Am. Stud. 2021, 24, 515–517. [Google Scholar] [CrossRef]
- Tomašev, N.; Paquet, U.; Hassabis, D.; Kramnik, V. Assessing game balance with AlphaZero: Exploring alternative rule sets in chess. arXiv 2020, arXiv:2009.04374. [Google Scholar]
- Available online: https://en.wikipedia.org/wiki/AeroplaneChess (accessed on 1 April 2022).
- Polk, A.W.S. Enhancing AI-based game playing using Adaptive Data Structures. Ph.D. Thesis, Carleton University, Ottawa, ON, Canada, 2016. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The position of the i-th blue plane | |
| The position of the opponent’s j-th plane in red | |
| The number of squares from the starting square to the current position of | |
| Possibility of plane to hit plane , that is, threat of to | |
| P | The threat matrix, , where |
| Incremented distance | |
| Opponent’s hit value | |
| Increased threat value of blue on red | |
| Increased threat value of red on blue | |
| O | Computational complexity |
| 1 | 2 | ⋯ | 29 | 30 | 31 | ⋯ | 63 | 64 | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.1667 | ⋯ | 0.00012 | 0.00025 | 0.000128 | ⋯ | 0 | 0 |
| 2 | 0 | 1 | ⋯ | 0 | 0.05556 | 0 | ⋯ | 0 | 0 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ||
| 29 | 0 | 0 | ⋯ | 1 | 0.1667 | 0.1667 | ⋯ | 0 | 0 |
| 30 | 0 | 0 | ⋯ | 0 | 1 | 0.1667 | ⋯ | 0 | 0 |
| 31 | 0 | 0 | ⋯ | 0 | 0 | 1 | ⋯ | 0 | 0 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ||
| 63 | 0 | 0 | ⋯ | 0 | 0 | 0 | ⋯ | 0 | 0 |
| 64 | 0 | 0 | ⋯ | 0 | 0 | 0 | ⋯ | 0 | 0 |
| (S, R) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.21 | 0.32 | 0.23 | 0.14 | 0.52 | 0.27 | 0.54 | 0.21 | 0.35 | 0.12 | 0.42 | 0.19 | 0.51 | 0.72 | 0.43 | 0.62 | 0.75 | 0.21 | * | 0.46 | |
| 0.17 | 0.13 | 0.03 | 0.41 | 0.12 | 0.07 | 0.27 | 0.24 | 0.15 | 0.02 | 0.12 | 0.29 | 0.31 | 0.25 | 0.03 | 0.02 | 0.15 | 0.41 | 0.65 | 0.07 | |
| 0.31 | 0.21 | 0.10 | 0.21 | 0.22 | 0.08 | 0.23 | 0.53 | 0.81 | 0.02 | 0.33 | 0.13 | * | * | 0.07 | 0.12 | 0.60 | 0.02 | 0.36 | 0.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, F.; Zhou, M. Threat Matrix: A Fast Algorithm for Human–Machine Chinese Ludo Gaming. Electronics 2022, 11, 1699. https://doi.org/10.3390/electronics11111699
Han F, Zhou M. Threat Matrix: A Fast Algorithm for Human–Machine Chinese Ludo Gaming. Electronics. 2022; 11(11):1699. https://doi.org/10.3390/electronics11111699
Chicago/Turabian StyleHan, Fuji, and Man Zhou. 2022. "Threat Matrix: A Fast Algorithm for Human–Machine Chinese Ludo Gaming" Electronics 11, no. 11: 1699. https://doi.org/10.3390/electronics11111699
APA StyleHan, F., & Zhou, M. (2022). Threat Matrix: A Fast Algorithm for Human–Machine Chinese Ludo Gaming. Electronics, 11(11), 1699. https://doi.org/10.3390/electronics11111699