
A Unified Forensic Model Applicable to the Database Forensics Field

 , , , , and
, , , , and 
Abstract
:1. Introduction
- (i)
- Conducting a comprehensive review to discover the research directions of the DBFI field;
- (ii)
- Developing a unified forensic investigation process model to solve the complexity, interoperability, and heterogeneity of the DBFI domain.
2. Related Work
3. Methodology
- (1)
- Step 1. Identifying and nominating domain models.
- (2)
- Step 2. Gathering domain processes.
- (3)
- Step 3. Manipulating and combining gathered processes.
- (4)
- Step 4. Identifying the relationships.
- (5)
- Step 5. Validation and Implementation.
- (1)
- Step 1. Identifying and nominating the domain models: This step involves identifying and selecting the DBFI models for development and validation purposes. Based on the coverage metrics [28,33], eighteen models were identified and nominated for development and validation purposes, as shown in Table 1.
- (2)
- (3)
- Step 3. Combining and proposing common processes: The mapping process [43] and harmonization process [44] were used in this study to propose common investigation processes. Thus, five main stages were proposed: Initialization stage, Acquiring stage, Investigation stage, Restoring and Recovering stage, and Evaluation stage. Each stage has several investigation processes. For example, the Initialization stage can cover the whole Investigation preparation for any investigation task. Table 2 displays the proposed stages and their processes.
- ✓
- Synonyms check using the Wordnet2 technique;
- ✓
- Synonyms check using the Thesaurus.com (accessed on 11 March 2022) technique;
- ✓
- Extraction of semantic functioning or meaning of each concept.
- (4)
- Step 4. Identifying the relationships: Based on discovering the relationships among the proposed investigation stages and processes in the literature, the UML relationships were used to draw the proposed model. Association and aggregation (composition) relationships were used to draw the proposed model. For example, the first stage, i.e., the Initialization stage, was linked to the second stage using association relationships, where the aggregation (composition) relationship between the Initialization stage and their investigation was used. Figure 5 shows the proposed unified investigation process model for the DBFI field.
- Initialization stage: This stage involves two processes: preparation and detection (see Figure 6). The Preparation process aims to prepare an investigation team and trust forensic tools, policies, and procedures for the investigation phase. The investigation team must comply with agency/company policies and procedures in doing the investigation, and it must follow the laws and regulations. Then, the team detects and verifies the database incident using specific forensic tools. The main resources for investigations are the OS log files, application logs, database logs, trace files, and alert files. When the database incident is detected, the investigation team moves to acquire stage to gather the data.

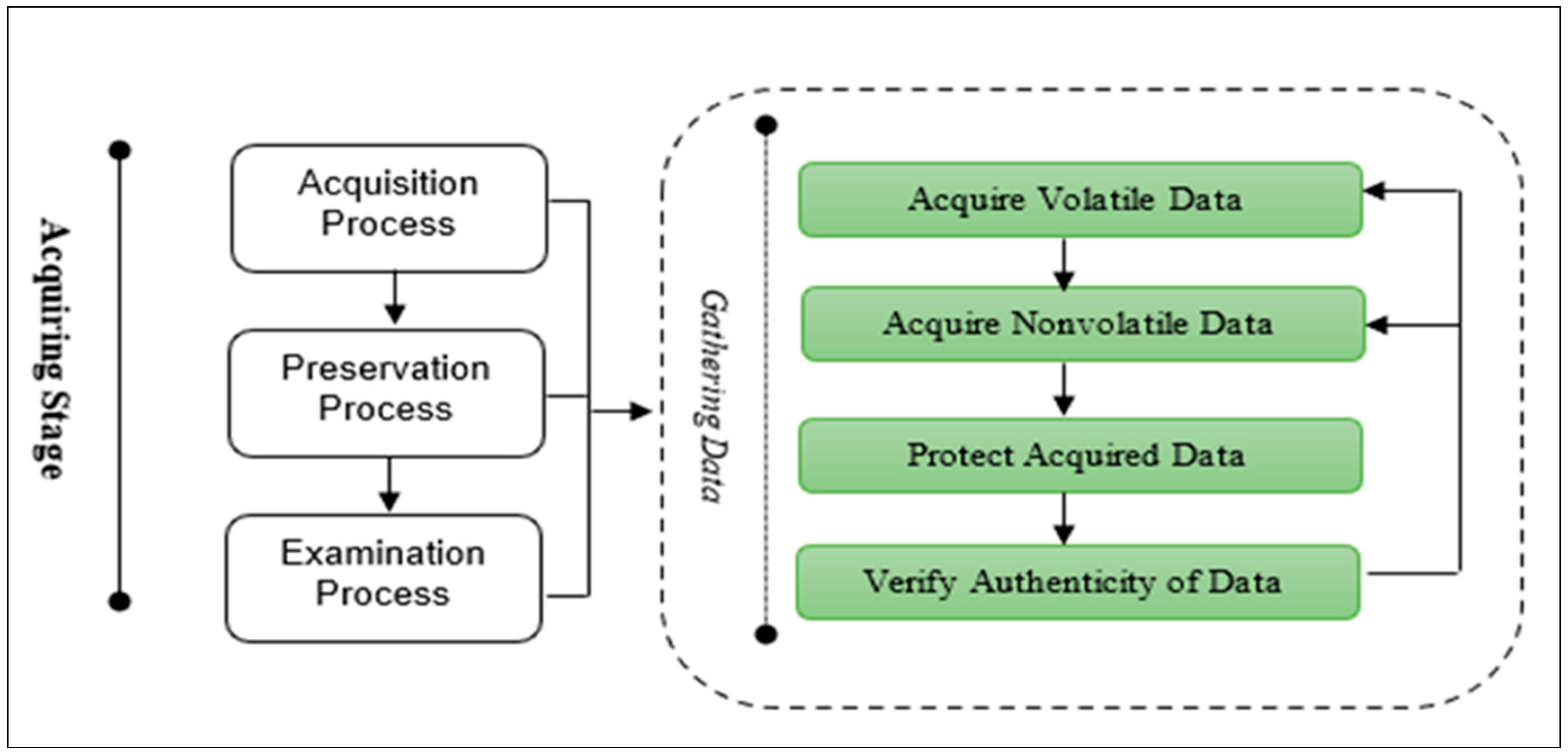
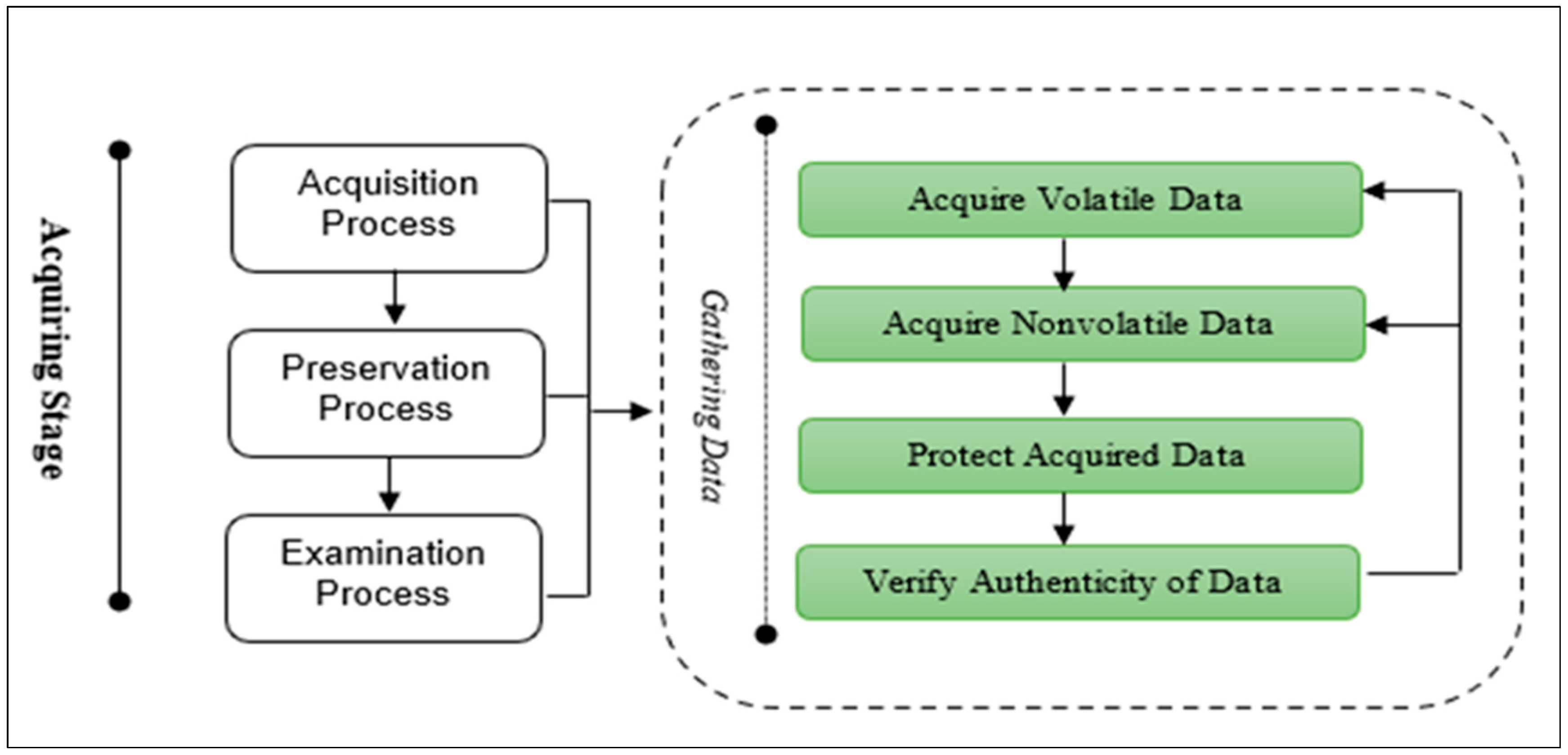
- Acquiring Stage: The main purpose of this stage is to gather, preserve, and examine the data to identify and reveal the database incidents. It consists of three main processes, as shown in Figure 7, which are: the Acquisition process, Preservation process, and Examination process. The Acquisition process is used to gather/acquire volatile and nonvolatile data from different resources. The acquired data need to be protected in terms of their integrity. The Preservation process is used to protect the acquired data using proper techniques, e.g., hashing algorithms. The investigation team should take a backup of the original data and hashed data in case tampering happens. The Examination process is used to check the authentication of the acquired data. Thus, the investigation team needs to rehash the gathered data and check the consistency of the data; in case of no matching, the investigation team should go back and take another copy of the original data. The investigation stage is required if the authenticity of the data is correct and exposed to no tampering.
- Investigation Stage: This is the main stage, which rebuilds and analyzes the timeline events, interprets, reports, documents, and presents the database incident. It consists of three main processes, as shown in Figure 8: Reconstruction process, Analysis process, and Reporting process. The timeline of the acquired data will be rebuilt to analyze and interpret to find similar patterns of the crime. Then, the chain of custody of the evidence is gathered and structured in robust documents. Finlay, the report should be prepared and submitted to the court. Investigators need to present the result in court and reply to all judges’ questions. This is the final stage of a real investigation; however, one of the main points, which is often neglected by investigators, is restoring and recovering data for business continuity. Therefore, the next stage is considered in the proposed model to fill this gap.

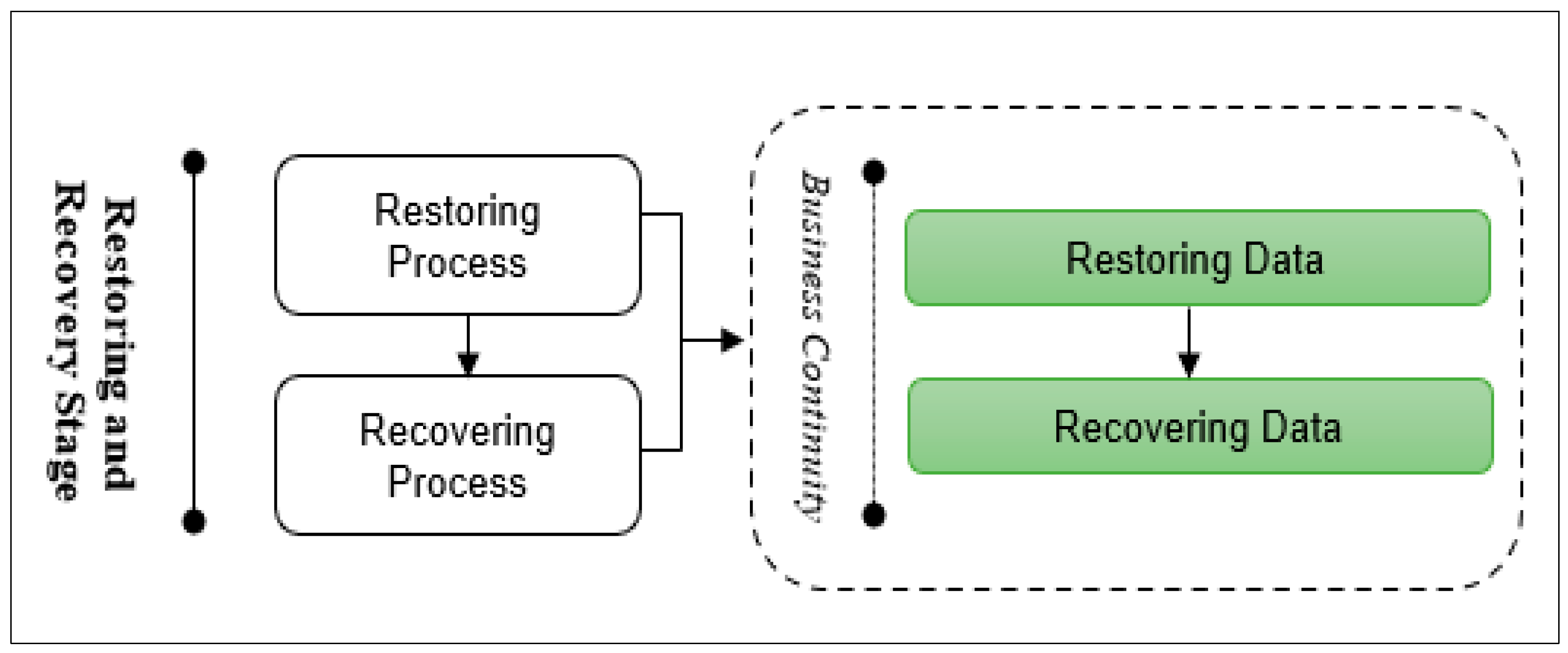
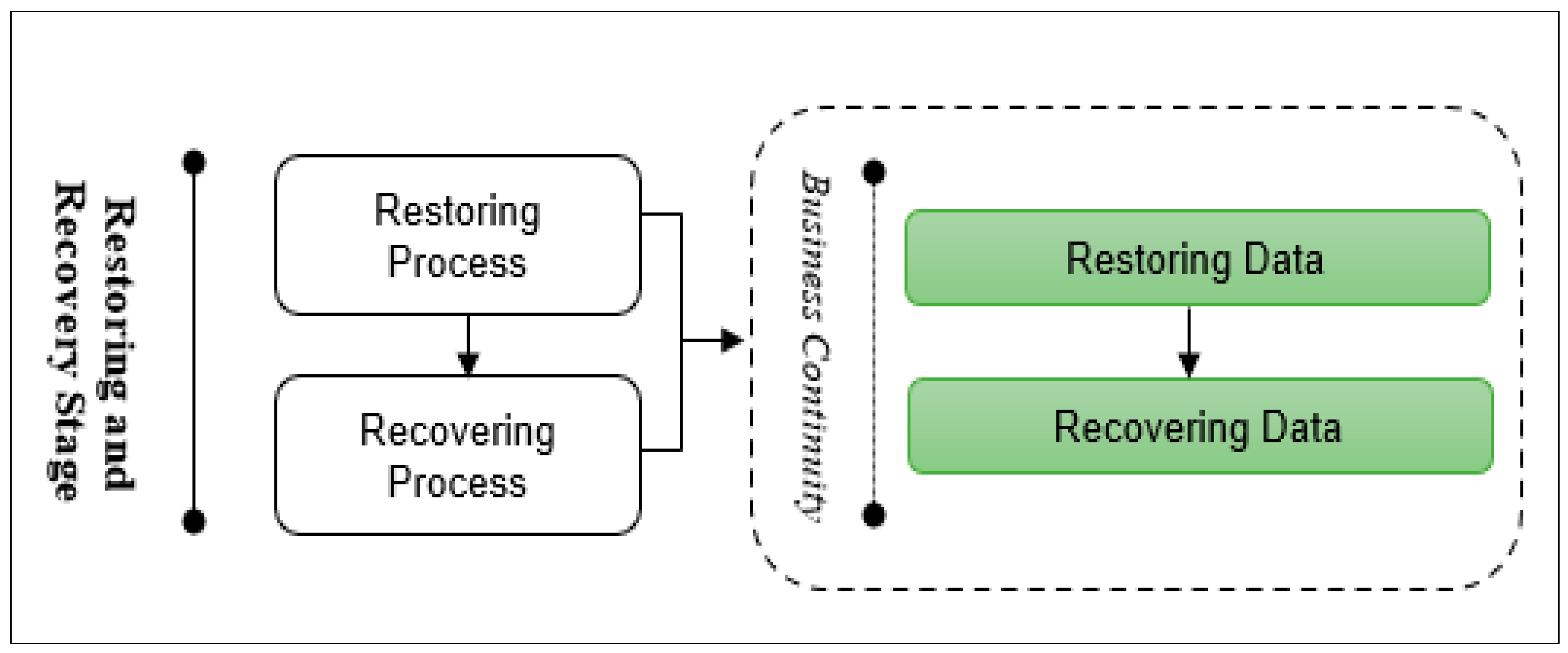
- Restoring and Recovering Stage: This stage aims to restore and recover the deleted/damaged data to the new database environment. This stage consists of two main processes, as shown in Figure 9: restoring and recovering data. Data recovery is the process of restoring data that has been lost, corrupted, or made inaccessible for any reason or accidentally deleted.
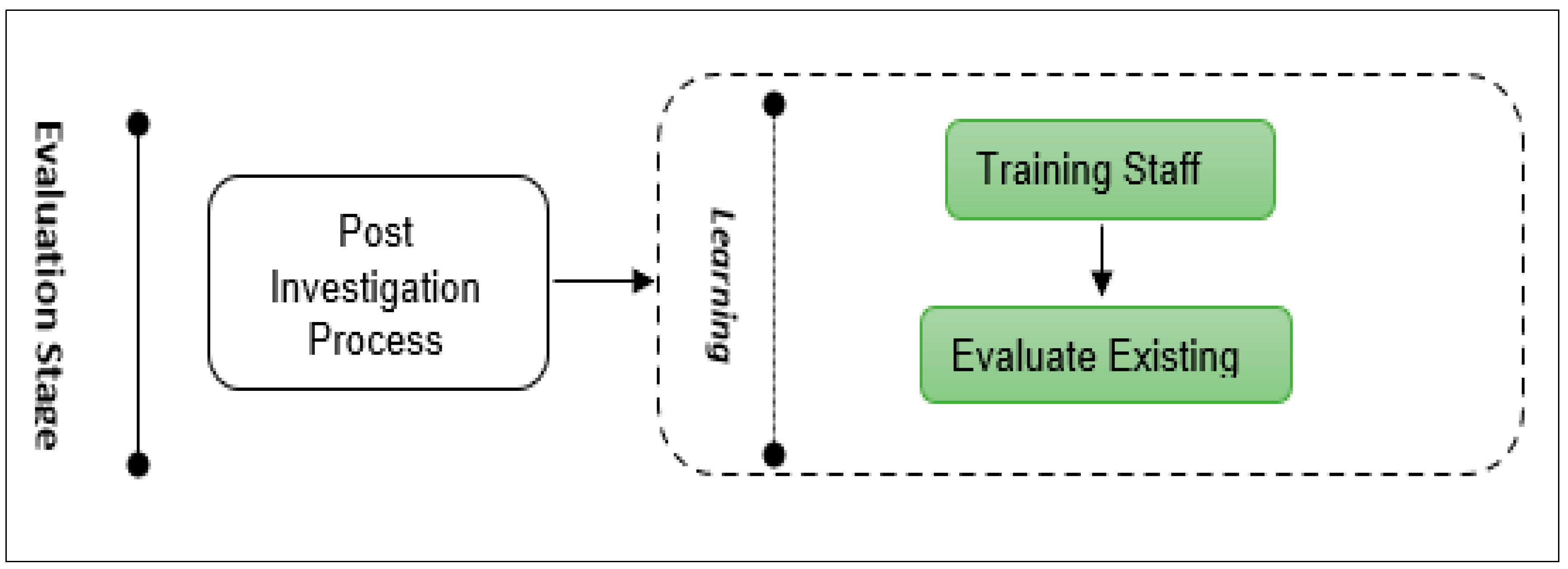
- Evaluation Stage: This stage needs to evaluate the investigation process to improve it and avoid any problems. This stage consists of the postinvestigation process, as shown in Figure 10. It is used to teach the staff the principles of the investigation and how they can deal with or face any database incidents. In addition, it is used to improve the whole investigation stage.

- (5)
- Step 5. Validation and Implementation Stage: Validation and Implementation are two significant processes used to assess the applicability of the proposed model to real investigations with real scenarios or real case studies. Thus, the proposed model was evaluated from two perspectives (as mentioned earlier): The Completeness perspective and the Implementation perspective, which are explained as follows:
- Completeness perspective: In this perspective, the focus was on the validation in case the proposed UFM was completed against the available DBFIs models. To finalize this process, a comparison of the UFM was made against other models [1]. The comparison was made to verify if the proposed UFM is effective and whether it can entirely translate and fit into the existing domain models. Table 3 shows the models used in the comparison. The proposed UFM is more comprehensive, and it incorporates activities that have been identified in the previous models. Table 3 shows that all the processes of the previously proposed models are covered in the proposed UFM.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Existing Database Forensics Investigation Models | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M 1 | M 2 | M 3 | M 4 | M 5 | M 6 | M 7 | M 8 | M 9 | M 10 | M 11 | M 12 | M 13 | M 14 | M 15 | M 16 | M 17 | M 18 | M 19 | |
| Initialization stage | √ | √ | √ | × | √ | √ | × | √ | √ | √ | √ | × | √ | √ | × | × | × | × | √ |
| Acquiring stage | √ | √ | √ | × | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | × | √ | × |
| Investigation stage | √ | √ | × | √ | × | √ | √ | √ | × | √ | √ | √ | √ | × | √ | √ | √ | √ | √ |
| Restoring and Recovering Stage | √ | √ | × | × | × | × | × | √ | × | × | × | × | × | × | × | × | × | √ | × |
| Evaluation Stage | × | × | × | × | × | × | × | × | × | × | × | × | × | × | × | × | × | × | × |
- Implementation perspective (experiments environment): The applicability of the proposed model to the real investigation of the database incidents is evaluated in this stage. To this end, FTK Imager and HashMyFiles forensic tools are used. The FTK Imager tool is used to capture the data, and the HashMyFiles tool is used to preserve the captured data. To do this, the authors used the following scenario: “We received a complaint from a customer called Arafat. He said that his credit card is not working, and he cannot login to his account”. For this scenario, the authors will use the environment of the following experiment, which is illustrated in Figure 11. The first three stages of the proposed UFM are used: the Initialization, Acquiring, and Investigation stages to capture and reveal malicious activities:
- ✓
- Initialization stage: The investigation team should review the policies and procedures of the organizations and the database investigation procedures before starting the investigation. They should prepare the trusted investigation tools. In this case, we prepared FTK Imager and HashMyFiles tools. The investigation team interviewed with DBA and the IT staff to gather the information needed to verify the database incident. The information (database files locations, passwords, accounts, users, IP, etc.) should be gathered through interviews. The version of the database is Oracle 11.2.0. The DBA informed us that he discovered that the account number of the customer was locked, and his secret key was changed. Then, we discovered that the database had been compromised. In this case, the volatile information is very important to detect the attack and find the path of the attack. For this purpose, the investigation team should move to the acquiring stage.
- ✓
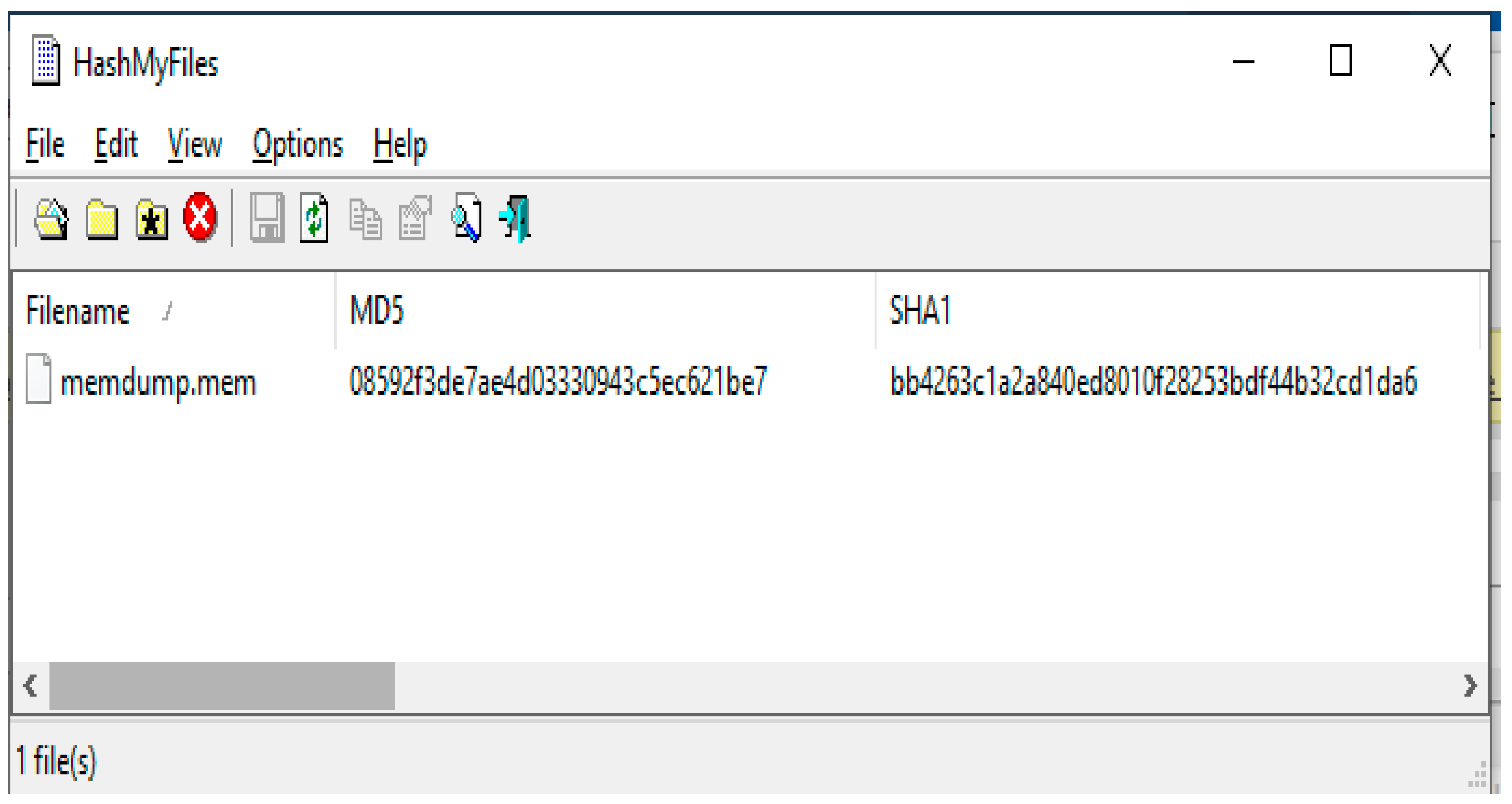
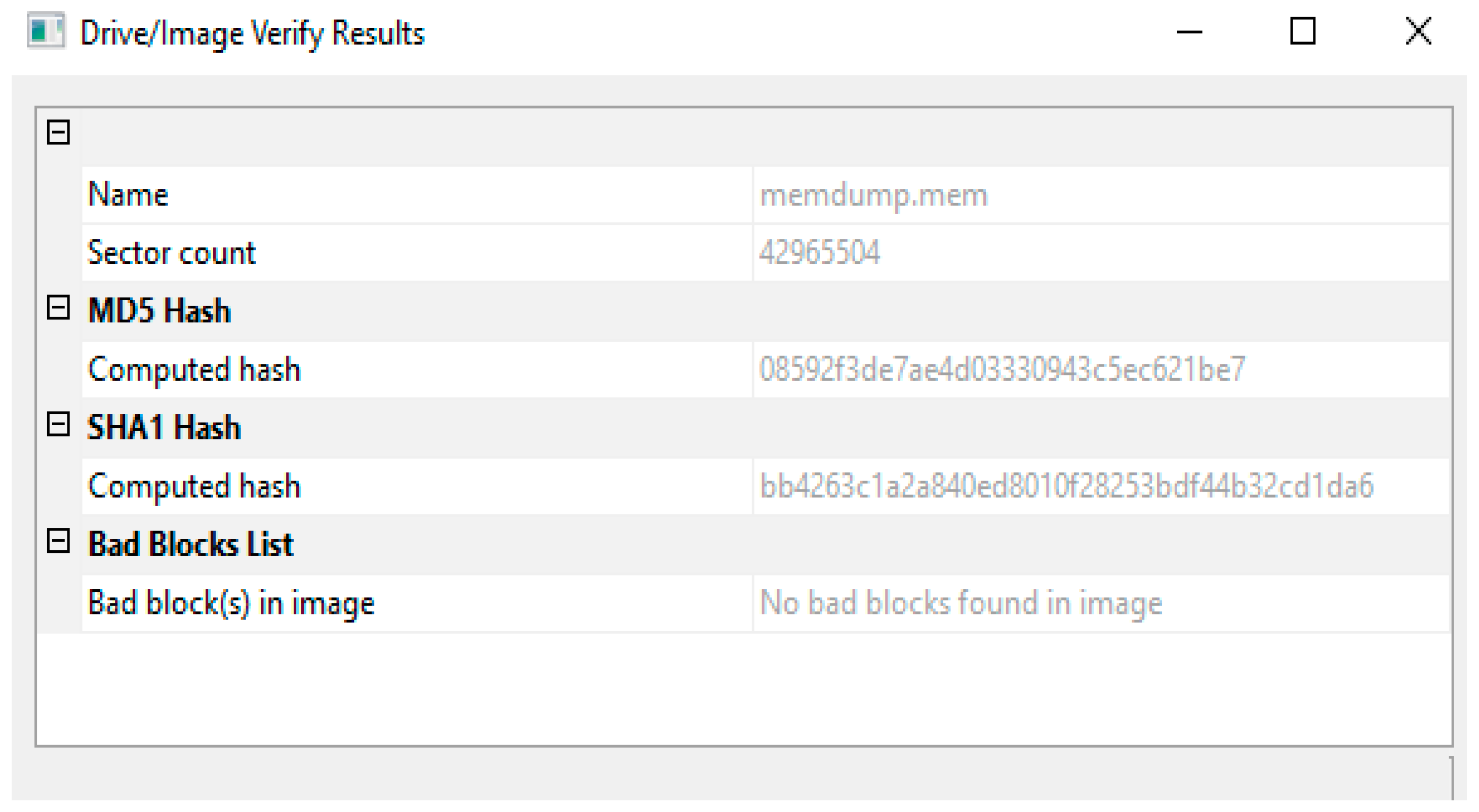
- Acquiring stage: In the second stage, the investigation team uses FTK Imager and HashMyFiles tools to capture and preserve volatile data. The investigation team should capture volatile and non-volatile data (in order), as shown in Figure 12. The captured data should be moved to an external flash disk to avoid any problem and then duplicated. The captured data should be protected from any tampering/updating. Thus, the HashMyFiles tool should be used for this purpose. The HashMyFiles tool is used to produce hashed values for the captured data, as shown in Figure 13. To check the consistency of the data before moving to the analysis procedure, the authentication of the captured data needs to be performed using the FTK Imager tool. Thus, the file “memdump”, which is already hashed, is verified, as shown in Figure 14. The authentication is conducted, the value is correct, has no tampering, and it is ready to move to the next stage of the investigation.
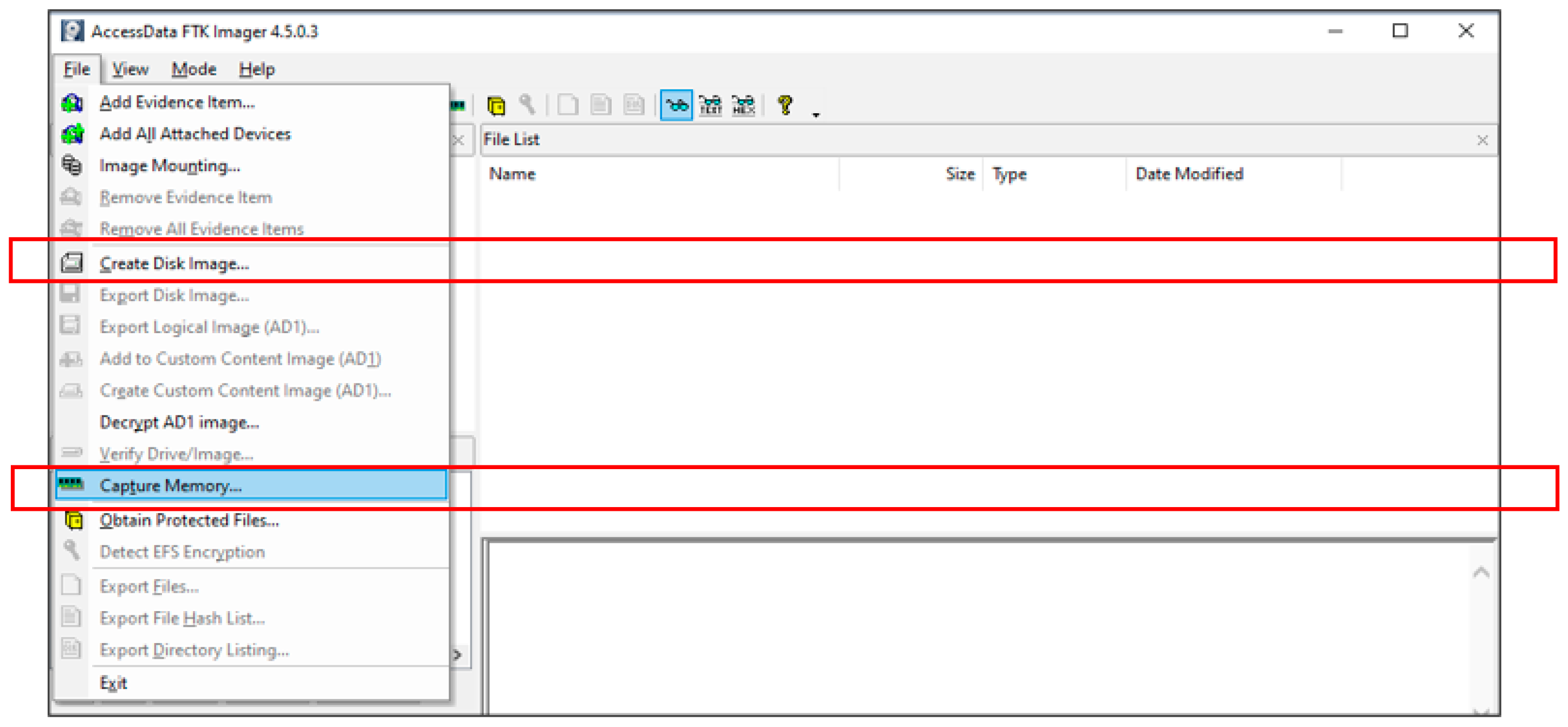
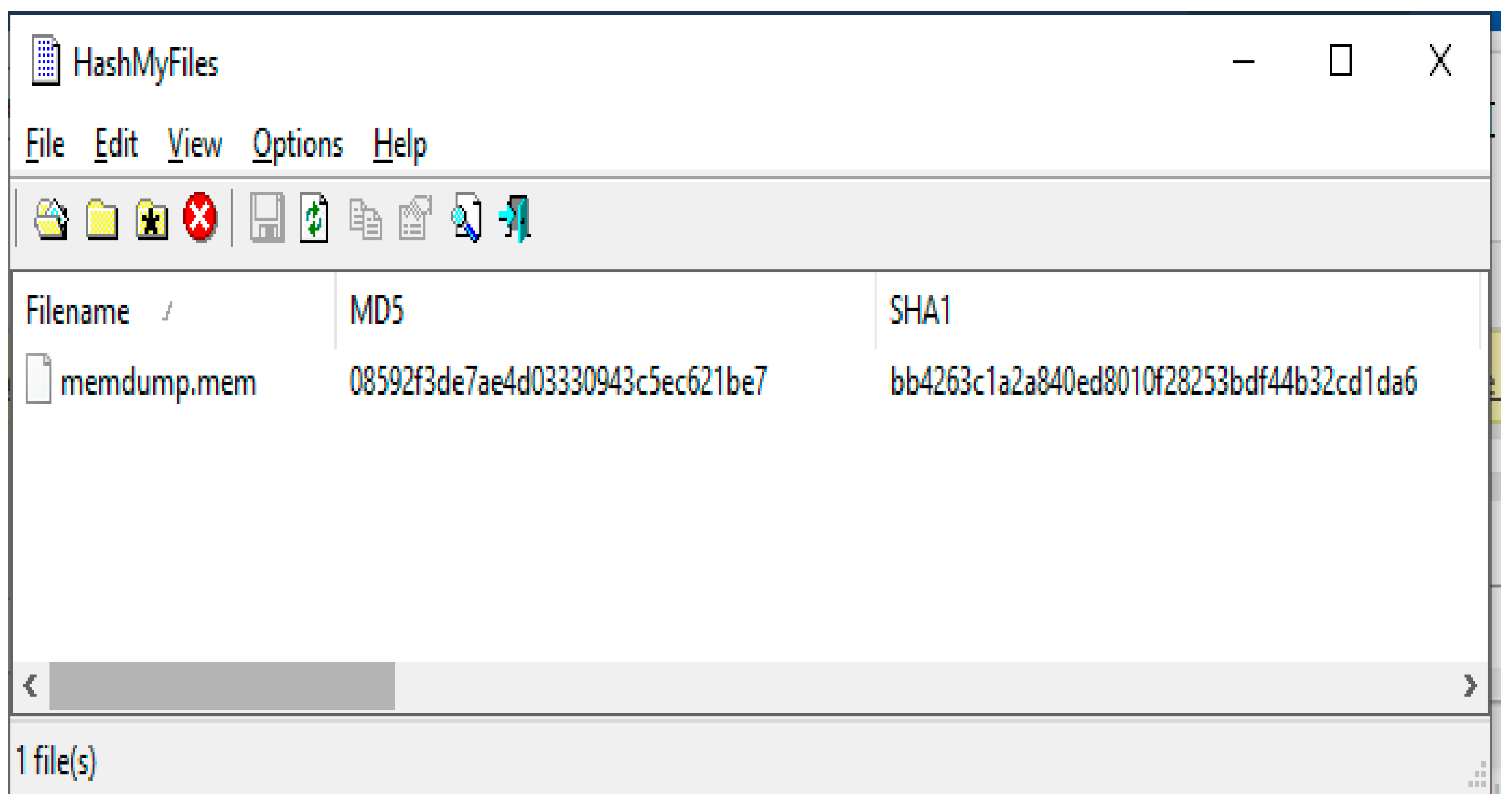

- ✓
- Investigation Stage: In this stage, the captured information is analyzed, and malicious activities are identified. The FTK Imager tool is used to search for malicious transactions. We started digging in the captured image and used some keywords based on the previous DBA’s information and some log files such as “Credit Card”, “CreditCard”, “Update”, “Delete”, and “Secret Key”. After trying all these keywords, it was found that the attacker had changed the victim’s secret key and changed it to 222, as shown in Figure 15.

4. Results and Discussion
5. Advantages of the Proposed Unified Forensic Model
- (1)
- Simplifying common communication amongst different DBFI domain practitioners through a common representation layer that includes all the processes, concepts, tasks, and activities that must exist in the DBFI domain;
- (2)
- Providing guidelines and new model-developing processes that assist domain practitioners in managing, sharing, and reusing DBFI domain knowledge;
- (3)
- Solving the heterogeneity and ambiguity of the DBFI domain; Generality and reusability of common processes.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Al-Dhaqm, A.; Razak, S.; Ikuesan, R.A.; R Kebande, V.; Hajar Othman, S. Face Validation of Database Forensic Investigation Metamodel. Infrastructures 2021, 6, 13. [Google Scholar] [CrossRef]
- Al-Dhaqm, A.; Razak, S.A.; Othman, S.H.; Nagdi, A.; Ali, A. A generic database forensic investigation process model. J. Teknol. 2016, 78. [Google Scholar] [CrossRef] [Green Version]
- Fasan, O.M.; Olivier, M. Reconstruction in database forensics. In Proceedings of the IFIP International Conference on Digital Forensics, Pretoria, South Africa, 3–5 January 2012; pp. 273–287. [Google Scholar]
- Beyers, H.Q. Database Forensics: Investigating Compromised Database Management Systems. Ph.D. Thesis, University of Pretoria, Pretoria, South Africa, 2014. [Google Scholar]
- Susaimanickam, R. A Workflow to Support Forensic Database Analysis. Ph.D. Thesis, Murdoch University, Murdoch, Australia, 2012. [Google Scholar]
- Fasan, O.M.; Olivier, M.S. On Dimensions of Reconstruction in Database Forensics. In Proceedings of the International Workshop on Digital Forensics and Incident Analysis, WDFIA, Crete, Greece, 6–8 June 2012; pp. 97–106. [Google Scholar]
- Yoon, J.; Jeong, D.; Kang, C.; Lee, S. Forensic investigation framework for the document store NoSQL DBMS: MongoDB as a case study. Digit. Investig. 2016, 17, 53–65. [Google Scholar] [CrossRef]
- Khanuja, H.K.; Adane, D.S. A framework for database forensic analysis. Comput. Sci. Eng. 2012, 2, 27–41. [Google Scholar] [CrossRef]
- Olivier, M.S. On metadata context in database forensics. Digit. Investig. 2009, 5, 115–123. [Google Scholar] [CrossRef] [Green Version]
- Delfanti, R.L.; Piccioni, D.E.; Handwerker, J.; Bahrami, N.; Krishnan, A.P.; Karunamuni, R.; Hattangadi-Gluth, J.A.; Seibert, T.M.; Srikant, A.; Jones, K.A.; et al. Glioma Groups Based on 1p/19q, IDH, and TERT Promoter Mutations in Tumors. N. Engl. J. Med. 2018, 372, 2499–2508. [Google Scholar] [CrossRef] [Green Version]
- Litchfield, D. Oracle Forensics Part 1: Dissecting the Redo Logs; NGSSoftware Insight Security Research (NISR), Next Generation Security Software Ltd.: Sutton, UK, 2007. [Google Scholar]
- Litchfield, D. Oracle Forensics Part 2: Locating Dropped Objects; NGSSoftware Insight Security Research (NISR) Publication, Next Generation Security Software: Sutton, UK, 2007. [Google Scholar]
- Litchfield, D. Oracle Forensics Part 3: Isolating Evidence of Attacks against the Authentication Mechanism; NGSSoftware Insight Security Research (NISR) Publication: Sutton, UK, March 2007. [Google Scholar]
- Litchfield, D. Oracle Forensics Part 4: Live Response; NGSSoftware Insight Security Research (NISR), Next Generation Security Software Ltd.: Sutton, UK, 2007. [Google Scholar]
- Fowler, K. SQL Server Forenisc Analysis; Pearson Education: Indianapolis, IN, USA, 2008. [Google Scholar]
- Son, N.; Lee, K.; Jeon, S.; Chung, H.; Lee, S.; Lee, C. The method of database server detection and investigation in the enterprise environment. In Proceedings of the FTRA International Conference on Secure and Trust Computing, Data Management, and Application, Loutraki, Greece, 28–30 June 2011; pp. 164–171. [Google Scholar]
- Frühwirt, P.; Huber, M.; Mulazzani, M.; Weippl, E.R. InnoDB database forensics. In Proceedings of the 2010 24th IEEE International Conference on Advanced Information Networking and Applications, Perth, WA, Australia, 20–23 April 2010; Volume 386, pp. 1028–1036. [Google Scholar] [CrossRef] [Green Version]
- Frühwirt, P.; Kieseberg, P.; Schrittwieser, S.; Huber, M.; Weippl, E. Innodb database forensics: Reconstructing data manipulation queries from redo logs. In Proceedings of the 2012 Seventh International Conference on Availability, Reliability and Security, Prague, Czech Republic, 20–24 August 2012; pp. 625–633. [Google Scholar]
- Frühwirt, P.; Kieseberg, P.; Schrittwieser, S.; Huber, M.; Weippl, E. InnoDB database forensics: Enhanced reconstruction of data manipulation queries from redo logs. Inf. Secur. Tech. Rep. 2013, 17, 227–238. [Google Scholar] [CrossRef]
- Lee, G.T.; Lee, S.; Tsomko, E.; Lee, S. Discovering methodology and scenario to detect covert database system. In Proceedings of the Future Generation Communication and Networking (FGCN 2007), Jeju Island, Korea, 6–8 December 2007; Volume 2, pp. 130–135. [Google Scholar]
- Azemović, J.; Mušić, D. Efficient model for detection data and data scheme tempering with purpose of valid forensic analysis. In Proceedings of the 2009 International Conference on Computer Engineering and Applications (ICCEA 2009), Manila, Philippines, 6–8 June 2009. [Google Scholar]
- Snodgrass, R.; Yao, S.; Collberg, C. Tamper Detection in Audit Logs. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004; pp. 504–515. [Google Scholar] [CrossRef] [Green Version]
- Khanuja, H.; Suratkar, S.S. Role of metadata in forensic analysis of database attacks. In Proceedings of the 2014 IEEE International Advance Computing Conference (IACC), New Delhi, India, 21–22 February 2014; pp. 457–462. [Google Scholar]
- Frühwirt, P.; Kieseberg, P.; Krombholz, K.; Weippl, E. Towards a forensic-aware database solution: Using a secured database replication protocol and transaction management for digital investigations. Digit. Investig. 2014, 11, 336–348. [Google Scholar] [CrossRef]
- Chopade, M.S.D.; Bere, S.S.; Kasar, M.N.B.; Moholkar, M.A. V SQL Query Recommendation Using Collaborative Query Log: A Survey. Int. J. Recent Innov. Trends Comput. Commun. 2004, 2, 3715–3721. [Google Scholar]
- Wright, P.M. Oracle database forensics using LogMiner. In June 2004 Conference; SANS Institute: London, UK, 2005; pp. 1–39. [Google Scholar]
- Yoon, J.; Lee, S. A method and tool to recover data deleted from a MongoDB. Digit. Investig. 2018, 24, 106–120. [Google Scholar] [CrossRef]
- Al-Dhaqm, A.; Abd Razak, S.; Othman, S.H.; Ali, A.; Ghaleb, F.A.; Rosman, A.S.; Marni, N. Database forensic investigation process models: A review. IEEE Access 2020, 8, 48477–48490. [Google Scholar] [CrossRef]
- Hauger, W.K.; Olivier, M.S. The state of database forensic research. In Proceedings of the 2015 Information Security for South Africa (ISSA), Johannesburg, South Africa, 12–13 August 2015; pp. 1–8. [Google Scholar]
- Bria, R.; Retnowardhani, A.; Utama, D.N. Five stages of database forensic analysis: A systematic literature review. In Proceedings of the 2018 International Conference on Information Management and Technology (ICIMTech), Jakarta, Indonesia, 3–5 September 2018; pp. 246–250. [Google Scholar]
- Wong, D.; Edwards, K. System and Method for Investigating a Data Operation Performed on a Database. U.S. Patent 10/879,466, 29 December 2005. [Google Scholar]
- Al-Dhaqm, A.; Razak, S.; Siddique, K.; Ikuesan, R.A.; Kebande, V.R. Towards the Development of an Integrated Incident Response Model for Database Forensic Investigation Field. IEEE Access 2020, 8, 45018–145032. [Google Scholar] [CrossRef]
- Kelly, S.; Pohjonen, R. Worst practices for domain-specific modeling. IEEE Softw. 2009, 26, 22–29. [Google Scholar] [CrossRef]
- Ogutu, J.O. A Methodology To Test The Richness of Forensic Evidence of Database Storage Engine: Analysis of MySQL Update Operation in InnoDB and MyISAM Storage Engines. Ph.D. Thesis, University of Nairobi, Nairobi, Kenya, 2016. [Google Scholar]
- Khanuja, H.K.; Adane, D. Forensic analysis of databases by combining multiple evidences. Int. J. Comput. Technol. 2013, 7, 654–663. [Google Scholar] [CrossRef]
- Adedayo, O.M.; Olivier, M.S. Ideal log setting for database forensics reconstruction. Digit. Investig. 2015, 12, 27–40. [Google Scholar] [CrossRef]
- Lee, D.; Choi, J.; Lee, S. Database forensic investigation based on table relationship analysis techniques. In Proceedings of the 2009 2nd International Conference on Computer Science and Its Applications, CSA 2009, Jeju Island, Korea, 10–12 December 2009; p. 5404235. [Google Scholar]
- Choi, J.; Choi, K.; Lee, S. Evidence investigation methodologies for detecting financial fraud based on forensic accounting. In Proceedings of the 2009 2nd International Conference on Computer Science and Its Applications, CSA 2009, Jeju Island, Korea, 10–12 December 2009; p. 5404202. [Google Scholar]
- Tripathi, S.; Meshram, B.B. Digital evidence for database tamper detection. J. Inf. Secur. 2012, 3, 113–121. [Google Scholar] [CrossRef] [Green Version]
- Wagner, J.; Rasin, A.; Grier, J. Database forensic analysis through internal structure carving. Digit. Investig. 2015, 14, S106–S115. [Google Scholar] [CrossRef] [Green Version]
- Caro, M.F.; Josyula, D.P.; Cox, M.T.; Jiménez, J.A. Design and validation of a metamodel for metacognition support in artificial intelligent systems. Biol. Inspired Cogn. Archit. 2014, 9, 82–104. [Google Scholar] [CrossRef]
- Bogen, A.C.; Dampier, D.A. Preparing for Large-Scale Investigations with Case Domain Modeling. In Proceedings of the Digital Forensics Research Conference, DFRWS, New Orleans, LA, USA, 17–19 August 2005. [Google Scholar]
- Selamat, S.R.; Yusof, R.; Sahib, S. Mapping process of digital forensic investigation framework. Int. J. Comput. Sci. Netw. Secur. 2008, 8, 163–169. [Google Scholar]
- Al-Dhaqm, A.; Razak, S.; Othman, S.H.; Choo, K.-K.R.; Glisson, W.B.; Ali, A.; Abrar, M. CDBFIP: Common Database Forensic Investigation Processes for Internet of Things. IEEE Access 2017, 5, 24401–24416. [Google Scholar] [CrossRef]
- Ali, A.; Abd Razak, S.; Othman, S.H.; Mohammed, A.; Saeed, F. A metamodel for mobile forensics investigation domain. PLoS ONE 2017, 12, e0176223. [Google Scholar] [CrossRef] [PubMed]
- Haghighi, P.D.; Burstein, F.; Li, H.; Wang, C. Integrating social media with ontologies for real-time crowd monitoring and decision support in mass gatherings. In Proceedings of the Pacific Asia Conference on Information Systems, Jeju Island, Korea, 18–22 June 2013. [Google Scholar]
- Akinyemi, J.A.; Clarke, C.L.A.; Kolla, M. Towards a collection-based results diversification. In Proceedings of the 9th international conference on Adaptivity, Personalization and Fusion of Heterogeneous Information, Paris, France, 28–30 April 2010; pp. 202–205. [Google Scholar]





| ID | Nominated Models | Extracted Processes |
|---|---|---|
| 1. | [34] | Detection process, Collection process, Reconstruction process, Restoring, and Recovering |
| 2. | [35] | Authentication, System Explanation, Evidence Collection, Timeline Construction, Analysis process, Recovering process, and Searching. |
| 3. | [14] | The preparation process, The ollection process |
| 4. | [36] | Preparation process, Incident Confirmation, Collection process, Analysis process |
| 5. | [37] | Preparation of Database Environment, Extraction process, Investigation process |
| 6. | [38] | Acquirement process, Investigation process, Financial Analysis |
| 7. | [9] | The extraction process, Restoration process |
| 8. | [16] | Server Discovery process, Gathering process, The examination process |
| 9. | [39] | Investigation process, Collection process, Analysis process |
| 10. | [8] | Identification process, Acquiring process, Investigation process, Reporting process |
| 11. | [5] | Crime Reporting process, Examination process, Physical Examination process, Digital Examination process, Documentation process, Postinvestigation process, and Postinvestigation, Analysis Process |
| 12. | [6] | Preparation process, Defining/Gaining process, Artefact Collection process, Volatile Collection process, Nonvolatile Collection process, Preservation process, Analysis process |
| 13. | [35] | Collection process, Analysis process |
| 14. | [4] | The preparation process, Collection process |
| 15. | [23] | Collection process, Preservation process, Analysis process |
| 16. | [24] | Gathering process, Examination process |
| 17. | [36] | Investigation process, Rebuilding process |
| 18. | [40] | The rebuilding process, Recovering process |
| 19. | [34] | Initial Analysis process, Implementation process, Analysis process |
| Existing Processes | Proposed Stages | Proposed Process for Each Stage |
|---|---|---|
| Detection process | Initialization Stage | Preparation process |
| Authentication, System Explanation | ||
| Preparation process | ||
| Preparation process, Incident Confirmation | ||
| Preparation of Database Environment | ||
| Acquirement process | ||
| Server Discovery process | ||
| Preparation process | Detection process | |
| Preparation process | ||
| Crime Reporting process | ||
| Preparation process | ||
| Preparation process | ||
| Investigation process | ||
| Initial Analysis process | ||
| Collection process | Acquiring Stage | Acquisition process |
| Evidence Collection | ||
| Collection process | ||
| Collection process | ||
| Extraction process | ||
| Investigation process | ||
| Extraction process | ||
| Collection process | ||
| Collection process | ||
| Collection process | Preservation process | |
| Physical Examination process, Digital Examination process | ||
| Defining Gaining process, Artefact Collection process, Volatile Collection process, Nonvolatile Collection process, Preservation process | ||
| Collection process | ||
| Collection process | ||
| Collection process, Preservation process | ||
| Gathering process | ||
| Implementation process | ||
| Examination process | ||
| Timeline Construction, Analysis process | Investigation Stage | Reconstruction process |
| Analysis process | ||
| Investigation process | ||
| Financial Analysis | Analysis process | |
| Investigation process | ||
| Analysis process | ||
| Analysis process, Reporting process | ||
| Analysis process | ||
| Analysis process | Reporting process | |
| Analysis process | ||
| Examination process | ||
| The investigation process and Rebuilding process | ||
| Rebuilding process | ||
| Analysis process | ||
| Restoring and recovering | Restoring and Recovering Stage | Restoring process |
| Recovering process, and searching | ||
| Restoration process | Recovering process | |
| Recovering process | ||
| Postinvestigation process | Evaluation Stage | Training Staff |
| Evaluation of Existing Investigation process |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alhussan, A.A.; Al-Dhaqm, A.; Yafooz, W.M.S.; Emara, A.-H.M.; Bin Abd Razak, S.; Khafaga, D.S. A Unified Forensic Model Applicable to the Database Forensics Field. Electronics 2022, 11, 1347. https://doi.org/10.3390/electronics11091347
Alhussan AA, Al-Dhaqm A, Yafooz WMS, Emara A-HM, Bin Abd Razak S, Khafaga DS. A Unified Forensic Model Applicable to the Database Forensics Field. Electronics. 2022; 11(9):1347. https://doi.org/10.3390/electronics11091347
Chicago/Turabian StyleAlhussan, Amel Ali, Arafat Al-Dhaqm, Wael M. S. Yafooz, Abdel-Hamid M. Emara, Shukor Bin Abd Razak, and Doaa Sami Khafaga. 2022. "A Unified Forensic Model Applicable to the Database Forensics Field" Electronics 11, no. 9: 1347. https://doi.org/10.3390/electronics11091347
APA StyleAlhussan, A. A., Al-Dhaqm, A., Yafooz, W. M. S., Emara, A.-H. M., Bin Abd Razak, S., & Khafaga, D. S. (2022). A Unified Forensic Model Applicable to the Database Forensics Field. Electronics, 11(9), 1347. https://doi.org/10.3390/electronics11091347