
Application of GIS and Machine Learning to Predict Flood Areas in Nigeria


Abstract
1. Introduction
1.1. An Overview of Machine Learning and Its Relevance to Flood Prediction
1.2. Flood Prediction and Modelling with ML Models
2. Materials and Methods
2.1. Description of the Study Area
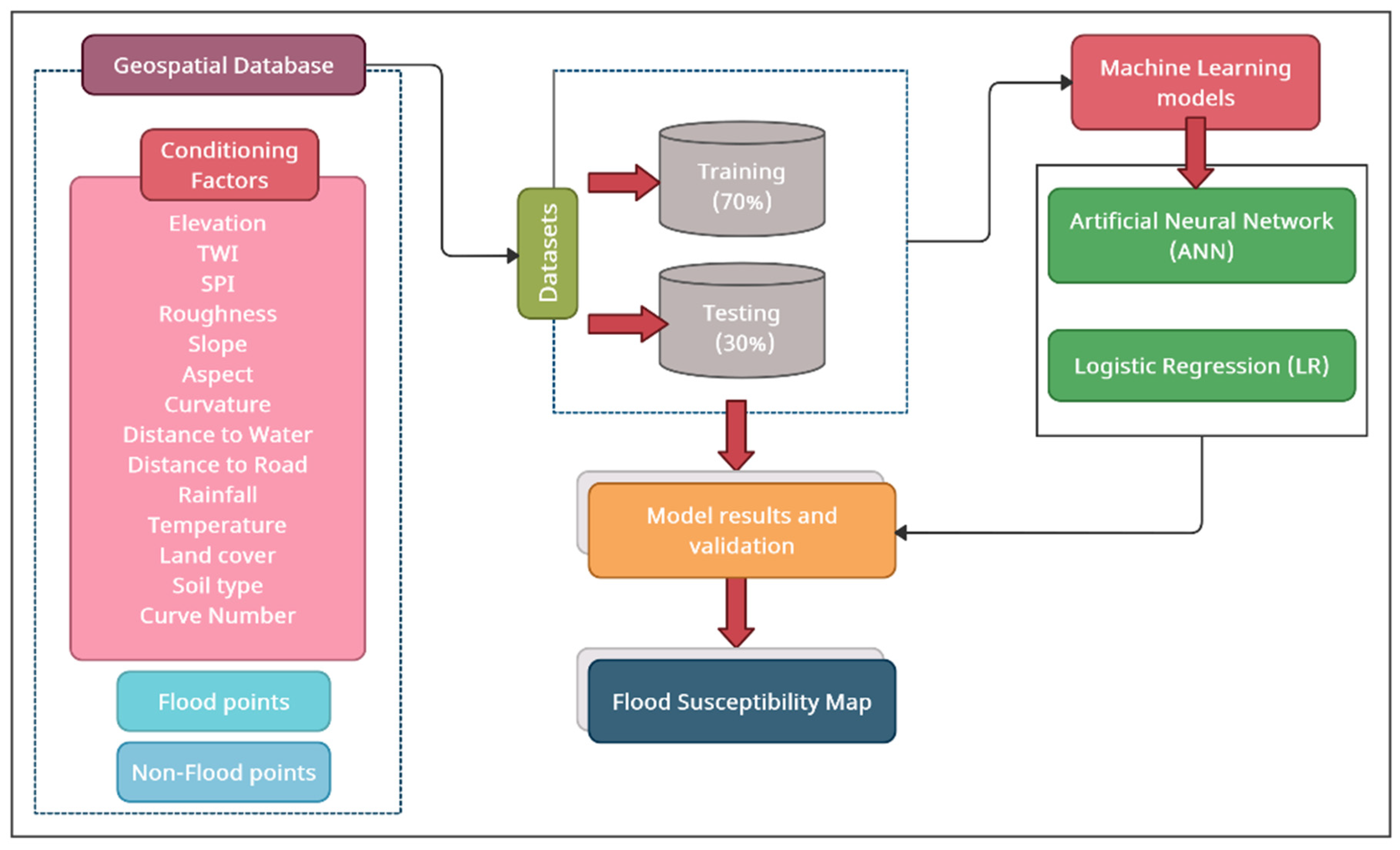
2.2. Methodology
2.2.1. Inventory Map of Historical Flood Events
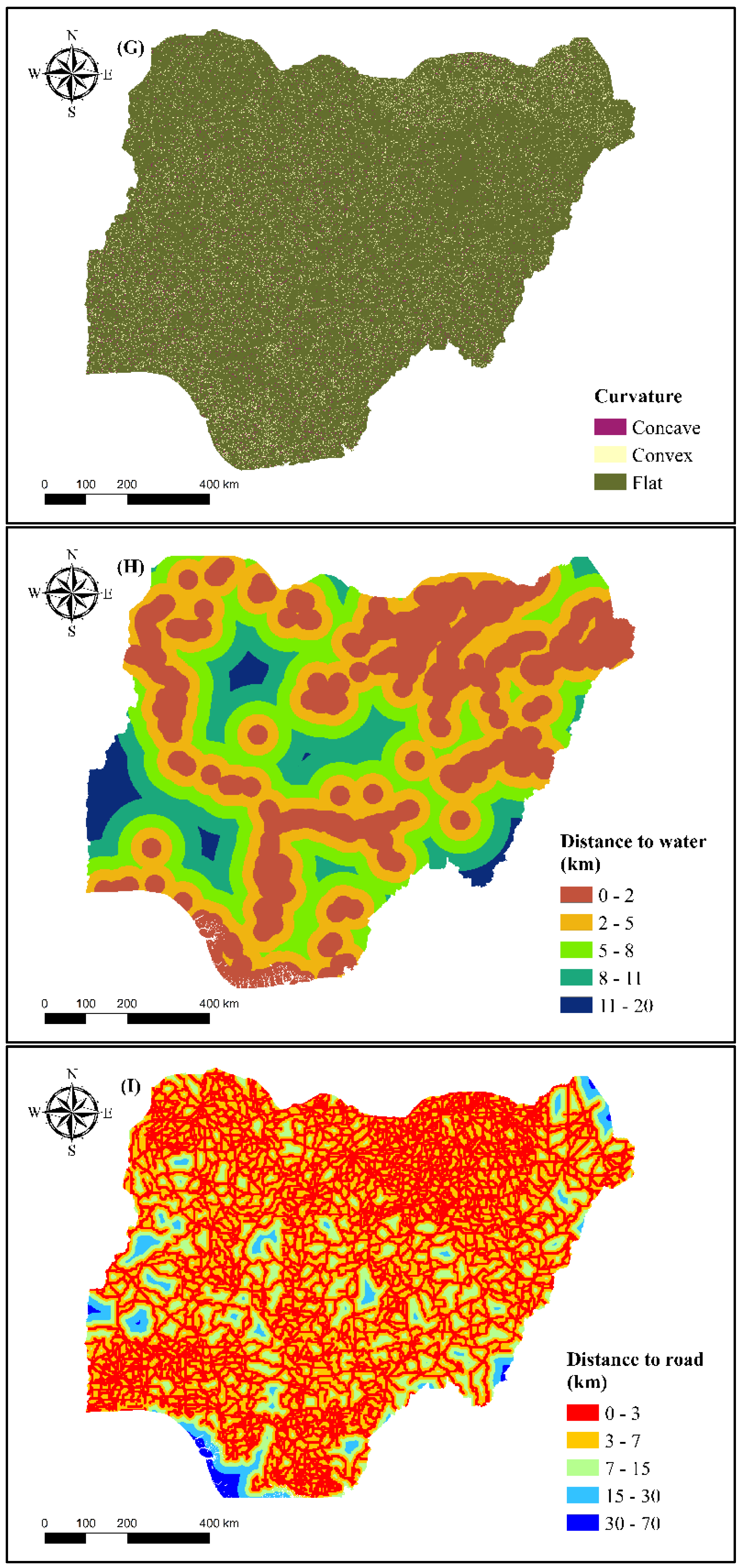
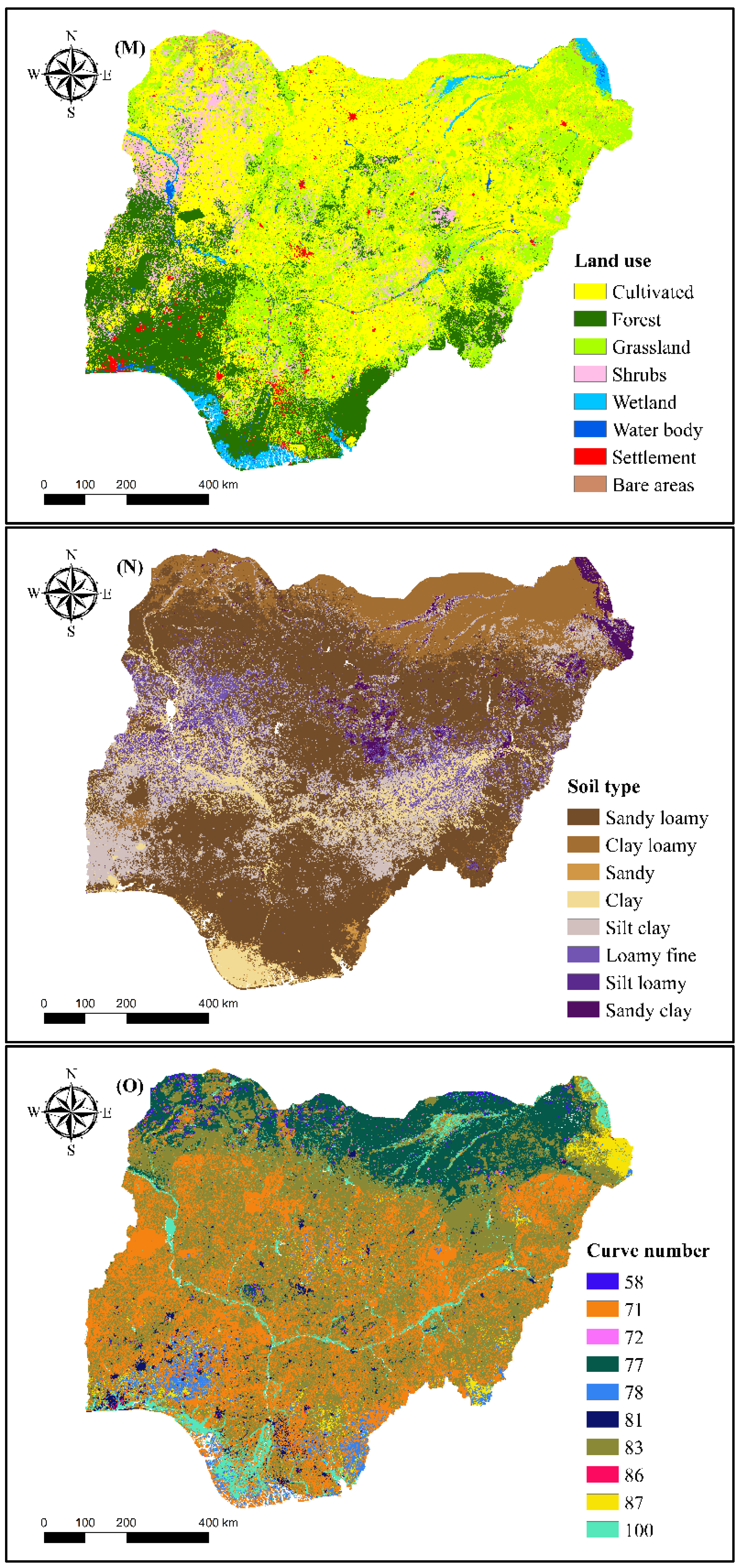
2.2.2. Flood Conditioning Factors
2.3. Machine Learning Models
2.3.1. Artificial Neural Network (ANN)
2.3.2. Logistic Regression (LR)
2.4. Correlation Analysis
2.5. Pearson’s Correlation Coefficients Estimation
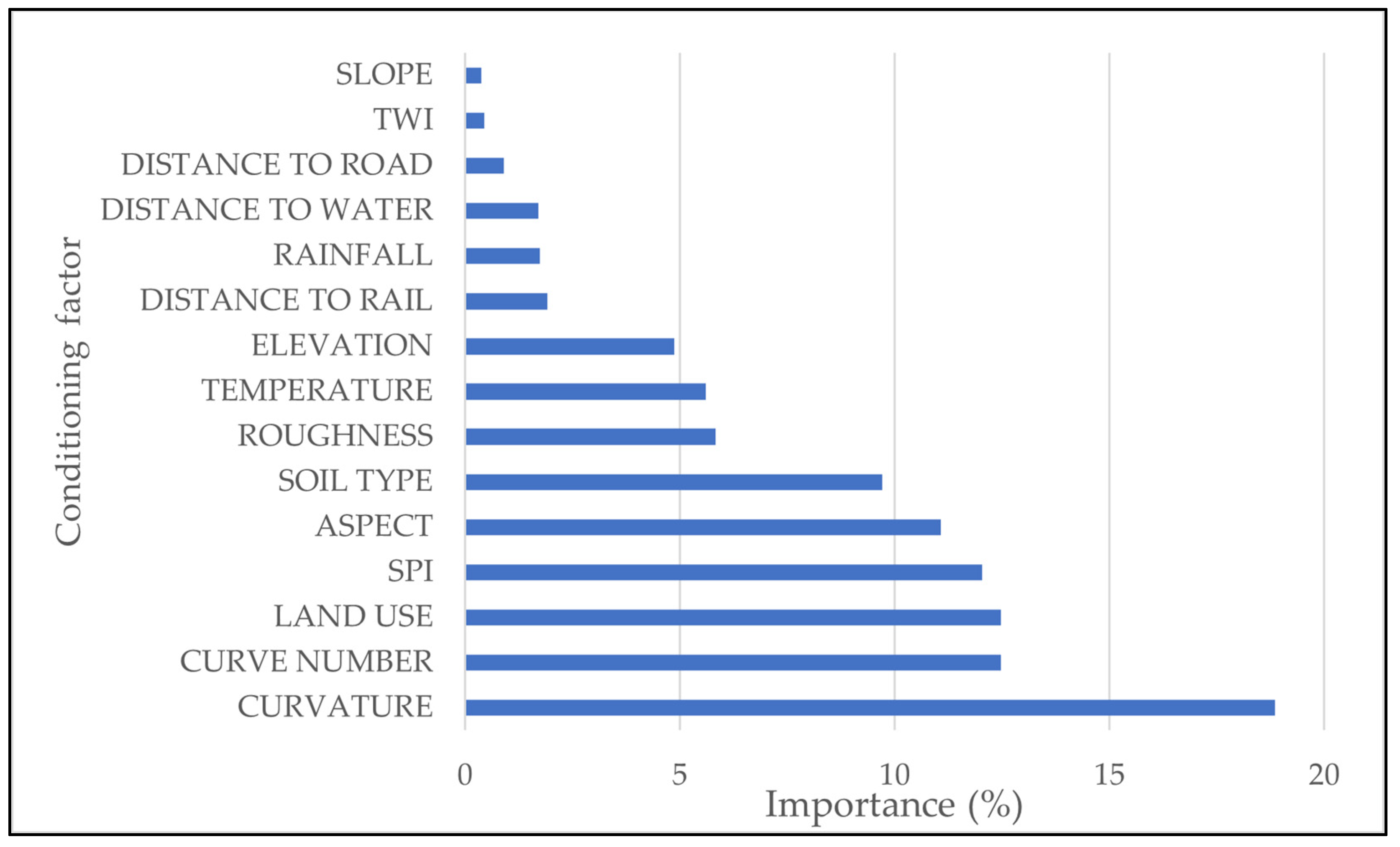
2.6. Variable Importance Estimation
2.7. Assessment of Modeling Accuracy
2.8. Model Performance Evaluation
3. Results
3.1. Artificial Neural Network Model (ANN)
3.2. Logistic Regression Model (LR)
3.3. Flood Susceptibility Map
3.4. Validation and Accuracy Assessment
4. Discussion
4.1. Variable Importance in Flood Susceptibility
4.2. Analysis of Flood Susceptibility Model Results
4.3. Correlation Analysis Results
4.4. Performance of the ANN and LR Models
Classification Performance
4.5. Advantages and Future Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Lee, S.; Kim, J.-C.; Jung, H.-S.; Lee, M.J.; Lee, S. Spatial prediction of flood susceptibility using random-forest and boosted-tree models in Seoul metropolitan city, Korea. Geomatics Nat. Hazards Risk 2017, 8, 1185–1203. [Google Scholar] [CrossRef]
- Ahmadlou, M.; Al-Fugara, A.; Al-Shabeeb, A.R.; Arora, A.; Al-Adamat, R.; Pham, Q.B.; Al-Ansari, N.; Linh, N.T.T.; Sajedi, H. Flood susceptibility mapping and assessment using a novel deep learning model combining multilayer perceptron and autoencoder neural networks. J. Flood Risk Manag. 2020, 14, e12683. [Google Scholar] [CrossRef]
- Diaz, J.H. Global Climate Changes, Natural Disasters, and Travel Health Risks. J. Travel Med. 2006, 13, 361–372. [Google Scholar] [CrossRef]
- Jamali, B.; Bach, P.M.; Deletic, A. Rainwater harvesting for urban flood management—An integrated modelling framework. Water Res. 2020, 171, 115372. [Google Scholar] [CrossRef] [PubMed]
- Haynes, K.; Coates, L.; Honert, R.V.D.; Gissing, A.; Bird, D.; de Oliveira, F.D.; D’Arcy, R.; Smith, C.; Radford, D. Exploring the circumstances surrounding flood fatalities in Australia—1900–2015 and the implications for policy and practice. Environ. Sci. Policy 2017, 76, 165–176. [Google Scholar] [CrossRef]
- Kabari, L.G.; Mazi, Y.C. Rain—Induced Flood Prediction for Niger Delta Sub-Region of Nigeria Using Neural Networks. Eur. J. Eng. Res. Sci. 2020, 5, 1124–1130. [Google Scholar] [CrossRef]
- Nkeki, F.N.; Henah, P.J.; Ojeh, V.N. Geospatial Techniques for the Assessment and Analysis of Flood Risk along the Niger-Benue Basin in Nigeria. J. Geogr. Inf. Syst. 2013, 5, 123–135. [Google Scholar] [CrossRef]
- Chioma, O.C.; Chitakira, M.; Olanrewaju, C.; Louw, E. Impacts of flood disasters in Nigeria: A critical evaluation of health implications and management. Jàmbá J. Disaster Risk Stud. 2019, 11, 557. [Google Scholar] [CrossRef]
- Guha-Sapir, D.; Hoyois, P.H.; Below, R. Annual Disaster Statistical Review 2015: The Numbers and Trends; CRED: Brussels, Belgium, 2016; Available online: http://www.cred.be/sites/default/files/ADSR_2015.pdf (accessed on 12 May 2019).
- Floodlist. Available online: https://floodlist.com/africa/nigeria-floods-october-2020 (accessed on 20 January 2022).
- Danso-Amoako, E.; Scholz, M.; Kalimeris, N.; Yang, Q.; Shao, J. Predicting dam failure risk for sustainable flood retention basins: A generic case study for the wider Greater Manchester area. Comput. Environ. Urban Syst. 2012, 36, 423–433. [Google Scholar] [CrossRef]
- Bui, D.T.; Hoang, N.-D.; Martínez-Álvarez, F.; Ngo, P.-T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A novel deep learning neural network approach for predicting flash flood susceptibility: A case study at a high frequency tropical storm area. Sci. Total Environ. 2020, 701, 134413. [Google Scholar] [CrossRef]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef] [PubMed]
- Lin, L.; Di, L.; Tang, J.; Yu, E.; Zhang, C.; Rahman, M.S.; Shrestha, R.; Kang, L. Improvement and Validation of NASA/MODIS NRT Global Flood Mapping. Remote Sens. 2019, 11, 205. [Google Scholar] [CrossRef]
- Panahi, M.; Jaafari, A.; Shirzadi, A.; Shahabi, H.; Rahmati, O.; Omidvar, E.; Lee, S.; Bui, D.T. Deep learning neural networks for spatially explicit prediction of flash flood probability. Geosci. Front. 2021, 12, 101076. [Google Scholar] [CrossRef]
- Zhao, M.; Hendon, H.H. Representation and prediction of the Indian Ocean dipole in the POAMA seasonal forecast model. Q. J. R. Meteorol. Soc. 2009, 135, 337–352. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K.-W. Flood Prediction Using Machine Learning Models: Literature Review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Suardiwerianto, Y. Flash Flood Modelling Using Data-Driven Models: Case Studies of Kathmandu Valley (Nepal) and Yuna Catchment (Dominican Republic). Master’s Thesis, UNESCO-IHE Institute for Water Education, Delft, The Netherlands, 2017. Available online: https://ihedelftrepository.contentdm.oclc.org/digital/collection/masters2/id/103719 (accessed on 12 January 2022).
- Valipour, M.; Banihabib, M.E.; Behbahani, S.M.R. Comparison of the ARMA, ARIMA, and the autoregressive artificial neural network models in forecasting the monthly inflow of Dez dam reservoir. J. Hydrol. 2013, 476, 433–441. [Google Scholar] [CrossRef]
- Meshram, S.G.; Singh, V.P.; Kisi, O.; Karimi, V.; Meshram, C. Application of Artificial Neural Networks, Support Vector Machine and Multiple Model-ANN to Sediment Yield Prediction. Water Resour. Manag. 2020, 34, 4561–4575. [Google Scholar] [CrossRef]
- Mekanik, F.; Imteaz, M.; Gato-Trinidad, S.; Elmahdi, A. Multiple regression and Artificial Neural Network for long-term rainfall forecasting using large scale climate modes. J. Hydrol. 2013, 503, 11–21. [Google Scholar] [CrossRef]
- Xu, Z.X.; Li, J.Y. Short-term inflow forecasting using an artificial neural network model. Hydrol. Process. 2002, 16, 2423–2439. [Google Scholar] [CrossRef]
- Kim, S.; Matsumi, Y.; Pan, S.; Mase, H. A real-time forecast model using artificial neural network for after-runner storm surges on the Tottori coast, Japan. Ocean Eng. 2016, 122, 44–53. [Google Scholar] [CrossRef]
- Wagenaar, D.; Curran, A.; Balbi, M.; Bhardwaj, A.; Soden, R.; Hartato, E.; Sarica, G.M.; Ruangpan, L.; Molinario, G.; Lallemant, D. Invited perspectives: How machine learning will change flood risk and impact assessment. Nat. Hazards Earth Syst. Sci. 2020, 20, 1149–1161. [Google Scholar] [CrossRef]
- Gareth, J.; Witten, D.; Trevor, H.; Tibshirani, R. Springer Texts in Statistics. In An Introduction to Statistical Learning, 1st ed.; Casella, G., Fienberg, S., Olkin, I., Eds.; Springer: New York, NY, USA, 2013; Volume 103, pp. 203–264. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, Y. Supervised Learning. In Encyclopedia of the Sciences of Learning; Seel, N.M., Ed.; Springer: Boston, MA, USA, 2012; pp. 192–194. [Google Scholar] [CrossRef]
- Ortiz-García, E.G.; Salcedo-Sanz, S.; Casanova-Mateo, C. Accurate precipitation prediction with support vector classifiers: A study including novel predictive variables and observational data. Atmos. Res. 2014, 139, 128–136. [Google Scholar] [CrossRef]
- Skidmore, A.K.; Turner, B.J.; Brinkhof, W.; Knowles, E. Performance of a neural network: Mapping forests using GIS and remotely sensed data. Photogramm. Eng. Remote Sens. 1997, 63, 501–514. [Google Scholar]
- Islam, A.R.M.T.; Talukdar, S.; Mahato, S.; Kundu, S.; Eibek, K.U.; Pham, Q.B.; Kuriqi, A.; Linh, N.T.T. Flood susceptibility modelling using advanced ensemble machine learning models. Geosci. Front. 2021, 12, 101075. [Google Scholar] [CrossRef]
- Khoirunisa, N.; Ku, C.-Y.; Liu, C.-Y. A GIS-Based Artificial Neural Network Model for Flood Susceptibility Assessment. Int. J. Environ. Res. Public Health 2021, 18, 1072. [Google Scholar] [CrossRef]
- Al-Juaidi, A.E.M.; Nassar, A.M.; Al-Juaidi, O.E.M. Evaluation of flood susceptibility mapping using logistic regression and GIS conditioning factors. Arab. J. Geosci. 2018, 11, 765. [Google Scholar] [CrossRef]
- Lee, J.; Kim, B. Scenario-Based Real-Time Flood Prediction with Logistic Regression. Water 2021, 13, 1191. [Google Scholar] [CrossRef]
- Ishaku, H.T.; Majid, M.R. X-Raying Rainfall Pattern and Variability in Northeastern Nigeria: Impacts on Access to Water Supply. J. Water Resour. Prot. 2010, 2, 952–959. [Google Scholar] [CrossRef][Green Version]
- Nigeria Floods Situation Report No. 2. Available online: https://reliefweb.int/report/nigeria/floods-situation-report-no-2-15-november-2012 (accessed on 21 July 2021).
- Tehrany, M.S.; Jones, S.; Shabani, F. Identifying the essential flood conditioning factors for flood prone area mapping using machine learning techniques. Catena 2019, 175, 174–192. [Google Scholar] [CrossRef]
- Brakenridge, G.R. Global Active Archive of Large Flood Events. Dartmouth Flood Observatory, University of Colorado, USA. Available online: http://floodobservatory.colorado.edu/Archives/ (accessed on 15 July 2021).
- Chung, C.-J.; Fabbri, A.G. Predicting landslides for risk analysis—Spatial models tested by a cross-validation technique. Geomorphology 2008, 94, 438–452. [Google Scholar] [CrossRef]
- Paul, G.C.; Saha, S.; Hembram, T.K. Application of the GIS-Based Probabilistic Models for Mapping the Flood Susceptibility in Bansloi Sub-basin of Ganga-Bhagirathi River and Their Comparison. Remote Sens. Earth Syst. Sci. 2019, 2, 120–146. [Google Scholar] [CrossRef]
- Ullah, K.; Zhang, J. GIS-based flood hazard mapping using relative frequency ratio method: A case study of Panjkora River Basin, eastern Hindu Kush, Pakistan. PLoS ONE 2020, 15, e0229153. [Google Scholar] [CrossRef] [PubMed]
- Rahman, M.; Ningsheng, C.; Islam, M.; Dewan, A.; Iqbal, J.; Washakh, R.M.A.; Shufeng, T. Flood Susceptibility Assessment in Bangladesh Using Machine Learning and Multi-criteria Decision Analysis. Earth Syst. Environ. 2019, 3, 585–601. [Google Scholar] [CrossRef]
- Campolo, M.; Soldati, A.; Andreussi, P. Artificial neural network approach to flood forecasting in the River Arno. Hydrol. Sci. J. 2003, 48, 381–398. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood susceptibility assessment using GIS-based support vector machine model with different kernel types. CATENA 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Fantin-Cruz, I.; Pedrollo, O.; Castro, N.M.; Girard, P.; Zeilhofer, P.; Hamilton, S.K. Historical reconstruction of floodplain inundation in the Pantanal (Brazil) using neural networks. J. Hydrol. 2011, 399, 376–384. [Google Scholar] [CrossRef]
- Dodangeh, E.; Choubin, B.; Eigdir, A.N.; Nabipour, N.; Panahi, M.; Shamshirband, S.; Mosavi, A. Integrated machine learning methods with resampling algorithms for flood susceptibility prediction. Sci. Total Environ. 2020, 705, 135983. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H.; Peng, L. Flood susceptibility mapping using convolutional neural network frameworks. J. Hydrol. 2020, 582, 124–482. [Google Scholar] [CrossRef]
- Kia, M.B.; Pirasteh, S.; Pradhan, B.; Mahmud, A.R.; Sulaiman, W.N.A.; Moradi, A. An artificial neural network model for flood simulation using GIS: Johor River Basin, Malaysia. Environ. Earth Sci. 2012, 67, 251–264. [Google Scholar] [CrossRef]
- Razavi-Termeh, S.V.; Kornejady, A.; Pourghasemi, H.R.; Keesstra, S. Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci. Total Environ. 2018, 615, 438–451. [Google Scholar] [CrossRef]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.-X.; Chen, W. Application of fuzzy weight of evidence and data mining techniques in construction of flood susceptibility map of Poyang County, China. Sci. Total Environ. 2018, 625, 575–588. [Google Scholar] [CrossRef] [PubMed]
- Tehrany, M.S.; Kumar, L.; Shabani, F. A novel GIS-based ensemble technique for flood susceptibility mapping using evidential belief function and support vector machine: Brisbane, Australia. PeerJ 2019, 7, e7653. [Google Scholar] [CrossRef] [PubMed]
- Abubakar, T.; Azra, E.; Mohammed, C. Selecting suitable drainage pattern to minimise flooding in Sangere village using GIS and remote sensing. Glob. J. Geol. Sci. 2012, 10, 129–140. [Google Scholar]
- Mojaddadi, H.; Pradhan, B.; Nampak, H.; Ahmad, N.; Ghazali, A.H. Ensemble machine-learning-based geospatial approach for flood risk assessment using multisensory remote-sensing data and GIS. Geomat. Nat. Haz. Risk 2017, 8, 1080–1102. [Google Scholar] [CrossRef]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef]
- Mahmoud, S.; Gan, T.Y. Urbanization and climate change implications in flood risk management: Developing an efficient decision support system for flood susceptibility mapping. Sci. Total Environ. 2018, 636, 152–167. [Google Scholar] [CrossRef]
- Casas, A.; Lane, S.N.; Yu, D.; Benito, G. A method for parameterising roughness and topographic sub-grid scale effects in hydraulic modelling from LiDAR data. Hydrol. Earth Syst. Sci. 2010, 14, 1567–1579. [Google Scholar] [CrossRef]
- Seo, Y.; Kim, S. River Stage Forecasting Using Wavelet Packet Decomposition and Data-driven Models. Procedia Eng. 2016, 154, 1225–1230. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Yue, J.; Tu, T. Mapping flood susceptibility in mountainous areas on a national scale in China. Sci. Total Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef]
- Arabameri, A.; Saha, S.; Mukherjee, K.; Blaschke, T.; Chen, W.; Ngo, P.; Band, S. Modeling Spatial Flood using Novel Ensemble Artificial Intelligence Approaches in Northern Iran. Remote Sens. 2020, 12, 3423. [Google Scholar] [CrossRef]
- Cao, C.; Xu, P.; Wang, Y.; Chen, J.; Zheng, L.; Niu, C. Flash Flood Hazard Susceptibility Mapping Using Frequency Ratio and Statistical Index Methods in Coalmine Subsidence Areas. Sustainability 2016, 8, 948. [Google Scholar] [CrossRef]
- Wasko, C. Review: Can temperature be used to inform changes to flood extremes with global warming? Philos. Trans. R. Soc. London. Ser. A Math. Phys. Eng. Sci. 2021, 379, 20190551. [Google Scholar] [CrossRef] [PubMed]
- Uddin, K.; Matin, M.A.; Meyer, F.J. Operational Flood Mapping Using Multi-Temporal Sentinel-1 SAR Images: A Case Study from Bangladesh. Remote Sens. 2019, 11, 1581. [Google Scholar] [CrossRef]
- Felzer, B.S.; Ember, C.R.; Cheng, R.; Jiang, M. The Relationships of Extreme Precipitation and Temperature Events with Ethnographic Reports of Droughts and Floods in Nonindustrial Societies. Weather. Clim. Soc. 2020, 12, 135–148. Available online: https://journals.ametsoc.org/view/journals/wcas/12/1/wcas-d-19-0045.1.xml (accessed on 17 March 2022). [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Xu, L. Assessment of urban flood susceptibility using semi-supervised machine learning model. Sci. Total Environ. 2019, 659, 940–949. [Google Scholar] [CrossRef]
- Woodrow, K.; Lindsay, J.B.; Berg, A.A. Evaluating DEM conditioning techniques, elevation source data, and grid resolution for field-scale hydrological parameter extraction. J. Hydrol. 2016, 540, 1022–1029. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Janizadeh, S.; Avand, M.; Jaafari, A.; Van Phong, T.; Bayat, M.; Ahmadisharaf, E.; Prakash, I.; Pham, B.T.; Lee, S. Prediction Success of Machine Learning Methods for Flash Flood Susceptibility Mapping in the Tafresh Watershed, Iran. Sustainability 2019, 11, 5426. [Google Scholar] [CrossRef]
- Jaafari, A.; Najafi, A.; Rezaeian, J.; Sattarian, A. Modeling erosion and sediment delivery from unpaved roads in the north mountainous forest of Iran. GEM Int. J. Geomath. 2014, 6, 343–356. [Google Scholar] [CrossRef]
- Shuster, W.D.; Bonta, J.; Thurston, H.; Warnemuende, E.; Smith, D.R. Impacts of impervious surface on watershed hydrology: A review. Urban Water J. 2005, 2, 263–275. [Google Scholar] [CrossRef]
- Devkota, K.C.; Regmi, A.D.; Pourghasemi, H.R.; Yoshida, K.; Pradhan, B.; Ryu, I.C.; Dhital, M.R.; Althuwaynee, O.F. Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in GIS and their comparison at Mugling–Narayanghat road section in Nepal Himalaya. Nat. Hazards 2013, 65, 135–165. [Google Scholar] [CrossRef]
- Falah, F.; Rahmati, O.; Rostami, M.; Ahmadisharaf, E.; Daliakopoulos, I.N.; Pourghasemi, H.R. 14—Artificial Neural Networks for Flood Susceptibility Mapping in Data-Scarce Urban Areas. In Spatial Modeling in GIS and R for Earth and Environmental Sciences; Pourghasemi, H.R., Gokceoglu, C., Eds.; Elsevier: Amsterdam, The Netherlands, 2019; pp. 323–336. [Google Scholar] [CrossRef]
- Luu, C.; Bui, Q.D.; Costache, R.; Nguyen, L.T.; Nguyen, T.T.; Van Phong, T.; Van Le, H.; Pham, B.T. Flood-prone area mapping using machine learning techniques: A case study of Quang Binh province, Vietnam. Nat. Hazards 2021, 108, 3229–3251. [Google Scholar] [CrossRef]
- Ross, C.W.; Prihodko, L.; Anchang, J.; Kumar, S.; Ji, W.J.; Hanan, N.P. HYSOGs250m, global gridded hydrologic soil groups for curve-number-based runoff modeling. Sci. Data 2018, 5, 180091. [Google Scholar] [CrossRef] [PubMed]
- Günther, F.; Fritsch, S. neuralnet: Training of Neural Networks. R J. 2010, 2, 30–38. [Google Scholar] [CrossRef]
- Strickland, J. Neural Networks Using R. Available online: https://bicorner.com/2015/05/13/neural-networks-using-r/ (accessed on 6 August 2021).
- Zhang, Z.; Laakso, T.; Wang, Z.; Pulkkinen, S.; Ahopelto, S.; Virrantaus, K.; Li, Y.; Cai, X.; Zhang, C.; Vahala, R.; et al. Comparative Study of AI-Based Methods—Application of Analyzing Inflow and Infiltration in Sanitary Sewer Subcatchments. Sustainability 2020, 12, 6254. [Google Scholar] [CrossRef]
- Zhang, Z. Neural networks: Further insights into error function, generalized weights and others. Ann. Transl. Med. 2016, 4, 300. [Google Scholar] [CrossRef]
- Liu, Q.; Fang, L.; Yu, G.; Wang, D.; Xiao, C.-L.; Wang, K. Detection of DNA base modifications by deep recurrent neural network on Oxford Nanopore sequencing data. Nat. Commun. 2019, 10, 2449. [Google Scholar] [CrossRef]
- Althuwaynee, O.F. First Simplified Step-by-Step Artificial Neural Network Methodology in R for Prediction Mapping using GIS Data. Udemy. 2021. Available online: https://www.udemy.com/course/how-to-use-ann-for-prediction-mapping-using-gis-data/learn/lecture/14033471 (accessed on 14 August 2021).
- Intrator, O.; Intrator, N. Interpreting neural-network results: A simulation study. Comput. Stat. Data Anal. 2001, 37, 373–393. [Google Scholar] [CrossRef]
- Atkinson, P.; Massari, R. Generalised Linear Modelling of Susceptibility to Landsliding in the Central Apennines, Italy. Comput. Geosci. 1998, 24, 373–385. [Google Scholar] [CrossRef]
- Ayalew, L.; Yamagishi, H. The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda-Yahiko Mountains, Central Japan. Geomorphology 2005, 65, 15–31. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Moradi, H.R.; Aghda, S.M.F. Landslide susceptibility mapping by binary logistic regression, analytical hierarchy process, and statistical index models and assessment of their performances. Nat. Hazards 2013, 69, 749–779. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Schuerman, J.R. Principal Components Analysis. Multivariate Analysis in the Human Services; Springer: Dordrecht, The Netherlands, 1983; p. 84. [Google Scholar] [CrossRef]
- Belsley, D.A. A guide to using the collinearity diagnostics. Comput. Econ. 1991, 4, 33–50. [Google Scholar] [CrossRef]
- Booth, G.D.; Niccolucci, M.J.; Schuster, E.G. Identifying Proxy Sets in Multiple Linear Regression: An Aid to Better Coefficient Interpretation; U.S Dept. of Agriculture, Forest Service, Intermountain Research Station: Ogden, UT, USA, 1994; Available online: https://archive.org/details/identifyingproxy470boot (accessed on 23 February 2022).
- Bai, S.-B.; Wang, J.; Lü, G.-N.; Zhou, P.-G.; Hou, S.-S.; Xu, S.-N. GIS-based logistic regression for landslide susceptibility mapping of the Zhongxian segment in the Three Gorges area, China. Geomorphology 2010, 115, 23–31. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.G.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- O’Brien, R.M. A Caution Regarding Rules of Thumb for Variance Inflation Factors. Qual. Quant. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- Olden, J.D.; Joy, M.K.; Death, R.G. An accurate comparison of methods for quantifying variable importance in artificial neural networks using simulated data. Ecol. Model. 2004, 178, 389–397. [Google Scholar] [CrossRef]
- Agwu, O.E.; Akpabio, J.U.; Dosunmu, A. Artificial neural network model for predicting the density of oil-based muds in high-temperature, high-pressure wells. J. Pet. Explor. Prod. Technol. 2019, 10, 1081–1095. [Google Scholar] [CrossRef]
- Ghasemian, B.; Shahabi, H.; Shirzadi, A.; Al-Ansari, N.; Jaafari, A.; Kress, V.R.; Geertsema, M.; Renoud, S.; Ahmad, A. A Robust Deep-Learning Model for Landslide Susceptibility Mapping: A Case Study of Kurdistan Province, Iran. Sensors 2022, 22, 1573. [Google Scholar] [CrossRef]
- Habahbeh, A.; Fadiya, S.O.; Akkaya, M. Factors influencing SMEs CloudERP adoption: A test with generalized linear model and artificial neural network. Data Brief 2018, 20, 969–977. [Google Scholar] [CrossRef]
- Tuokkola, T.; Koikkalainen, J.; Parkkola, R.; Karrasch, M.; Lötjönen, J.; Rinne, J.O. Visual rating method and tensor-based morphometry in the diagnosis of mild cognitive impairment and Alzheimer’s disease: A comparative magnetic resonance imaging study. Acta Radiol. 2016, 57, 348–355. [Google Scholar] [CrossRef] [PubMed]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Period | Contents of the Data | Data Type | Source |
|---|---|---|---|
| 1985–2020 | Location, date, validation, displaced, deaths, severity | Polygon (points) | EM-DAT, CRED |
| 1985–2020 | Location, date, affected | Polygon (points) | Dartmouth Flood Observatory (DFO) |
| Data | Sources | Format | Period |
|---|---|---|---|
| Rainfall | Nimet, Nigeria | vector | 1975–2015 |
| Temperature | Global Climate data: Worldclim | 1 km | 1975–2017 |
| Land cover | Globeland30 | 30 m | 2020 |
| Soil *a | The Harmonised World Soil Database v1.2 | vector | - |
| Soil *b | Global Hydrological Soil Group- ORNL DAAC | 250 m | 2020 |
| Elevation | USGS, Earthexplorer | 30 m | 2015 |
| Road network | NASA, Socioeconomic Data and Applications Center; Global Roads Open Access Dataset v1 | vector | 2010 |
| Rail network | OCHA, Nigeria | vector | 2009 |
| Water areas | OCHA, Nigeria | vector | 2010 |
| Parameters | Model Values | |
|---|---|---|
| ANN | Logistic | |
| Training | 70 | 70 |
| Testing | 30 | 30 |
| Number of hidden layers | 8 | 0 |
| Number of neurons | 64 | 0 |
| Activation function | logistic | logistic |
| Learning rate | 0.001 | 0.001 |
| Architecture selection | Trial-and-error | Trial-and-error |
| Factor | β Coefficient | Significance (p-Value) |
|---|---|---|
| Aspect | −0.0012 | 0.0022 ** |
| Curve Number | 0.0190 | 0.0219 * |
| Curvature | 0.0009 | 0.0005 *** |
| Elevation | −0.0004 | 0.3717 |
| Land use | −0.0076 | 0.0022 ** |
| Rainfall | 0.0001 | 0.0075 ** |
| Roughness | 0.0015 | 0.0028 ** |
| Soil type | −0.0043 | 0.035 * |
| Slope | 0.0007 | 0.0945 * |
| SPI | −0.2856 | 0.0271 * |
| Temperature | −0.0163 | 0.3035 |
| TWI | 0.0027 | 0.0934 * |
| Distance to Water | 0.0728 | 0.008 ** |
| Distance to Road | −0.2047 | 0.0002 *** |
| Distance to Railway | 0.0397 | 0.7256 |
| Conditioning Factor | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1.00 | ||||||||||||||
| 2 | −0.03 | 1.00 | |||||||||||||
| 3 | 0.58 | −0.01 | 1.00 | ||||||||||||
| 4 | 0.04 | 0.00 | −0.06 | 1.00 | |||||||||||
| 5 | 0.02 | −0.03 | 0.05 | −0.02 | 1.00 | ||||||||||
| 6 | −0.03 | 0.03 | −0.01 | 0.34 | 0.01 | 1.00 | |||||||||
| 7 | −0.03 | 0.01 | −0.05 | −0.65 | 0.10 | 0.20 | 1.00 | ||||||||
| 8 | 0.00 | 0.04 | 0.04 | 0.36 | −0.04 | 0.07 | 0.22 | 1.00 | |||||||
| 9 | 0.03 | −0.01 | 0.02 | 0.02 | −0.02 | 0.02 | 0.14 | −0.01 | 1.00 | ||||||
| 10 | 0.00 | −0.04 | −0.05 | −0.18 | −0.13 | 0.20 | −0.06 | 0.08 | 0.14 | 1.00 | |||||
| 11 | 0.20 | −0.03 | −0.11 | 0.01 | 0.00 | 0.04 | 0.00 | −0.07 | 0.01 | 0.01 | 1.00 | ||||
| 12 | −0.04 | −0.04 | −0.02 | 0.06 | −0.01 | −0.03 | 0.09 | 0.00 | 0.03 | 0.00 | 0.02 | 1.00 | |||
| 13 | 0.05 | −0.36 | 0.00 | −0.07 | −0.02 | −0.01 | −0.04 | −0.06 | 0.10 | −0.05 | −0.08 | −0.03 | 1.00 | ||
| 14 | −0.05 | 0.08 | 0.03 | −0.10 | −0.13 | 0.00 | −0.33 | −0.09 | 0.02 | 0.05 | 0.00 | 0.02 | −0.04 | 1.00 | |
| 15 | 0.16 | −0.02 | −0.10 | 0.04 | 0.03 | 0.03 | 0.10 | 0.01 | −0.02 | −0.02 | 0.05 | −0.01 | 0.00 | 0.17 | 1.00 |
| VIF | 1.64 | 1.18 | 1.56 | 2.25 | 1.09 | 1.24 | 2.13 | 1.27 | 1.08 | 1.12 | 1.06 | 1.02 | 1.21 | 1.25 | 1.07 |
| Model Parameters | ANN | LR | ||
|---|---|---|---|---|
| Training | Testing | Training | Testing | |
| MSE | 0.047 | 0.035 | 0.195 | 0.107 |
| RMSE | 0.217 | 0.188 | 0.442 | 0.327 |
| AUC | 0.964 | 0.764 | 0.677 | 0.625 |
| Accuracy | 0.907 | 0.875 | 0.772 | 0.784 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ighile, E.H.; Shirakawa, H.; Tanikawa, H. Application of GIS and Machine Learning to Predict Flood Areas in Nigeria. Sustainability 2022, 14, 5039. https://doi.org/10.3390/su14095039
Ighile EH, Shirakawa H, Tanikawa H. Application of GIS and Machine Learning to Predict Flood Areas in Nigeria. Sustainability. 2022; 14(9):5039. https://doi.org/10.3390/su14095039
Chicago/Turabian StyleIghile, Eseosa Halima, Hiroaki Shirakawa, and Hiroki Tanikawa. 2022. "Application of GIS and Machine Learning to Predict Flood Areas in Nigeria" Sustainability 14, no. 9: 5039. https://doi.org/10.3390/su14095039
APA StyleIghile, E. H., Shirakawa, H., & Tanikawa, H. (2022). Application of GIS and Machine Learning to Predict Flood Areas in Nigeria. Sustainability, 14(9), 5039. https://doi.org/10.3390/su14095039