
Biased Pressure: Cyclic Reinforcement Learning Model for Intelligent Traffic Signal Control


Abstract
:1. Introduction
- We propose a scalable multi-agent traffic light control system. Decentralized RL agents are used to control traffic signals. Each agent makes decisions based on its own observation. Since neighboring intersections or other intersections in the road network do not negotiate to make a decision, we can achieve a scalable model.
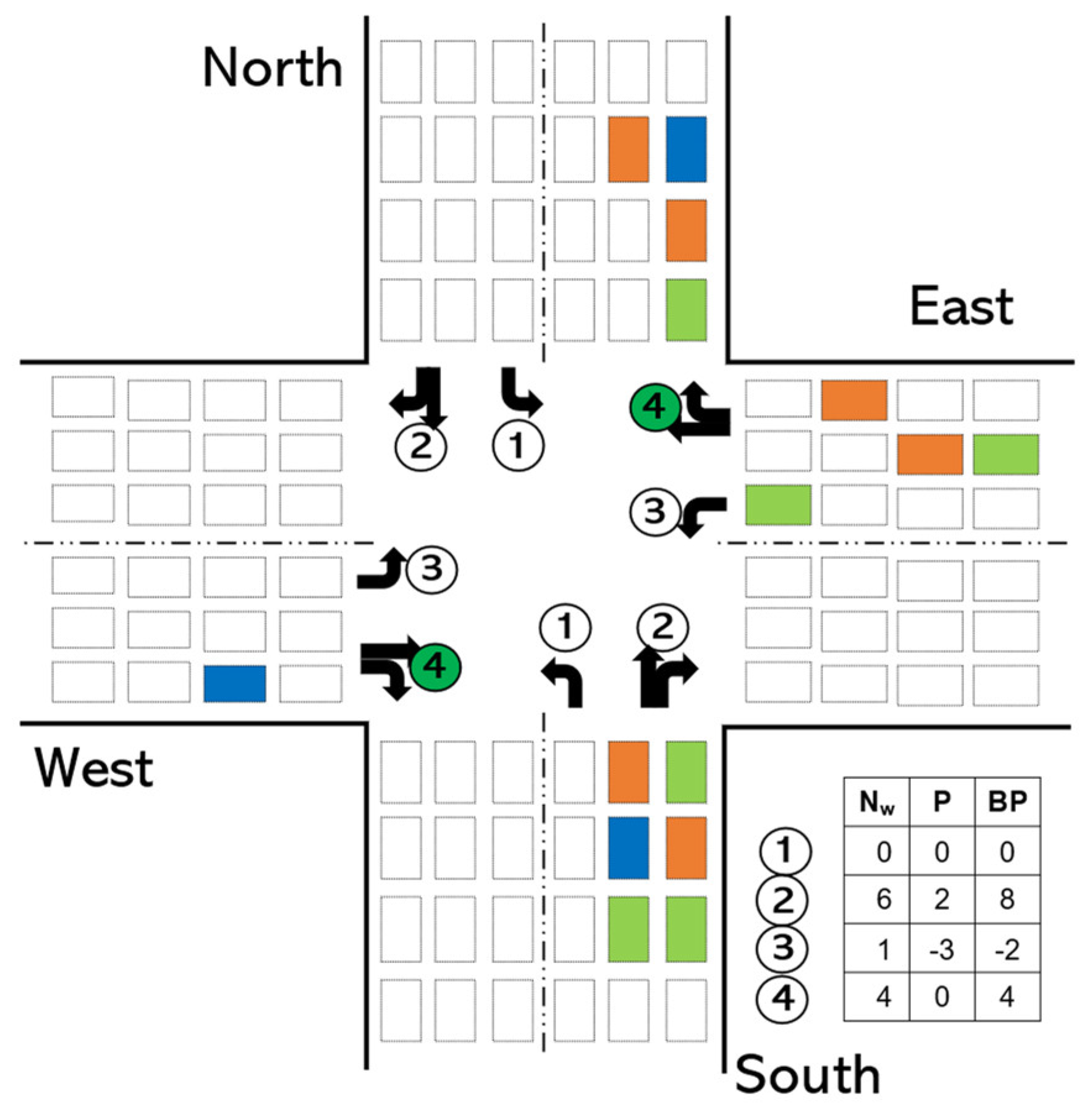
- We introduce a BP method to determine the phase duration of the traffic signal. BP is an optimized version of the pressure method from transportation engineering, which aims to maximize the throughput of an intersection. BP is especially useful when the action definition is based on cyclic phase control.
- We maintain must-have constraints of the traffic signal plan in the definitions of state, action, and reward function to make our method feasible for real-world applications. Our state and reward definitions are simple yet effective in design and do not depend on the number of traffic movements so that our method can be applied to different road structures with multiple allowed traffic movements.
2. Related Work
2.1. Conventional Traffic Light Control
2.2. RL-Based Traffic Light Control
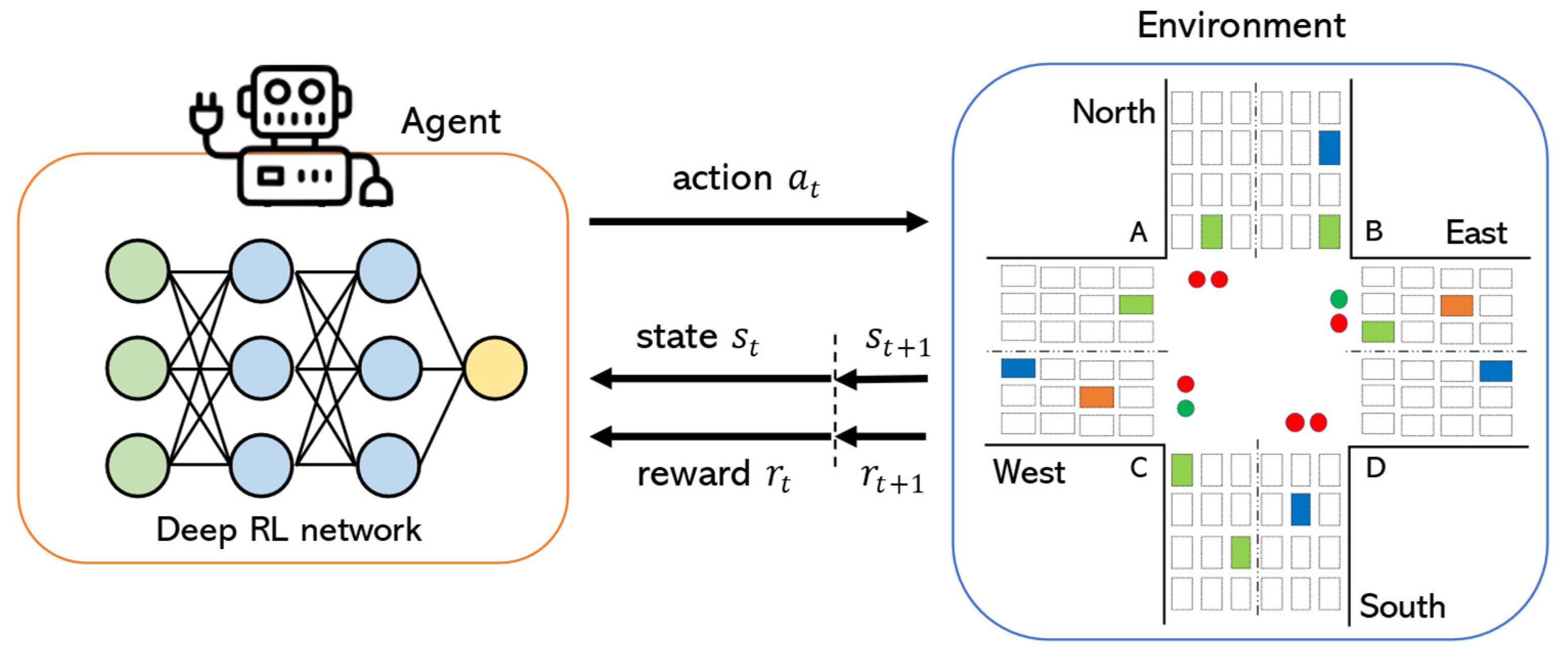
3. Background of Deep RL Algorithm
- is the state space,
- is the action space,
- is the reward function,
- is the transition function,
- [0,1) is the discount factor.
4. Methodology
4.1. Agent Design
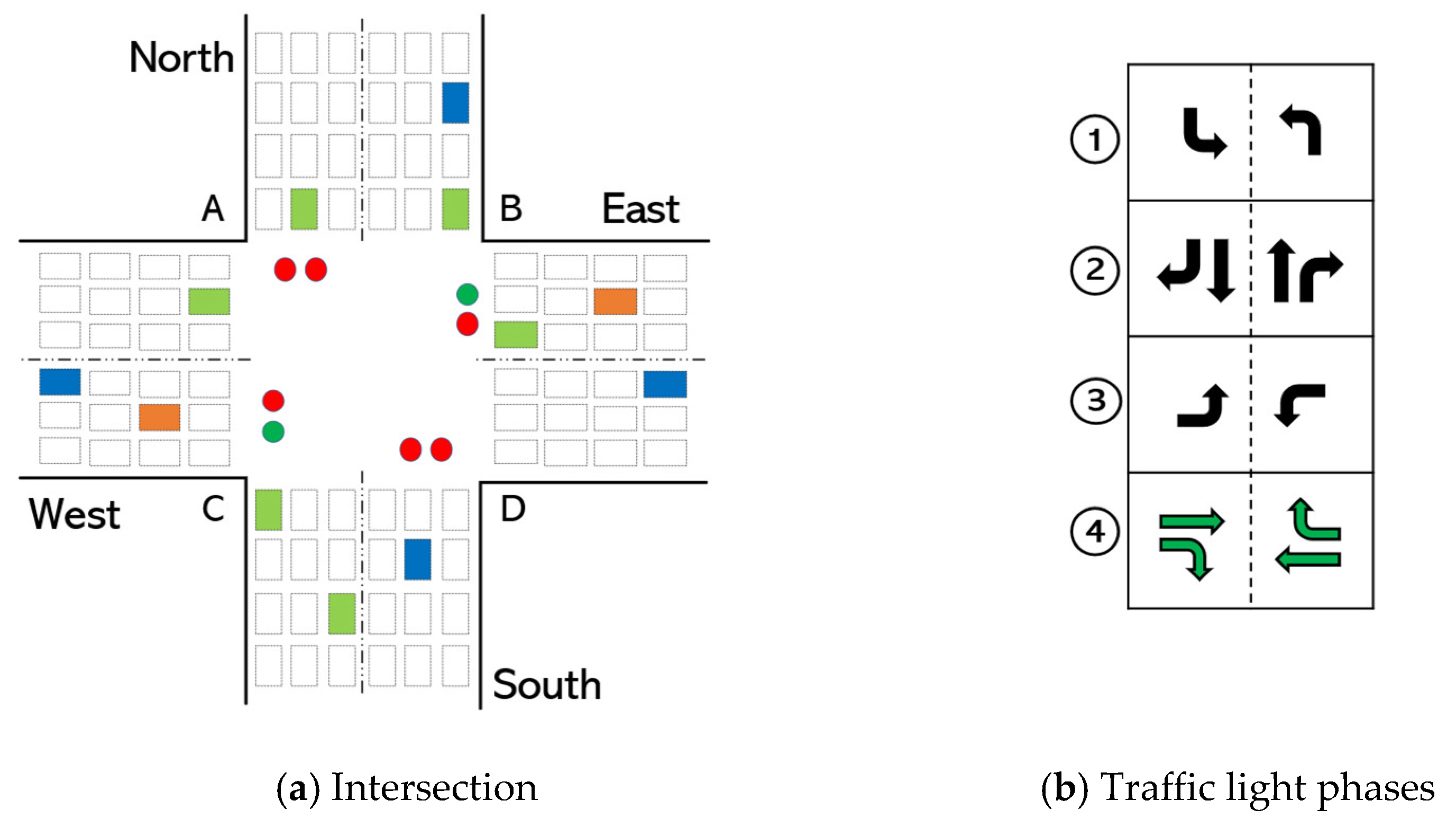
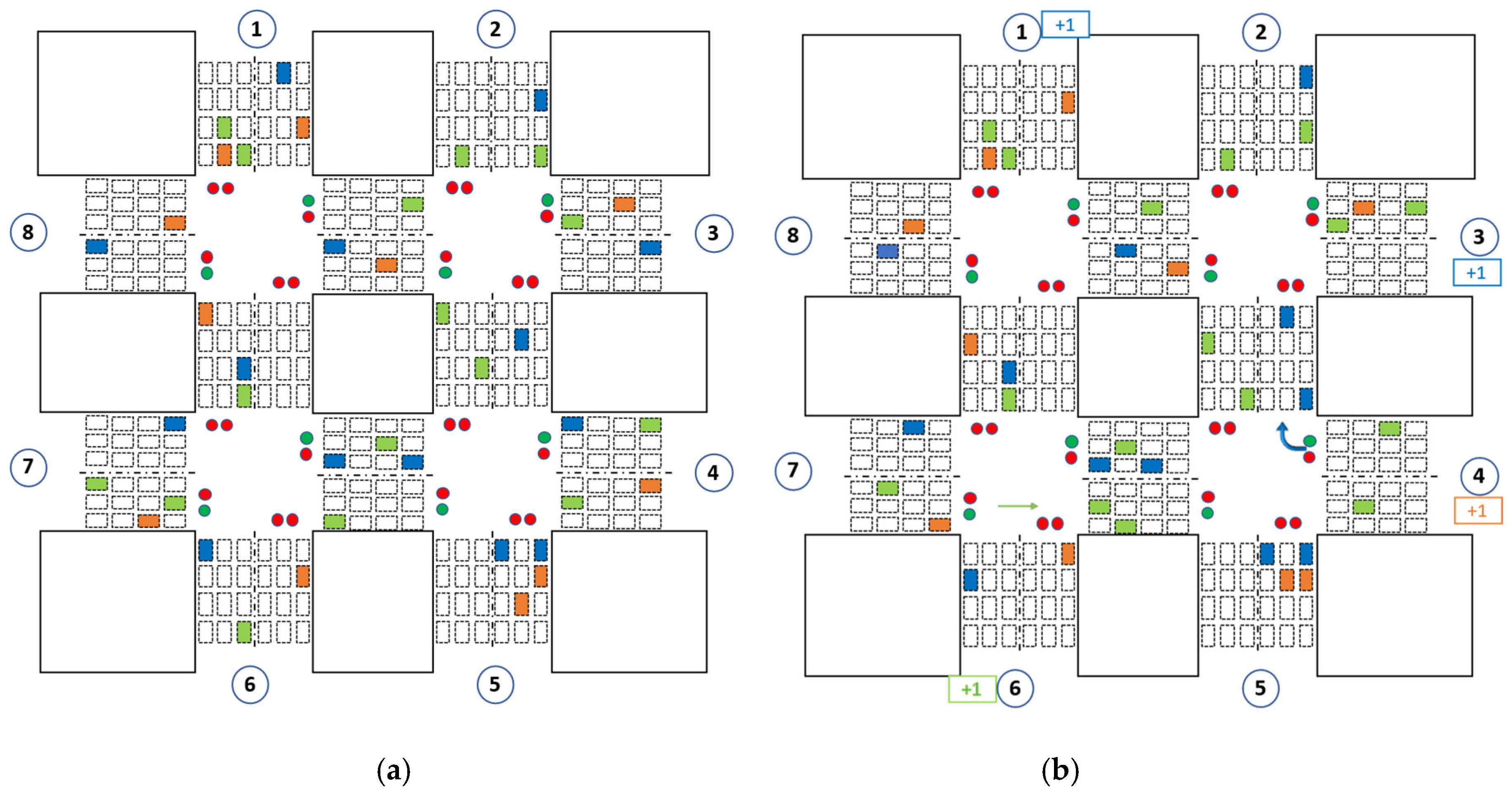
- In a real-world environment, the phase order in the traffic light is important for large intersections with pedestrian crossing sections. If the order of the traffic light is not preserved, pedestrians cannot cross the intersections safely. Additionally, some vehicles might end up waiting for a green light for a long time, which leads to phase starvation. Figure 2a shows an illustration of an intersection with four phases. When phase #2 is set (Figure 2b), pedestrians can cross the intersection through A–C and B–D directions; when phase #4 is set, they can cross through A–B and C–D.
- The minimum phase duration is necessary to enable safe pedestrian crossing. The minimum time required for safe crossing is determined by the width of the road in the intersection and the average walking speed of pedestrians. Generally, pedestrian walking speeds at the crosswalk in normal conditions range from 4.63 km/h to 5.37 km/h [56]. Thus, the minimum phase duration for roads, for example, with a width of 15 m and 20 m should be about 12 s and 15 s, respectively.
- Maximum phase duration is also necessary to prevent starvation of vehicles. Increasing the duration of the phase indefinitely, e.g., due to continuously incoming vehicles, may cause starvation in other lanes.
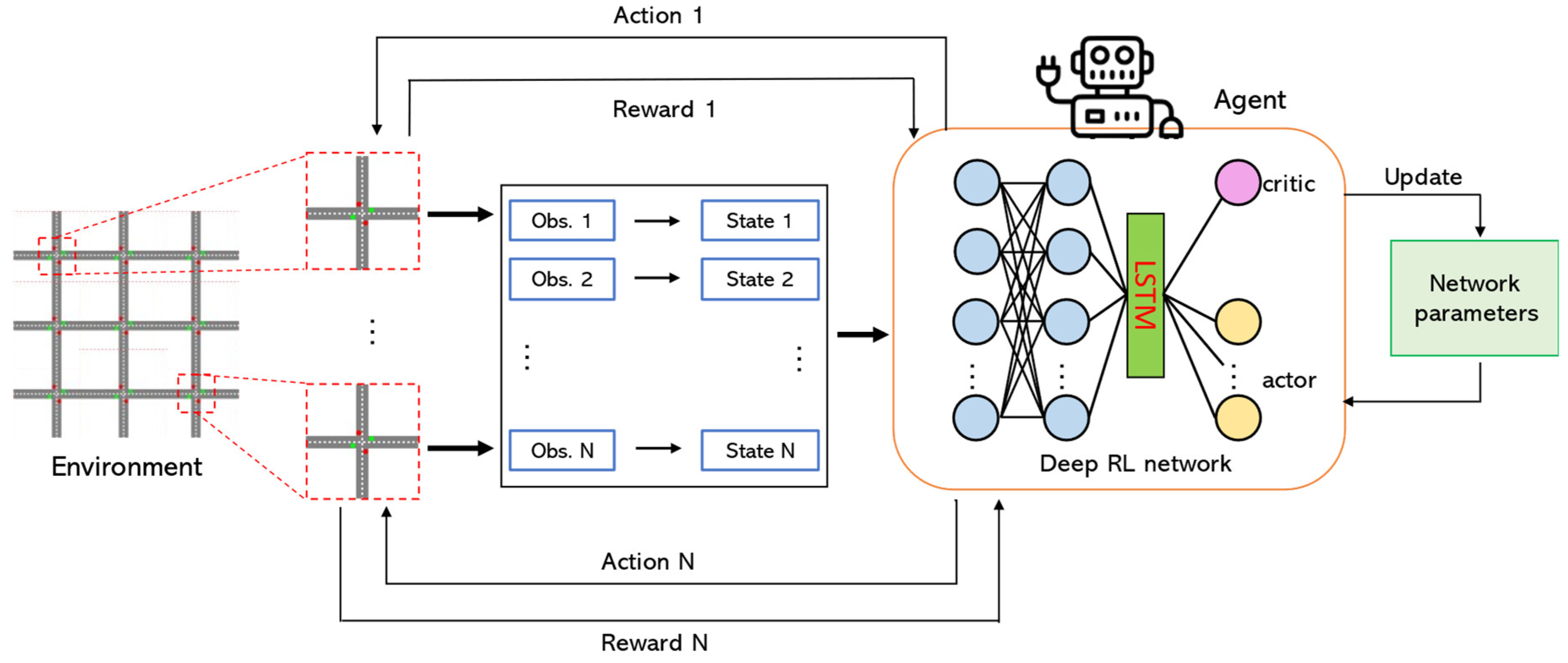
4.2. Framework Design and Training
5. Experimental Environment
5.1. Metrics for Performance Evaluation
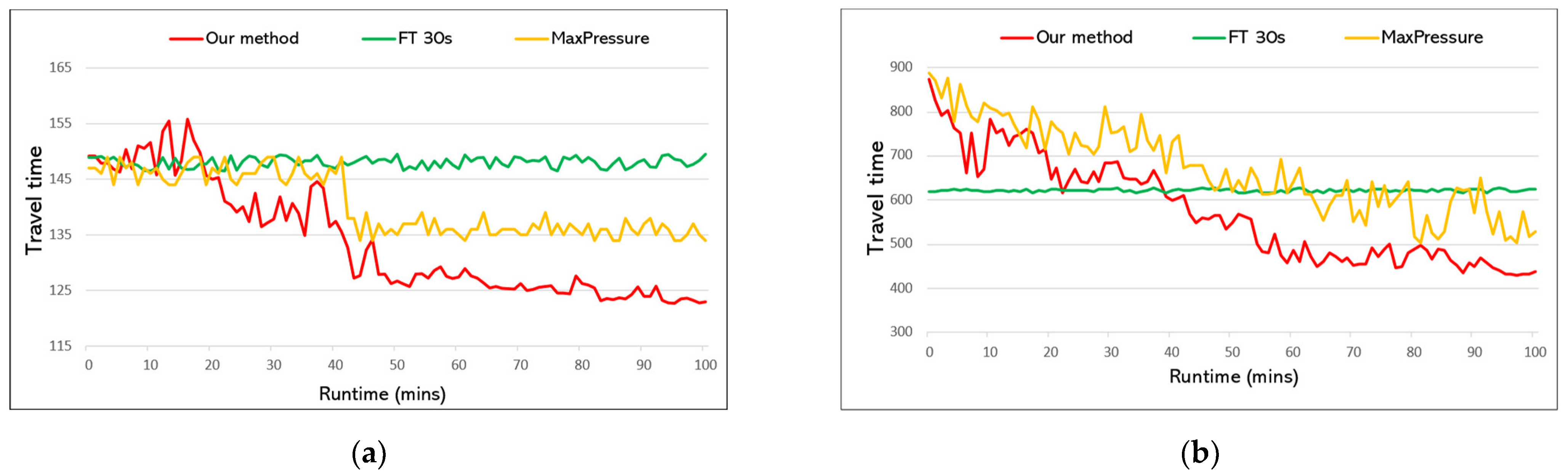
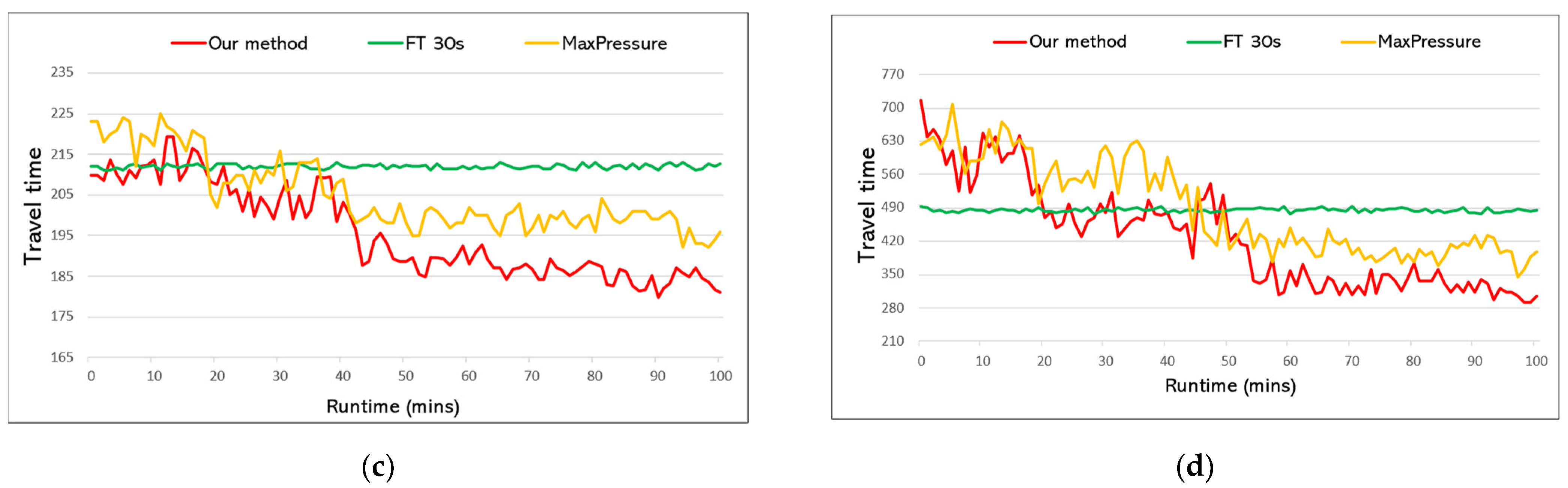
- Travel time. The average travel time of vehicles is measured in seconds. This metric is widely used by research works in the transportation field and traffic light control. It is calculated by dividing the travel time of all vehicles by the number of vehicles in the last two episodes. Shorter travel time is better in comparison. However, this metric alone cannot determine which traffic plan is better. For example, if the road is full due to a bad signal plan, then incoming cars cannot join the road network. Therefore, we also use throughput as a metric.
- Throughput. We denote the closed road network in the simulation as “city”. Then, throughput is measured by the number of vehicles that have left the city in the last two episodes of testing. For example, as shown in Figure 5, four vehicles have left the city between time step and . We sum the number of leaving vehicles during the whole two-episode duration to calculate throughput. Higher throughput is better in comparison.
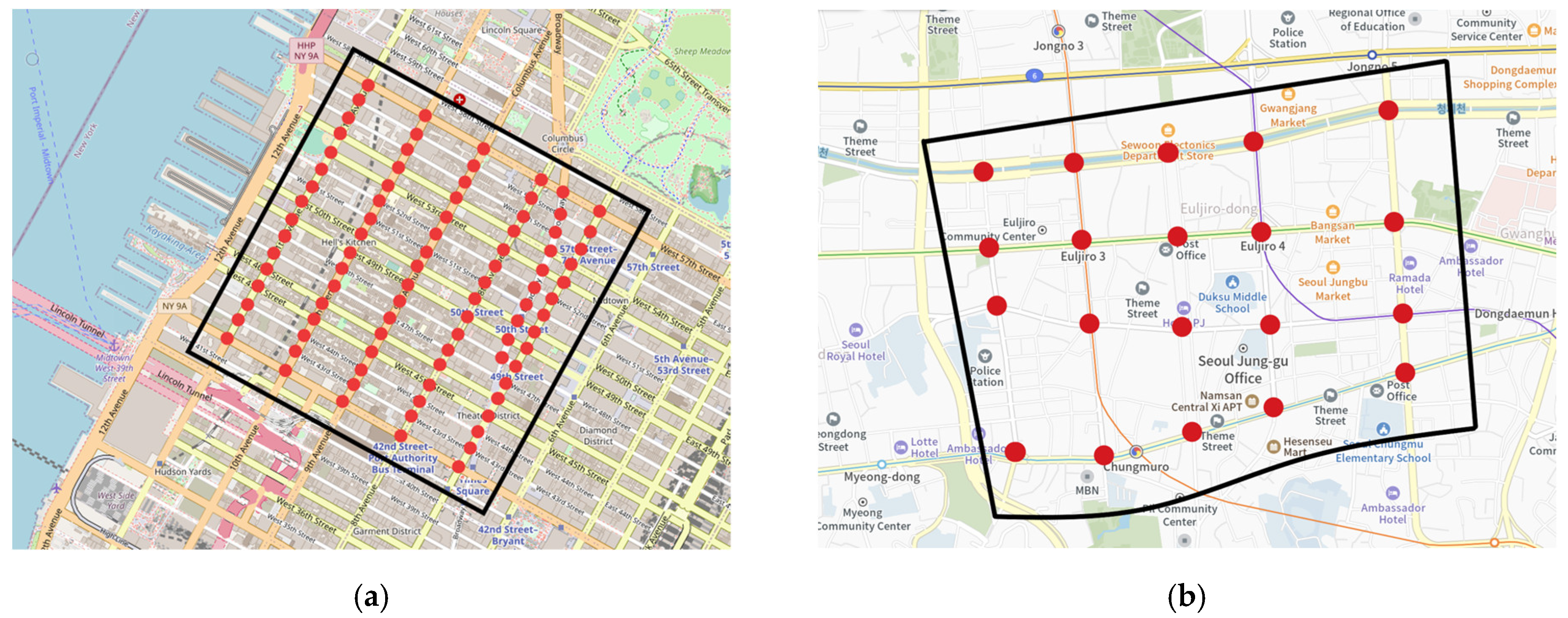
5.2. Datasets
5.3. Compared Methods
- 4.
- Fixed-time signal plan with GreenWave effect (FT). This is the most commonly used technique in real-world traffic light control systems. The cycle length, offset, and phase duration of each intersection is pre-determined based on historical data of the intersection. In this paper, we use 30 s and 40 s FT approaches, where FT 30 s and FT 40 s mean that the duration of green light in a phase is 30 s and 40 s, respectively.
- 5.
- MaxPressure [32]. This method uses queue length to represent the state and greedily selects the phase which minimizes the pressure of the intersection. By doing so, it aims to maximize the throughput of the intersection, and ultimately, the throughput of the whole network. MaxPressure method is selected for comparison because it is widely used on the recent state-of-the-art methods, such as MPLight [25] and PressLight [39].
- 6.
- BackPressure [35]. This method is an adaptation of MaxPressure for the cyclic scheme. In the beginning, cycle duration is fixed, and the duration of each phase is determined proportionally, depending on the pressure of each phase in the intersection.
- 7.
- 3DQN [21]. This method is the combination of DQN, Double DQN, and Dueling DQN. State representation is based on the image of vehicle positions in the incoming lanes. The authors divided the whole intersection into small grids and used a matrix to represent the position of each vehicle. The action is whether to increase or decrease the phase duration by 5 s. This is one of the state-of-the-art methods that adjusts the duration of each phase depending on the traffic, and this method beats previous works on DQN methods, such as [19] in terms of travel time.
6. Numerical Results
6.1. Ablation Study
6.2. Performance Comparison
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McCarthy, N. Traffic Congestion Costs U.S. Cities Billion of Dollars Every Year. Forbes. 2020. Available online: https://www.forbes.com/sites/niallmccarthy/2020/03/10/traffic-congestion-costs-us-cities-billions-of-dollars-every-year-infographic (accessed on 29 January 2022).
- Lee, S. Transport System Management (TSM). Seoul Solution. 2017. Available online: https://www.seoulsolution.kr/en/node/6537 (accessed on 29 January 2022).
- Wei, H.; Zheng, G.; Gayah, V.; Li, Z. A survey on traffic signal control methods. arXiv 2019, arXiv:1904.08117. [Google Scholar]
- Schrank, D.; Eisele, B.; Lomax, T.; Bak, J. 2015 Urban Mobility Scorecard; The Texas A&M Transportation Institute and INRIX: Bryan, TX, USA, 2015. [Google Scholar]
- Lowrie, P.R. Scats–A Traffic Responsive Method of Controlling Urban Traffic; Roads and Traffic Authority: Sydney, Australia, 1992. [Google Scholar]
- Hunt, P.B.; Robertson, D.I.; Bretherton, R.D.; Royle, M.C. The SCOOT on-line traffic signal optimisation technique. Traffic Eng. Control. 1982, 23, 190–192. [Google Scholar]
- Koonce, P.; Rodegerdts, L. Traffic Signal Timing Manual (No. FHWA-HOP-08-024); Federal Highway Administration: Washington, DC, USA, 2008. [Google Scholar]
- Roess, R.P.; Prassas, E.S.; McShane, W.R. Traffic Engineering; Pearson/Prentice Hall: London, UK, 2004. [Google Scholar]
- Corman, F.; D’Ariano, A.; Pacciarelli, D.; Pranzo, M. Evaluation of green wave policy in real-time railway traffic management. Transp. Res. Part C Emerg. Technol. 2009, 17, 607–616. [Google Scholar] [CrossRef]
- Wu, X.; Deng, S.; Du, X.; Ma, J. Green-wave traffic theory optimization and analysis. World J. Eng. Technol. 2014, 2, 14–19. [Google Scholar] [CrossRef] [Green Version]
- Vinod Chandra, S.S. A multi-agent ant colony optimization algorithm for effective vehicular traffic management. In Proceedings of the International Conference on Swarm Intelligence, Belgrade, Serbia, 14–20 July 2020; Springer: Cham, Switzerland, 2020; pp. 640–647. [Google Scholar]
- Sattari, M.R.J.; Malakooti, H.; Jalooli, A.; Noor, R.M. A Dynamic Vehicular Traffic Control Using Ant Colony and Traffic Light Optimization. In Advances in Systems Science; Springer: Cham, Switzerland, 2014; pp. 57–66. [Google Scholar] [CrossRef]
- Gao, K.; Zhang, Y.; Sadollah, A.; Su, R. Improved artificial bee colony algorithm for solving urban traffic light scheduling problem. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017; pp. 395–402. [Google Scholar] [CrossRef]
- Zhao, C.; Hu, X.; Wang, G. PDLight: A Deep Reinforcement Learning Traffic Light Control Algorithm with Pressure and Dynamic Light Duration. arXiv 2020, arXiv:2009.13711. [Google Scholar]
- Abdoos, M.; Mozayani, N.; Bazzan, A.L. Holonic multi-agent system for traffic signals control. Eng. Appl. Artif. Intell. 2013, 26, 1575–1587. [Google Scholar] [CrossRef]
- Wei, H.; Zheng, G.; Yao, H.; Li, Z. Intellilight: A reinforcement learning approach for intelligent traffic light control. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2496–2505. [Google Scholar]
- Aslani, M.; Mesgari, M.S.; Wiering, M. Adaptive traffic signal control with actor-critic methods in a real-world traffic network with different traffic disruption events. Transp. Res. Part C Emerg. Technol. 2017, 85, 732–752. [Google Scholar] [CrossRef] [Green Version]
- Casas, N. Deep deterministic policy gradient for urban traffic light control. arXiv 2017, arXiv:1703.09035. [Google Scholar]
- Li, L.; Lv, Y.; Wang, F.-Y. Traffic signal timing via deep reinforcement learning. IEEE/CAA J. Autom. Sin. 2016, 3, 247–254. [Google Scholar] [CrossRef]
- Mousavi, S.S.; Schukat, M.; Howley, E. Traffic light control using deep policy-gradient and value-function-based reinforcement learning. IET Intell. Transp. Syst. 2017, 11, 417–423. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Du, X.; Wang, G.; Han, Z. A Deep Reinforcement Learning Network for Traffic Light Cycle Control. IEEE Trans. Veh. Technol. 2019, 68, 1243–1253. [Google Scholar] [CrossRef] [Green Version]
- Abdoos, M.; Mozayani, N.; Bazzan, A.L. Traffic light control in non-stationary environments based on multi agent Q-learning. In Proceedings of the 2011 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 1580–1585. [Google Scholar]
- Wei, H.; Xu, N.; Zhang, H.; Zheng, G.; Zang, X.; Chen, C.; Zhang, W.; Zhu, Y.; Xu, K.; Li, Z. Colight: Learning network-level cooperation for traffic signal control. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 December 2019; pp. 1913–1922. [Google Scholar]
- Chen, C.; Wei, H.; Xu, N.; Zheng, G.; Yang, M.; Xiong, Y.; Xu, K.; Li, Z. Toward a Thousand Lights: Decentralized Deep Reinforcement Learning for Large-Scale Traffic Signal Control. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3414–3421. [Google Scholar] [CrossRef]
- Van der Pol, E.; Oliehoek, F.A. Coordinated deep reinforcement learners for traffic light control. In Proceedings of the Learning, Inference and Control of Multi-Agent Systems (at NIPS 2016), 9th December 2016, Barcelona, Spain; 2016. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Proceedings of the NIPs 1999, Denver, CO, USA, 29 November–4 December 1999; pp. 1057–1063. [Google Scholar]
- Miller, A.J. Settings for fixed-cycle traffic signals. J. Oper. Res. Soc. 1963, 14, 373–386. [Google Scholar] [CrossRef] [Green Version]
- Little, J.D.; Kelson, M.D.; Gartner, N.H. MAXBAND: A Versatile Program for Setting Signals on Arteries and Triangular Networks; Springer: Berlin/Heidelberg, Germany, 1981. [Google Scholar]
- Gershenson, C. Self-organizing traffic lights. arXiv 2004, arXiv:nlin/0411066. [Google Scholar]
- Cools, S.-B.; Gershenson, C.; D’Hooghe, B. Self-Organizing Traffic Lights: A Realistic Simulation. In Advances in Applied Self-Organizing Systems; Springer: London, UK, 2013; pp. 45–55. [Google Scholar] [CrossRef] [Green Version]
- Varaiya, P. The Max-Pressure Controller for Arbitrary Networks of Signalized Intersections. In Advances in Dynamic Network Modeling in Complex Transportation Systems; Springer: New York, NY, USA, 2013; pp. 27–66. [Google Scholar] [CrossRef]
- Varaiya, P. Max pressure control of a network of signalized intersections. Transp. Res. Part C Emerg. Technol. 2013, 36, 177–195. [Google Scholar] [CrossRef]
- Chu, T.; Wang, J.; Codeca, L.; Li, Z. Multi-Agent Deep Reinforcement Learning for Large-Scale Traffic Signal Control. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1086–1095. [Google Scholar] [CrossRef] [Green Version]
- Le, T.; Kovács, P.; Walton, N.; Vu, H.L.; Andrew, L.L.; Hoogendoorn, S.S. Decentralized signal control for urban road networks. Transp. Res. Part C Emerg. Technol. 2015, 58, 431–450. [Google Scholar] [CrossRef] [Green Version]
- Kuyer, L.; Whiteson, S.; Bakker, B.; Vlassis, N. Multiagent reinforcement learning for urban traffic control using coordination graphs. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2008; pp. 656–671. [Google Scholar]
- Arel, I.; Liu, C.; Urbanik, T.; Kohls, A. Reinforcement learning-based multi-agent system for network traffic signal control. IET Intell. Transp. Syst. 2010, 4, 128–135. [Google Scholar] [CrossRef] [Green Version]
- El-Tantawy, S.; Abdulhai, B.; AbdelGawad, H. Multiagent Reinforcement Learning for Integrated Network of Adaptive Traffic Signal Controllers (MARLIN-ATSC): Methodology and Large-Scale Application on Downtown Toronto. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1140–1150. [Google Scholar] [CrossRef]
- Wei, H.; Chen, C.; Zheng, G.; Wu, K.; Gayah, V.; Xu, K.; Li, Z. Presslight: Learning max pressure control to coordinate traffic signals in arterial network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1290–1298. [Google Scholar]
- Krajzewicz, D.; Erdmann, J.; Behrisch, M.; Bieker, L. Recent development and applications of SUMO-Simulation of Urban MObility. Int. J. Adv. Syst. Meas. 2012, 5. [Google Scholar]
- Abdoos, M.; Mozayani, N.; Bazzan, A.L.C. Hierarchical control of traffic signals using Q-learning with tile coding. Appl. Intell. 2014, 40, 201–213. [Google Scholar] [CrossRef]
- Abdulhai, B.; Pringle, R.; Karakoulas, G.J. Reinforcement Learning for True Adaptive Traffic Signal Control. J. Transp. Eng. 2003, 129, 278–285. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.-H.; Xia, X.-H.; Luo, Q. The Study of Reinforcement Learning for Traffic Self-Adaptive Control under Multiagent Markov Game Environment. Math. Probl. Eng. 2013, 2013, 962869. [Google Scholar] [CrossRef]
- Lioris, J.; Kurzhanskiy, A.; Triantafyllos, D.; Varaiya, P. Control experiments for a network of signalized intersections using the ‘Q’simulator. IFAC Proc. Vol. 2014, 47, 332–337. [Google Scholar] [CrossRef] [Green Version]
- Kalashnikov, D.; Irpan, A.; Pastor, P.; Ibarz, J.; Herzog, A.; Jang, E.; Quillen, D.; Holly, E.; Kalakrishnan, M.; Vanhoucke, V.; et al. Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation. arXiv 2018, arXiv:1806.10293. [Google Scholar]
- Deng, Y.; Bao, F.; Kong, Y.; Ren, Z.; Dai, Q. Deep Direct Reinforcement Learning for Financial Signal Representation and Trading. IEEE Trans. Neural Networks Learn. Syst. 2016, 28, 653–664. [Google Scholar] [CrossRef]
- Pan, X.; You, Y.; Wang, Z.; Lu, C. Virtual to Real Reinforcement Learning for Autonomous Driving. arXiv 2017, arXiv:1704.03952. [Google Scholar]
- Gottesman, O.; Johansson, F.; Komorowski, M.; Faisal, A.; Sontag, D.; Doshi-Velez, F.; Celi, L.A. Guidelines for reinforcement learning in healthcare. Nat. Med. 2019, 25, 16–18. [Google Scholar] [CrossRef]
- François-Lavet, V.; Taralla, D.; Ernst, D.; Fonteneau, R. Deep reinforcement learning solutions for energy microgrids management. In Proceedings of the European Workshop on Reinforcement Learning (EWRL 2016), Barcelona, Italy, 3–4 December 2016. [Google Scholar]
- Gauci, J.; Conti, E.; Liang, Y.; Virochsiri, K.; He, Y.; Kaden, Z.; Narayanan, V.; Ye, X.; Chen, Z.; Fujimoto, S. Horizon: Facebook’s open source applied reinforcement learning platform. arXiv 2018, arXiv:1811.00260. [Google Scholar]
- Tesauro, G. Temporal difference learning and TD-Gammon. Commun. ACM 1995, 38, 58–68. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Konda, V.R.; Tsitsiklis, J.N. Actor-critic algorithms. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000; pp. 1008–1014. [Google Scholar]
- Knoblauch, R.L.; Pietrucha, M.T.; Nitzburg, M. Field studies of pedestrian walking speed and start-up time. Transp. Res. Rec. 1996, 1538, 27–38. [Google Scholar] [CrossRef]
- Kuutti, S.; Bowden, R.; Joshi, H.; de Temple, R.; Fallah, S. End-to-end Reinforcement Learning for Autonomous Longitudinal Control Using Advantage Actor Critic with Temporal Context. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019. [Google Scholar] [CrossRef]
- Zhang, H.; Feng, S.; Liu, C.; Ding, Y.; Zhu, Y.; Zhou, Z.; Zhang, W.; Yu, Y.; Jin, H.; Li, Z. CityFlow: A Multi-Agent Reinforcement Learning Environment for Large Scale City Traffic Scenario. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3620–3624. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Config | Directions | Arrival Rate (vehicles/min) | Traffic Volume |
|---|---|---|---|
| 1 | All | 8 | Light (normal traffic) |
| 2 | NS & SN | 6 | |
| EW & WE | 10 | ||
| 3 | All | 15 | Heavy (rush hours) |
| 4 | NS & SN | 12 | |
| EW & WE | 18 |
| Dataset | Arrival Rate (Vehicles/min) | Number of Intersections | |||
|---|---|---|---|---|---|
| Mean | Std | Max | Min | ||
| New York | 46.12 | 3.42 | 53 | 40 | 90 |
| Seoul | 82.90 | 6.34 | 98 | 71 | 20 |
| Type | Travel Time | Throughput | ||||||
|---|---|---|---|---|---|---|---|---|
| Config 1 | Config 2 | Config 3 | Config 4 | Config 1 | Config 2 | Config 3 | Config 4 | |
| Cyclic BP | 112.69 | 123.10 | 182.47 | 179.93 | 4617 | 4508 | 9292 | 9356 |
| Non-cyclic BP | 107.14 | 119.76 | 163.91 | 158.71 | 4739 | 4632 | 9415 | 9498 |
| PressLight | 106.21 | 118.80 | 168.66 | 163.13 | 4751 | 4645 | 9384 | 9412 |
| Methods | Travel time | Throughput | ||||||
|---|---|---|---|---|---|---|---|---|
| Config 1 | Config 2 | Config 3 | Config 4 | Config 1 | Config 2 | Config 3 | Config 4 | |
| FT 30 s | 147.79 | 153.78 | 195.34 | 199.10 | 4298 | 4271 | 8680 | 8805 |
| FT 40 s | 155.23 | 159.41 | 200.74 | 201.94 | 4127 | 4236 | 8548 | 8690 |
| MaxPressure | 131.58 | 142.93 | 194.59 | 188.21 | 4490 | 4395 | 8971 | 9010 |
| BackPressure | 143.73 | 146.90 | 193.64 | 190.37 | 4285 | 4229 | 8730 | 8867 |
| 3DQN | 141.47 | 150.28 | 191.16 | 192.80 | 4331 | 4290 | 8863 | 8733 |
| Our method | 112.69 | 123.10 | 182.47 | 179.93 | 4617 | 4508 | 9292 | 9356 |
| Methods | Travel time | Throughput | ||||||
|---|---|---|---|---|---|---|---|---|
| Config 1 | Config 2 | Config 3 | Config 4 | Config 1 | Config 2 | Config 3 | Config 4 | |
| FT 30 s | 417.23 | 398.89 | 660.81 | 611.63 | 7163 | 7249 | 9570 | 10179 |
| FT 40 s | 430.28 | 414.81 | 612.61 | 601.27 | 7097 | 7118 | 9732 | 10319 |
| MaxPressure | 313.94 | 284.54 | 474.83 | 480.84 | 8219 | 8361 | 10113 | 11070 |
| BackPressure | 325.92 | 280.17 | 501.80 | 481.04 | 7592 | 8314 | 9920 | 11021 |
| 3DQN | 328.87 | 283.35 | 484.93 | 491.90 | 7931 | 8210 | 10187 | 10896 |
| Our method | 252.58 | 246.74 | 436.92 | 422.56 | 8412 | 8552 | 10665 | 11427 |
| Methods | Travel Time | Throughput | ||
|---|---|---|---|---|
| New York | Seoul | New York | Seoul | |
| FT 30 s | 196.25 | 162.03 | 2119 | 4248 |
| FT 40 s | 210.61 | 174.71 | 2087 | 4190 |
| MaxPressure | 195.42 | 131.29 | 2345 | 4455 |
| BackPressure | 202.78 | 132.85 | 2281 | 4492 |
| 3DQN | 189.30 | 137.68 | 2316 | 4331 |
| Our method | 152.90 | 123.48 | 2602 | 4736 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibrokhimov, B.; Kim, Y.-J.; Kang, S. Biased Pressure: Cyclic Reinforcement Learning Model for Intelligent Traffic Signal Control. Sensors 2022, 22, 2818. https://doi.org/10.3390/s22072818
Ibrokhimov B, Kim Y-J, Kang S. Biased Pressure: Cyclic Reinforcement Learning Model for Intelligent Traffic Signal Control. Sensors. 2022; 22(7):2818. https://doi.org/10.3390/s22072818
Chicago/Turabian StyleIbrokhimov, Bunyodbek, Young-Joo Kim, and Sanggil Kang. 2022. "Biased Pressure: Cyclic Reinforcement Learning Model for Intelligent Traffic Signal Control" Sensors 22, no. 7: 2818. https://doi.org/10.3390/s22072818
APA StyleIbrokhimov, B., Kim, Y.-J., & Kang, S. (2022). Biased Pressure: Cyclic Reinforcement Learning Model for Intelligent Traffic Signal Control. Sensors, 22(7), 2818. https://doi.org/10.3390/s22072818