
Intelligent Localization Sampling System Based on Deep Learning and Image Processing Technology

Abstract
:1. Introduction
- (1)
- Using the checkerboard calibration board and the MATLAB toolbox, the camera’s internal parameters and the distortion parameters have been determined. Then, the acquired images were distortion-corrected by OpenCV (Open Source Computer Vision Library) to improve the accuracy of sampling area detection and visual localization. The use of data augmentation has solved the problem of the lower availability of data sets of the same vehicle in different environments and weather conditions, as well as that of the low accuracy of the SSD algorithm when used in detecting compartments in some scenes;
- (2)
- The visual localization model was established, and the coordinates of the sampling point were located by color screening, image segmentation, and connecting body feature screening. The coordinates of the sampling point were converted from the image coordinate system (ICS) to the sampling plane coordinate system (SPCS), and then the robot was guided to the corresponding random point for accurate localization and sampling;
- (3)
- A sampling verification experiment was carried out on the delivery truck on the spot. The experimental results showed that the visual localization errors of the robot in the x-direction and y-direction were less than the error margins, which means it could meet the accuracy requirements of on-site localization and sampling, and facilitate automatic sampling by a robot.

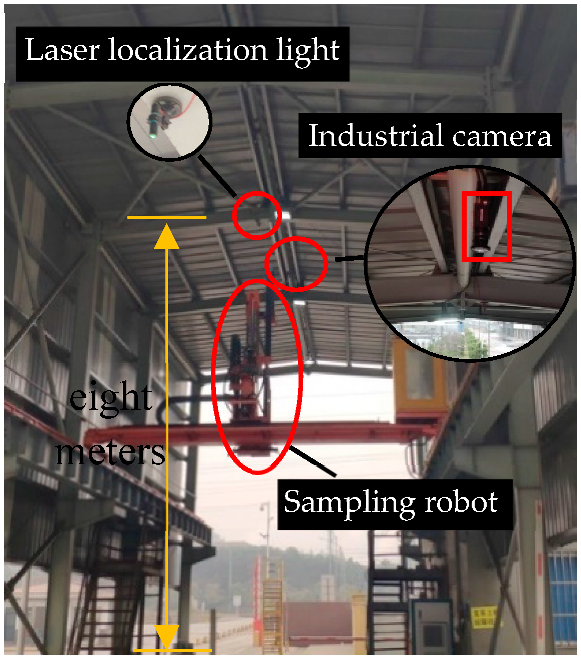
2. The Proposed System
2.1. Distortion Correction
2.1.1. Lens Distortion
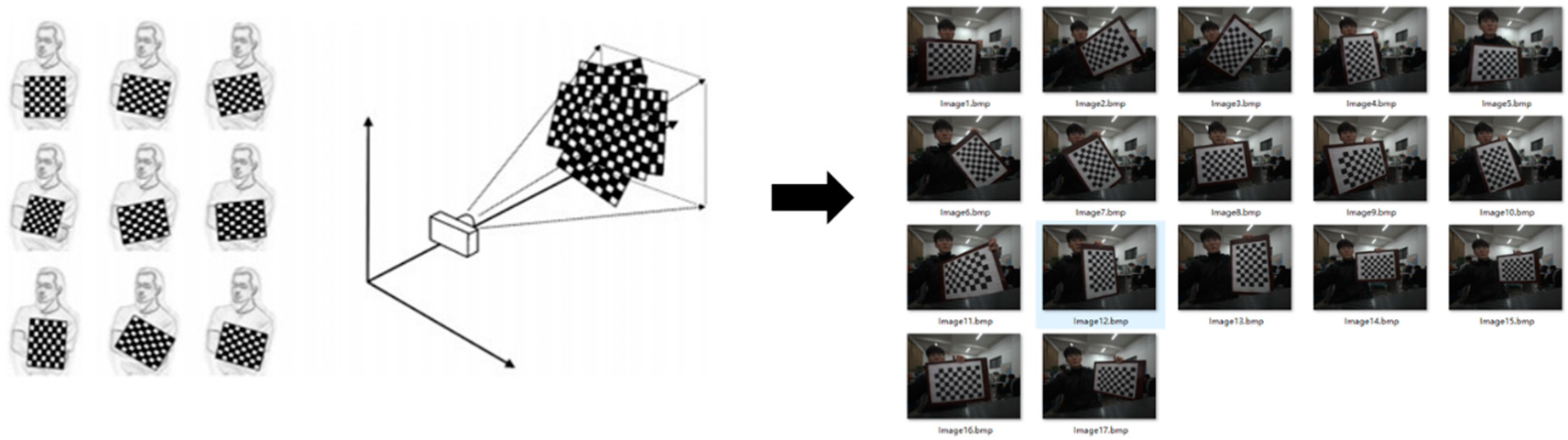
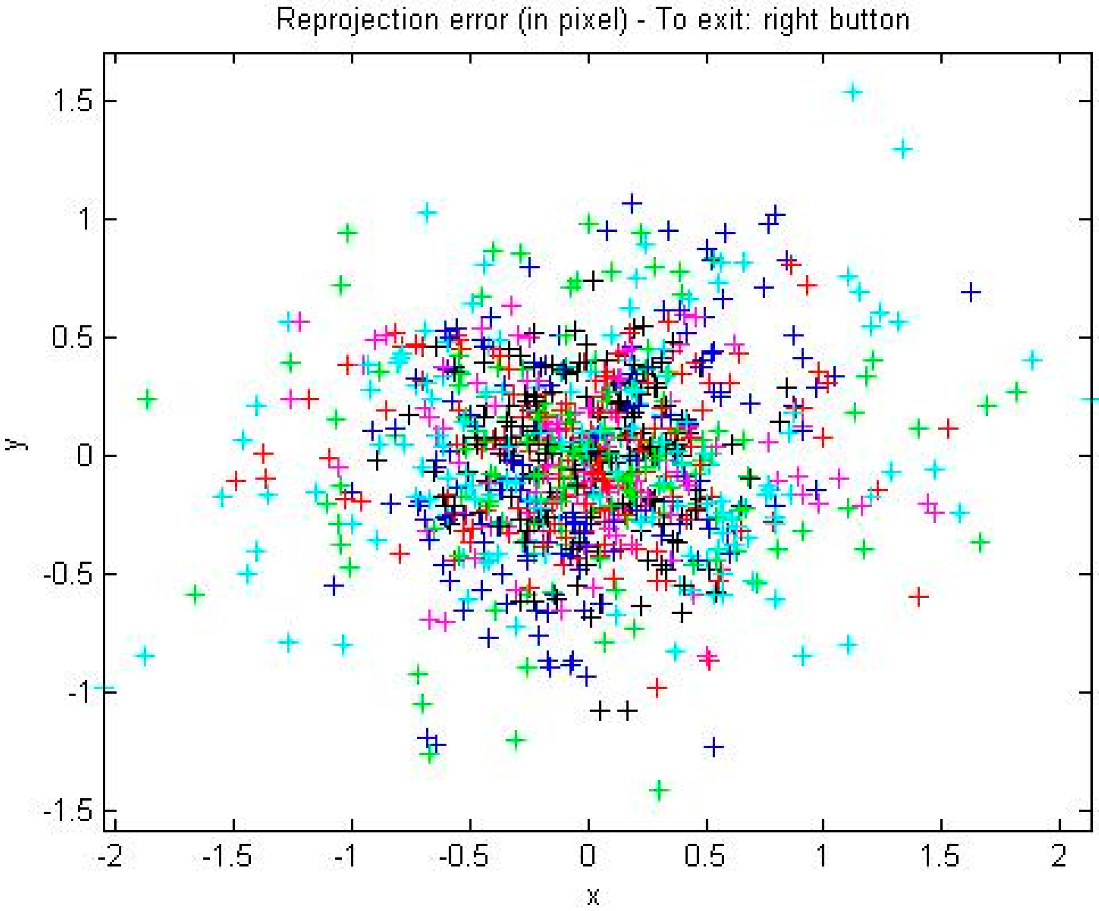
2.1.2. Camera Calibration
2.1.3. Distortion Correction Based on MATLAB Camera Calibration Toolbox
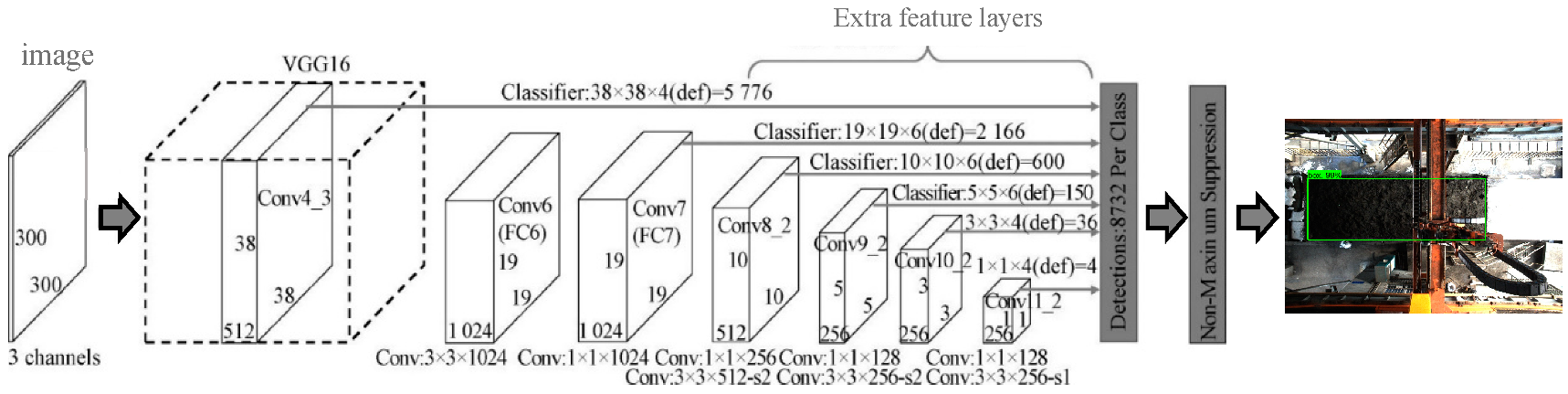
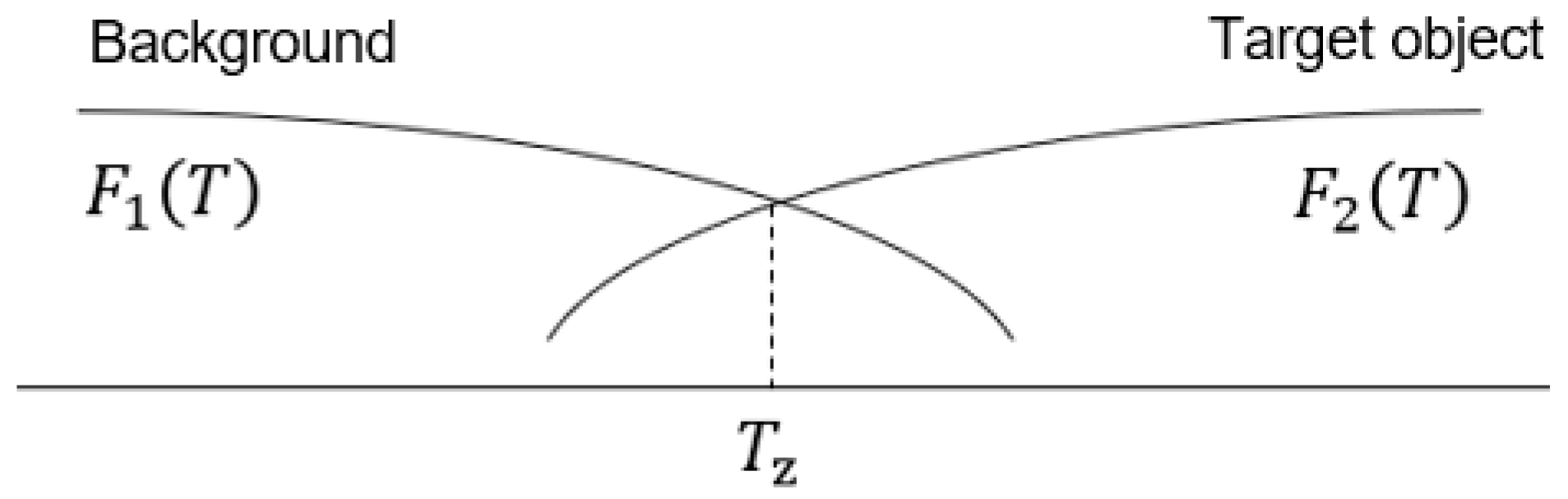
2.2. SSD Algorithm Is Used to Detect the Carriage Area
2.2.1. SSD Algorithm
2.2.2. Experimental Process and Analysis of Sampling Area Detection
Image Acquisition
Data Set Pre-Processing
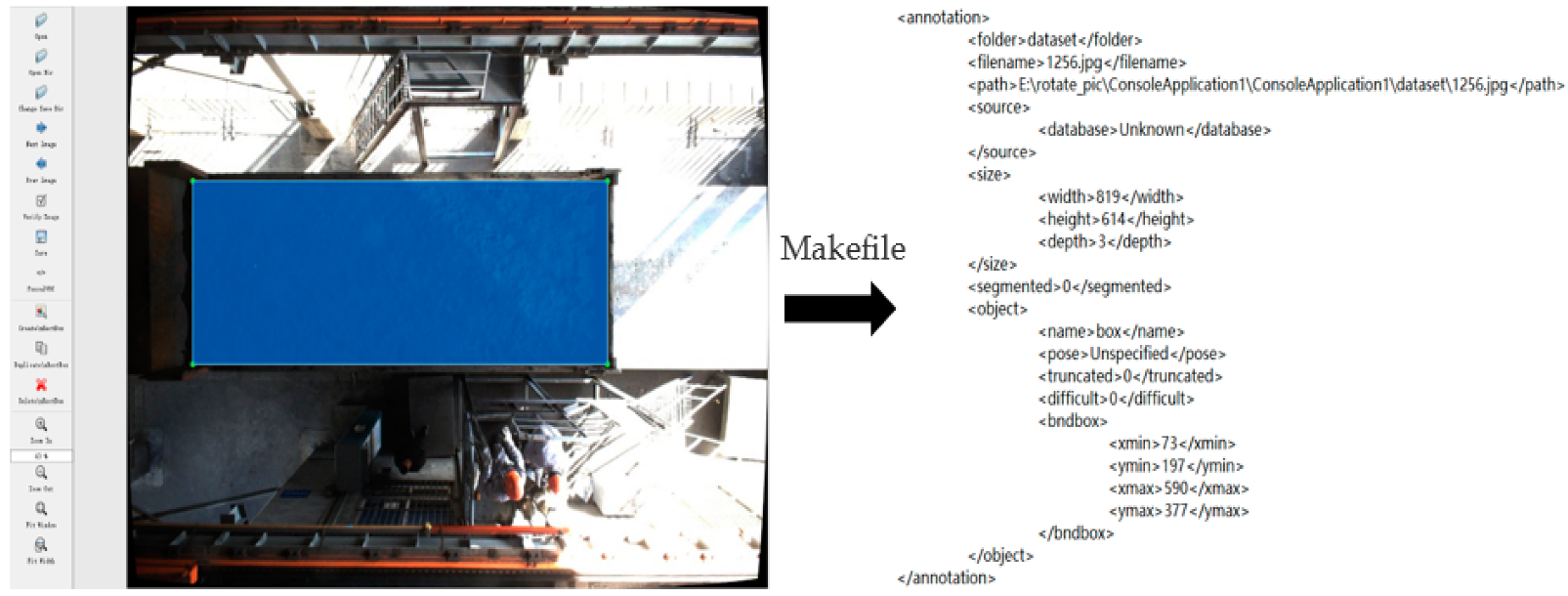
Data Set Annotation
Data Conversion and Division
2.2.3. Training Process
2.2.4. Regional Detection Results and Analysis
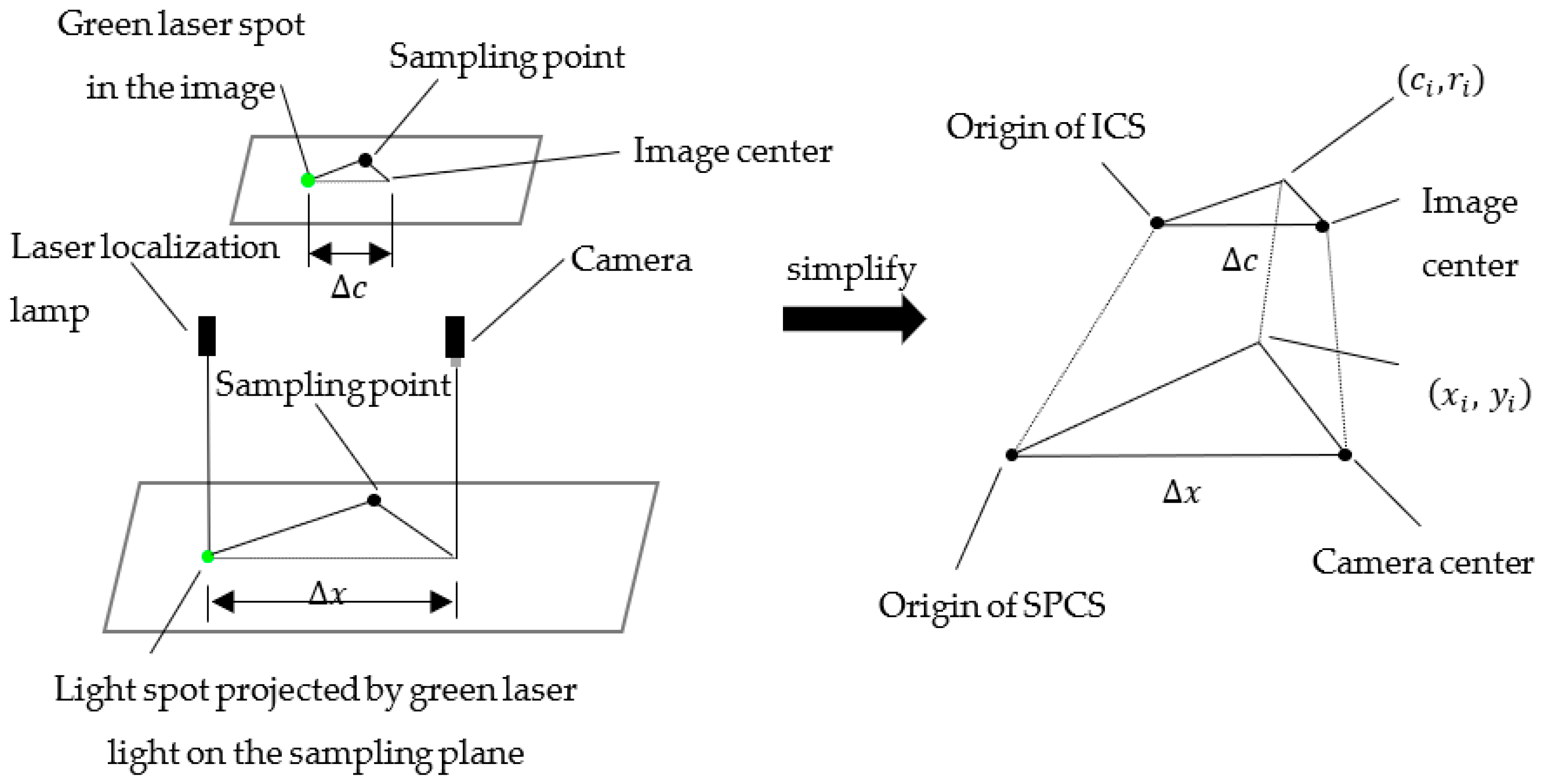
2.3. Visual Localization Model
- (1)
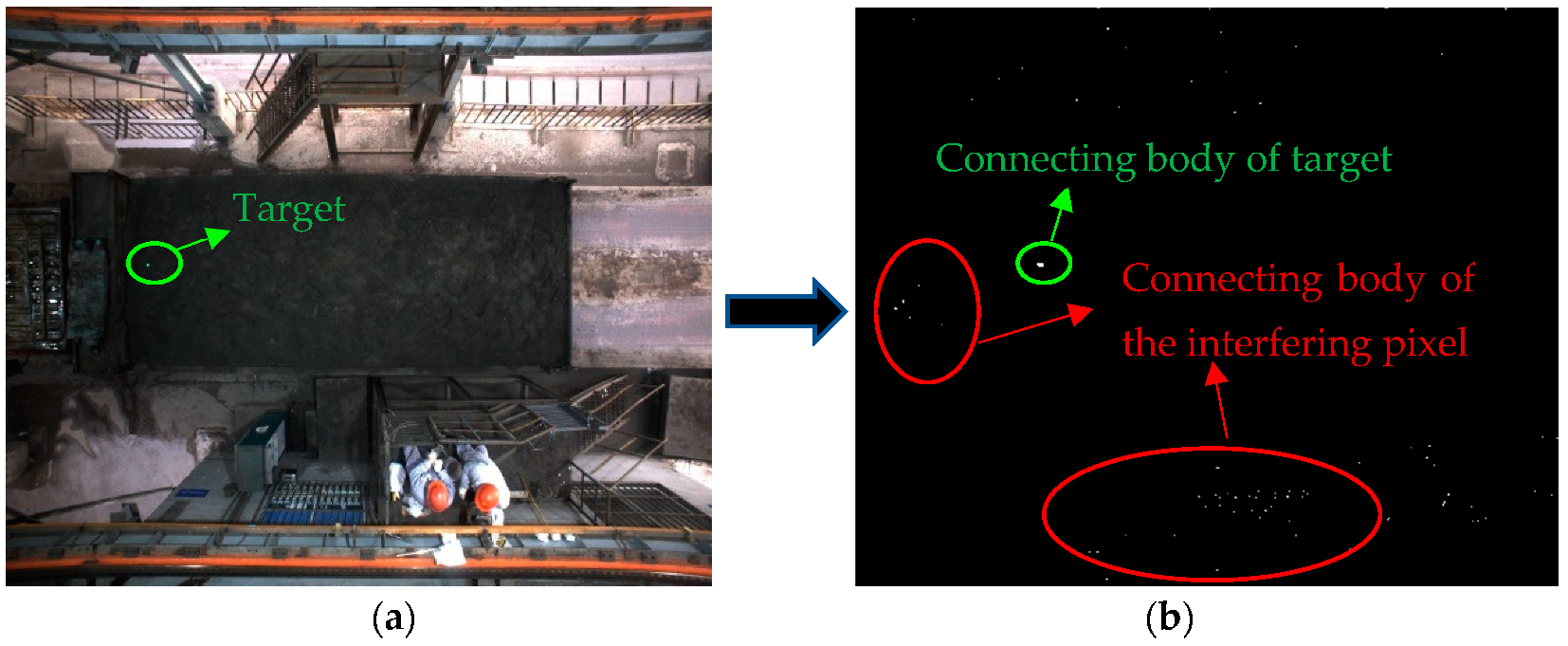
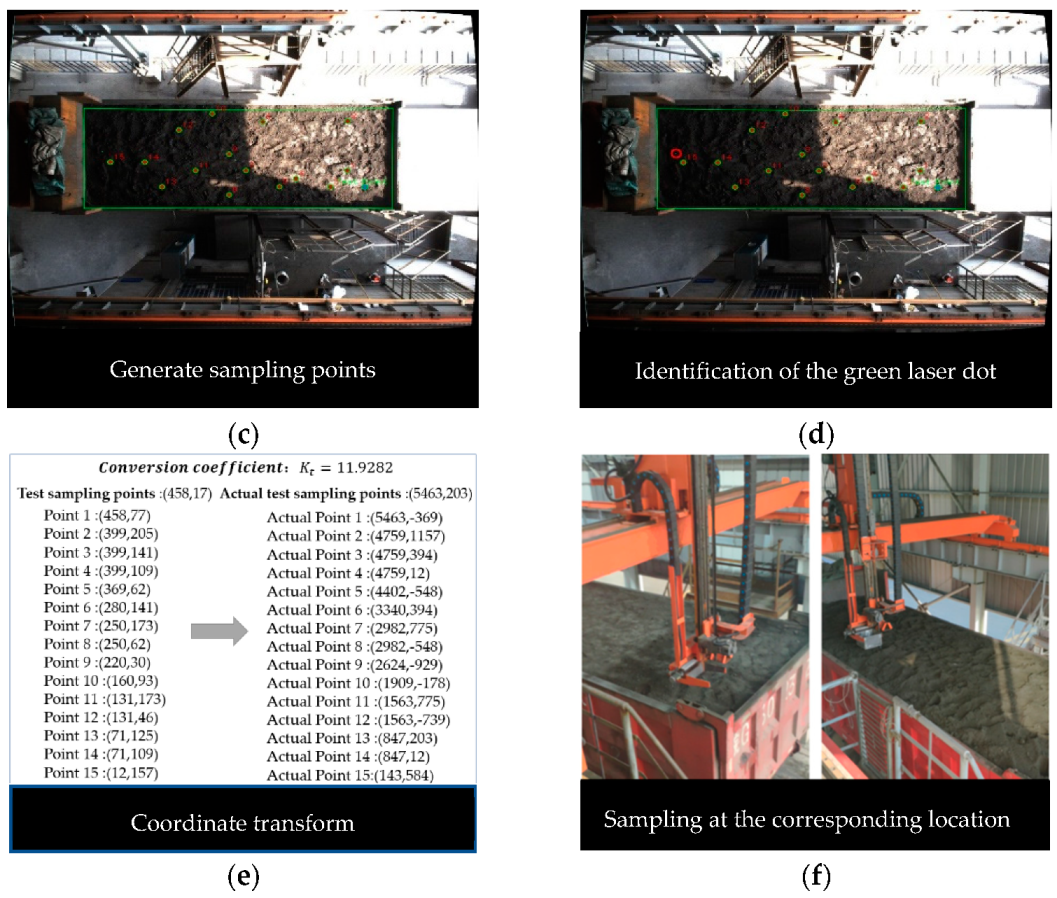
- After the laser localization lamp on the top projects the green spot onto the sampling plane, through the imaging characteristics of the laser spot, it can determine the position of the green laser spot in the image, and then calculate the distance Δc between the center point of the image and the centroid of the spot.
- (2)
- Based on the installation distance between the industrial camera and the laser localization lamp (∆x and ∆c), the factor of conversion Kt from the ICS to the SPCS is calculated, and then the conversion from the sampling point coordinates (ci, ri) of the ICS to the actual sampling point coordinates (xi, yi) of the SPCS is performed.
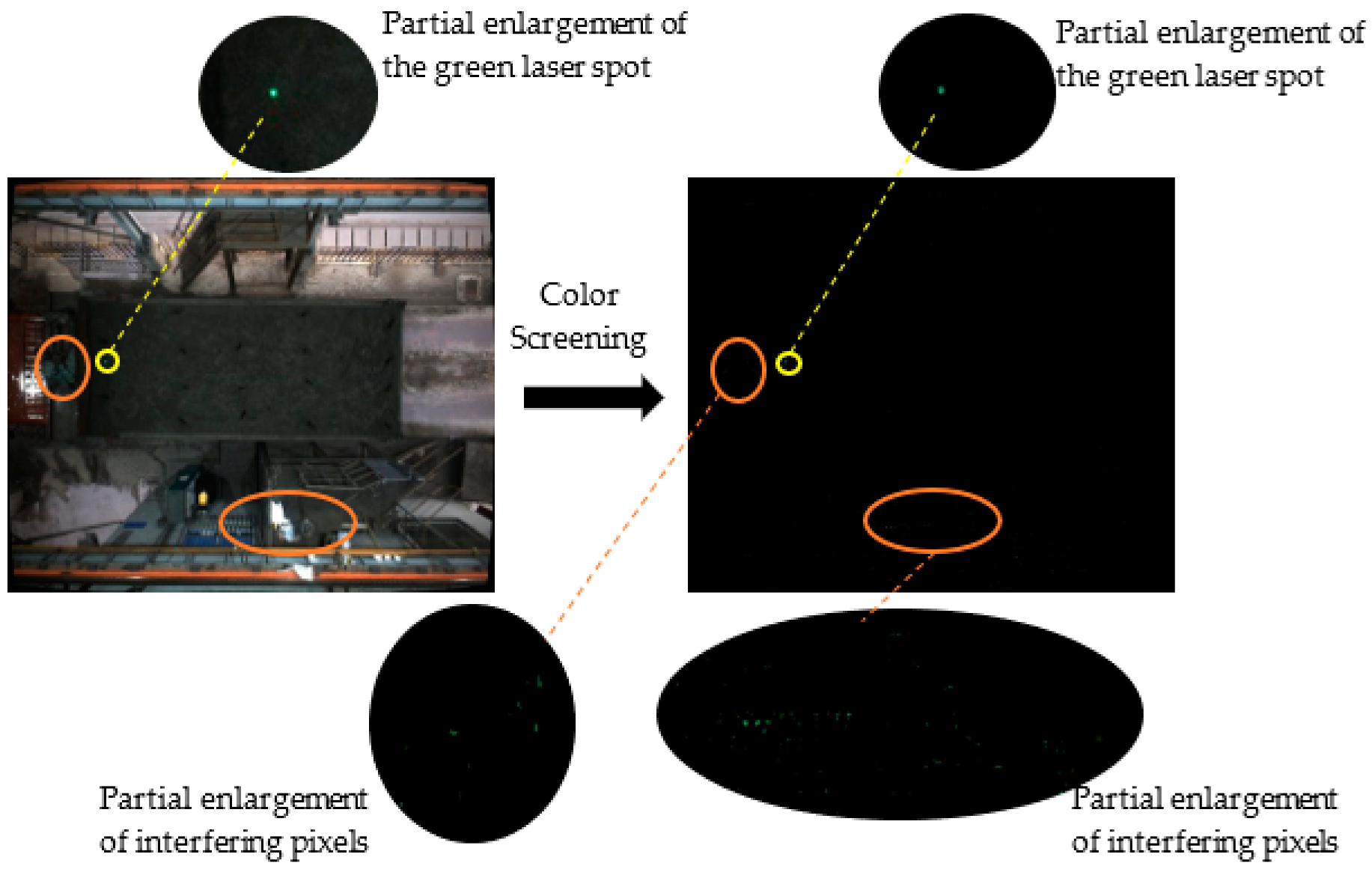
2.3.1. Spot Detection
2.3.2. Color Space Conversion
2.3.3. Color Feature Screening
2.3.4. Image Segmentation
2.3.5. Connecting Body Feature Screening
2.4. Coordinate Transform
3. Field Experiment Verification
4. Conclusions and Further Work
4.1. Conclusions
- (1)
- The lens’ internal parameters and distortion parameters were obtained using the MATLAB toolbox and a calibration plate, and OpenCV is used to correct the distortion of the picture, eliminating the influence of image distortion caused by the industrial wide-angle lens. This ensures the accuracy of localization and detection;
- (2)
- By means of data augmentation, a large number of training sets within different scenes were obtained, and experiments were conducted on the test set. The accuracy of the experimental results reached over 92%, which solves the problem whereby some scenes of the SSD algorithm were not detected accurately, and ensures the accuracy of the SSD detection area;
- (3)
- A vision localization model for bridge sampling robots has been constructed, which can precisely locate the sampling point, and convert the coordinates of the localization point from the ICS to the base coordinate system of the sampling robot, before guiding the sampling robot to the corresponding sampling point for accurate localization and sampling;
- (4)
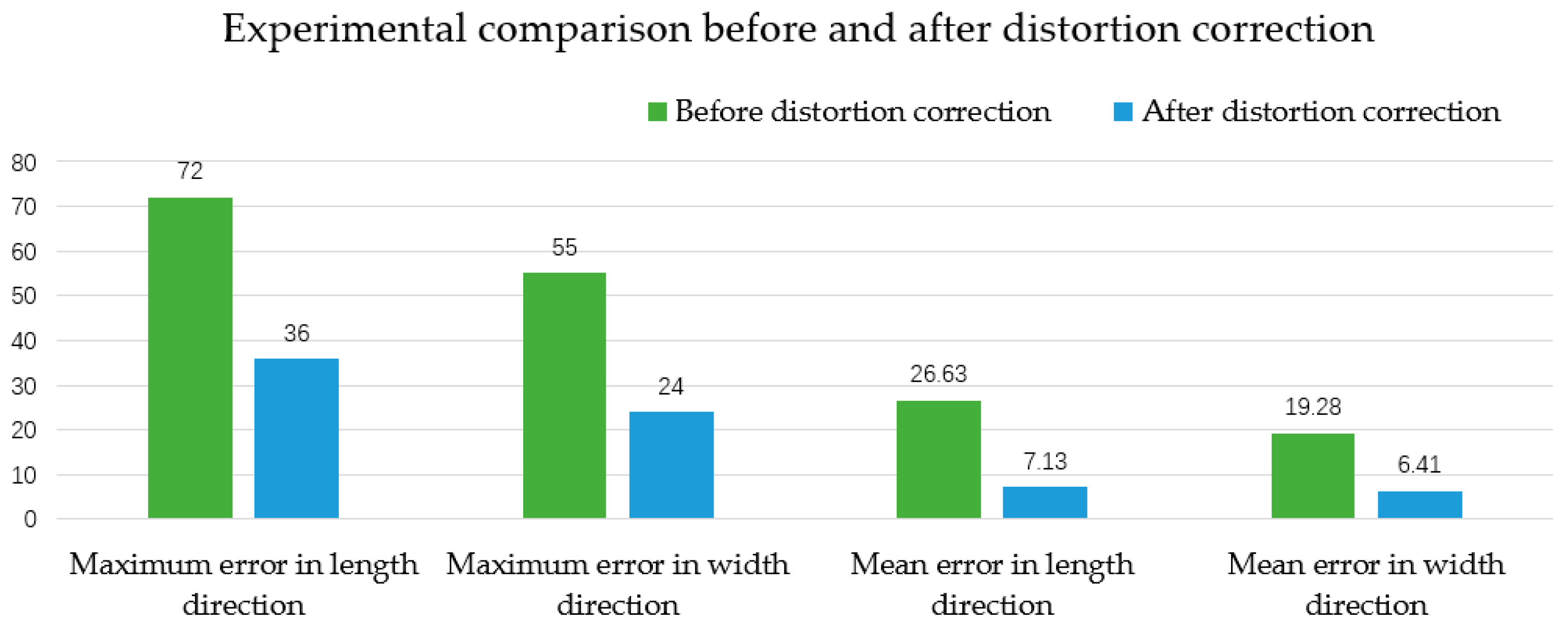
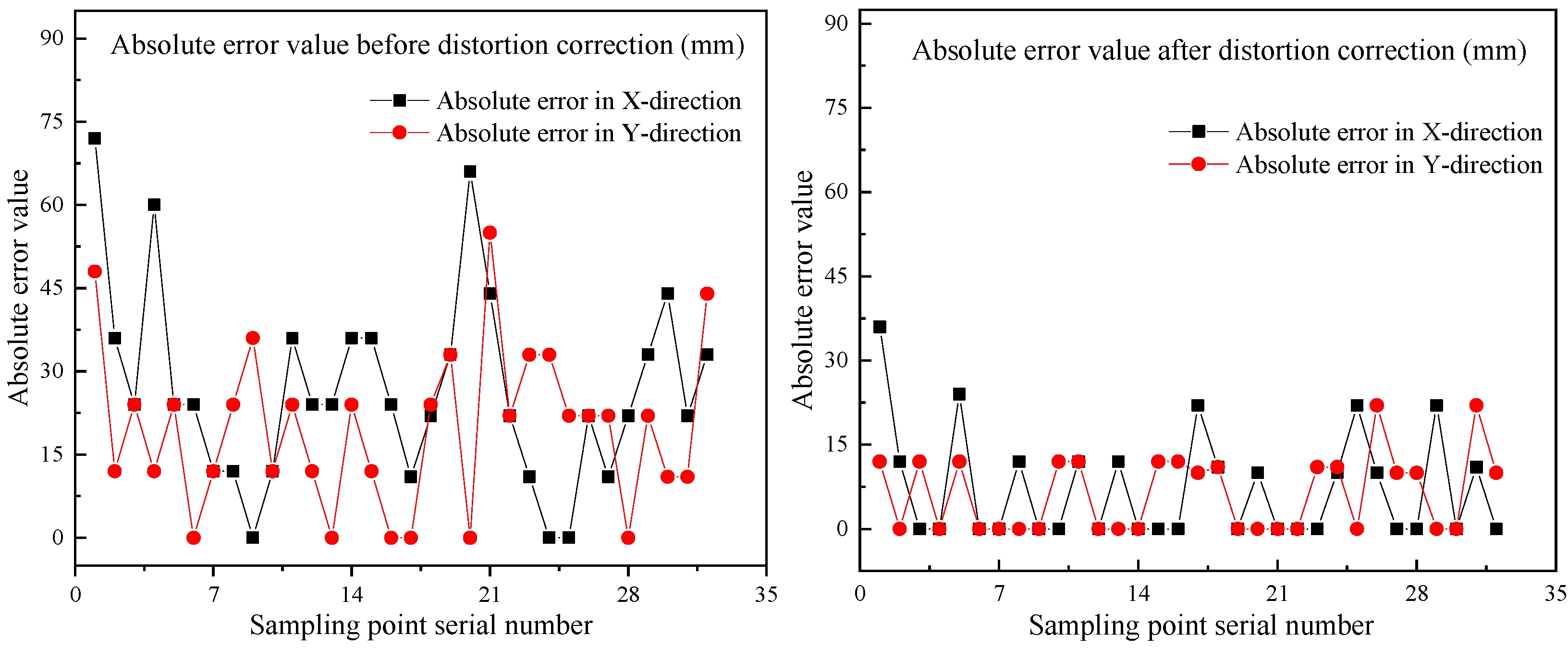
- The maximum error of the localization sampling system in the x-direction is 36 mm and the maximum error in the y-direction is 24 mm. This visual localization error is much smaller than the error margin in the corresponding direction, and the localization accuracy meets the error range requirement of industrialized mineral powder sampling. Compared with the traditional conventional sampling technology, it has the advantages of shorter sampling and positioning time (originally 3–5 min for a single point, but now 8 min for a total of 16 points), stronger intelligent working ability and larger sampling range (originally the sampler can only detect half of the carriage range, but now the full range can be detected). As such, the automation of robot mineral powder localization and sampling is successfully realized.
4.2. Further Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Barnewold, L.; Lottermoser, B.G. Identification of digital technologies and digitalisation trends in the mining industry. Int. J. Min. Sci. Technol. 2020, 30, 747–757. [Google Scholar] [CrossRef]
- Tang, Y.; Zhu, M.; Chen, Z.; Wu, C.; Chen, B.; Li, C. Seismic performance evaluation of recycled aggregate concrete-filled steel tubular columns with field strain detected via a novel mark-free vision method. Structures 2021, 37, 426–441. [Google Scholar] [CrossRef]
- Wu, F.; Duan, J.; Chen, S.; Ye, Y.; Ai, P.; Yang, Z. Multi-Target Recognition of Bananas and Automatic Positioning for the Inflorescence Axis Cutting Point. Front. Plant Sci. 2021, 12, 705021. [Google Scholar] [CrossRef] [PubMed]
- Xue, S.; Li, X.S.; Xie, J. A New Coal Sampling System for Measurement of Gas Content in Soft Coal Seams. Appl. Mech. Mater. 2011, 121–126, 2459–2464. [Google Scholar] [CrossRef]
- Conti, R.S.; Zlochower, I.A.; Sapko, M.J. Rapid Sampling of Products During Coal Mine Explosions. Combust. Sci. Technol. 2007, 75, 195–209. [Google Scholar] [CrossRef]
- Yang, N.; Xie, C.; Chen, Y.; Chen, M.; Zheng, J.; Zhang, M.; Li, L. The Design of Sampling Machine for Mineral Resources. In Proceedings of the 27th International Ocean and Polar Engineering Conference, San Francisco, CA, USA, 25 June 2017; pp. 17–21. [Google Scholar]
- Zhu, Q. Coal Sampling and Analysis Standards; IEA Clean Coal Centre: London, UK, 2014; pp. 18–37. [Google Scholar]
- Kissell, F.N.; Volkwein, J.C.; Kohler, J. Historical perspective of personal dust sampling in coal mines. In Proceedings of the Mine Ventilation Conference, Adelaide, Australia, 2002; pp. 1–5. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced Deep-Learning Techniques for Salient and Category-Specific Object Detection: A. Survey. IEEE Signal Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Xu, X.; Li, Y.; Wu, G.; Luo, J. Multi-modal Deep Feature Learning for RGB-D Object Detection. Pattern Recognit. 2017, 72, 300–313. [Google Scholar] [CrossRef]
- Ranjan, R.; Sankaranarayanan, S.; Bansal, A.; Bodla, N.; Chen, J.C.; Patel, V.M.; Castillo, C.D.; Chellappa, R. Deep Learning for Understanding Faces: Machines May Be Just as Good, or Better, than Humans. IEEE Signal Process. Mag. 2018, 35, 66–83. [Google Scholar] [CrossRef]
- Chin, T.W.; Yu, C.L.; Halpern, M.; Genc, H.; Tsao, S.L.; Reddi, V.J. Domain-Specific Approximation for Object Detection. IEEE Micro 2018, 38, 31–40. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. Computer Vision and Pattern Recognition. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. Computer Vision and Pattern Recognition. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 17 September 2016; Volume 9905, pp. 21–36. [Google Scholar]
- Kim, J.A.; Sung, J.Y.; Park, S.H. Comparison of Faster-RCNN, YOLO, and SSD for Real-Time Vehicle Type Recognition; IEEE: Seoul, Korea, 2020; pp. 1–4. [Google Scholar]
- Morera, Á.; Sánchez, Á.; Moreno, A.B.; Sappa, Á.D.; Vélez, J.F. SSD vs. YOLO for Detection of Outdoor Urban Advertising Panels under Multiple Variabilities. Sensors 2020, 20, 4587. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Jia, W.; Xu, S.; Liang, Z.; Zhao, Y.; Min, H.; Li, S.; Yu, Y. Real-time automatic helmet detection of motorcyclists in urban traffic using improved YOLOv5 detector. IET Image Process. 2021, 15, 3623–3637. [Google Scholar] [CrossRef]
- Tan, S.; Lu, G.; Jiang, Z.; Huang, L. Improved YOLOv5 Network Model and Application in Safety Helmet DeTaction. In Proceedings of the 2021 IEEE International Conference on Intelligence and Safety for Robotics, Tokoname, Japan, 10 May 2021; pp. 1–4. [Google Scholar]
- Deepa, R.; Tamilselvan, E.; Abrar, E.S.; Sampath, S. Comparison of Yolo, SSD, Faster RCNN for Real Time Tennis Ball Tracking for Action Decision Networks. In Proceedings of the 2019 International Conference on Advances in Computing and Communication Engineering (ICACCE), Sathyamangalam, India, 30 April 2020; pp. 1–4. [Google Scholar]
- Zhai, S.; Shang, D.; Wang, S.; Dong, S. DF-SSD: An Improved SSD Object Detection Algorithm Based on DenseNet and Feature Fusion. IEEE Access 2020, 8, 24344–24357. [Google Scholar] [CrossRef]
- Wang, X.; Hua, X.; Xiao, F.; Li, Y.; Hu, X.; Sun, P. Multi-Object Detection in Traffic Scenes Based on Improved SSD. Electronics 2018, 7, 302. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Hou, Q.; Xing, J.; Ju, J. SSD Object Detection Model Based on Multi-Frequency Feature Theory. IEEE Access 2020, 8, 82294–82305. [Google Scholar] [CrossRef]
- Li, Y.; Dong, H.; Li, H.; Zhang, X.; Zhang, B.; Xiao, Z. Multi-block SSD based on small object detection for UAV railway scene surveillance. Chin. J. Aeronaut. 2020, 33, 1747–1755. [Google Scholar] [CrossRef]
- Fu, C.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd:Deconvolutional single shot detector. Computer Vision and Pattern Recognition. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Advances in Neural Information Processing Systems 29, Proceedings of the Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; The MIT Press: Cambridge, MA, USA, 2016; pp. 379–387. [Google Scholar]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C. What size neural network gives optimal generalization? convergence properties of backpropagation. In Computer Science; University of Maryland: College Park, MD, USA, 1998; pp. 1–35. [Google Scholar]
- Leng, J.; Liu, Y. An enhanced SSD with feature fusion and visual reasoning for object Detection. Neural Comput. Appl. 2019, 31, 6549–6558. [Google Scholar] [CrossRef]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. In Computer Science; University of Maryland: College Park, MD, USA, 2017; pp. 1–35. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. Computer Vision and Pattern Recognition. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Al-Jubouri, Q.; Al-Azawi, R.J.; Al-Taee, M.; Young, I. Efficient individual identification of zebrafish using Hue/Saturation/Value color model. Egypt. J. Aquat. Res. 2018, 44, 271–277. [Google Scholar] [CrossRef]
- Harasthy, T.; Ovseník, Ľ.; Turán, J. Detector of Traffic Signs with using Hue-Saturation-Value color model. Carpathian J. Electron. Comput. Eng. 2013, 2, 21–25. [Google Scholar]
- Wandi, D.; Fauziah, F.; Hayati, N. Deteksi Kelayuan Pada Bunga Mawar dengan Metode Transformasi Ruang Warna Hue Saturation Intensity (HSI) dan Hue Saturation Value (HSV). J. Media Inform. Budidarma 2021, 5, 308–316. [Google Scholar] [CrossRef]
- Cantrell, K.; Erenas, M.M.; de Orbe-Paya, I.; Capitán-Vallvey, L.F. Use of the Hue Parameter of the Hue, Saturation, Value Color Space As a Quantitative Analytical Parameter for Bitonal Optical Sensors. Anal. Chem. 2010, 82, 531–542. [Google Scholar] [CrossRef]
- Wang, Z.; Jensen, J.R.; Im, J. An automatic region-based image segmentation algorithm for remote sensing applications. Environ. Model. Softw. 2010, 25, 1149–1165. [Google Scholar] [CrossRef]
- Ojeda, S.; Vallejos, R.; Bustos, O. A new image segmentation algorithm with applications to image inpainting. Comput. Stat. Data Anal. 2010, 54, 2082–2093. [Google Scholar] [CrossRef]
- Chouhan, S.S.; Kaul, A.; Singh, U.P. Image Segmentation Using Computational Intelligence Techniques: Review. Arch. Comput. Methods Eng. 2018, 26, 533–596. [Google Scholar] [CrossRef]
- Wang, J.; Shi, F.; Zhang, J.; Liu, Y. A new calibration model of camera lens distortion. Pattern Recognit. 2008, 41, 607–615. [Google Scholar] [CrossRef]
- Tang, Y.; Li, L.; Feng, W.; Liu, F.; Zou, X.; Chen, M. Binocular vision measurement and its application in full-field convex deformation of concrete-filled steel tubular columns. Measurement 2018, 130, 372–383. [Google Scholar] [CrossRef]
- Chen, M.; Tang, Y.; Zou, X.; Huang, K.; Li, L.; He, Y. High-accuracy multi-camera reconstruction enhanced by adaptive point cloud correction algorithm. Opt. Lasers Eng. 2019, 122, 170–183. [Google Scholar] [CrossRef]
- Remondino, F.; Fraser, C. Digital camera calibration methods Considerations and comparisons. ISPRS Comm. V Symp. Image Eng. Vis. Metrol. 2006, 36, 266–272. [Google Scholar]
- Zhang, Z. A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Meško, M.; Toth, Š. Laser Spot Detection. J.Inf. Control. Manag. Syst. 2013, 11, 35–42. [Google Scholar]
- Jayashree, R.A. RGB to HSI color space conversion via MACT algorithm. In Proceedings of the 2013 International Conference on Communication and Signal Processing, Melmaruvathur, India, 3–5 April 2013; pp. 561–565. [Google Scholar]
- Qi, Q.; Tian, Y.; Han, L. An improved image segmentation algorithm based on the maximum class variance method. In Proceedings of the MATEC Web of Conferences 2020, Beijing, China, 27–29 November 2020; Volume 309, pp. 1–4. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Liu, J.F.; Cao, X.L.; Xu, J.; Yao, Q.L.; Ni, H.Y. A new method for threshold determination of gray image. Geomech. Geophys. Geo-Energy Geo-Resour. 2020, 6, 72. [Google Scholar] [CrossRef]
- Liu, L.; Yang, N.; Lan, J.; Li, J. Image segmentation based on gray stretch and threshold algorithm. Optik 2015, 126, 626–629. [Google Scholar] [CrossRef]
- Guo, F.; Li, W.; Tang, J.; Zou, B.; Fan, Z. Automated glaucoma screening method based on image segmentation and feature extraction. Med. Biol. Eng. Comput. 2020, 5, 2567–2586. [Google Scholar] [CrossRef] [PubMed]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera Internal Parameters | x-Direction | y-Direction |
|---|---|---|
| Focal Length (fc) | 1167.20744 | 1166.56816 |
| ±∆fc | ±7.30839 | ±7.06835 |
| Principle Point (cc) | 1017.81138 | 773.90719 |
| ±∆cc | ±6.56265 | ±6.01459 |
| 0.0000 | Angle of Pixel Axes = 90.00000 | |
| ±0.0000 | ±0.00000 |
| Distortion Parameter | |||||
|---|---|---|---|---|---|
| ) | −0.11795 | 0.09822 | 0.00000 | 0.00074 | −0.00124 |
| ±0.01000 | ±0.02870 | ±0.00000 | ±0.00111 | ±0.00116 |
| Parameter Name | Numerical Value | Parameter Name | Numerical Value |
|---|---|---|---|
| weight_decay | 0.0005 | decay_factor | 0.95 |
| optimizer | Adam | batch_size | 8 |
| initial_learning_rate | 0.004 | num_steps | 20,000 |
| Sampling Range Detection Situation | Without Data Augmentation | With Data Augmentation |
|---|---|---|
| < 0.8 | 23 sheets | 7 sheets |
| Prediction box out of sampling range | 25 sheets | 6 sheets |
| No sampling range detected | 4 sheets | 3 sheets |
| and not exceeding the sampling range | 148 sheets | 184 sheets |
| Success ratio | 74% | 92% |
| Color Channel | Setting Range |
|---|---|
| H Channel (Hue Channel) | (55, 77) |
| S Channel (Saturation Channel) | (43, 255) |
| V Channel (Value Channel) | (46, 255) |
| Number | Sampling Plane | Number | Sampling Plane | ||
|---|---|---|---|---|---|
| 1 | (458, 65) | (5463, 775) | 9 | (220, 81) | (2624, 966) |
| 2 | (428, 33) | (5105, 394) | 10 | (220, 1) | (2624, 12) |
| 3 | (428, −62) | (5105, −739) | 11 | (190, −78) | (2266, −929) |
| 4 | (399, 65) | (4759, 775) | 12 | (160, 33) | (1909, 394) |
| 5 | (339, 49) | (4044, 584) | 13 | (131, −46) | (1563, −548) |
| 6 | (310, 65) | (3698, 775) | 14 | (101, 65) | (1205, 775) |
| 7 | (280, −62) | (3340, −739) | 15 | (71, 17) | (847, 203) |
| 8 | (250, 33) | (2982, 394) | 16 | (12, 17) | (143, 203) |
| Number | Sampling Plane | Absolute Error | Number | Sampling Plane | Absolute Error | ||
|---|---|---|---|---|---|---|---|
| 1 | (5463, 775) | (5499, 787) | (36, 12) | 9 | (2624, 966) | (2624, 966) | (0, 0) |
| 2 | (5105, 394) | (5117, 394) | (12, 0) | 10 | (2624, 12) | (2624, 0) | (0, 12) |
| 3 | (5105, −739) | (5105, −751) | (0, 12) | 11 | (2266, −929) | (2254, −917) | (12, 12) |
| 4 | (4759, 775) | (4759, 775) | (0, 0) | 12 | (1909, 394) | (1909, 394) | (0, 0) |
| 5 | (4044, 584) | (4068, 596) | (24, 12) | 13 | (1563, −548) | (1575, −548) | (12, 0) |
| 6 | (3698, 775) | (3698, 775) | (0, 0) | 14 | (1205, 775) | (1205, 775) | (0, 0) |
| 7 | (3340, −739) | (3340, −739) | (0, 0) | 15 | (847, 203) | (847, 215) | (0, 12) |
| 8 | (2982, 394) | (2994, 394) | (12, 0) | 16 | (143, 203) | (143, 215) | (0, 12) |
| Parameters | X-Direction | Y-Direction |
|---|---|---|
| Margin of error | 152.78 mm | 83.33 mm |
| Error between actual and localization |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, S.; Yang, Z.; Zhou, L.; Zou, S.; Xie, H. Intelligent Localization Sampling System Based on Deep Learning and Image Processing Technology. Sensors 2022, 22, 2021. https://doi.org/10.3390/s22052021
Yi S, Yang Z, Zhou L, Zou S, Xie H. Intelligent Localization Sampling System Based on Deep Learning and Image Processing Technology. Sensors. 2022; 22(5):2021. https://doi.org/10.3390/s22052021
Chicago/Turabian StyleYi, Shengxian, Zhongjiong Yang, Liqiang Zhou, Shaoxin Zou, and Huangxin Xie. 2022. "Intelligent Localization Sampling System Based on Deep Learning and Image Processing Technology" Sensors 22, no. 5: 2021. https://doi.org/10.3390/s22052021
APA StyleYi, S., Yang, Z., Zhou, L., Zou, S., & Xie, H. (2022). Intelligent Localization Sampling System Based on Deep Learning and Image Processing Technology. Sensors, 22(5), 2021. https://doi.org/10.3390/s22052021