
A Pruning Method for Deep Convolutional Network Based on Heat Map Generation Metrics


Abstract
:1. Introduction
- The pruning method for the purpose of network lightweight applies the scaling factor parameter of the normalization function in the deep learning model, KL scatter and other evaluation metrics to quantify the contribution of the network layers to the final result, and cannot evaluate the network feature extraction performance. It cannot improve the feature extraction ability of the network.
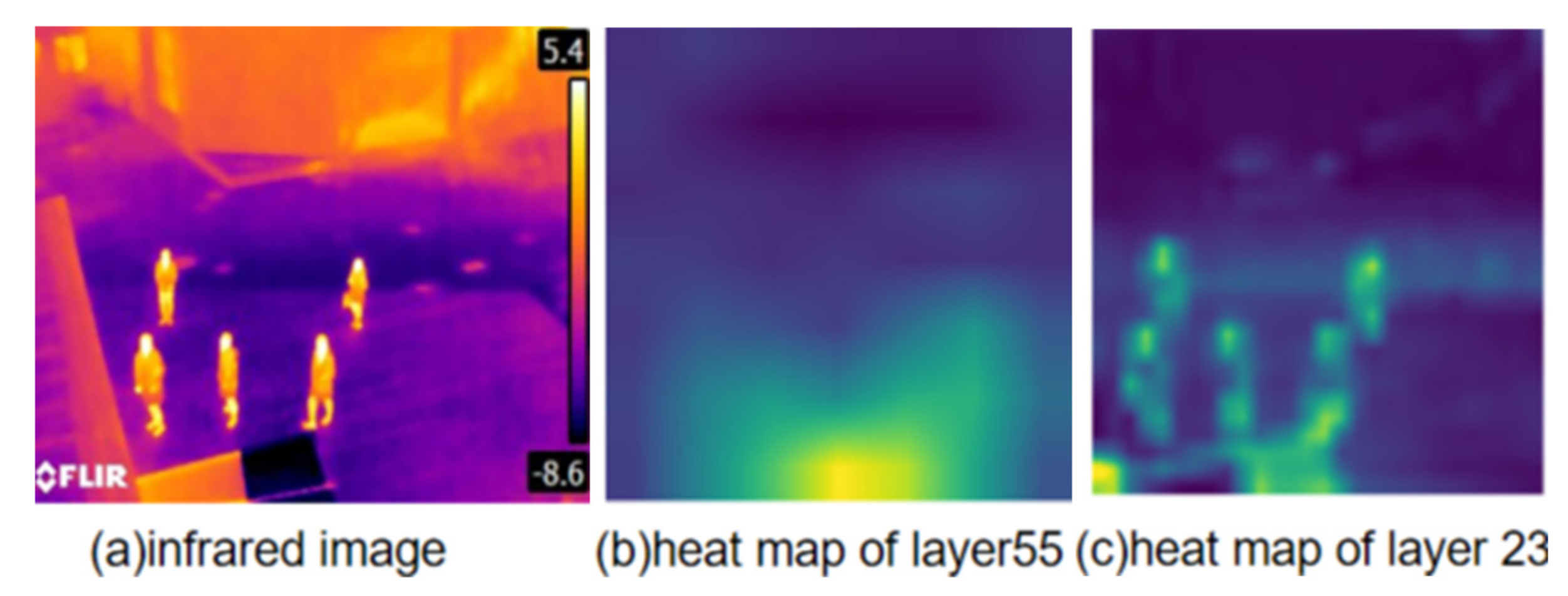
- Deep learning networks are known to be uninterpretable in terms of feature extraction at each layer. Although visualization tools can visualize the extraction of target and background features in an image by means of a heat map, it is not possible to describe what kind of features are extracted at each layer of the network and whether they are effective. However, it is not possible to describe from the visualization what features are extracted at each layer of the network and whether the extracted features are valid. This makes it impossible to determine how well the network layer is able to extract key features and whether it should be cut down. Figure 1b,c show a visualization of the features extracted by the yolov4 target detection network at different layers.
- The existing network pruning methods use a pre-trained model to train the network and fine-tune the pruned network model. However, this causes the initial parameters of the network to change, so that the parameters of each network layer are not at the same standard when the network is trained. When performing the network layer evaluation, each network layer is influenced by the parameters of the pre-trained model. The values of the corresponding network layer evaluation metrics also change.
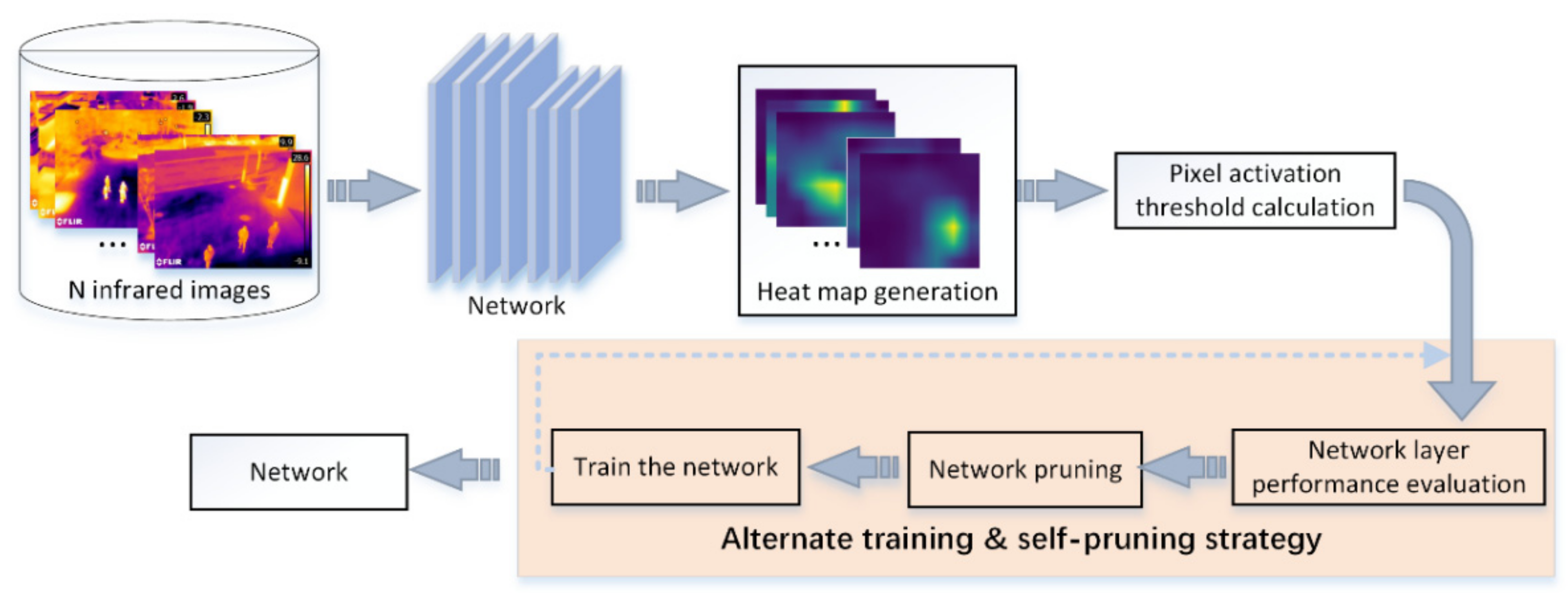
- This paper addresses the problem that some researchers are prone to misjudge the performance of network layers by observing visual images with the human eye or judging the feature extraction ability of the network layers by experience. In this paper, we propose a formula that can quantitatively describe the feature extraction performance of each network layer, including ‘foreground feature extraction capability metrics’ (F), ‘background feature suppression capability metrics’ (B), ‘network layer performance evaluation metrics’ (NPE). By objectively calculating the feature extraction capability of a network layer. Pruning of network layers to reduce incorrect pruning due to subjective errors in judgement.
- To address the problem that traditional network pruning methods fine-tune pre-trained models, which are prone to incorrect pruning. In this paper, we propose an alternating training and self-pruning strategy. Only the worst performing network layers in the model are pruned at a time, and the network is trained from zero. The operation of alternating network pruning and training from zero is repeated to improve the quality of extracted features.
2. Related Work
3. Methods
3.1. Overview
3.2. Heat Map Based NPE Construction Method
3.2.1. Compute F
3.2.2. Compute B
3.2.3. Compute NPE
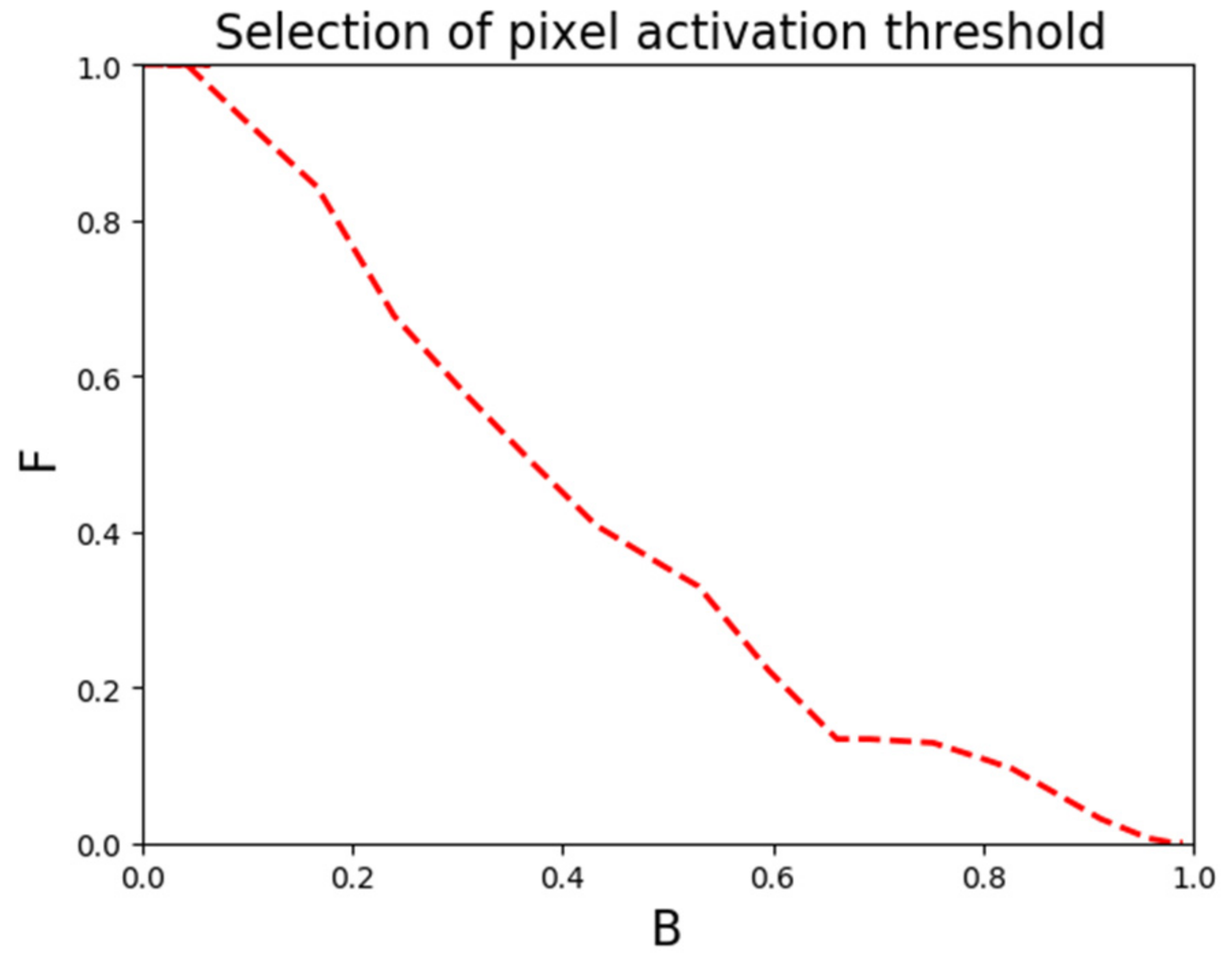
3.2.4. Obtain the Pixel Activation Threshold
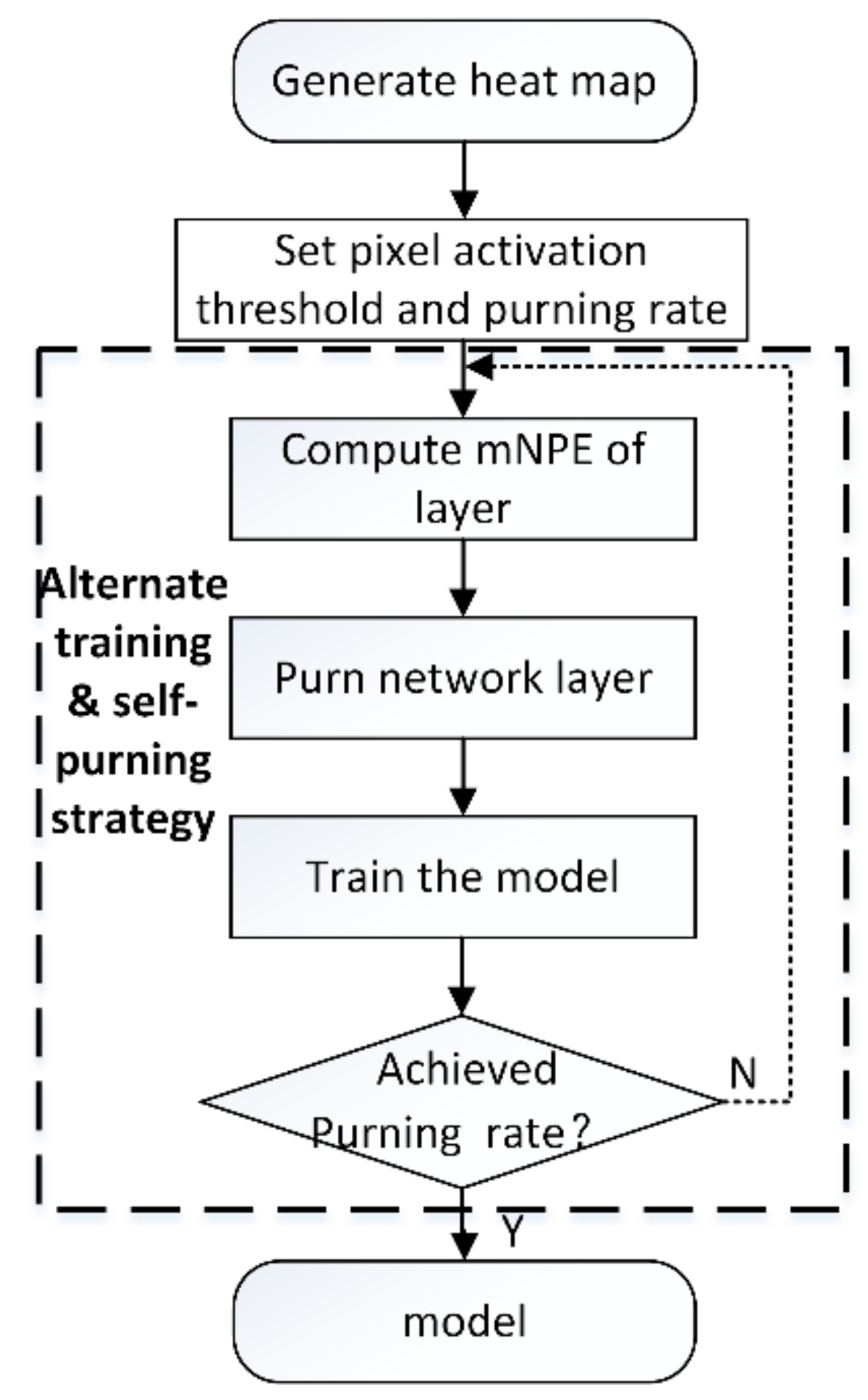
3.3. Alternating Training and Self-Pruning Strategy
- (1)
- Heat map generation. The Score-CAM algorithm is applied to obtain a heat map of the network layer that you want to evaluate.
- (2)
- Set the pixel activation threshold and pruning rate. Pixel activation thresholds are selected when F and B are approximately equal. The pruning rate is the ratio of the number of layers pruned to the total number of layers in the model. The number of layers to prune is determined by the pruning rate. In this paper, 10%, 20% and 30% are chosen as the pruning rates.
- (3)
- Calculate the mNPE of the network layer. When there is no target in the input image, the performance evaluation index of the network layer is all 0. It is impossible to compare the performance of the network layer. In order to reduce the chance of the input image, input n infrared images. Each network layer in the model to obtain n NPE, and calculate the average of n NPE as mNPE of the network layer.
4. Results
4.1. Overview
4.2. Experimental Details
4.2.1. Datasets
4.2.2. Experimental Environment
4.2.3. Experimental Performance Evaluation Metrics
4.3. Discussion
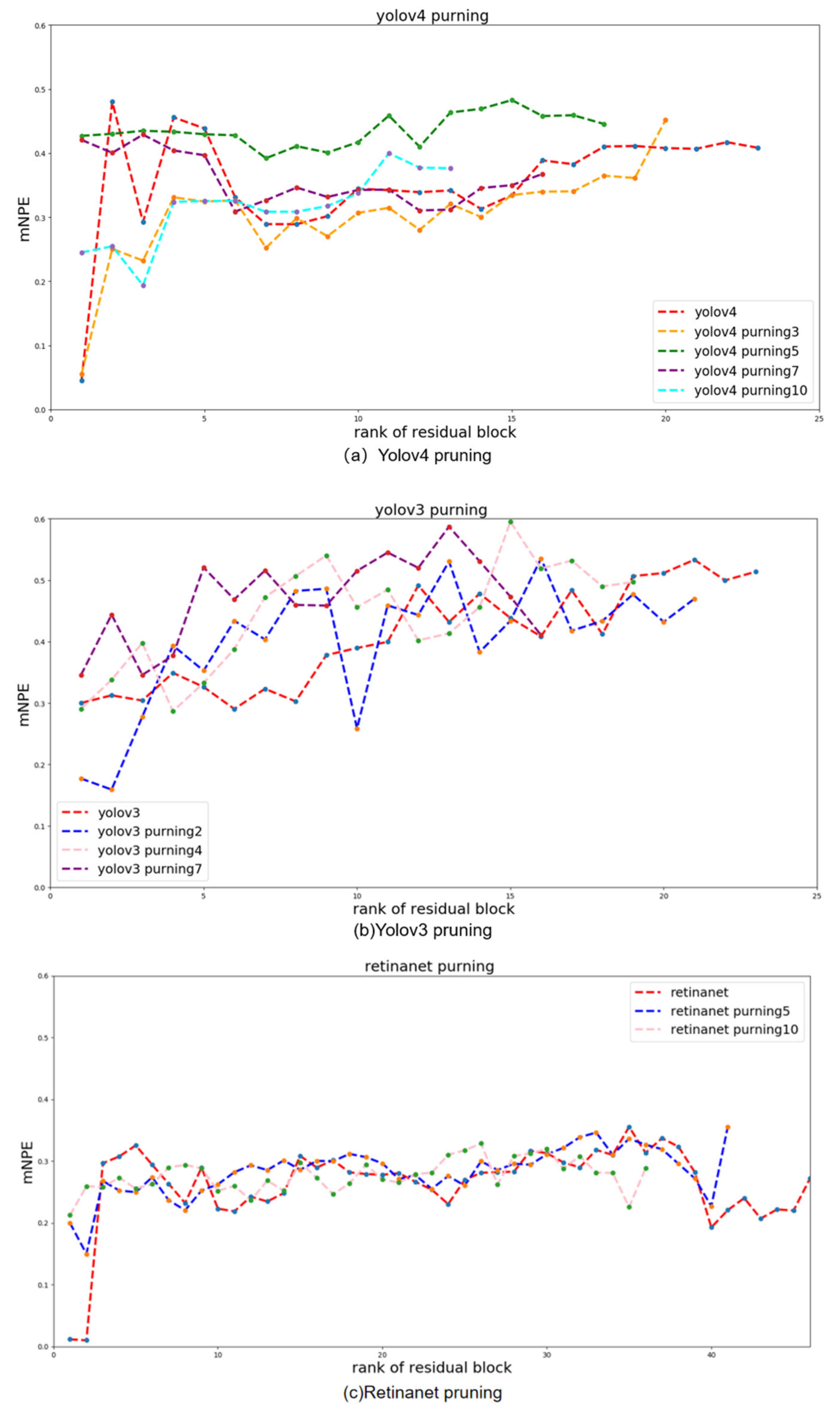
4.3.1. Ablation Experiments
4.3.2. Comparison Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision ICCV, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Liang, Y.; Huang, H.; Cai, Z.; Hao, Z.; Tan, K.C. Deep infrared pedestrian classification based on automatic image matting. Appl. Soft Comput. 2019, 77, 484–496. [Google Scholar] [CrossRef]
- Banan, A.; Nasri, A.; Taheri-Garavand, A. Deep learning-based appearance features extraction for automated carp species identification. Aquac. Eng. 2020, 89, 102053. [Google Scholar] [CrossRef]
- Sun, W.; Wang, R. Fully convolutional networks for semantic segmentation of very high resolution remotely sensed images combined with DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Gai, W.; Qi, M.; Ma, M.; Wang, L.; Yang, C.; Liu, J.; Bian, Y.; de Melo, G.; Liu, S.; Meng, X. Employing Shadows for Multi-Person Tracking Based on a Single RGB-D Camera. Sensors 2020, 20, 1056. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rasoulidanesh, M.; Yadav, S.; Herath, S.; Vaghei, Y.; Payandeh, S. Deep Attention Models for Human Tracking Using RGBD. Sensors 2019, 19, 750. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, Q.; Remil, O.; Guo, Y.; Wang, M.; Wei, M.; Wang, J. Object detection and tracking under occlusion for object-level RGB-D video segmentation. IEEE Trans. Multimed. 2017, 20, 580–592. [Google Scholar] [CrossRef]
- Kowalski, M.; Grudzień, A. High-resolution thermal face dataset for face and expression recognition. Metrol. Meas. Syst. 2018, 25, 403–415. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Liu, J.; Zhuang, B.; Zhuang, Z.; Guo, Y.; Tan, M. Discrimination-aware network pruning for deep model compression. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 99, 1. [Google Scholar] [CrossRef] [PubMed]
- Yu, R.; Li, A.; Chen, C.-F.; Lai, J.-H.; Morariu, V.I.; Han, X.; Gao, M.; Lin, C.-Y.; Davis, L.S. Nisp: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9194–9203. [Google Scholar]
- Molchanov, P.; Mallya, A.; Tyree, S.; Frosio, I.; Kautz, J. Importance Estimation for Neural Network Pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) IEEE, Long Beach, CA, USA, 15–20 June 2020. [Google Scholar]
- Huang, Z.; Wang, N. Data-driven sparse structure selection for deep neural networks. arXiv 2018, arXiv:1707.01213. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1389–1397. [Google Scholar]
- Zeng, W.; Xiong, Y.; Urtasun, R. Network Automatic Pruning: Start NAP and Take a Nap. arXiv 2021, arXiv:2101.06608. [Google Scholar]
- Luo, J.-H.; Zhang, H.; Zhou, H.-Y.; Xie, C.-W.; Wu, J.; Lin, W. Thinet: Pruning cnn filters for a thinner net. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2525–2538. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Luo, H.J.; Wu, J. Neural Network Pruning with Residual-Connections and Limited-Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) IEEE, Seattle, WA, USA, 13–19 June 2020; pp. 13–19. [Google Scholar]
- Zhang, W.; Wang, J.; Guo, X.; Chen, K.; Wang, N. Two-Stream RGB-D Human Detection Algorithm Based on RFB Network. IEEE Access 2020, 8, 123175–123181. [Google Scholar] [CrossRef]
- Zhang, W.; Guo, X.; Wang, J.; Wang, N.; Chen, K. Asymmetric Adaptive Fusion in a Two-Stream Network for RGB-D Human Detection. Sensors 2021, 21, 916. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhu, X. Vehicle Detection in the Aerial Infrared Images via an Improved Yolov3 Network. In Proceedings of the 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 372–376. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedntam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 839–847. [Google Scholar]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Mardziel, P.; Hi, X. Score-CAM: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 24–25. [Google Scholar]
- Li, C.; Cheng, H.; Hu, S.; Liu, X.; Tang, J.; Lin, L. Learning collaborative sparse representation for grayscale-thermal tracking. IEEE Trans. Image Processing 2016, 25, 5743–5756. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Zhuang, L.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the Value of Network Pruning. arXiv 2019, arXiv:1810.05270. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Network | Precision (%) | Recall (%) | Map (%) | F1 (%) | Time (ms) |
|---|---|---|---|---|---|---|
| Experiment 1 | yolov4(Baseline) | 0.735 | 0.885 | 0.899 | 0.803 | 5.7 |
| Experiment 2 | yolov4 pruning3 | 0.738 | 0.891 | 0.906 | 0.807 | 5.6 |
| Experiment 3 | yolov4 pruning5 | 0.926 | 0.825 | 0.914 | 0.872 | 5.6 |
| Experiment 4 | yolov4 pruning7 | 0.76 | 0.893 | 0.908 | 0.821 | 5.5 |
| Experiment 5 | yolov4 pruning10 | 0.907 | 0.819 | 0.899 | 0.861 | 5.4 |
| Experiment 6 | yolov3(Baseline) | 0.81 | 0.918 | 0.927 | 0.861 | 5.5 |
| Experiment 7 | yolov3 pruning2 | 0.951 | 0.913 | 0.93 | 0.93 | 5.4 |
| Experiment 8 | yolov3 pruning4 | 0.798 | 0.916 | 0.925 | 0.853 | 4.9 |
| Experiment 9 | yolov3 pruning7 | 0.83 | 0.92 | 0.932 | 0.873 | 4.6 |
| Experiment 10 | retinanet(Baseline) | 0.85 | 0.808 | 0.807 | 0.828 | 78.2 |
| Experiment 11 | retinanet pruned5 | 0.818 | 0.812 | 0.861 | 0.815 | 70.7 |
| Experiment 12 | retinanet pruned10 | 0.801 | 0.812 | 0.837 | 0.807 | 64.8 |
| Method | Model | GFLOPs | Params (107) | Error, % |
|---|---|---|---|---|
| Taylor-FO-BN-72% [18] | ResNet-50 | 1.34 | 0.79 | 28.31 |
| NISP -50-B [17] | ResNet-50 | 2.29 | 1.43 | 27.93 |
| ThiNet-72 [22] | ResNet-50 | 2.58 | 1.69 | 27.96 |
| Taylor-FO-BN-82% [18] | ResNet-34 | 2.83 | 1.72 | 27.17 |
| Li et al. [33] | ResNet-34 | 2.76 | 1.93 | 27.8 |
| Taylor-FO-BN-50% [18] | VGG11-BN | 6.93 | 3.18 | 30 |
| Slimming [19], from [34] | VGG11-BN | 6.93 | 3.18 | 31.38 |
| Method | Model | Precision | Recall | Map | F1 | Pruning Rate |
|---|---|---|---|---|---|---|
| Taylor-FO-BN [18] | retinanet | 0.86 | 0.703 | 0.824 | 0.774 | 10% |
| proposed | retinanet | 0.818 | 0.812 | 0.861 | 0.815 | 10% |
| Taylor-FO-BN [18] | yolov4 | 0.76 | 0.893 | 0.901 | 0.821 | 10% |
| proposed | yolov4 | 0.915 | 0.814 | 0.908 | 0.862 | 10% |
| Taylor-FO-BN [18] | yolov3 | 0.917 | 0.875 | 0.93 | 0.896 | 10% |
| proposed | yolov3 | 0.951 | 0.913 | 0.93 | 0.93 | 10% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Wang, N.; Chen, K.; Liu, Y.; Zhao, T. A Pruning Method for Deep Convolutional Network Based on Heat Map Generation Metrics. Sensors 2022, 22, 2022. https://doi.org/10.3390/s22052022
Zhang W, Wang N, Chen K, Liu Y, Zhao T. A Pruning Method for Deep Convolutional Network Based on Heat Map Generation Metrics. Sensors. 2022; 22(5):2022. https://doi.org/10.3390/s22052022
Chicago/Turabian StyleZhang, Wenli, Ning Wang, Kaizhen Chen, Yuxin Liu, and Tingsong Zhao. 2022. "A Pruning Method for Deep Convolutional Network Based on Heat Map Generation Metrics" Sensors 22, no. 5: 2022. https://doi.org/10.3390/s22052022
APA StyleZhang, W., Wang, N., Chen, K., Liu, Y., & Zhao, T. (2022). A Pruning Method for Deep Convolutional Network Based on Heat Map Generation Metrics. Sensors, 22(5), 2022. https://doi.org/10.3390/s22052022