In our experiments we used five different types of volatile species with different concentrations. They are acetone, methanol, ethanol, benzene, and isopropanol. The data set for these volatile species is made up of samples in R7 space where each sample correspond to the outputs of the gas and auxiliary sensors.
4.1. Samples Preparation
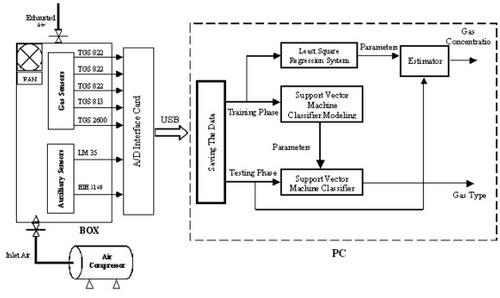
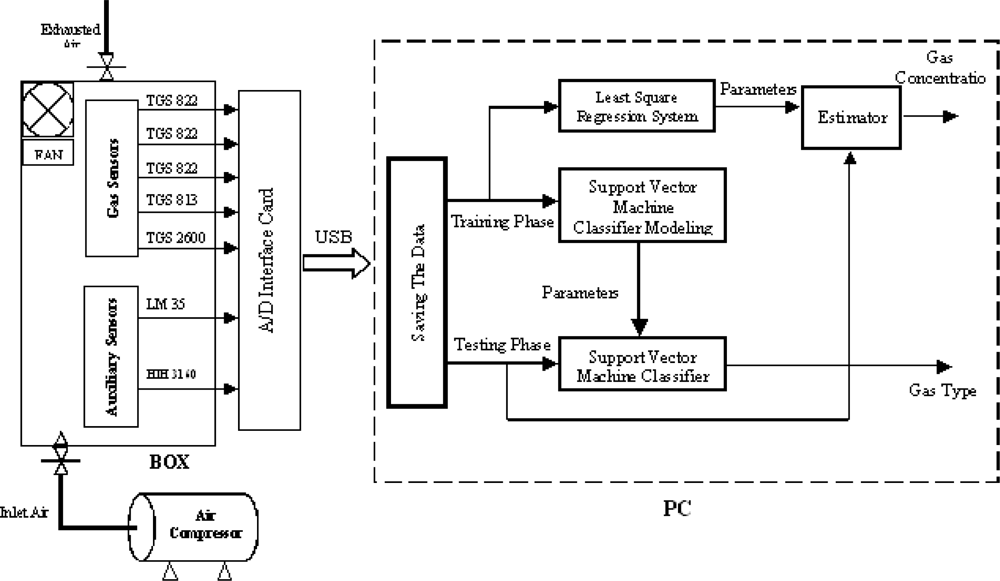
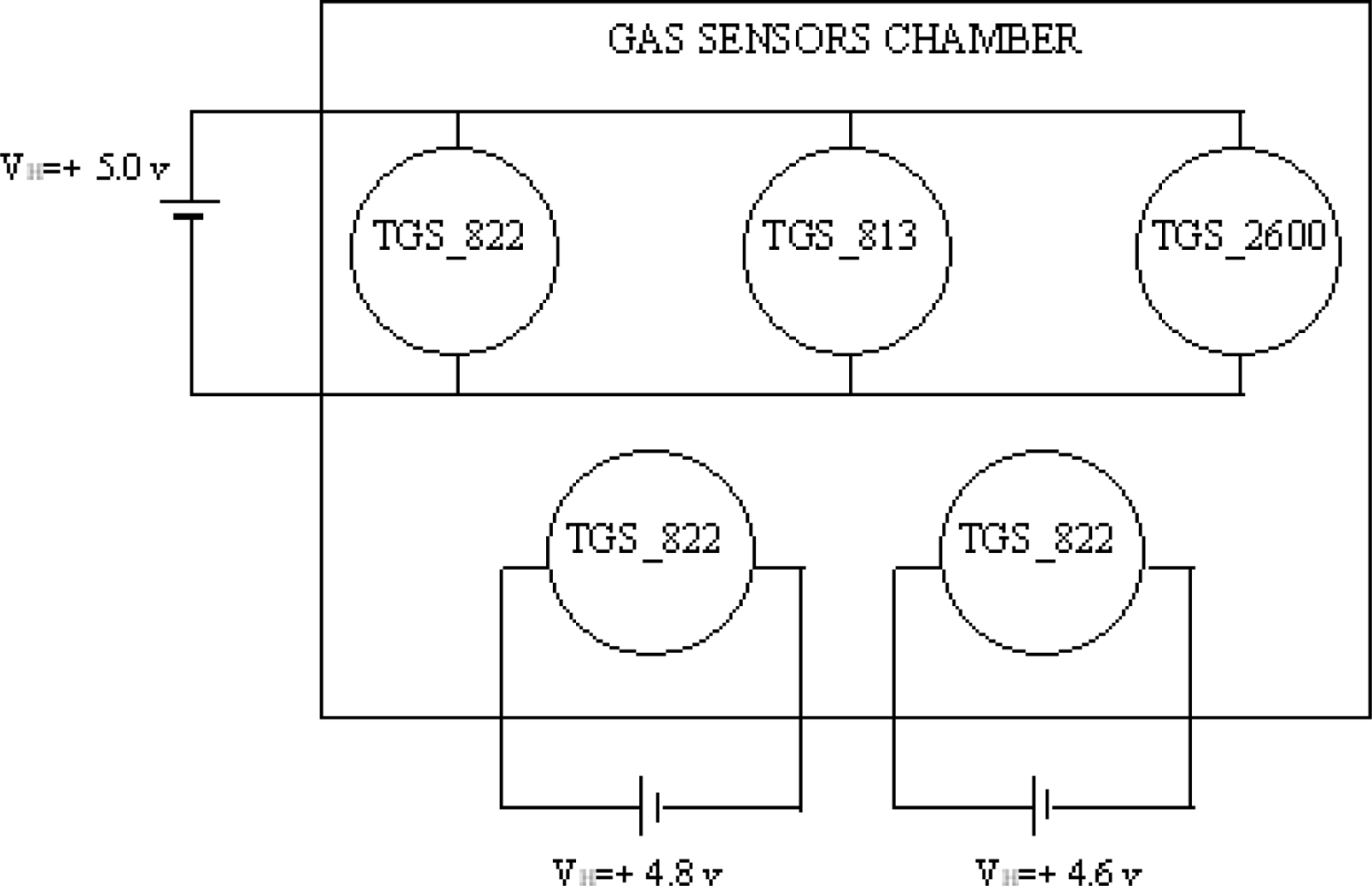
Our box contains the PCB (Printed Circuit Board) where we fixed two different types of sensors, i.e. gas sensors and auxiliary sensors. It also contains a fan for circulating the analyte inside during the test. The system encompasses one input for inlet air coming from an air compressor which has been used to clean the box and the gas sensors after each test. One output is used for the exhaust air. The inner dimensions of the box are 22 cm length, 14.5 cm width, and 10 cm height, while the effective volume is 3,000 cm
3. The amount of volatile compounds needed to create the desired concentration in the sensor chamber (our box) was introduced in the liquid phase using a high-precision liquid chromatography syringe. Since temperature, pressure and volume were known, the liquid needed to create the desired concentration of volatile species inside the box could be calculated using the ideal gas theory, as we explain below. The analyte concentration versus analyte volume injected is shown in
Table 1.
A syringe of 10 μL is used for injecting the test volatile compounds. We take methanol as an example for calculating the ppm (parts-per-million) for each compound. Methanol has a molecular weight
MW = 32.04 g/mol and density ρ = 0.7918 g/cm
3. The volume of the box is 3,000 cm
3; therefore, for example, to get 100 ppm inside the box, from
Table 1, we used 0.3 cm
3 of methanol.
The density of methanol is
Where:
∂ = the density of the gas of Methanol in g/L,
P = the Standard Atmospheric Pressure (in atm) is used as a reference for gas densities and volumes (equal 1 atm),
MW = Molecular Weight in g/mol,
R = universal gas constant in atm/mol.K (equal 0.0821 atm/mol.K),
T = temperature in Kelvin (TK = TC + 273.15).
As a result we get d = 1.33 g/L.
where
vgas is the volume occupied by the gas of methanol which is equal to 0.3*10
−3 l, ∂ is the density of the gas of Methanol as calculated before, ρ is the constant density of methanol, therefore;
vliq = (
vgas × ∂) / ρ ⇒
vliq = (0.3 * 10
−3 * 1.33) / 0.7918, the volume (
vliq) is 0.503*10
−6 l which provides 100 ppm of methanol. This means that if we want to get 100 ppm of methanol we must put 0.503 μL of liquid methanol in the box by using the syringe.
Table 2 shows different concentrations of Methanol (in ppm) versus its quantities (in μL).
4.2. Results
In the first analysis, we used a SVM with linear kernel, and we applied a multi-class classification by using the LIBSVM-2.82 package [
16]. The optimal regularization parameter
C was tuned experimentally by minimizing the leave-one-out cross-validation error over the training set.
In fact the program was trained as many times as the number of samples, each time leaving out one sample from training set, and considering such omitted sample as a testing sample check the classification correctness. The classification correctness rate is the average ratio of the number of samples correctly classified and the total number of samples. The results are shown in
Table 3 for different values of
C. We used 22 concentration samples for acetone, 22 for benzene, 20 for ethanol, 23 for isopropanol, and 21 for methanol. For each concentration the experiment was repeated twice, thus a total number of 216 classification calculations was performed.. By using linear kernel we got 100.00% classification correctness rate for C = 1,000 adopting a leave-one-out cross-validation scheme. We remark that such results are better than those obtained by supplying all sensors by the same heater voltage (in such case, in fact, the best classification correctness rate was 94.74%).
Once the classification process has been completed, the next step is to estimate the concentration of the classified analyte. To this aim, we use the least square regression approach. We build an approximation of the response (sensor resistance versus analyte concentration) for each sensor and each analyte. Then we use this approximation to find the concentration for each analyte type.
For sintered
SnO2 gas sensor, the concentration dependence of the response to a simple analyte exposure is nonlinear and can be described by a power law of the form [
23]
where
R is the sensor resistance,
δ a constant,
c the concentration of the analyte and ω an index that lies between 0.3 and 1.0. We applied this equation on all sensors for each analyte. The values of
δ ‘s and ω ‘s, are calculated as follows:
where
ω ≡ Ω,
δ ≡ exp(Δ) and
n is the number of samples, which are indexed by
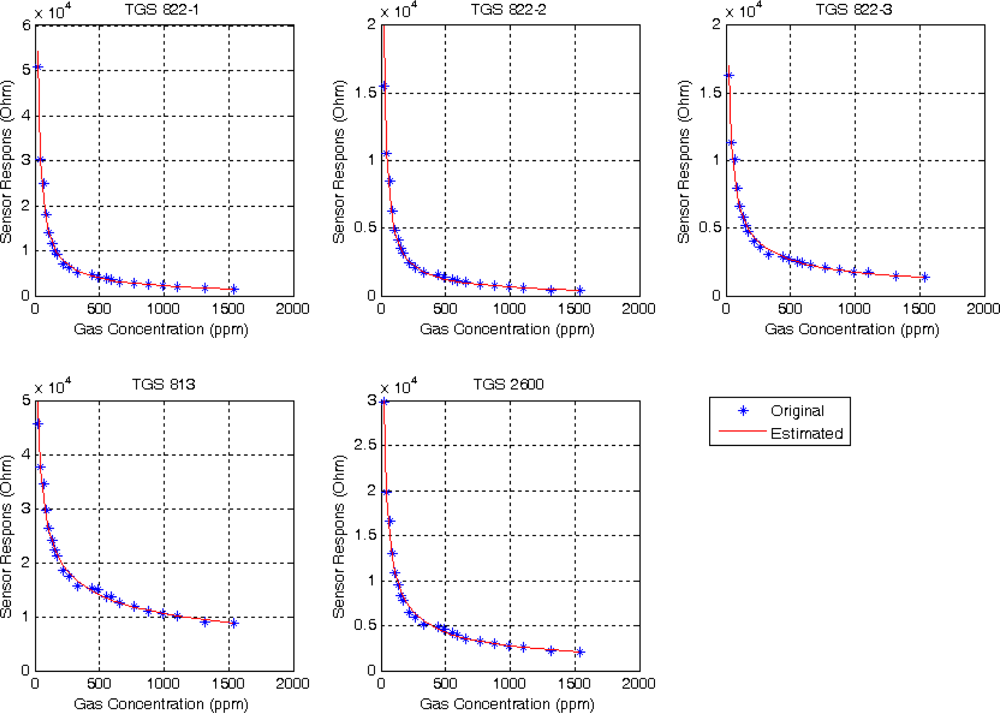
i.Figure 3 shows, as an example, the original concentrations with respect to their sensor resistances, as well as the estimated curve for the analyte acetone. We have five curves, one for each sensor.
The optimal estimate of the concentration is in our model a combination of the outputs of the diverse sensors. We have adopted the least square regression model to find the optimal weights on the basis of the experimental data. We come out in our experiments with five measures for each analyte sample. The weights α’s are obtained by solving the following minimization problem :
where
n is the number of analyte samples,
c̄ is the true concentration,
M is the number of sensors (in our case
M = 5),
c the concentrations that have been previously calculated (from
equation 8).
Tables 4–
8 show the real concentrations with respect to the results of the proposed method. For comparison purposes we add in the table also the results obtained by simply averaging the outcomes provided by the five sensors.
Finally we considered (
Table 9) the correlation coefficient (
C.C) as a measure for the estimation accuracy [
8]. The correlation coefficient is a number between 0.0 and 1.0. If there is no relationship between the predicted values and the actual values the correlation coefficient is 0.0 or very low (the predicted values are no better than random numbers). As the strength of the relationship between the predicted values and actual values increases so does the correlation coefficient. A perfect fit gives a coefficient of 1.0. Thus the higher correlation coefficient (near to 1.0) the better is the regressor [
7]. The correlation coefficient is calculated as follows:
where
C.C is the correlation coefficient,
X are the actual values,
X̂ are the predicted values, and
n is the number of data points.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}