1. Introduction
Wireless sensor networks (WSNs) have received attention increasingly in recent years. First, the sensor nodes can probe and collect environmental information, such as temperature, atmospheric pressure and irradiation by providing ubiquitous sensing, computing and communication capabilities. Second, thanks to the development of sensor node hardware technologies, the cost of sensor nodes has declined rapidly. This makes it possible to deploy large scale WSNs [
1]. WSNs are similar to mobile
ad-hoc networks (MANETs) in that they both involve multi-hop communications. However, there are two main differences. First, when an event occurs, multiple sensor nodes (denoted as data source nodes) around the event will transmit the sensed data back to one sensor node (denoted as the sink node). This is a
multipoint-to-point mode, distinct from the communication between any pair of two nodes in MANETs. Second, since data are collected by multiple data source nodes and sent back to one sink node, it results in redundant data received by the relay node. Each relay node could collect and process these received data and transmit only one copy of the data back to the sink in such a way to save energy, if the data can be aggregated by nature. This kind of energy saving routing by redundant data elimination is known as the data aggregation routing. Besides redundant data elimination, other possible data aggregation function including maximum (MAX), minimum (MIN) and average (AVG) functions.
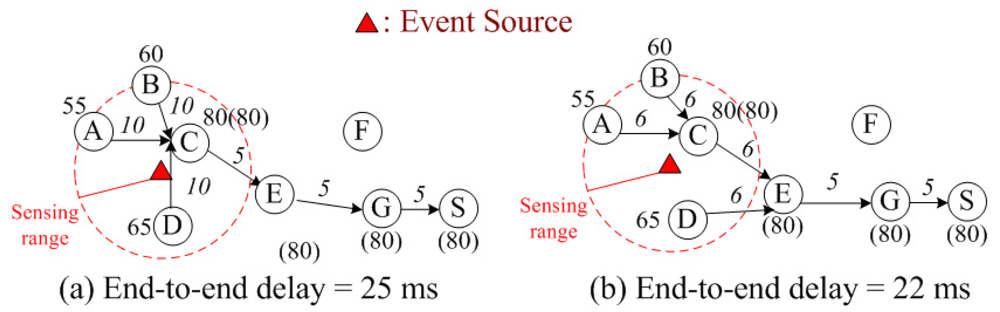
Figure 1 gives an illustrative example of returning the maximum temperature back to the sink node. The union of the routing paths from the data source nodes (i.e.,
A, B, C, D) back to the sink (i.e.,
S) constitutes the data aggregation tree. The number beside the node indicate the sensed temperature (in °F), and the number in parenthesis is the maximum temperature collected so far. Hence, node
E, which is the relay node in the data aggregation tree, sends only the maximum temperature (80°F) from its children nodes (i.e.,
C and
D) to node
G to save energy. Note that the number (in mini-second) beside the link is the link delay (including the transmission delay for sending data and the latency from retransmission(s)), which will be described more clearly in
Equation (4) in Section II.
Since each sensor node is powered by a battery and the exchange of batteries at the depleted sensor nodes is unlikely, data aggregation routing has been put forward as a particularly useful function for routing in terms of energy consumption in WSNs [
2,
3]. By data aggregation, redundant data could be eliminated. Based on this idea, energy-efficient routing is to encourage data aggregation as much as possible. However, the more flows are aggregated, the higher is the probability that the senders will experience data retransmissions [
3].
In WSNs, any sensor node that is within another's interference range trying to transmit simultaneously would result in collisions. When collisions occur, retransmissions are required to ensure that the data be successfully received. These retransmissions result in additional energy consumption. Beside additional energy consumption, extra latency from retransmissions increases the link delay. Because of this extra latency for each link delay, the end-to-end delay from data source nodes back to the sink node will be increased.
For example, in
Figure 1(a), the sensed data from three nodes (
A, B and
D) are aggregated at node
C and then sends only one copy of data to node
E. Because three nodes are aggregated at node
C, the extra latency from retransmissions makes the link delay link
BC̅ (10 ms) larger than the link delay at
Figure 1(b) (6 ms) where there are only two nodes aggregated at node
C. Hence, from the delay QoS perspective, we should not perform too much data aggregation so as to meet the delay QoS requirement of the WSN. Besides the delay QoS requirement itself, the longer the end-to-end delay becomes, the larger the energy consumption will be caused for sensor nodes operating in the idle mode to wait for data from downstream nodes in the data aggregation tree. For example, in
Figure 1(a), node
E will operate in the idle mode for 15 ms to wait for data from nodes
A, B, C and
D. In
Figure 1(b), node
E will operate in the idle mode for 12 ms. Hence, in
Figure 1(a), node
E will consume more energy to operate in the idle mode than in
Figure 1(b). The above example indicates that retransmissions introduce additional
energy consumption and
delay, which will jeopardize the advantages of data aggregations. An effective data aggregation algorithm should optimize the trade-off between energy saving from redundant data elimination and extra energy loss and additional delay from data retransmissions.
Basically, there are two operating stages (active stage and sleep stage) for sensor nodes in WSNs. In the sleep stage, a sensor node will turn off its transceiver so that there is no power consumption. Whereas, in the active stage, a sensor node could either transmit data or listen from other sensor nodes. To facilitate data communication, the sensor nodes in the data aggregation tree should be in the active stage, and all the nodes that are not included in the data aggregation tree (e.g., node
F in
Figure 1) are in the sleep stage to save energy. When a sensor node is transmitting data, it is in the transmission mode. When a sensor node is listening from other sensor nodes, it is in the idle mode. According to [
4], the energy consumption for a sensor operating in the idle mode is slightly less than that of a sensor operating in the transmission mode. Hence, to capture the real energy consumption in WSNs, we should not only consider energy consumption in the transmission mode but also account for energy consumption in the idle mode.
When a sensor node in a data aggregation tree waits for data from the downstream nodes, this sensor node would operate in the idle mode during the waiting time (which is the maximum end-to-end delay from the farthest downstream node). For example, in
Figure 1(a), node
G would spend 20 (= 10 + 5 + 5) ms to operate in the idle mode to wait for data transmissions from its farthest downstream nodes (i.e.,
A and
B) and then would spend 5 ms to operate in the transmission mode for data transmission. In this case, we observe that the power consumption in the idle mode is larger than that in the transmission mode. In addition, the additional retransmission latency that increases the end-to-end delay would make sensor nodes take longer time to operate in the idle mode, which in turn makes larger energy consumption. Therefore, the advantages of minimizing the end-to-end delay in WSNs include not only satisfying the delay QoS requirements of emergent events or real-time traffic but also minimizing the total energy consumption implicitly.
Intensive research has been conducted on data aggregation routing, but the important MAC layer retransmission issue as described above has been relatively seldom addressed. Krishnamachari [
5] devises three interesting suboptimal aggregation heuristics, called Shortest Paths Tree (SPT), Center at Nearest Source (CNS), and Greedy Incremental Tree (GIT), respectively. In the SPT scheme, each data source node finds the shortest path back to the sink node. The CNS scheme selects one node that is the nearest to the sink node as the aggregation node and other data source nodes connect to this aggregation node by using respective shortest hop paths. And in the GIT scheme, initially the member(s) in the tree is only the sink node. Each data source finds a shortest hop path to this tree and the data sources with the minimum hop along with the intermediate nodes on this path are included in this tree. This process is repeated until all data source nodes are included in the tree. In [
6], they propose centralized heuristic based on the Prim's minimal cost spanning tree algorithm to construct a data aggregation tree. This heuristic incorporates residual energy of sensor nodes into the Prim's algorithm in order to prolong the lifetime of sensor nodes. In [
2], they propose a rigorous mixed integer mathematical formulation for the data aggregation routing problem and propose solution approaches based on Lagrangean relaxation.
Several works have addressed the MAC aware data aggregation routing problem in WSNs. In [
3], they study the energy consumption tradeoffs between the data aggregation and retransmission in wireless sensor network by using the Carrier Sense Multiple Access with Collision Avoidance (CSMA/CA) MAC protocol. However, in this work, the energy consumption function does not consider the power consumption in idle mode that makes the proposed algorithm might not get the real energy efficient data aggregation tree. In addition, retransmission latency is not considered in [
3] so that it does not guarantee the delay QoS. In [
7], the authors propose the MAC Anycasting protocol to achieve spatial convergence, and the Randomized Waiting protocol to achieve the temporal convergence. These spatial convergence and temporal convergence properties maximize the advantages of data aggregation in Structure-free (i.e., no pre-constructed network structure) wireless sensor networks. In [
8,
9], the retransmission problem is circumvented by assigning different channels to the sensor nodes within each other's interference range. They devise interesting heuristics to tackle the data aggregation routing and channel assignment simultaneously.
Several works have addressed the latency issue for data aggregation in WSNs. In [
10], they study the tradeoff between data aggregation and latency in WSNs. Data aggregation tree is constructed by using the earliest-first, randomized, nearest-first and weighted-randomized to identify the parent node to relay the data from the data source node back to the sink node. Then assign different time slot to every sensor node on data aggregation tree that has the same parent node without collision but with the penalty of large latency. In [
11], they consider the latency issue in constructing a minimum energy data aggregation tree. A data aggregation tree is a balanced binary tree where initially the sink node finds the nearest two sensor node as its children, and each children node identify another two nearest node as its children node. This process is repeated until all data source nodes are included in this balanced data aggregation tree. After the data aggregation tree is determined, channel assignment is performed to minimize latency and transmission power. A similar idea is also shown in [
12]. However, restricting the data aggregation tree to be the balanced binary tree might lead to long data aggregation tree that has larger end-to-end delay and energy consumption.
How to minimize the energy consumption of MAC-aware data aggregation routing in WSNs under end-to-end delay QoS constraints (denoted as the E2EDAR problem) is challenging. To the best of our knowledge, there is no existing literature addressing this E2EDAR problem. In this paper, for the first time, we address the interplay between the advantages of data aggregation (i.e., redundant data elimination) and the disadvantages of data aggregation (i.e., retransmission) to meet the delay QoS requirement and in the same time to achieve energy efficient routing which considers the energy consumption in transmission mode and in idle mode.
We propose an optimization-based heuristics to solve this E2EDAR problem. The problem is first formulated as an integer and non-convex mathematical programming problem where the objective function is to minimize total power consumption (includes data transmission power and the power consumption in idle time to wait data from downstream nodes) subject to data aggregation tree, transmission power coverage and end-to-end delay. Then Lagrangean relaxation scheme in conjunction with the optimization-based heuristics is proposed to solve this problem. From the computational experiments, the proposed solution approaches outperform the existing heuristics.
The remainder of this paper is organized as follows. In Section 2, a mathematical formulation of the E2EDAR is proposed. In Section 3, solution approaches based on Lagrangean relaxation are presented. In Section 4, heuristics are developed for calculating good primal feasible solution. In Section 5, computational results are reported. Finally, Section 6 concludes this paper.
3. Solution Approach–Lagrangean Relaxation
The algorithm development is based upon Lagrangean relaxation. In (IP), by introducing Lagrangean multiplier vectors
u1, u2, u3, u4, u5, u6, u7, and
u8, we dualize
Constraints (6),
(8),
(11),
(12),
(13),
(14),
(26), and
(27) to obtain the following Lagrangean relaxation problem (LR). Basically, the more constraints are relaxed, the looser duality gap between the solutions to the dual problem and the primal problem. Loose duality gap might indicate that the solution to the primal problem might be too far from the optimal solution. On the other hand, if too little constraints are relaxed, we might not be able to solve the Lagrangean dual problem optimally. Then the solution to the dual problem is not a legitimate lower bound of the primal problem. As will be shown in the following paragraph, by relaxing these eight constraints in (P), the resulting (LR) problem can be further decomposed into a number of mutually independent and easily solvable subproblems, which is essential for effectively solving the dual problem so as to obtain tight lower bounds.
Problem (LR)
(LR) is then decomposed into the following 6 independent subproblems.
Subproblem 1: for
mnsubject to (23).
Subproblem 2: for
y(n,k)subject to (7), (10) and (18).
Subproblem 3: for
xspsubject to (9) and (17).
Subproblem 4: for
rn and
cnksubject to (20), (21) and (22).
Subproblem 5: for
znksubject to (19).
Subproblem 6: for
l(n,k)subject to (28).
(SUB1) can be further decomposed into |
N| independent subproblems. For each node
n∈
N,
subject to:
B ≥ mn ≥ 0.
When the coefficient of mn (i.e.,
) is positive, let mn = 0. When the coefficient of Cl (i.e.,
) is negative, let mn = B. The computational complexity for this algorithm is O(1) for each node n.
Subproblem 2 is to determine decision variable y(n,k).
The proposed algorithm to optimally solve (SUB2) is shown as follows.
Step 1. For every link (n, k), compute the coefficient
for each y(n,k). Then calculate the number of links whose coefficients are negative.
Step 2. For all outgoing links of node n, identify the link with the smallest coefficient. If the smallest coefficient is negative then set the corresponding y(n,k) to be 1 and the other outgoing links y(n,k) to be 0, otherwise set all outgoing link y(n,k) to be 0. Repeat Step 2 for all nodes.
Step 3. If the number of negative coefficient links (assume the number is θ) is smaller than max{hg, |Dg|}, assign the corresponding y(n,k) = 1 for these negative coefficient links. Then sort those links that have positive coefficient in ascending order. Identify {max{hg, |Dg|}–θ} number of smallest positive coefficient and let the corresponding y(n,k) = 1. Finally, let the other y(n,k) =0.
The computational complexity of the above algorithm is O(|N|2).
(SUB3) can be further decomposed into |S| independent shortest path problems with nonnegative arc weight whose value is
. For each shortest path problem it can be effectively solve by the Dijkstra's algorithm. The computational complexity of the Dijkstra's algorithm is O(|N|2) for each data source node.
(SUB4) can be optimally solved by exhaustively searching all combinations of radius rn and cnk. The computational complexity of (SUB4) is therefore O(|Rn| ×|T|) for each node n.
In (SUB5), if the corresponding coefficient
of link (n, k) is negative then set znk to be 1, otherwise 0. The computational complexity of (SUB5) is O(1) for each link (n, k).
We can further decompose (SUB6) into |
N|
2 independent subproblems. For each link (
n, k),
subject to:
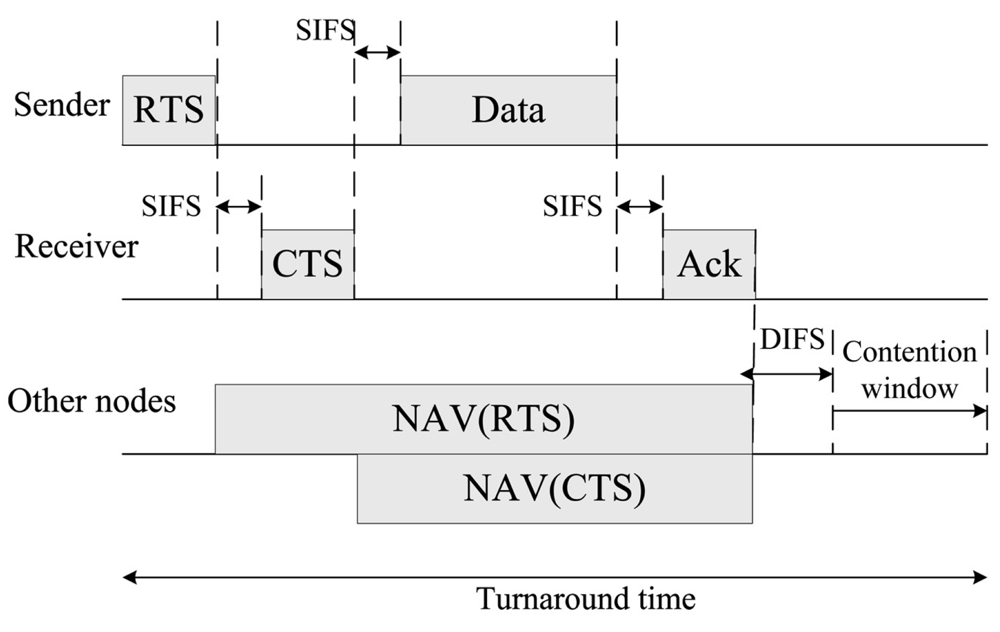
A ≥ l(n,k) e0.115·(RTS + SIFS + CTS + 330)
If
is negative then set
l(n,k) to be
e0.115·(
RTS +
SIFS +
CTS + 330). If
is positive then we can get the value of optimal value of
l(n,k) by the following procedure. Apply the first derivative with respect to
l(n,k) on the objective function of (SUB6.1) and let it be 0,
Then calculate the second derivative with respect to l(n,k) on the objective function of (SUB6.1).
Since the second derivative is larger than or equal to zero, the objective function of (SUB6.1) is a convex function. Then the optimal value of l(n,k) is either
or the boundary points (i.e., A or e0.115 (RTS + SIFS + CTS + 330)) that leads to the minimum value of objective function of (SUB6.1). The computational complexity of (SUB6.1) is O(1) for each link (n, k).
According to the algorithms proposed above, we could effectively solve the Lagrangean relaxation problem optimally. Based on the weak Lagrangean duality theorem,
ZD(
u1,u2,u3,u4,u5,u6,u7,u8) is a lower bound on
ZIP. We could calculate the tightest lower bound by using the Subgradient method [
15]. Note that the solutions to the dual problem may not be feasible for the primal problem due to the fact several constraints are relaxed. In the sequel, we propose a heuristic for getting the primal feasible solution.
4. Obtaining Primal Feasible Solutions
The basic idea of getting primal feasible solution (denoted as LGR-Primal) is first to identify the energy efficient data aggregation and then adjust the routing path to meet the end-to-end delay constraint. We choose the routing decision variables xsp from (SUB3) at the beginning to get good primal feasible solutions. Once the routing path xsp for each data source node s is determined, all the other decision variables, e.g., rn and ynk, can be calculated and the total energy consumption of the data aggregation tree can be obtained.
We perform rerouting algorithm to decrease the maximum end-to-end delay of the routing path for each data source node. The steps of the rerouting heuristic are as follows:
Identify the path (denoted as P) that incurs the maximum end-to-end delay.
Investigate nodes located on P one by one. For each checked node (denoted as n), examine each node (denoted as k) within the transmission radius of n. If the maximum end-to-end delay of node n plus the link delay, l(n,k), is smaller than the maximum end-to-end delay of node k, then reroute the outgoing link on the routing path of node n from the original routing link to the outgoing link (n, k). If no node k can be rerouted by n, then check the next node on P until the sink node is reached.
Update the decision variable y(n,k) and recalculate the maximum end-to-end delay of the new routing path.
If no node on path P can be rerouted, then stop the heuristic; otherwise, go to Step 1.
However, the union of the routing paths of all data source node might not be a data aggregation tree because the tree constraints [i.e.,
Constraints (6) and
(8)] are relaxed. We propose a drop heuristic to eliminate those links that form the cycle on the tree.
The algorithm for the drop heuristic is as follows:
Based on the solutions of (SUB3) we can get the set of decision variables, xsp, from which we can determine which link, ynk, is used on the routing path by source s. If ynk is 1, we set the arc weight of it corresponding link to be
; otherwise, we set the arc weight to be infinity.
According to the arc weight calculated in Step 1, we sort the links from small to large.
We sequentially remove the links from the largest arc weight to the smallest one, but we ignore the links with infinity costs. At the time when link, say link (n, k), is removed from the routing path, we need to check whether every source node still has a routing path to the sink node. If any source node is unable to reach the sink node after removing link (n, k), we restore link (n, k) onto the routing path. If every source still has a routing path to reach the sink node, we remove link (n, k) and investigate the next link with smaller arc weight until all the links used by the union of routing path xsp have been examined.
After executing the drop heuristic we get a data aggregation tree without any cycles. The computational complexity of this getting primal feasible heuristic (include rerouting and drop heuristic) is
O(|
S‖
N|
3). Note that the reasons that we choose
as the arc weight for performing drop heuristics is because these multipliers provide useful information for selecting the links. The first and the second term (i.e.,
u1 and
u2) indicate the tree violation cost. According to the Lagrangean multiplier update procedure [
15],
u1 and
u2 will be increased at the next iteration if the tree constraint (i.e.,
Constraints (1) and
(2)) is violated. Similarly,
u6 and
u7 will be increased at the next iteration if the link delay constraint [i.e.,
Constraints (14) and
(26)] is violated. Finally,
u8 will be increased at the next iteration if the retransmission times constraint [i.e.,
Constraint (27)] is violated. After several iterations, the links that violate these constraints will incur larger Lagrangean multipliers. Hence, by incorporating these multipliers into the arc weight setting, we try to drop the links that do not satisfy the tree, delay and retransmission constraints. In other words, by using the information from these Lagrangean multipliers, we get the energy efficient data aggregation tree with considering the
penalty cost from violating tree, delay and retransmission times constraints.
In the following, we show the complete algorithm (denoted as LGR) to solve Problem (P). The computational complexity of the above LGR algorithm is O(|N|4) for each iteration.
| Algorithm 1: The LGR Algorithm. |
| Begin |
| Input: Network topology, data source nodes, sink node and end-to-end delay QoS requirements |
| Output: Data aggregation tree |
| Initialize Lagrangean multiplier vectors ui(0) = 0, ∀i = 1,2,…,8. |
| UB = a very large positive number (e.g., M) and LB = a very small negative number (e.g., −M) //upper and lower bounds, respectively. |
| quiescence_age = 0, and step_size = 2. |
| For iteration = 1 to Max_Iteration_Number, perform the following: |
| Solve Subproblem 1, Subproblem 2, Subproblem 3, Subproblem 4, Subproblem 5 and Subproblem 6. |
| ComputeZLR in (LR). |
| If ZLR(u) > LB |
| LB = ZLR(u) and quiescence_age = 0. |
| Else quiescence_age = quiescence_age + 1. |
| If quiescence_age = Quiescence_Threshold |
| step_size = step_size/2 and quiescence_age = 0. |
| Run the LGR-Primal algorithm. |
| Compute the new upper bound ub. |
| If ub < UB then UB = ub. |
| Update the step_size. |
| Update the Lagrangean multiplier vectors. |
| End For |
| End |
5. Computational Experiments
The proposed algorithms for solving E2EDAR problem are coded in C and run on a PC with an INTEL™ PIV-2G CPU. Max_Iteration_Number and Improve_Threshold were set to 2,000 and 30, respectively. The step size coefficient, δ, is initialized as 2 and is halved when the objective function value of the dual problem is not improved in the number of Improve_Threshold iterations.
We assume that a sensor network operates in periodic mode where, the sensor nodes periodically report information to the sink node. The network topology comprises
N = 150 sensor nodes randomly placed in a 1 × 1 square unit area. The most top left node is selected as the sink node such that we could have a data aggregation tree with larger depth. The cost of the energy consumption function,
en(
rn) (in milliwatts), is defined as the {square of (100) × (Euclidean distance) × (energy consumption per millisecond when the sensor node is transmitting data)} (i.e., signal attenuation constant
α = 2). The energy consumption values for a sensor node in the transmitting mode and in the idle mode (i.e.,
Eidle) are all based on the experimental sensor node, MEDUSA, which is a low power sensor node developed by UCLA [
4]. The set of all possible transmission radii of a sensor node
n (i.e.,
Rn) is a discrete set and it is configured to begin from 0 to the maximum transmission radius with 0.01 step size. To evaluate the solution quality of our proposed algorithm, we implement four existing algorithms for comparison. The GIT and the CNS algorithms are proposed in [
5] and the third algorithm, CCA, is proposed in [
16]. The forth algorithm, LGRMAC, is proposed in [
3].
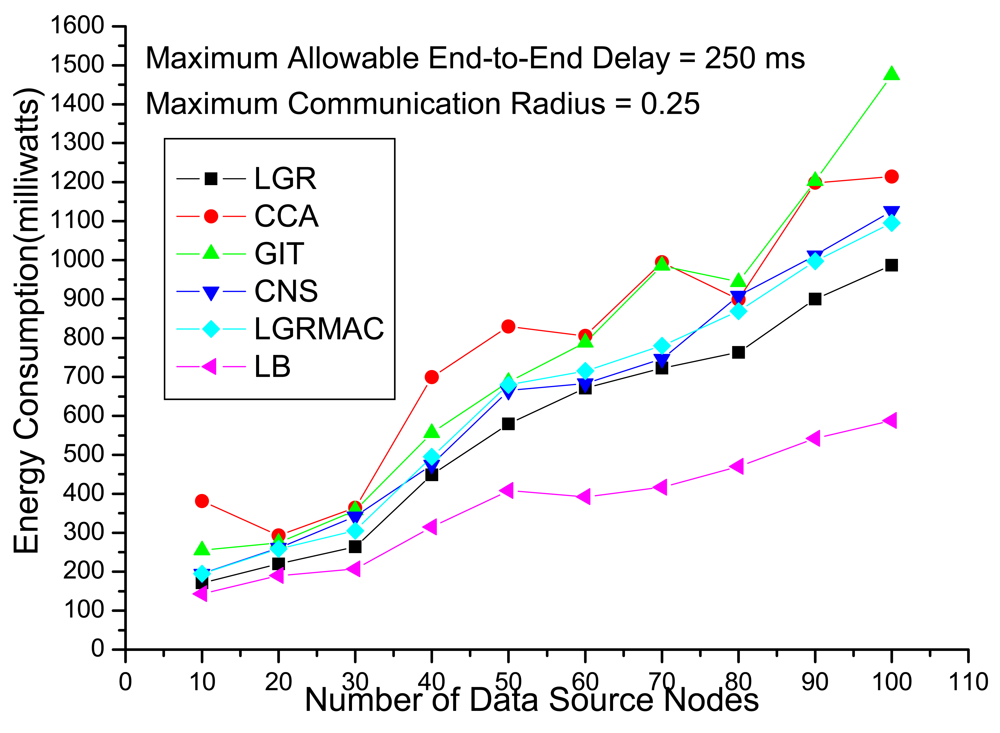
Figure 4 shows the total energy consumption with respect to the number of data source nodes under loose delay QoS requirements. Recall that in the objective function of (IP) (i.e.,
Equation (5)), the total energy function consists of energy consumption in transmissions (including data transmissions and retransmissions) and energy consumption in the idle period. For a data aggregation tree with a large delay, even though the delay constraint is not violated under loose delay QoS requirements, large energy consumption will still be incurred due to long idle time. The other heuristics (CCA, GIT, CNS and LGRMAC), that do not take the idle time energy consumption into account, may become less effective in calculating energy-efficient data-aggregation trees. On the other hand, the LGR algorithm that considers the penalty from delay and retransmissions can get the most energy-efficient data aggregation tree.
In
Figure 4, we also show the Lagrangean lower bounds (denote as LBs), which are theoretical lower bound on the optimal objective function value of the primal problem. The primal feasible solutions (i.e., LGR) are upper bound on the E2EDAR problem. Based on the weak Lagrangean duality theorem, the optimal solution must fall within the upper bound and the lower bound [
15]. The gap between LB and LGR is defined as (LGR – LB)/(LB) × 100%, which is an upper bound on how far LGR is from an optimal solution. It is observed that the gap is increasing with respect to the number of data source nodes, which is about 15% when the number of data source nodes is small and about 70% when the number of data source nodes becomes large.
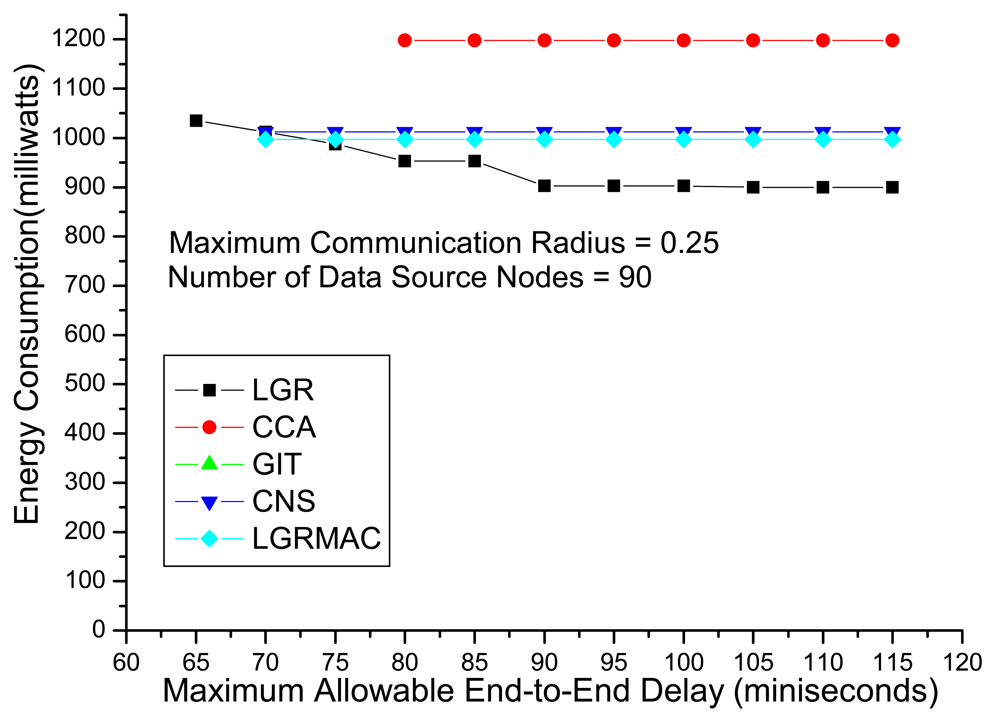
Figure 5 shows the energy consumption with respect to the maximum end-to-end delay (i.e.,
B). We observe that the CCA algorithm could obtain a feasible solution when
B = 80 ms, and
B = 70 ms for the CNS and the LGRMAC algorithms. The GIT algorithm could not identify any feasible solution even when
B = 115 ms. For the LGR algorithm, a feasible solution can be found even when
B = 65 ms. Besides LGR algorithm could locate feasible solution under stringent delay QoS requirements, the energy consumption is lower than the other heuristics under all maximum end-to-end delay. On the other hand, the CCA, the CNS and the LGRMAC heuristics always obtain the same data aggregation tree (i.e., energy consumption) regardless the value of the maximum allowable end-to-end delay. This is because these heuristics do not take the retransmission delay into consideration and only consider the energy consumption in the transmission mode. This kind of data aggregation design philosophy not only do not leverage on the loose delay QoS to minimize the total energy consumption but also is not applicable under stringent delay QoS requirements.
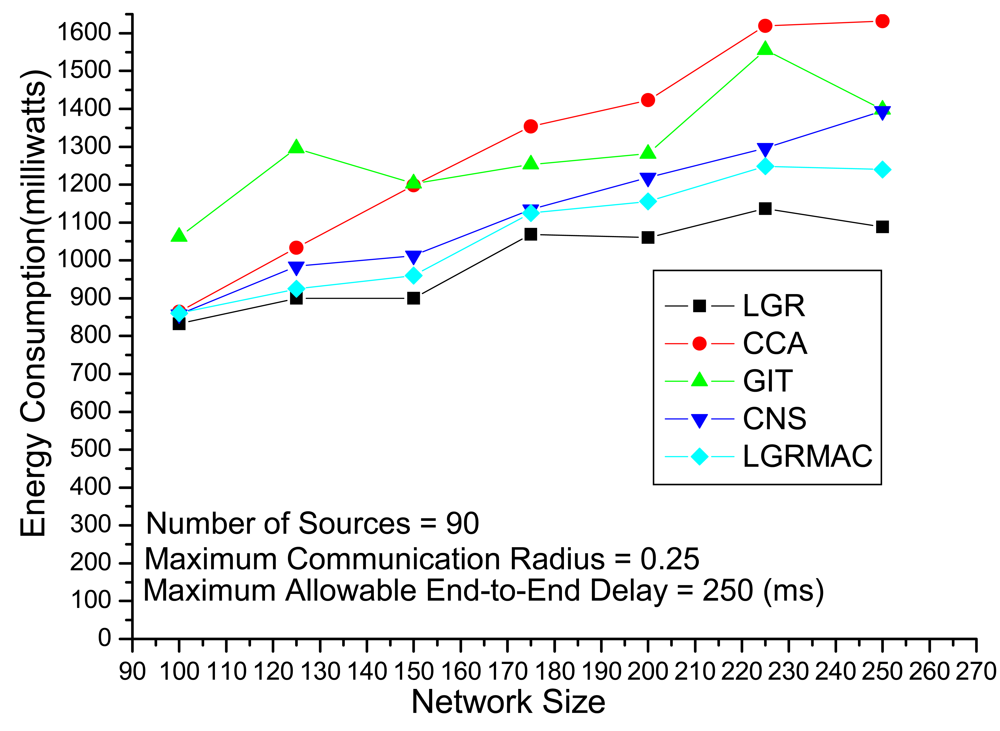
Figure 6 depicts the experiments evaluating the solution quality of different algorithms under different network sizes with 90 fixed sources and a loose delay constraint. Intuitively, when in large network size, there would be more data retransmission due to severe collisions. In other words, the solution approach should be more careful not to incur larger energy loss from data retransmission in large network size. Algorithms that do not address the retransmission will suffer from the extra energy loss from data retransmission. According to
Figure 6, we observe that the LGR algorithm outperforms the other heuristics, especially for large network sizes. This indicates that the LGR algorithm optimizes the trade-off between advantages from data aggregations and disadvantages from data retransmissions.
We summarize the improvement ratio of the LGR algorithm over the other 4 heuristics in
Table 1. The improvement ratio is defined as (other approach – LGR)/(LGR) × 100% to show the solution quality. In
Table 1, the improvement ratio of LGR over LGRMAC, CCA, CNS and GIT is up to 17%, 123%, 30% and 49%, respectively.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}