3.1. Overall Network Architecture
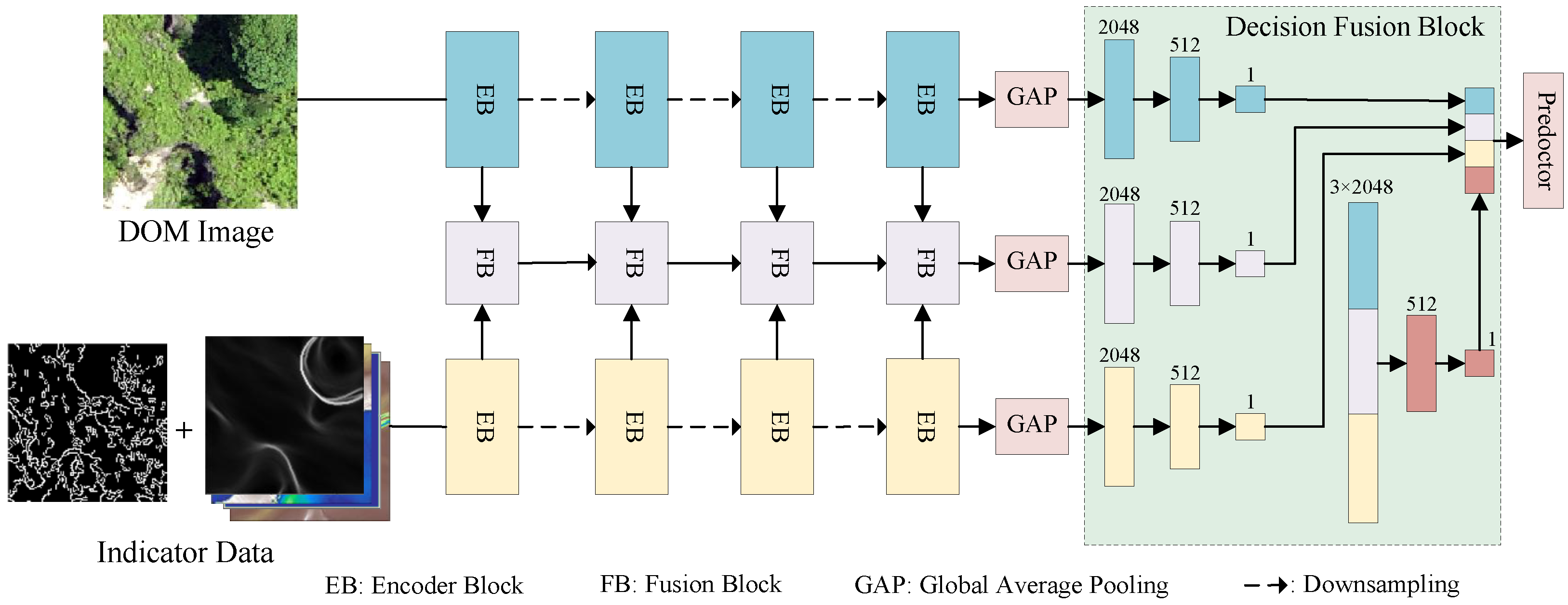
The network architecture of this study, illustrated in
Figure 4, takes DOM data and indicator data as inputs to different branches of the two-stream fusion network. Following data augmentation and regularization, the encoder of the model performs deep feature extraction on data from different branches by building multiple layers of Encoder Blocks (EBs), designed to learn complex features. After processing four EBs, the model generated four different-scale features.
At the same time, for different-scale DOM and DSM features extracted by EBs, a layer of feature fusion blocks (FBs) is constructed after each layer of EBs to fuse the multiscale features of the two branches. FBs receive the abstract features extracted by the EBs of the two branches and adopt and fuse two different attention mechanism blocks. Additionally, FBs also receivethe fused features of the previous layer to combine the information from different feature extraction levels.
To further enhance feature representation, FBs employ convolutional kernels with different receptive field sizes and attention mechanisms to capture multiscale semantic information, enabling the model to obtain a more comprehensive feature representation. After feature extraction, abstract features of different branches are passed through the global average pooling (GAP) layer and the linear layer to output the classification results, and each branch is individually predicted with a classification tensor. Finally, in the decision fusion block, the final Benggang classification is obtained after the prediction results are spliced and then passed through the linear layer.
3.2. Feature Extraction
ResNet [
19] is a landmark achievement in deep learning, which solves the problems of gradient vanishing and gradient explosion in deep network training by introducing residual connections. This breakthrough inspired numerous enhancements based on the ResNet architecture. SE-Net [
20] introduces a channel attention mechanism that compresses channel statistical information through global pooling. This mechanism simulates the inter-dependencies between feature map channels and uses global context information to selectively emphasize or suppress features. ResNeXt [
21] uses grouped convolutions in ResNet’s bottleneck block to convert multi-path structures into unified operations. SK-Net [
22] introduces feature map attention between the two network branches. RegNet [
23] is an architectural approach to network design through the search space and outperforms EfficientNet [
24]. ResNeSt [
25], through an SE-like block, introduces a spatial attention mechanism that can adaptively recalibrate channel feature responses, thus enabling the network to focus more on important feature channels while suppressing less important ones. Furthermore, ResNeSt implements multi-path representations through the Split-Attention block. This structure allows the network to learn independent features from different branches and establishes connections between branches with special attention mechanisms, capturing richer and more diverse feature representations.
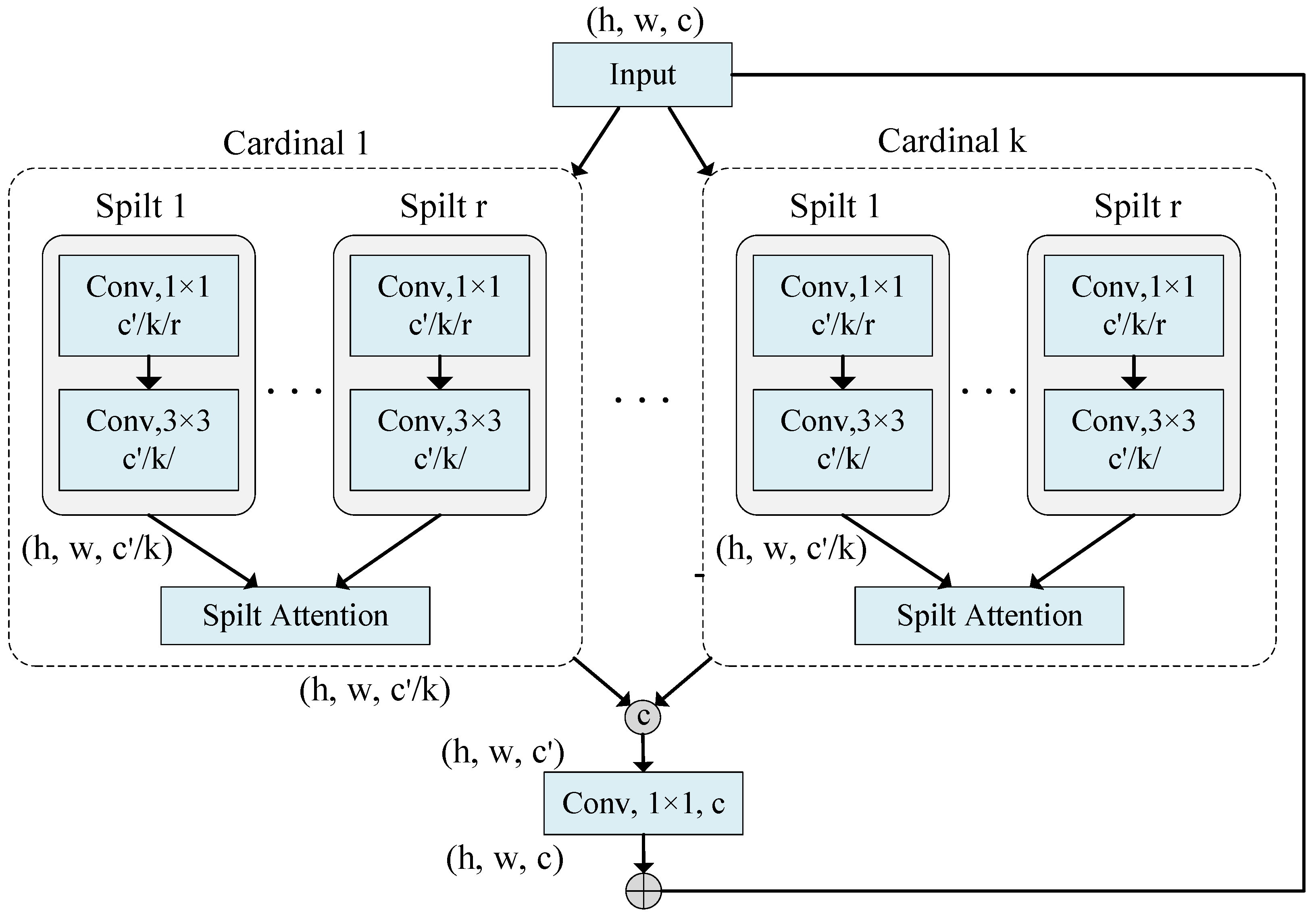
Building on these advancements, we adapt ResNeSt as the backbone network for feature extraction in both branches. The design of the Encoder Block (EB) is shown in
Figure 5. In this structure, the input feature map is divided into multiple cardinal groups, and each cardinal group is further subdivided into multiple splits. Each split undergoes feature transformation through 1 × 1 and 3 × 3 convolutional layers. The Split-Attention block then integrates these features using global average pooling and attention weight calculation to emphasize significant features while suppressing less important ones. Finally, the outputs of all splits are spliced and passed through a 1 × 1 convolutional layer for residual connections with the original inputs, forming the output features for each layer of the Encoder Block.
The features of different input data types are extracted by stacking multiple EB layers (four layers are used in this study) as follows:
where
denotes the current number of EB layers, and
and
denote the feature output of the first branch and the second branch, respectively. Using smaller convolutional kernels (e.g., 1 × 1) in the EB layer helps retain localized information, while stacking additional EB layers increases the network’s receptive field, enabling it to better capture high-level features from images.
3.3. Fusion Block
In recent years, many studies have adopted attention mechanisms and feature fusion techniques to enhance model performance in image identification tasks. Woo et al. [
26] proposed the Convolutional Block Attention Module (CBAM), a simple and effective attention module that sequentially infers channel attention (CA) and spatial attention (SA) maps, multiplying them with the input feature maps to adaptively refine the features. Subsequently, Zhang et al. [
27] grouped the channel dimensions and used the Shuffle Unit to construct both channel and spatial attention for each sub-feature, achieving information interaction via the “channel shuffle” operator. Liu et al. [
28] proposed Polarized Self-Attention (PSA) for pixel-level regression, using polarization filters to maintain high resolution during the calculation of channel and spatial attention. Tang et al. [
29] fused complementary information across modalities by calculating channel attention weights, weighting complementary features, and adding them to the original features during infrared and visible image fusion. Huo et al. [
30] significantly improved the classification accuracy in medical image fusion by splitting the channels and spatial attention mechanism of CBAM for fusion.
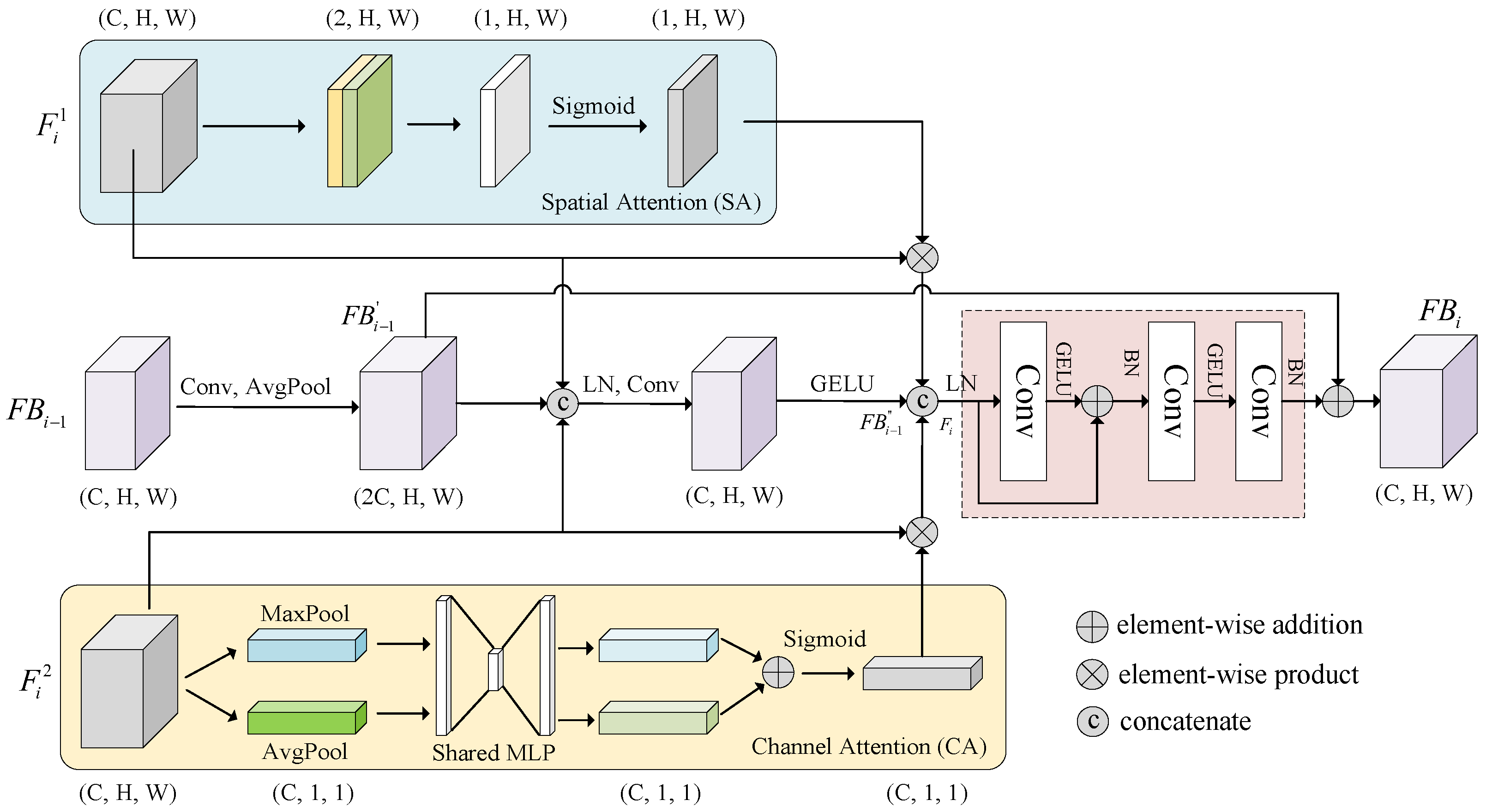
Building on these approaches, we proposed a feature fusion block that combines CA and SA mechanisms to integrate and refine DOM and indicator data features across different scales, as shown in
Figure 6. (C, H, W) represents the number of feature channels, C, and the height and width are H and W, respectively. The feature fusion layer processes feature inputs from three sources and fuses multiscale information by stacking multiple FB layers.
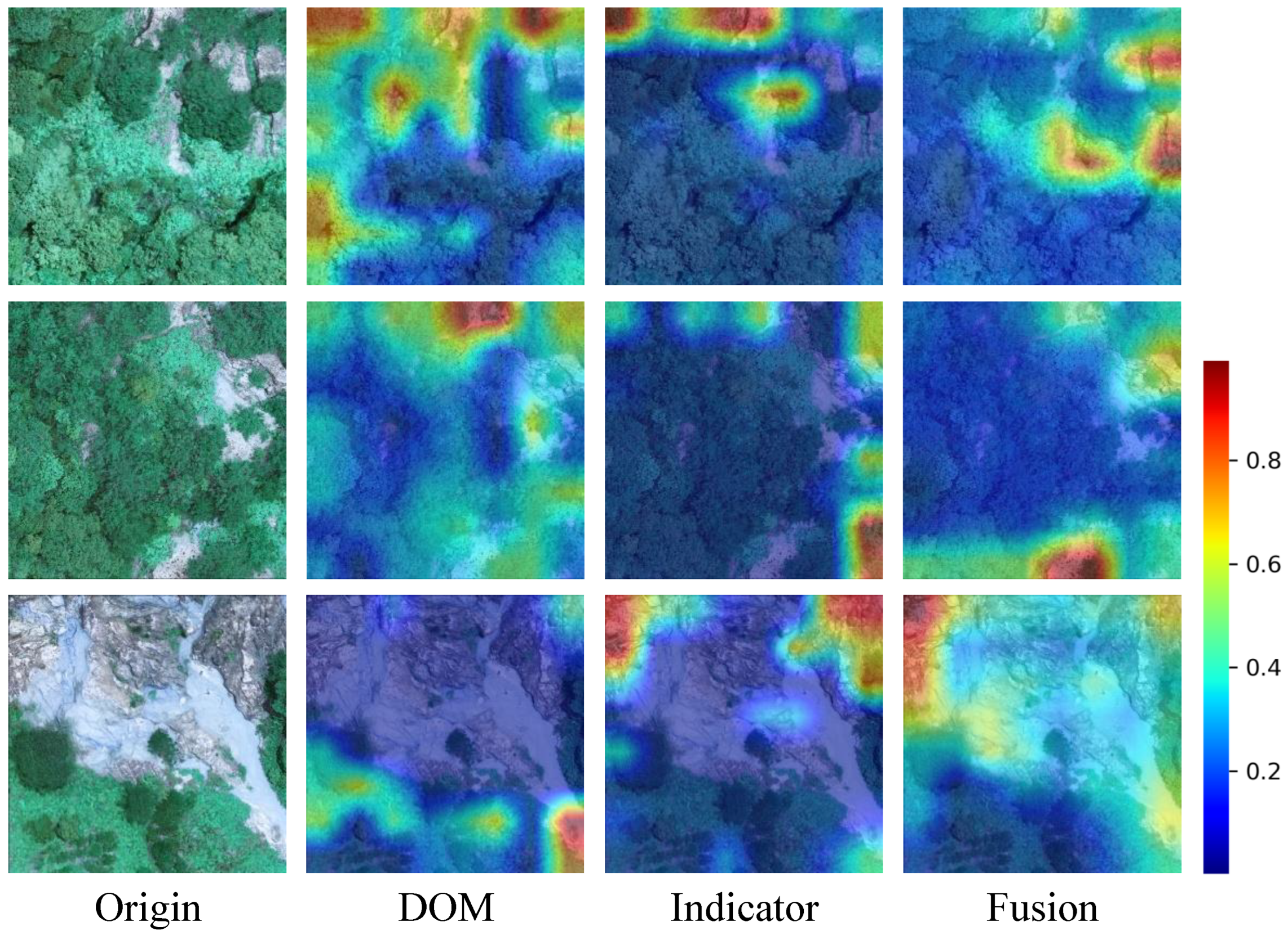
The first input consists of image branch features extracted from Benggang images, where i denotes the encoder’s layer count. These image features contain rich visual information on the surface features of Benggangs (e.g., collapse walls, erosion gullies). Using the spatial attention mechanism, these features are processed to generate , enabling the network to adaptively focus on key feature areas on images, such as areas with significant features of Benggangs, thereby enhancing feature representation.
The second input includes indicator data branch features , which are initially processed to obtain with the channel attention mechanism. After global max pooling and average pooling operations, the global maximum and average features are extracted. These two types of features are then fed into a shared MLP (multilayer perceptron), which generates channel-wise weight vectors by performing dimensionality reduction and expansion to capture inter-channel dependencies. Finally, the weights are normalized to the range [0, 1] via Sigmoid activation and applied to the original feature maps through element-wise multiplication, enabling adaptive weighting and recalibration of channel-wise features to emphasize informative channels and suppress irrelevant ones.
The third input consists of features from the previous FB layer,
, which are processed through convolution and average pooling to generate
(for the first layer,
only receives the first two inputs). These features are then concatenated with
to produce
by layer normalization and convolution operation. Layer normalization stabilizes network training, while convolution operations extract and integrate features. The calculations are as follows:
where
is a Sigmoid function, and
is the convolution operation of various kernel sizes.
is the average pooling layer.
is the maximum pooling layer.
is a multilayer perceptron with fully connected layers.
is feature concatenation.
is layer normalization, and
is an activation function.
is batch normalization.
For the features
,
, and
of the three branches mentioned above,
and
are first combined with the original features
, respectively, to obtain element-wise multiplication. These results are then concatenated with
to form the fused feature
, which fully integrates multi-source feature information. Finally, the fused feature
, after convolution through a residual network and two convolutional layers with a kernel size of
, is then added with
to obtain
, the fused feature of the
ith layer. After passing through four FB layers, the output of the fusion branch
is obtained. The calculations are as follows:
3.4. Decision Fusion Block
The decision fusion (DF) block integrates the prediction results of different features to produce a final classification label. The model processes input features using three parallel global average pooling (GAP) layers to perform down-sampling. The pooled features are then passed through three fully connected (FC) layers, reducing the feature dimensions sequentially from 2048 to 512, and finally to 1. This process yields three 1-dimensional outputs,
, calculated as follows:
Subsequently, the three 2048-dimensional outputs from
and
are concatenated into a
matrix
M. This matrix is further processed by a 512-dimensional fully connected layer (FC4) to produce
. The calculations are as follows:
Finally, the four 1-dimensional outputs,
, are concatenated and passed through a fully connected layer (FC5) to generate the final classification label
. Here,
denotes the
ith fully connected layer, and
represents the concatenation of vectors
a,
b, and
c. The computation is as follows:





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}