
A Novel 3D Approach with a CNN and Swin Transformer for Decoding EEG-Based Motor Imagery Classification


Abstract
1. Introduction
- We propose a novel and effective Convolution Swin Transformer (ConSwinFormer) network for rapid feature extraction of EEG signals for MI task classifications.
- Extensive experiments are conducted to research the impact of the Swin Transformer module and attention parameters.
- Data augmentation techniques, including segmentation and reconstruction (S&R) and random noise addition, effectively improve the model’s generalization ability on small datasets and reduce the risk of overfitting.
- Through spatio-temporal feature map visualization analysis, we enhance the interpretability of the model, providing new insights into brain region activities and collaborative work during the MI process.
2. Related Work
2.1. CNN, RNN, LSTM
2.2. Three-Dimensional CNN
2.3. Transformer
2.4. Swin Transformer
3. Methods
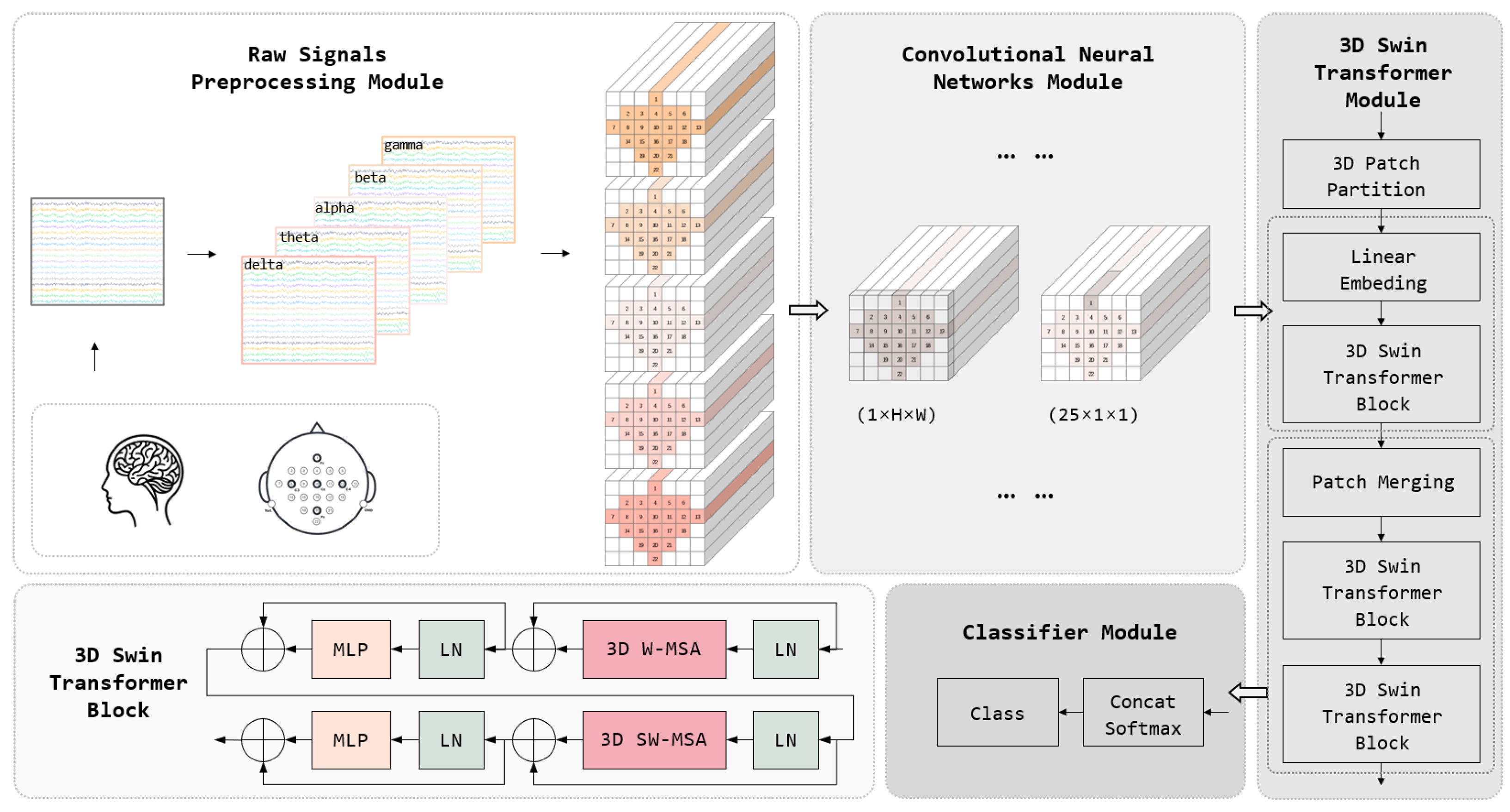
3.1. Overview
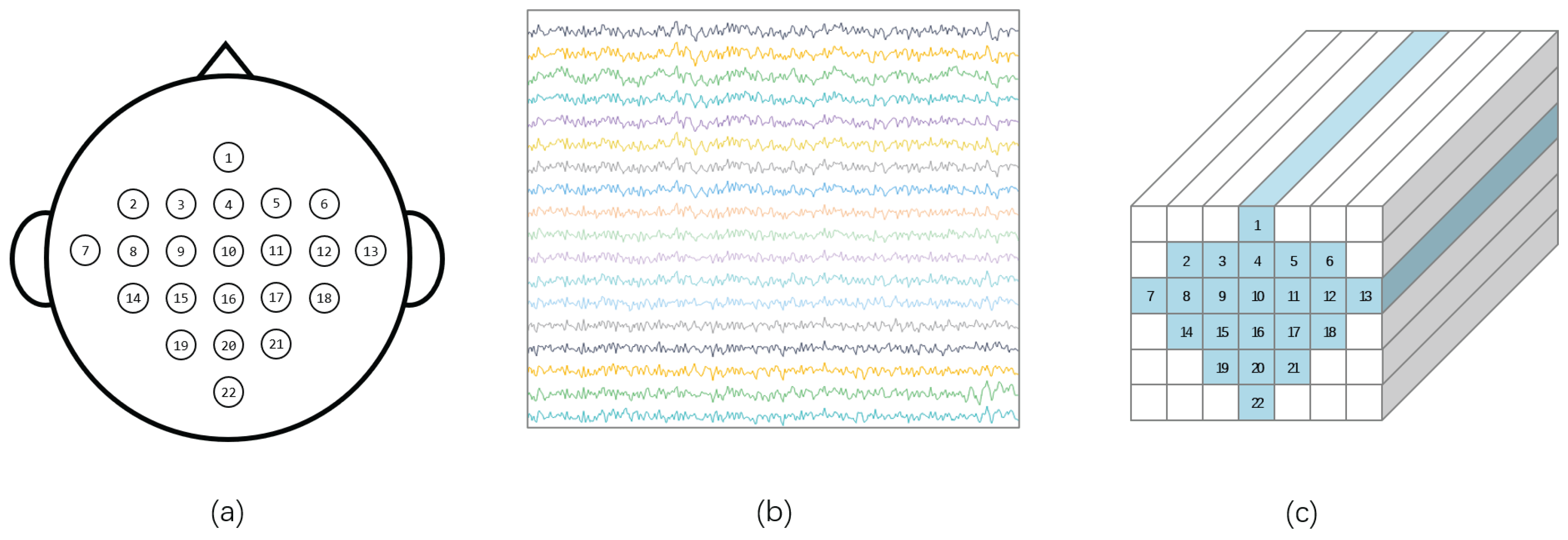
3.2. Preprocessing Module
3.3. CNN Module
3.4. Three-Dimensional Swin Transformer Module
3.4.1. Multi-Head Self-Attention Mechanism
3.4.2. Three-Dimensional W-MSA
3.4.3. Three-Dimensional SW-MSA
3.4.4. Hierarchical Structure
3.4.5. Three-Dimensional Relative Position Bias
4. Experiments and Results
4.1. Dataset
4.2. Data Augmentation
4.3. Experimental Details
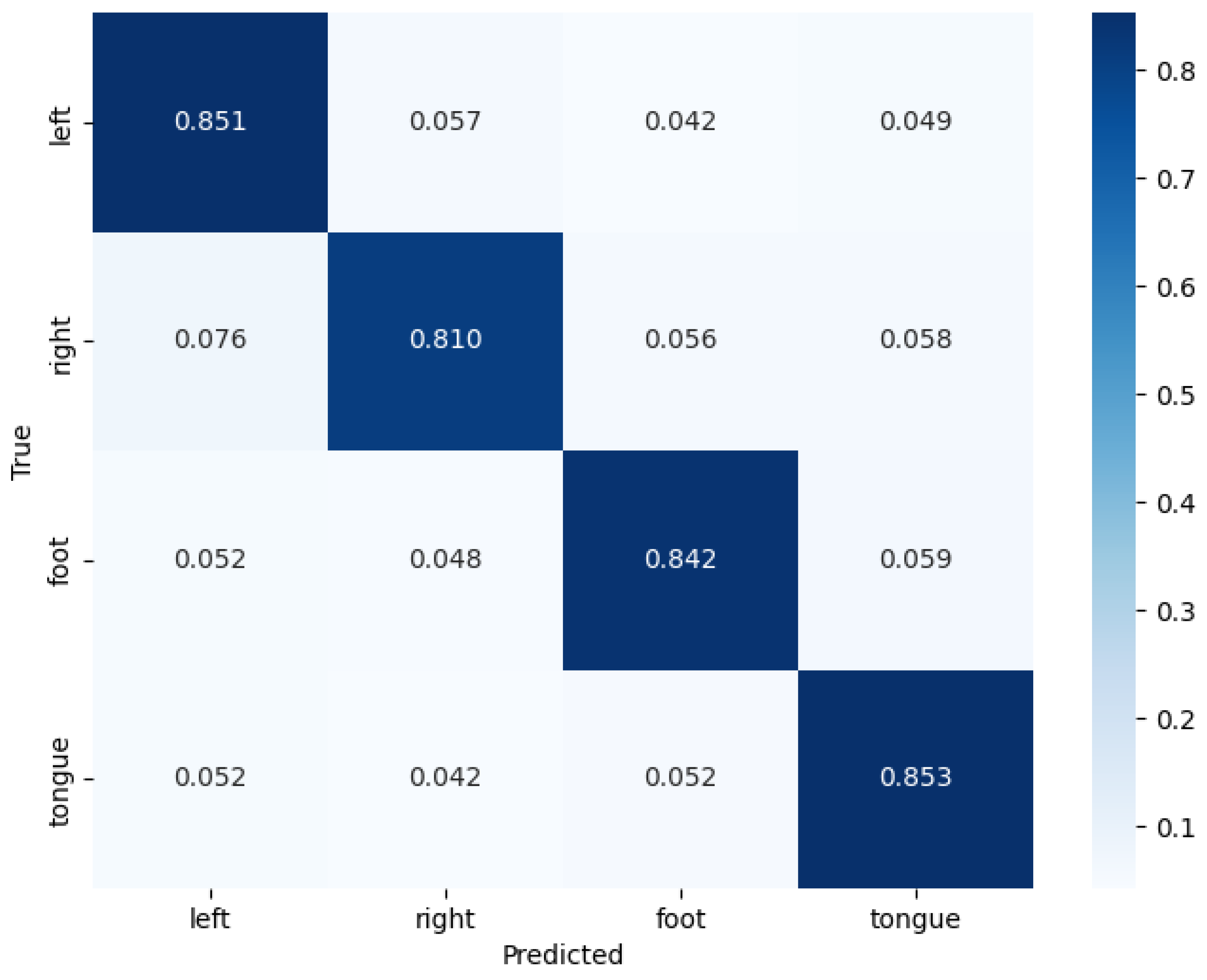
4.4. Experimental Results
4.5. Comparison
4.6. Ablation Experiments
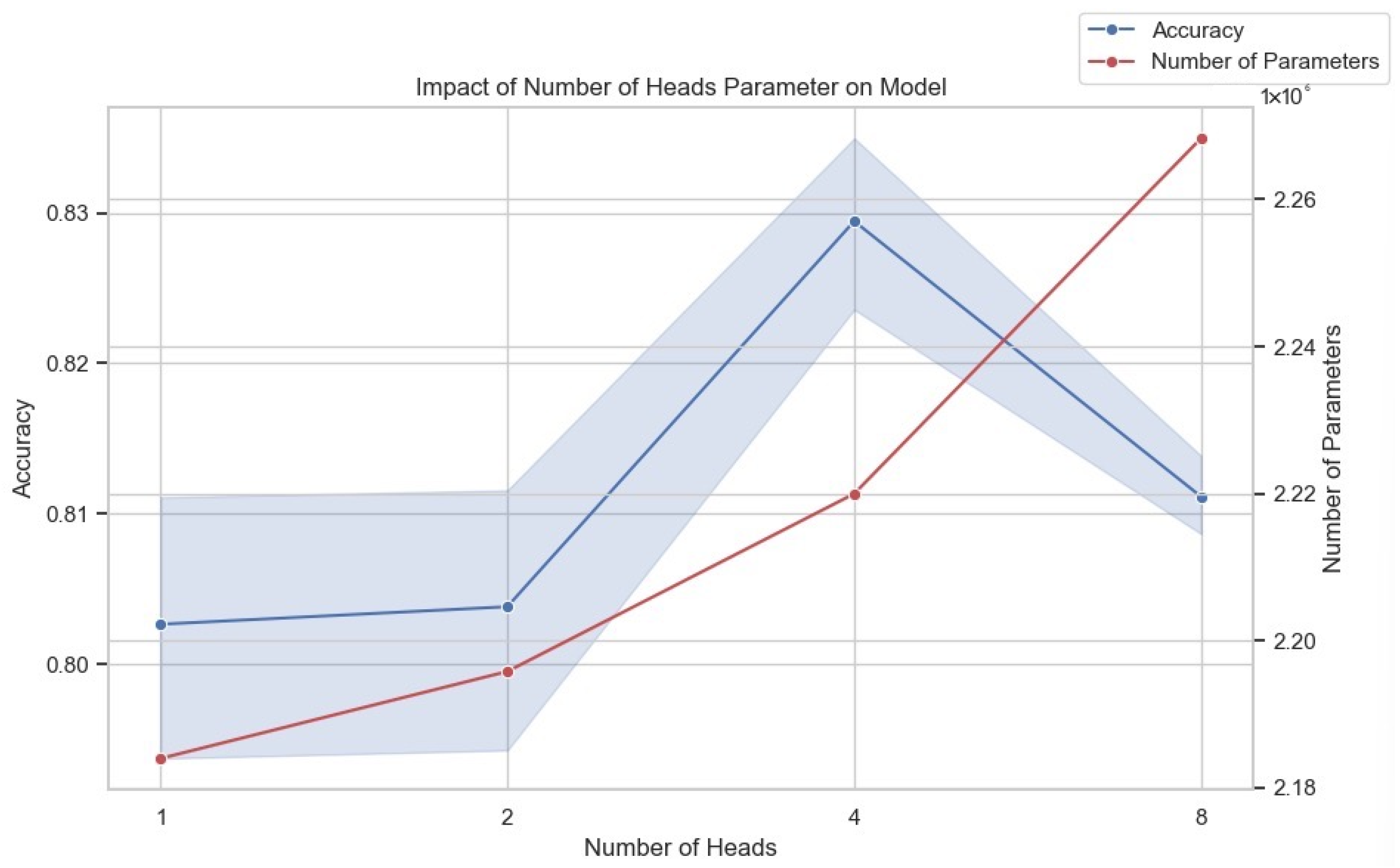
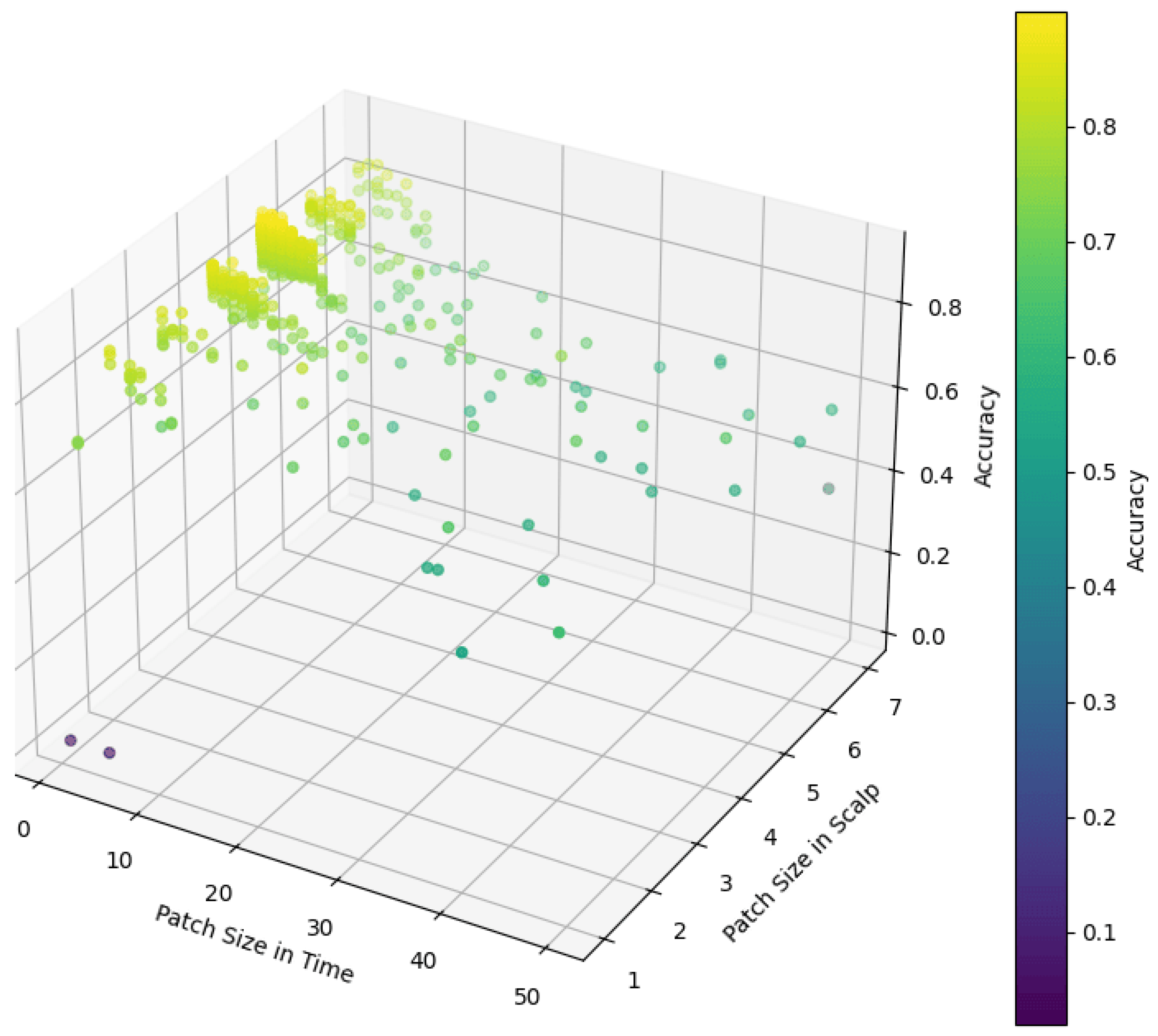
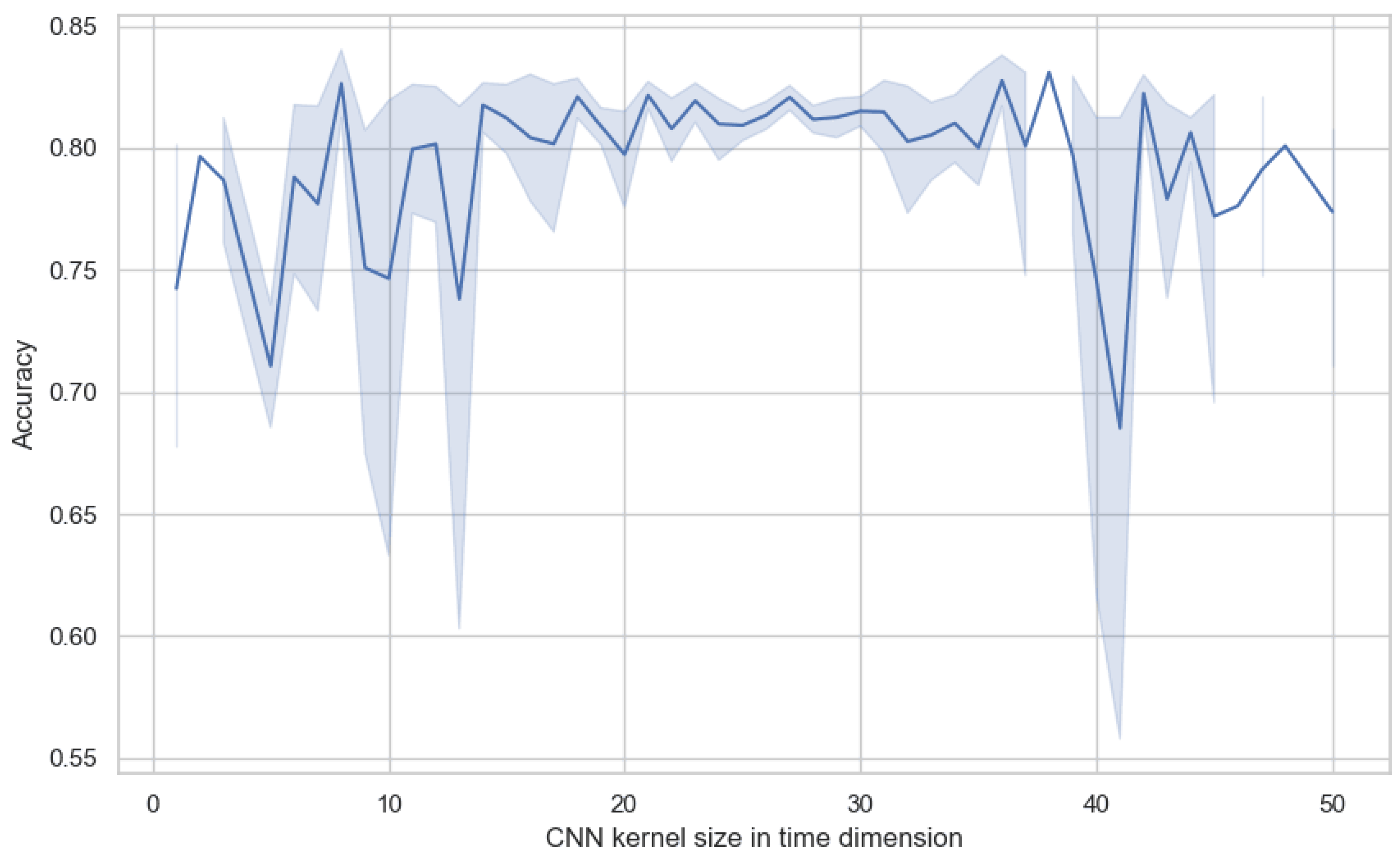
4.7. Parameter Sensitivity
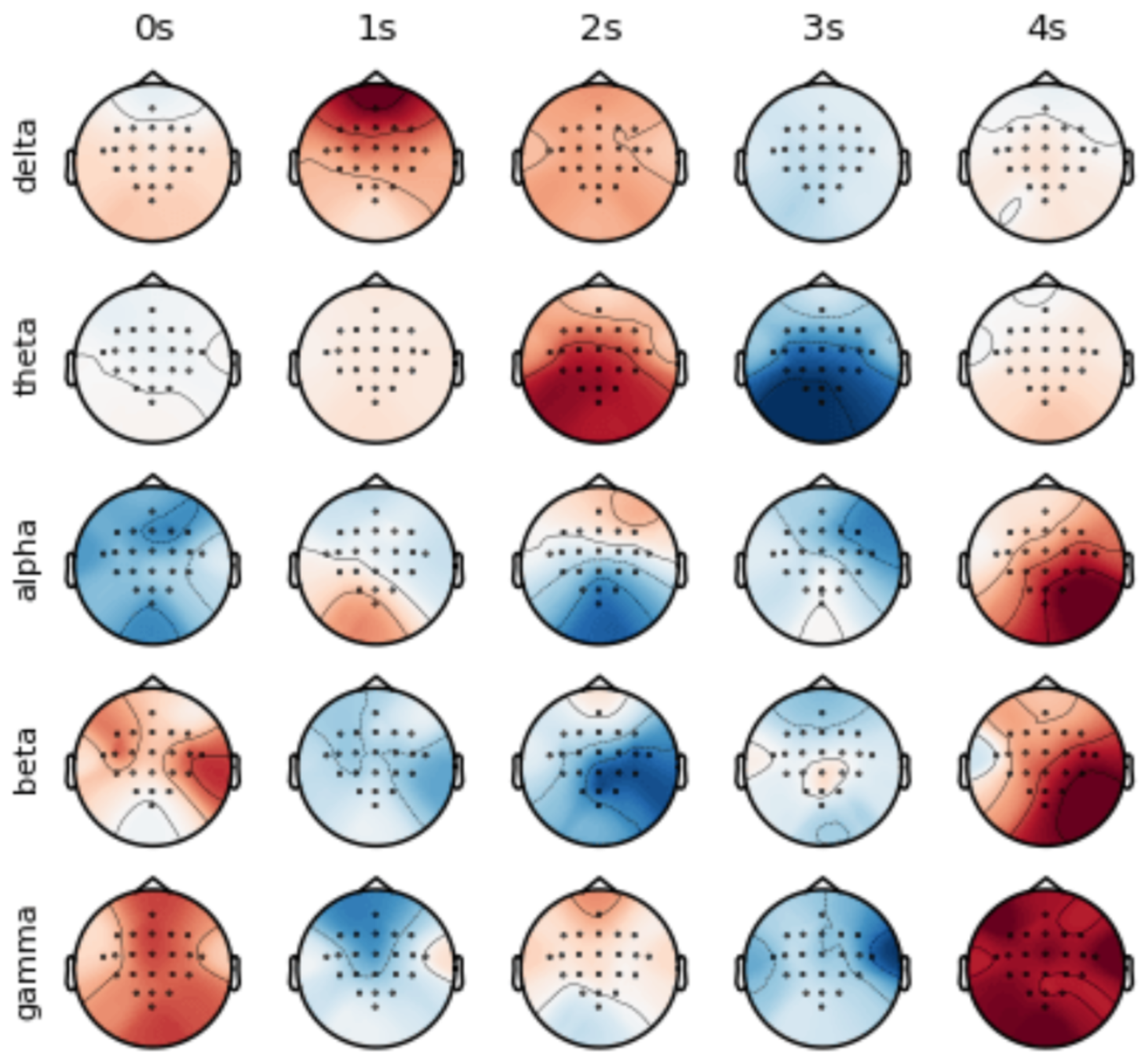
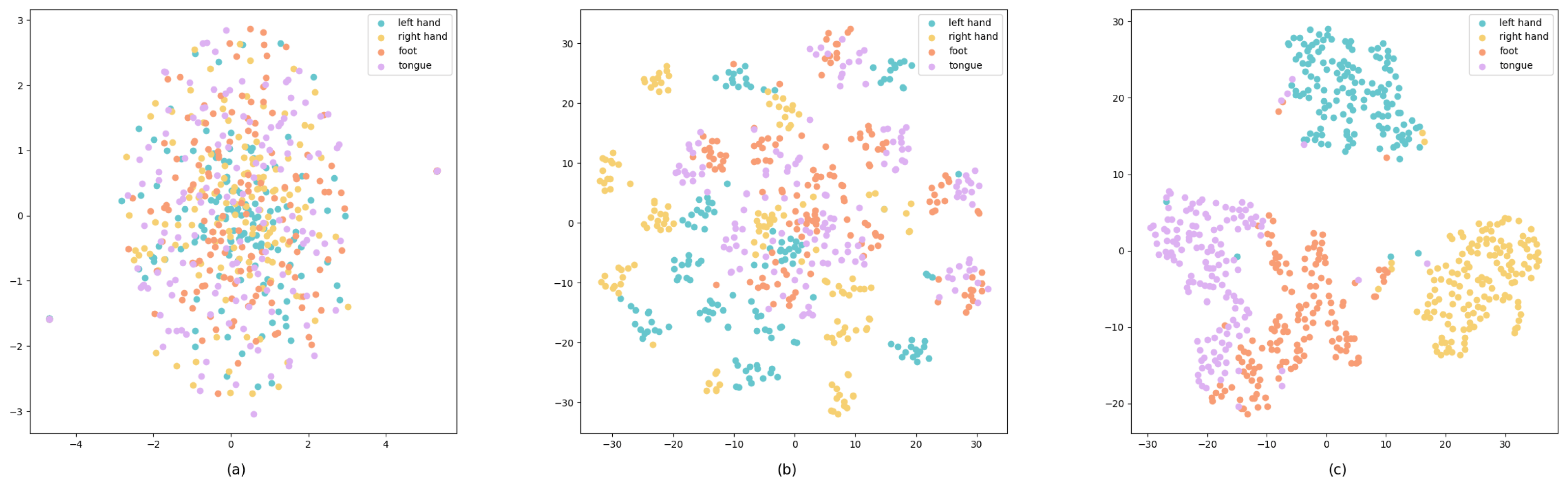
5. Visualization
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, B.; Yuan, H.; Meng, J.; Gao, S. Brain–computer interfaces. In Neural Engineering; Springer: Cham, Switzerland, 2020; pp. 131–183. [Google Scholar]
- Edelman, B.J.; Meng, J.; Suma, D.; Zurn, C.; Nagarajan, E.; Baxter, B.; Cline, C.C.; He, B. Noninvasive neuroimaging enhances continuous neural tracking for robotic device control. Sci. Robot. 2019, 4, eaaw6844. [Google Scholar] [CrossRef] [PubMed]
- Chaudhary, U.; Birbaumer, N.; Ramos-Murguialday, A. Brain–computer interfaces for communication and rehabilitation. Nat. Rev. Neurol. 2016, 12, 513–525. [Google Scholar] [CrossRef] [PubMed]
- Houssein, E.H.; Hammad, A.; Ali, A.A. Human emotion recognition from EEG-based brain–computer interface using machine learning: A comprehensive review. Neural Comput. Appl. 2022, 34, 12527–12557. [Google Scholar] [CrossRef]
- Voinas, A.E.; Das, R.; Khan, M.A.; Brunner, I.; Puthusserypady, S. Motor imagery EEG signal classification for stroke survivors rehabilitation. In Proceedings of the 2022 10th International Winter Conference on Brain-Computer Interface (BCI), Gangwon-do, Republic of Korea, 21–23 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–5. [Google Scholar]
- Wolpaw, J.R. Brain–computer interfaces. In Handbook of Clinical Neurology; Elsevier: Amsterdam, The Netherlands, 2013; Volume 110, pp. 67–74. [Google Scholar]
- Zander, T.O.; Kothe, C. Towards passive brain–computer interfaces: Applying brain–computer interface technology to human–machine systems in general. J. Neural Eng. 2011, 8, 025005. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Gao, S.; Gao, X. Common spatial pattern method for channel selelction in motor imagery based brain-computer interface. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 5392–5395. [Google Scholar]
- Ang, K.K.; Chin, Z.Y.; Zhang, H.; Guan, C. Filter bank common spatial pattern (FBCSP) in brain-computer interface. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 2390–2397. [Google Scholar]
- Dong, E.; Zhou, K.; Tong, J.; Du, S. A novel hybrid kernel function relevance vector machine for multi-task motor imagery EEG classification. Biomed. Signal Process. Control 2020, 60, 101991. [Google Scholar] [CrossRef]
- Jadhav, P.; Rajguru, G.; Datta, D.; Mukhopadhyay, S. Automatic sleep stage classification using time–frequency images of CWT and transfer learning using convolution neural network. Biocybern. Biomed. Eng. 2020, 40, 494–504. [Google Scholar] [CrossRef]
- Sadiq, M.T.; Yu, X.; Yuan, Z.; Fan, Z.; Rehman, A.U.; Li, G.; Xiao, G. Motor imagery EEG signals classification based on mode amplitude and frequency components using empirical wavelet transform. IEEE Access 2019, 7, 127678–127692. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.c. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Khademi, Z.; Ebrahimi, F.; Kordy, H.M. A transfer learning-based CNN and LSTM hybrid deep learning model to classify motor imagery EEG signals. Comput. Biol. Med. 2022, 143, 105288. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Qi, W.; Kong, D.; Wang, W. BrainGridNet: A two-branch depthwise CNN for decoding EEG-based multi-class motor imagery. Neural Netw. 2024, 170, 312–324. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Song, Y.; Jia, X.; Yang, L.; Xie, L. Transformer-based spatial-temporal feature learning for EEG decoding. arXiv 2021, arXiv:2106.11170. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Li, H.; Ding, M.; Zhang, R.; Xiu, C. Motor imagery EEG classification algorithm based on CNN-LSTM feature fusion network. Biomed. Signal Process. Control 2022, 72, 103342. [Google Scholar] [CrossRef]
- Liu, X.; Xiong, S.; Wang, X.; Liang, T.; Wang, H.; Liu, X. A compact multi-branch 1D convolutional neural network for EEG-based motor imagery classification. Biomed. Signal Process. Control 2023, 81, 104456. [Google Scholar] [CrossRef]
- Supakar, R.; Satvaya, P.; Chakrabarti, P. A deep learning based model using RNN-LSTM for the Detection of Schizophrenia from EEG data. Comput. Biol. Med. 2022, 151, 106225. [Google Scholar] [CrossRef] [PubMed]
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.U.; Altuwaijri, G.A.; Abdul, W.; Bencherif, M.A.; Faisal, M. Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: A review. Neural Comput. Appl. 2023, 35, 14681–14722. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, H.; Zhu, G.; You, F.; Kuang, S.; Sun, L. A multi-branch 3D convolutional neural network for EEG-based motor imagery classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 2164–2177. [Google Scholar] [CrossRef]
- Park, D.; Park, H.; Kim, S.; Choo, S.; Lee, S.; Nam, C.S.; Jung, J.Y. Spatio-temporal explanation of 3D-EEGNet for motor imagery EEG classification using permutation and saliency. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 4504–4513. [Google Scholar] [CrossRef]
- Li, M.-a.; Ruan, Z.-w. A novel decoding method for motor imagery tasks with 4D data representation and 3D convolutional neural networks. J. Neural Eng. 2021, 18, 046029. [Google Scholar] [CrossRef]
- Xie, J.; Zhang, J.; Sun, J.; Ma, Z.; Qin, L.; Li, G.; Zhou, H.; Zhan, Y. A transformer-based approach combining deep learning network and spatial-temporal information for raw EEG classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 2126–2136. [Google Scholar] [CrossRef]
- Luo, J.; Wang, Y.; Xia, S.; Lu, N.; Ren, X.; Shi, Z.; Hei, X. A shallow mirror transformer for subject-independent motor imagery BCI. Comput. Biol. Med. 2023, 164, 107254. [Google Scholar] [CrossRef] [PubMed]
- Deny, P.; Cheon, S.; Son, H.; Choi, K.W. Hierarchical Transformer for Motor Imagery-Based Brain Computer Interface. IEEE J. Biomed. Health Inform. 2023, 27, 5459–5470. [Google Scholar] [CrossRef]
- Ma, Y.; Song, Y.; Gao, F. A novel hybrid CNN-Transformer model for EEG Motor Imagery classification. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Xu, M.; Zhou, W.; Shen, X.; Wang, Y.; Mo, L.; Qiu, J. Swin-TCNet: Swin-based temporal-channel cascade network for motor imagery iEEG signal recognition. Biomed. Signal Process. Control 2023, 85, 104885. [Google Scholar] [CrossRef]
- Wang, H.; Cao, L.; Huang, C.; Jia, J.; Dong, Y.; Fan, C.; De Albuquerque, V.H.C. A novel algorithmic structure of EEG Channel Attention combined with Swin Transformer for motor patterns classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 3132–3141. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, R.; Zeng, Y.; Tong, L.; Lu, R.; Yan, B. MST-net: A multi-scale swin transformer network for EEG-based cognitive load assessment. Brain Res. Bull. 2024, 206, 110834. [Google Scholar] [CrossRef] [PubMed]
- Robinson, A.K.; Grootswagers, T.; Carlson, T.A. The influence of image masking on object representations during rapid serial visual presentation. NeuroImage 2019, 197, 224–231. [Google Scholar] [CrossRef]
- Al-Saegh, A.; Dawwd, S.A.; Abdul-Jabbar, J.M. Deep learning for motor imagery EEG-based classification: A review. Biomed. Signal Process. Control 2021, 63, 102172. [Google Scholar] [CrossRef]
- Kirar, J.S.; Agrawal, R. Relevant frequency band selection using Sequential forward feature selection for motor imagery brain computer interfaces. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 52–59. [Google Scholar]
- Zhang, D.; Yao, L.; Chen, K.; Wang, S.; Chang, X.; Liu, Y. Making sense of spatio-temporal preserving representations for EEG-based human intention recognition. IEEE Trans. Cybern. 2019, 50, 3033–3044. [Google Scholar] [CrossRef]
- Wei, C.S.; Koike-Akino, T.; Wang, Y. Spatial component-wise convolutional network (SCCNet) for motor-imagery EEG classification. In Proceedings of the 2019 9th International IEEE/EMBS Conference on Neural Engineering (NER), San Francisco, CA, USA, 20–23 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 328–331. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Brunner, C.; Leeb, R.; Müller-Putz, G.; Schlögl, A.; Pfurtscheller, G. BCI Competition 2008–Graz Data Set A; Institute for Knowledge Discovery (Laboratory Brain-Computer Interfaces), Graz University of Technology: Graz, Austria, 2008; Volume 16, pp. 1–6. [Google Scholar]
- Lotte, F. Signal processing approaches to minimize or suppress calibration time in oscillatory activity-based brain–computer interfaces. Proc. IEEE 2015, 103, 871–890. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Hallett, M.; Fieldman, J.; Cohen, L.G.; Sadato, N.; Pascual-Leone, A. Involvement of primary motor cortex in motor imagery and mental practice. Behav. Brain Sci. 1994, 17, 210. [Google Scholar] [CrossRef]
- Nam, C.S.; Jeon, Y.; Kim, Y.J.; Lee, I.; Park, K. Movement imagery-related lateralization of event-related (de) synchronization (ERD/ERS): Motor-imagery duration effects. Clin. Neurophysiol. 2011, 122, 567–577. [Google Scholar] [CrossRef]
- Choi, J.W.; Kim, B.H.; Huh, S.; Jo, S. Observing actions through immersive virtual reality enhances motor imagery training. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 1614–1622. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S01 | S02 | S03 | S04 | S05 | S06 | S07 | S08 | S09 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|
| FBCSP [9] | 76.00 | 56.50 | 81.25 | 61.00 | 55.00 | 42.25 | 82.75 | 81.25 | 70.75 | 67.42 ± 13.54 |
| PSCSP [10] | 80.00 | 65.36 | 87.14 | 67.50 | 55.54 | 50.18 | 91.79 | 84.11 | 87.86 | 74.39 ± 14.31 |
| Multi-branch 3D CNN [26] | 77.38 | 60.14 | 82.93 | 72.29 | 75.84 | 68.99 | 76.04 | 76.86 | 84.67 | 75.02 ± 6.92 |
| Transformer [19] | 91.67 | 71.67 | 95.00 | 78.33 | 61.67 | 66.67 | 96.67 | 93.33 | 88.33 | 82.59 ± 12.52 |
| CNN-Transformer [32] | 92.02 | 78.12 | 95.13 | 78.30 | 64.23 | 67.88 | 97.03 | 93.23 | 89.23 | 83.91 ± 11.49 |
| CMO-CNN [23] | 86.93 | 67.47 | 92.69 | 77.21 | 82.78 | 73.73 | 92.52 | 90.43 | 91.47 | 83.92 ± 8.69 |
| Our | 93.76 | 67.51 | 98.60 | 76.17 | 65.28 | 72.64 | 96.51 | 94.70 | 90.72 | 83.99 ± 12.64 |
| S01 | S02 | S03 | S04 | S05 | S06 | S07 | S08 | S09 | Avg | |
|---|---|---|---|---|---|---|---|---|---|---|
| CNN | 54.03 | 51.39 | 52.77 | 56.80 | 52.77 | 54.16 | 59.87 | 53.35 | 50.26 | 53.93 |
| Swin Transformer | 90.01 | 51.38 | 97.34 | 72.98 | 51.95 | 65.00 | 92.93 | 93.33 | 88.76 | 77.85 |
| ConSwinFormer | 93.76 | 67.51 | 98.60 | 76.17 | 65.28 | 72.64 | 96.51 | 94.70 | 90.72 | 83.99 |
| (0.5–4 Hz) | (4–8 Hz) | (9–12 Hz) | (13–30 Hz) | (31–50 Hz) | Full-Band | |
|---|---|---|---|---|---|---|
| 53.61 | 62.86 | 94.72 | 95.26 | 47.28 | 97.33 | 98.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, X.; Huo, H.; Ai, L.; Xu, D.; Li, C. A Novel 3D Approach with a CNN and Swin Transformer for Decoding EEG-Based Motor Imagery Classification. Sensors 2025, 25, 2922. https://doi.org/10.3390/s25092922
Deng X, Huo H, Ai L, Xu D, Li C. A Novel 3D Approach with a CNN and Swin Transformer for Decoding EEG-Based Motor Imagery Classification. Sensors. 2025; 25(9):2922. https://doi.org/10.3390/s25092922
Chicago/Turabian StyleDeng, Xin, Huaxiang Huo, Lijiao Ai, Daijiang Xu, and Chenhui Li. 2025. "A Novel 3D Approach with a CNN and Swin Transformer for Decoding EEG-Based Motor Imagery Classification" Sensors 25, no. 9: 2922. https://doi.org/10.3390/s25092922
APA StyleDeng, X., Huo, H., Ai, L., Xu, D., & Li, C. (2025). A Novel 3D Approach with a CNN and Swin Transformer for Decoding EEG-Based Motor Imagery Classification. Sensors, 25(9), 2922. https://doi.org/10.3390/s25092922