


A Two-Stage YOLOv5s–U-Net Framework for Defect Localization and Segmentation in Overhead Transmission Lines


Abstract
1. Introduction
- A small-scale transmission-line defect dataset is constructed to address the lack of publicly available datasets. This self-built dataset includes a variety of typical defects in transmission lines, which are annotated to meet the requirements for model training and validation;
- A two-stage transmission-line defect detection framework based on YOLOv5s and U-Net is proposed. By combining the advantages of detection and segmentation, this framework achieves the collaborative processing of global and local image features. For strand breakage, characterized by high contrast and structural mutations, YOLOv5s is used for direct localization. For surface-damage areas with fuzzy edges and low contrast, U-Net is used for fine pixel-level segmentation after initial detection, enhancing the recognition accuracy of complex defects;
- Transfer learning and loss function optimization are introduced to improve model performance. YOLOv5s is initialized with COCO pretrained weights, and U-Net uses a VGG16 encoder pretrained on ImageNet as the feature-extraction module. A composite loss function combining Dice Loss and Focal Loss is constructed to alleviate issues related to class imbalance and small-target recognition;
- By comparing it with single detection or segmentation models, the proposed two-stage method demonstrates advantages in detection efficiency, segmentation details, and robustness, achieving improved defect-recognition precision and detail retention.
2. Methods
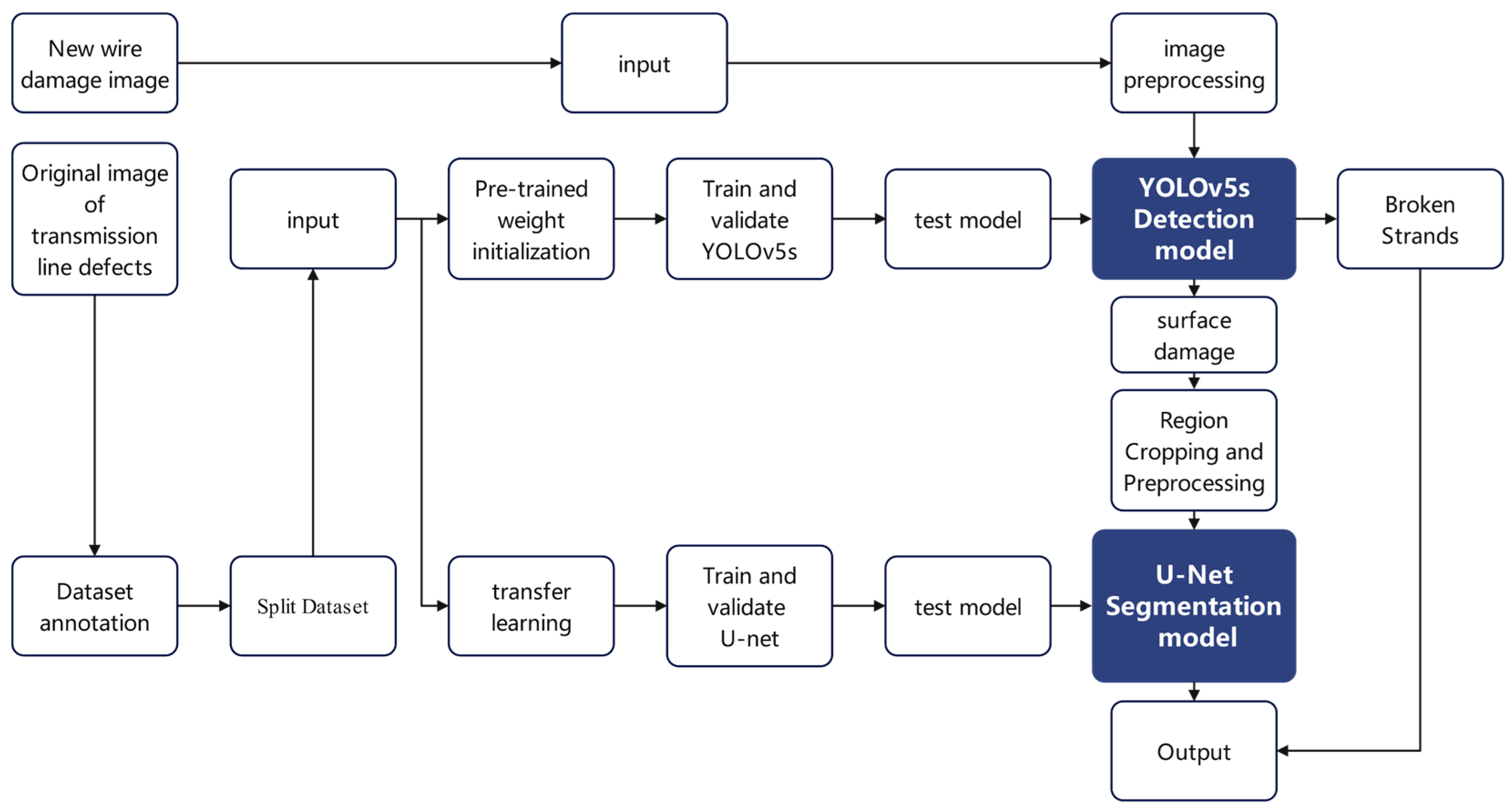
2.1. Model Structure of This Paper
Overall Framework Design
- Global defect localization: The original inspection image is fed into the YOLOv5s network, which outputs bounding boxes and confidence scores for potential defect areas, and directly locates strand-breakage regions;
- Candidate region cropping: A relaxed confidence threshold (>0.25) is applied to maximize the capture of surface damage, including those with weak features. Lowering the threshold improves recall, ensuring that small or low-contrast defects proceed to the segmentation stage;
- Local fine segmentation: Cropped ROIs (Regions of Interest) are resized to a standard input size and passed into the pretrained U-Net model, which outputs pixel-level masks representing the exact shapes and edges of the defects.
2.2. Two-Stage Model Framework
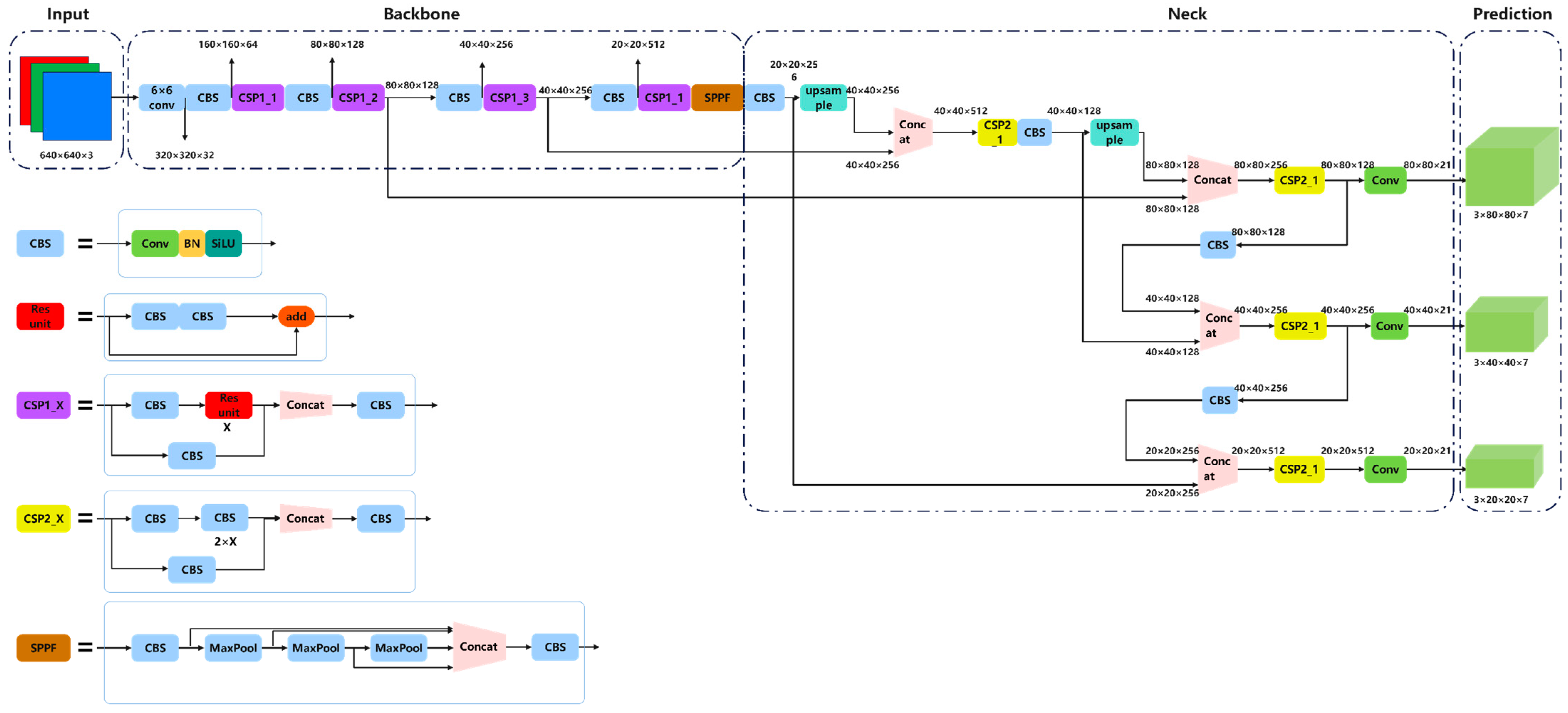
2.2.1. Global Detection
- Input layer
- 2.
- Backbone
- 3.
- Neck
- 4.
- Head
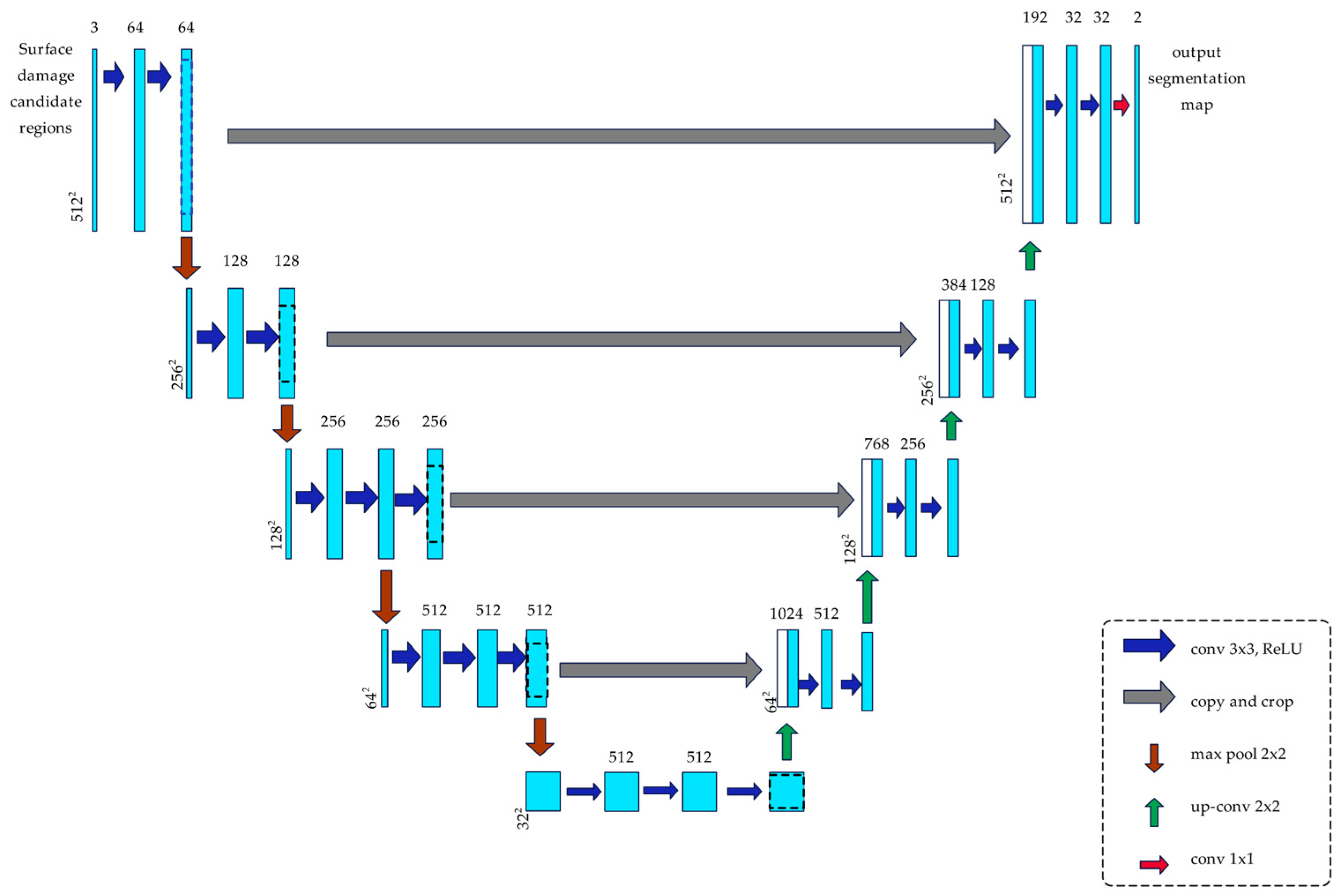
2.2.2. Local Fine Segmentation
- Transfer learning
- 2.
- Loss function
3. Results and Discussion
3.1. Datasets
3.2. Experimental Environment
3.3. Evaluation Indicators
- Recall
- 2.
- Precision
- 3.
- mAP
- Dice Coefficient;
- 2.
- MIoU
- 3.
- Precision
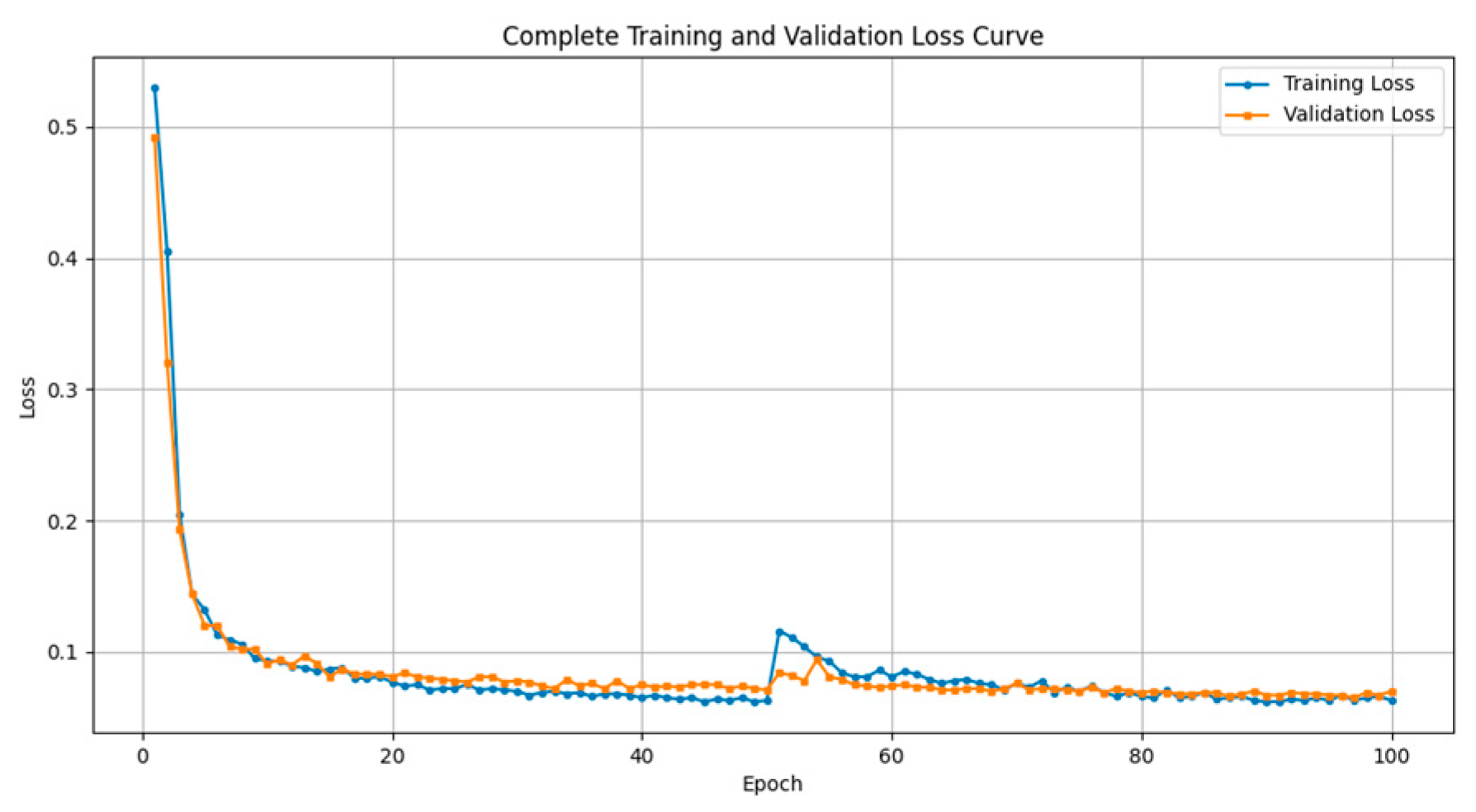
3.4. Analysis of Experimental Results
3.4.1. Target-Detection Performance Analysis
3.4.2. Semantic Segmentation Performance Analysis
3.4.3. Model Advantages
- Precision reflects the proportion of correctly identified defects among all detected instances. A higher precision indicates fewer false positives, which is critical for ensuring the safety of transmission systems;
- Recall measures the model’s ability to identify actual defects. A higher recall implies fewer missed detections, which is especially important for high-risk scenarios such as transmission-line monitoring to ensure that no defects are overlooked;
- Inference time directly affects the deployment efficiency and real-time applicability of the model. It is an essential metric to assess the system’s responsiveness and engineering viability in practical inspection tasks.
3.4.4. Future Improvement Directions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Katrasnik, J.; Pernus, F.; Likar, B. A Survey of Mobile Robots for Distribution Power Line Inspection. IEEE Trans. Power Deliv. 2010, 25, 485–493. [Google Scholar] [CrossRef]
- Alhassan, A.B.; Zhang, X.; Shen, H.; Xu, H. Power transmission line inspection robots: A review, trends and challenges for future research. Int. J. Electr. Power Energy Syst. 2020, 118, 105862. [Google Scholar] [CrossRef]
- Uddin, M.S.; Hossain, M.Z.; Fahim, S.R.; Sarker, S.K.; Bhuiyan, E.A.; Muyeen, S.M.; Das, S.K. On the protection of power system: Transmission line fault analysis based on an optimal machine learning approach. Energy Rep. 2022, 8, 10168–10182. [Google Scholar] [CrossRef]
- Fahim, S.R.; Sarker, Y.; Sarker, S.K.; Sheikh, M.R.I.; Das, S.K. Self attention convolutional neural network with time series imaging based feature extraction for transmission line fault detection and classification. Electr. Power Syst. Res. 2020, 187, 106437. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.F.; Liu, Y.H.; Li, E.; Peng, J.Z.; Liang, Z.Z. A Review on State-of-the-Art Power Line Inspection Techniques. IEEE Trans. Instru. Meas. 2020, 69, 9350–9365. [Google Scholar] [CrossRef]
- Prasad, A.; Belwin Edward, J.; Ravi, K. A review on fault classification methodologies in power transmission systems: Part—I. J. Electr. Syst. Inform. Technol. 2018, 5, 48–60. [Google Scholar] [CrossRef]
- Aggarwal, R.K.; Johns, A.T.; Jayasinghe, J.A.S.B.; Su, W. An overview of the condition monitoring of overhead lines. Electr. Power Syst. Res. 2000, 53, 15–22. [Google Scholar] [CrossRef]
- Jalil, B.; Leone, G.R.; Martinelli, M.; Moroni, D.; Pascali, M.A.; Berton, A. Fault Detection in Power Equipment via an Unmanned Aerial System Using Multi Modal Data. Sensors 2019, 19, 3014. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, G.; He, W.; Fan, F.; Ye, X. Key target and defect detection of high-voltage power transmission lines with deep learning. Int. J. Electr. Power Energy Syst. 2022, 142, 108277. [Google Scholar] [CrossRef]
- Nguyen, V.N.; Jenssen, R.; Roverso, D. Intelligent Monitoring and Inspection of Power Line Components Powered by UAVs and Deep Learning. IEEE Power Energy Technol. Syst. J. 2019, 6, 11–21. [Google Scholar] [CrossRef]
- Nguyen, V.N.; Jenssen, R.; Roverso, D. Automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Int. J. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, F.; Li, H.; Liu, X. An Online Technology for Measuring Icing Shape on Conductor Based on Vision and Force Sensors. IEEE Trans. Instrum. Meas. 2017, 66, 3180–3189. [Google Scholar] [CrossRef]
- Manninen, H.; Ramlal, C.J.; Singh, A.; Rocke, S.; Kilter, J.; Landsberg, M. Toward automatic condition assessment of high-voltage transmission infrastructure using deep learning techniques. Inter. J. Electr. Power Energy Syst. 2021, 128, 106726. [Google Scholar] [CrossRef]
- Sharma, H.; Bhujade, R.; Adithya, V.; Balamuralidhar, P. Vision-based detection of power distribution lines in complex remote surroundings. In Proceedings of the 2014 Twentieth National Conference on Communications (NCC), Kanpur, India, 28 February–2 March 2014. [Google Scholar] [CrossRef]
- Mirallès, F.; Pouliot, N.; Montambault, S. State-of-the-art review of computer vision for the management of power transmission lines. In Proceedings of the 2014 3rd International Conference on Applied Robotics for the Power Industry, Foz do Iguacu, Brazil, 14–16 October 2014. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, X.; Jia, J.; Liu, X. A Recognition Technology of Transmission Lines Conductor Break and Surface Damage Based on Aerial Image. IEEE Access 2019, 7, 59022–59036. [Google Scholar] [CrossRef]
- Jiang, X.; Xia, Y.; Zhang, Z.; Hu, J.; Hu, Q. Image Detection for Broken Strand Faults of Transmission Conductor Based on Optimized Gabor Filter. Autom. Electr. Power Syst. 2011, 35, 78–83. [Google Scholar]
- Wang, W.; Zhang, J.; Han, J.; Liu, L.; Zhu, M. Broken strand and foreign body fault detection method for power transmission line based on unmanned aerial vehicle image. J. Comput. Appl. 2015, 35, 2404–2408. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Jha, S.B.; Babiceanu, R.F. Deep CNN-based visual defect detection: Survey of current literature. Comput. Ind. 2023, 148, 103911. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, X. Survey of Applications of Material Defect Detection Based on Machine Vision and Deep Learning. Mater. Rev. 2022, 36, 226–234. [Google Scholar]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-Based Defect Detection and Classification Approaches for Industrial Applications—A SURVEY. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef]
- Liu, J.; Liu, C.; Wu, Y.; Xu, H.; Sun, Z. An Improved Method Based on Deep Learning for Insulator Fault Detection in Diverse Aerial Images. Energies 2021, 14, 4365. [Google Scholar] [CrossRef]
- Santos, T.; Cunha, T.; Dias, A.; Moreira, A.P.; Almeida, J. UAV Visual and Thermographic Power Line Detection Using Deep Learning. Sensors 2024, 24, 5678. [Google Scholar] [CrossRef]
- Liang, H.; Zuo, C.; Wei, W. Detection and Evaluation Method of Transmission Line Defects Based on Deep Learning. IEEE Access 2020, 8, 38448–38458. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, C.; Qu, H. Transmission Line Object Detection Method Based on Contextual Information Enhancement and Joint Heterogeneous Representation. Sensors 2022, 22, 6855. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, L.; Li, D. Transmission Line Abnormal Target Detection Based on Machine Learning Yolo V3. In Proceedings of the 2019 International Conference on Advanced Mechatronic Systems (ICAMechS), Kusatsu, Japan, 26–28 August 2019. [Google Scholar] [CrossRef]
- Wang, X.; Chen, X.; Chen, H.; Cao, Y.; Zhang, J. Foreign Object Detection Method in Transmission Lines Based on Improved YOLOv8n. In Proceedings of the 2024 10th International Symposium on System Security, Safety, and Reliability (ISSSR), Xiamen, China, 16–17 March 2024. [Google Scholar] [CrossRef]
- Hu, T.; Shen, L.; Wu, D.; Duan, Y.; Song, Y. Research on transmission line ice-cover segmentation based on improved U-Net and GAN. Electr. Power Syst. Res. 2023, 221, 109405. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015. [Google Scholar] [CrossRef]
- Wang, Y.; Shang, J.; Zhang, Y.; Liu, J.; Yang, L.; Botao, L. Real-Time Transmission Wire Defect Detection Method Based on Improved YOLOv7. South. Power Syst. Technol. 2023, 17, 127–134. [Google Scholar] [CrossRef]
- Yu, Y.; Lv, H.; Chen, W.; Wang, Y. Research on Defect Detection for Overhead Transmission Lines Based on the ABG-YOLOv8n Model. Energies 2024, 17, 5974. [Google Scholar] [CrossRef]
- Wu, Y.; Liao, T.; Chen, F.; Zeng, H.; Ouyang, S.; Guan, J. Overhead Power Line Damage Detection: An Innovative Approach Using Enhanced YOLOv8. Electronics 2024, 13, 739. [Google Scholar] [CrossRef]
- Song, Z.; Zhang, Y.; Huang, X.; Zhang, Y. Fast Fusion Net: Defect Detection and Fault Identification Methods for High-Voltage Overhead Power Lines. Eng. Appl. Artif. Intell. 2025, 151, 110646. [Google Scholar] [CrossRef]
- Yang, C.; Kong, Z.; Xie, Q.; Du, J. Image Recognition Method for Transmission Line Based on the DeepLab v3+ Deep Convolutional Network. Electr. Power Eng. Technol. 2021, 40, 189–194. [Google Scholar] [CrossRef]
- Zhai, X.; Li, X.; Zhai, Y. Defect Detection of Overhead Transmission Wires Based on Deep Learning. Power Syst. Technol. 2023, 47, 1022–1030. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Liao, K.-C.; Lau, J.; Hidayat, M. An Innovative Aircraft Skin Damage Assessment Using You Only Look Once-Version9: A Real-Time Material Evaluation System for Remote Inspection. Aerospace 2025, 12, 31. [Google Scholar] [CrossRef]
- Li, W.; Lambert-Garcia, R.; Getley, A.C.M.; Kim, K.; Bhagavath, S.; Majkut, M.; Rack, A.; Lee, P.D.; Leung, C.L.A. AM-SegNet for additive manufacturing in situ X-ray image segmentation and feature quantification. Virt. Phys. Prototyp. 2024, 19, e2325572. [Google Scholar] [CrossRef]
- Taylor, M.E.; Stone, P. Transfer Learning for Reinforcement Learning Domains: A Survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | Inference Time (s) |
|---|---|---|---|
| YOLOv5s (Single) | 0.89 | 0.85 | 0.05 |
| U-Net (Single) | 0.87 | 0.87 | 0.12 |
| YOLOv5s + U-Net (Two-stage) | 0.91 | 0.89 | 0.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, A.; Li, D.; Wang, A. A Two-Stage YOLOv5s–U-Net Framework for Defect Localization and Segmentation in Overhead Transmission Lines. Sensors 2025, 25, 2903. https://doi.org/10.3390/s25092903
Li A, Li D, Wang A. A Two-Stage YOLOv5s–U-Net Framework for Defect Localization and Segmentation in Overhead Transmission Lines. Sensors. 2025; 25(9):2903. https://doi.org/10.3390/s25092903
Chicago/Turabian StyleLi, Aohua, Dacheng Li, and Anjing Wang. 2025. "A Two-Stage YOLOv5s–U-Net Framework for Defect Localization and Segmentation in Overhead Transmission Lines" Sensors 25, no. 9: 2903. https://doi.org/10.3390/s25092903
APA StyleLi, A., Li, D., & Wang, A. (2025). A Two-Stage YOLOv5s–U-Net Framework for Defect Localization and Segmentation in Overhead Transmission Lines. Sensors, 25(9), 2903. https://doi.org/10.3390/s25092903