
Joint Task Offloading and Power Allocation for Satellite Edge Computing Networks


Abstract
1. Introduction
- We construct a multi-satellite SECN scenario, in which a single task is assumed to be divided into sub-tasks and offloaded to adjacent satellites. These sub-tasks will be processed on board. This offloading strategy makes full use of heterogeneous resources in the satellite network, reduces the load burden on individual satellites, and enables a more flexible resource scheduling scheme.
- We formulate an optimization problem mathematically, to minimize the maximum delay through resource allocation, in which transmission power and task assignment ratios are optimized.
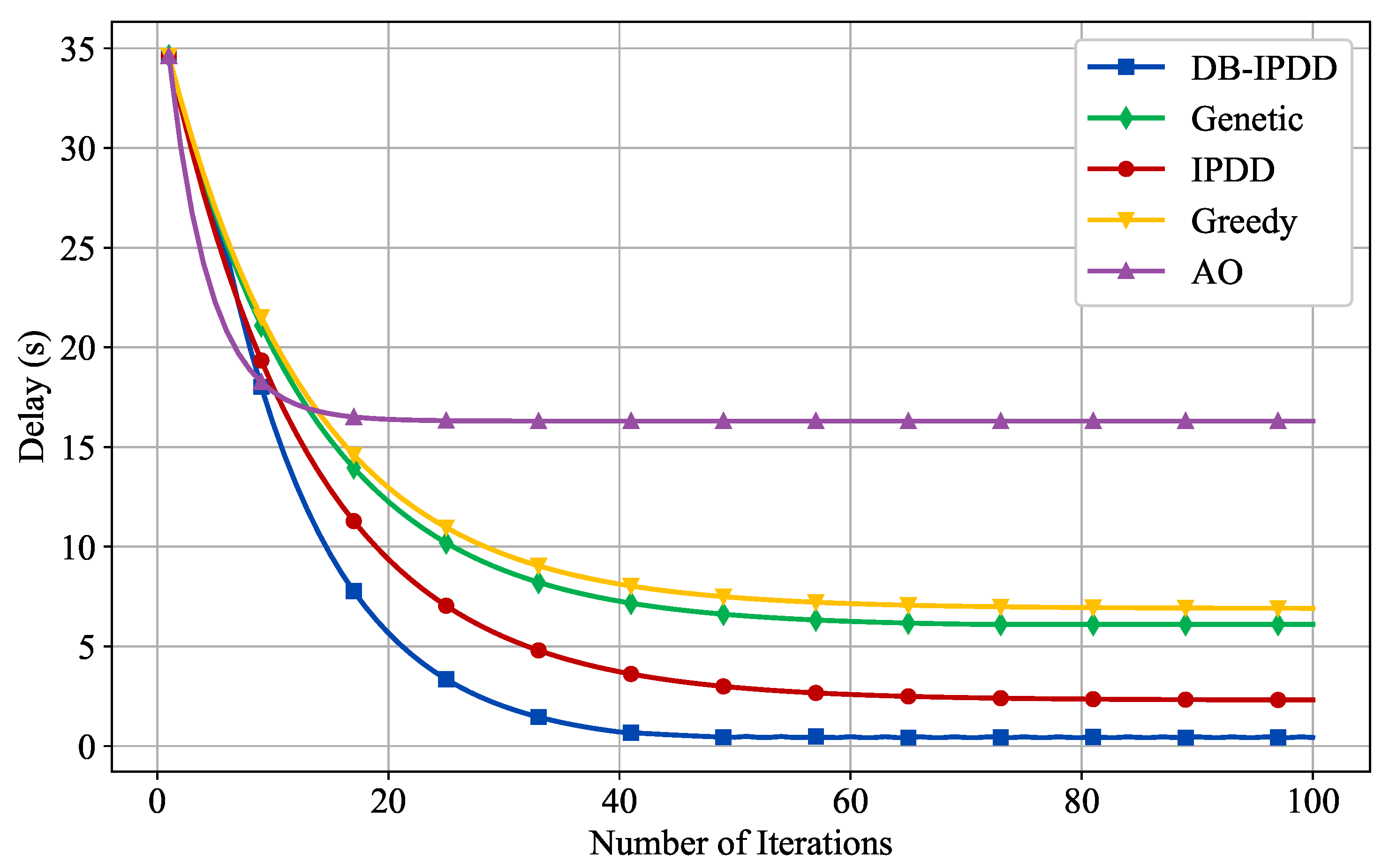
- We propose a distributed balance increasing penalty dual decomposition (DB-IPDD) algorithm. Our experimental validation across various orbital configurations demonstrates consistent 14.3% latency reduction compared with baseline approaches.
- We derive the optimal solution theoretically for the LEO satellite case, in which the resources are abundantly available. We further extend the analysis to the general case under specific conditions.
- Simulation results clearly show that the proposed solution greatly outperforms the baseline methods, and the transmission delay is significantly reduced.
2. Related Work
2.1. Task Offloading Strategy Design
2.2. SECN Architecture Design
3. System Model and Problem Formulation
3.1. System Model
3.2. Doppler Frequency Shift Model
3.3. Task Offloading Model
Energy Consumption Model
3.4. Resource Constraints
3.5. Problem Formulation
4. Resource Management Algorithm
4.1. Inner Loop Procedure
- 1.
- Initial values of , P, , W, V, , and are set to , , , , , , and , respectively; then, set and .
- 2.
- 3.
- 4.
- 5.
- 6.
4.2. Middle Loop Procedure
4.3. Outer Loop Procedure
| Algorithm 1: DB-IPDD Algorithm |
 |
4.4. Time Complexity of DB-IPDD
5. Performance Analysis
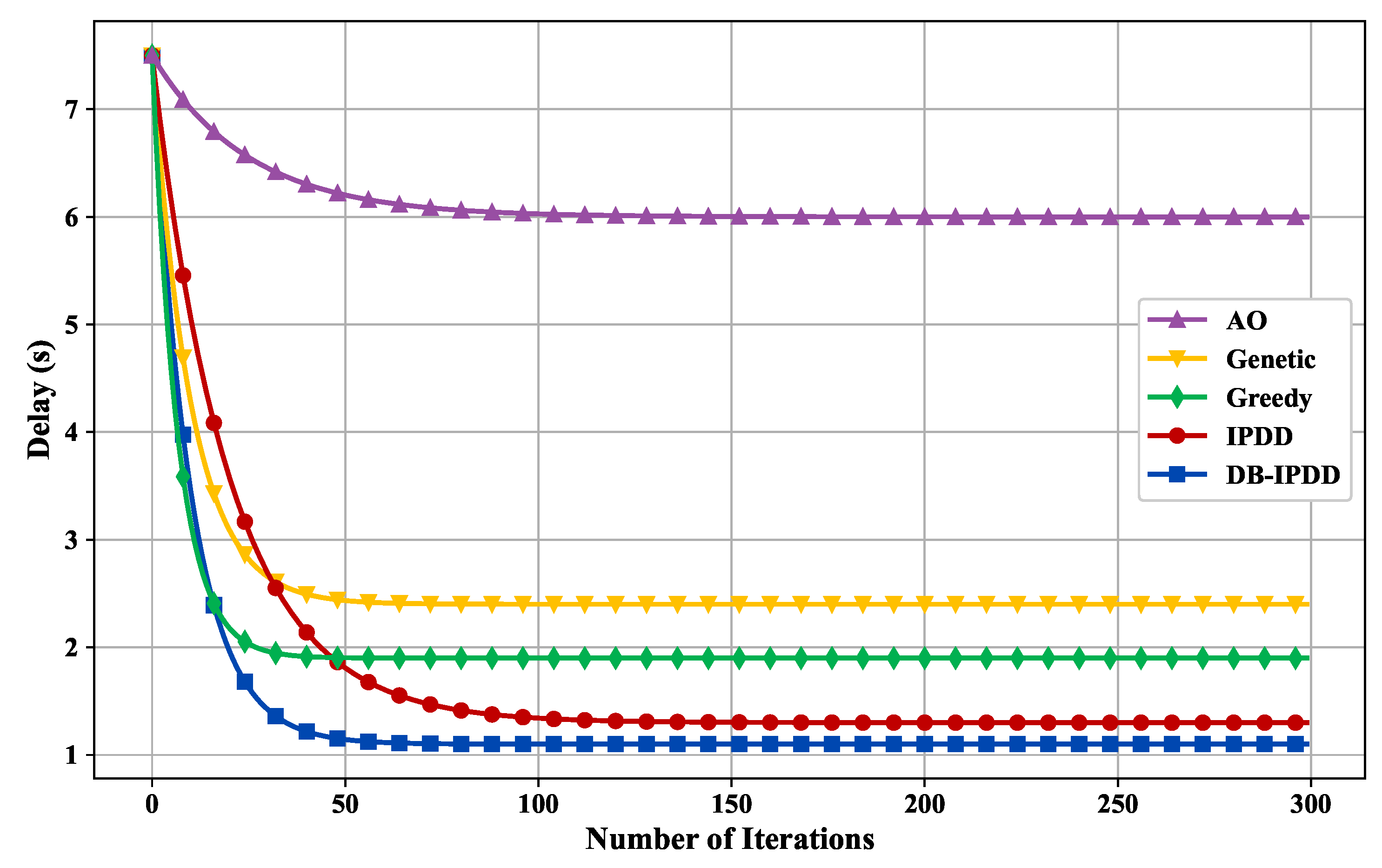
5.1. Delay Performance
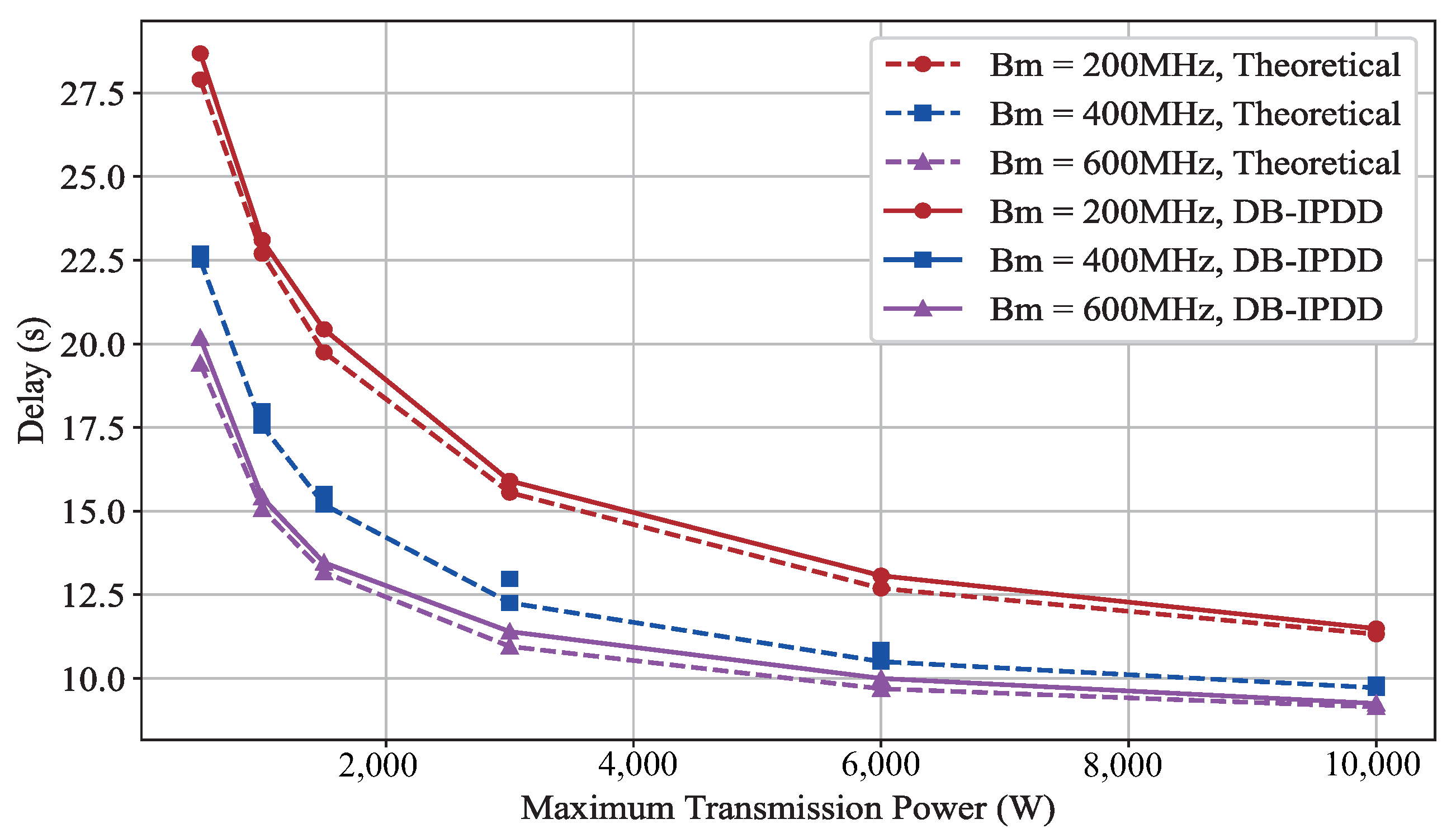
5.2. Transmit Power Impact on Delay Performance
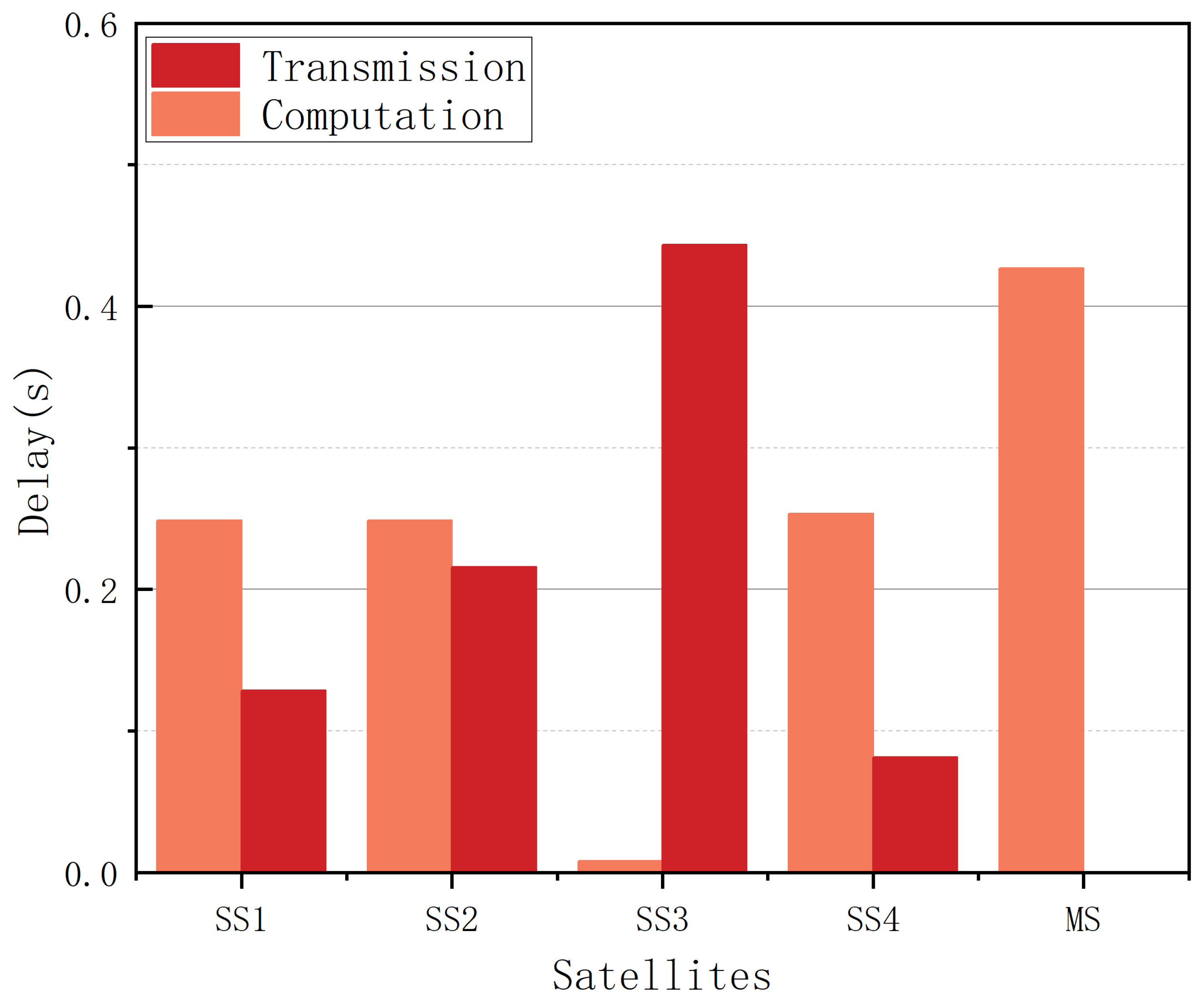
5.3. Delay Performance with Different SSs and Transmit Power
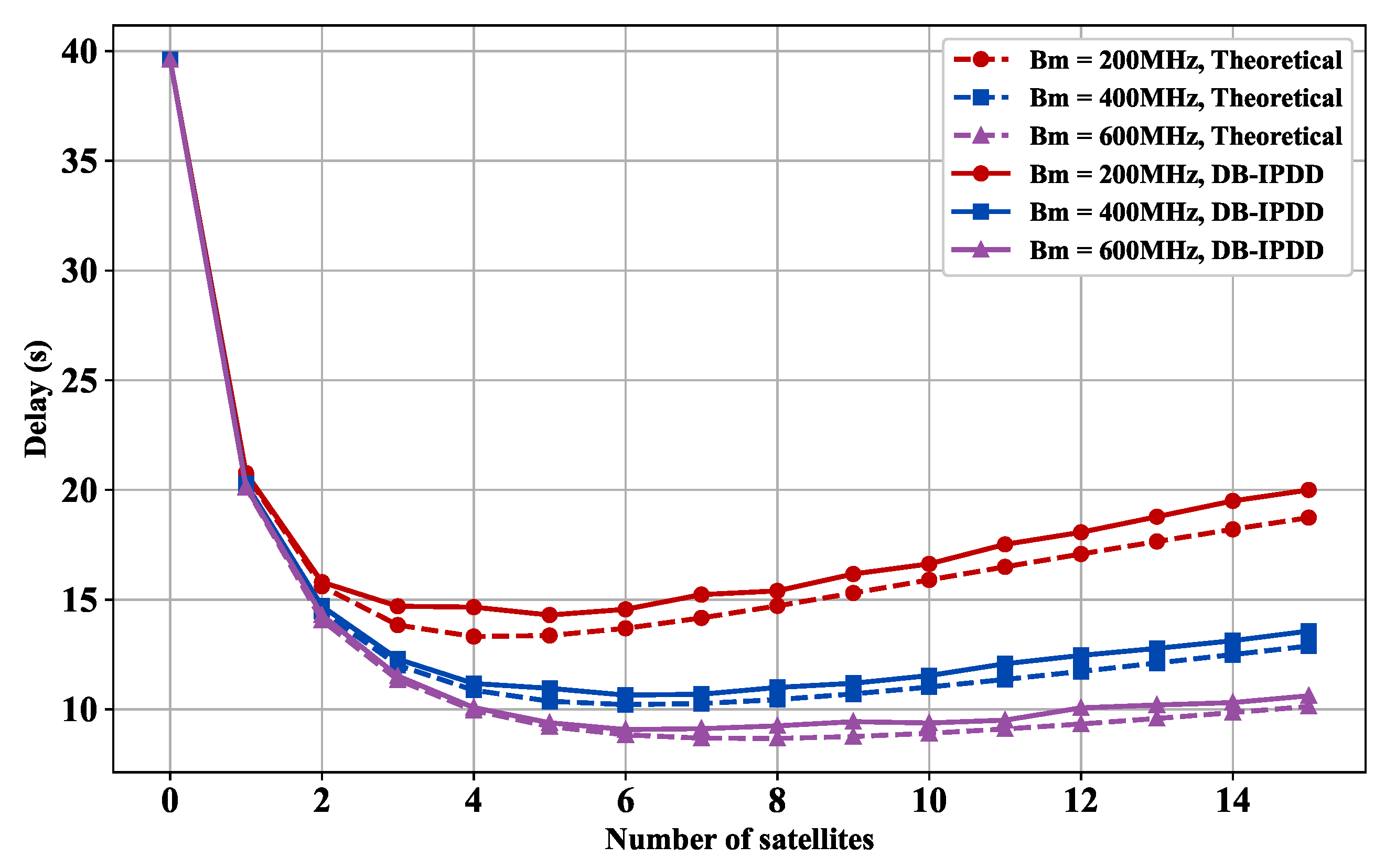
5.4. Delay Performance with Different SSs and Bandwidths
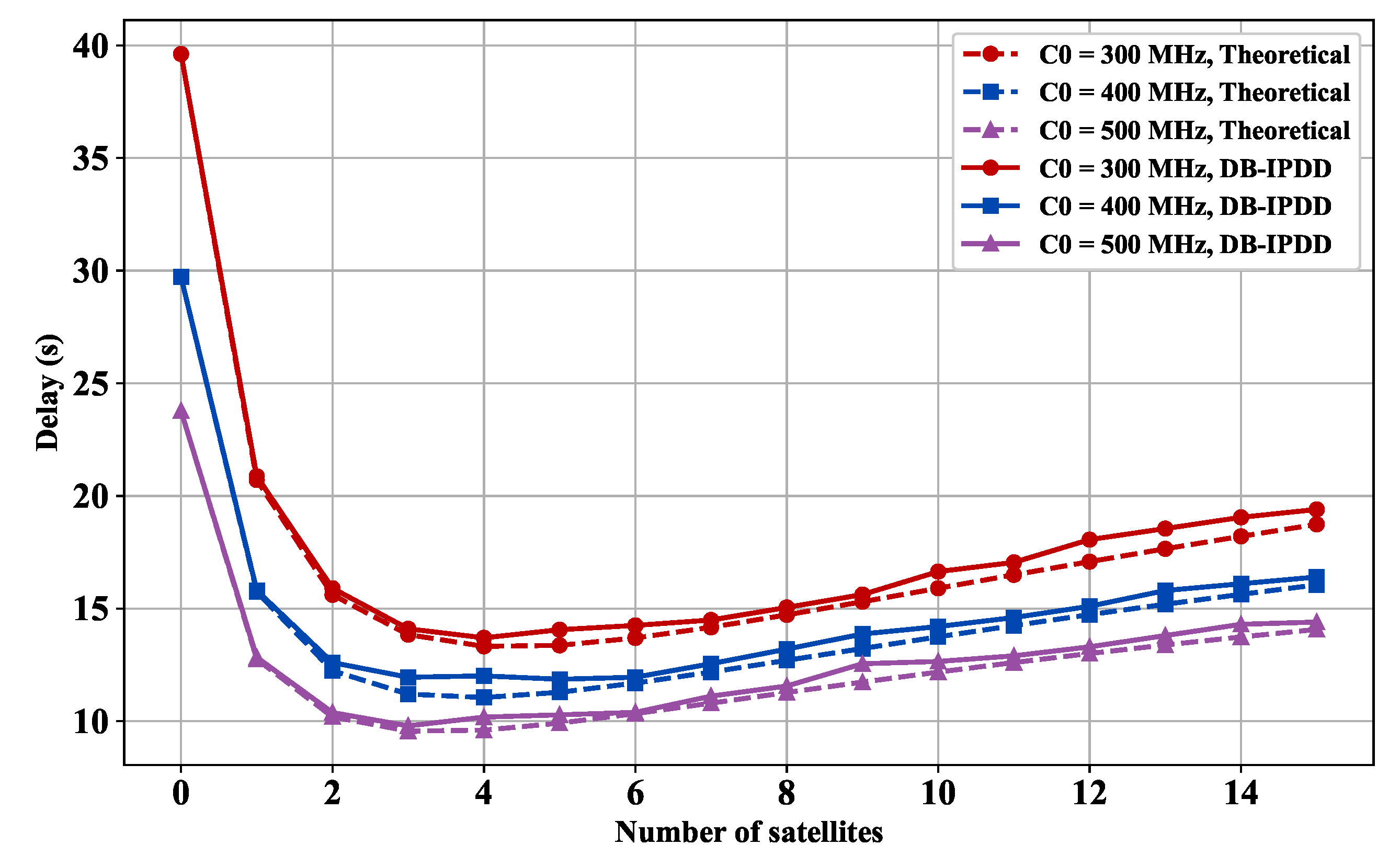
5.5. Delay Performance with Different SSs and Computation Resources
5.6. Delay Performance with Different Computation Resources and Different Bandwidths
5.7. Delay Performance with Different Main Frequencies and Transmission Powers
5.8. Delay Performance in General Conditions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Proof of Theorem 1
- Transfer a number of data from Satellite 1 to Satellite 2: by shifting some data processing tasks from Satellite 1 to Satellite 2, we can reduce the load and processing time on Satellite 1, potentially decreasing and increasing .
- Transfer a portion of power from Satellite 2 to Satellite 1: by reallocating power resources from Satellite 2 to Satellite 1, we can enhance the performance and transmission capability of Satellite 1, potentially reducing and multiplying .
References
- Xia, Q.; Wang, G.; Xu, Z.; Liang, W.; Xu, Z. Efficient Algorithms for Service Chaining in NFV-Enabled Satellite Edge Networks. IEEE Trans. Mob. Comput. 2024, 23, 5677–5694. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, R.; Kaushik, A.; Gao, X. Satellite Edge Computing with Collaborative Computation Offloading: An Intelligent Deep Deterministic Policy Gradient Approach. IEEE Internet Things J. 2023, 10, 9092–9107. [Google Scholar] [CrossRef]
- Ji, Z.; Wu, S.; Jiang, C. Cooperative Multi-Agent Deep Reinforcement Learning for Computation Offloading in Digital Twin Satellite Edge Networks. IEEE J. Sel. Areas Commun. 2023, 41, 3414–3429. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, J.; Guo, X.; Qu, Z. A game-theoretic approach to computation offloading in satellite edge computing. IEEE Access 2020, 8, 12510–12520. [Google Scholar] [CrossRef]
- Yousefpour, A.; Fung, C.; Nguyen, T.; Kadiyala, K.; Jalali, F.; Niakanlahiji, A.; Kong, J.; Jue, J.P. All one needs to know about fog computing and related edge computing paradigms: A complete survey. J. Syst. Archit. 2019, 98, 289–330. [Google Scholar] [CrossRef]
- Zhang, H.; Zhao, H.; Liu, R.; Gao, X.; Xu, S. Leader Federated Learning Optimization Using Deep Reinforcement Learning for Distributed Satellite Edge Intelligence. IEEE Trans. Serv. Comput. 2024, 17, 2544–2557. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, H.; Sun, K.; Huo, J.; Wang, N.; Leung, V.C.M. Partial Computation Offloading in Satellite-Based Three-Tier Cloud-Edge Integration Networks. IEEE Trans. Wirel. Commun. 2024, 23, 836–847. [Google Scholar] [CrossRef]
- Zhou, J.; Zhao, Y.; Zhao, L.; Cai, H.; Xiao, F. Adaptive Task Offloading with Spatiotemporal Load Awareness in Satellite Edge Computing. IEEE Trans. Netw. Sci. Eng. 2024, 11, 5311–5322. [Google Scholar] [CrossRef]
- Chen, D.; Liu, Y.C.; Kim, B.G.; Xie, J.; Hong, C.S.; Han, Z. Edge computing resources reservation in vehicular networks: A meta-learning approach. IEEE Trans. Veh. Technol. 2020, 69, 5634–5646. [Google Scholar] [CrossRef]
- Pham, Q.V.; Ruby, R.; Fang, F.; Nguyen, D.C.; Yang, Z.; Le, M.; Ding, Z.; Hwang, W.J. Aerial Computing: A New Computing Paradigm, Applications, and Challenges. IEEE Internet Things J. 2022, 9, 8339–8363. [Google Scholar] [CrossRef]
- Li, Y.; Gao, X.; Shi, M.; Kang, J.; Niyato, D.; Yang, K. Dynamic Weighted Energy Minimization for Aerial Edge Computing Networks. IEEE Internet Things J. 2025, 12, 683–697. [Google Scholar] [CrossRef]
- Letaief, K.B.; Shi, Y.; Lu, J.; Lu, J. Edge Artificial Intelligence for 6G: Vision, Enabling Technologies, and Applications. IEEE J. Sel. Areas Commun. 2022, 40, 5–36. [Google Scholar] [CrossRef]
- Fang, X.; Feng, W.; Wei, T.; Chen, Y.; Ge, N.; Wang, C.-X. 5G Embraces Satellites for 6G Ubiquitous IoT: Basic Models for Integrated Satellite Terrestrial Networks. IEEE Internet Things J. 2021, 8, 14399–14417. [Google Scholar] [CrossRef]
- Hassan, S.S.; Park, Y.M.; Tun, Y.K.; Saad, W.; Han, Z.; Hong, C.S. Satellite-Based ITS Data Offloading & Computation in 6G Networks: A Cooperative Multi-Agent Proximal Policy Optimization DRL with Attention Approach. IEEE Trans. Mob. Comput. 2024, 23, 4956–4974. [Google Scholar] [CrossRef]
- Xie, R.; Tang, Q.; Wang, Q.; Liu, X.; Yu, F.R.; Huang, T. Satellite-Terrestrial Integrated Edge Computing Networks: Architecture, Challenges, and Open Issues. IEEE Netw. 2020, 34, 224–231. [Google Scholar] [CrossRef]
- Shi, Q.; Hong, M. Penalty Dual Decomposition Method for Nonsmooth Nonconvex Optimization—Part I: Algorithms and Convergence Analysis. IEEE Trans. Signal Process. 2020, 68, 4108–4122. [Google Scholar] [CrossRef]
- Shi, Q.; Hong, M.; Fu, X.; Chang, T.-H. Penalty Dual Decomposition Method for Nonsmooth Nonconvex Optimization—Part II: Applications. IEEE Trans. Signal Process. 2020, 68, 4242–4257. [Google Scholar] [CrossRef]
- Li, Q.; Wang, S.; Ma, X.; Zhou, A.; Wang, Y.; Huang, G.; Liu, X. Battery-Aware Energy Optimization for Satellite Edge Computing. IEEE Trans. Serv. Comput. 2024, 17, 437–451. [Google Scholar] [CrossRef]
- Wu, J.; Jia, M.; Guo, Q.; Gu, X. Joint Optimization Computation Offloading and Resource Allocation for LEO Satellite with Edge Computing. In Proceedings of the 2023 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Beijing, China, 14–16 June 2023; pp. 1–5. [Google Scholar]
- Song, Z.; Hao, Y.; Liu, Y.; Sun, X. Energy-efficient multiaccess edge computing for terrestrial-satellite internet of things. IEEE Internet Things J. 2021, 8, 14202–14218. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, C.; Liu, L.; Lan, D.; Jiang, H.; Wan, S. Aerial edge computing on orbit: A task offloading and allocation scheme. IEEE Trans. Netw. Sci. Eng. 2022, 10, 275–285. [Google Scholar] [CrossRef]
- Yi, C.; Cai, J.; Su, Z. A multi-user mobile computation offloading and transmission scheduling mechanism for delay-sensitive applications. IEEE Trans. Mob. Comput. 2020, 19, 29–43. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient multi-user computation offloading for mobile-edge cloud computing. IEEE Trans. Netw. 2016, 24, 2795–2808. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, J.; Zhang, R.; Huang, Y.; Tong, J.; Xin, N.; Liu, L.; Xiong, Z. Energy-Efficient Computation Peer Offloading in Satellite Edge Computing Networks. IEEE Trans. Mob. Comput. 2024, 23, 3077–3091. [Google Scholar] [CrossRef]
- Zhou, J.; Yang, Q.; Zhao, L.; Dai, H.; Xiao, F. Mobility-Aware Computation Offloading in Satellite Edge Computing Networks. IEEE Trans. Mob. Comput. 2024, 23, 9135–9149. [Google Scholar] [CrossRef]
- Kim, T.; Kwak, J.; Choi, J.P. Satellite Edge Computing Architecture and Network Slice Scheduling for IoT Support. IEEE Internet Things J. 2022, 9, 14938–14951. [Google Scholar] [CrossRef]
- Qiu, C.; Yao, H.; Yu, F.R.; Xu, F.; Zhao, C. Deep Q-learning aided networking, caching, and computing resources allocation in softwaredefined satellite-terrestrial networks. IEEE Trans. Veh. Technol. 2019, 68, 5871–5883. [Google Scholar] [CrossRef]
- Hu, Q.; Cai, Y.; Yu, G.; Qin, Z.; Zhao, M.; Li, G.Y. Joint Offloading and Trajectory Design for UAV-Enabled Mobile Edge Computing Systems. IEEE Internet Things J. 2019, 6, 1879–1892. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviations | Description |
|---|---|
| N | Number of slots |
| M | Number of slave satellites |
| Energy upper limit to execute the whole task | |
| Energy upper limit of a satellite | |
| D | Data needs to be processed |
| The main frequency of the CPU | |
| The normalized transmission data rate | |
| The receiver noise power | |
| B | Communication bandwidth |
| Notation | Description |
| c | The light speed |
| The Chip’s coefficient | |
| s | Cycles needed to process 1 bit of data |
| The upper limit of the violation function | |
| The distance between the k-th slave satellite | |
| and the master satellite | |
| The ratios of the offloading data to slave satellite | |
| k at slot i | |
| The transmission delay to slave satellite | |
| k at slot i | |
| The local computing time | |
| The channel power gain at d = 1 m | |
| The Lagrange multiplier | |
| The transmission power to slave satellite | |
| k at slot i |
| Parameter | Default Value |
|---|---|
| B | 200 MHz |
| M | 4 |
| cycles/s | |
| 5000 W | |
| 3,000,000 J | |
| 1 W | |
| s | 0.1 |
| D | 1 GB |
| 0.01 | |
| 200 | |
| 1 | |
| 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhu, S.; Xiong, T.; Li, Y.; Su, Q.; Dai, J. Joint Task Offloading and Power Allocation for Satellite Edge Computing Networks. Sensors 2025, 25, 2892. https://doi.org/10.3390/s25092892
Li Y, Zhu S, Xiong T, Li Y, Su Q, Dai J. Joint Task Offloading and Power Allocation for Satellite Edge Computing Networks. Sensors. 2025; 25(9):2892. https://doi.org/10.3390/s25092892
Chicago/Turabian StyleLi, Yuxuan, Shibing Zhu, Ting Xiong, Yuwei Li, Qi Su, and Jianmei Dai. 2025. "Joint Task Offloading and Power Allocation for Satellite Edge Computing Networks" Sensors 25, no. 9: 2892. https://doi.org/10.3390/s25092892
APA StyleLi, Y., Zhu, S., Xiong, T., Li, Y., Su, Q., & Dai, J. (2025). Joint Task Offloading and Power Allocation for Satellite Edge Computing Networks. Sensors, 25(9), 2892. https://doi.org/10.3390/s25092892