
Image Fusion and Target Detection Based on Dual ResNet for Power Sensing Equipment
Abstract
1. Introduction
2. Related Works
2.1. SIFT Algorithm Principle
2.2. ResNet
2.3. Weighted Fusion Strategy
3. Proposed Target Detection Method
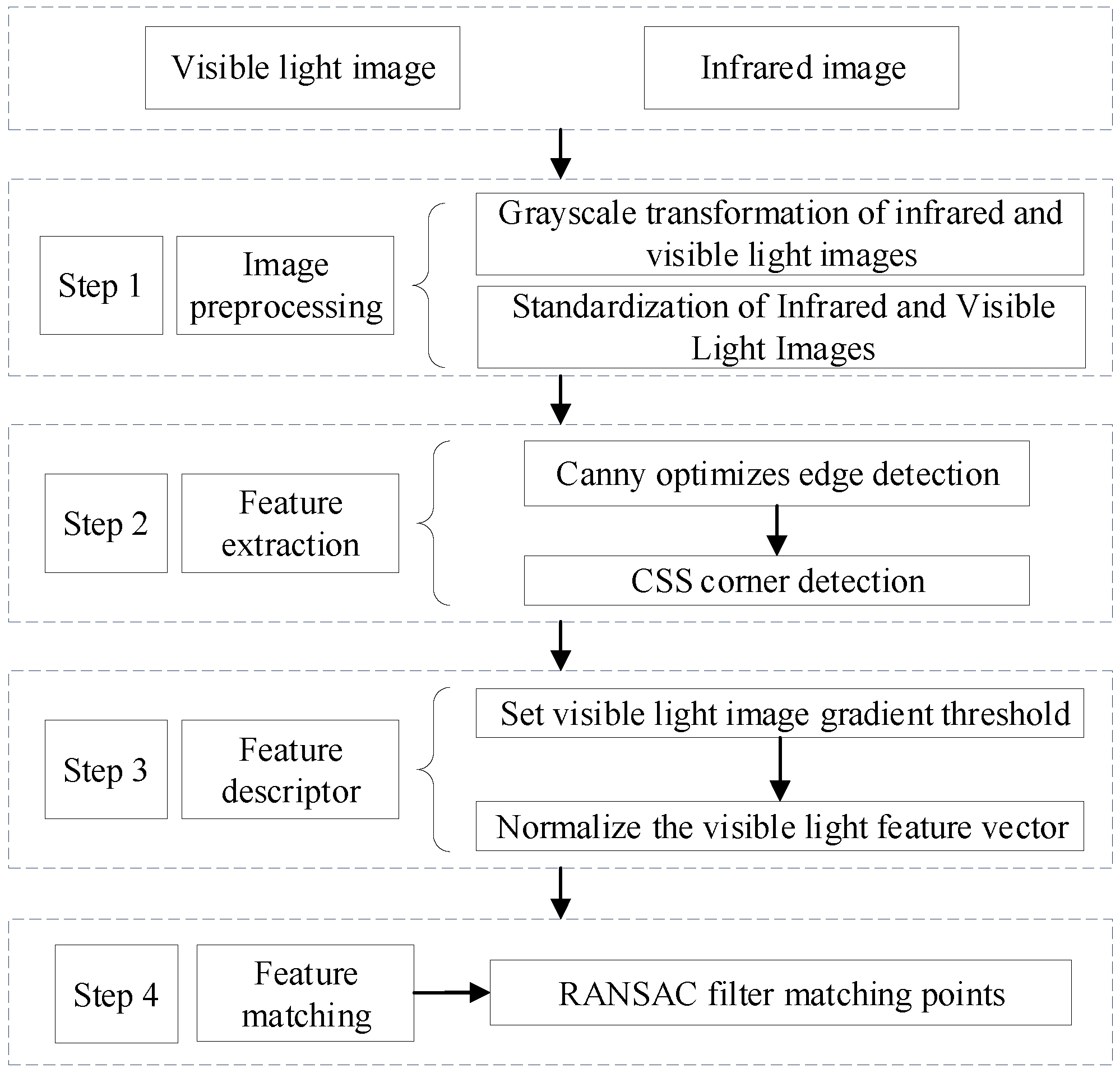
3.1. Image Registration Based on Improved SIFT Algorithm
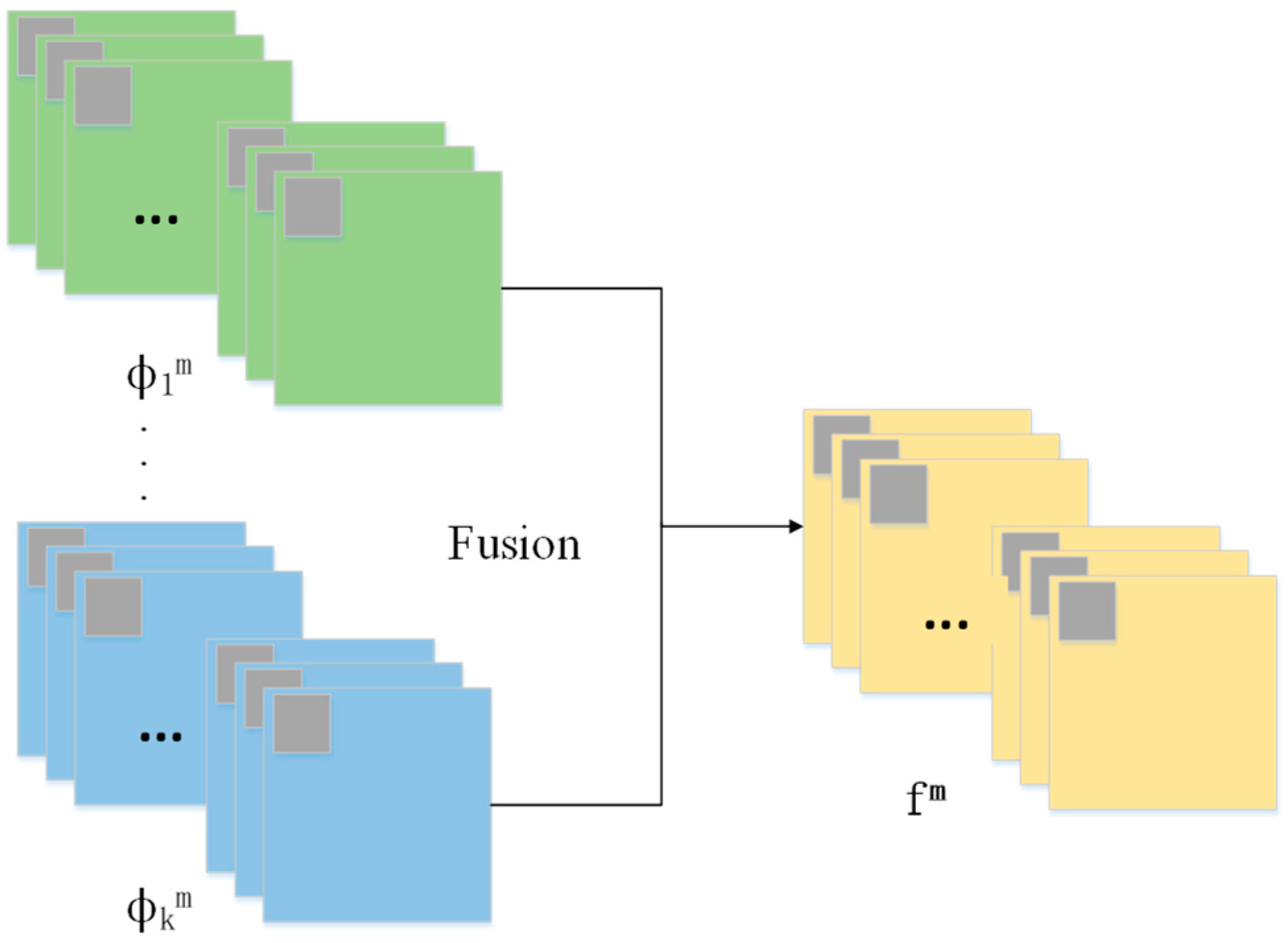
3.2. Image Fusion Based on Dual ResNet
4. Experimental Results and Analysis
4.1. Image Registration
4.2. Image Fusion
4.3. Target Detection Results and Analysis
4.3.1. Dataset
4.3.2. Experimental Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, Z.G.; Fan, Y.K.; Zhang, J. An Exploration of Image Recognition of Power Equipment Based on Deep Neural Network. Electr. Times 2021, 40–42. [Google Scholar]
- Chen, P.; Qin, L.M. Infrared image recognition of power equipment based on deep learning. J. Shanghai Electr. Power Univ. 2021, 37, 217–220+230. [Google Scholar]
- Wang, X.; Mao, H.M.; Li, T.B.; Zen, H.; Cheng, H.B. Infrared Image Recognition Algorithm for Power Equipment Based on Transfer Learning and R-FCN. Sens. Microsyst. 2021, 40, 147–150. [Google Scholar]
- Yang, H. Research on Multi-Source Remote Sensing Image Registration Method Based on Feature and Frequency Domain Similarity Measurement. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2021. [Google Scholar]
- Zhang, Y.; Zhang, F.; Jin, Y.; Cen, Y.; Voronin, V.; Wan, S. Local correlation ensemble with GCN based on attention features for cross-domain person Re-ID. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–22. [Google Scholar] [CrossRef]
- Huo, X.; Zou, Y.; Chen, Y.; Tan, J.Q. Fusion of infrared and visible images combined with dual-scale decomposition and significance analysis. Chin. J. Image Graph. 2021, 26, 2813–2825. [Google Scholar] [CrossRef]
- Zheng, Y. Research on Image Registration Algorithm Based on Improved Harris Scale Invariant Feature. J. Wu Zhou Univ. 2020, 30, 1–7. [Google Scholar]
- Guo, Z.; Yu, X.; Du, Q. Infrared and visible image fusion based on saliency and fast guided filtering. Infrared Phys. Technol. 2022, 123, 104178. [Google Scholar] [CrossRef]
- Duan, C.; Wang, Z.; Xing, C.; Lu, S. Infrared and visible image fusion using multi-scale edge-preserving decomposition and multiple saliency features. Opt.-Int. J. Light Electron Opt. 2021, 228, 165775. [Google Scholar] [CrossRef]
- Xie, Q.; Ma, L.; Guo, Z.; Fu, Q.; Shen, Z.; Wang, X. Infrared and visible image fusion based on NSST and phase consistency adaptive DUAL channel PCNN. Infrared Phys. Technol. 2023, 131, 104659. [Google Scholar] [CrossRef]
- Tong, Y.; Chen, J. Infrared and Visible Image Fusion Under Different Illumination Conditions Based on Illumination Effective Region Map. IEEE Access 2019, 7, 151661–151668. [Google Scholar] [CrossRef]
- Selvaraj, A.; Ganesan, P. Infrared and visible image fusion using multi-scale NSCT and rolling-guidance filter. IET Image Process. 2020, 14, 4210–4219. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Luo, D.; Liu, G.; Bavirisetti, D.P.; Cao, Y. Infrared and visible image fusion based on VPDE model and VGG network. Appl. Intell. 2023, 53, 24739–24764. [Google Scholar] [CrossRef]
- Fan, W.; Li, X.; Liu, Z. Fusion of visible and infrared images using GE-WA model and VGG-19 network. Sci. Rep. 2023, 13, 190. [Google Scholar] [CrossRef]
- Zhou, J.; Ren, K.; Wan, M.; Cheng, B.; Gu, G.; Chen, Q. An infrared and visible image fusion method based on VGG-19 network. Optik 2021, 248, 168084. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Elpeltagy, M.; Sallam, H. Automatic prediction of COVID-19 from chest images using modified ResNet50. Multimed. Tools Appl. 2021, 80, 26451–26463. [Google Scholar] [CrossRef]
- Islam, W.; Jones, M.; Faiz, R.; Sadeghipour, N.; Qiu, Y.; Zheng, B. Improving performance of breast lesion classification using a ResNet50 model optimized with a novel attention mechanism. Tomography 2022, 8, 2411–2425. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Li, L.; Zhu, H.; Liu, X.; Jiao, L. Adaptive multiscale deep fusion residual network for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8506–8521. [Google Scholar] [CrossRef]
- Huang, Z.; Cai, W.; Zhang, C.; Jiang, T. Fusion of MRI Images and PET Images Based on ResNet50. In Proceedings of the 2022 IEEE 5th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 16–18 December 2022; Volume 5, pp. 904–991. [Google Scholar]
- Niu, Z. A Lightweight Two-stream Fusion Deep Neural Network Based on ResNet Model for Sports Motion Image Recognition. Sens. Imaging 2021, 22, 26. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 21–23 September 2005; pp. 886–893. [Google Scholar]
- Xu, B.; Gong, J.; Sun, Z. Overview of Object Detection Models Based on Convolutional Neural Networks. Comput. Technol. Dev. 2019, 29, 87–92. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Guo, J.; Liu, L.; Xu, F.; Zheng, B. Airport scene aircraft detection method based on YOLOv3. Prog. Laser Optoelectron. 2019, 56, 111–119. [Google Scholar]
- Liu, M.; Fan, Y. Remote sensing image object detection algorithm based on improved YOLOv4. J. Test. Technol. 2024, 38, 54–59. [Google Scholar]
- Wang, L.; Hao, Y.; Pan, M.; Zhao, M.; Zhang, Y.; Zhang, M. Research on Improving YOLOv5s Defect Detection Algorithm in Power Inspection. Comput. Eng. Appl. 2024, 60, 256–265. [Google Scholar]
- Xu, D.; Wang, Z.; Xing, K.; Guo, Y. Improved YOLOv6 Remote Sensing Image Object Detection Algorithm. Comput. Eng. Appl. 2024, 60, 119–128. [Google Scholar]
- Sun, N.; Yang, Y.; Yang, Z.; Bu, Z. Design and Implementation of Optimization Model for Small Object Detection Experiment in Machine Vision. Lab. Res. Explor. 2023, 42, 32–39. [Google Scholar]
- Zhang, X.; Yang, X. Rubber seal ring defect detection method based on improved YOLOv7 tiny. J. Graph. Sci. 2024, 45, 446–453. [Google Scholar]
- Patankar, S.S.; Kadam, S.G.; Jadhav, A.; Gore, M. Image Registration using Shi-Tomasi and SIFT. In Proceedings of the 2023 2nd International Conference for Innovation in Technology (INOCON), Bangalore, India, 3–5 March 2023; pp. 1–4. [Google Scholar]
- Huang, H.B.; Li, X.; Nie, X.; Zhang, Y.; Feng, L. Research on remote sensing image registration based on SIFT algorithm. Laser J. 2021, 42, 97–102. [Google Scholar]
- Cai, T.W.; Fu, S. Infrared image registration based on improved SIFT algorithm. Meas. Control Technol. 2021, 40, 40–45. [Google Scholar]
- Pan, B.; Jiao, R.; Wang, J.; Han, Y. SAR image registration based on KECA-SAR-SIFT operator. In Proceedings of the 2022 2nd International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Fuzhou, China, 23–25 September 2022; pp. 114–119. [Google Scholar]
- Gu, Y.; Wang, H.; Bie, Y.; Yang, R.; Li, Y. Research on Image Registration of Different Wavebands Based on SIFT Algorithm. In Proceedings of the 2022 3rd China International SAR Symposium (CISS), Shanghai, China, 2–4 November 2022; pp. 1–5. [Google Scholar]
- Hou, X.; Chen, C.; Zhou, S.; Li, J. Robust face recognition based on non-negative sparse discriminative low-rank representation. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 5579–5583. [Google Scholar]
- Zou, B.; Li, H.; Zhang, L.; Cheng, Y. A SAR-SIFT like algorithm for PolSAR image registration. In Proceedings of the 2019 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 26–29 November 2019; pp. 1–5. [Google Scholar]
- Zhou, J.; Ma, M.D. Face expression recognition based on improved ResNet network. Comput. Technol. Dev. 2022, 32, 25–29. [Google Scholar]
- Jiang, Q.; Liu, Y.; Yan, Y.; Deng, J.; Fang, J.; Li, Z.; Jiang, X. A contour angle orientation for power equipment infrared and visible image registration. IEEE Trans. Power Deliv. 2020, 36, 2559–2569. [Google Scholar] [CrossRef]
- Gao, C.; Qi, D.; Zhang, Y.; Song, C.; Yu, Y. Infrared and visible image fusion method based on ResNet in a nonsubsampled contourlet transform domain. IEEE Access 2021, 9, 91883–91895. [Google Scholar] [CrossRef]
- Krueangsai, A.; Supratid, S. Effects of shortcut-level amount in lightweight ResNet of ResNet on object recognition with distinct number of categories. In Proceedings of the 2022 International Electrical Engineering Congress (iEECON), Khon Kaen, Thailand, 9–11 March 2022; pp. 1–4. [Google Scholar]
- Setiawan, A.W. The Effect of Image Dimension and Exposure Fusion Framework Enhancement in Pneumonia Detection Using Residual Neural Network. In Proceedings of the 2022 International Seminar on Application for Technology of Information and Communication (iSemantic), Semarang, Indonesia, 17–18 September 2022; pp. 41–45. [Google Scholar]
- Liu, K.T.; Gao, K.; Zhao, F.K. Research on Lane Line Detection Technology Based on Vision. Intell. Comput. Appl. 2021, 11, 139–142+148. [Google Scholar]
- Zhang, K.; Guo, Y.; Wang, X.; Yuan, J.; Ding, Q. Multiple feature reweight dense net for image classification. IEEE Access 2019, 7, 9872–9880. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. Infrared and visible image fusion using a deep learning framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar]
- Manchanda, M.; Sharma, R. An improved multimodal medical image fusion algorithm based on fuzzy transform. J. Vis. Commun. Image Represent. 2018, 51, 76–94. [Google Scholar] [CrossRef]
- He, X.M.; Zhang, L.J.; Chen, F.; Cai, Z.Z.; Wang, X.D. Four reference viewpoint fusion algorithm guided by depth and structural similarity. J. Ningbo Univ. (Sci. Eng. Ed.) 2022, 35, 96–104. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Output Size | Residual Blocks |
|---|---|---|
| stage1 | 56 × 56 | × 3 |
| stage2 | 28 × 28 | × 4 |
| stage3 | 14 × 14 | × 6 |
| stage4 | 7 × 7 | × 3 |
| Image Group | Correctly Matched Points Before Processing | Correctly Matched Points After Processing |
|---|---|---|
| a | 100 | 104 |
| b | 47 | 53 |
| c | 63 | 71 |
| d | 101 | 104 |
| Fusion Network | FMIdct | FMIw | Nabf | SSIM |
|---|---|---|---|---|
| first set of images | ||||
| VGG16 | 0.45742 | 0.47463 | 0.037007 | 0.61048 |
| VGG19 | 0.457 | 0.47492 | 0.036685 | 0.61068 |
| ResNet50 | 0.46511 | 0.48155 | 0.028673 | 0.6117 |
| ResNet50V2 | 0.46023 | 0.47891 | 0.031202 | 0.60852 |
| Dual ResNet | 0.46485 | 0.48102 | 0.029145 | 0.61304 |
| second set of images | ||||
| VGG16 | 0.41263 | 0.46453 | 0.20061 | 0.42201 |
| VGG19 | 0.41308 | 0.46811 | 0.19911 | 0.42128 |
| ResNet50 | 0.41717 | 0.46126 | 0.21659 | 0.45635 |
| ResNet50V2 | 0.41602 | 0.46021 | 0.22315 | 0.46374 |
| Dual ResNet | 0.41301 | 0.45926 | 0.23742 | 0.4737 |
| third set of images | ||||
| VGG16 | 0.43609 | 0.4581 | 0.060797 | 0.62918 |
| VGG19 | 0.43688 | 0.45977 | 0.060536 | 0.62938 |
| ResNet50 | 0.44487 | 0.46695 | 0.053607 | 0.63034 |
| ResNet50V2 | 0.44322 | 0.46635 | 0.054351 | 0.63135 |
| Dual ResNet | 0.44462 | 0.466 26 | 0.055443 | 0.63228 |
| fourth set of images | ||||
| VGG16 | 0.42913 | 0.45278 | 0.08904 | 0.60521 |
| VGG19 | 0.43107 | 0.45592 | 0.08862 | 0.60649 |
| ResNet50 | 0.43825 | 0.46311 | 0.07102 | 0.60783 |
| ResNet50V2 | 0.43589 | 0.46037 | 0.07519 | 0.60856 |
| Dual ResNet | 0.43794 | 0.46285 | 0.07306 | 0.61234 |
| Category | Precision | Recall | mAP | FLOPs | FPS | Parameters (M) |
|---|---|---|---|---|---|---|
| Visible image | 0.972 | 0.762 | 0.813 | N/A | N/A | N/A |
| Infrared image | 0.996 | 0.759 | 0.836 | N/A | N/A | N/A |
| VGG16 | 0.937 | 0.783 | 0.846 | 15.3 | 22 | 138 |
| VGG19 | 0.945 | 0.796 | 0.852 | 19.6 | 18 | 144 |
| ResNet50 | 0.952 | 0.804 | 0.858 | 7.6 | 35 | 23.5 |
| Dual ResNet | 0.965 | 0.816 | 0.865 | 15.2 | 28 | 25.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Yan, W.; Yuan, S.; Yu, Y.; Mao, Z.; Chen, R. Image Fusion and Target Detection Based on Dual ResNet for Power Sensing Equipment. Sensors 2025, 25, 2858. https://doi.org/10.3390/s25092858
Yang J, Yan W, Yuan S, Yu Y, Mao Z, Chen R. Image Fusion and Target Detection Based on Dual ResNet for Power Sensing Equipment. Sensors. 2025; 25(9):2858. https://doi.org/10.3390/s25092858
Chicago/Turabian StyleYang, Jie, Wei Yan, Shuai Yuan, Yu Yu, Zheng Mao, and Rui Chen. 2025. "Image Fusion and Target Detection Based on Dual ResNet for Power Sensing Equipment" Sensors 25, no. 9: 2858. https://doi.org/10.3390/s25092858
APA StyleYang, J., Yan, W., Yuan, S., Yu, Y., Mao, Z., & Chen, R. (2025). Image Fusion and Target Detection Based on Dual ResNet for Power Sensing Equipment. Sensors, 25(9), 2858. https://doi.org/10.3390/s25092858