Abstract
Currently, deep learning networks based on architectures such as CNN and Transformer have achieved significant advances in remote sensing image change detection, effectively addressing the issue of false changes due to spectral and radiometric discrepancies. However, when handling remote sensing image data from multiple sensors, different viewing angles, and extended periods, these models show limitations in modelling dynamic interactions and feature representations in change regions, restricting their ability to model the integrity and precision of irregular change areas. We propose the Context-Aware Global-Local Subspace Attention Change Detection Network (CGLCS-Net) to resolve these issues and introduce the Global-Local Context-Aware Selector (GLCAS) and the Subspace-based Self-Attention Fusion (SSAF) module. GLCAS dynamically selects receptive fields at different feature extraction stages through a joint pooling attention mechanism and depthwise separable convolution, enhancing global context and local feature extraction capabilities and improving feature representation for multi-scale and irregular change regions. The SSAF module establishes dynamic interactions between dual-temporal features via feature decomposition and self-attention mechanisms, focusing on semantic change areas to address challenges such as sensor viewpoint variations and the texture and spectral inconsistencies caused by long periods. Compared to ChangeFormer, CGLCS-Net achieved improvements in the IoU metric of 0.95%, 9.23%, and 13.16% on the three public datasets, i.e., LEVIR-CD, SYSU-CD, and S2Looking, respectively. Additionally, it reduced model parameters by 70.05%, floating-point operations by 7.5%, and inference time by 11.5%. These improvements enhance its applicability for continuous land use and land cover change monitoring.
1. Introduction
Change detection is a critical technology for identifying surface or scene changes by analyzing observation data from different periods. It is widely used in urban development [1,2], disaster management [3,4], deforestation [5,6], and environmental surveillance [7,8]. High-resolution remote sensing images can provide high-precision information about change regions. Still, two main challenges need to be addressed: On one hand, high-resolution images are known for their high spatial resolution and detailed information representation, which allows for the clear detection of object boundaries and subtle changes. However, this also introduces significant fine-grained noise, which imposes higher requirements on the robustness and sensitivity of detection models [9]. On the other hand, some remote sensing data are influenced by external factors such as weather and terrain due to the variety of platforms and sensor types, as well as different shooting angles and times during the imaging process [10]. This results in the same object displaying varying textures and spectral features across images, thereby increasing the complexity of feature alignment and model training [11]. Therefore, when processing multi-source, multi-temporal, and multi-angle high-resolution remote sensing images, the demands for change detection technology continue to rise. Models are required to have dynamic interaction modelling capabilities and accurate feature expression abilities.
Currently, commonly used change detection techniques are primarily based on CNN [12] and Transformer [13]. CNN-based networks for change detection typically perform initial feature extraction on dual-temporal images using an encoder with shared weights (such as ResNet [14], MobileNet [15], etc.) and apply differential methods [16,17], spatiotemporal attention mechanisms [18,19,20], or multi-scale feature fusion [21,22,23] to identify change regions. These methods achieve high precision and efficiency in capturing details and semantic information in change areas. For example, FC-Siam-conc [24] and FC-Siam-diff [24], based on a Siamese CNN architecture, fuse dual-temporal features through feature concatenation and feature differencing, respectively, to enhance the representation of change regions. DTCDSCN [25] uses a spatiotemporal attention mechanism to enhance the network’s focus on change regions, improving detection performance in key areas. SNUNet [26] addresses the loss of localization information in deep networks through dense connections, thus improving detection robustness. A2Net [27] integrates multi-scale features to effectively combine information from different scales, enhancing the network’s ability to extract change features. However, the local receptive field of CNNs is ineffective at expressing global context information and handling long-range dependencies, making it challenging to process scenarios that require global information [28]. Additionally, due to the fixed receptive field limitations in the same feature extraction layer [29], CNNs struggle to model irregular change regions, affecting the accuracy and detail preservation in change detection. In comparison, Transformer models can capture long-distance dependencies between features and excel at modelling global context information for complex scenes [30]. For instance, ChangeFormer [31] is a model built entirely on the Transformer architecture, using a decoder to generate difference maps from results computed by specific modules to complete the detection task. However, Transformers’ high dependency on large-scale labelled data and rapid computational complexity growth limit their use in high-resolution remote sensing image change detection [32].
Researchers have gradually explored hybrid architectures combining CNN and Transformer to address the abovementioned issues [33]. The TransUNetCD proposed by Li et al. [34] leverages the strengths of both CNN and Transformer, achieving complementarity by using CNN for local feature extraction and Transformer for global relationship modelling, resulting in an end-to-end encoder-decoder architecture for change detection. BIT, proposed by Chen et al. [35], enhances computational efficiency by combining CNN’s initial feature extraction ability with the Transformer’s non-local self-attention mechanism, significantly reducing the model’s resource demands in high-resolution image processing. The EATDer network, designed by Ma et al. [36], uses a Siamese architecture, with each branch capturing local and global information through three Self-Adaptive Vision Transformer (SAVT) blocks. An edge-aware decoder ensures clearer and smoother edges. DMINet, proposed by Feng et al. [37], integrates self-attention (SelfAtt) and cross-attention (CrossAtt), using a joint-time attention (JointAtt) block to regulate the global feature distribution of each input. This mechanism facilitates information coupling within layers while suppressing noise interference.
The hybrid architecture partially addresses the limitations of both Transformers and CNNs, combining local feature extraction with global context modelling capabilities. However, such architectures still face notable challenges. For example, in modelling deep interactions between dual-temporal features, they fail to fully capture the complex relationships and dynamic variations between dual-temporal image features, leading to inadequate representation of change regions. Additionally, during the dual-temporal feature extraction process in the backbone network, there is a lack of effective modelling of global context information. This limitation makes it difficult to fully integrate long-range dependencies and multi-scale features, thereby restricting the model’s accuracy and robustness in detecting complex change regions. Furthermore, as remote sensing image data volumes continue to grow, optimizing computational resources, reducing model complexity, and ensuring efficient operation for long-term, continuous monitoring tasks remain critical challenges. Although existing methods have improved computational efficiency to some extent, they still encounter significant computational costs when processing large-scale data.
We leverage the advantages of hybrid architectures combining CNN and Transformer and, based on the design concept of ChangeFormer, propose an improved change detection network—CGLCS-Net. This network reduces the number of parameters while enhancing the backbone network’s ability to model local and global features. Additionally, we introduce a dynamic interaction mechanism for dual-temporal feature modelling, further improving the detailed expression of change information. The main contributions of this paper are as follows:
- (1)
- We propose the Global-Local Context-Aware Selector (GLCAS) module, which combines depth convolution with different receptive fields and an adaptive selection mechanism to capture both local details and global dependencies rather than merely modelling dense dependencies. GLCAS reduces computational complexity, significantly improving the model’s ability to extract multi-scale features in complex scenes and effectively addresses the challenge of insufficiently capturing change features at different scales in multi-temporal remote sensing images for change detection.
- (2)
- We design the Subspace Self-Attention Fusion (SSAF) module, which dynamically models the differences between dual-temporal features to precisely focus on meaningful change regions in remote sensing images, addressing multi-view changes in remote sensing data. Guided by feature differences, SSAF enhances the model’s focus on change regions, improving its flexibility and accuracy when handling irregular boundaries and subtle changes.
- (3)
- We performed comparisons with 10 models. We conducted ablation experiments on three primary change detection datasets, validating the robustness and efficiency of CGLCS-Net and achieving state-of-the-art performance results.
2. Methodology
The overall architecture of CGLCS-Net comprises three parts: the Siamese Encoder, Feature Fusion module, and Decoder module, as shown in Figure 1.
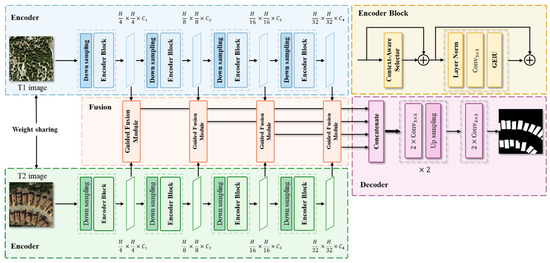
Figure 1.
Overall Architecture of CGLCS-Net.
2.1. Encoder
The encoder section utilizes a Siamese architecture with shared weights, significantly reducing the model’s parameter count and computational complexity compared to independent encoders while ensuring the consistent representation and context-awareness of dual-temporal features within the same semantic space. This provides a solid foundation for the precise modelling of differential features. This design focuses on the Global-Local Context-Aware Selector (GLCAS). The core of GLCAS is the combination of depthwise separable convolutions with different kernel sizes, allowing the network to comprehensively capture local details and global semantic information across different receptive fields at various stages. This design maintains low parameter count and computational complexity while meeting the extraction needs of multi-temporal and irregular change region multi-scale context features. The adaptive selection mechanism dynamically adjusts information fusion across different receptive fields, enhancing the model’s sensitivity to fine-grained changes.
2.2. Feature Fusion and Decoder
The feature fusion section employs the Subspace-based Self-Attention Fusion (SSAF) module, which focuses on dynamic interaction modelling between dual-temporal features. The SSAF module reduces computational complexity by decomposing dual-temporal features into different subspaces while using the difference features as query signals for the self-attention mechanism. This enables precise identification of key change regions within each subspace, removing noise generated by viewpoint and sensor variations and enhancing the network’s focus on meaningful change regions. The decoder section features a simple and efficient design, restoring spatial resolution through upsampling operations while concatenating and fusing features at various scales. Independent segmentation heads are used to produce the final change detection results, effectively ensuring the decoder remains computationally efficient.
The GLCAS and SSAF modules are described in detail as follows:
- Global-Local Context-Aware Selector
Building on Selective Kernel Networks [38], we replace the Transformer block in the ChangeFormer backbone to reduce the computational complexity and parameter count of feature extraction. We propose the Global-Local Context-Aware Selector (GLCAS), which introduces multi-scale depthwise separable convolutions to capture both local details and global context information. This approach dynamically adjusts the weight distribution of global and local features across different receptive fields in each feature extraction stage, as shown in Figure 2.
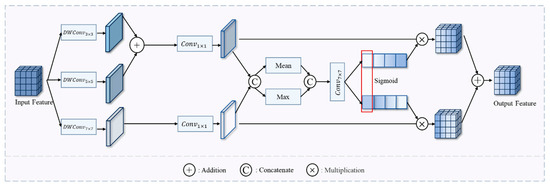
Figure 2.
GLCAS (Global-Local Context-Aware Selector).
We designed parallel depthwise separable convolutions with scales of 3 × 3, 5 × 5, and 7 × 7 to extract multi-scale features, allowing the model to simultaneously focus on local details, medium-scale features, and global context information. The 7 × 7 convolution is combined with a dilation rate of 3 to enlarge the receptive field, as shown in Equations (1)–(3).
where DWConv denotes the depthwise separable convolution, and dilation denotes the dilation rate.
An adaptive weighting strategy is employed in the feature fusion stage to dynamically modify the extracted multi-scale features. First, the small-scale and medium-scale features are summed and reduced in dimensionality via 1 × 1 convolutions, while the large-scale features undergo independent dimensionality reduction processing. This is shown in Equations (4) and (5):
Secondly, by performing feature concatenation along the channel dimension, we combine global average pooling and max pooling operations for feature aggregation. The aggregated features are then processed through a 1 × 1 convolutional layer followed by a sigmoid activation function to generate adaptive weights, as formalized below:
where denotes the channel-wise split operation. The adaptive weights are parameterized by and through learnable transformations.
Finally, we incorporate DropPath [39] regularization after feature fusion to enhance model robustness and prevent overfitting. This mechanism randomly discards features along specific paths during training, thereby enforcing more substantial generalization capabilities. The formulation is given by:
- 2.
- Subspace-based Self-Attention Fusion Module
To establish dynamic spatiotemporal variation relationships between dual-temporal features and difference features, we propose a Subspace-based Self-attention Assimilation Fusion module (SSAF) as illustrated in Figure 3. The SSAF module synergistically integrates self-attention mechanisms with external query mechanisms through compact subspace design. Specifically, it projects input features into three subspaces, achieving computational complexity reduction.
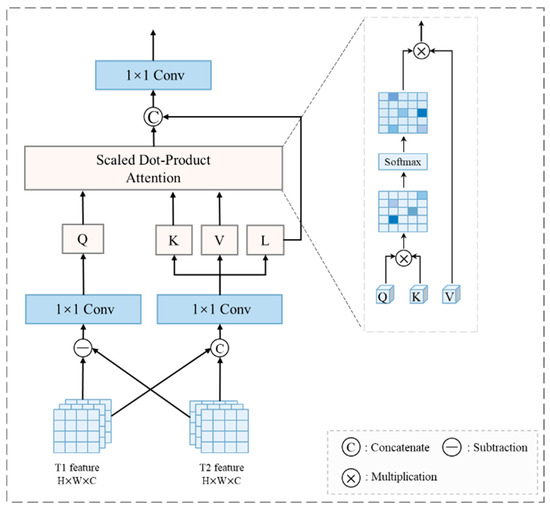
Figure 3.
SSAF (Subspace-based Self-Attention Fusion module).
In the feature decomposition stage, we sum the features from the T1 and T2 temporal phases, then project the aggregated features into three independent subspaces through 1 × 1 convolutional layers. The first subspace serves as the Key (K) to capture dynamic relationships between features, the second as the Value (V) to preserve salient change characteristics, while the third generates local residual features (denoted as l) to retain local details and original feature fidelity, as formalized in Equations (13) and (14):
During the feature subspace attention mechanism phase, the module explicitly models dynamic interactions between dual-temporal and difference features through attention computation between external query features Q and subspace features (Key K and Value V). This enables cross-feature-domain information fusion, where the different features are generated by taking the absolute value of the temporal feature differences. The mathematical formulation is given in Equation (15):
Building upon this framework, the query features Q are generated from the difference features through a 1 × 1 convolutional layer, which guides the attention mechanism to focus on change-sensitive regions. The formal implementation is given in Equation (16):
Subsequently, the attention weights are computed through dot products between query features Q and keys K, followed by Softmax normalization to ensure smoother weight distribution and improved optimization stability, as formalized in Equation (17). Finally, these weights are applied to values V to achieve aggregation and updating of dual-temporal change features:
where Softmax denotes the normalization function applied row-wise
Finally, the local residual features l and attention-enhanced global features attn are concatenated along the channel dimension, followed by a 1 × 1 convolutional layer for feature integration. The output features are subsequently fed into the decoder for change region extraction, as formalized in Equation (18):
3. Experiments
3.1. Dataset
We selected three widely applicable and representative remote sensing change detection datasets: LEVIR-CD [40], SYSU-CD [41], and S2Looking [42]. These datasets feature long temporal spans, multi-sensor sources, and multi-view characteristics. To facilitate fair comparisons with state-of-the-art methods, all remote sensing images were uniformly resized to 256 × 256 pixels, and standard dataset partitions were adopted to allocate training, validation, and test sets.
LEVIR-CD: Contains 637 high-resolution remote sensing images with original dimensions of 1024 × 1024 pixels, a spatial resolution of 0.5 m per pixel, and a temporal span of 5 to 14 years. The dataset primarily documents the growth and decline of buildings, covering diverse architectural types, including villa residences, high-rise apartments, small garages, and large warehouses. After resizing to 256 × 256 pixels, the dataset is partitioned into 7120 training images, 1024 validation images, and 2048 test images.
SYSU-CD: Contains 20,000 pairs of high-resolution remote sensing images captured in Hong Kong between 2007 and 2014, with original dimensions of 256 × 256 pixels and a spatial resolution of 0.5 m per pixel. The dataset records diverse change types, including new urban constructions, suburban expansion, pre-post-construction site changes, vegetation variations, road extensions, and marine development. It is partitioned into 12,000 training images, 4000 validation images, and 4000 test images.
S2Looking: Comprises 5000 dual-temporal satellite image pairs with off-nadir viewing angles from global rural areas. Original image dimensions are 1024 × 1024 pixels, with a spatial resolution of 0.5 to 0.8 m per pixel. The dataset focuses on land-cover changes in rural regions. After resizing, it is partitioned into 56,000 training images, 8000 validation images, and 16,000 test images.
3.2. Assessment Metric
The model’s accuracy is assessed on five standard evaluation metrics for change detection tasks [43]: Precision, Recall, F1 score, IoU (Intersection over Union), and OA (Overall Accuracy). These metrics are formulated as follows:
where TP denotes the number of pixels in the change areas correctly extracted by the network, TN represents the number of pixels in the unchanged areas correctly extracted, FP indicates the number of unchanged area pixels incorrectly classified as change area pixels, and FN refers to the number of change area pixels incorrectly classified as unchanged area pixels.
3.3. Experimental Environment
CGLCS-Net is developed based on the PyTorch = 2.0.0 + cu117 framework and trained on an NVIDIA RTX 4070 GPU. In the experiments, the hyperparameters are configured as follows: the batch size is set to 8, the optimizer is Adamw, and the initial learning rate is set to 0.0001, which is dynamically adjusted using a multi-step decay strategy to enhance the flexibility of parameter optimization. To improve the model’s generalization capability, various data augmentation techniques are extensively applied, including random cropping, random rotation, horizontal flipping, Gaussian blur, random hue adjustment, random saturation adjustment, and random brightness adjustment.
To address the issue of extreme class imbalance in change detection tasks, a hybrid loss function [44] is designed to mitigate the impact of sample imbalance on model training. This hybrid loss function combines a weighted cross-entropy loss [45] and a Dice loss [46], and its specific definition is as follows:
where: denotes the true pixel value, denotes the predicted pixel value, denotes the weight for class C, α and β are weight control parameters with values set to 1 and 0.5, and N denotes the total number of pixels.
3.4. Model Comparison
To thoroughly assess the performance of the CGLCS-Net model, it is compared with ten advanced change detection methods. These include CNN-based methods: FC-Siam-Conc, FC-Siam-Diff, DTCDSCN, SNUNet, DMINet, A2Net and ABMFNet [47], as well as Transformer-based methods: BIT, ChangeFormer, and EATDer.
The quantitative evaluation results show that CGLCS-Net achieved top-ranking scores compared to all ten advanced methods, as shown in Table 1, Table 2 and Table 3.

Table 1.
Quantitative evaluation results on the LEVIR-CD dataset (UNIT: %).
Table 2.
Quantitative evaluation results on the SYSU-CD dataset (UNIT: %).
Table 3.
Quantitative evaluation results on the S2LOOKING dataset (UNIT: %).
Table 1 presents the quantitative experimental results of the model on the LEVIR-CD dataset. Due to the long time span and the irregular shapes and scales of the change regions, this dataset places higher demands on the model’s ability to extract multi-scale features and model irregular regions. CGLCS-Net achieved the highest scores in Recall, F1, IoU, and OA across all evaluation metrics. In comparison to CNN-based models, FC-Siam-conc and FC-Siam-diff performed the poorest, suggesting that direct feature concatenation and difference methods are insufficient for feature capture. In contrast, DTCDSCN and ABMFNet, which incorporate spatiotemporal attention mechanisms, improved the model’s focus on change features, leading to better IoU and F1 scores. This indicates that spatiotemporal attention mechanisms can effectively help reduce misclassifications when dealing with long time spans and irregular regions. While A2Net achieved the highest Precision (92.96%), it had a relatively lower Recall (85.81%). On the other hand, CGLCS-Net demonstrated the optimal Recall value while maintaining 91.27% Precision through dynamic feature selection, confirming its advantage in feature extraction and processing using convolutional structures. When compared to Transformer-based models, CGLCS-Net also outperforms in comprehensive metrics, highlighting its superior ability to integrate global and local information. These results suggest that CGLCS-Net offers a significant advantage in extracting features from irregular regions with long time spans.
Table 2 presents the quantitative experimental results of various models on the SYSU-CD dataset. The SYSU-CD dataset is characterized by a wide variety of change types, a long time span, and a larger data volume. The experimental results show that CGLCS-Net achieved higher scores in Recall, F1, and IoU evaluation metrics. Compared to convolution-based models such as FC-Siam-conc, FC-Siam-diff, DTCDSCN, DMINet, A2Net, and ABMFNet, CGLCS-Net showed a slight decrease in Precision and OA (Overall Accuracy). Specifically, FC-Siam-conc and FC-Siam-diff achieved Precision scores of 83.51% and 86.14%, respectively, demonstrating strong precision but lower Recall. This suggests that these methods, which rely on difference calculation and feature concatenation, tend to overlook certain types of changes, failing to capture all changes comprehensively. In contrast, CGLCS-Net achieved 83.32% in Recall, a significant improvement, indicating that it can more comprehensively extract feature information from change regions, allowing it to identify more changes. Compared to Transformer-based models, CGLCS-Net also performed better in terms of balancing performance: while BIT (84.14%) and EATDer (81.02%) slightly outperformed CGLCS-Net in Precision, CGLCS-Net demonstrated a 7.88% and 0.97% improvement in F1 score over BIT (74.05%) and EATDer (80.96%), respectively, thanks to the effective noise reduction provided by its spatial-spectral attention mechanism (SSAF). This result confirms that the hybrid architecture of CGLCS-Net is better at coordinating global context modelling with local feature refinement, achieving a superior balance of performance in complex scenarios.
Table 3 presents the quantitative experimental results of the model on the S2Looking dataset. This dataset is characterized by varying ground-level viewpoints, complex rural object change patterns, and the absence of uniform boundaries. CGLCS-Net achieved the highest scores in Recall, F1, IoU, and OA across all evaluation metrics. While FC-Siam-conc achieved the highest Precision (84.23%), its Recall (34.18%) was significantly low, indicating that its strict difference threshold led to a high number of missed detections. FC-Siam-diff improved Recall to 50.62% by modifying the difference strategy, but its Precision dropped by 16.08%, reflecting the limited adaptability of simple feature operations in complex rural scenarios. In contrast, other convolution-based models such as DTCDSCN, SNUNet, DMINet, A2Net, and ABMFNet employed different strategies. Although these models exhibited lower Precision, they showed improvements in Recall and IoU, suggesting that the incorporation of attention mechanisms or enhanced multi-scale feature fusion can effectively improve the network’s ability to capture and locate features in scenes with varying viewpoints. When compared to Transformer-based models such as BIT, ChangeFormer, and EATDer, CGLCS-Net led in Recall (63.82%), F1 (64.35%), and IoU (47.43%), demonstrating its more comprehensive change detection capabilities. Although CGLCS-Net’s Precision (64.88%) is lower than that of ChangeFormer, its superior performance in F1 and IoU indicates that the model not only effectively captures detailed change features but also suppresses noise caused by viewpoint differences, thereby more accurately identifying change regions.
Figure 4 presents the visualization results for the LEVIR-CD dataset. The first and second rows show scenes with small building clusters where building shadow interference is present. CGLCS-Net significantly reduces misclassification and omission when extracting edge details, leading to more precise segmentation results. The third row shows scenes with lighting changes, where all ten other models exhibit significant misclassification, while CGLCS-Net maintains accurate segmentation without any misclassification. The fourth and fifth rows represent large building scenes, where CGLCS-Net provides a more complete segmentation of building interiors.
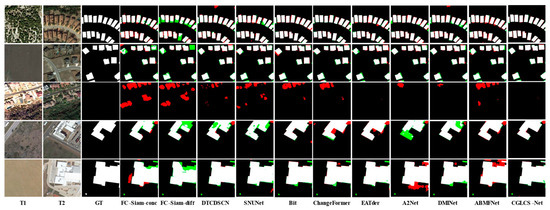
Figure 4.
Visualization Results of LEVIR–CD. T1 and T2 represent images taken at different time points. GT denotes the ground truth labels, red indicates FP, green signifies FN, black represents TN, and white denotes TP.
Figure 5 presents the visualization results for the SYSU-CD dataset. CGLCS-Net outperforms other comparison methods across various change types. The first and fourth rows show scenes with irregular buildings prone to tree occlusion and shadow interference. CGLCS-Net can capture the change regions more accurately, effectively reducing false positives and false negatives. The second, third, and fifth rows’ truth labels, red indicates FP, green signifies FN, black represents TN, and white denotes TP.
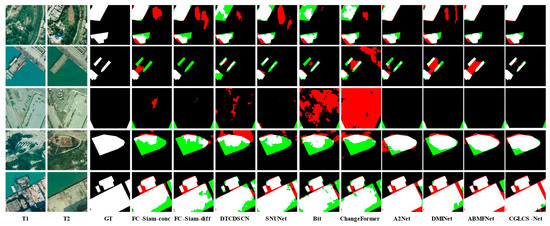
Figure 5.
Visualization Results of SYSU-CD. T1 and T2 represent images taken at different time points. GT denotes the ground truth labels, red indicates FP, green signifies FN, black represents TN, and white denotes TP.
Show scenes from the port building areas. CGLCS-Net demonstrates more stable performance in overcoming interference from lighting variations, texture differences, and color discrepancies, significantly reducing misclassification and omission.
Figure 6 presents the visualization results for the S2Looking dataset. The first, second, and third rows show small building cluster scenes, where CGLCS-Net produces more complete detection results when facing different color variations. The fourth and fifth rows show large building scenes, where CGLCS-Net achieves the complete extraction of change regions despite the influence of viewpoint differences and boundary shadows.

Figure 6.
Visualization Results of S2Looking. T1 and T2 represent images taken at different time points. GT denotes the ground truth labels, red indicates FP, green signifies FN, black represents TN, and white denotes TP.
3.5. Ablation Study
To thoroughly assess the effectiveness of the proposed modules and their contribution to the overall model performance, we conducted a series of ablation studies on the LEVIR-CD dataset, as shown in Table 4. We removed all Transformer Block modules from ChangeFormer and used them as the baseline (Baseline). In the feature fusion stage, we used only a simple concatenation strategy, significantly reducing the parameters and computational complexity but resulting in a 0.85% and 1.39% decrease in F1-score and IoU, respectively.
Table 4.
Ablation study results of the modules.
In the Baseline + GLCAS experiment, the parameter count increased from 10.71 M to 11.51 M, with F1-Score improving from 89.55% to 89.76% and IoU increasing from 81.09% to 81.42%. This demonstrates that the GLCAS module significantly enhances multi-scale feature representation through multi-scale depthwise separable convolutions and global-local dynamic fusion.
In the Baseline + SSAF experiment, the parameter count slightly increased to 11.28 M, with F1-Score rising to 89.91% and IoU increasing to 81.68%. This shows that the SSAF module effectively focuses on changing regions by modelling the dynamic interaction between dual-temporal and different features.
In the Baseline + GLCAS + SSAF experiment, the parameter count increased to 12.09 M, with F1-Score improving to 90.96% and IoU increasing to 83.43%. Compared to the Baseline model, IoU improved by 2.34%, proving that GLCAS and SSAF modules work synergistically in feature extraction and dynamic interaction modelling, significantly improving overall performance. Furthermore, compared to the original ChangeFormer model, CGLCS-Net (Baseline + GLCAS + SSAF) reduced the parameter count from 41.03 M to 12.09 M (a reduction of about 70.5%) while maintaining excellent detection performance. This demonstrates that CGLCS-Net excels not only in performance but also in lightweight design.
To further assess the impact of the pooling configuration in the Global-Local Context-Aware Selector (GLCAS), we conducted comparative experiments with different pooling methods (Max Pooling, Mean Pooling, and a combined pooling strategy), with the results shown in Table 5.
Table 5.
Ablation study results of GLCAS Pooling configuration (UNIT: %).
When Max Pooling was used to extract global context information, the F1-score was 89.79%, and the IoU was 81.47%, indicating that Max Pooling tends to preserve prominent features in the data and can effectively capture local extrema in the change regions. This demonstrates that Max Pooling outperforms the use of Mean Pooling alone. In contrast, Mean Pooling provides a smoother representation of global information, with F1-Score and IoU values of 89.54% and 81.06%, respectively. To combine the strengths of both methods, we used a combined pooling strategy, which resulted in a significant increase in F1-score to 90.96% and IoU to 83.43%. The combined pooling approach achieves complementarity between both methods, effectively capturing both significant and global smoothing features, significantly improving the GLCAS module’s ability to model complex change regions.
To further assess the impact of hyperparameters on model performance, we conducted multiple experiments on α and β in Equation (26). Table 6 presents the experimental results for the model under various combinations of these hyperparameters across several evaluation metrics. The results indicate that when α = 1 and β = 0.5, the model achieves the best accuracy, ensuring effective detection of changing regions while preventing an overemphasis on precision that could neglect recall. In contrast to other combinations of α and β, when the β weight is equal to or lower than α, the model exhibits lower recall and IoU but higher precision. This suggests that the model prioritizes pixel classification accuracy at the expense of its focus on changing regions.
Table 6.
Quantitative Results of the Loss Function Ablation Study (Unit: %).
3.6. Model Efficiency Analysis
We evaluated 11 models based on their parameter count (Params), floating-point operations (FLOPs), and inference time, as presented in Table 7. The image size used for the experiments was 3 × 256 × 256, with parameters measured in millions (M), floating-point operations in gigaflops (G), and inference time in seconds. CGLCS-Net, a model that combines convolutional and self-attention mechanisms, has 12.09 million parameters and 187.58 gigaflops of floating-point operations. In terms of computational efficiency, compared to the baseline model, ChangeFormer, CGLCS-Net reduces the parameter count by approximately 70%, floating-point operations by 7.5%, and inference time by 11.5%. Although CGLCS-Net’s computational complexity remains higher than most lightweight models, it demonstrates superior performance on the task. In the key evaluation metrics, the F1 score (90.96%) and Intersection over Union (IoU) (83.43%), CGLCS-Net outperforms all other models.
Table 7.
Quantitative Evaluation Results of Model Efficiency.
4. Conclusions
We propose CGLCS-Net, a high-resolution remote sensing image change detection network that integrates the Global-Local Context-Aware Selector (GLCAS) and the Subspace Self-Attention Fusion (SSAF) module. GLCAS addresses the challenge of balancing global context and local detail features in remote sensing images with complex scenes and varying-scale change features by combining multi-scale depthwise separable convolutions and an adaptive weighting mechanism. This significantly improves the model’s ability to extract multi-scale and irregular change regions. The SSAF module models the dynamic interaction between dual-temporal remote sensing image features and their differential features while preserving local residual features. It effectively handles the texture and spectral inconsistencies caused by sensor viewpoint differences and extensive periods, enhancing the detailed expression and precise modelling of change regions. The synergistic design of both modules effectively reduces the number of trainable parameters, significantly improving the model’s ability to analyze and detect complex change regions. Experimental results demonstrate that CGLCS-Net achieved optimal performance on the LEVIR-CD, SYSU-CD, and S2Looking public datasets, showcasing its superiority and robustness in handling diverse remote sensing change detection tasks. Future work will focus on optimizing the model structure and applying model compression techniques, including quantization and pruning, to reduce the floating-point operations of CGLCS-Net while preserving its existing performance. Furthermore, the feasibility of deploying CGLCS-Net for real-time, large-scale remote sensing image change detection on edge computing devices will be investigated.
Author Contributions
Conceptualization, K.L. and H.X.; methodology, H.X.; validation, C.H., J.H. and G.C.; writing—original draft preparation, H.X., J.H. and G.C.; writing—review and editing, K.L.; visualization, C.H.; project administration, H.X.; funding acquisition, K.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the North China Institute of Aerospace Engineering Doctoral Fund (BKY-2020-33): Research on Spatio-Temporal Data Fusion Analysis of Beijing-Tianjin-Hebei City Cluster. (Corresponding author: Hang Xue.) It was also funded by the Scientific Research Fund of North China Institute of Aerospace Engineering: Research on the Technology of Loss Assessment and Evaluation of Buildings in Urban Waterlogging Scenarios (CXPT-2025-03) and Study on Land Use Change Detection Based on Difference Selection and Multi-Scale Guidance Strategy (YKY-2025-128).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
We sincerely thank the anonymous reviewers for their critical comments and suggestions for improving the manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ning, X.; Zhang, H.; Zhang, R.; Huang, X. Multi-Stage Progressive Change Detection on High Resolution Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2024, 207, 231–244. [Google Scholar] [CrossRef]
- Khusni, U.; Dewangkoro, H.I.; Arymurthy, A.M. Urban Area Change Detection with Combining CNN and RNN from Sentinel-2 Multispectral Remote Sensing Data. In Proceedings of the 2020 3rd International Conference on Computer and Informatics Engineering (IC2IE), Yogyakarta, Indonesia, 15–16 September 2020; pp. 171–175. [Google Scholar]
- Brunner, D.; Bruzzone, L.; Lemoine, G. Change Detection for Earthquake Damage Assessment in Built-up Areas Using Very High Resolution Optical and SAR Imagery. In Proceedings of the 2010 IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; pp. 3210–3213. [Google Scholar]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A.; Zhang, L. Building Damage Assessment for Rapid Disaster Response with a Deep Object-Based Semantic Change Detection Framework: From Natural Disasters to Man-Made Disasters. Remote Sens. Environ. 2021, 265, 112636. [Google Scholar] [CrossRef]
- Khankeshizadeh, E.; Mohammadzadeh, A.; Moghimi, A.; Mohsenifar, A. FCD-R2U-Net: Forest Change Detection in Bi-Temporal Satellite Images Using the Recurrent Residual-Based U-Net. Earth Sci. Inform. 2022, 15, 2335–2347. [Google Scholar] [CrossRef]
- De Bem, P.; De Carvalho Junior, O.; Fontes Guimarães, R.; Trancoso Gomes, R. Change Detection of Deforestation in the Brazilian Amazon Using Landsat Data and Convolutional Neural Networks. Remote Sens. 2020, 12, 901. [Google Scholar] [CrossRef]
- Gao, F.; Wang, X.; Gao, Y.; Dong, J.; Wang, S. Sea Ice Change Detection in SAR Images Based on Convolutional-Wavelet Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1240–1244. [Google Scholar] [CrossRef]
- Yuan, B.; Fu, L.; Zou, Y.; Zhang, S.; Chen, X.; Li, F.; Deng, Z.; Xie, Y. Spatiotemporal Change Detection of Ecological Quality and the Associated Affecting Factors in Dongting Lake Basin, Based on RSEI. J. Clean. Prod. 2021, 302, 126995. [Google Scholar] [CrossRef]
- Lv, Z.; Liu, T.; Wan, Y.; Benediktsson, J.A.; Zhang, X. Post-Processing Approach for Refining Raw Land Cover Change Detection of Very High-Resolution Remote Sensing Images. Remote Sens. 2018, 10, 472. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Miao, J.; Li, S.; Bai, X.; Gan, W.; Wu, J.; Li, X. RS-NormGAN: Enhancing Change Detection of Multi-Temporal Optical Remote Sensing Images through Effective Radiometric Normalization. ISPRS J. Photogramm. Remote Sens. 2025, 221, 324–346. [Google Scholar] [CrossRef]
- Basavaraju, K.S.; Sravya, N.; Kevala, V.D.; Suresh, S.; Lal, S. SFSCDNet: A Deep Learning Model With Spatial Flow-Based Semantic Change Detection From Bi-Temporal Satellite Images. IEEE Access 2024, 12, 195032–195053. [Google Scholar] [CrossRef]
- Liu, W.; Lin, Y.; Liu, W.; Yu, Y.; Li, J. An Attention-Based Multiscale Transformer Network for Remote Sensing Image Change Detection. ISPRS J. Photogramm. Remote Sens. 2023, 202, 599–609. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical Remote Sensing Image Change Detection Based on Attention Mechanism and Image Difference. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7296–7307. [Google Scholar] [CrossRef]
- Liu, J.; Gong, M.; Qin, A.K.; Tan, K.C. Bipartite Differential Neural Network for Unsupervised Image Change Detection. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 876–890. [Google Scholar] [CrossRef]
- Tan, Y.; Sun, K.; Wei, J.; Gao, S.; Cui, W.; Duan, Y.; Liu, J.; Zhou, W. STFNet: A Spatiotemporal Fusion Network for Forest Change Detection Using Multi-Source Satellite Images. Remote Sens. 2024, 16, 4736. [Google Scholar] [CrossRef]
- Lei, D.; Ran, G.; Zhang, L.; Li, W. A Spatiotemporal Fusion Method Based on Multiscale Feature Extraction and Spatial Channel Attention Mechanism. Remote Sens. 2022, 14, 461. [Google Scholar] [CrossRef]
- Li, C.; Zhang, H.; Wang, Z.; Wu, Y.; Yang, F. Spatial-Temporal Attention Mechanism and Graph Convolutional Networks for Destination Prediction. Front. Neurorobot. 2022, 16, 925210. [Google Scholar] [CrossRef] [PubMed]
- Zeng, N.; Wu, P.; Wang, Z.; Li, H.; Liu, W.; Liu, X. A Small-Sized Object Detection Oriented Multi-Scale Feature Fusion Approach With Application to Defect Detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Du, Z.; Liang, Y. Object Detection of Remote Sensing Image Based on Multi-Scale Feature Fusion and Attention Mechanism. IEEE Access 2024, 12, 8619–8632. [Google Scholar] [CrossRef]
- Liu, Q.; Dong, L.; Zeng, Z.; Zhu, W.; Zhu, Y.; Meng, C. SSD with Multi-Scale Feature Fusion and Attention Mechanism. Sci. Rep. 2023, 13, 21387. [Google Scholar] [CrossRef]
- Caye Daudt, R.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building Change Detection for Remote Sensing Images Using a Dual-Task Constrained Deep Siamese Convolutional Network Model. IEEE Geosci. Remote Sens. Lett. 2021, 18, 811–815. [Google Scholar] [CrossRef]
- Sun, C.; Du, C.; Wu, J.; Chen, H. SUDANet: A Siamese UNet with Dense Attention Mechanism for Remote Sensing Image Change Detection. In Proceedings of the Pattern Recognition and Computer Vision; Yu, S., Zhang, Z., Yuen, P.C., Han, J., Tan, T., Guo, Y., Lai, J., Zhang, J., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 78–88. [Google Scholar]
- Li, Z.; Tang, C.; Liu, X.; Zhang, W.; Dou, J.; Wang, L.; Zomaya, A.Y. Lightweight Remote Sensing Change Detection With Progressive Feature Aggregation and Supervised Attention. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, M.; Huang, P.; Tang, W. CMLFormer: CNN and Multiscale Local-Context Transformer Network for Remote Sensing Images Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 7233–7241. [Google Scholar] [CrossRef]
- Li, M.; Lu, Y.; Cao, S.; Wang, X.; Xie, S. A Hyperspectral Image Classification Method Based on the Nonlocal Attention Mechanism of a Multiscale Convolutional Neural Network. Sensors 2023, 23, 3190. [Google Scholar] [CrossRef] [PubMed]
- Chang, J.; Cen, Y.; Cen, G. Asymmetric Network Combining CNN and Transformer for Building Extraction from Remote Sensing Images. Sensors 2024, 24, 6198. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar]
- Zhang, C.; Su, J.; Ju, Y.; Lam, K.-M.; Wang, Q. Efficient Inductive Vision Transformer for Oriented Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–20. [Google Scholar] [CrossRef]
- Liu, J.; Sun, H.; Katto, J. Learned Image Compression With Mixed Transformer-CNN Architectures. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14388–14397. [Google Scholar]
- Li, Q.; Zhong, R.; Du, X.; Du, Y. TransUNetCD: A Hybrid Transformer Network for Change Detection in Optical Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–19. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection With Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Ma, J.; Duan, J.; Tang, X.; Zhang, X.; Jiao, L. EATDer: Edge-Assisted Adaptive Transformer Detector for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Feng, Y.; Jiang, J.; Xu, H.; Zheng, J. Change Detection on Remote Sensing Images Using Dual-Branch Multilevel Intertemporal Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Zheng, Q.; Tian, X.; Yang, M.; Wu, Y.; Su, H. PAC-Bayesian Framework Based Drop-Path Method for 2D Discriminative Convolutional Network Pruning. Multidimens. Syst. Signal Process. 2020, 31, 793–827. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A Deeply Supervised Image Fusion Network for Change Detection in High Resolution Bi-Temporal Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Shen, L.; Lu, Y.; Chen, H.; Wei, H.; Xie, D.; Yue, J.; Chen, R.; Lv, S.; Jiang, B. S2Looking: A Satellite Side-Looking Dataset for Building Change Detection. Remote Sens. 2021, 13, 5094. [Google Scholar] [CrossRef]
- Wang, Z.; Gu, G.; Xia, M.; Weng, L.; Hu, K. Bitemporal Attention Sharing Network for Remote Sensing Image Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10368–10379. [Google Scholar] [CrossRef]
- Ben Naceur, M.; Akil, M.; Saouli, R.; Kachouri, R. Fully Automatic Brain Tumor Segmentation with Deep Learning-Based Selective Attention Using Overlapping Patches and Multi-Class Weighted Cross-Entropy. Med. Image Anal. 2020, 63, 101692. [Google Scholar] [CrossRef]
- Pan, F.; Wu, Z.; Liu, Q.; Xu, Y.; Wei, Z. DCFF-Net: A Densely Connected Feature Fusion Network for Change Detection in High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11974–11985. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. arXiv 2018, arXiv:1807.10221. [Google Scholar]
- Li, Y.; Weng, L.; Xia, M.; Hu, K.; Lin, H. Multi-Scale Fusion Siamese Network Based on Three-Branch Attention Mechanism for High-Resolution Remote Sensing Image Change Detection. Remote Sens. 2024, 16, 1665. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).