In this section, we conduct experiments on four publicly available datasets to evaluate and analyze the effectiveness of our approach.
4.1. Setting
Datasets: Consistent with PlaneTR [
16], we used the ScanNet [
17] dataset for both training and evaluation. The training set consisted of 50,000 images, and the validation set contained 760 images. Upon inspection, we found that the plane annotations in the NYUv2-Plane [
16] dataset used by PlaneTR contained numerous errors, as shown in
Figure 2. These errors included small holes, instances where a single plane was divided into multiple parts, and missing plane annotations. Consequently, we used the Matterport3D [
56], ICL-NUIM RGB-D [
57], and 2D-3D-S [
58] datasets for evaluating the generalization performance. We randomly selected 797, 152, and 5000 RGB-D images from these three datasets, respectively, as validation sets. Additionally, following the method in PlaneTR, we used HAWPv3 [
59] as the line segment detection model to extract line segments from the above three datasets. The line segments in the ScanNet dataset were the same as those used in PlaneTR.
Evaluation Metrics: We used three popular plane segmentation metrics [
6,
60], namely Rand Index (RI), Variation of Information (VI), and Segmentation Covering (SC). In line with PlaneTR [
16], we evaluated the plane detection capability of the proposed method using both pixel-wise and plane-wise recalls. It is important to note that this study focused on enhancing the plane segmentation ability of PlaneTR and did not consider other 3D reconstruction sub-tasks, such as depth estimation. Therefore, depth estimation metrics were not evaluated.
Implementation Details: Similarly to the general training method in prompt learning, we preloaded the pretrained weights of PlaneTR [
16] and froze the backbone and context encoder during training. The LPM and LPA were trained from scratch and used to fine-tune the context decoder and all prediction heads. For the loss function, we used the same setup as PlaneTR and used the Adam optimizer to train our network. The initial learning rate was set to
. The weight decay was set to
, and the batch size was set to 48. We trained SPL-PlaneTR on the ScanNet [
17] dataset for a total of 60 epochs using two RTX 3090D GPUs. During training, we used a cosine annealing learning rate scheduler, where the learning rate decayed following a cosine function from the initial value to 0 at the last epoch.
4.2. Results
Results from ScanNet Dataset: We compared our method with PlaneNet [
3], PlaneRCNN [
4], PlaneAE [
5], PlaneTR [
16], BT3DPR [
30], PlanePDM [
61], PlaneAC [
62], and PlaneSAM [
63].
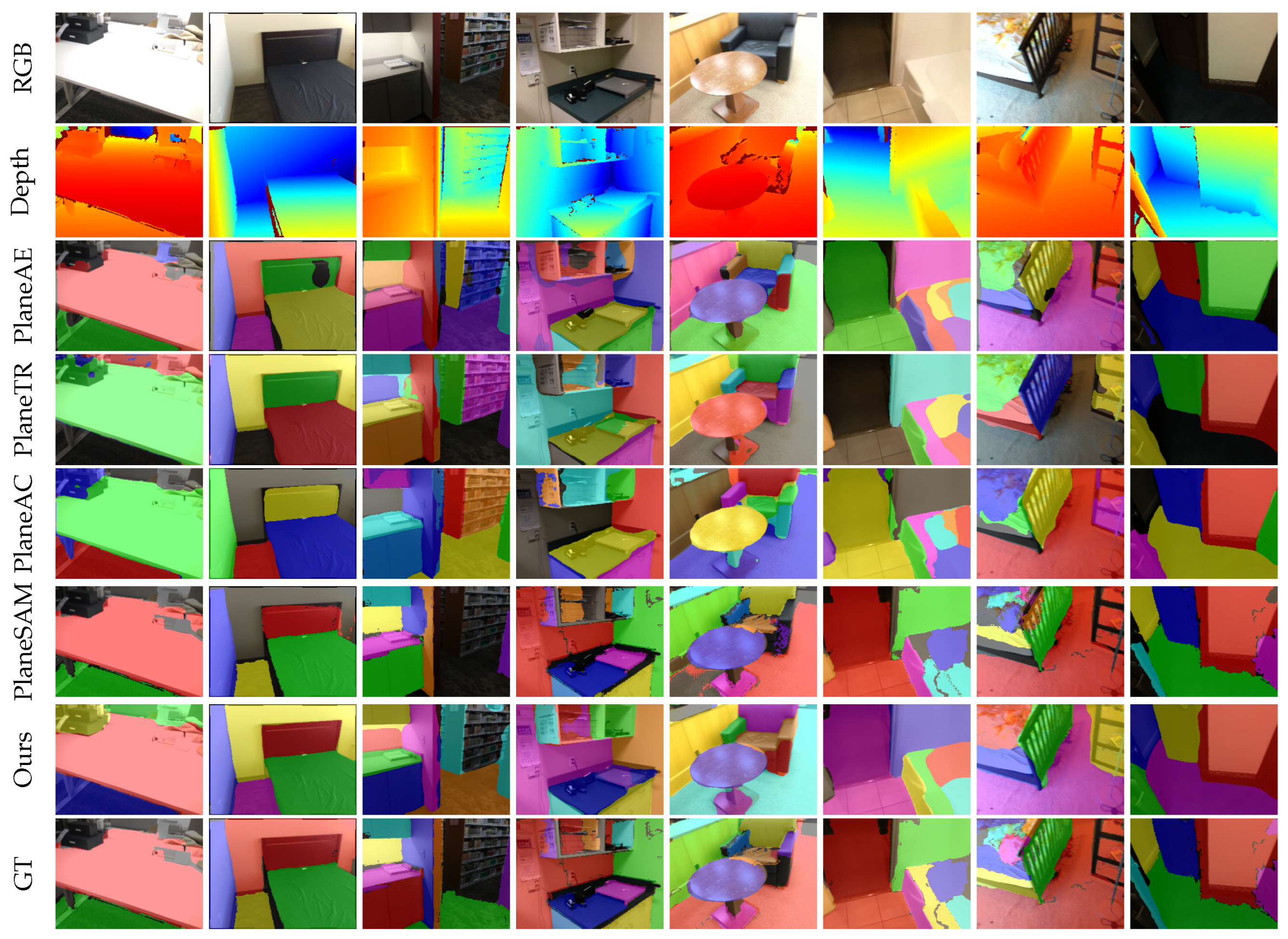
Figure 3 shows the plane segmentation results of the different methods on the ScanNet [
17] dataset. The results clearly show that our method can effectively segment planes from a single image. From a qualitative perspective, as observed in the third row of
Figure 3, PlaneAE struggles to handle the edges of plane instances effectively, resulting in the incomplete segmentation of plane boundaries and the presence of holes within the segmented planes. While PlaneTR performs better than PlaneAE in handling plane edges, it fails in some complex environments. For example, PlaneTR often misses dark-colored planes (as shown in the first, second, third, sixth, and eighth columns of the first row of
Figure 3). Additionally, PlaneTR tends to mix different planes, causing fragments of one plane to appear in another plane. Due to the similar architectural design of PlaneAC and PlaneTR, PlaneAC also faces the same issues. PlaneSAM reduces the impact of color variation by leveraging depth maps, allowing it to segment planes at various scales comprehensively. However, it tends to miss some planes. This is because PlaneSAM requires bounding boxes from an existing object detection model as input. The absence of a bounding box results in a failure to segment the corresponding plane. As shown in the seventh row of
Figure 3, SPL-PlaneTR can effectively handle the boundary regions of planes and does not fail to segment planes even when there are small spectral changes. This demonstrates that our method is more effective than PlaneTR in utilizing line segment information.
Next, we analyzed the results quantitatively.
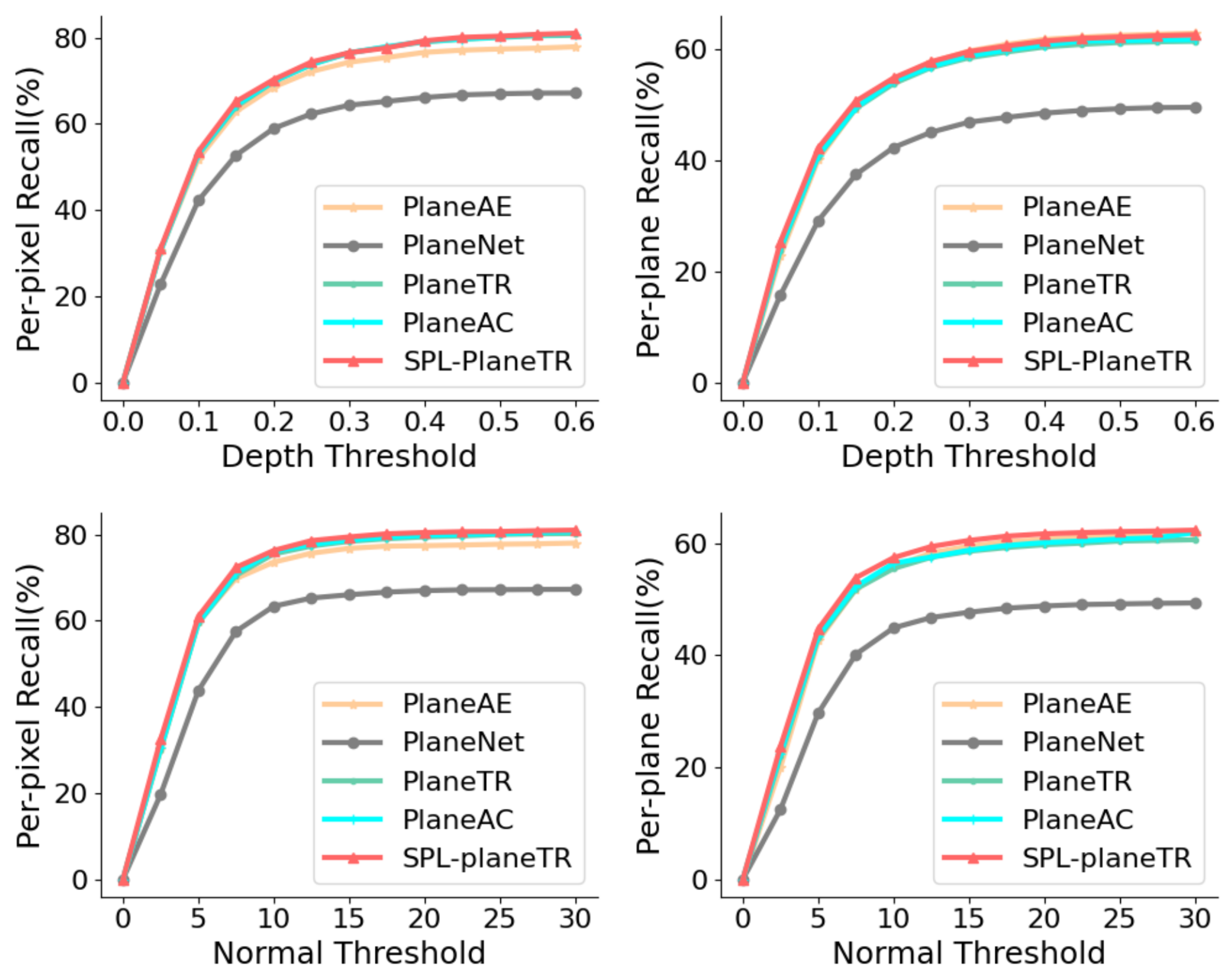
Figure 4 and
Table 1 show the pixel-wise and plane-wise recalls of various methods on the ScanNet dataset under different depth and normal thresholds. Our method outperforms PlaneTR and PlaneAC in all cases. When the depth threshold is set to 0.6, the plane-wise recall of our method is slightly lower than that of PlaneAE. According to [
16], this is because our method tends to detect entire planes. However, overall, our method still performs better than PlaneAE.
Table 2 displays the plane segmentation metrics for various methods on the ScanNet dataset. Although our method reduces the number of parameters compared to PlaneTR, it still outperforms PlaneAE, PlaneTR, BT3DPR, and PlanePDM, demonstrating competitive results. On the other hand, our method performs worse than PlaneAC and PlaneSAM. The main reason for this is that we focus on practicality and generalization, whereas PlaneAC and PlaneSAM introduce more parameters or computational burdens to improve performance.
Generalization Analysis: In this section, we evaluate the generalization capability of PlaneAE [
5], PlaneTR [
16], PlaneAC [
62], and SPL-PlaneTR on the Matterport3D [
56], ICL-NUIM RGB-D [
57], and 2D-3D-S [
58] datasets. All methods were trained only on the ScanNet [
17] dataset.
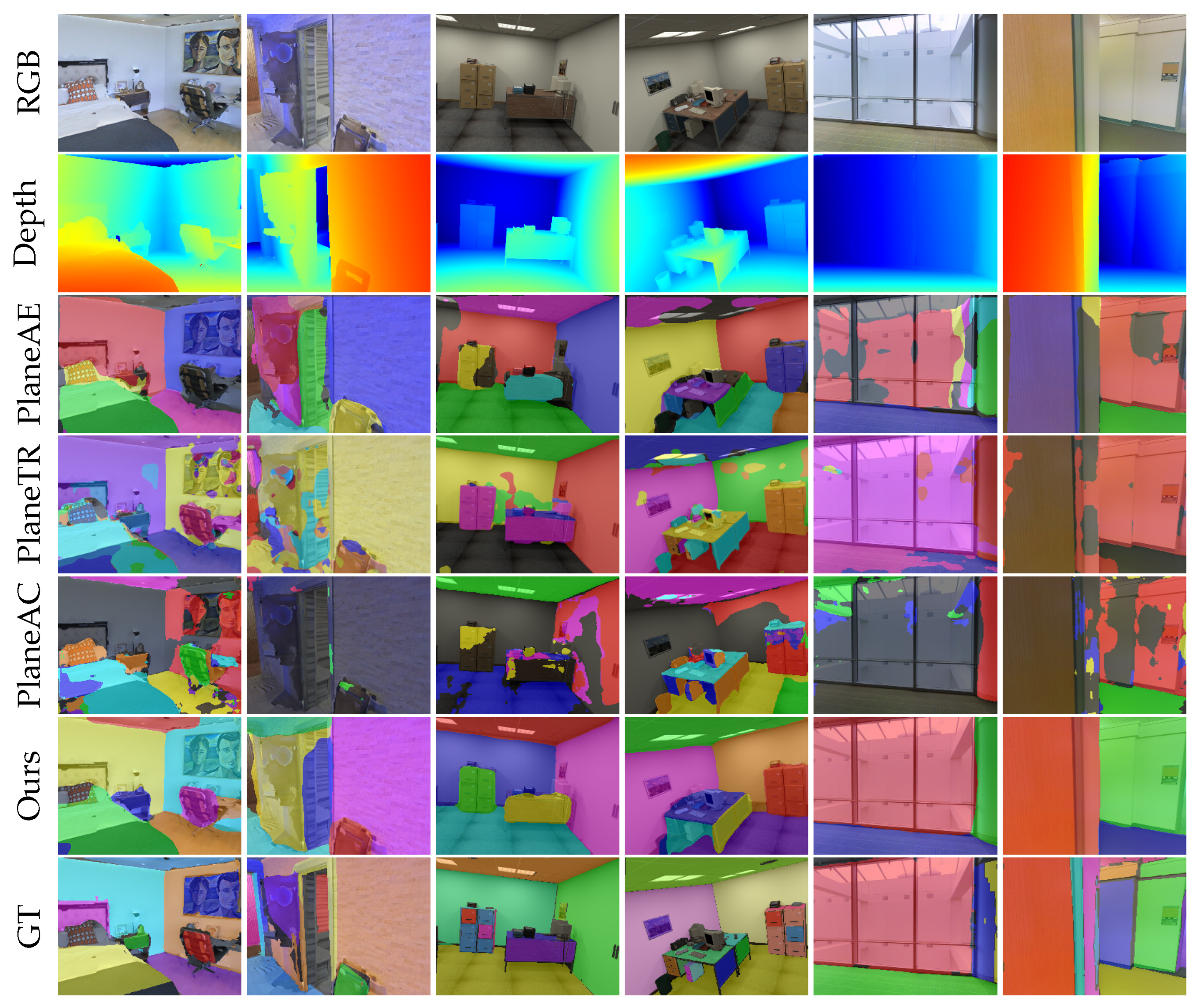
Figure 5 presents the segmentation results of these methods on unseen datasets. Qualitatively, it is shown that our method outperforms all other methods on the unseen datasets. PlaneTR and PlaneAC is almost unable to segment planes on the unseen data, mainly because they perform feature fusion after the decoding layer, which limits the line segment transformer’s ability to handle line segment information from unseen datasets. As a result, the line segment transformer fails to generate high-quality line segment feature sequences, leading to poor generalization performance. PlaneAE is capable of detecting and segmenting planes to some extent on unseen datasets, but it still cannot effectively solve issues like incomplete plane edge segmentation and holes within planes. As shown in the sixth row of
Figure 5, even when facing unseen images, SPL-PlaneTR is able to segment planes accurately without generating holes within planes.
For the quantitative analysis,
Table 3 presents the plane segmentation metrics for these methods on the three unseen datasets. Our method significantly outperforms PlaneAE, PlaneTR, and PlaneAC on the unseen datasets. This improvement is mainly attributed to the more robust feature extraction module of SPL-PlaneTR, which is capable of effectively extracting features from various unseen indoor scene images. It is worth noting that, like our method, PlaneAC is also built upon PlaneTR. However, its performance on the unseen data is notably inferior—not only to ours but even to the original PlaneTR. A possible reason for this shortcoming is that PlaneAC replaces the original self-attention mechanism with sparse attention and depth-wise convolutions, which limits the encoder’s ability to extract comprehensive features. As a result, although PlaneAC performs well on seen datasets, it fails to generalize effectively to more complex and previously unseen scenes.
Robustness Analysis: To thoroughly access the ability of our method to adapt to complex indoor scene plane segmentation tasks, we conducted a robustness study comparing PlaneTR [
16] and SPL-PlaneTR. First, we injected a certain level of noise into the ScanNet [
17] training set to examine how both methods would perform when the training data were contaminated. The noise injection method was the same as the hybrid data augmentation approach. As shown in
Table 4, the accuracy of PlaneTR decreases quickly with a reduction in data quality and falls below that of SPL-PlaneTR, while SPL-PlaneTR remains almost unaffected by the noise. This indicates that our method is more capable of learning feature representations from noisy images than PlaneTR. We also tested the noise resistance of our method by injecting Gaussian noise with a variance of 30 into the validation set. As shown in
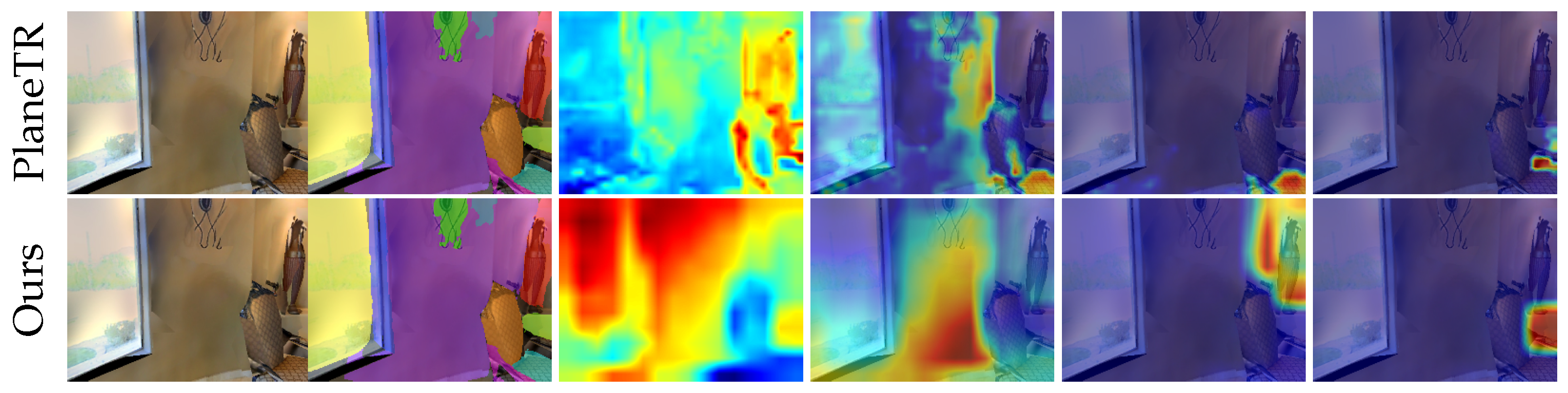
Figure 6, PlaneTR experiences significant missed detections after noise interference, while SPL-PlaneTR is still able to detect most of the planes and accurately segment them. From
Table 5, it can be observed that the accuracy of PlaneTR significantly drops after noise interference. In contrast, after training SPL-PlaneTR with hybrid data augmentation, VI only increases by approximately 0.08, while the RI and SC metrics decrease by only approximately 0.01 and 0.02, respectively. Additionally, we tested PlaneTR with the same data augmentation technique. As shown in the second and third rows of
Table 5 (where DA denotes data augmentation), even though both methods use data augmentation, our method still outperforms PlaneTR. This demonstrates that without the aid of data augmentation, our model structure is more robust against noise than PlaneTR. Based on this comprehensive analysis, our method’s robustness is significantly better than PlaneTR.
Parameter and Inference Time Comparison: To validate the practicality of our method, we compared the number of parameters and inference time of SPL-PlaneTR with the other methods. All methods were tested on the ScanNet [
17] dataset using a single RTX 3090D GPU. Due to the inherent design of PlaneSAM [
63], it required input images with a resolution of
, while all the other methods used an input resolution of
.
Table 6 presents a comparison of the number of parameters and inference time. As shown, our method achieves a competitive number of parameters and inference time. Although PlaneAE [
5] has a similar number of parameters and faster inference, its segmentation accuracy is significantly lower than ours. PlaneSAM has a small number of parameters, but its real-time performance is severely limited due to its reliance on an object detection model to provide bounding boxes in advance. As observed in rows 2 and 5 of
Table 6, we reduce the number of parameters in PlaneTR [
16] by approximately one-fifth while maintaining a comparable inference time. This reduction primarily benefits from the lightweight design of our line segment prompt module and line segment adapter. Moreover, by removing unnecessary linear projection layers in the plane decoder, the introduction of spatial queries does not result in a noticeable increase in the number of parameters.
4.3. Ablations
In this section, we conducted ablation experiments on the components of SPL-PlaneTR to validate the effectiveness of our method. We continued to use VI, RI, and SC as metrics to evaluate the plane segmentation performance. For the sake of simplicity, we used DA to denote data augmentation and SQ to denote spatial query.
LPM: We first conducted an ablation study on the LPM. From
Table 7, we observe that only using the LPM on the ScanNet dataset yields better results than only using spatial queries, but it falls short of PlaneTR [
16]. This is likely because the backbone and context encoder of PlaneTR were not fine-tuned, which may have limited the effective use of the line segment prompts. In terms of generalization, as shown in row 3 of
Table 8, using the LPM significantly improves the performance on unseen datasets, indicating that the LPM plays an important role in enhancing generalization. Furthermore, from row 5 of
Table 8, we can observe that combining both the LPM and spatial queries outperforms using spatial queries alone. This suggests that when faced with unseen images, the addition of the LPM enables the context encoder to provide high-quality features, which in turn helps spatial queries effectively recognize and locate planes.
LPA: Next, we investigated the impact of the LPA. From
Table 7 and
Table 8, we observe that incorporating the LPA improves plane segmentation accuracy across all four datasets. This indicates that after freezing the backbone and original encoder blocks, adapting image features to line prompts is necessary. The LPA effectively identifies informative regions from line prompts, allowing the network to focus on these key areas, thereby enhancing plane segmentation performance.
Spatial Query: In this part of our research, we conducted an ablation study on spatial queries. As shown in
Table 8, after incorporating spatial queries, the accuracy on three unseen datasets improves, demonstrating that spatial queries enhance the generalization capability of PlaneTR [
16]. This improvement can be attributed to the fact that, compared to traditional positional queries, spatial queries enable more accurate identification and the localization of planes in previously unseen indoor scene images. As indicated in the first row of
Table 7, the accuracy on the ScanNet [
17] dataset is relatively low after only introducing spatial queries. A potential reason for this is that while spatial queries reduce the reliance on content quality, the encoder—without line segment cues—still cannot provide the necessary content for spatial queries.
Hybrid Data Augmentation: Finally, we investigated the impact of the hybrid data augmentation training method on SPL-PlaneTR. As shown in the last two rows of
Table 7, adopting the hybrid data augmentation training approach improves plane segmentation performance on the seen dataset. This is because the training data become larger and more diverse, enabling SPL-PlaneTR to learn richer feature representations. Additionally, injecting random noise into training data helps alleviate overfitting. Regarding generalization, as observed in the last two rows of
Table 8, the hybrid data augmentation training approach slightly improves generalization. This improvement can be attributed to the ability of our approach in simulating complex indoor scenes, which enables the model to learn more diverse information.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}