
YOLOv8n-RF: A Dynamic Remote Control Finger Recognition Method for Suppressing False Detection

Abstract
1. Introduction
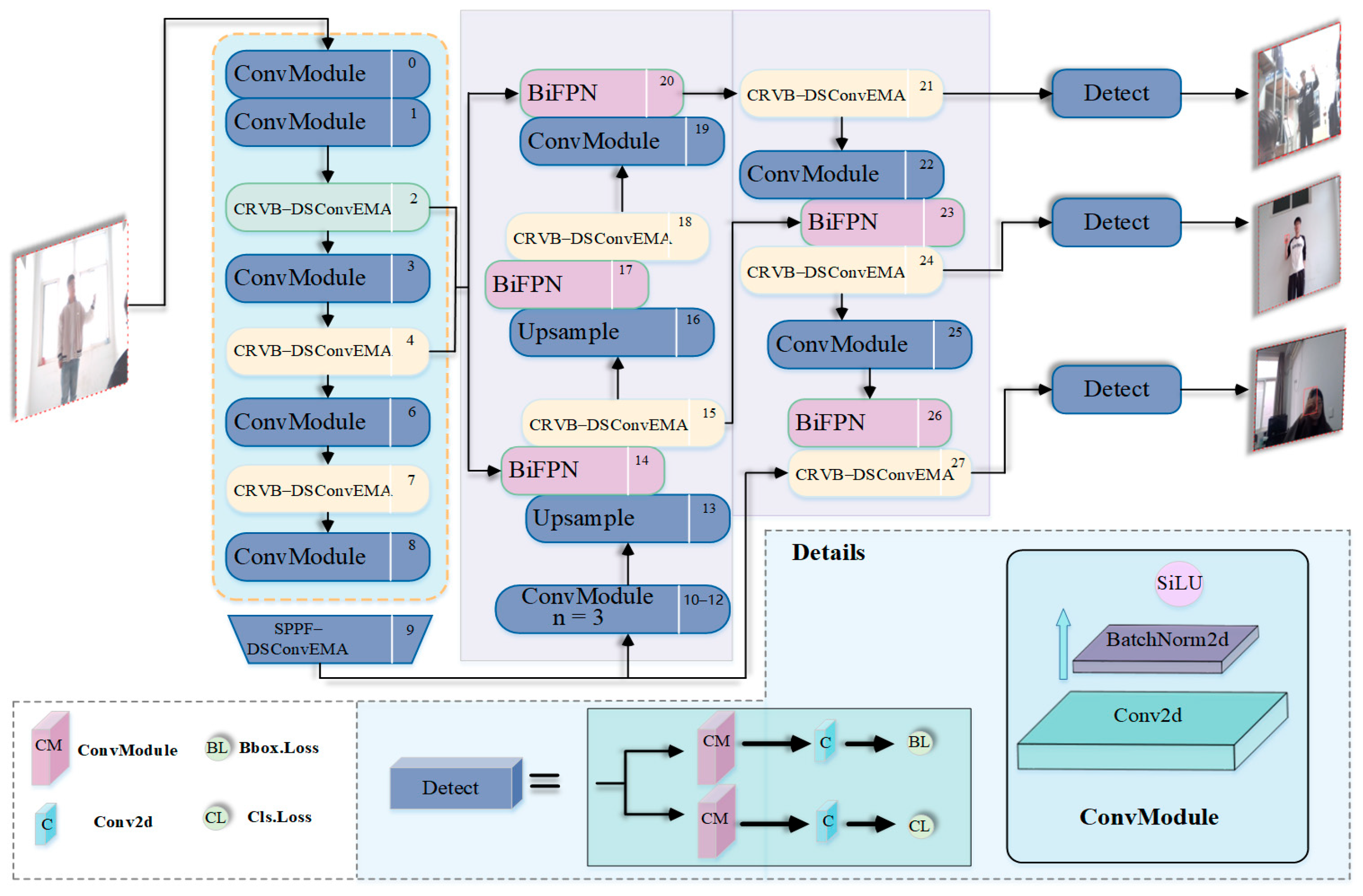
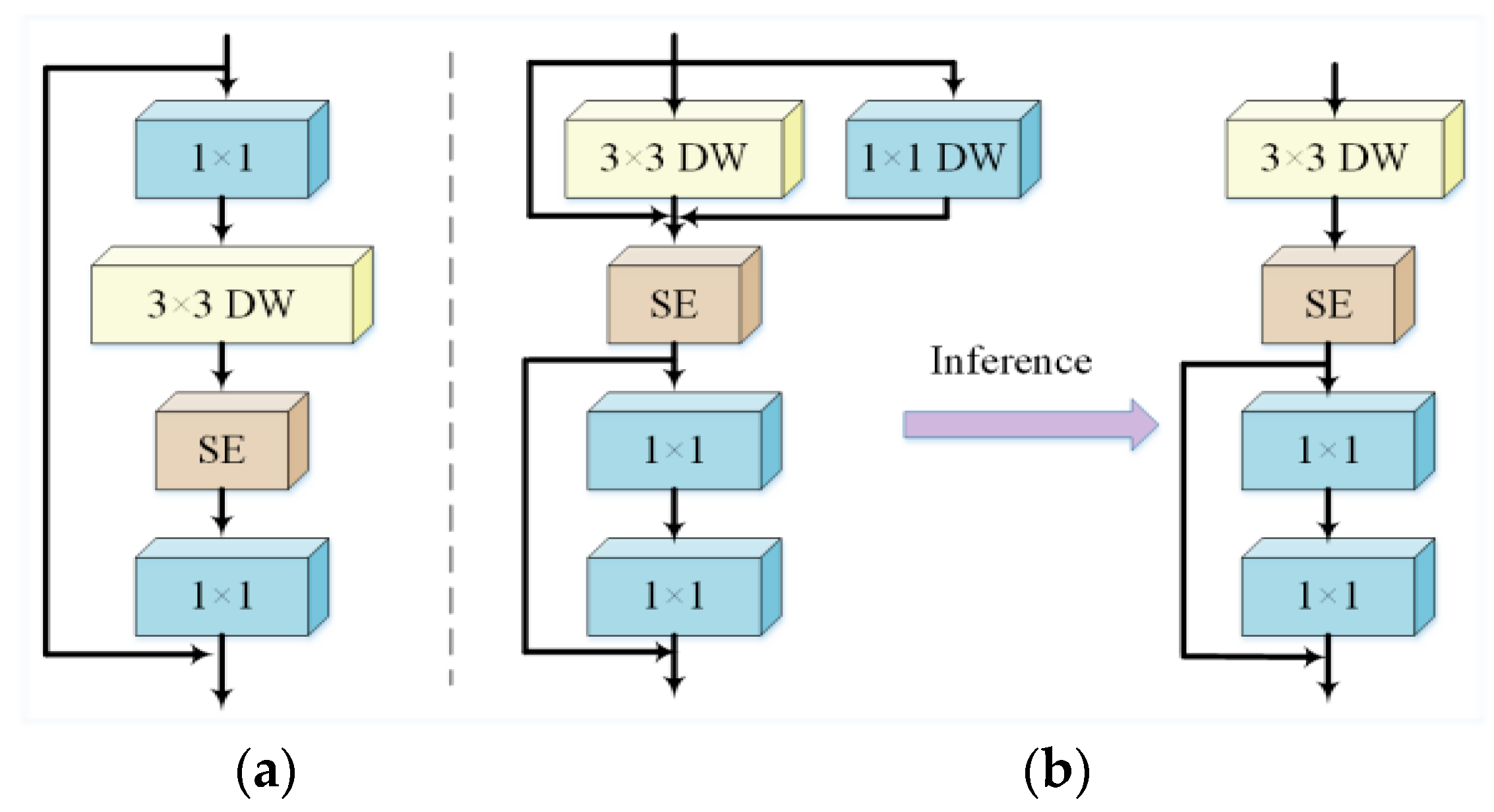
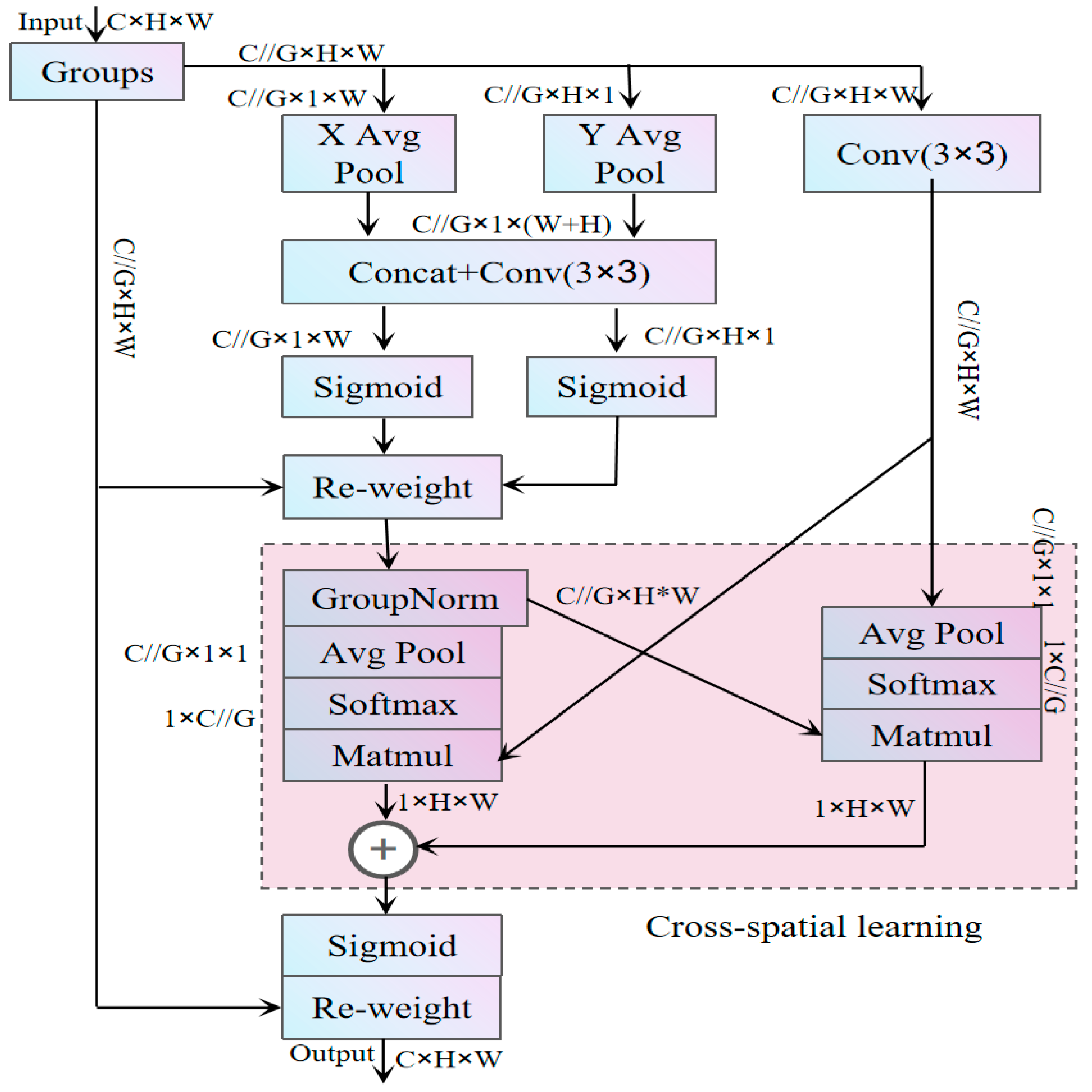
- The CRVB-DSConvEMA module is used to replace the C2f module, enabling the model to adaptively focus on local details in prominent gestures based on the input feature map. Additionally, it enhances features across multiple scales, different channels, and spatial information.
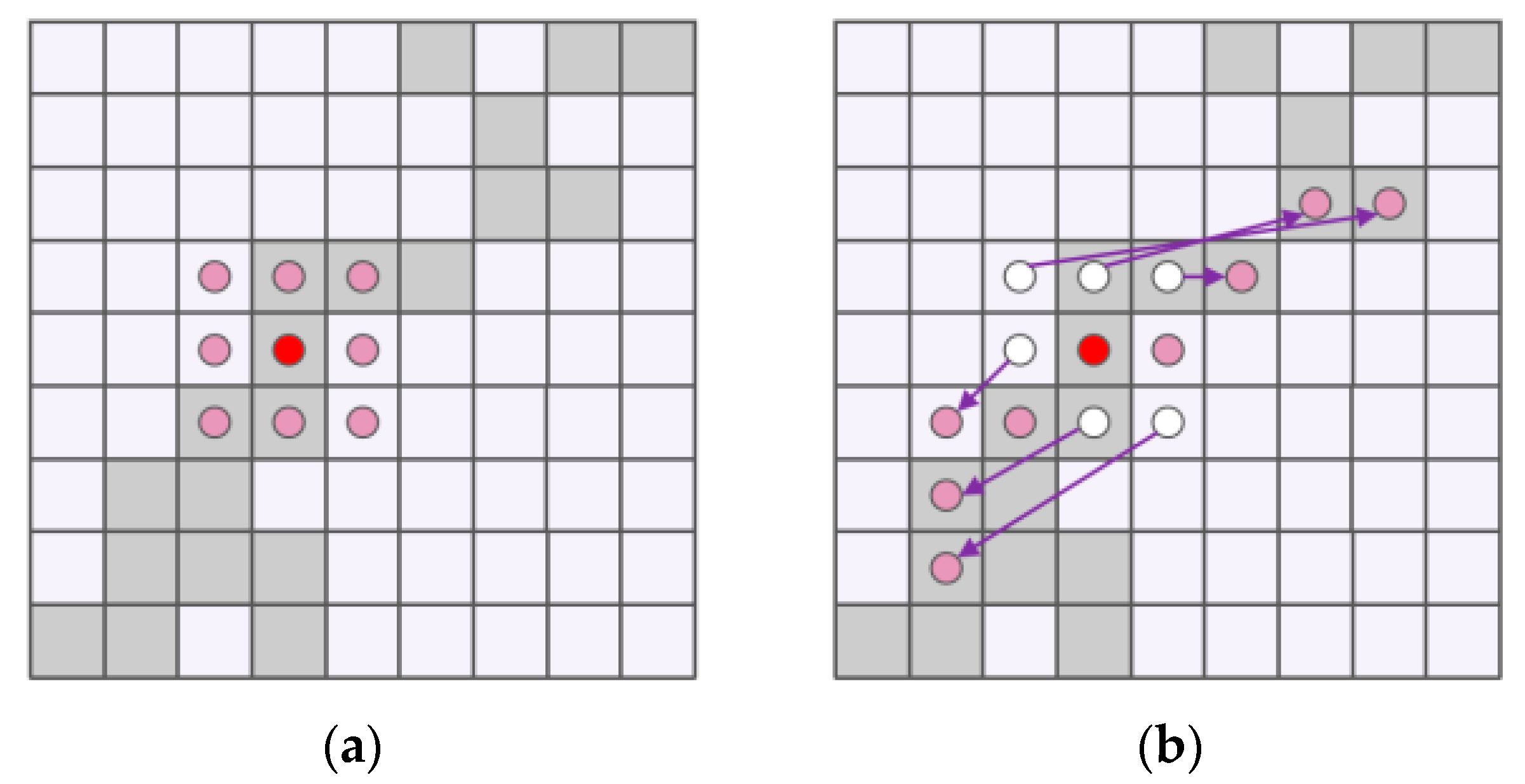
- The SPPF-DSConvEMA module is used to replace the SPPF module. By reconstructing partial channels and evenly distributing spatial semantics among sub-features, it preserves multi-angle information while improving computational efficiency. This approach further reduces false detections without increasing the model’s complexity.
- The BiFPN module is adopted in the Neck layer of YOLOv8n, enabling the model to achieve greater performance gains with minimal computational cost. While ensuring the effectiveness and accuracy of the previous two steps, this approach further reduces the model’s complexity.
2. Materials and Methods
2.1. Materials
2.1.1. RemoteFinger Dataset
2.1.2. HaGRID Dataset
2.1.3. Data Augmentation
| Algorithm 1. Gaussian Noise algorithm |
| : input image of size : noise mean (default 0) : noise standard deviation (controls intensity) AddGaussianNoise : # Initialize output image |
| for each pixel coordinate : for each channel : # Sample from Gaussian distribution end for end for return |
2.2. Methods
2.2.1. Network Architecture
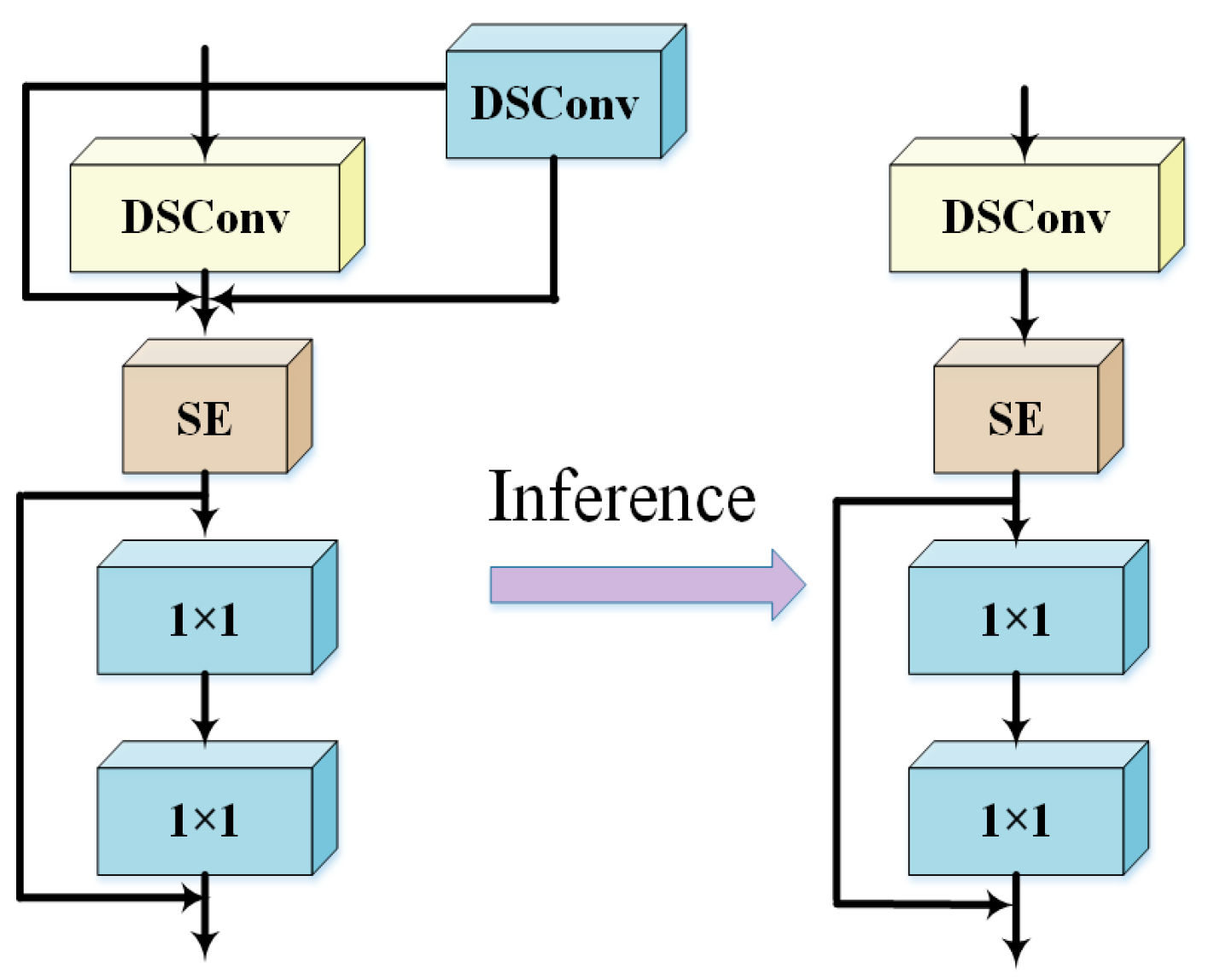
2.2.2. CRVB-DSConvEMA Module
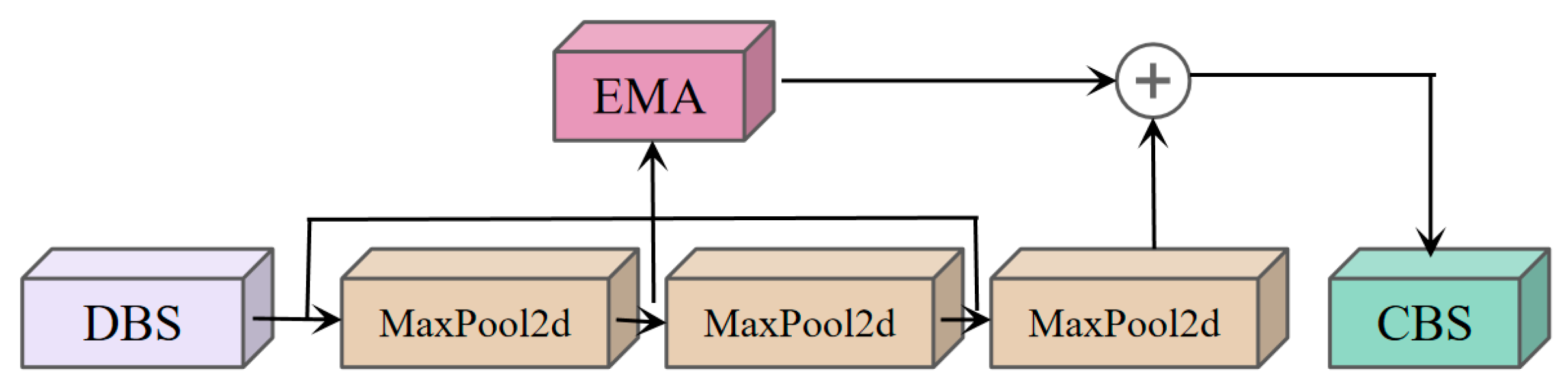
2.2.3. SPPF-DSConvEMA Module
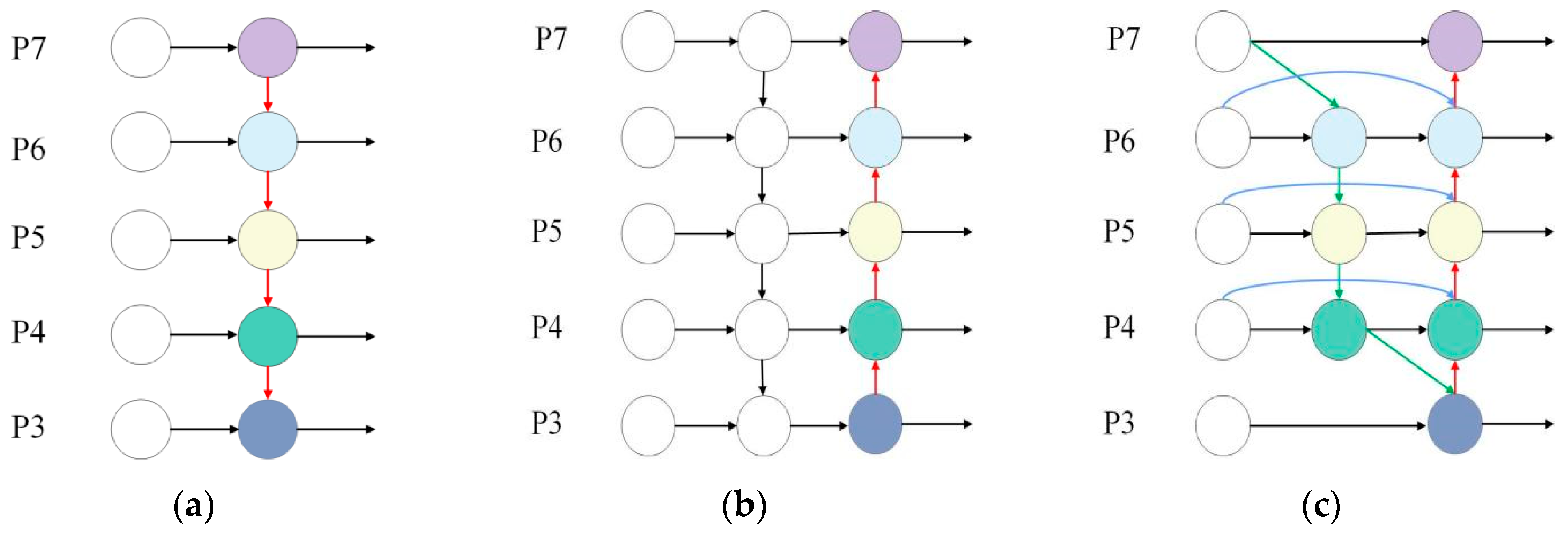
2.2.4. BiFPN Module
3. Results
3.1. Experimental Environment and Parameter Settings
3.2. Performance Evaluation Metrics
3.3. Experimental Analysis
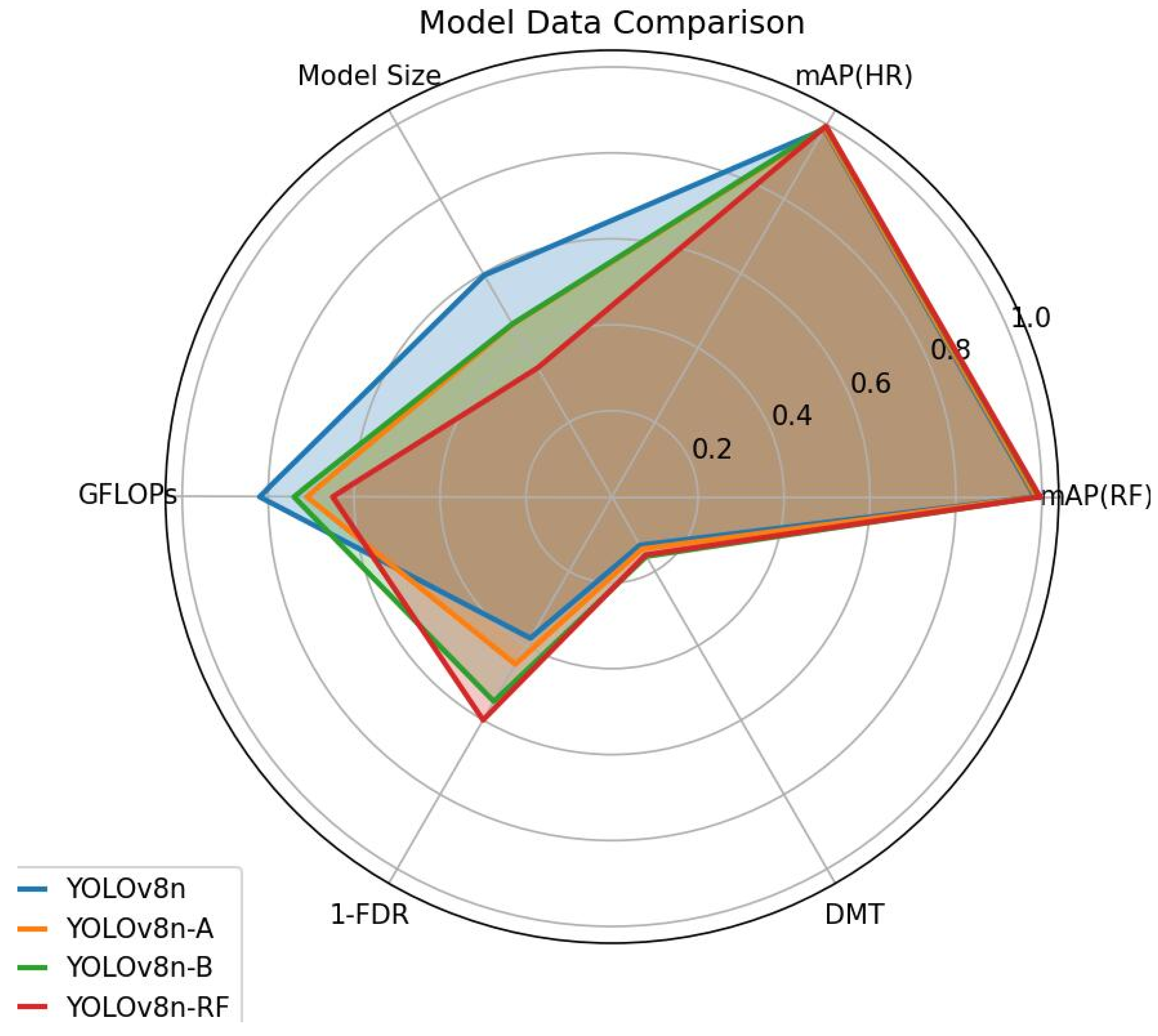
3.3.1. Ablation Experiment
3.3.2. Comparative Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, S.H.; Sohn, M.K.; Kim, D.J.; Kim, B.; Kim, H. Smart TV Interaction System Using Face and Hand Gesture Recognition. In Proceedings of the 2013 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–14 January 2013; pp. 173–174. [Google Scholar]
- Lian, S.; Hu, W.; Wang, K. Automatic user state recognition for hand gesture based low-cost television control system. IEEE Trans. Consum. Electron. 2014, 60, 107–115. [Google Scholar] [CrossRef]
- Ducloux, J.; Colla, P.; Petrashin, P.; Lancioni, W.; Toledo, L. Accelerometer-based Hand Gesture Recognition System for Interaction in Digital TV. In Proceedings of the 2014 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Montevideo, Uruguay, 12–15 May 2014; pp. 1537–1542. [Google Scholar]
- Dawar, N.; Kehtarnavaz, N. Real-time continuous detection and recognition of subject-specific smart TV gestures via fusion of depth and inertial sensing. IEEE Access 2018, 6, 7019–7028. [Google Scholar] [CrossRef]
- Wu, H.; Yang, L.; Fu, S.; Zhang, X. Beyond remote control: Exploring natural gesture inputs for smart TV systems. J. Ambient Intell. Smart Environ. 2019, 11, 335–354. [Google Scholar] [CrossRef]
- Zhang, Y.; Dong, S.; Zhu, C.; Balle, M.; Zhang, B.; Ran, L. Hand gesture recognition for smart devices by classifying deterministic Doppler signals. IEEE Trans. Microw. Theory Tech. 2020, 69, 365–377. [Google Scholar] [CrossRef]
- Liao, Z.; Luo, Z.; Huang, Q.; Zhang, L.; Wu, F.; Zhang, Q.; Wang, Y. SMART: Screen-Based Gesture Recognition on Commodity Mobile Devices. In Proceedings of the 2021 Annual International Conference on Mobile Computing and Networking (MobiCom), New Orleans, LA, USA, 25–29 October 2021; pp. 283–295. [Google Scholar]
- Alabdullah, B.I.; Ansar, H.; Mudawi, N.A.; Alazeb, A.; Alshahrani, A.; Alotaibi, S.S.; Jalal, A. Smart Home Automation-Based Hand Gesture Recognition Using Feature Fusion and Recurrent Neural Network. Sensors 2023, 23, 7523. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, Y.; Kato, K.; Furui, N.; Sakamoto, D.; Sugiura, Y. Exploring Gestural Interaction with a Cushion Interface for Smart Home Control. arXiv 2024, arXiv:2410.04730. [Google Scholar]
- Wang, H.; Xu, Y. Intelligent Television Operating System Based on Gesture Recognition. In Proceedings of the 2024 4th International Symposium on Computer Technology and Information Science (ISCTIS), Xi’an, China, 12–14 July 2024; pp. 218–222. [Google Scholar]
- Sahoo, J.P.; Prakash, A.J.; Pławiak, P.; Samantray, S. Real-Time Hand Gesture Recognition Using Fine-Tuned Convolutional Neural Network. Sensors 2022, 22, 706. [Google Scholar] [CrossRef] [PubMed]
- Faisal, M.A.A.; Abir, F.F.; Ahmed, M.U.; Ahad, M.A.R. Exploiting Domain Transformation and Deep Learning for Hand Gesture Recognition Using a Low-Cost Dataglove. Sci. Rep. 2022, 12, 21446. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Chen, K. A lightweight hand gesture recognition in complex backgrounds. Displays 2022, 74, 102226. [Google Scholar] [CrossRef]
- Mohammed, A.A.; Lv, J.; Islam, M.S.; Sang, Y. Multi-model ensemble gesture recognition network for high-accuracy dynamic hand gesture recognition. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 6829–6842. [Google Scholar] [CrossRef]
- Sun, Q.; Zhang, T.; Gao, S.; Yang, L.; Shao, F. Optimizing Gesture Recognition for Seamless UI Interaction Using Convolutional Neural Networks. arXiv 2024, arXiv:2411.15598. [Google Scholar]
- Miah, A.S.M.; Hasan, M.A.M.; Tomioka, Y.; Shin, J. Hand Gesture Recognition for Multi-Culture Sign Language Using Graph and General Deep Learning Network. IEEE Open J. Comput. Soc. 2024, 5, 144–155. [Google Scholar] [CrossRef]
- Garg, M.; Ghosh, D.; Pradhan, P.M. GestFormer: Multiscale Wavelet Pooling Transformer Network for Dynamic Hand Gesture Recognition. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024; pp. 2473–2483. [Google Scholar]
- Hu, F.; Zhang, L.; Yang, X.; Zhang, W.-A. EEG-based driver fatigue detection using spatio-temporal fusion network with brain region partitioning strategy. IEEE Trans. Intell. Transp. Syst. 2024, 25, 9618–9630. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, J.; Shan, W. Research on kiwifruit detection algorithm based on Faster-YOLOv8n. In Proceedings of the 2024 5th International Conference on Artificial Intelligence and Computer Engineering (ICAICE), Wuhu, China, 8–10 November 2024; pp. 399–403. [Google Scholar]
- Li, X.; Dai, S.; Zhang, Y.; Jiang, J. Steel defect detection based on improved YOLOv8n. In Proceedings of the 2024 9th International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Okinawa, Japan, 21–23 November 2024; pp. 818–823. [Google Scholar]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Rep ViT: Revisiting Mobile CNN From ViT Perspective. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 15909–15920. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Zhang, X.; Wang, M. Research on Pedestrian Tracking Technology for Autonomous Driving Scenarios. IEEE Access 2024, 12, 149662–149675. [Google Scholar] [CrossRef]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 6047–6056. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Han, K.; Wang, Y. Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism. arXiv 2023, arXiv:2309.11331. [Google Scholar]
- Qu, Z.; Gao, L.Y.; Wang, S.Y.; Yin, H.N.; Yi, T.M. An improved YOLOv5 method for large objects detection with multi-scale feature cross-layer fusion network. Image Vis. Comput. 2022, 125, 104518. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Volume | Pointer | Brightness | Total (Images) |
|---|---|---|---|---|
| Remote Finger 1.0 | 2100 | 2100 | 2100 | 6300 |
| Remote Finger | 2080 | 2080 | 2039 | 6199 |
| Dataset | Call | Like | Stop | Total (Images) |
|---|---|---|---|---|
| HaGRID | 1988 | 1988 | 1988 | 5994 |
| Name | Version |
|---|---|
| CPU | Intel(R) Xeon(R) Silver 4214R |
| GPU | RTX 3080 Ti(12 GB) *1 |
| OS | Ubuntu 18.04 |
| PyTorch | 1.13.0 |
| Python | 3.9.18 |
| CUDA | 11.7 |
| OpenCV | 4.8.1.78 |
| Name | Version |
|---|---|
| epoch | 100 |
| imgsz | 640 |
| batch | 32 |
| workers | 8 |
| device | 0 |
| CRVB-DSCovnEMA | SPPF-DSConvEMA | BiFPN | mAP (%) RF | mAP (%) HR | Model Size (M) | GFLOPs | 1-FDR Rock | DMT (ms) RF |
|---|---|---|---|---|---|---|---|---|
| - | - | - | 98.30 | 98.73 | 5.95 | 8.2 | 38 | 13.0 |
| √ | - | - | 98.70 | 98.92 | 4.63 | 7.1 | 45 | 14.0 |
| √ | √ | - | 99.30 | 99.43 | 4.64 | 7.4 | 55 | 16.0 |
| √ | √ | √ | 99.53 | 99.57 | 3.46 | 6.5 | 60 | 15.6 |
| Name | Model |
|---|---|
| YOLOv8n-A | CRVB-DSConvEMA |
| YOLOv8n-B | CRVB-DSConvEMA+SPPF-DSConvEMA |
| YOLOv8n-RF | CRVB-DSConvEMA+SPPF-DSConvEMA+BiFPN |
| Model | Call | Like | Stop | Volume | Pointer | Brightness | FDR | 1-FDR |
|---|---|---|---|---|---|---|---|---|
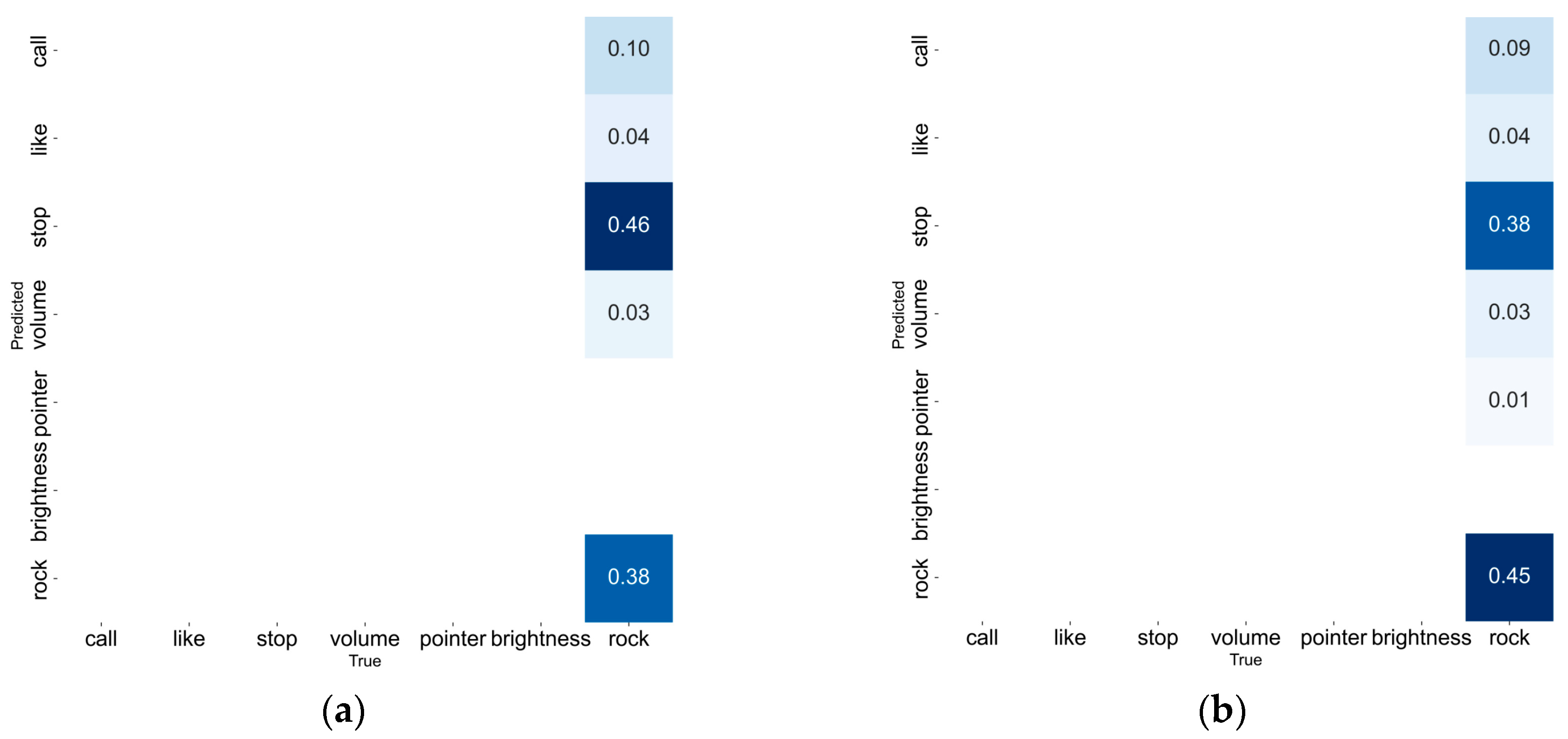
| YOLOv8n | 0.10 | 0.04 | 0.46 | 0.03 | - | - | 0.63 | 0.38 |
| YOLOv8n-A | 0.09 | 0.04 | 0.38 | 0.03 | 0.01 | - | 0.55 | 0.45 |
| YOLOv8n-B | 0.08 | 0.03 | 0.31 | 0.03 | - | - | 0.45 | 0.55 |
| YOLOv8n-RF | 0.05 | 0.06 | 0.29 | - | - | - | 0.40 | 0.60 |
| Model | mAP (%) RF | Recall (%) RF | mAP (%) HR | Recall (%) HR | Model Size (M) | GFLOPs | 1-FDR (%) Rock |
|---|---|---|---|---|---|---|---|
| SSD | 21.13 | - | 88.33 | - | 186 | - | 20 |
| MMDectionv3 | 47.43 | 58.33 | 65.00 | 64.00 | 59.9 | - | 40 |
| YOLOv5 | 98.67 | 98.50 | 99.33 | 97.50 | 5.01 | 7.1 | 28 |
| YOLOv6 | 97.43 | 96.83 | 99.20 | 98.33 | 8.28 | 11.8 | 20 |
| YOLOv7 | 98.70 | 99.23 | 99.00 | 98.67 | 11.7 | 13.2 | 39 |
| YOLOv8 | 98.30 | 98.20 | 98.73 | 98.50 | 5.95 | 8.2 | 38 |
| YOLOv9 | 98.53 | 97.43 | 99.37 | 99.53 | 5.80 | 11.0 | 30 |
| YOLOv8n-RF | 99.53 | 98.98 | 99.57 | 98.88 | 3.46 | 6.5 | 60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Wang, G.; Yao, Y. YOLOv8n-RF: A Dynamic Remote Control Finger Recognition Method for Suppressing False Detection. Sensors 2025, 25, 2768. https://doi.org/10.3390/s25092768
Wang Y, Wang G, Yao Y. YOLOv8n-RF: A Dynamic Remote Control Finger Recognition Method for Suppressing False Detection. Sensors. 2025; 25(9):2768. https://doi.org/10.3390/s25092768
Chicago/Turabian StyleWang, Yawen, Gaofeng Wang, and Yining Yao. 2025. "YOLOv8n-RF: A Dynamic Remote Control Finger Recognition Method for Suppressing False Detection" Sensors 25, no. 9: 2768. https://doi.org/10.3390/s25092768
APA StyleWang, Y., Wang, G., & Yao, Y. (2025). YOLOv8n-RF: A Dynamic Remote Control Finger Recognition Method for Suppressing False Detection. Sensors, 25(9), 2768. https://doi.org/10.3390/s25092768