1. Introduction
Wire ropes are extensively utilized in engineering due to their high strength, good flexibility, and strong load-bearing capacity. Lubrication is an essential part of wire rope daily care and maintenance. Grease helps reduce wear, prevent corrosion, and slow the propagation of fatigue micro-cracks on the wire surface [
1]. Lubricated wire ropes have a higher crack initiation threshold than unlubricated wire ropes [
2]. Consequently, adequate and consistent lubrication can prolong the service lifespan of wire ropes by two to three times. Currently, specialized wire rope lubrication devices are commonly used in industrial settings, offering benefits such as high efficiency, improved control, and uniform lubrication [
3,
4,
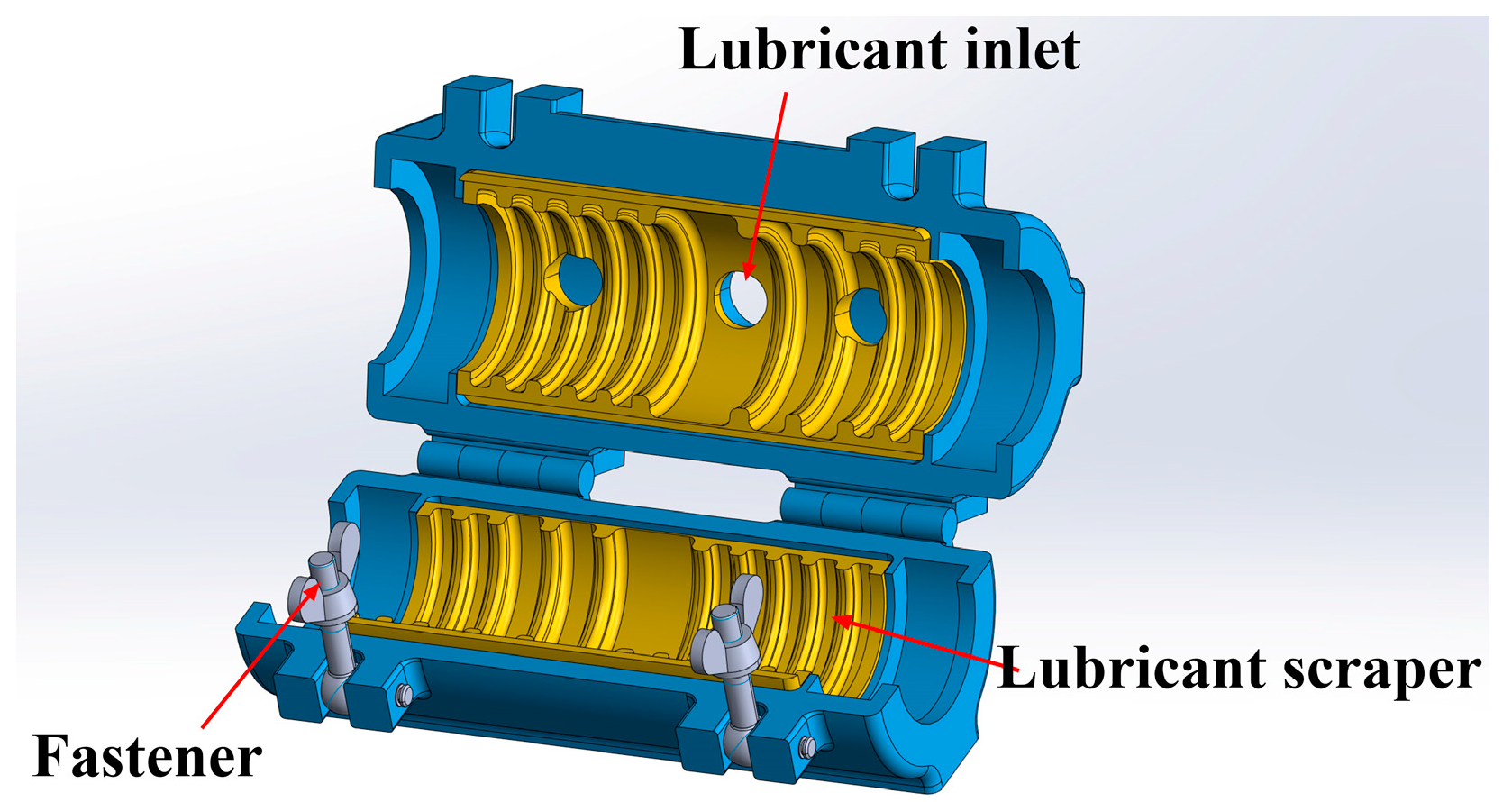
5]. The structure of the wire rope lubrication device is illustrated in
Figure 1. The apparatus comprises a lubricating chamber, a grease scraper made of a resin liner, and other components. The wire rope passes through the lubricating apparatus at a consistent speed. A uniform grease film is formed on the surface through its relative motion with the scraper, thereby protecting the wire rope.
Steel wire ropes should have grease applied to their surface within a specific range in thickness. The grease layer will not effectively lubricate and protect against corrosion if it is excessively thin. On the other hand, an excessively thick coating could cause the grease to fling off while the machine is operating, contaminating the workspace. The grease thickness on the surface of steel wire ropes frequently varies with adjustments in the lubrication device’s parameters in real-world lubrication operations. For example, the scraper may experience wear from extended contact with the wire rope, which can increase the amount of grease on the wire rope surface. The amount of grease coating is also influenced by the relative motion speed between the lubrication device and the wire rope. Therefore, monitoring and controlling the grease thickness on the surface of steel wire ropes is a crucial step in the lubrication process. At present, the assessment of the lubrication status of steel wire rope surfaces primarily relies on manual inspection. When measuring the grease thickness on steel wire rope surfaces with traditional measurement tools, there are a number of difficulties: (1) the grease, being in a liquid or soft solid state, poses challenges for traditional measuring tools to achieve accurate measurements; (2) the surface of the steel wire rope is inherently uneven and irregular, with peaks and valleys between its strands, resulting in an uneven distribution of grease; and (3) the conditions in engineering field environments are frequently limited, making it difficult to deploy high-precision and expensive measuring devices. Therefore, it is crucial to find an efficient and cost-effective method for identifying the lubrication status on the surface of steel wire ropes.
There have been certain advancements in machine vision technology for identifying surface damages on steel wire ropes, such as the work by Zhou et al. [
6], who implemented an improved YOLOv5 algorithm for detecting surface damages on moving mine steel wire ropes, achieving an average detection accuracy (mAP) of 82.3%. Jiang et al. [
7] employed the Mask-RCNN network to segment images of steel wire ropes and determined the lay length of the rope from resulting Voronoi diagrams, yielding an average error of 1.0672 mm. Pan et al. [
8] performed feature extraction on images of damaged steel wire ropes and employed the KNN method to categorize local defects, achieving a detection accuracy of 94.35% for failure categories. Nevertheless, none of this research has examined the application of imaging algorithms to ascertain the lubricating condition of steel wire ropes. The surface grease on steel wire ropes may become contaminated with tiny dust particles and impurities during operation, and reflections can arise under varying lighting circumstances, resulting in complex color details, substantial noise, and glare in the images. Moreover, capturing dynamic steel wire ropes might result in blurred images, complicating image characteristics and hindering feature extraction, which would lead to the suboptimal performance of traditional machine learning classification methods.
In recent years, with the rapid development of computer vision technology, the application of machine vision and deep learning in product inspection, defect detection, and quality control has become increasingly widespread. For example, Semitela et al. [
9] achieved automation in the quality monitoring of coating surfaces for heating equipment by developing an automated defect detection and classification system based on ResNet50. Ficzere et al. [
10] designed an algorithm utilizing machine vision and MATLAB 9.8.0.1721703 to measure the coating thickness of tablets, estimating the weight gain of coated tablets by visually comparing the diameter differences between uncoated and coated tablets. Gray-level co-occurrence matrix texture analysis and autoencoder classification techniques were used by Han et al. [
11] to classify fuel injection nozzle surfaces to determine the presence or absence of coatings. They also employed a YOLO-CNN detection algorithm to locate coating interfaces, achieving an accuracy of over 95%. To detect the thickness of the retinal nerve fiber layer (RNFL), Mariottoni et al. [
12] utilized a pretrained residual neural network, ResNet34, demonstrating excellent accuracy with a segmentation-free classification algorithm across both high-quality image sets and those containing errors or artifacts. Based on the aforementioned research, detection techniques that integrate deep learning and machine vision hold great potential for widespread application in sectors such as manufacturing and healthcare. Nevertheless, while the models utilized in these studies demonstrate high accuracy for their respective tasks, they do not take into account scenarios with limited hardware resources. The models above have relatively large number of parameters and substantial sizes; for example, the size of ResNet34 is approximately 80 MB, with around 21 M parameters.
Considering the diverse and complex operational environments of steel wire rope equipment, the proposed model should strive for high classification accuracy while being as lightweight as possible to accommodate resource-constrained deployment environments. Similar issues are faced in agricultural engineering; for example, to achieve the real-time recognition of plant diseases affecting crops such as wheat, coffee, and rice, Li et al. [
13] proposed an improved PMVT model based on MobileViT, achieving an increase in accuracy ranging from 1% to 3.3% across three datasets. However, their model’s parameter size and FLOPs were 5.06 M and 1.59 GFLOPs, respectively, representing increases of 0.11 M and 0.13 GFLOPs compared to the original MobileViT. For plant leaf disease detection, Singh et al. [
14] trained MobileViT with synthetic data produced by LeafyGAN, which improved accuracy by 20.7% on their PlantDoc dataset. However, they did not take into account the compression of their model, and the model’s parameters stayed the same. Therefore, based on the above research, this paper selects MobileViT as the basic model for the classification task of wire rope surface grease thickness and designs improvement strategies for both recognition accuracy enhancement and model compression. The goal is to improve model performance while also reducing hardware requirements.
In this research, we introduce a deep learning-based image classification approach to the field of steel wire rope maintenance engineering, selecting the lightweight MobileViT as the base network model due to its low computational cost and fast inference speed. We first reduce the model’s number of parameters and computational complexity by replacing some standard convolutions with the lightweight GhostConv. Next, to address the challenges of identifying images of lubricated steel wire ropes under varying lighting conditions and dynamic scenes, we design an improved MobileViT block that combines an efficient multi-scale attention module (EMA) and residual connections. Finally, the transfer learning method is used to further improve image recognition accuracy and speed up training. We refer to this improved model as GEMR-MobileViT. Experimental results on our self-constructed steel wire rope image dataset demonstrate that our GEMR-MobileViT model outperforms the current mainstream image classification models, and possesses significant advantages in terms of model lightweighting, making it suitable for deployment in embedded or mobile devices. This research facilitates the real-time monitoring of grease thickness on moving steel wire ropes under various working conditions. The main contributions of this paper are as follows:
An image acquisition platform was established, and steel wire rope lubrication experiments were conducted using a self-made lubrication device. A total of 1874 images of the lubricated surface of steel wire ropes were collected, and through data augmentation, the image dataset was expanded to 3478 images, which were categorized into five classes based on the thickness of the grease on the wire rope surface.
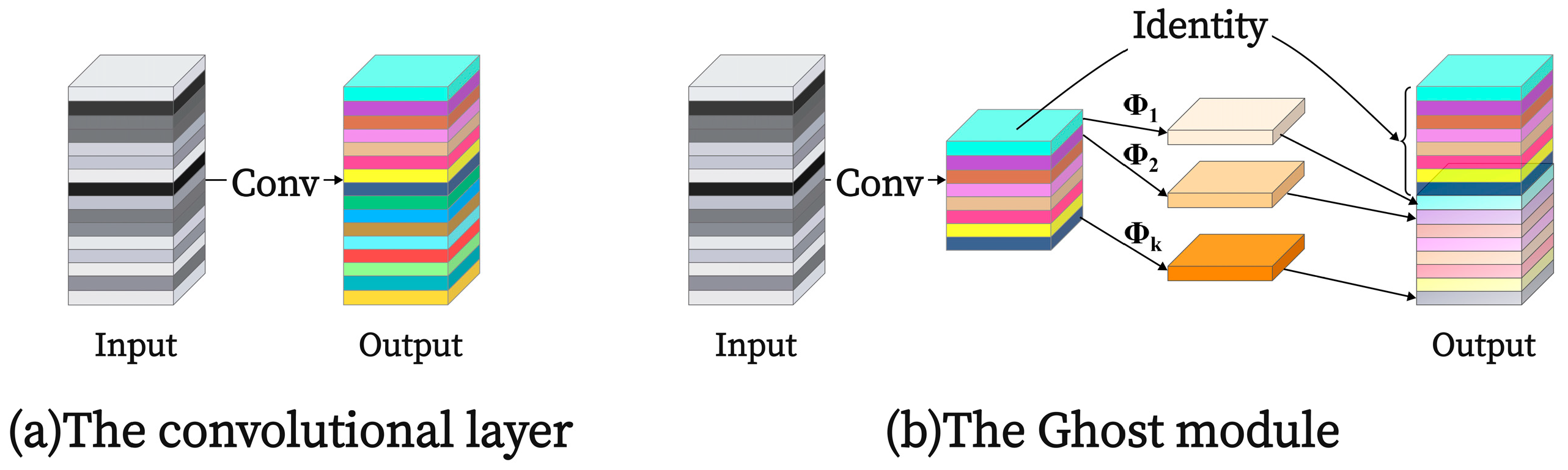
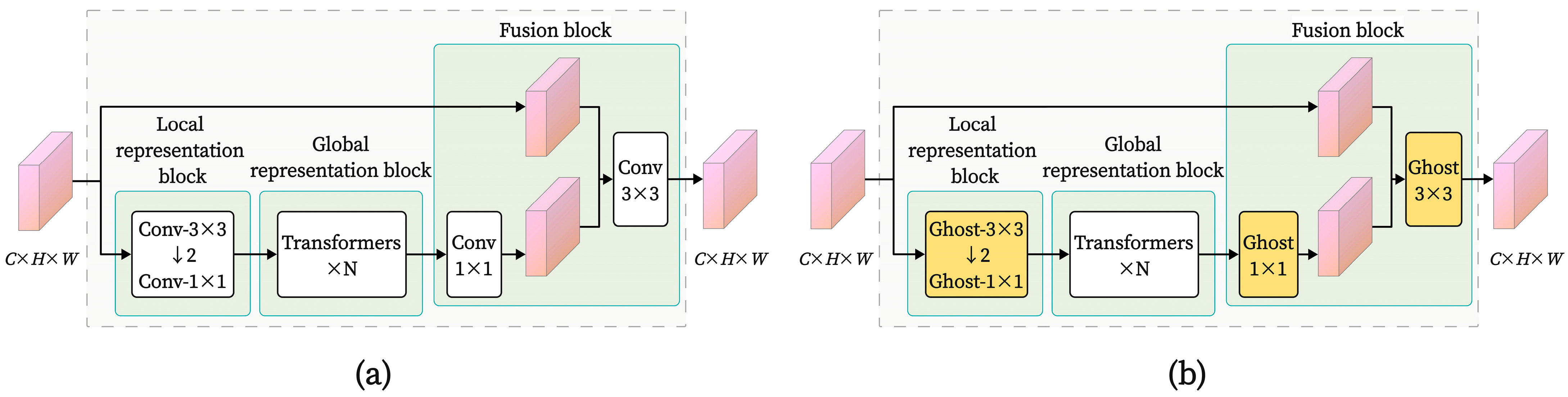
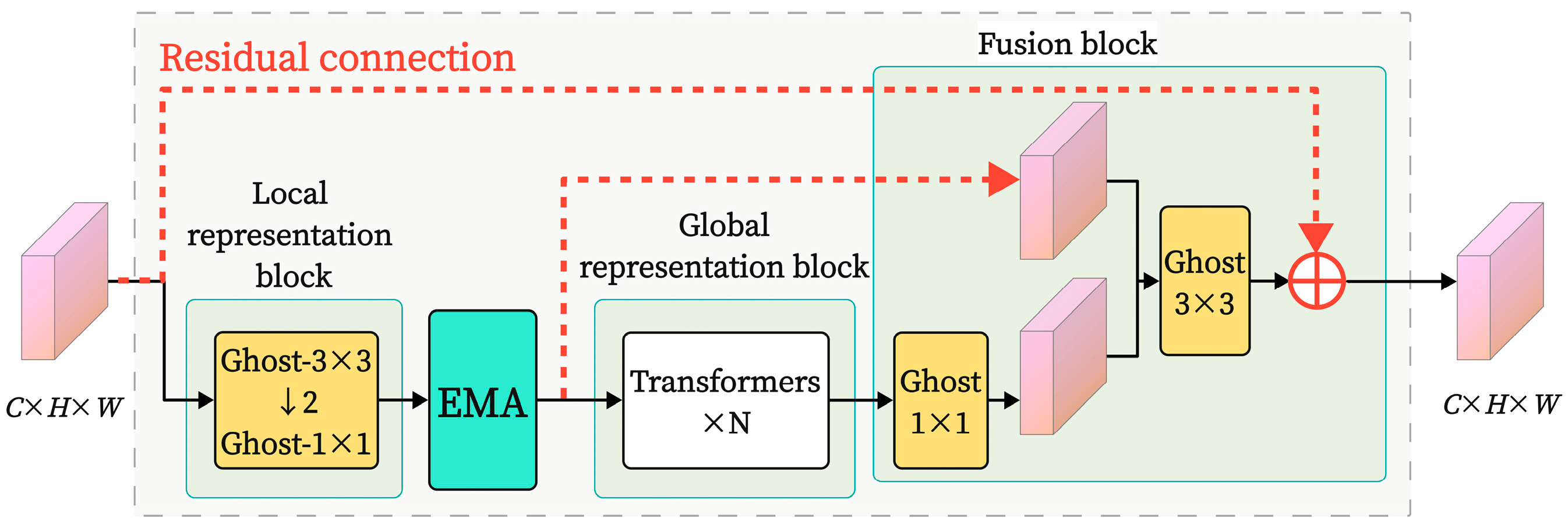
An improved GEMR-MobileViT network was proposed, incorporating a lightweight GhostConv and EMA module, combined with residual connections to enhance the model’s capability for feature extraction and fusion in images. Transfer learning techniques were employed to improve the model’s training efficiency.
The impact of adding the EMA module at different positions within the network was explored, and a comparison was made between the effects of common attention mechanism modules (SE, CA, CBAM) and EMA.
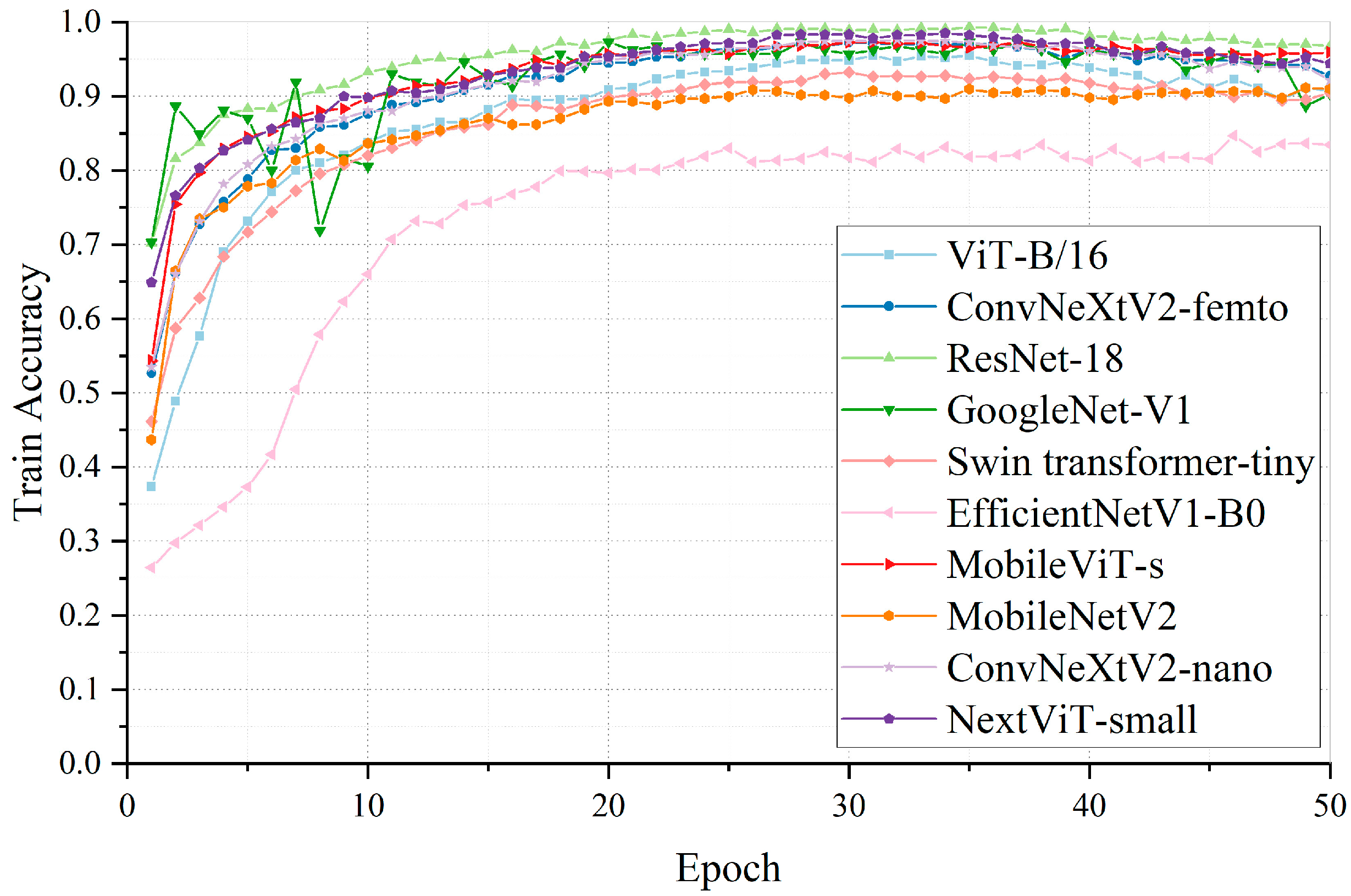
Comparative performance experiments were conducted on the self-constructed steel wire rope image dataset, evaluating the GEMR-MobileViT model against other mainstream image classification models (ConvNeXt, EfficientNet, Swin Transformer, ViT, ResNet, GoogLeNet).
5. Discussion
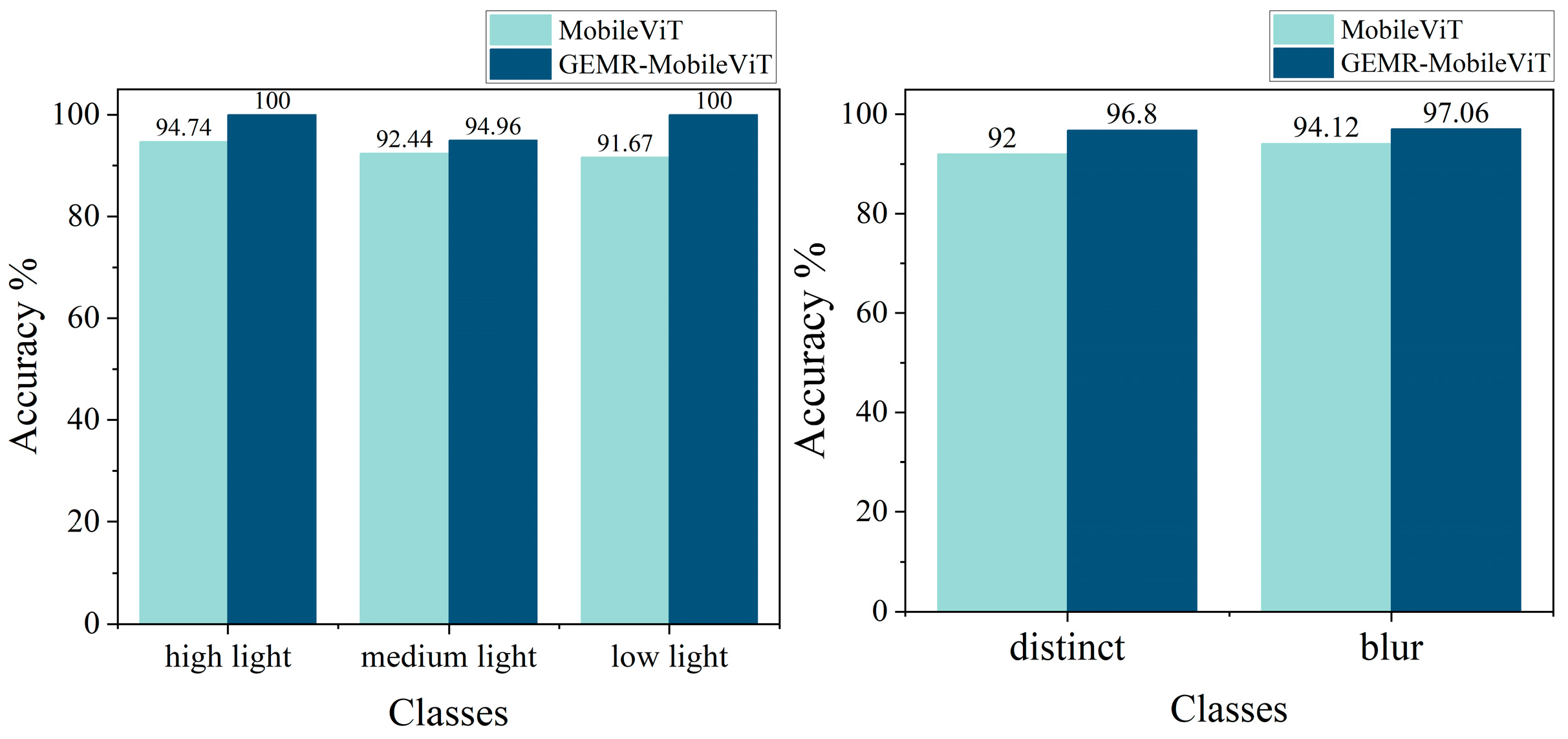
This paper presents an improved GEMR-MobileViT model to address the challenge of the automated detection of grease thickness on wire rope surfaces. GEMR-MobileViT reaches a recognition accuracy of 96.63% on a self-constructed dataset, and it demonstrates significant advantages in terms of lightweight design. Its robustness across various lighting conditions and dynamic scenarios was also validated, thus providing crucial technical support for the automation of wire rope maintenance operations.
Throughout the research process, we encountered several significant challenges. First, in the setting of training hyperparameters, after multiple comparative experiments, the Adam optimizer was selected. It combines the methods of momentum and adaptive learning rate, enabling faster convergence. Compared with other optimizers, such as SGD, Adam can better handle sparse gradients and unstable gradient changes, and the accuracy is comparable. The initial learning rate was set to 0.0001, which is the optimal value obtained through experimental verification, this value can accelerate the training process while ensuring the convergence of the model. The commonly used cross-entropy loss function was chosen as the loss function, and the number of training epochs was set to 50; this choice was determined based on the model’s performance on the validation set to avoid overfitting caused by excessive training epochs. The batch size was determined according to the computer’s hardware performance and was set to 16 to ensure the stability of the model and the training speed.
Next, the inherent complexities of field image capture—such as motion blur, uneven lighting, and contaminants adhering to lubricated surfaces—created substantial difficulties for feature extraction. These challenges necessitated sophisticated preprocessing and robust attention mechanisms. To address these issues, we developed an EMA mechanism module alongside a residual connection structure to enhance the model’s capacity for feature extraction and fusion.
Moreover, the complex environment of wire rope lubrication operations presented another obstacle: ensuring the model’s generalization capability across varying operational conditions. This was addressed through the application of transfer learning strategies and comprehensive data augmentation techniques to bolster the model’s generalizability.
Additionally, the model continues to face prediction errors when differentiating between wire rope categories with very similar thicknesses. This fine-grained differentiation remains a notable challenge in object classification using visual methods, especially when visual distinctions between categories are minimal. Such scenarios make it difficult for the model to capture sufficient discriminative features for accurate classification. Therefore, further enhancing the model’s ability to discern fine-grained features, particularly when distinguishing between closely resembling categories, remains a critical area for ongoing development and research.
Future research may explore several key directions: First, expanding the dataset to encompass more extreme environmental conditions—such as marine environments, mining sites, and high-altitude cableways—along with various specifications of steel wire ropes and lubricating greases is necessary to enhance the model’s robustness. Second, investigating more efficient attention mechanisms, network architectures, and training processes could improve the model’s ability to discern fine-grained features among similar thickness categories. Furthermore, integrating the model with image segmentation networks, such as U-Net, may facilitate assessments of the uniformity of the grease distribution on wire rope surfaces. Finally, establishing a closed-loop lubrication system through the integration of a feedback control mechanism based on model predictions has the potential to enhance the autonomy of industrial maintenance workflows. Our study establishes a foundational framework for intelligent lubrication monitoring, and the proposed methodologies could be applicable to similar tasks in other industrial surface inspection domains.
Furthermore, the findings of this study offer a novel perspective for investigating the impact of lubricating grease on the tribological properties of steel wire ropes. The research by Feng et al. [
28] demonstrated a direct correlation between the rheological properties of lubricating greases and the friction coefficients of steel wires, while Dyson et al. [
29] highlighted the significant role of lubricants in reducing wear during the breaking-in phase of wire ropes. Future research could leverage our model to further explore the tribological behavior of steel wire ropes under varying thicknesses of surface lubricating grease. This could provide valuable insights into the fundamental relationship between lubrication and friction.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}