
Enhancing Adversarial Defense via Brain Activity Integration Without Adversarial Examples


Abstract
1. Introduction
2. Related Work
2.1. Contrastive Language–Image Pretraining
2.2. Adversarial Attacks
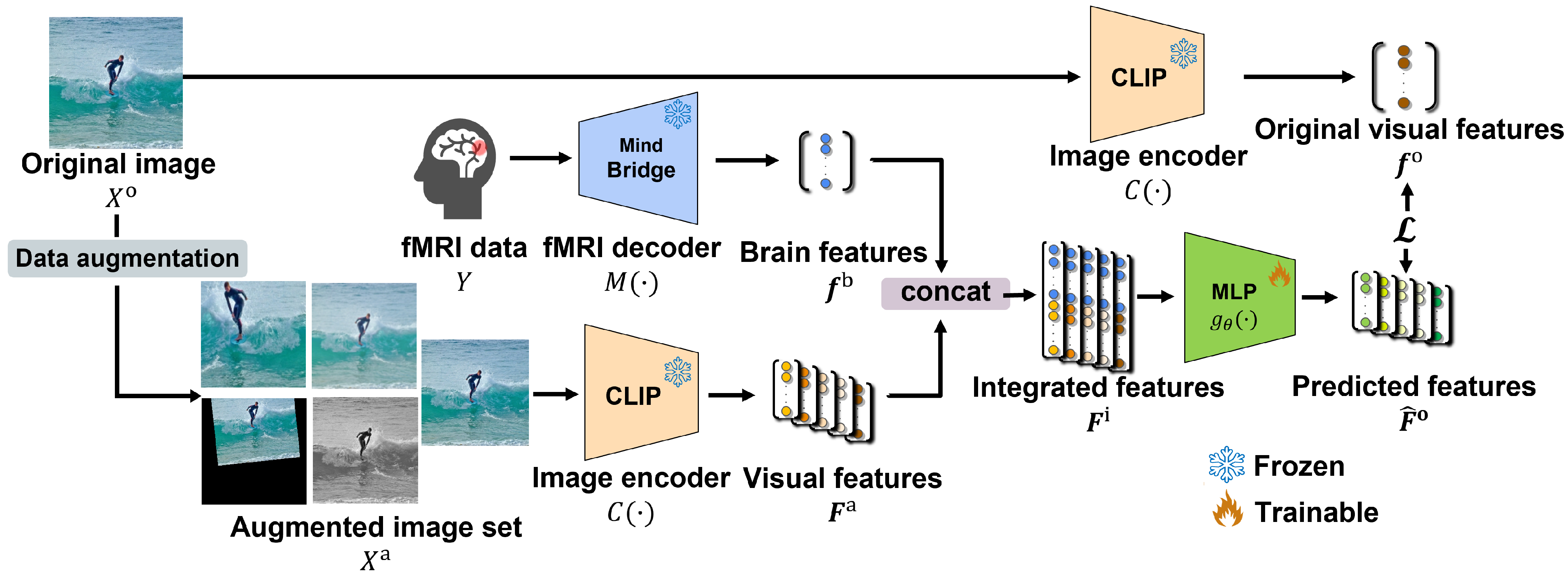
3. Proposed Method
3.1. Creation of Augmented Image Set
3.2. Feature Extraction and Integration
3.3. Training Process
4. Experiments
4.1. Experimental Settings
4.1.1. Dataset
4.1.2. Attack Settings
4.1.3. Evaluation Details
- Comparison Methods. To the best of our knowledge, no previous adversarial defense for the CLIP model requires neither adversarial examples nor degrades accuracy for clean images while being independent of attack types. Therefore, PM cannot be directly compared with other methods. In particular, several studies [41,42] that have considered new tasks do not adopt comparative methods; rather, they have conducted extensive experiments. Therefore, we also verified as many different perspectives as possible in the four comparison experiments. We used the following models:
- CLIPThis method involves the CLIP model with trained VIT-L/14. Adversarial examples are designed to deceive the model; thus, the output of this method indicates the success rate of the adversarial attack.
- PM w/o fMRIThis method involves the MLP model trained on only the augmented image set without fMRI data. By comparing this method with PM, we evaluated the effectiveness of brain activity.
- PM w/o fMRI with noiseThis method involves the MLP model trained on random noise data rather than fMRI data. This method represents the chance level, and by comparing brain activity with the chance level, we verified the significance of brain activity.
- RS:Randomized Smoothing [43]This method is a type of certified defense that mathematically guarantees that it can withstand all adversarial perturbations within a specific radius and basic defense method without adversarial examples for training. By comparing this method with PM, we show that PM is more effective than other defense methods that do not use adversarial examples.
- RSE:Random Self-Ensemble [44]This method is a type of ensemble smoothing that averages predicted results over multiple models or inputs. This method adds a random noise layer to the neural network and ensembles multiple predictions to improve robustness against adversarial attacks. We adopted it for the same reasons as RS.
- AT: Adversarial Training (ideal)This method involves the MLP model trained by adversarial training using each attack. AT (ideal) was trained with features extracted by the CLIP model from adversarial examples created using each attack against images in the training set. Note that “ideal” represents each attack to be used for the evaluation, and the obtained results correspond to the upper limit.
- Evaluation via Image and Text Similarity. We evaluated similarity using two modalities to evaluate how closely the predicted features resembled the original visual features.
- Image similarityFor image similarity using evaluation, we input clean images and adversarial examples generated by various attacks into each comparison model. The cosine similarity between the predicted features and the original visual features extracted using the CLIP vision encoder was then calculated, and the average of each value for all test datasets S was computed. This analysis enables us to evaluate how brain activity influences image features. The equation is expressed as follows:
- Text similarityFor text similarity using evaluation, we computed the cosine similarity between the predicted features of each comparison model and the text features extracted from the caption corresponding to the original image using the CLIP text encoder and calculated the average of each value for all test datasets S. This analysis enables us to evaluate how brain activity influences the relationship between image and text features. The equation is expressed as follows:
- Evaluation via Image-to-Text Retrieval. To further evaluate the impact of the predicted features on the downstream tasks, we performed quantitative and qualitative evaluations using image-to-text retrieval [45]. In this task, when adversarial examples and clean images are input into each model, the model calculates the cosine similarity between the predicted features and those of the annotated captions in the NSD test set [36] in the CLIP space. Retrieval accuracy was evaluated quantitatively using rank and recall@k metrics.
- RankFor each test sample, we determined the ranking position at which the correct caption appeared in the search results and calculated the average of each ranking for all test datasets S. Rank ranges from 1 to S, and the closer it is to 1, the better the model is at placing the correct caption at a higher position. The equation is expressed as follows:
- Recall@kFor each test sample, we calculated the proportion of correct caption appearing within the top-k retrieved results and computed the average of each value for all test datasets S. Recall ranges from 0 to 1, and the closer it is to 1, the better the model is at selecting the correct caption within the top-k results. The equation is expressed as follows:
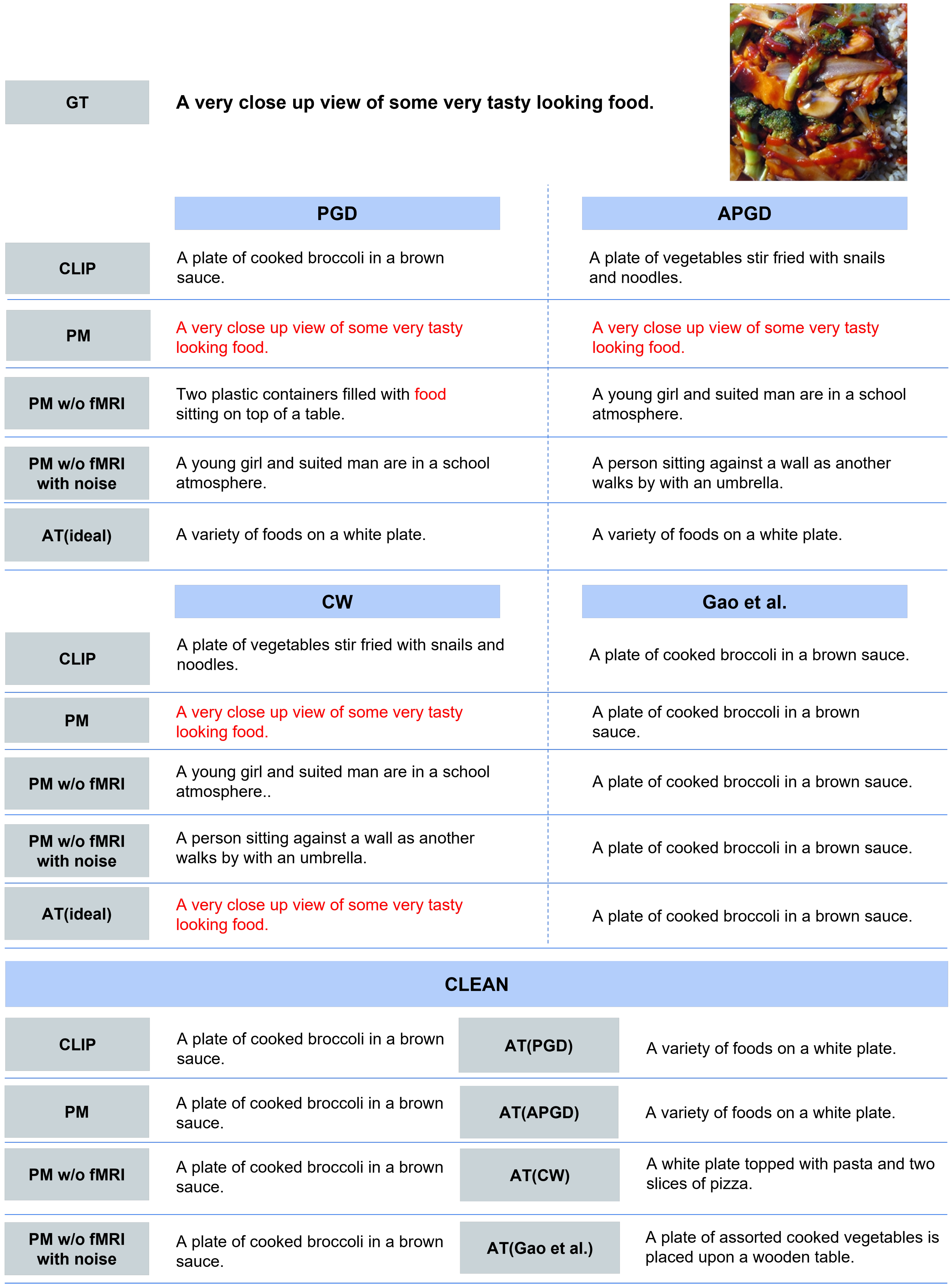
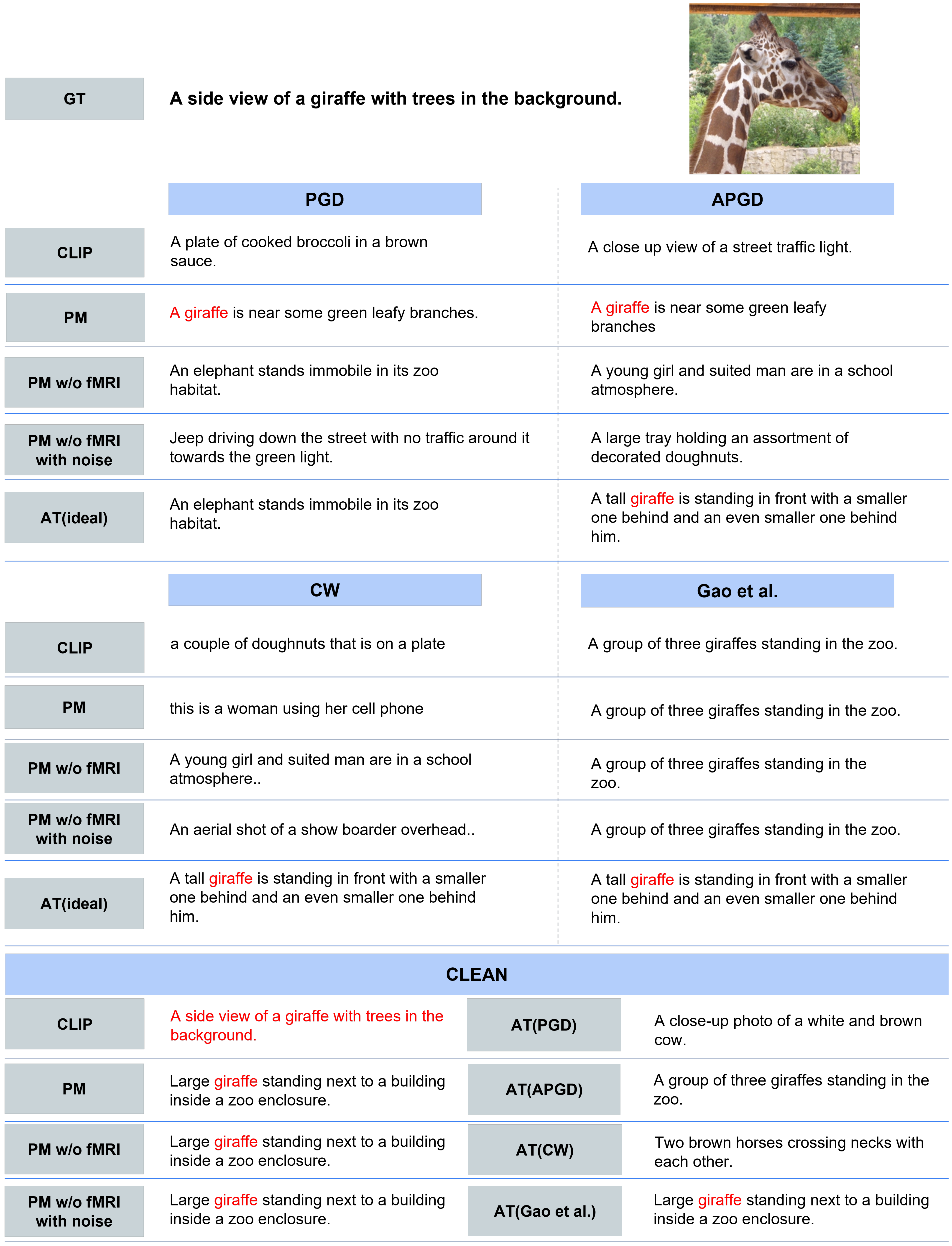
- In addition, for qualitative evaluation, we visualized the top-1 captions retrieved by each method when processing PGD, APGD, and CLEAN inputs. The motivation for employing this task is to effectively evaluate improvements against attacks that minimize the cosine similarity between the original image and the annotated caption.
4.1.4. Hypothesis Validation
4.1.5. Ethical Considerations
4.2. Results and Discussion
4.2.1. Evaluation via Image and Text Similarity
- Quantitative Evaluation. Table 2 presents the image similarity results. PM approaches the upper limit compared with each method. PM reaches approximately 90% of the upper limit for each attack. In addition, when clean images are input, the cosine similarity of each AT is approximately 0.7 at most, whereas PM achieves a very high value of 0.973. Table 3 presents the text similarity results. Although the improvement is smaller than that of the image similarity, it reaches approximately 80% of the upper limit for each attack. In particular, for PGD and APGD with a perturbation of , the text similarity is close to the upper limit. When clean images are input, the cosine similarity of each AT is 0.099–0.238, and PM exhibits higher values than CLIP. In terms of both evaluation metrics, a comparison of PM and PM w/o fMRI demonstrates that introducing brain activity in PM is effective.
4.2.2. Evaluation via Image-to-Text Retrieval
- Quantitative Evaluation. Table 6 presents the quantitative results of image-to-text retrieval. First, for each adversarial attack, all methods improved the text retrieval results compared with CLIP. PM outperformed PM w/o fMRI and PM w/o fMRI with noise for all attacks. In addition, PM approached the upper limit represented by AT (ideal). Next, for clean images, PM outperformed AT, which was trained on each adversarial example. Furthermore, PM closely approached CLIP and performed at a similar level to PM w/o fMRI and PM w/o fMRI with noise; this result demonstrates that PM effectively mitigates accuracy degradation for clean images.
- Qualitative Evaluation. As shown in Figure 5, for the three types of attacks, PM succeeded in retrieving the correct caption for images for which the other comparison methods retrieved completely different results. In addition, PM exhibits successful retrieval in various scenes, not only in specific scenes. In some cases, as shown in Figure 6, PM retrieved captions that were semantically close, although it was not completely successful. Figure 7 presents the top-5 image-to-text retrieval results for PGD. In this figure, PM outputs the correct caption within the top-5 results. This indicates that the PM is able to adequately retain and extract the original semantic features from the brain activity data despite the image being perturbed by the adversarial attack. These results demonstrate that brain activity retains correct caption information and enables caption retrieval at a higher rank.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, H.; Li, C.; Li, Y.; Lee, Y.J. Improved baselines with visual instruction tuning. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 26296–26306. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Khan, A.; AlBarri, S.; Manzoor, M.A. Contrastive Self-Supervised Learning: A Survey on Different Architectures. In Proceedings of the International Conference on Artificial Intelligence, Xiamen, China, 23–25 September 2022; pp. 1–6. [Google Scholar]
- Goh, G.; Cammarata, N.; Voss, C.; Carter, S.; Petrov, M.; Schubert, L.; Radford, A.; Olah, C. Multimodal neurons in artificial neural networks. Distill 2021, 6, e30. [Google Scholar] [CrossRef]
- Wang, C.; Jia, R.; Liu, X.; Song, D. Benchmarking Zero-Shot Robustness of Multimodal Foundation Models: A Pilot Study. arXiv 2024, arXiv:2403.10499. [Google Scholar]
- Zhang, W.E.; Sheng, Q.Z.; Alhazmi, A.; Li, C. Adversarial attacks on deep-learning models in natural language processing: A survey. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–41. [Google Scholar] [CrossRef]
- Novack, Z.; McAuley, J.; Lipton, Z.C.; Garg, S. Chils: Zero-shot image classification with hierarchical label sets. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 26342–26362. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Mokady, R.; Hertz, A.; Bermano, A.H. Clipcap: Clip prefix for image captioning. arXiv 2021, arXiv:2111.09734. [Google Scholar]
- Mao, C.; Geng, S.; Yang, J.; Wang, X.; Vondrick, C. Understanding zero-shot adversarial robustness for large-scale models. arXiv 2022, arXiv:2212.07016. [Google Scholar]
- Hendrycks, D.; Mazeika, M.; Kadavath, S.; Song, D. Using self-supervised learning can improve model robustness and uncertainty. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 15663–15674. [Google Scholar]
- Schlarmann, C.; Singh, N.D.; Croce, F.; Hein, M. Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024; pp. 43685–43704. [Google Scholar]
- Kim, M.; Tack, J.; Hwang, S.J. Adversarial self-supervised contrastive learning. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; pp. 2983–2994. [Google Scholar]
- Matsuo, E.; Kobayashi, I.; Nishimoto, S.; Nishida, S.; Asoh, H. Describing semantic representations of brain activity evoked by visual stimuli. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Miyazaki, Japan, 7–10 October 2018; pp. 576–583. [Google Scholar]
- Zhang, Y.; Tian, M.; Liu, B. An action decoding framework combined with deep neural network for predicting the semantics of human actions in videos from evoked brain activities. Front. Neuroinform. 2025, 19, 1526259. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Liu, B. An fMRI-based auditory decoding framework combined with convolutional neural network for predicting the semantics of real-life sounds from brain activity. Appl. Intell. 2025, 55, 118. [Google Scholar] [CrossRef]
- Posner, M.I.; Petersen, S.E. The attention system of the human brain. Annu. Rev. Neurosci. 1990, 13, 25–42. [Google Scholar] [CrossRef] [PubMed]
- Ross, A.; Jain, A.K. Human recognition using biometrics: An overview. Ann. Telecommun. 2007, 62, 11–35. [Google Scholar] [CrossRef]
- Rakhimberdina, Z.; Liu, X.; Murata, T. Strengthening robustness under adversarial attacks using brain visual codes. IEEE Access 2022, 10, 96149–96158. [Google Scholar] [CrossRef]
- Gupta, V.; Mishra, V.K.; Singhal, P.; Kumar, A. An Overview of Supervised Machine Learning Algorithm. In Proceedings of the International Conference on System Modeling & Advancement in Research Trends, Moradabad, India, 16–17 December 2022; pp. 87–92. [Google Scholar]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep learning vs. traditional computer vision. In Proceedings of the the Computer Vision Conference, Glasgow, UK, 23–28 August 2020; pp. 128–144. [Google Scholar]
- Baldrati, A.; Bertini, M.; Uricchio, T.; Del Bimbo, A. Effective Conditioned and Composed Image Retrieval Combining CLIP-Based Features. In Proceedings of the the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21466–21474. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Lin, J.; Gong, S. Gridclip: One-stage object detection by grid-level clip representation learning. arXiv 2023, arXiv:2303.09252. [Google Scholar]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. A survey on adversarial attacks and defences. CAAI Trans. Intell. Technol. 2021, 6, 25–45. [Google Scholar] [CrossRef]
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial attacks and defenses in deep learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Croce, F.; Hein, M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 2206–2216. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Guo, C.; Gardner, J.; You, Y.; Wilson, A.G.; Weinberger, K. Simple black-box adversarial attacks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2484–2493. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Athalye, A.; Lin, J. Black-box adversarial attacks with limited queries and information. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2137–2146. [Google Scholar]
- Jiang, L.; Ma, X.; Chen, S.; Bailey, J.; Jiang, Y.G. Black-box adversarial attacks on video recognition models. In Proceedings of the the ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 864–872. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Glover, G.H. Overview of functional magnetic resonance imaging. Neurosurg. Clin. 2011, 22, 133–139. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Liu, S.; Tan, Z.; Wang, X. Mindbridge: A cross-subject brain decoding framework. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 11333–11342. [Google Scholar]
- Allen, E.J.; St-Yves, G.; Wu, Y.; Breedlove, J.L.; Prince, J.S.; Dowdle, L.T.; Nau, M.; Caron, B.; Pestilli, F.; Charest, I.; et al. A massive 7T fMRI dataset to bridge cognitive neuroscience and artificial intelligence. Nat. Neurosci. 2022, 25, 116–126. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Chen, T.; Liu, S.; Chang, S.; Cheng, Y.; Amini, L.; Wang, Z. Adversarial robustness: From self-supervised pre-training to fine-tuning. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 699–708. [Google Scholar]
- Dong, J.; Moosavi-Dezfooli, S.M.; Lai, J.; Xie, X. The enemy of my enemy is my friend: Exploring inverse adversaries for improving adversarial training. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 24678–24687. [Google Scholar]
- Gao, S.; Jia, X.; Ren, X.; Tsang, I.; Guo, Q. Boosting Transferability in Vision-Language Attacks via Diversification along the Intersection Region of Adversarial Trajectory. arXiv 2024, arXiv:2403.12445. [Google Scholar]
- Horikawa, T.; Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nat. Commun. 2017, 8, 15037. [Google Scholar] [CrossRef] [PubMed]
- Takagi, Y.; Nishimoto, S. High-resolution image reconstruction with latent diffusion models from human brain activity. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14453–14463. [Google Scholar]
- Cohen, J.; Rosenfeld, E.; Kolter, Z. Certified adversarial robustness via randomized smoothing. In Proceedings of the International Conference on Machine Learning, Beijing, China, 8–11 November 2019; pp. 1310–1320. [Google Scholar]
- Liu, X.; Cheng, M.; Zhang, H.; Hsieh, C.J. Towards robust neural networks via random self-ensemble. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 369–385. [Google Scholar]
- Lu, D.; Wang, Z.; Wang, T.; Guan, W.; Gao, H.; Zheng, F. Set-level Guidance Attack: Boosting Adversarial Transferability of Vision-Language Pre-training Models. In Proceedings of the International Conference on Computer Vision, Chenzhou, China, 25–28 August 2023; pp. 102–111. [Google Scholar]
- Ponomarenko, N.; Zemliachenko, A.; Lukin, V.; Egiazarian, K.; Astola, J. Image lossy compression providing a required visual quality. In Proceedings of the Workshop on Video Processing and Quality Metrics for Consumer Electronics, Scottsdale, AZ, USA, 15 June 2013; pp. 17–21. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PGD [27] | APGD [28] | CW [29] | Gao et al. [40] | CLEAN | |
|---|---|---|---|---|---|
| PSNR (dB) | 44.6 | 44.6 | 43.3 | 43.5 | ∞ |
| SSIM | 0.988 | 0.987 | 0.985 | 0.989 | 1.000 |
| Methods | CLEAN | ||||||
|---|---|---|---|---|---|---|---|
| PGD | APGD | CW | PGD | APGD | CW | ||
| CLIP | 0.799 | 0.722 | 0.438 | 0.477 | 0.394 | 0.120 | 1.00 |
| PM | 0.751 | 0.746 | 0.728 | 0.732 | 0.728 | 0.713 | 0.973 |
| PM w/o fMRI | 0.557 | 0.525 | 0.380 | 0.428 | 0.394 | 0.282 | 0.991 |
| PM w/o fMRI with noise | 0.140 | 0.128 | 0.084 | 0.105 | 0.093 | 0.065 | 0.975 |
| RS [43] | 0.383 | 0.344 | 0.185 | 0.236 | 0.199 | 0.088 | 0.998 |
| RSE [44] | 0.441 | 0.399 | 0.223 | 0.279 | 0.239 | 0.112 | 0.995 |
| AT (ideal) | 0.889 | 0.865 | 0.800 | 0.801 | 0.790 | 0.794 | 0.780/0.774/0.681 () 0.724/0.703/0.581 () |
| Methods | CLEAN | ||||||
|---|---|---|---|---|---|---|---|
| PGD | APGD | CW | PGD | APGD | CW | ||
| CLIP | 0.166 | 0.128 | −0.095 | 0.0112 | −0.031 | −0.326 | 0.257 |
| PM | 0.167 | 0.165 | 0.148 | 0.156 | 0.153 | 0.128 | 0.258 |
| PM w/o fMRI | 0.150 | 0.135 | 0.048 | 0.089 | 0.071 | −0.039 | 0.264 |
| PM w/o fMRI with noise | 0.060 | 0.056 | 0.031 | 0.041 | 0.034 | 0.005 | 0.261 |
| RS [43] | 0.092 | 0.074 | −0.018 | 0.027 | 0.007 | −0.104 | 0.258 |
| RSE [44] | 0.111 | 0.091 | −0.011 | 0.039 | 0.016 | −0.105 | 0.259 |
| AT (ideal) | 0.221 | 0.207 | 0.171 | 0.161 | 0.166 | 0.207 | 0.238/0.227/0.184 () 0.135/0.176/0.099 () |
| Methods | ||||
|---|---|---|---|---|
| PGD | Gao et al. [40] | PGD | Gao et al. [40] | |
| PM | 0.751 | 0.899 | 0.732 | 0.769 |
| PM w/o fMRI | 0.557 | 0.898 | 0.428 | 0.731 |
| PM w/o fMRI with noise | 0.140 | 0.890 | 0.105 | 0.727 |
| RS [43] | 0.383 | 0.864 | 0.236 | 0.646 |
| RSE [44] | 0.441 | 0.870 | 0.279 | 0.660 |
| AT (PGD) | 0.889 | 0.745 | 0.801 | 0.685 |
| AT (Gao et al. [40]) | 0.629 | 0.921 | 0.636 | 0.849 |
| Methods | ||||
|---|---|---|---|---|
| PGD | Gao et al. [40] | PGD | Gao et al. [40] | |
| PM | 0.167 | 0.210 | 0.156 | 0.143 |
| PM w/o fMRI | 0.150 | 0.204 | 0.0894 | 0.121 |
| PM w/o fMRI with noise | 0.0600 | 0.208 | 0.0410 | 0.127 |
| RS [43] | 0.092 | 0.186 | 0.027 | 0.090 |
| RSE [44] | 0.111 | 0.190 | 0.039 | 0.095 |
| AT (PGD) | 0.221 | 0.207 | 0.161 | 0.157 |
| AT (Gao et al. [40]) | 0.152 | 0.227 | 0.130 | 0.192 |
| Methods | Rank | Recall@1 | Recall@5 | Recall@10 | |
|---|---|---|---|---|---|
| PGD | CLIP | 494.31 | 0.011 | 0.033 | 0.056 |
| PM | 197.17 | 0.019 | 0.068 | 0.103 | |
| PM w/o fMRI | 461.82 | 0.005 | 0.014 | 0.021 | |
| PM w/o fMRI with noise | 481.39 | 0.001 | 0.004 | 0.009 | |
| AT (ideal) | 144.94 | 0.011 | 0.059 | 0.111 | |
| APGD | CLIP | 651.23 | 0.003 | 0.011 | 0.020 |
| PM | 214.06 | 0.015 | 0.056 | 0.098 | |
| PM w/o fMRI | 541.91 | 0.001 | 0.010 | 0.015 | |
| PM w/o fMRI with noise | 513.71 | 0.001 | 0.006 | 0.008 | |
| AT (ideal) | 154.20 | 0.012 | 0.058 | 0.126 | |
| CW | CLIP | 949.20 | 0.000 | 0.000 | 0.002 |
| PM | 346.70 | 0.006 | 0.026 | 0.048 | |
| PM w/o fMRI | 866.49 | 0.000 | 0.000 | 0.002 | |
| PM w/o fMRI with noise | 707.11 | 0.000 | 0.001 | 0.002 | |
| AT (ideal) | 42.50 | 0.090 | 0.325 | 0.486 | |
| Gao et al. [40] | CLIP | 210.78 | 0.012 | 0.063 | 0.116 |
| PM | 117.71 | 0.040 | 0.131 | 0.204 | |
| PM w/o fMRI | 167.65 | 0.022 | 0.098 | 0.159 | |
| PM w/o fMRI with noise | 158.36 | 0.037 | 0.106 | 0.169 | |
| AT (ideal) | 67.12 | 0.048 | 0.176 | 0.296 | |
| CLEAN | CLIP | 4.96 | 0.485 | 0.771 | 0.872 |
| PM | 5.23 | 0.461 | 0.756 | 0.860 | |
| PM w/o fMRI | 5.10 | 0.474 | 0.763 | 0.859 | |
| PM w/o fMRI with noise | 5.21 | 0.467 | 0.762 | 0.860 | |
| AT (PGD) | 254.13 | 0.005 | 0.028 | 0.061 | |
| AT (APGD) | 42.66 | 0.061 | 0.225 | 0.366 | |
| AT (CW) | 352.05 | 0.001 | 0.020 | 0.038 | |
| AT (Gao et al. [40]) | 7.44 | 0.311 | 0.641 | 0.777 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nakajima, T.; Maeda, K.; Togo, R.; Ogawa, T.; Haseyama, M. Enhancing Adversarial Defense via Brain Activity Integration Without Adversarial Examples. Sensors 2025, 25, 2736. https://doi.org/10.3390/s25092736
Nakajima T, Maeda K, Togo R, Ogawa T, Haseyama M. Enhancing Adversarial Defense via Brain Activity Integration Without Adversarial Examples. Sensors. 2025; 25(9):2736. https://doi.org/10.3390/s25092736
Chicago/Turabian StyleNakajima, Tasuku, Keisuke Maeda, Ren Togo, Takahiro Ogawa, and Miki Haseyama. 2025. "Enhancing Adversarial Defense via Brain Activity Integration Without Adversarial Examples" Sensors 25, no. 9: 2736. https://doi.org/10.3390/s25092736
APA StyleNakajima, T., Maeda, K., Togo, R., Ogawa, T., & Haseyama, M. (2025). Enhancing Adversarial Defense via Brain Activity Integration Without Adversarial Examples. Sensors, 25(9), 2736. https://doi.org/10.3390/s25092736