1. Introduction
The application of automatic tree crown detection in high-resolution forest remote sensing images has been a topic attracting extensive attention over the last ten years [
1,
2,
3,
4]. Tree crown detection is the utmost and essential part of almost all methods of forest resource inventory and management based on remote sensing data [
5,
6]. A lot of work on forest resource inventory and crown delineation by using remote sensing data has been proposed, which has achieved good results in both the individual level and classification accuracy [
7]. Among these methods, tree crown detection is an indispensable key step, and its results play a decisive role in research. However, window-based filters are used in much of the work to find local maxima as potential tree crowns. It is theoretically feasible, but the implementation might fall short of expectations. A suitable filter size for various tree crowns is usually difficult to find, even if the adaptive filter method is adopted [
8].
Recently, convolutional neural networks using deep learning technology have been applied in image classification [
9,
10], target detection [
11,
12], image segmentation, etc. [
13]. Different from the traditional method of using filters for feature determination, the application of the convolution neural network performs better in learning advanced semantic information from training samples. In the aspect of tree crown detection, the convolutional neural network performs better in different scenes than the adaptive filters as the accuracy of supervised machine learning is usually high [
14].
With the constant increase in the data amount and collection speed, more remote sensing data processing work based on board has been put forward [
15]. In order to eliminate the delay between data collection and processing as much as possible and also to reduce the amount of data transmitted from satellites to the ground, FPGA has become one of the most popular on-board remote sensing data processing platforms among many high-performance platforms [
16] and graphics processors [
17]. The reasons are as follows: Firstly, compared with high-performance platforms and graphics processors, FPGA is usually smaller in size and weight and has the inherent reprogramming ability. Secondly, compared with graphics processors, FPGA consumes less power and generates less heat due to its characteristics for hardware programming [
18]. Apart from that, FPGA has the advantages of parallel computing and low delay in the optimization of neural networks. After being accelerated by FPGA hardware, the neural network algorithm can obtain faster computation speed and lower power consumption than on MCU or PC by controlling multiple accelerators through the assembly line to conduct computation, reuse RAM resources, make floating-point number hardware-oriented to reduce the number of instructions, and reduce the operation accuracy [
19,
20].
Therefore, FPGA is widely used in remote sensing detection. In hyperspectral remote sensing, since more hyperspectral [
21] applications require real- or near-real-time processing capabilities, reconfigurable hardware solutions such as field-programmable gate arrays have been consolidated during the last years as one of the standard choices for the fast processing of hyperspectral remotely sensed image [
22]. Due to the power limitation of (on-board space platforms) (spaceborne or airborne), the ultra-low power consumption of FPGA is widely welcomed by researchers [
23]. In some scenes with high demand for real-time processing and computing performance, such as natural disaster prediction, one of the solutions is to process the data using FPGA [
23]. With the increasing complexity of remote sensing image analysis algorithms, researchers will also tend to use FPGA for hardware acceleration to pursue higher computing performance [
24].
In recent years, scientists have applied neural network to the tree crown detection [
25,
26,
27]. In 2018, Ramesh Kestur et al. innovatively integrated the Extreme Learning Machine (ELM), a single-hidden-layer feedforward neural network classifier, with spectral–spatial analysis. Their study confirmed that ELM outperformed traditional K-means spectral–spatial clustering in classification accuracy, leveraging its computational efficiency (suitable for real-time processing) and synergistic optimization of spectral–spatial features. However, this method required post-processing spatial filtering to correct the misclassifications and manual adjustment of geometric thresholds (e.g., area and eccentricity), indicating limitations in automation [
17]. In 2019, Ben G. Weinstein et al. proposed a semi-supervised deep learning framework for RGB-based tree crown detection. By generating initial training samples through unsupervised LiDAR detection, this approach effectively reduced reliance on manual annotations. While cross-modal learning between LiDAR and RGB data enhanced model generalization, its performance was constrained by LiDAR dependency and exhibited reduced accuracy in dense canopy environments [
28]. In 2020, Jose R. G. Braga et al. achieved breakthrough results by applying Mask R-CNN to tropical forest crown detection. This method demonstrated robust instance segmentation capabilities for heterogeneous canopy structures and improved sample diversity through synthetic data augmentation. Nevertheless, it incurred high computational costs, potential domain discrepancies between synthetic and real-world data, and time-intensive training processes [
27]. Ben G. Weinstein et al. extend a recently developed deep learning approach to include data from a range of forest types and explore the potential for building a universal tree detection algorithm [
28]. Alin-Ionut Plesoianu et al. developed a reproducible deep learning ensemble based on Single Shot MultiBox Detector (SSD) models for individual tree crown (ITC) detection and species classification. Although the ensemble enhanced detection stability through multi-network integration, performance plateaued beyond two submodels, and its lack of spatial feature integration resulted in inferior crown boundary delineation compared to segmentation-based approaches [
5]. In 2021, Zhenbang Hao et al. explored training a mask region-based convolutional neural network (Mask R-CNN) for automatically and concurrently detecting discontinuous tree crowns and height of Chinese fir (Cunninghamia lanceolata (Lamb) Hook) in a plantation. Their framework achieved pixel-level instance segmentation and multi-attribute prediction, excelling in complex backgrounds and young stands. However, the intricate architecture increased computational demands, while reliance on high-precision instance masks and height labels elevated annotation costs [
29]. Zhafri Roslan et al. proposed a noise-canceling GAN-based Bodel by averaging the weights of a compressed image and a non-compressed image. Combined with the RetinaNet single-stage detector, this method improved small-target detection but was limited to crown localization without precise contour extraction, exhibiting weaker generalization capabilities compared to ensemble or segmentation models [
30]. In 2023, Yang Liu et al. significantly enhanced the accuracy and boundary consistency of canopy detection by integrating the strengths of deep convolutional neural networks (DCNNs) with decision trees and introducing superpixel segmentation technology. This approach facilitated direct mapping from pixels to semantic labels, thereby reducing the necessity for post-processing. However, the model’s performance is notably influenced by hyperparameters such as learning rate, tree depth, and the number of trees, necessitating careful tuning. Additionally, it heavily depends on large volumes of annotated data and exhibits suboptimal performance in segmenting individual trees within high-density canopy areas [
31].
Among segmentation architectures, U-Net has emerged as a benchmark model due to its unique encoder–decoder structure with skip connections, making it effective in capturing spatial detail across different scales. Originally proposed for biomedical image segmentation, U-Net’s ability to handle limited training data through data augmentation and its effectiveness in capturing fine-grained boundaries have led to adaptations in remote sensing applications. Recent variants like Sharp U-Net further optimize this architecture through depthwise separable convolutions, demonstrating 12.7% higher boundary accuracy in complex segmentation tasks compared to standard implementations [
32]. However, the direct application of U-Net in tree crown segmentation faces challenges including excessive parameter counts and computational complexity, which hinder real-time deployment on edge devices.
In the existing research, the application of FPGA platforms in canopy remote sensing image processing remains relatively limited. In 2019, the team led by Weijia Li at Tsinghua University proposed the PF-TCD algorithm [
33], which achieved the real-time detection of oil palm canopies from Quickbird satellite imagery in southern Malaysia. However, their focus was on traditional image processing and did not involve neural network acceleration. The current mainstream direction is to integrate computer vision and electronic technologies to promote intelligent forestry management, yet there is no literature reported on FPGA-based neural network acceleration for canopy segmentation. Therefore, it can be concluded that this research topic possesses a certain degree of cutting-edge and innovative characteristics, providing a solution with both academic value and application potential for the automated monitoring of forest resources.
2. Data
The study site is situated within the Jingyue Ecological Forest Farm, located in Changping District, Beijing, at a latitude and longitude of 40°10′52″ N, 116°11′24″ E (
Figure 1). The local climate is characterized by a typical temperate semi-humid and semi-arid monsoon climate, with an average annual temperature of approximately 19 °C, humidity of 60% R.H., and rainfall of 600 mm. These climatic features are highly consistent with the ecological forest areas of the North China urban agglomeration, demonstrating significant regional representativeness. The terrain is a relatively flat plain with undulations of less than 2 m, and the average elevation of the study area is about 43 m. Such topographic conditions are conducive to the stable acquisition of drone aerial data and avoid interference from mountain shadows in remote sensing image analysis.
According to the division of the forest farm and the direction of the road in the study area, it is divided into six regions. The data sources for this study are primarily concentrated in the four continuous regions located in the central quadrangle of the forest farm, as depicted in
Figure 1b, which are numbered 1, 2, 3, and 4, respectively. The research area consists of a manmade forest that is accessible to society, characterized by a blocky mixed forest composed of various coniferous and broad-leaved trees. In this area, coniferous trees are relatively sparse while broad-leaved trees are relatively dense. There are seven species of conifers present throughout the entire area including Pinus tabuliformis, Ginkgo biloba, and Juniperus chinensis. Additionally, there are four types of broad-leaved trees: Styphnolobium japonicum, Salix matsudana, Ailanthus altissima, and Populus nigra. Due to time constraints on research activities, it was not feasible to complete calibration for all the tree species datasets. Therefore, one of the most widely distributed coniferous broad-leaved trees—namely Pinus tabuliformis and Salix matsudana—has been selected to ensure representativeness in this study. The distribution patterns for tree species can be observed in
Figure 2b, with corresponding images provided in
Figure 2c.
The orthophoto image of the forest area utilized was acquired from the unmanned aerial vehicle (UAV) orthophoto imagery employed in Chong Zhang et al.’s study [
16]. The UAV aerial images were taken on the morning of 26 May 2023, under subdued sunlight and gentle wind conditions, which were conducive to remote sensing image data collection.
Based on the orthophoto image of the entire forest area, the selected study area is divided. As depicted in
Figure 2a, images from plots 2 to 4 are utilized for creating a training set and validation set, while the test set is located in an independent plot 1, avoiding geographical overlap with the training set to reduce the impact of spatial autocorrelation. Within plots 2, 3, and 4, images with a resolution of 512 pixels are segmented into 100 segments with a length–width ratio of 1:1. Among these segments, there are equal numbers (50 each) containing Pinus tabuliformis forests and Populus euphratica forests. The training images are further partitioned into a training set and validation set at a ratio of 7:3. Similarly, within plot number one, an additional hundred test images with the same resolution exclusively feature the Pinus tabuliformis and Populus euphratica tree species.
The deep learning model utilized in this study is supervised learning, necessitating the manual annotation of input images prior to model training [
17]. The Labelme annotation tool, based on the Anaconda3 virtual environment, was employed for classifying and annotating the segmentation of tree crown amplitude in images. Using the polygon creation tool, we manually delineated the canopy boundaries of each tree on the RGB images, assigned corresponding tree labels based on species information, and created a standard dataset for canopy segmentation in accordance with the PASCAL-VOC2012 dataset format.
4. FPGA Implementation
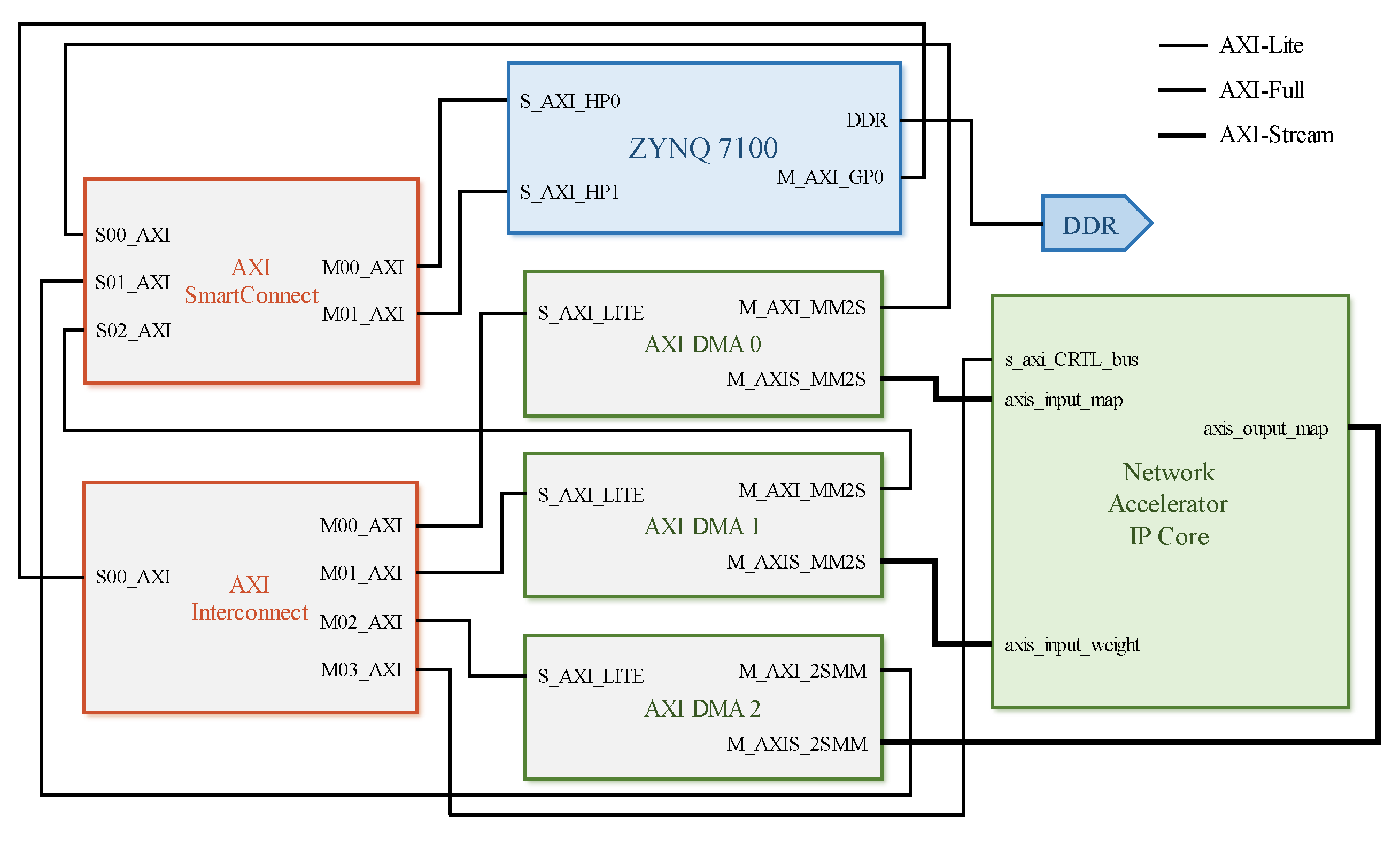
The ZynQ-MZ7100 development board (MLK, Changzhou, Jiangsu Province, China) is utilized for the synthesis and implementation of the SoC design featuring a neural network accelerator, as depicted in
Figure 6. The hardware specifications of the development board are detailed in
Table 3. The semantic segmentation of tree crown images is achieved through a collaborative software and hardware approach utilizing the forward reasoning process of the neural network model. The selected hardware resources on the development board for this research are moderate, indicating that the proposed neural network accelerator design scheme can be adapted to other Xilinx series development platforms with a degree of universality. The programmable SoC model installed on the development board is XC7Z100FFG900-2I (Xilinx, SAN Jose, CA, USA), with the chip parameters listed in
Table 3.
4.1. SoC Design
The system-on-chip (SoC) top-level design comprises four modules: The first module features an ARM processor core, with a single-core processor serving as the control core in this study. The second module is dedicated to the PL-end accelerator, focusing on enhancing the computational performance of specialized algorithmic components within the neural network that are not efficiently handled by the CPU, such as classical two-dimensional convolution operations. The third module consists of AXI DMA for the efficient transmission of feature maps and weights. Lastly, the fourth module encompasses the on-chip bus. This research design primarily utilizes the AXI4-Lite interface for configuring the control parameters and the DMA initialization of the neural network accelerator IP core, while employing AXI4-Stream and AXI-Full for data and weight transmission.
Figure 7 illustrates the hardware topology of SoC design in this study, which integrates both software and hardware elements. Within this model, only two parameters need to be set in advance for the convolutional layer, with a significantly smaller number of offset values compared to weights. To facilitate acceleration processes, offset values are stored in BRAM with high reading and writing efficiency accessible by both the PL side and PS side within FPGA resources being relatively small. In the ZYNQ 7100 SoC (MLK, Changzhou, Jiangsu Province, China), utilized as the development platform in this study, the BRAM capacity is limited to only 26.5 Mb (3.3 MB), which restricts its ability to store weights for larger models such as Lenet-5 neural networks. To ensure design versatility, off-chip DDR at the PS end is employed for storing neural network weights. The ZYNQ PS terminal is utilized for controlling data stream transmission and configuring the control registers of each module. In order to minimize delays caused by memory read/write operations, AXI-Stream and DMA are used for transmitting weight and feature map data. Given that the U-Net-light model consists of 30 layers and is fully implemented in hardware (PL-end), it consumes resources and has low reusability. Consequently, a neural network accelerator IP core has been developed to assist the ARM core processor in realizing the forward inference prediction process of the U-Net-light model. The accelerator primarily accelerates the convolution operation of each layer while maximum pooling and upsampling are computed by software on the PS terminal. The configuration of the accelerator (e.g., input/output image dimensions) is managed on the PS terminal.
4.2. Kernel: Accelerator
The findings from the C++ operations indicate that the convolution operation is the lengthiest and most prominent layer within the network structure. As a result, the focus of accelerator design is on expediting convolution operations. This paper’s designed convolutional accelerator has been tailored to accommodate a maximum input image size of 128 × 128, with a focus on enhancing operational efficiency and minimizing resource overhead.
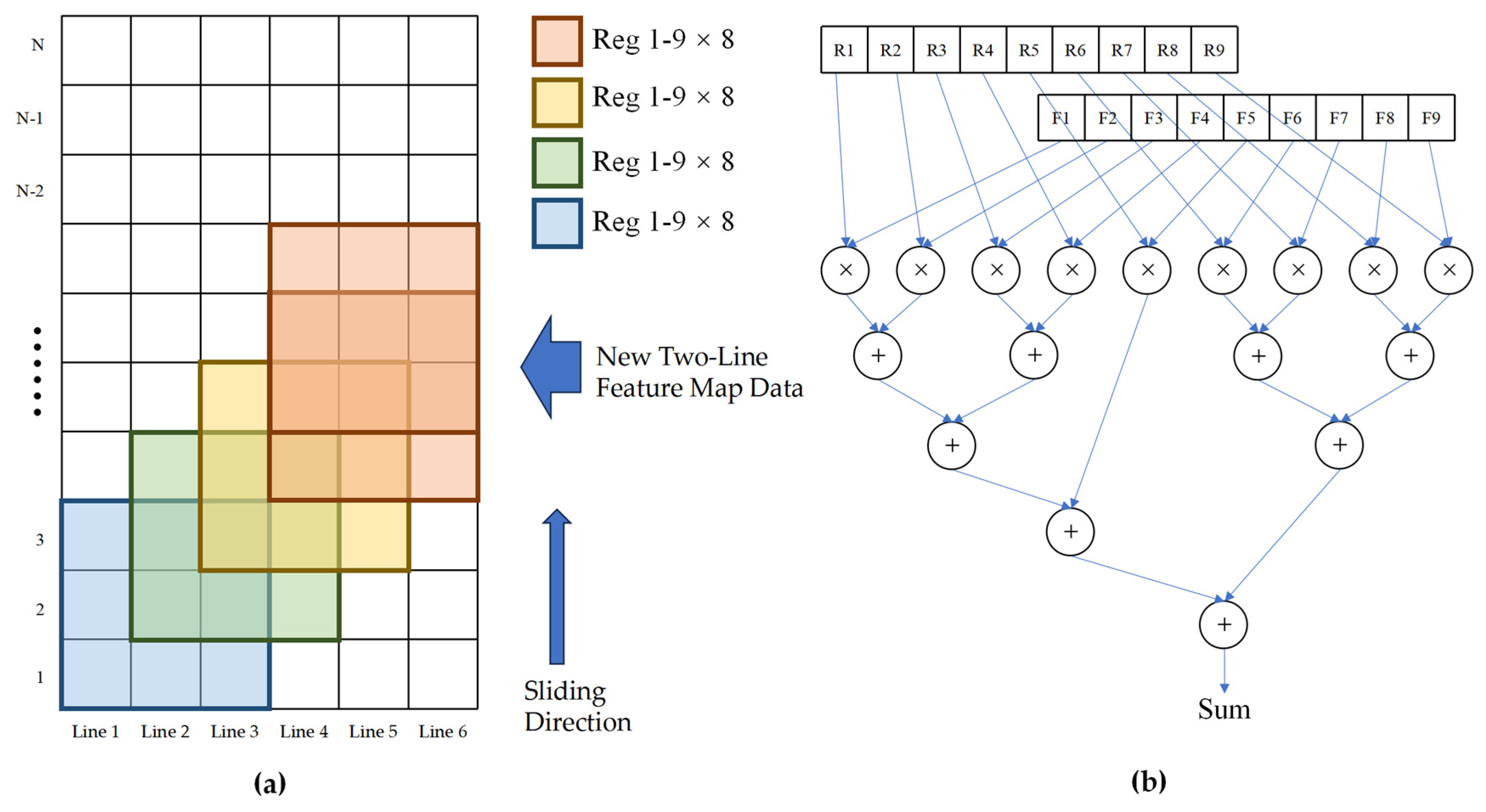
The IP core is developed using HLS mode, with the addition of ap_fixed.h header file to specify the data type. The weight and feature map are set to 16-bit fixed-point numbers, with 6 bits for the integer part and 10 bits for the decimal part. To accommodate the size of the convolution kernel (3 × 3 pixels), 6 row buffers are set in BRAM, allowing for the simultaneous computation of 4 sets of convolutions. In the column dimension, columns are divided into 8 groups, each performing one convolution operation simultaneously. Within each group of clock cycles, a total of 32 convolution operations are calculated using a tree structure for multiplicative accumulation calculation as depicted in
Figure 8b. After computing an image in the row buffer, it is shifted by two rows to prepare for the next round of computation. The implementation process of the IP core is illustrated in
Figure 8a.
In the hardware implementation described above, the C code loop structure is configured using pragma, with the inner loop being expanded by unroll. The operation of the 3 × 3 convolution kernel is transformed into a combination of logic for multiplication and accumulation, allowing for the simultaneous calculation of 32 convolutions. During the convolution calculation process, it is necessary to read feature graph values and weight bias values from BRAM to registers, perform calculations, and then write back the results to BRAM. A three-level pipeline calculation is achieved using pipeline parameters. Bias value stacking is completed before writing back to BRAM at the end of the calculation. The row buffer array in BRAM has been unfolded using cyclic expansion mode partitioning and stored in 8 blocks, respectively, to increase memory read/write interfaces and resolve issues related to read/write conflicts and data dependency within the pipeline.
7. Conclusions
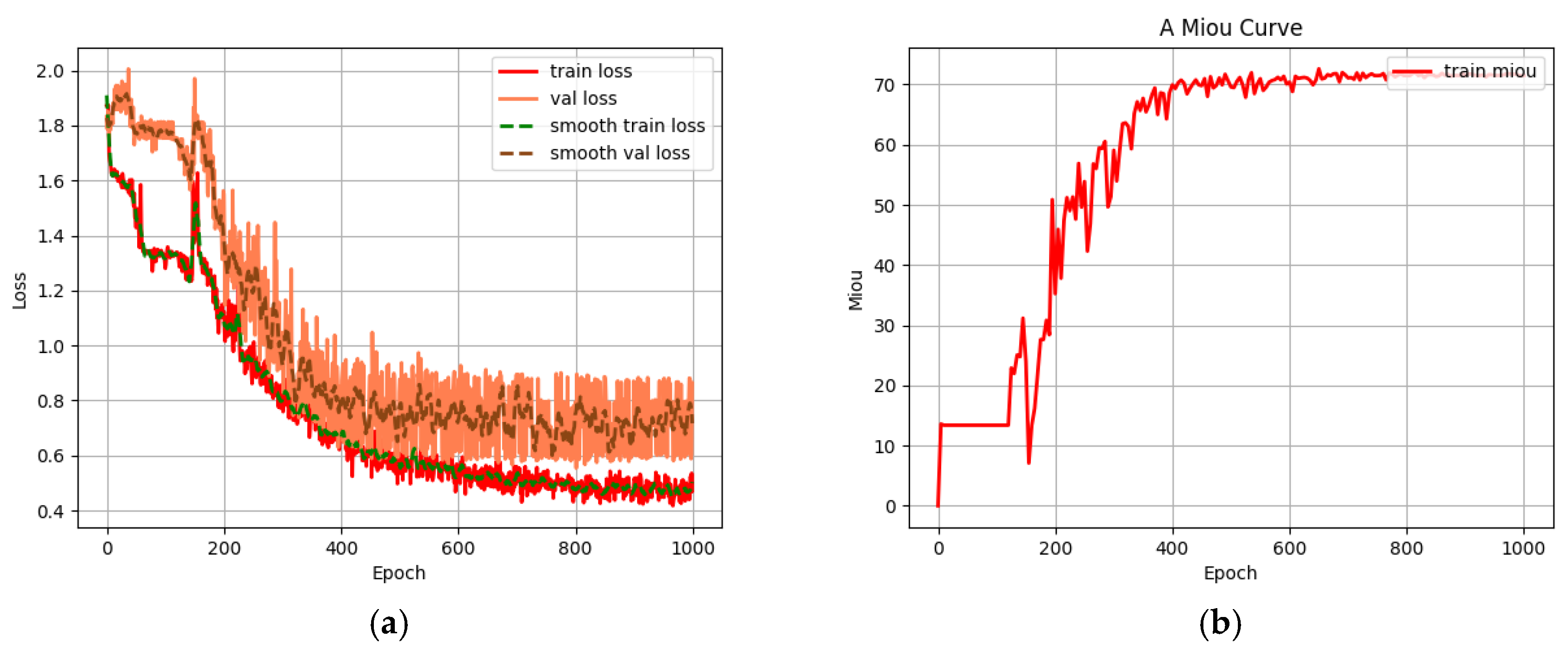
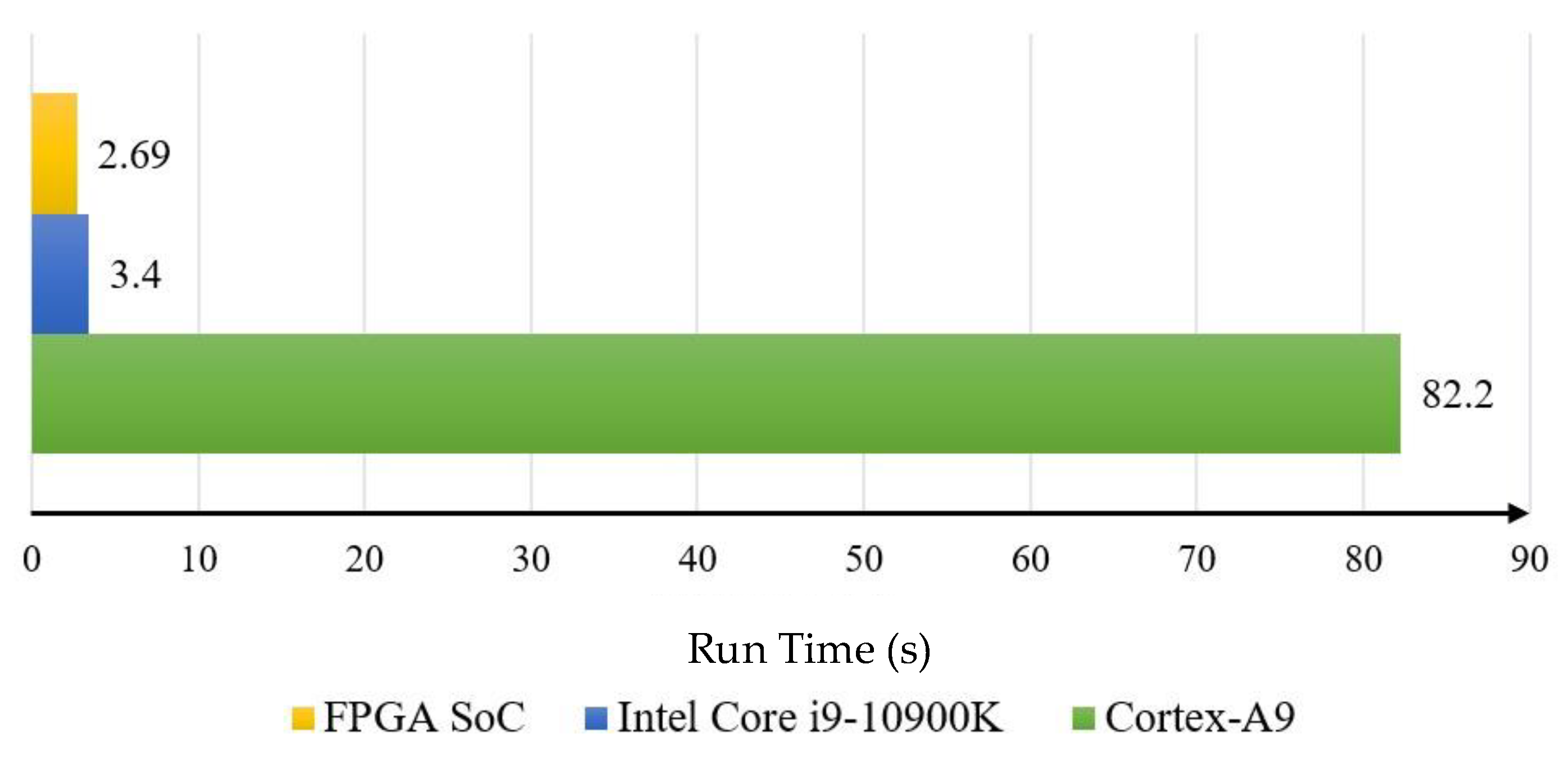
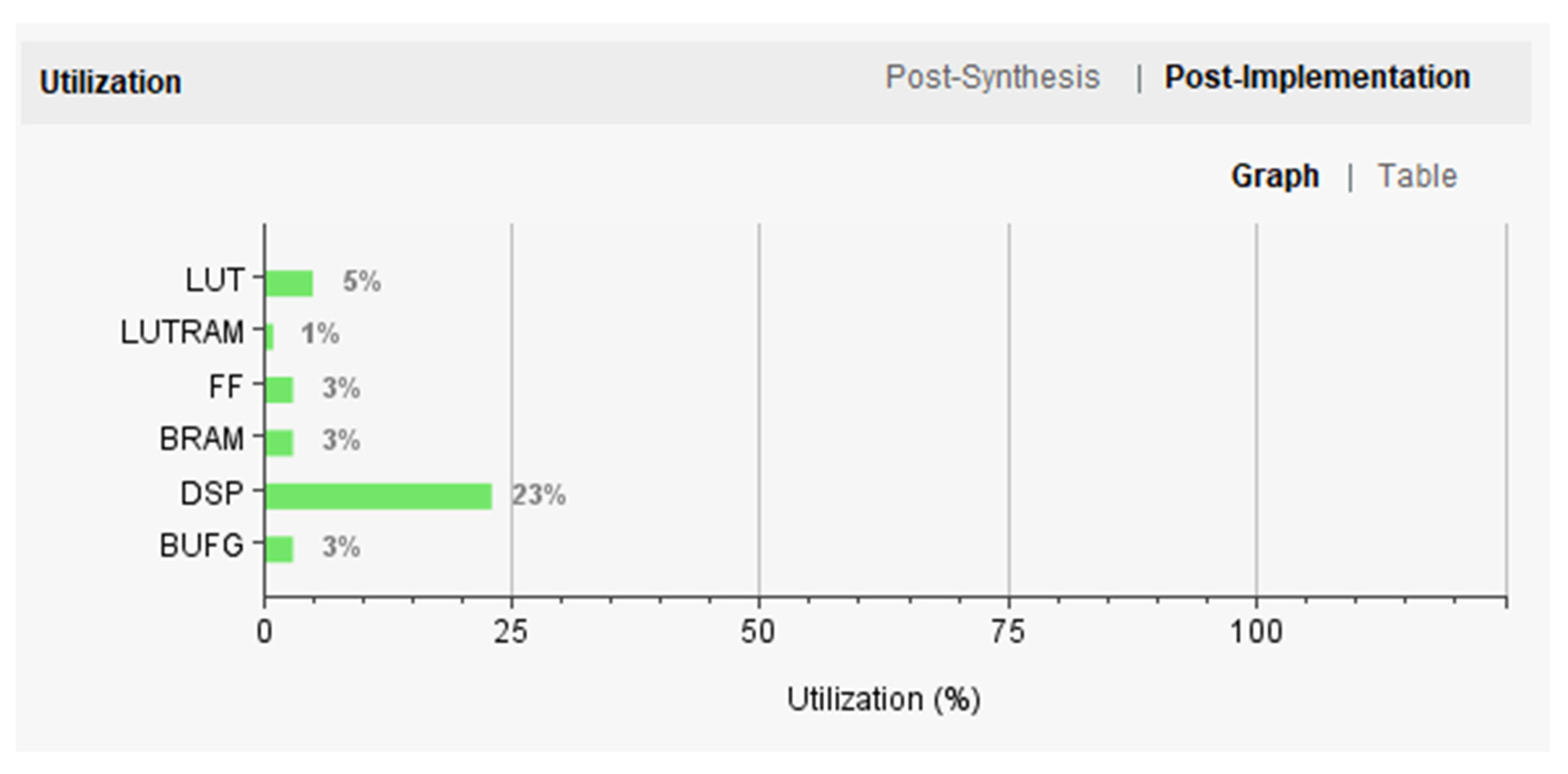
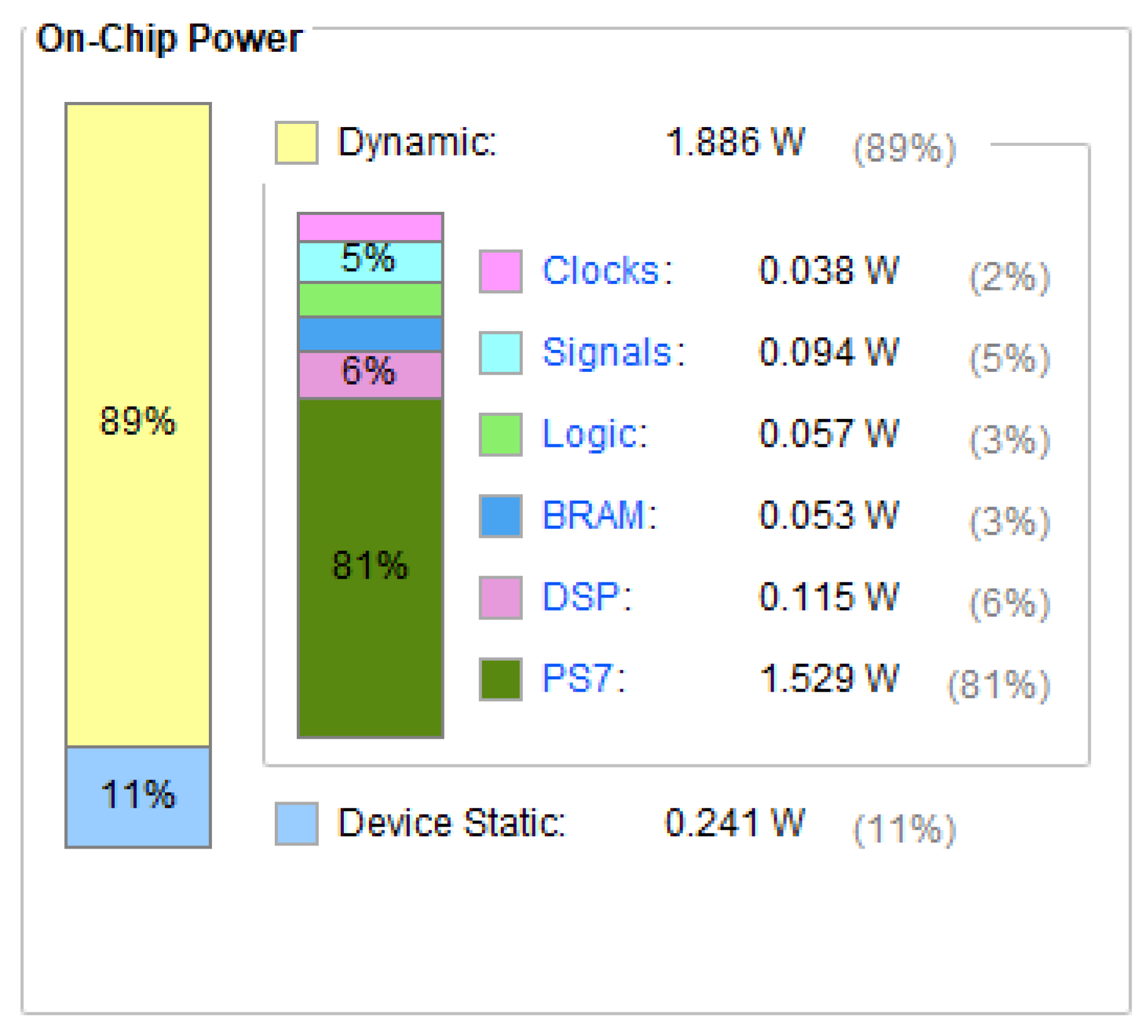
This paper focuses on the Jingyue Ecological Forest Plantation in Changping District, Beijing, and presents the design and training of a lightweight convolutional neural network, U-Net-light, tailored for embedded platforms and FPGAs. Based on the U-Net and VGG16 models, U-Net-light is optimized for crown width segmentation in mixed forests with a parameter count of just 1.56 MB. The model successfully classifies trees and segments crown widths for Pinus tabuliformis and Salix matsudana, achieving a reasoning accuracy of 85%. Deployed on the Xilinx ZYNQ 7100 programmable SoC platform, the U-Net-light model processes 128 × 128 pixel RGB tree crown images in just 2.69 s. The accelerator IP core designed in this study delivers a 31-fold acceleration compared to the ZYNQ PS end core, and the SoC architecture achieves a 1.3-fold acceleration compared to the high-end Intel Core™ i9-10900K CPU. In terms of hardware resource usage, the system consumes less than one-quarter of the target platform’s resources, with a total on-chip power consumption of only 2.127 W.
This paper proposes a lightweight deep learning model, U-Net-light, for tree canopy segmentation and tree species recognition. The study presents an SoC architecture and neural network accelerator IP core that enable the deployment of the U-Net-light model, achieving notable acceleration and demonstrating high platform versatility. In conclusion, this study holds significant theoretical value and promising practical applications.
The U-Net-light model and its FPGA-based SoC implementation exhibit certain limitations that require further refinement. The model’s generalization capability remains insufficient, evidenced by reduced pixel accuracy when handling image scaling and transformations, which limits its robustness in diverse forest environments such as complex canopy structures, varying light conditions, or seasonal changes. Additionally, performance degradation occurs in high-density canopy segmentation, making it challenging to accurately identify individual tree canopies in tropical or mixed forests. The dependence on manual annotations for training hinders scalability across large datasets. On the hardware side, while HLS development methods improve development efficiency, they deliver lower real-time performance compared to Verilog and other HDLs, especially with complex models. Current accelerators are optimized for convolution operations but lack adaptability to diverse network architectures, and system scalability is limited by data transmission bottlenecks, storage constraints, and environmental factors like weather conditions. Future improvements could focus on: optimizing accelerator designs for complex models, exploring hybrid HLS-HDL approaches, introducing data augmentation and semi-supervised learning to enhance generalization and reduce annotation dependency, and improving on-chip memory management to address environmental challenges.
This study provides theoretical methods and practical cases for the integration of lightweight deep learning models with edge computing. Its characteristics of low power consumption and high energy efficiency ratio have direct application value in fields such as dynamic forest resource monitoring and smart agriculture. In the future, through interdisciplinary collaboration and hardware iteration, this technology can be further advanced from laboratory validation to engineering implementation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}