1. Introduction
Tomatoes are a significant crop, with global production exceeding 180 million tons [
1]. However, due to their susceptibility to skin damage, wilting, and storage challenges [
2], they are primarily supplied to local and nearby markets. To improve the global coverage of the tomato supply chain and ensure efficient and safe transportation to domestic and international markets while maintaining quality, it is essential to select the appropriate ripeness stage based on transportation distance and storage duration at harvest [
3]. Although tomato harvesting robot systems have significantly improved the success rate and efficiency of continuous harvesting [
4], there are still limitations in the accuracy of ripeness detection. Developing algorithms for automated ripeness detection with high recognition rates is crucial for optimizing the distribution of tomatoes at different ripeness levels and enhancing harvesting automation efficiency [
5].
Significant advancements have been made in the application of drones within the fields of artificial intelligence and machine learning, particularly in smart agriculture. In the field of computer vision, drones can capture high-resolution images and videos, facilitating advanced functions such as image recognition, object tracking, and even 3D scanning [
6,
7]. As illustrated in
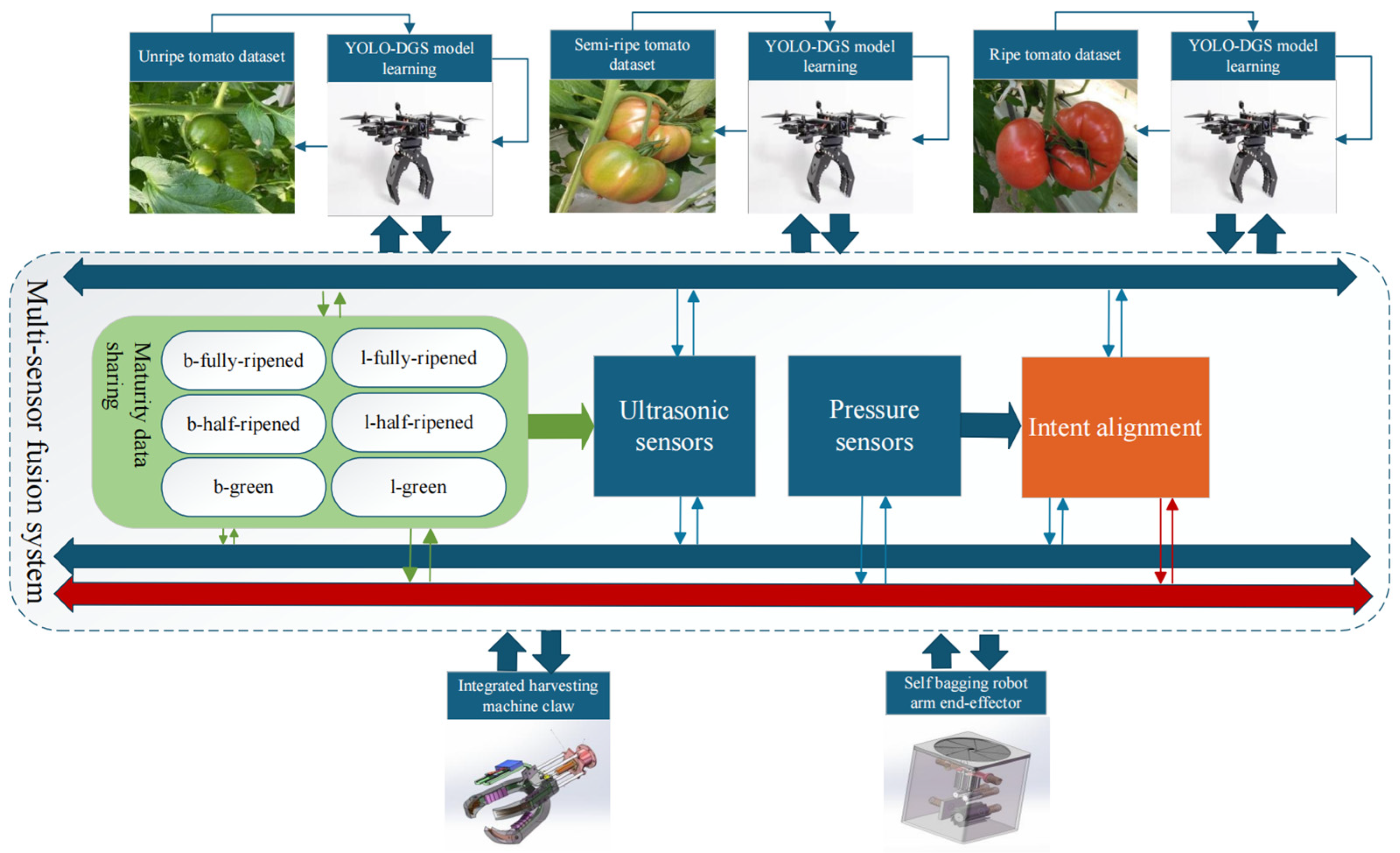
Figure 1, an intelligent tomato harvesting system designed for smart agriculture demonstrates the power of multi-sensor fusion technology [
8,
9,
10] and deep learning algorithms to enable fully automated operations [
11]. At the core of this system lies the YOLO-DGS object detection model, which was trained on a comprehensive tomato dataset encompassing various maturity levels, including semi-ripe and fully ripe stages. This model is capable of accurately identifying six distinct maturity stages, such as b-fully-ripened and l-half-ripened fruits. In terms of fruit harvesting, existing methods primarily combine manual bagging and manual picking, which rely on human labor and are limited by high labor costs and low harvesting efficiency [
12,
13,
14]. In the perception layer, the system integrates ultrasonic sensors for real-time distance measurement and obstacle avoidance, alongside pressure sensors to monitor harvesting force. These sensors, combined with visual recognition results, form a multi-dimensional perception network. The actuators feature an adaptive robotic end-effector [
15] that intelligently adjusts grasping force and angle based on fruit maturity and real-time sensor feedback, ensuring precise and damage-free harvesting. This system establishes a complete closed-loop workflow, seamlessly integrating environmental perception, fruit recognition, maturity assessment, and automated harvesting. It exemplifies the synergistic application of machine vision, multi-sensor fusion [
16], and intelligent control technologies in modern smart agriculture, offering an efficient and reliable solution for automated agricultural produce harvesting [
17]. The promotion of smart agriculture has also reduced the physical labor required of farmers and lowered the overall costs, bringing favorable opportunities for the development of agriculture [
18].
In recent years, scholars have conducted extensive research to address the challenges in fruit maturity detection. Firstly, for the image detection challenges in fruit maturity assessment, from 2019 to 2021, early approaches focused on basic detection frameworks. Liu et al. (2020) [
19] pioneered multi-level deep residual networks for tomato maturity recognition, achieving high precision but requiring intensive computational resources. Hsieh et al. (2021) [
20] integrated R-CNN with binocular imaging, demonstrating accurate localization in controlled greenhouse conditions but with accuracy decreasing under different light conditions. From 2021 to 2023, advancements addressed environmental robustness; Zu et al. (2021) [
21] implemented Mask R-CNN for all-weather green tomato detection, yet performance decreased with overlapping fruits. Li et al. (2023) [
22] developed MHSA-YOLOv8 for tomato counting, but in occluded scenes the F1 score was reduced. From 2024 to 2025, current solutions emphasize complex scenarios; Ji et al. (2024) [
23] introduced apple picking sequence planning, but dense foliage caused part of the path planning to fail. Dong et al. (2025) [
24] enhanced GPC-YOLO for unstructured environments, maintaining higher accuracy under occlusion but requiring higher power consumption. These studies have several core limitations, including a reduction in accuracy across methods due to severe occlusion, performance differences under light variations, and high computational costs that limit real-time applications. Secondly, for the algorithm deployment challenges, from 2022 to 2023, Zhou et al. [
25] combined YOLOv7 with classical image processing, improving positioning accuracy but requiring higher RAM for deployment. Zeng et al. [
26] created a mobile-optimized YOLO variant, yet model pruning caused mAP drop. From 2024 to 2025, Li et al. (2024) [
27] developed lightweight YOLOv5s for pitaya detection, but nighttime operations needed supplemental lighting. Wang et al. [
28] improved RT-DETR for tomato ripeness, though the ARM processor had high latency. Ji et al. (2025) [
29] incorporated Transformer modules, increasing model size and presenting challenges for edge devices. Thirdly, for the multi-sensor fusion approaches, Mu et al. [
30] demonstrated occluded tomato detection using RGB-D fusion, but it required more power consumption versus monocular systems. Li et al. [
31] advanced with dual-frequency LiDAR, but processing delays were greater. Wang et al. (2024) [
32] combined R-LBP with YOLO-CIT, improving citrus detection but requiring calibrated lighting.
In summary, it can be concluded that single-stage object detection algorithms based on neural networks have become mainstream in the field of fruit maturity detection. Although these efficient and accurate methods often involve high model complexity, resulting in slower computation and detection speeds, lightweight and fast detection methods tend to sacrifice accuracy [
33,
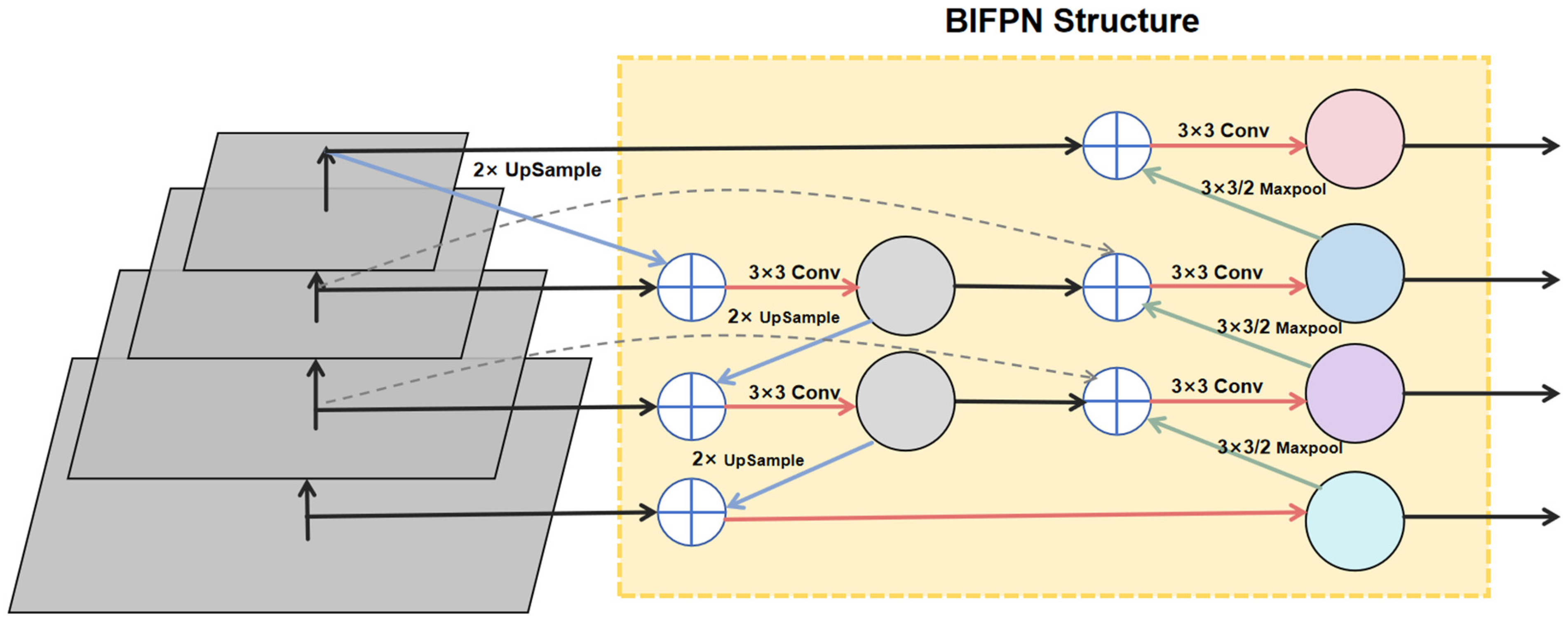
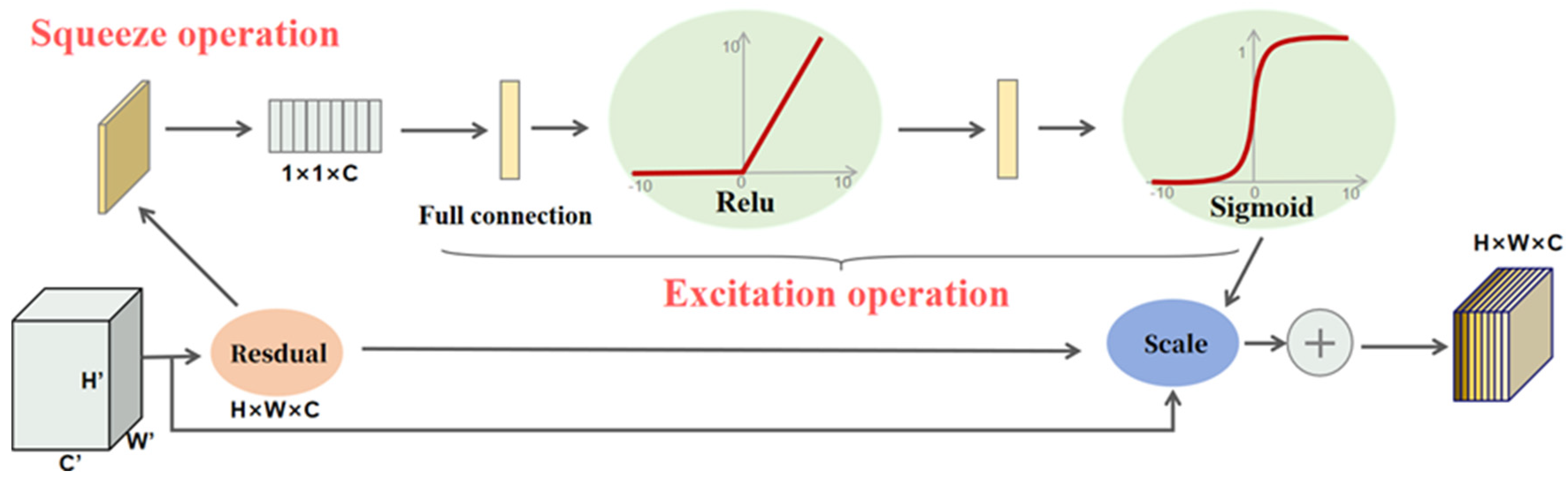
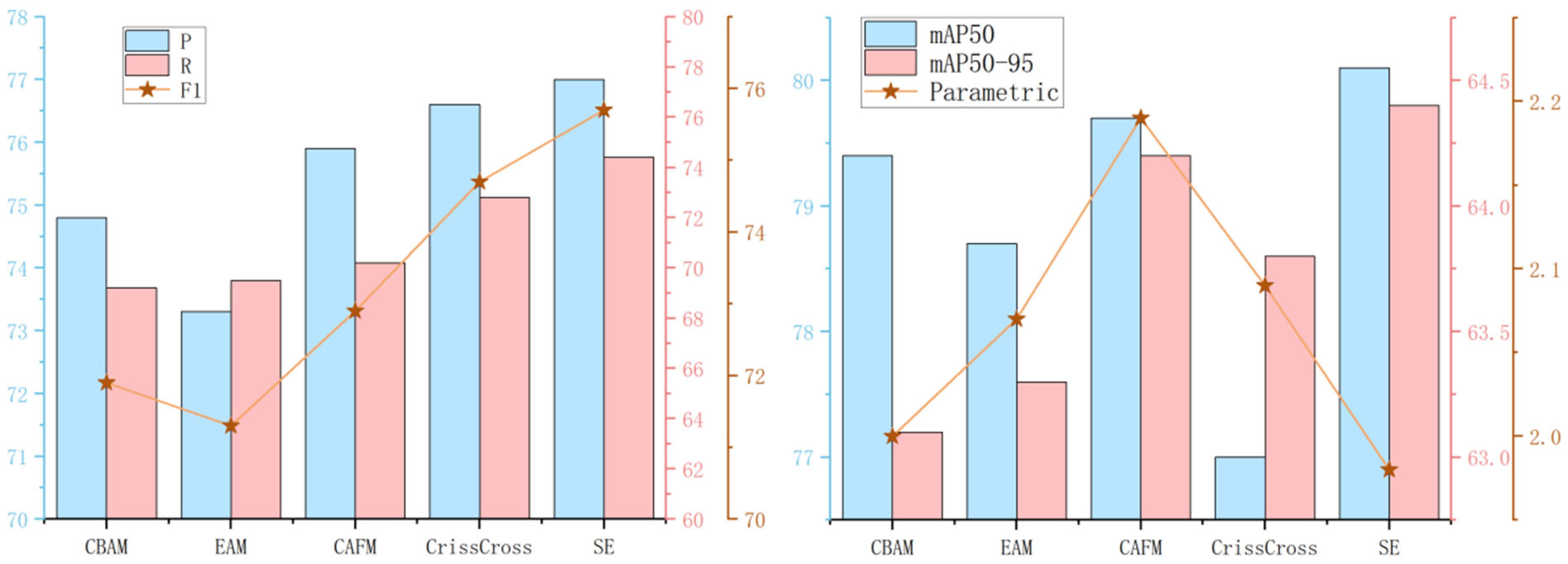
34]. In resource-constrained environments, achieving an ideal balance between speed, accuracy, and computational resource consumption to meet real-time detection requirements for industrial applications, while ensuring high-precision results and maintaining model efficiency, remains a significant challenge. Particularly in tomato maturity detection, the inconsistency in maturity within the same inflorescence and the severe occlusion scenarios prevalent in greenhouse environments can interfere with the recognition process. To address these issues, this paper proposes a lightweight model, YOLO-DGS (D-2Detect, G-C2f-GB, S-Squeeze-and-Excitation), based on an improved YOLO v10 algorithm. This method (1) introduces a novel segmented convolution calculation module, C2f-GB, which merges the Channel to Feature (C2f) module with GhostBottleneck. This module performs convolutional calculations on feature maps in stages, using fewer parameters and computations to generate more feature maps, thereby enhancing feature extraction while reducing parameter volume and computational complexity. (2) Reduces redundant detection layers in YOLO v10, improving the model’s ability to capture specific features and lowering parameter volume. (3) Integrates a bidirectional feature pyramid network (BiFPN) in the neck network, which improves traditional FPN’s information fusion by adding contextual information and assigning corresponding weights, thereby enhancing the expressiveness of the feature pyramid. (4) Incorporates a channel attention mechanism (Squeeze-and-Excitation) in the neck network to effectively detect different tomato maturities.
This paper is organized into five sections. To highlight the innovations of this study,
Section 1 summarizes previous research in the field.
Section 2 describes the enhanced network architecture designed for more lightweight and precise fruit maturity detection.
Section 3 presents an analysis of the results to evaluate the detection network’s performance. Finally,
Section 4 provides the conclusion.
5. Conclusions
The recognition of tomato maturity is affected by shooting distance, the number of targets, and background interference. Deep learning algorithms, due to their numerous parameters, often suffer from computational complexity and time-consuming processes, which lead to reduced accuracy and efficiency [
39,
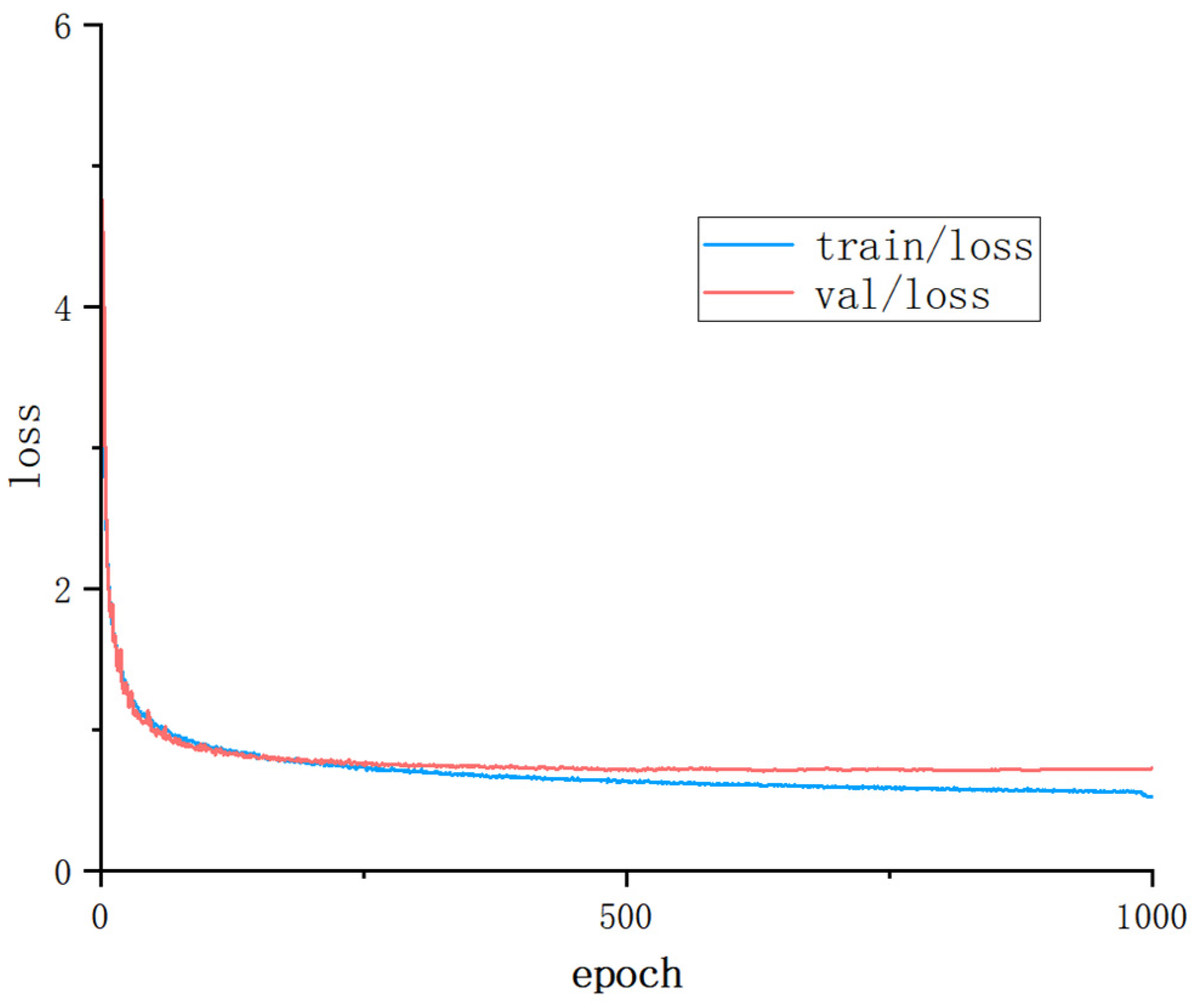
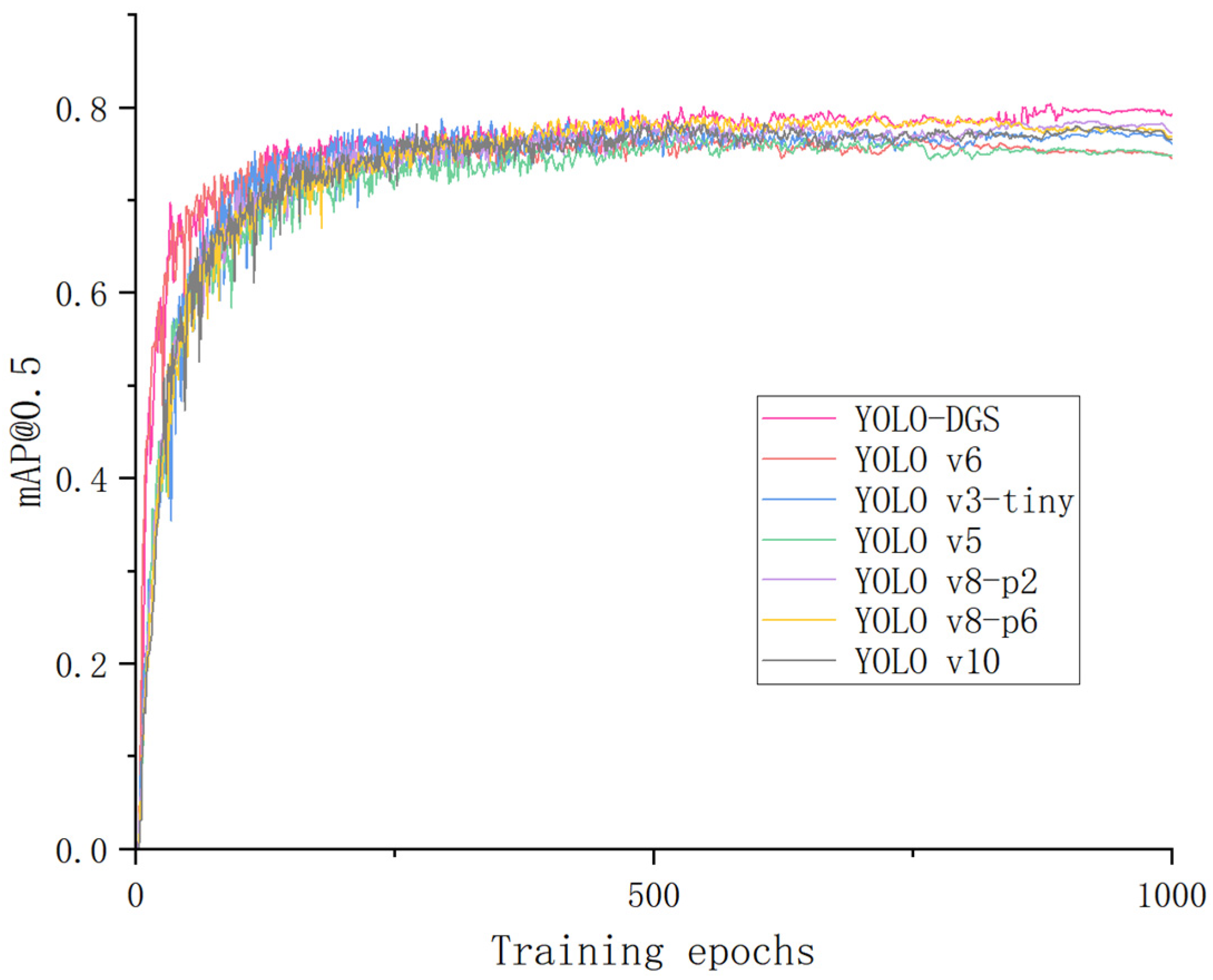
40]. To address the challenges in tomato ripeness recognition, this study proposes an optimized YOLO-DGS algorithm for efficient and accurate real-time tomato detection. The algorithm improves upon YOLO v10 with the following enhancements: (1) redundant object detection layers are removed to enhance the model’s ability to capture the features of specific detection targets and reduce the number of parameters; (2) a novel C2f-GB module is introduced, which uses fewer parameters and computational resources to generate more feature maps, improving the model’s feature extraction capability while reducing both parameter count and computational complexity; (3) a bidirectional feature pyramid network (BiFPN) is incorporated to more effectively capture feature representations at different scales, thereby improving the model’s ability to handle objects of varying sizes and complexities; (4) a channel attention mechanism (SE) is utilized to dynamically adjust channel attention, enhancing information utilization efficiency. To validate the effectiveness of the proposed algorithm, a series of fusion experiments were conducted, comparing the optimized YOLO-DGS model with different numbers of detection heads and various lightweight networks. The experimental results demonstrate that the YOLO-DGS model outperforms others in terms of mean accuracy, parameter count, and inference speed, achieving a better balance between efficiency and precision. This improvement not only enhances the accuracy and efficiency of tomato detection but also provides a lightweight design, making the algorithm more suitable for deployment on embedded devices, ultimately boosting the efficiency of automated tomato harvesting.
Despite certain progress achieved in the method for identifying tomato maturity, this approach still harbors numerous limitations. First and foremost, there is a limitation in terms of variety. Currently, this experiment has only been conducted on common tomatoes and cherry tomatoes. Tomatoes of different varieties exhibit disparities in color, shape, and maturity characteristics. This may impede the applicability of our method to other varieties. For instance, some special tomato varieties do not assume the typical red color when ripe. Take the “Emerald” tomato as an example; it remains green even when fully mature. With the existing color-based recognition method, it is extremely challenging to accurately determine its maturity level. Weather conditions also pose an objective limiting factor. Under overcast days or in insufficient lighting conditions, the color of the captured images will deviate, affecting the judgment of tomato maturity. On the other hand, under direct intense sunlight, the tomato surface will reflect light, causing distortion of color and texture information in the images, thereby reducing the accuracy of recognition.
In summary, although this study has addressed the issue of maturity identification for common tomatoes and cherry tomatoes under general circumstances, in the face of the above-mentioned special cases and variety differences, there is still significant room for improvement. In the future, we will further our research, delving deep into the maturity characteristics of different tomato varieties and optimizing the recognition algorithm to accommodate a wider range of varieties and complex environments. We will also conduct in-depth investigations into these special cases to continuously refine the method for identifying tomato maturity.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}