
A Vision-Based Method for Detecting the Position of Stacked Goods in Automated Storage and Retrieval Systems


Abstract
1. Introduction
- Development of STEGNet architecture and its lightweight variant MixFEGNet: We have engineered STEGNet based on STCNet, innovatively integrating fusion attention mechanisms (GFF + LAM) with the EG-FPN module. STEGNet achieves 93.49% mAP on the GY-WSBW-4D dataset and 83.2% mAP on WSGID-B, substantially outperforming baseline models. This innovation effectively addresses existing deep learning models’ inadequate feature extraction capabilities in complex warehouse environments.
- Proposal of a hybrid methodology integrating object detection networks with edge detection algorithms: Through Region of Interest (ROI)-guided analysis and geometric constraints, this approach significantly mitigates environmental interference, achieving pose estimation with a Mean Absolute Error within 4 cm, Root Mean Square Error below 6 cm, and Rotation Angle Error under 2°. This strategy overcomes the limitations of conventional edge detection methods in complex backgrounds, enabling consistent system performance in variable warehouse conditions.
- Implementation of Perspective-n-Point (PnP) algorithm-based 3D pose estimation from 2D imagery: We have constructed the GY-WSBW-4D and WSBW-Err datasets, with STCNet achieving an 80.8% success rate and MixFEGNet attaining a 76.3% success rate on the WSBW-Err dataset. Notably, MixFEGNet’s model size is only 66% of the baseline model and delivers 68% faster inference speed while maximally preserving accuracy, characteristics particularly advantageous for deployment in resource-constrained operational warehouse environments.
2. Related Work
2.1. Object Detection Algorithms
2.2. Pose Detection Algorithms
2.3. Application of Machine Vision in Warehouses
3. Methodology
3.1. Overall Framework
- Stack Surface Detection: multi-angle stack view images captured from four distinct perspectives are input into the stack surface detection network to identify each box surface as Regions of Interest (ROIs) for subsequent processing.
- Box Edge Detection: edge detection is performed by traversing the ROIs of each box surface from various angles to locate the actual edges and corner points in two-dimensional coordinates.
- Pose Estimation: the two-dimensional coordinates of box surface corner points, along with the camera intrinsic matrix, distortion coefficients, and box shape matrix, are provided to the pose estimation algorithm to calculate the boxes’ three-dimensional coordinates.
3.2. Stacked Goods Surface Detection Network
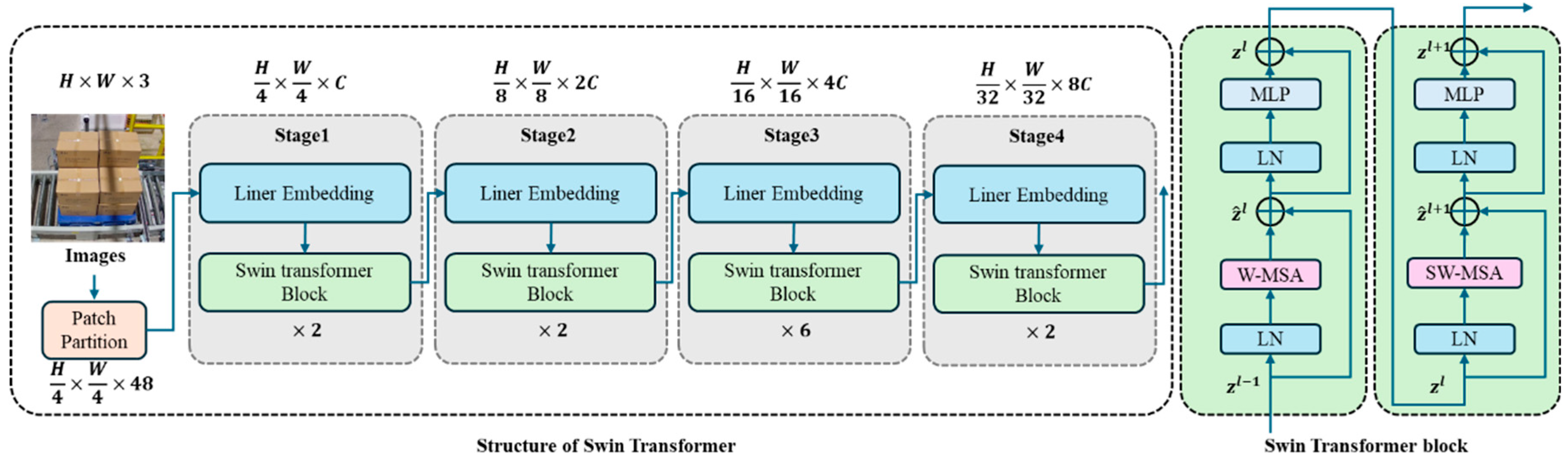
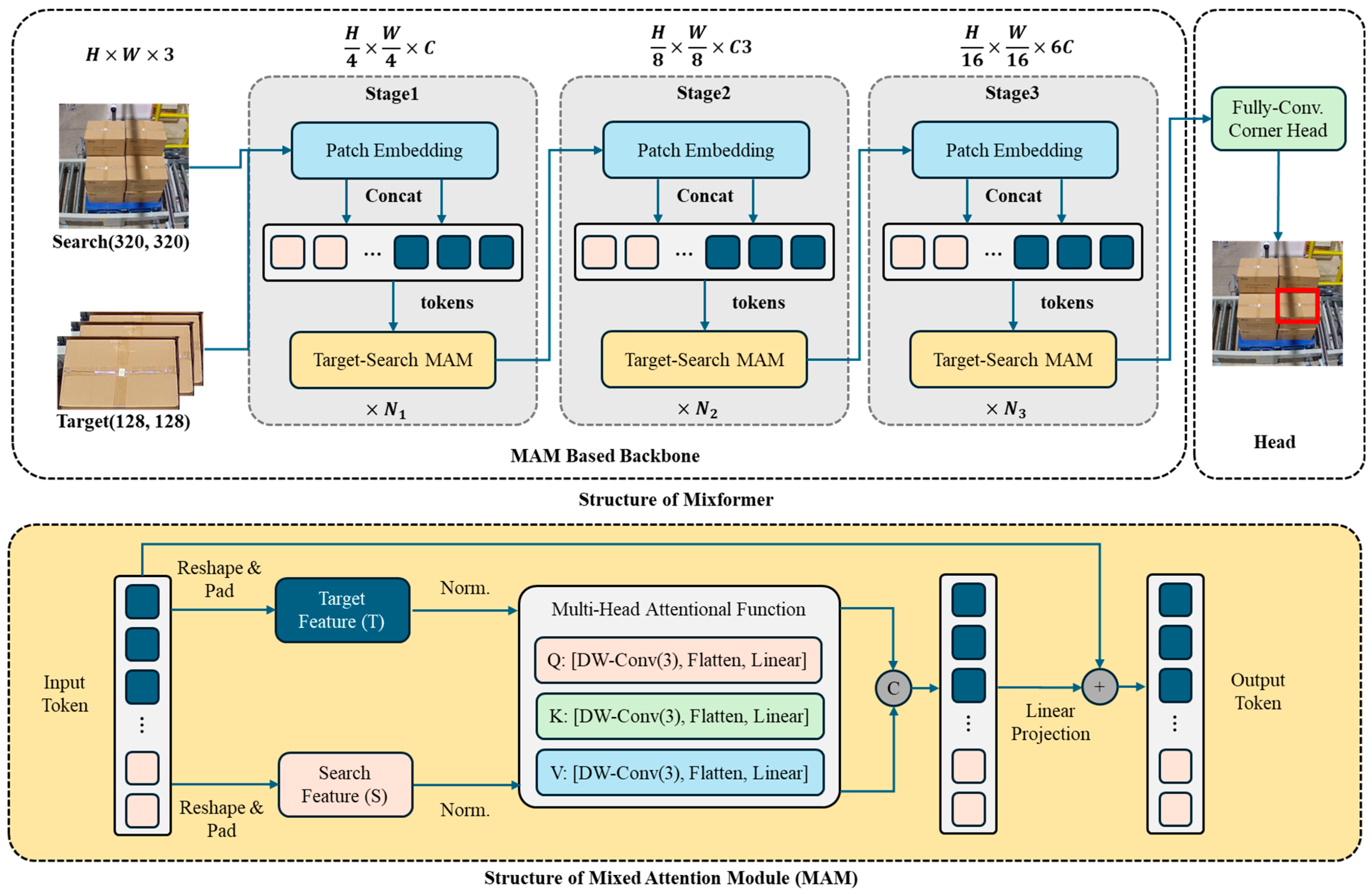
3.2.1. Feature Extractor
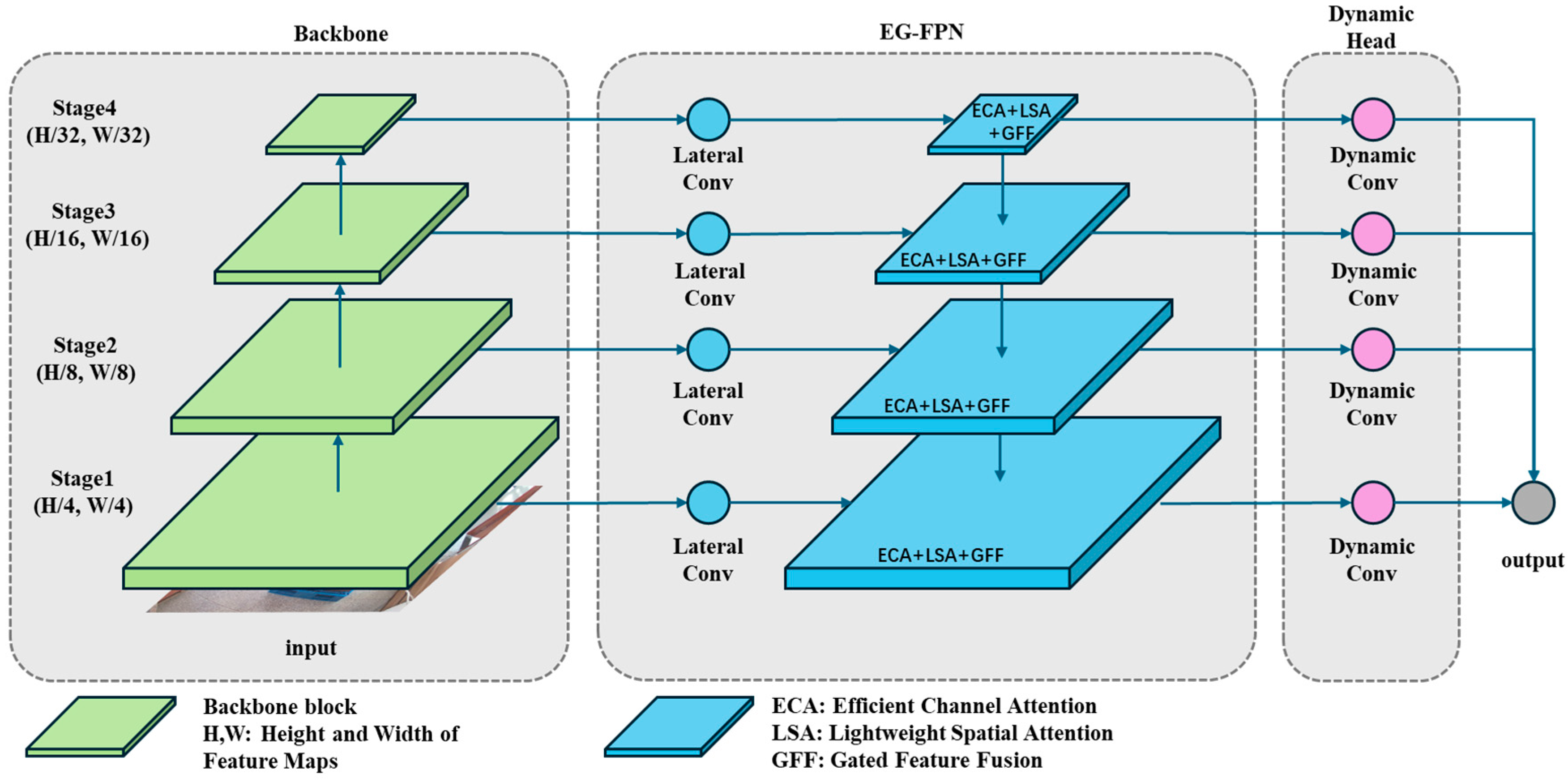
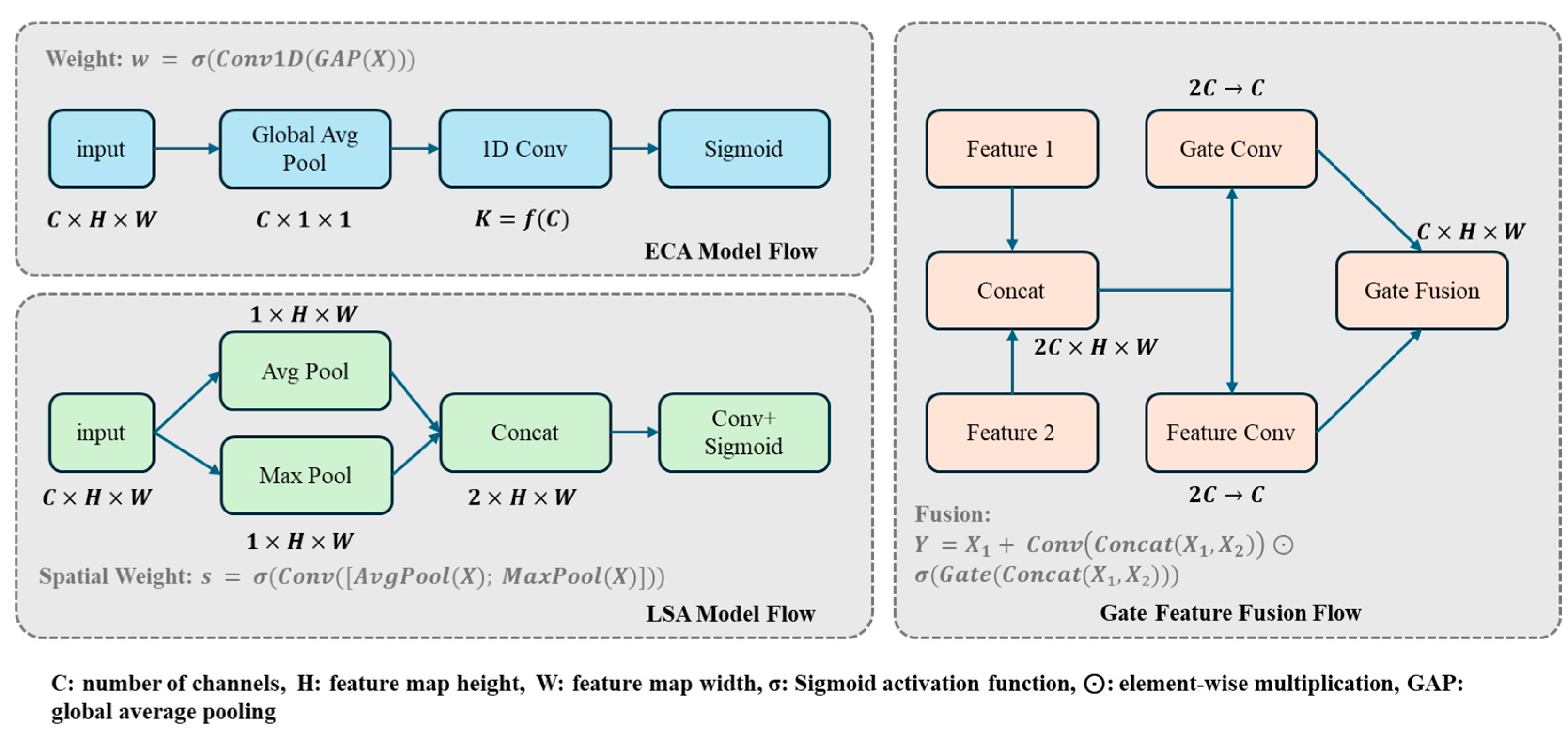
3.2.2. EG-FPN
3.2.3. Dynamic Cascade Output Head
3.3. Box Edge Detection Algorithm
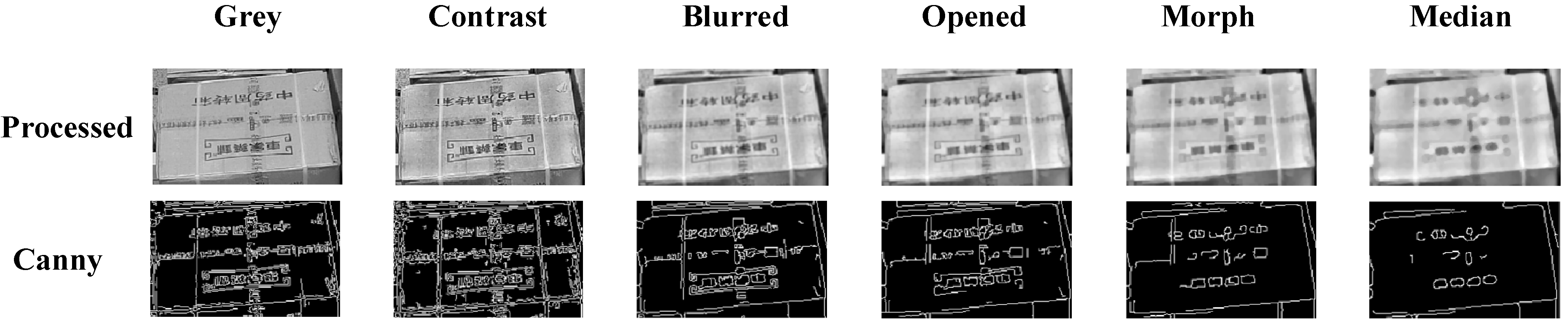
3.3.1. Image Preprocessing
- Opening operation:
- Closing operation:where and represent erosion and dilation operations, respectively. The opening operation removes small bright details while preserving the overall shape and size of larger objects, while the closing operation fills small holes and connects nearby objects.
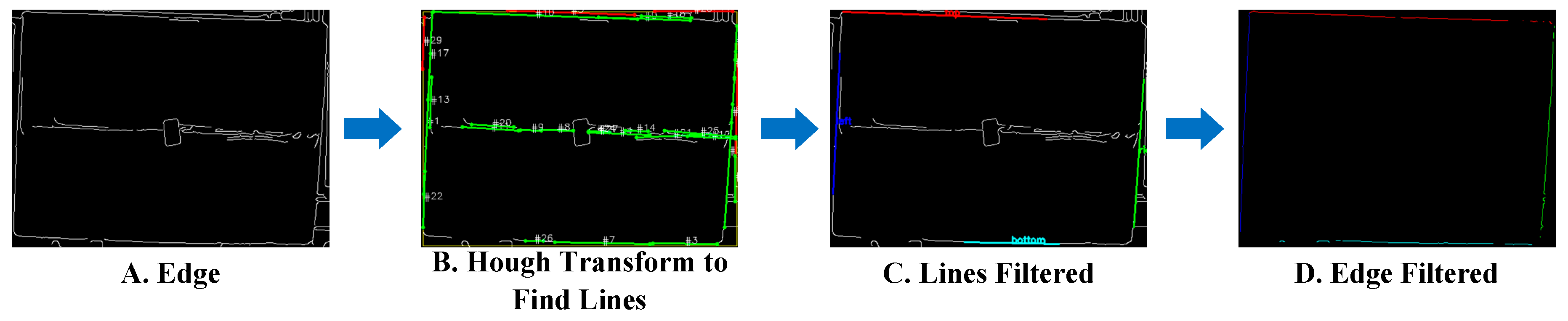
3.3.2. Edge Detection
3.3.3. Edge Filtering
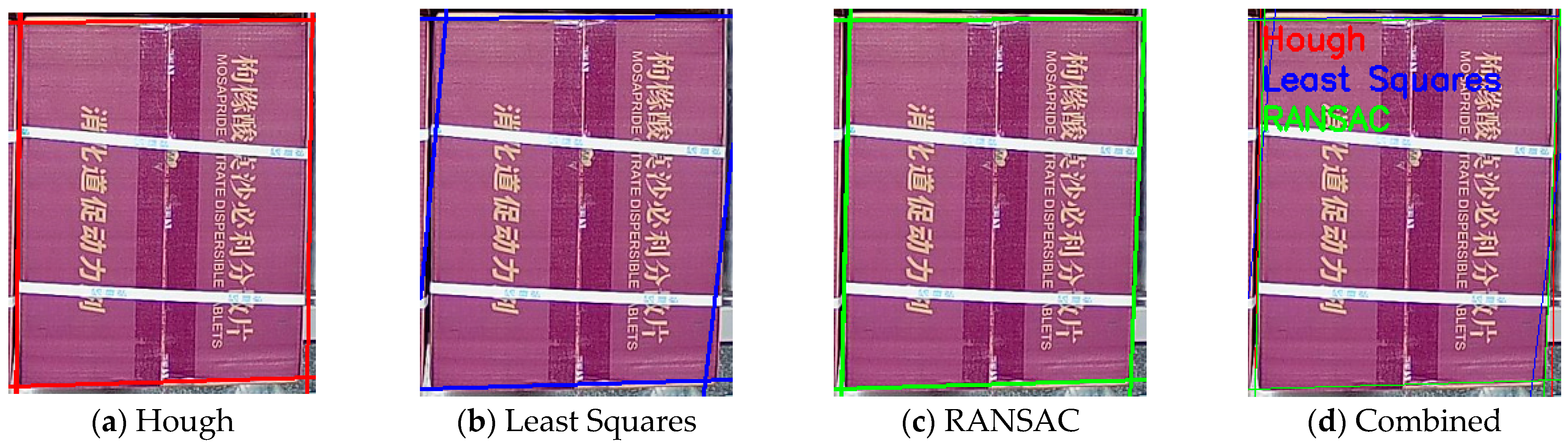
3.3.4. Line Fitting
3.3.5. Corner Detection and Selection
- The point lies within the region of interest:
- The angle between the two intersecting lines L1 and L2 that form the corner approximates a proper angle:
- The distance from the corner to the relevant lines falls within an acceptable range:
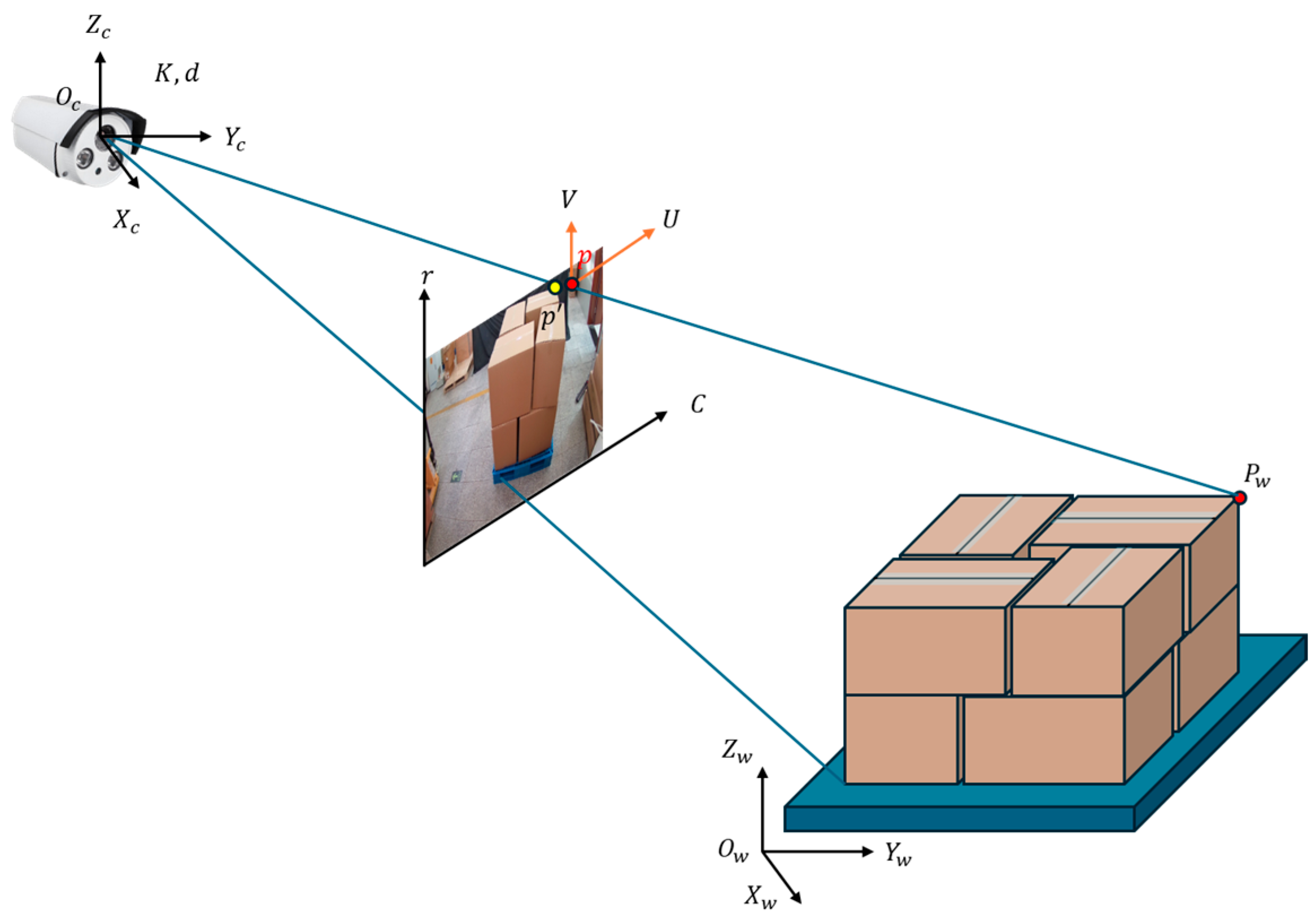
3.4. Pose Estimation
3.4.1. Camera Calibration
3.4.2. PnP Algorithm
| Algorithm 1: PnP Algorithm |
Input:
Step:
Return R, T, Pcam |
3.4.3. Multi-View Extension
4. Experiment and Results
4.1. Dataset
4.2. Implementation Details
4.2.1. Experimental Environment
4.2.2. Experimental Parameters
- Image Preprocessing: The CLAHE algorithm was configured with a block size of 8 × 8 and clipLimit of 2.0. Gaussian filtering used a 5 × 5 kernel with σ = 1.0, while both morphological operations and median filtering employed appropriate kernel sizes (3 × 3 and 5 × 5, respectively).
- Edge Detection: The Canny operator was implemented with optimized thresholds (Th = 150, Tl = 75) and a 3 × 3 Sobel kernel size. These parameters were selected to balance edge preservation and noise suppression effectively.
- Line Detection: The Hough transform parameters were set as follows: ρ resolution of 1 pixel, θ resolution of π/180 radians, minimum votes of 50, minimum line segment length of 50 pixels, and maximum gap of 10 pixels. We employed a 45-degree classification threshold and a 5-degree merging angle threshold for line classification and merging.
- Corner Detection: The clustering distance threshold for corners was set to 10 pixels, with an angle tolerance of ±10 degrees. The minimum and maximum line segment lengths were defined as 0.1 and 0.5 times the ROI diagonal length, respectively.
4.2.3. Model Architecture Details
4.2.4. Evaluation Metrics
- Evaluation Metrics of Detection Network
- Position Accuracy Metrics
- Pose Accuracy Metrics
- Accuracy Metrics
4.2.5. Camera Calibration Results
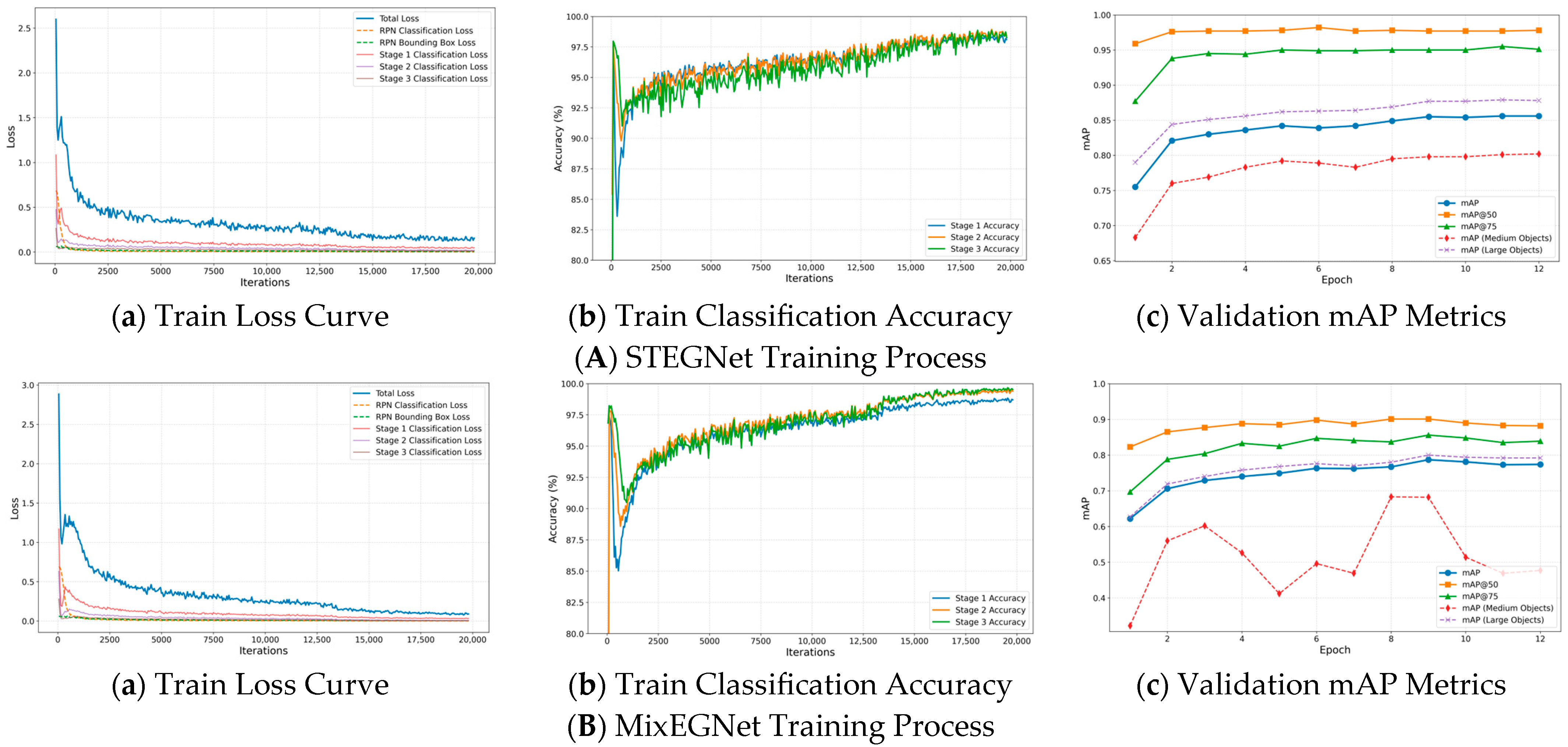
4.3. Training Process Analysis
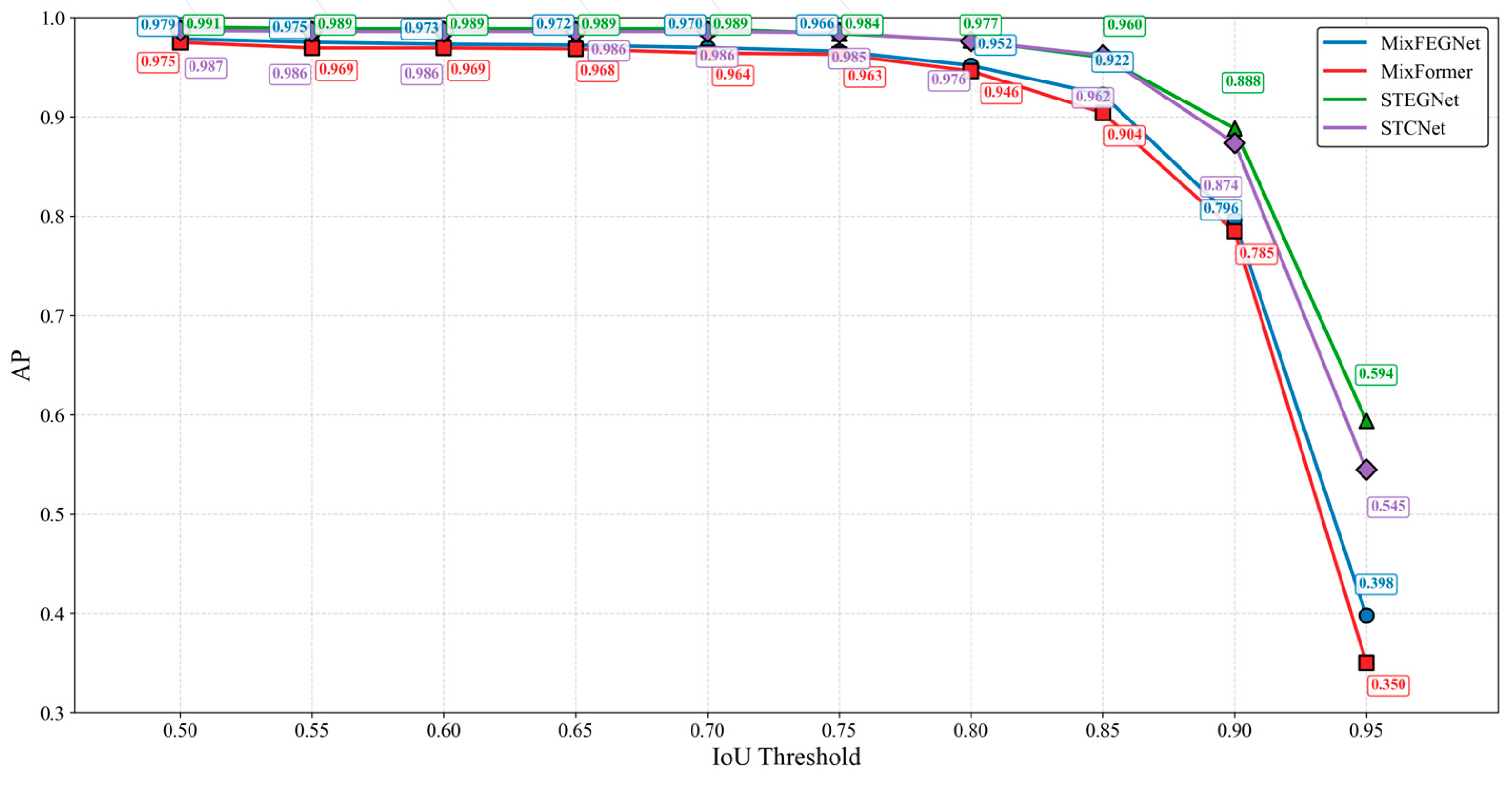
4.4. Comparative Experiments
4.5. Ablation Studies
4.6. Efficiency Analysis
4.7. Error Analysis
4.7.1. Limitations of the Proposed Method
- Color Dependency: The algorithm is primarily optimized for natural-color cardboard boxes (standard yellow–brown) commonly found in warehouse environments. The performance shows variations when processing different-colored boxes, with edge detection accuracy for low-contrast dark boxes decreasing by 4.95% points compared to natural-color boxes. High-contrast boxes also show a slight performance difference (1.31% point decrease in PA), as detailed in Section 4.7.2.
- Lighting Sensitivity: As quantified in our experiments, the algorithm’s performance varies under different lighting conditions. Edge detection accuracy decreases by approximately 7.53% points under dim lighting conditions and 10.57% points under uneven lighting compared to standard lighting conditions (see Section 4.7.3 for detailed analysis).
- Environmental Constraints: The algorithm assumes a relatively controlled warehouse environment. Background clutter (contributing to 13.7% of errors) significantly impacts performance, requiring additional preprocessing steps in complex real-world settings.
- Geometric Limitations: The current implementation struggles with high cargo stacks (3.4% of errors) and cases where box edges adhere to each other (6.8%), limiting its application in densely packed storage scenarios.
- Parameter Sensitivity: As shown in Table 11, approximately 26.5% of errors are related to algorithm parameter settings, indicating that the method requires careful calibration for each deployment environment.
4.7.2. Robustness for Cargo Box Color Variation
- Natural-color boxes (as shown in Figure 11c,d): standard yellow–brown cardboard boxes that represent the default color in most warehouse environments.
- High-contrast boxes (as shown in Figure 11a): light-colored boxes (such as white) that create clear contrast with the floor and surroundings.
- Low-contrast boxes (as shown in Figure 11b): dark-colored boxes that provide minimal contrast with shadows and dark surroundings.
- Target Detection Robustness: The STEGNet detection network demonstrated robustness across different box colors, with only a slight decrease (3.45%) in mAP for low-contrast boxes compared to natural-color boxes. This indicates that when properly trained, the deep learning-based detection component can effectively generalize across color variations.
- Edge Detection Performance Variation: We observed interesting performance differences across box color categories using Point Accuracy (PA) as our evaluation metric (with thresholds = 5 pt). High-contrast boxes showed a slightly different accuracy (71.95% PA) than natural-color boxes (73.26% PA), possibly influenced by brightness variations and surface reflectivity characteristics. Low-contrast boxes presented a somewhat lower accuracy (68.31% PA), representing a 4.95 percentage point difference compared to natural-color boxes. This variation appears to be related to the reduced edge gradients in grayscale conversion, where dark surfaces create edge patterns that can be more challenging to distinguish, and shadow effects become more influential in the detection process.
4.7.3. Sensitivity to Environmental Lighting Conditions
- Normal lighting: uniform overhead lighting (baseline condition).
- Dim lighting: simulating early morning/evening warehouse conditions.
- Bright lighting: simulating direct sunlight through windows.
- Uneven lighting: normal overall illumination with strong directional light creating shadows.
- Color Dependency: Our experiments with natural-color, high-contrast, and low-contrast boxes (Section 4.7.2) demonstrated performance variations, particularly for edge detection on low-contrast boxes (4.95 percentage point decrease in PA compared to natural-color boxes). In our future research, we plan to implement adaptive color-space transformations before edge detection, develop color-aware algorithms that adjust parameters based on detected box color, and expand our training dataset to include more diverse box colors. These enhancements will improve the algorithm’s versatility across various cargo types in real warehouse settings.
- Lighting Sensitivity: Our experiments across four lighting conditions (Section 4.7.3) revealed performance variations, especially under uneven lighting (10.57 percentage point decrease in edge detection accuracy compared to standard lighting). In future research, we plan to implement adaptive thresholding based on detected scene illumination, incorporate lighting normalization preprocessing, and explore depth camera integration to provide illumination-invariant structural information. From an engineering perspective, installing dedicated lighting systems in critical inspection areas would offer a cost-effective solution for maintaining consistent illumination.
- Environmental Constraints: To overcome challenges caused by background clutter (13.7% of errors), we recommend enhancing our preprocessing algorithms with advanced background segmentation techniques and implementing context-aware filtering methods. Engineering solutions include installing uniform background panels in inspection areas and optimizing camera placement to minimize background interference, thus creating more controlled conditions without extensive facility modifications.
- Geometric Limitations: For issues related to cargo stacking (tall stacks, edge adhesion, and occlusion accounting for 20.5% of errors), we will investigate multi-view fusion algorithms that combine information from different camera angles to resolve occlusion issues. Future work will also explore machine learning approaches (e.g., SVM or deep learning models) specifically trained to address edge adhesion problems. From an engineering perspective, adjusting the camera shooting distance and angle based on stack height can improve operational environments.
- Parameter Sensitivity: To address parameter-related issues (26.5% of errors), we will develop an adaptive parameter tuning system that automatically adjusts threshold values based on detected environmental conditions and cargo characteristics. This will involve creating a comprehensive parameter optimization framework that considers the interdependencies between algorithm components. From an engineering standpoint, we will provide clear parameter calibration guidelines for different operational scenarios to ensure optimal performance across diverse warehouse environments.
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, Z.; Chen, P.; Shi, W.; Li, J. IDA-Net: Intensity-distribution aware networks for semantic segmentation of 3D MLS point clouds in indoor corridor environments. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102904. [Google Scholar] [CrossRef]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3d point clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Abdelhalim, G.; Simon, K.; Bensch, R.; Parimi, S.; Qureshi, B.A. Automated AI-Based Annotation Framework for 3D Object Detection from LIDAR Data in Industrial Areas; SAE Technical Paper 0148-7191; SAE: Warrendale, PA, USA, 2024. [Google Scholar]
- Khalfallah, S.; Bouallegue, M.; Bouallegue, K. Object Detection for Autonomous Logistics: A YOLOv4 Tiny Approach with ROS Integration and LOCO Dataset Evaluation. Eng. Proc. 2024, 67, 65. [Google Scholar] [CrossRef]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef]
- Pang, Y.; Yuan, Y.; Li, X.; Pan, J. Efficient HOG human detection. Signal Process. 2011, 91, 773–781. [Google Scholar] [CrossRef]
- Oyallon, E.; Rabin, J. An analysis of the SURF method. Image Process. Line 2015, 5, 176–218. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Zong, Z.; Song, G.; Liu, Y. Detrs with collaborative hybrid assignments training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6748–6758. [Google Scholar]
- Bharati, P.; Pramanik, A. Deep learning techniques—R-CNN to mask R-CNN: A survey. In Computational Intelligence in Pattern Recognition: Proceedings of CIPR 2019; Springer: Singapore, 2020; pp. 657–668. [Google Scholar]
- Girshick, R. Fast r-cnn. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Howard, A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Koonce, B.; Koonce, B. EfficientNet. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: Berkeley, CA, USA, 2021; pp. 109–123. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Zhou, T.; Zhao, Y.; Wu, J. Resnext and res2net structures for speaker verification. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; pp. 301–307. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Li, S.; Xu, C.; Xie, M. A robust O (n) solution to the perspective-n-point problem. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1444–1450. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Illingworth, J.; Kittler, J. A survey of the Hough transform. Comput. Vis. Graph. Image Process. 1988, 44, 87–116. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 205–218. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 224–236. [Google Scholar]
- Noh, H.; Araujo, A.; Sim, J.; Weyand, T.; Han, B. Large-scale image retrieval with attentive deep local features. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3456–3465. [Google Scholar]
- Chen, Y.; Medioni, G. Object modelling by registration of multiple range images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Sensor Fusion IV: Control Paradigms and Data Structures; SPIE: Bellingham, WA, USA, 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Liu, B.; Liu, L.; Tian, F. An Improved SAC-IA Algorithm Based on Voxel Nearest Neighbor Search. Crit. Rev.TM Biomed. Eng. 2022, 50, 35–46. [Google Scholar] [CrossRef] [PubMed]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable cnn for joint description and detection of local features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8092–8101. [Google Scholar]
- Zeng, A.; Song, S.; Nießner, M.; Fisher, M.; Xiao, J.; Funkhouser, T. 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1802–1811. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Aoki, Y.; Goforth, H.; Srivatsan, R.A.; Lucey, S. Pointnetlk: Robust & efficient point cloud registration using pointnet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7163–7172. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2016: 19th International Conference, Athens, Greece, 17–21 October 2016; Proceedings, Part II 19; Springer: Berlin/Heidelberg, Germany, 2016; pp. 424–432. [Google Scholar]
- Dong, S. A separate 3D-SegNet based on priority queue for brain tumor segmentation. In Proceedings of the 2020 12th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 22–23 August 2020; Volume 2, pp. 140–143. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Park, K.; Patten, T.; Vincze, M. Pix2pose: Pixel-wise coordinate regression of objects for 6d pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7668–7677. [Google Scholar]
- He, S.; Wang, Y.; Liu, H. Image information recognition and classification of warehoused goods in intelligent logistics based on machine vision technology. Trait. Signal 2022, 39, 1275. [Google Scholar] [CrossRef]
- Daios, A.; Xanthopoulos, A.; Folinas, D.; Kostavelis, I. Towards automating stocktaking in warehouses: Challenges, trends, and reliable approaches. Procedia Comput. Sci. 2024, 232, 1437–1445. [Google Scholar] [CrossRef]
- Yoneyama, R.; Duran, A.J.; Del Pobil, A.P. Integrating sensor models in deep learning boosts performance: Application to monocular depth estimation in warehouse automation. Sensors 2021, 21, 1437. [Google Scholar] [CrossRef]
- Yin, H.; Chen, C.; Hao, C.; Huang, B. A Vision-based inventory method for stacked goods in stereoscopic warehouse. Neural Comput. Appl. 2022, 34, 20773–20790. [Google Scholar] [CrossRef]
- Cui, Y.; Jiang, C.; Wang, L.; Wu, G. Mixformer: End-to-end tracking with iterative mixed attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13608–13618. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
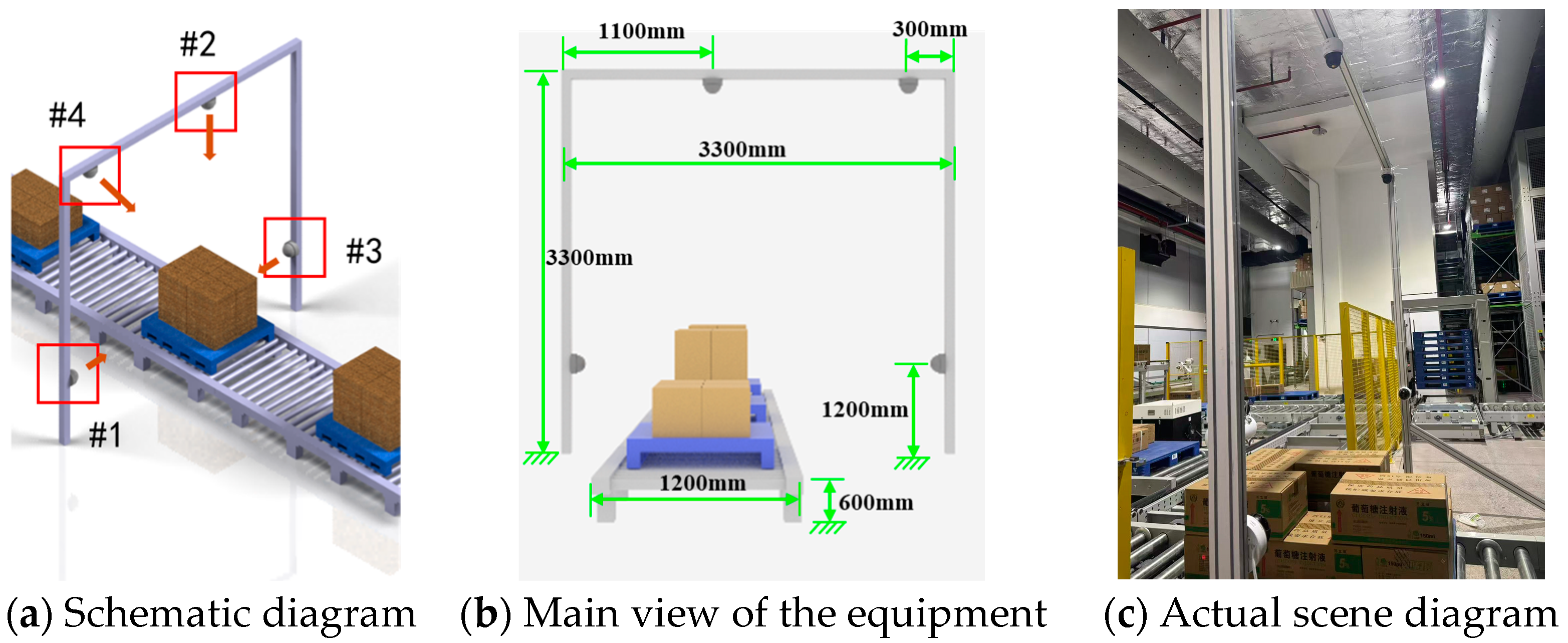
| Serial Number | Installation Location | Horizontal Shooting Angle | Vertical Shooting Angle | Dataset Name |
|---|---|---|---|---|
| #1 | 1200 mm from bottom to top on the left side of the shooting frame | Facing the center point of the largest stack of goods | Horizontal right | GY-WSBW-A |
| #2 | The top of the shooting frame, facing the center of the cargo stack | Vertically downward | Vertically downward | GY-WSBW-B |
| #3 | 1200 mm from bottom to top on the right side of the shooting frame | Facing the center point of the largest stack of goods | Horizontal left | GY-WSBW-C |
| #4 | Top of the shooting frame, 300 mm from right to left | Opposite to the right side of the conveyor line | Slant downward 45°∠ | GY-WSBW-D |
| Dataset Component | Total Images | Train Set | Val Set | Test Set | Annotations |
|---|---|---|---|---|---|
| GY-WSBW-A | 756 | 248 | 53 | 53 | ‘top’, ‘front’, ‘error’ |
| GY-WSBW-B | 756 | 248 | 53 | 53 | ‘top’, ‘front’, ‘error’ |
| GY-WSBW-C | 756 | 248 | 53 | 53 | ‘top’, ‘front’, ‘error’ |
| GY-WSBW-D | 756 | 248 | 53 | 53 | ‘top’, ‘front’, ‘error’ |
| GY-WSBW-4D | 3024 | 991 | 212 | 212 | 1415 annotated images |
| WSBW-Err | 150 | 105 | 22 | 23 | Unstable stacking patterns |
| Model | Year | Head | Backbone | Neck | Parameters |
|---|---|---|---|---|---|
| STCNet [60] | 2022 | Cascade | Swin-T | FPN | 59.7 M |
| FasterRCNN [18] | 2015 | RPN + RoI | ResNet50 | FPN | 40.3 M |
| CascadeRCNN [19] | 2018 | Cascade | ResNet50 | FPN | 60.6 M |
| SparseRCNN [62] | 2021 | Learnable Proposal | ResNet50 | FPN | 38.7 M |
| Dino [14] | 2022 | DETR | Swin-T | Deformable | 44.9 M |
| Co-DETR [15] | 2023 | DETR | Swin-T | Deformable | 56.0 M |
| Yolox [12] | 2021 | YOLO Head | CSPDarknet | PANet | 50.0 M |
| STEGNet | -- | Dynamic | Swin-T | EG-FPN | 49.7 M |
| MixFEGNet | -- | Dynamic | Mixformer | EG-FPN | 40.3 M |
| K | ||||
|---|---|---|---|---|
| px | 1.23 × 103 | 9.35 × 102 | 1.22 × 103 | 5.22 × 102 |
| d | |||||
|---|---|---|---|---|---|
| −3.67 × 10−1 | 2.05 × 10−1 | −1.18 × 10−3 | 1.14 × 10−4 | −1.30 × 10−1 |
| Dataset | WSGID-B [60] | GY-WSBW-4D | ||||
|---|---|---|---|---|---|---|
| mAP | Front | Upper | Total | Front | Upper | Total |
| STCNet [60] (Baseline) | 92.80 | 72.80 | 86.13 | 92.30 | 93.45 | 92.74 |
| FasterRCNN [18] | 91.73 | 71.82 | 85.09 | 91.64 | 92.47 | 91.96 |
| (1.07) | (0.98) | (1.04) | (0.66) | (0.98) | (0.78) | |
| CascadeRCNN [19] | 93.01 | 72.31 | 86.10 | 92.55 | 93.03 | 92.73 |
| (0.21) | (0.49) | (0.02) | (0.25) | (0.42) | (0.01) | |
| SparseRCNN [62] | 90.84 | 68.98 | 83.49 | 90.45 | 90.88 | 90.61 |
| (1.96) | (3.82) | (2.64) | (1.85) | (2.57) | (2.13) | |
| Dino [14] | 91.14 | 69.38 | 83.88 | 90.88 | 91.24 | 91.02 |
| (1.66) | (3.42) | (2.25) | (1.42) | (2.21) | (1.72) | |
| Co-DETR [15] | 93.18 | 72.52 | 86.24 | 92.68 | 93.28 | 92.86 |
| (0.38) | (0.28) | (0.11) | (0.38) | (0.17) | (0.15) | |
| Yolox [12] | 90.06 | 67.33 | 82.47 | 89.87 | 90.34 | 90.05 |
| (2.74) | (5.47) | (3.65) | (2.43) | (3.11) | (2.69) | |
| MixFEGNet | 92.38 | 72.25 | 85.66 | 87.60 | 91.37 | 89.03 |
| (0.42) | (0.55) | (0.46) | (4.70) | (2.08) | (3.71) | |
| STEGNet | 93.66 | 73.57 | 86.96 | 92.72 | 94.75 | 93.49 |
| (0.86) | (0.77) | (0.83) | (0.42) | (1.3) | (0.75) | |
| Models | MAE (cm) | RMSE (cm) | RAE (°) | PA (%) | BIA (%) |
|---|---|---|---|---|---|
| STCNet [60] | 3.92 | 7.26 | 2.2 | 60.34 | 78.2 |
| (baseline) | |||||
| MixFEGNet | 4.01 | 8.13 | 2.6 | 57.28 | 76.3 |
| (0.09) | (0.87) | (0.4) | (3.06) | (1.9) | |
| STEGNet | 3.79 | 5.88 | 1.5 | 63.27 | 80.8 |
| (0.13) | (1.38) | (0.7) | (2.93) | (2.6) |
| Auto Fusion | LSA | ECA | STEGNet | MixFEGNet | ||||
|---|---|---|---|---|---|---|---|---|
| AP50 | AP75 | mAP | AP50 | AP75 | mAP | |||
| 87.8 | 83.8 | 78.6 | 85.7 | 80.0 | 72.5 | |||
| √ | 88.2 | 83.1 | 78.4 | 86.3 | 79.9 | 72.4 | ||
| (+0.4) | (−0.7) | (−0.2) | (+0.6) | (−0.1) | (−0.1) | |||
| √ | √ | 88.3 | 84.0 | 79.1 | 88.1 | 82.7 | 76.9 | |
| (+0.5) | (+0.2) | (+0.5) | (+2.4) | (+2.7) | (+4.4) | |||
| √ | √ | 88.3 | 83.8 | 78.9 | 88.2 | 81.2 | 75.3 | |
| (+0.5) | (0.0) | (+0.3) | (+2.5) | (+1.2) | (+2.8) | |||
| √ | √ | √ | 88.5 | 84.0 | 79.5 | 88.2 | 83.9 | 77.4 |
| (+0.7) | (+0.2) | (+0.9) | (+2.5) | (+3.9) | (+4.9) | |||
| Algorithm | MAE (pt) | RMSE (pt) | PA (%) | |||
|---|---|---|---|---|---|---|
| Pre- Processing | Edge Detection | Edge Filtering | Line Fitting | |||
| √ | Canny | √ | RANSAC | 2.86 | 4.23 | 70.56 |
| Canny | √ | RANSAC | 5.97 | 10.49 | 53.24 | |
| √ | Sobel | √ | RANSAC | 4.33 | 8.47 | 63.17 |
| √ | Canny | RANSAC | 8.32 | 16.74 | 45.52 | |
| √ | Canny | √ | OLS | 3.13 | 5.01 | 68.34 |
| √ | Canny | √ | Houph | 2.99 | 4.33 | 70.12 |
| Model | Speed (FPS) | Model Size (MB) | GFLOPS |
|---|---|---|---|
| STCNet [60] | 12.67 | 280.79 | 130.32 |
| (baseline) | |||
| FasterRCNN [18] | 15.50 | 235.31 | 110.07 |
| (2.83) | (45.48) | (20.25) | |
| CascadeRCNN [19] | 10.20 | 269.43 | 121.32 |
| (2.47) | (11.36) | (9.00) | |
| SparseRCNN [62] | 18.23 | 238.80 | 115.47 |
| (5.56) | (40.48) | (14.85) | |
| Dino [14] | 8.31 | 420.11 | 181.73 |
| (4.36) | (139.32) | (51.41) | |
| Co-DETR [15] | 9.18 | 396.50 | 165.35 |
| (3.49) | (115.71) | (35.03) | |
| Yolox [12] | 18.97 | 209.83 | 119.45 |
| (6.3) | (70.96) | (10.87) | |
| STEGNet | 12.80 | 275.50 | 124.59 |
| (0.13) | (5.29) | (5.73) | |
| MixFEGNet | 21.28 | 186.19 | 113.68 |
| (9.15) | (94.6) | (16.64) |
| Main Reason | Details | Frequency | Error Precent |
|---|---|---|---|
| Stacking factors | Super-high cargo stack | 4 | 3.4 |
| Cargo box edge sticking | 8 | 6.8 | |
| Cargo box surface texture | 13 | 11.1 | |
| Cargo box cover | 12 | 10.3 | |
| Collection environmental factors | Background confusion | 16 | 13.7 |
| Reflective surface of cargo box | 18 | 15.4 | |
| The surface of the cargo box is too dark | 6 | 5.1 | |
| Shadow | 9 | 7.7 | |
| Algorithm parameter factors | Confidence threshold is too high or too low | 14 | 12.0 |
| The preprocessing algorithm parameters are too large or too small | 8 | 6.8 | |
| Edge filtering threshold is too large or too small | 9 | 7.7 |
| Box Color Category | STEGNet Detection (mAP) | Edge Detection Accuracy (PA) |
|---|---|---|
| Natural-color | 94.87% | 73.26% |
| High-contrast | 93.21% | 71.95% |
| Low-contrast | 91.42% | 68.31% |
| Box Color Category | STEGNet Detection (mAP) | Edge Detection Accuracy (PA) |
|---|---|---|
| Standard lighting | 93.49% | 71.85% |
| Low lighting | 88.73% | 64.32% |
| Bright lighting | 90.12% | 67.43% |
| Uneven lighting | 86.45% | 61.28% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Liu, J.; Yin, H.; Huang, B. A Vision-Based Method for Detecting the Position of Stacked Goods in Automated Storage and Retrieval Systems. Sensors 2025, 25, 2623. https://doi.org/10.3390/s25082623
Chen C, Liu J, Yin H, Huang B. A Vision-Based Method for Detecting the Position of Stacked Goods in Automated Storage and Retrieval Systems. Sensors. 2025; 25(8):2623. https://doi.org/10.3390/s25082623
Chicago/Turabian StyleChen, Chuanjun, Junjie Liu, Haonan Yin, and Biqing Huang. 2025. "A Vision-Based Method for Detecting the Position of Stacked Goods in Automated Storage and Retrieval Systems" Sensors 25, no. 8: 2623. https://doi.org/10.3390/s25082623
APA StyleChen, C., Liu, J., Yin, H., & Huang, B. (2025). A Vision-Based Method for Detecting the Position of Stacked Goods in Automated Storage and Retrieval Systems. Sensors, 25(8), 2623. https://doi.org/10.3390/s25082623